Statistical Inference Examples: Hypothesis Testing & CI
advertisement

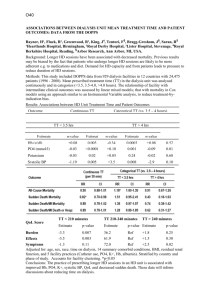
Some Examples of Statistical Inference Example – 1: Do pregnant women who smoke have babies with lower birth weight than those who do not smoke? A researcher thinks so. To test her conjecture she has recorded the birth weight of babies born at Shands in a given period, together with the smoking status of the mother and summarized the data as shown below: Smoking Status 1. Smokers 2. Nonsmokers Sample Statistics Sample Sample Sample Standard sizes (ni) Means ( X i ) Deviations (Si) 134 2733 grams 599 grams 5974 3118 grams 672 grams Do the above data support the conjecture of the researcher? ALWAYS: Before you dive-in to answer any problem, there are some questions you should ask yourself and find the answers in the statement of the problem. Here are the questions for this problem: Chapter 9 Examples, Fall 2007 Page 1 of 21 1. What type of a problem is this? a. How many populations, parameters, samples are there in this problem? Define the parameter(s). There are 2 populations (set of all pregnant women who smoke is population 1 and the set of all pregnant women who do not smoke is population 2) and we have 2 independent samples, one from each population. There are two parameters of interest: µ1 = µS = mean birth weight of babies born to ALL pregnant women who smoke and µ2 = µN = mean birth weight of babies born to ALL pregnant women who do not smoke We are interested in the difference between these means, i.e., µ1 – µ2. b. What type of data (random variable) do we have: quantitative or categorical? Why? c. Are the samples dependent or independent? Why? d. Hence, what type of problem do we have? Chapter 9 Examples, Fall 2007 Page 2 of 21 Comparing two population means using two independent samples. 2. What are hypotheses to be tested? Ho: µ1 – µ2 = 0 vs. Ha: µ1 – µ2 < 0 How can you tell? 3. What is the test statistic for this problem? Since we have quantitative data, (and the population variance is unknown) the test statistic to use is Estimator Number in Ho T ~ t( df ) Est. SE ( Estimator ) 4. In this problem, what are “Estimator”, “Number in Ho”, “Est. SE(Estimator) and “df” ( = the degrees of freedom)? Since we are interested in µ1 – µ2 (unknown), this difference is estimated by X 1 X 2 . [That is, the “estimator” of µ1 – µ2 is X 1 X 2 ]. Looking back to Ho, we see that we have Ho: µ1 – µ2= 0. Hence “Number in Ho” is 0. Chapter 9 Examples, Fall 2007 Page 3 of 21 We also know that the estimated SE (Estimator) S12 S22 is Est. SE ( X 1 X 2 ) . [Look at the n1 n2 table of formulas at the end of summary to Chapters 8 and 9.] Finally, since the two sample sizes are very different we will use df = smaller of (n1 – 1) and (n2 – 1) = 133. [Note that the df used by computer is different. Why?] So, (X X2) 0 T 1 ~ t(133) . 2 2 S1 S2 n1 n2 Since the df is too large, we will use the normal distribution. (Why?) 5. Are all the assumption needed for this procedure satisfied? a) First we need two independent random samples. Although the samples may be accepted as independent (with well defined populations), it is not clear whether these samples are random or not. The method of selection as well as the period of time the Chapter 9 Examples, Fall 2007 Page 4 of 21 samples were selected may have implications for some special characteristics for the pregnant women. We will assume that the samples are random and representative of the populations. Our results will be valid if this assumption is justifiable. b) The type of random variable (birth weight) is quantitative. So this assumption is satisfied. c) We do not know if the populations have normal distributions. [If we had sample data we could see if there are any extreme values indicating skewed distributions.] Since we have no way of knowing this, we will assume that the populations are normally distributed and our results will be valid if this assumption is approximately true. Chapter 9 Examples, Fall 2007 Page 5 of 21 6. What is the calculated value of the test statistic? Tcal ( X1 X 2 ) 0 2 1 2 2 S S n1 n2 (2733 3118) 0 2 2 7.34 599 672 134 5974 7. What is the p-value of the test? Before you write the formula for the p-value ALWAYS look at Ha. That determines the tail to look at. Ha: µ1 – µ2 < 0 so the p-value is P(T < Tcal) = P(T < –7.34). Since the df is large we may use the normal approximation to the t-distribution and write P-value = P(T < –7.34) = P(Z < – 7.34) = 0 (almost). [Sketch a graph and see the answer without looking at any table.] 