Hashing 2
advertisement

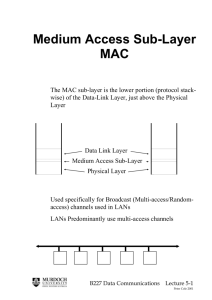
Hashing Part Two Better Collision Resolution Small parts of this material stolen from "File Organization and Access" by Austing and Cassel Hash function converts key to file address Collision is when two or more keys hash to the same address Collision Avoidance o Good Hash Function spreads out the keys evenly along the whole address space o Non-Dense File decreases chance of collisions and decreases probes after a collision Very simple collision resolution if H(key) = A, and A is already used, try A+1, then A+2, etc Advantages easy to implement guaranteed to use all addresses Disadvantages clustering / clumping Given the following hashes and linear probing: 1. 2. 3. 4. 5. adams = 20 bates = 22 cole = 20 dean = 21 evans = 23 Result of either ◦ poor hash function ◦ dense file Address Data 20 Adams 21 Cole 22 Bates 23 Dean 24 Evans 25 26 Instead of adding 1, spread out by random amount True random would not work. Instead use pseudo-random. While A is in use A = (A + R) mod T A = address R = prime T = Table Size 1. 2. 3. 4. 5. adams = 20 bates = 22 cole = 20 dean = 21 evans = 23 Linear Probing But what if 25 and 30 already had keys directly hashed to those locations? Cole would be at 35 -- 4 probes away. Random Probing, R = 5 Address Data 20 Adams Address Data 21 Dean 20 Adams 22 Bates 21 Cole 23 Evans 22 Bates 24 23 Dean 25 24 Evans 26 25 27 26 28 Cole Assuming a better hash function and less dense file are not options... And assuming linear and random probing lead to coalesced lists... Chaining : maintain a linked list of collisions, one head per address ◦ Example, after addition of Adams and Cole, and R=5: 19 : null 20 : 35 -> null 21 : null Advantage: Faster at resolving collisions Disadvantage : Space File Read Time = seek time + latency + data read time Smallest Readable Portion = 1 cluster = 4KB (usually) To access portion of a file, most of the time is in seek time and latency, not read time ◦ so, number of file reads is more important than size of reads, until size gets really big SO... reading a few records from a file takes no more time than reading just one record Given, collisions will occur... Why not just read 2, or 3, or 4 records instead of just 1 on each read operation? "Bucket" - a group of records at the same address "Hash File of Buckets" - hashed keys collide to small arrays of records in the data file use avg collisions and stddev? if 1000 records and 200 addresses ◦ then avg is 5.0 ◦ but stddev might be 1.0 start by determining how many records can fit in one or more disk clusters then design a good hash function to match that address space Advantages: Can achieve relatively fast access ◦ Remember, the hash function tells us where the record is located, so only 1 read operation. And even with collisions, the list of possible records is read into memory, which searches fast. ◦ Search Time = time to read bucket + time to search the array Disadvantages: What do we do when the bucket is full? ◦ solutions are similar to collision resolution ◦ we end up reading multiple sets of records Collisions will happen! Poisson Function: ◦ p(x) gives the probability that a given address will have had x records assigned to it. (r/N)x e-(r/N) p(x) = --------------x! N = number of available addresses r = number of records to be stored x = number of records assigned to a given address Given ◦ N = 1000 ◦ r = 1000 Probability that a given address will have exactly one, two, or three keys hashed to it: p(1) = 0.368 p(2) = 0.184 p(3) = 0.061 Given ◦ N = 10,000 ◦ R = 10,000 How many addresses should have one, two, or three keys hashed to them? 10,000 x p(1) = 10000x0.3679 = 3679 10,000 x p(2) = 10000x0.1839 = 1839 10,000 x p(3) = 10000x0.0613 = 613 So, 1839 keys will collide once and 613 will collide at least twice. Many of those collisions will disrupt probing. Given ◦ r = 500 ◦ N = 1000 ◦ one record per address Records that never collide = 303 Records that cannot go at their home = 107 Records at their home, but cause collisions = 90 Total = 500 Addresses with exact one record? N x p(1) = 1000 x 0.303 = 303 How many overflow records? 1 x N x p(2) + 2 x N x p(3) + 3 x N x p(4) + ... = N x [1 x p(2) + 2 x p(3) + 3 x p(4)] = 1000 x [ 1 x 0.076 + 2 x 0.013 + 3 x 0.002] = 107 Percentage of Records NOT stored at home address 107 / 500 = 21.4% Packing Density (%) Synonyms as percent of records 10 4.8 30 13.6 50 21.4 70 28.1 100 36.8 We must balance many factors: • file size • e.g., wasted space in hashed files • e.g., extra space for index files • disk access times • available memory • frequency of additions and deletions compared to searches Best Solution of All? probably a combination of indexed files, hashing, and buckets Thursday April 14 ◦ No Class Tuesday April 19 ◦ B-Trees Thursday April 21 ◦ Review