1.
Draw and explain the architecture of Google App Engine.
Google App Engine (GAE)
Google App Engine is the typical example of PaaS. Google App Engine is a fully
managed, serverless platform for developing and hosting web applications at scale.
The applications are designed to serve a multitude of users simultaneously, without
incurring a decline in overall performance. Third-party application providers can use
GAE to build cloud applications for providing services. The applications run in data a
center which is managed by Google engineers. Inside each data center, there are
thousands of servers forming different clusters. We can choose from several popular
languages, libraries, and frameworks to develop our apps, and then let App Engine
take care of provisioning servers and scaling our app instances based on demand.
Architecture of Google App Engine
The building blocks of Google’s cloud computing application include the Google File System,
the MapReduce programming framework, and Big Table. With these building blocks, Google
has built many cloud applications. The above Figure shows the overall architecture of the
Google cloud infrastructure. GAE runs the user program on Google’s infrastructure. As it is a
platform running third-party programs, application developers now do not need to worry
about the maintenance of servers. GAE can be thought of as the combination of several
software components. The frontend is an application framework which is similar to other web
application frameworks such as ASP, J2EE, and JSP. GAE supports Python and Java
programming environments. The applications can run similar to web application containers.
The frontend can be used as the dynamic web serving infrastructure which can provide the full
support of common technologies.
Features of App Engine
1. Popular language: Users can build the application using language runtimes such as Java,
Python, C#, Ruby, PHP etc.
2. Open and flexible: Custom runtimes allow users to bring any library and framework to
App Engine by supplying a Docker container.
3. Powerful application diagnostics: Google App engine uses cloud monitoring and cloud
logging to monitor the health and performance of the app and to diagnose and fix bugs
quickly it uses cloud debugger and error reporting.
4. Application versioning: It easily hosts different versions of the app, and create
development, test, staging, and production environments.
Google App Engine is one of the earliest PaaS Model which is fully scalable and simply a
small example of how high frequency of requests can be efficiently handled. Despite the
excellent architecture, there are too much restrictions, which makes the PaaS Model inclining
towards the properties of a SaaS with too much Lock-in. For example, PHP can not run
natively on the App Engine.
The two environments are:
App engine Standard environment
App engine Flexible environment
App engine Standard environment
The App Engine standard environment is based on container instances running on
Google's infrastructure. Containers are preconfigured with one of several available
runtimes.
The standard environment makes it easy to build and deploy an application that runs
reliably even under heavy load and with large amounts of data.
Applications run in a secure, sandboxed environment, allowing the standard
environment to distribute requests across multiple servers and scale servers to meet
traffic demands. Our application runs within its own secure, reliable environment that
is independent of the hardware, operating system, or physical location of the server.
Standard environment languages and runtimes: Google App Engine primarily
supports Go, PHP, Java, Python, Node. js, . NET, and Ruby applications, although it
can also support other languages via "custom runtimes".
App Engine flexible environment
App Engine allows developers to focus on what they do best: writing code. Based
on Compute Engine, the App Engine flexible environment automatically scales
our app up and down while also balancing the load.
Features
Customizable infrastructure - App Engine flexible environment instances
are Compute Engine virtual machines, which means that we can take advantage of
custom libraries, use SSH for debugging, and deploy our own Docker containers.
Performance options - Take advantage of a wide array of CPU and memory
configurations. we can specify how much CPU and memory each instance of our
application needs, and the App Engine flexible environment provisions the
necessary infrastructure for us.
Native feature support - Features such as microservices, authorization, SQL and
NoSQL databases, traffic splitting, logging, versioning, security scanning, and
content delivery networks are natively supported.
Managed virtual machines - App Engine manages our virtual machines, ensuring
that:
Instances are health-checked, healed as necessary, and co-located with other
services within the project.
Critical, backwards compatible updates are automatically applied to the
underlying operating system.
VM instances are automatically located by geographical region according to
the settings in our project. Google's management services ensure that all of a
project's VM instances are co-located for optimal performance.
All flexible instances may be restarted on a weekly basis if there are updates
available. This schedule is not guaranteed. During restarts, Google's
management services apply any necessary operating system and security
updates.
we always have root access to Compute Engine VM instances. SSH access to
VM instances in the App Engine flexible environment is disabled by default. If
we choose, we can enable root access to our app's VM instances.
Advantages of Google App Engine:
The Google App Engine has a lot of benefits that can help you advance your app ideas.
This comprises:
Infrastructure for Security: The Internet infrastructure that Google uses is
arguably the safest in the entire world. Since the application data and code are
hosted on extremely secure servers, there has rarely been any kind of illegal
access to date.
Faster Time to Market: For every organization, getting a product or service to
market quickly is crucial. When it comes to quickly releasing the product,
encouraging the development and maintenance of an app is essential. A firm can
grow swiftly with Google Cloud App Engine’s assistance.
Quick to Start: we don’t need to spend a lot of time prototyping or deploying
the app to users because there is no hardware or product to buy and maintain.
Easy to Use: The tools that you need to create, test, launch, and update the
applications are included in Google App Engine (GAE).
Rich set of APIs & Services: A number of built-in APIs and services in Google
App Engine enable developers to create strong, feature-rich apps.
Scalability: This is one of the deciding variables for the success of any
software. When using the Google app engine to construct apps, you may access
technologies like GFS, Big Table, and others that Google uses to build its own
apps.
Performance and Reliability: Among international brands, Google ranks
among the top ones. Therefore, we must bear that in mind while talking about
performance and reliability.
Cost Savings: To administer our servers, we don’t need to employ engineers or
even do it ourselves. The money we save might be put toward developing other
areas of our company.
Platform Independence: Since the app engine platform only has a few
dependencies, we can easily relocate all of your data to another environment.
