Lecture #11: Continuous Probability Distributions
advertisement

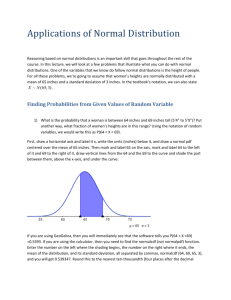
Lecture #11: Continuous Probability Distributions You’ve seen now how to handle a discrete random variable, by listing all its values along with their probabilities. But what if you’re dealing with a continuous random variable, like height or weight or duration – something measured – and you want to talk about the probability of the random variable taking on different values? Clearly you can’t just list all the possible values. You’d have to spend the rest of your life doing it, and even then you wouldn’t make a dent. Say you were weighing something, and the random variable is the weight. Even if you could give a probability for, say, 42.783 g and 42.784 g, you’d still have to list, for instance, 42.7835 g. Between each two rational numbers there is another one, and so on and so on. We say that these numbers are dense. We simply can’t list them all. So with continuous random variables a whole different approach to probability is used. First, we don’t speak of the probability that the random variable takes on an individual value. Instead we deal with the probability that the random variable falls within a certain range of values. The probability that the variable takes on an individual value is 0. Nothing weighs 42.783 g on the nose, but there may be a positive probability that whatever it is we’re weighing will weigh between 42.783 g and 42.784 g. And how do we find these probabilities of ranges of values? Not by adding up individual probabilities, as you can see, but by using a concept from calculus (don’t let that word scare you – you’ll find that it’s surprisingly easy to grasp): We look at what’s called the area under the curve. 1 Probability Density Functions Let me explain this using a really simple example. Let’s say that I arrive at work every morning between 7 a.m. and 9 a.m. I never come before 7 or after 9. It isn’t that I mostly arrive pretty near 8 a.m. I am as likely to arrive at 7:19 as at 7:58 as at 8:13 as at 8:45. In mathematical terms, my arrival times are uniformly distributed from 7 a.m. to 9 a.m. What fraction of the mornings will I arrive between 7:30 and 8? Another way to ask this question is: What is the probability that on a given morning I will arrive between 7:30 and 8? The answer is 1 or 0.25 or 25%. This is because since I arrive 100% of the 4 days between 7 a.m. and 9 a.m., and because I’m equally likely to arrive at any time between 7 and 9, and because the half hour from 7:30 to 8 is one-fourth of this two-hour interval, the probability that I’ll arrive between 7:30 and 8 is one-fourth of 100%, or 25%. I hope that seems obvious. But here’s how we’d do this using the probability distribution of a continuous random variable. Look at this graph: The t-axis represents my time of arrival at work. The thick line, which we call a probability density function, represents the probability of my arriving at work. The 2 probability is 0 before 7 a.m. (the thick line coincides with the t-axis), shoots up to a certain level at 7 and maintains that level, and then drops back down to 0 at 9 a.m.. What is this certain level? To find that, think back to discrete probability distributions. There, the P(X)’s all had to add up to 1. One of the X values was sure to occur. It’s the same thing in the continuous case, only now we talk about the total area under the curve equaling 1. In fact, that’s part of the definition of a probability density function: the total area under it must equal 1. In our case the area is a rectangle bounded by the vertical lines at 7 and at 9, the t-axis, and our probability density function. This area is 1. The area of a rectangle is the product of its height and its width. The width is 2 hours, from 7 to 9. So the height must be 1 1 , or 0.5, because 2 1 . 2 2 Now I’ll label the vertical axis with the 0.5 and shade in the area we’re interested in: In this system, the probability that I’ll arrive between 7:30 and 8 is equal to the shaded area. It too is a rectangle, with width its area is 1 1 (the half hour from 7:30 to 8) and height , so 2 2 1 1 1 0.25 25% . This is the same answer we got using common sense. 2 2 4 I just wanted to illustrate the concept of the probability density function (pdf) and area 3 under the curve, and especially to emphasize the defining characteristic of a pdf as having a total area underneath it (and above the horizontal axis) of 1. The Normal Distribution The most famous pdf is what we call the normal distribution. You’ve probably heard it called the bell curve. It is indeed bell-shaped. It quite accurately describes an enormous range of real-life phenomena where the final value of the random variable depends on many, many very small occurrences which themselves are random. If a random variable conforms to a normal distribution, we call it normally distributed. Heights of adult women in the U. S. are approximately normally distributed, as are the lengths of their feet and the circumferences of their heads. Same for adult men. Think of those vending machines that dispense terrible coffee and are supposed