Document
advertisement

Fundamentals of Embedded
Operating Systems
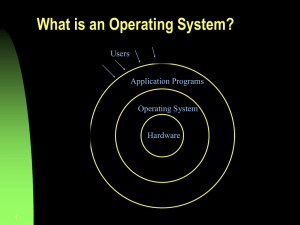
Operating System
Exploits the hardware resources of one
or more processors
Provides a set of services to system
users
Manages memory (primary and
secondary) and I/O devices
Foreground/Background
Systems
Small, simple systems usually don't have an
OS
Instead, an application consists of an infinite
loop that calls modules (functions) to perform
various actions in the “Background”.
Interrupt Service Routines (ISRs) handle
asynchronous events in the “Foreground”
Foreground/Background System
“Foreground”
ISR
while
loop
ISR
ISR
Code
Execution
“Background”
time
Why Embedded Operating
System?
For complex applications with a
multitude of functionality
mechanisms are required to implement
each functionality independent of the
others, but still make them work cooperatively
Embedded systems need
Multitasking
Multitasking - The ability to execute
more than one task or program at the
same time
CPU switches from one program to
another so quickly that it gives the
appearance of executing all of the
programs at the same time.
Example Multitasking
Telephone Answering Machine
Recording a
phone call
Operating the user’s
control panel
User has picked up
receiver
Nature of Multitasking
Cooperative multitasking -each program can
control the CPU for as long as it needs it. It
allows other programs to use it at times when
it does not use the CPU
Preemptive multitasking - Operating system
parcels out CPU time slices to each program
Complexities of multitasking
Multi-rate tasks
Periodic tasks
Concurrent tasks
Synchronous and asynchronous tasks
EXAMPLE: Complex Timing
Requirements of a compression unit
Uncompressed
Data
Character
Compressor
Compression
Table
Compressed
Data
Bit Queue
Cooperating Tasks
Data may be received and sent at different
rates - example one byte may be compressed to 2 bits
while another may be compressed to 6 bits
Data should be stored in input and output
queues to be read in a specific order
Time for packaging and emitting output
characters should not be so high that input
characters are lost
Fundamentals
How a System works
Wake Up Call -On Power_ON
Execute BIOS - instructions kept in Flash
Memory - type of read-only memory
(ROM) examines system hardware
Power-on self test (POST) checks the CPU,
memory and basic input-output systems
(BIOS) for errors and stores the result in a
special memory location
Processing Sequence
Power Up
BSP/OS
Initialization
Decompression
/Bootloading
Application code begins
Hardware Init
Board Support Package
BSP is a component that provides
board/hardware-specific details to OS
for the OS to provide hardwareabstractions to the tasks that use its
services
BSP is specific to both the board and
the OS for which it is written
BSP startup code
Initializes processor
Sets various parameters required by
processor for
Memory initialization
Clock setup
Setting up various components like cache
BSP also contains drivers for peripherals
Kernel
Most frequently used portion of OS
Resides permanently in main memory
Runs in privileged mode
Responds to calls from processes and
interrupts from devices
Kernel’s responsibility
Managing Processes
Context switching: alternating between the
different processes or tasks
Scheduling: deciding which task/process to
run next
Various scheduling algorithms
Critical sections = providing adequate
memory-protection when multiple
tasks/processes run concurrently
Various solutions to dealing with critical sections
Process
A process is a unique sequential execution of
a program
Execution context of the program
All information the operating system needs to manage
the process
Process Characteristics
Period - Time between successive executions
Rate - Inverse of Period
In a multi-rate system each process executes at
its own rate
Process Control Block (PCB)
Process Control Block
OS structure which holds the pieces of information
associated with a process
Process state: new, ready, running, waited,
halted, etc.
Program counter: contents of the PC
CPU registers: contents of the CPU registers
CPU scheduling information: information on
priority and scheduling parameters
PCB
Memorymanagement information:
Pointers to page or segment tables
Accounting information: CPU and real
time used, time limits, etc.
I/O status information: which I/O
devices (if any) this process has
allocated to it, list of open files, etc.
Process states
Executing
scheduled
Needs
Preempted data
Obtains data,
allocated CPU
Received data
Ready
Waiting
Needs data
Multithreading
Operating system supports multiple
threads of execution within a single
process
An executing process is divided into
threads that run concurrently
Thread – a dispatchable unit of work
Multi-threaded Process Model
Threads in Embedded
Applications
Lightweight processes are ideal for
embedded computing systems since
these platforms typically run only a few
programs
Concurrency within programs better
managed using threads
Context Switch
The CPU’s replacement of the currently
running task with a new one is called a
“context switch”
Simply saves the old context and “restores”
the new one
Actions:
Current task is interrupted
Processor’s registers for that particular task are
saved in a task-specific table
Task is placed on the “ready” list to await the next
time-slice
Context switch
Actions (more)
Task control block stores memory usage,
priority level, etc.
New task’s registers and status are loaded
into the processor
New task starts to run
Involves changing the stack pointer, the PC and
the PSR (program status register)
ARM instructions: Saving the context
STMIA
r13, {r0-r14}^ ; save all user registers
in space pointed to
by r13 in ascending
order
MRS
r0, SPSR
STMDB
r13, {r0, r15}
; get status register and put
it in r0
; save status register
and PC into context
block
ARM Instructions: Loading a new
process
ADR r0, NEWPROC ;
get address for pointer
LDR r13, [r0];
Load next context block in r13
LDMDB r13, {r0, r14};
Get status register and PC
MSR SPSR, r0;
Set status register
LDMIA r13, {r0-r14}^;
Get the registers
MOVS pc, r14;
Restore status register
When A Context-Switch Occur?
Time-slicing
Context switches
Time-slice: period of time a task can run before a
context-switch can replace it
Driven by periodic hardware interrupts from the
system timer
During a clock interrupt, the kernel’s scheduler
can determine if another process should run and
perform a context-switch
However, this doesn’t mean that there is a
context-switch at every time-slice!
Pre-emption
Preemption
Currently running task can be halted and
switched out by a higher-priority active
task
No need to wait until the end of the timeslice
Context Switch Overhead
Frequency of context switch depends upon
application
Overhead for Processor context-switch is the
amount of time required for the CPU to save
the current task’s context and restore the
next task’s context
Overhead for System context-switch is the
amount of time from the point that the task
was ready for context-switching to when it
was actually swapped in
Context switch overhead
How long does a system context-switch
take?
System context-switch time is a measure of
responsiveness
Time-slicing: a time-slice period + processor
context-switch time
Preemption is mostly preferred because it is
more responsive (system context-switch =
processor context-switch)
Process Scheduling
What is the scheduler?
Part of the operating system that decides
which process/task to run next
Uses a scheduling algorithm that enforces
some kind of policy that is designed to
meet some criteria
Scheduling
Criteria may vary
CPU utilization keep the CPU as busy as possible
Throughput maximize the number of processes
completed per time unit
Turnaround time minimize a process’ latency (run
time), i.e., time between task submission and
termination
Response time minimize the wait time for
interactive processes
Real-time must meet specific deadlines to prevent
“bad things” from happening
Scheduling Policies
Firstcome, firstserved (FCFS)
The first task that arrives at the request queue is
executed first, the second task is executed second
and so on
FCFS can make the wait time for a process very
long
Shortest Job First: Schedule processes
according to their run-times
Generally difficult to know the run-time of a
process
Priority Scheduling
ShortestJobFirst is a special case of
priority scheduling
Priority scheduling assigns a priority to
each process. Those with higher
priorities are run first.
Real Time Scheduling
Characteristics of Real-Time
Systems
Event-driven, reactive.
High cost of failure.
Concurrency/multiprogramming.
Stand-alone/continuous operation.
Reliability/fault-tolerance requirements.
Predictable behavior.
Example Real-Time Applications
Many real-time systems are control systems.
Example 1: A simple one-sensor, one-actuator control
system.
reference
input r(t)
A/D
A/D
rk
yk
control-law uk
D/A
computation
y(t)
sensor
u(t)
plant
actuator
The system
being controlled
Simple Control System
Basic Operation
set timer to interrupt periodically with period T;
at each timer interrupt do
do analog-to-digital conversion to get y;
compute control output u;
output u and do digital-to-analog conversion;
end do
T is called the sampling period. T is a key design choice.
Typical range for T: seconds to milliseconds.
Multi-rate Control Systems
More complicated control systems have
multiple sensors and actuators and must
support control loops of different rates.
Example:Helicopter flight controller
Do the following in each 1/180-sec. cycle:
validate sensor data and select data source;
if failure, reconfigure the system
Helicopter Controller
Every sixth cycle do:
keyboard input and mode selection;
data normalization and coordinate
transformation;
tracking reference update
control laws of the outer pitch-control loop;
control laws of the outer roll-control loop;
control laws of the outer yaw- and
collective-control loop
Hierarchical Control Systems
commands sampling
operator-system
rates may
interface
be minutes
or even
state
air traffic
hours
estimator
control
responses
Air traffic-flight
control hierarchy.
from sensors
virtual plant
navigation
flight
management
state
estimator
virtual plant
state
estimator
air data
flight
control
sampling
rates may
be secs.
physical plant or msecs.
Signal-Processing Systems
Signal-processing systems transform
data from one form to another.
Examples:
Digital filtering.
Video and voice
compression/decompression.
Radar signal processing.
Response times range from a few
milliseconds to a few seconds.
Example: Radar System
radar
sampled
digitized
data
memory
track
records
control
status
DSP
DSP
DSP
data
processor
track
records
signal
processors
signal
processing
parameters
Other Real-Time
Real-time
databases.
Applications
Transactions must complete by deadlines.
Main dilemma: Transaction scheduling algorithms and
real-time scheduling algorithms often have conflicting
goals.
Data may be subject to absolute and relative
temporal consistency requirements.
Multimedia.
Want to process audio and video frames at steady rates.
TV video rate is 30 frames/sec. HDTV is 60 frames/sec.
Telephone audio is 16 Kbits/sec. CD audio is 128 Kbits/sec.
Other requirements: Lip synchronization, low jitter,
low end-to-end response times (if interactive).
Are All Systems Real-Time
Systems?
Question: Is a payroll processing
system a real-time system?
It has a time constraint: Print the pay
checks every two weeks.
Perhaps it is a real-time system in a
definitional sense, but it doesn’t pay us
to view it as such.
We are interested in systems for which
it is not a priori obvious how to meet
The “Window of Scarcity”
Resources may be categorized as:
Abundant: Virtually any system design
methodology can be used to realize the timing
requirements of the application.
Insufficient: The application is ahead of the
technology curve; no design methodology can
be used to realize the timing requirements of
the application.
Sufficient but scarce: It is possible to realize
the timing requirements of the application, but
Example: Interactive/Multimedia
Applications
Requirements
(performance, scale)
Interactive
Video
The interesting
real-time
applications
are here
sufficient
but scarce
resources
insufficient
resources
High-quality
Audio
Network
File Access
abundant
resources
Remote
Login
1980
1990
2000
Hardware resources in year X
Hard vs. Soft Real Time
Task: A sequential piece of code.
Job: Instance of a task.
Jobs require resources to execute.
Example resources: CPU, network, disk, critical
section.
We will simply call all hardware resources
“processors”.
Release time of a job: The time instant
the job becomes ready to execute.
Absolute Deadline of a job: The time
instant by which the job must complete
execution.
Relative deadline of a job: “Deadline
Example
0
1
2
3 4
5
6
7
8
9 10 11 12 13 14 15
= job release
= job deadline
• Job is released at time 3.
• Its (absolute) deadline is at time 10.
• Its relative deadline is 7.
• Its response time is 6.
Hard Real-Time Systems
A hard deadline must be met.
If any hard deadline is ever missed, then
the system is incorrect.
Requires a means for validating that
deadlines are met.
Hard real-time system: A real-time
system in which all deadlines are hard.
We mostly consider hard real-time
systems in this course.
Examples: Nuclear power plant
Soft Real-Time Systems
A soft deadline may occasionally be
missed.
Question: How to define “occasionally”?
Soft real-time system: A real-time
system in which some deadlines are
soft.
Defining Use
“Occasionally”
One Approach:
probabilistic
requirements.
For example, 99% of deadlines will be met.
Another Approach: Define a “usefulness”
function for1 each job:
0
relative
deadline
Reference Model
Each job Ji is characterized by its release time
ri, absolute deadline di, relative deadline Di,
and execution time ei.
Sometimes a range of release times is specified: [ri,
ri+]. This range is called release-time jitter.
Likewise, sometimes instead of ei, execution
time is specified to range over [ei, ei+].
Note: It can be difficult to get a precise estimate of
ei (more on this later).
Periodic, Sporadic, Aperiodic Tasks
Periodic task:
We associate a period pi with each task Ti.
pi is the interval between job releases.
Sporadic and Aperiodic tasks: Released
at arbitrary times.
Sporadic: Has a hard deadline.
Aperiodic: Has no deadline or a soft deadline.
Examples
A periodic task Ti with ri = 2, pi = 5, ei = 2, Di =5 executes like this:
0
1
2
3 4
5
6
7
8
9 10 11 12 13 14 15 16 17 18
= job release
= job deadline
Classification of Scheduling
Algorithms
All scheduling
algorithms
static scheduling
(or offline, or clock driven)
dynamic scheduling
(or online, or priority driven)
static-priority
scheduling
dynamic-priority
scheduling
Summary of Lecture So Far
Real-time Systems
characteristics and mis-conceptions
the “window of scarcity”
Example real-time systems
simple control systems
multi-rate control systems
hierarchical control systems
signal processing systems
Terminology
Scheduling algorithms
Real Time Systems and You
Embedded real time systems enable us
to:
manage the vast power generation and
distribution networks,
control industrial processes for chemicals,
fuel, medicine, and manufactured products,
control automobiles, ships, trains and
airplanes,
conduct video conferencing over the
Internet and interactive electronic
commerce, and
Real-Time Systems
Timing requirements
meeting deadlines
Periodic and aperiodic tasks
Shared resources
Interrupts
What’s Important
Real-Time
Time- in Real-Time
Sharing
Systems
Metrics for real-time
systems differ
from that for
Systems
time-sharing systems.
Capacity
High
Schedulabilit
throughput
y
Responsiv Fast average
eness
response
Overload
Fairness
Ensured
worst-case
response
Stability
Scheduling Policies
CPU scheduling policy: a rule to select task to
run next
cyclic executive
rate monotonic/deadline monotonic
earliest deadline first
least laxity first
Assume preemptive, priority scheduling of
tasks
analyze effects of non-preemption later
Rate Monotonic Scheduling
(RMS)
Priorities of periodic tasks are based on their
rates: highest rate gets highest priority.
Theoretical basis
optimal fixed scheduling policy (when deadlines
are at end of period)
analytic formulas to check schedulability
Must distinguish between scheduling and
analysis
rate monotonic scheduling forms the basis for rate
monotonic analysis
however, we consider later how to analyze
systems in which rate monotonic scheduling is not
Rate Monotonic Analysis (RMA)
Rate-monotonic analysis is a set of
mathematical techniques for analyzing sets of
real-time tasks.
Basic theory applies only to independent,
periodic tasks, but has been extended to
address
priority inversion
task interactions
aperiodic tasks
Focus is on RMA, not RMS
Why Are Deadlines Missed?
For a given task, consider
preemption: time waiting for higher priority
tasks
execution: time to do its own work
blocking: time delayed by lower priority tasks
The task is schedulable if the sum of its
preemption, execution, and blocking is less
than its deadline.
Focus: identify the biggest hits among the
three and reduce, as needed, to achieve
schedulability
Example of Priority Inversion
Collision check: {... P ( ) ... V ( ) ...}
Update location: {... P ( ) ... V ( ) ...}
Attempts to lock data
resource (blocked)
Collision
check
Refresh
screen
Update
location
B
Rate Monotonic Theory Experience
Supported by several standards
POSIX Real-time Extensions
Various real-time versions of Linux
Java (Real-Time Specification for Java and
Distributed Real-Time Specification for Java)
Real-Time CORBA
Real-Time UML
Ada 83 and Ada 95
Windows 95/98
…
Summary
Real-time goals are:
fast response,
guaranteed deadlines, and
stability in overload.
Any scheduling approach may be used, but all
real-time systems should be analyzed for
timing.
Rate monotonic analysis
based on rate monotonic scheduling theory
analytic formulas to determine schedulability
framework for reasoning about system timing
behavior
Plan for Lectures
Present basic theory for periodic task sets
Extend basic theory to include
context switch overhead
preperiod deadlines
interrupts
Consider task interactions:
priority inversion
synchronization protocols (time allowing)
Extend theory to aperiodic tasks:
sporadic servers (time allowing)
A
Sample
Problem
Emergency
100 msec
Periodics
t1
Servers
50 msec
20 msec
Data Server
2 msec
150 msec
t2
20 msec
5 msec
Deadline 6 msec
after arrival
40 msec
Comm Server
350 msec
t3
Aperiodics
Routine
40 msec
10 msec
10 msec
2 msec
100 msec
Desired response
20 msec average
t2’s deadline is 20 msec before the end of each period
Rate Monotonic Analysis
Introduction
Periodic tasks
Extending basic theory
Synchronization and priority inversion
Aperiodic servers
A Sample Problem - Periodics
Emergency
Periodics
Servers
Aperiodics
100 msec
t1
50 msec
20 msec
Data Server
2 msec
150 msec
t2
20 msec
Deadline 6 msec
after arrival
40 msec
Comm Server
350 msec
t3
5 msec
Routine
40 msec
10 msec
10 msec
2 msec
100 msec
Desired response
20 msec average
t2’s deadline is 20 msec before the end of each period
Example of Priority
Semantics-Based Priority Assignment
Assignment
1
UIP = 10 = 0.10
11
VIP: UVIP = 25 = 0.44
IP:
VIP:
0
25
misses deadline
IP:
0
10
20
30
Policy-Based Priority Assignment
IP:
0
10
20
30
VIP:
0
25
Schedulability: UB Test
Utilization bound (UB) test: a set of n
independent periodic tasks scheduled by the
rate monotonic algorithm will always meet its
deadlines, for all task phasings, if
U(1)
U(2)
0.724
U(3)
0.720
=C1.0
U(4)
= 0.728
Cn = 0.756
1/ U(7)
n
1
--- + .... + --- < U(n) = n(2 - 1)
Tn U(5) = 0.743
= T0.828
U(8) =
1
= 0.779
U(6) = 0.734
U(9) =
Concepts and Definitions Periodics
Ci
Periodic task
Ui =
Ti
initiated at fixed intervals
must finish before start of next cycle
Task’s CPU utilization:
Ci = worst-case compute time (execution time) for
task ti
Ti = period of task
ti
CPU utilization for a set of tasks
U = U1 + U2 +...+ Un
Sample Problem: Applying UB
C
T
U
Test
Task t
20
100
0.200
1
Task t2
40
150
0.267
Task t3
100
350
0.286
Total utilization is .200 + .267 + .286 = .753
< U(3) = .779
The periodic tasks in the sample problem are
schedulable according to the UB test
Timeline for Sample Problem
0
100
200
t1
t2
t3
Scheduling Points
300
400
Exercise: Applying the UB Test
Given:
Task
t
t2
t
C
1
2
1
T
4
6
10
U
a. What is the total utilization?
b. Is the task set schedulable?
c. Draw the timeline.
d. What is the total utilization if C3 = 2 ?
