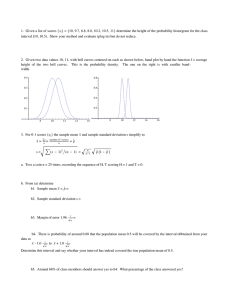
A branch of Applied Mathematics specializing in procedures for collecting, organizing, presenting, analyzing, and interpreting data from observations. Statistics involves much more than simply drawing graphs and computing averages. In education, it is frequently used to describe test results. In science, the data resulting from experiments must be collected and analyzed. Manufacturers can provide better products at reasonable costs through the use of statistical quality control techniques. In government, many kinds of statistical data are collected all the time. A knowledge of statistics can help you become more critical in your analysis of information; hence, you will not be misled by manufactured polls, graphs, and averages. Statistical Question → one that can be answered by collecting data that vary. Example of Statistical Questions: 1. How many hours do college students spend time in studying? (summarizing question) 2. Do college students spend more time in social media than studying? (comparing question) 3. Do students who spend more time in studying do better in exam? (relationship question) Example of Non-Statistical Questions: 1. How old are you? 2. What is your favorite subjects? It is the analysis of data that help to describe, show, and summarize data under study Organize, analyze and present data in a meaningful way It is used to describe a situation It explain already known data and limited to a sample and population having small size Types: Measure of central tendency & Measure of variability Results are shown with the help of charts, graphs, tables, etc. Commonly Used Summarizing Values Percentage Measures of central tendency and location Measures of variability Skewness and Kurtosis Examples: 1) Class average of examination 2) Range of students’ score 3) Average salary It is the analysis of random sample of data taken from a population to describe and make inference about the population Compares, test, and predict data It is used to explain the chance of occurrence of an event It attempts to reach the conclusion about the population Types: Estimation of parameters & Testing of hypothesis Results are shown with the help of probability scores Commonly Used Statistical Tools or Techniques Estimation of Parameters Testing of hypothesis (z-test, t-test, ANOVA, Chi-squares, regression, Time series analysis) Examples: 1) Significant relationships between job satisfaction and performance of CCDC employees 2) The use of module is significantly effective than the traditional method of teaching Two types of data: 1. QUANTITATIVE DATA - numerical values 2. QUALITATIVE DATA - categorical responses such as colors, information, or questions that are answerable by YES or NO, labels, genders, attitude, etc. QUANTITATIVE Discrete continuous - numerical characteristics or attributes associated with the population that can assume different values. - is collection of facts or information. - finite number of values; values are obtained by counting (number of students, number of passers, etc.) 2. Continuous - infinite number of values between two specific numbers; values are obtained by measuring (weight, height, temperature) Levels of Measurement Nominal - classifies and categorizes data Ex: type of blood, gender, religion, citizenship Ordinal - rank or order to show relationship Ex: President (officers), eldest (family order) Ratio - value of zero or starts at an absolute zero point Ex: mass, length, time, angle, energy, rating, electrical change, test results Interval - variables are measured based on a set of intervals on a certain scale Ex: temperature (freezing point, boiling point) 1. Discrete - this method is used when the objective is to determine the cause and effect relationship of a certain phenomenon under controlled condition. SAMPLING TECHNIQUES POPULATION includes all of the elements from a set of data; objects, events, organizations, countries, species, organisms, etc. SAMPLE is a subset taken from a population, either by random sampling or by non-random sampling A. RANDOM SAMPLING Selection of n elements derived from the N population, which is the subject of an investigation or experiment, where each point of the sample has an equal chance of being selected using the