Part5
advertisement

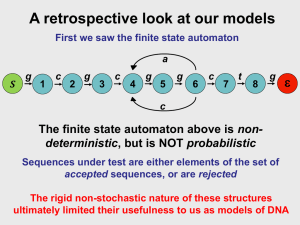
Cap. 6 HMMs HMMs HMM Basics – Architecture – Observable Markov Model – Hidden Markov Model HMM in Speech Recognition transitions Arquitecture states Observable Markov Model The observations is enough to know which state the system is. In other words, every state has a defined output. Raining Cloudy Transition Matrix Sun Playing with coins Transitions from one state to other means that the observation changed. This state represents the Tails This state represents the Heads P(H) represents the probability of throwing heads. This is the state sequence. Hidden Markov Model (HMM) Concept HMM Generator Types of HMMs Variatios of HMMs Structures Left-right HMM Architecture Concept The observations you DON´T exactly know which state the system is. Every state output has a set of possibilities, which can be modeled with a pdf. Two coin modeling. Transitions from one state to other means we change the coin. This state represents one coin. This state represents one coin Any coin can be either Tail of Head with this distribution. This is a possible state sequence. Tree coin modelling. This state represents one coin Transitions from one state to another means we change the coin. This state represents one coin. This state represents one coin. Any coin can be either Tail of Head with this distribution. This is a possible state sequence. We ask a person to take balls of any URN. All URNs have all colors. HMM Modelling Every URN as a different distribution of colors. HMM Generator 1. Choose an initial state. 2. Set t=1. 3. Choose ot=vk according to the probability distribution (bjk). 4. Transition to a new state j according to the state state transition probability for state. 5. Set t=t+1 6. If (t<T) return to step 3 7. end. Types of HMMs Full conected Left-rigth Parallel path Left-rigth Variations on HMM structures Null transitions Allows to generate short sequences and still going from state 1 to state N. Allows alternative word pronunciations. Every arch is a HMM itself. Allows arbitrary sequence length. Left-right HMM Architecture Finite State Networks, which consist of Transition Probabilities Initial State 1 bk O(t) 2 Internal States 3 b2O(t) 4 N-1 b3O(t) b4O(t) bk O(t) k Internal states has the probability of emitting a vector. O(t ) F1 k1 k 2 k 3 k 4 k 5 k 6 k 7 O(t ) F1 k Final state N b( N 1)1O(t) Other example Transition Probabilities Initial State 1 2 3 b2O(t) 4 b3O(t) Final state N N-1 b4O(t) b( N 1)1O(t) Internal states has the probability of emitting a vector. Probability Calculation a22 1 a12 a23 2 v1 P= a33 v2 3 v3 v4 a44 a34 a45 55 4 v5 v6 a12b2v1a22b2v2a22b2v a23b3v a34b4v a44b4v a45 3 4 5 6 Known as: Observed sequence /E//i//a/ a22 1 a12 F 1 v1 F 2 a33 a23 2 3 a44 a34 F 1 v 3 v F1 F1 F 2 4 F 2 v2 F 2 a45 4 F 1 v5 F 2 55 F1 v6 F 2 HMMs in Speech Recognition HMMs in Speech Recognition Introduction Isolated Word Recognition – DD-HMM Recognition Training – CD-HMM Recognition Training – Practical Problems and Solutions – Implementation Advise Connected Word Recognition DD-HMM Recognition Process Input Data O(t) [o(1)o(2)o(n)] It needs a model for unit of recognition. Codebook VQ M1 O(t) [ k1 , k 2 , k 3 )] M2 Probability