Psychological Testing and Assessment Overview:
▪
1. Measurement in Various Fields:
o
Every field, including
psychology, uses measurement
tools to gather and analyze
data.
o
Examples:
▪
o
Carat (for diamonds) or
Byte (for computers)
are units of
measurement that help
assess specific
characteristics in
different fields.
3. Testing vs. Assessment (A Semantic
Distinction):
o
Testing traditionally referred to
the administration and
interpretation of tests (e.g., IQ
tests or personality tests).
o
Assessment emerged as a more
inclusive term during World
War II, representing a broader
range of evaluative procedures
beyond just testing, including
interviews and behavioral
observations.
o
For example, the U.S. Office of
Strategic Services (OSS) during
World War II used a variety of
tools (including tests) to
evaluate military candidates for
specialized roles. They also
used innovative assessment
techniques, such as stressful
interviews, to evaluate
candidates’ ability to handle
real-world situations.
In Psychology, measurement is
crucial for evaluating
psychological characteristics
using various tools.
2. Historical Context of Psychological
Testing:
o
o
o
Roots in Early 20th Century
France:
▪
In 1905, Alfred Binet
developed a test to
place schoolchildren in
appropriate classes,
which had lasting global
implications.
▪
This test was later
adapted and used in
the U.S. during World
War I to assess recruits.
World War II Impact:
▪
Psychological testing
played a key role in
screening military
recruits.
▪
After the war, testing
expanded to measure
various psychological
variables such as
intelligence,
personality, and brain
function.
The Evolution of Testing:
The introduction of
Binet’s test led to an
increase in test
development, and thus,
the rise of a testing
enterprise (involving
test developers,
publishers, and users).
4. Psychological Testing vs. Psychological
Assessment:
o
Psychological Assessment:
▪
A comprehensive
process that involves
gathering and
integrating various
forms of psychological
data (e.g., tests,
interviews, case
studies, and behavioral
observations).
▪
The goal is to make a
psychological
evaluation based on
multiple sources of
data.
o
Psychological Testing:
▪
▪
o
Refers specifically to
the measurement of
specific psychological
variables (e.g.,
intelligence,
personality, cognitive
ability) using structured
devices or tests.
assessments, especially when
evaluating sensitive variables
like mental health or personal
characteristics.
Analysis for Your Study:
•
Focuses on obtaining
behavioral samples
that help measure
specific aspects of a
person’s psychological
functioning.
Key Difference: Psychological
assessment is more holistic,
integrating multiple data
sources, while psychological
testing is narrower, focused on
the measurement of specific
traits or behaviors.
•
Key Concept 1: The Growth of
Psychological Testing
o
Psychological testing evolved
from Binet’s initial schoolplacement test to a tool used in
large-scale military evaluations.
o
Over time, the range of tests
expanded to cover a broader
scope of psychological
attributes.
Key Concept 2: The Semantic Shift
from Testing to Assessment
o
5. Practical Applications:
o
Testing is often more
appropriate when a specific
measurement or evaluation is
needed, such as determining
intelligence, diagnosing a
mental health disorder, or
assessing cognitive abilities.
o
Assessment is more fitting
when a comprehensive
understanding of an individual’s
psychological state is required.
This may involve combining test
scores with interviews,
observations, and other
evaluative data.
•
Key Concept 3: Distinctions in
Application
o
6. Ethical Concerns in Assessment:
o
o
The OSS's methods during
World War II, which included
harsh interview techniques,
raise ethical concerns today.
Modern assessment methods
avoid such practices due to
potential harm to those being
evaluated.
Ethical considerations are
crucial in psychological
•
The introduction of
“assessment” marks a shift
toward a more integrated,
holistic view of understanding
individuals. Whereas testing is
concerned with the specific
measurement of psychological
variables, assessment involves a
more comprehensive
evaluation that may include
multiple tools, such as tests,
interviews, and observations.
The difference between testing
and assessment is crucial for
understanding when each is
appropriate. Testing is ideal for
situations where you need to
measure specific variables (e.g.,
intelligence), whereas
assessment is best for contexts
that require a broader, more
nuanced evaluation (e.g.,
clinical diagnosis or personnel
selection).
Key Concept 4: Ethical Considerations
o
The ethics of assessment are
highlighted by historical
examples, such as the OSS's
harsh techniques, which are
considered unethical by
modern standards. Today,
assessments must be designed
to ensure that they do not harm
the individuals being evaluated.
based. After
administering the test,
the tester simply adds
up the correct answers
or counts certain types
of responses. The focus
is typically on the result
of the test, with little
regard for how the
responses were
generated.
Takeaway for Your Study:
•
Understand the definitions of both
psychological testing and psychological
assessment, and recognize the
semantic distinction between them.
•
Be aware that psychological testing is
focused on measurement, while
psychological assessment is a more
comprehensive process that integrates
various data.
•
o
Assessment:
▪
Recognize that both practices are used
across different settings (clinical,
military, educational, business) and that
both require careful ethical
consideration.
By mastering these concepts, you will gain a
deeper understanding of how psychological
data is collected, interpreted, and applied in
real-world scenarios.
3. Role of Evaluator:
o
Testing:
▪
1. Objective:
o
Testing:
▪
o
The objective is to
obtain a numerical
gauge (usually a score)
of a specific ability or
attribute (e.g.,
intelligence, skill level).
The objective is to
answer a referral
question, solve a
problem, or make a
decision. Assessment
uses multiple tools of
evaluation to achieve
these goals.
2. Process:
o
o
▪
▪
Testing can be either
individual or group-
The assessor plays a
crucial role in selecting
the right tools of
evaluation (tests,
interviews,
observations) and in
interpreting the data
collected. The assessor
integrates all available
information to draw
conclusions.
4. Skill of Evaluator:
o
Testing:
▪
Testing:
The tester is not central
to the process. A
different tester can
generally be
substituted without
significantly altering the
evaluation or results.
Assessment:
Assessment:
▪
Assessment is generally
more individualized,
focusing on how the
individual processes
information rather than
just the final results. It’s
a more in-depth and
comprehensive
evaluation.
Testing requires
technician-like skills,
such as the ability to
administer, score, and
interpret the test
results. These skills are
relatively
straightforward and
focus on procedural
accuracy.
o
complex. It involves a
problem-solving
approach that uses
various data sources to
answer the referral
question or make an
informed decision. The
result is more
comprehensive and
reflective of the
individual’s overall
situation.
Assessment:
▪
Assessment demands
more advanced skills. It
requires educated
selection of tools,
evaluation expertise,
and the ability to
organize and integrate
multiple sources of
data in a thoughtful
and coherent manner.
Summary of Key Distinctions:
•
Testing is more quantitative, focused
on gathering specific measurements of
a particular ability or attribute. It is
more standardized, and its results are
often numeric (like test scores).
•
Assessment, on the other hand, is
qualitative and more individualized,
aiming to answer a complex question
or solve a specific problem. It involves
the integration of various data sources,
including tests, interviews, and
observations, and is guided by the
expertise of the assessor.
5. Outcome:
o
Testing:
▪
o
The outcome of testing
is typically a test score
or a series of scores
that reflect the
measured ability or
attribute (e.g., IQ score,
personality traits).
Assessment:
▪
The outcome of an
assessment is more
Varieties of Assessment
The term psychological assessment can be modified in numerous ways to specify the focus or context of
the evaluation. Some terms are self-explanatory, while others require further explanation to understand
the nuances of the assessment process. Below are a few examples and their definitions:
1. Therapeutic Psychological Assessment:
•
Definition: Assessment that includes a therapeutic component, meaning it is not just about
evaluation but also aims to have a healing or therapeutic impact on the individual being
assessed. It may involve interventions to address specific psychological issues during the
evaluation process.
2. Educational Assessment:
•
Definition: Broadly refers to the use of tests and other tools to evaluate a person’s abilities or
skills, specifically in the context of school or educational environments.
o
Common tools: intelligence tests, achievement tests, reading comprehension tests, etc.
3. Retrospective Assessment:
•
Definition: This type of assessment involves evaluating a person’s psychological state or traits as
they existed at some point in the past.
o
Challenges: It can be difficult to gather accurate data from the past, especially if the
individual is deceased (e.g., historical psychological evaluation) or if memory bias plays a
role in a living subject's recollection (e.g., assessing past trauma).
o
Example: Assessing the mental state of a person from a period before a significant life
event, using historical records or interviews with others who knew them at the time.
4. Remote Assessment:
•
Definition: Assessment conducted on a person who is not physically present, using tools such as
online platforms, phone interviews, or video calls.
o
Example: Psychological evaluations conducted via teletherapy or using software to
administer tests to people in different locations (such as patients in remote areas).
5. Ecological Momentary Assessment (EMA):
•
Definition: This approach refers to assessing individuals in real time during specific situations as
they occur naturally. It collects data about a person’s behavior, thoughts, or emotions in the
moment and at the location where the issue or behavior is happening.
o
Example: Using smartphones or other devices to track a person’s mood or behavioral
responses in relation to specific triggers (e.g., someone with PTSD tracking triggers or
anxiety in real time).
o
Applications: Used to address clinical issues like post-traumatic stress disorder (PTSD),
problematic smoking, and chronic pain in children.
The Process of Assessment:
Psychological assessment is a structured process that typically follows several steps:
1. Referral for Assessment:
o
The process begins when a referral is made by an individual or organization (e.g., a
teacher, counselor, judge, or human resources specialist). The referral typically presents
a specific question or problem that needs to be addressed.
▪
Example referral questions:
▪
“Can this child function in a general education environment?”
▪
“Is this defendant competent to stand trial?”
▪
“How well can this employee be expected to perform if promoted to an
executive position?”
2. Pre-Assessment Meetings:
o
Before the formal assessment, the assessor might meet with the assessee or others
(e.g., parents, colleagues, teachers) to clarify details about the reason for the referral
and to gain context.
3. Tool Selection:
o
Based on the referral question, the assessor prepares by selecting the appropriate tools
for evaluation. The selection process is guided by the type of assessment required, past
experience, and research.
▪
o
For example, if the assessment is for leadership in a corporate or military
setting, tools might be chosen that measure specific leadership abilities.
The selection process may also involve guidelines or research to inform decisions about
which tools are best suited to assess the variables in question.
4. Assessment Preparation:
o
The assessor’s training and experience are crucial in selecting the right tools and
ensuring their proper use. They may review relevant literature, research, or previous
case studies to guide their decisions.
▪
Example: When assessing leadership, research on behavioral studies,
psychological studies of leadership, or cultural considerations might influence
the selection of assessment tools.
Summary:
The variety of assessments includes therapeutic, educational, retrospective, remote, and ecological
momentary assessments, each with its own context and application. The process of assessment starts
with a referral, followed by understanding the context, selecting tools based on the purpose, and
preparing the evaluation. The assessor plays a key role in choosing the appropriate methods and tools,
ensuring that the process is customized to the individual’s needs and the referral question at hand. The
process of assessment is therefore flexible, individualized, and informed by professional expertise and
research.
Subsequent Steps in the Assessment Process:
After selecting the tools and procedures for the assessment, the formal assessment process begins. The
next steps include:
1. Conducting the Assessment: The assessor administers the tests, conducts interviews, or uses
other selected methods to evaluate the assessee's behavior, abilities, or psychological
characteristics.
2. Reporting the Findings: Once the assessment is completed, the assessor writes a report that
summarizes the findings. This report is designed to answer the referral question and provide
relevant insights or recommendations based on the assessment results.
3. Feedback Sessions: After the report is generated, there may be one or more feedback sessions
where the findings are shared with the assessee and/or other interested third parties (e.g.,
parents, referring professionals). These sessions help clarify the results and their implications.
Approaches to Psychological Assessment:
There are various approaches that assessors might take during the assessment process. Different
methods or models may be used depending on the assessor's philosophy, the nature of the assessment,
and the needs of the assessee.
1. Collaborative Psychological Assessment:
•
Definition: In collaborative psychological assessment, the process is viewed as a partnership
between the assessor and the assessee. The collaboration begins from the initial contact and
continues through the final feedback session.
o
The focus is on mutual involvement, where both the assessor and the assessee actively
engage in understanding the assessment process.
o
This approach may even include therapeutic elements as part of the assessment
process, encouraging the assessee to engage in self-discovery and gain new insights
through the evaluation (Finello, 2011; Fischer, 2006).
o
Example: The assessor and assessee work together, discussing each step of the process,
interpreting the results in real-time, and actively collaborating in decision-making.
2. Therapeutic Psychological Assessment:
•
Definition: Therapeutic psychological assessment is a collaborative assessment approach that
incorporates therapeutic elements into the process. In this method, the goal is not only to
assess but also to support the assessee's self-discovery and encourage personal growth.
o
This process may include moments of intervention where the assessee is provided with
feedback or insights aimed at improving psychological well-being (Finn, 2003, 2011).
o
Example: During the assessment, an assessee may receive feedback about their
personal challenges, which can help them gain better insight into their behaviors or
emotional responses.
3. Dynamic Assessment:
•
Definition: Dynamic assessment is an interactive and flexible approach to assessment that
typically involves three key phases:
1. Evaluation – The initial assessment phase.
2. Intervention – The assessor provides some type of support (e.g., feedback, hints,
instruction) to the assessee to help them perform better.
3. Re-evaluation – The assessee’s progress after the intervention is measured.
o
Dynamic assessment is commonly used in educational settings but can also be applied
in correctional, corporate, neuropsychological, and clinical settings.
o
The focus of dynamic assessment is to evaluate how the assessee processes and
benefits from the intervention.
o
Example: In an educational context, an assessor might give a student a task, then offer
hints or feedback to help the student solve the problem, and then measure how much
progress the student makes in completing similar tasks with more support.
o
Purpose: In education, dynamic assessment is particularly useful for measuring learning
potential—the ability to learn or improve with appropriate feedback. It's seen as a way
of measuring how well someone can learn to learn.
o
Example: Using dynamic assessment in classrooms to gauge not just what students
already know but also their potential to acquire new skills when given support.
4. Use of Technology in Dynamic Assessment:
•
Definition: Computers and other technological tools are frequently used to support dynamic
assessment, especially when the goal is to provide feedback or track progress over time.
Computers can offer real-time assistance, track performance, and allow for personalized
interventions.
o
Example: A computer program could be used to measure how well a student improves
their mathematical problem-solving skills after receiving hints or instruction.
Summary:
The assessment process involves several stages, beginning with the selection of tools, followed by
administering the assessment, writing a report, and conducting feedback sessions. The approach taken by
the assessor can vary, with collaborative assessment emphasizing a partnership between the assessor and
assessee, therapeutic assessment integrating self-discovery and therapeutic elements, and dynamic
assessment focusing on how individuals respond to interventions aimed at improving their performance.
Each approach can be tailored to the specific needs of the assessee, with dynamic assessment often
incorporating technological tools to enhance learning and provide ongoing support.
part of the format, determining how
long test-takers have to complete the
assessment.
1. Definition of a Test:
A psychological test is a tool designed to
measure various psychological variables such as
intelligence, personality, aptitude, attitudes, or
values. Unlike medical tests that often analyze
physical specimens (like blood), psychological
tests analyze behavior, either in real-time or
through responses to tasks like questionnaires.
•
Administration Procedures: Tests can
be administered in different ways.
Some require one-on-one interaction
with an examiner, while others are
designed for group administration
where participants can complete the
tasks independently.
•
Scoring and Interpretation: Scoring
involves assigning evaluative codes or
statements (numerical or otherwise) to
a test-taker's performance. There are
different scoring systems, such as
summing correct responses or using
more complex procedures.
Interpretation of scores may vary, and
some tests have detailed manuals for
interpreting scores, while others might
require the examiner to use their
judgment.
2. Key Variables of Psychological Tests:
Psychological tests differ in several ways:
•
Content: This refers to the subject
matter covered by the test. Even when
two tests measure the same trait (e.g.,
personality), they may have different
items based on their developers'
perspectives. For example, a
psychoanalytic personality test and a
behavioral personality test may differ
greatly in content and approach.
•
Format: The format refers to the
structure and layout of the test. It could
be administered in various forms, such
as pencil-and-paper, computerized, or
other forms. Time limits may also be a
3. Types of Scores:
•
Cut Scores: A cut score (also called a
cutoff score) is a reference point that
divides data into categories. It’s used to
make decisions (e.g., in educational
grading, job hiring, or licensing). There
are formal methods for deriving cut
scores, but sometimes they are set
informally based on intuition (e.g., a
teacher might decide a score of 65 is
the passing mark).
•
Score Interpretation: The emotional
consequences of scoring just above or
below a cut score can have significant
psychological impacts on individuals,
which is often not discussed in
measurement texts.
4. Psychometric Quality:
•
Psychometrics is the science of
psychological measurement. A test's
psychometric soundness refers to how
accurately and consistently it measures
what it intends to measure.
•
Psychometric Utility: This refers to the
practical value or usefulness of a test in
a particular context. For example, a test
of intelligence may be more useful in
certain school settings based on how
well it addresses the educational goals
and requirements of that environment.
5. Different Scoring Methods and
Interpretation Guides:
Some tests require self-scoring, some are
scored by a computer, while others require
manual scoring by trained professionals. Tests
like intelligence tests typically have specific
manuals that guide scoring and interpretation,
while tests like the Rorschach Inkblot Test might
not have a manual and require the examiner to
rely on guides for interpretation.
Practical Application:
•
Imagine Developing a Personality Test:
If you were to develop a test for a trait
like "goth" personality, you would need
to define what characteristics make up
this trait. What behaviors or
preferences would indicate a "goth"
personality? You would then include
items that directly assess these aspects
(e.g., interests in music, fashion choices,
attitudes toward mainstream culture).
The key is to ensure that the test
measures what it is intended to
measure, even if the definition is
subjective.
•
Testing Intelligence in Schools:
Different intelligence tests may have
varying levels of utility in a school
setting. For example, one test might be
more culturally appropriate for the
student population, while another
might be more effective in assessing
specific cognitive abilities relevant to a
particular school’s curriculum.
