Abstract
advertisement

ABSTRACT:
In this study we present a robust target detection algorithm on hyperspectral images. The proposed
approach does not lie on Euclidean space and takes advantage of the limited subclass information of
target such as shape, rotation and size. This approach describes a fast method for computation of
covariance descriptor based on hyperspectral images. The experimental results show a promising
performance improvement in terms of lower false alarm rate, prediction accuracy, compared with the
conventional algorithms which lie on Euclidean space.
INTRODUCTION
As the technology’s advance, hyperspectral image technology has got rapid development. The
applications of hyperspectral image data have extended to agriculture, environment, mine, and so on.
Due to providing much higher resolution, hyperspectral image data could use rather than RGB image
data. Hyperspectral image data is superior to RGB data to discriminate the ground objects and their
characteristics.
The applications of hyperspectral sensor imagery (HSI) for automatic target detection and recognition
(ATD/R) can be considered quite new and exciting area of research. Hyperspectral sensors are one of
the best passive sensors which can simultaneously record hundreds of narrow bands from the
electromagnetic spectrum, which in turns create a new image cube is called a hyperspectral data cube.
[ONCEKI CALISMALAR]
Some of the main limitations with these techniques are the computation complexity for sub-pixel
detection and the tradeoff between in a low false alarm and detection rate. Because of the high
dimensionality of hyperspectral image data, special spectral bands must be selected which have the
greatest influences on discriminating embedded targets from hyperspectral image data. A low false
positive rate coupled with a high detection rate is necessary; especially in military area where target
detection was wide area surveillance is needed. In these tasks, a very low false positive rate is
compulsory to increase the level of confidence that the targets identified are real.
Goals of the Work: Our main goal is to design a target detection algorithm that is showing promising
performance in terms of computation and false alarm rate. According to our, the technique can be
divided into four sections: Elimination of unnecessary pixel spectra, dimension reduction, grouping
candidate pixel spectra and target checking. Figure 1 provides an overview of our approach for
detecting a known set of targets in a hyperspectral image.
The rest of this paper describes our methodology used to investigate target detection in detail. These
targets are man-made six randomized rotated target with total sixty six pixel in well-known Urban Image
[ref]
2. ELIMINATING UNNECESSARY SPECTRA
In this paper, we have chosen a covariance descriptor both for target detection and eliminating
unnecessary spectra data from image data. A brief description of the eliminating algorithm is as follows.
At each spectra, we construct a feature matrix. For a given spectra, we compute the covariance matrix
of the features. This descriptor has low dimensionality and it is invariant to in-plane rotations and size.
Covariance matrix of interested area does not vary from interested spectra of image data. For each
spectra, covariance distance to target covariance of spectra is calculated.
2.1 Feature Arrangements
Each spectra is converted to a number of bands of spectra x 4 dimensional matrix.
Burada porikli gibi vectoru göster
Where m(y) is the mean of the spectra, and d’d’’ are the first and second order derivates respectively.
The covariance of each spectra is producing a 4x4 matrix to compare with target spectra 4x4 matrix.
2.2 Distance Metric
Covariance matrices are not suitable for arithmetic operations such as multiplication or addition
because of not lying on the Euclidean space,. We need to compute distances between the covariance
matrices corresponding to the target spectra and the candidate spectra. We use the distance measure
proposed in [xxxxxx] to measure the dissimilarity of two covariance matrices. Shortly, sum of the
squared logarithms of the generalized eigenvalues are used to compute the similarity between
covariance matrices as
and xk are the generalized eigenvectors. At each spectra pixel, we search the whole image to find the
spectra which has the smallest distance from the target spectra. Figure x indicates our algorithm
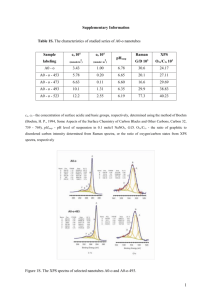
performance compared with Vector Angle, Fourier Phase and Derivative Difference algorithms.
Following roc analysis indicate %0, %10, and %30, %60 variance of the Gaussian noise added and filtered
with a mean filter respectively.
ROC Analizlerini koy
3. DIMENSION REDUCTION
Mutual information measures how much one random variable tells us about another. High mutual
information indicates a large reduction in uncertainty; low mutual information indicates a small
reduction; and zero mutual information between two random variables means the variables are
independent. [wikipedia reference] In this paper we aim to introduce mutual information based
dimension reduction. The goal is to select a feature subset set that best characterizes the statistical
property of a target classification variable, subject to the constraint that these features are mutually as
dissimilar to each other as possible, but marginally as similar to the classification variable as possible.
The fundamental idea of our algorithm is that it selects first 10 bands that maximizes its mutual
information, and does this using entire data set. If a band has expressions randomly or uniformly
distributed in different spectra, its mutual information with these spectra data is zero. If a band is
strongly differentially expressed for different spectra data, it should have large mutual information. As a
result of this, we use mutual information as a measure of relevance of bands.
Formally, the mutual information of two discrete random variables X and Y can be defined as: mutual
information of two variables and is based on their joint probabilistic distribution
wiki
At this stage we have used “Minimum Redundancy Maximum Relevance Feature Selection”
algorithm.[ref] The idea of minimum redundancy is selecting spectra mutually maximally dissimilar. The
minimum redundancy condition is
To measure the level of discriminator powers of bands when they are differentially expressed for
different targeted classes, we again use mutual information I(h,gi) between targeted classes
={h1,h2,…,hK} (we call h the classification variable) and the band expression gi. Thus I(h,gi) quantifies the
relevance of gi for the classification task. Class information is obtained by stage 1 of our algorithm. In
our case, classes should be considered only two. And as it described in [], the redundancy and relevance
feature set is obtained by optimizing these two equations. We have also used :
And shortly can be expressed as
As a result of this stage, unnecessary bands can be eliminated and only best bands which are describing
our image data the best will be used for grouping.
4. GROUPING DATA
NON-RIGID OBJECT LOCALIZATION FROM COLOR MODEL USING MEAN SHIFT
In our algorithm the only parameter that our approach need is window size. This parameter can be
estimated as :
H = Latitude / size of target
T