Solution: Applying the UB Test
a. What is the total utilization? .25 + .34
+ .10 =0 .69 5
20
10
15
Task
t task set schedulable? Yes: .69
b. Is
the
< U(3) = .779
Task t2
c. Draw the timeline.
Task t
d. What is the total utilization if C3 = 2 ?
.25 + .34 + .20 = .79 > U(3)
Toward a More Precise Test
UB test has three possible outcomes:
0 < U < U(n)
Success
U(n) < U < 1.00
Inconclusive
1.00 < U Overload
UB test is conservative.
A more precise test can be applied.
Theorem: The worst-case phasing of a task
occurs when it arrives simultaneously with all its
RT Test
higherSchedulability:
priority tasks.
Theorem: for a set of independent, periodic tasks,
if each task meets its first deadline, with worsti 1 the deadline will always
i
case task phasing,
be
an
where a 0 = C j
met. a n+1 = C i + T C j
j = 1
j = 1
j
Response time (RT) or Completion Time test:
let an = response time of task i. an of task I
may be computed by the following iterative
formula:
• This
test must be repeated for every task ti if required
• i.e. the value of i will change depending upon the task you are looking at
• Stop test once current iteration yields a value of an+1 beyond the deadline (else,
you may never terminate).
• The ‘square bracketish’ thingies represent the ‘ceiling’ function, NOT brackets
Example: Applying RT Test -1
Taking the sample problem, we increase the
compute time of t1 from 20 to 40; is the task
C
T
U
set still schedulable?
40
0.4
Task t:
Task t2:
Task t:
20
40
100
100
150
350
0.200
0.267
0.286
Utilization of first two tasks: 0.667 < U(2)
= 0.828
first two tasks are schedulable by UB test
Utilization of all three tasks: 0.953 > U(3)
= 0.779
Example: Applying RT Test -2
3
Use RT
test to determine if t3 meets its
a = C = C + C + C = 40 + 40 + 100 = 180
j
1 i 2= 3
3
first0 deadline:
j=1
i 1
a1 = C i +
j = 1
a0
Tj
2
Cj = C3 +
j = 1
a0
Tj
Cj
= 100 + 180 ( 40 ) + 180 ( 40 ) = 100 + 80 + 80 = 260
100
150
Example: Applying the RT Test
2 a1
260 (40) + 260 (40) = 00
-3
C = 100
a =C +
+
j
2
3
j = 1 Tj
100
150
2 a2
a =C +
C = 100 + 300 (40) + 300 (40) = 00
3
3
j
T
100
150
j =1 j
a3 = a2 = 300 Done!
Task t3 is schedulable using RT test
a 3 = 300 < T = 350
0
t1
100
200
Timeline for Example
300
t2
t3
t 3 completes its work at t = 300
Exercise: Applying RT Test
Task t1: C1 = 1
Task t2: C2 = 2
Task t3: C3 = 2
T1 = 4
T2 = 6
T3 = 10
a) Apply the UB test
b) Draw timeline
c) Apply RT test
a) UBSolution:
test
Applying RT Test
t and t2 OK -- no change from previous exercise
.25 + .34 + .20 = .79 > .779 ==> Test inconclusive for t
b) RT test and timeline
0
5
10
15
Task t
Task t2
Task t
All work completed at t = 6
20
Solution: Applying RT Test
c) RT test
(cont.)
3
a
0
=
Cj =
C +C +C
1
2
3
= 1 +2 +2
= 5
j=1
2
a 1 = C3 +
j = 1
2
a 2 = C3 +
j = 1
a0
Tj
a1
Tj
Cj = 2 +
5
Cj = 2 +
6
1 +
2 = 2+2+2 = 6
6
4
4
5
1 +
6
2 = 2+2+2 = 6
6
Done
Summary
UB test is simple but conservative.
RT test is more exact but also more
complicated.
To this point, UB and RT tests share the same
limitations:
all tasks run on a single processor
all tasks are periodic and noninteracting
deadlines are always at the end of the period
there are no interrupts
Rate-monotonic priorities are assigned
there is zero context switch overhead
Scheduler
Scheduler saves state of calling process
- copies procedure call state and
registers to memory
Determines next process to be executed
Preemptive Multitasking
Context switch caused by Interrupt
On Interrupt - CPU passes control to
Operating System (OS)
OS tasks
Interrupt Handler saves context of executing
process
OS schedules next process
Context of scheduled process is loaded
On returning from Interrupt - new process
starts executing from where it was
interrupted earlier
Job parameters for Embedded
applications
Temporal parameters - timing constraints
Functional parameters - Intrinsic
properties
Interconnection parameters dependencies on other jobs
Resource parameters - resource
requirements of memory, sequence numbers,
mutexes, database locks etc.
Characterization of an
application
Release time of tasks
Absolute deadline of each task
Relative deadline
Laxity
Execution time - may be varying [ei-, ei+]
Preemptivity - whether a task is preemptive
Resource requirements
Radar System
Example
to
illustrate
the
functioning of a complex system
as a subset of tasks and jobs and
their dependencies
A Radar Signal Processing and
Tracking application
I/O Subsystem - samples and digitizes the
echo signal from the radar and places the
sampled values in shared memory
Array of digital signal processors process the sampled values and produce data
Data processors - analyze data, interface
with display devices, generate commands to
control radar, select parameters to be used by
signal processors for next cycle of data
collection and analysis
Working principle for a
Radar system
If there is an object at distance x from
antenna, echo signal returns to antenna 2x/c
seconds after transmitted pulse
Echo signal collected should be stronger than
when there is no reflected signal
Frequency of reflected signal changes when
object is moving
Analysis of strength and frequency identifies
the position and velocities of objects
Keeping track of objects
Time taken by antenna to collect echo signal
from distance d is divided into interval ranges
of d/c
The echo signals collected in each interval is
placed in a buffer
Fourier transform of each segment performed
Characteristics of the transform determines
the object’s characteristics
A track record for each calculated position
and velocity of object is kept in memory
Calculating temporal and
resource constraints
Time for signal processing dominated
by Fourier Transform computation deterministic O(n log n)
Stored Track records are analyzed for
false returns since there can be noise
Tracking an object
Tracker assigns each measured value to
a trajectory if it is within a threshold
(track gate)
If the trajectory is an existing one, the
object’s position and velocity is updated
If the trajectory is new - the measured
value gives the position and velocity of
a new object
Data association
X1
X3
T1
X2
T2
X1 is assigned to T1 - defines T1
X3 initially assigned to both T1 and T2, then
deleted from T1, assigned to T2, defines T2
X2 initiates new trajectory
Types
of
real
time
tasks
Jittered - When actual release time of a task
is not known but the range of release time is
known [ri-, ri+]
Aperiodic jobs - Released at random time
instants
Sporadic jobs - Inter-release times of these
tasks can be arbitrarily small
Periodic - each task is executed repeatedly at
regular or semiregular time intervals
Periodic tasks
Let T1, T2, .., Tn be a set of tasks
Let Ji,1, Ji,2, ….. Ji,k be individual jobs in Ti
Phase Φi - Release time ri,1 of first job of Ti
H = LCM of Φi, i = 1,..,n
H is called the hyperperiod of the tasks
Period pi of task Ti is the minimum length of
all time intervals between release times of
consecutive jobs in Ti
Hard vs. Soft time constraints
Hard deadline - imposed on a job if
the results produced after the deadline
are disastrous
example - signaling a train
Soft deadline - when a few misses of
deadlines does not cause a disaster
example - transmission of movie
Laxity - specification of constraint type
Nature of tasks
Aperiodic tasks - usually do not have
hard deadlines
Sporadic tasks - have hard deadlines
Periodic tasks - usually have hard
deadlines
Responding to external events
Execute aperiodic or sporadic jobs
Example - pilot changes the autopilot
from cruise mode to stand-by mode system responds by reconfiguring
but continues to execute the control
tasks to fly the airplane
System modeling assumptions
If task is aperiodic or sporadic probability distribution of inter-arrival
times have to be assumed for system
analysis
If execution time is not deterministic maximum time may be assumed - but
may lead to under-utilization of CPU
and unacceptably large designs
Precedence constraints -
Task graph
A partial order relation (< ) may exist
among a set of jobs
(6,13]
(4,11]
(0,7]
(2,9]
(2,5]
(0,5]
(5,8]
(4,8]
(8,11]
(11,14]
(5,20]
(conditional block]
Temporal Dependencies
Temporal dependency between two jobs - if
the jobs are constrained to complete within a
certain amount of time relative to one
another
Temporal distance - difference in
completion times of two jobs
example - for lip synchronization time
between display of each frame and the
generation of the corresponding audio
segment must be no more than 160 msec.
AND/OR precedence
constraints
An AND job is one which has more
than one predecessor and can begin
execution after all its predecessors have
completed
An (m/n) OR job can begin execution as
soon as any m out of its n predecessors
have completed
Other dependencies
Data dependency - shared data
Pipeline - producer-consumer
relationship
Functional parameters
Preemptivity of jobs
Criticality of jobs
Optional jobs - if an optional job
completes late or is not executed,
system performance degrades but
remains satisfactory
Resource requirements for
data association
Data dependent
Memory requirements can be quite high
for multiple-hypothesis tracking
For n established trajectories and m
measured values
time complexity of gating - O(nm log m)
time complexity for tracking - O(nm log
nm)
Controlling the operations of a
radar
Controller may change radar operation mode
- from searching an object to tracking an
object
Controller may alter the signal processing
parameters - threshold
Responsiveness and iteration rate of the
feedback process increase as the total
response time of signal processing and
tracking decreases
Aim of Scheduling in
embedded systems
Satisfy real-time constraints for all
processes
Ensure effective resource utilization
Scheduling
Rate Monotonic or Earliest Deadline First
Number of priority levels supported - 32
minimum - many support between 128-256
FIFO or Round-Robin scheduling for equalpriority threads
Thread priorities may be changed at run-time
Some more Priority Inversion Control - priority inheritance
or Ceiling Protocols
Memory management - mapping virtual
addresses to physical addresses, no paging
Networking - type of networking supported
Real Time task scheduling
Tasks may have soft or hard deadlines
Tasks have priorities - may be changing
Tasks may be preemptible or nonpreemptible
Tasks may be periodic, sporadic or
aperiodic
Scheduling multiple tasks
A set of computations are schedulable on
one or more processors if there exist enough
processor cycles, that is enough time, to
execute all the computations
Each activity has associated temporal
parameters
task activation time / release time - t
deadline by which it is to be completed-
d
execution time - c
Feasibility and optimality of
schedules
A valid schedule is feasible if every job
completes by its deadline
A set of jobs is schedulable if a feasible
schedule exists
A scheduling algorithm is optimal if it can
generate a feasible schedule whenever such a
schedule exists
if an optimal algorithm fails to find a feasible
schedule for a set of tasks then they are not
schedulable
Quality of a schedule
Measured in terms of tardiness
Tardiness of a job measures how late it
completes with respect to its deadline
zero :
if completed before deadline
(time of completion - deadline) :
if completed later
Performance measure in terms
of lateness
Lateness - difference between completion
time and deadline
may be negative
Scheduling may try to minimize absolute
average lateness
Example - transmission of packets in a packet
switched network - each packet of a message
have to be buffered till all of them reach requires buffer space hence large arrival time
jitters will mean more buffer space
requirement - minimizing lateness minimizes
average buffer occupancy time
Response time
Response time = length of time from release
time of task to the instant when it completes
Maximum allowable response time of a job is
called its relative deadline
Most frequently used Performance
measure for soft real time tasks average response time
CPU utilization
The maximum number (N) of jobs in
each hyperperiod = ni=1 (H/pi)
ui - Utilization of task Ti
ui = ei / pi
total utilization of CPU =
ni=1 (ui)
Example
T1, T2, T3 - three periodic tasks
p1 = 3, p2 = 4, p3 = 10
e1 = 1, e2 = 1, e3 = 3
u1 = 0.33, u2 = 0.25, u3 = 0.3
total utilization = 0.88
CPU is utilized 88% of time
Mixed job scheduling
Soft real time jobs - minimize average
response time
Miss rate - percentage of jobs that are
completed late
Loss rate - Percentage of jobs discarded
Hard real time jobs - all to be
completed within deadline
Real time scheduling
approaches
Clock driven scheduling - scheduler runs
at regular spaced time instants
Priority based scheduling - algorithms
that never leave any resource idle
makes locally optimal decisions whenever
necessary
the CPU is given to the highest priority job that is
in the ready state
scheduling policy may decide the priority
Clock driven scheduling
First Come First Serve - strictly according
to system assigned fixed priority
Round Robin - A process is allocated a fixed
unit of time
Weighted Round Robin - Different time
slice allocated to different jobs
jobs have to be preemptive
assigns CPU to jobs from a FIFO ready queue
Problems with clock based
scheduling algorithms
Process characteristics like activation
time, compute time or deadlines are not
taken into consideration at execution
time
Hence feasible schedules may not be
produced even if they exist
Priority-driven scheduling with
process parameters
Priority calculated on the basis of
compute time or deadlines
Static - priority assigned before
execution starts
Dynamic - priority may change during
execution
Mixed - static and dynamic assignments
used simultaneously
Priorities of processes
Static or Fixed priority system - Each
process is assigned a priority before it starts
executing and the priority does not change
Dynamic priority - Priorities of systems
change during execution - priority may be
a function of process parameters like
compute time or slack time
Priority driven scheduling of
periodic tasks
Scheduling decisions are made immediately
upon job releases and completions
Context switch overhead is small
Unlimited priority levels
Fixed priority - same priority for all jobs in a
task
Dynamic priority - priority of task changes
with release and completion of jobs
Earliest Deadline First (EDF)
The ready process with the earliest future
deadline is assigned highest priority and
hence gets the CPU
When preemption is allowed and jobs do not
contend for resources, the EDF algorithm can
produce a feasible schedule of a set of jobs J
with arbitrary release times and deadlines on
a processor if and only if J has a feasible
schedule
Any feasible schedule of a set of jobs
J can be transformed into an EDF
schedule
Ji
Jk
I2
I1
dk d i
Jk
Jk
Jk
Jk
Ji
Ji
Latest Release Time (LRT)
scheduling algorithm
No advantage in completing jobs early if goal is
to meet deadlines only
Deadline is set to release time and Release
time is set to deadline
Start with latest release time and schedule jobs
backwards starting from latest deadline in
order
Guaranteed to find a feasible schedule for a
set of jobs J which do not contend for
resources, have arbitrary release times and
deadlines on a processor if and only if such a
schedule exists
J2,
2(5,8]
J1, 3 (0,6]
J3, 2(2,7]
Start scheduling backwards
to meet deadline but not earlier
J1
0
2
J2
J3
4
6
8
Least Slack Time (LST)
Slack time for a process at time t and
having deadline at time d = (d - t) c´ , where c´ is the remaining execution
time
The process with the least slack time is
given the highest priority
Overheads analysis of
scheduling methods
EDF - produces optimal schedule for a
uni-processor system if one exists
LST - requires execution time
scheduling
Rate Monotonic Scheduling
Assigns fixed priorities in reverse order of
period length
Task - T(periodicity, execution_time)
shorter the period higher the priority
T1 (4,1), T2(5,2), T3(20,5)
R(T1) R(T2)
C(T1) C(T2)
Optimality of Rate monotonic
algorithm
Rate monotonic is an optimal priority
assignment method
if a schedule that meets all deadlines
exists with fixed priorities then RM
will produce a feasible schedule
Deadline-monotonic
scheduling
Priorities assigned according to relative
deadlines
shorter the relative deadline higher the
priority
Let task be represented as Ti (ri, p i, ei, di)
T1(50, 50, 25, 100), T2(0, 62.5, 10, 20),
T3(0,125,25,50)
T2
10
T3
T1
T2
35 50 62.5 72.5
T1
T2
87.5 100 125 135
T3
140
Rate Monotonic Scheduling of
same set of tasks
Let task be represented as Ti (ri, p i, ei, di)
T1(50, 50, 25, 100), T2(0, 62.5, 10, 20),
T3(0,125,25,50)
0 10 35 50 62.5 75 85.5 100
MISSED DEADLINE
125 135 150
175 185
MISSED DEADLINE
Comparison
If DM fails to find a schedule then RM
will definitely fail
DM may be able to produce a feasible
schedule even if RM fails
Table-driven scheduling
Order of process execution is determined at
design time - periodic process scheduling
Processes can also be merged into a
sequence to minimize context switching
overhead
Processes communicating with static data
flow triggered by the same event can be
clustered and scheduled statically
This allows for local data-flow optimization,
including pipelining and buffering.
Event driven Reactive Systems
for unpredictable workloads
can accommodate dynamic variations in
user demands and resource availability
Off-line schedules to handle
aperiodic tasks
Let there be n periodic tasks in the
system
Assume that aperiodic jobs are released
at unexpected time instants and join
aperiodic job queue
Timer sends kth interrupt at time tk
Scheduler schedules tasks from
schedule at timer interrupts
Clock driven scheduler - Cyclic
Executive
Do forever
accept timer interrupt at time instant tk
if current job is not completed take
appropriate action
if a job in current block Lk is not released take
appropriate action
wake up periodic server to execute jobs in
current block
sleep until periodic server completes
Cyclic executive contd.
While the aperiodic job queue is non-empty
wake up the job at head of queue
sleep until aperiodic job completes
remove aperiodic job form queue
endwhile
sleep until next clock interrupt
aperiodic jobs are given least priority bad average response time
Slack Stealing - to improve
average response time
Every periodic job slice must be scheduled in
a frame that ends no later than its deadline
Let the total amount of time allocated to all
slices in frame k be xk
Slack time available in frame k = f - xk
If aperiodic job queue is non-empty at the
beginning of time frame f, aperiodic jobs may
be scheduled for slack time without causing
any deadline miss
Scheduling sporadic jobs
Since sporadic jobs hard relative
deadlines, they should be completed or
rejected immediately if scheduler
cannot find a feasible schedule
When rejected appropriate remedial
actions can be taken in time
Example - Quality control
system using a robot arm
Camera detects defective part on conveyor
belt - robot arm is to remove it
Sporadic task to remove is initiated - have to
be completed before part moves beyond
reach of arm - deadline fixed as function of
conveyor belt speed
If removal cannot be accomplished on time raise alarm to move part manually
EDF scheduling of accepted
jobs
Acceptance Test - to check whether a new
sporadic job can be scheduled along with
existing periodic jobs
Scheduler maintains queue of accepted
sporadic jobs in non-decreasing order of
deadlines
Run Cyclic Executive algorithm to pick up
sporadic jobs from this queue to execute in
slack time
Setting OS parameters for real
time task execution
Set scheduler type
User may want to run task at kernel space
rather than user space - system may hang
Under LINUX - RTLINUX runs at kernel level preempts Linux processes from maintaining
control of system
RTLInux has limited capability - for many
facilities it passes on task to Linux
Sample tasks in VXWorks
Taskspawn(taskid, taskpriority,
taskpointer, other parameters)
Alternatively:
A function in user space can be invoked
by RT Linux interrupt or timer
This function is like a signal handler
though cannot make system calls
Some commercial versions like Lineo
make use of this
Improving the Linux behaviour
RTLinux holds all interrupts and makes
all calls on behalf of Linux
Monta Vista’s Embedded Linux - makes
kernel fully “preemptable” - kernel calls
can be interrupted - leads to system
hang and locks with injudicious
programming
Aspects of OS affecting
application behavior
Computing application time on
an OS
OS is deterministic - if the worst-case
execution time of each of its system calls is
calculable.
