Chapter 8
DNA and RNA
Biology 100
Structure of DNA
Deoxyribonucleic Acid (DNA) serves as the
memory/blueprint for proteins in the cell.
The building block of DNA (and RNA) is the nucleotide:
What composes the nucleotide?
Phosphate Group
5C deoxyribose sugar (ribose sugar for RNA)
Nitrogenous base
Two important functions of DNA
Pass genetic info
Control synthesis of a protein
Structure of DNA
There are 4 different bases in DNA
Adenine (A) and guanine (G) have double rings. These are
known as Purines.
Thymine (T) and cytosine (C) have single rings. These are
Pyrimidines.
On a single strand, the
phosphate group of one
nucleotide forms a covalent
bond with the sugar of the next.
Structure of DNA
The base pairs of DNA are:
Thymine pairs with Adenine
Guanine pairs with Cytosine
Give the complementary strand:
AT C G GT C A CT G G
T A G C C A GT G A C C
Structure of DNA
Rosalind Franklin suggested that the structure of
DNA was a helix.
In1953, James Watson and Francis Crick took
some of Rosalind’s x-ray diffraction images of
DNA and correctly determined that it was a
double helix.
Using Tinker toys, they made their model of
DNA.
The final structure of DNA:
Sugar-phosphate bond on
the outside, and the nitrogen
bases on the inside,
connected by hydrogen
bonds.
Structure of DNA
DNA has bases pair up in groups of
two. Guanine will pair with Cytosine,
and Adenine will pair with Thymine.
This is known as base complementarity.
DNA resembles a ladder with the sides
of the ladder formed by the sugarphosphate backbones. The rungs are
the complementary bases held together
by hydrogen bonds.
The ladder is twisted like a spiral helix,
known as the double helix.
DNA Replication
Cells constantly grow and divide, so DNA needs to be copied
for each new cell.
First, DNA helicase unwinds the DNA double helix for about
1,000 nucleotides and forms a replication bubble.
DNA Replication
Then, DNA polymerase assembles a complementary new strand
on each old one, using free DNA nucleotides, building two
strands in opposite directions.
DNA Replication
DNA ligase attaches one new strand to the previously
replicated segment, and helicase unwinds another section.
DNA Replication
After replication, there are two molecules of identical DNA.
Each DNA will have one strand from the original DNA
molecules (the parent strand), and one from the replicated
DNA (daughter strand).
This makes the strand semiconservative.
DNA Replication
DNA Replication
Once every 10,000 bases, DNA
polymerase adds the wrong
nucleotide.
Before proceeding to the next
nucleotide, it proofreads the
copy against the parental strand
and corrects the error most of
the time.
The actual error rate is about 1
or 2 errors per billion
nucleotides.
If each human diploid cell
contains 6.2 billion nucleotides,
are any two cells actually
identical?
Why is the DNA code important?
The order of the nitrogenous
bases in DNA is the genetic
information that codes for
proteins.
Proteins help provide the cell
with structure. Enzymes are
also made of proteins, which
help carry out chemical
reactions.
A gene is a section of the
DNA double helix with
information for synthesizing a
specific protein.
RNA
Ribonucleic Acid (RNA)is
the other type of nucleic
acid used in protein
production.
RNA is single-stranded,
and has ribose as it’s 5C
sugar.
In RNA, the base pairs are:
Uracil with Adenine
Guanine with Cytosine
Find the complementary strand:
A C U G G UA C
U GA C C A U G
Cell Differentiation
All cells will use the information
in their DNA to produce the
same “house-keeping” proteins.
But differentiated cells will
express (“turn on”) genes that
have the information for proteins
which support their specific
activities.
In the end, only a small fraction
of genes are expressed in any
particular cell type.
Cell Differentiation
Different differentiated
cells also like to vary in
the level of expression,
how much of a protein is
synthesized.
Individual cells vary their
level of expression of a
gene over time as demand
for their protein product
increases and decreases.
Adult Stem Cells
In most cases, once a cell have
become differentiated, it is locked
into that path and cannot be
transformed into another cell type.
In contrast, stem cells are
unspecialized cells that renew
themselves in this undifferentiated
form.
Under appropriate conditions,
some cells differentiate to fulfill
specific needs that an organism has.
