Group functions using SQL
advertisement

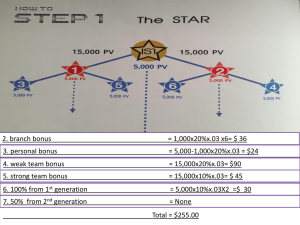
Group functions using SQL Additional information in speaker notes! Group functions 1 update first_pay 2 set bonus = null 3 where name = 'Donald Brown’; SQL> SELECT * FROM first_pay; PAY_ ---1111 2222 3333 4444 5555 6666 7777 8888 NAME -------------------Linda Costa John Davidson Susan Ash Stephen York Richard Jones Joanne Brown Donald Brown Paula Adams JO -CI IN AP CM CI IN CI IN STARTDATE SALARY BONUS --------- --------- --------15-JAN-97 45000 1000 25-SEP-92 40000 1500 05-FEB-00 25000 500 03-JUL-97 42000 2000 30-OCT-92 50000 2000 18-AUG-94 48000 2000 05-NOV-99 45000 12-DEC-98 45000 2000 For these exercises, I wanted a null value in one of the fields. The update above put a null value in the bonus field for Donald Brown. Group functions SQL> SELECT COUNT(*) 2 FROM first_pay; COUNT * essentially does a count on everything and ignores null values. I think of it as a count of rows/records. COUNT(*) --------8 SQL> SELECT COUNT(name) 2 FROM first_pay; COUNT(name) counts the names. In this case, each row/record has a name so the result is 8. COUNT(NAME) ----------8 SQL> SELECT COUNT(bonus) 2 FROM first_pay; COUNT(BONUS) -----------7 As shown on the previous slide, bonus now has one record where the bonus is null. Therefore the COUNT(bonus) returns 7. Group functions SQL> SELECT COUNT(NVL(bonus,0)) 2 FROM first_pay; COUNT(NVL(BONUS,0)) ------------------8 SQL> SELECT COUNT(NVL(bonus,1000)) 2 FROM first_pay; COUNT(NVL(BONUS,1000)) ---------------------8 In these examples, I am replacing null values in bonus with a value. In the first example, I replaced it with 0 and in the second example I replaced it with 1000. It doesn’t matter what the replacement is, what matters is that it is no longer a null value and therefore it shows I the count. Group functions In this SUM, the record with a null value is ignored. The total is 11000. SQL> SELECT SUM(bonus) 2 FROM first_pay; SQL> SELECT * FROM first_pay; PAY_ ---1111 2222 3333 4444 5555 6666 7777 8888 NAME -------------------Linda Costa John Davidson Susan Ash Stephen York Richard Jones Joanne Brown Donald Brown Paula Adams JO -CI IN AP CM CI IN CI IN STARTDATE SALARY BONUS --------- --------- --------15-JAN-97 45000 1000 25-SEP-92 40000 1500 05-FEB-00 25000 500 03-JUL-97 42000 2000 30-OCT-92 50000 2000 18-AUG-94 48000 2000 05-NOV-99 45000 12-DEC-98 45000 2000 SUM(BONUS) ---------11000 SQL> SELECT SUM(NVL(bonus,0)) 2 FROM first_pay; In this SUM, the record with the null value is set to 0. It is now included in the sum but has no impact because it is 0. SUM(NVL(BONUS,0)) ----------------11000 SQL> SELECT SUM(NVL(bonus, 1000)) 2 FROM first_pay; SUM(NVL(BONUS,1000)) -------------------12000 In this SUM, the record with the null value is set to 1000. It is included in the sum and clearly impacts the total which is now 1000 bigger. Group functions SQL> SELECT SUM(bonus), AVG(bonus) 2 FROM first_pay; In this example, the sum is taken of the 7 rows that do not contain null values and the sum is divided by the count of the 7 rows that do not contain null values to yield the average. SUM(BONUS) AVG(BONUS) ---------- ---------11000 1571.4286 SQL> SELECT SUM(NVL(bonus,0)), AVG(NVL(bonus,0)) 2 FROM first_pay; SUM(NVL(BONUS,0)) AVG(NVL(BONUS,0)) ----------------- ----------------11000 1375 In this example, the average is taken using all 8 columns because the NVL put a 0 in the column that contained a null. The sum divided by 8 is shown as the average. SQL> SELECT SUM(NVL(bonus,1000)), AVG(NVL(bonus,1000)) 2 FROM first_pay; This time I am including the 1000 in the average so the sum SUM(NVL(BONUS,1000)) AVG(NVL(BONUS,1000)) for the average is 1000 higher -------------------- -------------------and the division is still by 8 12000 1500 giving me the answer of 1500. Group functions SQL> SELECT MIN(salary), MAX(salary) 2 FROM first_pay; MIN(SALARY) MAX(SALARY) ----------- ----------25000 50000 SQL> SELECT MIN(bonus), MAX(bonus) 2 FROM first_pay; This statement extracts the minimum salary and the maximum salary from the first_pay