appropriate sampling technique. Types of Random Sampling Techniques 1. Lottery Sampling - each member of the population has an equal chance of being selected. Systematic sampling - members of the population are listed and samples are selected at intervals called sample intervals. In this technique, every nth item in the list will be selected from a randomly selected starting point. Ex: If you want to draw a 200 sample from a population of 6,000, select every 3rd person in the list. 3. Stratified random sampling - members of the population are grouped on the basis of their homogeneity. This technique is used when there are number of distinct subgroups in the population within which full representation is required. The sample is constructed by classifying the population into sub-populations or strata on the basis of certain characteristics of the population, such as age, gender or socioeconomic status. 2. COLLECTION OF DATA Statistical of Data it focuses in determining the charges in the attitude, characteristics and behavior of people or other subjects. This technique includes watching and recording actions and behaviors. The person who gathers the data is called an investigator while the person being observed is called the subject. - oral or verbal communication where the interviewer asks questions in any mode (face to face, telephone, or virtual) to an interviewee. - gathered through a set of question that is mailed or handed to respondents who are expected to read and understand them. - if you have a big number pf samples, it is the most practical way to use, in a national level, surveys are usually covered by the government and other forms of surveying organization such as Philippine Statistic Authority (PSA). Example: Select a sample of 400 students from the population which are grouped according to the cities they came from. The table shows the number of students per city. City Population (N) A B C D Solution: To determine the number of students to be taken as sample from each city, we divide the number of students per city by total population (N=28,000) multiply the result by the total sample size (n=400). City A B C D Population (N) 12,000 10,000 4,000 2,000 Total= 28,000 Sample (n) x (400) = 171 x (400) = 143 x (400) = 57 x (400) = 29 Total= 400 12,000 28,000 10,000 28,000 4,000 28,000 2,000 28,000 Cluster Sampling - applied on a geographical basis. Generally, first sampling is performed at higher levels before going down to lower levels. 4. 12,000 10,000 4,000 2,000 Some forms of graphs for ungrouped frequency distributions are pie hart, bar graph, and line graph PIE CHART (Pie Graph) Used to show how all the parts of something are related to the whole. It is represented by a circle divided into slices or sectors of various sizes that show each part’s relationship to the whole and to other parts of the circle. BAR GRAPH Uses rectangles (or bars) of uniform width to represent data, particularly the nominal or categorical type of data. The height of the rectangle denotes the frequency of the variable. Two types of bar graph: - sometimes called a column chart. Used to show the changes in the numerical value of a variable over a period of time. Example: Samples are taken randomly from the provinces first, follows by cities, municipalities, or barangays, and then from households. Multi-stage Sampling - uses a combination of different sampling techniques. 5. Example: Selecting respondents for a national election survey, use the lottery method first for regions and cities, then use stratified sampling to determine the number of respondents from selected areas and clusters. - used to represent changes in data over a period of time. Data like changes in temperature, income, population, and the like can be represented by a line graph. Data are represented by points and are joined by line segments. A line graph may be curved, broken, or straight. DATA refers to information that is collected and recorded. It can be in the form of numbers, words, measurement, and much more. Grouped Data is the type of data which is classified into groups after collection. Ungrouped Data which is also known as raw data that has not been placed in any group or category after collection. When data are presented as graph, they are easily interpreted