IntroCUDASlides
advertisement

Programming Massively Parallel
Processors Using CUDA & C++AMP
Lecture 1 - Introduction
Wen-mei Hwu, Izzat El Hajj
CEA-EDF-Inria Summer School 2013
Course Goals
• Learn how to program massively parallel
processors and achieve
– high performance
– functionality and maintainability
– scalability across future generations
• Technical subjects
– principles and patterns of parallel algorithms
– processor architecture features and constraints
– programming API, tools and techniques
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
2
Text/Notes
• D. Kirk and W. Hwu, “Programming
Massively Parallel Processors – A Handson Approach,” 2nd Edition, Morgan
Kaufman Publisher, 2012,
• NVIDIA, NVidia CUDA C Programming
Guide, version 5.0, NVidia, 2013
(reference book)
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
3
Course Sessions Overview
Monday
• Lecture 1
• Lecture 2
• Lab Session 1
Wednesday
• Lecture 5
• Lecture 6
• Lab Session 2
Tuesday
• Lecture 3
• Lecture 4
Thursday
• Lab Session 3
Friday
• Lab Session 4
• Lab Session 5
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
4
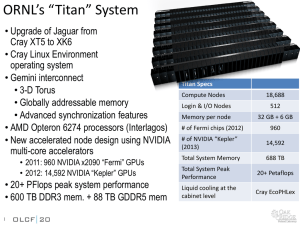
Blue Waters Hardware
Cray System & Storage cabinets: • >300
Compute nodes: • >25,000
Usable Storage Bandwidth: • >1 TB/s
System Memory: • >1.5 Petabytes
Memory per core module: • 4 GB
Gemin Interconnect Topology: • 3D Torus
Usable Storage: • >25 Petabytes
Peak performance: • >11.5 Petaflops
Number of AMD Interlogos processors: • >49,000
Number of AMD x86 core modules: • >380,000
Number of NVIDIA Kepler GPUs: • >4,000
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
5
Cray XK7 Compute Node
XK7 Compute Node
Characteristics
AMD Series 6200
(Interlagos)
NVIDIA Kepler
Host Memory
32GB
1600 MT/s DDR3
NVIDIA Tesla X2090
Memory
6GB GDDR5 capacity
Gemini High Speed
Interconnect
Keplers in final installation
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
Z
Y
X
6
CPU and GPU have very different
design philosophy
GPU
CPU
Throughput Oriented Cores
Latency Oriented Cores
Chip
Chip
Compute Unit
Core
Cache/Local Mem
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
Registers
SIMD Unit
Control
SIMD
Unit
Threading
Registers
Local Cache
7
CPUs: Latency Oriented Design
• Large caches
– Convert long latency
memory accesses to short
latency cache accesses
ALU
ALU
ALU
Control
• Sophisticated control
– Branch prediction for
reduced branch latency
– Data forwarding for
reduced data latency
ALU
CPU
Cache
DRAM
• Powerful ALU
– Reduced operation latency
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
8
GPUs: Throughput Oriented
Design
• Small caches
– To boost memory
throughput
• Simple control
– No branch prediction
– No data forwarding
GPU
• Energy efficient ALUs
– Many, long latency but
heavily pipelined for high
throughput
• Require massive number
of threads to tolerate
latencies
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
DRAM
9
Winning Applications Use Both
CPU and GPU
• CPUs for sequential
parts where latency
matters
– CPUs can be 10+X
faster than GPUs for
sequential code
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
• GPUs for parallel
parts where
throughput wins
– GPUs can be 10+X
faster than CPUs for
parallel code
10
Heterogeneous parallel computing is
catching on.
Financial
Analysis
Scientific
Simulation
Engineering
Simulation
Data
Intensive
Analytics
Medical
Imaging
Digital Audio
Processing
Digital Video
Processing
Computer
Vision
Biomedical
Informatics
Electronic
Design
Automation
Statistical
Modeling
Ray Tracing
Rendering
Interactive
Physics
Numerical
Methods
• 280 submissions to GPU Computing Gems
– 110 articles included in two volumes
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
11
What is the stake?
• Scalable and portable software lasts
through many hardware generations
Scalable algorithms and libraries can
be the best legacy we can leave behind
from this era
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
12
Introduction to CUDA C
Objective
• To learn about data parallelism and the
basic features of CUDA C that enable
exploitation of data parallelism
– Hierarchical thread organization
– Main interfaces for launching parallel
execution
– Thread index(es) to data index mapping
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
14
Parallel Programming Work Flow
• Identify compute intensive parts of an
application
• Adopt scalable algorithms
• Optimize data arrangements to maximize
locality
• Performance Tuning
• Pay attention to code portability and
maintainability
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
15
Massive
Parallelism Regularity
© David Kirk/NVIDIA
16
and Wen-mei W. Hwu,
CUDA /OpenCL – Execution Model
• Integrated host+device app C program
– Serial or modestly parallel parts in host C code
– Highly parallel parts in device SPMD kernel C code
Serial Code (host)
Parallel Kernel (device)
KernelA<<< nBlk, nTid >>>(args);
...
