3. Probability
advertisement

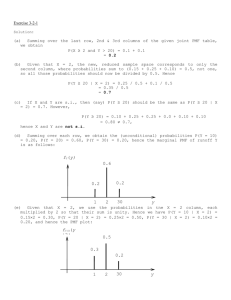
3. Probability and Random Variables 3.1 Definitions The probability of an event is a numerical measure of its likelihood. It is a number between 0 and 1, and larger the number, larger the likelihood. A probability of 0 means that the event certainly will not occur and a probability of 1 that it certainly will. Before we get to the concepts of probability we need to overview some concepts from set theory. We start with the concept of an element. If we are concerned with all the employees of a company, then each employee, and nothing else, is an element. If we are concerned with the number of defectives among 100 parts that are being inspected then each integer 0, 1, 2, ..., 100, and nothing else, is an element. Definition 3.1.1: A set is a collection of elements. We denote sets by uppercase letters A, B etc. and elements by lower case letters x, y etc. If x belongs to A we write x A . If x does not belong to A, we write x A . Two sets are equal if they contain the same collection of elements. Definition 3.1.2: The universal set is one that contains all the elements. We denote the universal set by S. Definition 3.1.3: The empty set is one that contains no elements. We denote the empty set by . Definition 3.1.4: If every element that belongs to A also belongs to B, then A is a subset of B. If A is a subset of B then we write A B . Definition 3.1.5: The intersection of two sets A and B is the set of all elements that belong to both A and B. We denote the intersection of A and B as A B . Definition 3.1.6: The union of two sets A and B is the set of all elements that belong to A or B or both. We denote the union of A and B as A B . Note that A B denotes elements in A and B, and A B denotes elements in A or B. Definition 3.1.7: The complement of a set A is the set of all elements that do not belong to A. A. A ; A A; A S A; A S S; S ; S ; A A ; A A S . We denote the complement of A by Definition 3.1.8: Two sets A and B are said to be disjoint if they have no element in common. We shall now relate these set theory concepts to probability theory. Suppose an experiment may result in any one of several outcomes. The outcomes then become the elements. In probability theory, elements are referred to as sample points, the universal set is referred to as the sample space and a set of sample points is referred to as an event. We say that an event has occurred if any one of the sample points that belong to it has occurred. Definition 3.1.9: If every sample point in a finite sample space is equally likely, then the probability of an event is the number of sample points that belong to the event divided by the number of sample points in the whole sample space. Let P(A) denote the probability of event A, n(A) the number of sample points in A and n(S) the number of sample points in S. We can then write the formula for P(A) as P(A) = n(A)/n(S). (3.1.1) Suppose we toss a die. There are six sample points 1, 2, ..., 6 each of which is equally likely. Let A denote the event where an odd number shows up. Event A then contains three sample points 1, 3, and 5. The probability of A is therefore 3/6 or 1/2. Suppose we pick a card at random from a standard deck of playing cards. There are 52 sample points in the sample space, each one equally likely. Let A denote the event we pick an ace. Then event A contains 4 sample points and therefore the probability of A is 4/52 = 1/13. Often, we need to calculate the probability of the intersection or union of events. Formula 3.1.1 can be extended for this purpose. We have P( A B ) = n( A B )/n(S) (3.1.2) P( A B ) is also known as the joint probability of events A and B. P( A B ) = n( A B )/n(S). (3.1.3) 14 A ) = n(S) n(A) we can write P( A ) = [n(S) n(A)]/n(S) which gives P( A ) = 1 P(A) (3.1.4) Consider n( A B ) in Equation 3.1.3. Can we replace it with [n(A) + n(B)]? No. If A and B have some Noting that n( common elements, then they will be counted twice in [n(A) + n(B)]. To avoid this double counting, we can subtract n( A B ) from [n(A) + n(B)] and get n( A B ) = n(A) + n(B) n( A B ). Equation 3.1.3 can then be rewritten as P( A B ) = P(A) + P(B) P( A B ) (3.1.5) This Equation 3.1.5 is very useful since most of the time the right hand side probabilities are known and we will need to calculate P( A B ). This equation is