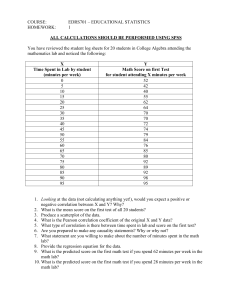
Chapter 3: Describing Relationships Contents Materials for Opening Activity: CSI Stats If you don’t have time to ―frame‖ one of the teachers in your math department, you can use the handprint and list of suspects included here. Chapter 3 Project and Rubric Having your students do projects is a great way for them to get hands-on experience with data that is of interest to them. It is also a great way to help students practice their communication skills, which is important for the AP exam. Use the description and rubric provided here, or modify the electronic version on the Instructor’s Resource CD. Examples of Computer Output Students must be able to interpret computer output on the AP exam. In most cases, this means output from a regression analysis. At this point, students should know how to state the equation of the least-squares regression line and find the values of r, r2, and s from computer output. After Chapter 12, they should be able to understand nearly everything else the computer output provides. Additional Content: Timeplots Timeplots are a very common type of graph that show the trend of a variable over time. However, because they are not part of the AP Topic Outline, we did not include them in the textbook. If you would like to give your students some exposure to this topic, there is a short expositional passage and a couple of exercises with solutions. Quizzes, Tests, and Solutions © 2011 BFW Publishers The Practice of Statistics, 4/e- Chapter 3 95 Chapter 3 Opening Activity: CSI Stats 96 The Practice of Statistics, 4/e- Chapter 3 © 2011 BFW Publishers Chapter 3 Opening Activity: CSI Stats Here is a list of suspects, along with their heights: Name Height (cm) Tony Pecharich 181 Shawn Jacobsen 178 Sarah Volk 152 Anne Godlewski 163 Nina McCourtney 170 Mike Davenport 188 Brian Baumann 182 Lisa Windes 160 Jenny Hagen 161 Chris Hebert 186 Trish Yetman 158 © 2011 BFW Publishers The Practice of Statistics, 4/e- Chapter 3 97 Chapter 3 Project: Investigating Relationships What is a better predictor of battery life in netbooks, weight or cost? What is a better predictor of the cost of a used car, age or number of miles? What is a better predictor of winning percentage, points scored or points allowed? What is a better predictor of success in AP Statistics, SAT score or GPA? In this project you will investigate which of two possible explanatory variables is a better predictor of a response variable by doing a thorough analysis and comparison of the relationships between each pair of variables. Your report/poster should include the following components: 1. Introduction: In this section you will introduce the context of your study, define the variables you will be investigating, and discuss any preliminary hypotheses you might have about the relationships between the variables. 2. Data Collection: In this section you will describe how you obtained your data. If it is from the Internet, make sure to cite the specific page. Include the data in a table and make sure you have at least 10 observations. 3. Graphs: Display the relationships in well-labeled scatterplots. Make sure to display the response variable on the same scale in each plot. Describe the relationships in each scatterplot and compare the relationships. 4. Numerical Summaries and Interpretations: Calculate and interpret the correlation, equation of the least-squares regression line, the standard deviation of the residuals s and r2 for each relationship. Also, make and describe the residual plots for each relationship. 5. Conclusion and Discussion: Decide which of your explanatory variables does a better job of predicting the response variable, citing specific evidence from the graphs and numerical summaries. Discuss when it would be appropriate to make predictions using the least-squares regression line and any potential limitations of your model. 98 The Practice of Statistics, 4/e- Chapter 3 © 2011 BFW Publishers Chapter 3 Project Rubric Note: If a project doesn’t meet the minimum requirements for a 1 in a category, a score of 0 is possible. Introduction and Data Collection 4 = Complete Describes the context of the research Clearly defines the variables and any preliminary hypotheses Specifically describes how the data were collected (including source, if appropriate) Includes appropriate amount of data and displays in a table 3 = Substantial Clearly introduces the context of the research and the variables being used Describes how the data were collected or includes the data in a table 2 = Developing Introduces the context of the research, but doesn’t specifically define variables. Describes how data were collected, but doesn’t include the data (or vice-versa) 1 = Minimal Briefly describes the context of the research or the method of data collection Graphs 4 = Complete Scatterplots are correctly drawn, clearly labeled and easy to compare Important characteristics of the graphs are described and compared Residual plots are correctly displayed and interpreted 3 = Substantial Includes all three characteristics above, but makes one of the following errors o Scatterplots are correctly drawn, but some labels are missing o Scatterplots are compared, but the descriptions are weak or some comparisons are missing o Residual plot is included, but not interpreted correctly 2 = Developing Includes scatterplots with appropriate descriptions and comparisons, but no residual plots OR includes both scatterplots and residual plots with weak descriptions or no descriptions 1 = Minimal Only scatterplots are included with little or no descriptions or interpretations © 2011 BFW Publishers The Practice of Statistics, 4/e- Chapter 3 99 Numerical Summaries 4 = Complete Includes all of the numerical summaries (r, slope, y intercept, s, r2) All numerical summaries are interpreted correctly in context 3 = Substantial Includes all of the numerical summaries, but the interpretations are weak and/or lack context 2 = Developing Includes most or all of the numerical summaries but several interpretations are missing or incorrect or not written in context 1 = Minimal Some numerical summaries are included Conclusions 4 = Complete Makes a reasonable conclusion about which explanatory variable is a better predictor Decision is based on specific evidence from the graphs and numerical summaries Discusses when making predictions is appropriate (i.e. discusses extrapolation) Shows evidence of critical reflection (discusses possible errors, shortcomings, limitations, etc.) 3 = Substantial Makes a reasonable conclusion citing evidence from graphs and numerical summaries Discusses when to make predictions or shows some other evidence of critical reflection 2 = Developing Makes a reasonable conclusion based on evidence from graphs and numerical summaries 1 = Minimal Makes a reasonable conclusion with little or no reference to specific evidence Overall Presentation/Communication 4 = Complete Clear, holistic picture of the project Project is well organized, neat and easy to read Ideas are well communicated, including appropriate transitions between sections. 