Stem cells in bone marrow (adult
stem cells) specialize into any role
that blood cells undertake in the
body.
These stem cells are multipotent capable of many roles, but not all.
Adult Stem Cells
Recent research has indicated
that some adult stem cells may
be even more flexible than
previously thought, perhaps
close to pluripotent.
They may not only be able to
differentiate into the
specialized cells characteristic
of their tissues, but they may
also be able to specialize into
other cell types.
Fetal Stem Cells
Embryonic (fetal) stem cells
are pluripotent.
Cultured cells can be induced
to specialize into all types of
adult cells.
They are typically obtained
from an early developmental
stage, the blastocyst.
Embryonic stem cells are also
available in umbilical cord
blood.
Stem Cells
After extracting undifferentiated
cells from a blastocyst, cells are
cultured on feeder plates.
If the embryonic stem cells are
allowed to clump together, they
can spontaneously differentiate.
By including specific molecules
into the cultures or otherwise
changing conditions, the clumps
can be directed to differentiate
into specific cell types.
Bone Marrow
Individuals may suffer deficiencies
in red or white blood cells caused
by cancer, anemia, inherited genetic
diseases, or immune-system
disorders.
Typically, healthy bone marrow,
containing blood-forming stem
cells, is extracted from a donor.
The bone marrow is introduced
into the recipient’s blood.
The new stem cells repopulate the
bone marrow and restore the
population of blood cells.
Potential Application of Stem Cells
Type-1 Diabetes
In type 1 (juvenile) diabetes, the immune system attacks
insulin-producing cells in the pancreas, leading to diabetes =
elevated glucose levels.
New stem cells may be able to replace to the lost cells.
Heart Disease
If cardiac muscle cells are deprived of oxygen because of
blocked arteries, they die and are replaced by scar tissue.
Stem cells may allow regeneration of cardiac tissue if they can
differentiate into muscles cells and integrate into the heart.
Potential Application
of Stem Cells
In individuals with Parkinson’s disease, neurons which produce the
neurotransmitter dopamine die, leading to uncoordinated
movements.
Preliminary studies indicate that neural stem cells can be injected
into the brains of Parkinson’s patients, reducing disease symptoms
Potential Application of Stem Cells
A patient’s DNA is extracted
and injected into an enucleated
egg.
A similar technique was used
to produce the first cloned
mammal, the sheep Dolly, in
1996.
The embryonic stem cells
would then induced to develop
into a specific tissue needed by
the patient.
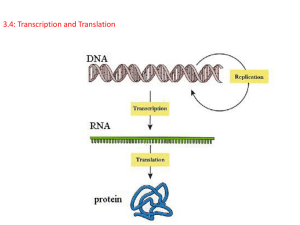
Protein Synthesis
Also known as the central dogma
of gene expression.
Protein synthesis occurs in two
steps, transcription and
translation.
In transcription, a gene, a region
of information contained in the
order of nucleotides in DNA, is
copied as RNA.
In translation, information on
mRNA is used to direct the order
with which amino acids are linked
together to form polypeptides at
the ribosomes.
How information is stored in DNA
The genetic code is a language in which all “words” are three
letters long (triplets) and combinations of the nitrogen bases.
The letters: A,T,C,G in DNA or A,U,C,G in RNA, are the
alphabet.
As triplets, 43 combinations = 64 “words”
There are 20 amino acids commonly used in proteins. Each
“word” is a code for an amino acid.
64 words are more than enough to specify 20 amino acids
Each word, a unique combination of three nucleotides, is
called a codon.
Genetic Code
Each codon indicates only
one amino acid.
There is more than one
codon for most amino
acids. Except for
tryptophan or methionine,
each amino acids has 2-6
possible codons.
The 3rd position, the
wobble position is less
critical in dictating specific
amino acids.
Genetic Code
AUG is the start codon
(Methionine), which tells
the mRNA to begin
translation. If AUG is not
found, translation will not
begin.
There are three stop
codons (UAA, UAG, UGA)
the protein will be
released.
Genetic Code
During translation, codons
are read without pause or
skipping from the start
codon to the stop codon.
The start codon establishes
the reading frame, the blocks
of 3 nucleotides that will
translated.
Any nucleotide is part of
only one triplet, they do
not overlap.
Codons
Which codon is it?