of each model . P( M q / O) q=12 , ,,Q MQ Higher Probability P( M i / O) P( M k / O) k i P( O / M i ) P( M i ) P(O / M k ) P( M k ) P(O) P(O) Recognised word P(O / Mi ) P( Mi ) P(O / M k ) P( M k ) k i P(O / M i ) P(O / M k ) k i k i; P(M k ) P(M k ) q=1,2,M Vector Quantisation (VQ) Convert an infinite number of parametric vectors to a finite set of vectors. codebook v 11 2 v1 K v 1 v 12 v 22 v 2K v 1p v 2p v Kp codeword Each speech vector is assigned a new vector (codeword). Choosen from a codebook, using: k arg min d v, v i vi In fact, every vector can be represented by a value k, which is the index of the codeword closer to the vector. Constructing the codebook Goal: mind v P p 1 p ,vk k 1,, K; K 2n Table vectors Training vectors Clustering algorithms are used to solve this problem. Metodologies to calculate P(O / Mi ) Direct calculation Total Verisimilitude (Forward Procedure) – Takes into account all possible state’s sequences. Higher Verisimilitude (Viterbi algorithm) – Dynamic programming – Also obtains the optimal sequence assignment. Backward Procedure Direct Calculation State sequence q=[q1,q2,...,qT] P(O/Mk)= S P(O/q, Mk)P(q/ Mk) Probability of the observation given the state sequence and the Model. bq1,o(1) bq2,o(2) bq3,o(3) ...bqT,o(T) The problem with this calculation needs (2T-1) NT multiplications and NT-1 additions. Probability of the sequence given the Model. a1q1 aq1,q2 aq2,q3 ...aqT,qT For N=5 and T=100, it needs around 1072computations!! Total Verisimilitude 1 2 3 o(1) o( 2 ) i o( 3) O( t ) o(1), o( 2), , o( t ) i (t ) P(O( t ), s(t ) i / M k 1 i (t ) 0 0 i = 1; t = 0 o( t ) 1 < i < N; t = 0 P(O / M k ) j (T )a jN j 2 Addition over all possible predecesors. N Transition Probability form j to i N 1 ) j (t 1) a b ji io(t) j 1 i = 1;0 < t T N 1 N-1 1 i N 0t T Once being in state i Probability of being emit h the vector o(t) in time t 1 in a predecessor state j . Algorithm Initialization 1 i (t ) 0 0 i = 1; t = 0 i = 1;0 < t T 1 < i < N; t = 0 Recursion: N 1 i (t ) j (t 1)a ji biO ( t ) k j 1 Termination: N 1 P(O / M k ) j (T )a jN j 2 1 i N 0t T Example Observed Signal 290 720 330 285 O(t ) 820 1160 975 2298 Using the codebook we obtain the Templates(references): O(t ) k 1 2 1 3 Codebook index 1 2 3 F1 300 725 290 F2 850 1100 2325 1 i (t ) 0 0 i = 1;0 < t N 1 < i < N; t = 0 i (t ) j (t 1)a ji biO ( t ) k j 1 N 1 1.0 1 0.3 0.2 0.7 0.5 2 3 0.3 0.5 0.5 5 4 b2 (1) 0.8 b2 (1) 01 . b2 (1) 01 . b2 ( 2) 01 . b2 (2) 0.7 b2 (2) 01 . b2 (3) 01 . b2 (3) 0.2 b2 (3) 0.8 N 1 s O(t ) k 1 2 1 3 i = 1; t = 0 P(O / M k ) j (T )a jN j 2 0.00477 0.0 0.0 0.024 0.01008 0.00954 0.0 0.0 0.28 0.0204 0.00311 0.0 0.8 0.16 0.00256 0.00005 1.0 0.0 0.0 0.0 0.0 t Higher Verisimilitude 1 2 3 o(1) o( 2 ) i o( 3) O( t ) o(1), o(2), , o(t) i (t ) P(O( t ), s(t ) i / M k ) 1 i (t ) 0 0 N-1 o( t ) Transition Probability form j to i max j (t 1) a ji 1i N N bio(t) 1 i N 0t T i = 1; t = 0 i = 1;0 < t T Once being in state i Probability of being emit h the vector o(t) 1 < i < N; t = 0 in time t 1 Over all possible in a predecessor state j . P(O / M k ) max j (T )a jN predecesors. 