Chapter 5: Matrix approach to simple linear
advertisement

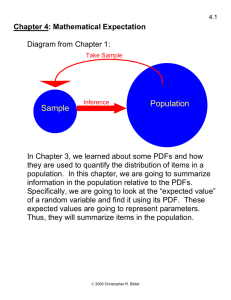
5.1
Chapter 5: Matrix approach to simple linear regression
analysis
You need to understand matrix algebra for multiple
regression! Fox’s Section 8.2 contains information about
how to use R for matrix algebra.
5.1 Matrices
What is a matrix?
“A matrix is a rectangular array of elements arranged in
rows and columns” (p. 176 of KNN)
Example:
1 2 3
4 5 6
Dimension – Size of matrix: # rows # columns = rc
Example: 23
Symbolic representation of a matrix:
Example:
a12
a
A 11
a21 a22
a13
a23
2012 Christopher R. Bilder
5.2
where aij is the row i and column j element of A
a11=1 from the above example
Notice that the matrix A is in bold. When bolding is not
possible (writing on a piece of paper or chalkboard), the
letter is underlined - A
a11 is often called the “(1,1) element” of A, a12 is called
the “(1,2) element” of A,…
Example: rc matrix
a11 a12
a
a22
21
A
ai1 ai2
ar1 ar 2
a1j
a2 j
aij
arj
a1c
a2c
aic
arc
Example: Square matrix is rc where r=c
Example: HS and College GPA
2012 Christopher R. Bilder
5.3
1 3.04
1 2.35
1 2.70
X
1 2.28
1 1.88
The above 202 matrix contains the HS GPAs in the
second column.
Vector – a r1 (column vector) or 1c (row vector) matrix –
special case of a matrix
Example: Symbolic representation of a 31 column vector
a1
A a 2
a3
Example: HS and College GPA
3.10
2.30
3.00
Y
2.20
1.60
The above 201 vector contains the College GPAs.
2012 Christopher R. Bilder
5.4
Transpose: Interchange the rows and columns of a matrix or
vector
Example:
a11
a12 a13
a
a
A 11
A
and
12
a
a
a
22
23
21
a13
A is 23 and A is 32
a21
a22
a23
The symbol indicates a transpose, and it is said as the
word “prime”. Thus, the transpose of A is “A prime”.
Example: HS and College GPA
Y 3.10 2.30 3.00
2.20 1.60
2012 Christopher R. Bilder
5.5
5.2 Matrix addition and subtraction
Add or subtract the corresponding elements of matrices
with the same dimension.
Example:
1 2 3
1 10 1
and
B
Suppose A
. Then
4 5 6
5 5 8
0 12 2
2 8 4
A B
and A B
.
9 10 14
1 0 2
Example: Using R (basic_matrix_algebra.R)
> A<-matrix(data = c(1, 2, 3,
4, 5, 6), nrow = 2, ncol = 3, byrow =
TRUE)
> class(A)
[1] "matrix"
> B<-matrix(data = c(-1, 10, -1, 5, 5, 8), nrow = 2, ncol =
3, byrow = TRUE)
> A+B
[,1] [,2] [,3]
[1,]
0
12
2
[2,]
9
10
14
> A-B
[,1] [,2] [,3]
[1,]
2
-8
4
[2,]
-1
0
-2
2012 Christopher R. Bilder
5.6
Notes:
1. Be careful with the byrow option. By default, this is set
to FALSE. Thus, the numbers would be entered into
the matrix by columns. For example,
>
matrix(data = c(1, 2, 3, 4, 5, 6), nrow = 2, ncol = 3)
[,1] [,2] [,3]
[1,]
1
3
5
[2,]
2
4
6
2. The class of these objects is “matrix”.
3. A vector can be represented as a “matrix” class type or
a type of its own.
>
y<-matrix(data = c(1,2,3), nrow = 3, ncol = 1, byrow
= TRUE)
>
y
[,1]
[1,]
1
[2,]
2
[3,]
3
>
class(y)
[1] "matrix"
>
>
[1]
>
[1]
>
[1]
x<-c(1,2,3)
x
1 2 3
class(x)
"numeric"
is.vector(x)
TRUE
This can present some confusion when vectors are
multiplied with other vectors or matrices because no
specific row or column dimensions are given. More on
this shortly.
