Centro Nacional de
Instituto Epidemiología
de Salud
Carlos III
Roberto Pastor-Barriuso
BIOESTADÍSTICA
Centro Nacional de
Instituto Epidemiología
de Salud
Carlos III
MINISTERIO
DE ECONOMÍA
Y COMPETITIVIDAD
Instituto
de Salud
Carlos III
Centro
Nacional de
Epidemiología
Centro Nacional de Epidemiología
Instituto de Salud Carlos III
Monforte de Lemos, 5
28029 MADRID (ESPAÑA)
Tel.: 91 822 20 00
Fax: 91 387 78 15
http://www.isciii.es
Catálogo general de publicaciones oficiales:
http://publicacionesoficiales.boe.es/
Para obtener este libro de forma gratuita en internet (formato pdf):
http://publicaciones.isciii.es/
http://creativecommons.org/licenses/by-nc-sa/2.1/es/
EDITA: CENTRO NACIONAL DE EPIDEMIOLOGÍA – Instituto de Salud Carlos III
Madrid, diciembre de 2012
N.I.P.O. (en línea): 477-11-083-3
I.S.B.N.: 978-84-695-3775-6
Imprime: Agencia Estatal Boletín Oficial del Estado.
Avda. de Manoteras, 54. 28050 – MADRID
BIOESTADÍSTICA
Roberto Pastor-Barriuso
Científico Titular
Centro Nacional de Epidemiología,
Instituto de Salud Carlos III,
Madrid
Para citar este libro
Pastor-Barriuso R. Bioestadística. Madrid: Centro Nacional de Epidemiología, Instituto de
Salud Carlos III, 2012.
Este texto puede ser reproducido siempre que se cite su procedencia.
A la memoria de Carmen
A Marta, Pablo, Miguel y Antonio
ÍNDICE
1 Estadística descriptiva
1.1 Introducción
1.2 Medidas de tendencia central
1.2.1 Media aritmética
1.2.2 Mediana
1.2.3 Media geométrica
1.3 Medidas de posición: cuantiles
1.4 Medidas de dispersión
1.4.1 Varianza y desviación típica
1.4.2 Rango intercuartílico
1.4.3 Coeficiente de variación
1.5 Representaciones gráficas
1.5.1 Diagrama de barras
1.5.2 Histograma y polígono de frecuencias
1.5.3 Gráfico de tallo y hojas
1.5.4 Diagrama de caja
1.6 Referencias
2 Probabilidad
2.1
2.2
2.3
2.4
2.5
2.6
Introducción
Concepto y definiciones de probabilidad
Probabilidad condicional e independencia de sucesos
Regla de la probabilidad total
Teorema de Bayes
Referencias
3 Variables aleatorias y distribuciones de probabilidad
3.1 Introducción
3.2 Distribuciones de probabilidad discretas
3.2.1 Distribución binomial
3.2.2 Distribución de Poisson
3.2.3 Aproximación de Poisson a la distribución binomial
3.3 Distribuciones de probabilidad continuas
3.3.1 Distribución normal
3.3.2 Aproximación normal a la distribución binomial
3.3.3 Aproximación normal a la distribución de Poisson
3.4 Combinación lineal de variables aleatorias
3.5 Referencias
1
1
3
3
4
5
5
6
6
7
7
8
8
9
10
11
12
13
13
14
16
18
18
20
21
21
22
24
26
29
29
31
34
36
37
39
vii
Índice
4 Principios de muestreo y estimación
4.1 Introducción
4.2 Principales tipos de muestreo probabilístico
4.2.1 Muestreo aleatorio simple
4.2.2 Muestreo sistemático
4.2.3 Muestreo estratificado
4.2.4 Muestreo por conglomerados
4.2.5 Muestreo polietápico
4.3 Estimación en el muestreo aleatorio simple
4.3.1 Estimación puntual de una media poblacional
4.3.2 Error estándar de la media muestral
4.3.3 Teorema central del límite
4.3.4 Estimación de una proporción poblacional
4.4 Referencias
5 Inferencia estadística
5.1 Introducción
5.2 Estimación puntual
5.3 Estimación por intervalo
5.3.1 Distribución t de Student
5.3.2 Intervalo de confianza para una media poblacional
5.4 Contraste de hipótesis
5.4.1 Formulación de hipótesis
5.4.2 Contraste estadístico para la media de una población
5.4.3 Errores y potencia de un contraste de hipótesis
5.5 Referencias
6 Inferencia sobre medias
6.1 Introducción
6.2 Inferencia sobre una media y varianza poblacional
6.2.1 Inferencia sobre la media de una población
6.2.2 Inferencia sobre la varianza de una población
6.3 Comparación de medias en dos muestras independientes
6.3.1 Comparación de medias en distribuciones con igual varianza
6.3.2 Contraste para la igualdad de varianzas
6.3.3 Comparación de medias en distribuciones con distinta varianza
6.4 Comparación de medias en dos muestras dependientes
6.5 Referencias
viii
41
41
42
43
43
44
46
47
49
49
51
53
55
58
59
59
60
62
62
63
67
67
69
72
76
79
79
80
80
81
83
85
88
90
92
95
Índice
7 Inferencia sobre proporciones
7.1
7.2
7.3
7.4
7.5
7.6
Introducción
Inferencia sobre una proporción poblacional
Comparación de proporciones en dos muestras independientes
Asociación estadística en una tabla de contingencia
Test de tendencia en una tabla r×2
Medidas de efecto en una tabla de contingencia
7.6.1 Riesgo relativo
7.6.2 Odds ratio
7.7 Comparación de proporciones en dos muestras dependientes
7.8 Apéndice: corrección por continuidad
7.9 Referencias
8 Métodos no paramétricos
8.1
8.2
8.3
8.4
8.5
Introducción
Test de la suma de rangos de Wilcoxon
Test de los rangos con signo de Wilcoxon
Test exacto de Fisher
Referencias
9 Determinación del tamaño muestral
9.1 Introducción
9.2 Tamaño muestral para la estimación de un parámetro poblacional
9.2.1 Tamaño muestral para la estimación de una media
9.2.2 Tamaño muestral para la estimación de una proporción
9.3 Tamaño muestral para la comparación de medias
9.3.1 Tamaño muestral para la comparación de medias en dos muestras
independientes
9.3.2 Tamaño muestral para la comparación de medias en dos muestras
dependientes
9.4 Tamaño muestral para la comparación de proporciones
9.4.1 Tamaño muestral para la comparación de proporciones en dos muestras
independientes
9.4.2 Tamaño muestral para la comparación de proporciones en dos muestras
dependientes
9.5 Referencias
10 Correlación y regresión lineal simple
10.1 Introducción
10.2 Coeficiente de correlación
97
97
97
99
102
106
107
108
111
114
117
120
121
121
122
129
134
138
139
139
140
140
141
142
143
146
148
148
152
154
155
155
155
ix
Índice
10.2.1 Coeficiente de correlación muestral de Pearson
10.2.2 Coeficiente de correlación de los rangos de Spearman
10.3 Regresión lineal simple
10.3.1 Estimación de la recta de regresión
10.3.2 Contraste del modelo de regresión lineal simple
10.3.3 Inferencia sobre los parámetros de la recta de regresión
10.3.4 Bandas de confianza y predicción para la recta de regresión
10.3.5 Evaluación de las asunciones del modelo de regresión lineal simple
10.3.6 Observaciones atípicas e influyentes
10.3.7 Variable explicativa dicotómica
10.4 Referencias
11 Regresión lineal múltiple
11.1 Introducción
11.2 Estructura de la regresión lineal múltiple
11.3 Estimación e inferencia de la ecuación de regresión
11.3.1 Estimación de los coeficientes de regresión
11.3.2 Inferencia sobre los coeficientes de regresión
11.3.3 Inferencia sobre la ecuación de regresión
11.4 Contrastes de hipótesis en regresión lineal múltiple
11.4.1 Contraste global del modelo de regresión lineal múltiple
11.4.2 Contrastes parciales
11.5 Variables explicativas politómicas
11.6 Regresión polinomial
11.7 Confusión e interacción en regresión lineal
11.7.1 Control de la confusión en regresión lineal
11.7.2 Evaluación de la interacción en regresión lineal
11.8 Apéndice: formulación matricial de la regresión lineal múltiple
11.9 Referencias
Apéndice: tablas estadísticas
x
158
161
164
166
169
173
175
178
184
190
191
193
193
194
196
197
200
201
203
203
206
210
215
218
218
221
228
232
233
TEMA 1
ESTADÍSTICA DESCRIPTIVA
1.1
INTRODUCCIÓN
La estadística es la rama de las matemáticas aplicadas que permite estudiar fenómenos cuyos
resultados son en parte inciertos. Al estudiar sistemas biológicos, esta incertidumbre se debe al
desconocimiento de muchos de los mecanismos fisiológicos y fisiopatológicos, a la incapacidad
de medir todos los determinantes de la enfermedad y a los errores de medida que inevitablemente
se producen. Así, al realizar observaciones en clínica o en salud pública, los resultados obtenidos
contienen una parte sistemática o estructural, que aporta información sobre las relaciones entre
las variables estudiadas, y una parte de “ruido” aleatorio. El objeto de la estadística consiste en
extraer la máxima información sobre estas relaciones estructurales a partir de los datos recogidos.
