Signal Spaces
advertisement

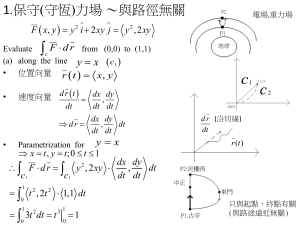
Signal Spaces Much can be done with signals by drawing an analogy between signals and vectors. A vector is a quantity with magnitude and direction. magnitude q (NE Direction) There are two fundamental operations associated with vectors: scalar multiplication and vector addition. Scalar multiplication is scaling the magnitude of a vector by a value. a 2a Vector addition is accomplished by placing the tail of one vector to the tip of another vector. a b b a a+b A vector can be described by a magnitude and an angle, or it can be described in terms of coordinates. Rather than use x-y coordinates we can describe the coordinates using unit vectors. The unit vector for the “x” coordinate is i. The unit vector for the “y” coordinate is j. Thus we can describe vector a as (4,3) a j i We can also describe a as 4i + 3j. Suppose we had a second vector b = 4i + j. The sum of the vectors a and b could be described easily in terms of unit vectors: a + b = 8i + 4j. In general, if a = ax i + ay j and b = bx i + by j , we have a + b = (ax+bx )i + (ay+by )j . In other words, the x-component of the sum is the sum of the x-components of the terms, and the ycomponent of the sum is the sum of the ycomponents of the terms. At this point we draw an analogy from vectors to signals. Let a(t) and b(t) be sampled functions a(t) b(t) When we add two functions together, we add their respective samples together as we would add the xcomponents, y-components and other components together. a(t) b(t) a(t) + b(t) We can think of the different sample times as different dimensions. In MATLAB, we could create two vectors (onedimensional matrices), and add them together: >> a = [3 4 1 2]; >> b = [2 3 4 2]; >> a + b ans = 5 7 5 4 You can think of the four values in each vector as, say, w-components, x-components, y-components and z-components. We can add additional components as well. We will now examine another vector operation and show an analogous operation to signals. This operation is the dot product. Given two vectors, a and b, the dot product of the two vectors is defined to be the product of their magnitudes times the cosine of the angle between them: a•b |a| |b| cosqab. If the two vectors are in the same direction, the dot product is merely the ordinary product of the magnitudes. b a a•b = |a| |b|. If the two vectors are perpendicular, then the dot product is zero. a b a•b = 0. The dot product of the unit vector i with itself is one. So is the dot product of the unit vector j with itself. i•i = 1. j•j = 1. The dot product of the unit vector i the unit vector j is zero. i•j = 0. Suppose a = ax i + ay j and b = bx i + by j , Their dot product is a • b = (ax i + ay j )• (bxi + by j ) . Using the dot products of unit vectors from the previous slide, we have a • b = axbx + ayby . As with vector addition, we can draw an analogy for the dot product to signals. Let a(t) and b(t) be sampled functions (as before). We define the inner product of the two signals to be the sum of the products of the samples from a(t) and b(t). The notation for the inner product between two signals a(t) and b(t) is a(t ), b(t ) . The inner product is a generalization of the dot product. If we had, say, four sample times, t1, t2, t3, t4, the inner product would be a(t ), b(t ) a(t1 )b(t1 ) a(t2 )b(t2 ) a(t3 )b(t3 ) a(t4 )b(t4 ). Let us take the inner product of our previous sampled signals a(t) and b(t): a(t) 4 3 2 1 4 b(t) 3 2 2 a(t ), b(t ) (3)( 2) (4)(3) (1)( 4) (2)( 2) 26. In MATLAB, we would take the inner product as follows: >> a = [3 4 1 2]; >> b = [2 3 4 2]; >> a * b’ ans = 26 In general, the inner product of a pair of sampled signals would be a(t ), b(t ) a(tn )b(t n ). n 1 N Now, what happens as the time between samples decreases and the number of samples increases? Eventually, we approach the inner product of a pair of continuous signals. a(t ), b(t ) 0 a(t )b(t ) dt. T Again, the inner product can be thought of as the sum of products of two signals. Example: Find the inner product of the following two functions: t ( 0 t 1 ), a(t ) 0 (elsewhere ). 