Brief Probability Overview
advertisement

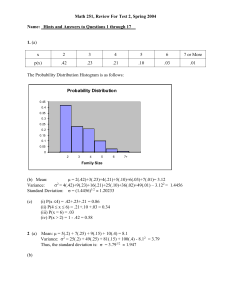
Lecture 6
Brief Probability Overview
A probability space is a triplet {, , P} in which is a set, is a family of subsets of
, representing the events, and P is a probability measure on .
has some closure properties to guarantee that operations between events are contained
in :
1.
2. For A , the complement of A, denoted Ac
3. For A1 , A2 ,, An , , A1 A2 An
P : [0,1] satisfying:
1. P() 1
2. For an infinite sequence of mutually disjoint events
A1 , A2 ,, An , , Ai A j , P( A1 A2 An ) P( A j ) .
j 1
A random variable (r.v.)on is a measurable function X : R . Measurability
means that all events expressed in terms of X belong to the family . In particular it is
enough to require that { : X ( ) x} , for all x R .
Every random variable has a probability distribution. For a discrete random variable we
define f ( x) P( : X ( ) x) . For a continuous random variable, we define the
cumulative distribution function F ( x) P( : X ( ) x) . In most cases, F (x) is smooth
x
enough such that there exists f ( x) 0, integrable , and such that F(x)
f(t)dt . f is called
the probability density function of the random variable X.
We define the mean, variance and standard deviation (whenever the quantities exist) of a
random variable by:
E ( X ) x f ( x) dx,
R
V ( X ) E ( X ) 2 ( x ) 2 f ( x) dx E ( X 2 ) 2 , if X is continuous, and
2
R
x f ( x), and ( x ) 2 f ( x) x 2 f ( x) 2 , if X is discrete.
2
x
x
x
The standard deviation is defined by .
Example 1. Consider flipping a coin once and observing whether it lands Heads or Tails.
Define the random variable X 1 if the coin lands Heads, and X 0 if the coin lands
Tails. Then, X is a discrete random variable with probability distribution
f (0) P( X 0) 0.5 , and f (1) P( X 1) 0.5 .
X is a particular example of a Bernoulli random variable.
Definition 1. A random variable that takes only the values 0 and 1, and for which
P( X 1) p, 0 p 1 is called a Bernoulli random variable.
2
Example 2. Imagine yourself blindfolded and having to cut a ribbon of length 1 yard
suspended between two posts. Define a random variable to be the length of one of the
two pieces of ribbon after you cut it. This is an example of a continuous random variable.
Assuming that you have equal chance of making the cut at any point on the ribbon, the
probability of cutting a piece of length say d is proportional to d, and since the total
length is one, the probability is exactly d. This is an example of a uniform random
variable. Its probability density function is f ( x) 1, for all x [0,1] .
If we want to find the probability that the length of the cut piece is less than 0.5 of a yard,
0.5
we compute P( X 0.5)
f ( x) dx 0.5 . Similarly, the probability that its length is
0
between 0.25 and 0.5 is:
0.5
P(0.25 X 0.5)
f ( x) dx 0.25
0.25
In general, a uniform random variable on an interval [a, b] has a probability density
1
, for all x [a, b] .
function given by f ( x)
ba
A very important example of a continuous random variable is the normal random
variable.
The probability density function of a normal random variable is given by
( x )2
1
2
f ( x, , )
e 2 , x R ,
2
where R, and >0 . is the mean of the random variable, and is the standard
deviation. The figure below shows the changes in the densities of normal variables when
the values of and change.
Definition 2. Two events A and B are independent if P( A B) P( A) P( B) .