En estadística se distinguen dos grandes grupos de técnicas:
yy La estadística descriptiva, en la que se estudian las técnicas necesarias para la organización,
presentación y resumen de los datos obtenidos.
yy La estadística inferencial, en la que se estudian las bases lógicas y las técnicas mediante
las cuales pueden establecerse conclusiones sobre la población a estudio a partir de los
resultados obtenidos en una muestra.
El análisis de una base de datos siempre partirá de técnicas simples de resumen de los datos y
presentación de los resultados. A partir de estos resultados iniciales, y en función del diseño del
estudio y de las hipótesis preestablecidas, se aplicarán las técnicas de inferencia estadística que
permitirán obtener conclusiones acerca de las relaciones estructurales entre las variables
estudiadas. Las técnicas de estadística descriptiva no precisan de asunciones para su
interpretación, pero en contrapartida la información que proporcionan no es fácilmente
generalizable. La estadística inferencial permite esta generalización, pero requiere ciertas
asunciones que deben verificarse para tener un grado razonable de seguridad en las inferencias.
A continuación se definen algunos conceptos generales que aparecen repetidamente a lo
largo de la exposición:
yy Población es el conjunto de todos los elementos que cumplen ciertas propiedades y entre
los cuales se desea estudiar un determinado fenómeno.
yy Muestra es un subconjunto de la población seleccionado mediante un mecanismo más o
menos explícito. En general, rara vez se dispone de los recursos necesarios para estudiar a
toda la población y, en consecuencia, suelen emplearse muestras obtenidas a partir de
estas poblaciones.
Ejemplo 1.1 Algunos ejemplos de poblaciones son:
—— Las personas residentes en Washington D.C. a 1 de enero de 2010.
—— Las personas infectadas con el virus de inmunodeficiencia humana en Brasil a día de
hoy.
Pastor-Barriuso R.
1
Estadística descriptiva
Para estas poblaciones, algunas muestras podrían ser:
— 500 residentes en Washington D.C. a 1 de enero de 2010 seleccionados mediante
llamadas telefónicas aleatorias.
— Todas las personas que acuden a un hospital de Río de Janeiro durante el presente año
para realizarse un test del virus de inmunodeficiencia humana y que resultan ser
positivas.
yy Variables son propiedades o cualidades que presentan los elementos de una población.
Las variables pueden clasificarse en:
Variables cualitativas o atributos son aquellas que no pueden medirse numéricamente
y que, a su vez, pueden ser:
—— Nominales, en las que no pueden ordenarse las diferentes categorías.
—— Ordinales, en las que pueden ordenarse las categorías, pero no puede establecerse
la distancia relativa entre las mismas.
Variables cuantitativas son aquellas que tienen una interpretación numérica y que se
subdividen en:
—— Discretas, sólo pueden tomar unos valores concretos dentro de un intervalo.
—— Continuas, pueden tomar cualquier valor dentro de un intervalo.
En la práctica, todas las variables continuas que medimos son discretas en el sentido de
que, debido a las limitaciones de los sistemas de medida, las variables continuas no
pueden adoptar todos los valores dentro de un intervalo. De cara a los análisis posteriores,
la principal distinción se establece, por tanto, entre variables con relativamente pocas
categorías (como número de hijos) frente a variables con muchas categorías (como
niveles de colesterol en sangre).
Ejemplo 1.2 Algunos ejemplos de variables son:
—— Variables cualitativas nominales: sexo, raza, estado civil (soltero, casado, viudo,
separado, divorciado), religión (católico, protestante, otros), nacionalidad.
—— Variables cualitativas ordinales: salud auto-percibida (buena, regular, mala), severidad
de la enfermedad (leve, moderada, grave). Por ejemplo, para esta última variable
ordinal, podemos establecer un orden de severidad, pero no podemos decir que la
diferencia de severidad entre un paciente moderado y uno leve sea la misma que entre
uno grave y uno moderado.
—— Variables cuantitativas discretas: número de hijos, número de dientes cariados.
—— Variables cuantitativas continuas: edad, peso, altura, presión arterial, niveles de
colesterol en sangre.
yy Estadístico es cualquier operación realizada sobre los valores de una variable.
yy Parámetro es un valor de la población sobre el que se desea realizar inferencias a partir
de estadísticos obtenidos de la muestra, que en este caso se denominan estimadores. Por
convención, los parámetros poblacionales se denotan con letras del alfabeto griego,
mientras que los estimadores muestrales se denotan con letras de nuestro alfabeto.
2
Pastor-Barriuso R.
alrededor de qué valor se agrupan los datos observados. Las medidas de tendencia
Medidas de tendencia central
central de la muestra sirven tanto para resumir los resultados observados como para
realizar inferencias acerca de los parámetros poblacionales correspondientes. A
Ejemplo 1.3 Algunos ejemplos de estadísticos incluyen:
1.2 MEDIDAS DE TENDENCIA CENTRAL
describendelos
principales
—— La media de continuación
los valores desecolesterol
una
muestra. estimadores de la tendencia central de una
—— El valor
más variable.
alto de
colesterol
de unaacerca
muestra.
Las medidas
de tendencia
central
informan
de cuál es el valor más representativo
—— La suma de los valores de colesterol de una muestra elevados al cuadrado.
de una determinada variable o, dicho de forma equivalente, estos estimadores indican
Así, por ejemplo,1.2.1
la media
delaritmética
colesterol en una población, que se denotaría por μ, es un
Media
parámetro
que
se
estima
a
partir
de la media de los valores de colesterol en una muestra
1.2 MEDIDAS
DE
TENDENCIA
CENTRAL
alrededor
de
qué
valor
se
agrupan
los
datos
observados.
medidas
delatendencia
se define
como
suma de cada uno de los
La media aritmética,
denotada
por
obtenida de esa población,
que se representaría
por x ., Las
Las
detema,
tendencia
central
acerca
deresultados
es elpara
valor
más representativo
central
la muestra
sirven
tanto
para resumir
los
observados
como
para
En medidas
elde
presente
se
revisan
las informan
herramientas
fundamentales
la realización
derealizadas.
un
análisisSi denotamos
valores
muestrales
dividida
por
elcuál
número
de
observaciones
descriptivo de las variables recogidas en una muestra, tanto mediante estimadores de la tendencia
de unaposición
determinada
variable
o,los
dicho
de forma
equivalente,
estos
estimadores
indican
central,
y dispersión
como
mediante
la utilización
representaciones
gráficas.
realizar
inferencias
acerca
de
parámetros
correspondientes.