For RTOS - real-time behavior is published as
a datasheet providing the minimum, average,
and maximum number of clock cycles
required by each system call.
These numbers may be different for different
processors.
Interrupt Latency
Interrupt latency is the total length of
time from an interrupt signal arriving at
the processor to the start of the
associated interrupt service routine
(ISR).
Interrupt processing executing ISR
Processor must finish executing the
current instruction
Interrupt type must be recognized processor does it without slowing or
suspending the running task
CPU's context is saved and the ISR
associated with the interrupt is started.
Interrupt disabling
Interrupts are disabled within system
calls - the worst-case interrupt latency
increases by the maximum amount of
time that they are turned off.
A real-time project might require a
guaranteed interrupt response time as
short as 1s, while another may require
only 100s.
Designing a simple scheduler
void Scheduler(void)
{
int stop=0, newtick = 0;
while(!stop)
{
while(!newtick); // Wait for timer tick
newtick = 0;
thread1();
thread2();
...
threadn();
if(newtick) // overrun
OverrunHandler(); //Could make reset dependi
}
Preemptive kernels
kernel schedule is checked with a defined
period, each tick
it checks if there is a ready-to-run thread
which has a higher priority than the executing
thread - in that case, the scheduler performs
a context switch
Executing thread goes to ready state
Puts special demands on communication
between threads and handling common
resources
Resource Access Control
Mutually Exclusive resources
mutex
write-lock
connection sockets
printers
Resource allocated to a job on a nonpreemptive basis
Resource conflicts
Two jobs conflict with one another if
they require the same resource
Two jobs contend with one another if
one job requests for a resource already
held by another job
When a job does not get the requested
resource it is blocked - moved from the
ready queue
Resource access protocol
using Critical Sections
Critical section - a segment of a job
beginning at a lock and ending at a
matching unlock
Mutually exclusive Resources can
be used inside a non-preemptive
critical section (NPCS) only
Properties of NPCS
No priority inversion - a job is blocked if
another job is executing its critical
section
Mutual exclusion guaranteed
However, blocking occurs even when
there is no resource contention
Priority inversion
Priority(J1) > Priority(J2) > Priority(J3)
J1 and J3 currently executing
J1 requests for R - R held by J3
J3 blocks J1 - inversion of priority
J2 starts executing - does not need R preempts J3 and executes
J2 lengthens duration of priority
inversion
Priority Inheritance Protocol
At release time t a job starts with its assigned
priority (t)
When job Jk requests for R, if R is free it is
allocated to Jk else Jk is blocked
The job Jl that blocks Jk inherits the current
priority of Jk and executes with that priority
since the blocked process had the
highest priority, the blocking process
inherits it - overall execution time
should reduce
cannot prevent deadlocks
Priority Ceiling Protocol - when
maximum resource use is known
(R) - Priority ceiling of resource R is
the highest priority of all the jobs that
require R
^(t) - current ceiling of system is
equal to the highest priority ceiling of
resources in use at the time
At release time t a job starts with its assigned priority
(t)
When job Jk requests for R,
If R is not free Jk is blocked
If R is free
then if (t) > ^(t), R is allocated to Jk
else if Jk is the job holding the resources whose
priority ceiling is equal to^(t), R is allocated to Jk
else Jk is blocked
The blocking process inherits the highest priority of
the blocked process
Example
P(J0)>P(J1) > P(J2) > P(J3)
J2 books R2 - ^(t) = P(J2)
^(t) = P(J2)
J3 requests R1 - ^(t) = P(J2) > P(J3)
- J3 blocked
J1 requests R1 - ^(t) = P(J2) < P(J1)
- R1 allotted to J1
^(t) = P(J1)
Example continued
J2 requests R1 - J2 is blocked
J1 requests R2 - ^(t) = P(J1) R2 is
allocated to J1
J0 requests R1 - (t) > ^(t) but J0
does not hold any resource - so J0
blocked
J1 inherits P(J0)
Duration of blocking
When resource access of preemptive,
priority driven jobs are controlled by the
priority ceiling protocol, a job can be
blocked for at most one duration of
once critical section
Upper bound on blocking time can
be computed and checked for
generating feasible schedules
A case study
What really happened on Mars
Rover Pathfinder?
Mars Pathfinder mission
1997
Landed on Martian surface on 4th July
Gathered and transmitted voluminous data
back to Earth, including the panoramic
pictures that were a bit hit on the Web
But a few days into the mission of gathering
meteorological data, Pathfinder started
experiencing total system resets, each
resulting in losses of data
Pathfinder software
Was executing on VXWorks
VxWorks implements preemptive
priority scheduling of threads
Tasks on the Pathfinder spacecraft were
executed as threads with priorities
Priorities were assigned reflecting the
relative urgency of these tasks
Information Bus
Pathfinder contained an "information
bus", which was a shared memory area
used for passing information between
different components of the spacecraft
Access to the bus was synchronized
with mutual exclusion locks (mutexes).
Tasks running on Pathfinder
A bus management task ran frequently with
high priority to move certain kinds of data in
and out of the information bus
The meteorological data gathering task ran as
an infrequent, low priority thread, and used
the information bus to publish its data
A communications task that ran with medium
priority
Priority inversion
While meteorological task had lock on
information bus and was working on it
An interrupt caused the bus management
thread to be scheduled
The high priority thread attempted to acquire
the same mutex in order to retrieve published
data - but would be blocked on the mutex,
waiting until the meteorological thread
finished
Things were fine!
Most of the time - meteorological
thread eventually released the bus and
things were fine!
But at times!
While the low priority meteorological
task blocked the high priority bus
management task, the medium priority
communications task interrupted and
started running!
This was a long running task and hence
delayed the bus management task
further
Watchdog timer!
After some time a watch dog timer
sensed that the high priority bus
management task has not run for quite
some time!
“something must have gone wrong
drastically! RESET SYSTEM!”
Debugging
Total system trace - history of execution
along with context switches, use of
synchronization objects and interrupts
Took weeks for engineers to reproduce
the scenario and identify the cause
Priority Inheritance had been
turned off!
To save time
Had it been on the low-priority
meteorological thread would have inherited
the priority of the high-priority bus
management thread that it blocked and
would have been scheduled with higher
priority
than
the
medium-priority
communications task. On finishing the bus
management task would have run first and
then the communications task!
http://catless.ncl.ac.uk/Risks/1
9.49.html
Analysis presented by
David Wilner,
Chief Technical Officer of Wind
River Systems.
Interactive Embedded System
Continuously interacts with its environment
under strict timing constraints - called the
external constraints
It is important for the application developer
to know how these external constraints
translate to time and resource budgets called the internal constraints, on the tasks of
the system.
Knowing these budgets
Reduces the complexity of the system 's
design and validation problem and
helps the designers have a
simultaneous control on the system's
functional as well as temporal
correctness..
Wheel Pulses
Read Speed
Accumulate
Pulses
Compute Total km
Filter Speed
Speedometer
LCD Display Driver
Compute Partial km
Resettable Trip
Odometer
Lifetime
Odometer
Example constraint specification
Task Graph
Embedded Flexible
Applications
Applications that are designed and
implemented to trade off at run-time
the quality of results (services) they
produce for the amounts of time and
resources they use to produce the
results
graceful degradation in result quality or in
timeliness
for voice transmission a poorer quality with
fewer encoded bits may be tolerable but
not transmission delay
Characterizing Flexible
Applications
A Flexible job has an optional component
which can be discarded when necessary in
order to reduce the job’s processor time and
resource demands by deadline
Firm deadlines (m, N) - If at least m jobs
among any consecutive N m jobs in the
task must be complete in time
N is the failure window of the task
Criteria of Optimality
Errors and Rewards
Static Quality metrics
Dynamic Failures and firm deadlines
QoS vs. timeliness
Firm quality - fixed resource demands degrade gracefully by relaxing their
timeliness
Firm deadlines - flexible resource
demands but hard deadlines - degrade
gracefully by relaxing the result quality
Multimedia data
communication
Voice, video and data transfer over ATM
networks
ATM's ABR (available bit rate) service
provides minimum rate guarantees
Guaranteeing QoS
Bandwidth
Delay
Loss
have to be guaranteed in a certain range
Solution: Rate allocation switch algorithm
to ensure general form of fairness to
enhance the bandwidth capability.
QoS-aware middleware
Two major types of QoS-aware middleware
(1) Reservation-based Systems
(2) Adaptation-based Systems
Both of them require application-specific
Quality of Service (QoS) specifications
QoS-aware middleware
Both of them require application-specific
Quality of Service (QoS) specifications
Configuration graphs
Resource requirements
Mobility rendering
Adaptation rules to be provided by application
developers or users.
Executing Flexible tasks
Sieve Method
Milestone method
Multiple Version method
Completion times are more critical than
absolute time of completion
Sieve method
Discardable optional job is a Sieve
Example - MPEG video transmission
transmission of I-frames mandatory
transmission of B- and P-frames optional
MPEG Compression idea
In video often one frame differs very little
from the previous frame
In two sequential frames there's not that
much difference between a single item
Certain frames are encoded in terms of
changes applied to surrounding frames
Amount of information required to describe
changes is much less than the amount of
information it requires to describe the whole
frame again.
Frame 3
Frame 1
Frame 2 - predicted
I, P, and B frames
I frames are coded spatially only
P frames are forward predicted based
on previous I and P frames
B frames are coded based on a forward
prediction from a previous I or P frame,
as well as a backward prediction from a
succeeding I or P frame
Encoding of B frames
First B frame is predicted from the first
I frame and first P frame
Second B frame is predicted from the
second and third P frames
Third B frame is predicted from the
third P frame and the first I frame of
the next group of pictures.
Some information
not there
More information
MPEG video transmission
All I frames to be sent
All P frames to be sent if possible
B frames to be sent optionally
Quality of video produced on receipt
depends on what has been transmitted
Milestone method for
scheduling Flexible
Applications
Monotone Job - A job whose result
converges monotonically to desired
quality with increasing running time
A monotone computation job is
implemented using an incremental
algorithm whose result converges
monotonically to the desired result with
increasing running time
Implementation
Programmer identifies optional parts of
program
During execution - intermediate results are
saved with quality indicator - tracking
error, least mean square error etc.
Runtime decisions to schedule processes are
taken on the basis of current state of results
Example
Layered encoding techniques in
transmission of video, images and
voices
Approximate query processing
Incremental information gathering
Multiple version method
Each flexible job has a primary version
and one or more alternative versions
Primary version produces precise result,
needs more resources and execution
time
Alternative methods has small execution
time, use fewer resources but generate
imprecise result
Multiple version method
scheduling
Scheduler chooses version according to
available resources
A set of jobs scheduled together for
optimal quality
Computational model
J=M+O
Release times and deadlines of M and O
are same as that of J
M is predecessor of O
execution time of J ej = em + eo
Valid schedule
Time given to J is em
J is complete when M is complete
Feasible schedule - one in which every
mandatory job is completed within
deadline
Optimal scheduling algorithms
All mandatory jobs completed on time
Fast convergence to good quality result
Since quality of successor jobs may
depend on quality of predecessor jobs,
maximize the result quality of each
flexible application
Error and rewards
Let maximum error be 1 - when
optional part is discarded completely
If x is the length of the optional job
completed then €(x) denotes the error
in the result produced by this job
€(0) = 1 and €(eo) = 0
Error €(x) = 1 - x/ eo
Quality metrics - Performance
measures
Total error for a set of tasks =
wti
€(xi)
wti is penalty for not completing task i
Minimize average error
A Case Study: Sunrayce car
control/monitoring system:
Data
Analyzer
collecting
Car
Sensor
s
GUI
Technical Details
A workstation, which
collects data from 70
sensors with total
sampling rate of 80Hz.
The needed response
times ranged from 200
to 300 ms
One RT task per sensor
executing with 0.0125
period on a 20Mhz i386based computer
running RT-Linux.
RT Tasks:
communica
ting with
sensors
Linux
processes:
analyzer,
GUI (Based
on QT
widget)
RT-Linux: Scheduling
Priority-based scheduler
Earliest Deadline First (EDF)
Rate Monotonic (RM)
Additional facilities through Linux kernel
module
RT-Linux problems
Problems
Unable to support soft real-time
No schedulability analysis
Unable to support complicated
synchronization protocols(?)
Solutions
Flexible Real Time Logic
Provide both HARD guarantee and
FLEXIBLE behavior at the same time
Approach:
Each task as a sequence of mandatory and
optional components
Separate executions of components in two
scheduling levels
FRTL extension to RTLinux
Mandatory components versus optional
components
Both hard real-time constraints and the
ability to dynamically adapt their responses
to changes in the environment (soft realtime).
Provides a complete schedulability test,
including kernel overhead.
FRTL: Software architecture
Shared Memory Space
Mandatory
1
Task
N
Task
2
Task 1
Mandatory 1
Mandatory M1
Version
1
Task
K
Task
2
Optional 1
Version 1
Version M1
Second-Level Scheduler
First-Level Scheduler
FRTL: Task Model
Tasks -> Components
Mandatory
Optional
Unique Version (UV)
Successive Versions (SV)
Alternative Versions (AV)
FRTL:Smart Car
Mandatory components:
Data collectors
Options components:
Data analysis, GUI
UV
SV
AV
Storage manager
Linux
Version
1
Task
K
Task
2
Optional 1
Version 1
RT
Task
s
Mandatory
1
Task
N
Task
2
Task 1
Other
processes
Version M1
Mandatory 1
Second-Level Scheduler
Mandatory M1
Linux kernel
First-Level Scheduler
Hardware
Design and Implementation
Two level Scheduler
For different kind of components
Strict hierarchy
Reclaimed spare capacity(why and how)
Difference from RT-Linux
Explicit division of optional and mandatory
t
t0
t1
t2
Detailed Design
First level scheduler
Modified scheduler from RT-Linux
Schedule optional components based on available
slack, interval
Second level scheduler
Non-real-time
Optional server
Regular Linux process
Mandatory
Optional
Optional
V
X
Mandatory
Second level scheduler
Customized
To decide on:
Next component to run
Version to be executed
Time to be executed
Tasks constrained by temporal
distance
Temporal distance between two jobs =
difference in their completion times
The distance constraint of task Ti is
Ci if
fi,1 - ri Ci
fi,k+1 - fi,k Ci
If the completion times of all jobs in Ti
according to a schedule satisfy these
inequalities then Ti meets its distance
constraints
Distance Constraint Monotonic
(DCM)
Algorithm
Priorities assigned to tasks on the basis of
their temporal distance constraint - smaller
the distance constraint higher the priority
Find the maximum response time of the
highest priority task
This is used as a release guard to ensure that
subsequent tasks are not released any sooner
than necessary
this allows more low priority tasks to be
scheduled feasibly
Verification of schedules
Final testing on a specific processor or a
coprocessor and with the required sizes of
program and data memory
All hardware and software data other than
those reused must be estimated
Implement each single process with the
target synthesis tool or compiler and then run
them on the (simulated) target platform
Inter Process Communication
Processes communicate with each
other and with kernel to
coordinate their activities
Producer-Consumer Problem
Paradigm for cooperating processes,
producer process produces information
that is consumed by a consumer
process.
unbounded-buffer places no practical limit
on the size of the buffer.
bounded-buffer assumes that there is a
fixed buffer size.
Bounded-Buffer - shared data
#define BUFFER_SIZE 10
typedef struct {
...
} item;
item buffer[BUFFER_SIZE];
int in = 0;
int out = 0;
int counter = 0;
Bounded-Buffer - producer
item nextProduced;
while (1) {
while (counter == BUFFER_SIZE)
; /* do nothing */
buffer[in] = nextProduced;
in = (in + 1) % BUFFER_SIZE;
counter++;
}
Bounded-Buffer
Consumer process
item nextConsumed;
while (1) {
while (counter == 0)
; /* do nothing */
nextConsumed = buffer[out];
out = (out + 1) % BUFFER_SIZE;
counter--;
}
Bounded Buffer
The statements
counter++;
counter--;
must be performed atomically.
Atomic operation means an operation that
completes in its entirety without interruption.
Bounded Buffer
The statement “count++” may be
implemented in machine language as:
register1 = counter
register1 = register1 + 1
counter = register1
The statement “count—” may be
implemented as:
register2 = counter
register2 = register2 – 1
counter = register2
Bounded Buffer
If both the producer and consumer
attempt to update the buffer
concurrently, the assembly language
statements may get interleaved.
Interleaving depends upon how the
producer and consumer processes are
scheduled.
Bounded Buffer
Assume counter is initially 5. One interleaving
of statements is:
producer: register1 = counter (register1 =
5)
producer: register1 = register1 + 1
(register1 = 6)
consumer: register2 = counter (register2 =
5)
consumer: register2 = register2 – 1
(register2 = 4)
producer: counter = register1 (counter = 6)
consumer: counter = register2 (counter =
4)
Race Condition
Race condition: The situation where several
processes access – and manipulate shared
data concurrently. The final value of the
shared data depends upon which process
finishes last.
To prevent race conditions, concurrent
processes must be synchronized.
The
Critical-Section
Problem
n processes all competing to use some
shared data
Each process has a code segment, called
critical section, in which the shared data
is accessed.
Problem – ensure that when one
process is executing in its critical
section, no other process is allowed
to execute in its critical section.
IPC mechanisms
•Pipes/FIFOs, queues
•Mapped Shared Memory
•Semaphores
•Mutexes, Condition Variables
•Signals, RT Signals
•timers/alarms
•sleep() and nanosleep()
•Watchdogs, Task Regs,
•Partitions/Buffers emulated by tool kits
Shared Memory
CPU1
CPU2
Shared Location
write
read
Bus
Pipes for redirection
Pipes are unidirectional byte streams
which connect the standard output from
one process into the standard input of
another process
Processes are unaware of redirection
It is the shell which sets up these
temporary
pipes
between
the
processes.