1. Definition of an Interview in Psychological
Assessment:
An interview is a method of gathering
information through direct communication,
often involving reciprocal exchange. Unlike
casual conversations, psychological interviews
focus not only on the content of what is being
said but also on nonverbal cues (e.g., body
language, facial expressions, eye contact, and
the interviewee’s reaction to questions). The
interview can be conducted in various formats,
including face-to-face, by telephone, online, or
even via text messaging.
2. Verbal and Nonverbal Behavior:
In face-to-face interviews, nonverbal behavior
plays a significant role in assessing the
interviewee. Interviewers observe:
•
Body language: movements, posture,
and gestures.
•
Facial expressions: reactions to
questions or situations.
•
Eye contact: the extent to which the
interviewee engages with the
interviewer.
•
Willingness to cooperate: how open
and responsive the interviewee is.
•
Appearance: how the interviewee is
dressed and whether it’s neat or
appropriate for the setting.
For interviews conducted by phone or text, the
interviewer may rely on changes in voice tone,
pitch, pauses, or emotional responses, as
nonverbal cues are limited.
3. Types of Interviews:
•
•
•
•
Diagnostic Interviews: Used by
psychologists to assess individuals in
clinical settings for conditions like
mental health issues or to make
treatment decisions.
Selection Interviews: Used in human
resources to assist in hiring or
promotion decisions.
Therapeutic Interviews: Aimed at both
gathering information and making
changes in the interviewee’s behavior
or thinking. One specific technique here
is motivational interviewing, which
combines person-centered skills with
techniques designed to alter behavior
and motivation. It has been successfully
applied in various contexts, including
addiction therapy, health behavior
change, and even through nontraditional mediums like text messaging
and the internet.
Panel Interviews: Involve multiple
interviewers to minimize the bias of a
single interviewer, though they may be
costly and time-consuming.
4. Purpose of Interviews:
Interviews can be used to:
•
Gather information for diagnostic or
treatment purposes in clinical settings.
•
Assist in decisions regarding
educational interventions or
placements (e.g., school psychologists).
•
Provide insight for legal decisions, such
as assessing criminal responsibility (e.g.,
in court cases).
•
Gather data for consumer behavior
studies or market research.
•
Help assess personnel for hiring, firing,
and promotion decisions in the
workplace.
5. Skills of the Interviewer:
The quality of the interview depends heavily on
the interviewer's skills, such as:
•
Pacing: Knowing when to ask questions
and when to pause.
•
Rapport-building: Establishing a
connection and trust with the
interviewee.
•
Empathy and Genuineness: Being able
to convey understanding and
authenticity.
•
Flexibility: Adapting the approach to
different interviewees and situations.
•
Active Listening: Being sensitive to
verbal and nonverbal cues and
responding appropriately.
The interviewer’s personality and interviewing
style can also affect the responses given by the
interviewee. For example, an interviewer with a
calm, approachable style might elicit more
honest and thoughtful responses compared to a
more aggressive or unempathetic approach.
6. Motivational Interviewing:
A specific technique used in clinical psychology
and counseling is motivational interviewing. It
is defined as a therapeutic dialogue that
combines empathy, person-centered listening,
and cognitive-behavioral techniques to alter a
person’s motivation and promote behavior
change. This method is widely used for
addressing issues like addiction, health
behaviors, and other psychological challenges.
7. Applications of the Interview in Various
Fields:
Interviews are used across many disciplines
beyond psychology:
•
Media: Interviews are a staple of
television, radio, and internet
journalism. Effective interviewers in
media need to possess skills in asking
insightful questions and responding to
interviewees in ways that elicit valuable
information.
•
Education: In education, portfolio
assessments (e.g., a collection of
student work or an instructor’s
materials) are used alongside interviews
for hiring decisions and evaluating
educational abilities. For example, an
instructor’s portfolio could include
lesson plans, published research, and
visual aids
1. Case History Data
2. Behavioral Observation
Case history data refers to records, documents,
and other forms of information that capture the
background of an individual. These records
could be formal or informal and can include files
from institutions like schools, hospitals, and
criminal justice agencies. The data may also
come from letters, photographs, social media
posts, and even work samples.
Behavioral observation is the process of
watching and recording an individual’s actions,
either qualitatively (descriptive) or
quantitatively (measured). It is frequently used
in clinical, educational, and organizational
settings to assess and monitor behavior.
Types of Case History Data:
•
Official records: Institutional
documents, reports from schools,
hospitals, or criminal justice agencies.
•
Informal sources: Photos, family
albums, social media posts (e.g.,
Facebook or Twitter), letters, and
personal memorabilia.
•
Other items: Audiotapes, work
samples, artwork, and hobby-related
materials.
Types of Behavioral Observation:
•
Naturalistic observation: Observing
behavior in its natural context, such as
observing children with autism in
playground settings rather than
controlled labs.
•
Controlled observation: Conducting
observations in settings like classrooms,
clinics, or behavioral research labs.
Uses in Assessment:
•
Therapeutic intervention: Behavioral
observation helps design interventions,
such as observing children’s social
interactions or the performance of
patients in daily tasks (e.g., grocery
shopping skills).
•
Selection and placement: In
organizational settings, observing
individuals can help identify those with
the right skills for specific tasks.
Uses in Assessment:
•
Clinical evaluations: Helps understand
a person’s adjustment and the events
leading to changes in behavior.
•
Neuropsychological assessments:
Provides historical context about brain
functioning prior to injury or trauma.
•
Educational settings: Helps understand
academic or behavioral performance
and assists in placement decisions.
Case Study/History: A case study is a detailed
report on an individual or event based on
collected case history data. It is used to
illustrate the relationship between personality
and environment or to understand phenomena
like groupthink (a psychological event in
decision-making processes).
Pros and Cons of Case History Data:
•
Pros: Provides rich, contextual
background, which can help inform
diagnosis and decisions (e.g., in
neuropsychology or school
placements).
•
Cons: Can be incomplete, biased, or
difficult to verify. There may also be
issues with privacy and ethics,
especially in using social media data.
Pros and Cons of Behavioral Observation:
•
Pros: Provides direct, real-time data on
behavior, which can be insightful for
diagnosing and designing interventions.
•
Cons: Observing real-world behavior
outside controlled settings can be timeconsuming and logistically challenging.
Also, it may not capture every aspect of
the behavior of interest if only some
behaviors are targeted for observation.
3. Role-Play Tests
A role-play test involves participants acting out
a simulated situation to assess various skills,
such as decision-making, problem-solving, or
emotional response. Role play is commonly
used in training environments or in clinical
assessments.
Uses in Assessment:
•
•
•
Corporate/Organizational Contexts:
Employees may be asked to mediate
disputes or handle hypothetical
scenarios, which helps assess
managerial or leadership abilities.
Clinical Contexts: Role plays can
simulate real-life situations (e.g., for
substance abuse patients), allowing
clinicians to evaluate coping
mechanisms or behavioral responses
before and after therapy.
Training: For example, astronauts might
role-play emergency scenarios to
simulate space conditions without the
need for an actual space mission.
paper, computers can serve as test
administrators, providing automated and
consistent administration of tests.
Roles Computers Play in Test Administration:
•
Efficient Scoring: Computers can score
tests within seconds, producing not
only raw scores but also patterns in the
data.
•
On-Site or Centralized Processing:
Computers may process data locally on
the test-taker's device or send it to a
central location for processing (via
teleprocessing, mail, or courier).
•
Test Reports: After scoring, the
computer can generate various types of
reports, from simple score lists to
detailed, interpretive reports. Some of
these reports can integrate data from
other sources (e.g., medical records,
behavioral observations).
Pros and Cons of Role-Play as an Assessment
Tool:
•
•
Pros: Provides a controlled
environment to assess specific skills
without the real-world consequences. It
can simulate rare or challenging
situations, saving time and resources.
Cons: May not be fully representative of
how someone would react in real-life
situations. It also requires proper setup
and may be artificial, which can limit its
applicability for some types of
evaluation.
2. Types of Computer-Generated Reports
Computers can generate different kinds of
reports based on the test data:
•
Scoring Reports: Basic report showing
the test scores.
•
Extended Scoring Reports: Include
detailed statistical analysis of test
performance.
•
Interpretive Reports: Provide numerical
or narrative interpretations of scores,
highlighting key observations.
•
Consultative Reports: Provide expert
opinions or analysis, typically aimed at
professionals working in assessment or
clinical settings.
•
Integrative Reports: Incorporate other
relevant data (e.g., medication history,
behavioral observations) into the test
results.
Summary:
Each of these assessment methods—Case
History Data, Behavioral Observation, and
Role-Play Tests—provides valuable insights but
also has limitations. Here are the key points:
•
Case History Data: Useful for
understanding a person’s background,
but there are concerns about
completeness, bias, and ethical issues.
•
Behavioral Observation: Provides direct
data on behavior, though practical
limitations exist (e.g., time and access).
•
Role-Play Tests: Effective in simulating
real-world situations for skills
assessment, but may lack the
authenticity of actual behavior.
1. Computers in Test Administration
Computers are increasingly used to administer
tests, both online and offline. Beyond just
replacing traditional tools like pencils and
3. CAPA (Computer-Assisted Psychological
Assessment)
CAPA refers to the use of computers to assist in
the psychological assessment process. The term
"assisted" refers to how computers help test
users, not the test-takers themselves.
Computers can:
•
•
Aid in Test Administration: By
simplifying and automating processes
like scoring and interpretation.
•
Psychometrically Sound: Enables the
use of complex mathematical models
that would have been difficult to apply
manually.
•
Customizability: Test users can create
tailor-made assessments with
integrated scoring and interpretation
features.
Enhance Efficiency: Reduces the time
and effort required to manually score
and interpret tests.
Example of CAPA Tool:
•
scoring and interpretation, leading to
faster results.
Q-Interactive: A product from Pearson
Assessments that allows test
administrators to use two iPads (one for
the tester and one for the test-taker)
connected via Bluetooth. This
eliminates the need for traditional test
kits, and the scoring is immediate.
However, the tool has limitations, such
as only supporting a limited number of
tests and not being compatible with
Android or Windows systems.
Challenges of CAPA:
•
Limited Test Availability: Not all tests
are available in the computerized
format.
•
Selection Caution: Test users must
carefully select tests based on the
objectives of the assessment and the
characteristics of the test-taker.
•
Technical Limitations: Some systems
(like Q-Interactive) are limited in
compatibility and available tests,
requiring test users to revert to
traditional methods in certain
situations.
4. Computer Adaptive Testing (CAT)
CAT refers to a type of testing where the
computer adapts the test based on the testtaker’s responses:
•
•
Adaptive Nature: For example, if a testtaker struggles with a set of math
questions, the test might automatically
switch to questions in another subject
like English.
Real-Time Feedback: Some CAT
systems provide real-time feedback,
which can enhance motivation and
engagement during the test.
5. Advantages and Challenges of CAPA
Advantages of CAPA:
•
Time and Efficiency: Automates
previously time-consuming tasks like
Conclusion
Computers have revolutionized the field of
psychological assessment by providing tools
that allow for faster, more efficient test
administration, scoring, and interpretation.
CAPA and CAT are significant advancements,
offering tailored assessments and dynamic
testing experiences. However, test users must
consider the pros and cons, such as technical
limitations and the careful selection of tests,
when integrating computers into the
assessment process.
Pros of CAPA
1.
Time Savings: CAPA significantly reduces
the amount of time professionals spend on
administering tests, scoring, and
interpreting results.
2.
Minimized Human Error: Scoring errors due
to human mistakes, lapses in attention, or
judgment are minimized.
3.
Standardized Administration: CAPA
ensures that the test is administered in a
standardized manner with minimal
variation between test-takers.
4.
Standardized Interpretation: The
interpretation of test results is consistent
across all test-takers, eliminating variability
that could stem from individual professional
judgment.
5.
Increased Accuracy: Computers are able to
combine data according to rules more
accurately than humans.
Cons of CAPA
1.
Learning Curve: Professionals must still
spend time familiarizing themselves with
software, hardware, and other
documentation related to the test and its
interpretation.
2.
Software/Hardware Errors: There is a risk
of malfunction due to software glitches or
hardware issues, which can be difficult to
identify and resolve.
3.
Test-Taker Disadvantages: Some testtakers may struggle with CAPA systems,
particularly if they are unable to use
familiar test-taking strategies (e.g.,
previewing questions, skipping, or revisiting
questions).
4.
Limited Flexibility in Interpretation: The
standardized interpretation may not always
be ideal, as alternative viewpoints or
flexibility in interpretation could sometimes
provide better insights.
5.
Lack of Contextual Understanding: While
computers can apply rules accurately, they
lack human flexibility and may miss
exceptions or nuances in context that a
human evaluator could recognize.
6.
Use of Nonprofessionals in Administration:
Nonprofessionals can help in administering
the test, making it easier to handle large
groups of test-takers.
7.
Development of Guidelines: Professional
groups, like the APA (American
Psychological Association), create
guidelines and standards to ensure the
proper use of CAPA products.
8.
Paper-to-Computer Conversion: Paper-andpencil tests can be converted into
computer-based formats, leading to quicker
scoring and interpretation.
9.
Security: CAPA products can be secured
using traditional means, as well as modern
high-tech solutions like firewalls to protect
sensitive data.
10. Adaptive Testing: CAPA can automatically
adjust the test content and length based on
a test-taker's responses, personalizing the
test.
6.
Limited Observation of Test-Taker
Behavior: Since nonprofessionals can assist
with test administration, there is less
opportunity for professionals to observe
test-takers' behavior and account for
extraneous factors influencing the results.
7.
Unregulated Test Creation: Profit-driven
nonprofessionals might create and
distribute tests without adhering to
professional standards or guidelines, which
can affect the quality of the assessment.
8.
Test Conversion Issues: The process of
converting traditional paper tests into
computer-based formats may raise
concerns about whether the computerized
version is equivalent to the original paper
version.
9.
Security Vulnerabilities: While electronic
security measures exist, CAPA systems are
still vulnerable to hacking, computer
viruses, and other cyber threats that could
compromise data integrity.
10. Inconsistent Test Experience: Since not all
test-takers will experience the same test
content (due to adaptive testing), this can
create variability in the testing experience
for different individuals.
Who Are the Parties in the Assessment
Enterprise?
In psychological assessment, several key parties
are involved in the process:
1. Test Developers and Publishers: These
are the individuals or organizations that
create and distribute tests. They design
the tests, ensure their validity and
reliability, and often publish them for
use by professionals. The American
Psychological Association (APA)
estimates that more than 20,000 new
psychological tests are developed each
year. These tests can be created for
specific research purposes, as
refinements of existing tests, or for
broader distribution. Test developers
adhere to standards for ethical and
responsible test development, ensuring
that the tests are both scientifically
sound and fair in their use.
2. Test Users: This group includes
professionals who administer, interpret,
and use tests in practice. This may
include psychologists, counselors,
school psychologists, human resources
professionals, and other professionals
who may use assessments in their work.
However, there is ongoing debate over
who should be allowed to use
psychological tests, especially when it
comes to non-psychologists, like
occupational therapists or HR
executives, seeking access to these
tools. Ethical and professional
guidelines help define which individuals
are qualified to use psychological tests.
3. Test takers: The people being evaluated
through the test are called testtakers or
assessee. The experiences of testtakers
can vary widely depending on factors
like test anxiety, understanding of the
assessment, and cooperation with the
process. For example, someone
experiencing emotional distress or
physical discomfort may have different
test outcomes than someone in a more
neutral state. Additionally, some
testtakers may be influenced by
coaching, preconceived notions, or
personal strategies for answering
questions.
In a more unusual context, even deceased
individuals can be considered "testtakers"
through a psychological autopsy, which
reconstructs a person’s psychological profile
posthumously using archival records,
interviews, and artifacts.
4. Society at Large: Society also plays a
role in the assessment enterprise
because the results of tests can have
wide-reaching implications for
individuals, groups, and communities.
The ethical use of psychological tests
influences how individuals are treated
in educational, employment, and
clinical settings, and the outcomes of
these tests can shape societal policies
or perceptions.
Key Reflection Questions
1. Cautions for Internet Test Users: When
using tests from the internet, it is
important to be cautious about the
source of the test. Are the tests
developed by reputable professionals?
Are they scientifically valid? Are they
ethically designed and appropriate for
the intended use?
2. Using Video vs. Paper-and-Pencil Tests:
Video assessments may be beneficial in
contexts where non-verbal behavior,
social interactions, or performance in
realistic scenarios needs to be
evaluated, like in the assessment of
social skills or job interviews. However,
video assessments can present pitfalls
like subjectivity, cost, or the lack of
control over the test-taker's
environment.
Conclusion
The assessment enterprise involves a range of
parties, including test developers, users,
testtakers, and society at large. The
involvement of these groups raises important
ethical, professional, and practical questions
about who is qualified to administer tests, the
impact of the tests on individuals, and how tests
should be conducted. In considering these
issues, it is essential to adhere to established
ethical guidelines to ensure fairness, accuracy,
and respect for those being test
In What Types of Settings Are Assessments
Conducted, and Why?
•
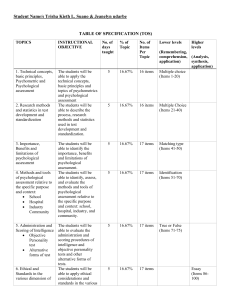
1. Educational Settings
•
•
Purpose: In schools, assessments are
primarily conducted to evaluate
students’ abilities, achievements, and
learning progress. They help identify
children who may have special needs,
determine academic placement, and
measure achievement levels.
•
3. Counseling Settings
•
Purpose: Counseling assessments are
intended to assist clients in improving
their emotional and psychological wellbeing. These settings focus on
interventions aimed at enhancing
social adjustment, career direction, and
personal development.
•
Types of Tests:
Types of Tests:
o
Achievement Tests: Assess
how much a student has
learned.
o
Diagnostic Tests: Identify
learning difficulties and areas
requiring intervention.
o
Informal Evaluations: Teacher
observations and less formal
evaluations contribute to
assessing students'
performance in areas like social
interactions or participation in
class.