8. What is the decision? Since p-value < any reasonable level of significance (α), we will reject Ho. Remember that the decision rule is always: “Reject Ho when p-value α” Chapter 9 Examples, Fall 2007 Page 6 of 21 9. What is the conclusion of the test? The observed data strongly support the researcher’s conjecture that on the average pregnant women who smoke have babies with lower birth weight than those who do not smoke [assuming that the samples are representative of the two populations and that the distributions of the populations are not too far from the normal distribution). 10. What is the CI? Interpret what you have found. Suppose we have observed the following output from Minitab: Two-Sample T-Test and CI Sample 1 2 N 134 5972 Mean 2733 3118 StDev 599 672 SE Mean 51.7 8.7 Difference = mu(1) – mu(2) Estimate for difference = –385.000 95% CI for difference (– 488.738, – 281.262) T-Test of difference = 0 (vs <): T-Value = – 7.34 P-Value = 0.000 DF = 140 Why is df = 140 and not 134? What does p-value = 0.000 mean? Why is SE Mean = 51.7 or 8.7? Chapter 9 Examples, Fall 2007 Page 7 of 21 Now we can see that the 95% CI for µ1 – µ2, calculated using the general formula for CI, is CI Estimator ME S12 S 22 * ( X1 X 2 ) t n1 n2 5992 6722 (2733 3118) 1.96 134 5972 ( 488.738, 281.262). What does this tell us? We are 95% confident that the mean birth weight of babies born to mothers who smoke is between 281.262 grams and 488.738 grams less than the mean birth weight of babies born to mothers who do not smoke. Note that this is a (– , –) type of confidence interval meaning that there is a significant difference between the two population means (since zero is not in the CI); actually, we can say more: we can state that the second population mean is larger than the first one (with 95% confidence). Why is t(140) = 1.96? Chapter 9 Examples, Fall 2007 Page 8 of 21 11. Do the results of the CI and significance test agree? Must they agree? Why or why not? Although the results do agree here (because we rejected Ho) they do not NEED TO AGREE ALL THE TIME. In general, the results of significance test and CI MUST AGREE WHEN Ha is 2-SIDED [What is a 2-sided hypothesis?] Example – 2: Many children are diagnosed each year with asthma. In an effort to educate these children about their condition, an educational video was developed. To test the effectiveness of this video, ten randomly selected children, of elementary school age, who had been recently diagnosed, were chosen to participate in a study. A nurse asked the children a series of questions about asthma, then showed them the video and asked the same questions again. The children’s scores were as follows: Child 1 2 3 4 5 6 7 8 9 10 Before 61 60 52 74 64 75 42 63 53 56 After 67 62 54 83 60 89 44 67 62 57 Chapter 9 Examples, Fall 2007 Page 9 of 21 1) What type of a problem is this? a) What is the random variable? Is it continuous or discrete? b) How many populations, samples, parameters are there? c) Are samples dependent or independent? d) Hence? 2) Assumptions? a) Random sample? b) Normal population? c) What else? 3) Parameter(s) of interest? µd = µbefore – µafter 4) Hypotheses? Ho: µd = 0 vs. Ha: µd < 0 [Why?] 5) Test Statistic T X d 0 ~ t( n1) Sd / n 6) What is n in this problem? Why? 7) The p-value? First look at Ha: µd < 0. Thus, P-Value = P(T Tcal) X 0 4.5 0 2.78 Where Tcal d Sd / n 5.13/ 10 Chapter 9 Examples, Fall 2007 Page 10 of 21 So, p-value= P(T – 2.78)=P(T +2.78) [Why?] Looking at the row with df = 9 we see that P(T 2.262) = 0.025 P(T 2.78) = p-value and P(T 2.821)= 0.010. Hence 0.010 < p-value < 0.025 8) Decision? Since 0.01 < p-value < 0.05 < 0.10, we will reject Ho at α = 0.05 and α = 0.10, but not at α = 0.01. 