A
por n el
tamaño
muestral
ypoblacionales
por xi el de
valor
observado
para
el
sujeto
i-ésimo, i = 1, ..., n,
alrededor de se
quédescriben
valor
se agrupan
los dada
datosestimadores
observados. de
Laslamedidas
de tendencia
la media
por
continuación
los vendría
principales
tendencia
central de una
1.2 MEDIDAS DE TENDENCIA CENTRAL
central de la muestra sirven tanto para resumir los resultados observados como para
variable.
n
... + x n
x1 +más
x 2 +representativo
1 es
Las medidas de tendencia central informan acerca de
cuál
de una
.
x=
xeli =valor
determinada
variable acerca
o, dichodedelos
forma
equivalente,
estos
estimadores
indican
alrededor
de qué
realizar inferencias
parámetros
poblacionales
correspondientes.
A
n i =1
n
valor se
agrupan
los datos observados. Las medidas de tendencia central de la muestra sirven
1.2.1
Media
aritmética
tanto
para resumir
los resultados
observados
como para
inferencias
continuación
se describen
los principales
estimadores
de larealizar
tendencia
central deacerca
una de los
La
media
es
la
medida
de
tendencia
central
más
utilizada
yprincipales
de más fácil
parámetros
poblacionales
correspondientes.
A continuación
sededescriben
como la suma
cada unolos
de los
La
media aritmética,
denotada
por x , se define
estimadores
variable. de la tendencia central de una variable.
interpretación. Corresponde al “centro de gravedad” de los datos de la muestra. Su
valores muestrales dividida por el número de observaciones realizadas. Si denotamos
1.2.1 Media
principal limitación es que está muy influenciada por los valores extremos y, en este
1.2.1
Media aritmética
aritmética
por n el tamaño muestral y por xi el valor observado para el sujeto i-ésimo, i = 1, ..., n,
mediaaritmética,
aritmética,caso,
denotada
como
lalasuma
dede
cada
unouno
dede
los
LaLamedia
denotada
por
,, seundefine
define
comode
cada
delalos
valores
puede
noxser
fiel reflejo
lasuma
tendencia
central
distribución.
muestrales
divididadada
por por
el número de observaciones realizadas. Si denotamos por n el tamaño
la
media vendría
valores ymuestrales
dividida
por el para
número
de observaciones
Si denotamos
muestral
por xi el valor
observado
el sujeto
i-ésimo, i = 1,realizadas.
..., n, la media
vendría dada por
Ejemplo 1.4 En este y en los sucesivos ejemplos sobre estimadores muestrales, se
n
... +elx nsujeto i-ésimo, i = 1, ..., n,
x1 + x 2 +para
1 valor
por n el tamaño muestral y por
.
x =xi el
x i =observado
utilizarán
colesterol HDL obtenidos en los 10 primeros sujetos del
n i =los
1 valores del n
la media vendría dada por
La media es la medida de
tendencia
centralStudy
más on
utilizada
y de más
fácil interpretación.
estudio
“European
Antioxidants,
Myocardial
Infarction and Cancer of
Corresponde
de gravedad”
de los
datos más
de lautilizada
muestra. ySudeprincipal
limitación es que
La media al
es“centro
la medida
de tendencia
central
más
fácil
... +caso,
x1 +y, xen
x n puede no ser un fiel reflejo de la
1 nextremos
está muy influenciada por losthe
valores
este
2 +
un estudio
multicéntrico de casos y controles realizado
.
=
xBreast“
x(EURAMIC),
i =
tendencia centralCorresponde
de la distribución.
n i =1 de gravedad”
n de los datos de la muestra. Su
interpretación.
al “centro
entre 1991 y 1992 en ocho países Europeos e Israel para evaluar el efecto de los
Ejemplo
1.4 En
esteestá
y de
enmuy
los influenciada
sucesivos
ejemplos
estimadores
muestrales,
principal
limitación
es
por infarto
los sobre
valores
extremos
y,
en en
este se
antioxidantes
el que
riesgo
desarrollar
unmás
primer
agudo
de
miocardio
La
media
es laen
medida
de tendencia
central
utilizada
y de
más
fácil
utilizarán los valores del colesterol HDL obtenidos en los 10 primeros sujetos del estudio
“European
Study
on valores
Antioxidants,
Myocardial
Infarction
and 1,29,
Cancer
of 0,84,
the Breast”
hombres
adultos.
obtenidos
fueroncentral
0,89,
1,58,
1,42,
caso,
puede no
ser
unLos
fiel
reflejo
de
la de
tendencia
dedatos
la0,79,
distribución.
interpretación.
Corresponde
al “centro
gravedad”
de los
de la muestra.
Su
(EURAMIC), un estudio multicéntrico de casos y controles realizado entre 1991 y 1992
en ocho países Europeos e Israel para evaluar el efecto de los antioxidantes en el riesgo
1,06,
0,87,
1,96 yes1,53
media de los
del colesterol
en
principal
limitación
que mmol/l.
está muyLa
influenciada
porniveles
los valores
extremos HDL
y, en este
de
desarrollar
un este
primer
agudo deejemplos
miocardio
en hombres
adultos.
Los valores
Ejemplo
1.4 En
y eninfarto
los sucesivos
sobre
estimadores
muestrales,
se
obtenidos fueron 0,89, 1,58, 0,79, 1,29, 1,42, 0,84, 1,06, 0,87, 1,96 y 1,53 mmol/l. La
caso,
puede
no ser un fiel es
reflejo de la tendencia central de la distribución.
estos
10 participantes
media de los niveles del colesterol HDL en estos 10 participantes es
utilizarán los valores del colesterol HDL obtenidos en los 10 primeros sujetos del
1 10y en los0,sucesivos
89 + 1,58 +ejemplos
... + 1,53sobre estimadores muestrales, se
Ejemplo
1.4 xEn
= esteStudy
x i =on Antioxidants,
= 1,223Infarction
mmol/l. and Cancer of
estudio
“European
Myocardial
10 i =1
10
utilizarán los valores del colesterol HDL obtenidos en los 10 primeros sujetos del
the Breast“ (EURAMIC), un estudio multicéntrico de casos y controles realizado
estudio
“European
Studylas
onsiguientes
Antioxidants,
Myocardial Infarction and Cancer
of
Pastor-Barriuso
R.
La media
aritmética
presenta
propiedades:
entre 1991 y 1992 en ocho países Europeos e Israel para evaluar el efecto de los
•
the Breast“
(EURAMIC),
un Si
estudio
multicéntrico
de casos
y controles
Cambio
de origen
(traslación).
se suma
una constante
a cada
uno de losrealizado
datos
3
iLa media de los niveles del colesterol HDL en
1,06, 0,87,MEDIDAS
1,96
y 1,53
mmol/l.
de una
variable
o,
dicho de
forma
estimadores indican
10TENDENCIA
10
DE
CENTRAL
i =1
antioxidantes 1.2
en el riesgo
dedeterminada
desarrollar
un primer
de equivalente,
miocardio
enestoscorrespondientes.
realizar
inferencias
acercainfarto
de los agudo
parámetros
poblacionales
A
estos 10 participantes
esde qué valor se agrupan los datos observados. Las medidas de tendencia
alrededor
hombres adultos.