also known as the Addition Rule for probabilities. S A *** ** * B * * ** ** *** Figure 3.1.1. A Venn diagram Let us apply the above formulas to the case depicted in the Venn diagram of Figure 3.1.1. We see the sample space S with two events A and B. Let each of the *’s represent a sample point, and assume that they are all equally likely. Now, n(A) = 8 and n(S) = 15. Hence, P(A) = 8/15. Similarly, P(B) = 6/15 or 2/5; P( A B ) = 2/15; P( A B ) = 12/15. Note that the equations 3.1.4 and 3.1.5 are satisfied. Next we shall see an important concept called conditional probability. Refer to the Venn diagram in Figure 3.1.1. When we are calculating P(A), let us say we are told event B has occurred. In other words, the actual outcome is one of the *’s in B. Can we still say P(A) = 8/15? No. The sample points we can consider now are only those inside B. In effect, B has become our new sample space. Within this new sample space which contains 6 sample points, 2 belong to A. Hence, P(A) given that event B has occurred is 2/6 or 1/3. We call this the conditional probability of A given B and denote it by P(A | B). The event written after the vertical line | is the condition. We shall write this as our next formula. P(A | B) = n( A B )/n(B) (3.1.6) Combining the formulas 3.1.1, 3.1.2 and 3.1.6, we can write P(A | B) = P( A B )/P(B) (3.1.7) Formula 3.1.7 is the famous Bayes’ Rule named after an 18th century English clergyman who wrote much about this rule. This formula can be re-written with P( A B ) on the left hand side: P( A B ) = P(B)*P(A | B) (3.1.8a) Or, we may interchange A and B and write the above formula as: P( A B ) = P(A)*P(B | A) (3.1.8b) The Formula 3.1.8 (a or b) is known as the Multiplication Rule of probabilities. At times P(A) and P(A | B) may be the same, which would imply that the occurrence of event B did not in any way influence the probability of event A. We then say A and B are independent events. Definition 3.1.10: Two events A and B are said to be independent if P(A) = P(A | B). As an example, consider the experiment of selecting one adult at random from a community. The sample space S then contains all the adults in the community. Let A denote those with lung disease and B denote those who smoke. If P(A) is found to be equal to P(A | B), then we have reason to believe that smoking does not influence the chances of one getting a lung disease. We would then declare that smoking and getting a lung disease are independent. If the opposite is true, we would then declare them dependent. Thus, independence among events is an important practical concept. It can be shown that if A and B are independent events then the pairs A & B are all independent pairs. B , A & B, A & 15 In Figure 3.1.1, we see that P(A) = 8/15 and P(A | B) = 1/3. Hence A and B are not independent events. An important consequence of independence is that the joint probability of two independent events will be equal to the product of their individual probabilities. Looking at the definition of independence and Formula 3.1.8a, we can write “when A and B are independent P( A B ) = P(A)*P(B).” (3.1.9) Formula 3.1.9 extends to any number of independent events: P( A1 A2 ... An ) = P(A1)*P(A2)*...*P(An). (3.1.10) 3.2 Cross Tabulation Template Figure 3.2.1. Cross Tabulation, Joint, Marginal & Conditional Probabilities [Workbook: Crosstabs.xls; Sheet: Crosstabs] The template for calculating joint, marginal and conditional probabilities starting from a cross tabulation is shown in Figure 3.2.1. For the data shown in the figure, the marginal probability of Row 1 is 0.2599 and that of Col 1 is 0.3061. The conditional probability P(Row 1| Col 1) = 0.2543 and the conditional probability P(Col 1 | Row 1) = 0.2995. You may enter short names in place of Row 1, Col 1 etc. If the data you have is not a cross tabulation but a joint probability table, then enter the joint probabilities, at they are, in the cross tabulation data area. The template will still calculate all the probabilities correctly. 