Lexical Analyzer, Flex - College of Engineering and Computer
advertisement

Compiler Design
3. Lexical Analyzer, Flex
Kanat Bolazar
January 26, 2010
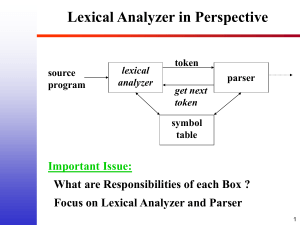
Lexical Analyzer
• The main task of the lexical analyzer is to read the input
source program, scanning the characters, and produce a
sequence of tokens that the parser can use for syntactic
analysis.
• The interface may be to be called by the parser to produce one
token at a time
– Maintain internal state of reading the input program (with lines)
– Have a function “getNextToken” that will read some characters at the
current state of the input and return a token to the parser
• Other tasks of the lexical analyzer include
– Skipping or hiding whitespace and comments
– Keeping track of line numbers for error reporting
• Sometimes it can also produce the annotated lines for error reports
– Produce the value of the token
– Optional: Insert identifiers into the symbol table
2
Character Level Scanning
• The lexical analyzer needs to have a well-defined valid
character set
– Produce invalid character errors
– Delete invalid characters from token stream so as not to be used in
the parser analysis
• E.g. don’t want invisible characters in error messages
• For every end-of-line, keep track of line numbers for error
reporting
• Skip over or hide whitespace and comments
– If comments are nested (not common), must keep track of nesting to
find end of comments
– May produce hidden tokens, for convenience of scanner structure
• Always produce an end-of-file token
– Important that quoted strings and comments don’t get stuck if an
unexpected end of file occurs
3
Tokens, Token Types and Values
• The set of tokens is typically something like the following
table
– Or may have separate token types for different operators
or reserved words
–Type
May want to
keep
with each token
Token
Token
Value line number
Informal Description
Integer constant
Numeric value
Numbers like 3, -5, 12 without decimal pts.
Floating constant
Numeric value
Numbers like 3.0, -5.1, 12.2456789
Reserved word
Word string
Words like if, then, class, …
Identifiers
Symbol table index
Words not reserved starting with letter or _ and
containing only letters, _, and digits
Relations
Operator string
<, <=, ==, …
Operators
Operator string
=, +, - , ++, …
Char constant
Char value
‘A’, …
String
String
“this is a string”, …
Hidden: end-of-line
Hidden: comment
4
Token Actions
• Each token recognized can have an action function
– Many token types produce a value
• In the case of numeric values, make sure property numeric errors
produced, e.g. integer overflow
– Put identifiers in the symbol table
• Note that at this time, no effort is made to distinguish scope; there
will be one symbol table entry for each identifier
– Later, separate scope instances will be produced
• Other types of actions
– End-of-line (can be treated as a token type that doesn’t output to the
parser)
• Increment line number
• Get next line of input to scan
5
Testing
• Execute lexical analyzer with test cases and compare results
with expected results
• Test cases
– Exercise every part of lexical analyzer code
– Produce every error message
– Don’t have to be valid programs – just valid sequence of tokens
6
Lex and Yacc
• Two classical tools for compilers:
– Lex: A Lexical Analyzer Generator
– Yacc: “Yet Another Compiler Compiler”
• Lex creates programs that scan your tokens one by one.
• Yacc takes a grammar (sentence structure) and generates a
parser.
Input
Lexical Rules
Grammar Rules
Lex
Yacc
yylex()
yyparse()
Parsed Input
7
Flex: A Fast Scanner Generator
• Often, instead of the standard Lex and Yacc, Flex and Bison
are used:
– Flex: A fast lexical analyzer
– (GNU) Bison: A drop-in replacement for (backwards compatible
with) Yacc
• Resources:
– http://en.wikipedia.org/wiki/Flex_lexical_analyser
– http://en.wikipedia.org/wiki/GNU_Bison
– http://dinosaur.compilertools.net/
(the Lex & Yacc Page)
8
Flex Example 1: Delete This
• Shortest Flex example, “deletethis.l”:
%%
deletethis
• This scanner will match and not echo (default behavior) the
word “deletethis”.