9) Conclusion? The observed data indicate that the video is effective in increasing the knowledge of elementary school aged children’s about asthma at 5% level of significance. The following output is obtained from Minitab. Interpret the results: Chapter 9 Examples, Fall 2007 Page 11 of 21 Paired T-Test and CI: before, after Paired T for before – after before after Difference N 10 10 10 Mean StDev SE Mean 60.0000 10.0000 3.1623 64.5000 13.2267 4.1826 – 4.50000 5.12619 1.62104 95% CI for mean difference: (– 8.16705, – 0.83295) T-Test of mean difference = 0 (vs < 0): T-Value = – 2.78 P-Value = 0.011 First note that the p-value here is consistent with what we found “by hand,” it is in fact between 1% and 2.5%. Hence we will reject Ho at 5% and 10% level of significance but not at 1% level of significance. Next, note that the confidence interval has both ends negative, which indicates that the mean of the population of scores before watching the video is larger than the mean of the population of scores after watching the video, i.e., we are 95% confident that watching the video is effective in increasing the children’s knowledge. Chapter 9 Examples, Fall 2007 Page 12 of 21 Actually, we could use 1 – p-value = 1 – 0.011 = 0.989 And state that we are 98.9% confident that the video increases the average level of children’s knowledge on asthma. But we cannot make it at 99% level of confidence. [So what? What is so special about 99%?] Let’s have a look at some other cases. Suppose in another study (of the same problem) we found some different p-values, as shown below. What can we conclude in each case? a) When p-value = 0.03 and α = 0.10, α = 0.05, α = 0.01, p-value < α, Reject Ho. Results significant. p-value < α, Reject Ho. Results significant. p-value > α, Do NOT Reject Ho. Results NOT significant We can reject Ho at α = 0.10 and 0.05 but NOT at 0.01 Results are significant at 10% and 5% level of significance but NOT at 1% level of significance. We can be 90% and 95% confident that there is a significant difference but NOT 99% confident Taking 1 – p-value = 1 – 0.03 = 0.97, we can be 97% confident that there is a significant difference between the population means. Chapter 9 Examples, Fall 2007 Page 13 of 21 b) When p-value = 0.09 and α = 0.10, α = 0.05, α = 0.01, p-value < α, Reject Ho. Results significant. p-value > α, Do NOT Reject Ho. Results NOT significant p-value > α, Do NOT Reject Ho. Results NOT significant We can reject Ho at α = 0.10 but NOT at 0.01 or 0.05 Results are significant at 10% level of significance but NOT at 1% or 5% level of significance. We can be 90% confident that there is a significant difference but NOT 95% or 99% confident Taking 1 – p-value = 1 – 0.09 = 0.91, we can be 97% confident that there is a significant difference between the population means. c) When p-value = 0.12 and α = 0.10, 0.05 05 0.01, p-value > α, Do NOT Reject Ho. Results NOT significant Results are not significant at any reasonable level of significance. We can NOT reject Ho at α = 0.10 or 0.05 or 0.01(or at any reasonable level of significance). Results are NOT significant at 10% and 5% and 1% level of significance. There is no significant difference between the population means at any reasonable level of significance. There is not enough evidence to indicate any difference between the population means. Chapter 9 Examples, Fall 2007 Page 14 of 21 Example – 3: [Agresti and Franklin, problem 9.6, modified] A Swedish study selected a random sample of 684 patients who had suffered a stroke and asked them to take a low does of aspirin daily. Another independent sample of 676 stroke patients was given placebo to be taken daily. The Minitab output of the analysis of the data is shown below, where X is the number of deaths due to heart attack during a follow up study of about 3 years. Was aspirin effective to reduce heart attacks among patients who suffered a stroke? Test and CI for Two Proportions Sample X N Sample p 1 28 684 0.040936 2 18 676 0.026627 Difference p(1) – p(2) Estimated difference = 0.0143085 95% CI for difference:(–0.00486898, 0.0334859) Test for difference = 0 (vs not = 0): Z = 1.46 p-value = 0.144 Interpret this output. Chapter 9 Examples, Fall 2007 Page 15 of 21 1. What is/are the population(s) and samples? Population 1: The set of heart stroke patients who take a low does of aspirin every day. Sample 1: The 684 patients selected from the first population Population 2: The set of all heart stroke patients who take placebo (i.e. nothing) [Why?] Sample 2: The 676 patients selected from the second population A question: Do such populations physically exist? 