Example: Standardized tests such as
the SAT or GRE measure academic
proficiency and are used for college
admissions.
•
•
Purpose: In clinical settings,
assessments help diagnose behavior
problems, psychological disorders, and
evaluate individuals for therapeutic
interventions.
o
Personality and Interest
Inventories: Assess a person’s
social, emotional, and cognitive
functioning.
o
Career Counseling
Assessments: Help determine
career paths suited to an
individual's interests and
abilities.
Example: A counselor might use a
personality inventory to assess a
client’s coping mechanisms for stress.
4. Geriatric Settings
•
Purpose: Psychological assessments
for older adults typically focus on
cognitive decline, mental health issues,
and quality of life. This is especially
relevant given the growing aging
population.
•
Types of Tests:
2. Clinical Settings
•
Example: Intelligence tests or
personality assessments may be used
by clinicians to help in diagnosis or
therapeutic decisions.
o
Cognitive Functioning Tests:
Screen for conditions like
dementia or Alzheimer's
disease.
o
Quality of Life Evaluations:
Assess overall life satisfaction,
social support, and emotional
well-being.
Types of Tests:
o
o
o
Psychological Tests: Used to
assess personality, intelligence,
and neuropsychological health.
Behavioral Assessments:
Applied to screen or diagnose
conditions like ADHD, anxiety,
depression, or schizophrenia.
Forensic Evaluations: In some
cases, psychologists assess
defendants’ mental health or a
prisoner’s rehabilitation status
for legal purposes.
•
Example: Tools for dementia diagnosis
or assessments of mental health,
including screening for depression in
elderly individuals.
5. Business and Military Settings
•
•
•
Purpose: Assessments in these
environments are often used to
evaluate employee performance,
suitability for specific roles, leadership
qualities, and potential for promotion.
Types of Tests:
o
Aptitude Tests: Measure a
person's skills and ability to
perform specific tasks (e.g.,
attention to detail).
o
Personality and Leadership
Assessments: Used for
leadership development and
team dynamics in both military
and business settings.
•
o
Specialization Exams: For
professionals to demonstrate
expertise in a specialized area
(e.g., board certifications for
doctors).
Example: A psychologist might have to
pass a certification exam to practice
psychology.
7. Academic Research Settings
•
Purpose: Academic research often
relies on measurements and tests to
study various psychological
phenomena. Researchers use
assessment tools to gather data and
test hypotheses.
o
Behavioral and Cognitive
Assessments: Used to study
specific behaviors, cognitive
processes, or phenomena.
o
Surveys and Questionnaires:
Frequently used for data
collection in social psychology
and other research domains.
Example: Researchers may assess
individuals' emotional responses to
stimuli in a study on mood regulation.
•
Purpose: There are many other
specialized settings in which
assessments are used, including
consumer research, product
development, and engineering
psychology.
•
Types of Tests:
Types of Tests:
Licensing Exams: Assess the
knowledge and skills required
for specific professions (e.g.,
medical licensing or bar exams
for lawyers).
Types of Tests:
8. Other Settings
Purpose: These assessments ensure
that professionals meet the necessary
qualifications and standards to practice
in regulated fields. Licensing exams are
one example.
o
•
•
Example: Air traffic controllers might
be assessed for their ability to stay
focused for long periods, while military
officers may undergo leadership
evaluations.
6. Governmental and Organizational
Credentialing
•
•
•
o
Market Research Assessments:
Used to understand consumer
preferences and improve
product design.
o
Ergonomic Testing: Focuses on
optimizing tools and
environments to fit human
needs and improve safety or
efficiency.
Example: Companies use psychological
assessments to study consumer
behavior or preferences for new
products.
Why Are Assessments Conducted?
Assessments serve multiple functions, such as
identifying areas of need, diagnosing
psychological or cognitive conditions, guiding
personal or professional development, and
improving overall decision-making in various
settings. Whether for academic placement,
clinical diagnosis, career counseling, or
research, assessments are essential tools for
understanding individuals’ abilities, behaviors,
and mental health.
In summary, assessments are conducted in
diverse settings to gather information, guide
interventions, and make informed decisions
about individuals' well-being, performance,
and potential.
1. Legal/Court Settings
•
•
Purpose: Courts rely on psychological
assessments and expert testimony to
inform decisions regarding legal
competence and mental health status.
For example, questions like “Is this
defendant competent to stand trial?”
or “Did the defendant know right from
wrong at the time of the criminal act?”
are central to legal proceedings.
Surveys, Questionnaires, and
Data Collection: Used to gather
information on the program's
progress, participant
satisfaction, and effectiveness.
o
Outcome Measures: These
evaluate whether the
program’s desired changes
have occurred, such as health
improvements or academic
advancements.
Assessment Tools:
o
o
•
o
Competency Evaluations:
Psychological assessments
help determine if a defendant
understands the legal
proceedings or can assist in
their own defense.
Insanity Defense Assessments:
Evaluate whether a defendant
had the mental capacity to
understand the nature of their
crime and whether they were
aware of the moral wrongness
at the time.
Example: A forensic psychologist might
administer personality tests or
intelligence assessments to evaluate
whether a defendant is capable of
standing trial or whether mental illness
played a role in the commission of a
crime.
•
Example: A government health
program aiming to reduce smoking
rates may use pre- and post-program
surveys to measure behavior changes
and the effectiveness of interventions.
3. Health Psychology
•
Purpose: Health psychology explores
how psychological factors influence
health and illness, focusing on the
relationship between behavior,
lifestyle, and physical health.
Psychological tests in health
psychology help assess health
behaviors, treatment progress, and the
outcomes of interventions.
•
Assessment Tools:
o
Personality and Behavior
Assessments: These help
understand how certain
personality traits (e.g., stress
levels, coping mechanisms)
might affect a person’s health
outcomes.
o
Lifestyle and Health Behavior
Surveys: These might measure
things like smoking habits,
exercise routines, or eating
habits and how they impact
physical health.
2. Program Evaluation
•
•
Purpose: Measurement plays a crucial
role in evaluating the effectiveness of
various programs, ranging from
government initiatives to privately
funded projects. These evaluations aim
to answer questions such as:
o
Is the program achieving its
goals?
o
Where should funds be
allocated to maximize impact?
o
How can the program be
improved or refined?
Assessment Tools:
•
Example: Researchers in health
psychology may compare smokers and
nonsmokers using personality and
behavioral tests to understand how
certain psychological traits affect
longevity and quality of life.
4. Other Research and Practice Areas
•
Purpose: Psychological assessment
tools are integral across nearly every
specialty in psychology. Whether in
clinical, educational, business, or health
settings, measurement techniques
provide crucial insights into human
behavior and aid in treatment,
research, and decision-making.
•
Accuracy and Objectivity: Assessments
help provide accurate and
standardized ways of measuring
behaviors, capabilities, and health
statuses. This ensures that decisions
(legal, therapeutic, educational, or
organizational) are based on objective
data.
•
Assessment Tools:
•
Improvement and Intervention: In
clinical, health, and counseling settings,
psychological tests are used to tailor
interventions, track progress, and
determine the effectiveness of
treatment programs.
•
Policy and Program Effectiveness: In
public programs or private initiatives,
assessments provide data on program
outcomes and suggest areas for
improvement, ensuring that resources
are used efficiently.
•
o
Interviews and Surveys: Used
widely to gather data on
various psychological
phenomena.
o
Behavioral Observations: Help
assess how people behave in
different environments, such
as the workplace or during
therapy.
o
Psychometric Tests: Designed
to assess specific traits like
intelligence, personality, or
psychological disorders.
Example: In organizational psychology,
employee motivation and job
satisfaction might be measured using
standardized personality inventories or
job engagement surveys.
Why Are These Tools Important?
In summary, psychological tests and
measurements are essential tools used to
gather data, make informed decisions,
evaluate programs, and improve individual and
societal well-being across various domains.
Whether it's determining legal competency,
understanding health behaviors, or assessing
the effectiveness of an intervention, these
tools provide vital insights for shaping
outcomes.
A Historical Perspective
•
Ancient Testing in China: The earliest known testing systems were in China, around 2200 B.C.E.,
used to select government officials based on written exams. The content of these tests varied
across dynasties, covering subjects such as military strategy, law, literature, and social rites.
Success on these exams brought privileges, including exemption from taxes and even torture.
•
Greco-Roman and Medieval Views: In ancient Greece and Rome, people were categorized
based on their bodily fluids, which were believed to influence their personality. The Middle
Ages had more peculiar concerns, such as determining who might be “in league with the
Devil,” influencing the nature of tests during this time.
•
Renaissance to the 18th Century: Psychological measurement began to take shape, with
Christian von Wolff in the 18th century laying the groundwork for psychology as a science.
Darwin’s work on natural selection in 1859 sparked interest in individual differences in both
humans and animals, which led to early psychological testing.
•
Francis Galton and Measurement: Galton’s studies on heredity, first with peas and later with
humans, advanced psychological measurement methods. He developed tools such as
questionnaires, rating scales, and self-report inventories, alongside his work on statistical
concepts like correlation.
•
Wilhelm Wundt: Wundt, known as the father of experimental psychology, focused on human
abilities like reaction time and attention span. He emphasized understanding people's
similarities rather than differences, contrasting with Galton’s focus on individual variations.
Wundt's students, including James McKeen Cattell, expanded the field of psychological
testing.
The 20th Century and Psychological Testing
•
Early Intelligence Testing: Alfred Binet, a French psychologist, created the first intelligence test
in the early 20th century to help identify children in need of special education. This test laid the
foundation for intelligence testing, which became widely used in schools and beyond.
•
David Wechsler and Adult Intelligence: In 1939, Wechsler introduced an intelligence test for
adults, the Wechsler-Bellevue Scale, which would evolve into the Wechsler Adult Intelligence
Scale (WAIS). This was a critical advancement in intelligence testing.
•
Group Intelligence Tests: During World War I and World War II, the need to quickly assess large
groups led to the development of group intelligence tests. These tests were designed for
military recruits but eventually had widespread civilian applications.
•
Personality Testing: In the early 20th century, the field expanded to include tests of
personality, with the development of the Woodworth Psychoneurotic Inventory, a self-report
personality test. However, self-report methods raised concerns due to their reliance on the
individual's insight and honesty.
•
Projective Tests: To address the limitations of self-report methods, projective tests were
developed, such as the Rorschach inkblot test. These tests assume that people project their
inner thoughts, fears, and desires onto ambiguous stimuli, providing insight into their
unconscious motivations.
Reflection Questions: The chapter includes thought-provoking questions encouraging readers to
consider the evolving nature of psychological testing and its application in various contexts, such as
the comparison between ancient and modern civil service exams or the evolving definitions of
intelligence across the lifespan.
Cultural Sensitivity in Testing: Early intelligence testing did not consider cultural and
language differences, leading to misinterpretation of results. Tests developed without
including minority groups, such as in the case of the Wechsler-Bellevue Intelligence Scale,
showed how cultural bias can skew results. This is evident in tests like the Wechsler
Intelligence Scale for Children (WISC), which, when first developed, included no minority
children in its sample.
Language Barriers and Miscommunication: If test-takers cannot understand the language
of the test or if cultural idioms are used that are unfamiliar to them, their responses may not
reflect their true abilities. For example, a child from a Hispanic background might struggle
with a question about going to the store for bread if that child is more accustomed to tortillas
being the staple food.
Cultural-Specific Tests: In response to these issues, some test developers began creating
culture-specific tests. However, this approach has its own limitations because it still doesn't
account for the wide range of cultural differences within a population.
Bias in Historical Testing: One example provided was Henry H. Goddard’s use of intelligence
tests to assess immigrants coming into the U.S. at Ellis Island. His findings, which showed high
rates of mental deficiency among various immigrant groups, were later criticized for failing to
account for cultural and language barriers, as well as for using flawed translation methods.
Importance of Context in Assessment: The text stresses the importance of understanding
an individual's cultural background when making psychological assessments, recognizing that
intelligence and other psychological traits are culturally relative. For example, in collectivist
cultures, behaviors that may be considered pathological in an individualistic culture, like
dependency, could be seen as normal or even desirable.
Role of the Assessor: Assessors must be sensitive to the culture of the person being tested,
considering how cultural norms may affect behavior during an assessment. The way
nonverbal cues are interpreted and the pace at which individuals process information can
differ depending on cultural background.
Future of Cultural Sensitivity in Testing: Today, the test development process is more
inclusive. Developers try to create tests that are fair for all cultural groups by piloting them
with diverse samples, analyzing potential biases, and refining items that may
disproportionately affect certain groups.
1. Historical Bias in Testing
The Wechsler-Bellevue Intelligence Scale and the Wechsler Intelligence Scale for Children (WISC),
which became widely used, initially contained samples with no minority representation. The omission
was due to concerns over the appropriateness of norms for minority groups, particularly Black
Americans. Early intelligence tests were developed primarily for White populations, leading to biases
when applied to other cultural groups. Tests like the WISC posed problems, such as asking questions
based on cultural knowledge (e.g., knowledge of bread), which did not align with the experiences of
children from different cultural backgrounds (e.g., Hispanic children familiar with tortillas).
2. Steps to Address Bias in Modern Testing
Today, test developers take steps to address potential cultural bias by ensuring that a sample of
individuals from different cultural backgrounds is included in test development. The process involves
administering preliminary versions to a representative sample, gathering feedback on test items, and
analyzing them for any potential biases related to race, gender, or culture. This helps ensure that the
tests are appropriate for a diverse population, reflecting cultural sensitivity and inclusivity.
3. Language and Communication Barriers
Verbal communication is a critical aspect of assessment. Tests must be conducted in a language or
dialect that the assessee understands to avoid misunderstandings that may affect the results. In
instances where a translator is required, it's essential that the translator is skilled and knowledgeable
to avoid miscommunication and unintended bias. Additionally, cultural differences in language use,
such as idioms, vocabulary, and even the speed at which someone speaks or answers, can influence
how individuals perform on assessments.
4. Nonverbal Communication and Cultural Differences
Nonverbal communication also plays a significant role in assessment. Different cultures may interpret
nonverbal cues, such as eye contact, body posture, or facial expressions, in varying ways. For example,
in American culture, avoiding eye contact may be seen as deceitful, whereas in other cultures, it could
be a sign of respect. Misunderstanding these nonverbal cues can lead to misinterpretation of test
results, making it critical for assessors to be aware of cultural differences in body language.
5. Cultural Relativity of Psychological Traits
Assessments should take into account the cultural context of the individual being assessed. What is
considered normal or pathological in one culture may not be perceived the same way in another. For
example, a diagnosis of dependent personality disorder might be viewed as problematic in
individualist cultures (like the U.S.), but it may be more culturally acceptable in collectivist cultures,
where dependence on others is a norm. This highlights the importance of applying culturally
appropriate standards when evaluating psychological traits.
6. The Need for Cultural Sensitivity in Testing
Cultural assimilation plays a significant role in how well someone performs on tests developed for a
particular culture. Those who have not been assimilated or exposed to the dominant culture may
struggle with tests that assume knowledge of cultural norms. Responsible test users and clinicians
should consider the extent to which a person has assimilated to the dominant culture and how that
may influence their performance on assessments.
7. Ethical Considerations
The text also raises ethical questions related to how test results are interpreted. It is crucial for
professionals to be aware of potential biases in testing and to ask questions about the
appropriateness of norms used, the individual's cultural background, and the applicability of the test
results. These considerations are especially important in clinical and legal settings where assessments
are used to make important decisions about an individual's capabilities, diagnosis, or treatment.
In conclusion, the text emphasizes the importance of cultural awareness in psychological assessment
and the need for continuous efforts to ensure fairness and equity in the testing process. Responsible
test development, sensitive administration, and thoughtful interpretation are necessary to avoid
biases and to better understand the diverse backgrounds of test-takers.
Henry Herbert Goddard's career, while marked by significant achievements in psychology, is deeply
controversial and illustrates the dangers of improper research methods and flawed assumptions in
scientific work. His life and contributions are a case study in how the field of psychology, particularly
intelligence testing, can become entangled with social and political ideologies. Goddard, originally
trained in psychology, played a pivotal role in introducing Alfred Binet’s intelligence tests to the United
States, where they were used to diagnose and make decisions about individuals, from immigrants to
criminals. However, his methods and interpretations often led to harmful, unfounded conclusions.
His famous work The Kallikak Family used a questionable methodology to claim that intelligence,
specifically "feeblemindedness," was hereditary. His conclusions were not based on objective testing
of family members but on anecdotal reports and flawed data, such as assumptions based on physical
appearance. These claims were used to support eugenics—promoting the idea that individuals with
"lower intelligence" should be segregated or sterilized.
Goddard’s research had broad implications, particularly in the early 20th century, when intelligence
tests were used for purposes ranging from special education to military recruitment to immigration
screening. The tests, often used inappropriately or without consideration of cultural or language
differences, led to significant misclassification, especially of immigrants at Ellis Island, many of whom
were deemed intellectually deficient.
His support of eugenics, which advocated for the sterilization of those he deemed mentally deficient,
and his influence on social policies left a troubling legacy. This problematic association with eugenicist
ideas became more evident later, as his works were cited by groups with dangerous agendas, such as
the Nazi regime, which used similar pseudo-scientific ideas to justify atrocities like forced sterilizations
and mass genocide.
Despite these controversial aspects, Goddard made contributions that led to advancements in
educational psychology and the recognition of the importance of special education laws. However, his
legacy serves as a cautionary tale about the intersection of science, ethics, and social values. His work
underscores the need for critical thinking in the development and use of psychological tests,
particularly with respect to cultural sensitivity and scientific rigor.
Goddard's life reflects the complexities of historical figures who operated within the context of their
times. While he may not have had malicious intent, his work was influenced by the prevailing scientific
and societal views, which included biases about intelligence, race, and heredity. His career emphasizes
the importance of examining the ethical implications of psychological research and the ways in which
science can be misused to perpetuate harmful societal ideologies.
