")
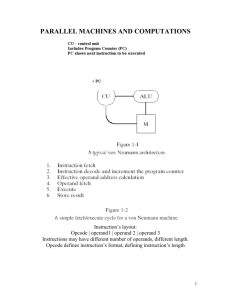
MUHAMMAD AL-XORAZMIY NOMIDAGI TOSHKENT AXBOROT TEXNOLOGIYALARI UNIVERSITETI Assignment - 4 Group: SRM401-1 Student: Matyoqubov Fazliddin Teacher: Xoldorov Shohruhmirzo Toshkent 2023 Software of parallel computers - Architecture of parallelization systems, MIMD architecture Parallel computing involves using multiple central processing units (CPUs) to solve one computational problem. For many years researchers have used parallel computing when working on computationally challenging problems such as nuclear weapons simulation. More recently, economists have applied parallel computing to large-scale matrix problems (Nagurney and Eydeland, 1992; Chabini et al.,1994), the solution of non-linear dynamic models (Coleman, 1993), and simulation (Liu and Rubin, 1996). Nagurney (1996) provides an overview of the application of parallel computing to economics. In addition to these applications, parallel computing can be used to reduce the time it takes to solve estimation problems in econometrics. While this review will not discuss the details of the estimation process, a simple illustration is helpful.1 Consider estimating the parameters of a maximum likelihood model with data on 4800 independent observations. Suppose that a four processor Unix workstation is available to solve the problem, and let Ts be the amount of time it takes to solve the problem in serial. If the data can be broken up into 1200 person subsets so that View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by The University of North Carolina at Greensboro all four processors are used to solve the problem at the same time, the time it takes to find a solution may be approximately one fourth of Ts. Von Neumann’s architecture was first published by John von Neumann in 1945. It is based on the stored-program computer concept where computer memory is used to store both program instructions and data. Program instructions tell the computer to do something. Central Processing Unit: o the electronic circuit responsible for executing the instructions of a computer program. Memory Unit: o consists of random access memory (RAM) Unlike a hard drive (secondary memory), this memory is fast and directly accessible by the CPU. Arithmetic Logic Unit: o carries out arithmetic (add, subtract etc) and logic (AND, OR, NOT etc) operations. Control unit: o reads and interprets instructions from the memory unit. o controls the operation of the ALU, memory and input/output devices, telling them how to respond to the program instructions. Registers o Registers are high-speed storage areas in the CPU. All data must be stored in a register before it can be processed. Input/Output Devices: o The interface to the human operator, e.g. keyboard, mouse, monitor, speakers, printer, etc. Parallel computers still follow this basic design, just multiplied in units. The basic, fundamental architecture remains the same. Parallel computers can be classified based on various criteria: number of data & instruction streams computer hardware structure (tightly or loosely coupled) degree of parallelism (the number of binary digits that can be processed within a unit time by a computer system) Today there is no completely satisfactory classification of the different types of parallel systems. The most popular taxonomy of computer architecture is the Flynn’s classification. SISD Conventional single-processor von Neumann’s computers are classified as SISD systems. Examples: Historical supercomputers such as the Control Data Corporation 6600. SIMD The SIMD model of parallel computing consists of two parts: a front-end computer of the usual von Neumann style, and a processor array. The processor array is a set of identical synchronized processing elements capable of simultaneously performing the same operation on different data. The application program is executed by the front-end in the usual serial way, but issues commands to the processor array to carry out SIMD operations in parallel. All modern desktop/laptop processors are classified as SIMD systems. MIMD Multiple-instruction multiple-data streams (MIMD) parallel architectures are made of multiple processors and multiple memory modules connected via some interconnection network. They fall into two broad categories: shared memory or message passing. Processors exchange information through their central shared memory in shared memory systems, and exchange information through their interconnection network in message-passing systems. MIMD shared memory system A shared memory system typically accomplishes inter-processor coordination through a global memory shared by all processors. Because access to shared memory is balanced, these systems are also called SMP (symmetric multiprocessor) systems MIMD message passing system A message-passing system (also referred to as distributed memory) typically combines the local memory and processor at each node of the interconnection network. There is no global memory, so it is necessary to move data from one local memory to another employing message-passing. This is typically done by a Send/Receive pair of commands, which must be written into the application software by a programmer. MISD In the MISD category, the same stream of data flows through a linear array of processors executing different instruction streams. In practice, there is no viable MISD machine In summary, MIMD architecture forms the basis for parallel computers, and the associated software infrastructure includes programming models, compilers, libraries, operating systems, development tools, middleware, and more. Effective parallel programming requires careful consideration of both the hardware architecture and the software tools and techniques employed.