Differences with other application hosting
Compared to other scalable hosting services such as Amazon EC2, App Engine
provides more infrastructure to make it easy to write scalable applications, but can
only run a limited range of applications designed for that infrastructure.
App Engine's infrastructure removes many of the system administration and
development challenges of building applications to scale to hundreds of requests
per second and beyond. Google handles deploying code to a cluster, monitoring,
failover, and launching application instances as necessary.
While other services let users install and configure nearly any *NIX compatible
software, App Engine requires developers to use only its supported languages,
APIs, and frameworks. Current APIs allow storing and retrieving data from the
document-oriented Google Cloud Datastore database; making HTTP requests;
sending e-mail; manipulating images; and caching. Google Cloud SQL can be
used for App Engine applications requiring a relational MySQL compatible
database backend.
Per-day and per-minute quotas restrict bandwidth and CPU use, number of
requests served, number of concurrent requests, and calls to the various APIs, and
individual requests are terminated if they take more than 60 seconds or return
more than 32MB of data.
2.
What are merits and concerns when using cloud services for IoT applications?
Explain.
IoT in the Cloud:
The Internet of Things, or IoT, refers to the network of physical devices, vehicles,
appliances, and other items embedded with sensors, software, and network connectivity,
which enables these objects to connect and exchange data. IoT in the cloud means storing
and processing the massive amounts of data generated by these interconnected devices in
the cloud, rather than on local servers or in traditional data centers.
Some of the key functions of cloud-based IoT platforms are:
Data storage and management: IoT devices generate a staggering amount of data. This
data needs to be stored, managed, and processed efficiently. Cloud storage provides a
scalable, cost-effective solution for storing and managing IoT data.
Scalability and flexibility: As the number of IoT devices increases, so does the need for
storage and processing power. Cloud computing provides a scalable, flexible solution
that can easily adapt to these changing needs.
Real-time processing and analytics: IoT devices often need to process and analyze
data in real-time to provide valuable insights and make informed decisions. Cloud
computing provides the necessary infrastructure and processing power to carry out these
real-time operations.
Cloud-based IoT platforms are transforming industries all over the world. From smart homes
that can be controlled remotely through a smartphone, to intelligent manufacturing systems
that can monitor and improve production efficiency, IoT in the cloud is changing the way we
live and work.
Benefits of Cloud-Based IoT Platforms:
Some of the key benefits of integrating IoT devices with cloud-based platforms are:
1. Greater scalability: Cloud-based IoT platforms offer immense scalability. The cloud's
elastic nature allows organizations to add or remove IoT devices without worrying about
the infrastructure's capability to handle the increased or decreased load. As the number
of connected devices in an IoT network can fluctuate, having a platform that can scale
according to the need is a huge advantage.
2. Speed and efficiency: Cloud platforms have robust processing capabilities that allow
data to be processed in near real-time. IoT devices constantly generate large amounts of
3.
4.
5.
6.
7.
8.
data that need to be processed quickly to make timely decisions. With cloud computing,
this high-speed data processing becomes possible, increasing efficiency and the speed at
which actions can be taken.
Reduced operational costs: One of the significant advantages of cloud-based IoT
platforms is the reduction in operational costs. With the cloud, businesses don't need to
invest heavily in setting up physical infrastructure or worry about its maintenance. The
pay-as-you-go model allows organizations to pay for only what they use, leading to
considerable cost savings.
Simplified device management: Cloud platforms often come with robust IoT device
management features that make it easy to monitor, manage, and maintain a large number
of devices. This includes functionality for remote device monitoring, firmware and
software updates, troubleshooting, and more, all of which can be done from a central
location.
Advanced data analytics: IoT devices generate massive amounts of data. Using the
power of the cloud, this data can be processed and analyzed more effectively, revealing
insights that can lead to better business decisions. Furthermore, the integration of
machine learning and artificial intelligence technologies can help in predictive analysis,
anomaly detection, and other advanced analytics tasks.
Data redundancy and recovery: Cloud-based platforms usually have excellent data
redundancy and recovery protocols in place. Data is often backed up in multiple
locations, which ensures that in the event of any failure or loss of data, a backup is
readily available.
Global accessibility: One of the key features of cloud services is the ability to access
the system from anywhere in the world, as long as you have an internet connection. This
allows for remote monitoring and control of IoT devices, enabling real-time responses
regardless of geographical location.
Improved interoperability: Cloud-based IoT platforms tend to support a wide range of
protocols and standards, making it easier to integrate different types of IoT devices and
applications. This improved interoperability can lead to more effective IoT solutions.
Key Challenges in Cloud-Based IoT Implementation:
While IoT in the Cloud has significant benefits, organizations can face several challenges
during implementation. Here is an overview of these challenges and how to overcome them.
1. Data Security and Privacy Issues:
The vast number of connected devices in an IoT network presents multiple entry
points for potential cyber-attacks. In many cases, the sensitivity of the data collected
makes such attacks very damaging. Additionally, the global nature of the cloud means
that data could be stored in different geographical locations, each with its own set of
privacy laws and regulations, making compliance a complex task.
To address these issues, businesses must implement robust security measures at every
level of the IoT network, from the devices to the cloud. These might include
encryption, secure device authentication, firewalls, and intrusion detection systems.
Additionally, organizations should ensure that their cloud service provider complies
with all relevant privacy laws and regulations.
2. Network Connectivity and Latency:
Another significant challenge in implementing IoT in the Cloud is ensuring reliable
network connectivity and low latency. The performance of an IoT system heavily
relies on the ability of devices to transmit data to the cloud quickly and reliably.
However, issues such as weak signal strength, network congestion, or failures in the
network infrastructure can lead to connectivity problems and high latency, impacting
the performance of the IoT system.
