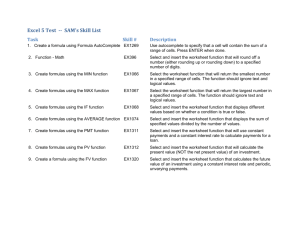
Simulation Tutorial
advertisement

Excel Simulation Tutorial: Sound’s Alive Company
I. In the worksheet SoundPhase1.xlsx, rename Sheet2 to Simulation. This is where the
simulation results will be collected and processed. (See Exhibit 1 of this handout to
see a diagram of what the worksheet should look like after step 5 of this tutorial.)
II. Enter probability distributions for three input variables in the Proformas worksheet:
Gross Revenue Growth Rate cell B4: =norminv(rand(),D4,E4)
2004 Gross Revenue cell B12:
=C12+(E12-C12)*(rand()+rand())/2
2004 Overhead Costs cell B15:
=C15+(E15-C15)*rand()
These three formulas assume that 1) the gross revenue rate in cell B4 can be described
by a normal distribution with the expected value in cell D4 and the standard deviation
in cell E4, 2) first year gross revenues in cell B12 can be described by a symmetrical
triangular distribution where the lowest dollar amount is in cell C12, the highest dollar
amount is in cell E12 and the most likely amount is halfway between these two values
and 3) first year overhead costs in cell B15 can be described by a uniform distribution
where values between the numbers shown in cells C15 and E15 are equally likely to
occur.
III. Select the output variables to be simulated and the information to be recorded:
Go to the new Simulation worksheet from part 1. Enter the following formulas in
the specified cells:
Cell
Formula
B3
= Proformas!B31
C3
= Proformas!B4
D3
= Proformas!B12
E3
=Proformas!B15
These formulas are being setup in the formula row for a data table command. Excel
will collect information from these four Proforma cells for each column input
(iteration number) and put the values in the data table on the Simulation worksheet.
The way this model has just been setup, four sets of data will be collected during the
simulation run to describe the possible values for 1) simulated NPV output result, 2)
simulated revenue growth rate assumption, 3) simulated 2004 gross revenue
assumption and 4) simulated 2004 overhead cost assumption. Enter the names for
these variables in their respective cells in row 1 to document your results. Leave a
blank row between the new headings and the formulas.
IV. Set the settings for the simulation run:
In cell A3 of the new Simulation worksheet, type in the heading Iteration#. Fill
column A (starting with row 3) with consecutive numbers ranging from 1 to 100. You
will be simulating 100 scenarios or “iterations” for this tutorial.
V. Perform a simulation run and view the results:
Highlight the data table (cells A3 to E103) by positioning cursor in A3 and pressing
[Ctrl][Shift]*. Select the Data Table menu option. For the column input option in the
dialog box, enter any blank cell reference (for example $G$5). Press OK. For each row
of the data table, Excel will put the iteration number into this meaningless cell $G$5.
This entry however will cause the rand() functions entered in the Proformas worksheet to
recalculate, thereby generating a new scenario and the data table command will place the
new values for the three simulated input variables along with the resulting NPV output
value in the next row of the Simulation worksheet. Your table should be filled with the
results of 100 scenarios after this command.
Currently in each cell of the data table is a Table function. Any time you edit any cell,
this command will recalculate and new scenarios will be generated. This will make it
difficult to calculate meaningful descriptive statistics. To prevent this, highlight cells B4
to E103 and select the COPY command. (Note: Be careful not to include row 3 with the
formulas). DO NOT MOVE the cursor or highlighted area. Immediately select the EDIT
PASTE SPECIAL VALUE command. This will place numbers over the table command
functions and you will not have the forementioned problem.
VI.
Summarize your iteration results with descriptive statistics:
Place the cursor on the Simulation sheet. Select the Data Analysis menu option. Click
on Descriptive Statistics and set the dialog box with the following options:
INPUT RANGE: B4:E103 Grouped by Columns
NEW WORKSHEET PLY: Statistics
SUMMARY STATISTICS: Toggled on
Press OK and a new sheet named Statistics will be created. The sheet will contain data
similar in format to that displayed at top of Exhibit 2. The numbers will be different as
they are the result of different random numbers being selected on the Proformas
worksheet with the rand() functions. With this information you can see the mean
expected outcome as well as information that describes the uncertainty in this variable.
VII.
