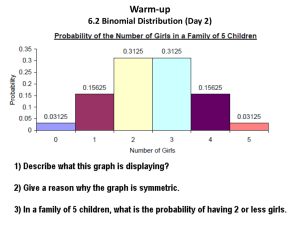
Probability Distribution
advertisement

Page 1 of 6 Probability Distribution Notes 0501-ProbDist.doc Discrete Probability Distributions In order to study inferential statistics, we need to combine the concepts from descriptive statistics and probability. This combination makes up the basics of probability distributions. Descriptive statistics allows us to collect and represent data with graphs and certain measures – central tendencies and variations. In descriptive statistics, we developed frequency distributions by using measures (in classes or categories) and frequencies. We construct probability distributions by considering the number of possible outcomes and the probabilities of those outcomes. The measure is called a random variable. Random variable – has a single numerical value, determined by chance, for each outcome. Probability distribution – represents all values of a random variable and probability of each value. Just as there are discrete and continuous data, there are discrete and continuous random variables. Discrete random variable – finite number of values or a “countable” number of values – values that can be counted. [Values can be represented by the set of counting numbers. You might think of counting stepping stones in a walkway.] Continuous random variable – infinite number of values with no gaps between the values. [You might consider drawing a line, the sweeping hand on a clock, or the analog speedometer on a car.] In this section, we restrict our discussion to discrete probability distributions. Each probability distribution must satisfy the following two conditions. 1. P( x) 1 where x assumes all possible values of the random variable 2. 0 P(x) 1 for every value of x As we found the mean and standard deviation with data in descriptive statistics, we can find the mean and standard deviation for probability distributions by using the following formulas. 1. [ x P( x)] mean of probability distribution 2. 2 [( x )2 P( x)] 3. 2 [ x2 P( x)] 2 variance of probability distribution variance of probability distribution 4. [ x 2 P( x)] 2 standard deviation of probability distribution Round answers to one decimal-place more than that of the random variable. Page 2 of 6 Probability Distribution Notes 0501-ProbDist.doc Recall that the Range Rule of Thumb defines unusual values as those values more than two standard deviations away form the mean. Thus, a value x is unusual if either x < - 2 or x > + 2 Unusual values Usual values -2 Unusual values 2 The range rule of thumb can be paralleled in probability distributions by thinking of the probability of an event. Event A is unusual if P(A) 0.05. Let x represent the random variable. Then, we may summary as follows. x successes among n trials is unusually high if P(x or more) 0.05 low if P(x or fewer) 0.05 The expected value, E, of a probability distribution is defined to be the mean value of a probability distribution: E = [ x P( x)] . A certain organization sells raffle tickets every year as a fund-raiser. Suppose you buy a raffle ticket for $5.00. One of 500 tickets will be the winning ticket worth $1,000. How much would you expect to win or lose if you bought one ticket each year for a large number of years. If you win, you win $1000 less $5 for the ticket yields $995 for the win. If you lose, you lose $5 that you paid for the ticket. Since one of the 500 tickets will win, the probability of winning is 0.002 (1 of 500); thus, the probability of losing is 499 out of 500 or 0.998. Expected value = expected winnings minus expected losses 1 499 (995) (5) 500 500 1.99 4.99 $3.00 E= So if you were to buy such a raffle ticket each year for a large number of years, you would expect to win some and lose some. Overall you would expect to lose $3.00. Probability Distribution Notes 0501-ProbDist.doc Page 3 of 6 We have already defined random variable and probability distribution. Two discrete probability distributions of primary importance are the binominal probability distribution and the Poisson probability distribution. The following discussion concerns the binomial probability distribution that can be used to find probabilities of success/failure, true/false, boy/girl, go/stay, and similar types of situations. There are four characteristics that a probability distribution must have in order to be a binomial probability distribution. Binomial probability distribution results from a procedure described as follows: 1. The procedure has a fixed number of trials. [n trials] 2. The trials must be independent. 3. Each trial is in one of two mutually exclusive categories. 