Chapter 6: Probability
advertisement

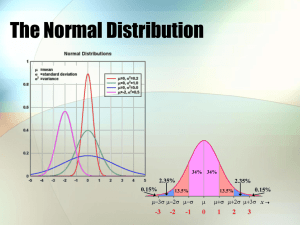
COURSE: JUST 3900 INTRODUCTORY STATISTICS FOR CRIMINAL JUSTICE Chapter 6: Probability Instructor: Dr. John J. Kerbs, Associate Professor Joint Ph.D. in Social Work and Sociology Probability Probability is a method for measuring and quantifying the likelihood of obtaining a specific sample from a specific population. We define probability as a fraction or a proportion. The probability of any specific outcome is determined by a ratio comparing the frequency of occurrence for that outcome relative to the total number of possible outcomes. Probability (Continued) Inferential statistics use sample data to answer questions about populations Probability is used to predict what kinds of samples are likely to be obtained from a population. Probability (Continued) Whenever the scores in a population are variable, it is impossible to predict with perfect accuracy exactly which score(s) will be obtained when you take a sample from the population. In this situation, researchers rely on probability to determine the relative likelihood for specific samples. Thus, although you may not be able to predict exactly which value(s) will be obtained for a sample, it is possible to determine which outcomes have high probability and which have low probability. Probability (Continued) Definition: For a situation in which several different outcomes are possible, the probability for any specific outcome is defined as a fraction or a proportion of all possible outcomes. If the possible outcomes are identified as A, B, C, D, and so on, then the following formula applies: Other Notation: p(outcome) = . . . Remember: You can express probabilities as 1. Fractions 2. Percentages 3. Decimals - - most commonly used approach Probability and Sampling To assure that the definition of probability is accurate, the use of random sampling is necessary. Random sampling requires that each member of a population has an equal chance of being selected. If more than one person is being selected, the probabilities must stay constant from one selection to the next - - Thus, the next requirement below. Independent random sampling includes the conditions of random sampling and further requires that the probability of being selected remains constant for each selection Probability and Sampling Two main approaches to random sampling Approach #1: Keeps probabilities from changing from one selection to another Random Sampling with Replacement: This approach to sampling requires that you return each person to the population before you make another selection. aka - - Independent Random Sampling, which keeps a constant probability of selection Approach #2: Selections are random, but there is no maintenance of constant probability. Random Sampling without Replacement: This approach does not maintain constant probability from one selection to the next selection Probability and Sampling Card example for sampling with replacement with constant probability p(ace of diamonds) = 1/52, replace card p(ace of diamonds) = 1/52, replace card… Card example for sampling without replacement and no assumption of constant probability p(ace of diamonds) = 1/52, then next draw p(ace of diamonds) = 1/51, then next draw p(ace of diamonds) = 1/50, then next draw NOTICE HOW PROBABILITY OF SELECTION IS NOT CONSTANT WITHOUT REPLACEMENT Probability (Continued) When a population of scores is represented by a frequency distribution, probabilities can be defined by proportions of the distribution. Probability values are expressed by a fraction or proportion. In graphs, probability can be defined as a proportion of area under the curve. Probability and the Normal Distribution Probability and the Normal Distribution If a vertical line is drawn through a normal distribution, several things occur. The line divides the distribution into two sections. The larger section is called the body and the smaller section is called the tail. The exact location of the line can be specified by a z-score. Probability and the Normal Distribution (Continued) The unit normal table lists several different proportions corresponding to each z-score location. Column A of the table lists z-score values. For each z-score location, columns B and C list the proportions in the body and tail, respectively. Finally, column D lists the proportion between the mean and the z-score location. Because probability is equivalent to proportion, the table values can also be used to determine probabilities. The Normal Distribution Example z = 0.34 B + C = 1.00 Probability and the Normal Distribution (cont'd.) To find the probability corresponding to a particular score (X value), you first transform the score into a z-score, then look up the zscore in the table and read across the row to find the appropriate proportion/probability. To find the score (X value) corresponding to a particular proportion, you first look up the proportion in the table, read across the row to find the corresponding z-score, and then transform the z-score into an X value. Probability and the Normal Distribution (cont'd.) 4 Key Facts about Unit Normal (z) Tables 1. The body (column B) always represents the larger part of the distribution and the tail (column C) is always the smaller section, whether on the right or left side. 2. The normal distribution is symmetrical; therefore, the proportions will be the same for the positive and negative values of a specific z-score . 