rev")
FPGA and ASIC Technology Comparison
Part 1
Intro to VHDL or
Intro to Verilog
3
days
FPGA and ASIC
Technology Comparison
Curriculum
Path
FPGA vs. ASIC
Design Flow
ASIC to FPGA Coding
Conversion
Virtex-5 Coding Techniques
Spartan-3 Coding Techniques
Fundamentals of
FPGA Design
Designing for
Performance
for
1
day
2
days
Advanced FPGA
Implementation
ASIC Design
2
days
Minimum: 6
months design
experience
Welcome
If you are an experienced ASIC designer transitioning to FPGAs,
this course will help you reduce your learning curve by
leveraging your ASIC experience
Careful attention to how FPGAs are different than ASICs will help
you create a fast and reliable FPGA design
Objectives
After completing this training you will be able to:
Describe the differences between ASIC and FPGA architectures
Explain the features of Xilinx FPGA architecture
Benefit from the Xilinx dedicated resources
Contrasting Architectures
ASIC architecture compared to the Xilinx FPGA architecture
– Gates versus LUTs
– Delays
– Performance
Fundamental part selection considerations
– Cost
– Size
– Performance
– Volume
– Analog circuitry
– Time to market
– Reprogrammability
Standard Cell
Advantages
– Lowest price for high-volume
production (greater than 200K per year)
– Fastest clock frequency (performance)
– Unlimited size
– Integrated analog functions
• Custom ASICs
– Low power
Disadvantages
– Highest non-recurring engineering
costs
– Longest design cycle
– Limited vendor IP with high cost
– High cost for engineering change
orders
Embedded Array
Advantages
– Low price for medium-volume to
high-volume production
– Performance only slightly slower than a
standard cell
– 50+ million gates
– Custom macro support
– More flexibility than an FPGA
– Low power
Disadvantages
–
–
–
–
High non-recurring engineering costs
Design cycle longer than an FPGA
Vendor IP has high cost
Generally digital only
Xilinx FPGAs
Field-Programmable Gate Arrays
Advantages
– Lowest cost for low-volume to mediumvolume production
– No non-recurring engineering costs
– Standard product
– Fastest time to market
– Xilinx has extensive library of IP
• Inexpensive compared to ASIC vendors
– Ability to make bug fixes quickly
and inexpensively
Disadvantages
– Slower performance
– Size limited to ~25 million system gates
– Digital only
Field-Programmable Gate Arrays
Xilinx FPGAs are made using SRAM
Today’s FPGAs use 65-nm copper CMOS process
Potential to accommodate 25M system gates
– Includes RAM and logic gates
Performance up to 550 MHz
Integrated synthesis, simulation, and place & route
tools
– PC and UNIX
– Inexpensive: $2500 or less for the ISE Design Suite
• Use of third-party tools will increase costs
• Free ISE WebPACK is available
Configuration Introduction
When does configuration happen?
– On power up
– On demand
Why do FPGAs need to be configured?
− FPGA configuration memory is volatile
− Configuration data is stored in a PROM or other external data
source
What do you need to know about FPGA configuration?
