honors statistics tutorial
advertisement

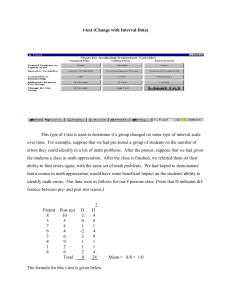
HONORS STATISTICS TUTORIAL To help you with this tutorial, Log into http://www.gla.ac.uk/sums/users/jdbmcdonald/PrePost_TTest/pandt1.html Introducing Experimental Design Many experiments compare two sets of measurements of the same variable. There are many ways of setting up an experiment to produce such data, but when we talk about experimental design, we are referring to a specific aspect of the experiment: whether or not the two sets of measurements can be sensibly paired off with each other. If you can pair off each measurement from one sample with a natural partner from the other sample, then you have a paired design. This may be because you are measuring something twice under different conditions (sometimes called a repeated measures design) or because the two things you are measuring are naturally related; EX: Comparing the running speed of horses for a week of eating one type of feed with the same horses for a week on a different type of feed would be a paired design as you can pair off measurements from the same horse. If there is no sensible way of pairing off the values from the two samples, then you have an independent design. EX: Comparing the running speeds of horses and zebras would be an independent design as there is no sensible way to pair off each horse with each zebra. What is a Hypothesis? A hypothesis is designed to be tested as being either supported or not supported (refuted) by experimental data. This means that a hypothesis will have an opposite, which is the fact that the hypothesis should be rejected! There is a vocabulary that comes with all of this. Here it is: The experimental (or research) hypothesis is the prediction that your theory makes, or the effect you suspect you will see. This is referred to as H1. The null hypothesis is the statement that the effect described in the experimental hypothesis does not exist. This is referred to as H0. One thing to remember when wording your hypotheses is that it is important to decide whether or not you expect to see a difference in a particular direction. If you think that coffee improves memory, then you expect memory scores to be better for coffee drinkers, so there is an expected direction. Here are lists of sentences that represent either an experimental hypothesis or a null hypothesis. Work through them saying which category each falls into and say whether the hypothesis has a direction or not. CHOOSE EITHER: EXPERIMENTAL HYPOTHESIS OR NULL Alcohol consumption does not affect reaction time _________ Does the hypothesis have a direction? _______ Sports drinks improve recovery time after exercise _________ Does the hypothesis have a direction? _______ There is a difference between the ability of girls and boys to learn statistics. ___________ Does the above hypothesis have a direction? ________ Application Here are the two hypotheses from your study. Which is the null and which is the experimental hypothesis? Post-ninth grade student heights will be significantly higher than pre-ninth grade student heights. ________ There is no difference in Pre/Post ninth grade heights ______________________ Is your experimental hypothesis looking for an effect in a certain direction? __________ Introducing Central Tendency The measure of central tendency of your data is the single value that best represents all of the data. It is the value that you would pick if you had to guess which of your data points somebody had chosen at random. This value often (but certainly not always) lies in the 'middle' of the data, in the sense that it has as many values above it as it has below. There are three main measures of central tendency: The mean is the result of adding all the values in your data together and dividing the total by the number of data points you have. The mean is the measure that people often refer to as the average. For example, the mean height is 180 meters; The median is the result of arranging the values in order and finding the middle value in the resulting list. For example, the median age is 45; The mode is the most commonly occurring value in your data. This corresponds to the highest bar in the frequency histogram. For example, the most common number of children in a family is 2. The most appropriate measure for a given data set depends on the data itself. Continuous values such as height are suitable for using the mean, for example 'The mean height is 32.5 cm'. The mode is not a good measure to use with continuous values measured to high accuracy as such data may not contain any repeated values. For example, if you measured the height of ten people to the nearest millimeter, you might get ten different values; Discrete values such as number of children are better suited to the mode or median, thus avoiding 'The average is 2.3 children'; Categorical data such as Color of cars sold should use the mode, for example, 'Red is the most common car color'. Application Your experiment generated data describing two variables. The independent variable, separates your experimental samples into pre-test and post-test. The dependent variable, takes discrete numeric values. Standard Deviation The average of your data summarizes it all in a single value. That certainly throws away a lot of information. If you were to know one more thing about the data, after the average, what would be the most useful thing? The range (largest and smallest) might be useful, but there is a different measure that is even better - the standard deviation. The standard deviation measures how much the data varies: A large number means the data varies a lot A small number means the data varies a little A standard deviation of zero indicates that all the values in the data are identical The standard deviation tells you something more about the average too, as it measures variation in terms of how far from the mean all the values in the sample fall. Values are further from the mean on average when standard deviation is large than they are when it is small. Application A. The standard deviation for when is pre-test is 5.88 B. The standard deviation for when is post-test is 7.88 Which sample has the most variation between its values? Samples and Populations Explanation When You Cannot Measure Everyone We have already seen that data from experiments is generated by taking measurements from a number of different experimental units. For example, we might measure the height of 20 people or the acidity level in 30 soil samples. It is very rare indeed that we will have measured every possible unit (every person in the world or every bit of soil). To make a distinction between the few we have measured and all that we might measure, we use the following words: The population refers to every unit in existence; A sample refers to those units that we have measured. Here are the key points to remember about sampling: What makes up a population depends on the definition you choose for your study. It might be as broad as all people or as narrow as the male members of class 3B; A very common method of collecting