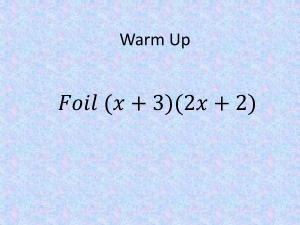Introduction
advertisement

Optimal Control • Motivation • Bellman’s Principle of Optimality • Discrete-Time Systems • Continuous-Time Systems • Steady-State Infinite Horizon Optimal Control • Illustrative Examples Motivation • Control design based on pole-placement often has non unique solutions • Best locations for eigenvalues are difficult to determine • Optimal control minimizes a performance index based on time response • Control gains result from solving the optimal control problem Quadratic Functions Single variable quadratic function: f ( x ) qx 2 bx c Multi-variable quadratic function: f (x) x Qx b x c T T Where Q is a symmetric (QT=Q) nxn matrix and b is an nx1 vector It can be shown that the Jacobian of f is f x x 1 f f x 2 f T T 2x Q b x n 2-Variable Quadratic Example Quadratic function of 2 variables: 2 2 f (x ) x 1 2 x 2 2 x 1x 2 2 x 1 Matrix representation: f ( x ) x 1 1 x 2 1 1 x 1 2 2 x2 x1 0 x 2 Quadratic Optimization The value of x that minimizes f(x) (denoted by x*) f T T sets 2 x Q b 0 2 Qx b 0 x or equivalently x 1 1 Q b 2 Provided that the Hessian of f, H f x x T 2f 2 x 1 2 f x x 1 2 2 f x x 1 n is positive definite f 2 2 x 1 x 2 f 2 x 2 2 f x 1 x n 2 f x 2x n 2Q 2 f 2 x n f 2 x 2x n Positive Definite Matrixes Definition: A symmetric matrix H is said to be positive definite (denoted by H>0) if xTHx>0 for any non zero vector x (semi positive definite if it only satisfies xTHx0 for any x (denoted by H 0) ). Positive definiteness (Sylvester) test: H is positive definite iff all the principal minors of H are positive: h 11 0 , h 11 h 12 h 21 h 22 0 , , h 11 h 12 h 1n h 21 h 22 h2n hn1 hn2 h nn 0 2-Variable Quadratic Optimization Example f ( x ) x 1 1 x 1 1 x 2 2 x 1 2 2 x1 0 x 2 Q Optimal solution: 1 1 1 1 x Q b 2 2 1 2 H 2Q 2 1 2 1 2 2 0 1 5 2 0 4 10 4 20 3 16 10 5 1 14 1 5 10 8 20 5 6 10 10 4 20 -3 -4 0 1 10 -1 -2 12 -1 5 10 0 1 20 x2 0 0 -1 20 1 18 5 2 Thus x* minimizes f(x) 20 20 2 20 0 -5 -5 0 x1 5 Discrete-Time Linear Quadratic (LQ) Optimal Control Given discrete-time state equation x (k 1) G x (k ) H u (k ) Find control sequence u(k) to minimize J 1 2 x (N ) S x ( N ) T 1 2 N 1 x T (k ) Qx (k ) u (k )Ru (k ) k0 S, Q 0, R 0 and symmetric T Comments on Discrete-Time LQ Performance Index (PI) • Control objective is to make x small by penalizing large inputs and states • PI makes a compromise between performance and control action uTRu xTQx t Principle of Optimality 4 2 7 5 9 1 3 8 6 Bellman’s Principle of Optimality: At any intermediate state xi in an optimal path from x0 to xf, the policy from xi to goal xf must itself constitute optimal policy Discrete-Time LQ Formulation Optimization of the last input (k=N-1): JN 1 2 x (N ) Sx (N ) T 1 2 u (N 1)Ru (N 1) T Where x(N)=Gx(n-1)+Hu(n-1). The optimal input at the last