1 j N Algorithm Inicialisation Recursion: 1 i (t ) 0 0 i = 1; t = 0 i = 1;0 < t T 1 < i < N; t = 0 i (t ) max j (t 1)a ji bio( t ) k 1 j N i (t ) arg max j (t 1)a ji bio(t )k 1 j N Termination: 1 j N P(O / M k ) max j (T )a jN P (O / M k ) arg max j (T )a jN 1 j N Backtracking: q(t)=Fi(q(t+1)) 1 i N 0t T For sequence tracking. 1 i (t ) 0 0 i = 1;0 < t T 1 < i < N; t = 0 1.0 i (t ) max j (t 1)a ji bio( t ) k 1 j N P(O / M k ) max j (T )a jN 1 j N s O(t ) k 1 2 1 3 i = 1; t = 0 1 0.3 0.2 0.7 0.5 2 3 0.3 0.5 0.5 5 4 b2 (1) 0.8 b2 (1) 01 . b2 (1) 01 . b2 ( 2) 01 . b2 (2) 0.7 b2 (2) 01 . b2 (3) 01 . b2 (3) 0.2 b2 (3) 0.8 0.00235 0.0 0.0 0.024 0.0084 0.0047 0.0 0.0 0.28 0.0196 0.00274 0.0 0.8 0.16 0.00256 0.00005 1.0 0.0 0.0 0.0 0.0 t Backward Procedure Is an alternative way to calculate P(O/Mk). We will see later how the forward and Backward Procedures are used to solve the training problem. 1 N-1 i j2 j1 o( t 1) O' ( t ) o( t 1), o( t 2 ), , o( T ) i (t ) P(O' ( t ), s(t ) i / M k o( t 2 ) o( t 3) i (T ) aiN P(O / M k ) 1 (0) N o( T ) Transition Probability form i to j N 1 ) a b jo(t 1) (t 1) j ij j 2 Addition over all possible successors. N-1 Once being in state j emit h the vectoro( t 1) 1 j N 0t T Probability of being in time t 1 in a successor state j and have emitted O'. (t 1) O(t ) k 1 2 1 3 i (T ) aiN N 1 a b j 2 ij jo(t 1) 1.0 1 jo( t ) 0.5 2 3 0.005 0.01 0.2 0.5 0.07356 0.0144 0.12 0.0 0.05628 0.0144 0.12 0.0 0.0 0.0 0.0 0.7 b2 (1) 0.8 b3 (1) 01 . b2 ( 2) 01 . b3 (2) 0.7 b2 (3) 01 . b3 (3) 0.2 s 0.0045024 0.3 0.2 0.0 0.3 0.5 0.5 5 4 b4 (1) 01 . b4 (2) 01 . b4 (3) 0.8 t Training Training Introduction Reestimation equations Iterating reestimation equations Introduction In last section is was assume that we knew the HMM parameters. However, we did not know it. HMM can learn from training data. Before proceed it is convenient to define a backward probability Input Data O(t) [o(1)o(2)o(n)] Codebook VQ N , p, k O(t) [ k1 , k 2 , k 3 )] Training M1 M2 Probability of each model . P( M q / O) q=12 , ,,Q MQ 1 2 i o(1) o( 2 ) o( 3) j2 j1 o( t ) o( t 1) N N-1 o( t 2 ) o( t 3) o( T ) O o(1), o( 2), , o( T ) P(O, s(t ) i / M k ) i (t ) i (t ) This represents the probability of emitting O and be at state From this equation, we can obtain the probability of been at state i i at time in time t given t. O. P(O, s(t ) i / M k ) P(O / M k ) P( s(t ) i / O, M k ) P(O, s(t ) i / M k ) P( s(t ) i / O, M k ) P(O / M k ) P( s(t ) i / O, M k ) 1 (t ) i (t ) p i p P( O / M k ) Reestimation Equations One Observation: – Transition Probability reestimation equation – State Emission Discrete Probability reestimation equation Multiple Observations Transition Probability The re-estimation formula for aij is given by: T 1 1 i (t )aij b jo ( t ) j (t 1) t 1 p aij T 1 1 i (t ) j (t ) t 1 p Prove: Expected number of transition from state i Transition Probability Reestimation Prove To obtain the re-estimation formula for aij , first lets define: P(O, s(t ) i, s(t 1) j,/ M k ) i (t )aij b jo(t ) j (t 1) P(O, s(t ) i, s(t 1) j, / M k ) P(O / M k )P(s(t ) i, s(t 1) j / O, M k ) P(O, s(t ) i , s(t 1) j / M k ) P( s(t ) i , s(t 1) j / O, M k ) P( O / M k ) 1 P( s(t ) i , s(t 1) j ,/ O, M k ) i (t )aij b jo( t ) j (t 1) p p P( O / M k ) Hence, the expected number of transition i->j is given by: T 1 1 i (t )aij b jo( t ) j (t 1) t 1 p Therefore, the