samples, known as simple random sampling attempts to ensure that each member of the population has an equal chance of being picked as part of a sample; Descriptive statistics are used to describe certain aspects of a sample (for example, 'The sample mean is 5.4'); Inferential statistics are used to make statements about the whole population based only on what we know about a given sample. The difference between a statistic inferred from the sample and the true population statistic is known as sampling error; The larger a sample gets, the smaller sampling error is likely to get. Application Now we will look at the data from your study. You have collected 30 paired measurements, so you have two samples of 30 each. One is from students in the pre-ninth grade sample and the other is from students in the post-ninth grade sample. Does the data you have collected represent a sample of a larger population, or have you collected a measurement from every possible student there is? ____________________________ What kind of statistics would you use to describe the sample we have collected? Descriptive or Inferential What kind of statistics would you use to infer things about the population based on that sample? Descriptive or Inferential If you doubled your sample size, how would that affect sampling error? Increase or Reduce the sampling error? Choosing a T-Test Explanation Paired or Independent t-test? There are two types of t-test, the paired t-test and the independent t-test. This page tells you how to pick the right one for your data. We have already seen that when comparing two samples, it is important to know whether or not the samples are paired. The section on experimental design covers this in more detail, but here is a quick recap: With paired (dependent) samples, it is possible to take each measurement in one sample and pair it sensibly with one measurement in the other sample. This might be because measurements were taken from the same group twice (repeated measures) or because there is some other way to join measurements, for example, comparing the IQ of older and younger brothers; With independent samples, there is no sensible way to pair off the measurements. One of the reasons that you need to identify the type of experimental design that you are dealing with is that you need to use the right t-test for the right design: The paired t-test is used when you have a paired design The independent t-test is used when you have an independent design The other thing you need to decide at this point is easy to decide, but can be slightly harder to understand. You need to decide which of the following types of effect you expect to find: The first mean to be larger than the second The first mean to be smaller than the second The first mean to be different from the second in either direction You will see this choice referred to in literature and textbooks as the number of tails of the test. The tail is the extreme end of the distribution of the data and your experiment can be one of two types: One tailed tests expect the effect to be in a certain direction, so the first two points above are examples of 1 tailed experiments Two tailed tests are used when you have no idea which sample will be larger than the other, but you are looking for any difference. The third point above is such a case. If you have stated your experimental hypothesis with care, it will tell you which type of effect you are looking for. For example, the hypothesis that "Coffee improves memory" is one tailed because you expect an improvement. The hypothesis, "Men weigh a different amount from women" suggests a two tailed test as no direction is implied. So remember, don't be vague with your hypothesis if you are looking for a specific effect! Exploration Here are a few questions to test yourself to make sure you understand the choice of t-test type and tail number. 1. An experiment measures people's lung capacity before and then after an exercise program to see if their fitness has improved. Which t-test would you use? ______________ How many tails does the test have? ________ 2. A different experiment measures the lung capacity of one group who took one exercise program and another group who took a different exercise program to see if there was a difference. Which t-test would you use? ____________ How many tails does the test have? __________ Application Your experiment compares pre-ninth grade heights with post-ninth grade heights and is measured from the same students under both conditions, Pre- and Post-. Your experimental hypothesis is "Post-ninth grade heights will be significantly higher than Pre-ninth grade heights.", so you know which direction you expect the difference to be in. What is your experimental design? Paired or Independent Which t-test should you choose? Paired t-test or Independent t-test How many tails does your experiment have? 1 tailed or 2 tailed Paired t-test Explanation What a Paired T-Test Does A paired t-test compares two samples in cases where each value in one sample has a natural partner in the other. The concept of paired samples is covered in more detail in the section on choosing a t-test. What a Paired T-Test Measures A paired t-test looks at the difference between paired values in two samples, takes into account the variation of values within each sample, and produces a single number known as a t-value. You can find out how likely it is that two samples from the same population (i.e. where there should be no difference) would produce a t-value as big, or bigger, than yours. This value is called a p-value. So, a t-test measures how different two samples are (the t-value) and tells you how likely it is that such a difference would appear in two samples from the same population (the p-value). P-values How to use a Paired T-Test You will use a software package (EXCEL) to perform a t-test. Software can perform the calculations to produce t-values and p-values, but it is your responsibility to do the following: Pick the right kind of t-test, in this case, a paired t-test and the right direction of test (one or two tailed). See the sections on choosing a t-test for more on this; Ensure the distribution of your data is suitable for a t-test. See the sections on the normal distribution for more on this; Know how to interpret the results of doing a t-test. See the sections on t-values and p-values for more on this. One final practical point: each value in one sample is paired with a single value in the other. When you enter your data into a computer for analysis by a software package, make sure the paired values are lined up. This usually means having data in two columns where each row represents a single pair. The fact that values are paired is very important! T-TEST = A WAY TO COMPARE THE MEANS OF SETS OF DATA USING STATISTICS. p-test = STATISTICAL SIGNIFICANCE BETWEEN THE MEANS. IF THERE IS A STATISTICAL SIGNIFICANCE (p<0.05), the means are statistically significant. The standard benchmark is 5% (0.05) and this is called the significance level. Information from :http://www.gla.ac.uk/sums/users/jdbmcdonald/PrePost_TTest/pandt1.html