Previously, when making inferences about the population mean
advertisement

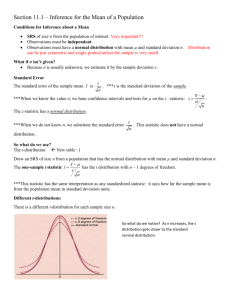
Chapter 16 Inference about a Population Mean Conditions for inference Previously, when making inferences about the population mean, , we were assuming: (1) Our data (observations) are a simple random sample (SRS) of size n from the population. (2) Observations come from a normal distribution with parameters and . (3) Population standard deviation is known. Then we were constructing confidence interval for the population mean based on _________ distribution (one-sample z statistic): This holds approximately for large samples even if the assumption (2) is not satisfied. Why? Issue: In a more realistic setting, assumption (3) is not satisfied, i.e., the standard deviation is unknown. So what can we do to handle real-life problems? We replace the population standard deviation, by its estimate: And we get one-sample t statistic: When making inferences about the population mean with unknown we use the one-sample t statistic (Note that we still need the assumptions 1 and 2). But one-sample t statistic doesn’t have normal distribution, it has 1 t-distributions We specify a particular t-distribution by giving its degrees of freedom (d.f.). How does t-distribution compare with standard normal distribution? Similarities: Difference: As the d.f. k increases, the tk distribution approaches the Normal(0,1) distribution. Notation: tk represents the t-distribution with k d.f. Confidence Intervals for a Population Mean (standard deviation is unknown) Confidence interval for when is unknown (t -CI) A (1-) confidence interval for is given by where t* is the upper /2 critical value for the tn-1 distribution, i.e., 2 Ex: What critical value t* from Table C would you use to make a CI for the population mean in each of the following situations? a) A 95% CI based on n = 10 observations. b) A 90% CI based on n = 26 observations. c) An 80% CI from a sample of size 7. Ex: Suppose the JC-Penny wishes to know the average income of the households in the Dallas area before they decide to open another store here. A random sample of 21 households is taken and the income of these sampled households turns out to average $35,000 with a standard deviation of $15,000. Give a 90% confidence interval for the unknown average income of the households in Dallas area. 3 Matched Pairs t Procedures As we mentioned in Chapter 8, comparative studies are more convincing than single-sample investigations. For that reason, one sample- inference is less common than comparative inference. In a matched pairs design, subjects are matched in pairs and each treatment is given to one subject in each pair. The experimenter can toss a coin to assign two treatments to the two subjects in each pair. Example 1. Suppose a college placement center wants to estimate µ, the difference in mean, starting salaries for men and women graduates who seek jobs through the center. If it independently samples men and women, the starting salaries may vary because of their different college majors and differences in grade point averages. To eliminate these sources of variability, the placement center could match male and female job-seekers according to their majors and GPAs. Then the differences between the starting salaries of each pair in the sample could be used to make an inference about µ. Example 2. Suppose you wish to estimate the difference in mean absorption rate into the bloodstream for two drugs that relieve pain. If you independently sample people, the absorption rates might vary because of age, weight, sex, etc. It may be possible to obtain two measurements on the same person. First, we administer one of the two drugs and record the time until absorption. After a sufficient amount of time, the other drug is administered and a second measurement on absorption time is obtained. The differences between the measurements for each person in the sample could then be used to estimate µ. Another situation calling for matched pairs is before-and-after observations on the same subjects. Example 3. Suppose you wish to estimate the difference in mean blood pressure before and after taking a drug. We will obtain the first measurement before a patient is taking the drug and second measurement after a sufficient amount of time that the patient was taking the drug. The differences between the measurements for each person in the sample could then be used to estimate µ. If the samples are matched pairs, apply one-sample t procedures to the differences of observed responses. 4 Example. An experiment is conducted to compare the starting salaries of male and female college graduates who find jobs. Pairs are formed by choosing a male and a female with the same major and similar GPA. Suppose a random sample of 10 pairs is formed in this manner and the starting annual salary of each person is recorded. Let µ1 be the mean starting salary for males and let µ2 be the mean starting salary for females. Compute a 95% confidence interval for the mean difference µ = µ1-µ2. Pair 1 2 3 4 5 6 7 8 9 10 Male (in $) 29300 41500 40400 38500 43500 37800 69500 41200 38400 59200 Female (in $) 28800 41600 39800 38500 42600 38000 69200 40100 38200 58500 Difference (male – female) 500 - 100 600 0 900 - 200 300 1100 200 700 The sample average of the paired difference x and the sample standard deviation of the paired difference s The 95% paired difference CI for = 1-2 is 5