3. Proportions are always positive, even if the corresponding z-score is negative. To find proportions for negative z-scores, look up the corresponding proportion for the positive value of z. 4. A negative z-score means that the tail of the distribution is on the left side and the body is on the right, and vice versa for a positive z-score. Probability and the Normal Distribution (cont'd.) See Column C in Unit Normal Table on page 699 Note: z = + 0.25 here. Your book had a typo on p. 174 and listed it as a negative z-score. Please correct in your book Note: z = - 0.25 here. Book is correct for this side of the graph Percentiles and Percentile Ranks The percentile rank for a specific X value is the percentage of individuals with scores at or below that value. When a score is referred to by its rank, the score is called a percentile. The percentile rank for a score in a normal distribution is simply the proportion to the left of the score. Percentiles and Percentile Ranks 0 +0.25 P(z>1.00) Tail = 0.1587 Or 15.87% Look up 10% in Tail Tail = 0.1003 For z = 1.28 P(z<1.50) Body = 0.9332 Or 93.32% P(z<-0.50) Tail = 0.3085 Or 30.85% Think Symmetry!!!!! 30% on each side of μ = 0 Look up z for .30 or 30% between μ=0 and z (see Column D) Z=+/- 0.84 for proportion .2995 Percentiles and Percentile Ranks Percentile ranks represent specific scores as a percentage of individuals in the distribution who have scores that are less than or equal to the specific score. For example, if 80% of all JUST3900 students had term grades that were less than or equal to 87, then a score of 87 has a percentile rank of 80%. Thus, a score of 87 puts students at the 80th percentile. Percentiles and Percentile Ranks Imagine that the population of all drug abusing offenders are assessed for their drug cravings on a scale from 0 (no cravings) to 150 (intense cravings). The assessment finds μ = 100 and σ = 15 and we need to determine what proportion of drug abusing offenders have cravings that fall between scores of 115 and 130. Percentiles and Percentile Ranks The assessment finds μ = 100 and σ = 15 and we need to determine what proportion of drug abusing offenders have cravings that fall between scores of 115 and 140. Step 1: Find z-scores for two values For x = 115: z = (x- μ)/ σ = (115-100)/15 = 1.00 For x = 140: z = (x- μ)/ σ = (140-100)/15 = 2.67 Step 2: Find corresponding proportion between the two z-scores p(1.00<z<2.67) = .1587 - .0038 = 0.1549 or 15.49% Percentiles and Percentile Ranks Please note that you must be able to convert raw scores (i.e., x values) into z-scores Use the z-score formula z = (x- μ) / σ z-scores into proportions and probabilities proportions and probabilities into z-scores Z-scores into raw scores (i.e., x values) Use the z-score formula z = (x- μ) / σ Please remember that it is impossible to directly transform an x value into a proportion or probability without first converting the x value into a z-score and then into a probability or proportion Probability and the Binomial Distribution for Two Outcomes Binomial distributions are formed by a series of observations (for example, 100 coin tosses) for which there are exactly two possible outcomes (heads and tails) The two outcomes are identified as A and B, with probabilities of p(A) = p and p(B) = q. p + q = 1.00 The distribution shows the probability for each value of X, where X is the number of occurrences of A in a series of n observations. Probability and the Binomial Distribution (cont'd.) When pn and qn are both equal to or greater than 10, the binomial distribution is closely approximated by a normal distribution with a mean of μ = pn and a standard deviation of σ = npq. In this situation, a z-score can be computed for each value of X and the unit normal table can be used to determine probabilities for specific outcomes. Within the normal distribution, each value of X has a corresponding z-score as follows: Binomial Distributions Probability and Inferential Statistics Probability is important because it establishes a link between samples and populations. For any known population, it is possible to determine the probability of obtaining any specific sample. In later chapters, we will use this link as the foundation for inferential statistics. Probability and Inferential Statistics (cont'd.) The general goal of inferential statistics is to use the information from a sample to reach a general conclusion (inference) about an unknown population. Typically a researcher begins with a sample. Probability and Inferential Statistics (cont'd.) If the sample has a high probability of being obtained from a specific population, then the researcher can conclude that the sample is likely to have come from that population. If the sample has a very low probability of being obtained from a specific population, then it is reasonable for the researcher to conclude that the specific population is probably not the source for the sample. Research Study - - Likelihood of Predicting a Card’s Suit 15 Times in a Row for in 48 Trials Actual Score Value Real Limits μ = pn μ = (1/4)*48 = 12 qn = (3/4)*48 Thus, z = 1.17 and p = .1210 or 12.10% Research Study If the x-score is 440, is this an extreme value as defined by the book? The goal of this study is to determine whether the treatment has an effect. As a primer for the next chapter, extreme effects are considered those that are defined by scores that are very unlikely to be obtained from the original population by random chance, thus providing evidence of treatment effects. Cutoff scores for 1-tail tests: Scores with p<0.05 (z = 1.65) Scores with p<0.01 (z = 2.33) Scores with p<0.001 (z = 3.11) Value as discussed in book on page 190-191 Cutoff scores for 2-tail tests: Scores with p<0.05 (z = +/-1.96) w/0.025 per tail Scores with p<0.01 (z = +/-2.58) w/0.005 per tail Scores with p<0.001 (z = +/-3.30) w/0.0005 per tail