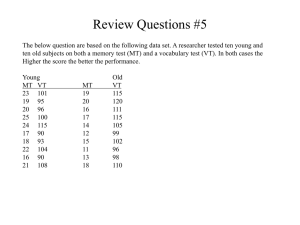
Business Analytics Homework 4 SOLUTIONS Problem 1 The first step of this problem is to compute a naïve DiD estimate for the SIS program, in which 2011 is our before period and 2012 our after. We can calculate averages for both periods for both the treated and untreated groups. The DiD analysis then yields the following results: We see that scores for non-treated students decreased by 0.56 points or 3.35%, while scores for students enrolled in the SIS program increased by 4 points or 45.07%. The difference in difference is then 48.42%, implying the SIS program is a success. Author affiliation * Columbia Business School Copyright information © Daniel Guetta This case is for teaching purposes only and does not represent an endorsement or judgment of the material included. However, this analysis does not account for regression to the mean. Therefore, we will compute a shrinkage coefficient using the 2010 and 2011 data and then recompute this DiD. First, we plot 2011 test scores against 2010 test scores. We can then use statsmodels to fit a linear regression and find the slope of the regression line. This slope will serve as the shrinkage coefficient. Page 2 Note: the notation Q(“2011 ST”) forces statsmodels to use the variable name as Quoted in the Q statement. Otherwise, it would think ‘2011’ and ‘ST’ are separate variables and return an error. The regression summary provides the slope of our regression line, 0.6107. Since this slope is less than 1, we can conclude there is regression to the mean in test scores. Using this, we will construct a shrinkage estimate of 2012 scores accoriding to the following formula: 2012 Est = c *(2011 Actual) + (1-c)*(2011 Average) We also want to calculate the RMSE of this estimate, which is done by first calculting the error between our 2012 predicted score and the 2012 actual scores. This new `Pred Err` column will give us an RMSE of 4.22. Finally, we can redo our DiD analysis, now using the predicted 2012 scores as the before scores and the actual 2012 scores our after scores. Page 3 Looking at the results, we see the difference in differences to be only 13.08%, far lower than our initial estimate. Our first approach determined the difference in scores between 2011 and 2012 between the two groups, but this does not necessarily reflect the true impact of SIS. It is expected that the distribution of test scores would change between 2011 and 2012 due to regression to the mean, and not due only to SIS. The second method compares 2012 actual scores with 2012 predicted scores and therefore incorporates the effect of regression to the mean. This method more accurately reflects the impact of the SIS program. Page 4 Problem 2 As hotel owners, we want to understand the behavior of our customers as best as we can. Specifically, we want to know the expected number of guests on any given night, as well as the probability of having all rooms occupied. To do this, we first create a model that simulates, for a single night, the twenty rooms in our hotel and outputs the number of guests that showed and whether or not the hotel is full. The above code will simulate the hotel on a single night, but this information is not sufficient enough to inform our management and operation of the hotel – it only reflects one specific night. Instead, we need to know what occupancy looks like on average. To do so, we will simulate 1,000 nights of operation of the hotel and look at the average occupany, as well as how often the hotel was full. Since we will later want to observe the effect of overbooking, we write a function that handles an arbitrary number of bookings. Page 5 This function accepts a number of bookings, 20 in the case of part (b), 21 in part (c), and 22-24 in part (d), and returns the results of 1,000 simulated nights for that number of bookings. Specifically, the function returns the average occupancy, the probability the hotel is full, and the average number of walks (if the number of bookings is less than or equal to the number of rooms this will always be zero). Using this fuction, we can see how these metrics vary for multiple numbers of bookings and plot the results. Page 6 We see that the average occupancy increases linearly with the number of bookings, which is exactly what we’d expect to see since the probability of a customer showing for their booking remains constant at 84%. In fact, the average occupancy for each number of bookings is extremely close to the theoretical expected value: 0.84*(number of bookings). The average fill rate (probability of the hotel being fully occupied) increases slowly at first and then accelerates before leveling out around 27 or 28 bookings. Lastly, the average number of walks increases very slowly at first until, as expected, the average occupancy begins to rise above 20. At this point the average walks starts to grow rapidly. In determining the optimal level of bookings, we must consider the implicit trade-off between ensuring full occupancy and walking guests to another hotel. For example, if we set the level of bookings at 25, we expect the hotel to be full 80% of the time (a dramatic improvement compared to 3.4% when accepting exactly 20 bookings), but expect to walk 2 guests each night. It often costs money to walk guests since the hotel without open rooms usually pays for the guest to stay at another hotel and comps the guest. At the same time, having unoccupied rooms also comes with an opportunity cost equal to the unseen revenue. In this case, determining the optimal level of bookings is a problem of cost minimization. There are many other factors we might want to consider as well, including, for exmaple, the effects on reputation from walking guests (will they leave a scatching review on TripAdvisor?), and a multitude of cost functions can be constructed and then minimized to find the optimal level of bookings. Page 7 Problem 3 Let’s first formulate our optimization problem. The decision variables will be the amount we invest in each bond (A through E). We will denote these amounts xA through xE respectively, and measure them in millions of dollars. The objective is to maximize the after-tax yield for each