CSCIE89 – Fraud in Credit Card Transactions | Marcos Pastor
CSCIE89 Final Project. Pastor, Marcos.
Fraud in credit card transactions.
Problem Statement.
Every card transaction submitted to the payment network for approval can potentially be a
fraudulent transaction, the business necessity to predict this feature is very high and the amount
of available data around the transaction and the billions of transactions submitted every day
makes this a very good candidate for a Machine Learning solution. Some of the available
business features that will help with this prediction are amount, card present versus remote, debit
or credit, expiration date, cardholder personal data…
Dataset:
The only public dataset that I found is a very well-known dataset in Kaggle with anonymized
credit card transactions. https://www.kaggle.com/mlgulb/creditcardfraud/downloads/creditcardfraud.zip/3
This dataset presents transactions that occurred in two days, where we have 492 frauds out of
284,807 transactions. The dataset is highly unbalanced, the positive class (frauds) account for
0.172% of all transactions.
The main constraint is that we lose all the possible business knowledge and intuition that can be
applied with the meaning of the original variables.
Hardware:
Intel Nuc7i7bnh, Intel(R) Core(TM) i7-7567U CPU @ 3.50GHz with 4 Cores, 32 GB DDR4
GTX 1070 Graphic Card GV-N1070IXEB-8GD eGPU
Software:
Ubuntu 18.04.2 LTS
Python 3.6.7, pip 19.1, venv with tensorflow-gpu==1.13.1 and many others
NVIDIA-SMI 418.43
Driver Version: 418.43
CUDA Version: 10.1
Strategy:
I’ll use a simple Sequential Deep Learning Network with Keras to predict the fraud transactions
and I’ll play with the hyperparameters to obtain the best possible solution. Because of the highly
unbalanced of the data, we’ll use the confusion matrix and the precision and recall for success
measurement.
I’ll also solve the same problem using Auto Encoders and compare the results, this will make the
final solution more robust to business questions. Auto Encoders provides a fresh view where the
network is trained only using normal transactions, and detecting the fraud is a high abnormal
value of the measurement of the distance between the original transaction and the reconstruction.
YouTube:
https://youtu.be/PSKYrhpp70g
https://youtu.be/VHPsXJePL_c
1
CSCIE89 – Fraud in Credit Card Transactions | Marcos Pastor
Problem understanding.
Any highly unbalanced problem has the main concern about predicting always the value with
bigger weight and get naive very good accuracy, in this example, if we take any percentage for
testing in a perfect linear way, and we always predict normal (not fraud) transaction, the
accuracy would be 1 – 0.00173 = 0.9983. The primary goal is to create a model that can predict
fraud transactions, improve the accuracy is not the goal. That’s the reason that we’re adding
precision and recall measures.
cc = pd.read_csv('creditcard.csv')
cc.head()
# visualize correlation between all variables
corr = cc.corr()
sns.heatmap(corr)
#Quick view of correlation between variable Class and rest ov variables sorted
2
CSCIE89 – Fraud in Credit Card Transactions | Marcos Pastor
corr.Class.sort_values()
No high correlation between any variables and Class, and the ones with some correlation don’t
have any special meaning, we can see also that Time and Amount won’t have any special impact
by themselves to predict a fraud transaction.
V17
-0.326481
V14
-0.302544
V12
-0.260593
V10
-0.216883
V16
-0.196539
V3
-0.192961
V7
-0.187257
V18
-0.111485
V1
-0.101347
V9
-0.097733
V5
-0.094974
V6
-0.043643
Time
-0.012323
V24
-0.007221
V13
-0.004570
V15
-0.004223
V23
-0.002685
V22
0.000805
V25
0.003308
V26
0.004455
Amount
0.005632
V28
0.009536
V27
0.017580
V8
0.019875
V20
0.020090
V19
0.034783
V21
0.040413
V2
0.091289
V4
0.133447
V11
0.154876
Class
1.000000
Name: Class, dtype: float64
Based in a simple manual observation of the data, we have 28 unknown variables result of a PCA
transformation that should be useful to predict the fraud or not of a transaction, the amount that
we’ll normalize to train the model, and time.
Time by itself don’t add a business intuition to make fraud decisions unless it’s tight to person by
person patterns, having only 2 days of information and with no information linked to specific
users, suggest that this variable could be not useful, we’ll drop it from the model.
Class is the dependent variable that we want to predict.
