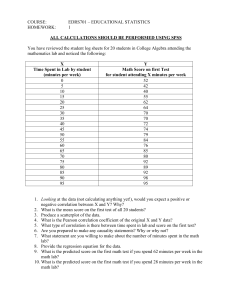
Topic: Linear Correlation WELCOME BSP STUDENTS!!! Get ready to be challenged… Learn something new every day by adapting the ‘New Normal’ INTRODUCTION: Recall that in research we want to not only demonstrate a relationship but also describe and summarize the relationship. The one remaining type of descriptive statistic for us to discuss is used to summarize relationships, and it is called the correlation coefficient. In the following sections, we’ll consider when these statistics are used and what they tell us. Then we’ll see how to compute the two most common versions of the correlation coefficient. Correlation, like the mean, is a concept that you were probably familiar with before taking a statistics course. If we tell you that music ability is correlated with mathematical ability you may be skeptical, but it is very likely that you know what we mean. If we don’t say that the two variables are negatively correlated, it is reasonable to assume that we are implying that the variables are positively correlated; that is, when someone has a good deal of musical ability he or she tends to be good at math (and vice versa), while low musical ability tends to go with low math ability. And if we say that depression and college grades are negatively correlated, you probably know that this means low scores on one variable tend to be paired with high scores on the other. LESSON PROPER Correlation is a statistical technique that is used to measure and describe a relationship between two variables. Correlation means association - more precisely it is a measure of the extent to which two variables are related. There are three possible results of a correlational study: a positive correlation, a negative correlation, and no correlation. A relationship—a correlation—can exist, even though one variable does not cause or influence the other. Two requirements must be met to confidently conclude that X causes Y. 1. X must occur before Y 2. X must be the only variable that can influence Y The Characteristics of a Relationship 1. The Direction of the Relationship: The sign of the correlation that is either positive or negative would describe the relationship direction. Positive Relationship. This result when one value increases the other value also increases - meaning that the two variables are moving in the same direction. This is the direct correlation or the positive correlation. Negative correlation tends to go in the opposite direction. As the x variable increases the y variable decreases. This is the inverse relationship or the negative relationship. Positive Correlation . Negative Correlation No Correlation Source: Understanding Statistics in the Behavioral Sciences, R.R. Pagano Example: A drink concessioner Positive relationship: when the temperature is high, you tend to sell a lot of beer. When the temperature is low, you sell relatively little beer. Negative relationship: On cold days, you sell much more coffee than on hot days. In a nonlinear, or curvilinear, relationship, as the scores change, the scores do not tend to only increase or only decrease: At some point, the scores change their direction of change. Nonlinear relationships come in many different shapes, but Figure below shows two common ones. The scatterplot on the left shows the relationship between a person’s age and the amount of time required to move from one place to another. Very young children move slowly, but as age increases, movement time decreases. Beyond a certain age, however, the time scores change direction and begin to increase. (Such a relationship is called Ushaped.) The scatterplot on the right shows the relationship between the number of alcoholic drinks consumed and feeling well. At first, people tend to feel better as they drink, but Source: Statistics for the Behavioral Sciences, Gravetter & Wallnau beyond a certain point, drinking more makes them feel progressively worse. 2. The Form of the Relationship: The relationships tend to have a linear form, that is, the points in the scatter plot tend to form a straight line. However, a special correlations exist for measuring other forms. The form is specified by the type of correlation used. The Pearson correlation measures linear form. 3. The Strength or Consistency of the Relationship: The consistency of the relationship is measured by the numerical value of the correlation. A correlation of 1.00 indicates a perfectly consistent relationship and 0.00 indicates no relationship at all. For the Pearson correlation, 𝑟 = 1.00 (or – 1.00)means that the data points fit perfectly on a straight line. A perfect relationship is one in which a positive or negative relationship exists and all of the points fall on the line. An imperfect relationship is one in which a relationship exists, but all of the points do not fall on the line. Type of Correlation Coefficients Correlation Coefficient Types of Scales Pearson Product Moment Spearman Rank-Order Phi Point