Key Points:
•
•
•
•
Group Differences in Test Scores:
o
Tests often show systematic group differences (e.g., cultural, racial).
o
When these differences result in failure to achieve desired outcomes (e.g., job or
education), it can lead to conflict and discrimination concerns.
Fairness and Criteria for Selection:
o
Equal opportunity advocates argue tests should measure only relevant skills (e.g., job
ability).
o
However, test criteria like physical requirements (e.g., height for police officers) can
disadvantage certain cultural groups, leading to claims of discrimination.
Affirmative Action:
o
Aims to address discrimination and promote equal opportunity by considering group
membership when evaluating test results.
o
This can involve adjusting scores based on group identity, but critics argue this
undermines fairness, calling it “inequity in equity”.
Legal and Ethical Challenges:
•
o
High-stakes tests (for jobs, education, parole) can impact lives dramatically, leading to
legal scrutiny.
o
Courts and legislators often weigh the balance between fairness and ensuring tests
don’t unfairly discriminate.
Public Perception and Policy:
o
Tests are seen as tools that may deny opportunities or rights.
o
There is public concern over how tests may unintentionally favor some groups,
prompting calls for oversight.
Analysis:
•
The use of tests in vocational, educational, and other settings can be problematic if group
differences impact the fairness of outcomes.
•
While objective measurement is often the goal, certain criteria (e.g., height, appearance) may
disproportionately disadvantage specific groups.
•
Affirmative action is controversial as it seeks to correct imbalances, but it risks creating new
inequalities by altering scores based on group membership.
•
Legal and ethical standards must be closely examined to ensure that tests are both fair and
useful, without inadvertently reinforcing discrimination.
Legal and Ethical Considerations:
Laws vs. Ethics:
•
Laws are rules that individuals must obey for societal benefit (e.g., traffic laws) but can
become controversial when applied to sensitive issues like abortion, capital punishment, and
affirmative action.
•
Ethics refers to principles of right conduct (e.g., “Never shoot ‘em in the back” in the Old
West) and sets standards of care and conduct for professionals.
Public Concerns on Testing:
•
The public has historically misunderstood psychological testing, sometimes leading to
misconceptions (e.g., “The only thing tests measure is the ability to take tests”).
•
No Child Left Behind Act (2001) and the Common Core State Standards (2010) sparked
significant public debate about testing in education.
•
Public discomfort with testing first grew post-World War I and increased after World War II and
the Sputnik launch, which led to large-scale testing programs in schools to identify talented
students.
•
Concerns grew in the 1960s when articles questioned intelligence tests and their fairness,
especially regarding racial disparities, leading to congressional hearings on the matter.
Legislation and Testing:
•
Public concern about testing led to legislative involvement and regulations. Congressional
hearings and laws were created to oversee the use of tests.
•
The National Defense Education Act (1958) funded testing programs to identify talented
students in response to Sputnik, leading to proliferation of testing in schools.
•
By the 1970s, minimum competency testing programs were enacted by various states,
reflecting growing state-level involvement in testing policy.
Ethical and Legal Issues in Testing and Assessment
Key Concepts:
•
Laws vs. Ethics: Laws are legally enforceable rules meant for societal good, while ethics are
moral principles guiding right conduct. While laws are universally applicable, ethics may vary
between professions. For instance, ethical principles in journalism demand presenting all sides
of an issue, and in research, data integrity is paramount. The standard of care in a profession,
such as psychology, is often shaped by these ethical norms.
•
Public Concerns About Testing: The public's understanding of psychological assessments has
often been limited, leading to misconceptions like "tests only measure the ability to take
tests." Such misunderstandings can result in public backlash, legislative action, or even
lawsuits. For example, the No Child Left Behind Act (2001) and Common Core Standards
sparked debates about the fairness and accuracy of educational assessments, often leading to
public protests or political opposition.
History of Testing Concerns:
•
Early Concerns: The public’s discomfort with testing dates back to the aftermath of World War
I, when military tests were adapted for civilian use. In the 1940s, following the launch of
Sputnik, tests to identify gifted children gained attention, prompting concerns over their
validity and fairness. By the 1960s, testing controversies reached a peak due to debates on the
nature of intelligence and racial differences in test scores.
•
Legislative Actions: Over time, various legislative actions have been implemented to address
public concerns. The National Defense Education Act (1958) increased government funding
for educational assessments, but public concern about the fairness of such tests grew. These
concerns were amplified in the 1970s when controversial theories about intelligence and race,
such as those proposed by Arthur Jensen, gained attention. This led to Congressional hearings
and calls for reform in psychological testing.
Significant Legislation and Case Law
Truth-in-Testing Laws:
•
Aimed at providing test-takers with more transparency about the tests they take, these laws
require test developers to disclose key information, such as test purpose, content, and scoring
procedures. This was implemented to reduce confusion and to prevent unfair practices but
posed challenges to test developers who argued that revealing too much could undermine
the test's effectiveness.
Key Court Cases:
1.
Adarand Constructors, Inc. v. Pena (1995): This case dealt with affirmative action policies and
whether they violated the Equal Protection Clause. The ruling required more stringent scrutiny
of race-based decisions in government contracting.
2. Jaffee v. Redmond (1996): This case emphasized the importance of confidentiality between a
psychotherapist and a client, which extends to psychological assessments and tests.
3. Grutter v. Bollinger (2003): The U.S. Supreme Court upheld the use of race as one factor in
admissions decisions at public universities, acknowledging the role of diversity in educational
settings.
4. Ricci v. DeStefano (2009): This case highlighted the tension between the use of raceconscious hiring practices and the protection against discrimination based on race, underlining
the complex balance between achieving diversity and ensuring fairness in hiring.
Testing and Employment Discrimination:
•
Disparate Treatment vs. Disparate Impact: Disparate treatment refers to intentional
discrimination, while disparate impact refers to unintentional discrimination that results from
seemingly neutral practices. Both are key concepts in legal challenges related to the use of
tests in employment, education, and other sectors.
•
Discrimination Claims: Legal challenges often revolve around whether employment tests
unfairly exclude certain groups. Employers must demonstrate that their selection procedures,
including tests, are valid and job-related. In cases of reverse discrimination, the issue is
whether certain practices unintentionally favor minority groups at the expense of majority
groups, regardless of qualifications.
Impact of Litigation on Testing Practices:
•
Lawsuits related to testing can result in significant financial and operational consequences for
employers. In addition to the immediate legal costs, such cases may result in changes to hiring
and testing protocols. For example, an employer found guilty of discrimination may have to
overhaul its hiring processes, which can be a lengthy and expensive endeavor.
Conclusion
Legal and ethical considerations in testing and assessment are crucial in shaping fair and effective
practices. While laws often respond to societal concerns about fairness and equity, ethics provides the
framework for maintaining integrity and trust in testing practices. The challenge lies in balancing the
needs of test developers, test-takers, and society at large, ensuring that tests are both scientifically
valid and ethically sound.
Reflection Questions:
1.
How can truth-in-testing laws be modified to better balance the needs of test-takers and
developers?
2. How can both government and private sectors address the skill gaps between different
groups, especially in employment testing and education?
•
Daubert is not applied uniformly across
jurisdictions; some still rely on the Frye
standard.
•
Example: In Zink v. State (2009), neuroimaging evidence was excluded under
the Frye standard.
Litigation and Legal Change:
•
Litigation can bring attention to
important issues, leading to legislative
changes.
•
Cases like PARC v. Commonwealth of
Pennsylvania (1971) and Mills v. Board of
Education of District of Columbia (1972)
spurred federal laws ensuring
education for children with disabilities.
Role of Expert Testimony:
•
•
Psychologists often act as expert
witnesses in civil, criminal, or
administrative cases.
They provide opinions on issues like
mental competence, emotional
distress, custody, and injury
evaluations.
Early History of Testing and Standards:
•
APA formed its first committee on
mental measurement in 1895 and
continued to explore testing-related
issues.
•
In 1916 and 1921, symposia were held
to address issues related to expanding
test usage.
•
In 1954, APA published Technical
Recommendations for Psychological
Tests and Diagnostic Tests, setting
forth testing standards.
Daubert v. Merrell Dow Pharmaceuticals
(1993):
•
A landmark case that reshaped the
admissibility of expert testimony.
•
Rejected the Frye standard of "general
acceptance" in favor of trial judges
having discretion to assess expert
testimony based on factors like
testability and error potential.
Testing Standards and Ethical
Considerations:
•
Over time, APA and other
organizations collaborated to develop
detailed testing standards, which were
periodically updated.
•
In 1950, APA defined three levels of
tests based on the expertise required
for their administration:
Federal Rules of Evidence (Rule 702):
•
•
Rule 702 allows broader expert
testimony beyond general acceptance,
assisting juries with understanding
complex issues.
Daubert expanded this to include
opinions from experts in non-scientific
fields (e.g., psychologists with personal
experience).
Subsequent Rulings:
•
•
General Electric Co. v. Joiner (1997)
emphasized the exclusion of unreliable
expert testimony.
Kumho Tire Co. Ltd. v. Carmichael
(1999) expanded Daubert principles to
include all expert testimony, not just
scientific research-based ones.
Jurisdictional Variability:
o
Level A: Basic tests that require
general orientation and
minimal knowledge.
o
Level B: Tests requiring
technical knowledge of
psychology and related fields.
o
Level C: Advanced tests
requiring substantial
understanding and supervised
experience.
Ethical Mandates for Test Use:
•
Psychological tests should only be
administered by qualified
professionals.
•
The Code of Fair Testing Practices in
Education sets standards in four areas:
test development, interpreting scores,
striving for fairness, and informing testtakers.
Criticism and Debate:
•
The law remains controversial with
critics arguing that suicide is never
rational and fearing that it could
normalize suicide.
•
Concerns about unethical practices,
where professionals may be hired to
give opinions supporting the decision.
•
Some fear that physician-assisted
suicide may be granted even for
individuals with mental health
problems rather than just physical
illness.
Legal Action and Qualifications:
•
•
•
APA has supported legal actions to
limit the use of psychological tests to
qualified personnel.
Some view these legal actions
skeptically, but they aim to ensure that
only qualified individuals conduct
assessments to protect public welfare.
Since 1987, APA has provided model
psychologist licensing laws to regulate
test usage and differentiation between
psychological testing and psychological
assessment.
Professional Ethics:
•
Mental health professionals, including
psychologists and psychiatrists, have
ethical codes requiring suicide
prevention.
•
The ODDA places clinicians in a
challenging position where they may
need to assess for physician-assisted
suicide, which conflicts with their usual
duty to prevent suicide.
Challenges with Test Use for People with
Disabilities:
•
Modifying tests for people with
disabilities can be challenging,
depending on the nature of the
disability (e.g., blindness).
•
Ethical issues arise in determining how
test stimuli are transformed, how
results are interpreted, and what
standards are applied.
First Case Under ODDA:
•
Ethical Issues with Terminally Ill Individuals:
•
•
In states like Oregon with “Death with
Dignity” laws, psychological
evaluations are required for individuals
requesting assistance in dying.
Evaluation of Death-with-Dignity Requests:
•
The psychological evaluation plays a
crucial role in life-or-death decisions,
raising complex ethical concerns.
Oregon's Death with Dignity Act (ODDA):
•
•
•
Enacted in 1997, allows terminally ill
patients with less than 6 months to live
to request a lethal dose of medication.
The first patient to use the ODDA
described the experience as peaceful,
in contrast to the often painful
struggles of individuals trying to end
their lives by other means.
Many psychologists in Oregon, when
surveyed, indicated they would decline
to perform the competency
assessment required under the ODDA,
citing ethical or personal reasons.
ODDA Assessment Process:
•
A psychological evaluation is required
to ensure the patient is competent to
make this life-ending decision and to
rule out psychiatric disorders affecting
judgment.
1. Review of Records and Case History:
Gather patient records to understand
their current functioning, medical
condition, and mental health.
•
The law does not consider this action
as suicide, assisted suicide, or
homicide.
2. Consultation with Treating
Professionals: Consult with the
patient's physician and other
professionals for additional insights.
•
3. Patient Interviews: Conduct
interviews to understand the patient's
reasoning, medical condition,
emotional and psychological state, and
any external pressures influencing their
decision.
•
4. Interviews with Family and
Significant Others: Assess family’s
perspective on the patient’s
adjustment and current situation.
•
5. Assessment of Competence:
Evaluate the patient’s reasoning and
decision-making capacity regarding
their request, using clinical and possibly
formal competency tests.
•
6. Assessment of Psychopathology:
Identify if the desire to end life is
influenced by psychiatric conditions
such as depression, anxiety, dementia,
etc.
•
scoring and interpretation
procedures are widely
available, but the quality and
relevance of the
interpretations often come
into question.
o
•
7. Reporting Findings and
Recommendations: Report the
findings on the patient's competence,
mental state, and any factors
influencing their request, and make
appropriate recommendations.
Ethical and Professional Concerns:
o
Poorly regulated online tests
could erode public trust in
legitimate psychological tests.
o
There’s an ongoing concern
about the differences in results
and experiences between tests
administered orally, online, or
with paper-and-pencil.
Advantages and Issues of Computer-Assisted
Psychological Assessment (CAPA):
•
Advantages:
o
•
•
International Guidelines:
o
Convenience: Computerized
tests are simpler to administer
and score, with a wide range of
testing activities available
online.
Major Issues:
o
o
o
Access and Security of
Software: Despite safeguards,
software may still be copied or
pirated. Unlike traditional test
kits, computerized tests are
easier to duplicate.
Comparability of Test Versions:
Many tests are now available in
both paper-and-pencil and
computerized formats.
However, there has been
insufficient research on how
these versions compare.
Value of Computerized
Interpretations: Computerized
•
Unregulated Online
Psychological Testing:
Numerous websites offer
psychological tests, but many
of them do not meet
professional standards. This
raises concerns about the
public’s perception of
psychological assessments and
the potential harm of
unregulated testing.
The International Test
Commission developed
guidelines to improve the
quality and security of online
testing. These guidelines focus
on technical aspects, quality,
and security to address these
concerns.
Guidelines for Special Populations:
o
The American Psychological
Association (APA) issues
special guidelines to support
professionals in working with
specific populations. These
guidelines help ensure
informed and developmentally
appropriate services.
o
Example: In 2015, APA
published guidelines for
psychological practice with
Transgender and Gender
Nonconforming (TGNC)
people, acknowledging gender
as a non-binary construct and
encouraging proper training for
psychology trainees to work
competently with TGNC
individuals.
•
Other Resources:
o
Other organizations, such as
the Royal College of
Psychiatrists and various
international groups, also offer
best practices and guidelines
for specialized psychological
assessments, particularly in
areas like gender dysphoria.
1. The Right of Informed Consent
Testtakers must be fully informed about the purpose of the evaluation, how the test data will be used,
and who will have access to the results. This is essential for them to provide informed consent to
participate. The language used in this disclosure should be understandable to the testtaker, whether
they are a young child, someone with limited language skills, or an individual with a cognitive disability.
Competency in giving informed consent is an important consideration. It involves understanding the
issues, being able to reason about them, and appreciating the situation. Some individuals, such as
those with cognitive impairments or psychiatric disorders, may struggle with providing informed
consent, and thus a legal guardian or representative may need to provide consent on their behalf. In
certain research settings, deception may be used, but it should be limited and followed by a debriefing
to ensure ethical standards are met.
2. The Right to Be Informed of Test Findings
Testtakers have a right to receive information about the results of their tests in language that is clear
and understandable. This includes not only the findings themselves but also any recommendations
based on those findings. Testtakers should also be made aware if the results are invalidated or if there
were any issues with the test administration. Ethical and legal standards now require full disclosure of
test findings, unlike the past when assessors often kept results minimal to avoid creating distress.
3. The Right to Privacy and Confidentiality
Privacy refers to an individual's control over the sharing of their personal information, while
confidentiality is the duty of the professional to protect that information. Testtakers’ personal data
must be safeguarded, and there are legal protections, such as the privileged communications
between psychologists and their clients. However, confidentiality is not absolute. There are situations
where information might be disclosed, such as if a client is a threat to themselves or others, as seen in
the Tarasoff v. Regents of the University of California case.
Psychologists must also take precautions to protect test data, whether it is stored physically or
electronically. There are specific regulations like HIPAA (Health Insurance Portability and Accountability
Act) to guide how personal health information should be managed and protected.
4. The Right to the Least Stigmatizing Label
This right ensures that testtakers are not given labels that could cause harm or discrimination. Test
results should be communicated in a way that minimizes stigma, and any diagnoses or labels should
be used cautiously and appropriately.
Ethical Dilemmas in Test Administration:
•
Third-Party Observers: The presence of third-party observers during an assessment raises
ethical concerns. These observers might influence the test results, leading to biased or
inaccurate data. Some advocate for the prohibition of third-party observers, while others
argue that they are necessary in certain contexts, such as for legal or professional oversight.
•
Privacy Violations and Legal Orders: There may be legal situations in which a psychologist is
compelled to disclose confidential information. For example, if a person is at risk of harm, such
as a client threatening to commit violence, the professional may need to breach confidentiality
to protect the individual or others.
The Right to the Least
Stigmatizing Label
The principle of assigning
the least stigmatizing label
when reporting test results
is a key ethical guideline in
psychological assessments.
This principle helps ensure
that testtakers are not
unfairly or harmfully labeled
in a way that could affect
their lives and how others
perceive them. Labels can
carry significant social
weight, and being careful
with the terminology used in
test reports is essential to
prevent undue harm.
The Case of Jo Ann Iverson
The case of Jo Ann Iverson
highlights the potential
harm of stigmatizing labels.
Jo Ann, a 9-year-old girl with
claustrophobia, was
evaluated by a psychologist,
Arden Frandsen, who used
the term "feeble-minded, at
the high-grade moron level"
to describe her intellectual
abilities based on a StanfordBinet Intelligence Test. This
label was included in a
report sent to her school,
where it led to embarrassing
rumors about Jo Ann’s
mental condition.