• Compile and run it:
$ flex deletethis.l
# creates lex.yy.c
$ gcc -o scan lex.yy.c -lfl # fl: flex library
$ ./scan
This deletethis is not deletethis useful.
This is not useful.
^D
9
Flex Example 2: Replace This
• Another very short Flex example, “replacer.l”:
%%
replacethis printf(“replaced”);
• This scanner will match “replacethis” and replace it with
“replaced”.
• Compile and run it:
$ flex -o replacer.yy.c replacer.l
$ gcc -o replacer replacer.yy.c -lfl
$ ./replacer
This replacethis is not very replacethis useful.
This replaced is not very replaced useful.
Please dontreplacethisatall.
Please dontreplacedatall.
10
Flex Example 3: Common Errors
• Let's replace “the the” with “the”:
%%
the the
printf(“the”);
uhh
• Unfortunately, this does not work: The second “the” is
considered part of C code:
%%
the
the printf(“the”);
• Also, the open and close matching double quotes used in
documents will give errors, so you must always replace:
“the” →
"the"
11
Flex Example 3: Common Errors, cont'd
• You discover such errors when you compile the C code, not
when you use flex:
$ flex -o errors.yy.c errors.l
$ gcc -o errors errors.yy.c -lfl
errors.l: In function ‘yylex’:
errors.l:2: error: ‘the’ undeclared
...
• The error is reported back in our errors.l file, but we can also
find it in errors.yy.c:
case 1:
YY_RULE_SETUP
#line 2 "errors.l"
<-- For error reporting
the
<-- the ?
printf("the");
not C code
YY_BREAK
case 2:
12
Flex Example 4: Replace Duplicate
• Let's replace “the the” with “the”:
%%
"the the" printf("the");
• This time, it works:
$ flex -o duplicate.yy.c duplicate.l
$ gcc -o duplicate duplicate.yy.c -lfl
$ ./duplicate
This is the the file.
This is the file.
This is the the the file.
This is the the file.
Lathe theory
Latheory
13
Flex Example 4: Replace And Delete
• Let's replace “the the” with “the” and delete “uhh”:
%%
"the the" printf("the");
uhh
• Run as before:
This uhh is the the uhhh file.
This is the h file.
• Generally, lexical rules are pattern-action pairs:
%%
pattern1
action1 (C code)
pattern2
action2
...
• Tokens almost never go across space chars as in "the the" above.
14
Flex File Structure
• In Lex and Flex, the general rule file structure is:
definitions
%%
rules
%%
user code
• Definitions:
DIGIT
[0-9]
ID [a-z][a-z0-9]*
• can be used later in rules with {DIGIT}, {ID}, etc:
{DIGIT}+"."{DIGIT}*
• This is the same as:
([0-9])+"."([0-9])*
15
Flex Example 5: Count Lines
int num_lines = 0, num_chars = 0;
%%
\n ++num_lines; ++num_chars;
. ++num_chars;
%%
main()
{
yylex();
printf( "# of lines = %d, # of chars = %d\n",
num_lines, num_chars );
16
Some Regular Expressions for Flex
•
•
•
•
•
•
•
\"[^"]*\"
string
"\t"|"\n"\" "
whitespace (most common forms)
[a-zA-Z]
[a-zA-Z_][a-zA-Z0-9_]* identifier: allows a, aX, a45__
[0-9]*"."[0-9]+
allows .5 but not 5.
[0-9]+"."[0-9]*
allows 5. but not .5
[0-9]*"."[0-9]*
allows . by itself !!
17
Resources
• Aho, Lam, Sethi, and Ullman, Compilers: Principles,
Techniques, and Tools, 2nd ed. Addison-Wesley, 2006. (The
“purple dragon book”)
• Flex Manual. Available as single postscript file at the Lex
and Yacc page online:
– http://dinosaur.compilertools.net/#flex
– http://en.wikipedia.org/wiki/Flex_lexical_analyser
18