Los
valores
obtenidossecentral
fueron
0,89,
1,58,
0,79, 1,29,
1,42,
Estadística
descriptiva
Las
medidas
de tendencia
informan
acerca
de estimadores
cuál
es el0,84,
valor
representativo
continuación
describen
los
principales
de lamás
tendencia
central de una
La media aritmética presenta las siguientes propiedades:
central
sirven
tanto
losHDL
resultados
observados como para
1,06, 0,87, 1,96
1,53
mmol/l.
media
niveles
delresumir
colesterol
en estimadores
+o,1,los
+
+ 1para
1de10laLamuestra
0,89 de
58
...de
,53
de yuna
determinada
variable
dicho
forma
equivalente,
estos
indican
variable.
x
x
=
1,223
mmol/l.
=
=
i
• Cambio de origen
(traslación).
Si se suma una constante a cada uno de los datos
10
10
La media aritmética
presenta las siguientes propiedades:
i =1
realizar inferencias
acerca de los parámetros poblacionales correspondientes. A
estos 10 participantes
alrededoresde qué valor se agrupan los datos observados. Las medidas de tendencia
Cambio
deMedia
origende
(traslación).
Si se sumaesuna
constante
a cada
unomás
de los
de unayymuestra,
media
la muestra resultante
igual
a la media
inicial
la datos de una
1.2.1la
aritmética
muestra,
la
media
de
la
muestra
resultante
es
igual
a
la
media
inicial
más
la constante
continuación
se
describen
los
principales
estimadores
de
la
tendencia
central
de
una
La mediacentral
aritmética
las
siguientes
propiedades:
de10 lapresenta
muestra
sirven
tanto
para
resumir los resultados observados como para
+
+
+
1
0
,
89
1
,
58
...
1
,
53
=i =xxi i++ c,
= mmol/l.
Un cambio
cambio
origen
que se
si siyiyaritmética,
c, entonces
ypor
Un
origen
constante
utilizada;
media
denotada
x ,++secc..define
como de
ladesuma
deque
cada
unorealiza
de loscon
x = utilizada;
xLa
= 1,223
i =
10variable.
10
frecuencia
es el centrado
de la variable, que consiste en restar a cada valor de la muestra
i =1
• Cambio
de origen
(traslación).
Side
se los
suma
una constante
a cada uno
de los datos
realizar
inferencias
acerca
parámetros
poblacionales
correspondientes.
A
sucon
media.
Lamuestrales
media
decentrado
una
variable
será,
por
tanto,enigual
a 0.a
valores
dividida
porlacentrada
elvariable,
número
de observaciones
realizadas.
Si denotamos
se realiza
frecuencia
es el
de
que
consiste
restar
yy 1.2.1
Cambio
escala
(unidades).
Si seestimadores
multiplica
cada
de losmás
datos
de unacontinuación
muestra,
la Media
media
de
la muestra
resultante
es igual a la
inicial
la de
sede
describen
los principales
demedia
la uno
tendencia
central
deuna
una muestra por
aritmética
media aritmética
lasmuestra
propiedades:
el una
valorvariable
observado
el
sujeto
i = 1, ..., n,
por
nsiguientes
el tamaño
muestral
ymedia
por xide
cada presenta
valor
la
media.
Lamuestra
centrada
será,
por i-ésimo,
unade
constante,
la su
media
de la
resultante
es igual
a para
la media
inicial
por la constante
entonces
== cxx .,+sec.define
utilizada;
si
ci,, entonces
Un cambio
que
constante
utilizada;
si yaritmética,
comode
la origen
suma de
cada uno de los
La
media
denotadaypor
variable.
i =yx
i +cx
i =
Cambio de origen
Si se
suma
una constante
a cada uno de los datos
vendría
dada
por
tanto, (traslación).
igual ala0.media
yy Cambio simultáneo de origen y escala. Si se multiplica cada uno de los datos de una
valores
muestrales
dividida
el
número
de
observaciones
realizadas.
Si denotamos
se realiza
con
frecuencia
es
el constante
centrado
depor
laresultado
variable,
que
consiste
enmás
restar
a la media
muestra
por
una
ales
le
suma
otra
constante,
de la muestra
de una muestra,
la
media
dearitmética
la
muestra
resultante
igual
acada
lanse
media
inicial
la
1.2.1
Media
• Cambio
de escala
(unidades).
Si seymultiplica
uno
de
los
datos
de
una
+
+
...
+
x
x
x
1
1
2
n
resultante es igual a la media inicial
por la primera
constante, más. la segunda constante; si
x =valor
xi =
por
n=c el
tamaño
muestral
ymedia
por
xse
observado
paraque
elcada
sujeto
i eluna
cada
valor
desi
lay=iaritmética,
muestra
su
media.
La
de
variable
centrada
será,
por i-ésimo,
n
x
+
c
,
entonces
=
c
+
c
.
y
+
c
,
entonces
y
=
x
+
c
.
Un
cambio
de
origen
constante
utilizada;
La
media
denotada
por
x
,
define
como
la
suma
de los i = 1, ..., n,
=
i
1
i
1 ii constante,
2
muestra por
una
la media1 de la2muestra resultante esnde
igual
a launo
media
media vendría dada por
tanto, igual
ala0.
valores
muestrales
dividida
el
devalores
observaciones
denotamos
Ejemplo
1.5
Para
transformar
los
colesterol
mmol/l
se realiza coninicial
frecuencia
el
la
variable,
que
consiste
en= restar
a HDLSi
yi =decxtendencia
ydel
cmás
x realizadas.
. utilizada
por
laes
constante
utilizada;
si número
i, entonces
Lacentrado
media
esde
lapor
medida
central
y de
de
más fácila mg/dl se
multiplica por el factor de conversión 38,8. Así, utilizando la propiedad del cambio de
• Cambio de escala (unidades). Si se multiplica cada
n uno de los datos de una
valor
observado
sujeto
=de1,la...,
n,
por
n elescala,
tamaño
yCorresponde
por
xde
+el
...uno
+por
x +para
xcada
xde
1alse
lamuestral
media
del
colesterol
HDL
encentrada
mg/dl
se
calcularía
directamente
amuestra.
partir
de
i el
cada valor• deCambio
la muestra
su
media.
media
una
variable
2 será,
ndei-ésimo,
interpretación.
“centro
los
datosi de
Susu
simultáneo
deLa
origen
y escala.
Si
multiplica
datos
. los
x=
x i = 1de gravedad”
media en mmol/l como 1,223·38,8
=
47,45
mg/dl.
n i =1 resultante esnigual a la media
muestra
unavendría
constante,
lapor
media de la muestra
la por
media
dada
tanto, igual auna
0.
limitacióny es
que está muy
por los valores
extremos y, en este
muestra principal
por una constante
al resultado
se leinfluenciada
suma otra constante,
la media
cxtendencia
y = c más
x . utilizada y de más fácil
inicial por
la constante
utilizada;
si yi =de
1.2.2
Mediana
i, entoncescentral
La media
es multiplica
la medida
Cambio de escala
(unidades).