Although the court ruled in
favor of the psychologist,
stating that the report was
made in good faith, the
harm caused to Jo Ann and
her family by the
stigmatizing label was
evident. Jo Ann's case
underscores the importance
of using language in
psychological reports that is
both respectful and mindful
of the potential long-term
effects on the individual.
Even though the
psychologist likely used
terminology from the test
manual, the consequences
for Jo Ann were harmful.
Ethical Implications
This case illustrates why the
least stigmatizing label
standard is vital. A label like
“high-grade moron” can
lead to social discrimination,
diminished self-esteem, and
unfair treatment. The
psychological field now
prioritizes avoiding such
terms and advocating for
more neutral, respectful
language. Professionals
must remember that labels
should not define a person
in a way that limits their
potential or exposes them
to harm.
Application of This Principle
In practice, psychologists
should consider the
following when assigning
labels:
•
•
•
Use descriptive
terms that focus on
the individual's
specific abilities or
challenges, rather
than using outdated
or derogatory
terminology.
When possible,
avoid using labels
that could create or
reinforce negative
stereotypes.
Test results should
be communicated
with sensitivity to
the impact on the
testtaker’s life,
taking into account
their mental and
emotional wellbeing.
Jo Ann Iverson’s story
highlights the significance of
this ethical guideline in
protecting the dignity and
future of those undergoing
psychological assessments.
By ensuring that test results
and labels are presented
thoughtfully, professionals
can reduce the potential for
stigma and promote better
outcomes for individuals
receiving evaluations.
Affirmative Action
Affirmative action refers to
policies or practices
designed to counteract
historical discrimination by
providing equal
opportunities to historically
marginalized groups, such as
minorities and women, in
education, employment,
and other areas. In
psychological testing, this
often involves ensuring that
tests are not biased against
certain groups and that their
results are fairly used.
Albemarle Paper Company v.
Moody
This 1975 U.S. Supreme
Court case dealt with the
issue of employment
discrimination and the use of
standardized tests in hiring
practices. It ruled that
employers must show that
their employment tests are
valid and predictive of job
performance to avoid
discrimination under Title VII
of the Civil Rights Act.
Alfred Binet
Binet was a French
psychologist who, with his
colleague Theodore Simon,
developed the first practical
intelligence test (the BinetSimon scale) in the early
20th century. His work laid
the foundation for modern
intelligence testing.
James McKeen Cattell
An American psychologist
known for his work on
mental testing, Cattell was
one of the first to apply
statistical methods to the
study of individual
differences in cognitive
abilities and was a key figure
in the development of
psychological testing.
Charles Darwin
Darwin's theory of evolution
and natural selection
influenced psychological
testing, particularly in the
areas of individual
differences and the role of
heredity in cognitive abilities.
His work inspired eugenics
and intelligence testing
debates.
Code of Fair Testing
Practices in Education
This code provides ethical
guidelines for the use of
tests in educational settings.
It emphasizes fairness,
accuracy, and respect for
test takers' rights in
educational assessments.
Code of Professional Ethics
This refers to ethical
guidelines established by
professional psychological
organizations (e.g., the
American Psychological
Association) to govern the
conduct of psychologists in
various areas, including
testing and assessment.
Collectivist Culture
In collectivist cultures,
individuals are more likely to
prioritize the needs and
goals of the group over
personal desires. This
cultural difference can affect
how individuals respond to
psychological assessments,
as test norms may reflect
individualistic values.
Confidentiality
Confidentiality is the ethical
and legal obligation to
protect the privacy of test
takers and ensure that their
test results and personal
information are not
disclosed without their
consent, except under
specific legal or professional
circumstances.
Culture
Culture refers to the shared
values, customs, practices,
and behaviors of a group of
people. It plays a crucial role
in shaping individuals'
cognitive processes, and it is
important for psychological
tests to be culturally
sensitive and free from bias.
Culture-Specific Test
A culture-specific test is
designed to assess
individuals within a particular
cultural group, taking into
account their unique
experiences, values, and
norms. It contrasts with
culturally neutral tests,
which aim to assess
cognitive abilities without
cultural bias.
Debra P. v. Turlington
This 1981 case involved a
legal challenge against
Florida's use of a high school
graduation test that
disproportionately affected
Black students. The court
ruled that the test was
discriminatory and not a
valid measure of academic
achievement.
Discrimination
Discrimination in
psychological testing occurs
when individuals are treated
unfairly or differently based
on characteristics such as
race, gender, or
socioeconomic status. This
can occur during the test
development,
administration, or
interpretation stages.
Disparate Impact
Disparate impact refers to a
situation where a seemingly
neutral test or policy has a
disproportionately negative
effect on a particular group,
even if the intention was not
to discriminate. It is often a
focus in employment and
educational testing.
Disparate Treatment
Disparate treatment occurs
when individuals or groups
are treated differently based
on characteristics like race or
gender, and such treatment
may be intentional or explicit
in the context of testing.
Ethics
Ethics refers to moral
principles that govern the
conduct of psychologists
and other professionals,
particularly in testing and
assessment. Ethical
standards ensure that test
results are used in fair,
responsible, and respectful
ways.
Eugenics
Eugenics is the controversial
belief in improving the
genetic quality of the human
population through selective
breeding or other methods,
often tied to the
development and use of
intelligence tests in the early
20th century.
Francis Galton
Galton was a British
polymath who contributed
to the development of
psychological testing by
pioneering research in the
measurement of intelligence
and the application of
statistical methods to
psychological traits.
Henry H. Goddard
Goddard was an American
psychologist and eugenicist
who translated and
popularized the Binet-Simon
intelligence test in the U.S.
He also played a role in using
intelligence testing for
immigration policies.
Griggs v. Duke Power
Company
This 1971 Supreme Court
case involved a challenge to
an employment test that
had a disparate impact on
Black applicants. The Court
ruled that employment tests
must be job-related and
cannot discriminate against
minority groups.
HIPAA
The Health Insurance
Portability and
Accountability Act (HIPAA)
establishes privacy
protections for individuals'
health information, including
psychological test results. It
regulates how healthcare
providers handle and
disclose personal health
data.
A 1996 Supreme Court case
that recognized the
psychotherapist-patient
privilege, affirming that
communications between a
patient and therapist are
protected from disclosure in
court.
Hired Gun
Larry P. v. Riles
A "hired gun" is a term used
to describe an expert or
professional who is paid to
provide testimony or
opinions in legal cases, often
in a way that favors the
party paying for their
services.
This 1984 case involved a
challenge to the use of IQ
tests in California for placing
Black children in special
education programs. The
court ruled that IQ tests
were culturally biased and
discriminatory.
Hobson v. Hansen
Laws
A landmark 1967 case in
which the court found that
the use of intelligence tests
to track students into
different educational paths
disproportionately harmed
Black students, leading to
the dismantling of
discriminatory educational
practices.
Laws in psychological
testing refer to legal
regulations that govern how
tests are administered,
interpreted, and used,
ensuring that tests are fair,
valid, and ethical.
Individualist Culture
In individualist cultures,
individuals are encouraged
to prioritize personal goals
and achievements.
Psychological assessments
in individualistic societies
often focus on individual
traits and abilities rather
than group dynamics or
collective needs.
Informed Consent
Informed consent is the
process by which a testtaker
is fully informed about the
purpose, procedures, risks,
and uses of a psychological
assessment, and voluntarily
agrees to participate.
Jaffee v. Redmond
Litigation
Litigation in the context of
psychological testing refers
to legal proceedings
involving disputes over the
fairness, validity, and
application of tests in
educational, employment,
or clinical settings.
Minimum Competency
Testing Programs
These programs involve
standardized tests designed
to assess whether students
have acquired the basic skills
necessary for academic
success. They have been
controversial, particularly
regarding their fairness for
minority or disadvantaged
students.
Christiana D. Morgan
Morgan was an American
psychologist known for her
work on projective tests,
particularly the Thematic
Apperception Test (TAT),
which she co-developed
with Henry Murray.
Henry A. Murray
Murray was a psychologist
who developed the
Thematic Apperception Test
(TAT), a projective test used
to assess an individual's
personality through their
interpretations of
ambiguous images.
ODDA
ODDA stands for Objective
Data-Driven Assessment,
which refers to a form of
assessment that emphasizes
collecting and analyzing
data through standardized,
objective methods to make
decisions.
Karl Pearson
Pearson was a British
statistician who made
significant contributions to
the development of
statistical methods in
psychology, including the
correlation coefficient,
which measures the
relationship between two
variables.
Privacy Right
The privacy right refers to an
individual's right to control
personal information,
particularly in the context of
psychological assessments,
where test results and
personal data must be kept
confidential.
Privileged Information
Privileged information refers
to confidential
communication protected
by law from disclosure, such
as the communications
between a psychologist and
a client, which cannot
typically be shared without
consent.
Projective Test
A projective test is a type of
personality test in which
individuals respond to
ambiguous stimuli, such as
pictures or words, and their
responses are thought to
reveal underlying thoughts,
feelings, and attitudes.
Psychoanalysis
Psychoanalysis is a
therapeutic approach
developed by Sigmund
Freud that aims to explore
unconscious thoughts and
desires through techniques
such as dream analysis and
free association.
Public Law 105-17
This law, also known as the
Individuals with Disabilities
Education Act (IDEA),
ensures that children with
disabilities have access to a
free and appropriate public
education and that their
educational needs are
assessed and addressed.
Quota System
A quota system refers to a
method of allocating
positions or opportunities
(such as in employment or
education) based on a fixed
proportion, often used to
promote diversity, but
controversial when it
involves race or gender.
Reverse Discrimination
Reverse discrimination
refers to policies or practices
that favor historically
marginalized groups to the
point where individuals from
historically advantaged
groups feel they are being
unfairly treated.
Hermann Rorschach
Rorschach was a Swiss
psychiatrist best known for
developing the Rorschach
inkblot test, a projective test
used to assess personality
and emotional functioning.
Self-Report
A self-report is a method of
assessment in which
individuals provide
responses about their own
behavior, attitudes, or
experiences, often used in
personality and
psychological inventories.
Sputnik
The launch of the Sputnik
satellite in 1957 by the Soviet
Union sparked the "Sputnik
crisis," leading to increased
attention to science and
technology education in the
U.S. It also had an impact on
intelligence testing in
education.
Standard of Care
The standard of care refers
to the level of competence
and responsibility expected
of professionals, including
psychologists, in their field,
ensuring that they provide
appropriate and ethical
services.
Tarasoff v. Regents of the
University of California
A landmark 1976 case in
which the court ruled that a
psychologist has a duty to
warn potential victims if a
client threatens harm to
them, establishing the dutyto-warn principle in mental
health law.
Truth-in-Testing Legislation
These laws require that
standardized tests be
transparent, ensuring that
individuals know how their
test results will be used and
that the tests are fair and
unbiased.
David Wechsler
Wechsler was a prominent
psychologist who developed
several widely used
intelligence tests, including
the Wechsler Adult
Intelligence Scale (WAIS)
and the Wechsler
Intelligence Scale for
Children (WISC).
Lightner Witmer
Witmer was an American
psychologist who founded
the first psychological clinic
in 1896, which marked the
beginning of the clinical
psychology field, focusing
on the assessment and
treatment of individuals with
psychological problems.
Robert S. Woodworth
Woodworth was an
American psychologist
known for his development
of the Woodworth Personal
Data Sheet, one of the first
objective personality tests,
and his contributions to
experimental psychology.
Wilhelm Max Wundt
Wundt is often considered
the father of modern
psychology and founded the
first psychological laboratory
in 1879. He is known for his
work in experimental
psychology and the study of
consciousness.
Key Concepts in Measurement
1. Measurement and Scales:
o
Measurement is defined as assigning numbers or symbols to characteristics
of objects based on specific rules.
o
Scale refers to the set of numbers or symbols that represent the
characteristics of what is being measured. The scale could be continuous or
discrete, depending on the type of variable being measured.
o
Error in Measurement: All measurements involve some level of error. This
can arise from various factors, such as environmental conditions or
instrument limitations. For example, a test score may contain errors due to a
distracting thunderstorm or the selection of specific test items.
2. Four Levels of Measurement: The text introduces four distinct levels of
measurement, each offering different degrees of sophistication and types of
mathematical analysis that are appropriate:
o
o
o
o
Nominal Scales:
▪
These involve classification into categories. Numbers are used for
classification purposes but cannot be meaningfully added, subtracted,
or ranked. For example, diagnostic categories in clinical psychology
are nominal; someone is classified as having a disorder or not, without
any implication of order.
▪
Example: Yes/No questions like "Have you ever been convicted of a
felony?" categorize responses into two groups without any numerical
interpretation.
Ordinal Scales:
▪
These scales not only allow for classification but also enable rank
ordering. The numbers indicate an order, but the distances between
ranks are not necessarily equal.
▪
Example: Ranking job applicants by desirability or psychotherapy
patients by urgency for treatment.
▪
Key Limitation: The differences between ranks are not necessarily
uniform (e.g., the difference between 1st and 2nd place could be small,
while the difference between 2nd and 3rd could be large).
Interval Scales:
▪
These scales allow for classification, ranking, and equal intervals
between scale points. However, they do not have an absolute zero
point, meaning that zero does not represent a complete absence of the
measured trait.
▪
Example: IQ scores—an IQ of 100 is considered the same distance from
120 as 80 is from 100, but an IQ of 0 does not represent the total
absence of intelligence.
Ratio Scales:
▪
These scales possess all the properties of nominal, ordinal, and
interval scales, but also have a true zero point, meaning that
mathematical operations like multiplication
meaningful.
and division
are
▪
Example: Measuring time to complete a task, such as assembling a
puzzle. The time taken can be halved (e.g., 30 seconds is half of 60
seconds), and zero seconds would represent the absence of time
taken to complete the task.
▪
Key Insight: While this scale has a true zero, real-life scenarios may
not always allow for the possibility of achieving this zero value (e.g.,
no one can complete a task in exactly zero time).
Statistical Analysis:
•
Different levels of measurement determine which types of statistical analyses are
appropriate. For instance:
o
Nominal data can only be counted (how many in each category).
o
Ordinal data allows for rank-order analysis but no meaningful average.
o
Interval and Ratio data allow for more advanced statistical operations,
including means and standard deviations.
The Role of Errors in Measurement:
•
Measurement always involves some degree of error, and it is important to account
for these errors in test construction and analysis. For instance, test scores can be
influenced by external factors (like environmental distractions) or internal factors
(like an individual’s mood or test anxiety).
Thinking Critically About Scales:
The chapter also poses a series of reflective questions for readers to consider:
•
How can test creators reduce error when administering a test?
•
What are other examples of nominal, ordinal, interval, or ratio scales in everyday
life?
This refresher not only reiterates basic statistical concepts but also emphasizes the
importance of understanding how data is measured and categorized. The use of statistical
tools for interpreting test scores can add meaning to raw numbers and help psychologists,
teachers, and researchers make informed decisions based on test data.
Ratio Scale Examples:
•
•
•
Height: In centimeters or inches. The scale has a true zero (i.e., no height at all) and
allows for comparisons such as "twice as tall."
Weight: Measured in kilograms or pounds. A weight of 0 indicates no weight, and a
person weighing 80 kg is twice as heavy as someone weighing 40 kg.
Reaction Time: Time taken for an individual to respond to a stimulus, typically
measured in seconds or milliseconds. A reaction time of 0 seconds would mean no
response, and times can be compared proportionally (e.g., 10 seconds is twice as long as
5 seconds).
Interval Scale Examples:
•
Temperature: Measured in Celsius or Fahrenheit. These scales have equal intervals
between measurements (e.g., the difference between 10°C and 20°C is the same as
•
between 20°C and 30°C), but there's no true zero point. A temperature of 0°C doesn't
mean "no temperature," it just marks the freezing point of water.
IQ Scores: Typically measured on an interval scale. The difference between an IQ of 100
and 110 is the same as between 110 and 120. However, 0 on the IQ scale doesn't imply a
complete lack of intelligence, making it not a true zero.
Why Psychologists Sometimes Treat Ordinal Data as Interval Data:
Psychologists sometimes treat ordinal data (e.g., rankings) as interval data to apply more
sophisticated statistical methods that assume equal intervals, such as computing means. For
example, many personality tests are based on ranking individuals' traits, and while the data are
technically ordinal, analysts might treat them as interval-level data to take advantage of tools like
averages and standard deviations.
However, as Kerlinger cautioned, such data must be interpreted carefully. If the intervals are
unequal (for instance, the difference in personality traits between two individuals may not be
equal across different parts of the scale), treating the data as interval could lead to misleading
conclusions.
Frequency Distributions:
In your example, when you have a set of raw scores (like test scores), one of the first steps is
often to organize the data in a frequency distribution. This can help you and others understand
the pattern of scores. For instance:
•
•
You can create a simple frequency distribution, where each individual score is listed
with how many times it occurred. For instance, if a score of 80 occurred 5 times in a class
of 25 students, you'd note that in your table.
You can also create grouped frequency distributions where you group scores into
ranges, such as 0–10, 11–20, and so on, which can help you observe patterns and outliers
more easily.
This kind of data organization is fundamental in making sense of test results and communicating
those results effectively. Would you like to explore more about how to work with frequency
distributions or other methods of summarizing data?
Measures of Central Tendency
Measures of central tendency are statistics that summarize a distribution of data by identifying
the center or typical value. These measures help provide a single representative number for the data.
The most common measures are the mean, median, and mode. Here’s a breakdown:
1. Mean (Arithmetic Mean):
The mean is often referred to as the "average." It is the sum of all the scores in the dataset
divided by the number of scores. This measure takes into account every value in the data set and is
typically the most commonly used measure of central tendency, especially for interval or ratio data
when the distribution is approximately normal (symmetrical).
•
Formula for the mean:
Xˉ=ΣXn\bar{X} = \frac{\Sigma X}{n}Xˉ=nΣX
where:
o
Xˉ\bar{X}Xˉ is the mean,
o
ΣX\Sigma XΣX is the sum of all the test scores,
o
nnn is the number of scores.