Example
ls | pr | lpr - pipes the output
from the ls command - into the
standard input of the pr command
which paginates them - finally the
standard output from the pr command is
piped into the standard input of the lpr
command which prints the results on
the default printer
Setting up a PIPE
A pipe is implemented using two file data
structures pointing to the same temporary
VFS inode
VFS inode points at a physical page within
memory
Each file data structure point to different file
operation routine vectors - one for writing to
the pipe, the other for reading from the pipe.
Reading and Writing
Processes do not see the underlying
differences from the generic system calls
which read and write to ordinary files
Writing process copies bytes into the shared
data page
Reading process copies bytes from the shared
data page
OS synchronizes access to the pipe - to make
sure that the reader and the writer of the
pipe are in step - uses locks, wait queues
and signals.
Named Pipes - FIFO
Unlike pipes - FIFOs are not temporary
objects
FIFOs are entities in the file system created through system calls
Processes can use a FIFO if they have
appropriate access rights to it
Using FIFOs
fd_fifo = rtf_create(fifo_num, fifo_size)
rtf_destroy(fifo_num)
open() and close() fifo
read() - read data from FIFO
write() - write data into FIFO
Real-Time Code--Handler for the Control FIFO
int my_handler(unsigned int fifo)
{
struct my_msg_struct msg;
int err;
int handler_fd, rt_fd;
handler_fd = open("/dev/rtf0",
O_NONBLOCK);
while ((err = read(handler_fd, &msg,
sizeof(msg)))
== sizeof(msg)) {
char dest[10];
sprintf(dest,"/dev/rtf%d",msg.task+1
);
rt_fd = open(dest, O_NONBLOCK);
write(rt_fd, &msg, sizeof(msg));
close(rt_fd);
}
close(handler_fd);
if (err < 0)
rtl_printf("Error getting data in
handler,%d\n",err);
return 0;
}
Semaphores
Semaphore is a location in memory whose
value can be tested and set by more than
one process
The test and set operation is uninterruptible
or atomic - once started nothing can interfere
it
Current value of semaphore is the result of
the test and set operation - can be positive or
negative.
Semaphores
Binary semaphores - synchronizing
constructs
Counting semaphores - keeping track of
how many tasks are waiting on it
Wait and Signal operations
Synchronization Hardware
Test and modify the content of a word
atomically
.
boolean TestAndSet(boolean &target)
{
boolean rv = target;
target = true;
return rv;
}
Mutual Exclusion with Testand-Set
Shared data:
boolean lock = false;
Process Pi
do {
while (TestAndSet(lock)) ;
critical section
lock = false;
remainder section
}
Synchronization Hardware
Atomically swap two variables.
void Swap(boolean &a, boolean
&b) {
boolean temp = a;
a = b;
b = temp;
}
Mutual
Exclusion
with
Swap
Shared data (initialized to false):
boolean lock;
boolean waiting[n];
Process Pi
do {
key = true;
while (key == true)
Swap(lock,key);
critical section
lock = false;
remainder section
}
Semaphores used for
implementing critical regions
Cooperating processes reading records
from and writing records to a single
data file in a coordinated way
Critical Regions of Kernel
When modules cannot be preempted
While handling interrupts
While holding a spinlock, writelock, or
readlock - for reentrancy or data
protection reasons
While the kernel is executing the
scheduler itself - not to confuse it
while is is finding the "best" task
Semaphore Implementation
Define a semaphore as a record
typedef struct {
int value;
struct process *L;
} semaphore;
Assume two simple operations:
block suspends the process that invokes it.
wakeup(P) resumes the execution of a blocked
process P.
Semaphore Operations in
RTOS
semTake(S.semid, timeout)
if (S.count > 0) then S.count --;
else block calling task in S.waitingQ;
semGive(S.semid)
if (S.waitingQ is non-empty) then
wakeup a process in S.waitingQ;
else S.count ++;
Producer-Consumer Problem
Semaphore Q=1
producer
semTake(Q)
Counter++;
semGive(Q)
Consumer
semTake(Q)
counter- -;
semGive(Q)
Semaphore Options
• Tasks
pending on a semaphore can be
queued in priority order
(SEM_Q_PRIORITY) or in first-in first-out
order (SEM_Q_FIFO).
• When
tasks try to lock (take) a semaphore,
they can specify a specific length of time to
wait or WAIT_FOREVER.
Binary Semaphores
Most versatile, efficient, and
conceptually simple type of semaphore.
Can be used to control mutually
exclusive access to shared devices or
data structures
Can be used to synchronize multiple
tasks, or task-level and interrupt-level
processes
Binary semaphore
Can be only in two states - full or empty
Creating a semaphore
SEM_ID semMutex;
/* create a binary semaphore
that is initially full */
semMutex = semBCreate
(SEM_Q_PRIORITY, SEM_FULL);
Taking binary semaphores
A task takes a binary semaphore - using
sem_take()
If the semaphore is full, the semaphore
is made empty, and the calling task
continues executing.
If the semaphore is empty, the task will
be blocked - pending the availability of
the semaphore.
Giving binary semaphores
When a task gives a binary semaphore uses semGive()
The next available task in the pend
queue is unblocked
If no task is pending on this
semaphore, the semaphore becomes
full
Unblocking Tasks
If a semaphore is given, and a task
is unblocked that is of higher
priority than the task that called
semGive( ), the unblocked task will
preempt the calling task.
What happens?
S1
….
semTake(P)
S2
semTake(Q)
semTake(P)
semTake(Q)
………
………
Caution!
There is no restriction on the same
semaphore being given, taken, or
flushed by multiple tasks
There is no danger in any number of
processes taking a semaphore
If a task accidentally gives a semaphore
it had not taken, mutual exclusion could
be lost.
Synchronization with binary
semaphores
SEM_ID semSync; /* ID of sync semaphore */ init ()
{ intConnect (..., eventInterruptSvcRout, ...);
semSync = semBCreate (SEM_Q_FIFO, SEM_EMPTY);
taskSpawn (..., task1); }
task1 ()
{ semTake (semSync, WAIT_FOREVER); /* wait for event */
... /* process event */ }
eventInterruptSvcRout () { semGive (semSync); /* let task 1 process
event */ ... }
semFlush()
A semFlush( ) on a binary semaphore
will atomically unblock all pended tasks
in the semaphore queue
All tasks will be unblocked at once,
before any actually execute
Mutex Semaphores
Mutex semaphores are used when
multiple tasks share a resource (data
structure, file, hardware).
Mutex semaphores prevent multiple
tasks from accessing the resource at
the same time, and possibly corrupting
it
Mutexes have a sense of ownership:
only the task that has set the mutex
can release it
Special type of Binary
semaphore
Mutexes are meant to address IPC
issues related to
recursive access to resources
priority inversion
deletion safety
Difference with Binary
semaphore
It can only be used for mutual exclusion
(not for synchronization)
It can only be given by the task that
took it
It may not be taken or given from
interrupt level
The semFlush( ) operation is illegal.
Using Mutex Semaphores
Create mutex for the resource with
semMCreate( ).
A task wanting to use the resource calls
semTake( ) to block until the resource is
available
When done with the resource, a task calls
semGive( ) to allow other tasks to use the
resource.
Speciality of Mutex
Semaphores
These can be locked in a recursive
fashion. A task that owns a mutex can
acquire it again without blocking. The task
must release the mutex as many times as it
has acquired it.
• If a task tA owns a delete-safe mutex
semaphore, and another task tB tries to
delete tA, then tB will block until tA gives
up ownership of the mutex. Thus, the
mutex owner is safe from deletion while
operating on the shared resource.
Recursive access to resource
Recursion is possible because the
system keeps track of which task
currently owns a mutual-exclusion
semaphore.
SEM_ID semM;
semM = semMCreate (...);
funcA () {
semTake (semM, WAIT_FOREVER);
funcB ()
{
semTake (semM, WAIT_FOREVER);
... funcB ();
... semGive (semM); }
... semGive (semM);
}
Priority Inheritance Protocol
• Mutual
exclusion semaphores can use a
priority inversion protocol to be
inversion-safe.
Inversion-safe mutexes prevent the priority inversion
problem.
A task which owns such a mutex is temporarily
boosted to the priority of the highest priority task
waiting for the mutex. It falls back to its regular
priority when it no longer owns an inversion-safe
mutex.
This prevents a high priority task from being blocked
for an indeterminate amount of time waiting for a
mutex owned by a low priority task which cannot
execute because it has been preempted by an
intermediate priority task!
TASK-DELETION SAFETY
Task owning the semaphore with option
SEM_DELETE_SAFE selected will be
protected from deletion as long as it owns the
semaphore.
Deleting a task executing in a critical region
can be catastrophic. The resource could be
left in a corrupted state and the semaphore
guarding the resource would be unavailable,
effectively shutting off all access to the
resource.
Counting Semaphores
Binary semaphores keep track of whether
or not an event has occurred, but not how
many times the event has occurred
Counting semaphores keep a count of
how many times the event has occurred,
but not serviced.
May be used to ensure that the event is
serviced as many times as it occurs.
May also be used to maintain an atomic
count of multiple equivalent available
resources.
Bounded-Buffer Problem
Shared data
semaphore full, empty, mutex;
Initially:
full = 0, empty = n, mutex = 1
Bounded-Buffer Problem
Producer
Process
do {
…
produce an item in nextp
…
semTake(empty);
semTake(mutex);
…
add nextp to buffer
count = count+1;
…
semGive(mutex);
semGive(full);
} while (1);
Bounded-Buffer Problem
Consumer
Process
do
{
nextc
semTake(full)
semTake(mutex);
…
remove an item from buffer to
count = count -1; …
semGive(mutex);
semGive(empty);
…
consume the item in nextc
…
Producer-Consumer Problem
Full, Empty – counting semaphores
mutex – Binary semaphore / mutex
Readers-Writers Problem
Shared data
semaphore cs_lock, wrt;
Initially
cs_lock = 1, wrt = 1, readcount = 0
Readers-Writers Problem Writer
Process
semTake(wrt);
…
writing is performed
…
semGive(wrt);
Readers-Writers Problem Reader
semTake(cs_lock);
Process
readcount++;
if (readcount == 1)
semTake(wrt);
semGive(cs_lock);
…
reading is performed
…
semTake(mutex);
readcount--;
if (readcount == 0)
semGive(wrt);
semGive(mutex):
Types of semaphores
Cs_lock – mutex / binary semaphore
Wrt – binary / counting semaphore
Communication through
message passing
Synchronous and
Asynchronous message
passing between tasks
Blocking - process goes into a waiting
state after sending a blocking
communication till response is received
Non-blocking - Process continues
execution after sending communication
Message Passing
Each entity has its own message
send/receive unit
Messages not stored on communication
links
Communicating processes may or may
not be executing at the same rate
Message passing in RT Linux
For sending
destination - pid of intended receiver
queue - message queue in the intended
process where the message will be
deposited
msg - the actual message data - pointer to
a memory
ack-queue - message queue where reply is
expected
Message passing in RT Linux
contd.
For receiving
queue - message queue in which the
message will be stored
msg - the actual message data - pointer to
a memory
correspondent - who sent the message?
ack-queue - message queue where reply is
expected
Message Queues
One or more processes can write
messages for one or more processes
Each msqid_ds contains two queues one for readers and one for writers
Process parameters are checked for
permission
A reading process may choose types of
messages it wants to read
Creating message queues
Linux maintains a list of message queues the
msgque vector - each element of which
points to a msqid_ds data structure
msqid_ds fully describes the message queue
When message queues are created a new
msqid_ds data structure is allocated from
system memory and inserted into the vector.
Message queues in VxWorks
Allows variable number of messages of
variable length queued on FIFO
Any task can send a message to or
receive messages from a queue
Multiple tasks can send and receive
from the same message queue
Two way communication between two
tasks usually require two queues
Message queues in VxWorks
msgQCreate(int maxMsgs, int
maxMsgLength, int options)
msgQDelete(MSG_Q_ID msgQId)
msgQSend(MSG_Q_ID msgQId, char
*Buffer, UINT nBytes, int timeout, int
priority)
msgQReceive(MSG_Q_ID msgQId, char
*Buffer, UINT nbytes, int timeout)
Message queue
High priority messages – at head of
queue
A task can wait for messages to be
delivered to a message queue or for
putting messages into a queue
Timeout parameter – decides how many
clock ticks to wait for
Shared memory
communication in RTLinux
Independent tasks ask the kernel to allocate
a memory of specific size for sharing data
with a specific tag
data = mbuff_alloc(“sh_mem”, size_buff)
For each process executing the above counter
is incremented
Memory is freed by each process
mbuff_free(“sh_mem”, (void *)data);
For each call counter is decremented
Access control to shared
memory
Access to shared memory areas is
controlled via keys and access rights
checking
Once the memory is being shared,
there are no checks on how the
processes are using it
Semaphores are used to synchronize
access to the memory.
Signals
A signal is a software notification to a
task or a process of an event.
A signal is generated when the event
that causes the signal occurs.
A signal is delivered when a task or a
process takes action based on that
signal.
Signal states
The lifetime of a signal is the interval
between its generation and its delivery.
A signal that has been generated but
not yet delivered is pending.
There may be considerable time
between signal generation and signal
delivery.
IPC through signals
Signals can asynchronously alter the control
flow of task
Any task can raise a signal for a particular
task
The task being signaled immediately
suspends its current thread of execution and
the task specified signal handler routine is
executed the next time the task is scheduled
to run
Signal handling
Signal handler is invoked even if the task is
blocked on some action or event
Signal handler is a user supplied routine that
is bound to a specific signal and performs
whatever actions are necessary whenever the
signal is received
Signals are most appropriate for error and
exception handling, rather than general
intertask communication
Calling a signal
A signal can be raised by calling kill(),
which is analogous to an interrupt or
hardware exception
A signal is bound to a particular signal
with sigaction()
While the signal handler is running,
other signals are blocked from delivery
Blocking signals
Tasks can block the occurence of certain
signals with sigprocmask()
If a signal is blocked when it is raised, its
handler routine will be called when the signal
becomes unblocked.
Processes can choose to ignore most of the
signals that are generated- other than
SIGSTOP - halt execution SIGKILL exit
Communication through
signals
Kernel can and super users can send
signals to all processes
Normal processes can only send signals
to processes with the same uid and gid
Signals are generated by setting the
appropriate bit in the task_struct's
signal field
Receiving Signals
If the process has not blocked the
signal and is waiting but interruptible
(in state Interruptible) then it is woken
up by changing its state to Running
If the default handling is needed, then
Linux can optimize the handling of the
signal
Handling SIGNALS
If a signal has not been blocked, processes
can either choose to handle SIGNALS
themselves or allow the kernel to handle
them
Kernel handles the signals by taking default
actions
Example - SIGFPE (floating point
exception) - core dump and then
exit.
Responding to SIGNALS
Scheduler schedules the process next
time
Either process handler or default
handler is executed
Example - SIGWINCH (the X
window changed focus)- will cause
focus to change to a new window
Presentation of SIGNALS
Every time a process exits from a system call
its signal and blocked fields are checked
If there are any unblocked signals - they are
now delivered
For example - a process is writing a character
to the terminal - executing a system call when it finishes then SIGNALS are checked
Defining signal handlers
void sigHandlerFunction(int
signalNumber)
{
.............. /* signal
handler code */
..............
..............
}
Directing a signal to a specific
task
kill(int, int)
first argument : the task id to which
signal will be sent
second argument : the signal to be sent
to the task .
Installing signal handlers
The sigaction function installs signal
handlers for a task:
int sigaction(int signo, const struct sigaction
*pAct, struct sigaction *pOact)
Sigaction parameters
Holds the handler information
signal number to be caught
a pointer to the new handler
structure(of type struct sigaction)
and a pointer to the old structure(also
of type struct sigaction)
Sample SIGNALS in Linux
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL
5) SIGTRAP 6) SIGIOT 7) SIGBUS 8) SIGFPE
9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR2
13) SIGPIPE 14) SIGALRM 15) SIGTERM 17) SIGCHLD
18) SIGCONT 19) SIGSTOP 20) SIGTSTP 21) SIGTTIN
22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO
30) SIGPWR
Interrupt handling
System becomes aware of external
events via the interrupt mechanism
Response of a real-time systems
depends on the speed of the system's
response to interrupts
Speed of processing interrupt handlers
is crucial to system performance.
Interrupt Service Routines
May be written by users
Users may write an interrupt service
routine (ISR) and attach it to a
particular interrupt using the intConnect
routine provided by VxWorks
Caution!
Since many interrupts may occur within
a short time of each other and a higher
interrupt will block lower priority
interrupts, it is necessary to keep the
ISR processing to a minimum
This is the responsibility of the
application writer
Interrupt Handling
Non-preemptible portions of Interrupt
handler are kept small and efficient
Interrupt handlers are scheduled and
executed with appropriate levels of
priority
Some rules for writing ISRs
ISR's should not invoke functions which may
cause ``blocking'' of the caller : for
example semTake
Ideally it should only contain semGive()
malloc and free cannot be used because they
call functions which may cause blocking and
thus all creation and deletion functions are
forbidden since they use malloc and free
Some more
An ISR must not perform I/O through the I/O
system. A call to a device driver may block
the system if the caller needs to wait for the
device
ISRs should not use floating point instructions
since these registers are not saved on entry
to the ISR or else the registers must be saved
using the functions in fppALib
However, floating point operations are time
intensive and should be anyway avoided in
ISRs.
Interrupt handling
Interrupts are handled by C routines which is
connected to given interrupt vector by
Intconnect()
An interrupt can be handled by application
thread – kernel driver is not needed
All interrupt handlers use one common
special stack which is prepared by system
during start up
Exceptions
When a task causes a hardware
exception such as illegal instruction –
task is suspended
Is ISR causes error – system unsafe –
since ISR has no context that can be
suspended
Most OS store exception in low memory
and execute a system restart
Types of ISRs
Non-nested handlers - this routine
cannot be pre-empted by another
interrupt
Nested handlers - This routine can be
preempted by another interrupt
whereby that ISR will start executing
Non-nested handlers
Interrupt is raised
All interrupts disabled
Processor jumps to ISR
ISR saves context of current process
ISR executes
ISR re-enables interrupts
Context is restored
Nested Interrupt handlers
Non-reentrant code -executed with
interrupts disabled
Reentrant code - executed with
interrupts enabled
Re-entrancy
If multiple tasks are executing the same
piece of code, the code is executed
separately in the context of each task
Local variables defined by the common
function and the arguments passed on
to the function are stored in the stacks
of the respective tasks
Stack utilization
Task A
int foo( int b)
{ int a;
…}
Task B
Task A’s stack
a allocated for A
Changes to local
variable ‘a’
in context of task A
does not affect instance
of ‘a’ in context of task B
Task B’s stack
a allocated for B
Another scenario
int a; /* a is a global variable */
int foo (int b)
{
a = 1;
…}
Clashes can occur with two instances of foo() being
called by two tasks
Re-entrant code
Uses only local variables i.e. variables
allocated on local stack only
Does not use variables that has static
storage (global and static)
Calls only re-entrant functions
If global variables are used they should
be accessed in a mutually exclusive way
How things work
A task which wishes to generate
interrupt is the interruptGenerator()
the interruptGenerator task
generates a hard interrupt using
sysBusIntGen(INTERRUPT_NUM,I
NTERRUPT_LEVEL)
This is caught by interruptCatcher
Handling interrupt
interruptCatcher is able to handle the
hardware interrupt by installing an interrupt
handler, interruptHandler
interruptCatcher "attaches" to the
hardware interrupt using
intConnect(INUM_TO_IVEC(INTERRUPT
_LEVEL),(VOIDFUNCPTR)interruptHandl
er, i)
INUM_TO_IVEC(INTERRUPT_LEVEL) is a
macro that converts a hardware interrupt
number to a vector.