re-estimation formula for aij is given by: T 1 1 i (t )aij b jo(t ) j (t 1) t 1 p aˆ ij T 1 1 i (t ) j (t ) t 1 p Expected number of transition from state i State Emision Probabilty reestimation The reestimator for bik can be calculated as follows: bik 1 i (t ) i (t ) t o ( t ) k p T 1 i (t ) i (t ) t 1 p bik Prove: k State Emision Probability reestimation equation Prove The number of times that state i is busy is given by: T 1 i (t ) i (t ) p t 1 and the number of times a specific vector k is emitted is given by: 1 i (t )i (t ) p t o ( t ) k State Emision Probabilty reestimation Therefore, a new estimator for bik can be calculated as follows: bik 1 i (t ) i (t ) p t o ( t ) k T 1 i (t ) i (t ) p t 1 Multiple Observation Sequences To have sufficient data to make estimations reliable estimates of the model parameters, one have to use multiple observations. A multiple observation is defined as follows: O [O(1) , O( 2) ,O( R) ] Since the reestimation formulas are based on frequency of occurrence of various events, the reestimation formulas are modified by adding together the individual frequencies of occurrence for each sequence. Thus, the modified reestimation formulas are: r R b j ,o ( t ) R aij 1 r r r i ( t ) i ( t ) r 1 t o r ( t ) k p R Tr 1 r r r i ( t ) i ( t ) r 1 t 1 p T r 1 r 1 t 1 1 r r r i ( t ) a ij b j ,o r ( t 1 ) i ( t 1) p Tr R r 1 t 1 R aiN r 1 R 1 r r r i ( t ) i ( t ) p 1 r r r i ( T ) i ( T ) p Tr r 1 t 1 1 r r ( t ) r i i (t ) p Iterating Reestimation Equations Since, alphas and betas calculations depends on alphas and betas, hence reestimation formulas need an initial model. If we define the current model as M k , and we define the reestimated model as ' M . k , then it has been proven that model ' M k in M’kk is more likely than model M Mk, the sense that P(O| M ) P(O| M k ) ' k Training Input Data O(t) [o(1)o(2)o(n)] Mk Codebook VQ O(t) [ k1 , k 2 , k 3 )] Re-estimation equations M k' M1 M2 Probability of each model . P( M q / O) q=12 , ,,Q MQ M k M k' ' Mk M Moreover, if we iterate k in place of and repeat the iteration procedure until some limitation point is reached, we then can improve the probability of ??? being observed. Input Data O(t) [o(1)o(2)o(n)] Codebook VQ O(t) [ k1 , k 2 , k 3 )] M k M k' Training Mk P(O| M k ) No Re-estimation equations P(O| M k' ) P(O| M k ) Yes M k' Mi M2 Probability of each model P( M q / O) q=12 , ,,Q MQ P(O| M k' ) Discrete HMM Disadvantages Require VQ. – Codebook with few vectors: poor representation of the acoustic space. – Codebook with many vectors: needs high storage space and requires large training set. Continuous HMM Assume a parametric model for the speech vector variations in a state. Initial State 1 2 b2O(t) 3 4 b3O(t) Final state N N-1 b4O(t) b( N 1)1O(t) It common to assume a multivariable Gaussian distribution. characterised for the means and variances. In this case: 1 b j (o(t )) (2 ) p / 2 C j 1 2 e 1 o(t ) j 2 T Cj 1 o ( t ) j Assuming the observations vectors are not correlated: p b j (o(t )) k 1 1 (2 ) p/2 jk e 1 2 2jk o k ( t ) jk 2 In this case, every speech component is modeled as a one dimensional Gaussian distribution: jk Pj v k 1 (2 ) 1/ 2 jk jk and we calculate: b v P v P v P v P v j j j 1 