To overcome this challenge, businesses must invest in reliable and high-performance
network infrastructure. This could include dedicated IoT networks, high-speed
internet connections, and edge computing solutions that process data closer to the
source, reducing latency. MQTT is a scalable, reliable protocol that is becoming a
standard for connecting IoT devices to the cloud.
3. Integration with Existing Systems:
Finally, integrating IoT devices and cloud platforms with existing systems and
technologies can be a formidable task. This is due to the diversity of IoT devices and
the lack of standardized protocols for communication and data exchange. As a result,
businesses may face difficulties in ensuring that their IoT devices can effectively
communicate with the cloud and other systems in their IT infrastructure.
To address this, businesses should consider using middleware or IoT platforms that
provide standardized protocols and APIs for communication and data exchange.
Additionally, they could seek assistance from expert IoT consultants or systems
integrators.
3.
Draw and elaborate various components of Amazon technologies and services
architecture.
AWS is a beginner-friendly platform to use. We can easily create and deploy
websites or any application here on AWS. It is also cost-effective as we only have to
pay for what we use. There is no particular long-term contract or commitment for
payments. Moreover, it provides high performance, availability, scalability, and
security. AWS architecture plays a vital role in enhancing the overall performance of
this platform for customers to use it to the fullest. So, they can choose AWS as their
cloud provider without any doubt.
Types of Deployment Models in Cloud Computing
Various deployment models that AWS provides are public cloud, private cloud,
community cloud, and hybrid cloud.
Public Cloud
If something needs to be deployed openly for public users on the network, the public
cloud can be used. This model is best for those organizations that have grown and
fluctuating demands.
Private Cloud
A private cloud provides better security control. This model is generally used by
independent companies. Here, all the data is backed internally, as well as with
firewalls, so that later it can be hosted either externally or internally. If an
organization seeks higher security, availability, and management, a private cloud is
the best option to go for.
Community Cloud
In this type, different organizations that belong to the same area or community
manually share the cloud setups. For example, banks use the community cloud setup.
Hybrid Cloud
This model includes the features of both public and private clouds. In this model,
resources can be easily provided via internal or external providers. It is best suitable
in cases where companies need scalability, security, and flexibility. In this model, the
companies may use a private cloud for data security but will interact with users
through the public cloud.
AWS Architecture
The above diagram is a simple AWS architecture diagram that shows the basic
structure of Amazon Web Services architecture. It shows the basic AWS services,
such as Route 53, Elastic Load Balancer, EC2, security groups, CloudFront, Amazon
S3 bucket, etc. By using S3 (Simple Storage Service), companies can easily store and
retrieve data of various types using Application Programming Interface calls.
AWS comes with so many handy options such as configuration server, individual
server mapping, and pricing. As we can see in the AWS architecture diagram that a
custom virtual private cloud is created to secure the web application and resources are
spread across availability zones to provide redundancy during maintenance. Web
servers are deployed on AWS EC2 instances. External traffic to the servers is
balanced by Elastic Load Balancer.
We can add or remove instances and scale up or down on the basis of dynamic scaling
policies. Amazon CloudFront distribution helps us minimize latency. It also maintains
the edge locations across the globe—an edge location is a cache for web and
streaming content. Route 53 domain name service, on the other hand, is used for the
registration and management of our Internet domain.
Benefits of AWS architecture
The AWS architecture makes it possible to offer the best services to clients
based on web services technologies, adding or removing virtual servers, the
selection of services, etc. AWS services and resources are available worldwide
24/7 and 365 days of the year where solutions are easily deployed according to
clients’ requirements.
Its feature of memory management makes it very fast and resilient for clients
to host websites and get affirmative results.
Clients can scale up and down the resources according to their needs.
Clients can get more time to do their business tasks and leave the rest to AWS
as AWS is fully loaded with advanced features to reduce workload.
It provides end-to-end security and privacy to its clients by ensuring the three
pillars of security—confidentiality, integrity, and availability—of the client
data.
Key Components of AWS Architecture
Load Balancing
The load balancing component of AWS architecture facilitates the
enhancement of the application and the efficiency of the server. The hardware
load balancer is generally used as a common network appliance in the
architecture of traditional web applications to perform load balancing. But
with AWS Elastic Load Balancer, the delivery of load balancing has become
more efficient. Traffic is easily distributed to EC2 instances across various
availability zones in AWS. The traffic is distributed to dynamic additions as
well.
Elastic Load Balancing
It can smoothly collapse or increase the capacity of load balancing by tuning a
few of the traffic demands. Sticky sessions are also supported to achieve
advanced routing services.
Amazon CloudFront
This component is mainly used for the delivery of the content on the website.
The content can be of many types, such as streaming content, static or
dynamic that are stored in global network locations. Users can request the
content from any closest location in an automatic way, which ultimately
enhances the performance.
Elastic Load Balancer
ELB components become handy when the required traffic to the web servers
needs to be delivered. It increases the performance greatly. Dynamic growth
can be easily achieved through an Elastic Load Balancer. Based on various
traffic conditions, its capacity can be adjusted.
Security Management
AWS is mainly known for its secure environment where users can deploy their
work without a doubt. It provides a security grouping feature. This is very
similar to inbound network firewalls and ports, source IP ranges, and protocols
that need to be specified to reach EC2 instances.
ElastiCache
This tool is very handy in AWS when the memory cache needs to be managed
in the cloud. In memory management, clearing cache plays a big role to help
reduce the load on the server. Frequently used information is easily cached to
increase scalability, reliability, and performance.
Amazon RDS
RDS stands for Relational Database. It offers services very similar to MySQL
and Microsoft SQL Server and is very user-friendly and easily accessible.
Bottom of Form
AWS Cloud Computing Models
The three Cloud Computing models through which AWS provides its services to
clients worldwide are: Iaas, Paas and SaaS
IaaS
IaaS stands for Infrastructure as a Service, and it is a type of Cloud
Computing that provides a virtualized environment of computer resources
over the Internet to the clients. It provides clients with on-demand network
connectivity, storage, and processing. This model manages IT infrastructures
such as servers, storage, and networking resources. Clients can also build their
versions of the application on these resources.
