mec12130-sup-0001-DocumentS1
advertisement

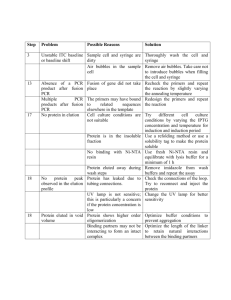
Supplemental Document 1 – Gene Data Collection, Sequence Alignment & Phylogenetic Analyses Methods of DNA extraction followed Starrett & Hedin (2007). PCR amplification conditions for the CO1 and 28S gene regions followed Starrett & Hedin (2007), although we also used the 28S primers ZX1 and ZR2 to amplify 28S for some specimens (see Bond & Hedin 2006). EF1G PCR reactions were conducted in two rounds using primers and reaction conditions from Ayoub et al. (2007). For the first round, primers EF1gF78 and EF1gR1258 were used. One microliter of this PCR product was used in a nested PCR using primers EF1gF218 and EF1gR1090. An anonymous nuclear gene was discovered as a PCR amplicon using primers designed to amplify mygalmorph spidroin proteins, but this amplicon has no similarity to spidroin sequences (Starrett and Hayashi, unpublished). Internal primers were redesigned (AtUk-F CAGGATTTCTTGGGAATGTGAGC, AtUk-R GCTGCCCTATGTAGGCGTCC) and the gene region was amplified in 25 uL reactions that consisted of 1 μL genomic DNA, 0.1 mM each primer, 0.5 mM each dNTP (Fisher), 67 mM Tris, 3 mM MgCl2, and 16.6 mM (NH4)2SO4. The reaction was carried out for 40 cycles of 94° C for 30 seconds, 59° C for 40 seconds, and 72° C for one minute. PCR products were purified using either PEG or with Montage PCR filter units (Millipore), and sequenced in both directions at the SDSU Microchemical Core Facility or at the UCR IIGB Genomics Core Instrument Facility. Sequencher 4.5 (Gene Codes) was used to edit and assemble sequence contigs. The lengthvariable 28S data were aligned manually in MacClade 4.0 (Maddison & Maddison 2003). We compared this to an algorithmic alignment, where we used the Geneious Pro 4.5 MUSCLE plug-in (Drummond et al. 2011) to re-align multiple length-variable regions, using the “refine existing alignment” tool starting from an initial manual alignment. Phylogenetic analyses were conducted on individual data partitions in order to explicitly assess genealogical congruence across loci with regards to geographic groupings. Identical sequences from the same sampling location were merged prior to phylogenetic analysis; exceptions included 28S sequences not merged because of ambiguous sites or length differences (due to amplicon size differences) but that were otherwise identical. Sequence evolution models were chosen using jModelTest 0.1.1 (Posada 2008); model likelihoods were calculated under three substitution schemes (JC, HKY, GTR) on a fixed BIONJ tree, allowing for unequal base frequencies and among-site rate variation. From these likelihood scores model selection was based on the Akaike Information Criterion (AIC). Bayesian analyses were conducted using MrBayes v3.1 (Huelsenbeck & Ronquist 2001; Ronquist & Huelsenbeck 2003). The CO1 data were analyzed using a partitioned strategy (see Ronquist & Huelsenbeck 2003; Nylander et al. 2004; Brandley et al. 2005), where a separate model was applied to each CO1 codon position. Because of few variable first and second position sites, individual nuclear datasets were not partitioned. For partitioned CO1 analyses, estimated parameters (revmat, statefreq, gamma shape, pinvar) for each partition were “unlinked”. Default cold and heated chain parameters were used in all Bayesian analyses. Two independent searches were run for multiple millions of generations, and we considered the sampling of the posterior distribution to be adequate when the average standard deviation of split frequencies dropped below 0.01 (Ronquist et al. 2005). The first 20-40% of tree topologies were discarded as burn-in, and from this post burn-in tree set we generated a majority rule consensus tree with mean branch-length estimates. References Ayoub NA, Garb JE, Hedin M, Hayashi CY (2007) Utility of the nuclear proteincoding gene, elongation factor-1 gamma (EF-1), for spider systematics, emphasizing family level relationships of tarantulas and their kin (Araneae: Mygalomorphae). Molecular Phylogenetics and Evolution, 42, 394-409. Bond JE, Hedin M (2006) A total evidence assessment of the phylogeny of North American euctenizine trapdoor spiders (Araneae, Mygalomorphae, Cyrtaucheniidae) using Bayesian inference. Molecular Phylogenetics and Evolution, 41, 70-85. Brandley MC, Schmitz A, Reeder TW (2005) Partitioned Bayesian analyses, partition choice, and the phylogenetic relationships of scincid lizards. Systematic Biology, 54, 373-390. Drummond AJ, Ashton B, Buxton S, Cheung M, Cooper A, Duran C, Field M, Heled J, Kearse M, Markowitz S, Moir R, Stones-Havas S, Sturrock S, Thierer T, Wilson A (2011) Geneious v5.4, Available from http://www.geneious.com/ Huelsenbeck JP, Ronquist F (2001) MRBAYES: Bayesian inference of phylogeny. Bioinformatics, 17, 754-755. Maddison DR, Maddison WP (2003) MacClade 4, Release Version 4.07. Sinauer Associates, Inc., Sunderland, Massachusetts. Nylander JAA, Ronquist F, Huelsenbeck JP, Nieves-Aldrey JL (2004) Bayesian phylogenetic analysis of combined data. Systematic Biology, 53, 47-67. Posada D (2008) jModelTest: Phylogenetic model averaging. Molecular Biology & Evolution, 25, 1253-1256. Ronquist F, Huelsenbeck JP (2003) MrBayes 3: Bayesian phylogenetic inference under mixed models. Bioinformatics, 19, 1572-1574. Ronquist F, Huelsenbeck JP, van der Mark P (2005) MrBayes 3.1 Manual, Draft 5/26/2005, online at http://mrbayes.csit.fsu.edu/manual.php. Starrett J, Hedin M (2007) Multilocus genealogies reveal multiple cryptic species and biogeographic complexity in the California turret spider Antrodiaetus riversi (Mygalomorphae, Antrodiaetidae). Molecular Ecology, 16, 583-604.