3 = Substantial Project is organized and easy to read, but lacks clear communication or a holistic picture of the project 2 = Developing Project is not well organized or communication is poor 1 = Minimal Communication and organization are very poor 100 The Practice of Statistics, 4/e- Chapter 3 © 2011 BFW Publishers Examples of Computer Output Example: Body Weight and Pack Weight Minitab Output: Predictor Constant Body Weight Coef 16.265 0.09080 S = 2.26954 SE Coef 3.937 0.02831 R-Sq = 63.2% T 4.13 3.21 P 0.006 0.018 R-Sq(adj) = 57.0% JMP Output: Summary of Fit RSquare RSquare Adj Root Mean Square Error Mean of Response Observations (or Sum Wgts) 0.631536 0.570126 2.26954 28.625 8 Parameter Estimates Term Intercept Body Weight Estimate 16.264927 0.0907994 Std Error 3.93692 0.028314 t Ratio 4.13 3.21 Prob>|t| 0.0061 0.0184 Example: Age and Gesell Scores Minitab Output: Predictor Constant Age (months) Coef 109.874 -1.1270 SE Coef 5.068 0.3102 S = 11.0229 R-Sq = 41.0% T 21.68 -3.63 P 0.000 0.002 R-Sq(adj) = 37.9% JMP Output: Summary of Fit RSquare RSquare Adj Root Mean Square Error Mean of Response Observations (or Sum Wgts) 0.409971 0.378917 11.02291 93.66667 21 Parameter Estimates Term Intercept Age © 2011 BFW Publishers Estimate 109.87384 -1.126989 Std Error 5.067802 0.310172 t Ratio 21.68 -3.63 Prob>|t| <.0001 0.0018 The Practice of Statistics, 4/e- Chapter 3 101 Alternate Example: Used Hondas Minitab Output: Predictor Constant Miles Coef 18773.3 -86.18 S = 971.647 SE Coef 856.2 15.95 R-Sq = 76.4% T 21.93 -5.40 P 0.000 0.000 R-Sq(adj) = 73.8% JMP Output: Summary of Fit RSquare RSquare Adj Root Mean Square Error Mean of Response Observations (or Sum Wgts) 0.764451 0.738279 971.6474 14425 11 Parameter Estimates Term Intercept Miles Estimate 18773.284 -86.1822 Std Error 856.2452 15.94638 t Ratio 21.93 -5.40 Prob>|t| <.0001 0.0004 Alternate Example: Track and Field Minitab Output: Predictor Constant sprint Coef 304.56 -27.629 S = 31.9772 SE Coef 50.73 7.413 R-Sq = 55.8% T 6.00 -3.73 P 0.000 0.003 R-Sq(adj) = 51.8% JMP Output: Summary of Fit RSquare RSquare Adj Root Mean Square Error Mean of Response Observations (or Sum Wgts) 0.55809 0.517916 31.97723 118.3846 13 Parameter Estimates Term Intercept Sprint 102 Estimate 304.55979 -27.62874 Std Error 50.73181 7.412755 t Ratio 6.00 -3.73 Prob>|t| <.0001 0.0033 The Practice of Statistics, 4/e- Chapter 3 © 2011 BFW Publishers Alternate Example: Netbooks (using weight to predict battery life, outlier included) Minitab Output: Predictor Constant weight Coef -16.046 7.944 S = 1.61655 SE Coef 4.622 1.698 R-Sq = 52.2% T -3.47 4.68 P 0.002 0.000 R-Sq(adj) = 49.9% JMP Output: Summary of Fit RSquare RSquare Adj Root Mean Square Error Mean of Response Observations (or Sum Wgts) 0.522413 0.498534 1.616548 5.511364 22 Parameter Estimates Term Intercept weight Estimate -16.04591 7.9440542 Std Error 4.621775 1.698425 t Ratio -3.47 4.68 Prob>|t| 0.0024 0.0001 Alternate Example: Netbooks (using price to predict battery life, outliers included) Minitab Output: Predictor Constant price Coef 6.553 -0.002933 S = 2.33333 SE Coef 3.326 0.009258 R-Sq = 0.5% T 1.97 -0.32 P 0.063 0.755 R-Sq(adj) = 0.0% JMP Output: Summary of Fit RSquare RSquare Adj Root Mean Square Error Mean of Response Observations (or Sum Wgts) 0.004993 -0.04476 2.333326 5.511364 22 Parameter Estimates Term Intercept price © 2011 BFW Publishers Estimate 6.5531967 -0.002933 Std Error 3.32603 0.009258 t Ratio 1.97 -0.32 Prob>|t| 0.0628 0.7547 The Practice of Statistics, 4/e- Chapter 3 103 Data Exploration: The SAT Essay Minitab Output: Predictor Constant Words Coef 1.1728 0.010370 S = 0.792095 SE Coef 0.3193 0.001037 R-Sq = 77.5% T 3.67 10.00 P 0.001 0.000 R-Sq(adj) = 76.8% JMP Output: Summary of Fit RSquare RSquare Adj Root Mean Square Error Mean of Response Observations (or Sum Wgts) 0.77528 0.767532 0.792095 4.032258 31 Parameter Estimates Term Intercept Words 104 Estimate 1.1727949 0.0103701 Std Error 0.319318 0.001037 t Ratio 3.67 10.00 Prob>|t| 0.0010 <.0001 The Practice of Statistics, 4/e- Chapter 3 © 2011 BFW Publishers Chapter 3 Additional Content: Time Plots Many variables are measured at intervals over time. We might, for example, measure the height of a growing child or the price of a stock at the end of each month. In these examples, our main interest is change over time. To display change over time, make a time plot. DEFINITION: Time plot A time plot of a variable plots each observation against the time at which it was measured. Always put time on the horizontal scale of your plot and the variable you are measuring on the vertical scale. Connecting the data points by lines helps emphasize any change over time. The figure to the right is a time plot of the number of single-family homes started by builders each month from January 1990 to July 2008. The counts are in thousands of homes. When you examine a time plot, look once again for an overall pattern and for strong deviations from the pattern. The figure to the right shows strong cycles, regular up-and-down movements in monthly housing starts. Housing starts are highest in the summer and lowest in the winter. No one wants to build in extreme winter weather! Another common overall pattern in a time plot is a trend, a long-term upward or downward Time plot of the monthly count of new singlefamily houses started (in thousands) between movement over time. Many economic variables show an upward trend. Incomes, house prices, and January 1990 and July 2008 (unfortunately) college tuitions tend to move generally upward over time. In the figure, we see an upward trend in the number of singlefamily homes built over time—until 2006, that is. The downturn in housing that began in mid2006 is a clear departure from this pattern. © 2011 BFW Publishers The Practice of Statistics, 4/e- Chapter 3 105 Exercises for Time Plots 1. Orange prices make me sour The figure below is a time plot of the average cost of fresh oranges each month from January 2000 to December 2008. These data, from the Bureau of Labor Statistics monthly survey of retail prices, are ―index numbers‖ rather than prices in dollars and cents. That is, they give each month’s price as a percent of the price in a base period (in this case, the years 1982 to 1984). So 250 means ―250% of the base price.‖ (a) The graph shows strong seasonal variation. How is this visible in the graph? Why would you expect the price of fresh oranges to show seasonal variation? (b) What is the overall trend in orange prices during this period, after we take account of the seasonal variation? 2. The Everglades Water levels in Everglades National Park are critical to the survival of this unique region. The figure to the right is a time plot of water levels from mid-August 2000 to mid-June 2003 at a water-monitoring station in Shark River Slough, the main path for surface water moving through the ―river of grass‖ that is the Everglades. (a) The graph shows strong seasonal variation. How is this visible in the graph? Why would you expect water levels in the Everglades to show seasonal variation? (b) Do you see a clear overall trend in the graph? Explain. 106 The Practice of Statistics, 4/e- Chapter 3 © 2011 BFW Publishers Solutions to Time Plot Exercises (1a) The graph moves up and down during each year, with the lowest prices happening in January of each year. This makes sense because oranges tend to ripen about the same time each year, making them cheaper during January than other times of the year. (1b) The overall trend shows that orange prices are increasing over the years 2000-2008. Both the minimum and maximum prices during each year seem to be increasing over time. (2a) During each year, the water level rises above average in the winter and falls below average in the summer. This isn’t surprising as water levels tend to be lower in the summer due to evaporation and other weather-related factors. (2b) There is no increasing or decreasing trend, but there seems to be slightly less variation from the lowest levels to the highest levels in the most recent years. © 2011 BFW Publishers The Practice of Statistics, 4/e- Chapter 3 107 Quiz 3.1A AP Statistics Name: The scatterplot below shows the fuel efficiency (in miles per gallon) and weight (in pounds) of twenty 2009 subcompact cars. Fuel efficiency and Car weight Fuel Efficiency, MPG 50 40 30 20 10 2500 3000 3500 4000 4500 Car weight 1. Is there a clear explanatory variable and response variable in this setting? If so, tell which is which. If not, explain why not. 2. Does the scatterplot show a positive association, negative association, or neither? Explain why this makes sense. 3. How would you describe the form of the relationship? 108 The Practice of Statistics, 4/e- Chapter 3 © 2011 BFW Publishers 4. Which of the following is closest to the correlation between car weight and fuel efficiency for these 20 vehicles? Explain. r = – 0.9 r = – 0.6 r= 0 r = 0.4 5. There is one ―unusual point‖ on the graph. Explain what is ―unusual‖ about this car. 6. What effect would removing the ―unusual point‖ have on the correlation? Justify your answer. 7. If we converted the car weights to metric tons (1 metric ton ≈ 2,205 pounds). How would the correlation change? Explain. © 2011 BFW Publishers The Practice of Statistics, 4/e- Chapter 3 109 Quiz 3.1B AP Statistics Name: Below is a scatterplot relating systolic blood pressure and age for 14 men from 42 to 67 years old. Scatterplot of Systolic Blood Pressure vs Age 210 200 190 SBP 180 170 160 150 140 130 120 40 45 50 55 AGE 60 65 70 1. Is there a clear explanatory variable and response variable in this setting? If so, tell which is which. If not, explain why not. 2. Does the scatterplot show a positive association, negative association, or neither? What does this tell you about the relationship between age and systolic blood pressure? 