step is obtained by setting JN u (N 1) x (N ) S T x (N ) u (N 1) u (N 1)R 0 T Solving for u(N-1) gives u (N 1) Kx (N 1), K R H SH SG T 1 Optimal Value of JN-1 Substituting the optimal value of u(N-1) in JN gives JN * 1 2 x (N 1) ( G HK ) PN ( G HK ) K RK x (N 1) T T T The optimal value of u(N-2) may be obtained by minimizing JN 1 JN * JN 1 where 1 2 1 2 x (N 1) Qx (N 1) T x (N 1) PN 1x (N 1) T 1 2 1 2 u (N 2 ) Rx (N 2 ) T u (N 2 ) Rx (N 2 ) T PN 1 ( G HK ) PN ( G HK ) K RK Q T T But JN-1 is of the same form as JN with the indexes decremented by one. Summary of Discrete-Time LQ Solution Control law: u (k ) K k x (k ), K k R H Pk 1H B Pk 1G T T Ricatti Equation Pk G H K k Pk 1 G H K k Q K k RK k , T T Optimal Cost: J x 1 2 T x ( 0 ) P0 x ( 0 ) k N 1, ,1,0 Comments on Continuous-Time LQ Solution • Control law is a time varying state feedback law • Matrix Pk can be computed recursively from the Ricatti equation by decrementing the index k from N to 0. • In most cases P and K have steady-state solutions as N approaches infinity Matlab Example y Find the discrete-time (T=0.1) optimal controller that minimizes u M=1 99 J 5 y (100 ) 2 y 2 (k ) u (k ) 2 k 0 Solution: State Equation x 1 position, x 2 velocity, u f orce x 1 x 2 d x 1 0 dt x 2 0 x2 u 1 x 1 0 u 0 x 2 1 Discretized Equation and PI Weighting Matrices Discretized Equation: x 1 ( k 1) 1 x 2 ( k 1) 0 T x 1 ( k ) T 2 2 u (k ) 1 x 2 (k ) T Performance Index Weigthing Matrices: 10 J x (100 ) 2 0 1 T PN 0 2 1 90 T x (100 ) x ( k ) 0 2 k 0 0 Q 0 2 x ( k ) 2 u (k ) 0 R System Definition in Matlab %System: dx1/dt=x2, dx2/dt=u %System Matrices Ac=[0 1;0 0]; Bc=[0;1]; [G,H]=c2d(Ac,Bc,0.1); %Performance Index Matrices N=100; PN=[10 0;0 0]; Q=[1 0;0 0]; R=2; Ricatti Equation Computation %Initialize gain K and S matrices P=zeros(2,2,N+1); K=zeros(N,2); P(:,:,N+1)=PN; %Computation of gain K and S matrices for k=N:-1:1 Pkp1=P(:,:,k+1); Kk=(R+H'*Pkp1*H)\(H'*Pkp1*G); Gcl=G-H*Kk; Pk=Gcl'*Pkp1*Gcl+Q+Kk'*R*Kk; K(k,:)=Kk; P(:,:,k)=Pk; end LQ Controller Simulation %Simulation x=zeros(N+1,2); x0=[1;0]; x(1,:)=x0'; for k=1:N xk=x(k,:)'; uk=-K(k,:)*xk; xkp1=G*xk+H*uk; x(k+1,:)=xkp1'; end %plot results Plot of P and K Matrices Elements of P 25 P11 P12 P22 20 15 10 5 0 0 2 4 6 8 10 Elements of K 1.5 K1 K2 1 0.5 0 0 2 4 6 Time (sec) 8 10 Plot of State Variables 1 States x1 x2 0.5 0 -0.5 0 2 4 6 8 10 0 2 4 6 8 10 0.2 Input 0 -0.2 -0.4 -0.6 -0.8 Time (sec) Linear Quadratic Regulator Given discrete-time state equation x (k 1) G x (k ) H u (k ) Find control sequence u(k) to minimize J 1 2 x T (k ) Qx (k ) u (k )Ru (k ) T k 0 S, Q 0, R 0 and symmetric Solution is obtained as the limiting case of Ricatti Eq. Summary of LQR Solution Control law: u (k ) Kx (k ), K R H PH H PG T T Ricatti Equation P G H K P G H K Q K RK T T Optimal Cost: J 1 2 T x (0 ) P x (0 )