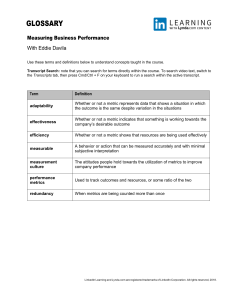
The performance engineering effort should include: 1. A review of the system architecture from the standpoints of performance, reliability, and scalability 2. An evaluation of performance characteristics of the technologies proposed in the architecture specification, including quick performance testing of any proposed platforms 3. Incremental performance testing following incremental functional testing of the system, followed by suggestions for architectural and design revisions as needed 4. Retesting to overcome the issues revealed and remedied as a result of the previous step Performance engineer should be engaged in all stages of a software project. Performance Engineer Would Ask: Can the system carry the peak load? Will the system cope with a surge in load? What will be the performance impacts of adding new functionality to a system? Will the system be able to carry an increase in load? What is the performance impact of increasing the size of the user base? Can the system meet customer expectations or engineering needs if the average response time requirement is 2 seconds rather than 1 second? The performance engineering effort should include: A review of the system architecture from the standpoints of performance, reliability, and scalability An evaluation of performance characteristics of the technologies proposed in the architecture specification, including quick performance testing of any proposed platforms Incremental performance testing following incremental functional testing of the system, followed by suggestions for architectural and design revisions as needed Retesting to overcome the issues revealed and remedied as a result of the previous step The response time is a standard measure of how long it takes a system to perform a particular activity. This metric is defined as the difference between the time at which an activity is completed and the time at which it was initiated. The average response time is the arithmetic mean of the response times that have been observed. The average device utilization is a standard measure of the proportion of time that a device, such as a CPU, disk, or other I/O device, is busy. For this metric to be valid, the length of time during which the average was taken should be stated, because averages taken over long intervals tend to hide fluctuations, while those taken over short intervals tend to reveal them. - The average utilization of a device may be obtained indirectly from the average service time, if known, and the number of jobs served during the observation period. Alternatively, it can be obtained by direct measurement of the system and is usually available directly from the host operating system. It is an example of a time-averaged statistic, which is not the same thing as a sample statistic. The average throughput of a system is the rate at which the system completes units of a particular activity. A performance metric should inform us about the behavior of the system in the context of its domain of application and/or in the context of its resource usage. Linearity: If a metric changes by a given ratio, so should the performance it quantifies. Reliability: A metric is considered reliable if System A outperforms System B whenever the metric indicates that it does. - For example, if the measured CPU utilization drops by 50%, this means that the processor load has actually dropped by 50% Repeatability: If the same experiment is run two or more times on the same system under identical configurations, the metrics that are obtained from the experiments should have the same value each time. Ease of measurement: A metric is particularly useful if it can be obtained directly from system measurements or simply calculated from them. Consistency: A metric is said to be consistent if its definition and the units in which it is expressed are the same across all systems and configurations. Mononumerosis: The tendency to fixate on a single number or to focus too much on a single metric. - Can result in a poor design or purchasing decision, because the chosen metric may not reflect critical system characteristics described by other metrics Domain-related performance metrics are specialized metrics designed to evaluate the effectiveness, efficiency, and quality of operations or processes within specific domains or industries. - Information Technology (IT) - System Uptime: Measures the availability and reliability of IT services. - Response Time: The time it takes for a system to respond to a user request. - Throughput: The amount of data processed by an application in a given amount of time. - Error Rate: The frequency of errors encountered during system or software operations. An explicit metric contains complete information about what it describes. - The average number of transactions per second of a given transaction type is an explicit metric, as is the average response time of each transaction of each type. By contrast, the number of users logged in describes the offered load only implicitly. - Because the average number of transactions per second of each type generated by the average user is unspecified. In the absence of that specification, any requirement or other description involving the number of users logged in is ambiguous and incomplete, even if it is possible to count the number of users logged in at any instant. Performance Metrics For Transient Loads: In some types of systems, the average value of a performance measure is less important than the amount of time required to complete a given amount of work. Performance models of computer systems are used to predict system capacity and delays - They can also be used to predict the performance impact of changes such as increasing or decreasing demand, increasing the numbers of processors, moving data from one disk to another, or changing scheduling rules Desirable Requirement Qualities: Clear and Unambiguous: Each requirement should convey a single, clear meaning that is not open to interpretation. This clarity prevents misunderstandings and errors in implementation. Complete: All necessary information is included to implement the requirement. This means specifying what needs to be done, as well as any constraints or conditions that must be met. Consistent: Requirements should not conflict with each other. All documents and descriptions should be aligned and not contradict any other requirement or existing system components. Verifiable: It must be possible to test the requirement using a cost-effective method to ensure it has been met. This could be through inspection, demonstration, test, or analysis. Feasible: The requirement should be achievable within the project's constraints, such as time, budget, and technology. It should be realistic and attainable with current resources and knowledge. Relevant: Each requirement should contribute to the overall objectives of the project. It should be necessary for the system or product and not include unnecessary functionality. Traceable: There should be a clear trace from a requirement through to its implementation and testing. This helps in managing changes and ensuring that all requirements are addressed. Modifiable: Requirements should be documented in a way that allows for easy modification if necessary. This includes being organized and structured in a way that changes can be made without excessive impact. Prioritized: Requirements often need to be prioritized to manage trade-offs and allocate resources effectively. This involves determining which requirements are critical, important, or nice-to-have. Understandable by all stakeholders: Requirements should be written in a language that is accessible to all stakeholders, including customers, developers, testers, and managers, to ensure that everyone has a common understanding. Response time: the length of time from a job’s arrival to its service completion Waiting time: the length of time