2012 Christopher R. Bilder
5.7
4. A transpose of a matrix can be done using the t()
function. For example,
>
t(A)
[,1] [,2]
[1,]
1
4
[2,]
2
5
[3,]
3
6
Example: Simple linear regression model
Yi=E(Yi) + i for i=1,…,n can be represented as
Y E( Y ) where
Y1
Y
Y 2 , E(Y )
Yn
E(Y1 )
1
E(Y )
2
, and 2
E(Y
)
n
n
2012 Christopher R. Bilder
5.8
5.3 Matrix multiplication
Scalar - 11 matrix
Example: Matrix multiplied by a scalar
ca11 ca12
cA
ca21 ca22
ca13
where c is a scalar
ca23
1 2 3
2 4 6
2
A
Let A
and
c=2.
Then
.
4 5 6
8 10 12
Multiplying two matrices
Suppose you want to multiply the matrices A and B; i.e.,
AB or AB. In order to do this, you need the number of
columns of A to be the same as the number of rows as
B. For example, suppose A is 23 and B is 310. You
can multiply these matrices. However if B is 410
instead, these matrices could NOT be multiplied.
The resulting dimension of C=AB
1. The number of rows of A is the number of rows of C.
2. The number of columns of B is the number of rows of
C.
3. In other words, C A B where the dimension of the
wy
w z z y
matrices are shown below them.
2012 Christopher R. Bilder
5.9
How to multiply two matrices – an example
3 0
1 2 3
1 2 . Notice that A
and
B
Suppose A
4 5 6
0 1
is 23 and B is 32 so C=AB can be done.
3 0
1 2 3
C AB
1
2
4
5
6
0 1
1 3 2 1 3 0 1 0 2 2 3 1
4 3 5 1 6 0 4 0 5 2 6 1
5 7
17 16
The “cross product” of the rows of A and the columns of
B are taken to form C
In the above example, D=BAAB where BA is:
2012 Christopher R. Bilder
5.10
3 0
1 2
BA 1 2
4 5
0 1
3 1 0 4
1 1 2 4
0 1 1 4
3
6
3 2 0 5 3 3 0 6
1 2 2 5 1 3 2 6
0 2 1 5 0 3 1 6
3 6 9
9 12 15
4 5 6
In general for a 23 matrix times a 32 matrix:
b11 b12
a11 a12 a13
C AB
b21 b22
a21 a22 a23 b
31 b32
a11b11 a12b21 a13b31 a11b12 a12b22 a13b32
a
b
a
b
a
b
a
b
a
b
a
b
22 21
23 31
21 12
22 22
23 32
21 11
Example: Using R (basic_matrix_algebra.R)
>
>
A<-matrix(data = c(1, 2, 3, 4, 5, 6), nrow = 2, ncol =
3, byrow = TRUE)
B<-matrix(data = c(3, 0, 1, 2, 0, 1), nrow = 3, ncol =
2, byrow = TRUE)
2012 Christopher R. Bilder
5.11
>
>
C<-A%*%B
D<-B%*%A
>
C
[,1] [,2]
[1,]
5
7
[2,]
17
16
>
D
[,1] [,2] [,3]
[1,]
3
6
9
[2,]
9
12
15
[3,]
4
5
6
>
#What is A*B?
>
A*B
Error in A * B : non-conformable arrays
Notes:
1. %*% is used for multiplying matrices and/or vectors
2. * means to perform elementwise multiplications. Here
is an example where this can be done:
>
>
E<-A
A*E
[,1] [,2] [,3]
[1,]
1
4
9
[2,]
16
25
36
The (i,i) elements of each matrix are multiplied
together.
3. Multiplying vectors with other vectors or matrices can
be confusing since no row or column dimensions are
2012 Christopher R. Bilder
5.12
given for a vector object. For example, suppose x =
1
2 , a 31 vector
3
>
>
x<-c(1,2,3)
x%*%x
[,1]
[1,]
14
>
A%*%x
[,1]
[1,]
14
[2,]
32
How does R know that we want xx (11) instead of
xx (33) when we have not told R that x is 31?
Similarly, how does R know that Ax is 21? From the
R help for %*% in the Base package:
Multiplies two matrices, if they are conformable. If
one argument is a vector, it will be promoted to
either a row or column matrix to make the two
arguments conformable. If both are vectors it will
return the inner product.
An inner product produces a scalar value. If you
wanted xx (33), one can use the outer product %o%
> x%o%x #outer product
[,1] [,2] [,3]
[1,]
1
2
3
[2,]
2
4
6
[3,]
3
6
9
2012 Christopher R. Bilder
5.13
We will only need to use %*% in this class.