to put 6 fluid ounces in a paper cup. If you actually measured the volume of many of these filled cups, made a histogram of the volumes, and let your eyes get out of focus so you saw the tops of the bars as a curved line, that curve would be bell-shaped. Most of the cups would have close to 6 fluid ounces in them; there would be the same number with a certain amount less as there are with that certain amount more (the histogram would be symmetrical), and as you got further and further away from 6 the bars would be shorter and shorter. Here’s a representation of this normal distribution: 4 It’s symmetrical around 6, the mean of the distribution of X, the random variable that represents the number of fluid ounces deposited in a cup, and in theory the pdf never touches the x-axis (though of course you couldn’t have a negative number of fluid ounces in a cup, for instance), and because it’s a pdf the total area under the curve is 1. So if you want to know what fraction of the cups have at least 6 fluid ounces of coffee, you represent the situation this way: and the answer, of course, would be P(X > 6) = 0.5. You’ll be delighted to learn that for the purposes of continuous random variables, it makes no difference whether we say “greater than” or “at least,” because there is zero probability associated with X=6. If we wanted to know P(6.5 < X < 7), the probability that a cup has between 6.5 and 7 fluid ounces, we would make this drawing: 5 There are an infinite number of normal distributions. The shape and location of their pdf’s depends entirely on the mean and the standard deviation of the distribution. The mean determines the central point of the distribution. Here are two normal pdf’s with different means but the same standard deviation: And here are two normal pdf’s with the same mean but different standard deviations: The smaller the standard deviation (i.e. the less varied the values of the random variable), the pointier the pdf. The mean is apparent from looking at a normal pdf – it’s the value of the random variable directly under the hump. How about the standard deviation? It’s more subtle, and you don’t have to worry about it, but if you want your drawing to be accurate, then at 6 one standard deviation below the mean, , and at one standard deviation above the mean, , the pdf has what we call in calculus inflection points. Inflection points are points where a curve changes what we call its concavity – roughly, it goes from being cupped upward to being cupped downward, or vice versa. Here’s an example with a sine curve, which changes it concavity an infinite number of times throughout its span. I’ve marked the inflection points: Let me do the same with our original normal curve: looks to be located approximately at 6.7 fluid ounces, which would mean that 0.7 , which is larger than it should be (that machine needs servicing – it’s way out of whack!!). (For those of you interested in the math behind this, here is the formula for a normal pdf: y 1 2 x 2 e 2 7 where is the mean of the normal distribution and is its standard deviation. It contains two of the most famous numbers in mathematics, , which, as you remember, is the ratio between the circumference and diameter of all circles, and e, which you might remember from Intermediate Algebra as being the natural logarithmic base. ) The great thing about normal distributions is that we know exactly what fraction of the data falls within any interval, in particular within one standard deviation of the mean, within two standard deviations of the mean, and a whopping 99.7% of the data lie within three standard deviations of the mean. We can also find the percent of data that lie in any interval at all. We used to do this by means of what’s called the standard normal table, an ingenious but cumbersome chart that requires lots of preliminary calculations and lacks the level of accuracy we would like to achieve. If you want to look at one, try this: http://www.sjsu.edu/faculty/gerstman/EpiInfo/z-table.htm 8 With graphing calculators and computer math packages we can do much better, much more easily. I’ll do the following problems as they would be done on the TI-83 or TI-84. You can find more explanation in the Calculator Practice section of this class meeting (#13). Practice Problems: Finding Probabilities for Normal Distributions For all these problems, we’re going to assume that women’s heights are normally distributed with a mean of 65 inches and a standard deviation of 3 inches. 1) What is the probability that a woman is between 64 inches and 69 inches tall (5’4” to 5’9”)? Put another way, what fraction of women’s heights are in this range? We would write this P(64 < X < 69). First, draw a horizontal axis and label it x, write the units (inches) below it, and draw a normal pdf centered over the mean of 65 inches. Then mark and label 65 on the axis, mark and label 64 to the left of it and 69 to the right of it, draw vertical lines from the 64 and the 69 to the curve and shade the part between them, above the x-axis, and under the curve: Using the normalcdf (not normalpdf) function, enter the number on the left where the shading begins, the number on the right where it ends, the mean of the distribution, and its standard deviation, all separated by commas, 9 normalcdf (64, 69, 65, 3), and you will get 0.539347. Round this to the nearest ten-thousandth (four places after the decimal point), or equivalently to the nearest hundredth of a percent, and you come up with the correct answer: 0.5393, or 53.93%. 