Si
se
uno de
los
caso,
puede
noigual
ser un
fielnmedia
reflejo
tendencia
central
de la distribución.
de la muestra
resultante
es
acada
inicial
por
la+deprimera
constante,
más la
+ xladatos
+
...
x1 de
xuna
1la
2
n
.
x = xi =
La
mediana
es origen
el valor
un variable
que deja
por
ellos50%
dede
losladatos
de laSumuestra
n al
n encima
interpretación.
Corresponde
deesgravedad”
de
datos
de
muestra.
• Cambio
simultáneo
de
y de
escala.
Si
multiplica
cada
unolade
los
datos
=1 “centro
i se
muestra
por una
muestra
resultante
media
=50%.
cla
c2, entonces
= c1igual
x + aces
segunda
si yi de
1 xi +
2. necesario ordenar los valores de la
y constante,
por constante;
debajolaelmedia
otro
Para
calcular
lay mediana,
Ejemplo
1.4 En
este
y en los
sucesivos
ejemplos la
sobre
estimadores
muestrales,
se
muestra
de menor
a mayor.
Si el
tamaño
muestral
nconstante,
es
mediana
viene
dada
principal
limitación
esi,resultado
que
está
muy
porimpar,
los valores
extremos
y, en
estepor el
unalamuestra
por
una
constante
al
se
suma
la
media
cx
entonces
y le=influenciada
c xmás
. otra
inicial por
constante
utilizada;
si yi =y de
La
media
es
la
medida
tendencia
central
utilizada
y
de
más
fácil
valor (n + 1)/2-ésimo. Si n es par, la mediana viene dada por la media aritmética de los
utilizarán
loslosvalores
deldelcolesterol
HDL
en
los
10 primeros
sujetos del
Ejemplo
1.5
Para
transformar
valores
colesterol
HDL
dede
mmol/l
aque
mg/dl
se influenciada
valores
(n/2)
y (n/2
+ser
1)-ésimos.
La inicial
principal
ventaja
de
laobtenidos
mediana
es
caso,
puede
un
fiel
reflejo
de lapor
tendencia
central
la distribución.
de la muestra
resultante
esnoigual
a laal
media
la primera
constante,
más
lano está
interpretación.
Corresponde
“centro
de
gravedad”
de
los
datos
de
la
muestra.
Su
Cambio simultáneo
de
origen
y
escala.
Si
se
multiplica
cada
uno
de
los
datos
de
por los valores extremos. No obstante, se utiliza menos que la media como medida de
estudio
Study
on Antioxidants,
Infarction and Cancer of
multiplica
porcentral
de “European
conversión
38,8. estadístico
Así,
utilizando
la Myocardial
propiedad
tendencia
porque
su tratamiento
es más
complejo.del
segunda
constante;
sielyfactor
i = c1xi + c2, entonces y = c1 x + c2.
principal
limitación
es
que
está
muy
influenciada
por
los
valores
extremos
y, en muestrales,
este
una muestra por
una constante
y
al
resultado
se
le
suma
otra
constante,
la
media
Ejemplo 1.4 En este y en los sucesivos ejemplos sobre estimadores
se
themedia
Breast“
(EURAMIC),
unen
estudio
multicéntrico
de casos y controles realizado
cambio de
escala,
la
del
colesterol
HDL
mg/dl
se
calcularía
Ejemplo 1.6 Para obtener la mediana del colesterol HDL en la muestra del estudio
puedeesno
ser un
reflejo
de
lapor
tendencia
central
de la distribución.
de la muestra caso,
resultante
igual
a lafiel
media
inicial
la primera
constante,
más
utilizarán
valores
del
colesterol
HDL
obtenidos
enala
los
10 primeros
sujetos
EURAMIC,
se los
ordena
en primer
lugar los
valores
de
menor
a mayor;
esto es,
0,79, del
0,84,
Ejemplo 1.5 Para
transformar
los
valores
del
colesterol
HDL
de
mmol/l
se
entre
1991
y 1992
en ochocomo
países1,223
Europeos
e 47,45
Israelmg/dl
para
evaluar el efecto de los
⋅
38,8
=
mg/dl.
directamente
a
partir
de
su
media
en
mmol/l
0,87, 0,89, 1,06, 1,29, 1,42, 1,53, 1,58 y 1,96 mmol/l. Como el tamaño muestral es par
c1xi + c2“European
, entonces yStudy
= c1on
x + c2 .
segunda constante; si yi = estudio
Infarction
and Cancer
of 6º),
(n
10),
la
mediana
la media
de
los
dos valores
centrales
(en este
caso,
el se
5º y el
multiplica por
el=factor
deEn
conversión
38,8.
Así,Antioxidants,
utilizando
la Myocardial
propiedad
del
Ejemplo
1.4
este yserá
en los
sucesivos
ejemplos
sobre
estimadores
muestrales,
que corresponde a (1,06 + 1,29)/2 = 1,175 mmol/l.
5
6
themedia
Breast“
(EURAMIC),
unen
estudio
multicéntrico
de casos y controles realizado
cambio de escala,
la
del
colesterol
HDL
mg/dl
se
calcularía
utilizarán los
los 10 se
primeros sujetos del
Ejemplo 1.5 Para transformar
losvalores
valoresdel
delcolesterol
colesterolHDL
HDLobtenidos
de mmol/lena mg/dl
Comparación de la media aritmética y la mediana. En las distribuciones simétricas
entre
1991
y 1992
en ocho
países
Europeos
Israeles
para
evaluar el efectoigual
de losa la
(ambas
colas
lamedia
distribución
soncomo
semejantes),
la =emedia
aproximadamente
⋅38,8
47,45
mg/dl.
directamente
a partir
dedesu
en Así,
mmol/l
1,223
estudio
“European
Study
on Antioxidants,
Myocardial
and Cancer of
multiplica
por el
factor
de conversión
38,8.
utilizando
la propiedad
delInfarction
mediana. En distribuciones sesgadas positivamente (la cola superior de la distribución es mayor
quelathe
lamedia
inferior),
la media HDL
tiende
ser mayor
que la mediana;
querealizado
en distribuciones
Breast“
(EURAMIC),
unenaestudio
multicéntrico
de casosmientras
y controles
5
cambio de escala,
del colesterol
mg/dl
se
calcularía
6
sesgadas negativamente (la cola inferior de la distribución es mayor que la superior), la media
tiende a ser
menor
que en
la mediana.
LaEuropeos
comparación
de lapara
media y la mediana permite evaluar,
1991
y 1992
ocho
países
Israel
⋅38,8 = e47,45
mg/dl.evaluar el efecto de los
directamente a partirentre
de su
media
en mmol/l
como
1,223
por tanto, la asimetría de una distribución.
6
Ejemplo 1.7 En la muestra del estudio EURAMIC la media
del colesterol 5HDL es
ligeramente superior a la mediana (1,223 y 1,175 mmol/l, respectivamente). En
consecuencia, la distribución de estos 10 valores del colesterol HDL es aproximadamente
simétrica con un leve sesgo positivo.
4
Pastor-Barriuso R.
de estos
consecuencia, la distribución
del
HDL es
x G = ∏
x i 10
= nvalores
x1 x 2 ⋅ ...
⋅ xcolesterol
n .
i =1
aproximadamente simétrica con un leve sesgo positivo.
Medidas de posición: cuantiles
1.2.3 Media geométrica
En la práctica, la forma más sencilla de calcular la media geométrica consiste en
La1.2.3
media geométrica,
denotada por xG , se define como la raíz n-ésima del producto de
1.2.3 Media
Mediageométrica
geométrica
calcular
primero
el logaritmo de cada valor muestral, hallar a continuación la media de
los
valores
de una muestra
de tamaño
La
mediageométrica,
geométrica,
denotada
por la
xGn,
lalaraíz
La
media
denotada
,, se define
define como
como
raízn-ésima
n-ésima
delproducto
producto
los
logaritmos
y deshacer
finalmente
transformación
logarítmica.