Determine the Distribution of Outcomes by Creating a Histogram:
Type Bins in cell A20 of the Statistics worksheet. Fill cells A21:A45 with numbers that
start at –500 and increase in increments of 500 up to 11,000. In cell B20, type
Frequency. Highlight cells B21:B45 and type the array function:
=frequency(Simulation!$B$4:$B$103,Statistics!$A$21:$A$45) [Ctrl][Shift][Enter]
Column B should now be filled with numbers that describe how many scenarios were
identified as NPV outcomes that were in the range between the bin value in the previous
row and the bin value in the current row. Note that the frequency formula with {}
brackets has been inserted into every cell in B21:B45. This is because the frequency
formula is an array function. Like the Data Table function, you must select the entire
array if you wish to delete the formula.
To normalize the units calculated in the frequency column, we would like to calculate the
percent of outcomes that occurred in the bin range. These percents can then be
interpreted as the probability that an outcome in this range will occur. In cell C20, type
Probability. In cell C21, enter the formula =B21/$B$15. Copy the formula in cell C21 to
cells C22:C45.
The sheet will now contain data similar in format to that displayed in Exhibit 2. The
numbers will be different as they are the result of different random numbers being
selected on the Simulation worksheet. To create the histogram that you see in Exhibit 2,
you will need to graph the probability cells C21:C45 as a Column Graph with the bins
identified in cells A21:A45 as the X-axis values.
VIII.
Identify likelihoods of key target values:
In the Statistics worksheet, enter the following:
Cell E40:
Cell F40:
Cell E41:
Cell F41:
Target Value:
0
P(Exceed Value):
=1-percentrank(Simulation!B4:B103,Statistics!F40)
The formula in cell F41 will count the percent of values in range B4:B103 that exceed the
value entered in cell F40. In our example, the decision criterion was that the NPV should
be positive. Setting F40=0 returns the probability that Sound’s Alive venture will
successfully meet the stated criterion. Note that percentrank calculates the percent of
values below the target value, so to calculate the percent of values above you must
subtract the percentrank value from 100% (or 1.0). You can change F40 to try other
values.
IX.
Confidence Intervals for the Output Parameters
If you delete the results from this simulation run and repeat steps V-VIII, you will find
that your results will not be the same due to different random numbers and thereby
different input assumptions that will be simulated for the three input variables Revenue
Growth %, 2004 Revenues and 2004 Overhead Costs. If you have simulated enough
iterations however, the key statistical results should not be too different between runs.
How different your results might be can be estimated by calculating confidence intervals
for the key output estimates such as the expected values or the probability of meeting a
target value.
To calculate a 95% confidence interval for the mean NPV, program the following
formulas in the Statistics workbook:
48
49
50
A
Mean NPV
Lower Confidence Level
Upper Confidence Level
B
=B3
=$B$48-1.96*$B$4
=$B$48+1.96*$B$4
Here the 1.96 is the z-value associated with a 95% confidence level for the result and cell
B4 should refer to the standard error calculated in the Statistical results. The standard
error is the standard deviation divided by the number of iterations included in the
analysis. It represents the amount of uncertainty that exists around the estimated mean
value according to the Central Limit Theorem.
To calculate a 95% confidence interval for the probability of a positive NPV, program
the following formulas in the Statistics workbook:
41
42
43
E
P(Exceed Value)
Lower Confidence Level
Upper Confidence Level
F
=1-percentrank formula entered earlier
=$F$41-1.96*sqrt($F$41*(1-$F$41)/$B$15)
=$F$41+1.96*sqrt($F$41*(1-$F$41)/$B$15)
Here the 1.96 is the z-value associated with a 95% confidence level for the result and
sqrt($F$41*(1-$F$41)/$B$15) is the formula that calculates the standard error for a
proportion p. The standard error is the square root of (p*(1-p) divided by the number of
iterations included in the analysis). It represents the amount of uncertainty that exists
around an estimated proportion according to the Central Limit Theorem.
