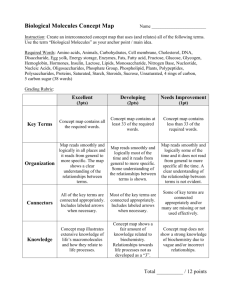
Pre-EXAM
advertisement

Pre-EXAM
-------------------------------------------------------------------------------------------------------1. You need to find out which genes are differentially expressed in cancer in
mouse. You want study differential expression at gene level (as opposed to
transcript level) and you want to focus on known genes (as opposed to finding
novel ones). You have a limited budget for sequencing, so you have to select one
of the following options:
a) obtain 120 million reads (75 bp, single end) from one control sample and one
cancer sample
b) obtain 30 million reads (75 bp, single end) from four control samples and four
cancer samples
c) obtain 90 million reads (150 bp, single end) from one control sample and one
cancer sample
Which option would you choose and why?
2- If your focus was discovering novel transcripts rather than detecting
differential expression, what kind of reads would you order (single end/ paired
end, shorter/longer) and why?
3- RNAseq data analysis involves several steps and quality control can be
performed at different stages of analysis. List what kind of quality aspects can
be measured. As a bonus list names of software for each of these steps.
-------------------------------------------------------------------------------------------------------Practice exam NGS 1 (2p)
A common problem when performing de-novo assembly of next generation
sequencing reads is that the same sequence pattern can occur more than once in
the target sequence. This causes the assembly to break into a set of “contigs”.
In the illustrated case below, the same pattern symbolized by a yellow arrow
occurs three times in the sequenced genome:
Which of the following strategies could reasonably be expected to reduce this
problem? (2p)
YES
I)
II)
III)
IV)
NO
Using paired-end reads
Increasing the read length
Quality trimming of the read data
“Barcoding” the DNA with index sequences
Check “yes” or “no” boxes for +0.5p per correct answer. -0.5p for incorrect
answers, leave both blank for 0p. Total sum will not be counted as negative.
Practice exam NGS 2 (4p)
A researcher is mapping her NGS reads to a reference sequence to find bases that
differ between the reference and the sequenced sample (called single nucleotide
polymorphisms, “SNPs”). One such SNP is reported at the position shown in the
figure.
The researcher is viewing the mapping output using the Tablet software with
settings enabled to show the read direction as green / blue and bases differing
from the reference sequence as red.
a) A false SNP is reported at the indicated position. What is the likely
cause(s)? (2p)
b) Suggest one thing you could do to avoid this problem. (2p)
Introduction to Protein Analysis: Training Questions
Questions
A. Which of the following regular expressions would be matched by sequence
DWILKDG?
1. D-M-x-[ILV]-x{2}-G
2. [DN]-W-x-[ILV]-[RKH]-x-G
3. [DN]-W-x{2}-[ILV]-G
4. D-W-I-[ILMV]-x-K-[GA]
B. Analyze the following protein sequence. What is the function? Do you have
an idea of the structure? Give the evidences that you find (patterns,
profiles,…)
>TRFE_CHICK
YFAVAVARKDSNVNWNNLKGKKSCHTAVGRTAGWVIPMGLIHNRTGTCNFDEYFSEGCAPGS
PPNSRLCQLCQGSGGIPP
EKCVASSHEKYFGYTGALRCLVEKGDVAFIQHSTVEENTGGKNKADWAKNLQMDDFELLCTDG
RRANVMDYRECNLAEVP
THAVVVRPEKANKIRDLLERQEKRFG
NGS
1- What is "low-complexity" sequence? (1p)
2- Explain sequence contaminants and some usual cases (1p)
3- Assembly has three main steps, name them (1p)
------------------------------------------------------------------------------------------------------UNIX
Question 1.
a. In how many ways cat command can be used in unix? (1 pt)
b. Which command you can use to walk upwards and downwards in a file? (1 pt)
Question 2. Write commands that do the following:
a. Lists all files that contains "seq" in the filename (0.5 pt)
b. Creates a new directory “unix” (0.5 pt)
c. Copy the content of the files with word "seq" in the filename into a file called
"tot.txt" (1 pt)
d. Write a one-line command that shows how many files you have in your
current working directory. (2 pt)
1) QTL studies in livestock have been very productive (see animalQTLdb:
http://www.animalgenome.org/QTLdb/ ) why is it hard to identify the
genes underlying the QTL (2P)
2) How can we use gene expression studies to increase the resolution of QTL
studies? (4p)
Using the sequence beowanswer to the following questions:
1- Which species does this sequence belongs to? (1P)
2- Translate this nucleotide sequence to protein (1P)
3- Find out which splice variant this belongs to (1P)
4- Find the cow homolog to this gene and answer if this splice variant is
known in bovine. (4P)
>xng
ATGGGGACTTCCCATCCGGCGTTCCTGGTCTTAGGCTGTCTTCTCACAGGGCTGAGCCTA
ATCCTCTGCCAGCTTTCATTACCCTCTATCCTTCCAAATGAAAATGAAAAGGTTGTGCAG
CTGAATTCATCCTTTTCTCTGAGATGCTTTGGGGAGAGTGAAGTGAGCTGGCAGTACCCC
ATGTCTGAAGAAGAGAGCTCCGATGTGGAAATCAGAAATGAAGAAAACAACAGCGGCCTT
TTTGTGACGGTCTTGGAAGTGAGCAGTGCCTCGGCGGCCCACACAGGGTTGTACACTTGC
TATTACAACCACACTCAGACAGAAGAGAATGAGCTTGAAGGCAGGCACATTTACATCTAT
GTGCCAGACCCAGATGTAGCCTTTGTACCTCTAGGAATGACGGATTATTTAGTCATCGTG
GAGGATGATGATTCTGCCATTATACCTTGTCGCACAACTGATCCCGAGACTCCT
Give examples of why the following steps are important and what the outcome is
when performing a genome-wide association analysis with PLINK (5p).
1)
2)
3)
4)
5)
Making a binary PED file
Perform basic statistics
Perform basic association analysis
Check for stratification
Test the region for genome-wide significance