− What happens during configuration
− How to set up various configuration modes and daisy chains
Configuration
Cost of ownership is reduced with the ability to reconfigure the
hardware—extending the life of the product
• Reduces the costly physical deployment
of repair technicians
• Extends the life of the product
Upgrades
Bug fixes
Adding additional functionality
Faster time to market
Partial reconfiguration
FPGA Configuration Methods
Xilinx Cables:
JTAG
Slave Serial
Slave SelectMAP
Microprocessor:
JTAG
Slave Serial
Slave SelectMAP
FPGA
Xilinx PROMs:
Slave/Master
Serial
Slave/Master
SelectMAP
Commodity Flash:
Slave SelectMAP
SPI*
BPI*
*SPI and BPI support is available in the newer Virtex™-5 and Spartan™-3E families
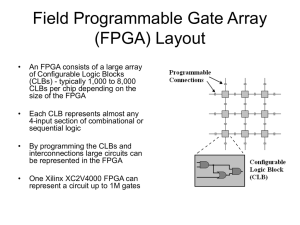
Five Primary Elements
Configurable
logic blocks
Xilinx FPGAs
Dedicated
blocks
Input and
output blocks
Routing
* Clocking
Resources
Logic Cells
Logic cells include
Carry
out
– Combinatorial logic, arithmetic
logic, and a register
Combinatorial logic is
implemented using Look-Up
Tables (LUTs)
Register functions can
include latches, JK, SR, D,
and T-type flip-flops
Arithmetic logic is a
dedicated carry chain for
implementing fast arithmetic
operations
Carry
Chain
D
LUT
Q
Carry
in
S/R
Combinatorial Logic
LUTs function as a ROM
A B C D E F Z
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
0
0
1
1
0
0
0
1
0
1
0
1
0
0
0
1
1
1
. . .
0
0
0
0
0
0
0
0
1
1
1
1
1
1
1
1
0
0
1
1
0
1
0
1
0
0
0
1
Combinatorial Logic
A
B
C
D
E
F
They generate
the output
value…
LUT
Z
for a given set
of inputs
Constant delay through a LUT
Limited by the number of inputs and
outputs, not by complexity
Wide Input Functions
For wider input functions,
LUTs can be combined
using a multiplexer
These muxes are dedicated,
so they are fast
LUT
LUT
MUX
LUT
LUT-Based Memory
Can store 64 bits of memory as
either a RAM or a ROM
Fundamentally, the LUT is a ROM
Can become RAM with activation of
configuration write strobe
Combine multiple LUTs for larger
memories—larger in both in depth and width
128 x 8 is not uncommon
6-input LUT contains two 5-input LUTs, which
adds more flexibility
LUT
Carry Logic
The carry logic chain is dedicated logic
that computes high-speed arithmetic
logic functions
The carry chain generally consists of a
multiplexer and an XOR gate
– The LUT computes the multiplexer selector
– The multiplexer determines the carry-out
– The XOR gate computes the addition
Memory Blocks
Support single- and dual-port
synchronous operations
In dual-port mode, these RAM blocks
support fully independent ports for
both
reading and writing
Each RAM block can be configured
for 36 kb
– Can be used as 2 independent 18-kb
RAMs
Dedicated cascade logic allows 2 RAM
blocks to be configured as 72 kb
Blocks of memory are generally
spread out across the die
Dedicated FIFO logic enables each
RAM to be configured as a FIFO
Block RAM Configurations
Configurations
available on each port
Independent
configurations on ports
A and B, read and write
– Supports data-width
conversion, including
parity bits
Configuration
Depth
Data Bits
Parity Bits
32k x 1
32 kb
1
0
16k x 2
16 kb
2
0
8k x 4
8 kb
4
0
4k x 9
4 kb
8
1
2k x 18
2 kb
16
2
1k x 36
1 kb
32
4
IN 8 bit
Port A: 8 bits
Port B: 32 bits
OUT 32 bit
IOB Element
Input path
– Two DDR registers
Output path
– Two DDR registers
– Two 3-state enable DDR registers
Each path can be combinatorial
or registered
Separate clocks and clock enables
for I and O
Set and reset signals are shared
IOB Element
Default I/O standard varies by family
– Fast and slow slew rate
– Programmable drive strength
– Other I/O standards
Built in SERDES functionality
– ISERDES divides input data by up to 10
– OSERDES multiplies output data by up to 10
DSP Slice
25x18 Multiply
Dedicated A
Cascading
ALU Mode
Pattern Detection
Independent
C input
Routing
A combination of programmable and
dedicated
routing lines
Dedicated routing