Runtime scenario
interruptCatcher running and doing normal
processing
interruptGenerator generates a hardware
interrupt
interruptCatcher suspends its normal
processing and branches to
interruptHandler
After handling interrupt control is passed
back to interruptCatcher
Syntax sysBusIntGen
STATUS sysBusIntGen
(
int intLevel, /* bus interrupt
level to generate
*/
int vector
/* interrupt
vector to generate (0-255)
*/
)
RETURNS OK, or ERROR if intLevel is
out of range or the board cannot
generate a bus interrupt.
Syntax intConnet
STATUS intConnect
( VOIDFUNCPTR * vector, /* interrupt
vector to attach to */
VOIDFUNCPTR routine, /* routine to be
called */
int parameter /* parameter to be passed
to routine */ )
intConnect()
Connects a specified C routine to a
specified interrupt vector
The address of routine is stored at
vector so that routine is called with
parameter when the interrupt occurs
The routine is invoked in supervisor
mode at interrupt level
Context of execution
A proper C environment is established
The necessary registers saved and the stack
set up
The routine can be any normal C code,
except that it must not invoke certain
operating system functions that may block or
perform I/O operations
This routine simply calls intHandlerCreate( )
and intVecSet( ). The address of the handler
returned by intHandlerCreate( ) is what
actually goes in the interrupt vector.
Delayed function call
Kernel is in an unknown state when Interrupt
occurs
ISR does minimal activities and queues a
delayed function call (DFC) to perform
detailed processing
Extended processing in a service routine
delays the servicing of other interrupt sources
that share the interrupt signal and delays the
resumption of normal processing
Before a DFC runs
Kernel is guaranteed to be in a known
state
Hence a DFC can:
call general Kernel functions
signal a thread
access previously allocated memory and
existing data structures, but cannot
allocate or free memory.
Running a DFC
A DFC runs after all service routines have
been called, but before control returns to
applications
During the execution of a DFC, interrupts
(IRQs and FIQs) are enabled so that
execution time is not as critical as the
execution time of an ISR
DFC can be interrupted, by an IRQ and a FIQ,
but cannot be interrupted by a Kernel exec
call or a Kernel server call.
Memory management
Program execution
Program must be brought into memory and
placed within a process for it to be run.
Input queue – collection of processes on the
disk that are waiting to be brought into
memory to run the program.
User programs go through several steps
before being run.
Binding of Instructions and Data to
Memory
Address binding of instructions and data to memory addresses can
happen at three different stages.
Compile time: If memory location
known a priori, absolute code can be
generated; must recompile code if
starting location changes.
Load time: Must generate relocatable
code if memory location is not known at
compile time.
Execution time: Binding delayed until
run time if the process can be moved
during its execution from one memory
segment to another. Need hardware
support for address maps (e.g., base and
Precious resource
Though cost of memory has gone down
- even 8MB Flash and a few MB RAM
are precious in embedded systems
No hard disks - no virtual memory
management!
Memory Management Unit
All modern operating system kernels
utilize the address translation
mechanism to implement virtual
addressing and separate address spaces
Most embedded operating system
kernels do not provide for memory
protection - to keep the code size less
Memory protection
1) Limit access by one process to the
memory regions of other processes
2) Limit access by user processes to
kernel memory.
Memory protection scheme
Possible to provide protection using
MMU hardware with an order of
magnitude less code
Virtual memory management or
swapping is not feasible
Domain based protection
A domain is a set of memory pages that
are mapped using a set of page tables
A set of memory pages associated with
the operating system kernel called the
kernel map is kept
The kernel map is mapped into all
domains but is accessible only in
supervisor mode.
Basic
operations
Insert the mapping of a page into a domain
Remove the mapping of a page from a
domain
Insert the mapping of a page into the kernel
map
Remove the mapping of a page from the
kernel map
Update a domain to reflect the current
mappings in the kernel map
Memory management data
structures
Region Table: an array of regions that track
the allocations of all the physical memory in
the system
Page Tables: each process belongs to a
protection domain that is defined by the page
tables that are associated with that process
Kernel Map: a list of mappings that are
entered into all the page tables in the system
but are accessible only when the CPU is in
supervisor mode
Region
The basic unit of memory allocation is the
region.
A region is defined as a page-aligned,
contiguous sequence of addressable locations
that are tracked by a starting address and a
length that must be a multiple of the page
size.
The entire physical memory on a given
machine is managed using a boundary-tag
heap implementation.
Each region is tracked using its
starting address - start, and length, len.
Each region is owned by the process that allocated
it originally, or by a process to which
ownership has been transferred after allocation.
The proc field tracks which process currently
owns the region.
Two double-linked lists of region data
structures are maintained, using the prev
and next fields, each in ascending order of
starting address.
The first is the free list,
those regions that are not allocated to any process.
The second is the allocated list,
those regions that are being used by some process.
Region
management
valid_region() - routine to check whether a pointer,
specified by the start parameter, corresponds to the
starting address of some region. It also serves as a
general lookup routine for locating a region data
structure given a starting address.
region_clear() - routine sets the fields of a region
data structure to initialized values
Heap
management
region_insert() - routine inserts a region in
ascending starting address order into a double-linked
region list, specified by the list parameter. This
routine is used to insert a region into either the free
or allocated region lists.
region_remove() - routine removes a region from the
specified list.
region_split() - routine takes one region and splits it
into two regions. The size parameter specifies the
offset from the beginning of the original region
where the split is to occur.
Page Tables
The page table records are kept in a
single-linked list
If multiple threads are executed within
a single protection domain, the refcnt
field tracks the total number of threads
within the domain.
The pd field points to the actual page
table data structures
There is a single pointer to the page
tables themselves.
Page tables are arranged contiguously
in memory.
Page table management
Vm_map (single page), vm_map_range(multiple
rages), vm_unmap(), vm_unmap_range() - They
enter and remove address mappings to and from
page tables
The page found at the location specified by the
parameter is inserted with the protection attributes
specified by the attr parameters into the specified
page tables.
Kernel map
Memory used to hold the kernel and its
associated data structures are mapped into
all the page tables in the system.
Kernel memory protection is provided by
making these pages accessible only when the
CPU has entered supervisor mode and that
happens only when an interrupt occurs or a
system call is made
The result is that system calls require only a
transition from user to supervisor mode
rather than a full context switch.
Kernel map entries
The kernel map is an array of
kernel map entries where each
entry represents a region that is
entered in the kernel map
The start and len fields track the
starting address and length of
the region.
attr field stores the attributes
that are associated with the
pages in the region
Static memory allocation
Global variables
Static variables
Memory allocation at compile time / link
time and do not vary when the program
is executing
De-allocation or freeing memory is
compiler’s headache
Automatic allocation
Local variables
Allocation at run time
Allocation is automatic in runtime stack
De-allocation is compiler’s responsibility
Dynamic variables
Demanded at run time
Allocated from heap
De-allocation is programmer’s
responsibility
Allocating memory
dynamically
Malloc - allocates amount of memory
Memory allocated in multiples of fixed
units
Size of memory available for use - not
entire heap!
Since parts of memory are required to
maintain heap
Effect of unit size
Unit size = 16/32 bytes
Requested memory = 70 bytes
Case I - allocated memory = 80 bytes
Case II - allocated memory = 96 bytes
Amount of memory required to maintain
information about blocks is inversely
proportional to size of chunks
Heap management
During OS startup a chunk of memory is
assigned for heap
All allocations and deallocations are parts of it
Heap manager maintains free list
Free blocks arranged in
decreasing order of size
increasing size
physical proximity
Working principle
Decreasing order - fastest - if first block
cannot hold no other block can hold
Increasing order - best fit - slower but
better managed
Physical proximity - blocks can be
coalesced easily
Heap fragmentation
Available memory is scattered
throughout the heap - but no single
request can be entertained
Internal fragmentation - unused
memory resting with processes
External fragmentation - unused
memory scattered all over the heap
Freeing memory
If a memory is freed twice it can lead to
dangerous consequences - can lead to
unpredictable behaviour
If pointer has been reused for some
other purpose - freeing a memory twice
can lead to de-allocation of newly
allocated pointer
Memory leaks
int main(void)
{ int i=0; int *p;
for(i=0; i<10; i++) {
p = (int *) malloc(sizeof(int));
}
An amount of memory that has been
rendered useless and inaccessible to
the system
Memory leaks in RT systems
Sender processes send messages - receiver
processes should free memory
If memory is allocated inside a function and a
local variable is used to access it - its scope
will not be available outside the function
Allocation and freeing routines should be
robust
Use of external modules
Heap compaction
Rearrangement
When?
Leads to non-determinism
Avoidable
Dynamic memory allocation is not
encouraged for embedded applications
What is the output?
int *example ()
{ int A[5] = {1, 2, 3, 4, 5};
return(A);}
void main ()
{ int i;
int *B = example();
for (i=0; i<5; i++)
printf("%d\n", B[i]);}
Explanation
Program initializes an integer pointer by
calling ``example'', which allocates an array
of five integers and returns it
Array is local to “example”
As a result, the pointer that is returned by
``example'' is ``dangling''--it is pointing to a
memory location that will soon be reused.
So garbage is printed out.
Dangling pointers
When there are more than one pointers
to a block
If first block owns the block
Before freeing the block the first block
should verify whether there are other
blocks pointing to it
When block is freed with the pointers
left pointing to it - dangling pointers
Memory management in
VxWorks
Protected address spaces
There is no any protection between user
and system space and among different
processes in basic VxWorks OS.
All processes have unlimited access into
whole memory space. Memory protection is
available as optional package (VxVMI).
RTLinux
Statically allocated memory
No address space protection
Shared memory as the only
synchronization primitives between realtime tasks
Memory MAP in Windows CE
The internal RAM is divided between
application execution and application/data
storage
User decides how much storage is used for
either purpose
Programs or data stored in internal RAM is
compressed real time to maximize storage
capabilities - compression ratio is
approximately 2 to 1
Applications
Any programs or data that is stored on
flash cards is not compressed
The application execution RAM is used
to store system and data for currently
executing applications
In place execution in ROM
Applications that exist in ROM are not
transferred from ROM to RAM at the
time of execution
Execute in place allows for faster
execution of applications and reduces
the RAM overhead required
Windows CE 2.0 allows for compressed
executables in ROM
Paging
Windows CE 2.0, uses paging to
reduce the amount of ram that is
required at any given time to run all the
applications that are loaded
The operating system reloads pages as
needed to run the application from rom
or flash
Memory management
Addressing Locations in
Memory
Data inside a computer is accessed by means
of metallic conductors called address lines
Each of them carries a bit of information, the
same as a data line
A group of address lines is called an
address bus
Each can be on or off - addresses can be
represented as a series of ones and zeros.
Accessing the Outside World
Ports provide access to outside-world
devices
Example
: printer
serial communications
disk drives
sound cards - all use ports for monitoring
and control
Using A0 through A9 for
addressing Ports
A9 is always high
Range of port addresses is 0X200 through
0X3FF:
A9 A8
A7 A6 A5 A4
A3 A2 A1 A0
1 0
0 0 0 0
0 0 0 0
= 0X200 minimum port address
A9 A8
A7 A6 A5 A4
A3 A2 A1 A0
1 1
1 1 1 1
1 1 1 1
= 0X3FF maximum port address
Port read or write
Depends on the state of the Input/Output
Read and Write (IOR/IOW) lines
The appropriate line must be low
If both are high, then port I/O will not take
place The Input/Output Read line is
abbreviated IOR
A line called Address Enable (AEN) must
be low for port access.
Accessing the Outside World
Ports provide access to outside-world
devices
Example
: printer
serial communications
disk drives
sound cards - all use ports for monitoring
and control
Multistep Processing of a User
Program
Contiguous Allocation
Main memory usually into two partitions:
Resident operating system, usually held in low
memory with interrupt vector.
User processes then held in high memory.
Single-partition allocation
Relocation-register scheme used to protect user
processes from each other, and from changing
operating-system code and data.
Relocation register contains value of smallest
physical address; limit register contains range of
logical addresses – each logical address must be
less than the limit register.
Contiguous Allocation (Cont.)
Multiple-partition allocation
Hole – block of available memory; holes of various
size are scattered throughout memory.
When a process arrives, it is allocated memory
from a hole large enough to accommodate it.
Operating system maintains information about:
a) allocated partitions b) free partitions (hole)
OS
OS
OS
OS
process 5
process 5
process 5
process 5
process 9
process 9
process 8
process 2
process 10
process 2
process 2
process 2
Logical vs. Physical Address
Space
The concept of a logical address space that is
bound to a separate physical address space is
central to proper memory management.
Logical address – generated by the CPU; also
referred to as virtual address.
Physical address – address seen by the memory
unit.
Logical and physical addresses are the same
in compile-time and load-time addressbinding schemes; logical (virtual) and physical
addresses differ in execution-time addressbinding scheme.
Paging
Logical address space of a process can be
noncontiguous; process is allocated physical memory
whenever the latter is available.
Divide physical memory into fixed-sized blocks called
frames (size is power of 2, between 512 bytes and
8192 bytes).
Divide logical memory into blocks of same size called
pages.
Keep track of all free frames.
To run a program of size n pages, need to find n free
frames and load program.
Set up a page table to translate logical to physical
addresses.
Internal fragmentation.
Memory-Management Unit
(MMU)
Hardware device that maps virtual to physical
address.
In MMU scheme, the value in the relocation
register is added to every address generated
by a user process at the time it is sent to
memory.
The user program deals with logical
addresses; it never sees the real physical
addresses.
Dynamic relocation using a
relocation register
Dynamic Loading
Routine is not loaded until it is called
Better memory-space utilization; unused
routine is never loaded.
Useful when large amounts of code are
needed to handle infrequently occurring
cases.
No special support from the operating system
is required implemented through program
design.
Dynamic Linking
Linking postponed until execution time.
Small piece of code, stub, used to locate the
appropriate memory-resident library routine.
Stub replaces itself with the address of the
routine, and executes the routine.
Operating system needed to check if routine
is in processes’ memory address.
Dynamic linking is particularly useful for
libraries.
Hardware Support for Relocation and
Limit Registers
Address Translation Scheme
Address generated by CPU is divided
into:
Page number (p) – used as an index into a
page table which contains base address of
each page in physical memory.
Page offset (d) – combined with base
address to define the physical memory
address that is sent to the memory unit.
Address Translation
Architecture
Paging Example
Paging Example
Free Frames
Before allocation
After allocation
Implementation of Page Table
Page table is kept in main memory.
Page-table base register (PTBR) points to the
page table.
Page-table length register (PRLR) indicates
size of the page table.
In this scheme every data/instruction access
requires two memory accesses. One for the
page table and one for the data/instruction.
The two memory access problem can be
solved by the use of a special fast-lookup
hardware cache called associative memory or
translation look-aside buffers (TLBs)
Associative Memory
Associative memory – parallel search
Page #
Frame #
Address translation (A´, A´´)
If A´ is in associative register, get frame # out.
Otherwise get frame # from page table in memory
Paging Hardware With TLB
Effective Access Time
Associative Lookup = time unit
Assume memory cycle time is 1 microsecond
Hit ratio – percentage of times that a page
number is found in the associative registers;
ration related to number of associative
registers.
Hit ratio =
Effective Access Time (EAT)
EAT = (1 + ) + (2 + )(1 – )
=2+–
Memory Protection
Memory protection implemented by
associating protection bit with each frame.
Valid-invalid bit attached to each entry in the
page table:
“valid” indicates that the associated page is in the
process’ logical address space, and is thus a legal
page.
“invalid” indicates that the page is not in the
process’ logical address space.
Valid (v) or Invalid (i) Bit In A
Page Table
Page Table Structure
Hierarchical Paging
Hashed Page Tables
Inverted Page Tables
Hierarchical Page Tables
Break up the logical address space into
multiple page tables.
A simple technique is a two-level page
table.
Two-Level Paging Example
A logical address (on 32-bit machine with
4K page size) is divided into:
a page number consisting of 20 bits.
a page offset consisting of 12 bits.
Since the page table is paged, the page
number is further divided into:
a 10-bit page number.
a 10-bit page offset.
page number
pi
p2
Thus, a logical address is as follows:
10
10
page offset
d
12
Two-Level Page-Table Scheme
Address-Translation Scheme
Address-translation scheme for a two-level
32-bit paging architecture
Hashed Page Tables
Common in address spaces > 32 bits.
The virtual page number is hashed into a
page table. This page table contains a chain
of elements hashing to the same location.
Virtual page numbers are compared in this
chain searching for a match. If a match is
found, the corresponding physical frame is
extracted.
Hashed Page Table
Inverted Page Table
One entry for each real page of memory.
Entry consists of the virtual address of the
page stored in that real memory location,
with information about the process that owns
that page.
Decreases memory needed to store each
page table, but increases time needed to
search the table when a page reference
occurs.
Use hash table to limit the search to one —
or at most a few — page-table entries.
Inverted Page Table
Architecture
Shared Pages
Shared code
One copy of read-only (reentrant) code shared
among processes (i.e., text editors, compilers,
window systems).
Shared code must appear in same location in the
logical address space of all processes.
Private code and data
Each process keeps a separate copy of the code
and data.
The pages for the private code and data can
appear anywhere in the logical address space.
Shared Pages Example
Segmentation
Memory-management scheme that supports user
view of memory.
A program is a collection of segments. A segment is
a logical unit such as:
main program,
procedure,
function,
method,
object,
local variables, global variables,
common block,
stack,
symbol table, arrays
User’s View of a Program
Logical View of Segmentation
1
1
4
2
3
2
4
3
user space
physical memory space
Segmentation Architecture
Logical address consists of a two tuple:
<segment-number, offset>,
Segment table – maps two-dimensional
physical addresses; each table entry has:
base – contains the starting physical address
where the segments reside in memory.
limit – specifies the length of the segment.
Segment-table base register (STBR) points to
the segment table’s location in memory.
Segment-table length register (STLR)
indicates number of segments used by a
program;
segment number s is legal if s <
Segmentation Architecture
(Cont.)