Example: HS and College GPA (HS_college_GPA_ch5.R)
1
1
1
X
1
1
3.04
3.10
2.30
2.35
3.00
2.70
Y
and
2.20
2.28
1.88
1.60
Find XX, XY, and YY
> #Read in the data
> gpa<-read.table(file =
"C:\\chris\\UNL\\STAT870\\Chapter1\\gpa.txt",
header=TRUE, sep = "")
> head(gpa)
HS.GPA College.GPA
1
3.04
3.1
2
2.35
2.3
3
2.70
3.0
4
2.05
1.9
5
2.83
2.5
6
4.32
3.7
> X<-cbind(1, gpa$HS.GPA)
> Y<-gpa$College.GPA
> X
[,1] [,2]
2012 Christopher R. Bilder
5.14
[1,]
[2,]
[3,]
[4,]
[5,]
[6,]
[7,]
[8,]
[9,]
[10,]
[11,]
[12,]
[13,]
[14,]
[15,]
[16,]
[17,]
[18,]
[19,]
[20,]
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
3.04
2.35
2.70
2.05
2.83
4.32
3.39
2.32
2.69
0.83
2.39
3.65
1.85
3.83
1.22
1.48
2.28
4.00
2.28
1.88
> Y
[1] 3.1 2.3 3.0 1.9 2.5 3.7 3.4 2.6 2.8 1.6 2.0 2.9 2.3
3.2 1.8 1.4 2.0 3.8 2.2
[20] 1.6
> t(X)%*%X
[,1]
[,2]
[1,] 20.00 51.3800
[2,] 51.38 148.4634
> t(X)%*%Y
[,1]
[1,] 50.100
[2,] 140.229
> t(Y)%*%Y
[,1]
[1,] 135.15
Notes:
2012 Christopher R. Bilder
5.15
1. The cbind() function combines items by “c”olumns.
Since 1 is only one element, it will replicate itself for
all elements that you are combining so that one full
matrix is formed. There is also a rbind() function that
combines by rows. Thus, rbind(a,b) forms a matrix
with a above b.
y1
y n
2
2. Y Y y1,y2 ,...,yn yi2
i1
yn
y1 n
n
xi1yi
yi
xn1 y2
i1
x11 x21
i1
n
3. X Y
n
xn2 x y x y
x12 x22
i2 i
i2 i
i
1
i
1
yn
since x11=…=xn1=1
4. XX
x11
x12
1
x12
x21
x22
1
x22
x11 x12
xn1 x21 x22
xn2
x
x
n2
n1
1 x12
n
1 1 x22
n x
xn2
i2
i
1
1 xn2
2012 Christopher R. Bilder
xi2
i 1
n
2
xi2
i 1
n
5.16
5. Here’s another way to get the X matrix
> mod.fit<-lm(formula = College.GPA ~ HS.GPA, data =
gpa)
> model.matrix(object = mod.fit)
(Intercept) HS.GPA
1
1
3.04
2
1
2.35
3
1
2.70
4
1
2.05
5
1
2.83
6
1
4.32
7
1
3.39
8
1
2.32
9
1
2.69
10
1
0.83
11
1
2.39
12
1
3.65
13
1
1.85
14
1
3.83
15
1
1.22
16
1
1.48
17
1
2.28
18
1
4.00
19
1
2.28
20
1
1.88
attr(,"assign")
[1] 0 1
2012 Christopher R. Bilder
5.17
5.4 Special types of matrices
Symmetric matrix: If A=A, then A is symmetric.
1 2
1 2
,
A
Example: A
2 3
2 3
Diagonal matrix: A square matrix whose “off-diagonal”
elements are 0.
0
a11 0
Example: A 0 a22 0
0
0 a33
Identity matrix: A diagonal matrix with 1’s on the diagonal.
1 0 0
Example: I 0 1 0
0 0 1
Note that “I” (the letter I, not the number one) usually
denotes the identity matrix.
Vector and matrix of 1’s
1
1
A column vector of 1’s: 1 j
r 1
r 1
1
2012 Christopher R. Bilder
5.18
1 1
1 1
A matrix of 1’s: J
r r
1 1
Notes:
1. j j r
1
1
1
r 1 r 1
2. j j J
r 1r 1
r r
3. J J r J
r r r r
r r
0
0
Vector of 0’s: 0
r 1
0
2012 Christopher R. Bilder
5.19
5.5 Linear dependence and rank of matrix
1 2 6
Let A 3 4 12 . Think of each column of A as a
5 6 18
vector; i.e., A = [A1, A2, A3]. Note that 3A2=A3. This
means the columns of A are “linearly dependent.”
Formally, a set of column vectors are linearly dependent
if there exists constants 1, 2,…, n (not all zero) such
that 1A1+2A2+…+cAc=0. A set of column vectors are
linearly independent if 1A1+2A2+…+cAc=0 only for
1=2=…=c=0 .