Example:
If the scores are 5, 7, 9, and 10, the mean would be:
Xˉ=5+7+9+104=314=7.75\bar{X} = \frac{5 + 7 + 9 + 10}{4} = \frac{31}{4} = 7.75Xˉ=45+7+9+10
=431=7.75
2. Mean from a Frequency Distribution:
When you have a frequency distribution (where scores are grouped into intervals or classes),
the formula for calculating the mean becomes:
Xˉ=Σ(f×X)n\bar{X} = \frac{\Sigma (f \times X)}{n}Xˉ=nΣ(f×X)
Where:
•
fff is the frequency of each class interval,
•
XXX is the midpoint of each class interval,
•
nnn is the total number of observations.
For example, let's say we have a grouped frequency distribution like this:
Class Interval
Frequency (f)
Midpoint (X)
f×Xf \times Xf×X
40–44
5
42
210
45–49
8
47
376
50–54
10
52
520
55–59
2
57
114
Total
25
The formula would give:
Xˉ=122025=48.8\bar{X} = \frac{1220}{25} = 48.8Xˉ=251220=48.8
In this case, the mean of the grouped data is 48.8.
1220
3. Median:
The median is the middle value of a data set when the values are arranged in order (either
ascending or descending). If there is an odd number of data points, the median is the value in the
middle. If there is an even number of data points, the median is the average of the two middle values.
•
For an odd number of scores:
The median is the value at the position n+12\frac{n+1}{2}2n+1.
•
For an even number of scores:
The median is the average of the values at positions n2\frac{n}{2}2n and n2+1\frac{n}{2} + 12n
+1.
4. Mode:
The mode is the score or value that appears most frequently in a data set. It can be useful when
analyzing categorical or nominal data. There may be no mode (if all values are unique), one mode, or
multiple modes (if several values are tied for the most frequent).
Why Use These Measures?
•
The mean is typically the most informative measure for interval and ratio data, especially when
the distribution is symmetrical.
•
The median is more useful when dealing with skewed data or outliers because it is less sensitive
to extreme values.
•
The mode can be useful for identifying the most common value, especially in categorical data.
Example for Mean from Grouped Data:
Let's say you're working with a grouped frequency distribution of scores (as shown above), and
you calculate the mean of 48.8. This gives you a summary of where the "center" of the distribution lies.
Summary of When to Use Each Measure:
•
Mean: Used when data is continuous and approximately normal, and you need to consider all
data points.
•
Median: Best when the data is skewed or has outliers (since it's less affected by extreme
values).
•
Mode: Useful for categorical data or when you want to know the most frequent score.
If you have a specific set of data or if you'd like to calculate one of these measures, feel free to
share, and I can help walk you through the process!
Median:
•
The median is the middle value in a data set when the scores are arranged in either ascending
or descending order.
•
If there is an odd number of scores, the median is the middle score.
•
If there is an even number of scores, the median is the average of the two middle scores.
Example (from your text):
For 10 scores: 66, 65, 61, 59, 53, 52, 41, 36, 35, 32:
•
Order them: 66, 65, 61, 59, 53, 52, 41, 36, 35, 32.
•
The middle scores are 53 and 52, so the median = (53 + 52) / 2 = 52.5.
•
The median is useful when there are extreme scores (outliers) or when the data is skewed. It is
an appropriate measure for ordinal, interval, and ratio data.
Mode:
•
The mode is the most frequently occurring score in a data set.
•
A distribution can have:
o
One mode (unimodal)
o
Two modes (bimodal)
o
More than two modes (multimodal)
Example (from your text):
For the scores: 43, 34, 45, 51, 42, 31, 51:
•
The most frequent score is 51 (appears twice), so 51 is the mode.
•
The mode can be helpful in cases where you want to identify the most common or frequent
observation, such as analyzing customer preferences or the most common score in a test.
Key Points:
•
The mode is simple to find, and unlike the mean, it doesn't require complex calculations.
•
However, the mode might not represent the "central" tendency if the most frequent score is an
extreme value.
Summary:
•
Median: Middle score; good when data is skewed or has outliers.
•
Mode: Most frequent score; useful for qualitative data or identifying common occurrences.
•
The mean is often the most stable and reliable measure of central tendency, but median and
mode are valuable in certain situations where distribution isn't symmetrical or has outliers.
Measures of Variability - Summary for Board Exam:
Variability refers to the spread or dispersion of scores in a data set. Understanding variability helps to
understand how different the data points are from the mean.
Key Measures of Variability:
1. Range:
o
The simplest measure of variability.
o
Calculated as the difference between the highest and lowest scores in the data set.
o
Example: If the highest score is 60 and the lowest score is 40, the range is 60−40=2060 40 = 2060−40=20.
o
Limitation: It can be heavily influenced by extreme scores (outliers), making it a less
reliable measure.
2. Interquartile Range (IQR):
o
Divides the data into four equal parts (quartiles).
o
The IQR is the difference between the third quartile (Q3) and the first quartile (Q1), i.e.,
Q3−Q1Q3 - Q1Q3−Q1.
o
More robust than the range because it focuses on the middle 50% of the data, excluding
extreme outliers.
3. Semi-Interquartile Range:
o
This is half of the IQR. It is Q3−Q12\frac{Q3 - Q1}{2}2Q3−Q1.
o
It is useful for understanding the spread of the middle 50% of the data, especially when
the data set is large.
4. Average Deviation (AD):
o
The average of the absolute deviations from the mean.
o
Formula: AD=∑∣X−mean∣nAD = \frac{\sum |X - \text{mean}|}{n}AD=n∑∣X−mean∣, where
XXX represents individual data points.
o
Rarely used because it doesn't consider the direction of deviations (positive or
negative).
o
Provides a measure of the average distance from the mean.
5. Variance:
o
Measures the average squared deviations from the mean.
o
The formula for variance (s2s^2s2) is: s2=∑(X−mean)2ns^2 = \frac{\sum (X \text{mean})^2}{n}s2=n∑(X−mean)2
o
Variance is more widely used in statistical analyses as it includes squared deviations,
which make it more sensitive to outliers.
6. Standard Deviation (SD):
o
The square root of the variance.
o
It gives a more intuitive measure of spread because it is in the same units as the data
(unlike variance which is in squared units).
o
Formula: s=s2=∑(X−mean)2ns = \sqrt{s^2} = \sqrt{\frac{\sum (X \text{mean})^2}{n}}s=s2=n∑(X−mean)2
o
Standard deviation is a key measure in psychology and other fields for assessing
variability.
o
It accounts for every data point's distance from the mean, making it a more complete
measure than the range.
Calculating Standard Deviation:
•
To find the standard deviation:
1. Find the mean of the data.
2. Subtract the mean from each data point to find the deviation.
3. Square each deviation.
4. Find the average of the squared deviations (variance).
5. Take the square root of the variance to get the standard deviation.
Population vs Sample Standard Deviation:
•
If the data represents a sample from a larger population, use n−1n-1n−1 in the denominator to
get an unbiased estimate (this is called Bessel's correction).
•
For data from an entire population, use nnn in the denominator.
Standard Deviation vs Average Deviation:
•
Standard deviation provides more insight because it considers all deviations and is based on
squared differences, while average deviation uses absolute values and is not as useful for
further calculations.
Why Use Standard Deviation?
•
Standard deviation is widely used because it gives a more comprehensive measure of variability,
factoring in all deviations from the mean and providing insights into how scores are spread out
in relation to the mean. It's particularly helpful when the data follows a normal distribution.
Key Takeaway:
•
Standard deviation is often preferred because it accounts for all data points and is
mathematically more versatile, especially when analyzing normally distributed data
Skewness
Skewness refers to the lack of symmetry in a distribution:
•
Positive skew: A distribution is positively skewed when the majority of scores are clustered
toward the lower end of the scale, with a tail stretching to the higher end. This often indicates
that the test was too difficult, and most test-takers scored poorly.
o
For example, the Marine Corps Ability and Endurance Screening Test might produce a
positively skewed distribution where only a few participants perform exceptionally well.
•
Negative skew: A negatively skewed distribution occurs when most scores are at the higher end,
with a tail stretching toward the lower end. This might suggest that the test was too easy, as a
majority of test-takers perform well, and only a few score poorly.
•
Skewness in distributions: Skewness is neither inherently good nor bad; it simply indicates the
nature of the distribution. In some cases, it might even be desirable, depending on the context
(like the Marine Corps example).
Kurtosis
Kurtosis describes the "peakedness" of a distribution:
•
Platykurtic: Distributions that are relatively flat, indicating fewer extreme scores.
•
Leptokurtic: Distributions that are sharply peaked, with heavier tails. This means there are more
extreme values at both ends of the distribution.
•
Mesokurtic: Distributions with a normal peak and similar characteristics to a normal
distribution.
Kurtosis gives a shorthand description of a distribution’s shape in terms of how extreme or concentrated
the values are around the mean.
The Normal Curve
The normal curve (or bell curve) is central to many statistical methods:
•
It is symmetrical with the mean, median, and mode all equal, and it is bell-shaped.
•
The curve approaches, but never touches, the horizontal axis.
•
It is important because many psychological tests aim for their scores to follow a normal
distribution, where most people score near the average, and fewer people score very high or
very low.
The Area Under the Normal Curve
The area under the normal curve can be broken down into standard deviations, which allows us to
understand the proportion of scores that fall within certain ranges.
In your example of a National Spelling Test with a mean of 50 and a standard deviation of 15:
•
A score that is 1 standard deviation above the mean would be 65 (50 + 15), which helps us
understand the spread of scores in terms of standard deviations.
•
Normal Distribution: The normal distribution is described as a bell-shaped curve that is
symmetric and characterized by a mean, median, and mode all being equal. The area
under the curve represents percentages of scores falling within standard deviations (like
68%, 95%, and 99.74%).
Understanding Tails in the Normal Distribution: Scores that fall within the tails of the
distribution (i.e., more than two standard deviations away from the mean) can have
significant real-life consequences, such as identifying individuals with intellectual
disabilities or those who are gifted. The article highlights that mental ability performance
at these extremes impacts life outcomes and classifications.
Standard Scores: These are derived from raw scores and help compare test takers’
performance relative to others. The text explains various systems for standard scores,
including:
o Z-scores: Represent how many standard deviations a raw score is from the mean.
It’s calculated by subtracting the mean from the raw score and dividing by the
standard deviation.
o T-scores: Similar to Z-scores but with a mean of 50 and a standard deviation of
10.
o Stanines: A standard score system that divides scores into nine units, each
representing half a standard deviation, often used in school testing.
Normalized Standard Scores: When raw data is skewed and doesn't fit a normal
distribution, it may be "normalized" so that it conforms to the normal distribution. This
process helps make the scores comparable to those from other tests that are normally
distributed.
•
•
•
The passage uses the example of a spelling test to demonstrate the application of z-scores, Tscores, and how these can give us valuable insights into the relative performance of test-takers.
Standard scores make it easier to interpret where a score falls in comparison to others, regardless
of raw score differences. They provide clarity and context to the results.
1. Correlation Basics:
o
Correlation measures the degree of relationship between two variables. It can tell us if
one variable increases or decreases as another one does.
o
The correlation coefficient (r) quantifies this relationship on a scale from -1 to +1,
where:
o
▪
+1 indicates a perfect positive correlation (both variables increase or decrease
together).
▪
-1 indicates a perfect negative correlation (one variable increases while the
other decreases).
▪
0 indicates no correlation (no relationship between the variables).
Magnitude matters, meaning a correlation of -0.99 is just as strong as +0.99, though
with the opposite direction.
2. Positive and Negative Correlations:
o
Positive correlation: Both variables increase together (e.g., height and weight of
children).
o
Negative correlation: One variable increases while the other decreases (e.g., car
mileage and trade-in value).
o
Zero correlation: No predictable relationship between the two variables.
3. Correlation Does Not Imply Causation:
o
Just because two variables are correlated doesn’t mean one causes the other. For
example, a high correlation between hat size and spelling ability doesn’t suggest that
hat size causes better spelling.
o
Correlation can be useful for prediction, though—if you know one variable, you might
predict the other with some accuracy.
4. The Pearson r:
o
This is the most widely used method to calculate correlation, especially when the
relationship is linear and the data is continuous.
o
The Pearson r uses the deviation of scores from their mean and measures how the
scores on two variables correspond.
o
Formula for Pearson r: r=∑(X−Xˉ)(Y−Yˉ)∑(X−Xˉ)2∑(Y−Yˉ)2r = \frac{\sum (X - \bar{X})(Y \bar{Y})}{\sqrt{\sum (X - \bar{X})^2 \sum (Y - \bar{Y})^2}}r=∑(X−Xˉ)2∑(Y−Yˉ)2
∑(X−Xˉ)(Y−Yˉ)
▪
Σ is the sum of the terms.
▪
X and Y are the values for the two variables.
▪
Xˉ\bar{X}Xˉ and Yˉ\bar{Y}Yˉ are the means for X and Y.
5. Statistical Significance:
o
Once you calculate the Pearson r, you can assess whether the correlation is statistically
significant (i.e., whether it is likely to have occurred by chance).
o
Statistical significance tables help determine whether a correlation coefficient is
meaningful, depending on the sample size.
6. Coefficient of Determination (r²):
o
r² is derived from the correlation coefficient and tells you how much variance in one
variable is explained by the other variable.
o
For example, if r = 0.9, then r² = 0.81, meaning that 81% of the variance is shared by the
two variables.
7. Psychometric Trivia:
o
The Pearson r is also called the "product-moment" correlation because it involves
multiplying deviations (moments) from the mean for both variables.
Reflection Points:
•
Perfect Correlations: It’s rare in psychological research to find perfect correlations. Variables are
often correlated, but not perfectly so.
•
Zero Correlations: Sometimes, the correlation between two variables might be zero, which can
still be meaningful because it shows that there is no relationship between them.
Key Concepts:
1. Spearman’s Rho (ρ):
o
Spearman's Rho is a correlation coefficient used when data are in ordinal (ranked) form
or when the sample size is small (fewer than 30 pairs of measurements).
o
It is also called a rank-order correlation coefficient because it is based on the ranks of
the data rather than their raw values.
o
This statistic is especially useful when the data do not meet the assumptions required
for the Pearson r, such as when the variables are not continuous or the relationship is
not linear.
o
Spearman's rho provides a measure of how well the relationship between two variables
can be described using a monotonic function (one that consistently increases or
decreases, but not necessarily at a constant rate).
2. When to Use Spearman’s Rho:
o
When both variables are ordinal (ranked).
o
When the sample size is small (fewer than 30 pairs of observations).
o
When the relationship between variables is not expected to be linear (i.e., not suitable
for Pearson r).
3. Graphical Representations of Correlation:
o
Scatterplots (or scatter diagrams/graphs) are a common way to visually represent
correlation. They display data points for two variables, with one placed on the x-axis and
the other on the y-axis.
o
Key Benefits of Scatterplots:
▪
Direction: The slope or direction of the points on the plot indicates whether the
relationship is positive (rising line) or negative (falling line).
▪
Strength: The closer the points are to forming a straight line, the stronger the
correlation. The more dispersed the points, the weaker the correlation.
▪
Nonlinearity: Scatterplots also help detect curvilinearity (nonlinear
relationships). If the data points curve, the relationship between the variables
may not be linear, which is a key consideration when choosing statistical
methods.
4. Curvilinearity:
o
Curvilinearity refers to situations where the relationship between the two variables is
not a straight line. If the scatterplot suggests a curve, then a Pearson r might not be the
right method, and alternative statistical techniques may be needed.
o
Example: If a graph shows a U-shaped or inverted U-shaped curve, this indicates a nonlinear relationship.
Visualizing Correlation:
•
Positive Correlation: When both variables increase or decrease together. A scatterplot showing
this would show points that form an upward-sloping line.
•
Negative Correlation: When one variable increases while the other decreases. The scatterplot
for this would show points forming a downward-sloping line.
•
No Correlation: When there’s no predictable relationship between the two variables. The points
would appear randomly scattered with no apparent pattern.
Special Considerations:
•
Significance of Spearman's Rho: Special tables are used to determine if the Spearman's rho
coefficient is statistically significant, especially when the sample size is small.
Summary:
•
Spearman’s rho is an important tool when working with non-continuous or ordinal data, or
when dealing with small sample sizes. For linear relationships, Pearson r is usually preferred, but
when the relationship isn’t linear or the data is ranked, Spearman’s rho offers an effective
alternative.
Definition
1. Arithmetic Mean:
Definition:
The arithmetic mean is the sum of all values in
a dataset divided by the number of values.
Situation:
A group of five friends recorded the number of
books they read this month: 2, 3, 5, 8, and 12
books. What is the arithmetic mean?
A. 6
B. 5
C. 4
Answer:
A. 6
Explanation:
The mean is calculated by adding all values:
(2+3+5+8+12)/5=30/5=6(2 + 3 + 5 + 8 + 12) / 5 =
30 / 5 = 6(2+3+5+8+12)/5=30/5=6.
So, the mean is 6.
2. Average Deviation:
Definition:
Average deviation is the average of the
absolute differences between each data point
and the mean.
Situation:
For the following dataset: 4, 7, 8, 5, 6, what is
the average deviation?
The mean of the data is 6.
A. 1
B. 2
C. 3
Answer:
A. 1
Explanation:
First, find the absolute deviations from the
mean (6):
|4 - 6| = 2, |7 - 6| = 1, |8 - 6| = 2, |5 - 6| = 1, |6
- 6| = 0
Average deviation = (2+1+2+1+0)/5=6/5=1.2(2
+ 1 + 2 + 1 + 0) / 5 = 6 / 5 =
1.2(2+1+2+1+0)/5=6/5=1.2.
Rounded, the answer is 1.
3. Bar Graph:
Definition:
A bar graph is a chart that uses rectangular
bars to represent data, with the length of each
bar proportional to the value it represents.