– Global clocks with predefined clock tree
– Regional clocks and IO clocks
– Global low-skew routing resources for other
high-fanout signals
– Carry chain routing
– Dedicated routing among other dedicated
resources
General interconnect
– Routing of local signals between CLBs and
IOBs
Clock Management
Dedicated clock trees are pre-optimized clock
networks that balance the skew and minimize
delay
Virtex-5 FPGA has 32 separate clock networks
Spartan-3 FPGA has 8 separate clock networks
Each can be configured for a built-in clock enable (BUFGCE) or
switching clock sources (BUFGMUX)
Local clock routing includes regional (BUFR) and SERDES
(BUFIO)
Clock Management
PLL
Digital Clock Manager
(DCM) consists of…
– Digital Delay Locked Loop
(DLL)
– Digital Frequency
Synthesis (DFS)
– Digital Phase Shifter (DPS)
CMT
I/O Translators
Programmable input and output thresholds
Supported standards include
– LVCMOS (several classes), LVPECL, HSTL
(several classes), SSTL (several classes), PCI,
PCI-X, LVDS (several classes), GTL, GTL+, and
HyperTransport™ (LDT) technology
-
Supported standards vary, check your data sheet
Different I/O standards require a separate input and output
reference voltage for each bank supporting a separate I/O
standard
Generally, each bank can support several standards, as long as
they share the same vref (input) or vcco (output)
Dedicated and Special Resources
Clock management (CMT)
– DCM and PLL
– Dedicated clock trees (not
shown)
Test logic
–
Built-in JTAG
I/O translators
–
Supporting many different thresholds
Other resources
–
Dual-Data Rate (DDR) registers in IOB
– SERDES resources
Dedicated Cores
– Block RAM
– DSP Slices
– Gigabit transceivers, MGTs (all devices)
– Tri-mode Ethernet MAC (all devices)
– PCI Express® core (all devices)
Additional FXT Cores
– PowerPC® 440 processors (not shown)
– Faster GTX transceiver (not shown)
Other Resources
Embedded processor cores
– 32-bit PowerPC 440 processor core (hard)
– MicroBlaze processor core (soft)
Digitally controlled termination resistance (DCI)
Summary
FPGA flexibility
– Reconfigurable logic
– Time to market
– Lowest “cost of change”
Xilinx combinatorial resources use flexible LUTs
Xilinx slices also contain registers, carry logic, clocking
resources, and dedicated muxes to improve the performance for
all applications
Xilinx FPGAs have dedicated resources for DSP, RAM, PCI,
EMAC, and I/O that make these critical paths equivalent to a
custom ASIC
Where Can I Learn More?
Xilinx online documents
– www.support.xilinx.com
• Software manuals
• Data sheets
• Application notes
• User guides
Xilinx Education Services courses
– www.xilinx.com/training
• Xilinx tools and architecture courses
• Hardware description language courses
• Free Videos
FPGA and ASIC Technology Comparison
Part 2
Intro to VHDL or
Intro to Verilog
3
days
FPGA and ASIC
Technology Comparison
Curriculum
Path
FPGA vs. ASIC
Design Flow
ASIC to FPGA Coding
Conversion
Virtex-5 Coding Techniques
Spartan-3 Coding Techniques
Fundamentals of
FPGA Design
Designing for
Performance
for
1
day
2
days
Advanced FPGA
Implementation
ASIC Design
2
days
Welcome
If you are an experienced ASIC designer transitioning to FPGAs,
this course will help you reduce your learning curve by
leveraging your ASIC experience
Careful attention to how FPGAs are different than ASICs will help
you create a fast and reliable FPGA design
Objectives
After completing this training you will be able to:
Describe how a simple logic implementation can differ between
ASIC and FPGAs
Recognize gate counts as an estimation of design size
Explain some of the FPGA design practices you must follow to
get peak performance in your FPGA
Gate Comparison
In retargeting HDL code for an ASIC design to an FPGA, gate
conversion is rarely one to one
A 0.13-µ standard cell can have up to 100K gates per mm2
– A Virtex®-5 FPGA has about 20K usable gates per mm2
Why the difference?
