Classification: Hands
advertisement

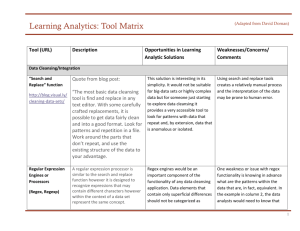
Classification: Hands-on Activity Hands-on activity • Predicting gaming the system in RapidMiner Open RapidMiner • And open classifier.xml • We currently have the model set up to build a decision tree with action-level cross-validation • Click the Run button (blue triangle) Check model goodness • Go to AUC (AUC is another way of referring to A’) • Pretty good, eh? • What’s the problem? Check model goodness • This model uses data from the same student both to train and test • And more seriously… Re-run • Move W-J48 above XValidation • Disable XValidation – Right-click Xvalidation and click on Enable Operator • Run the model • Click on text view • What do you see? Check model goodness • • • • • • • • • • … W-J48 J48 pruned tree -----------------pknow <= 0.071168 | student = N46z59pQP58: N (10.0) | student = N5LMy832c47: N (5.0) | student = N668lBbaKFE: N (16.0) | student = N6O31vedZbI: N (1.0) | student = tB4vqSxzqo: G (10.0) | student = N3hSu07XfGd: N (6.0) | student = N6bJ4auIa8L: N (10.0) | What’s wrong with this? What’s wrong with this? • It’s fitting to the student! • Definitely not a model that could be used with new students! Which features should we remove • For a model that has some hope of being generalizable • (Open the data set in Excel to take a look) • WEKA-CTA1Z04-fordev.csv on your USB flash drive Which features should we remove • For a model that has some hope of being generalizable – – – – – – Num Student Lesson Lspair Skill Cell • Leave group in, it’s a special case So… • Let’s quickly go into excel, do that, and re-save (with a new file name) • Now go back to RapidMiner • Change the file name in CSVExampleSource to your new file name • Run again So… • Anything wrong here? So… • Yup, no model. • So everything we had was over-fitting Let’s take • A more extensive data set • Specifically, one with additional distilled features • WEKA-CTA1Z04-allfeatures.csv What to do • Remove the same over-fitting features as before • Change the file name in CSVExampleSource to your new file name • Run! • What A’ do you get? But wait… • We still are using data from the same student in both the training set and test set • Replace XValidation with BatchXValidation – Right-click on XValidation, click Replace Operator, go to Validation, go to Other – If you look at ChangeAttributeRole, you’ll see that we are using “group” to set up the cross-validation level (and group refers to a pre-chosen group of students, approximately equal in number of students and number of actions) • Run! • What A’ do you get? A’ • What A’ do you get? – For me, the incorrect cross-validation did not actually make a difference… this time. – Did it make a difference for any of you? – (It does make a difference sometimes!) More things worth trying • Adding interaction features – F1 * F2… • You just need to enable a disabled operator… That takes a while! • Can you filter out the interaction parameters that are closely correlated to each other? Trying out other algorithms • What if you want to use step regression instead of J48? • Or logistic regression? • Or decision stumps? • Can you replace the W-J48 operator with these? Thanks!