#Read the data, normalize amount, and drop original amount and time for now
cc['n_amount'] = StandardScaler().fit_transform(cc['Amount'].values.reshape(-1,1))
cc = cc.drop(['Amount'],axis=1)
cc = cc.drop(['Time'],axis=1)
cc.head()
3
CSCIE89 – Fraud in Credit Card Transactions | Marcos Pastor
Model sequential solution.
My first approach for the network architecture was a naive sequential architecture with fully
connected layers. In this case, we are ignoring that we almost don’t have any data for the fraud
transactions and in therory, it would be difficult for the network to learn how to differenciate the
normal from the fraud transactions.
The results were better than expected, the training was overall very fast and I adjusted the
network using the loss function, the activation function, the optimizer and trying diverse sizes of
a similar network architecture.
In order to compare different options and choose the network with the best performance, I was
using the loss of the training and the confusion matrix applied to the test dataset. I tried to use the
validation loss, but the model was not performing correctly.
my_pred = model.predict(x_test)
my_score = model.evaluate(x_test, y_test)
confusion_compare = (my_pred > 0.5)
cm = confusion_matrix(y_test, confusion_compare)
print(cm)
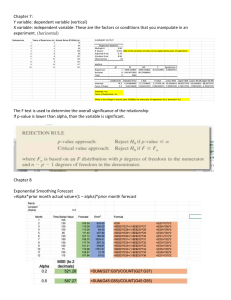
We’ll see in the next results of the different tests this type of confusion matrix:
[[a1 a2]
[b1 b2]]
a1 = transactions predicted as normal that were actually normal
b2 = transactions predicted as fraud that were actually fraud
a2 = false positive, transactions predicted as not-fraud that were actually fraud
b1 = false negative, transactions predicted as fraud that were actually not-fraud
The sizes that worked better for my network were with 64 and 128 neurons with 2 layers, and
128, 256 and 512 with 3 layers, some other sizes that I tried with 3 layers were 64-128-64 and
64-128-256.
I tested different activation functions, for example ReLU and LeakyRelu.
my_alpha = 0.05
model = Sequential()
model.add(Dense(128,input_dim=29))
model.add(LeakyReLU(alpha=my_alpha))
model.add(Dense(256))
model.add(LeakyReLU(alpha=my_alpha))
4
CSCIE89 – Fraud in Credit Card Transactions | Marcos Pastor
model.add(Dense(512))
model.add(LeakyReLU(alpha=my_alpha))
model.add(Dense(1,activation='sigmoid'))
model.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics =
['accuracy'])
LeakyRelu with alpha = 0.05
Epoch 48/100
227845/227845 [==============================] - 9s 38us/step - loss: 0.0016 - acc:
0.9998
Epoch 00048: early stopping
Confusion Matrix:
[[56829
[
26
30]
77]]
LeakyRelu with my_alpha
= 0.01
Epoch 37/100
227845/227845 [==============================] - 9s 38us/step - loss: 0.0016 - acc:
0.9997
Epoch 00037: early stopping
Confusion Matrix:
[[56850
[
27
9]
76]]
I also tested the model with RMSprop, Adam and Adagrad. RMSProp performed very poorly and
discarded in the first attempt. Adam was performing good, as we can see in the previous results,
but Adagrad was the one with better results in terms of loss and Confusion Matrix:
my_alpha = 0.01
model = Sequential()
model.add(Dense(128, input_dim=29))
model.add(LeakyReLU(alpha=my_alpha))
model.add(Dense(256))
model.add(LeakyReLU(alpha=my_alpha))
model.add(Dense(512))
model.add(LeakyReLU(alpha=my_alpha))
model.add(Dense(1,activation='sigmoid'))
model.compile(optimizer = 'adagrad', loss = 'binary_crossentropy', metrics =
['accuracy'])
Epoch 96/100
227845/227845 [==============================] - 8s 34us/step - loss: 1.3001e-04 acc: 1.0000
Epoch 00096: early stopping
Confusion Matrix:
[[56856
[
24
3]
79]]
Although the training seems not to be overfitting, we’ll test also adding a regularizer and check if
the model can train more epochs and learn better weights. Adding the regularizer to the 3 Dense
layers didn’t work as expected, the loss was having problems to keep going down and the
progress was slower than expected. I finally kept the regularizer in the last Dense layer and train
again:
my_alpha = 0.01
5
CSCIE89 – Fraud in Credit Card Transactions | Marcos Pastor
model = Sequential()
model.add(Dense(128, input_dim=29))
model.add(LeakyReLU(alpha=my_alpha))
model.add(Dense(256))
model.add(LeakyReLU(alpha=my_alpha))
model.add(Dense(512,kernel_regularizer = regularizers.l2(0.001)))
model.add(LeakyReLU(alpha=my_alpha))
model.add(Dense(1,activation='sigmoid'))
model.compile(optimizer = 'adagrad', loss = 'binary_crossentropy', metrics =
['accuracy'])
Results after 200 epochs:
Epoch 100/100
227845/227845 [==============================] - 9s 38us/step - loss: 5.6172e-04 acc: 0.9999
Confusion Matrix:
[[56854
[
24
5]
79]]
Results after 400 epochs:
Epoch 200/200
227845/227845 [==============================] - 8s 35us/step - loss: 3.0213e-04 acc: 1.0000
Confusion Matrix:
[[56854
[
24
5]
79]]
I concluded that regularization is not adding any value and we can obtain the same results faster
with less training if we remove the regularization.