and compared. Data in an ungrouped frequency distribution can be presented graphically to give a better picture of the distribution. Some forms of graphs for grouped frequency distribution are the Histogram and Ogive. HISTOGRAM A bar graph that shows the frequency of data that occur within a certain interval. In a histogram, the bars are always vertical, the width of each bar is based on the size of the interval it represents, and there are no gaps because their bases cover a continuous range of possible values. Ie for a given ungrouped data to be transformed as a group data. Example: the following are the test scores of students. Construct a suitable frequency table. Use 6 as the desired number of class interval. OGIVE Also called the cumulative frequency graph or cumulative frequency curve is a graph plotted from a cumulative frequency table. Frequency Distribution Table Frequency - the number of occurrence of a data Frequency Table - a table that lists items and shows the number of times the items occur. Steps in constructing a frequency table (for ungrouped data) Step 1: Make 3 columns. Arrange the data in order in the first column. Step 2: Make a tally. Step 3: Count the tallies then write the frequencies. Step 4: Total all the frequencies Steps in constructing a frequency distribution table 1. Determine the range. Range is the difference between the highest value H and the lowest value L in the set of data. R = H - L 2. Determine the desired number of the class interval or categories. The ideal number of class interval in somewhere between 5 and 15. 3. Determine the class width or approximate size of the class interval by dividing the range by the desired number of class intervals. Class Width = 𝑅𝑎𝑛𝑔𝑒 𝐶𝑙𝑎𝑠𝑠 𝐼𝑛𝑡𝑒𝑟𝑣𝑎𝑙𝑠 W= 𝑹 𝑪𝒍 4. Write the class intervals starting with the lowest lower value as determined in the data. Then add the class width to the starting point to get the next interval. Do this until the highest value is contained in the last interval. 5. Tally the corresponding number of scores in each interval. Then summarize the results or sum up the tallies under the frequency column. 14 15 30 26 30 10 10 30 34 20 30 10 22 18 14 21 19 11 Solution: 1. Determine the range. 19 15 40 22 26 16 10 15 20 36 17 29 18 28 40 36 37 R=H-L = 40 - 10 = 30 2. Class interval = 6 3. Determine the Class Width W= 𝑹 𝑪𝒍 = 𝟑𝟎 𝟔 =5 4. Write the class interval starting with the lowest lower value as determined in the data. - starting with 10 and with W = 5, the class intervals are: 10 - 15, 16 - 21, 22 - 27, 28 - 33, 34 - 39, 40 -45. 5. Tally the corresponding number of scores in each interval. Then summarize the results or sum up the tallies under the frequency column. Scores 10 - 15 16 - 21 22 - 27 28 - 33 34 - 39 40 - 45 Tally IIII IIII IIII IIII IIII IIII I IIII II TOTAL Frequency 10 9 4 6 4 2 35 DATA → refers to information that is collected and recorded. It can be in the form of numbers, words, measurement and much more. UNGROUPED DATA → which is also known as raw data that has not been placed in any group or category after collection. GROUPED DATA → the type of data which is classified into groups after collection. Measures of Central Tendency of Ungrouped Data MEAN or the Arithmetic Mean Most commonly used measure of central position. It is used to describe a set of data where the measures cluster or concentrate at a point. ∑𝒙 ̅ = 𝒙 𝑵 Where ∑ 𝑥 = the summation of 𝑥 (sum of the measures 𝑁 = number of values of 𝑥 Example: The grade in Probability of 10 students are 87, 84, 85, 85, 86, 90, 79, 82, 78, 76. What is the average grade of the 10 students? Sulotion: ∑𝒙 ̅ = 𝒙 𝑵 𝑥̅ = 87 + 84 + 85 + 85 + 8610+ 90 + 79 + 82 + 78 _76 𝑥̅ = 832 10 𝑥̅ = 83.2 Hence, the average grade of the 10 students is 83.2. MEDIAN Middle value or term in a set of data arranged according to size/magnitude (either increasing or decreasing) For data with two median, add the two middle values and divide it by two. Example 1: The library logbook shows that 58, 60, 54, 35, and 97 books, respectively, were borrowed from Monday to Friday last week. Find the median. Solution: Arrange the data in increasing order. 35, 54, 58, 60, 97 Since the middle value is the median, then the median is 58. Example 2: Andrea’s scores in 10 quizzes, during the first quarter are 8, 7, 6, 10, 9, 5, 9, 6, 10, and 7. Find the median. Solution: Arrange the data in increasing order. 