3. How would you describe the form of the relationship? 110 The Practice of Statistics, 4/e- Chapter 3 © 2011 BFW Publishers 4. Which of the following is closest to the correlation between systolic blood pressure and age for this group of 14 men? Explain. r = 0.9 r = 0.5 r = 0.2 r = 0.2 5. There is one ―unusual point‖ on the graph. Explain what is ―unusual‖ about this subject. 6. What effect would removing the ―unusual point‖ have on the correlation? Justify your answer. 7. Suppose we rescaled the ages so that they were expressed as number of years above (+) or below (–) 50 years old. That is, suppose we subtract 50 from each value. How would the correlation change? Explain. © 2011 BFW Publishers The Practice of Statistics, 4/e- Chapter 3 111 Quiz 3.1C AP Statistics Name: A student wonders if tall women tend to date taller men. She measures herself, her dormitory roommate, and the women in the adjoining rooms; then she measures the next man each woman dates. Here are the data (heights in inches): Women Men 66 72 64 68 66 70 65 68 70 71 65 65 1. Is there a clear explanatory variable and response variable in this setting? If so, tell which is which. If not, explain why not. 2. Make a well-labeled scatterplot of these data. 3. Based on the scatterplot, describe the pattern, if any, in the relationship between the heights of women and the heights of the men they date. 112 The Practice of Statistics, 4/e- Chapter 3 © 2011 BFW Publishers 4. Use your calculator to find the correlation r between the heights of the men and women. Do the data show any evidence that taller women tend to date taller men? Explain. 5. How would r change if all the men were 6 inches shorter than the heights given in the table? heights were measured in centimeters rather than inches? (There are 2.54 centimeters in an inch.) 6. Suppose another 70-inch-tall female who dated a 73-in-tall male were added to the data set. How would this influence r? © 2011 BFW Publishers The Practice of Statistics, 4/e- Chapter 3 113 Quiz 3.2A AP Statistics Name: The table and scatterplot below show the relationship between student enrollment (in thousands) and total number of property crimes (burglary and theft) in 2006 for eight colleges and universities in a certain U.S. state. No. of Property Crimes (y) 201 6 42 141 138 601 230 294 Scatterplot of burglary vs enrollment 600 Number of property crimes, 2006 Enrollment (in 1000s) (x) 16 2 9 10 14 26 21 19 500 400 300 200 100 0 -100 0 5 10 15 20 25 Student enrollment (in 1000s) The equation of the least-squares regression line is yˆ 112.58 21.83x , where ŷ = predicted number of property crimes and x = student enrollment in thousands. 1. Interpret the slope of the least-squares line in the context of the problem. 2. How many crimes would you predict on a campus with enrollment of 14 thousand students? Show your work. 3. Find the residual for the campus with 14 thousand students and 138 property crimes. Show your work. Interpret the value of the residual in the context of the problem. 114 The Practice of Statistics, 4/e- Chapter 3 © 2011 BFW Publishers 4. Use the scatterplot to make a rough sketch of the residual plot for these data. (No calculations are necessary). 5. Would the slope of the regression line change if the point (26, 601) were removed from the data set? In what direction? 6. The value of r 2 for these data is 0.801. Interpret this value in the context of the problem. 7. Is the given least-squares regression line a good model for these data? Support your answer with appropriate evidence from your answers above. © 2011 BFW Publishers The Practice of Statistics, 4/e- Chapter 3 115 Quiz 3.2B AP Statistics Name: The table and scatterplot below describe the relationship between latitude and average July temperature in the twelve largest U.S. cities. Latitude (x) 40 34 42 29 40 33 32 29 32 37 42 39 July Temp (y) 77 74 75 84 77 94 71 85 86 70 74 75 Latitude and summer temperatures for major cities 95 90 July Temp City New York Los Angeles Chicago Houston Philadelphia Phoenix San Diego San Antonio Dallas San Jose Detroit Indianapolis 85 80 75 70 30 32 34 36 38 40 42 Latitude The equation of the least-squares regression line is yˆ 106.5 0.782 x , where ŷ = July temperature in Fº and x = latitude. 1. Interpret the slope of the least-squares line in the context of the problem. 2. Predict the average July temperature for a city at a latitude of 42 degrees. Show your work. 3. Find the value of the residual for Detroit. Show your work. Interpret the value of the residual in the context of the problem. 116 The Practice of Statistics, 4/e- Chapter 3 © 2011 BFW Publishers 4. Use the scatterplot to make a rough sketch of the residual plot for these data. (No calculations are necessary). 5. Phoenix has a very large positive residual. How would the slope of the regression line change if it were removed from the data set? 6. The value of r 2 for these data is 0.277. Interpret this value in the context of the problem. 7. Is the given least-squares regression line a good model for using latitude to predict average July temperature of U.S. cities? Support your answer with appropriate evidence from your answers above. © 2011 BFW Publishers The Practice of Statistics, 4/e- Chapter 3 117 Quiz 3.2C AP Statistics Name: 1. Below is some data on the relationship between the price of a certain manufacturer’s flatpanel LCD televisions and the area of the screen. We would like to use these data to predict the price of televisions based on size. Scatterplot of Price vs area Price (dollars) 250 265 330 375 575 650 700 600 500 Price Screen Area (sq. inches) 154 207 289 437 584 683 400 300 200 100 200 300 400 500 600 700 area (a) Use your calculator to find the equation of the least-squares regression equation. Write the equation below, defining any variables you use. (b) Explain what is meant by ―least squares‖ in the expression ―least-squares regression line.‖ (c) This manufacturer also produces a television with a screen size of 943 square inches. Would it be reasonable to use this equation to predict the price of that television? Explain. (d) Calculate the residual for the television that has a screen area of 437 square inches. What does this number suggest about the cost of this television, relative to the others? 118 The Practice of Statistics, 4/e- Chapter 3 © 2011 BFW Publishers 2. Alana’s favorite exercise machine is a stair climber. On the ―random‖ setting, it changes speeds at regular intervals, so the total number of simulated ―floors‖ she climbs varies from session to session. She also exercises for different lengths of time each session. She decides to explore the relationship between the number of minutes she works out on the stair climber and the number of floors it tells her that she’s climbed. She records minutes of climbing time and number of floors climbed for six exercise sessions. Computer output and a residual plot from a linear regression analysis of the data are shown below. Predictor Constant Minutes Coef -3.822 5.2150 R-Sq = 98.9% T -0.70 18.76 P 0.522 0.000 Residuals Versus Minutes 3 2 R-Sq(adj) = 98.6% Residual S = 2.34720 SE Coef 5.458 0.2779 1 0 -1 -2 15.0 17.5 20.0 22.5 25.0 Minutes (a) What is the equation of the least-squares line? Be sure to define any variables you use. (b) Is a line an appropriate model for these data? Justify your answer. (c) Interpret the value of s (S = 2.3472) in the context of this problem. © 2011 BFW Publishers The Practice of Statistics, 4/e- Chapter 3 119 Test 3A AP Statistics Name: Part 1: Multiple Choice. Circle the letter corresponding to the best answer. 1. Other things being equal, larger automobile engines consume more fuel. You are planning an experiment to study the effect of engine size (in liters) on the gas mileage (in miles per gallon) of sport utility vehicles. In this study, (a) gas mileage is a response variable, and you expect to find a negative association. (b) gas mileage is a response variable, and you expect to find a positive association. (c) gas mileage is an explanatory variable, and you expect to find a strong negative association. (d) gas mileage is an explanatory variable, and you expect to find a strong positive association. (e) gas mileage is an explanatory variable, and you expect to find very little association. 