1. What type of study do we have here? Why? What type of variable do we have? How many populations? How many samples? Hence? Define the parameters of interest? p1 = Proportion who die in the population of all patients who take a low does of aspirin daily. p2 = Proportion who die in the population of all patients who take nothing (placebo) Chapter 9 Examples, Fall 2007 Page 16 of 21 2. What are the hypotheses? Ho: p1 – p2 = 0 vs. Ha: p1 – p2 > 0 How can we tell? 3. What is the test statistic? pˆ1 pˆ 2 Z ~ N (0,1) 1 1 pˆ (1 pˆ ) n1 n2 4. What are the assumptions? Are they satisfied? a) Independent Random Samples b) Categorical variable c) Observed number of “Success”s 10 in both samples d) Observed number of “Failure”s 10 in both samples 5. What is the p-value of the test? First look at Ha: p1 – p2 > 0. So p-value = P(Z 1.46) But, P(Z 1.46) = P(Z – 1.46) by symmetry of the normal distribution. So, p-value =0.0749 [from z-tables]. But the computer output gives p-value = 0.144. Is something wrong? Chapter 9 Examples, Fall 2007 Page 17 of 21 How do we find the calculated value of the test statistic? pˆ1 pˆ 2 Z cal 1 1 pˆ (1 pˆ ) n1 n2 0.040936 0.026627 1 1 0.0338(1 0.0338) 684 676 1.46 What is p̂ and how is it found? If Ho is true, then p1 = p2 and we may just call it p. Then, p is estimated by “pooling” the two samples, so p̂ is called the “pooled sample estimate.” It is calculated as X X2 28 18 pˆ 1 0.0338 n1 n2 684 676 6. What is the decision? Since the p-value = 0.0749 > 0.05 > 0.01, we fail to reject Ho at 1% and 5% levels of significance. However, at 10% level of significance we reject Ho. 7. What is the conclusion? Chapter 9 Examples, Fall 2007 Page 18 of 21 The observed data do not give sufficient support to the claim that aspirin is effective in reducing heart attacks (p-value = 0.0749). 8. What does the confidence interval tell us? A 95% CI for the difference of population proportions is found as (– 0.00486898, 0.0334859) Since the CI contains zero, we fail to reject Ho. Remember that a definition of a confidence interval is “the set of all acceptable hypotheses.” Since zero is in the CI, Ho: p1 – p2 = 0 is an acceptable hypothesis and hence we do not reject it. 9. How was the confidence interval found? The general formula for a CI is ( Estimator ± (t* or z*) SE(Estimator) ). In this problem parameter of interest is p1 – p2 and it is estimated by pˆ1 pˆ 2 and hence pˆ1 (1 pˆ1 ) pˆ 2 (1 pˆ 2 ) * ˆ ˆ CI ( p1 p2 ) z n n 1 2 0.040936(0.959064) 0.026627(0.973373) (0.040936 0.026627) 1.96 684 676 0.014309 0.0191778 ( 0.00486898 , 0.0334859) Chapter 9 Examples, Fall 2007 Page 19 of 21 10. Do the results of the CI and significance test agree? Must they agree? When MUST the two agree? Some more work for you: Look at other examples and problems in text. Make sure you can identify the problems and solve them by hand. Also, identify the problem type for the following examples. Make sure to ask the relevant questions before you decide on the type of problem. Example – 4: There is no known cure for fibromyalgia – a mysterious ailment with symptoms that include stiffness, fatigue, and pain. But acupuncture may help, according to research from the Mayo Clinic. Twenty-five patients underwent six sessions of acupuncture, while 25 received a simulated version. A month later, those who go the real thing had less pain and felt significantly less tired and anxious. Example – 5: Nearly 20% of pregnancies end in miscarriage, often for no apparent reason. Example – 6: It’s well known that older moms have a higher chance of miscarrying, but a recently published study of 14,000 women shows that the father’s age matters too. If he’s 40 or older, the mother’s risk of miscarrying is three times higher than if the dad is under 25. Chapter 9 Examples, Fall 2007 Page 20 of 21 Example – 7: If you suffer from high blood pressure and high cholesterol, make sure you’re being treated for both. Having the two problem together dramatically increases the risk of hear attack and stroke. In a study of nearly 3,000 men and women conducted by the University of California, Irvine it was found that less than one third of high-risk patients are actually prescribed medication for both problems. Example- 8: In case you need encouragement: It takes only 14 days to start seeing good results from flossing, says a New York University study of 51 sets of twins. All the participants brushed regularly, but one twin in each pair also flossed. After two weeks, the flossing twins had significantly less gum bleeding. Chapter 9 Examples, Fall 2007 Page 21 of 21