The rank of a matrix is the maximum number of linearly
independent columns in the matrix.
rank(A)=2
2012 Christopher R. Bilder
5.20
5.6 Inverse of a matrix
Note that the inverse of a scalar, say b, is b-1. For
example, the inverse of b=3 is 3-1=1/3. Also, bb-1=1. In
matrix algebra, the inverse of a matrix is another matrix.
For example, the inverse of A is A-1, and AA-1=A-1A=I.
Note that A must be a square matrix.
1
1 2 1 2
,
A
Example: A
1.5 0.5
3 4
Check:
1 ( 2) 2 1.5 1 1 2 * ( 0.5) 1 0
1
AA
0 1
3
(
2)
4
1.5
3
1
4
*
(
0.5)
Finding the inverse
For a general way, see a matrix algebra book (such as:
Kolman, 1988). For a 22 matrix, there is a simple
a11 a12
formula. Let A
. Then
a21 a22
a22 a12
1
1
A
.
a11a22 a12 a21 a21 a11
Verify AA-1=I on your own.
Example: Using R (basic_matrix_algebra.R)
>
A<-matrix(data = c(1, 2, 3, 4), nrow = 2, ncol = 2,
byrow = TRUE)
2012 Christopher R. Bilder
5.21
>
solve(A)
[,1] [,2]
[1,] -2.0 1.0
[2,] 1.5 -0.5
>
A%*%solve(A)
[,1]
[,2]
[1,]
1 1.110223e-16
[2,]
0 1.000000e+00
>
solve(A)%*%A
[,1] [,2]
[1,] 1.000000e+00
0
[2,] 1.110223e-16
1
>
round(solve(A)%*%A, 2)
[,1] [,2]
[1,]
1
0
[2,]
0
1
The solve() function inverts a matrix in R. The
solve(A,b) function can also be used to “solve” for x in
Ax = b since A-1Ax = A-1b Ix = A-1b x = A-1b
Example: HS and College GPA (HS_college_GPA_ch5.R)
1 3.04
3.10
1 2.35
2.30
1 2.70
3.00
Remember that X
and Y
1 2.28
2.20
1 1.88
1.60
Find (XX)-1 and (XX)-1XY
2012 Christopher R. Bilder
5.22
> solve(t(X)%*%X)
[,1]
[,2]
[1,] 0.4507584 -0.15599781
[2,] -0.1559978 0.06072316
> solve(t(X)%*%X) %*% t(X)%*%Y
[,1]
[1,] 0.7075776
[2,] 0.6996584
From previous output:
> mod.fit<-lm(formula = College.GPA ~ HS.GPA, data = gpa)
> mod.fit$coefficients
(Intercept)
HS.GPA
0.7075776
0.6996584
b0
Note that (XX)-1XY = !!!
b1
>
>
>
#Another way to get (X'X)^(-1)
sum.fit<-summary(mod.fit)
sum.fit$cov.unscaled
(Intercept)
HS.GPA
(Intercept)
0.4507584 -0.15599781
HS.GPA
-0.1559978 0.06072316
Read “Uses of Inverse Matrix” on p. 192 of KNN on your
own.
2012 Christopher R. Bilder
5.23
5.7 Some basic theorems of matrices
Read on your own.
5.8 Random vectors and matrices
A random vector or random matrix contains elements that
are random variables.
Example: Simple linear regression model
Yi=E(Yi) + i for i=1,…,n can be represented as
Y E( Y ) where
Y1
1
Y
2
Y and 2 are random vectors.
Y
n
n
Expectation of random vector or matrix: Find the expected
value of the individual elements
Example:
Y1 E(Y1 ) 0 1X1
X
Y
E(Y
2
2)
1 2
0
E( Y ) E
Y
E(Y
)
X
n
n
0
1
n
2012 Christopher R. Bilder
5.24
1 E(1 ) 0
0
E(
2
2)
since we assume
E(ε ) E
E(
)
n
n
0
i~N(0,2)
Variance-covariance matrix of a random vector
Let Z1 and Z2 be random variables. Remember that
Var(Z1)=E(Z1-1)2 where E(Z1)=1.
The covariance of Z1 and Z2 is defined as Cov(Z1,Z2) =
E[(Z1-1)(Z2-2)]. The covariance measures the
relationship between Z1 and Z2. See p. 4.26 of my
Chapter 4 STAT 380 notes for a more mathematical
explanation (http://www.chrisbilder.com/
stat380/schedule.htm). Note that the correlation
between Z1 and Z2 is
Corr(Z1,Z2 )
Cov(Z1,Z2 )
Var(Z1 ) Var(Z2 )
.