2. In a statistics course, a linear regression equation was computed to predict the final-exam score from the score on the first test. The equation was ŷ = 10 + 0.9x where y is the finalexam score and x is the score on the first test. Carla scored 95 on the first test. What is the predicted value of her score on the final exam? (a) 85.5 (b) 90 (c) 95 (d) 95.5 (e) none of these 3. In the course described in #2, Bill scored a 90 on the first test and a 93 on the final exam. What is the value of his residual? (a) –2.0 (b) 2.0 (c) 3.0 (d) 93 (e) none of these 4. The correlation between the heights of fathers and the heights of their (fully grown) sons is r = 0.52. This value was based on both variables being measured in inches. If fathers' heights were measured in feet (one foot equals 12 inches), and sons' heights were measured in furlongs (one furlong equals 7920 inches), the correlation between heights of fathers and heights of sons would be (a) much smaller than 0.52 (b) slightly smaller than 0.52 (c) unchanged: equal to 0.52 (d) slightly larger than 0.52 (e) much larger than 0.52 5. All but one of the following statements contains an error. Which statement could be correct? (a) There is a correlation of 0.54 between the position a football player plays and his weight. (b) We found a correlation of r = –0.63 between gender and political party preference. (c) The correlation between the distance travelled by a hiker and the time spent hiking is r = 0.9 meters per second. (d) We found a high correlation between the height and age of children: r = 1.12. (e) The correlation between mid-August soil moisture and the per-acre yield of tomatoes is r = 0.53. 120 The Practice of Statistics, 4/e- Chapter 3 © 2011 BFW Publishers 6. A set of data describes the relationship between the size of annual salary raises and the performance ratings for employees of a certain company. The least squares regression equation is yˆ = 1400 + 2000x where y is the raise amount (in dollars) and x is the performance rating. Which of the following statements is not necessarily true? (a) For each one-point increase in performance rating, the raise will increase on average by $2000. (b) The actual relationship between salary raises and performance rating is linear. (c) A rating of 0 will yield a predicted raise of $1400. (d) The correlation between salary raise and performance rating is positive. (e) If the average performance rating is 1.2, then the average raise is $3800. 7. A least-squares regression line for predicting weights of basketball players on the basis of their heights produced the residual plot below. Residuals versus Height 30 RESIDUAL 20 10 0 -10 -20 72 74 76 78 80 82 84 86 HEIGHT What does the residual plot tell you about the linear model? (a) A residual plot is not an appropriate means for evaluating a linear model. (b) The curved pattern in the residual plot suggests that there is no association between the weight and height of basketball players. (c) The curved pattern in the residual plot suggests that the linear model is not appropriate. (d) There are not enough data points to draw any conclusions from the residual plot. (e) The linear model is appropriate, because there are approximately the same number of points above and below the horizontal line in the residual plot. © 2011 BFW Publishers The Practice of Statistics, 4/e- Chapter 3 121 Use the following to answer questions 8 and 9. One concern about the depletion of the ozone layer is that the increase in ultraviolet (UV) light will decrease crop yields. An experiment was conducted in a green house where soybean plants were exposed to varying levels of UV, measured in Dobson units. At the end of the experiment the yield (kg) was measured. A regression analysis was performed with the following results: 8. The least-squares regression line is the line that (a) minimizes the sum of the distances between the actual UV values and the predicted UV values. (b) minimizes the sum of the squared residuals between the actual yield and the predicted yield. (c) minimizes the sum of the distances between the actual yield and the predicted UV. (d) minimizes the sum of the squared residuals between the actual UV reading and the predicted UV values. (e) minimizes the perpendicular distance between the regression line and each data point. 9. Which of the following is correct? (a) If the UV value increases by 1 Dobson unit, the yield is expected to increase by 0.0463 kg. (b) If the yield increases by 1 kg, the UV value is expected to decrease by 0.0463 Dobson units. (c) If the UV value increases by 1 Dobson unit, the yield is expected to decrease by 0.0463 kg. (d) The predicted yield is 4.3 kg when the UV value is 20 Dobson units. (e) None of the above is correct. 10. Which statements below about least-squares regression are correct? I. Switching the explanatory and response variables will not change the least-squares regression line. II. The slope of the line is very sensitive to outliers with large residuals. III. A value of r2 close to 1 does not guarantee that the relationship between the variables is linear. (a) Only I is correct. (b) Only II is correct. (c) Only III is correct. (d) Both II and III are correct. (e) All three statements—I, II, and III—are correct. 122 The Practice of Statistics, 4/e- Chapter 3 © 2011 BFW Publishers Part 2: Free Response Show all your work. Indicate clearly the methods you use, because you will be graded on the correctness of your methods as well as on the accuracy and completeness of your results and explanations. Questions 11-15 relate to the following. A certain psychologist counsels people who are getting divorced. A random sample of ten of her patients provided the data in the following scatterplot, where x = number of years of courtship before marriage, and y = number of years of marriage before divorce. Marriage length vs. courtship length 20.0 Length of marriage, years 17.5 15.0 12.5 10.0 7.5 5.0 0 1 2 3 Length of courtship. years 4 5 11. Describe what the scatterplot reveals about the relationship between length of courtship and length of marriage. 12. Suppose a new point at (4.5, 8), that is, years of courtship = 4.5 and years of marriage = 8, were added to the plot. What effect, if any, will this new point have on the correlation between courtship duration and marriage duration? Explain. © 2011 BFW Publishers The Practice of Statistics, 4/e- Chapter 3 123 Below is the computer output for the regression of length of marriage versus length of courtship. Predictor Constant courtship Coef 5.710 2.4559 S = 2.74982 SE Coef 1.880 0.6669 R-Sq = 62.9% T 3.04 3.68 P 0.016 0.006 R-Sq(adj) = 58.3% 13. What is the slope of the regression line? Interpret the slope in the context of this problem. 14. Explain what the quantity S = 2.74982 measures in the context of this problem. 15. The psychologist is curious about whether having children has an impact on this relationship. She draws a second scatterplot, with those couples who have children as open squares and couples without children as closed circles. Marriage length vs. courtship length Length of marriage, years 20.0 17.5 15.0 12.5 10.0 7.5 5.0 0 1 2 3 4 5 Length of courtship, years Comment on the impact that having children has on the relationship between length of courtship and length of marriage for these patients. 124 The Practice of Statistics, 4/e- Chapter 3 © 2011 BFW Publishers One weekend, a statistician notices that some of the cars in his neighborhood are very clean and others are quite dirty. He decides to explore this phenomenon, and asks 15 of his neighbors how many times they wash their cars each year and how much they paid in car repair costs last year. His results are in the table below: x = number of car washes per year y = repairs costs for last year Mean Standard deviation 6.4 $955.30 3.78 $323.50 The correlation for these to two variables is r = -0.71 16. Find the equation of the least-squares regression line (with y as the response variable). 17. What percentage of the variation in repair costs can be explained by the number of times per year a car is washed? 