5, 6, 6, 7, 7, 8, 9, 9, 10, 10 Since the number of measures is even, then the median is the average of the two middle score. Md = 7 +2 8 = 7.5 Hence, the median of the set of scores is 7.5. MODE The measure of value which occurs most frequently in a set of data The value with the greatest frequency. To find the mode for a set of data: 1. Select the measures that appears most often in the set: 2. If two or more measures appear the same number of times, then each of these values is a mode” and 3. If every measure appears the same number of times, then the set of data has no mode. MEASURES OF VARIABILITY (UNGROUPED DATA) Measure of dispersion or variability refer to the spread of the values about the mean. These are important quantities used by statistician in evaluation. Smaller dispersion of score arising from the comparison often indicates more consistency and more reliability. The most commonly used measures of dispersion are the range, the average deviation, the standard deviation, and the variance. 1. -- the difference between the largest value and the smallest value. R=H-L Where R = range, H = highest value, L = lowest value Example: Test score of 10, 8, 9, ,7, 5, and 3. R=H-L R = 10 - 3 R=7 2. -- the dispersion of a set of data about the average ̅| A.D. = ∑|𝒙−𝒙 𝑵 Where A.D is the average deviation; 𝑥 is the individual score; 𝑥̅ is the mean; and 𝑁 is the number scores |𝒙 − 𝒙 ̅| is the absolute value of the deviation from the mean. Procedure in computing the average deviation: 1) Find the mean for all the cases. 2) Find the absolute difference between each score and the mean. 3) Find the sum of the difference and divide by 𝑁. 𝑁 is the number scores. Example: Find the average deviation of 12, 17, 13, 18, 15, 14, 17, 11. 1) Find the mean 𝑥̅ . ∑𝑥 𝑥̅ = = 12 + 17 + 13 + 18 +9 15 + 14 + 17 + 11 𝑁 135 𝑥̅ = 9 = 15 2) Find the absolute difference between each score and the mean. |𝑥 − 𝑥̅ | = |12 − 15| = 3 = |17 − 15| = 2 = |13 − 15| = 2 = |18 − 15| = 3 = |18 − 15| = 3 = |15 − 15| = 0 = |14 − 15| = 1 = |17 − 15| = 2 = |11 − 15| = 4 = |12 − 15| = 3 3) Find the sum of the absolute difference ∑|𝑥 − 𝑥̅ |. |𝑥 − 𝑥̅ | = |12 − 15| = 3 = |17 − 15| = 2 = |13 − 15| = 2 = |18 − 15| = 3 = |18 − 15| = 3 = |15 − 15| = 0 = |14 − 15| = 1 = |17 − 15| = 2 = |11 − 15| = 4 = |12 − 15| = 3 ∑|𝑥 − 𝑥̅ | = 20 x 12 17 13 18 18 15 14 17 11 𝑥̅ 15 15 15 15 15 15 15 15 15 |𝑥 − 𝑥̅ | 3 2 2 3 3 0 1 2 4 Example: compute the standard deviation of the set of test scores: 39, 10, 24, 16, 19, 26, 29, 30, 5. 1) Find the mean. 2) Find the deviation from the mean (𝑥 − 𝑥̅ ). 3) Square the deviations (𝑥 − 𝑥̅ )2 . 4) Add all the squared deviations ∑(𝑥 − 𝑥̅ )2 . 5) Tabulate the results obtained: 6) Compute the standard deviation (SD) using the formula ̅) SD = √∑(𝒙−𝒙 𝑵 𝟐 (𝑥 − 𝑥̅ )2 𝑥 5 10 16 19 24 26 29 30 39 ∑(𝑥 − 𝑥̅ )2 4. -- the variance ꝺ2 of a data is equal to 1⁄𝑁 . ꝺ𝟐 = ∑(𝒙−𝒙 ̅ )𝟐 𝑵 Where ꝺ2 is the variance; 𝑁 is the total number of observations; x is the raw score; and 𝑥̅ is the mean of the data. Variance is not only useful, it can be computed with ease, and it can also be broken into two or more component sums of squares that yield useful information. ∑|𝑥 − 𝑥̅ | = 20 4) Solve for the average deviation by dividing the result in step 3 by 𝑁 . A.D. = 3. ∑|𝑥−𝑥 ̅| 𝑁 = 20 9 ∑(𝑓𝑥) ∑𝑓 = 2.22 Median : 𝑙𝑏𝑚𝑐 + [ -differentiates sets of scores with equal averages. But the advantage of standard deviation over mean deviation is that it has several applications in inferential statistics. ̅) SD = √∑(𝒙−𝒙 𝑵 Mean : 𝑥̅ = ∑𝑓 2 − <𝑐𝑓 𝑓𝑚𝑐 ]i i = interval 𝑙𝑏 = lower boundary → LL - 0.5 𝑐𝑓 = cumulative frequency 𝑓𝑚𝑐 = frequency of the median class mc = median class → ∑2𝑓 = 40 = 20th 2 𝟐 Where SD is the standard deviation; 𝑥 is the individual score; 𝑥̅ is the mean; and Mode : 𝑙𝑏𝑚𝑜 + [ 2 𝐷1 +𝐷2 ]i mo = modal class = highest frequency 𝐷1 = difference 𝐷2 = difference 𝑥 41-45 36-40 31-35 26-30 21-25 16-20 𝑖=5 𝑓 1 8 8 14 7 2 𝑥̅ 43 38 33 28 23 18 ∑ = 40 𝑓𝑥 43 304 264 392 161 36 ∑ = 1,200 1,200 Mean = 40 𝑥̅ = 30 40 −9 Median = 25.5 + [ 214 ]5 25.5 + [11 ]5 = 29.43 14 Mode = 25.5 + [6 +6 7]5 6 25.5 + [13 ]5 = 27.81 𝐷1 = 14 - 8 = 𝐷2 = 14 - 7 = 6 7 𝑙𝑏 40.5 35.5 30.5 25.5 20.5 15.5 < 𝑐𝑓 40 39 31 23 9 2