between a job’s arrival and the time at which it begins service Queue length: the number of jobs present in the system, including the number inservice Metric: a quantitative measure that is used to assess the degree to which a software system, process, or project possesses a given attribute related to quality. Little Law: average queue length = average throughput x average response time Due to the quantitative nature of performance requirements, they must be written in measurable terms, expressed in correct statistical terms, and written in terms of one or more metrics that are informative about the problem domain. They must also be written in terms of metrics suitable for the time scale within which the system must respond to stimuli and must be mathematically consistent. Anti-Patterns: - All the time / Of the time - Time interval unclear/unrealistic - Resource Utilization - Resource utilization depends on the hardware and on the volume of activity - Better to specify hardware component and time - Number of Users - No statement about what the users do, or how often they do it - No statement about how many users are logged in at the same time - No distinction between types of users - Scalability - Does not tell us anything about the dimensions in which the system should be scaled, such as the number of logged-in users, the number of account holders Ambiguity Definition: Requirements that are open to multiple interpretations. Example: "The system should load fast." Over-Specification Definition: Requirements that include too much detail, potentially limiting solutions. Example: "The system shall use algorithm X to sort data." Gold Plating Definition: Adding unnecessary features or requirements not requested by stakeholders. Example: Including advanced reporting features nobody asked for. Out of Scope Definition: Requirements that fall outside the project's scope, leading to scope creep. Example: "The system shall support real-time collaboration," for a simple information site project. Wishful Thinking Definition: Requirements based on unproven or unrealistic assumptions or technologies. Example: "The system shall have 100% uptime." Forward Referencing Definition: Requirements that reference other not yet defined requirements, documents, or functionalities. Example: "As per the specifications in Document XYZ (not yet written)..." Contradictory Requirements Definition: Requirements that conflict with each other, making it impossible to satisfy all simultaneously. Example: "The system must be accessible offline" vs. "The system must update data in real-time." Not User-Centric Definition: Requirements that focus too much on system internals rather than on user needs and outcomes. Example: Detailed technical specifications with no clear linkage to user benefits. Determining Performance Needs: - What is the main purpose of the system? - What are the functions of the system? - Where does the system traffic come from? - Is it externally driven? - Does it come from a limited set of sources? - Are there any monitoring and/or cleanup processes that make system demands at fixed intervals, at irregular intervals, or that run continuously in the background? - What are the risks and impacts if the system does not meet its performance requirements? - How much data loss can be tolerated? - Etc. Time-varying Behavior - Conveyor systems at airports are subject to higher demands during peak travel periods than during quiet periods. The demand on one or more portions of the conveyor system abruptly increases when several planes arrive at a terminal in succession. Traceability: reduces the risk of inconsistency propagating through performance requirements throughout the lifecycle - Why has this performance requirement been specified? - To what business need does the performance requirement respond? - To what engineering needs does the performance requirement respond? - Does the performance requirement enable conformance to a government or industrial regulation? - Who proposed the requirement? Reference work items and reference workloads are needed to establish the context for domain-specific metrics. - A reference work item may be a particular kind of transaction or set of transactions and activities. - A reference workload specifies the mix and volumes of the transactions and activities. - A reference scenario might be a set of workloads, or a set of actions to be carried out upon the occurrence of a specific type of event. Why might a performance engineer or system manager need to measure system resource usage and system performance? - To ensure that the system is not overloaded - To verify the effects of system changes - To ensure that the performance of the system is meeting requirements, engineering needs, and customer needs - To anticipate the onset of system malfunctions A production system should be measured continuously so that baseline patterns for system resource usage can be established for different times of day and for different times of the year. Performance Measurement vs Performance Testing Performance measurement - is concerned solely with how performance data should be measured and collected. - can be done while a system is under test or while it is in production. - should always be done for systems that are in production to ensure that they are running properly. Performance testing - is an exercise in which a system is subjected to loads in a controlled manner. - Measurements of resource usage and system performance are taken during the performance test for subsequent analysis. Study Notes: System Performance Engineering 1. Performance Basics Definition: System performance involves quick response times, speed, and scalability. Influence: Directly affects the system’s functionality and user perception. 2. Performance Requirements Drivers: Shape the system architecture and technology choices. Contractual and Regulatory: Linked to agreements and compliance needs. 3. Performance Engineering Process Steps: Review system architecture for performance, reliability, and scalability. Evaluate and test performance characteristics of proposed technologies. Perform incremental performance testing and suggest necessary revisions. Retest to address any issues found. 4. Role of Performance Engineers Activities: Involved in all stages of a software project, from design to testing. Key Focus: Ensure the interactions between system components and hardware optimize performance. 5. Performance Metrics Examples Response Time: Time for a system to complete an activity. Device Utilization: Percentage of time a device is active. Throughput: Rate at which the system completes activities. 6. Performance Models Purpose: Predict system behavior under various conditions and identify potential performance bottlenecks. Utilization: Help in decision-making for system enhancements or configurations. 7. Performance Laws and Principles Little's Law: Relates average response time, throughput, and queue length. Utilization Law: Links completion rate, average service time, and overall utilization. 8. Workload Characteristics Types: Regular background activities vs. sudden bursty traffic. Reference Workloads: Used to predict and model performance in real-world scenarios. 9. Importance of Measurement and Testing Performance Testing: Essential for verifying if performance requirements are met. Tools and Techniques: Utilize specific metrics and tools for accurate system performance evaluation. 10. Scalability Concerns Vertical vs. Horizontal Scaling: Approaches to handling increased loads by enhancing or distributing resources. Load, Space, and Structural Scalability: Various dimensions in which system capacity can expand or contract effectively. 11. Antipatterns and Best Practices Avoiding Common Pitfalls: Recognize and steer clear of practices that can degrade system performance. Best Practices: Implement proven methods to enhance and maintain optimal performance.