Relocation.
dynamic
by segment table
Sharing.
shared segments
same segment number
Allocation.
first fit/best fit
external fragmentation
Segmentation Architecture
(Cont.)
Protection. With each entry in segment table
associate:
validation bit = 0 illegal segment
read/write/execute privileges
Protection bits associated with segments;
code sharing occurs at segment level.
Since segments vary in length, memory
allocation is a dynamic storage-allocation
problem.
A segmentation example is shown in the
following diagram
Segmentation Hardware
Example of Segmentation
Sharing of Segments
Segmentation with Paging –
Intel 386
As shown in the following diagram, the
Intel 386 uses segmentation with paging
for memory management with a twolevel paging scheme.
Intel 30386 Address
Translation
I/O Management
Categories of I/O Devices
Human readable
Used to communicate with the user
Printers
Video display terminals
Display
Keyboard
Mouse
Categories of I/O Devices
Machine readable
Used to communicate with electronic
equipment
Disk and tape drives
Sensors
Controllers
Actuators
Categories of I/O Devices
Communication
Used to communicate with remote devices
Digital line drivers
Modems
Differences in I/O Devices
Data rate
May be differences of several orders of
magnitude between the data transfer rates
Differences in I/O Devices
Application
Disk used to store files requires filemanagement software
Disk used to store virtual memory pages
needs special hardware and software to
support it
Terminal used by system administrator may
have a higher priority
Differences in I/O Devices
Complexity of control
Unit of transfer
Data may be transferred as a stream of bytes for a
terminal or in larger blocks for a disk
Data representation
Encoding schemes
Error conditions
Devices respond to errors differently
Differences in I/O Devices
Programmed I/O
Process is busy-waiting for the operation to
complete
Interrupt-driven I/O
I/O command is issued
Processor continues executing instructions
I/O module sends an interrupt when done
Evolution of the I/O Function
Processor directly controls a peripheral
device
Controller or I/O module is added
Processor uses programmed I/O without
interrupts
Processor does not need to handle details
of external devices
Evolution of the I/O Function
Controller or I/O module with interrupts
Processor does not spend time waiting for
an I/O operation to be performed
Direct Memory Access
Blocks of data are moved into memory
without involving the processor
Processor involved at beginning and end
only
Evolution of the I/O Function
I/O module is a separate processor
I/O processor
I/O module has its own local memory
Its a computer in its own right
Role of device driver
Software layer between applications
using the device and the actual device
Implements kernel code to access the
hardware
Handles concurrency between multiple
simultaneous accesses
Does not implement policies about
usage
Writing device drivers
Write kernel code to access hardware
Choose the appearance of the device
Handle concurrency of device access
Memory mapping on the device
Classes of devices
Character devices – can be accessed as
a stream of bytes – console
Block devices – allow transfer of blocks
–disk
Network interfaces – device that is able
to exchange data with other hosts – not
stream oriented – hence not easily
mapped into file systems
Other types
SCSI – a SCSI controller provides the SCSI
subsystem with access to the actual interface
cable
SCSI – communication protocol between the
computer and peripheral device
SCSI abstraction is part of kernel – a device
driver implements the mapping between the
abstraction and the cable through the SCSI
controller
SCSI bus
CPU
Monitor
Disk
•Disk
cache
Bridge/memory
SCSI Controller
Graphics Controller controller
memory
PCI BUS
IDE Disk controller
Expansion bus inferface
keyboard
disk
disk
Expansion bus
Parallel port
Serial Port
Memory Mapped I/O
A part of the CPU's address space is
interpreted not as accesses to memorybut as accesses to a device
Some architectures define devices to
be at a fixed address, but most have
some method of discovering devices
The PCI bus walk is a good example of
such a scheme
Accessing the memory
Physical addresses are of type unsigned long.
Call ioremap() to get an address suitable for
passing to the accessor functions
ioremap will return an address suitable for
accessing the device
When device module exits - call iounmap in
order to return the address space to the
kernel
Direct Memory Access
Takes control of the system from the CPU to
transfer data to and from memory over the
system bus
Cycle stealing is used to transfer data on the
system bus
The instruction cycle is suspended so data
can be transferred
The CPU pauses one bus cycle
No interrupts occur
Do not save context
Operating System Design
Issues
Generality
Desirable to handle all I/O devices in a
uniform manner
Hide most of the details of device I/O in
lower-level routines so that processes and
upper levels see devices in general terms
such as read, write, open, close, lock,
unlock
Operating System Design
Issues
Efficiency
Most I/O devices extremely slow compared
to main memory
Use of multiprogramming allows for some
processes to be waiting on I/O while
another process executes
I/O cannot keep up with processor speed
Swapping is used to bring in additional
Ready processes which is an I/O operation
I/O Buffering
Reasons for buffering
Processes must wait for I/O to complete
before proceeding
Certain pages must remain in main
memory during I/O
I/O Buffering
Block-oriented
Information is stored in fixed sized blocks
Transfers are made a block at a time
Used for disks and tapes
Stream-oriented
Transfer information as a stream of bytes
Used for terminals, printers, communication ports,
mouse, and most other devices that are not
secondary storage
Single Buffer
Operating system assigns a buffer in
main memory for an I/O request
Block-oriented
Input transfers made to buffer
Block moved to user space when needed
Another block is moved into the buffer
Read ahead
I/O Buffering
Single Buffer
Block-oriented
User process can process one block of data
while next block is read in
Swapping can occur since input is taking
place in system memory, not user memory
Operating system keeps track of
assignment of system buffers to user
processes
Single Buffer
Stream-oriented
Used a line at time
User input from a terminal is one line at a
time with carriage return signaling the end
of the line
Output to the terminal is one line at a time
Double Buffer
Use two system buffers instead of one
A process can transfer data to or from
one buffer while the operating system
empties or fills the other buffer
Circular Buffer
More than two buffers are used
Each individual buffer is one unit in a
circular buffer
Used when I/O operation must keep up
with process
I/O Buffering
Controlling a hardware device
Driver is the abstraction layer between
software concepts and hardware circuitry –
talks to both of them
Data bits written to the device appear on the
output pins and voltage levels on the input
pins are directly accessible by the processor
Every peripheral device is controlled by
writing and reading its registers
Device registers are accessed at consecutive
memory addresses either in memory address
or in I/O address space
Accessing the device
Drivers read and write memory-mapped
registers on the device
Functions - readb, readw, readl, readq,
writeb, writew, writel and writeq.
Read and write functions are ordered compiler cannot reorder them for
optimization
Device Drivers
Black Boxes - make a particular piece of
hardware respond to a well-defined internal
programming interface
Details of device’s working hidden from user
User issues standardized calls independent of
the driver
OS maps calls to a device specific operation
I/O Hardware
Device communicates with a computer
via port
Daisy chain – Device A plugs into
device B, device B plugs into device C,
device C plugs into port of computer
Ports
Typically consists of 4 registers
Status
Data in
Data out
Control
Port registers
Data in – read by the host to get input
Data out – written by the host for sending
output
Status – states to indicate whether current
command is completed, whether data is
available for reading etc.
Control – Can be written by host to start a
command or change the device mode
Device Controller
Operates a port or a device or a bus
Simple controller – serial port controller
Complex controller – SCSI bus controller
implements SCSI protocol, usually a
separate circuit board plugged into the
computer. Contains a processor,
microcode and some private memory
Communication
Special I/O instructions that specify the
transfer of a byte or word to an I/O
port address
I/O instruction triggers bus lines to
select the proper device and to move
bits into or out of device register
Combination
Graphics controller has I/O ports for basic
control operations
Has large memory-mapped regions for
holding screen’s contents
Process sends output to the screen by writing
data to the memory-mapped region
Controller generates the screen image based
on this content
Transforming I/O to hardware
operations
Process issues I/O call
System call code in kernel checks the
parameters for correctness
I/O subsystem performs physical I/O
Schedules request
Sends request to device driver – via a
subroutine call or via an in-kernel message
Actions of the device driver
Device driver allocates kernel buffer
space
Sends commands to device controller
Device controller operates the device
hardware
Device driver may poll for status and
data or may set up a DMA transfer into
kernel memory
DMA controller
Generates an interrupt when transfer is
complete
Correct interrupt handler receives interrupt
via the interrupt vector table, stores data and
signals device driver
Device driver receives signal, decides which
I/O request is completed, determines the
request’s status and signals the I/O kernel
subsystem that request is completed
Kernel transfers data to user process space
Request I/O
Can satisfy
request
No
Process unblocked
Yes
Transfer data to
process space
Request to I/O subsystem
Device driver
Process request
Issue commands to
Device controller
Monitor device
Receive interrupt
Signal to kernel
Receive interrupt
Interrupt on completion
Kernel Programming
Kernel executes at highest level supervisor mode
Modules run in kernel space
Modules can access all resources in an
unconstrained fashion
Kernel modules
Normal applications run once
Modules are registered to provide
service in future whenever required
Modules can call kernel exported
functions only
Building Modules
#define MODULE
#include <linux/module.h>
int init_module(void)
{printk (“<1>Hello World!\n”); return
0;}
void cleanup_module(void)
{printk(“<1>Goodbye Harsh World\n”);}
•<1> denotes priority of the message
Kernel modules versus
Applications
insmod - loads module for future use,
calls init_module()
rmmod - unloads module calls
clean_up()
Running Kernel Modules
Gcc -c hello.c
insmod ./hello.o
Hello World
rmmod hello
Goodbye Harsh World
init_module()
Cleanup_module()
register_capability()
unregister_capability()
User space and Kernel space
OS provides a consistent view of
hardware to all programs
OS protects programs from
unauthorized access
CPU enforces protection of system
software by implementing different
operating modalities or levels
Protection Levels provided by
CPU
Supervisor mode – everything is allowed
Kernel modules execute in this mode
User mode – processors regulate direct
access to hardware and unauthorized access
to memory
Each mode has its own memory mapping
Execution of system calls
Execution transfers from user space to
kernel space
Kernel code executing a system call
works in the context of a process
Kernel is then able to access data in
process’s address space
Hardware Interrupts
Interrupt handling code is asynchronous
with respect to processes
Does not execute in the context of any
process
Modules extend kernel functionality –
executes in kernel space
Concurrency in the kernel
Kernel code should be reentrant code capable of running in more than one context
at the same time
Data structures to be designed to keep
multiple threads of executions separate
Shared data should be accessed carefully
Symmetric Multiple Processors
Though kernel modules are noninterruptible for single processors –
concurrency conditions if not taken care
of can cause problems when multiple
processors are there in a system
Kernel Symbol Table
Symbols defined by one module can be
accessed by another module
A kernel module can access other
kernel modules only
Hierarchical definitions of modules
preferred for defining device drivers
Keeping track of tasks
Kernel maintains task_structure
Kernel maintains Resource structure
Keeps track of USAGE
A kernel module cannot be unloaded
while it is in use
Types of devices
Character devices – accessed as stream of
bytes, implements open(), close(), read() and
write()
Block devices - accessed as multiples of
blocks (eg. 1KB) – still available as file
entities
Network Interfaces – in charge of sending
and receiving data packets driven by the
network subsystem of kernel
Device driver header files
system functions
device register addresses
content definitions
driver global variable definitions
Device registers
Device registers are defined in the device
driver header and are based on the device
For a character mode device, these registers
commonly refer to port addresses
I/O address
status bits
control bits
Toggle commands for the device are defined as
their device codes.
Example initialization
/* define the registers */
#define RRDATA 0x01 /*
receive */
#define RTDATA 0x02 /*
transmit */
#define RSTATUS 0x03 /*
status */
#define RCONTRL 0x04 /*
control */
Defining status of registers
#define SRRDY 0x01 /*
received data ready */
#define STRDY 0x02 /*
transmitter ready */
#define SPERR 0x08 /* parity
error */
#define SCTS 0x40 /* clear to
send status */
System resources used
I/O ports
I/O Memory
Interrupt Lines
DMA channels (ISA)
Memory – kmalloc(), kfree()
Writing and reading I/O ports
and I/O memory
Device drivers access I.O ports and I/O
memory (I/O regions) both at
initialization tine and during normal
operations
Device drivers probe memory regions
by reading and writing to discover its
exclusive address zones
Linux resource allocation
mechanism
Text files store resource registration information /proc/ioports, /proc/iomem
0000-001f : dma1
0020-003f : pic1
0040-005f : timer
0060-006f : keyboard
03c0-03df : vga+
03f8-03ff : serial (set)
5800-581f : Intel Corpn. 82371AB PIIX4 USB
D000-dfff : PCI Bus #1
Interface to access I/O
registry
Int check_region(unsigned long start,
unsigned long len);
Whether a range of ports is available
Struct resource *request_region(unsigned
ling start, unsigned long len, char *name);
to block a range of ports
Void release_region(unsigned long start,
unsigned long len);
Release resource
Resource
allocation
Struct resource {
const char *name;
Unsigned long start, end;
Unsigend long flags;
Struct resource *parent, *sibling, *child;}
Top level – I/O ports
Child level – resources associated to a particular bus slot
At boot time - Struct resource ioport_resource = {“PCI IO”,
0x0000, IO_SPACE_LIMIT, IORESOURCE_IO};
IO_SPACE_LIMIT may be 16 bits of address space (x86), 32
bits (SPARC), 64 bits (SPARC64)
Creating resources of a given
type
Sub ranges of a given resource may be
created with allocate_resource()
During initialization a new resource is
created for a region that is actually
allocated to a physical device
Driver requests a subset of a particular
resource and mark it as busy through
__request_region
Advantages of layered
The port spaceapproach
is subdivided into distinct sub
ranges that reflect the hardware of the
system
I/O structure of system is clearly depicted in
kernel data structures
E800-e8ff : Adaptec AHA-294OU2/W / 7890
E800-e8be : aic7xxx
Specifies that range e800-e8ff is allocated to
an Adaptec card which has identified itself to
the PCI bus driver
The aic7xxx driver has then requested most
of that range
scull – Simple Character Utility
for Loading Localities
Scull is a char driver that writes on a memory
area as though it were a device
Hardware independent
Major and minor numbers –
crw------- 1 rubini tty 4 1 Aug 16 22:22 tty1
Tty1 (virtual console) managed by driver 4
Minor numbers used by drivers only
Minor number
Most significant four bits identifies type
of device
Least significant four bits identified
individual devices – how they function
#define type(dev) (MINOR(dev) >> 4)
#define NUM(dev) (MINOR(dev) & 0xf)
Struct File to represent
devices
struct file is a kernel data structure
file structure represents an open file
Created by the kernel on open() and is
passed to any function that operates on the
file, until the last close()
After all instances of the file are closed, the
kernel releases the data structure
An open file is different from a disk file,
represented by struct inode.
Pointer to file
A pointer to struct file is usually called
either file or filp ("file pointer")
file refers to the structure and filp to a
pointer to the structure
Attributes of struct file
mode_t f_mode - FMODE_READ and/or
FMODE_WRITE
loff_t f_pos - current reading or writing
position. The driver can only read this value if
it needs to know the current position in the
file
Only read and write should update a position
using the pointer they receive as the last
argument
Checking
status
to
lock
unsigned int f_flags - These are the
file flags, such as
O_RDONLY, O_NONBLOCK, and
O_SYNC
A driver needs to check the flag for
nonblocking operations
read/write permission should be
checked using f_mode instead of f_flags
File operations
struct file_operations *f_op - The
operations associated with the file
Kernel assigns the pointer as part of its
implementation of open - and then
reads it when it needs to dispatch any
operations
The value in filp->f_op is never saved
for later reference
Imposing similar front end method overriding
file operations associated with a file can
be changed
Example - the code for open associated
with major number 1 (/dev/null,
/dev/zero, and so on) substitutes the
operations in filp->f_op depending on
the minor number being opened
data
void *private_data -The open system call
sets this pointer to NULL before calling the
openmethod for the driver
The driver can use the field to point to
allocated data
private_data is a useful resource for
preserving state information across system
calls and is used by most of our sample
modules.
Directory
entry
struct dentry *f_dentry - The
directory entry (dentry) structure
associated with the file
Device driver writers normally need not
concern themselves with dentry
structures, other than to access the
inode structure as filp->f_dentry>d_inode.
File operations for different
devices
Struct file_operations *scull_fop_array[]={
&scull_fops,
/* type 0 */
&scull_priv_fops, /* type 1*/
&scull_pipe_fops, /* type 2 */
&scull_sngl_fops, /* type 3 */
&scull_user_fops, /* type 4 */
&scull_wusr_fops } /* type 5 */
#define SCULL_MAX_TYPE 5
int type = TYPE(inodei_rdev);
filp f_op = scull_fop_array[type];
Kernel invokes open according to device number
File operations for char
devices
An open char device is identified
internally by a file
Kernel uses file operations to access the
driver’s functions
Each file is associated to its own set of
functions
Operations implement system calls
Struct
file_operations
loff_t(*llseek)(struct file *,loff_t, int) – llseek method
changes the current read/write position in a file and
returns new position
ssize_t (*read)(struct file *, char *, size_t, loff_t *) –
retrieve data from the device – nonnegative return
value given number of bytes read
Ssize_t(*write) (struct file *, const char *, size_t,
loff_t *) – sends data to device
Int (*ioctl)(struct inode *, struct file *, unsigned int,
unsigned long) – device specific commands like
formatting
int (*open) (struct inode *, struct file *) – first
operation
Int (*release)(struct indoe *, struct file *) – when file
open method
Does all initializations in preparation for later
operations
Increment the usage count
Check for device-specific errors
Initialize the device if it is being used for the
first time
Identify the minor number and update the
f_op pointer, if necessary
Allocate and fill any data structure to be put
in filpprivate-data
Closing a device
Close() routine is used only after the
process is finished with the device
Close() disables interrupts from the
device and issues any shut-down
commands
All internal references to the device will
be reset
Closing the device
close() routines are not usually required
in many device drivers because the
device is treated as being available
throughout
Exceptions are removable media and
exclusive-use devices
Some modems require closing (close())
to allow the line to be hung up.
Writing to a char device
write() checks the arguments of the
instruction for validity
Copies the data from the process
memory to the device driver buffer
When all data is copied, or the buffer is
full - I/O is initiated to the device until
the buffer is empty, at which point the
process is repeated
Read a character
The read() operation for character
mode devices transfers data from the
device to the process memory
The operation is analogous to that of
the write procedure
Buffer size
A small buffer is used when several
characters are to be copied at once by read()
or write(), rather than continually copying
single characters
clist implements a small buffer used by
character mode devices as a series of linked
lists that use getc and putc to move
characters on and off the buffer respectively
A header for clist maintains a count of the
contents.