2 t b(t ) 0 (0 t 1), (elsewhere ). Solution: 0 4 4 0 t 3 dt . t4 1 1 t t dt a(t )b(t ) dt 1 0 a(t ), b(t ) 1 0 T 2 Example: Find the inner product of the following two functions: 1 ( 0 t 1 ), a(t ) 0 (elsewhere ). 2t 1 (0 t 1), b(t ) 0 (elsewhere ). t 2 t 0. 0 2t dt 1 dt 12t 1 dt 1 a(t ), b(t ) 0 1 0 0 1 0 1 T When the inner product of two signals is equal to zero, we say that the two signals are orthogonal. When two vectors are perpendicular, their dot product is zero. When two signals are orthogonal, their inner product is zero. Just as the inner product is a generalization of the dot product, we generalize the idea of two vectors being perpendicular if their dot product is zero to the idea of two signals being orthogonal if their inner product is zero. Example: Find the inner product of the following two functions: sin c t a(t ) 0 (0 t T ), (elsewhere ). cos t ( 0 t T ), c b(t ) (elsewhere ). 0 Let T be an integral multiple of periods of sin ct or cos ct. 12 (0) 0. a(t ), b(t ) 0 2 1 T 0 sin 2 ctdt sin c t cos ct dt T The functions sine and cosine are orthogonal to each other. Example: Find the inner product of cos ct (0 t T ), a(t ) 0 (elsewhere ) with itself. Again, let T be an integral multiple of periods of sin ct or cos ct. 12 (0) T2 . 2 2 1 T 0 2 c t dt 1 cos 2 1 cos 2 c t dt T 0 a (t ), a (t ) cos c t cos c t dt T 0 T The inner product of a signal with itself is equal to its energy. The dot product of a signal with itself is equal to its magnitude-squared (exercise). Exercise: Find the inner product of a(t) with itself, b(t) with itself and a(t) with b(t), where T2 sin ct (0 t T ), a(t ) (elsewhere ). 0 T2 cos ct b(t ) 0 (0 t T ), (elsewhere ). As before, let T be an integral multiple of periods of sin ct or cos ct. Now, back to ordinary vectors. One of the most famous theorems in vectors is something called the Cauchy-Schwarz inequality. It shows how dot products of two vectors compare with their magnitudes. It also applies to inner products. Let us introduce a scalar g. Using this scalar along with our two vectors a and b, let us take the inner product of a+ gb with itself. a gb, a gb a, a 2g a, b g 2 b, b . (We have exploited some properties of the inner product which should not be too hard to verify, namely distributivity and scalar multiplication.) The expression on the right-hand side of this equation is a quadratic in g. If we were to graph this expression versus g, we would get a parabola. The graph would take one of the following three forms: g Two Roots g One Root g No (Real) Roots We know, however, that since this expression is equal to the inner product of something with itself <a+ gb a+ gb>, that the expression must be greater than or equal to zero. Thus only the last two graphs pertain to this expression. a, a 2g a, b g 2 b, b 0. If this is true, then the quadratic expression must have at most one root. If there is at most one root, then the discriminant of the quadratic must be negative or zero: 2 a, b 2 4 b, b a, a 0. Simplifying, we have a, b a, a b, b . 2 Thus we have the statement of the CauchySchwarz inequality. This expression is a non-strict inequality. In some cases, we have equality. Suppose a and b are orthogonal (qab = 90°). a, b 0. In this case, the Cauchy-Schwarz inequality is met easily (zero is less than or equal to anything positive). Suppose a and b are in the same direction (qab = 0°). a, b a b . In this case, the Cauchy-Schwarz inequality is an equality: the upper-bound on <a,b> is met. Thus, the maximum value of <a,b> is achieved when a and b are collinear (in the same direction). The Cauchy-Schwarz inequality as an upper bound on <a,b> is the basis for digital demodulation. If we wished to detect a signal a by taking its inner product with some signal b, the optimal value of b is some scalar multiple of a. a <a,b> Detector If we use the inner product of signals, the inner product detector becomes a(t) X b(t) <a,b> So the optimal digital detector is simply an application of the Cauchy-Schwarz inequality. The optimal “local oscillator” signal b(t) is simply whatever signal that we wish to detect. Using our previous notation a(t) is equal to s(t) if there is no noise, or r(t)=s(t)+n(t) if there is