If X and Y are random variables, we can define their joint probability distribution as
having the density f ( x, y ) satisfying:
f ( x, y ) 0, f ( x, y )dx dy 1, if X and Y are continuous random variables, and
R2
f ( x, y ) 0, f ( x, y ) 1, if X and Y are discrete random variables.
x
y
From the joint probability distribution we may derive the probability distributions of the
variables X and Y; we denote them f X ( x), fY ( y ) and we refer to them as the marginal
probability distributions of the variables X and Y, respectively. We have:
f X ( x) f ( x, y ) dy, fY ( y ) f ( x, y ) dx, if X and Y are continuous r.v., and
R
f X ( x)
f ( x, y), f
y
R
Y
( x)
f ( x, y), if X and Y are discrete r.v.
x
Definition 3. The random variables X and Y are independent if f ( x, y) f X ( x) fY ( y) .
Properties
1. If X and Y are random variables and a and b are real numbers, then
E (aX bY ) aE ( X ) bE (Y )
The property generalizes to a linear combination of n random variables.
n
n
i 1
i 1
E ( ai X i ) ai E ( X i ) .
2. If X and Y are independent random variables, h1 , h2 are real functions, and a and b are
real numbers, then
E h1 ( X )h2 (Y ) E h1 ( X ) E h2 (Y )
V (aX bY ) a 2V ( X ) b 2V (Y )
Again, the property generalizes to a linear combination of independent random variables:
n
n
i 1
i 1
V ( ai X i ) ai2V ( X i )
3. If X i , i 1,..., n are independent normally distributed random variables, with means i
n
and variances i2 , and a1 ,..., an are real numbers, then Y ai X i , is a normal
i 1
n
n
i 1
i 1
random variable with mean ai i and variance 2 ai i2 .
The Central Limit Theorem
Let X 1 ,..., X n be independent and identically distributed random variables (i.i.d. for short)
all having a distribution with mean and standard deviation . Then X
approximately normal, N ( ,
2
n
2
n
X
n
i
is
) (the notation means, the mean is and the variance is
.
A graduate version of the Central Limit Theorem is:
Let X1 ,..., X n ,... be a sequence of iid random variables all having mean and standard
deviation . Then
n
Sn
X
i 1
i
n
n
converges in distribution to a standard normal variable, N (0, 1) .
And now, here are some exercises to refresh your probability knowledge.
EXERCISES
1. Consider the model d 2, N 1, r 1/10, S (0) 6, S (1, 1 ) 11/ 2, S (1, 2 ) 77 /10 .
(This was also Exercise 1 in Lecture 3.) Find the expected value of the stock price,
the variance and the standard deviation with respect to the risk-neutral probability
measure.
2. Consider the one step binomial model with d 1 r u , r being the risk free interest
rate corresponding to one step. Find a formula for the mean and the standard
deviation of the stock price with respect to the risk neutral probability measure.
3. Let Y be a binomial random variable with n trials and probability p of success. Notice
that Y can be seen as a sum of n independent Bernoulli random variables which take
n
the value 1 with probability p, that is
Y X i , where X i are i.i.d. Bernoulli
i 1
r.v.(think that you add 1 each time you have a success in a trial, so Y counts he
number of successes). Use this representation to derive the formulae for the mean and
variance of the binomial distribution, i.e., np, 2 np(1 p) .
4. Repeat Exercise 2 for the two-step binomial model.
5. Find formulae for the mean and variance of the stock price in the binomial model that
has n steps. (Hint: By all means do not do brute force computations, but rather use the
distribution of the stock price.)
6. We define the covariance of two random variables by
Cov( X , Y ) E ( X X )(Y Y )
Show that Cov( X , Y ) E ( XY ) X Y .
7. Let X and Y be random variables (I did not say independent) having
E ( X ) 19, E (Y ) 25,V ( X ) 25, V (Y ) 144, and ( X , Y ) 1/ 2 .
Cov( X , Y )
Note: ( X , Y )
. ( X , Y ) is called the coefficient of correlation.
V ( X )V (Y )
Compute the following quantities:
a) Cov( X , Y ) b) Cov( X Y , X Y ) c) V ( X Y ) d) V (3 X 4Y )