11 - GWin
advertisement

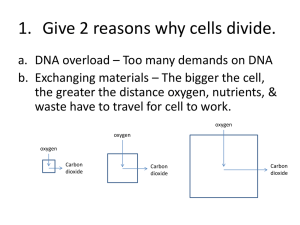
DNA sequencing I Historical method – SangerN “chain termination” Latest method – ion torrent – seq. via pH measurement Both rely on DNA polymerase to copy template, i.e. “sequencing by synthesis” Old technology – chain terminationNobel: clone target DNA in bac. to get ~1011 copies needed for 4 seq rxns: DNA template + primer + pol + dNTP + ddATP (or ddCTP etc., each in separate tube); ddNTP’s lack 3’OH, incorporate normally but can’t be extended; run gel w/4 lanes; bands in G lane show size of frags. ending in G, etc. Di-dexoy NTPs lack 3’OH group They are incorporated normally, but next base can’t be chemically attached because it attaches thru 3’ O missing OH More elegant later method: label each ddNTP with a diff. colored fluor run electrophoresis products in single lane camera records color of products as they run off the bottom of the gel * ** * Each sequencing run -> ~500bp of sequence this method used for human genome project But needed ~108 seq rxns, 107 gels even @ 104 gels/d, $10/rxn -> 1000 days (3yrs) and $1B Latest method - Ion Torrent Part A: produce ~107 copies of individual DNA fragments on mm-sized beads because sequencing method requires multiple identical target molecules/bead Part B: read sequence by primer extension synthesis, 1 base at a time, detecting pH change when dNTPs are incorporated in individual wells containing single beads, using array of ion-sensitive field effect transistors (ISFETs) Part A - method to put many copies of single short piece of DNA on micron-size bead; diff. DNAs on diff. beads Shear target DNA; select pieces ~200 bp in length (how?) Ligate forked adapter oligos to ends of sheared DNA F R’ R’ F Note this allows all pieces to be amplified with oligos F and R (the reverse complement of R’ /= F) (without fork, F and F’ would be at 5’ and 3’ ends and their annealing on single templates would impede pcr) Make water-in-oil emulsion containing: 1) pcr reagents to amplify DNA using primers F and R 2) hydrophilic micron-size beads with lots of oligos F attached via their 5’ ends 3) bead and DNA concentration adjusted such that ~1 DNA fragment and 1 bead/water droplet F Each droplet acts like test tube to isolate individ. DNA species. Because many copies of F are on each bead, many product strands ( ~107) starting with F get attached to each bead Break emulsion with soap, spin down beads, melt off non-covalently attached strand, spin down beads - most now have single-stranded DNA starting with F and ending with R’ Enrich for beads that have such templates by capturing them on paramagnetic beads with oligo R on them, collecting with magnet, and then melting them off Centrifuge enriched beads into wells just big enough to hold a single bead Part B: to get sequence, add primer R, DNA pol and a single dNTP, e.g. dATP; if T is next base on template, A will be incorporated, generating ~107 H+ ions as dATP ->dAMP+PP+H+ If T is not the next base, no H+ will be produced http://upload.wikimedia.org/wikipedia/commons/1/10/DNTP_nucleotide_incorporation_reaction.svg A run of n bases of the same type -> ~n*107 H+ ions Flow in dATP, record H+ signal, wash repeat with dCTP, then dTTP, then dGTP then repeat cycle of 4 dNTP additions … G T C A Sequence of H+ signals (1, 2, 0, 0, 1 …) tells you sequence A CC A… Electrical detection of H+ ions with ISFET H+ ions accumulating on gate induce e- carriers below, which allows current to flow between S and D H+ H+ -- http://www.google.com/imgres?q=ion+sensitive+field+effect+transistor&um=1&hl=en&biw=1410 &bih=773&tbm=isch&tbnid=w8xp90Qj4QYOHM:&imgrefurl=http://www.wtec.org/loyola/mcc/me ms_eu/Pages/Chapter5.html&docid=ja485HSUF4DTXM&imgurl=http://www.wtec.org/loyola/mcc/mems_eu/Media/5_4. jpe&w=504&h=196&ei=CCW3TvfKNuTi2QWIzZTQDQ&zoom=1&iact=hc&vpx=280&vpy=281&dur=6 335&hovh=140&hovw=360&tx=150&ty=81&sig=114362777222024808894&page=1&tbnh=70&tb nw=181&start=0&ndsp=22&ved=1t:429,r:1,s:0 SEM image of cross section of chip with wells on top and sets of S and D electrodes below small size of wells -> ~106 wells/ 1cm2 chip ? rationale for position of multiple FETs inflow Attach top, walls and