Situation:
A company tracks sales of different products in
a bar graph. Which of the following is true
about bar graphs?
A. They can only show continuous data
B. They are useful for comparing categories
C. They are not suitable for displaying large
datasets
Answer:
B. They are useful for comparing categories
Explanation:
Bar graphs are ideal for comparing quantities
across different categories, not for displaying
continuous data.
4. Bimodal Distribution:
Definition:
A bimodal distribution has two different
modes, which appear as distinct peaks in the
data's frequency distribution.
Situation:
The test scores of two groups of students, one
from a morning class and one from an evening
class, show two peaks in their frequency
distribution. What is this called?
A. Unimodal Distribution
B. Bimodal Distribution
C. Normal Distribution
Answer:
B. Bimodal Distribution
Explanation:
A bimodal distribution has two modes (peaks).
In this case, the two groups of students
contribute to two peaks in the distribution.
5. Bivariate Distribution:
Definition:
A bivariate distribution refers to the
distribution of two variables simultaneously,
often used in correlation and regression
analysis.
Situation:
A researcher is studying the relationship
between hours of study and exam scores in a
class of 30 students. What type of distribution
is this?
A. Univariate Distribution
B. Bivariate Distribution
C. Multivariate Distribution
Answer:
B. Bivariate Distribution
Explanation:
Since the researcher is looking at two
variables, hours of study and exam scores, the
distribution is bivariate.
6. Coefficient of Correlation:
Definition:
The coefficient of correlation (typically
Pearson’s rrr) measures the strength and
direction of the linear relationship between
two variables.
Situation:
In a study, the correlation between the
number of hours studied and test scores is
found to be 0.85. What does this indicate?
A. Strong negative correlation
B. Weak positive correlation
C. Strong positive correlation
Answer:
C. Strong positive correlation
Explanation:
A correlation coefficient of 0.85 indicates a
strong positive relationship. As one variable
increases, so does the other.
7. Coefficient of Determination:
Definition:
The coefficient of determination (r2r^2r2)
measures the proportion of the variance in the
dependent variable that is predictable from
the independent variable.
Situation:
In a regression analysis, r2=0.64r^2 =
0.64r2=0.64. What does this indicate?
A. 64% of the variance in the dependent
variable is explained by the independent
variable
B. 36% of the variance is explained by the
independent variable
C. There is no relationship between the
variables
Answer:
A. 64% of the variance in the dependent
variable is explained by the independent
variable
Explanation:
An r2r^2r2 value of 0.64 means that 64% of the
variability in the dependent variable can be
explained by the independent variable.
8. Correlation:
Definition:
Correlation refers to a statistical relationship
or association between two variables.
Situation:
A researcher finds that as the temperature
rises, ice cream sales increase. What type of
relationship is this?
A. Negative Correlation
B. Positive Correlation
C. No Correlation
Answer:
B. Positive Correlation
Explanation:
As one variable (temperature) increases, the
other variable (ice cream sales) also increases,
showing a positive correlation.
9. Curvilinearity:
Definition:
Curvilinearity refers to a relationship between
two variables that is not linear, but instead
follows a curved pattern.
Situation:
A scatter plot shows a U-shaped pattern
between age and job satisfaction. What type
of relationship is this?
A. Linear Relationship
B. Curvilinear Relationship
C. No Relationship
Answer:
B. Curvilinear Relationship
Explanation:
A U-shaped pattern indicates curvilinearity,
meaning the relationship between the
variables is not linear.
10. Distribution:
Definition:
A distribution refers to how the values of a
dataset are spread out across different values
or intervals.
Situation:
In a normal distribution, the majority of the
data points cluster around the mean, and the
distribution is symmetric. What is this an
example of?
A. Skewed Distribution
B. Uniform Distribution
C. Normal Distribution
Answer:
C. Normal Distribution
Explanation:
In a normal distribution, data points tend to
cluster around the mean, and the distribution
is symmetric, creating a bell-shaped curve.
11. Dynamometer:
Definition:
A dynamometer is a device used to measure
force, torque, or power.
Situation:
An engineer uses a dynamometer to measure
the force exerted by a car engine. What is the
engineer measuring?
A. Speed
B. Force
C. Distance
Answer:
B. Force
Explanation:
A dynamometer is used to measure force,
which can help in determining the power
output of engines or other mechanical
systems.
1. Effect Size:
Definition:
Effect size quantifies the magnitude of the
difference between two groups or the strength
of a relationship between variables. It is
commonly used to understand the practical
significance of a finding.
Situation:
A study finds that Group A has a mean score of
60, and Group B has a mean score of 50. The
standard deviation is 10. What is the effect size
using Cohen's d?
A. 0.5
B. 1.0
C. 2.0
Answer:
A. 0.5
Explanation:
Cohen’s d = (M1 - M2) / SD = (60 - 50) / 10 = 10
/ 10 = 1.0, so B is the correct answer, not A.
2. Error:
Definition:
Error refers to the difference between a
measured or observed value and the true value.
Situation:
If a thermometer reads 22°C, but the true
temperature is 20°C, what is the error in the
measurement?
A. 0°C
B. 2°C
C. 4°C
Answer:
B. 2°C
Explanation:
The error is the difference between the
observed value (22°C) and the true value (20°C).
Thus, 22 - 20 = 2°C.
3. Evidence-Based Practice:
Definition:
Evidence-based practice involves making
decisions and adopting practices based on the
best available research evidence.
Situation:
A doctor uses the latest clinical research to
decide on the best treatment for a patient.
What type of practice is this?
A. Intuitive Practice
B. Evidence-Based Practice
C. Experimental Practice
Answer:
B. Evidence-Based Practice
Explanation:
The practice of using research findings to
inform decision-making is termed evidencebased practice.
4. Frequency Distribution:
Definition:
A frequency distribution is a table that shows
the number of occurrences of each value or
range of values in a dataset.
Situation:
The ages of 10 people are: 12, 14, 12, 15, 13,
12, 14, 13, 14, 15. What is the frequency
distribution for this dataset?
A. 12: 3, 13: 2, 14: 3, 15: 2
B. 12: 2, 13: 3, 14: 3, 15: 2
C. 12: 2, 13: 2, 14: 2, 15: 4
Definition:
A graph is a visual representation of data that
shows the relationship between variables.
Situation:
Which of the following is a visual tool for
displaying data relationships?
A. Graph
B. Text Summary
C. Table
Answer:
A. Graph
Explanation:
A graph visually represents data relationships,
whereas tables or text summaries present data
in a different form.
7. Grouped Frequency Distribution:
Answer:
A. 12: 3, 13: 2, 14: 3, 15: 2
Explanation:
In this dataset, 12 appears 3 times, 13 appears 2
times, 14 appears 3 times, and 15 appears 2
times.
Definition:
A grouped frequency distribution is used when
data are grouped into intervals or ranges to
make the distribution easier to interpret.
5. Frequency Polygon:
A. Ungrouped Frequency Distribution
B. Grouped Frequency Distribution
C. Cumulative Frequency Distribution
Definition:
A frequency polygon is a graphical
representation of a frequency distribution,
created by connecting the midpoints of bars in a
histogram.
Situation:
You have the frequency distribution for a
dataset and plot a line graph connecting the
midpoints of the bars. What is this called?
A. Histogram
B. Frequency Polygon
C. Scatterplot
Answer:
B. Frequency Polygon
Explanation:
A frequency polygon is a line graph that
connects the midpoints of the bars of a
histogram.
6. Graph:
Situation:
A dataset of ages is grouped into intervals like
10-19, 20-29, etc. This is an example of:
Answer:
B. Grouped Frequency Distribution
Explanation:
Data grouped into intervals, like age ranges, is
known as a grouped frequency distribution.
8. Histogram:
Definition:
A histogram is a type of bar graph used to
represent the frequency distribution of a
continuous variable.
Situation:
A researcher uses bars to represent the
frequency of heights in a population. This is an
example of:
A. Histogram
B. Line Graph
C. Pie Chart
Answer:
A. Histogram
Explanation:
Histograms use bars to represent the frequency
of continuous data.
points are concentrated in the tails versus the
center.
9. Interquartile Range (IQR):
A. High Kurtosis
B. Low Kurtosis
C. Normal Kurtosis
Definition:
The interquartile range (IQR) is the difference
between the 75th percentile (Q3) and the 25th
percentile (Q1) in a dataset.
Situation:
The first quartile of a dataset is 10, and the
third quartile is 20. What is the IQR?
A. 10
B. 20
C. 30
Answer:
A. 10
Explanation:
The IQR is calculated as Q3−Q1=20−10=10Q3 Q1 = 20 - 10 = 10Q3−Q1=20−10=10.
10. Interval Scale:
Definition:
An interval scale is a type of measurement scale
where the differences between values are
meaningful, but there is no true zero point.
Situation:
Temperature in Celsius is measured. What type
of scale is used?
A. Ratio Scale
B. Interval Scale
C. Ordinal Scale
Answer:
B. Interval Scale
Explanation:
The temperature scale is an interval scale
because the differences between values are
meaningful, but zero does not represent the
absence of temperature.
11. Kurtosis:
Definition:
Kurtosis measures the "tailedness" of a
distribution, indicating the extent to which data
Situation:
A distribution with very heavy tails, where
extreme values occur more often than a normal
distribution, has:
Answer:
A. High Kurtosis
Explanation:
High kurtosis indicates a distribution with heavy
tails (more extreme values).
12. Leptokurtic:
Definition:
A leptokurtic distribution has a higher peak and
heavier tails than a normal distribution.
Situation:
A distribution that is more peaked and has
more extreme values than a normal distribution
is:
A. Leptokurtic
B. Platykurtic
C. Normal
Answer:
A. Leptokurtic
Explanation:
Leptokurtic distributions have higher peaks and
more extreme values in the tails.
13. Linear Transformation:
Definition:
A linear transformation involves scaling
(multiplying by a constant) and shifting (adding
a constant) the values of a dataset.
Situation:
A dataset is transformed by multiplying every
value by 2 and adding 5. What type of
transformation is this?
A. Linear Transformation
B. Nonlinear Transformation
C. Log Transformation
Answer:
A. Linear Transformation
Explanation:
Multiplying and adding constants are
characteristics of a linear transformation.
14. Mean:
Definition:
The mean is the arithmetic average of a set of
values, calculated by summing all the values
and dividing by the number of values.
Situation:
The values are 5, 7, 8, 10, and 15. What is the
mean?
A. 8
B. 9
C. 7.5
Answer:
B. 9
Explanation:
The sum is 5+7+8+10+15=455 + 7 + 8 + 10 + 15
= 455+7+8+10+15=45, and dividing by 5 gives
45/5=945 / 5 = 945/5=9.
15. Measurement:
Definition:
Measurement refers to the process of assigning
numbers or values to a variable or attribute
based on a set of rules.
Situation:
When recording the height of a person, what
are you performing?
A. Measurement
B. Data Analysis
C. Data Interpretation
Answer:
A. Measurement
Explanation:
Recording height involves assigning a value to a
person's attribute, which is a form of
measurement.
16. Measure of Central Tendency:
Definition:
A measure of central tendency is a statistical
measure used to determine the center of a
distribution. Common measures include the
mean, median, and mode.
Situation:
In a dataset with the values 3, 5, 7, 8, 10, the
measure of central tendency is:
A. Mean
B. Mode
C. Median
Answer:
A. Mean
Explanation:
The mean is typically considered the measure of
central tendency.
17. Measure of Variability:
Definition:
A measure of variability describes the spread or
dispersion of a dataset. Common measures
include range, variance, and standard deviation.
Situation:
If the standard deviation of a dataset is low,
what does it indicate?
A. The data points are spread out
B. The data points are close to the mean
C. The data points are all equal
Answer:
B. The data points are close to the mean
Explanation:
A low standard deviation indicates that the data
points are clustered close to the mean.
1. Median:
Definition:
The median is the middle value in a dataset
when the values are arranged in ascending or
descending order.
Situation:
For the following dataset: 3, 5, 8, 10, 12. What
is the median?
A. 5
B. 8
C. 10
Answer:
B. 8
Explanation:
The median is the middle value in the ordered
set (3, 5, 8, 10, 12), so the median is 8.
2. Mesokurtic:
Definition:
A mesokurtic distribution is one that has the
same level of peakedness as a normal
distribution, i.e., it is neither too flat nor too
peaked.
Situation:
Which distribution is considered to have a
normal level of peakedness?
A. Leptokurtic
B. Mesokurtic
C. Platykurtic
Answer:
B. Mesokurtic
Explanation:
A mesokurtic distribution has a normal level of
peakedness, similar to a bell-shaped curve.
3. Meta-Analysis:
Definition:
Meta-analysis is a statistical technique used to
combine results from multiple studies to
identify patterns or overall effects.
Situation:
A researcher combines data from several
clinical trials to determine the overall
effectiveness of a drug. This process is called:
A. Systematic Review
B. Meta-Analysis
C. Literature Review
Answer:
B. Meta-Analysis
Explanation:
Meta-analysis combines data from multiple
studies to calculate an overall effect or result.
4. Mode:
Definition:
The mode is the value that appears most
frequently in a dataset.
Situation:
In the dataset 5, 7, 7, 8, 10, what is the mode?
A. 7
B. 8
C. 10
Answer:
A. 7
Explanation:
The number 7 appears twice, more frequently
than any other value, so it is the mode.
5. Negative Skew:
Definition:
A negatively skewed distribution has a long tail
on the left side, meaning that most of the data
points are concentrated on the right.
Situation:
Which of the following distributions has a long
tail on the left side?
A. Positive Skew
B. Negative Skew
C. Normal Distribution
Answer:
B. Negative Skew
Explanation:
A negative skew has a long tail on the left side
of the distribution.
6. Nominal Scale:
Definition:
A nominal scale is a measurement scale that
classifies data into distinct categories that do
not have any inherent order.
Situation:
What type of scale is used to categorize
individuals by their favorite color (red, blue,
green)?
A. Ordinal Scale
B. Nominal Scale
C. Interval Scale
Answer:
B. Nominal Scale
Explanation:
A nominal scale categorizes data without any
ordering, such as color preferences.
7. Nonlinear Transformation:
Definition:
A nonlinear transformation involves applying a
function that alters the relationship between
the data values in a non-constant way (e.g.,
logarithmic or exponential transformations).
Situation:
Which of the following would be an example of
a nonlinear transformation?
A. Adding a constant value to every data point
B. Taking the square root of each data point
C. Multiplying each data point by a constant
Answer:
B. Taking the square root of each data point
Explanation:
Taking the square root is a nonlinear
transformation because it changes the data in a
non-constant way.
8. Normal Curve:
Definition:
A normal curve (or bell curve) is a symmetric,
unimodal distribution where the mean, median,
and mode are all equal.
Situation:
What type of distribution is symmetric and has
a bell-shaped curve?
A. Normal Curve
B. Bimodal Distribution
C. Skewed Distribution
Answer:
A. Normal Curve
Explanation:
A normal curve is symmetric and has a bellshaped distribution, with the mean, median,
and mode at the center.
9. Normalized Standard Score Scale:
Definition:
A normalized standard score scale (e.g., zscores) transforms data to have a mean of 0
and a standard deviation of 1.
Situation:
If a z-score is calculated for a data point and
results in a value of 2, what does this mean?
A. The data point is 2 standard deviations
above the mean
B. The data point is 2 standard deviations
below the mean
C. The data point is at the mean
Answer:
A. The data point is 2 standard deviations
above the mean
Explanation:
A z-score of 2 indicates that the value is 2
standard deviations above the mean.
10. Normalizing a Distribution:
Definition:
Normalizing a distribution involves transforming
data to fit a normal distribution, typically by
applying mathematical transformations.
Situation:
Which of the following actions involves
transforming data to make it fit a normal
distribution?
A. Normalizing a Distribution
B. Rescaling the Data
C. Trimming the Data
Answer:
A. Normalizing a Distribution
Explanation:
Normalizing a distribution adjusts the data to fit
a normal distribution.
11. Ordinal Scale:
Definition:
An ordinal scale is a measurement scale that
categorizes data with a meaningful order but no
precise differences between the categories.
Situation:
Which scale is used when ranking participants in
a race (1st, 2nd, 3rd)?
A. Ratio Scale
B. Ordinal Scale
C. Nominal Scale
Answer:
B. Ordinal Scale
Explanation:
An ordinal scale ranks data in a meaningful
order (e.g., race positions), but the differences
between ranks are not necessarily equal.
12. Outlier:
Definition:
An outlier is a data point that is significantly
different from other data points in a dataset.
Situation:
Which of the following would be considered an
outlier in the dataset: 2, 3, 5, 7, 100?
A. 5
B. 100
C. 7
Answer:
B. 100
Explanation:
The value 100 is significantly larger than the
other data points, making it an outlier.
13. Pearson r:
Definition:
The Pearson r is a measure of the linear
correlation between two variables, ranging
from -1 (perfect negative correlation) to +1
(perfect positive correlation).
Situation:
A Pearson r value of 0.8 indicates:
A. No correlation
B. Strong positive correlation
C. Strong negative correlation
Answer:
B. Strong positive correlation
Explanation:
A Pearson r value of 0.8 indicates a strong
positive correlation between the two variables.
14. Platykurtic:
Definition:
A platykurtic distribution has a flatter peak and
lighter tails compared to a normal distribution.
Situation:
Which distribution has a flatter peak and lighter
tails than the normal distribution?
A. Platykurtic
B. Leptokurtic
C. Normal Distribution
Answer:
A. Platykurtic
Explanation:
Platykurtic distributions are flatter and have
lighter tails compared to the normal
distribution.
15. Positive Skew:
Definition:
A positively skewed distribution has a long tail
on the right side, meaning most of the data are
concentrated on the left.
Situation:
Which distribution has a long tail on the right
side?
A. Positive Skew
B. Negative Skew
C. Normal Distribution
Answer:
A. Positive Skew
Explanation:
A positive skew has a long tail on the right side
of the distribution.