4. The probabilities remain constant for each trial. Notations: P(success) = P(S) = p probability of success in one of the n trials P(failure) = P(F) = 1 – p = q probability of failure in one of the n trials n = fixed number of trials; x = number of successes, where 0 x n P(x) = probability of getting exactly x successes among the n trials P(x a) = probability of getting x-values less than or equal to the value of a. P(x a) = probability of getting x-values greater than or equal to the value of a. NOTE: Success (failure) does not necessarily mean good (bad). One of the four conditions required for a binomial probability distribution is that the trials must be independent. If sampling is done with replacement, the trials will be independent. However, if sampling is done without replacement, the trials are not independent. When sampling with or without replacement, the trials may be considered to be independent if the sample size is no more than 5% of the population size. If n 0.05N, then the trials may be considered to be independent. We should be able to calculate binomial probabilities by any of three methods: by formula, from table values, and by using technology. n! p x q n x for x 0,1, 2,..., n (n x)! x ! Factorial definition: n! = n(n – 1)(n – 2)21; 0! = 1; 1! = 1 Formula for Binomial Probabilities: P( x) Example (Formula): Find the probability of 2 successes of 5 trials when the probability of success is 0.3. 5! 5 4 3! P( x 2) 0.320.752 (0.09)(0.343) = 10(0.03087) = 0.3087 (5 2)!2! 3! 2! Use of Binomial Probabilities Table: You will have to adjust your table use to the particular book that contains the table. Use of Technology to Find Binomial Probabilities: Two technologies that we will use to calculate binomial probabilities are the TI-83 calculator and the StatDisk computer software. Page 4 of 6 Probability Distribution Notes 0501-ProbDist.doc Use of TI-83 Calculator and StatDisk to Compute Binomial Probability Distribution Values Example (TI-83): First, we will find 5 factorial. To find 5! using the TI-83 calculator, enter 5, press MATH, PRB, 4:!, ENTER. We get the answer 120. So 5! = 120. Example (TI-83): Find the probability that 2 successes will occur out of 5 trials if the probability of success is 0.3. Press 2nd VARS [DISTR]. Scroll down to 0:binompdf( Press ENTER. Enter 5,.3,2) and press ENTER to get the answer .3087. Click Analysis and click either Binomial Probabilities or Probability Distributions and Binomial Distribution. The number of trials n = 3 and the probability of success is p = 0.5. For example, suppose we flip a coin three times and record the number of heads each time. The mean number of successes is 1.5 with a standard deviation of 0.8660. The results are read as follows: The probability of getting x = 0 heads is P(x = 0) = 0.125. P(x ≤ 2) = 0.875. P(x ≥ 0) = 1.000. Page 5 of 6 Probability Distribution Notes 0501-ProbDist.doc Mean, Variance, and Standard Deviation for Binomial Distribution Earlier we found the mean, variance, and standard deviation for probability distributions by using the following formulas: 1. [ x P( x)] mean of probability distribution 3. 2 [ x2 P( x)] 2 variance of probability distribution 4. [ x 2 P( x)] 2 standard deviation of probability distribution Since the binomial probability distribution has the four special characteristics, the three formulas above are equivalent to the three formulas below: [n = number of trials, p = probability of success, q = probability of failure] 5. n p mean of probability distribution 6. n p q variance of probability distribution 7. n p q standard deviation of probability distribution 2 Recalling the range rule of thumb, we have the following limits for usual values: maximum usual value = + 2 minimum usual value = - 2 Consider rolling a die three times and recording the number of times five spots show on the top face. We could use formulas 1, 3, and 4 to find the mean, variance, and standard deviation, respectively. Or we could use formulas 5, 6, and 7 to find the mean, variance, and standard deviation, respectively. Below we have used both sets of formulas. Let x = number of times five spots show; P(x) = probability that number shows. x 0 1 2 3 P(x) 0.5787 0.3472 0.0694 0.0046 Sum = xP(x) 0.0000 0.3472 0.1388 0.0138 0.4998 x2 0 1 4 9 Sum = x2P(x) 0.000 0.3472 0.2776 0.0414 0.6662 By Formula 1, the mean is [ x P( x)] = 0.500. By Formula 5, the mean is n p = 3(1/6) = 3/6 = 0.5 By Formula 4, the standard deviation is [ x2 P( x)] 2 0.6662 (0.5)2 0.4162 By Formula 7, the standard deviation is n p q 3 (1/ 6)(5/ 6) 0.417 0.645 Seems fairly obvious that Formulas 5, 6, and 7 are easier to use than Formulas 1, 3, and 4. 0.645 Page 6 of 6 Probability Distribution Notes 0501-ProbDist.doc Binomial Generator for Binomial Distributions Generate Random Binomial Distributions 1. Click on Data and Binomial Generator 2. Enter Sample Size, Success Probability, Number of Trials. 3. Click Copy after the Random Sample is Generated. NOTE: If left blank, the Seed is a random number that causes different sample data to be created whenever the same parameters, number of values, success probability, and number of trials, are used. The seed is based on the time and is automatically produced each time the Generate button is pressed. Whenever the same parameters and Seed are used, STATDISK will generate identical random samples. In any case, the Seed used is shown for future reference. 4. To move the sample to another STATDISK module, click the Copy button. 5. Next, select the Sample Editor to open the Statdisk Data Window, and press the Paste button in that display. Since the Paste button affects the entire sample display, the sample being moved is placed in the proper column. (For more information about how to move data, see the General Instructions or the Help in the in the Sample Editor module.)