j 2 j p Recognition using CD-HMM Input Data O(t) [o(1)o(2)o(n)] It needs a model for unit of recognition. M1 M2 Recogniser Probability of each model. P( M q / O) q=12 , ,,Q MQ Higher Probability P( M i / O) P( M k / O) k i Recognised word P( O / M i ) P( M i ) P(O / M k ) P( M k ) P(O) P(O) k i P(O / Mi ) P( Mi ) P(O / M k ) P( M k ) k i P(O / Mi ) P(O / M k ) k i; P( M k ) P( M k ) q=12 , , M It uses the same equations of DD-HMM, however bi ,o( k ) is a continuous distribution. Thus, we can use either: – Forward Procedure – Viterbi Algorithm – Backward Procedure Training CD-HMM Alphas and betas are calculated as before. The transition probabilities are also calculated as before. The re-estimation formula are: – For the mean 1 r r r ( t ) ( t ) o ( t ) i pr i r 1 t 1 ˆ i R Tr 1 r r p r i (t ) i (t ) r 1 t 1 Tr R – For the covariance: Number of times in state i was visited. 1 T r r r r ( t ) ( t ) o ( t ) o (t ) j i i i r p r 1 t 1 R Tr 1 r ir (t ) ir (t ) r 1 t 1 p R ˆ ij Values of the vector in state i. Tr – For the variance (diagonal elements): R 2 ii Tr 1 p r 1 t 1 r 2 1 r r ( t ) ( t ) i pr i r 1 t 1 R ir (t ) ir (t )o r (t ) ik T r Sometimes, the Gaussian Distribution is not very good distribution model: In this case a mixture of Gaussians can be used: b ( v ) c N v , , c M j m1 jm jm M c m1 jm 1 jm Practical Problems and Solutions Computational Underflow Insufficient data training Initial Estimates State Duration HMM Modelling Computational Underflow Alfa beta’s values get very small as number of states and times increases: Solutions: – Scaling alphas at every time t. c( t ) 1 N .1 s 1 si (t ) i (t ) c(t )i (t ) The LogProbability can be obtain as follows: T Plog S (O / Mk ) log(c(i )) – Using logProbabilities – Scaling betas t 1 1 i (t ) 0 0 i = 1;0 < t T 1 < i < N; t = 0 1.0 i (t ) max j (t 1)a ji bio( t ) k 1 j N P(O / M k ) max j (T )a jN 1 j N s O(t ) k 1 2 1 3 i = 1; t = 0 1 0.3 0.2 0.5 2 3 0.3 0.5 0.5 5 4 b2 (1) 0.8 b2 (1) 01 . b2 (1) 01 . b2 ( 2) 01 . b2 (2) 0.7 b2 (2) 01 . b2 (3) 01 . b2 (3) 0.2 b2 (3) 0.8 T Plog S (O / Mk ) log(c(i )) 4.6 t 1 1.0 0.0 0.0 0.075 0.2529 0.6338 0.0 0.0 0.875 0.3877 0.2038 0.0 1.0 0.05 0.3594 0.1624 1.0 0.0 0.0 0.0 1.25 0.7 2.5 4.49 0.0 2.25 3.1556 t 1 i (t ) 0 0 i = 1;0 < t T 1 < i < N; t = 0 1.0 i (t ) max j (t 1)a ji bio( t ) k 1 j N s O(t ) k 1 2 1 3 i = 1; t = 0 1 0.7 0.5 2 3 0.3 0.5 0.5 5 4 b2 (1) 0.8 b2 (1) 01 . b2 (1) 01 . b2 ( 2) 01 . b2 (2) 0.7 b2 (2) 01 . b2 (3) 01 . b2 (3) 0.2 b2 (3) 0.8 T Plog S (O / Mk ) log(c(i )) 4.6 t 1 Demostración 0.0 0.0 0.3*01=0.03 0.0 0.0 0.5*0.7=0.35 0.0 1.0 0.2*0.1=0.02 1.0 0.0 0.0 1.25 0.3 0.2 2.5 0.0 0.0 t Using log Probability 1 2 3 o(1) o( 2 ) i o( 3) O( t ) o(1), o( 2), , o( t ) (t ) log P(O( t ), s(t ) i / M k ) ' i 0 i' (t ) N-1 o( t ) min 1 j N N Transition logProbability form j to i j' (t 1) log(a ji ) log(bio(t) ) 1 i N 0t T i=1;t=0 i=1;0<t T logProbability of being 1<i<N;t=0 in time t 1 Over all possible in a predecessor state j . predecessors. P(O / M k ) min j' (T ) log(a jN ) 1 j N Once being in state i emit the vector o(t) Algorithm Inicialisation Recursion: 0 i' (t ) i=1;t=0 i=1;0<t T 1<i<N;t=0 i' (t ) min j' '(t 1) log a ji log bio( t ) 1 j N 0t T i' (t ) arg min j' (t 1) log a ji log bio(t ) 1 j N Termination: P(O / M k ) min j' (t 1) log a jN 1 j N P(O / M k ) arg min j' (t 1) log a jN 1 j N Backtracking: q(t ) i' (q(t 1)) For sequence tracking. 