16. Quartile:
Definition:
A quartile divides a dataset into four equal
parts. The first quartile (Q1) represents the 25th
percentile, the second (Q2) is the median (50th
percentile), and the third (Q3) represents the
75th percentile.
Situation:
In a dataset of 100 values, what does the third
quartile (Q3) represent?
A. The lowest 25% of the values
B. The median of the upper half of the data
C. The highest 25% of the values
Answer:
B. The median of the upper half of the data
Explanation:
Q3 is the median of the upper half of the
dataset.
17. Range:
Definition:
The range is the difference between the
maximum and minimum values in a dataset.
Situation:
For the dataset 3, 7, 5, 10, 8, what is the range?
A. 7
B. 5
C. 2
Answer:
A. 7
Explanation:
The range is the difference between the
maximum value (10) and the minimum value
(3), so 10 - 3 = 7.
18. Rank-Order/Rank-Difference:
Definition:
Rank-order or rank-difference is a method of
ranking values in a dataset to measure
correlation (Spearman’s rho, for example).
Situation:
If a researcher ranks participants' scores from
highest to lowest, what method are they using?
A. Rank-Order
B. Raw Score Analysis
C. Normalization
Answer:
A. Rank-Order
Explanation:
Rank-order is used when participants' values
are ranked in order.
19. Correlation Coefficient:
Definition:
The correlation coefficient measures the
strength and direction of a linear relationship
between two variables.
Situation:
A correlation coefficient of -0.9 indicates:
A. A very weak positive correlation
B. A very strong negative correlation
C. No correlation
Answer:
B. A very strong negative correlation
Explanation:
A value of -0.9 indicates a very strong negative
correlation.
20. Ratio Scale:
Definition:
A ratio scale is a measurement scale that has a
true zero point and allows for the comparison
of absolute magnitudes.
Situation:
Which scale allows for meaningful ratios, such
as twice as much?
A. Ordinal Scale
B. Ratio Scale
C. Nominal Scale
Answer:
B. Ratio Scale
Explanation:
A ratio scale has a true zero point and allows for
meaningful comparisons of ratios, such as twice
as much.
21. Raw Score:
Definition:
A raw score is the original, untransformed score
in a dataset.
Situation:
In a test with scores of 45, 60, and 75, which is
the raw score?
A. 45
B. 60
C. 75
Answer:
C. 75
Explanation:
The raw score refers to the original score, and
75 is the raw score in this case.
1. Scale:
Definition:
A scale refers to the system or range of values
used to measure a variable, like the Likert scale
(used for attitudes), or measurement scales like
nominal, ordinal, interval, and ratio.
Situation:
Which of the following is a scale used for
measuring attitudes?
A. Nominal Scale
B. Likert Scale
C. Ordinal Scale
Answer:
B. Likert Scale
Explanation:
A Likert scale is commonly used to measure
attitudes and opinions with responses like
"Strongly Agree" or "Strongly Disagree."
2. Scatter Diagram / Scattergram / Scatterplot:
Definition:
A scatter diagram (also called a scatterplot or
scattergram) is a graph that displays the
relationship between two quantitative
variables, with each point representing an
observation in the dataset.
Situation:
What type of graph would you use to visually
represent the relationship between height and
weight for a group of individuals?
A. Bar Graph
B. Histogram
C. Scatterplot
Answer:
C. Scatterplot
Explanation:
A scatterplot is used to display the relationship
between two quantitative variables, such as
height and weight.
3. Semi-Interquartile Range:
Definition:
The semi-interquartile range is half of the
interquartile range (IQR), which measures the
spread of the middle 50% of the data.
Situation:
If the first quartile (Q1) is 25 and the third
quartile (Q3) is 75, what is the semiinterquartile range?
A. 25
B. 50
C. 12.5
Answer:
B. 50
Explanation:
The interquartile range (IQR) is 75 - 25 = 50. The
semi-interquartile range is half of that, so 50 ÷ 2
= 25.
4. Skewness:
Definition:
Skewness measures the asymmetry of a
distribution. A positive skew means the tail is on
the right, and a negative skew means the tail is
on the left.
Situation:
In a dataset of test scores, the distribution has a
long tail to the right. This indicates:
A. Positive Skew
B. Negative Skew
C. Symmetrical Distribution
Answer:
A. Positive Skew
Explanation:
A long tail on the right side indicates a positive
skew, meaning most data points are clustered
on the left side.
5. Spearman’s Rho:
Definition:
Spearman's rho (ρ) is a non-parametric measure
of correlation used to assess the strength and
direction of the relationship between two
ranked variables.
Situation:
You want to assess the relationship between
the ranking of students in Math and English
exams. Which correlation method would you
use?
A. Pearson r
B. Spearman’s rho
C. Regression Analysis
Answer:
B. Spearman’s rho
Explanation:
Spearman's rho is used when the data are
ranked or ordinal in nature.
6. Standard Deviation:
Definition:
Standard deviation is a measure of the amount
of variation or dispersion of a set of data values.
A higher standard deviation indicates that the
values are more spread out.
Situation:
If the dataset has a mean of 50 and a standard
deviation of 5, what is the range of values for
one standard deviation from the mean?
A. 45 to 55
B. 40 to 60
C. 35 to 65
Answer:
A. 45 to 55
Explanation:
One standard deviation from the mean (50)
would be between 45 (50 - 5) and 55 (50 + 5).
7. Standard Score (Z-Score):
Definition:
A standard score (z-score) represents the
number of standard deviations a data point is
from the mean. A z-score of 0 means the data
point is exactly at the mean.
Situation:
A student's score on a test is 75, and the mean
score is 70 with a standard deviation of 5. What
is the student's z-score?
A. 0.5
B. 1
C. 5
Answer:
A. 0.5
Explanation:
Z-score = (X - Mean) / Standard Deviation = (75 70) / 5 = 0.5.
8. Stanine:
Definition:
Stanine is a method of scaling scores on a 9point scale where 5 is the average score. It is
used to simplify and interpret test scores.
Situation:
A student scores 4 on a stanine scale. What
does this indicate about their performance?
A. Below average
B. Above average
C. Average
Answer:
A. Below average
Explanation:
A stanine score of 4 is below average (stanine 5
is the average score).
9. T-Score:
Definition:
A T-score is a standardized score where the
mean is set to 50 and the standard deviation is
set to 10. It is often used in psychological
testing.
Situation:
A student has a T-score of 60. What does this
tell us?
A. The student performed above average
B. The student performed below average
C. The student performed at the average level
Answer:
A. The student performed above average
Explanation:
A T-score of 60 indicates the student is above
the mean, since the average T-score is 50.
10. Tail:
Definition:
A tail in a distribution refers to the ends of the
distribution where the data points become less
frequent. In a skewed distribution, the tail is
extended in the direction of the skew.
Situation:
In a normal distribution, the tails represent:
A. The most frequent data points
B. The extreme values in the data
C. The median value
Answer:
B. The extreme values in the data
Explanation:
The tails of a normal distribution represent the
less frequent, extreme data points.
11. Variability:
Definition:
Variability refers to how spread out or
dispersed the values in a dataset are. Measures
of variability include range, variance, and
standard deviation.
Situation:
Which of the following would indicate that a
dataset has high variability?
A. Most data points are close to the mean
B. The data points are spread out over a wide
range
C. All the data points are the same
Answer:
B. The data points are spread out over a wide
range
Explanation:
High variability means the data points are
spread out over a wide range of values.
12. Variance:
Definition:
Variance is the average of the squared
deviations from the mean. It measures the
spread of data points in a dataset.
Situation:
In a dataset with a mean of 10, the squared
deviations from the mean are 4, 9, and 16.
What is the variance?
A. 7.5
B. 9
C. 5.25
Answer:
A. 7.5
Explanation:
Variance = (4 + 9 + 16) / 3 = 7.5.
13. Z-Score:
Definition:
A z-score indicates how many standard
deviations a data point is away from the mean.
It is used to standardize different data sets and
compare them.
Situation:
In a class with an average score of 80 and a
standard deviation of 10, a student scores 70.
What is their z-score?
A. -1
B. 1
C. 0
Answer:
A. -1
Explanation:
Z-score = (X - Mean) / Standard Deviation = (70 80) / 10 = -1.
Key Points of Chapter 4
1. Psychological Traits and States Exist
•
Psychological traits refer to consistent and enduring characteristics that distinguish one person
from another (e.g., intelligence, personality).
•
Psychological states are temporary variations in behavior (e.g., mood).
•
Psychological traits can be inferred from observable behaviors such as actions, responses, and
answers to tests.
•
These traits are not constant; they can change over time or vary depending on the context (e.g.,
a person may act differently in different social situations).
2. Psychological Traits and States Can Be Quantified and Measured
•
Once traits and states are defined, they can be measured through various types of tests.
•
Test developers must carefully define the construct they are measuring (e.g., aggression,
intelligence) and ensure that the test items accurately reflect those definitions.
•
For example, a test of aggression could focus on behaviors like physical harm or verbal
aggression, depending on how the trait is defined.
•
Cumulative scoring is used in many tests, where the final score reflects the accumulation of
correct responses or behavior consistent with the trait being measured (e.g., spelling tests).
3. Context and Reference Group
•
The interpretation of a person's behavior or test results can vary depending on the context and
the reference group used for comparison.
•
For instance, what is considered shy or aggressive might differ across situations or groups (e.g.,
a shy person in a public speaking situation might score higher on shyness compared to someone
in a social setting with friends).
4. Traits and Situations
•
Traits are not fixed and can manifest differently depending on the situation. For example,
someone might act aggressively in some settings (e.g., with family) but behave calmly in others
(e.g., with a supervisor).
•
Psychological traits are influenced by both the strength of the trait within the individual and the
nature of the situation in which the behavior occurs.
Key Considerations for a Good Psychological Test
•
A good test should be reliable and valid, meaning it consistently measures what it is supposed to
measure and produces meaningful, interpretable results.
•
Test developers must ensure clarity in defining the traits or states being measured and construct
items that accurately capture those constructs.
•
The weighting of items (how much importance is placed on different types of responses) should
reflect the value of the behaviors or characteristics being assessed.
Assumption 3: Test-Related Behavior Predicts Non-Test-Related Behavior
Tests often require behaviors, such as answering questions or performing tasks, which are not directly
related to the behaviors the test aims to predict (e.g., work performance, personality traits). However,
test behavior serves as a sample from which predictions can be made about future or non-test-related
behaviors, such as job performance. In some legal situations, tests can also be used to postdict behavior,
offering insights into someone's state of mind during past events.
Assumption 4: Tests and Other Measurement Techniques Have Strengths and Weaknesses
Test users need to understand the strengths and limitations of the tests they use. This includes knowing
how the test was developed, under what circumstances it should be used, how it should be
administered, and how results should be interpreted. Ethical codes emphasize that professionals must
be well-informed about these aspects and the limitations of each test.
Assumption 5: Various Sources of Error Are Part of the Assessment Process
Error is a natural part of testing and assessment. Factors other than the trait being measured, such as
the test-taker's health, the assessor's conduct, or even random factors like the weather, can introduce
error into the results. This error is considered a component of the measurement process, and
professionals need to account for it when interpreting test scores. Classical Test Theory (CTT) assumes
that each test-taker has a "true score" that would be obtained without error.
Assumption 6: Testing and Assessment Can Be Conducted in a Fair and Unbiased Manner
Although tests are designed to be fair, issues can arise when tests are used with individuals whose
background differs from those the test was intended for. Political and societal factors may complicate
fairness, particularly in areas like hiring or selection processes. While fairness is a goal, it is important to
recognize that tests are tools that can be used appropriately or inappropriately.
Assumption 7: Testing and Assessment Benefit Society
A world without testing and assessment would lead to major societal issues, as decisions regarding
professional qualifications, hiring, educational placements, and health diagnoses would be arbitrary.
Tests provide a way to ensure that individuals are qualified for critical roles, such as surgeons or pilots,
and help diagnose issues in fields like education and neuropsychology. Testing plays a crucial role in
making decisions that affect individuals' lives and society as a whole.
What’s a "Good Test"?
A "good test" must meet several criteria to be considered effective and reliable. These criteria are not
just based on logic but also on psychometric principles, such as reliability and validity.
1. Reliability
A reliable test consistently produces the same results under the same conditions. A reliable measuring
tool minimizes error in measurements, ensuring that results are reproducible. For example, a scale that
consistently reads 1 pound when measuring a certified 1-pound weight is considered reliable. However,
even a scale that consistently gives an incorrect reading (like 1.3 pounds) is still reliable, as long as it
gives the same incorrect result each time. In contrast, a scale that produces random results (1.7 pounds
one time, 0.9 pounds the next) is unreliable.
In psychology, a test must be consistently dependable to be useful. Whether measuring physical traits or
psychological attributes, reliability ensures that the test consistently measures the same construct when
administered repeatedly.
2. Validity
A valid test measures what it claims to measure. For example, if a scale measures weight, it should
accurately measure weight, not some other variable. In the case of psychological assessments, the
validity of a test depends on whether it truly measures the construct it’s designed to assess. For
instance, an intelligence test is valid if it accurately measures intelligence.
However, defining constructs like intelligence can be controversial. Different definitions of intelligence
can lead to disagreements about the validity of a test. When evaluating validity, experts examine factors
such as:
•
Content Validity: Do the test items represent the full range of the construct?
•
Criterion-related Validity: How well do test scores predict outcomes or behaviors that are
relevant to the construct (e.g., job performance for a test measuring work-related skills)?
•
Construct Validity: How well do test scores align with theoretical concepts associated with the
construct? For example, an introversion test should be inversely related to an extraversion test.
3. Other Considerations for a Good Test
In addition to reliability and validity, a good test must:
•
Be easy to administer, score, and interpret for trained professionals.
•
Be useful, meaning it provides meaningful results that can lead to actionable insights or
decisions, benefiting the individual or society.
•
Have norms to compare test scores to a reference group. Norms provide a baseline to interpret
an individual’s score in the context of a broader population.
Norms
Norms refer to the typical scores or behaviors of a particular group, which serve as a reference point for
interpreting individual test results. Norm-referenced testing compares an individual’s score against a
group’s scores, allowing us to understand where the individual stands relative to others.
Norms can be based on various factors, such as age or gender, and help provide a context for evaluating
test performance. For example, a test designed for children might have norms based on age groups, and
the test results can then be compared to those of other children in the same age group to assess
whether the child’s performance is typical, above average, or below average.
intelligence, personality, motivation, or
other mental traits.
Definitions
1. Age-Equivalent Scores
•
•
Definition: Age-equivalent scores refer
to scores that indicate the age at which
the average individual in a normative
sample would have achieved a
particular score. For example, if a child
scores at the level of a 10-year-old on a
test, the child’s score would be
reported as an age-equivalent score of
10 years.
Summary: These scores are useful for
understanding a child's performance
relative to their age group but can be
misleading because they do not account
for variations in development across
different children.
•
5. Content-Referenced Testing and Assessment
•
Definition: Content-referenced testing
refers to assessment where the focus is
on measuring how well a person has
mastered specific content or skills. The
test is designed to assess an individual’s
knowledge or ability in relation to a
predefined set of content.
•
Summary: This approach contrasts with
norm-referenced testing, as it is not
concerned with comparing individuals
to each other but with evaluating their
understanding of specific content.
2. Age Norms
•
•
Definition: Age norms are statistical
data used to compare an individual's
test performance to that of others
within the same age group. These
norms provide a way to interpret test
results by determining how an
individual's score compares to the
average scores of peers.
Summary: Age norms help assess
whether a person’s abilities are typical
for their age group, aiding in
understanding development over time.
6. Convenience Sample
•
Definition: A convenience sample is a
type of non-random sampling where
individuals are selected based on ease
of access, such as participants who are
readily available or willing to
participate.
•
Summary: While practical, convenience
samples may not represent the broader
population and can introduce bias into
research findings.
3. Classical Test Theory (CTT)
•
•
Definition: Classical Test Theory (CTT) is
a framework for understanding test
scores. It assumes that each individual’s
observed score is made up of a true
score (the actual ability or trait being
measured) and an error score (any
inaccuracies in measurement).
Summary: CTT is foundational in
psychometrics, focusing on reliability
and validity, helping improve test
construction and interpretation by
analyzing error and consistency.
7. Criterion
•
Definition: A criterion is a standard or
benchmark used to evaluate the
success, performance, or achievement
of an individual, typically in relation to a
specific goal or set of expectations.
•
Summary: Criterion-based assessments
measure how well an individual meets a
predefined standard rather than
comparing them to others, ensuring
that the focus is on individual
performance or mastery of skills.
4. Construct
•
Definition: A construct is a
psychological concept or trait that a test
aims to measure. This could be
Summary: Constructs are abstract
concepts that can be measured through
various assessment tools, and it is
crucial to ensure that the assessment
accurately reflects the intended
construct.
8. Criterion-Referenced Testing and
Assessment
•
Definition: Criterion-referenced testing
assesses whether an individual has
achieved specific criteria or standards,
focusing on mastery of the material or
skills rather than comparing
performance to others.
•
Summary: It provides clear benchmarks
(like passing a test), making it useful in
education and professional
certifications.
•
Definition: Developmental norms refer
to the typical developmental milestones
or abilities at different ages, used to
compare an individual’s development
against general population trends for
their age group.
•
Summary: These norms are essential
for identifying whether a child’s
development is on track or if there may
be delays, supporting targeted
interventions when needed.
9. Cumulative Scoring
•
•
Definition: Cumulative scoring refers to
the practice of adding up points over
time, so a person’s score reflects their
total achievement or progress over
multiple assessments.
Summary: This approach is often used
in longitudinal assessments or when
considering a person’s performance
over an extended period, allowing for
tracking improvements or identifying
patterns.
10. Developmental Norms
11. Situational Questions and Answers
•
Definition: Situational questions are
designed to assess how an individual
would respond to a specific scenario or
problem, often used to measure
practical judgment or decision-making
skills.
•
Summary: These assessments can be
especially useful in fields like
counseling, psychology, or
management, where real-world
decision-making abilities are critical.