table. This extract the minimum bonus and the maximum bonus from the first_pay table. Note that there is a null value in this column that is not dealt with. MIN(BONUS) MAX(BONUS) ---------- ---------500 2000 SQL> SELECT MIN(NVL(bonus,0)), MAX(NVL(bonus,0)) 2 FROM first_pay; In this example, the null value is MIN(NVL(BONUS,0)) MAX(NVL(BONUS,0)) replaced by 0 in both the MIN and ----------------- ----------------MAX function. This means that 0 2000 the MIN field now sees the field with 0 as the minimum. Group functions SQL> SELECT jobcode, count(name) 2 FROM first_pay 3 GROUP BY jobcode; JO COUNT(NAME) -- ----------AP 1 CI 3 CM 1 IN 3 In this example, I want to get a count of how many people there are with each jobcode. This mean I need to GROUP BY jobcode. Because I am grouping on job code and therefore looking for a total by jobcode, I am allowed to SELECT the jobcode field. Since I want a count of the number of people with a specific jobcode I need to do a count. I put name in count because I was thinking of counting the people. Note that I could have used COUNT(*) as shown below. SQL> SELECT jobcode, count(*) 2 FROM first_pay 3 GROUP BY jobcode; JO COUNT(*) -- --------AP 1 CI 3 CM 1 IN 3 Group functions SQL> SELECT * FROM first_pay; PAY_ ---1111 2222 3333 4444 5555 6666 7777 8888 SQL> 2 3 4 NAME -------------------Linda Costa John Davidson Susan Ash Stephen York Richard Jones Joanne Brown Donald Brown Paula Adams SELECT jobcode, COUNT(name) FROM first_pay WHERE salary <= 45000 GROUP BY jobcode; JO COUNT(NAME) -- ----------AP 1 CI 2 CM 1 IN 2 JO -CI IN AP CM CI IN CI IN STARTDATE SALARY BONUS --------- --------- --------15-JAN-97 45000 1000 25-SEP-92 40000 1500 05-FEB-00 25000 500 03-JUL-97 42000 2000 30-OCT-92 50000 2000 18-AUG-94 48000 2000 05-NOV-99 45000 12-DEC-98 45000 2000 In this example, I want to only include people in the groups when their salary is <= 45000. As you can see this excludes one record from the CI group and one record from the IN group. Group functions SQL> 2 3 4 5 SELECT jobcode, COUNT(name) FROM first_pay WHERE salary <= 45000 GROUP BY jobcode ORDER BY jobcode desc; JO COUNT(NAME) -- ----------IN 2 CM 1 CI 2 AP 1 SQL> 2 3 4 5 SELECT jobcode, COUNT(name) FROM first_pay WHERE salary <= 45000 GROUP BY jobcode ORDER BY COUNT(name); JO COUNT(NAME) -- ----------AP 1 CM 1 CI 2 IN 2 In this example I want the output to be ordered by jobcode in descending order. The ORDER BY clause can be used to achieve this goal. Note on the previous slide, the results were in default order which is in ascending order by the GROUP BY column/field. In this example, I want to order by the count instead of by the group by field/column. Again, the GROUP BY clause can be used to achieve this goal. Because I did not specify ascending or descending, the default of ascending is used. Group functions SQL> SELECT * FROM first_pay; PAY_ ---1111 2222 3333 4444 5555 6666 7777 8888 SQL> 2 3 4 JO -AP CI CM NAME -------------------Linda Costa John Davidson Susan Ash Stephen York Richard Jones Joanne Brown Donald Brown Paula Adams JO -CI IN AP CM CI IN CI IN STARTDATE SALARY BONUS --------- --------- --------15-JAN-97 45000 1000 25-SEP-92 40000 1500 05-FEB-00 25000 500 03-JUL-97 42000 2000 30-OCT-92 50000 2000 18-AUG-94 48000 2000 05-NOV-99 45000 12-DEC-98 45000 2000 SELECT jobcode, COUNT(name) FROM first_pay WHERE jobcode != 'IN' In this example I want to group by jobcode GROUP BY jobcode; except that in doing the grouping, I want to exclude all records where the jobcode = ‘IN’ COUNT(NAME) ----------As you can see the results are correct. 