Scull_open
int scull_open(struct inode *inode, struct file *filp) {
Scull_Dev *dev;
int num = NUM(inodei_rdev);
Int type = TYPE(inode i_rdev);
If (!filp private_data && type) {
if (type > SCULL_MAX_TYPE) return –ENODEV;
filp f_op = scull_fop_array[type];
Return filp f_op open(inode, filp);}
Dev = (Scull_Dev *)filp private_data;
dev = (Scull_Dev *)filp private_data;
If(!dev) {
if (num >= scull_nr_devs) return –ENODEV;
dev = &scull_devices[num];
filp private_data = dev; }
MOD_INC_USE_COUNT;
If( (filp f_flags & O_ACCMODE) == O_WRONLY) {
MOD_DEC_USE_COUNT;
return –ERESTARTSYS; }
Scull_trim(dev);
up(&dev sem); }
return 0; }
Memory allocation Policy
Each device is a linked list of pointers each of
which points to a Scull_Dev structure
Each structure can point to at most 4 million
bytes by default
Released source uses an array of 1000
pointers to areas of 4000 bytes – quantum
Scull’s memory usage
typedef struct Scull_Dev {
void **data;
struct Scull_Dev *next; /* next list item */
int quantum;
int qset; /* current array size */
unsigned long size;
devfs_handle_t handle;
unsigned int access_key;
struct semaphore sem} Scull_Dev;
Memory allocation policy
The region of memory used by scull is
variable in length
The more you write, the more it grows
Ttrimming is performed by overwriting
the device with a shorter file.
Implementation
Code uses kmallocand kfree without
resorting to allocation of whole pages,
although that would be more efficient
No limit on the size of the "device" area
- it’s a bad idea to put arbitrary limits
on data items being managed
Practically, scull can be used to
temporarily eat system's memory
Scull_trim()
The function scull_trim is in charge of
freeing the whole data area
Is invoked by scull_open when the file
is opened for writing
Walks through the list and frees any
quantum and quantum set it finds.
List size
. There is only one list element for
every four megabytes of data and the
maximum size of the device is limited
by the computer's memory size.
Choosing the appropriate values for the
quantum and the quantum set is a
question of policy, rather than
mechanism
Quantum
Writing a single byte in scull consumes
eight or twelve thousand bytes of
memory: four thousand for the
quantum and four or eight thousand for
the quantum set (according to whether
a pointer is represented in 32 bits or 64
bits on the target platform)
A huge amount of data - overhead of
the linked list is not too bad
Read()
Returns a value equaling the count
argument passed to the read system
call - the requested number of bytes
has been transferred
If the value is positive, but smaller than
count, only part of the data has been
transferred
Read failures
Most often, the application program will retry
the read
For instance, if you read using the fread
function, the library function reissues the
system call till completion of the requested
data transfer.
If the value is 0, end-of-file was reached.
-EINTR (interrupted system call) or -EFAULT
(bad address).
Write()
If the value equals count, the requested
number of bytes has been transferred
write, like read, can transfer less data than
was requested, according to the following
rules for the return value:
If the value is positive, but smaller than
count, only part of the data has been
transferred. The program will most likely retry
writing the rest of the data.
Write() failures
If the value is 0, nothing was written -
not an error, and there is no reason to
return an error code
Standard library retries the call to write.
A negative value means an error
occurred
Memory barrier
Place a memory barrier between operations
that must be visible to the hardware (or to
another processor) in a particular order
#include <linux/kernel.h>
void barrier(void) - tells the compiler to
insert a memory barrierCompiled code will
store to memory all values that are currently
modified and resident in CPU registers, and
will reread them later when they are needed.
Reordering of instructions
z=x+3;
y=x+2;
z=x+1;
reordered
Z=x+3;
z=x+1;
y=x+2;
Optimizing performance
The compiler can cache data values into CPU
registers without writing them to memory
If it stores them, both write and read
operations can operate on cache memory
without ever reaching physical RAM.
Reordering can happen both at compiler
level and at hardware level - RISC
Reordering for peripheral
devices
Optimizations can be fatal to correct I/O
operations because the processor
cannot anticipate a situation in which
some other process (running on a
separate processor, or something
happening inside an I/O controller)
depends on the order of memory access
No caching
A driver must therefore ensure that no
caching is performed and no read or
write reordering takes place when
accessing registers
Disable any hardware cache when
accessing I/O regions - either memory
mapped or I/O mapped
Ordering of instructions
#include <linux/kernel.h>
void barrier(void) – compiled code will store to
memory all values that are currently modified and
resident in CPU registers and will reread them
later when needed
#include <asm/system.h>
Void rmb(void) – all reads are serialized
Void wmb(void) – all writes are serialized
Void mb(void) – all instructions are serialized
Example - ensure order of
writes
Write1(dev registers.addr,
io_destination_address);
Write1(dev registers.size, io_size);
Write1(dev registers.operation,
DEV_READ);
Wmb();
Write1(dev registers.control, DEV_GO)
Effects
Memory barriers affect performance should be used where really needed
The different types of barriers can also
have different performance
characteristics, so it is worthwhile to
use the most specific type possible
Example
. For example, on the x86 architecture wmb() does nothing - since writes
outside the processor are not reordered
Reads are reordered however - rmb()
necessary
mb() will be slower than wmb()
Preemption model
The preemption model used is to allow the
kernel to be preempted at any time when it is
not locked
Very different from the model where
preemption is actively requested by the
currently executing code
When an event occurs that causes a higher
priority task to be executable - the system
will preempt the current task and run the
higher priority task
Preemption is not allowed
when:
While handling interrupts
While doing "bottom half" processing.
Bottom half processing is work that an
interrupt routine needs to do, but which
can be done at a more relaxed pace
Preemption not contd.
While holding a spinlock, writelock, or
readlock - these locks were put in the kernel
to protect it from other processors in
Symmetric Multiprocessing (SMP) Systems
While these locks are held, the kernel is not
preemptable for reentrancy or data protection
reasons (just as in the SMP case)
Scheduler cannot be
preempted
The scheduler is charged with executing
the "best" task and if it is engaged in
making that decision, it should not be
confused by asking it to give up the
processor
At all other times preemption is allowed
Basic interrupt entry code
It never returns to a user with a pending soft
interrupt, context switch, or signal delivery
It never returns to system code with a
pending soft interrupt, or allowed context
switch pending
"allowed" means that the preemption lock
count is zero
Preemption lock count
Preemption lock count is incremented
whenever a spinlock, writelock,
readlock, interrupt or trap is taken
decremented when ever these
conditions clear
TASK_PREEMPTING flag
This flag is set whenever preemption is
taken up
Tells the scheduler that the task is to be
treated as running, even though its
actual state may be other than running
Housekeeping
This allows preemption to occur during
wake_up set up times when the kernel sets
the current tasks state to something other
than running and then does other set up
work on the way to calling the scheduler
The scheduler can distinguish between the
preemption call and the completion of the
wake_up set up
.
Using Digital I/O ports
Byte-wide I/O location either memorymapped or port mapped
When a value is written to an output
location – the electrical signals on the
output pins change according to value
When an input is read the current logic
level seen on input pins is returned as
individual bit values
Using I/O memory
A region of RAM-like locations that the
device makes available to the processor
over the bus
The exact method depends on the
computer architecture, bus and the
device
If access is through page tables then
ioremap is called before doing any I/O
Directly mapped memory
On some platforms (like MIPS processor
based PDAs) part of the memory is reserved
for I/O locations
Memory management is disabled
Unsigned readb(address) /* read a byte*/
Unsigned readw(address) /* read a byte*/
Unsigned readl(address) /* read a byte*/
void writeb(unsigned value, address) /* write a
byte*/
Unsigned readb(address) /* read a byte*/
Unsigned readb(address) /* read a byte*/
Unsigned readb(address) /* read a byte*/
CPU Issues That Influence
Device Driver Design
Control status register (CSR) access
I/O copy operation
Direct memory access (DMA) operation
Memory mapping
64-bit versus 32-bit
Memory barriers
Control Status Register Issues
Device drivers access a device's control status
register (CSR) addresses directly through a
device register structure
This method involves declaring a device
register structure that describes the device's
characteristics, which include a device's
control status register
Knowing the device register structure, the
driver accesses the device's CSR addresses
through the member that maps to it.
I/O Copy Operation Issues
I/O copy operations can differ markedly from
one device driver to another because of the
differences in CPU architectures
To provide portability when performing I/O
copy operations - generic kernel interfaces to
the system-level interfaces required by device
drivers to perform an I/O copy operation may
be provided by some OS
Kernel Interfaces
String interfaces
Virtual memory interfaces
Data copying interfaces
Hardware-related interfaces
Kernel-related interfaces
Interfaces related to interrupt handler registration
Interfaces related to the I/O handle
Interfaces related to direct memory access
Miscellaneous interfaces
Ioctl functions
Performs a variety of control functions
on devices and STREAMS
For non-STREAMS files, the functions
performed by this call are devicespecific control functions
Generic functions are also provided by
more than one device driver
Parameters
to
ioctl
PPCLAIM - claims access to port
PPEXCL - exclusive access
PPNEGOT - Performs IEEE 1284 negotiation
to decide on a protocol using which the host
and the peripheral transfer data
PPSETMODE - Sets which IEEE 1284 protocol
to use for the read and write calls
Controlling the device
PPWCONTROL - Sets the control lines.
The ioctl parameter is a pointer to an
unsigned char, the bitwise OR of the
control line values in
include/linux/parport.h.
PPRCONTROL - Returns the last value
written to the control register, in the
form of an unsigned char
Data Transfer
PPDATADIR - Controls the data line drivers.
This is only needed in conjunction with
PPWDATA or PPRDATA.
PPWDATA - Sets the data lines (if in forward
mode) The ioctl parameter is a pointer to an
unsigned char.
PPRDATA - Reads the data lines (if in reverse
mode). The ioctl parameter is a pointer to an
unsigned char.
Copying Data from User address
Space to Kernel Address Space
User address space - unprotected
Copy to the protected kernel address
space
Call processor-specific copy functions
to do the transfer
Copying Data from User
Address Space to Kernel
Address Space
register struct buf *bp; int err; caddr_t
buff_addr; caddr_t kern_addr;
.
.
.
if (err = copyin(buff_addr,kern_addr,bp>b_resid))
Sample write_buffer for
printer device
Initialize written = 0;
down(sem) - Take and hold semaphore for
the entire duration of the operation
while (written < count)
(wait_event_interruptible(shortp_out_queue)
- write out to device and Wait till some
buffer space is available
(copy_from_user((char *) shortp_out_head,
buf, space))
up(sem) - Signal semaphore
up(&shortp_out_sem);
Sample write to printer device
Check device status
If busy then wait for some time and
then go out
If device is not busy then send output
to device
Set next pointer to appropriate position
static void shortp_do_write()
{unsigned char cr = inb(shortp_base + SP_CONTROL);
/* Make sure the device is ready for us */
if((inb(shortp_base + SP_STATUS)&SP_SR_BUSY)= 0)
{// printk (KERN_INFO "shortprint:
waiting for printer busy\n");
//
printk (KERN_INFO "Status is 0x%x\n",
inb(shortp_base + SP_STATUS));
while((inb(shortp_base + SP_STATUS)&SP_SR_BUSY==0)
{set_current_state(TASK_INTERRUPTIBLE);
schedule_timeout(10*HZ); }
}/* Mark output active and start up timer */
if (! shortp_output_active)
{shortp_output_active = 1;
shortp_timer.expires = jiffies + TIMEOUT;
add_timer (&shortp_timer);
}
else
mod_timer(&shortp_timer, jiffies + TIMEOUT);
/* Strobe a byte out to the device */
outb_p(*shortp_out_tail, shortp_base+SP_DATA);
shortp_incr_out_bp(&shortp_out_tail, 1);
if (shortp_delay) udelay(shortp_delay);
outb_p(cr|SP_CR_STROBE, shortp_base + SP_CONTROL);
if (shortp_delay) udelay(shortp_delay);
outb_p(cr & ~SP_CR_STROBE,
shortp_base+SP_CONTROL);
nwrote++;}
Hardware-Related
Interfaces
allow device drivers to perform tasks
related to the hardware
Delays the calling interface a specified
number of microseconds
Set the interrupt priority mask
Event Timing
For designing timers or timed
applications
To develop Interrupt handlers for target
boards
Measure average interrupt latencies
Linux Timing Sources
Date
resolution 1s
formatter - %s
Returns number of elapsed seconds since some
set time
Jiffies resolution 10 ms
kernel variable jiffies is incremented by 1 every
10 ms
Returns number of units elapsed since booting
Processor Specific Registers
(PSR)
Variable resolution
Usually two 32-bit counters that increment on
each system clock cycle
Kernel call rdtsc (read TimeStampCounter)
returns counter value for pentium processor
Kernel call get_tbl() returns mftb register
value for PowerPcs
For all platforms:
Get_cycles – returns a count of system
clock cycles that fit into a single CPU
register
Do_gettimeofday
Resolution – 1 µs
Fills the timeval data structure with
number of seconds and microseconds
elapsed since booting
Interrupt Handlers
Ordinary C code
Do not run in any specific process
context - cannot transfer data to or
from user space
Cannot sleep, or allocate memory other
than locking a semaphore
Typically wakes up processes sleeping
on a device’s interurpt
Interrupt Latency
Measure of time between an event
occurring and when the processor
executes the interrupt handler code
Even with microsecond timing access
application cannot have millisecond
accuracy if system interrupt latency
exceeds a milisecond
Measuring Interrupt Latency
Hardware propagation time
Register saving
Software execution – can be slow
Usually hardware propagation and
register saving times – O(10 µs)
Disabling interrupts – cli()
During interrupt disabled other interrupts can
occur – but their service routines cannot
occur till they are enabled
Developers disable interrupts to protect
critical sections of their code
Example
video card driver may disable interrupt for 16 ms
while waiting for a video sync.
Serial card driver might disable interrupt during a
byte transmission
TIPS for good programming
Disable interrupts only when absolutely
necessary
While interrupts are disabled system timers
will not be updated
Network packets will not be transferred to
and from buffers
Video information will not be updated
Perform Interrupt servicing as quickly as
possible
For lengthy tasks – split interrupt handler into
tasklets
Calculating Interrupt latency
Init() – configures processor’s interrupt
controller and port settings, creates
/proc/interrupt_latency
Proc_read() – reading from the file generates
an interrupt signal
Interrupt_latency() – executed on interrupt
Cleanup – frees interrupt 7 and removes
/proc directory
RTLinux - Hard real-time OS
Quality of service - defined by
Real time performance
reliability
reconfigurability
Event notification in Windows
CE
Uses event objects to notify a thread when to
perform its task or to indicate that a
particular event has occurred
For example, a thread that writes to a buffer
resets the event object to a signaled state
when it has finished writing
Asynchronous - After writing the event
object to notify the thread - the thread starts
performing other tasks.
Creating Events
Createevent() - function to create an event
object
Pulseevent() -provides a single operation
that sets the state of the specified event
object to signaled
Setevent() and Resetevent() functions set
the state of the event object to signaled and
non-signaled, respectively.
Delaying the Calling Interface
DELAY(10000)
Process is on spinlock for 10000 microseconds before continuing execution
The range of delays is system dependent, due to its
relation to the granularity of the system clock For any
delay value, the actual delay may vary by plus or
minus one clock tick.
Using DELAY is not encouraged since processor will
be consumed for the specified time interval but
unavailable to service other processes - other than
BOOTING
Rather sleep and timeout interfaces are encouraged
instead of the DELAY interface
Setting Interrupt Priority Mask
spl interfaces set the CPU priority to
various interrupt levels
Current CPU priority level determines
which types of interrupts are masked
(disabled) and which are unmasked
(enabled)
Calling spl0 would unmask all interrupts
Calling spl7 would mask all interrupts
Calling an spl interface between 0 and 7 would mask all interrupts at that level and at
all lower levels
Interrupt Handling
Cli() – disable interrupts
Sti() – enable interrupts
Save_flags(flags) –
Restore_flags() –
Spin_lock_irqsave() – provides locking
and interrupt control together
Preparing the parallel port
Parallel port can generate interrupts on being
instructed to do so
Standard – setting bit 4 of port 2 (0x37a/
0x27a) enables interrupt reporting
If interrupts enabled – whenever electrical
signal at pin 10 (ACK bit) changes from low
to high – parallel port generates an interrupt
Installing Interrupt handlers
Interrupt lines are precious since only
15/16 of them
Kernel keeps registry of interrupt lines
like that of I/O ports
A module requests for an interrupt
channel (IRQ) before using it and
releases it when done
Implementation
Int request_irq(unsigned int irq,
void(*handler)(int, void *, struct pt_regs *),
unsigned long flags,
const char *dev_name,
void *dev_id); - requests for interrupt no. irq,
returns 0 (success) or (- .) (error code) eg. EBUSY
Void free_irq(unsigned int irq, void *dev_id);
Sample code
If(short_irq >= 0) {
result = request_irq(short_irq, short_interrupt,
SA_INTERRUPT, “short”, NULL);
If(result ) {
printk(KERN_INFO, “short: can’t get assigned irq %I
\n”, short_irq);
rhort_irq = -1;
}
else { outb(0x10, short_base+2);
}}
Writing Interrupt Handlers
Handler runs at interrupt time and has
some restrcitions
A handler can’t transfer data from user
space since it does not execute in the
context of a process
Cannot call sleep() or lock a
semaphore, or allocate memory or call
scheduler
Typical task for an interrupt
handler
Awake processes sleeping on the device if the
interrupt signals the event they are waiting
Eample: Device frame grabbe
A process would acquire a sequence of
images by continuously reading the device –
read call blocks before reading each frame –
while the interrupt handler awakens a process
as soon as each new frame arrives
Role of a Interrupt Handler
Give feedback to its device about
interrupt reception and to read or write
data according to meaning of the
interrupt being serviced
Should execute in a minimum amount
of time
void short_interrupt(int irq,, void *dev_id, struct pt_regs *regs)
{
struct timeval tv;
int written;
do_gettimeofday(&tv);
/* write a 16-byte record. Assume PAGE_SIZE is a multiple of 16*/
written = sprintf((char *)short_head, “%08u.%06u\n”,
(int)(tv.tv_sec % 100000000), (int)(tv.v_usec));
short_incr-bp(&short_head, written);
wake_up_interuptible(&short_queue); /* wake up sleeping procs*/
}
Static inline void short_incr_bp(volatile unsigned long *index,
int delta) {
Unsigned long new = *index + delta;
Barrier ();
*index = (new >= (short_buffer + PAGE_SIZE)) ? Short_bufer : new;}
Explanation
Short_interrupt – gets time of day and prints
it to a page_sized circular buffer
Wakes up reading processes – since there is
now data to read
Short_incr_bp wraps a pointer into the
circular buffer
Implements barrier so that the two values of
index are not used in an optimized fashion
Bottom-Half processing
Top half – routine that actually responds
to the interrupt – registered with
request_irq
Bottom-half is scheduled by top-half to
be executed later
All interrupts are enabled during
bottom-half execution
Typically
Top half saves device data to devicespecific buffer
Schedules bottom half and exits
Bottom half does other work and wakes
up sleeping processes
Bottom halves also cannot sleep, cannot
access user space and cannot invoke
scheduler
Tasklets
Special functions that may be scheduled
to run, in interrupt context at a systemdetermined safe time
DECALRE_TASKLET(name, function,
data);
void short_do_tasklet(unsigned long);
DECALRE_TASKLET(short_tasklet,
short_do_tasklet,0);
Scheduling bottom-half
tasklets
void short_tl_interrupt(int irq, void
*dev_id, struct pt_regs *regs)
{ do_gettimeofday((struct timeval *)
tv_head);
short incr_tv(&tv_head);
tasklet_schedule(&short_tasklet);
short_bh_count++; }
Executing tasklets
void shot_do_tasklet()
{
….
written =…
short_incr_bp(…);
…
wake_up_interruptible(&short_queue);
}
Scheduling executions
Task queues – list of tasks owned by the
kernel module declaring and queueing thm
DECALRETASK_QUEUE(name) – declaring a
task queue;
int queue_task() – to enqueue a task
void run_task_queue(task_queue *list) –used
to consume a queue of accumulated tasks
Types of pre-defined task
queues
The scheduler queue – runs in process
context – runs out o a dedicated kernel
thread keventd and is accessed by a
function called schedule_task()
Tq_timer – is run by the timer tick
Tq_immediate – this queue is run as
soon as possible either at return from
system call or when scheduler is run
Porting device drivers
Tools available which provide skeletal driver
code customized for user hardware
Cross Operating System capabilities provided
Example driver development Toolkit WinDriver
Features of WinDriver
enables developers to create applications that
access new or existing hardware
designed to enable creation of high
performance PCI/Compact, PCI/USB/ISA/ISA,
PnP/EISA based device drivers.