Serial Code (host)
Parallel Kernel (device)
KernelB<<< nBlk, nTid >>>(args);
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
...
17
The Von-Neumann Model
Memory
I/O
Processing Unit
Processor
ALU
Reg
File
Control Unit
PC
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
IR
18
Arrays of Parallel Threads
• A CUDA kernel is executed by a grid (array) of
threads
– Each thread is a virtualized Von-Neumann Processor
– All threads in a grid run the same kernel code (SPMD)
– Each thread has an index that it uses to compute
memory addresses and make control decisions
tid = compute thread index
work(tid)
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
19
Thread Blocks: Scalable Cooperation
• Divide thread array into multiple blocks
– Threads within a block cooperate via shared
memory, atomic operations and barrier
synchronization
– Threads in different blocks cannot cooperate
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
20
Computing the Thread Index
gridDim.x
# of blocks
in grid
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
21
Computing the Thread Index
gridDim.x
blockIdx.x
# of blocks
in grid
position of
block in grid
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
22
Computing the Thread Index
gridDim.x
blockIdx.x
blockDim.x
# of blocks
in grid
position of
block in grid
# threads
in block
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
23
Computing the Thread Index
gridDim.x
blockIdx.x
blockDim.x
threadIdx.x
# of blocks
in grid
position of
block in grid
# threads
in block
position of
thread in block
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
24
Computing the Thread Index
gridDim.x
blockIdx.x
blockDim.x
threadIdx.x
# of blocks
in grid
position of
block in grid
# threads
in block
position of
thread in block
tid = blockIdx.x*blockDim.x + threadIdx.x
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
25
blockIdx and threadIdx
•
Each thread uses indices to
decide what data to work on
–
–
•
blockIdx: 1D, 2D, or 3D
(CUDA 4.0)
threadIdx: 1D, 2D, or 3D
Simplifies memory
addressing when processing
multidimensional data
–
–
–
Image processing
Solving PDEs on volumes
…
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
26
Vector Addition – Conceptual View
vector A
A[0]
A[1]
A[2]
A[3]
A[4]
…
A[N-1]
vector B
B[0]
B[1]
B[2]
B[3]
B[4]
…
B[N-1]
+
+
+
+
+
C[0]
C[1]
C[2]
C[3]
C[4]
vector C
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
+
…
C[N-1]
27
Vector Addition – Traditional C
Code
// Compute vector sum C = A+B
void vecAdd(float* A, float* B, float* C, int n)
{
for (i = 0, i < n, i++)
C[i] = A[i] + B[i];
}
int main()
{
// Memory allocation for A_h, B_h, and C_h
// I/O to read A_h and B_h, N elements
…
vecAdd(A_h, B_h, C_h, N);
}
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
28
Heterogeneous Computing vecAdd
Host Code
#include <cuda.h>
void vecAdd(float* A, float* B, float*
C, int n){
int size = n* sizeof(float);
float* A_d, B_d, C_d;
...
1. // Allocate device memory for A, B, and C
// copy A and B to device memory
Part 1
2. // Kernel launch code – to have the device
// to perform the actual vector addition
Host Memory
3. // copy C from the device memory
// Free device vectors
}
Device Memory
GPU
Part 2
CPU
Part 3
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
29
Control Flow
CPU
GPU
cudaMalloc(...)
cudaMemcpy(...)
kernel<<<...>>>(...)
cudaMemcpy(...)
cudaFree(...)
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
30
Partial Overview of CUDA Memories
•
•
(Device) Grid
Device code can:
– R/W per-thread registers
– R/W per-grid global memory
Block (0, 0)
Host code can
– Transfer data to/from per grid
global memory
Host
Block (1, 0)
Registers
Registers
Registers
Registers
Thread (0, 0)
Thread (1, 0)
Thread (0, 0)
Thread (1, 0)
Global
Memory
We will cover more later.
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
31
CUDA Device Memory
Management API functions
(Device) Grid
• cudaMalloc()
Block (0, 0)
– Allocates object in the device
global memory
– Two parameters
• Address of a pointer to the
allocated object
• Size of of allocated object in
terms of bytes
• cudaFree()
– Frees object from device
global memory
Host
Block (1, 0)
Registers
Registers
Registers
Registers
Thread (0, 0)
Thread (1, 0)
Thread (0, 0)
Thread (1, 0)
Global
Memory
• Pointer to freed object
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
32
Host-Device Data Transfer API
functions
• cudaMemcpy()
(Device) Grid
– memory data transfer
– Requires four parameters
•
•
•
•
Pointer to destination
Pointer to source
Number of bytes copied
Type/Direction of transfer
Host
– Transfer to device is
asynchronous
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
Block (0, 0)
Block (1, 0)
Registers
Registers
Registers
Registers
Thread (0, 0)
Thread (1, 0)
Thread (0, 0)
Thread (1, 0)
Global
Memory
33
void vecAdd(float* A, float* B, float* C, int n) {
int size = n * sizeof(float);
float* A_d, B_d, C_d;
1.