18. Based on these data, can we conclude that washing your car frequently will reduce repair costs? Explain. © 2011 BFW Publishers The Practice of Statistics, 4/e- Chapter 3 125 Test 3B AP Statistics Name: Part 1: Multiple Choice. Circle the letter corresponding to the best answer. Questions 1 and 2 refer to the following information: For children between the ages of 18 months and 29 months, there is an approximately linear relationship between height and age. The relationship can be represented by ŷ = 64.93 + 0.63x, where y represents height (in centimeters) and x represents age (in months). 1. Joseph is 22.5 months old. What is his predicted height? (a) 50.80 (b) 64.96 (c) 65.96 (d) 79.11 (e) 87.40 2. Loretta is 20 months old and is 80 centimeters tall. What is her residual? (a) 2.47 (b) 2.47 (c) –12.60 (d) 12.60 (e) 77.53 3. You have data for many families on the parents’ income and the years of education their eldest child completes. Your initial examination of the data indicates that children from wealthier families tend to go to school for longer. When you make a scatterplot, (a) the explanatory variable is parents’ income, and you expect to see a negative association. (b) the explanatory variable is parents’ income, and you expect to see a positive association. (c) the explanatory variable is parents’ income, and you expect to see very little association. (d) the explanatory variable is years of education, and you expect to see a negative association. (e) the explanatory variable is years of education, and you expect to see a positive association. 4. A community college announces that the correlation between college entrance exam grades and scholastic achievement was found to be –1.08. On the basis of this you would tell the college that (a) the entrance exam is a good predictor of success. (b) the exam is a poor predictor of success. (c) students who do best on this exam will be poor students. (d) students at this school are underachieving. (e) the college should hire a new statistician. 5. An agricultural economist says that the correlation between corn prices and soybean prices is r = 0.7. This means that (a) when corn prices are above average, soybean prices also tend to be above average. (b) there is almost no relation between corn prices and soybean prices. (c) when corn prices are above average, soybean prices tend to be below average. (d) when soybean prices go up by 1 dollar, corn prices go up by 70 cents. (e) the economist is confused, because correlation makes no sense in this situation. 126 The Practice of Statistics, 4/e- Chapter 3 © 2011 BFW Publishers 6. Which of the following statements is/are true? I. Correlation and regression require that there are clearly-identified explanatory and response variables. II. Scatterplots require that both variables be quantitative. III. Every least-squares regression line passes through ( x , y ). (a) (b) (c) (d) (e) I and II only I and III only II and III only I, II, and III None of the above 7. There is an approximate linear relationship between the height of females and their age (from 5 to 18 years) described by predicted height = 50.3 + 6.01(age) where height is measured in centimeters and age in years. Which of the following is not correct? (a) The estimated slope is 6.01, which implies that female children between the ages off 5 and 18 increase in height by about 6 cm for each year they grow older. (b) The estimated height of a female child who is 10 years old is about 110 cm. (c) The estimated intercept is 50.3 cm. We can conclude from this that the typical height of female children at birth is 50.3 cm. (d) The average height of female children when they are 5 years old is about 50% of the average height when they are 18 years old. (e) My niece is about 8 years old and is about 115 cm tall. She is taller than average for girls her age. 8. You are interested in predicting the cost of heating houses on the basis of how many rooms the house has. A scatterplot of 25 houses reveals a strong linear relationship between these variables, so you calculate a least-squares regression line. ―Least-squares‖ refers to (a) Minimizing the sum of the squares of the 25 houses’ heating costs. (b) Minimizing the sum of the squares of the number of rooms in each of the 25 houses. (c) Minimizing the sum of the products of each house’s actual heating costs and the predicted heating cost based on the regression equation. (d) Minimizing the sum of the squares of the difference between each house’s heating costs and number of rooms. (e) Minimizing the sum of the squares of the residuals. © 2011 BFW Publishers The Practice of Statistics, 4/e- Chapter 3 127 9. A study of the fuel economy for various automobiles plotted the fuel consumption (in liters of gasoline used per 100 kilometers traveled) vs. speed (in kilometers per hour). A leastsquares line was fit to the data. Here is the residual plot from this least-squares fit. Residuals versus Speed 15 Residual 10 5 0 -5 0 10 20 30 40 50 60 70 80 90 speed What does the residual plot tell you about the linear model? (a) The residual plot confirms the linearity of the fuel economy data. (b) The residual plot does not confirm nor rule out the linearity of the data. (c) The residual plot suggests that the model may be linear, but more data points are needed to confirm this. (d) The residual plot clearly indicates that the data isn’t linear. (e) A residual plot is not an appropriate means for evaluating a linear model. Leonardo da Vinci, the renowned painter, speculated that an ideal human would have an armspan (distance from the outstretched fingertip of the left hand to the outstretched fingertip of the right hand) that was equal to his height. The following computer regression printout shows the results of a least-squares regression of armspan on height, both in inches, for a sample of 18 high school students. Predictor Constant Height R-sq = 87.1% Coef. SE Coef 11.5474 5.6 0.84024 0.08091 R-sq(adj.) = 86.3% T 2.06 10.4 P 0.0558 0.000 10. Which of the following statements is false? (a) This least-squares regression model would make a prediction that is 1.64 inches higher than da Vinci projected for a 62-inch tall student. (b) If one of the students in the sample had a height of 70.5 inches and an armspan of 68 inches, then the residual for this student would be –2.78 inches. (c) The least-squares regression line has a steeper slope than the equation for da Vinci’s relationship between armspan and height. (d) For every one-inch increase in height, the regression model predicts about a 0.84-inch increase in armspan. (e) For a student 66 inches tall, our model would predict an armspan of about 67 inches. 128 The Practice of Statistics, 4/e- Chapter 3 © 2011 BFW Publishers Part 2: Free Response Show all your work. Indicate clearly the methods you use, because you will be graded on the correctness of your methods as well as on the accuracy and completeness of your results and explanations. How are traffic delays related to the number of cars on the road? Below is data on the total number of hours of delay per year at 10 major highway intersections in the western United States versus traffic volume (measured by average number of vehicles per day that pass through the intersection). Scatterplot of annual hours of delay vs vehicles per day 28000 Hours of delay per year 26000 24000 22000 20000 18000 16000 14000 12000 10000 200000 220000 240000 260000 280000 300000 320000 average vehicles per day 11. Describe what the scatterplot reveals about the relationship between traffic delays and number of cars on the road. 12. Suppose another data point at (200000, 24000), that is 200,000 vehicles per day and 24,000 hours of delay per year, were added to the plot. What effect, if any, will this new point have on the correlation between these two variables? Explain. © 2011 BFW Publishers The Practice of Statistics, 4/e- Chapter 3 129 Below is computer output for the regression of hours of delay versus number of vehicle per day. Predictor Constant vehicles per day S = 3899.57 Coef -3629 0.07822 R-Sq = 48.6% SE Coef 7367 0.02684 T -0.49 2.91 P 0.634 0.017 R-Sq(adj) = 42.8% 13. What is the slope of the regression line? Interpret the slope in the context of this problem. 14. Explain what the quantity S = 3899.57 measures in the context of this problem. 