PaaS
The Platform-as-a-Service model offers a platform to clients where they can
develop, run, and manage any sort of application. PaaS can be offered to the
clients via public, private, or hybrid clouds. Services offered by this model are
databases, emails, queues, workflow engines, etc. In this model, the cloud
service providers are responsible for the better functionality of resources.
SaaS
SaaS stands for Software as a Service, and it is a form of Cloud Computing
model where applications are successfully deployed over the Internet to be
used as services. This model helps clients get rid of the complex processes of
software and hardware management. They are also allowed to customize a few
things such as the color of their brand logo, etc.
Advantages of AWS
Economical
AWS allows its clients to pay only for the services that they use, which makes
it much economical. Moreover, if we are planning to create a physical server,
it will cost us for installing and configuring expensive hardware. So, it is
better to go for cloud services from cloud service providers, especially AWS,
which are cost-effective and reliable at the same time.
Reliability
AWS is highly reliable as it provides 24/7 service throughout the year. If any
of the servers gets failed, the hosted applications and services will still be
available as they are easily shifted to any of the other servers automatically.
Limitless Storage Capacity
Users always worry about the storage capacity, but AWS provides almost
unlimited storage such that users do not need to pay a penny extra for storage.
They get as much storage as they want.
Backup and Recovery
AWS makes it easier to store, backup, and restore data as compared to storing
it on a physical device. These days, almost all cloud service providers have the
feature to recover the entire data in the case of any data loss, so it is suitable
and useful for any industry.
Easier Information Access
After registering on the AWS cloud service providing platform, users can
access their information from anywhere in the world, provided they have a
good Internet connection. However, these facilities vary with the kind of
account chosen or the plan opted for.
Disadvantages of AWS
Technical Issues
AWS provides services to numerous users every day without fail. However, at
times, there may occur a serious problem in the system that causes a
temporary suspension of a company’s business processes. In case the Internet
availability is down, then the company will not be able to use any sort of
application, cloud data, or servers that it was accessing through AWS.
Security Issues
Companies seek security the most when they go for cloud services because
storing data and important files is always a risky task. There are chances that
hackers may break into the system. However, AWS is designed in such a way
that it provides higher scalability, reliability, security, and flexibility.
Difficulty in Switching Between Service Providers
Although cloud service providers provide full assurance regarding their
services when companies want to switch to any other cloud service, they find
it very difficult to integrate the current cloud applications into the new cloud
platform. This applies to AWS services as well.
4.
Explain the DHT 11 sensor interfacing diagram with Arduino and program?
Dht11 Sensor:
The DHT11 is a commonly used Temperature and humidity sensor that comes with a
dedicated NTC thermistor to measure temperature and humidity sensing components. When
the temperature changes, the resistance of the NTC thermistor also changes. This change in
resistance is measured and the temperature is calculated from it.
The humidity sensing component consists of a moisture-holding substrate sandwiched in
between two electrodes. When the substrate absorbs water content, the resistance between the
two electrodes decreases. The change in resistance between the two electrodes is proportional
to the relative humidity. Higher relative humidity decreases the resistance between the
electrodes, while lower relative humidity increases the resistance between the electrodes.
This change in resistance is measured with the onboard MCU’s ADC and the relative
humidity is calculated.
DHT11 Pinouts:
DHT11 SPECIFICATION:
Operating Voltage: 3.5V to 5.5V
Operating current: 0.3mA (measuring) 60uA (standby)
Output: Serial data
Temperature Range: 0°C to 50°C
Humidity Range: 20% to 90%
Resolution: Temperature and Humidity both are 16-bit
Accuracy: ±1°C and ±1%
Dht11 Sensor Interfacing with Arduino Microcontroller
The DHT11 Sensor is factory calibrated and outputs serial data and hence it is highly easy to
set it up. The connection diagram for this sensor is shown below.
In the above diagram, the data pin is connected to an I/O pin of the MCU and a 5K pull-up
resistor is used. This data pin outputs the value of both temperature and humidity as serial
data. If we are trying to interface DHT11 with Arduino then there are ready-made libraries
for it which will give us a quick start.
Each DHT11 element is strictly calibrated in the laboratory which is extremely accurate in
humidity calibration. The calibration coefficients are stored as programmes in the OTP
memory, which are used by the sensor’s internal signal detecting process.
DHT11 1-Wire Communication Protocol
Single-bus data format is used for communication and synchronization between MCU and
DHT11 sensor. One communication process is about 4ms. Data consists of decimal and
integral parts. Complete data transmission is 40bit, and the sensor sends higher data bit first.
Data format is as follows: 8bit integral RH data + 8bit decimal RH data + 8bit integral T data
+ 8bit decimal T data + 8bit checksum. If the data transmission is right, the check-sum should
be the last 8bit of "8bit integral RH data + 8bit decimal RH data + 8bit integral T data + 8bit
decimal T data".
When MCU sends a start signal, DHT11 changes from the low-power-consumption mode to
the running mode, waiting for MCU to complete the start signal. Once it is completed,
DHT11 sends a response signal of 40-bit data that include the relative humidity and
temperature information to the MCU. Users can choose to collect (read) some data. Without
the start signal from MCU, DHT11 will not give the response signal to MCU. Once data is
collected, DHT11 will change to the low power-consumption mode until it receives a start
signal from MCU again.