of our individual bonds. Denoting the yield for each bond A through E as rA through rE, we can write this as E r x i i A i Finally, we need to consider the constraints. We begin by dealing with two constraints that are no explicitely mentioned in the list of bullet points: The total amount invested in all the bonds in total cannot exceed $12M E x 12 i A i Bonds cannot be shorted, only bought xi 0 i Government and agency bonds must total at least $4M xB xC xD 4 No more than $8M can be invested in any one bond xi 8 i The average quality of the portfolio cannot exceed 1.4 on the bank’s rating scale. Let Qi denote the quality rating of bond i. The constraint can then be written as: Q x 1.4 x E i A E i i A i i (The left hand side of the constraint calculates the average quality weighted by the amount of each bond bought). The average number of years to maturity of the portfolio cannot exceed 5 years. Let Mi denote the number of years to maturity of bond i. the constraint can then be written as: Mx 5 x E i A E i A i i i Page 8 Our opttimization problem can therefore be written as follows: max s.t. E r xi i A i E i A xi 12 xB xC xD 4 Q x 1.4 x Mx 5 x E i A E i i i i A E i A E i A i i i xi 0 i xi 8 i Before we can code up this optimization problem in Python, we need to determine whether it is a linear or nonlinear optimization program. Initially, the average constraints might look like they make the program nonlinear, because we have a fraction with decision variables at the top and bottom of the fraction. Thankfully, we can turn these into linear constraints by simply multiplying by the denominator of each fraction: max s.t. E r xi i A i E i A xi 12 xB xC xD 4 E i A E i A Qi xi 1.4 i A xi E M i x i 5 i A x i E xi 0 i xi 8 i It turns out it’s actually even simpler, because if you think about it, the sum of all x variables will always be equal to 12 million exactly (it would make no sense to invest less than your budget) so you could replace the sums in red above with $12M. But we’ll leave it as-is for now. In this new form, the optimization problem is a linear program. We can therefore use PuLP to solve it. See the Jupyter notebook for the solution, which prescribes the following purchase amounts: Page 9 Problem 4 Here we are looking to determine the optimal number of croissants for the bakery to produce, given a known demand function. First, though, we need to better understand the behavior of the bakery’s customers. The above code draws two random numbers, the morning demand and afternoon demand, from to the distributions described in the problem. To determine the distribution for the afternoon demand, it also determines if the day is sunny or rainy. For each day, the code returns the total demand. Using this list of demands a histogram can be produced, and when sorted, the 10th and 90th percentiles are simple to produce. Page 10 Now we can take the simulation code and wrap it inside a function in order to iterate with different quantities of croissants. Additionally, we also want to calculate the profit each day, which we can do using the following line of pseudocode. profit = price * min(total demand, croissants) – cost * croissants Note that we use the minimum function because no matter how high the demand, we can only ever sell the number of croissants we’ve baked in the morning. If 120 croissants are baked in the morning, the expected profit is $269.67. Now we can loop through different numbers of croissants and look at the expected profit at each number. Page 11 It appears that the maximum expected profit is achieved at around 120 croissants. Digging deeper shows that the maximum expected profit of $269.94, only 27 cents higher than at 120, is achieved at 117 croissants. Problem 5 First, we must formulate our problem. The decision variables will be the number of units of each machine the factory will produce. We denote these amounts 𝑥 through 𝑥 . Denoting the net profits per unit as 𝑝 through 𝑝 , we write our objective as follows. 𝑝 𝑥 Next, we consider our constraints. 1500 laptops will be produced 𝑥 + 𝑥 = 1500 1000 desktops will be produced 𝑥 + 𝑥 = 1000 No more than 600 machines can be customized 𝑥 + 𝑥 ≤ 600 Production should not exceed demand for any machine. Let 𝑑 denote the demand for machine 𝑖 Page 12 𝑥 ≤𝑑 ∀𝑖 To solve this problem, we will again use PuLP. First, we create a DataFrame including all the given data. Next, we create our variables: Then, we must deal with our constraints. The first two constrain the number of laptops produced to 1500 and the number of desktops to 1000. The third limits the total number of customized machines to 600. The fourth limits production of each machine to its demand since overproducing will always yield a worse result than not. Alternatively, we could have not included this constraint and instead included a penalty (cost of unsold machines) in our objective. Finally, we set our objective. Page 13 Solving our optimization problem yields the following results: which produces a total profit of $405,000. If we are able to customize 200 more machines, we yield a new solution which produces a total profit of $440,000. If we manufacture 100 fewer laptops, we yield another new solution that is also more profitable than the first, netting a total profit of $410,000. Note: There is another way to think about this problem that does not require the use of optimization. First, because the custom machines are always more profitable than the standard machines, it makes sense to customize as many as possible – in the case of this base problem, all 600. Our constraints now allow us to write our four variables in terms of just two. 𝑙 + 𝑙 = 1500 𝑑 + 𝑑 = 1000 𝑙 + 𝑑 = 600 Eliminating 𝑑 and combining: Page 14 𝑙 + 𝑑 = 1900 Looking now at our demand data, the factory must produce all 1200 standard laptops and all 700 standard desktops in order to satisfy the constraints of the problem. From this we can calculate the remaining values. When up to 800 machines can be customized, we get the following: 𝑙 + 𝑑 = 1700 In this case there are multiple values that satisfy all constraints, so we must use PuLP to find the maximum profit. The result is similar in the case of producing 100 fewer laptops. Page 15