The “Pearson correlation coefficient” which is denoted by
r and estimates Corr(Z1, Z2)
2012 Christopher R. Bilder
5.25
n
Remember that r
(Xi X)(Yi Y)
i 1
n
n
2
(Xi X) (Yi Y)2
i1
i1
where X=Z1 and Y=Z2.
Notes:
Cov(Z1,Z1)=E[(Z1-1)(Z1-1)]=E[(Z1-1)2]=Var(Z1)
If Z1 and Z2 are independent, then Cov(Z1,Z2)=0.
A variance-covariance matrix (most often just called the
covariance matrix) is a matrix whose elements are the
variances and covariances of random variables.
Z1
Example: Let Z . The covariance matrix of Z is
Z2
Cov(Z1,Z2 )
Var(Z1 )
Cov(Z) =
Var(Z2 )
Cov(Z1,Z2 )
Note that Cov(Z1,Z2)=Cov(Z2,Z1) and Cov(Zi,Zi)=Var(Zi)
KNN denote Cov(Z) by 2{Z}. The notation that I am
using is much more prevalent and there is less chance
for confusion (like Z being multiplied by 2 in 2{Z}).
Example: Simple linear regression model
2012 Christopher R. Bilder
5.26
0
0
Var(1 )
0
Var(2 )
0
Cov( )
0
0
Var(
)
n
2 0
0
2
0
0
= 2I
2
0
0
since Cov(i,i)=0 (Remember that i ~ INDEPENDENT
N(0,2)).
What is Cov(Y)?
Note that all covariance matrices are symmetric!
Some basic results
Let W = AY where Y is a random vector and A is a
matrix of constants (no random variables in it).
The following results follow:
1. E(A) = A
Remember this is like saying E(3) = 3
2012 Christopher R. Bilder
5.27
2. E(W) = E(AY) = AE(Y)
Again, this is like saying E(3Y1)=3E(Y1)
3. Cov(W) = Cov(AY) = ACov(Y)A
You may have seen before that Var(aY1) = a2Var(Y1)
where a is a constant.
Example:
1 1
Y1
Y1 Y2
and
Y
W
Let A
.
Then
.
1 0
Y2
Y1
2.
1 1 Y1
E( W ) E
1 0 Y2
E(Y1 ) E(Y2 )
E(Y
)
1
1 1 Y1
1 0 E Y
2
3.
2012 Christopher R. Bilder
5.28
1 1 Y1 1 1
Y1 1 1
Cov( W ) Cov
Y 1 0 Cov Y 1 0
1
0
2
2
Cov(Y1,Y2 ) 1 1
1 1 Var(Y1 )
Var(Y2 ) 1 0
1 0 Cov(Y1,Y2 )
Var(Y1 ) Cov(Y1,Y2 ) Cov(Y1,Y2 ) Var(Y2 ) 1 1
1 0
Var(Y1 )
Cov(Y1,Y2 )
Var(Y1 ) Var(Y2 ) 2Cov(Y1,Y2 ) Var(Y1 ) Cov(Y1,Y2 )
Var(Y1 ) Cov(Y1,Y2 )
Var(Y1 )
2012 Christopher R. Bilder
5.29
5.9 Simple linear regression model in matrix terms
Yi=0+1Xi+i where i~ independent N(0,2) and i=1,…,n
The model can be rewritten as
Y1=0+1X1+1
Y2=0+1X2+2
Yn=0+1Xn+n
In matrix terms, let
Y1
1 X1
Y
1 X
2
2
Y , X=
,
Y
1
X
n
n
1
0
2
and
1
n
Then Y = X + , which is
Y1 1 X1
1 0 X11 1
Y 1 X
X
2 1
2
2
0
2
2 0
1
X
Y
1
X
n 1
n
n
n
n 0
Note that E(Y) = E(X + ) = E(X) + E() = X since E() = 0
and X are constants.
2012 Christopher R. Bilder
5.30
5.10 Least squares estimation of regression parameters
From Chapter 1: The least squares method tries to find
the b0 and b1 such that SSE = (Y- Ŷ )2 = (residual)2 is
minimized. Formulas for b0 and b1 are derived using
calculus.
