chapter18-learning
advertisement

What is learning?
“Learning denotes changes in a system that ... enable a
system to do the same task more efficiently the next
time.” –Herbert Simon
“Learning is any process by which a system improves
performance from experience.” –Herbert Simon
“Learning is constructing or modifying representations of
what is being experienced.”
–Ryszard Michalski
“Learning is making useful changes in our minds.” –
Marvin Minsky
1
Machine Learning - Example
One of my favorite AI/Machine Learning sites:
http://www.20q.net/
2
Why learn?
Build software agents that can adapt to their users or to other
software agents or to changing environments
Personalized news or mail filter
Personalized tutoring
Mars robot
Develop systems that are too difficult/expensive to construct
manually because they require specific detailed skills or
knowledge tuned to a specific task
Large, complex AI systems cannot be completely derived by hand
and require dynamic updating to incorporate new information.
Discover new things or structure that were previously unknown to
humans
Examples: data mining, scientific discovery
3
4
Applications
Assign object/event to one of a given finite set of
categories.
Medical diagnosis
Credit card applications or transactions
Fraud detection in e-commerce
Spam filtering in email
Recommended books, movies, music
Financial investments
Spoken words
Handwritten letters
5
Major paradigms of machine learning
Rote learning – “Learning by memorization.”
Employed by first machine learning systems, in 1950s
Samuel’s Checkers program
Supervised learning – Use specific examples to reach general conclusions or
extract general rules
Classification (Concept learning)
Regression
Unsupervised learning (Clustering) – Unsupervised identification of natural
groups in data
Reinforcement learning– Feedback (positive or negative reward) given at the
end of a sequence of steps
Analogy – Determine correspondence between two different representations
Discovery – Unsupervised, specific goal not given
6
Rote Learning is Limited
Memorize I/O pairs and perform exact matching with
new inputs
If a computer has not seen the precise case before, it
cannot apply its experience
We want computers to “generalize” from prior experience
Generalization is the most important factor in learning
7
The inductive learning problem
Extrapolate from a given set of examples to make
accurate predictions about future examples
Supervised versus unsupervised learning
Learn an unknown function f(X) = Y, where X is an input
example and Y is the desired output.
Supervised learning implies we are given a training set of
(X, Y) pairs by a “teacher”
Unsupervised learning means we are only given the Xs.
Semi-supervised learning: mostly unlabelled data
8
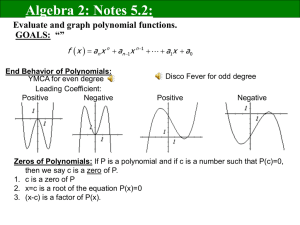
Types of supervised learning
x2=color
Tangerines
Oranges
a)
Classification:
•
We are given the label of the training objects: {(x1,x2,y=T/O)}
•
We are interested in classifying future objects: (x1’,x2’) with
the correct label.
I.e. Find y’ for given (x1’,x2’).
x1=size
Tangerines
Not Tangerines
b)
Concept Learning:
•
We are given positive and negative samples for the concept
we want to learn (e.g.Tangerine): {(x1,x2,y=+/-)}
•
We are interested in classifying future objects as member of
the class (or positive example for the concept) or not.
I.e. Answer +/- for given (x1’,x2’).
9
Types of Supervised Learning
Regression
Target function is continuous rather than class membership
y=f(x)
10
Example
Positive Examples
Negative Examples
How does this symbol classify?
•Concept
•Solid Red Circle in a (regular?) Polygon
•What about?
•Figures on left side of page
•Figures drawn before 5pm 2/2/89 <etc>
11
Inductive learning framework: Feature Space
Raw input data from sensors are typically preprocessed to obtain a
feature vector, X, that adequately describes all of the relevant
features for classifying examples
Each x is a list of (attribute, value) pairs
x = [Color=Orange Shape=Round Weight=200g ]
Each attribute can be discrete or continuous
Each example can be interpreted as a point in an n-dimensional
feature space, where n is the number of attributes
Model space M defines the possible hypotheses
M: X → C , M = {m1, … mn} (possibly infinite)
Training data can be used to direct the search for a good
(consistent, complete, simple) hypothesis in the model space
12
Feature Space
Size
Big
?
Gray
Color
2500
Weight
A “concept” is then a (possibly disjoint) volume in this space.
13
Learning: Key Steps
• data and assumptions
– what data is available for the learning task?
– what can we assume about the problem?
• representation
– how should we represent the examples to be classified
• method and estimation
– what are the possible hypotheses?
– what learning algorithm to use to infer the most likely hypothesis?
– how do we adjust our predictions based on the feedback?
• evaluation
– how well are we doing?
…
14
15
Evaluation of Learning Systems
Experimental
Conduct controlled cross-validation experiments to compare
various methods on a variety of benchmark datasets.
Gather data on their performance, e.g. test accuracy, trainingtime, testing-time.
Analyze differences for statistical significance.
Theoretical
Analyze algorithms mathematically and prove theorems about
their:
Computational complexity
Ability to fit training data
Sample complexity (number of training examples needed to learn
an accurate function)
16
Measuring Performance
Performance of the learner can be measured in one of the
following ways, as suitable for the application:
Accuracy performance
Number of mistakes
Mean Square Error
Solution quality (length, efficiency)
Speed of performance
…
17
18
Curse of Dimensionality
19
Curse of Dimensionality
Imagine a learning task, such as recognizing printed
characters.
Intuitively, adding more attributes would help the learner,
as more information never hurts, right?
In fact, sometimes it does, due to what is called
curse of dimensionality
it can be summarized as the situation where the available data
may not be sufficient to compensate for the increased number of
parameters that comes with increased dimensionality
20
Polynomial Curve Fitting
22
Sum-of-Squares Error Function
23
0th Order Polynomial
24
1st Order Polynomial
25
3rd Order Polynomial
26
9th Order Polynomial
27
Over-fitting
Root-Mean-Square (RMS) Error:
28
Data Set Size:
9th Order Polynomial
29
Data Set Size:
9th Order Polynomial
30
Issues in Machine Learning
Training Experience
Target Function
When and how can prior knowledge guide the learning process?
Evaluation:
How much training data is sufficient?
How does number of training examples influence accuracy?
What is the best strategy for choosing a useful next training experience? How it affects complexity?
Prior Knowledge/Domain Knowledge:
What learning algorithms exist for learning general target functions from specific training examples?
Which algorithms can approximate functions well (and when)?
How does noisy data influence accuracy?
How does number of training samples influence accuracy?
Training Data:
What should we aim to learn?
What should the representation of the target function be (features, hypothesis class,…)
Learning:
What can be the training experience (labelled samples, self-play,…)
What specific target functions/performance measure should the system attempt to learn?
…
32