Inflow/outflow ports for fluidics Top view of assembled ~1cm2 chip outflow Reader with chip clamped in place Position of inflow and outflow -> only central ovoid of sensors exposed to sample Histogram pH readings from wells exposed to same solution shows sensor uniformity with s.d. ~DpH from single base incorporation (~0.02) Unclear if this is very important since you can check each sensor w/ known bases at start of run Blue = time course of pH change in 1 well due to single base incorporation Red = not fully disclosed model of pH change expected as a result of dNTP flowing by, diffusing into well, DNA pol incorporating base, H+ produced and diffusing out 8 2 1 Model simulations for pH change due to 1 to 8 base incorporations (e.g. TTTT..) They sample pH change in individual wells many times during cycle, then fit data to these curves to infer how many bases were Incorporated; the inference of # of bases = “raw data” Raw data for first 100 flows of dNTPs reading a sequence Note signal from bases presumably not incorporated (<<1) gradually increases. Why do you think signal degrades? Phasing Their explanation is that polymerase slips behind or jumps ahead on some of the ~107 identical templates on a bead, then mixing in sequence from templates “out of phase”; slippage could be due to failure to incorporate a base on some templates due to loss of polymerase (pol molecules can diffuse out of well); jumping ahead could be due to incomplete wash out of previous base: e.g. if seq. is C-T-C-G and not all dCTP washed out after 1st C, during T cycle a dTTP and then dCTP could be incorporated on some templates, and these would then be ahead by 1 base when the next base is flowed in Can you use this information to “clean up” signal? It allows them to model which particular sequencedependent erroneous signals might be mixed in, and subtract them -> “corrected base calls” Note improved uniformity and closeness to integer values But they don’t provide enough info to evaluate procedure “Phasing” problem is inherent to all methods that rely on coordinating state of many molecules that go through cyclic changes What tends to keep DNA synthesis in phase on different templates in their system? If a sensor could sense the state of single-molecules, would phasing-type problems disappear? Keep this in mind wrt future methods Even after data processing, the maximum # of bases they can read accurately from each bead is currently ~100. 98% 100% Histogram of read lengths with indicated accuracy They stop reads when (not-fullydisclosed) error checking thresholds are exceeded Other accuracy estimates from sequencing bacterial DNAs which have been sequenced by other methods 100% 99% 99% 97% Homopolymer length Position in read 1 3 5 60 120 E Coli: 4.7M bases: consensus seq. with 11-fold coverage has 1228 errors (.03%), 1171 (95%) of which are deletions How many would this predict in a human genome? What is “fold-coverage”? “coverage”? They also used this method to sequence the genome of Gordon Moore (of Moore’s Law!) To estimate accuracy, they compared SNPs identified using ion torrent vs another method (SOLiD) The good news: they disagreed <0.1% of the time when both called het. or hom. SNPS The bad news: they disagreed or missed >1M out of ~3M SNPS Cost estimates: They sell the Ion Torrent reader without chips (fluidics and computer??) for ~$50,000 They used >1000 chips for Gordon Moore: @ ~$100 -> $100,000/human genome sequence Note 1000 chips x 106wells/chip x 100 bases/well = 1011 bases = 30*(3x109) = 30x “coverage” This is first report with ion torrent, so expect technical improvements and cost reductions … They claim 109 wells/chip are feasible, so possibly 1 chip/genome… but how much can the error rate be reduced? Main points Appreciate cleverness of emulsion pcr to put many copies of individual sequences on beads. If they are limited by sensitivity of detection of H+, they may not be able to use much smaller beads (# H+ ions ~bead area) Major new advance is the method of electrical detection of base incorporation, which allows them to get away from specialized biochemistry and expensive optical detection methods used in competing methods – next week!