// Transfer A and B to device memory
cudaMalloc((void **) &A_d, size);
cudaMemcpy(A_d, A, size, cudaMemcpyHostToDevice);
cudaMalloc((void **) &B_d, size);
cudaMemcpy(B_d, B, size, cudaMemcpyHostToDevice);
// Allocate device memory for
cudaMalloc((void **) &C_d, size);
2.
3.
// Kernel invocation code – to be shown later
...
// Transfer C from device to host
cudaMemcpy(C, C_d, size, cudaMemcpyDeviceToHost);
// Free device memory for A, B, C
cudaFree(A_d); cudaFree(B_d); cudaFree (C_d);
}
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
34
Example: Vector Addition Kernel
Input Vector 1:
Input Vector 2:
assign 1 thread
per element
Output Vector:
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
35
Example: Vector Addition Kernel
Input Vector 1:
Input Vector 2:
Output Vector:
quantization of global thread
count due to block organization
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
36
Example: Vector Addition Kernel
Input Vector 1:
Input Vector 2:
Output Vector:
boundary checks
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
37
Example: Vector Addition Kernel
Input Vector 1:
Input Vector 2:
Output Vector:
data padding
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
38
Example: Vector Addition Kernel
Device Code
// Compute vector sum C = A+B
// Each thread performs one pair-wise addition
__global__
void vecAddKernel(float* A_d, float* B_d, float* C_d, int n)
{
int i = threadIdx.x + blockDim.x * blockIdx.x;
if(i<n) C_d[i] = A_d[i] + B_d[i];
}
int vectAdd(float* A, float* B, float* C, int n)
{
// A_d, B_d, C_d allocations and copies omitted
// Run ceil(n/256) blocks of 256 threads each
vecAddKernel<<<ceil(n/256), 256>>>(A_d, B_d, C_d, n);
}
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
39
Example: Vector Addition Kernel
// Compute vector sum C = A+B
// Each thread performs one pair-wise addition
__global__
void vecAddKernel(float* A_d, float* B_d, float* C_d, int n)
{
int i = threadIdx.x + blockDim.x * blockIdx.x;
if(i<n) C_d[i] = A_d[i] + B_d[i];
}
Host Code
int vectAdd(float* A, float* B, float* C, int n)
{
// A_d, B_d, C_d allocations and copies omitted
// Run ceil(n/256) blocks of 256 threads each
vecAddKernel<<<ceil(n/256), 256>>>(A_d, B_d, C_d, n);
}
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
40
More on Kernel Launch
int vecAdd(float* A, float* B, float* C, int n) {
// A_d, B_d, C_d allocations and copies omitted
// Run ceil(n/256) blocks of 256 threads each
dim3 DimGrid(n/256, 1, 1);
if (n%256) DimGrid.x++;
dim3 DimBlock(256, 1, 1);
Host Code
vecAddKernnel<<<DimGrid,DimBlock>>>(A_d, B_d, C_d, n);
}
• Any call to a kernel function is asynchronous from CUDA 1.0 on,
explicit synch needed for blocking
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
41
Kernel execution in a nutshell
__host__
Void vecAdd()
{
dim3 DimGrid(ceil(n/256,1,1);
dim3 DimBlock(256,1,1);
__global__
void vecAddKernel(float *A_d,
float *B_d, float *C_d, int n)
{
int i = blockIdx.x * blockDim.x
+ threadIdx.x;
vecAddKernel<<<DimGrid,DimBlock>>>
(A_d,B_d,C_d,n);
if( i<n ) C_d[i] = A_d[i]+B_d[i];
}
}
Kernel
•••
Blk 0
Blk N-1
Schedule onto multiprocessors
M0
GPU
•••
Mk
RAM
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
42
More on CUDA Function Declarations
Executed
on the:
Only callable
from the:
__device__ float DeviceFunc()
device
device
__global__ void
device
host
host
host
__host__
KernelFunc()
float HostFunc()
__global__ defines a kernel function
• Each “__” consists of two underscore characters
• A kernel function must return void
__device__ and __host__ can be used together
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
43
Compiling A CUDA Program
Integrated C programs with CUDA extensions
NVCC Compiler
Host Code
Device Code (PTX)
Host C Compiler/ Linker
Device Just-in-Time Compiler
Heterogeneous Computing Platform with
CPUs, GPUs
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
44
ANY MORE QUESTIONS?
© David Kirk/NVIDIA and
Wen-mei W. Hwu, 2007-2013
45