Now I’ll try again previous training with 200 epochs, increasing the patience for early stopping
to 30 steps and using the parameter restore_best_weights = True to see if we can improve the
results. Actually, the resulst were slightly interesting:
Epoch 200/200
227845/227845 [==============================] - 8s 35us/step - loss: 1.7455e-04 acc: 1.0000
Confusion Matrix:
[[56850
[
22
9]
81]]
Classification Report:
precision
0
1
1.00
0.90
recall
1.00
0.79
f1-score
support
1.00
0.84
56859
103
I finally decided that although the given time variable makes no sense, none of the others have
also any meaning, therefore I kept the same network architecture, I normalized time and I
6
CSCIE89 – Fraud in Credit Card Transactions | Marcos Pastor
repeated the training. The results are one of the best after training, but the differences are not
significant:
Epoch 200/200
227845/227845 [==============================] - 7s 33us/step - loss: 1.5835e-04 acc: 1.0000
Confusion Matrix:
[[56857
[
26
2]
77]]
Classification Report:
precision
recall
f1-score
support
0
1
1.00
0.97
1.00
0.75
1.00
0.85
56859
103
micro avg
macro avg
weighted avg
1.00
0.99
1.00
1.00
0.87
1.00
1.00
0.92
1.00
56962
56962
56962
Autoencoder solution.
An alternative approach would be to think that the fraud transactions are anomalies and look for
a solution based in autoencoders detecting the anomalies during the reconstruction.
During this approach, I will train the network only using normal transactions, and therefore,
we’ll have a model that should be able to reconstuct as close as possible only normal
transactions.
The goal is in the validation phase, feed into the network normal and fraud transactions, if the
model performs correctly, it should be able to reconstruct normal transactions very good, but
when the model tries to reconstruct a fraud transactions, it should perform worse, therefore we
can measure the distance between the reconstructed transaction and the original transactions, and
above certain threshold, decide that a transactions is an anomaly and therefore is fraudulent.
I kept all the hyperparameters and decisions used for the Sequential model, our optimizer is
Adagrad, I tested both loss = ‘binary_crossentropy’ and ‘mse’, in theory, ‘mse’ should perform
better, but that was not the case, although the difference is not significant. The values of loss are
cominn negatives, I can solve it using ‘mse’ instead of ‘binary_crossentropy’, but the
performance is worse.
I first tested with activation=’relu’ and later with activation=’LeakyReLU’, I didn’t find any
improvement as I found out in the Sequence model. Actually, the implementation of LeakyReLU
is completely different, because it has to be added as a new layer on top of the Dense layer.
I trained the network with several sizes fot the encoder layers, the one that got better results is
the one with encoded layers with sizes 25, 20 y 15, the input layer had 30 values.