0 i (t ) i = 1;0 < t T 1 < i < N; t = 0 1.0 (t ) min '(t 1) log a ji log bio( t ) ' i O(t ) k 1 2 1 3 i = 1; t = 0 1 j N ' j 1 s P(O / M k ) min j' (t 1) log a jN 1 j N P(O / M k ) arg min j' (t 1) log a jN 1 j N 0.7 0.5 2 3 b2 (1) 0.8 b3 (1) 01 . b2 ( 2) 01 . b3 (2) 0.7 b2 (3) 01 . b3 (3) 0.2 i' (t ) arg min j' (t 1) log a ji log bio( t ) 1 j N 0.3 0.2 0.3 0.5 0.5 5 4 b4 (1) 01 . b4 (2) 01 . b4 (3) 0.8 6.046 Inf Inf 3.72 4.77 5.3531 Inf Inf 1.273 3.93 5.897 Inf 0.223 4.1331 5.976 09.886 0.0 Inf Inf Inf Inf t Scaling Betas The betas also suffer the underflow problem. Hence, we have to scale them or use logProbability. The scaling factor for alpha and beta at time t should be the same. Hence, the recommended procedure is – for time t calculate the alphas values calculate the scaling factor and store it. – for time t calculate the betas; scale the betas with the scaled factor used for the alphas at time t. Insufficient data training Since there are low-probability events, hence poor parameter estimation. In example, if the training set is to small some symbols could not be in the training set. bik 1 i (t ) i (t ) t o ( t ) k p This is zero if not symbol is counted. T 1 i (t ) i (t ) t 1 p Solutions: – set parameter thresholds. – Train with more data (if possible). Initial Estimates Reestimation equations give parameter values which converge to a local maximum. – Experience shown that aij parameters converge to the global parameter without problem. state distribution function (bi,o(t) ) or parameters (mean and variance) need good initial estimates. – Segmental k-means Segmentation into States Segmental k-means Segmentation into states State Duration HMM Modelling For most physical signals, the exponential distribution is inappropriate. In order to improve modeling, we have to incorporate state duration information in a HMM. – Incorporate state duration information into the mechanics of HMMs. – Heuristic method. Heuristic for incorporating state duration into HMM At training: – Segmental k-means algorithm is used. – Calculate the state duration probability pj(d). At recognition: – Viterbi algorithm to obtain The logProbability and the best segmentation via backtracking. – The duration of each state is measure from the state segmentation. – A post processor increases the logProbability as follows: N log Pˆ q,O/Mk log Pq,O/Mk α d log [p j (d j )] j 1 Implementation Advise If the number of models, in the decoding process, is very large, then try to save memory. Observe that for a given time t, it only need a limited quantity of information: s 0.00477 0.0 0.0 0.024 0.01008 0.00954 0.0 0.0 0.28 0.0204 0.00311 0.0 0.8 0.16 0.00256 0.00005 0.0 0.0 0.0 0.0 t s 0.00477 0.0 0.0 0.024 0.01008 0.00954 0.0 0.0 0.28 0.0204 0.00311 0.0 0.8 0.16 0.00256 0.00005 0.0 0.0 0.0 0.0 s 0.00932 0.0 0.0 0.037 0.02008 0.0154 0.0 0.0 0.61 0.074 0.00561 0.0 0.8 0.32 0.0046 0.00025 0.0 0.0 0.0 0.0 s s 0.00932 0.0 0.0 0.037 0.02008 0.0154 0.0 0.0 0.61 0.074 0.00561 0.01972 s 0.0 s 0.0 0.0 0.0 0.8 0.32 0.037 0.0046 0.02008 0.00025 0.0154 0.0 0.0 