Applications
Measure temperature and humidity
Local Weather station
Automatic climate control
Environment monitoring
Program:
#include <Adafruit_Sensor.h>
#include <DHT.h>
#include <DHT_U.h>
#define DHTTYPE DHT11 // DHT 11
#define DHTPIN 2
DHT_Unified dht(DHTPIN, DHTTYPE);
uint32_t delayMS;
void setup()
{
Serial.begin(9600);
dht.begin();
sensor_t sensor;
delayMS = sensor.min_delay / 1000;
}
void loop()
{
sensors_event_t event;
dht.temperature().getEvent(&event);
Serial.print(F("Temperature: "));
Serial.print(event.temperature);
Serial.println(F("°C"));
dht.humidity().getEvent(&event);
Serial.print(F("Humidity: "));
Serial.print(event.relative_humidity);
Serial.println(F("%"));
delay(delayMS);
}
Firstly, we have included all the necessary libraries and defined the sensor type as
DHT11 and the sensor pin as digital pin 2 and then created an instance for the DHT
library also created a variable to declare the minimum delay.
In the setup function, we have initialized serial communication and the DHT library.
Then the minimum delay for the data refresh.
In the loop function, we have created an event, using this event the temperature and
humidity data is read from the DHT11 sensor then the value is printed to the serial
monitor.
OUTPUT:
5.
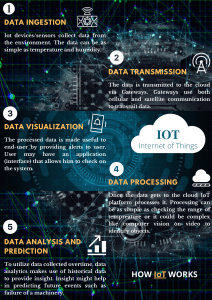
Explain in detail about various IoT communication model?
IoT devices are found everywhere and will enable circulatory intelligence in the
future. For operational perception, it is important and useful to understand how
various IoT devices communicate with each other. Communication models used in
IoT have great value. The IoTs allow people and things to be connected any time, any
space, with anything and anyone, using any network and any service.
Types of Communication Model:
1. Request & Response Model:– This model follows client-server architecture.
The
client, when required, requests the information from the server. This
request is usually in the encoded format.
This model is stateless since the data between the requests is not retained and
each request is independently handled.
The server Categories the request, and fetches the data from the database and
its resource representation. This data is converted to response and is
transferred in an encoded format to the client. The client, in turn, receives the
response.
On the other hand — In Request-Response communication model client
sends a request to the server and the server responds to the request. When the
server receives the request it decides how to respond, fetches the data
retrieves resources, and prepares the response, and sends it to the client.
Example: Sending a spreadsheet to the printer — the spreadsheet program is
the client.
2. Publisher-Subscriber Model:-This model comprises three entities: Publishers,
Brokers, and Consumers.
Publishers are the source of data. It sends the data to the topic which are
managed by the broker. They are not aware of consumers.
Consumers subscribe to the topics which are managed by the broker.
Hence, Brokers responsibility is to accept data from publishers and send it
to the appropriate consumers. The broker only has the information
regarding the consumer to which a particular topic belongs to which the
publisher is unaware of.
Example: Public sensors with a massive base of uniform users that will use
the data.
3. Push-Pull Model:– The push-pull model constitutes data publishers, data
consumers, and data queues.
Publishers and Consumers are not aware of each other.
Publishers publish the message/data and push it into the queue. The
consumers, present on the other side, pull the data out of the queue.
Thus, the queue acts as the buffer for the message when the difference
occurs in the rate of push or pull of data on the side of a publisher and
consumer.
Queues help in decoupling the messaging between the producer and
consumer. Queues also act as a buffer which helps in situations where
there is a mismatch between the rate at which the producers push the
data and consumers pull the data.
Example: Queues help in decoupling the messaging between the
producers and consumer
4. Exclusive Pair :
Exclusive Pair is the bi-directional model, including full-duplex
communication among client and server. The connection is constant and
remains open till the client sends a request to close the connection.
The Server has the record of all the connections which has been
opened.
This is a state-full connection model and the server is aware of all
open connections.
WebSocket based communication API is fully based on this model.
Example: The WebSocket-based communication API.
6. What is an Ultrasonic Sensor? Draw interfacing diagram of Ultrasonic Sensor with
Raspberry Pi .And also write the program for the same.
Ultrasonic sensors use sound waves above the 20 kHz range to detect objects in
proximity, similar to how bats use echolocation to maneuver without colliding into
obstacles. In the automotive space, ultrasonic sensors are prevalent for ADAS (Advanced
Driver-Assistant Systems) applications, specifically for parking assist where 4–16 sensors
are used to detect obstacles when parking a vehicle. In the industrial space, ultrasonic
sensors are used in robotics and other applications that require reliable presence,
proximity, or position sensing.
The Ultrasonic sensor is a very inexpensive electronic component that can be used for a
multitude of applications. It is used in almost all robotics projects as almost all of them
are either required to measure the distance or for object intrusion. It is generally used with
Arduino or other microcontrollers which provide 5V.
Working of the Ultrasonic sensor
1. A 5V pulse is applied to the TRIG pin for at least 10 microseconds.
2. Now the transmitter will emit light pulses of the wave at 40kHz. The number of
pulses is chosen to eight to keep the ultrasonic wave unique from other
background noise at the time of detection.
3. Now as the transmitted wave goes forward, the ECHO pin goes high and emits a
pulse for 38 milliseconds.
4. The ECHO pin goes low after 38ms if the wave does not get reflected.
5. If the transmitted wave gets reflected, then the ECHO pin will immediately go
low. And the width of the output pulse will be anywhere from 150 microseconds
to 25 milliseconds.
6. The width of the pulse from the ECHO pin is used to calculate the distance of the
object from the sensor.
Ultrasonic sensor Pinouts:
1.VCC pin: For Power supply
2.TRIG pin: This pin is the input pin and transmits the waves.
3.ECHO pin: This pin is the output pin and it detects the reflected wave.
4.GND pin: This pin is the ground pin.
The Ultrasonic sensor can measure from about 2 cm to 400 cm and it draws very little
current so it can be used with battery-powered devices.
Interfacing with Raspberry Pi
The circuit diagrams for this are very simple as we simply have to connect all 4 pins
to the GPIO pins of the Raspberry Pi.