Xilinx has programmable logic in addition to the functional logic
– Routing
– Multiplexers
– Configuration memory registers
This means built-in design flexibility!
Gate Translation
Separate out logic, flip-flops, RAM, cores, and I/O
– Partition cores into logic and RAM
Assume
– 6 to 24 gates per LUT (depending on the number of inputs used)
– RAM bits are equivalent
– Up to 100 ASIC gates per I/O; translate to IOBs
– 7 gates per register
So what design strategy do you think you need to use?
– To get the most out of the FPGA try to use as many features as possible,
especially the FPGA’s dedicated hardware
Example
ASIC
FPGA
250K logic gates
20,800 to 41,600 LUTs
Four 32-kb blocks
Equivalent
of RAM
Equivalent number of
243 pads, including
pins
power and ground
Depending on the number of LUTs needed, this design could use
a Virtex-5 LX30, LX50, or LX85 FPGA
Gate Counts
Gate counts are
influenced by
Coding style
Metal layers
Process geometry
Library quality
Placement and routing
algorithms
Core contents (RAM
versus gates)
I/O requirements
Special features
CONCLUSION
Any ASIC-to-FPGA gate
counting method is only a
rough estimate.
Taking ASIC code directly to
an FPGA will not utilize the
dedicated resources of the
FPGA.
AND Gate Example
8-input AND gate
VHDL
For vec(7 downto 0)
Verilog
For vec(7.0)
and_out <= vec(0) AND vec(1) AND vec(2) AND vec(3) AND
vec(4) AND vec(5) AND vec(6) AND vec(7);
assign and_out = & vec;
ASIC Implementation
8-input AND gate
Two four-input NAND gates
feeding a two-input NOR
gate
Approximate gate count = 14
Approximate delay in a standard-cell
ASIC with 0.13-µ process = 0.47 ns
Beware of ASIC libraries
with very wide gate types!
Xilinx Implementation
8-input AND gate implemented in
three 4-input LUTs and two logic
levels
Approximate max delay in a Spartan®-3 FPGA = 0.678 ns
Approximate gate count = 18 gates
Approximate max delay in a Virtex-5 FPGA = 0.435 ns
Approximate gate count = 18 gates
Question
How many 4-input LUTs would be
required to implement a 32-input
OR gate?
How many Logic Levels would they
generate?
Answer
LUT
How many 4-input LUTs would be
required to implement a 32-input
OR gate? 11
LUT
LUT
LUT
How many Logic Levels would they
generate? 3
LUT
LUT
LUT
LUT
LUT
If net delays ~ .3 ns and LUT delays ~.2 ns then total
delay would be 2(.3) + 3(.2) ~ 1.2 ns
LUT
…in a Spartan®-3 FPGA
LUT
How do you think this would be implemented in Virtex-5
with a 6-input LUT? (Answer: 7 LUTs and 2 Logic Levels)
Tri-State Busses
Some ASIC designs have large tri-state busses
– There are no tri-state buffers associated with each slice in the newest
FPGAs
– These will have to be re-synthesized and be mapped to LUTs and the F7
and F8 dedicated muxes
– You may need to code these with a CASE statement and a high-Z output
– The F7 can implement an 8-to-1 mux
– The F8 can implement a 16-to-1 mux
Registered AND gate
VHDL
process (clk)
begin
if rising_edge(clk) then
vec_q <= vec;
and_out <= vec_q(0) AND vec_q(1) AND vec_q(2) AND vec_q(3)
AND vec_q(4) AND vec_q(5) AND vec_q(6) AND vec_q(7);
end if;
end process;
Verilog
always @ (posedge clk)
begin
vec_q <= vec;
and_out <= & vec_q;
end
Performance Comparison
A comparison of the achieved performance for the registered 8input AND gate
– Virtex-5 FPGA
• ~550 MHz
• ~88 gates
– 0.13-µ standard cell ASIC
• ~850 MHz
• ~77 gates
Typical high-performance frequencies (no optimization for the
FPGA)
– Virtex-5 FPGA
• ~275 MHz for four-levels of LUT (combinatorial) logic
– 0.13-µ standard cell ASIC
• ~550 MHz for equivalent logic
Don’t forget to optimize
your HDL code!
