A. The Two-Way Table
advertisement

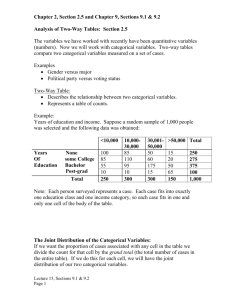
Chapter 9: Analysis of Two-Way Tables II. A. B. C. D. E. Data Analysis for Two-Way Tables (IPS section 9.1 pages 612-620) The Two-Way Table – A two-way table of counts organizes data about two categorical variables. Values of the row variable label the rows that run across the table, and values of the column variable label the columns that run down the table. Two-way tables are often used to summarize large amounts of data by grouping outcomes into categories. Each combination of values for these two variables is called a cell. For each cell, a proportion is obtained by dividing the cell entry by the total sample size. The collection of these proportions is the joint distribution of the two categorical variables. Marginal Distributions – The row totals and column totals in a two-way table give the marginal distributions of the two variables separately. It is clearer to present these distributions as percents of the table total. Marginal distributions do not give any information about the relationships between the variables. Describing Relations in Two-Way Tables – Relationships among categorical variables are described by calculating appropriate percents from the counts given. Conditional Distributions – When we condition one the value of one variable and calculate the distribution of the other variable, we obtain a conditional distribution. To find the conditional distribution of the row variable for one specific value of the column variable, look only at that one column in the table. Find each entry in the column as a percent of the column total. There is a conditional distribution of the row variable for each column in the table. Comparing these conditional distributions is one way to describe the association between the row and column variables. It is particularly useful when the column variable is the explanatory variable. When the row variable is explanatory, find the conditional distribution of the column variable for each row and compare these distributions. Bar graphs are a flexible means of presenting categorical data. There is not single best way to describe an association between two categorical variables. Simpson’s Paradox – An association or comparison that holds for all of several groups can reverse direction when the data are combined to form a single group. This reversal is called Simpson’s paradox. III. Inference for Two-Way Tables (IPS section 9.2 pages 620-629) A. The Hypothesis: No Association – The null hypothesis Ho of interest in a two-way table is that there is no association between the row variable and the column variable. B. Expected Cell Counts – To test the null hypothesis in r x c tables, we compare the observed cell counts with expected cell counts calculated under the assumption that the null hypothesis is true. A numerical summary of the comparison will be our test statistic. row total x column total expected cell count = n C. Chi-Square Statistic – The chi-square statistic is a measure of how much the observed cell counts in a two-way table diverge from the expected cell counts. The recipe for the statistic is (observed count - expected count)2 expected count where “observed” represents an observed sample count, “expected” represents the expected count for the same cell, and the sum is over all r x c cells in the table. D. Chi-Square Distribution (denoted 2 ) - Like the t distribution, the 2 distributions form a family described by a single parameter, the degrees of freedom. We use 2 (df) to indicate a particular member of this family. 2 distributions take only positive values and are skewed to the right. X2 E. Chi-Square Test for Two-Way Tables – The null hypothesis Ho is that there is no association between the row and column variables in a two-way table. The alternative is that these variables are related. If Ho is true, the chi-square statistic 2 has approximated a 2 distribution with (r-1)(c-1) degrees of freedom. The P-value for the chi-square test is P( 2 ≥ X2) where 2 is a random variable having the 2 (df) distribution with df = (r-1)(c-1). The chi-square test always uses the upper tail of the 2 distribution because any deviation from the null hypothesis makes that statistic larger. The approximation of the distribution of X2 by 2 becomes more accurate as the cell counts increase. F. The Chi-Square Test and the z Test – A comparison of the proportions of “successes” in two populations leads to a 2 x 2 table. We can compute two population proportions either by the chi-square test or by the two-sample z test from section 8.2. In fact, these tests always give exactly the same result, because the 2 statistic is equal to the square of the z statistic, and 2 (1) critical values are equal to the squares of the corresponding N(0,1) critical values. The advantage of the z test is that we can test either one-sided or two-sided alternatives. The chi-square test always tests the twosided alternative. Of course, the chi-square test can compare more than two populations, whereas the z test compares only two.