Python code for Raspberry Pi
import RPi.GPIO as GPIO
import time
#GPIO Mode (BOARD / BCM)
GPIO.setmode(GPIO.BCM)
#set GPIO Pins
GPIO_TRIGGER = 18
GPIO_ECHO = 24
#set GPIO direction (IN / OUT)
GPIO.setup(GPIO_TRIGGER, GPIO.OUT)
GPIO.setup(GPIO_ECHO, GPIO.IN)
def distance():
# set Trigger to HIGH
GPIO.output(GPIO_TRIGGER, True)
# set Trigger after 0.01ms to LOW
time.sleep(0.00001)
GPIO.output(GPIO_TRIGGER, False)
StartTime = time.time()
StopTime = time.time()
# save StartTime
while GPIO.input(GPIO_ECHO) == 0:
StartTime = time.time()
# save time of arrival
while GPIO.input(GPIO_ECHO) == 1:
StopTime = time.time()
# time difference between start and arrival
TimeElapsed = StopTime - StartTime
# multiply with the sonic speed (34300 cm/s)
# and divide by 2, because there and back
distance = (TimeElapsed * 34300) / 2
return distance
if __name__ == '__main__':
try:
while True:
dist = distance()
print ("Measured Distance = %.1f cm" % dist)
time.sleep(1)
# Reset by pressing CTRL + C
except KeyboardInterrupt:
print("Measurement stopped by User")
GPIO.cleanup()
7.
Explain in detail about IoT Hub message routing to send device-to-cloud
messages to different endpoints.
Message routing enables us to send messages from our devices to cloud services in
an automated, scalable, and reliable manner. Message routing can be used for:
Sending device telemetry messages and events to the built-in endpoint and
custom endpoints. Events that can be routed include device lifecycle events,
device twin change events, digital twin change events, and device connection
state events.
Filtering data before routing it to various endpoints by applying rich queries.
Message routing allows us to query on the message properties and message body
as well as device twin tags and device twin properties.
Routing endpoints
Each IoT hub has a default built-in endpoint (messages/events) that is compatible
with Event Hubs. We also can create custom endpoints that point to other services in
our Azure subscription.
Each message is routed to all endpoints whose routing queries it matches. In other
words, a message can be routed to multiple endpoints. If a message matches multiple
routes that point to the same endpoint, IoT Hub delivers the message to that endpoint
only once.
IoT Hub currently supports the following endpoints:
Built-in endpoint
Storage containers
Service Bus queues
Service Bus topics
Event Hubs
Cosmos DB
Built-in endpoint
We can use standard Event Hubs integration and SDKs to receive device-to-cloud
messages from the built-in endpoint (messages/events). Once a route is created,
data stops flowing to the built-in endpoint unless a route is created to that
endpoint. Even if no routes are created, a fallback route must be enabled to route
messages to the built-in endpoint. The fallback is enabled by default if we create
our hub using the portal or the CLI.
Azure Storage as a routing endpoint
IoT Hub supports writing data to Azure Storage in the Apache Avro format and
the JSON format. The default is AVRO. When using JSON encoding, we must set
the contentType property to application/json and contentEncoding property
to UTF-8 in the message system properties. Both of these values are caseinsensitive. If the content encoding isn't set, then IoT Hub writes the messages in
base 64 encoded format.
The encoding format can be set only when the blob storage endpoint is
configured; it can't be edited for an existing endpoint
IoT Hub batches messages and writes data to storage whenever the batch reaches
a certain size or a certain amount of time has elapsed.
Service Bus queues and Service Bus topics as a routing endpoint
Service Bus queues and topics used as IoT Hub endpoints must not
have Sessions or Duplicate Detection enabled. If either of those options are
enabled, the endpoint appears as Unreachable in the Azure portal.
Event hubs as a routing endpoint
Apart from the built-in-Event Hubs compatible endpoint, we can also route data to
custom endpoints of type Event Hubs.
Route to an endpoint in another subscription
If the endpoint resource is in a different subscription than our IoT hub, we need to
configure our IoT hub as a trusted Microsoft service before creating a custom
endpoint. When we do create the custom endpoint, set the Authentication type to
user-assigned identity.
Routing queries : IoT Hub message routing provides a querying capability to
filter the data before routing it to the endpoints. Each routing query we configure
has the following properties:
Property
Description
Name
The unique name that identifies the query.
Source
The origin of the data stream to be acted upon. For example,
device telemetry.
Condition The query expression for the routing query that is run against
the message application properties, system properties, message
body, device twin tags, and device twin properties to determine
if it's a match for the endpoint.
Endpoint The name of the endpoint where IoT Hub sends messages that
match the query. We recommend that you choose an endpoint
in the same region as your IoT hub.
A single message may match the condition on multiple routing queries, in which case
IoT Hub delivers the message to the endpoint associated with each matched query. IoT
Hub also automatically deduplicates message delivery, so if a message matches
multiple queries that have the same destination, it's only written once to that
destination.
Limitations for device connection state events
Device connection state events are available for devices connecting using either the
MQTT or AMQP protocol, or using either of these protocols over WebSockets.
Requests made only with HTTPS won't trigger device connection state notifications.
For IoT Hub to start sending device connection state events, after opening a
connection a device must call either the cloud-to-device receive message operation or
the device-to-cloud send telemetry operation. Outside of the Azure IoT SDKs, in
MQTT these operations equate to SUBSCRIBE or PUBLISH operations on the
appropriate messaging topics. Over AMQP these operations equate to attaching or
transferring a message on the appropriate link paths.
IoT Hub doesn't report each individual device connect and disconnect, but rather
publishes the current connection state taken at a periodic, 60-second snapshot.
Receiving either the same connection state event with different sequence numbers or
different connection state events both mean that there was a change in the device
connection state during the 60-second window.