Biserial Both scales Interval or ratio Both scales Ordinal Both scales are naturally dichotomus One scale dichotomous one scale interval or ratio Where and Why Correlations are Used 1. Prediction 3. Reliability 2. Validity 4. Theory Verification The formula for the Pearson Product Moment Coeficient of Correlation is: 𝑛 ∑ 𝑥𝑦 − ∑ 𝑥 ∑ 𝑦 𝑟= √[𝑛 ∑ 𝑥 2 − (∑ 𝑥)2 ][𝑛 ∑ 𝑦 2 − (∑ 𝑦)2 ] Where: 𝑟 = The Pearson Product Moment Coefficient of Correlation 𝑛 = sample size ∑ 𝑥𝑦 = the sum of the product of x and y ∑ 𝑥 ∑ 𝑦 = the product of the sum of ∑ 𝑥 and ∑ 𝑦 2 ∑ 𝑥 = sum of squares of x ∑ 𝑥2 = sum of squares of y Hypothesis Tests with the Pearson Correlation The basic question for this hypothesis test is whether a correlation exists in the population. The Hypotheses: Null hypothess 𝐻0 : 𝜌 = 0 Alternative hypothesis 𝐻1 : 𝜌 ≠ 0 (There is no population correlation) ( There is a real correlation) When there is specific prediction anout the direction of the correlation, it is possible to do a directional, or one-tailed test. 𝐻0 : 𝜌 ≤ 0 (The population correlation is not positive) 𝐻1 : 𝜌 > 0 (There population correlation is positive) The purpose of the hypothesis is to decide between the following two alternatives: 1. There is no correlation in the population 𝜌 = 0, and the sample value is the result of sampling error. 2. The non-zero sample correlation accurately represents a real, nonzer correlation in the population. This is the alternative stated in 𝐻1 . Degrees of Freedom for the Correlation Test The hypothesis test for the Pearson correlation has degrees of freedom defined by 𝑑𝑓 = 𝑛 − 2. Example 1: Below are the midterm (x) and final (y) grades. 75 80 𝑥 𝑦 70 75 65 65 90 95 85 90 85 85 80 90 70 75 65 70 90 90 Solving Stepwise Method I. Problem: Is there a significant relationship between the midterm and the final examination of 10 students in Mathematics? II. Hypotheses: H0: There is no significant relationship between the midterm grades and the final examination/ grades of 10 students in Mathematics. H1: There is no significant relationship between the midterm grades and the final examination/ grades of 10 students in Mathematics. III. Level of Significance: 𝛼 = 0.05 𝑑𝑓 = 𝑛 − 2 = 10 − 2 =8 𝑟. 05 = 0.632 IV. Decision Rule: If the computed 𝑟 value is greater than the 𝑟 tabular value, reject H0. V. Statistics: 𝑥 𝑦 𝑥2 𝑦2 𝑥𝑦 75 70 65 90 85 85 80 70 65 90 80 75 65 95 90 85 90 75 70 90 5625 4900 4225 8100 7225 7225 6400 4900 4225 8100 6400 5625 4225 9025 8100 7225 8100 5625 4900 8100 6000 5250 4225 8550 7650 7225 7200 5250 4550 8100 ∑ 𝑥 = 775 ∑ 𝑦 = 815 ∑ 𝑥 2 = 60,925 ∑ 𝑦 2 = 67,325 ∑ 𝑥𝑦 = 64,000 𝑥̅ = 77.5 𝑦̅ = 77.5 𝑟= 𝑛 ∑ 𝑥𝑦 − ∑ 𝑥 ∑ 𝑦 √[𝑛 ∑ 𝑥 2 − (∑ 𝑥)2 ][𝑛 ∑ 𝑦 2 − (∑ 𝑦)2 ] = = 10(64,000)−(775)(815) √[10(60,925)−(775)2 ][10(67,325)−(815)2 ] = 8,375 √[8,625][9,025] = 8,375 √[609,250−600,625][673,250−664,225] 8,375 √7,7840,625 = 8,375 8,822.73 𝑟 = 0.949 VI. Conclusion/Implication: Since the computed value of 𝑟 which is 0.949 is greater than the tabular value of 0.632 at 0.05 level of significance with 8 degrees of freedom, the null hypothesis is disconfirmed in favor of the research hypothesis. This means that there is a significant relationship between the midterm grades of students and the final examination. It implies that the higher the midterm graddes the higher also are the final grades beacause the value of r is positive. Likewise, the lower the midterm grades the loweralso the final grades. Coefficient of Determination The value 𝑟 2 is called the coefficient of determination because it measures the proportion of variability in one variable that can be determined from the relationship with the other variable. Using example 1: What is the coefficient of determination when 𝑟 = .949? 𝐶𝐷 = 𝑟 2 ∗ 100% = (0.949)2 ∗ 100% = 0.9006 ∗ 100% = 90.06% This 90.06% indicates that the final examination grade depends on the midterm grades. Thus, the final grade is influenced by the midterm grade Example : A correlation of 𝑟 = 0.80 (or −0.80), means 𝑟 2 = 0.64 (or 64%) of the variability in the 𝑌 scores can be predicted from the relationship with 𝑋 In statistics, the correlation coefficient r measures the strength and direction of a linear relationship between to variables on a scatter plot. The value of r is always between +1 and -1. To interpret its value, see which of the following values your correlation r is closest to: Exactly – 1 -0.70 to - 0.99 -0.50 to - 0.69 -0.30 to - 0.49 0 +0.30 to +0.49 +0.50 to +0.69 +0.70 to +0.99 Exactly +1 = A perfect downhill (negative) linear relationship = A strong downhill (negative) linear relationship = A moderate downhill (negative) relationship = A weak downhill (negative) linear relationship = No linear relationship = a weak uphill (positive) linear relationship = a moderate uphill (positive) relationship = a strong uphill (positive) linear relationship = A perfect uphill (positive) linear relationship Scatter Diagrams are convenient mathematical tools to study the correlation between two random