It can be shown that b0 and b1 can be found from solving
the “normal equations”:
n
n
i 1
i 1
nb0 b1 Xi Yi
n
n
i 1
i 1
n
b0 Xi b1 X Xi Yi
2
i
i 1
The normal equations can be rewritten as XXb XY
b0
where b . In Section 5.3, it was shown that
b1
Y1 n
Yi
1 Y2
i1
1 1
XY
and
n
X
X
X
2
n
1
Xi Yi
i
1
Yn
1 X1
n
1 1 X2
1 1
XX
n X
Xn
X1 X2
i
i
1
1 Xn
Thus, XXb XY can be written as
2012 Christopher R. Bilder
Xi
i 1
.
n
2
Xi
i 1
n
5.31
n
n
n
Xi
Yi
b0 i1
i 1
n
b n
n
2 1
Xi Xi
Xi Yi
i 1
i1
i 1
n
n
nb b
Xi
Yi
0
1
i1
i 1
n
n
n
2
b0 Xi b1 Xi Xi Yi
i 1
i1
i1
Suppose both sides of XXb XY are multiplied by
(XX)-1. Then
( X X )1 X Xb ( X X )1 X Y
Ib ( X X )1 X Y
b ( X X )1 X Y
Therefore, we have a way to find b using matrix algebra!
Note that
b ( X X )1 X Y
n
n
Xi
i1
Xi
i 1
n
2
Xi
i 1
n
1
n
Yi
i1
n
Xi Yi
i1
2012 Christopher R. Bilder
5.32
1
n
Xi2
i1
n
Xi
i1
n
Xi
Yi
i1
i 1
n
n Xi Yi
i1
n
Y
X
X
X
Y
1
n (X X) Y X n X Y
n
n
n X Xi
i 1
2
i
2
i 1
n
i 1
n
i 1
2
n
i
i 1
n
i
i 1
n
2
i
i 1
n
i
i 1
n
i
i 1
i
i
n
i
i 1
i
i
Y b1X
(Xi X)(Yi Y)
2
(Xi X)
Example: HS and College GPA (HS_college_GPA_ch5.R)
1 3.04
3.10
1 2.35
2.30
1 2.70
3.00
Remember that X
and Y
1 2.28
2.20
1 1.88
1.60
Find b ( X X )1 X Y . We already did this on p. 5.22.
> solve(t(X)%*%X) %*% t(X)%*%Y
[,1]
[1,] 0.7075776
[2,] 0.6996584
2012 Christopher R. Bilder
5.33
>
>
#Using the formulation of solve for x in Ax = b
solve(t(X)%*%X, t(X)%*%Y)
[,1]
[1,] 0.7075776
[2,] 0.6996584
From previous output:
> mod.fit<-lm(formula = College.GPA ~ HS.GPA, data = gpa)
> mod.fit$coefficients
(Intercept)
HS.GPA
0.7075776
0.6996584
2012 Christopher R. Bilder
5.34
5.11 Fitted values and residuals
Ŷ1
Let Yˆ . Then Yˆ Xb since
Ŷ
n
Ŷ1 1 X1
b0 b1X1
b
0
b1
Y
ˆ
b0 b1Xn
n 1 Xn
ˆ Xb X(XX )1 X ' Y ΗY where H=X(XX)-1X
Hat matrix: Y
is the hat matrix
Why is this called the Hat matrix?
We will use this in Chapter 10 to measure the influence
of observations on the estimated regression line.
Residuals:
ˆ1
e1 Y1 Y
Let e
Y Yˆ Y HY Y(I H)
ˆn
en Yn Y
Covariance matrix of the residuals:
Cov(e) = Cov(Y(I-H)) = (I-H)Cov(Y)(I-H)
2012 Christopher R. Bilder
5.35
Now, Cov(Y) = Cov(X + ) = Cov() since X are
constants. And, Cov() = 2I
Also, (I-H) = (I-H) and (I-H)(I-H) = (I-H). (I-H) is called a
symmetric “idempotent” matrix. You can use matrix
algebra to see this result on your own (replace H with
X(XX)-1X and multiply out).
Thus, Cov(e) = (I-H)2I(I-H) = 2(I-H).
The estimated covariance matrix of the residuals is then
Cov(e) MSE (I H) ˆ 2 (I H), say . Note that KNN
would denote Cov(e) as s2{e}. The Cov(e) notation is
more predominantly used.