UUU
Phenylalanine
UGA
Stop
AUG
Methionine (Start)
GAA
Glutamic Acid
Types of RNA
Messenger RNA (mRNA)
has the specific information
necessary to place amino
acids in the correct order
to build the right
polypeptide.
Simply put, it is the
template to guide the
synthesis of a chain of
amino acids that form a
protein.
Types of RNA
Transfer RNA (tRNA)
molecules carry specific
amino acids from the
cytoplasm to the
ribosome.
Each tRNA has an amino
acid binding site to which
a specific amino acid is
attached.
Each tRNA has an anticodon region, an area
complementary to the
codon on mRNA.
Types of RNA
Ribosomal RNA (rRNA)
combines with proteins to
form ribosomes.
The rRNA and protein
molecules combine to form
large ribosomal subunits
and small ribosomal
subunits in the nucleolus.
Transcription
Transcription occurs in three
parts:
Initiation, the key enzyme,
RNA polymerase, finds the
correct region of DNA to
begin the process.
Elongation, the DNA double
helix unwinds a bit and RNA
polymerase makes a RNA copy
of the DNA template.
Termination, the RNA
polymerase reaches the end of
the gene and releases the RNA
molecule.
Synthesis of RNA
A gene consists of several sections.
The promotor sequence is the site where transcription factor
proteins and RNA polymerase bind initially.
The core of the gene consists of the protein code, the
information required for synthesizing a protein.
The termination sequence indicates the end of the gene, the
end for transcription.
Transcription Initiation
In eukaryotes, proteins
called transcription factors
bind to the promotor
region.
They assist the binding of
RNA polymerase to the
correct spot.
Translation - Elongation
Once RNA polymerase
binds, the DNA double
helix begins to unwind.
One strand has the
information for the gene,
the coding strand.
RNA polymerase copies
the coding strand as an
RNA strand.
Transcription - Termination
Elongation continues until RNA polymerase reaches a specific
DNA sequence called a terminator.
At this point the new RNA strand is either released or cut free.
Translation of Proteins
Translation also has three
stages:
In initiation, mRNA,
tRNA, and the small and
large ribosomal subunits
are brought together.
In elongation, the
information on the mRNA
is used to order tRNA
carrying the correct amino
acids.
At termination, the
components, including the
new polypeptide, separate.
Translation - Initiation
Initiation starts when
mRNA binds to the small
ribosomal subunit.
The initiator tRNA,
carrying the amino acid
methionine, binds because
of its complementary
anticodon to the start
codon.
Next, the large ribosomal
subunit connects to this
complex.
Translation - Elongation
The next tRNA with the correct
amino acid slip into place.
The ribosome catalyzes a peptide
bond between amino acids.
The old tRNA is released.
The whole complex: mRNA and
tRNA with growing polypeptide,
slides down the ribosome by 3
nucleotides (translocation).
Translation - Elongation
The next tRNA with an anticodon matching the next codon
slips into place.
This cycle of tRNA positioning, peptide bond formation, old
tRNA release, moving of the mRNA + tRNA + polypeptide
continues.
Translation - Termination
When the process reaches
the stop codon, a release
factor protein enters the
ribosome.
The release factor breaks
the bond between the last
tRNA and the polypeptide.
The polypeptide floats
away
The mRNA is released.
Protein Synthesis
Control of Protein Synthesis
As part of differentiation, cells
turn some genes off and others
on.
Plus, they can control how
quickly/often a gene is
transcribed and how often a
mRNA from that gene is
translated.
If a section of chromosome is
tightly coiled (like during
mitosis), transcription factors
and RNA polymerase cannot
access the promotor sequence.
Any genes in these regions are
turned off.
Control of Protein Synthesis
If acetyl groups (-COCH3) are
attached to histone proteins at
a section of DNA,
transcription occurs more
easily.
If methyl groups (-CH3) are
attached to the DNA itself, the
methylated genes are turned
off.
Enzymes actively control
which sections of a
chromosome have methylation
and acetylation
Control of Protein Synthesis
Without activated transcription
factors, a gene will be
transcribed, but at a low level.
If activated transcription factors
are present, RNA polymerase
can bind more easily to the
promotor.
Transcription occurs faster.