15. Below is the same scatterplot, but with the six intersections in California plotted as circles and the four in other western states plotted as squares. Scatterplot of annual hours of delay vs vehicles per day 28000 26000 Hours of delay per year 24000 22000 20000 18000 16000 14000 12000 10000 200000 220000 240000 260000 280000 average vehicles per day 300000 320000 Comment on how the relationship between average number of vehicles per day and hours of delay per year differs between the California intersections and the intersections in other western states. 130 The Practice of Statistics, 4/e- Chapter 3 © 2011 BFW Publishers An ecologist studying breeding habits of the common crossbill in different years finds that there is a linear relationship between the number of breeding pairs of crossbills and the abundance of the spruce cones. Below are statistics on eight years of measurements, where x = average number of cones per tree and y = number of breeding pairs of crossbills in a certain forest. x = mean number of cones/tree y = number of crossbill pairs Mean Standard deviation 23.0 18.0 16.2 15.1 The correlation between x and y is r = 0.968 16. Find the equation of the least-squares regression line (with y as the response variable). 17. What percentage of the variation in numbers of breeding pairs of crossbills can be accounted for by this regression? 18. Based on these data, can we conclude that the abundance of spruce cones is responsible for the number of breeding pairs of crossbills? Explain. © 2011 BFW Publishers The Practice of Statistics, 4/e- Chapter 3 131 Test 3C AP Statistics Name: Part 1: Multiple Choice. Circle the letter corresponding to the best answer. 1. On May 11, 50 randomly selected subjects had their systolic blood pressure (SBP) recorded twice—the first time at about 9:00 a.m. and the second time at about 2:00 p.m. If one were to examine the relationship between the morning and afternoon readings, then one might expect the correlation to be (a) near zero, as morning and afternoon readings should be independent. (b) high and positive, as those with relatively high readings in the morning will tend to have relatively high readings in the afternoon. (c) high and negative, as those with relatively high readings in the morning will tend to have relatively low readings in the afternoon. (d) near zero, as correlation measures the strength of the linear association. (e) near zero, as blood pressure readings should follow approximately a Normal distribution. 2. If data set A of (x, y) data has correlation r = 0.65, and a second data set B has correlation r = –0.65, then (a) the points in A fall closer to a linear pattern than the points in B. (b) the points in B fall closer to a linear pattern than the points in A. (c) A and B are similar in the extent to which they display a linear pattern. (d) you can’t tell which data set displays a stronger linear pattern without seeing the scatterplots. (e) a mistake has been made—r cannot be negative. 3. A regression of the amount of calories in a serving of breakfast cereal vs. the amount of fat gave the following results: Predicted Calories = 97.1053 + 9.6525(Fat). Which of the following is false? (a) It is estimated that for every additional gram of fat in the cereal, the number of calories increases by about 10. (b) It is estimated that in cereals with no fat, the total amount of calories is about 97. (c) If a cereal has 2 g of fat, then it is estimated that the total number of calories is about 116. (d) The correlation between amount of fat and calories is positive. (e) If one cereal has 140 calories and 5 g of fat. Its residual is about 5 calories. 4. A copy machine dealer has data on the number of copy machines x at each of 89 customer locations and the number of service calls in a month y at each location. Summary calculations give x = 8.4, s x = 2.1, y = 14.2, s y = 3.8, and r = 0.86. What is the slope of the least-squares regression line of number of service calls on number of copiers? (a) 0.86 (b) 1.56 (c) 0.48 (d) 2.82 (e) Can’t tell from the information given 5. In the setting of the previous problem, about what percent of the variation in the number of service calls is explained by the linear relation between number of service calls and number of machines? (a) 86% (b) 93% (c) 74% (d) 55% (e) Can’t tell from the information given 132 The Practice of Statistics, 4/e- Chapter 3 © 2011 BFW Publishers 6. A study examined the relationship between the sepal length and sepal width for two varieties of an exotic tropical plant. Varieties X and O are represented by x’s and o’s, respectively, in the following scatterplot. Which of the following statements is true? (a) Considering Variety X only, there is a positive correlation between sepal length and width. (b) Considering Variety O only, the least-squares regression line for predicting sepal length from sepal width has a positive slope. (c) Considering both varieties together, there is a negative correlation between sepal length and width. (d) Considering each variety separately, there is a negative correlation between sepal length and width. (e) Considering both varieties together, the least-squares regression line for predicting sepal length from sepal width has a negative slope. 7. Suppose we fit a least-squares regression line to a set of data. What is true if a plot of the residuals shows a curved pattern? (a) A straight line is not a good model for the data. (b) The correlation must be 0. (c) The correlation must be positive. (d) Outliers must be present. (e) The regression line might or might not be a good model for the data, depending on the extent of the curve. 8. Mr. Nerdly asked the students in his AP Statistics class to report their overall grade point averages and their SAT Math scores. The scatterplot below provides information about his students’ data. The dark line is the least-squares regression line for the data, and its equation is yˆ 410.54 67.3x . SAT Math versus GPA SAT Math score 700 650 600 550 2.5 3.0 3.5 4.0 GPA Which of the following statements about the circled point is false? (a) This student has a grade point average of about 2.9 and an SAT Math score of about 690. (b) If we used the least-squares line to predict this student’s SAT Math score, we would make a prediction that is too low. (c) This student’s residual is negative. (d) Removing this data point would cause the correlation coefficient to increase. (e) Removing this student’s data point would increase the slope of the least-squares line. © 2011 BFW Publishers The Practice of Statistics, 4/e- Chapter 3 133 Are jet skis (otherwise known as personal watercraft, or PWC) dangerous? An article in the August 1997 issue of the Journal of the American Medical Association reported on a survey that tracked emergency room visits at randomly selected hospitals nationwide. The study recorded data on the number of jet skis in use and the number of accidents related to their use for the years 1990–1995. Computer output and a residual plot from a linear regression of jet-ski related injuries versus jet skis in use (PWC) are shown below. Questions 9 and 10 refer to these data. Residuals Versus PWC Predictor Constant PWC S = 1218.65 Coef -2745 0.018078 SE Coef 1372 0.002805 R-Sq = 91.2% T -2.00 6.44 (response is injuries) P 0.116 0.003 1500 1000 R-Sq(adj) = 89.0% 9. The circled point represents a year when the number of PWC in use was 240,000. The number of observed injuries in that year was closest to: (a) 350 (b) 1250 (c) 1600 (d) 2800 (e) 7300 Residual 500 0 -500 -1000 200000 300000 400000 500000 PWC 600000 700000 10. Which of the following best describes what s = 1218.65 represents in this setting? (a) The standard deviation of the observed values of the response variable, injuries. (b) The standard deviation of the predicted values of the response variable, injuries. (c) The standard deviation of the observed values of the explanatory variable, PWC’s in use. (d) The average of the products of each standardized value for PWC and the corresponding standardized value for injuries. (e) The standard deviation of the residuals. 134 The Practice of Statistics, 4/e- Chapter 3 © 2011 BFW Publishers 800000 Part 2: Free Response Show all your work. Indicate clearly the methods you use, because you will be graded on the correctness of your methods as well as on the accuracy and completeness of your results and explanations. Because elderly people may have difficulty standing to have their heights measured, a study looked at predicting overall height from height to the knee. Here are data (in centimeters) for five elderly men: Knee Height, cm. 57.7 47.4 43.5 44.8 55.2 Height, cm 192 153 146 163 169 11. Which variable is explanatory and which is response in this situation? 