2012 Christopher R. Bilder
5.36
5.12 Analysis of variance results
Sums of Squares
n
From Chapters 1 and 2: SSTO (Yi Y)2 ,
i 1
n
n
i 1
i 1
ˆ 2 , and SSR SSTO SSE (Yˆ i Y)2
SSE (Yi Y)
These can be rewritten using matrices:
1
SSTO Y Y Y JY
n
Y1
1
Y1
Yn
Y
n 1
Yn
1
Yi2 Yi
i 1
n i1
n
n
2
Y1
Yi
i 1
Yn
n
1 n
Yi Yi
i 1
n i1
n
1
Yn
1
2
n
(Yi Y)2
i 1
SSE ee e1
e1
n
n
2
en
ei (Yi Yˆ i )2
i1
i 1
en
2012 Christopher R. Bilder
1 Y1
1 Yn
5.37
1
SSR bX Y Y JY SSTO SSE
n
Example: HS and College GPA (HS_college_GPA_ch5.R)
Continuing the same program
> n<-length(Y)
>
>
>
>
>
#Can not use rows here since R does not
know Y's dimension
#Could use nrow(X) as well - X is a nx2
matrix
b<-solve(t(X)%*%X) %*% t(X)%*%Y
Y.hat<-X%*%b
e<-Y-Y.hat
H<-X%*%solve(t(X)%*%X)%*%t(X)
> J<-matrix(data = 1, nrow = n, ncol = n)
>
#Notice that R will repeat 1 the correct number of
times to fill the matrix
> SSTO<-t(Y)%*%Y - 1/n%*%t(Y)%*%J%*%Y
> SSE<-t(e)%*%e
> MSE<-SSE/(n-nrow(b))
> #Notice how MSE uses * to do the multiplying since it is
a scalar. Also diag(n) creates an identity matrix.
Diag(c(1,2)) would create a 2x2 diagonal matrix with
elements 1 and 2 on the diagonal
> Cov.e<-MSE*(diag(n) - H) #Does not work!
Error in MSE * (diag(n) - H) : non-conformable arrays
> Cov.e<-as.numeric(MSE)*(diag(n) - H) #The as.numeric()
removes 1x1 matrix
meaning from MSE
> SSR = SSTO - SSE
> data.frame(X, Y, Y.hat, e)
X1
X2
Y
Y.hat
e
2012 Christopher R. Bilder
5.38
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
3.04
2.35
2.70
2.05
2.83
4.32
3.39
2.32
2.69
0.83
2.39
3.65
1.85
3.83
1.22
1.48
2.28
4.00
2.28
1.88
3.1
2.3
3.0
1.9
2.5
3.7
3.4
2.6
2.8
1.6
2.0
2.9
2.3
3.2
1.8
1.4
2.0
3.8
2.2
1.6
2.834539
2.351775
2.596655
2.141877
2.687611
3.730102
3.079420
2.330785
2.589659
1.288294
2.379761
3.261331
2.001946
3.387269
1.561161
1.743072
2.302799
3.506211
2.302799
2.022935
0.26546091
-0.05177482
0.40334475
-0.24187731
-0.18761083
-0.03010181
0.32058048
0.26921493
0.21034134
0.31170591
-0.37976115
-0.36133070
0.29805437
-0.18726921
0.23883914
-0.34307203
-0.30279873
0.29378887
-0.10279873
-0.42293538
> data.frame(n, SSTO, SSE, MSE, SSR)
n
SSTO
SSE
MSE
SSR
1 20 9.6495 1.587966 0.08822035 8.061534
> round(Cov.e[1:5, 1:5],6) #5x5 part of Cov(e)
[,1]
[,2]
[,3]
[,4]
[,5]
[1,] 0.082621 -0.003858 -0.004742 -0.003101 -0.005070
[2,] -0.003858 0.083552 -0.004257 -0.005020 -0.004105
[3,] -0.004742 -0.004257 0.083717 -0.004047 -0.004594
[4,] -0.003101 -0.005020 -0.004047 0.082366 -0.003685
[5,] -0.005070 -0.004105 -0.004594 -0.003685 0.083444
> #From past work
> data.frame(X = model.matrix(mod.fit), Y.hat =
mod.fit$fitted.values, e = mod.fit$residuals)
X..Intercept. X.HS.GPA
Y.hat
e
1
1
3.04 2.834539 0.26546091
2
1
2.35 2.351775 -0.05177482
3
1
2.70 2.596655 0.40334475
4
1
2.05 2.141877 -0.24187731
5
1
2.83 2.687611 -0.18761083
6
1
4.32 3.730102 -0.03010181
2012 Christopher R. Bilder
5.39
7
8
9
10
11
12
13
14
15
16
17
18
19
20
1
1
1
1
1
1
1
1
1
1
1
1
1
1
3.39
2.32
2.69
0.83
2.39
3.65
1.85
3.83
1.22
1.48
2.28
4.00
2.28
1.88
3.079420
2.330785
2.589659
1.288294
2.379761
3.261331
2.001946
3.387269
1.561161
1.743072
2.302799
3.506211
2.302799
2.022935
0.32058048
0.26921493
0.21034134
0.31170591
-0.37976115
-0.36133070
0.29805437
-0.18726921
0.23883914
-0.34307203
-0.30279873
0.29378887
-0.10279873
-0.42293538
> anova(mod.fit)
Analysis of Variance Table
Response: College.GPA
Df Sum Sq Mean Sq F value
Pr(>F)
HS.GPA
1 8.0615 8.0615
91.38 1.779e-08 ***
Residuals 18 1.5880 0.0882
--Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 '
' 1
2012 Christopher R. Bilder
5.40
5.13 Inferences in Regression Analysis
Covariance matrix of b:
Cov(b0 ,b1 )
Var(b0 )
2
1
Cov(b)
(
X
X
)
Var(b1 )
Cov(b0 ,b1 )
Why?