variables. As the name suggests, they are a form of a sheet of paper upon which the data points corresponding to the variables of interest, are scattered. Judging by the shape of the pattern that the data points form on this sheet of paper, we can determine the association between the two variables, and can further apply the best suitable correlation analysis technique. A scatterplot is a graph that shows the location of each data point formed by a pair of X–Y scores. A data point that is relatively far from the majority of data points in the scatterplot is referred to as an outlier—it lies out of the general pattern. Example. Draw the scatter diagram for the given pair of variables and understand the type of correlation between them. No. of Students Marks obtained (out of 100) 12 40-50 10 50-60 8 60-70 7 70-80 5 80-90 2 90-100 Solution: Here, we take the two variables for consideration as: M: The marks obtained out of 100 S: Number of students Since the values of M is in the form of bins, we can use the center point of each class in the scatter diagram instead. So let us first choose the axes of our diagram. X-axis – Marks obtained out of 100 Y-axis – Number of Students Spearman Rank Order of Coefficient Correlation (𝒓𝒔 ). The Spearman Rho is a non-parametric test of correlation for it does not require normality in distribution. It is used to look into the significant relationship of two variables when ranking is used. Steps in Computing Spearman Rho 1. Rank the data in x from highest to lowest (Create a temporary rank column and arrange the score from highest to lowest. The highest score gets the rank) 2. In case of similar scores, add the RANKS (not the scores) and divide it by the number of similar scores. The temporary ranks will guide you as to what rank is next. 3. Rank the data in y from highest to lowest. 4. Compute the difference between the rank of x and y 5. Square the difference of the ranks 6. Find the summation of the squared difference. 7. Determine the n 8. Use the formula given Point Biserial Correlation Coefficient (rpbi) The point biserial correlation coefficient (rpbi) is a statistics used to estimate the degree of relationship between a dichotomous and an interval or ratio scale. If a researcher want to find out the degree of relationships between gender (male and female) and IQ score (scale) the point biserial correlation coefficient is appropriate. The interpretation of which is similar to Pearson r - that can range -1 to +1. To find the point biserial correlation, the dichotomous or binomial variable is converted to numerical values. We can assign a value of zero (0) to one category and a value of one (1) to the other category. Then use the regular Pearson Correlation formula to convert the data. It is customary to use zero (0) and one (1) but using other two different numbers would work equally well and would not affect the value of correlation. Example: A researcher wants to determine if gender is related to IQ. Since IQ is continuous data and gender is dichotomous, the point-biserial correlation coefficient is appropriate. Some Examples of Dichotomous variables:: 1. Male vs. female 2. College graduate vs. not a college graduate 3. First-born child vs. later born child 4. success vs. failure on a particular task 5. Older than 30 years versus younger than 30 years. Phi-coefficient. This statistics is used for variables that are both nominal and dichotomous. In this statistics, contingency table is used to present the data. It is a two dimensional table containing frequencies by categories. It is more appropriate for two by two since each variable only take two values. Two-step procedure in computing phi (𝜑): 1. Convert each of the dichotomous variables to numerical values by assigning a 0 to one category and a 1 to the other category for each of the variables. 2. Use the regular Pearson formula with the converted scores. Example: A researcher is interested in examining the relationship between the birth-order position and personality. A random sample of n=8 individuals is obtained, and each individual is classified in terms of birthorder position as first-born or only child versus later-born. Then each individual’s personality is classified either introvert or extrovert. The original measurements are then converted to numerical values by the following assignments: Birth Order Personality 1st or only child = 0 Later-born child = 1 Introvert = 0 Extrovert = 1 The original data and the converted scores are as follows: Original Data Converted Scores Birth Order X Personality Y Birth Order X Personality Y 1st 3rd Only 2nd 4th 2nd Only 3rd Introvert Extrovert Extrovert Extrovert Extrovert Introvert Introvert Extrovert 0 1 0 1 1 1 0 1 0 1 1 1 1 0 0 1 Interpretation of the Phi coefficient -1.0 to -0.7 -0.7 to -0.3 -0.3 to +0.3 +0.3 to +0.7 +0.7 to +1.0 = strong negative association = weak negative association = little or no association = weak positive association = strong positive association