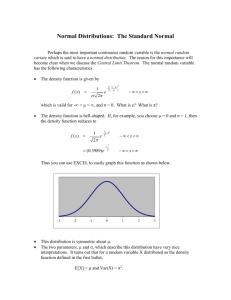
lOMoARcPSD|35125377 ISDS 361A - Final Cheat Sheet Business Analytics I (California State University, Fullerton) Studocu is not sponsored or endorsed by any college or university Downloaded by David Lu (davidlu6381@gmail.com) lOMoARcPSD|35125377 Statistics – a way to get information from data Scales of measurement: Nominal – qualitative or categorical and labels are used to denote the categories Ordinal – Same as nominal but there is ordering or ranking that is meaningful Interval – Quantitative or numerical in nature (sat scores, grades etc) Descriptive statistics – summary of important aspects of a data set (includes collecting data, organizing the data, presenting with charts etc. Business Statistics is analyzing the data Parameter (Variable) – A descriptive measure of the population that is of interest Statistic – A descriptive measure that is calculated from the sample Sampling: Examine part of the whole or population (impractical, prohibitive, costly) Randomized sample (every item in the population has an equal change of being in the sample Non-Random Sampling Errors: Selection Bias (one subset has unequal change of being selected) Non-response Bias (When data is unavailable or unattainable) Measurement errors (Inaccuracies in getting/recording data, ambiguous questions etc) Symmetrical Normal Distribution Single Mode Mean is recommended Mean = Median = Mode 50% of the probability on each side of the mean Skewed to the left Negatively Skewed Single Mode Median is better measure Mean < Median Q2 close to Q3 Bi-Modal – 2 modes Empirical Rule (Symmetrical Distribution) 68% within 1 SD 95% within 2 SD 100% within 3 SD (99.7%) If 2 population means are not equal, we use coefficient of variation (C.V.) Data is facts and figures. Decision Science – Getting info from data Cross Sectional – Data collected at the same time Time series data – Collected over several time periods Inferential Statistics – goes beyond data to draw conclusions about population based on sample data. Population – a set of items under the study Random Sample – A random subset chosen from the population Purpose of Inferential Stats To make inferences about a parameter of a population based on information obtained from a statistic of the sample. Sources of statistical data: Designed experiment Public Source Survey Observation studies Shape (Distribution) -Histogram (symmetry, skewness, modality) Location – Central tendency (mean, median, mode) Variability / Spread – range, IQR, variance, standard deviation Skewed to the right Positively Skewed Single Mode Median is better measure Mean > Median Q2 close to Q1 Range (Max – Min) – Best for limited data i.e. under 10 data only uses 2 values Interquartile Range – IQR (Q3 – Q1) Measure variablitily of the middle 50% of data Variance (Not meaningful) Standard Deviation (σ) = uses all of the data (most efficient) Outliers Formula = Q1 - 1.5(IQR) and Q3 + 1.5(IQR) (IQR Formula = Q3-Q1) Chebyshev’s Rule (Non-Symmetrical Distribution) Matched Pair – W/Pop Std. =(Xbar1-Xbar2)/SQRT((std1^2/samp1)+(std2^2/samp2)) p-value =1-NORM.S.DIST(Test Stat, True) Continuous – Fractions (time, height, weight). (361 always uses continuous) Any value within an interval CAN NEVER BE EXACTLY ANYTHING Random Variable – A numerical description of the outcome of an event Probability Distribution – The collection of all possible values of the random variable X and the associated probabilities P(X=x) Discrete – No fraction, Whole #’s, P(X=1) A discrete number of possible values Higher Standard Deviation – Wider Spread Lower Standard Deviation – Narrower Spread Standard Normal Distribution – mean is 0 and standard deviation is 1 Location: Mean = average (range of data) Median =median (range of data) Mode (Single) = mode.sngl (range of data) Mode (Multiple) =mode.mult (range of data) If Test Stat is < C.V. Do not reject H0 3 treatments 10 observations, SSE=399.6 MSE? 399.6 / 3*10 – 3 EXCEL COMMANDS Variability Range =Max(range of data)-Min(range of data) IQR =(Quartile.exc(range of data),3)- (Quartile.exc(range of data),1) Standard Deviation =stdev.p (range of data) for population =stdev.s (range of data) for sample For a random variable X with mean = 10, variance =25, P(X>20)? (x-mean)/sqrt(var) Inferential stats goes beyond data at disposal, descriptive does not. Downloaded by David Lu (davidlu6381@gmail.com) lOMoARcPSD|35125377 Sampling Distribution, Sample Mean (x̄ ) 1. Convert x̄ into: Z = (x̄ - x) / SE a. SE of x̄ = σ / 2. Solve for probability a. P(x̄ < x1) = NORM.S.DIST(Z,TRUE) b. P(x̄ > x1) = 1-NORM.S.DIST(Z,TRUE) c. (between) P(x1 < x- < x2) = NORM.S.DIST(Z2,TRUE) – NORM.S.DIST(-Z1,TRUE) or NORM.S.DIST(X/SE,TRUE) – NORM.S.DIST(-X/SE,TRUE) Interval Estimation of p (proportions %) 1. Find: CV = -NORM.S.INV(a/2) 2. Find: SE of p̂ = 3. Find confidence interval (UL and LL) of µ with p̂ +/- ME a. ME = CV * SE of p̂ Sampling Distribution, Sample Proportion (p̂ ) 1. Find: p̂ = x/n 2. Find SD = 3. Check distrib: when n*p ≥ 5 or n(1-p) ≥ 5; then distrib is normal 4. Same “P rules” as Finding Prob Norm Distrib = NORM.S.DIST functions Sample size in interval estimation of p 1. Find: Za/2 = NORM.S.INV(a/2) 2. Determine ME (desired) Solve: Solve: n =(((NORM.S.INV(0.05/2)/0.06)^2)*(0.47*(1-0.47))) Type I Error – Incorrectly rejected H0 when H0 is true Hypothesis Testing (known SD ) 1. Determine H0 and Ha 2. Find: SE of x̄ = / a. =( /SQRT(n)) 3. Find: Z = x̄ -mean / SE of x̄ 4. Find: CV =NORM.S.INV(a) (left) or =-NORM.S.INV(a) (right) (a/2) for two tailed 5. Find: p-value =1-NORM.S.DIST(6.45,TRUE) 6. Reject H0 if Z > CV or Z < -CV Null Hypothesis (H0): tentative assumption, can possibly be disproved using sample evidence, always is =, ≥, ≤ Interval Estimation of µ with known population σ 1. Find: CV = -NORM.S.INV(a/2) 2. Find: SE of x̄ = pop σ / a. = σ /SQRT(n) 3. Find confidence interval (UL and LL) of µ with x̄ +/- ME a. ME = CV * SE of x̄ b. **ME = confidence.norm(α, ,n) TIM! LOOK IN BOX TO LEFT! <<<<<<<<<<<<<<<<<<< Recommended sample size, in interval estimation when σ is known 1. Find: Za/2 = NORM.S.INV(a/2) 2. Determine ME (desired margin of error) 3. Solve: n = =SD^2*(z/a)^2 Interval Estimation of µ with unknown population σ 1. Find: CV = -T.INV(a/2, n-1) 2. Find: SE of x̄ = s / =σ /SQRT(n) 3. Find confidence interval (UL and LL) of µ with x̄ +/- ME a. ME = confidence.norm(α, ,n) Alternative Hypothesis (Ha): opposite of null, often what the test attempts to establish. If x̄ > H0, Everything to right in Excel If x̄ < H0, Everything to the left in Excel Type II Error – Incorrectly accepted / not rejected H0 when H0 is false. Hypothesis Testing (P-Value Method average) 1. Determine H0 and Ha 2. Find: SE of x̄ = / 3. Test Statistic: x̄ -Ha/SE a. = (x̄ -Ha)/SE) 4. Find: a. P-Value = 1-NORM.S.DIST (Z,True) for P (Z>Zobs) test b. P-Value = NORM.S.DIST (Z,Ture) for P (Z<Zobs) test 5. Reject H0 if P < a Reject H0 if Z > Standard C.V. Reject H0 if P-value < a ***If P-value is less than α, Reject Hypothesis Testing (Population Proportion %) 1. Determine H0 and Ha 2. Find: SE of p = a. =SQRT((*(1-))/n) 3. Test Statistic: -Ha/S = (-Ha)/SE) 4. Find: a. P-Value = 1-NORM.S.DIST (Z,True) for P (Z>Zobs) test (lower) b. P-Value = NORM.S.DIST (Z,True) for P (Z<Zobs) test (upper) Reject H0 if P < a Hypothesis Testing (µ Differences Known SD) (matched samples) Find Critical Value (Za/2) =NORM.S.INV(a/2) i.e. for 95% confidence it’s =NORM.S.INV(.05/2) At 90% confidence, it will always be +/- 1.65 At 95% confidence, it will always be +/- 1.96 At 98% confidence, it will always be +/- 2.33 At 99% confidence, it will always be +/- 2.58 Step 2 – Find Margin of Error a. = x̄ +(CV* (/SQRT(n))) CV = =-NORM.S.INV(0.025) =1.96 Sample proportion of p̂ Normal when: np ≥ 5 & n(1-p) ≥ 5 Find P Value of Proportion =Z*(SQRT(P*(1-P)/n)) If sample size increases, probability increases. If sample size decrease, probability decreases. 1. Find P Value =NORM.S.DIST(Z,TRUE) 2. Find CV =NORM.S.INV(a/2) 3. Test Statistic =( x̄ -µ)/( /SQRT(n)) # on horizonal axis =NORM.INV Area under the curve = NORM.DIST If you know SD, it’s a Z test If you do not know SD, it’s a T test. In ANOVA, treatments refer to different levels of a factor A descriptive measure of linear association between two variables is the correlation coefficient If F is less than F Critical Value, Do not reject P value > alpha, Do not reject 1-F.DIST(F,df1, df2,TRUE) Test Stat CV F.INV(.95,df(test),df(error) Mathematical solution procedure is called least square method. R^2 is coefficient of determ Higher R^2 the better the model. Between Groups – Treatments Within groups – error Central Limit Theorem – Even if X does not have a normal distribution, x̄ will be approximately normal if n is ≥ 30 The only other way to be normal is if X is normal. ANOVA – Factor: Sales, Car Waxes (Top Column) Treatment: 3 Types of car waxes (# of columns) Experimental Units – Cars Response Variable - # of washes ŷ = b0 + b1, x ŷ is predicted variable b0 is estimate of B0 b1 is estimate of B1 x is independent variable Regression analysis is a statistical procedure that describes how one dependent, and one or more independent variables are related. 1. 2. Enter the information on excel Go to Data – Data Analysis (must be enabled) Choose “t-Test: Paired Two Sample for Means 3. a. b. c. d. e. f. g. Var 1 range: choose first column (w/header) Var 2 range: choose sec column (w/header) Hypothesized Mean Difference = 0 Click box for Labels (if you included header) Alpha will be given (.05 or .01) Output range, click any empty cell in Excel You have your t stat; determine right tail or left tail and you have your critical & p-value Downloaded by David Lu (davidlu6381@gmail.com) Hypothesis Testing (Unknown SD) 1. 2. 3. 4. 5. 6. 7. 8. Determine H0 and Ha Find: SE of x̄ = / = s/SQRT(n) Find: T = x̄ - mean / SE of x̄ =( x̄ - µ)/SE Find: CV =T.INV(a,n-1) (left) or =T.INV(a,n-1) (right) or =T.INV(a/2,n-1) for 2-tailed Find: P-Value = T.DIST(T,n-1,TRUE) for P(t < T) test P-Value = 1-T.DIST(T,n-1,TRUE) for P(t > T) test P-Value = 2*T.DIST(T,n-1,TRUE) for two-tailed test Reject H0 if P < a SE of = =( /SQRT(n)) SE of = = SQRT(P*(1-P)/n) Hypothesis Testing (µ Differences Unknown SD) (chart) 1. Use spreadsheet from Canvas with SE 2. Determine H0 and Ha (always 0) 3. SE X1-X2 a. =SQRT((s1^2/n1)/(s2^2/n2) b. Test stat =(x1-x2)/SE (SE from excel) c. P-value =1-T.DIST(T,DF,TRUE) d. The Degree of Freedom (DF) is on spreadsheet. Regression: Y=B0 + B1, X + E Y=Dependent Variable (like to predict) B0 = Intercept B1=Slope X=Independent Variable E=Error Term (unexplained variation) Regression H0: B1 = 0 Ha: B1 ≠ 0 T-Stat = b1 – B1 / se(b1) p-value= 2*P(t>t-stat) or 2q*(1-T.DIST(F,df-1,True) Rows (blocks) Columns (treatments) Test stat for treatments C.V. = F.INV P-value = 1-F.DIST > Alpha, do not reject