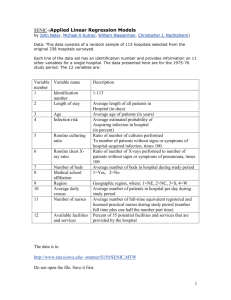
Supplementary Methods (doc 46K)
")
Supplemental Methods
Statistical Analysis
Two Data Analysis Teams (DAT), DAT8 (DKFZ) and DAT25 (SAS), respectively, generated predictive models for this study. DAT8 trained classifiers using either 'prediction analysis of microarrays' (PAM
1
) or recursive feature elimination (RFE
2
) for variable selection, and either
PAM or support vector machines (SVM) as classifying algorithm. Nested cross-validation
(5xCV for outer loop, 5xCV for inner loop) was performed for classifier training
3
, and was repeated 10 times to determine variance of the performance estimate. All calculations were carried out with R (version 2.7.2)
4
, using the Bioconductor
5
packages limma
6
, e1071, pamr
1
, rfe (http://stat.genopole.cnrs.fr/~cambroise), and MCRestimate 3 . DAT25 used discrimant analysis (DA), generalized linear models (GLM), logistic regression (LR), partial least squares (PLS), partition trees (PT) or radial basis machines (RBM) as classifiers and combined them with feature selection based on t-tests. Discriminant analysis (DA) is a multivariate statistical method for predicting a classification variable from a set of observed predictor variables by classifying each observation into one of the groups. Normal (Fisher) discriminant analysis fits a multivariate normal distribution to each class, and can be regarded as inverse prediction from a multivariate analysis of variance. General linear model selection
(GLM) performs effect selection in the framework of general linear regression models. A variety of model selection methods are available, including forward, backward, step-wise, lasso, and least-angle regression. The process offers extensive capabilities for customizing the selection with a wide variety of selection and stopping criteria, from traditional and computationally efficient significance-level-based criteria to more computationally intensive validation-based criteria. Logistic regression (LR) can be used to predict a categorical dependent variable from a set of continuous responses and to determine the percent of variance in the dependent variables explained by the independents. It models the probability of the response using a link function. Partial least square (PLS) is a method for simultaneously modeling variability in both dependent variables and predictor variables. PLS has been found to be a useful dimension reduction technique as well as principal analysis. The method works by extracting successive linear combinations of the predictor variables, but the linear combinations are chosen to jointly maximize covariance between the response and the predictors. Partition tree (PT) recursively partitions data according to optimal splitting relationships created between dependent and predictor variables. It creates simple tree-based rules for predicting the dependent variable. Radial basis machine (RBM) is one type of
support vector machine classification methods that uses radial basis kernel function to compute smooth predictions. Calculations have been performed by means of SAS (SAS,
Cary, NC, USA).
For all classifiers, predictive performance on the training set was determined by ten-times repeated nested cross-validation (5xCV for outer loop, 5xCV for inner loop) and used to build final classifiers. Classifiers were furthermore combined with feature selection (by PAM, by the t-test, or by RFE
2
). Parameters of the learning algorithms were optimized in the inner cross validation loop, and predictive performance determined on the held-out samples from the outer cross validation loop. This workflow was repeated to account for the initial random partitioning in cross validation, and to obtain the standard deviation of repeated classification, which can serve as an estimate of the robustness of the classification.
References
1. Tibshirani R, Hastie T, Narasimhan B, Chu G. Diagnosis of multiple cancer types by shrunken centroids of gene expression. Proc Natl Acad Sci U S A 2002; 99 (10) : 6567-
6572.
2. Guyon I, Weston J, Barnhill S, Vapnik V. Gene Selection for Cancer Classification using Support Vector Machines. Machine Learning 2002; 46: 389-422.
3. Ruschhaupt M, Huber W, Poustka A, Mansmann U. A compendium to ensure computational reproducibility in high-dimensional classification tasks. Stat Appl
Genet Mol Biol 2004; 3: Article37.
4. R Development Core Team (2008). R: A language and environment for statistical computing. R Foundation for Statistical Computing: Vienna, Austria.
5. Gentleman RC, Carey VJ, Bates DM, Bolstad B, Dettling M, Dudoit S , et al .
Bioconductor: open software development for computational biology and bioinformatics. Genome Biol 2004; 5 (10) : R80.
6. Smyth GK. Limma: linear models for microarray data. In: Gentleman R, Carey V,
Dudoit S, Irizarry RA, Huber W (eds). Bioinformatics and Computational Biology
Solutions using R and Bioconductor . Springer: New York, 2005, pp 397-420.