ModelingStepExercise
advertisement

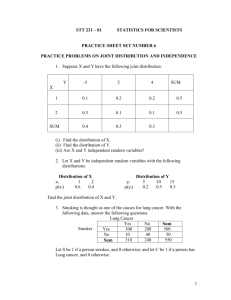
Exercise on Step 1, The Modeling Step Recall Forum F2, where we "completely identified" the random variable of interest as explained in Types of Variables. Therein we identified one qualitative and two quantitative random variables of interest. That was assigned because it is the first part of the first step of statistical inference. Indeed (IMHO), the first step of scientific research in general is to identify the variables you wish to observe through sampling or experimentation. Objectives The objectives of this exercise is to introduce the following concepts. The first step of statistical inference (estimation and significance testing) is to formulate a model for the proposed (observational or experimental) study. All studies include observation of random variables. We use what we know, the sample (data), to make inferences about what is unknown, the parameters of the population (or experimental phenomena). Choice of the optimal inferential procedure depends on the parameters of interest and the assumptions we believe are valid for the study at hand. The assumptions are assumptions about the underlying distributions of the random variables of interest. Instructions For F4, each of us will perform what I call Step 1, the Modeling Step, of my 6-Step Method of Statistical Inference, as summarized briefly in Statistical Inference 6-Step Overview, and as explained fully in 6-Step Method of Estimation. The key to, assumptions of, and formulas for, the four models we will entertain are in Univariate Formulas Tabulated. Document1 1 2/8/2016 We will perform Step 1 three times: 1. Step 1 for estimation of the (population) proportion of the qualitative random variables of interest we identified in F2 Example a. RV of interest Let Xi denote the sex (male, female) of the i-th randomly sampled Stage 4 lung cancer patient in southwest Virginia, i = 1, 2, ..., 100 b. Parameter of interest Let φ denote the proportion of females among all Stage 4 lung cancer patient in southwest Virginia. c. Assumptions (about the underlying distribution) None 2. Step 1 for estimation of the (population) mean of the continuous quantitative random variables of interest we identified in F2, assuming that the underlying distribution is the Normal distribution Example a. RV of interest Let Yi denote the age (yr) of the i-th randomly sampled Stage 4 lung cancer patient in southwest Virginia, i = 1, 2, ..., 100 b. Parameter of interest Let 𝜇 denote the mean age (yr) of all Stage 4 lung cancer patient in southwest Virginia. c. Assumptions (about the underlying distribution) We assume that Yi is Normally distributed Document1 2 2/8/2016 3. Step 1 for estimation of the (population) standard deviation of the continuous quantitative random variables of interest we identified in F2, assuming that the underlying distribution is the Normal distribution Example d. RV of interest Let Yi denote the age (yr) of the i-th randomly sampled Stage 4 lung cancer patient in southwest Virginia, i = 1, 2, ..., 100 e. Parameter of interest Let 𝜎 denote the standard deviation of age (yr) of all Stage 4 lung cancer patient in southwest Virginia. f. Assumptions (about the underlying distribution) We assume that Yi is Normally distributed. Note well The modeling step, being the interface between the biology (psychology, engineering, whatever subject matter) and statistics (a.k.a. analytics) is the most challenging step for both statisticians and non-statisticians. The modeling step involves imagination and creativity. Once the model is formulates, the statistical paradigm is framed, and subsequent steps are nearly automatic and, for the most part, computerized. In first-semester introductory courses, the models are the simplest models, involving only one or two variables. In subsequent courses the models get much more elaborate, employing multiple variables and equations for relationships among the variables. Document1 3 2/8/2016