7
CSCIE89 – Fraud in Credit Card Transactions | Marcos Pastor
Steps to prepare the data:
#separate data for training and validation,
normal_train = cc[cc.Class == 0]
fraud = cc[cc.Class == 1]
#we only want to train in the normal transactions
x_train_n, x_test_n = train_test_split(normal_train, test_size = 0.2,
random_state=mpg_seed)
x_train = x_train_n.drop(['Class'], axis =1)
x_test = x_test_n.drop(['Class'], axis =1)
# for the reconstruccion we'll combine normal and fraudulent transactions, the model
should be able to detect the
#anomaly of the fraud transactions
xf_test = x_test_n.append(fraud)
# TODO we need to shuffle, separate the Class with 1 and 0 for reconstruccion and
compare
xf_test = shuffle(xf_test)
y_test = xf_test.Class
xf_test = xf_test.drop(['Class'], axis =1)
xf_test.head()
#double check that index is the same
y_test.head()
134042
0
148874
0
147169
0
96893
0
101213
0
Name: Class, dtype: int64
Training looping over different sizes:
input_dim = 30
# possible sizes of our encoded representations
encoding_dims = [27, 25]
encoding_dims_2 = [22, 20]
encoding_dims_3 = [18, 15]
#placeholders
encoding_dim = 20
encoding_dim_2 = 15
encoding_dim_3 = 10
#parameter for LeakyRelu
my_alpha = 0.01
epochs = 100
#to accumulate and compare
id_r, decod_r, xf_r, hist_r = [], [], [], []
#lopp to repeate trainings using different sizes
for encoding_dim in encoding_dims:
for encoding_dim_2 in encoding_dims_2:
for encoding_dim_3 in encoding_dims_3:
8
CSCIE89 – Fraud in Credit Card Transactions | Marcos Pastor
# this is our input placeholder
input_img = Input(shape=(input_dim,))
# "encoded" is the encoded representation of the input
encoded = Dense(encoding_dim)(input_img)
encoded_2 = Dense(encoding_dim_2)(LeakyReLU(alpha=my_alpha)(encoded))
encoded_3 = Dense(encoding_dim_3,
activity_regularizer=regularizers.l1(10e-5))(LeakyReLU(alpha=my_alpha)(encoded_2))
# "decoded" is the lossy reconstruction of the input
decoded_3 = Dense(encoding_dim_2)(LeakyReLU(alpha=my_alpha)(encoded_3))
decoded_2 = Dense(encoding_dim)(LeakyReLU(alpha=my_alpha)(decoded_3))
decoded = Dense(input_dim,
activation='sigmoid')(LeakyReLU(alpha=my_alpha)(decoded_2))
# this model maps an input to its reconstruction
autoencoder = Model(input_img, decoded)
print(autoencoder.summary())
autoencoder.compile(optimizer='adagrad', loss='binary_crossentropy',
metrics=['mae'])
early_stopping = EarlyStopping(monitor='loss', min_delta=0, patience=10,
verbose=1, mode='auto')
hist = autoencoder.fit(x_train, x_train,
epochs=epochs,
batch_size=256,
shuffle=True,
validation_data = (x_test, x_test),
callbacks=[early_stopping])
id_str = 'auto_encoder'+str(encoding_dim)+'_'+str(encoding_dim_2) +
'_'+str(encoding_dim_3)+ \
'_'+str(epochs)+'_lrelu_bin_cross.h5'
autoencoder.save_weights(id_str)
decoded_imgs = autoencoder.predict(xf_test)
decod_r.append(decoded_imgs)
xf_r.append(xf_test)
id_r.append(id_str)
hist_r.append(hist)
The complexity now would be to define the treshold when a transaction would be fraud because
its reconstruccion has a large distance of the original values.
Let’s reconstruct the values for all the testing dataset that was including about 20% of the normal
transaction + all the fraud transactions.
For every reconstruccion, lets calculate the distance with the original value, and then we’ll order
the results descending by distance. Instead of deciding a threshold value, we make the decision
of compare our results with the 500 transaction with larger distance.
ind =0
for dd in decod_r:
mse_dd = np.mean(np.power(xf_r[ind] - dd,2), axis =1)
mse_test_label_dd = pd.DataFrame({"mse":mse_dd, "Class":y_test})
mse_test_label_sort = mse_test_label_dd.sort_values("mse", axis = 0, ascending =
False)
print(len(mse_test_label_sort.head(500)[mse_test_label_sort["Class"]==1]), ind,
id_r[ind])
ind = ind + 1
221 0 auto_encoder27_22_18_100_lrelu_bin_cross.h5
219 1 auto_encoder27_22_15_100_lrelu_bin_cross.h5
9
CSCIE89 – Fraud in Credit Card Transactions | Marcos Pastor
217
223
222
219
223
224
2
3
4
5
6
7
auto_encoder27_20_18_100_lrelu_bin_cross.h5
auto_encoder27_20_15_100_lrelu_bin_cross.h5
auto_encoder25_22_18_100_lrelu_bin_cross.h5
auto_encoder25_22_15_100_lrelu_bin_cross.h5
auto_encoder25_20_18_100_lrelu_bin_cross.h5
auto_encoder25_20_15_100_lrelu_bin_cross.h5
We know that we have fraud 492 transactions, therefore, for the case with the best results:
True positives = 224
False positives = 500 – 224 = 276
False negatives = 492 – 224 = 268
Precision = 224 / 500 = 0.448
Recall = 224 / 492 = 0.455
Although this methodology could work in theory, the results demonstrate that performs quite
worse than our sequence model.
10