Supported operating systems - Windows 9x,
NT, NT Embedded, 2000, CE, Me, Linux,
Solaris, OS/2 and VxWorks
Support for ..
Interrupt and i/o handling
Memory mapped devices
DMA transfers
Plug and Play
multiple board, multiple bus and
multiple CPU handling.
High performance accesses
Use Kernel PlugIn feature to run
application in kernel mode
This feature then provides a very highspeed direct path to the hardware from
your code
High speed data streaming , I/O
mapped I/O etc.
VxWorks
Operating system (OS) used for new control
system
Like Linux, VxWorks is a multi-task OS and is
a "real-time" OS because the programmer
can have control on the way the tasks are
executed (the "scheduling").
VxWorks is a "preemptive" multi-task OS
Memory Layout
•Interrupt Vector Table: Table of exception/interrupt vectors.
•SM Anchor: Anchor for the shared memory network
• (if there is shared memory on the board).
•Boot Line: ASCII string of boot parameters.
•Exception Message: ASCII string of the fatal exception
message.
•Initial Stack: Initial stack for usrInit( ), until usrRoot( )
gets allocated stack.
•System Image: Entry point for VxWorks.
•WDB Memory Pool:
Size depends on the macro
WDB_POOL_SIZE which defaults to one-sixteenth of the
system memory pool. This space is used by the target server
to support host-based tools.
• Modify WDB_POOL_SIZE under INCLUDE_WDB.
•Interrupt Stack: Location depends on system image size.
• Size is defined by ISR_STACK_SIZE under
INCLUDE_KERNEL.
•System Memory Pool : Size depends on size of system image
and interrupt stack. The end of the free memory pool for this
board is returned by sysMemTop( ).
Building a VxWorks System
Image for a targer
Compiling and linking modules
Use make available with development
platforms on UNIX platforms with CPU
name specified
Use project building on Windows
platform with target architecture
specified
Example
% cd ${WIND_BASE}/target/src/usr
% cp usrLib.c usrLib.c.orig
% cp develDir/usrLib.c usrLib.c
% make CPU=I80386
% cd
${WIND_BASE}/target/config/epc4 %
make
%ld68k -o vxWorks -X -N -Ttext
1000 -e _sysInit sysALib.o
sysLib.o \usrConfig.o version.o
/tornado/target/lib/libcpugnuvx.a
Scheduling tasks of same
priority
VxWorks uses "Round-Robin"
scheduling
CPU will spend alternatively a certain
amount of time ("time slice") on each
task until they are completed
The time slice length can be defined by
the programmer.
Priority levels
Each task has a priority level ranging from 0
(for the highest priority) to 255 (for the
lowest priority)
If a task T2 of priority P2>P1 is called either
by the user or by a taskSpawn while T1 is
running, then T1 is suspended right away and
T2 is executed
Developing VxWorks
applications
A VxWorks software consists of one or
several tasks developed on a dedicated
computer using a development
environment like "Tornado"
(available for many platforms
Once compiled and linked, the tasks are
then loaded into the memory of the
VxWorks computer
Setting task parameters
#include "taskLib.h"
int run_first_test(void)
{
taskSpawn("1st_test",150,VX_FP_
TASK,7000,first_test,0,0,0,0,
0,0,0,0,0,0);
}
Task first_test set at priority level
150.
taskSpawn("1st_test",150,VX_FP_TASK
,7000,first_test,0,0,0,0,0,0,0,0,0,
0);
VX_FP_TASK - a macro indicating that floating
point computing is required
7000 is a standard size for the stack to use.
The task spawned is first_test and will
appear in the task list (‘i’) with the name
1st_test as specified by the first argument
The last ten parameters are the parameters of the
function to spawn - 0 since first_test has no
parameter in input
Scheduling
Uses interrupt-driven, priority-based
task scheduling.
Fast context switch times and low
interrupt latency.
Round Robin scheduling (SCHED_RR)
and preemptive priority driven
scheduling (SCHED_FIFO)
Task Context (Task Control
Block)
a thread of execution - task's program counter
the CPU registers and floating-point registers
a stack for dynamic variables and function
calls
I/O assignments for standard input, output,
and error
a delay timer
a
TCB(contd.)
timeslice timer
kernel
control structures
signal
handlers
debugging
and performance
monitoring values
Scheduling library
sched_setparam( ) Set a task's priority.
sched_getparam( ) Get the scheduling
parameters for a specified task.
sched_setscheduler( ) Set scheduling policy
and parameters for a task.
sched_yield( ) Relinquish the CPU.
sched_getscheduler( ) Get the current
scheduling policy.
Scheduling lib. Contd.
sched_get_priority_max( ) - Get the
maximum priority.
sched_get_priority_min( ) - Get the
minimum priority.
sched_rr_get_interval( ) - If roundrobin scheduling, get the time slice
length
Shared memory
Intertask communication is provided by a
chunk of RAM that can be accessed at any
time by any task running under VxWorks
[home/iota]> cd
/home/tornado/map
[home/iota]> more .gmem
Displays the organization of the shared
memory
Organization of shared
memory
. Each line gives the name of the block and
its size
The minimal size is 4 kbytes (0x00001000)
To add a new block, edit .gmem and add a
line with the name of the block and its size.
Using shared memory
A new block MY_BLOCK is to be used in
a task
Define a pointer on the block in your task as
following:
#include "map.h"
...
any_type *pMy_block;
...
pMy_block=(any_type*)map("MY_BLOCK
",sizeof(any_type));.
Shared memory data
The pointer can have any type, including
pointer on a structure.
Only one task has the right to modify a
variable stored in shared memory- in order
to ensure correct intertask communication
No control is done by the VxWorks OS - it
is the responsibility of the programmer to
enforce this rule
Interrupt Stacks (processor
specific)
VxWorks for ARM uses a separate
interrupt stack
The ARM architecture has a dedicated
stack pointer for its IRQ interrupt mode
VxWorks installs stub routines to make
handlers reentrant
Reentrant Handlers
Base-level interrupt handler installed at
initialization store the address of the
handler
The handler returns to the stub routine
to restore the processor state to what it
was before the exception occurred
A device driver can install an interrupt
handler by calling intConnect( ).
Interrupt Descriptor(Vector)
Table
Occupies the address range 0x0 to 0x800
Vector numbers 0x0 to 0x1f are handled by
the default exception handler.
Vector numbers 0x20 to 0xff are handled
by the default interrupt handler.
By default, vector numbers 0x20 to 0x2f
are mapped to IRQ levels 0 to 15.
Interrupt Locks and Latency
Disabling of interrupts for mutual
exclusion
Gguarantees exclusive access to the CPU:
funcA ()
{
int lock = intLock();
.
.
critical region that
cannot be interrupted
.
intUnlock (lock);
}
Preemptive Locks and
Latency
Tasks are not to be preempted
Interrupt Service Routines can execute
funcA ()
{ taskLock ();
. . critical region that cannot be interrupted ;
.taskUnlock (); }
Semaphores
semBCreate( ) Allocate and initialize a binary
semaphore.
semMCreate( ) Allocate and initialize a mutualexclusion semaphore.
semCCreate( ) Allocate and initialize a counting
semaphore.
semDelete( )
Terminate and free a semaphore.
semTake( )
Take a semaphore.
semGive( )
Give a semaphore.
semFlush( )
Unblock all tasks that are waiting for
a semaphore.
Example
#include "vxWorks.h"
#include "semLib.h”
SEM_ID semMutex;
/* Create a binary semaphore that is initially
full. Tasks * * blocked on semaphore wait in
priority order. */
semMutex =
semBCreate(SEM_Q_PRIORITY,
SEM_FULL);
Resource allocation
If the execution of T2 has been completed,
T2 is discarded from the schedule
When a resource needed for T2 is missing, T2
is turned in "pending" state
CPU will resume the execution of T1, unless a
task T3 of priority P3 such that P3<P2 and
P3>P1 has been spawned by T2
Priority Inversion
Priority inversion arises when a higher-priority
task is forced to wait an indefinite period of
time for a lower-priority task to complete
Mutual-exclusion is implemented through a
semaphore that has the option
SEM_INVERSION_SAFE
semId = semMCreate (SEM_Q_PRIORITY |
SEM_INVERSION_SAFE);
Recursive Resource Access
Mutual-exclusion semaphores can be taken
recursively
The semaphore can be taken more than once
by the same task that owns it before finally
being released
Needed to execute routines that call each
other but also require mutually exclusive
access to a resource
System keeps track of owner of semaphore.
Message Queues
Allow a variable number of messages,
each of variable length, to be queued
Any task or ISR can send messages to
a message queue.
Any task can receive messages from a
message queue.
Multiple tasks can send to and receive
from the same message queue
Using message queues
msgQCreate( ) - Allocate and initialize a
message queue.
msgQDelete( ) - Terminate and free a
message queue.
msgQSend( ) - Send a message to a
message queue.
msgQReceive( ) - Receive a message
from a message queue
Signals
Signals asynchronously alter the control
flow of a task.
Any task or ISR can raise a signal for a
particular task.
The signaled task suspends its current
thread of execution and executes the
task-specified signal handler routine the
next time it is scheduled to run.
Signals and Interrupts
Signals are analogous to hardware interrupts.
The basic signal facility provides a set of 31
distinct signals.
A signal handler binds to a particular signal
with sigvec( ) or sigaction( ) in much the
same way that an ISR is connected to an
interrupt vector with intConnect( ).
Signal Handler
The signal handler executes in the receiving
task's context and makes use of that task's
stack.
The signal handler is invoked even if the task
is blocked.
Signals are more appropriate for error and
exception handling than as a general-purpose
inter-task communication mechanism.
Signal Handlers and ISRs
Signal Handlers should be treated like
ISRs
Should not call routines that can block
Safe to use only those routines that are
used by ISRs
Support for Devices
Serial I/O Devices (Terminal and PseudoTerminal Devices)
buffered serial byte streams.
each device has a ring buffer (circular buffer) for
both input and output
Reading from a tty device extracts bytes from the
input ring
Writing to a tty device adds bytes to the output
ring
Size of each ring buffer - specified when the
device is created during system initialization.
Other devices
Pipe Devices
Block devices
SCSI drivers - wide range of hard disks
Network devices
Structure of the SCSI
Subsystem
SCSI subsystem supports libraries and
drivers
SCSI messages
disconnects
minimum period and maximum REQ/ACK offset
tagged command queuing
wide data transfer
Device specific settings - other than default
typedef struct /* SCSI_OPTIONS - programmable */
{
UINT
selTimeOut; /* device selection
time-out (us)
*/
BOOL
messages;
/* FALSE => do not use
SCSI messages
*/
BOOL
disconnect;
/* FALSE => do not use
disconnect
*/
UINT8
maxOffset;
/* max sync xfer
offset (0 => async.) */
UINT8
minPeriod;
/* min sync xfer
period (x 4 ns)
*/
SCSI_TAG_TYPE tagType; /* default tag type
*/
UINT
maxTags;
/** max cmd tags
available (0 => untag
*/
UINT8
xferWidth;
/* wide data trnsfr
width in SCSI units */
} SCSI_OPTIONS;
Dynamic Power Management
power management policies under control of
OS components
User level policy decisions
While techniques for scaling processor voltage and
frequency requirements is quite old this is a very
new concept - explored by
IBM Low-Power Computing Research Center
IBM Linux Technology Center
Monta Vista Software
Processor based power
management techniques
Dynamic power management strategies
based on voltage and frequency scaling.
CPU power consumption typically decreases
with the cube of voltage
Frequencies typically scale linearly with
voltage
Power-performance can be tuned to trade-off
to the needs of the application.
Dynamic Power Management
architecture supports
Ability of processors (like IBM PowerPC
405LP) to rapidly scale internal and
external bus frequencies in concert with
or independent of CPU frequency
manage power consumption based on
the states of peripheral devices
IBM PowerPC 405LP
embedded
processor
Battery operated portable systems
Supports aggressive power management
strategies
Scales frequencies with a latency of a few
microseconds
Scales voltages with latencies measured in
tens of microseconds
without disrupting system operations during
the scaling events.
PowerWise Interface
defines a 2-wire serial interface
connecting the integrated power
controller of a SoC processor system
with a PMIC voltage regulation system
that enables system designers to
dynamically adjust the supply and
threshold voltages on digital processors.
The PWI specification
the operating states
the physical interface
the register set
the command set
the data communication protocol for
messaging between the PWI-master
and the PWI-slave
PWI command
operating state control
register read, register write
voltage adjust commands -
Context of a process -
process state
Data in CPU registers
Data in Main Memory
Code being executed
Program counter to indicate which
instruction is being executed
High Level View of DPM
User/Application
Space
Policy Manager
OS kernel
Policies
DPM
Terminology
DPM policies - Named Data Structures
Policy managers - set of executable programs
that activates policies by name
may be active (real time response to events) /
passive (policy change on a long time frame)
can execute as part of kernel or in user space
On initialization system starts executing
under a particular DPM policy
Operating Points
Operating point is described by
core voltage
CPU and bus frequencies
states of peripheral devices
associated energy cost
Set of rules and procedures move the
system from one operating point to
another as a response to external
events
Example - Different operating points
associated to different system states
Interrupt recvd.
Intr.
Idle
Int handling
Task1
task2
task3
Scheduling
System
idle
Device constraint
Management
States of on-board and external peripheral
devices have a tremendous influence on
system-wide energy consumption and on the
choice of operating point
Enabling of LCD controller implies memory bus
frequency high enough to satisfy refresh rate of
display and also specific pixel clock frequency
LCD may be disabled when system operating as
MP3 player
power consumption of the devices
they control
Example - When system is not producing or
consuming audio data, the audio CODEC
interface
powers down the external CODEC chip
commands on-board clock and power manager to
remove clock from the CODEC interface peripheral
Since the CODEC is a DMA peripheral, these changes
alter bandwidth requirements for on-board
peripheral bus.- triggers a change in operating
point
Congruence class of Operating
Points
Individual device drivers do not have global
view of system
Centralized DPM policy structure defines a
congruence class of operating points - group
of operating points that the system designer
considers equivalent from specific operating
states modulo a power management strategy
at any time any one member is selected to
act as the operating point
Example device
CPU core - IBM PowerPC 405LP
VGA (640 X 480) LCD panel - receives a variablespeed pixel clock generated by on-chip clock dividers
Pixel clock frequency determines the LCD refresh
rates and PLB bandwidth to the SDRAM framebuffer
required to service the LCD
External Security chip - requires the 405LP to source
a precise 33MHz clock via an external clock port
V : 1.8
TASK
V : 1.8
V : 1.8
CPU : 266
CPU : 266
CPU : 266
PLB : 133
PLB : 133
PLB : 133
PXL : 4
PXL : 22
PXL : 22
EXT : 0
EXT : 0
EXT : 33
IDLE
V : 1.0
V : 1.0
V : 1.0
CPU : 8
CPU : 33
CPU : 33
PLB : 8
PLB : 33
PLB : 33
PXL : 0
PXL :17
PXL :17
EXT : 0
EXT : 0
EXT : 33
Security chip disabled
TASK
V : 1.8
LCD enabled
Dynamic Display
V : 1.8
V : 1.8
CPU : 266
CPU : 266
CPU : 266
PLB : 133
PLB : 133
PLB : 133
PXL : 4
PXL : 22
PXL : 22
EXT : 0
EXT : 0
EXT : 33
IDLE
Static Display
V : 1.0
V : 1.0
V : 1.0
CPU : 8
CPU : 33
CPU : 33
PLB : 8
PLB : 33
PLB : 33
PXL : 0
PXL :17
PXL :17
EXT : 0
EXT : 0
EXT : 33
Security chip enabled
V : 1.8
LCD enabled
Clock sourced
TASK
V : 1.8
V : 1.8
CPU : 266
CPU : 266
CPU : 266
PLB : 133
PLB : 133
PLB : 133
PXL : 4
PXL : 22
PXL : 22
EXT : 0
EXT : 0
EXT : 33
IDLE
V : 1.0
V : 1.0
V : 1.0
CPU : 8
CPU : 33
CPU : 33
PLB : 8
PLB : 33
PLB : 33
PXL : 0
PXL :17
PXL :17
EXT : 0
EXT : 0
EXT : 33
Implementation - abstract API
assert_constraint()
remove_constraint()
set_operating_state()
set_policy()
set_task_state()
Visible to kernel only
Visible from a user context
implemented through system calls
Requirements:
Services of a sophisticated, state-of-the-art
operating system
High resolution and user-friendly graphical user
interfaces (GUIs)
TCP/IP connectivity
Substitution of reliable (and low power) flash
memory solid state disk for conventional disk
drives
Support for 32-bit ultra-high-speed CPUs
Use of large memory arrays
Seemingly infinite capacity storage devices
including CD-ROMs and hard disks.
Embedded devices today Intelligent dedicated systems and
appliances used in
interface
monitoring
communications
control applications
Embedded Linux
Small enough to fit into a single floppy
Modular - scaled to compact configurations
Freely available source code - customize it for
unique embedded applications
Rich cadre of device support
Reliable and robust
Multiple versions - specifically for "thin
server" or "firewall" applications, small
footprint versions, and real-time enhanced
versions
Commercial versions
Including development tools, useful utilities, and
support
Installation tools to automate and simplify the
process of generating a hardware-specific Linux
configuration
Support for specific needs of various embedded
and real-time computing platforms and
environments (e.g. special CompactPCI system
features)