12. Construct a scatterplot on your calculator and draw a rough sketch of your calculator’s display. Describe the form, direction, and strength of the relationship that you see. 13. Use your calculator to determine the least-squares regression line. Write the equation below. Be sure to define any variables you use. 14. Suppose a sixth elderly man with a knee height of 57 cm. and a height of 150 cm is added. What impact would this have on (a) the correlation and (b) the slope of the regression line? 15. Should you use your regression line from Question 13 to predict the height of an elderly man whose knee height is 70 centimeters? If so, do it. If not, explain why not. © 2011 BFW Publishers The Practice of Statistics, 4/e- Chapter 3 135 Scientists studying outbreaks of locusts in Tanzania found a negative correlation between the amount of rainfall (in inches) in the wet season and the relative abundance of adult red locusts 18 months later. (Relative abundance is measure on a 1 to 5 scale, where a ―5‖ means five times as many locusts as ―1.‖) The least-squares regression equation for this relationship is: Predicted relative abundance = 6.7 – 0.12(rainfall) 16. Interpret the slope of this line in the context of the problem. 17. The correlation between these two variables is –0.75. If the amount of rainfall were measured in centimeters rather than inches, how would the correlation change? Explain. 18. Explain what ―least-squares‖ means in term of the variables involved. 19. Would it be appropriate for the scientists to conclude that changes in rainfall are responsible for variations in the relative abundance of red locusts in this region? Why or why not? 136 The Practice of Statistics, 4/e- Chapter 3 © 2011 BFW Publishers Chapter 3 Solutions Quiz 3.1A 1. Car weight is the explanatory variable, Fuel efficiency is response. We expect a car’s weight to be a major factor in determining its fuel efficiency. 2. The association is negative. This makes sense because it takes more fuel to move a heavier car. 3. The form is linear, with the exception of one outlier in the y (fuel efficiency) direction. 4. r = – 0.6. The relationship is negative, but because of the outlier it is not as high as –0.9. 5. This car has remarkably high fuel efficiency—far better than any other car in the data set (In fact, it’s a gas-electric hybrid). 6. Removing this point would make the correlation much closer to –1. 7. This would not change the correlation at all, since the units in which variables are expressed has no impact on the correlation. Quiz 3.1B 1. Age is the explanatory variable, systolic blood pressure is response. We expect men’s age to be a factor in systolic blood pressure (SBP). SBP does not influence age! 2. The association is positive. This suggests that older men are more likely to suffer from high blood pressure. 3. The form is linear, with the exception of one outlier in the y (systolic blood pressure) direction. 4. r = 0.5—a moderate positive relationship. If not for the outlier, r might be as high as 0.9. 5. This man has unusually high systolic blood pressure—higher than for any other subject—even though he is not among the oldest men. 6. Removing this point would make the correlation much closer to 1. 7. This would not change the correlation at all, since subtracting 50 from each score would not change its distance from the mean. Quiz 3.1C 1. Since the student’s question is, ―Do taller women date taller men?‖ the implication is that the women’s heights explain the heights of their dates. 2. See graph below. 3. Answers may vary. While the scatterplot appears to show that the relationship between the heights of women and the heights of the men is somewhat positive, it does not appear be a very strong relationship. Whether it is linear or not is difficult to determine with so few data points—especially since there are no women between 66 and 70 inches in height. 4. r = 0.566. Since r is positive, here is some evidence that tall women tend to date taller men. 5. Subtracting the same amount from each y value will not change the correlation, nor would multiplying each height by a constant to convert the heights into centimeters. 6. Adding this point to the data would reinforce the weak positive trend, thereby making the correlation much closer to 1. Scatterplot of Men vs Women 72 71 Men 70 69 68 67 66 65 64 © 2011 BFW Publishers 65 66 67 Women 68 69 70 The Practice of Statistics, 4/e- Chapter 3 137 Quiz 3.2A 1. For each 1000-student increase in enrollment, the predicted number of property crimes increases by 21.83. 2. yˆ 112.58 21.83(14) 193.04 crimes. 3. y yˆ 138 193.04 55.04 . The actual number of property crimes at this college is 55.04 fewer than the number of crimes predicted by this linear model. 4. See graph below. 5. That point has a high, positive residual, so it tends to ―pull‖ the line toward it. Removing it would reduce the slope. 6. 80.1% of the variation in property crimes can be accounted for by the regression of property crimes on enrollment. 7. Answers will vary and will depend on the appearance residual plot sketched in #4. Some students will suggest that there is enough of a ―U‖ shape in the residual plot to suggest that the linear model is not appropriate. Others will say the lack of pattern in residuals suggests that a linear fit is appropriate. Residuals versus Enrollment 150 100 Residual 50 0 -50 -100 0 5 10 15 20 25 Enrollment Quiz 3.2B 1. For each 1-degree increase in latitude, the predicted average July temperature decreases by 0.782 degrees. 2. yˆ 106.5 0.782 42 ; yˆ 73.66degrees. 3. y yˆ 74 0.782 42 106.5 74 73.66 0.34 . The actual average July temperature in Detroit is 0.34 degrees higher that the average July temperature predicted by this linear model. 4. See graph below. 5. Since Phoenix’s residual is large and positive, and Phoenix is at a relatively low latitude, the slope of the line would increase (that is, get closer to 0). 6. 28% of the variability in average July temperature can be accounted for by the regression of average July temperature on latitude. 7. Answers will vary and will depend on the appearance residual plot sketched in #4. Some students will say that there is no distinctive pattern in the residuals, so the linear model is a good fit. Others may argue that the variability is much larger for smaller values of latitude than for higher values of latitude and therefore this model is not appropriate. Residuals Versus Latitude 15 10 Residual 5 0 -5 -10 30 138 32 34 36 Latitude 38 40 42 The Practice of Statistics, 4/e- Chapter 3 © 2011 BFW Publishers Quiz 3.2C 1. (a) yˆ 105.74 0.769 x ; ŷ = predicted price, x = screen area. (b) The least-squares regression line is the line that minimizes the sum of the squared deviations between observed prices and prices predicted by the linear model. (c) 943 sq. in. is well beyond the range of screen areas used to produce the regression line, so this would be extrapolation. We cannot be sure that the relationship described by this line holds outside the range of available data. (d) y yˆ 375 (.769(437) 105.74) 375 441.79 66.79 . Since the residual is negative, the observed value is lower than the value predicted by the regression. This suggests that this particular television is a good buy! 2. (a) yˆ 3.822 5.215x ; x = minutes of exercise, ŷ = predicted number of floors climbed. (b) Since there is no distinctive pattern in the residuals, the linear model is a good fit. (c) On average, the predicted values will be about 2.35 floors from the actual values. © 2011 BFW Publishers The Practice of Statistics, 4/e- Chapter 3 139 Test 3A Part 1 1. a We expect fuel efficiency to be (at least partially) determined by engine size, with larger engines consuming more fuel. Hence the gas mileage should go down as engine size goes up. 2. d yˆ 10 0.9 95 95.5 3. b y yˆ 93 10 0.9 90 93 91 2 4. c Correlation is not affected by the units in which the variables are expressed. 5. e (a) and (b) are incorrect because one or more of the variables is categorical; (c) is incorrect because r cannot have units, such as meters per second; (d) is incorrect because r cannot be greater than 1. 