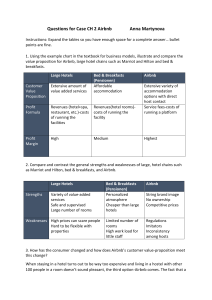
“Decoding Airbnb in the Big Apple” Team: MIS 6356 11 (Daksh Goyal, Nitin Kumar, Sai Krishna Lanka, Wen Lou) Objective: The aim of the proposal is to perform analyses on New York City Airbnb dataset and uncover insights of the sharing economy in one of the biggest cities of the world. Background: Airbnb has been a one of the most successful company since its inception in 2008. According to Airbnb Newsrooms, currently Airbnb has more than 6 million listings in more than 191 countries and regions and operating in more than 100,000 cities. As the one of the most popular cities in the world, New York City has been one of the hottest markets for Airbnb. With close to 50,000 listings in the city, Airbnb has interwoven with the rental landscape within 10 years of its inception. Analyses on such a dataset would not only provide intuition about the rental metrics but also shed some light on the socio-economic setting of the city. Dataset: The second-hand dataset is taken from Inside Airbnb which provides non-commercial set of tools and data that allows us to explore how Airbnb is really being used in cities around the world. The New York Airbnb dataset is compiled on 12 September 2019 Completed Tasks: Task: Analyse the growth of Airbnb network in New York. Response: For this visualization task, we plotted a map for hosts that have registered with Airbnb from 2008 till present in the city of New York. The plots infer that there continues to be a meteoric rise in the Airbnb listings and the popularity never ceased at any point of time. Task: Find the median price of Airbnb listings across boroughs and neighbourhoods. Response: Since entities involving with price or income generally tend to be right skewed (outliers on the higher end), median is considered to be the best measure of central tendency. To capture the data well, we take the logarithm of listing price per single guest and plot a boxplot with respect to the five boroughs in New York city. Coinciding with intuition of high cost of living in Manhattan and Brooklyn, the Airbnb prices are similar to the expectations. To visualize in depth pricing analysis of neighbourhoods in each borough, a heatmap of prices with respect to the neighbourhoods having minimum of 10 listings are plotted on the New York city. This provides crucial insights on the median price range of neighbourhoods. The region around East River including North Brooklyn and South Manhattan are the costliest places. Task: Find the most common amenities provided across Airbnb listings. Response: Each listing includes a set of amenities that are available for the guests. These amenities include from basic necessities like Air conditioning to fancy stuff such as electric profiling beds. The picture on the right show the amenities provided in first two listings. Our aim is to determine a set of five common amenities that are mentioned across Airbnb listings. This provides a business value for hosts who are willing to sublet their apartment and should include such amenities in their listing. We are only interested in the support of the amenities as the other features such as confidence and lift would not make much sense in this scenario. From the above results, we can clearly observe that the listings must have air conditioning, heating, kitchen, smoke detector, essentials such as bathing essentials, mattresses etc. and most importantly “WIFI”. In fact, more that 70% listings have the set of these amenities. Task: What does it take to be an Airbnb Super Host? Response: According to Airbnb, hosts must have to meet following criteria to become a super host, which are as follows, 4.8+ overall rating 10+ stays <1% cancellation rate 90% response rate For our analysis, we would like to find the characteristics of a Super Host with parameters such as, The above dataframe is cleaned after considering following assumptions: Out of 48377 records, only 27123 records have complete cases i.e., do not have any null values. We are not considering 10+ stays and <1% cancellation for our analysis as we do not have data from the Airbnb regarding those attributes. We are considering a new parameter “review_frequency_per_month” which is a function of three attributes namely, “first_review”, “last_review” and “number_of_reviews”. The formula is given by, number_of_reviews review_frequency_per_month = month(last_review −first_review) This attribute captures the attributes perfectly to give a single metric for our analysis. Drop “first_review”, “last_review” and “number_of_reviews” from the dataframe. We split the data into 70% training and 30% validation to develop a classification tree and measure its performance. The decision tree shows that the most important features are “review_score_rating”, “host_response_rate” and “review_frequenct_per_month”. With 78.6% accuracy on training set and 77.92% accuracy on validation set, our model is decent enough to classify the superhosts. Training set Validation set Second part of our analysis include classifying super host using random forest. With 80% accuracy on validation set, random forest doesn’t increase the performance compared to the decision tree developed earlier. Since our aim is to provide a simple classification model, we stick with the decision tree which classifies pretty good with its simple design. Random forest also provides a plot for the most important features that are important to classify. Supporting our simple model, the three features “review_score_rating”, “host_response_rate” and “review_frequenct_per_month” tend to be the most important predictors of the lot. To-do Task: Predict price based on “neighborhood_group_cleansed” (Manhattan and Brooklyn), “neighborhood_cleansed” (include only Manhattan and Brooklyn), “property_type” (prominent ones), “room_type” (= Entire home/apt) with 1 bedroom and 1 bathroom Find correlation between point 5 and https://www.zumper.com/blog/2019/01/mapped-newyork-city-neighborhood-rent-prices-winter-2019/ in Manhattan and Brooklyn (real estate setting) Word cloud generator for “host_about” Word cloud generator for different ranges of “review_scores_ratings” (sampling few ids from the dataset per review bin) Recommender system for listings based on “neighborhood_group_cleansed” “neighborhood_cleansed” (2-mile radius), total number of guests (“guests_included”), price per guest (“price”/“guests_included”), length of stay (>= “minimum_nights”) References: Get the Data. Retrieved from http://insideairbnb.com/get-the-data.html About Us. Retrieved from https://press.airbnb.com/en-us/about-us/ About Inside Airbnb. Retrieved from http://insideairbnb.com/about.html Airbnb Superhost. Retrieved from https://www.airbnb.com/superhost Airbnb Rental Listings Dataset Mining. Retrieved from https://towardsdatascience.com/airbnb-rental-listings-dataset-mining-f972ed08ddec New York Maps. Retrieved from https://rpubs.com/jhofman/nycmaps