Omics - Tresch Group
advertisement

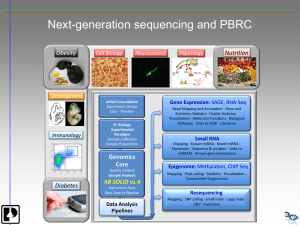
‘Omics’ - Analysis of high dimensional Data Achim Tresch Computational Biology Schedule Monday Lecture: Introduction to Omics Motivation: Transcriptomics Sebastian • Experimental techniques Dümcke • Data analysis (overview) Data exploration of univariate data • Measures of location and scale • Bar plot, box plot, histogramm, density plot Data exploration of bivariate data • Odds ratio, correlation crosstable, scatter plot, QQ-plot Exercises: Introduction to R and Bioconductor Forensic bioinformatics Arijit Das Henrik Failmezger Omics Omics (Wikipedia): Omics informally refers to a field of study in biology such as genomics, proteomics or metabolomics. Omics aims at the collective characterization and quantification of pools of biologically / biochemically similar molecules that translate into the structure, function, and dynamics of an organism or organisms. Ingredients for omics research: - High throughput experimental techniques for the simultaneous measurements of large numbers of molecules - Statistical methods for the appropriate analysis of high dimensional data. Generally, Omics data analysis takes longer than data generation! Genomics: Transcriptomics Techniques for RNA quantification - Northern Blot - Reporter genes low-medium throughput - Reverse Transkriptase PCR - Microarrays high throughput - RNA-Sequencing Northern Blot RNA (or DNA) is separated by the size on a gel, transfered to the membrane and hybridized with gene-specific probe RNA -> Nothern blot DNA -> Southern blot Low throughput and poor quantification Molecular Biology of the Cell (© Garland Science 2008) RT-PCR RNA DNA Reverse transcription PCR The course of PCR (amount of doublestranded DNA) is monitored using a specific fluorescent dye N Differences in concentration of particular mRNA in different samples can be calculated as 2N, with N being the difference in the number of cycles to obtain the same amount of product Medium throughput, high precision Molecular Biology of the Cell (© Garland Science 2008) Microarrays mRNA is converted to cDNA and labeled, and subsequently hybridized to an array of gene-specific probes (either spotted cDNA samples or oligonucleotides, either one or two sample(s) per microarray) Differences in expression between samples are determined as a ratio of fluorescence signals at individual spots. High throughput, medium precision (low dynamic range) Molecular Biology of the Cell (© Garland Science 2008) Next generation sequencing (NGS) Massively parallel sequencing techniques enable sequencing of genome-wide cellular RNA pools Typical sequencing read lentgh is 30-100 nucleotides RNA or cDNA has to be fragmented A single run comprises 106-108 reactions, depending on a platform, so most RNAs are covered by multiple “reads“ read occurence for a particular gene reflects expression level Zyklusvorlesung Molekularbiologie WS 2009/10 High throughput, precision depends on sequencing depth (#reads) Next generation sequencing (NGS) Illumina (Solexa) sequencing DNA fragments are coupled to glass slide and subjected to Bridge amplification. 106-108 individual reads of 30-100 bp are produced at a time by using fluorescently labeled removable terminator tags Sample preparation Sequencing Transcriptomics with Microarrays Workflow of a microarray experiment Experimental design Frame a biological question Choose a microarray platform Decide on biological and technical replicates Design the series of hybridization days Technical performance Obtain the samples Isolate total RNA Label cDNA or mRNA Perform the hybridizations Scan the chips weeks Statistical analysis Data mining Extract fluorescence intensities Cluster analysis and pattern recognition Normalize data to remove biases Study lists of genome ontologies Estimate expression changes Identify differentially expressd transcripts Search for regulatory motifs Reconstruct regulatory circuits Design validation and follow-up experiments days-weeks months After: Gibson, G and SV Muse, 2004. Transcriptomics with Microarrays labeled sample Sample amplification and labeling sample injected into microarray RNA sample Fluorescence intensity translated into mRNA abundance Probe array scanning and intensity quantitation Probe array hybridization Probe array washing and staining RNA Sample preparation RNA Sample preparation Hybridization onto microarray Quakenbush, 2006 Hybridization onto microarray Hybridization onto microarray mismatch probes perfect match probes probe pair Each gene is represented by 11-20 probe pairs of 25nt length, consisting of a perfect match probe and a mismatch probe. Perfect match probes are complementary to specific sequences of the target gene, preferentially located at the 3’ end of a gene. The mismatch probe is identical to the perfect match probe, except for the middle base. It is designed to detect unspecific binding. Affymetrix Microarrays – Probe Synthesis For the extension of all oligonucleotides by one base, four litographic steps with complementary masks are performed, one mask for each base A, C, T, G. Affymetrix raw Data Greyscale and false color image of the fluorescence readout Data Analysis Detection of differentially expressed genes genes Identification of similar samples and co-regulated genes in a multi-sample comparison samples Data Analysis A) B) C) D) E) Cluster Analysis Pearson correlation matrix Venn diagram Summary statistics up-/down regulation [ Phenotypic analysis ] Koschubs et al., EMBO J, 2009. Data Analysis: Gene Ontology 35 % of genes in genome % percentage in signifikant gene list 30 % of total changing genes 25 20 Response to chemical stimulus 15 Vitamin metabolic process 10 5 0 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 GO te rm_biologica l process Microarray Databases ArrayExpress (European Bioinformatics Institute) Gene Expression Omnibus (NCBI) http://www.ebi.ac.uk/arrayexpress Acknowledgement Dietmar Martin Gene Center, LMU Munich