Cov(b) = Cov[(XX)-1XY]
= (XX)-1XCov(Y)[(XX)-1X]
= (XX)-1XCov(Y)X(XX)-1
= (XX)-1X2IX(XX)-1
= 2(XX)-1XX(XX)-1
= 2(XX)-1
Remember that for two matrices C and B, (CB) =
BC
Estimated covariance matrix of b:
Var(b0 )
Cov(b0 ,b1 )
Cov(b)
Cov(b0 ,b1 )
Var(b1 )
1
X2
X
2
2
n
(X
(X
i X)
i X)
MSE
X
1
2
2
(Xi X)
(Xi X)
MSE ( X X )1
2012 Christopher R. Bilder
5.41
Note that the Var(bi ) is from Sections 2.1 and 2.2. The
Cov(b0 ,b1 ) is new.
Estimated variance used in the C.I. for E(Yh):
2
1
(X
X)
h
1
ˆ
Var(Yh ) MSE( Xh ( X X ) Xh ) MSE
2
n
(X
X)
i
where Xh = [1, Xh]
Why?
Var(Yˆ h ) Var( Xh b)
Xh Cov(b)Xh
2 Xh ( X X )1 Xh
Since b is a vector, I replaced Var() with Cov() (just
notation)
Estimated variance used in the P.I. for Yh(new):
Var(Yh(new ) Yˆ h ) MSE(1 Xh ( X X )1 Xh )
1 (Xh X)2
MSE 1
2
n
(X
X)
i
Example: HS and College GPA (HS_college_GPA_ch5.R)
>
>
cov.beta.hat<-as.numeric(MSE)*solve(t(X)%*%X)
cov.beta.hat
[,1]
[,2]
[1,] 0.03976606 -0.013762181
2012 Christopher R. Bilder
5.42
[2,] -0.01376218
0.005357019
>
>
>
#From earlier
sum.fit<-summary(mod.fit)
sum.fit$cov.unscaled #Another way to get (X'X)^(-1)
(Intercept)
HS.GPA
(Intercept)
0.4507584 -0.15599781
HS.GPA
-0.1559978 0.06072316
>
sum.fit$sigma^2 * sum.fit$cov.unscaled
(Intercept)
HS.GPA
(Intercept) 0.03976606 -0.013762181
HS.GPA
-0.01376218 0.005357019
>
>
#One more way to get the covariance matrix
vcov(mod.fit)
(Intercept)
HS.GPA
(Intercept) 0.03976606 -0.013762181
HS.GPA
-0.01376218 0.005357019
>
>
>
#Find Var(Y^)
X.h<-c(1,1.88)
as.numeric(MSE)*X.h%*%solve(t(X)%*%X)%*%X.h
[,1]
[1,] 0.006954107
>
>
#Find Var(Y-Y^)
as.numeric(MSE)* (1+X.h%*%solve(t(X)%*%X)%*%X.h)
[,1]
[1,] 0.09517446
>
>
>
>
>
>
>
#From HS_college_GPA_ch2.R
n<-nrow(gpa)
X.h<-1.88
Y.hat.h<-as.numeric(mod.fit$coefficients[1] +
mod.fit$coefficients[2]*X.h)
#as.numeric just removes an unneeded name
ssx<-var(gpa$HS.GPA)*(n-1) #SUM( (X_i - X_bar)^2 )
X.bar<-mean(gpa$HS.GPA)
MSE * (1/n + (X.h - X.bar)^2 / ssx) #Taken from the
C.I. formula
[,1]
2012 Christopher R. Bilder
5.43
[1,] 0.006954107
>
MSE * (1 + 1/n + (X.h - X.bar)^2 / ssx) #Taken from
the P.I. formula
[,1]
[1,] 0.09517446
2012 Christopher R. Bilder