ASIC versus FPGA
Combinatorial logic implemented in an ASIC is typically
faster than in an FPGA implementation
– The fine-grain architecture of an ASIC allows wider input functions
to be implemented with significantly less delay
– ASICs have a dedicated routing structure rather than a
programmable routing structure
Critical paths typically include I/O, RAM, PCI™
technology, EMAC, and DSP resources
– Xilinx has dedicated FPGA resources to implement these
functions, making these paths equivalent to an ASIC
implementation
• Remember: Xilinx Virtex-5 devices are cutting-edge ASICs
Don’t forget to include Xilinx-dedicated
resources in your design!
Pipelining
fMAX =
n MHz
fMAX
2n MHz
D Q
D Q
One
Level
Two Logic Levels
D Q
D Q
One
Level
D Q
Sequential Design
How do you get high performance from an FPGA?
Pipelining
– For large combinatorial paths, additional registers may need to
be inferred to break up combinatorial paths to increase
performance
– This technique increases the size of the design
– This is not as likely to be needed for Virtex-5 FPGA designs
because the Virtex-5 FPGA has a 6-input LUT
– Evaluate the number of logic levels your design has by
generating a timing report from the ISE® Design Suite or your
synthesis tool
– Usually the registers are added at a hierarchical boundary
Don’t forget to evaluate the number of logic levels
for your timing-critical paths!
Timing Constraints
How do you get high performance from an FPGA?
Timing constraints
– Timing constraints communicate the performance goals to the
implementation tools
– Global timing constraints constrain virtually all the paths in your design
based on your system frequency, input, and output times (PERIOD,
OFFSET IN, OFFSET OUT)
– Path-specific timing constraints need to be added to constrain multicycle paths and false paths
Adding timing constraints is essential if you want
good system speed!
Coding Style
How do you get high performance out of an FPGA?
Coding style has a large impact on the performance
– Because FPGA combinatorial and routing resources are inherently slower,
the HDL coding style needs to be improved
– Write your code to limit the number of logic levels inferred
– Learn about proper HDL coding styles by listening to the REL modules
Don’t waste time! Evaluate your HDL!
Synchronous Design
How do you get reliability out of an FPGA?
Always build a synchronous design
– Asynchronous circuits are less reliable
– Lot variations exist for all FPGAs, which means that your design has to be
able to work for faster devices
Timing constraints
– Cannot fix asynchronous design problems—only you can
Synchronous Design Methodology
One clock (or at least as few as possible)
Use one edge (all flip-flops use rising or falling edge)
Use D-type flip-flops
Register the outputs of each behavioral block
In place of multiple clocks, use clock enables
Synchronize asynchronous signals to the “single” clock
(synchronization circuits)
Do NOT create
– Gated, derived, or divided clocks
– Local asynchronous set/reset
– Avoid global asynchronous set/reset
Get it right the first time!
Summary
Don’t worry too much about gate counting methodologies. They
are only rough estimates, anyway
Optimize your HDL coding style
Instantiate Xilinx-dedicated hardware resources into your design
to improve your system speed and maximize what you get from
your FPGA
Pipeline your timing-critical paths
Timing constraints are a primary means for improving system
speed
Get your design to work properly the first time by designing
synchronously
Where Can I Learn More?