8. Explain RESTful Web Service along with examples.
REST or Representational State Transfer is an architectural style that can be
applied to web services to create and enhance properties like performance,
scalability, and modifiability. RESTful web services are generally highly
scalable, light, and maintainable and are used to create APIs for web-based
applications. It exposes API from an application in a secure and stateless manner
to the client. The protocol for REST is HTTP. In this architecture style, clients
and servers use a standardized interface and protocol to exchange representation
of resources.
REST emerged as the predominant Web service design model just a couple of
years after its launch, measured by the number of Web services that use it.
Owing to its more straightforward style, it has mostly displaced SOAP and
WSDL-based interface design.
REST became popular due to the following reasons:
1. It allows web applications built using different programming languages to
communicate with each other. Also, web applications may reside in different
environments, like on Windows, or for example, Linux.
2. Mobile devices have become more popular than desktops. Using REST, you
don’t need to worry about the underlying layer for the device. Therefore, it
saves the amount of effort it would take to code applications on mobiles to
talk with normal web applications.
3. Modern applications have to be made compatible with the Cloud. As Cloudbased architectures work using the REST principle, it makes sense for web
services to be programmed using the REST service-based architecture.
RESTful Architecture:
1. Division of State and Functionality: State and functionality are divided
into distributed resources. This is because every resource has to be accessible
via normal HTTP commands. That means a user should be able to issue
the GET request to get a file, issue the POST or PUT request to put a file on
the server, or issue the DELETE request to delete a file from the server.
2. Stateless, Layered, Caching-Support, Client/Server Architecture: A type
of architecture where the web browser acts as the client, and the web server
acts as the server hosting the application, is called a client/server
architecture. The state of the application should not be maintained by REST.
The architecture should also be layered, meaning that there can be
intermediate servers between the client and the end server. It should also be
able to implement a well-managed caching mechanism.
Principles of RESTful applications:
1. URI Resource Identification: A RESTful web service should have a set of
resources that can be used to select targets of interactions with clients. These
resources can be identified by URI (Uniform Resource Identifiers). The
URIs provide a global addressing space and help with service discovery.
2. Uniform Interface: Resources should have a uniform or fixed set of
operations, such as PUT, GET, POST, and DELETE operations. This is a
key principle that differentiates between a REST web service and a nonREST web service.
3. Self-Descriptive Messages: As resources are decoupled from their
representation, content can be accessed through a large number of formats
like HTML, PDF, JPEG, XML, plain text, JSON, etc. The metadata of the
resource can be used for various purposes like control caching, detecting
transmission errors, finding the appropriate representation format, and
performing authentication or access control.
4. Use of Hyperlinks for State Interactions: In REST, interactions with a
resource are stateless, that is, request messages are self-contained. So
explicit state transfer concept is used to provide stateful interactions. URI
rewriting, cookies, and form fields can be used to implement the exchange of
state. A state can also be embedded in response messages and can be used to
point to valid future states of interaction.
Advantages of RESTful web services:
1. Speed: As there is no strict specification, RESTful web services are faster as
compared to SOAP. It also consumes fewer resources and bandwidth.
2. Compatible with SOAP: RESTful web services are compatible with SOAP,
which can be used as the implementation.
3. Language and Platform Independency: RESTful web services can be
written in any programming language and can be used on any platform.
4. Supports Various Data Formats: It permits the use of several data formats
like HTML, XML, Plain Text, JSON, etc.
Example :
Here is an example of a simple RESTful service that allows a client to create,
read, update, and delete (CRUD) a resource :
// GET /resource/123
// Returns the state of the resource with ID 123
app.get('/resource/:id', function(req, res) {
var id = req.params.id;
var resource = findResourceById(id);
res.json(resource);
});
// POST /resource
// Creates a new resource with the state specified in the request body
app.post('/resource', function(req, res) {
var resource = req.body;
var id = createResource(resource);
res.json({ id: id });
});
// PUT /resource/123
// Updates the state of the resource with ID 123 with the state specified in the
request body
app.put('/resource/:id', function(req, res) {
var id = req.params.id;
var resource = req.body;
updateResource(id, resource);
res.sendStatus(200);
});
// DELETE /resource/123
// Deletes the resource with ID 123
app.delete('/resource/:id', function(req, res) {
var id = req.params.id;
deleteResource(id);
res.sendStatus(200);
});
In this example, the service uses the GET, POST, PUT, and DELETE HTTP
methods to implement the CRUD operations on a resource. The service uses the
app.get(), app.post(), app.put(), and app.delete() methods to register the appropriate
handler functions for each operation. The req and res objects represent the request
and response, respectively, and are used to access information about the request and
send a response to the client.
9. Describe features of MQTT and COAP Communication Models.
The IoT needs standard protocols.Two of the most promising for small devices are
MQTT and CoAP.
Both MQTT and CoAP:
Are open standards
Are better suited to constrained environments than HTTP
Provide mechanisms for asynchronous communication
Run on IP
Have a range of implementations
MQTT gives flexibility in communication patterns and acts purely as a pipe for
binary data. CoAP is designed for interoperability with the web.
MQTT:
MQTT is a publish/subscribe messaging protocol designed for lightweight M2M
communications. It was originally developed by IBM and is now an open standard.
Architecture
MQTT has a client/server model, where every sensor is a client and connects to a
server, known as a broker, over TCP.
MQTT is message oriented. Every message is a discrete chunk of data, opaque to
the broker.
Every message is published to an address, known as a topic. Clients may subscribe
to multiple topics. Every client subscribed to a topic receives every message
published to the topic.
For example, imagine a simple network with three clients and a central broker.
All three clients open TCP connections with the broker. Clients B and C subscribe
to the topic temperature.
At a later time, Client A publishes a value of 22.5 for topic temperature. The broker
forwards the message to all subscribed clients.
