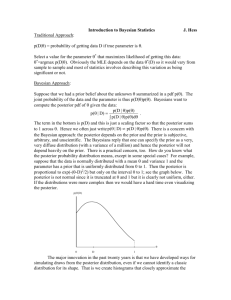
Data Quality Sharp 5 - Mayo Clinic Informatics
advertisement

Data Quality
Sharp project 5
June 2010
Statistical Problems with Data
Quality in EHR
• Missing Data
• Uncertain Diagnosis
• Uneven/unequal precision / measurement
error
• Bias
•…
Missing Data: (Rage in
Statistical Theory)
• Common problem with observational/
retrospective data
• Statistical approaches
– Imputation
– Multiple imputation (MI) (Statisticians have
acronyms too)
– Regression with residual error
– draw from Posterior distribution
Missing Data– Empirical approach
• Regression on Y with Missing X-variables
• “X is missing” is also information.
• Analyze data set using
– Imputation (mean?)
– “missing” indicator
– Empirical approach– let data tell you what to
do
Uncertain diagnosis
• Universal problem with health data
• No Gold standard
• Disease/health is a spectrum, not a
dichotomy
• Probabilistic perspective
– Probability (Peripheral Arterial Disease)
– From {0,1} to [0-1] as phenotype
– More realistic phenotype?
Uncertain Diagnosis
• Result is a probability
• Probability is a posterior distribution of a
0/1 variable
– Use p itself (certainty equivalent)
• Analogous to single imputation
– Use multiple imputation
• “1” with probability p, “0” with probability 1-p
Uncertain Diagnosis– PAD
example (eMERGE)
• Mayo Vascular Lab Database– n=18000
• Gold Standard— Ankle/Brachial Index
(ABI)
• Use of Diagnostic / procedural codes
– ICD-9 / HICDA / CPT
• Logistic regression of gold standard (PAD
by ABI) on diagnostic codes
• posterior probability of PAD
Uncertain Diagnosis
• Model for Pr(PAD)– 90% predictive value
• Export model for Pr{PAD} to patients
without gold standard ascertainment?
• (Coding practices?)
Uncertain Diagnosis
• Use Pr{PAD} in analysis of
– Incidence of PAD
– Incidence trends
– Surveillance
– Analysis of etiology, risk factors
Unequal Precision of continuous
phenotype
• eMERGE example: Red Blood Count
• Use retrospective Laboratory Data
• N=3000, K=20,000
– 1 measurement 100 measurements/subject
• Account for differential precision
• Components of variance
• Weighted regression?
• Posterior distribution– same model fits
Sample from Posterior
Distribution
• Missing Data, uncertain diagnosis, unequal
precision can all be represented by
sampling from posterior distribution
• They are all the “same problem”
• Statistical / computational tools for this
have been developed
– Markov Chain Monte Carlo (MCMC)
– Multiple Imputation
Summary: Data Quality
• ‘Data’ is not ‘a number’ but ‘a posterior
distribution’
– Mean and variance
– Posterior probability
• Data quality
– Don’t try to change it
– Measure it
– Allow for it-- propagation of error
What is “Data”?
• Data is whatever input goes into the next
procedure.
• (= output from previous procedure)
• ‘Propagation of error’
• Output of NLP is also “Data”
How Assess Data Quality?
• What if there is no Gold Standard?
• Use any external standard
– E.g. outcome data
• Stronger predictive relationship= better
signal/noise ratio?
• “Errors-in-variables” principle
– Larger error in X –> Smaller beta for Y|X
Summary: Help!
• What are the important tasks in Data
Quality?
– Measurement?
– Allowance for?
• Important tasks for this Project?
– Integrate with other projects