1 3 1 Group functions SQL> SELECT * FROM first_pay; PAY_ ---1111 2222 3333 4444 5555 6666 7777 8888 NAME -------------------Linda Costa John Davidson Susan Ash Stephen York Richard Jones Joanne Brown Donald Brown Paula Adams JO -CI IN AP CM CI IN CI IN STARTDATE SALARY BONUS --------- --------- --------15-JAN-97 45000 1000 25-SEP-92 40000 1500 05-FEB-00 25000 500 03-JUL-97 42000 2000 30-OCT-92 50000 2000 18-AUG-94 48000 2000 05-NOV-99 45000 12-DEC-98 45000 2000 SQL> SELECT jobcode, bonus, SUM(salary) 2 FROM first_pay 3 GROUP BY jobcode, bonus; This example groups by jobcode and then bonus within jobcode. In fact there are only JO BONUS SUM(SALARY) two records with the the same jobcode and -- --------- ----------the same bonus, record 6666 and record AP 500 25000 8888. They are shown at the bottom. For all CI 1000 45000 of the other groupings there happens to be CI 2000 50000 only one record. CI 45000 CM 2000 42000 IN 1500 40000 IN 2000 93000 Group functions SQL> SELECT * FROM donor; IDNO ----11111 12121 22222 23456 33333 34567 NAME --------------Stephen Daniels Jennifer Ames Carl Hersey Susan Ash Nancy Taylor Robert Brooks STADR --------------123 Elm St 24 Benefit St 24 Benefit St 21 Main St 26 Oak St 36 Pine St CITY ---------Seekonk Providence Providence Fall River Fall River Fall River ST -MA RI RI MA MA MA ZIP ----02345 02045 02045 02720 02720 02720 DATEFST YRGOAL CONTACT --------- --------- -----------03-JUL-98 500 John Smith 24-MAY-97 400 Susan Jones 03-JAN-98 Susan Jones 04-MAR-92 100 Amy Costa 04-MAR-92 50 John Adams 04-APR-98 50 Amy Costa 6 rows selected. SQL> SELECT state, contact, SUM(yrgoal) 2 FROM donor 3 GROUP BY state, contact; ST -MA MA MA RI CONTACT SUM(YRGOAL) ------------ ----------Amy Costa 150 John Adams 50 John Smith 500 Susan Jones 400 This shows grouping by state and then contact within state. Two records go into MA Amy Costa and two records go into RI Susan Jones. The other two totals are made up from one record each. Group functions SQL> SELECT jobcode, MIN(salary), MAX(salary) 2 FROM first_pay 3 GROUP BY jobcode; This shows the minimum and maximum salary for each jobcode. JO MIN(SALARY) MAX(SALARY) -- ----------- ----------AP 25000 25000 CI 45000 50000 CM 42000 42000 IN 40000 48000 SQL> SELECT jobcode, AVG(salary) 2 FROM first_pay 3 GROUP BY jobcode; Shows the average JO AVG(SALARY) salary of each -- ----------jobcode group. AP 25000 CI 46666.667 CM 42000 IN 44333.333 Group functions SQL> SELECT jobcode, AVG(salary) 2 FROM first_pay 3 GROUP BY jobcode; From previous slide. JO AVG(SALARY) -- ----------AP 25000 CI 46666.667 CM 42000 IN 44333.333 SQL> SELECT jobcode, MIN(AVG(salary)), MAX(AVG(salary)) 2 FROM first_pay 3 GROUP BY jobcode; Jobcode can not be SELECT jobcode, MIN(AVG(salary)), MAX(AVG(salary)) used in this context. * ERROR at line 1: ORA-00937: not a single-group group function SQL> SELECT MIN(AVG(salary)), MAX(AVG(salary)) 2 FROM first_pay 3 GROUP BY jobcode; This returns the minimum group average and the MIN(AVG(SALARY)) MAX(AVG(SALARY)) maximum group average. ---------------- ---------------25000 46666.667 Group functions SQL> SELECT jobcode, SUM(salary), SUM(bonus) 2 FROM first_pay 3 GROUP BY jobcode; JO SUM(SALARY) SUM(BONUS) -- ----------- ---------AP 25000 500 CI 140000 3000 CM 42000 2000 IN 133000 5500 SQL> 2 3 4 This example shows the sum of salary and sum of bonus for all jobcodes. Now I decided I only wanted to see those groups where either the sum of the salary was greater than 75000 or the sum of the bonus was greater than 3000. This excludes AP because it meets neither criteria and it excludes CM because it also meets neither criteria. SELECT jobcode, SUM(salary), SUM(bonus) FROM first_pay GROUP BY jobcode HAVING SUM(salary) > 75000 OR SUM(bonus) > 3000; JO SUM(SALARY) SUM(BONUS) -- ----------- ---------CI 140000 3000 IN 133000 5500 Because I am testing the groups after they have been formed, I have to use the HAVING clause. Group function SQL> SELECT jobcode, SUM(salary), SUM(bonus) 2 FROM first_pay 3 WHERE SUM(salary) > 75000 OR SUM(bonus) > 3000 4 GROUP BY jobcode; WHERE SUM(salary) > 75000 OR SUM(bonus) > 3000 This is the error that * results from using the ERROR at line 3: WHERE clause ORA-00934: group function is not allowed here inappropriately. The HAVING clause should have been used here as shown on the previous slide. SQL> SELECT jobcode, SUM(salary), SUM(bonus) 2 FROM first_pay 3 GROUP BY jobcode 4 HAVING SUM(salary) > 75000 OR SUM(bonus) > 3000; JO SUM(SALARY) SUM(BONUS) -- ----------- ---------CI 140000 3000 IN 133000 5500 Correct code using the HAVING clause (copied from previous slide).