The publisher subscriber model allows MQTT clients to communicate one-to-one, one-tomany and many-to-one.
Topic matching
In MQTT, topics are hierarchical, like a filing system (eg.
kitchen/oven/temperature). Wildcards are allowed when registering a subscription
(but not when publishing) allowing whole hierarchies to be observed by clients.
The wildcard + matches any single directory name, # matches any number of
directories of any name.
For example, the topic kitchen/+/temperature matches kitchen/foo/temperature but
not kitchen/foo/bar/temperature
kitchen/# matches kitchen/fridge/compressor/valve1/temperature
Application Level QoS
MQTT supports three quality of service levels, ―Fire and forget‖, ―delivered at least
once‖ and ―delivered exactly once‖.
Last Will And Testament
MQTT clients can register a custom ―last will and testament‖ message to be sent by
the broker if they disconnect. These messages can be used to signal to subscribers
when a device disconnects.
Persistence
MQTT has support for persistent messages stored on the broker. When publishing
messages, clients may request that the broker persists the message. Only the most
recent persistent message is stored. When a client subscribes to a topic, any
persisted message will be sent to the client.
Unlike a message queue, MQTT brokers do not allow persisted messages to back up
inside the server.
Security
MQTT brokers may require username and password authentication from clients to
connect. To ensure privacy, the TCP connection may be encrypted with SSL/TLS.
MQTT-SN
Even though MQTT is designed to be lightweight, it has two drawbacks for very
constrained devices.
Every MQTT client must support TCP and will typically hold a connection open to
the broker at all times. For some environments where packet loss is high or
computing resources are scarce, this is a problem.
MQTT topic names are often long strings which make them impractical for
802.15.4.
Both of these shortcomings are addressed by the MQTT-SN protocol, which defines
a UDP mapping of MQTT and adds broker support for indexing topic names.
CoAP:
CoAP is the Constrained Application Protocol from the CoRE (Constrained
Resource Environments) IETF group.
Architecture
Like HTTP, CoAP is a document transfer protocol. Unlike HTTP, CoAP is designed
for the needs of constrained devices.
CoAP packets are much smaller than HTTP TCP flows. Bitfields and mappings
from strings to integers are used extensively to save space. Packets are simple to
generate and can be parsed in place without consuming extra RAM in constrained
devices.
CoAP runs over UDP, not TCP. Clients and servers communicate through
connectionless datagrams. Retries and reordering are implemented in the application
stack. Removing the need for TCP may allow full IP networking in small
microcontrollers. CoAP allows UDP broadcast and multicast to be used for
addressing.
CoAP follows a client/server model. Clients make requests to servers, servers send
back responses. Clients may GET, PUT, POST and DELETE resources.
CoAP is designed to interoperate with HTTP and the RESTful web at large through
simple proxies.
Because CoAP is datagram based, it may be used on top of SMS and other packet
based communications protocols.
Application Level QoS
Requests and response messages may be marked as ―confirmable‖ or
―nonconfirmable‖. Confirmable messages must be acknowledged by the receiver
with an ack packet.
Nonconfirmable messages are ―fire and forget‖.
Content Negotiation
Like HTTP, CoAP supports content negotiation. Clients use Accept options to
express a preferred representation of a resource and servers reply with a ContentType option to tell clients what they’re getting. As with HTTP, this allows client
and server to evolve independently, adding new representations without affecting
each other.
CoAP requests may use query strings in the form ?a=b&c=d . These can be used to
provide search, paging and other features to clients.
Security
Because CoAP is built on top of UDP not TCP, SSL/TLS are not available to
provide security. DTLS, Datagram Transport Layer Security provides the same
assurances as TLS but for transfers of data over UDP. Typically, DTLS capable
CoAP devices will support RSA and AES or ECC and AES.
Observe
CoAP extends the HTTP request model with the ability to observe a resource. When
the observe flag is set on a CoAP GET request, the server may continue to reply
after the initial document has been transferred. This allows servers to stream state
changes to clients as they occur. Either end may cancel the observation.
Resource Discovery
CoAP defines a standard mechanism for resource discovery. Servers provide a list
of their resources (along with metadata about them) at /.well-known/core. These
links are in the application/link-format media type and allow a client to discover
what resources are provided and what media types they are.
NAT Issues
In CoAP, a sensor node is typically a server, not a client (though it may be both).
The sensor (or actuator) provides resources which can be accessed by clients to read
or alter the state of the sensor.
As CoAP sensors are servers, they must be able to receive inbound packets. To
function properly behind NAT, a device may first send a request out to the server, as
is done in LWM2M, allowing the router to associate the two. Although CoAP does
not require IPv6, it is easiest used in IP environments where devices are directly
routable.
Comparison
MQTT and CoAP are both useful as IoT protocols, but have fundamental
differences.
MQTT is a many-to-many communication protocol for passing messages between
multiple clients through a central broker. It decouples producer and consumer by
letting clients publish and having the broker decide where to route and copy
messages. While MQTT has some support for persistence, it does best as a
communications bus for live data.
CoAP is, primarily, a one-to-one protocol for transferring state information between
client and server. While it has support for observing resources, CoAP is best suited
to a state transfer model, not purely event based.
MQTT clients make a long-lived outgoing TCP connection to a broker. This usually
presents no problem for devices behind NAT. CoAP clients and servers both send
and receive UDP packets. In NAT environments, tunnelling or port forwarding can
be used to allow CoAP, or devices may first initiate a connection to the head-end as
in LWM2M.
MQTT provides no support for labelling messages with types or other metadata to
help clients understand it. MQTT messages can be used for any purpose, but all
clients must know the message formats up-front to allow communication. CoAP,
conversely, provides inbuilt support for content negotiation and discovery allowing
devices to probe each other to find ways of exchanging data.