Paradel
calcular
losdede los
valores de una muestra de tamaño n,
los valores
una muestra
de tamaño
n, 1 / n y cuando el logaritmo y el
logaritmos
se de
puede
usar cualquier
base,
n siempre
x G = ∏ x i = n x1 x 2 ⋅ ... ⋅ x n .
1
i =Notar
1que
/n
antilogaritmo estén en la misma base.
la media geométrica sólo puede
n
x i calcular
= n x1lax 2media
⋅ ... ⋅ x ngeométrica
.
En la práctica, la forma más xsencilla
consiste en calcular
G =
∏de
=
1
i
emplearse
como
medida
de
tendencia
central
en
variables
que
toman
valores
primero
el
logaritmo
de
cada
valor
muestral,
hallar
a
continuación
la
media
de positivos.
losenlogaritmos y
En la práctica, la forma más sencilla de calcular la media geométrica consiste
deshacer finalmente la transformación logarítmica. Para calcular los logaritmos se puede usar
cualquier
base, siempre
ymás
cuando
el logaritmo
y ellaantilogaritmo
estén en
la misma
base.deNotar
calcular
primero
logaritmo
de cada
valor
muestral,
hallar
a continuación
laen
media
En la práctica,
laelforma
sencilla
de
calcular
media
geométrica
consiste
Ejemplo
1.8
Para
calcular
la
media
geométrica
del
colesterol
HDL
en
la
muestra
que la media geométrica sólo puede emplearse como medida de tendencia central en variables
que
tomanprimero
valores
los
logaritmos
y deshacer
finalmente
transformación
logarítmica.
Para calcular
calcular
elpositivos.
logaritmo
de cadalavalor
muestral, hallar
a continuación
la medialos
de
del estudio EURAMIC, se halla primero el logaritmo natural de cada uno de los
Ejemplo
1.8
Para
calcular
labase,
media
geométrica
del
colesterol
HDL
en la muestra
del
los logaritmos
y deshacer
finalmente
la transformación
logarítmica.
Para
los
logaritmos
se puede
usar cualquier
siempre
y cuando
el logaritmo
ycalcular
el
valores
yEURAMIC,
a continuación
se calcula
suelmedia
aritmética,
estudio
se
halla
primero
logaritmo
natural
de
cada
uno
de
los
valores
ya
consecuencia, la distribución de estos 10 valores del colesterol HDL es
continuación
se
calcula
su media
aritmética,
logaritmos
seestén
puede
cualquier
base,
siempre
el logaritmosólo
y elpuede
antilogaritmo
enusar
la misma
base.
Notar
que lay cuando
media geométrica
aproximadamente simétrica
log(0sesgo
,89) +positivo.
... + log(1,53)
1 10 con un leve
log
log
x
=
x
=
antilogaritmo
estén
en
la
misma
base.
Notar
que
la
media geométrica
sólo puede
i
emplearse como medida deGtendencia
central
en
variables
10 i =1
10que toman valores positivos.
,425
− 0,117central
+ ... + 0en
emplearse como medida de tendencia
variables que toman valores positivos.
= 0,155.
1.2.3 Media geométrica=
10geométrica del colesterol HDL en la muestra
Ejemplo 1.8 Para calcular la media
La
mediageométrica,
geométrica
es, porlatanto,
=colesterol
1,168
La
media
denotada
por xGgeométrica
,=seexp(0,155)
define del
como
la raízmmol/l.
n-ésimaendel
producto de
Ejemplo
Para calcular
media
muestra
del
estudio1.8
EURAMIC,
se halla
primero el logaritmo
naturalHDL
de cada la
uno
de los
La media geométrica es, por tanto, xG = exp(0,155) = 1,168 mmol/l.
Allos
igual
que la
la media
geométrica
útil comonatural
medidade
decada
tendencia
valores
demediana,
una muestra
dehalla
tamaño
n, eleslogaritmo
del
estudio
EURAMIC,
se
primero
uno decentral
los para
valores
a continuación
seque
calcula
su media
aritmética,
variables
muyyasimétricas,
en las
un pequeño
grupo
de observaciones extremas tienen una
excesiva
influencia
sobre la la
media
La1 /media
geométrica
tiene
ventaja adicional de
valores
continuación
se aritmética.
calcula
su media
aritmética,
Al igual
que ylaamediana,
media
geométrica
es
como medida
delatendencia
n útil
n
10 sencillo
presentar un tratamiento estadístico
más
que
la
mediana.
1,53)
1
x1)x 2+ ⋅...
...+⋅ xlog(
∏x x i= log(=0n,89
n .
log xG = x G= log
i
central para variables muy asimétricas,
en
las
que
un
pequeño
grupo
de) observaciones
i =1 log(0,89) + 10
10
=1
... + log(1,53
1 i10
log x G = log x i =
− 0,i117
+ ... + 0,425
10 .
=1
1.3 MEDIDAS
POSICIÓN:
= 10 CUANTILES
= aritmética.
0,155
extremas
tienen unaDE
excesiva
influencia
sobre la media
La media geométrica
En la práctica, la forma más sencilla
de
calcular
la
media
geométrica consiste en
− 0,117 +10... + 0,425
. respecto al resto de la muestra.
= 0,155con
Los cuantiles indican la posición=relativa de una observación
8
10
calcular primero
el logaritmo
de cadamás
valor
muestral, hallar a continuación la media de
A continuación
se describen
los cuantiles
utilizados:
La media geométrica es, por tanto, xG = exp(0,155) = 1,168 mmol/l.
yy Percentiles son los valores de una variable que dejan un determinado porcentaje de los
losLa
logaritmos
y deshacer
Para calcular los
media geométrica
es,finalmente
por tanto, laxGtransformación
= exp(0,155) =logarítmica.
1,168 mmol/l.
datos por debajo de ellos. Así, por ejemplo,
el percentil 10 es el valor superior al 10% de
las
observaciones,
pero inferior
90% restante.
Lacomo
mediana
corresponde,
por tanto, al
Allogaritmos
igual
que se
la mediana,
media al
geométrica
es útil
medida
de tendencia
puede usarlacualquier
base, siempre
y cuando
el logaritmo
y el
percentil 50. En una muestra de tamaño n, previamente ordenada de menor a mayor, el
Al igual que la mediana, la media geométrica es útil como medida de tendencia
percentil
p-ésimo
seendefine
como:
antilogaritmo
estén
la
misma
base.
que
media geométrica
sólo puede
central
para variables
muy
asimétricas,
enNotar
las que
unlapequeño
grupo de observaciones
Sipara
np/100
es un número
entero, la media
deque
las observaciones
(np/100)
y (np/100 + 1)-ésimas.
central
variables
muy asimétricas,
en las
un pequeño grupo
de observaciones
emplearse
como
medida de
tendenciasobre
central
en
variables
que toman
valores
positivos.
extremas
tienen
una
excesiva
influencia
la
media
aritmética.
La
media
geométrica
Si np/100 no es un número entero, el valor k-ésimo de la muestra, siendo
k el menor
extremas
tienen
una excesiva
influencia sobre la media aritmética. La media geométrica
entero
superior
a np/100.