6. b Without examining a residual plot, we don’t know whether the form of the relationship is linear. The calculation of the regression assumes the relationship is linear. 7. c A linear model is only appropriate if there is no discernable pattern in the residual plot. 8. b The least squares line minimizes the squares of the vertical distances between the points and the line, which is the difference between observed and predicted values of the response variable, yield. 9. c (c) interprets the equation’s y-intercept. (a) would be true if it said decrease; (b) mixes up the explanatory and response variables; (d) predicted yield when UV = 20 is yˆ 3.98 .046285 20 3.05 . 10. c Statement I is incorrect because the line would minimize residuals for the other variable. Statement II is incorrect because large outliers in the y direction that are near the center of the distribution with respect to x will have an impact on the y-intercept of the regression equation, but may not have an impact on slope. (See ―Correlation and Regression wisdom‖ in Section 3.2). Part 2 11. There appears to be a moderately strong, positive, linear relationship between length of courtship and length of marriage. 12. The correlation would decrease, since this point is well outside the linear pattern in the other points, so it weakens the linear association. 13. Slope = 2.4559. For each 1-year increase in length of courtship, predicted length of marriage increases by 2.4559 years. 14. The observed values for length of marriage for these ten couples was, on average, 2.7498 years away from the marriage length values predicted by the regression line. 15. Answers will vary. It appears that couples that have children have both longer courtships and longer marriages. It also appears that the relationship between these variables is stronger for couples with children. s 323.5 16. Slope = b r y 0.71 60.763 ; 3.78 sx Y-intercept = a y bx 955.3 60.763 6.4 1344.18 . So yˆ 1344.18 60.763x . 17. r 2 0.5041 , or 50.41%. 18. No. Since this was not a controlled experiment, there could be lurking variables that are responsible for the association observed here. Perhaps the frequency with which drivers wash their cars is confounded with other good car-maintenance habits, such as changing the car’s oil frequently. 140 The Practice of Statistics, 4/e- Chapter 3 © 2011 BFW Publishers Test 3B Part 1 1. d yˆ 64.93 0.63 22.5 79.11 2. b y yˆ 80 64.93 0.63 20 2.47 3. b You expect parents’ income to have an impact on their children’s education level—not the other way around—and since students from wealthier families go to school for longer, the relationship is positive. 4. e r cannot be lower than –1, so something is wrong with the results. 5. a A positive correlation means that large values of one variable are associated with large values of the other, and small values are similarly associated. 6. c Statement I is not true: an explanatory-response relationship is required for regression, but not for correlation. Statements II and III are fundamental characteristics of correlation and regression, respectively. 7. c The question explicitly states that this relationship only holds for females from age 5 to 18 years old. We cannot extrapolate to height at birth. 8. e Least-squares regression minimizes the sum of the squared vertical distances between observed value of the response variable and the predicted values. That is, the sum of the squared residuals. 9. d A linear model is only appropriate if there is no discernable pattern in the residual plot; the curved pattern in the residuals suggests a non-linear relationship. 10. c This statement is not true because a line describing da Vinci’s projection would have a slope of 1 (in fact, the equation would be y x ) and the slope of the least-squares regression line is 0.84024. Part 2 11. There is a moderately weak, positive, linear relationship between average number of vehicles per day on the road and hours of traffic delay per year at these intersections. 12. The correlation would decrease, since this point is well outside the linear pattern in the other points, so it weakens the linear association. 13. The slope is 0.07822. For every additional vehicle per day on the road, the total annual traffic delay increases by 0.07822 hours. 14. The observed values for hours of delay per year at these 10 intersections was, on average, 3899.57 hours away from the total hours of delay predicted by the regression line. 15. Answers will vary. One good answer: The intersection with the greatest number of vehicles per day were in California, and there appears to be a great increase in hours of delay for each 1-car increase in vehicles—that is, a larger slope—for the California intersections. Also, non-California intersections had longer delays for a specific number of vehicles. s 15.1 16. Slope = b r y 0.968 0.9023 ; s 16.2 x Y-intercept = a y bx 18.0 0.9023 23.0 2.7529 . So yˆ 2.7529 0.9023x . 17. r 2 0.937 , or 93.7%. 18. No. Since this was not a controlled experiment, we do not know the impact of any lurking variables. For example, perhaps the abundance of spruce cones is confounded with the abundance of some other good supply that hasn’t been measured. © 2011 BFW Publishers The Practice of Statistics, 4/e- Chapter 3 141 Test 3C Part 1 1. b The correlation (r) will be positive when high values of one variable are associated with high values of the other, and relatively high when the relationship is strongly linear, as two measurements of SBP on the same person ought to be. 2. d It is quite possible to have a very high correlation—even higher than 0.65 ––when the data is quite non-linear, so we can’t tell anything without looking at the scatterplots. 3. e The residual is yobserved yˆ 140 (97.1053 9.6525(5) 5.37 . That is, about –5, not 5. s 3.8 4. b Slope = b r y 0.86 1.56 2.1 sx 5. c r2 = 0.74 6. d Within each variety, a wider sepal is associated with a short sepal length, so the correlation coefficient will be negative in both cases. (When the data for the two varieties is combined, the relationship appears to be positive, rather than negative). 7. a A linear model is only appropriate if there is no discernable pattern in the residual plot. 8. c Since this point is above the line, its residual is positive. 9. d The residual for this point is about 1250, so the observed value is about 1250 more than the predicted value of 2745 0.018078(240,000) 1593.7 , or close to 2800. 10. e s in the computer output is the standard deviation of the residuals, s resid n2 2 . Part 2 11. Since we want to predict overall height from knee height, the explanatory variable is knee height and the response variable is overall height. 12. See below for scatterplot. There is a moderately strong, positive, linear relationship between overall height and knee height. 13. yˆ 43.9 2.4276 x , where ŷ = predicted overall height and x = knee height. 14. The new person does not fit the pattern established by the original data: his overall height is low for his knee height. This would reduce the correlation and also reduce the slope of the regression line. 15. You should not use this equation to predict the height of a man whose knee height is 70 cm., because this value of x is well beyond the range of the data used to produce the line. 16. For every additional inch of rainfall in the wet season, the predicted relative abundance of locusts decreases by 0.12. 17. The correlation coefficient does not change when the units for either variable are changed, because it is calculated from standard scores, which are independent of units. 18. The ―least-squares‖ line is the line that minimizes the sum of the squared differences between observed relative abundance measurements and relative abundance measurements predicted by the regression equation. 19. No. Since this was not a controlled experiment, we do not know the impact of any lurking variables on the abundance of locusts. For example, the amount of rainfall in the wet season may be confounded with some other important variable: perhaps the abundance of an animal that preys on the locust is also influenced by rainfall, so it’s predation that influences the locust’s abundance. Scatterplot for 12: Body height vs knee height 190 body height 180 170 160 150 140 45.0 47.5 50.0 52.5 55.0 57.5 knee height 142 The Practice of Statistics, 4/e- Chapter 3 © 2011 BFW Publishers