noise. The “local oscillator signal” b(t) is simply s(t) [we do not wish to detect the noise component]. r(t) X s s(t) The resultant filter is called a matched filter. We “match” the signal that we wish to detect s(t) with a “local oscillator” signal s(t). Another way to think of the inner product operation or matched filter operation is as a vector projection. Suppose we have two vectors a and b. a b The projection of a onto b is the “shadow” a casts on b from “sunlight” directly above. a projection b The magnitude of the projection is magnitude of a times the cosine of the angle between a and b. projection a cosq ab . The projection can be defined in terms of the inner product: projection a, b b . The actual projection itself is a vector in the direction of b. To form this vector, we multiply the magnitude by a unit vector in the direction of b. b unit vecto r . b a, b b projection . b b The denominator |b||b| can be expressed as the magnitude squared of b or the inner product of b with itself. projection a, b b, b b. If the magnitude of b is unity, the projection becomes projection a, b b. The signal b has unity magnitude in the following matched filter: s(t) X ds(t) s (2/T) cos ct This was the detector with the “normalized” local oscillator. Let us do an example of projections with signals. Example: “Project” t2 onto t. Restrict the interval of the signals to [0,1]. 1 projection a, b b, b b t 0 1 0 t 3 dt t. 2 dt Evaluating the integrals, we have 1 projection t 0 1 0 3 t dt 2 dt t 1 4 1 3 t 34 t. Let us plot the original function t2 and its projection onto t. t2 and Its Projection onto t 1 0.9 t 0.8 2 t2, (3/4)t 0.7 0.6 0.5 (3/4)t 0.4 0.3 0.2 0.1 0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 t 1 The projection (3/4)t can be thought of as the best linear approximation to t2 over the interval [0,1]. (It is the best linear approximation in the minimum, meansquared error sense.) When we project a vector onto another vector, we take the best approximation of the first vector in the direction of the second vector. a projection b We can also project onto multiple vectors: c projection a projection b If we were to add the two projections (onto b and c), we would no longer have an approximation to a, but rather we would have exactly a. Example: Let us project cos(ct + q) onto cos(ct) and sin(ct) . 1 cos( t q ) cos t dt cosine projection cos t. cos t dt c 0 c 1 c 2 c 0 1 cos( t q ) sin t dt sine projection sin t. sin t dt c 0 1 0 c c 2 c Evaluating the integrals, we have cos( 2 t q ) cosq dt cosine projection cos t cos 2 t 1dt cosq dt cos t 1 dt 1 1 0 2 c c 1 1 0 2 c 1 1 2 0 1 2 1 0 cos q cos ct . c 1 cos( t q ) sin t dt sine projection sin t sin t dt sin( 2 t q ) sin q dt sin t 1 cos 2 t dt sin q dt sin t 1 dt c 0 1 c c 2 c 0 1 1 0 2 c c 1 1 0 2 c 1 1 2 0 1 2 1 0 sin q sin c t . c Adding the two projections, we have cosq cos ct sin q sin ct . This should not be surprising because cos(ct q ) cos ct cosq sin ct sin q . Example: Let us project an arbitrary function x(t) onto cos(ct), cos(2ct), cos(3ct), … Restrict the interval of the signals to [0,T], where T is an integral multiple of cycles of cos(ct). We will be projecting x(t) onto cos(nct), for n=1,2,3, … These projections will then be summed. x(t ) projection onto cos(n ct ). n 1 projection onto cos(n t ) T x(t ) cos n c t dt 0 c T 0 T 0 cos 2 n c t dt cos n c t x(t ) cos n c t dt 1 cos 2n t dt T 1 0 2 T 0 cos n c t c x(t ) cos n c t dt 1 2 T cos n c t T 2 T x(t ) cos n c t dt cos n c t 0 So the summation of the projections is x(t ) T2 x(t ) cos n c t dt cos n c t. 0 n 1 Or, T x(t ) an cos n c t , n 1 where T an T2 x(t ) cos nct dt. 0 We have just derived the trigonometric Fourier series (for cosine). Exercise: Project an arbitrary function x(t) onto sin(nct), n=1,2,3, … (Complete the trigonometric Fourier series.) Exercise: Project an arbitrary function x(t) onto ejnct, for n=0,±1,±2, … (Derive the complex exponential Fourier series.) The previous examples an exercises worked because we were projecting onto orthogonal signals. If the signals were not orthogonal, we could not simply sum the projections and expect to reconstruct the original signal.