8
Ejemplo
1.8 Para acalcular
la media10,
geométrica
colesterol
HDL
en lapara
muestra
yy Deciles,
corresponden
los percentiles
20, ..., 90.del
Los
deciles se
utilizan
dividir
8
la muestra en 10 grupos de igual tamaño.
del estudio EURAMIC, se halla primero el logaritmo natural de cada uno de los
yy Quintiles, corresponden a los percentiles 20, 40, 60 y 80, y dividen la muestra en 5 grupos
de igual tamaño.
valores y a continuación se calcula su media aritmética,
log(0,89) + ... + log(1,53)
1 10
log x G = log x i =
10 i =1
10
− 0,117 + ... + 0,425
Pastor-Barriuso R.
5
mmol/l. De igual forma, como 10p/100 = 2,5 no es un número entero para p = 25,
Estadística descriptiva
el percentil 25 es el tercer valor de la muestra, que corresponde a 0,87 mmol/l.
yy Cuartiles, corresponden a los percentiles 25, 50 y 75, y dividen la muestra en 4 grupos de
Es importante recordar que, para calcular cuantiles, los valores de la muestra deben
igual tamaño.
yy Terciles,
corresponden
a los
33,3 y 66,7,
y dividen
muestra
3 grupos
estar
previamente
ordenados.
Sipercentiles
el tamaño muestral
es grande,
la laforma
másenrápida
de de
igual tamaño.
obtener los cuantiles manualmente es realizando un gráfico de tallo y hojas (ver más
Ejemplo 1.9 Los 10 valores del colesterol HDL ordenados de menor a mayor son 0,79,
0,84, 0,87, 0,89, 1,06, 1,29, 1,42, 1,53, 1,58 y 1,96 mmol/l. Dado que 10p/100 = 1 es un
adelante).
número entero para p = 10, el percentil 10 es la media de la primera y segunda observación,
que corresponde a (0,79 + 0,84)/2 = 0,815 mmol/l. De igual forma, como 10p/100 = 2,5
no es un número
entero para p = 25, el percentil 25 es el tercer valor de la muestra, que
1.4 MEDIDAS
DE DISPERSIÓN
corresponde a 0,87 mmol/l.
Las medidas de dispersión indican el grado de variabilidad de los datos y se
Es importante
recordar
que, para calcular cuantiles, los valores de la muestra deben estar
1.2 MEDIDAS DE
TENDENCIA
CENTRAL
previamente ordenados. Si el tamaño muestral es grande, la forma más rápida de obtener los
complementan
con lasesmedidas
de un
tendencia
la descripción
de una muestra.
cuantiles
manualmente
realizando
gráfico central
de tallo en
y hojas
(ver más adelante).
Las medidas de tendencia central informan acerca de cuál es el valor más representativo
En este apartado se presentan las principales medidas de dispersión.
de una determinada
variable o, dicho
de forma equivalente, estos estimadores indican
1.4 MEDIDAS
DE DISPERSIÓN
1.4.1
Varianza
y desviación
típica
Las
medidas
de dispersión
indican
el grado Las
de variabilidad
los datos y se complementan con
alrededor de qué
valor
se agrupan
los datos
observados.
medidas de de
tendencia
las medidas de tendencia central en la descripción
de
una
muestra.
En este apartado se presentan
2
La
varianza
muestral,
denotada
por
s
,
se
define
como
la
suma
de los cuadrados de las
las principales
medidas
dispersión.
central de la muestra
sirven tanto
paraderesumir
los resultados observados como para
diferencias
entre
valor de
la muestra ycorrespondientes.
su media, dividida
realizar inferencias
acerca
de los
parámetros
poblacionales
A por el tamaño muestral
1.4.1
Varianza
y cada
desviación
típica
1, muestral,
varianza
denotada
por s2, se define
como la suma
de los
cuadrados de las diferencias
continuación La
semenos
describen
los principales
estimadores
de la tendencia
central
de una
entre cada valor de la muestra y su media, dividida por el tamaño muestral menos 1,
variable.
media, el número de valores independientes
de la muestra
(denominado “grados de
1 n
1 n 2
2
2
( xi − x ) =
s =
x i − nx 2 .
1 i =1
n − 1 i =1 la media y n - 1 valores, el
libertad”) para el cálculo denla−varianza
es n - 1 (conocida
1.2.1 Media aritmética
Como puede apreciarse, cuanto más dispersos estén los datos, mayores serán los cuadrados de
valor
restante
se(x
deduciría
automáticamente).
más
formal paradeesta
2
La media aritmética,
denotada
por
define
comola
lavarianza
sumaUna
de
uno
de las
los
las
desviaciones
y cuanto
mayor
será
s2cada
.justificación
Notar
que
desviaciones
Como
puede apreciarse,
más
dispersos
estén
los
datos,
mayores
serán loscada valor
i – x ), se
respecto de la media se elevan al cuadrado para evitar que se compensen las desviaciones
definición
de por
la varianza
se aaporta
en el2Tema
5.
positivas
(valores
media)
lasrealizadas.
negativas
inferiores
la media).
Cabe
valores muestrales
dividida
el
número
delaobservaciones
Si
denotamos
y mayor
será la(valores
varianza
s2. Notaraque
las
cuadrados
de lassuperiores
desviaciones
(x
i - x )con
destacar también que, en la fórmula de la varianza muestral, el denominador es n – 1 en lugar de n.
Lasevarianza
muestral
es observado
difícil
de interpretar
como
medida
dispersión,
ya que sus
por n el tamaño
muestral
xcada
valor
para
el
sujeto
ide=de
1,
..., n, independientes
Esto
debey por
ade
que,
vez
calculada
lalamedia,
elsei-ésimo,
número
valores
i eluna
desviaciones
valor
respecto
de
media
elevan al
cuadrado
para evitar quedesela
muestra (denominado “grados de libertad”) para el cálculo de la varianza es n – 1 (conocida la
unidades
son
las
de la el
variable
originalse
al deduciría
cuadrado.automáticamente).
La medida de dispersión
más
la media vendría
dada
media
y npor
– 1las
valores,
valorpositivas
restante
compensen
desviaciones
(valores
superiores a la media)Una
con justificación
las negativasmás
formal para esta definición de la varianza se aporta en el Tema 5.
utilizada es la desviación
típica o desviación estándar s, que se define como la raíz
(valores
inferiores
Cabe
también
que,
la fórmula
varianza
+ ...destacar
+ x n como
x +de
x 2interpretar
1a nlaesmedia).
La varianza
muestral
difícil
medida
deen
dispersión,
yade
quelasus
unidades
.
x = xi = 1
son
las
de
la
variable
original
al
cuadrado.
La
medida
de
dispersión
más
utilizada
es
la
desviación
n i =1
n
cuadrada de la varianza
muestral,
el denominador
n - 1seen
lugarcomo
de n.laEsto
debe a que,
vez calculada la
típica
o desviación
estándar es
s, que
define
raízse
cuadrada
de launa
varianza
10
La media es la medida de tendencia central más utilizada
1 yn de más fácil
2
s=
( xi − x )
n − 1 i =1
interpretación. Corresponde al “centro de gravedad” de los datos de la muestra. Su
y, en consecuencia, presenta las mismas unidades que la variable original. Al igual que la media,
principal limitación
es que típica
está muy
influenciada
por
valores
extremos
y, (gran
en este
lay,desviación
está
influenciada
porlos
valores
muy
extremos
desviación
respecto
en consecuencia,
presenta
las mismas
unidades
que
la variable
original.