2) What is the probability that a woman is taller than 5 feet, 10 inches, or 70 inches? Put another way, what fraction of women are taller than 70 inches? This would be written as P(X > 70). Start the same way as in Problem 1, but you have to mark and label only one number besides the mean, the 70. Then shade to the right of the 70, because that’s where the taller heights are: The only complication using normalcdf is that there is no number on the right where the shading ends, so put in a big one, and if you’re not sure if it’s big enough put in a bigger one and see if it changes your answer, at least to the nearest ten-thousandth. normalcdf ( 70, 1000, 65, 3) 0.04779 , so the rounded answer is 0.0478, or 4.78%. 3) What is the probability that a woman is shorter than 67 inches, or what fraction of women are shorter than 67 inches, written P(X < 67)? 10 This time you shade to the left: And, since the shading goes all the way to the left, in theory anyway, there is no smallest shaded number, so just proceed the way you did in Problem 2, testing with a smaller number if you not sure yours was small enough: Normalcdf (0, 67, 65, 3) 0.74507 , making the answer 0.7451, or 74.51%. Practice Problems: Finding Cut-offs for Normal Distributions In the problems above, we found the probability that the random variable falls within a certain range. Now we’re going to reverse the process. We’ll start with the probability of a certain range, and then we’ll have to find the values of the random variable that determine that range. I’ll call these values cut-offs. In these three problems, we’ll use the same situation as above: Women’s heights are normally distributed with a mean of 65 inches and a standard deviation of 3 inches. 1) How short does a woman have to be to be in the shortest 10% of women? If we call this cut-off c, this could be written as finding c such that P(X < c) = 0.10. We’ll do the same kind of diagram as before, but this time we’ll label the known probability, 10%, and we do this above the shaded area, definitely not on the xaxis, because it’s an area, not a height. The hardest part of the diagram is deciding which side of the mean to put the c on and which side of the c to shade. 11 You really have to think about it. In this case, since by definition 50% of women are shorter than the mean, the cut-off for 10% has to be less than the mean: Using the calculator, which will find a cut-off using the invNorm function, followed by the percent of data under the normal curve to the left of (always to the left of, no matter which side of c the shading is on) the cut-off, then the mean and standard deviation, separated by commas, we get invNorm (0.10, 65, 3) 61.1553 , or, to the nearest inch, like the mean and standard deviation, 61 inches. So about 10% of women are shorter than 61 inches. You can check this using normalcdf, and you might as well use more of the cut-off than we rounded to, for greater assurance that your check shows you got the right answer. You get normalcdf (0, 61.1553, 65, 3), which come to 0.0999997, or 10%. 2) How tall does a woman have to be to be in the tallest fourth of women? (What is the cut-off for the tallest 25% of women?) If we call this height c, we want to find the value of c such that P(X > c) = 0.25. Here’s the diagram: 12 Even though we shaded the area to the right of the cut-off, because that’s where the tallest 25% of women are, when we use invNorm we must put in 0.75 ( 1 0.25 ), because the calculator finds cut-offs for areas to the left only: invNorm (0.75, 65, 3) 67.02 , or about 67 inches. Checking with normalcdf (67.02, 1000, 65, 3), we get about 0.25037, pretty close to 25%. 3) What if we’re interested in finding cut-offs for a middle group of women’s heights, say the middle 40%? Obviously, we’re looking for two numbers here, one on either side of the mean. Call them c1 and c2 : To use invNorm, we must find out how much area is under the curve to the left of c1 . Well, if 100% of area is under the entire curve, then what’s left over after taking away the middle 40% is 1 0.40 0.60 , and since that 60% is split evenly between the two tails (the parts at the sides), that gives 30% for each tail. So c1 is 13 the number such that P(X < c1 ) = 0.30, and invNorm (0.30, 65, 3) 63.4268 , or 63 inches. How much area is there under the curve to the left of c2 ? Either subtract the 30% to the right from 100%, or add up the 30% in the left tail and the 40% in the middle, and you’ll get 70% either way. So c2 is the number such that P(X < c2 ) = 0.70, and invNorm (0.70, 65, 3) 66.5732 , or 67 inches. So to the nearest inch, the middle 40% of heights go from 63 to 67 inches. The check is normalcdf (63.4268, 66.5732, 65, 3) 0.39999968 , or 40%. © 2009 by Deborah H. White 14