NPV
Iteration#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
9101.845
6606.95
3564.165
8612.53
2820.059
5728.982
8341.419
3416.608
3385.52
2332.875
4392.405
4051.427
4151.182
4383.257
8090.669
6271.318
4013.706
6251.096
5515.711
1644.921
5146.773
3819.825
3630.245
2803.757
5892.478
4697.768
6087.439
2436.479
3773.692
8966.976
2244.815
5188.279
1920.217
6922.613
6575.704
7526.402
5611.717
8878.347
5181.765
4016.892
2551.479
4601.338
3074.584
6159.828
2978.951
7440.104
6426.696
2982.847
2808.404
Revenue
Growth
0.101207
0.101669
0.107313
0.111708
0.074338
0.076786
0.123244
0.09183
0.129655
0.07653
0.113608
0.085025
0.088709
0.097472
0.114438
0.085606
0.112897
0.087259
0.099156
0.119285
0.105516
0.092759
0.098211
0.112582
0.12027
0.106121
0.092213
0.103202
0.074077
0.089746
0.099149
0.107571
0.097267
0.104362
0.080991
0.100893
0.121493
0.069281
0.112868
0.098864
0.105914
0.14672
0.141011
0.090003
0.094583
0.051258
0.09807
0.118136
0.110891
2004 Rev 2004 OH
7659.069
6283.583
5689.987
7610.534
5799.081
6226.372
6956.12
5408.23
4757.55
4822.266
5858.289
5750.33
5455.022
5871.827
7528.385
6510.003
5141.297
6586.9
6201.107
4794.771
6136.624
5601.614
5603.858
4807.263
6444.911
5972.589
6529.09
5340.037
5801.552
7571.435
5125.936
5683.251
5293.659
7380.127
7117.52
6853.36
6644.264
7872.302
6201.917
5750.639
4808.926
5094.748
5331.233
7140.657
5791.177
7921.845
6626.449
5299.636
5505.664
1334.867
1077.899
1764.384
1581.836
1911.606
1173.508
1198.815
1463.294
1133.562
1276.221
1642.751
1470.061
1199.748
1538.558
1735.328
1278.443
1135.226
1366.61
1405.981
1775.255
1540.395
1483.912
1597.246
1298.148
1650.008
1571.444
1419.515
1857.806
1543.888
1200.444
1714.632
1133.481
1976.131
1957.093
1649.029
1223.494
1950.988
1300.398
1643.312
1582.755
1356.21
1091.167
1864.212
1909.001
1988.164
1726.633
1422.617
1711.786
1915.718
Exhibit 1: Simulation Results
Column1
NPV
Column2
Mean
4905.212688 Mean
Standard Error
205.4070703 Standard Error
Median
4747.708995 Median
Mode
#N/A
Mode
Standard Deviation 2054.070703 Standard Deviation
Sample Variance
4219206.452 Sample Variance
Kurtosis
-0.530144965 Kurtosis
Skewness
0.087481119 Skewness
Range
9934.501224 Range
Minimum
-118.2677592 Minimum
Maximum
9816.233465 Maximum
Sum
490521.2688 Sum
Count
100 Count
Growth Rate
0.098933334
0.001714621
0.097708253
#N/A
0.017146211
0.000293993
0.54071435
0.173829517
0.095461597
0.051258319
0.146719915
9.893333374
100
Column3
Mean
Standard Error
Median
Mode
Standard Deviation
Sample Variance
Kurtosis
Skewness
Range
Minimum
Maximum
Sum
Count
2004 Revenue
6001.904398
88.03190167
5855.71256
#N/A
880.3190167
774961.5711
-0.572576425
0.247911191
3767.842492
4154.002478
7921.84497
600190.4398
100
EXHIBIT 2:
Possible Results from 100 iterations for the Sound's Alive Company Problem
Bins
Frequency
Total
Mean NPV
Lower Confidence:
Upper Confidence:
0
0
1
0
0
3
3
4
10
6
7
13
6
6
8
9
6
6
5
3
3
0
1
0
0
100
4905.212688
4502.61483
5307.810546
Probability
0.00%
0.00%
1.00%
0.00%
0.00%
3.00%
3.00%
4.00%
10.00%
6.00%
7.00%
13.00%
6.00%
6.00%
8.00%
9.00%
6.00%
6.00%
5.00%
3.00%
3.00%
0.00%
1.00%
0.00%
0.00%
100%
2004 Overhead
Mean
1460.355294
Standard Error
28.28686353
Median
1431.72936
Mode
#N/A
Standard Deviation 282.8686353
Sample Variance
80014.66483
Kurtosis
-1.266152938
Skewness
0.160289462
Range
965.0407923
Minimum
1023.123668
Maximum
1988.16446
Sum
146035.5294
Count
100
14.00%
12.00%
10.00%
8.00%
6.00%
4.00%
2.00%
0.00%
-1000
-500
0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
5500
6000
6500
7000
7500
8000
8500
9000
9500
10000
10500
-1000
-500
0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
5500
6000
6500
7000
7500
8000
8500
9000
9500
10000
10500
11000
Column4
NPV
Target Value
P(Exceed Value)
Lower Confidence
Upper Confidence
0
99.90%
99.281%
100.519%