3.3 Random Variables Many quantities in the real world are not known for sure. The outside temperature tomorrow, the price of a particular stock next week, the number of highway accidents during next month and the tensile strength of a randomly selected bolt are all uncertain. But we have to deal with uncertain quantities in 16 practice and may even have to make serious decisions based on them. Hence we study them. Uncertain quantities are called random variables. Definition 3.3.1: A random variable is an uncertain quantity whose value depends on chance. Quantities such as length, time, weight and speed can vary continuously and are therefore continuous. A length can be 16.204596... yards, and is continuous. But the number of employees in a company is discrete. It can be 2048 of 2049 but not 2048.35076... . A random variable can be either continuous or discrete. Definition 3.3.2: A random variable is discrete if it can assume at most a countable number of possible values. If it can assume an uncountable number of possible values then it is continuous. When a random variable is discrete, it can be described fully by tabulating all of its possible values and the corresponding probabilities. The sheet named “Probability Distn..” in Random Variables.xls, reproduced in Figure 3.4.1, contains the Radio Sales data from Bowerman/O’Connell. The random variable X described in the table can assume any one of the values listed under column x, namely, 0, 1, 2, 3, 4, 5. The P(x) column contains the corresponding probabilities. That is, P(X = 0) = 0.03, P(X = 1) = 0.2 and so on. The probabilities should add to 1. Another useful probability is the cumulative probability F(x) defined as F(x) = P(X x). It can be used to calculate the probability that X will be between two given values, because P(x1 X x2) = F(x2) F(x1). Figure 3.3.1. Discrete Probability Table [Workbook: Random Variables.xls; Sheet: Probability Distn.] Although the exact value of a random value is not known for sure, what would be a good representative value? It could be the mean, the median or the mode. Definition 3.3.3: The mean of a random variable is called its expected value, E[X], and is defined as = E[X] = x * P( x ) (3.3.1) allx Definition 3.3.4: The median of a random variable X is that value x for which F(x) = 0.5. Definition 3.3.5: The mode of a random variable X is that value x for which P(x) is the maximum. Definition 3.3.6: The variance of a random variable X, written V(X) or 2, is the expected value of its squared deviation from the mean. Formally, 17 2 = V(x) = E[(x )2]. (3.3.2) In other words, if h(x) is defined as h(x) = (x )2, then the variance is E[h(X)]. There is also another formula for V(x) which is useful if V(x) is to be calculated manually. It is: V(x) = E[X2] 2 (3.3.3) The advantage of Formula (3.3.3) is that it does not require the calculation of deviations; the disadvantage is that requires the calculation of E[X2] which can be tedious when the x-values are large. We shall next see the definitions of descriptive statistics of a random variable. Definition 3.3.7: The standard deviation of a random variable, , is the positive square root of its variance. Definition 3.3.8: The skewness of a random variable is the expected value of z3 where z = (x )/. Definition 3.3.9: The (absolute) kurtosis of a random variable is the expected value of z4. Figure 3.3.2 shows the sheet named Descriptive Stats in the template Random Variables.xls. This sheet can be used to calculate the descriptive statistics of any random variable. Enter the x-values and the corresponding probabilities in columns A and B. Figure 3.3.2. Descriptive Statistics of a Random Variable [Workbook: Random Variables; Sheet: Descriptive Stats] 3.4 Exercises 1. Do exercise 3-36 to 46 in the textbook. [Hint: Construct and use a Joint Probability Table.] 2. A company has bought 10 castings at a cost of $2540 each. It spends an additional $480 to machine all of them into finished parts. Since the machining is delicate, errors are possible and some parts are likely to be rejected. The production manager of the company believes, based on past experience, that the exact number that will be rejected will follow the following probability distribution: # Rejected Probability 0 0.72 1 0.17 2 0.07 3 0.03 4 0.01 i. What is the expected value, variance, skewness and (absolute) kurtosis of the number of parts rejected. ii. The cost per good part is calculated by dividing the total cost by the number of good parts. Construct the probability distribution table for the cost per good part. iii. What is the expected value, variance, skewness and (absolute) kurtosis of the cost per good part? 3. Do exercises 3-49, 50 and 51 in the textbook.