Xilinx Answers Browser
– www.support.xilinx.com Answers Browser window
• Enter keywords like “pipelining” or “period constraint”
Xilinx Education Services courses
– www.xilinx.com/training
• Xilinx tools and architecture courses
Fundamentals of FPGA Design
» Learn about synchronous design, global timing constraints, the
Architecture Wizard, and the CORE Generator™ tool
Designing for Performance
» Learn about avoiding metastability, path-specific timing
constraints, and the Timing Analyzer
• Free Video-based Training
» Learn about proper HDL coding techniques
Trademark Information
Xilinx is disclosing this Document and Intellectual Property (hereinafter “the Design”) to you for use in the development of designs to operate on,
or interface with Xilinx FPGAs. Except as stated herein, none of the Design may be copied, reproduced, distributed, republished, downloaded,
displayed, posted, or transmitted in any form or by any means including, but not limited to, electronic, mechanical, photocopying, recording, or
otherwise, without the prior written consent of Xilinx. Any unauthorized use of the Design may violate copyright laws, trademark laws, the laws of
privacy and publicity, and communications regulations and statutes.
Xilinx does not assume any liability arising out of the application or use of the Design; nor does Xilinx convey any license under its patents,
copyrights, or any rights of others. You are responsible for obtaining any rights you may require for your use or implementation of the Design.
Xilinx reserves the right to make changes, at any time, to the Design as deemed desirable in the sole discretion of Xilinx. Xilinx assumes no
obligation to correct any errors contained herein or to advise you of any correction if such be made. Xilinx will not assume any liability for the
accuracy or correctness of any engineering or technical support or assistance provided to you in connection with the Design.
THE DESIGN IS PROVIDED “AS IS" WITH ALL FAULTS, AND THE ENTIRE RISK AS TO ITS FUNCTION AND IMPLEMENTATION IS WITH
YOU. YOU ACKNOWLEDGE AND AGREE THAT YOU HAVE NOT RELIED ON ANY ORAL OR WRITTEN INFORMATION OR ADVICE,
WHETHER GIVEN BY XILINX, OR ITS AGENTS OR EMPLOYEES. XILINX MAKES NO OTHER WARRANTIES, WHETHER EXPRESS,
IMPLIED, OR STATUTORY, REGARDING THE DESIGN, INCLUDING ANY WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
PARTICULAR PURPOSE, TITLE, AND NONINFRINGEMENT OF THIRD-PARTY RIGHTS.
IN NO EVENT WILL XILINX BE LIABLE FOR ANY CONSEQUENTIAL, INDIRECT, EXEMPLARY, SPECIAL, OR INCIDENTAL DAMAGES,
INCLUDING ANY LOST DATA AND LOST PROFITS, ARISING FROM OR RELATING TO YOUR USE OF THE DESIGN, EVEN IF YOU HAVE
BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. THE TOTAL CUMULATIVE LIABILITY OF XILINX IN CONNECTION WITH
YOUR USE OF THE DESIGN, WHETHER IN CONTRACT OR TORT OR OTHERWISE, WILL IN NO EVENT EXCEED THE AMOUNT OF
FEES PAID BY YOU TO XILINX HEREUNDER FOR USE OF THE DESIGN. YOU ACKNOWLEDGE THAT THE FEES, IF ANY, REFLECT
THE ALLOCATION OF RISK SET FORTH IN THIS AGREEMENT AND THAT XILINX WOULD NOT MAKE AVAILABLE THE DESIGN TO YOU
WITHOUT THESE LIMITATIONS OF LIABILITY.
The Design is not designed or intended for use in the development of on-line control equipment in hazardous environments requiring fail-safe
controls, such as in the operation of nuclear facilities, aircraft navigation or communications systems, air traffic control, life support, or weapons
systems (“High-Risk Applications”). Xilinx specifically disclaims any express or implied warranties of fitness for such High-Risk Applications. You
represent that use of the Design in such High-Risk Applications is fully at your risk.
© 2012 Xilinx, Inc. All rights reserved. XILINX, the Xilinx logo, and other designated brands included herein are trademarks of Xilinx, Inc.
PowerPC is a trademark of IBM, Inc.
 rev")