0.0 0.610.0 0.0 0.074 0.0 0.00561 0.0 0.8 0.0046 0.02008 0.00025 0.0154 0.0 0.0 0.0 0.0 0.8 0.32 0.037 0.0 0.61 0.0 0.0 0.074 0.0 0.0 0.32 0.037 0.0 0.61 0.0 0.8 0.32 0.0046 0.0 0.0 0.0 0.0 0.0 0.0 0.0133 0.0 0.00561 0.00025 0.0035 0.0154 0.0046 0.02008 0.074 0.00561 0.00025 0.0 0.0 0.0 Connected Word Recognition Problems with isolated word recognition: – we don´t know the limits of the words. – Increases variability coarticulation of words Speech velocity Solutions: – – – – Unconstrained End Point Matching DP in two dimensions one-pass DP algorithm. Viterbi Viterbi Algorithm 0.3 1.0 0.2 1.0 0.1 1.0 0.2 0.5 0.5 0.3 0.3 0.6 0.7 0.3 0.3 0.7 0.8 0.2 0.5 0.5 0.4 0.6 0.9 0.1 1. Inicialisation: Each state as a token t 2. Calculate every state of every model using: t.probj t.probj+log(aij) t.startj 3. Update every internal state of every model: max(t.probj+log(aij)) frame at which the token at state j enter the model 0.3 0.2 4. Update state N of every model: 1.0 5. Find mode with higher logProbability 0.7 0.5 0.5 0.5 0.3 6. Update limits table 7. Copy token in state 1 of each model. 0.0 0 Inf 0 -Inf 4.5 4.5 0 -Inf 0 1.2 0 3.2 0 2.1 0 0 2.2 0 2.7 0 5.2 0 0 2.5 0 5.3 0 5.3 0.2 0.1 1.0 w.model w.start 2 1 0 0 0.3 0.7 0.2 0.1 0.7 0.0 0 Inf 0 -Inf 0 -Inf 0 4.5 0 2.3 0 3.5 0 4.3 0 4.5 0 7.3 0 4.5 0 1.3 0 4.5 4.5 0 2.7 0 0 0 For N words 0.3 1.0 0.2 1.0 0.1 1.0 0.2 0.5 0.5 0.3 0.3 0.6 0.7 0.3 0.3 0.7 0.8 0.2 0.5 0.5 0.4 0.6 0.9 0.1 Recovering the uttered words. Array w, is the same length as the number of observations. This array gives information of the limits of the words. At the end of the utterance, value w.model[M] stores the last HMM recognised sequence, and the predecesor models are obtain by “tracking back” trough the array. Finite State Syntax (FSS) With token passing the FSS are straightforward implemented. Monterrey Monterrey to Frankfort Frankfort from Houston Houston Cap. 8 Large Vocabulary Continuous Speech Recognition Problems with isolated word recognition: – Do not easily account for variations in word pronunciation accross different dialects, etc. Solution: – Use subword speech units. Problems with large vocabulary continuous Speech Recognition: – we don´t know the limits of the subword units. – Increases variability coarticulation of subword units Speech velocity La probabilidad MAP (Maximum A Posteriory) de la cadena de palabras W dadas la observaciones: P(W / O) max P(O / W ) W Utilizando la regla de Bayes: P(O / W ) P(W ) P(W / O) P(O) ya que P(O) es independiente de W P( M i / O) arg max P(O / M i ) P( M i ) Mi Modelo Acústico: •Sub-palabras. •PhoneLike Units(PLU):50 •Syllable-like Units (SLU): 10,000 •Dyad: 2000 •Acústicas (Clustering): 256-512 Modelo de Lenguaje: •Restricciones •Sintácticas: •“parser” o •n-gram (n=2,3,4) •Par de palabras (word pair) •semánticas del Lenguaje. Issues in the choice of subword units sets Depende de la: – Sensibilidad del contexto – De lo fácil de entrenar – Ejemplo: PLU exageradamente sensibles al contexto (varian mucho al variar el contexto), pero por ser tan pocas son sencillas de entrenar. SLU muy poco sensibles al contexto, pero son muchos y muy difícil de entrenar (mejor entrenamos todas las palabra). Subword unit Models based on HMMs Normalmente es de tres estados. 