Often activated transcription
factors will enhance
transcription of several genes
whose proteins will work
together in the cell.
Control of Protein Synthesis
Some genes are transcribed
more often because of the
presence of enhancer DNA
regions.
Activators that bind to the
enhancer region make it easier
to transcription factors and
RNA polymerase to bind to the
promotor.
Other DNA regions, called
silencers, decrease the rate of
transcription.
Control of Protein Synthesis
Once a mRNA has finished transcription of one polypeptide, it is
available to produce another.
Eventually, the mRNA will be degraded, but the rate of
degradation is under active control.
The mRNA that is translated into a protein which assists iron
absorption is degraded much faster when the cell has abundant
supplies of iron.
Protein Synthesis
In bacteria, one gene is transcribed
into one mRNA which is translated
into one protein.
In eukaryotes, one gene can
produce several different proteins.
Eukaryotic gene include exons
which have information for
proteins and introns which do not.
The introns are removed during
post-transcriptional processing.
The exons are joined together.
Protein Synthesis
In alternative splicing, some
sections of the original mRNA
are removed in some versions,
but other sections are removed in
other versions.
The result is that the same gene
can produce two different
proteins.
Alternative splicing is behind the
observation that the 20,000
genes in the human genome lead
to 80,000 to 100,000 different
proteins.
In fruit flies, the gene for sex
determination contains two
possible stop signs.
In some individuals, the first stop
codon is removed.
The protein that is translated
from this splicing leads to the
development of a female fruit fly.
If the first stop codon is not
spliced, no functional protein is
transcribed.
The fruit fly develops as a male
Point Mutation
Mutations are changes in the DNA
sequence of an organism.
The changes may be as minor as altering
a single nucleotide to deletion/addition
of whole chromosomes or even sets of
chromosomes.
In a point mutation, a single nucleotide is
changed to one of the other three.
If the change occurs outside a gene or if
it does not impact the amino acid put in
place, then it is a silent mutation.
Both GGG and GGA are codons for
glycine.
Mutation
A nonsense mutation occurs when the
change switches a codon from
indicating an amino acid to a stop
codon.
Translation of the mRNA that results
will lead to a non-functional protein.
A missense mutation results in the
substitution of one amino acid for
another during translation.
While GGA is the codon for glycine,
the mutated GCA is the codon for
alanine.
Consequences of changes in the
primary structure of a polypeptide
range from minor to catastrophic.
Mutations: Sickle Cell Anemia
Sickle cell anemia is the result of a missense mutation.
The mutated protein leads to sickle-shaped red blood cells
and sickle cell anemia.
Sickle Cell Anemia
Without modern medical
treatment, most individuals with
sickle cell anemia die in the late
teens.
Yet, the sickle cell mutation is
common in parts of India and
central Africa.
These are areas with high
frequencies of the malaria parasite.
Before drug treatments, individuals
with two normal hemoglobin genes
would die from malaria.
Individuals with one normal
hemoglobin gene and one sickle cell
gene are resistant to malaria.
Insertion/Deletion
An insertion mutation adds one or
more nucleotides to a DNA
sequence.
A deletion mutation removes one
or more nucleotides from a
DNA sequence.
Both mutations cause frameshifts
and changes in primary
structure of polypeptides
because ribosomes will read the
wrong sets of three nucleotides
during translation.
Chromosomal Mutations
Some mutagens or genetic accidents
can cause breaks on chromosomes
which may result in separate
chromosomes.
Movements of segments from one
chromosome to another translocations and insertions
Loss of whole segments - deletions.
The pieces may become inserted
into similar chromosomes
(duplication) or oriented in the
opposite direction (inversion).
Chromosome Mutations
Errors during meiosis and
fertilization (rarely mitosis) can
result in cells which have too
many or too few chromosomes.
This usually upsets the balance of
genes which lead to normal
development.
In humans, this usually results in
spontaneous abortion of the
embryo long before birth.
Chromosomal Mutation
In the most common form of
Down syndrome, individuals have
three copies of chromosomes 21,
the smallest chromosomes with the
fewest genes.
These individuals have
characteristic physical appearance,
and physiological and mental
challenges.
The risk of Down syndrome
increases dramatically as the age of
the mother increases.
0.04% of births for mothers < 30
>1.25% of births for mothers > 30