0.1 0.3 1.0 0.6 0.8 0.9 0.1 0.2 Subword Training 1. Given a label training set of speech sentences, where every sentece consists of speech waveforms and Its transcripts into words SW W1W2W3W4 ... WI – Assuming that the waveform segmentation into words is NOT available. A word lexicon thats provide a transcription of every word in the training set in terms of the set of subword units being trained is available. Table 8.2 Rabiner & Juang). Therefore, the sentences are represented in terms of its subwords, as follow: S U U 1 W1 U 2 W1 U L W1 W1 U1 W2 U 2 W2 U L W2 W2 U 1 W3 U 2 W3 U L W3 W3 U1 WI U 2 WI U L WI WI 2. Create an extended (composite) HMM for each sentence as follow: – Replace each subword unit by its HMM W2 W1 – Incorporate Silences between words and at the begining and end of each sentence. Sil W1 Sil W2 Sil 3. Estimate the subword unit model parameters which maximize the likelihood of the models for all the given training data using: – Forward-backward procedure – Segmental K-means training procedure W1 Sil Sil Sil Segmental K-means training procedure Initialization Clustering Estimation Segmentation Iteration Fig. 8.5 Fig. 8.6 Language Models for Large Vocabulary Speech Recognitin Goal: – Provide an estimate of the probability of a word sequence PW Pw1 w2 w3 wQ for the given recognition task. This can be solved as follows: PW Pw1 w2 w3 wQ Pw1 Pw2 | w1 Pw3 | w1 w2 PwQ | w1 w2 wQ 1 Since, it is impossible to reliable estimate the conditional probabilities, Pw j | w1 w2 w j 1 hence in practice it is used an N-gram word model: PwQ | w1w2 wQ1 PwQ | w j N 1w j N 2 w j 1 En practice, realiable estimators are obtained for N=2 (bigram) or possible N=3 (trigram). Smoothing Since many trigrams are rarerly found, even in large amount of text. Smoothing is used as follows: Pw3 | w1 w2 3 Pw3 | w1 w2 2 Pw3 | w2 1 Pw3 3 2 1 1 Optimal Linear Smoothing Recognition 0.3 1.0 0.2 1.0 0.1 1.0 0.2 0.5 0.5 0.3 0.3 0.6 0.7 0.3 0.3 0.7 0.8 0.2 0.5 0.5 0.4 0.6 0.9 0.1 1. Inicialisation: Each state as a token t 2. Calculate every state of every model using: t.probj t.probj+log(aij) t.startj 3. Update every internal state of every model: max(t.probj+log(aij)) frame at which the token at state j enter the model 0.3 0.2 4. Update state N of every model: 1.0 5. Find mode with higher logProbability 0.7 0.5 0.5 0.5 0.3 6. Update limits table 7. Copy token in state 1 of each model. 0.0 0 Inf 0 -Inf 4.5 4.5 0 -Inf 0 1.2 0 3.2 0 2.1 0 0 2.2 0 2.7 0 5.2 0 0 2.5 0 5.3 0 5.3 0.2 0.1 1.0 w.model w.start 2 1 0 0 0.3 0.7 0.2 0.1 0.7 0.0 0 Inf 0 -Inf 0 -Inf 0 4.5 0 2.3 0 3.5 0 4.3 0 4.5 0 7.3 0 4.5 0 1.3 0 4.5 4.5 0 2.7 0 0 0 For N subunits 0.3 1.0 0.2 1.0 0.1 1.0 0.2 0.5 0.5 0.3 0.3 0.6 0.7 0.3 0.3 0.7 0.8 0.2 0.5 0.5 0.4 0.6 0.9 0.1 Recovering the uttered words. Array w, is the same length as the number of observations. This array gives information of the limits of the words. At the end of the utterance, value w.model[M] stores the last HMM recognised sequence, and the predecesor models are obtain by “tracking back” trough the array. Finite State Syntax (FSS) With token passing the FSS are straightforward implemented. Monterrey Monterrey to Frankfort Frankfort from Houston Houston