Al igual
que de la
caso, puede nolaser
un fiel
de la típica
tendencia
de la distribución.
media,
lareflejo
desviación
está central
influenciada
por valores muy extremos (gran
6
Pastor-Barriuso R.
desviación respecto de la media), que inflarían la estimación resultante, no siendo un
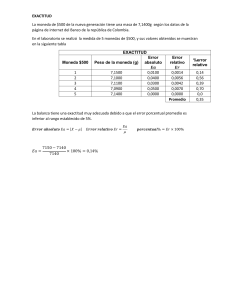
Ejemplo 1.4 En este y en los sucesivos ejemplos sobre estimadores muestrales, se
desviación respecto de la media), que inflarían la estimación resultante, no siendo un
buen reflejo de la dispersión global de los datos.
realizar
de los parámetros
poblacionales
correspondientes. A
bueninferencias
reflejo de acerca
la dispersión
global de los
datos.
Medidas de dispersión
Ejemplo
1.10 Conocida
la media
del colesterol
en loscentral
10 primeros
continuación
se describen
los principales
estimadores
de laHDL
tendencia
de una
Ejemplo
1.10 Conocida
la mediaa del
colesterol
HDL
en los 10 primeros
mbio de origen
(traslación).
Si se suma
una constante
cada xuno
de los mmol/l,
datos la varianza vendría dada
= 1,223
participantes
del estudio
EURAMIC,
variable.
media), que inflarían la estimación resultante, no siendo un buen reflejo de la dispersión global
del estudio EURAMIC, x = 1,223 mmol/l, la varianza vendría dada
de losparticipantes
datos.
na muestra, la varianza
pory la desviación típica no cambian; si yi = xi + c,
1.2.1 Media aritmética
por
2
1.10 Conocida la media del colesterol HDL en los 10 primeros participantes
nces s y = s x2 y sy = sEjemplo
x.
define
como
suma
los
La media aritmética,
por x ,=se1,223
varianza
vendría
por
del estudiodenotada
EURAMIC,
(mmol/l,
0,89
− 1,la
223
) 2 + de
... +cada
(1,53uno
−dada
1de
,223
)2
1 10
2
2
s = ( xi − x ) =
9 + (1,53 − 1,223) 2
(0,89
− 1,223
) 2 + ...
19 10
i =1cada uno 2de los
mbio de escala
(unidades).
Si
se
multiplica
datos
de una
valores muestrales dividida
el
número
de
observaciones
realizadas.
Si denotamos
s 2 = por
x
x
(
−
)
=
+i ... + 0,094
90,111
92
i =1
DE TENDENCIA CENTRAL =
= 0,156 (mmol/l)
stra por una
la varianza
a la varianza
pori-ésimo, i = 1, ..., n,
9igual
porconstante,
n el tamaño
muestralresultante
y por
xi el
valor
parainicial
el sujeto
0,111
...
094
+es
+ 0,observado
=
= 0,156 (mmol/l) 2
9 valor
tendencia
central
acerca
cuáles
esigual
el
representativo
onstante
allacuadrado
y la desviación
típica
a lamás
desviación
típica
mediainforman
vendría
dada
porde
la desviación
desviación típica por s = 0,156 = 0,395 mmol/l.
yy la
2estimadores
2
2
nada
o, dicho
desidesviación
forma
yi = cxequivalente,
sestos
y sy == cs
. Unmmol/l.
cambio
ial porvariable
dicha constante;
i, entonces
xindican
0,395
y la
típica por
y ns==c s0
x ,156
+
+
...
+
x
x
x
1
1
2
n
Algunas propiedadesxde= la varianza
x i = y la desviación .típica son:
é valor se agrupanAlgunas
los datos
observados.deLas
medidas
de
n
n valores
propiedades
la
varianza
y latendencia
desviación
típica
son:
i =1 de todos
scala que se realizayy con
frecuencia
es (traslación).
la división
los
de
una
Cambio
de origen
Si se suma
una
constante
a cada
uno de los datos de una muestra,
Algunas
propiedades
de la varianza
la desviación
la varianza
y la desviación
típica noycambian;
si yi = típica
xi + c, son:
entonces sy2 = sx2 y sy = sx.
uestra sirven tanto para resumir los resultados observados como para
stra por su desviación
típica.
La desviación
típicacentral
de la variable
resultante
La media
es la medida
de (unidades).
tendencia
más utilizada
y de
yy Cambio
de escala
Si se multiplica
cada
unomás
de fácil
los datos de una muestra por
una constante,
la varianza
resultante es igual
a la varianza inicial por la constante al
cias acerca de los parámetros
poblacionales
correspondientes.
A
, por tanto,interpretación.
igual a 1.
Corresponde
al “centro
de gravedad”
los datos de
la muestra.
Su dicha constante;
cuadrado
y la desviación
típica
es igual a ladedesviación
típica
inicial por
11
2 2
cxi, entoncesde
sy2la
= ctendencia
sx y sy =central
csx. Undecambio
si yi = estimadores
e describen los principales
una de escala que se realiza con frecuencia
edades delprincipal
cambio de
origen
y
escala
se
emplean
para
la
estandarización
de
limitación
es que
está muy
pormuestra
los valores
extremos
y, entípica.
este La desviación
11
es la división
de todos
los influenciada
valores de una
por su
desviación
típica de la variable resultante será, por tanto, igual a 1.
que consiste
en puede
restarlenoa ser
los un
valores
de unadevariable
su media
y dividirlos
por
caso,
fiel reflejo
la tendencia
central
de la distribución.
Las propiedades del cambio de origen y escala se emplean para la estandarización de variables,
que consiste
en restarle
a los valores
de una0variable
su media y dividirlos por su desviación
itmética
ción
típica. La variable
estandarizada
resultante
tiene media
y desviación
1.2típica.
MEDIDAS
DE
TENDENCIA
CENTRAL
La 1.4
variable
estandarizada
resultante
tiene media
y desviación
típica 1; essedecir, si zi =
Ejemplo
En este
y en los sucesivos
ejemplos
sobre 0estimadores
muestrales,
por
x
,
se
define
como
la
suma
de
cada
uno
de
los
sética,
decir,denotada
si zi = (x(x
x
)/
s
,
entonces
z
=
0
y
s
=
1.
–
)/s
,
entonces
=
0
y
s
=
1.
ii
xx
zz
utilizarán
los
valores
del
colesterol
HDLacerca
obtenidos
en los
primeros
sujetos del
Las medidas de tendencia central informan
de cuál
es el10valor
más representativo
ales dividida por el número de observaciones realizadas. Si denotamos
1.4.2 Rango intercuartílico
go intercuartílico
estudio
“European
Study o,
ondicho
Antioxidants,
and Cancer
of
de una
determinada
variable
de formaMyocardial
equivalente,Infarction
estos estimadores
indican
muestral y porEl
xi rango
el valor
observado
para
el
sujeto
i-ésimo,
i
=
1,
...,
n,
intercuartílico
se define
la diferencia
entre
el tercer y el primer cuartil (percentiles
ntercuartílico se define como
la diferencia
entrecomo
el tercer
y el primer
cuartil
the
Breast“
(EURAMIC),
un
estudio
multicéntrico
de
casos
controles
realizado
alrededor
derespectivamente).
qué valor se agrupan
los datos
observados.indica
Las medidas
de tendencia
75 y 25,
El rango
intercuartílico
layamplitud
del
50% central de la
a dada por
muestra
y
se
usa
como
medida
de
dispersión
cuando
la
variable
presenta
valores
extremos. En
es 75 y 25, respectivamente). El rango intercuartílico indica la amplitud del
entre
1991
y
1992
en
ocho
países
Europeos
e
Israel
para
evaluar
el
efecto
de
los
central
de lasuele
muestra
sirven tantode
para
resumir los
resultados
para
tal caso,
ir acompañado
la mediana
como
medida observados
de tendenciacomo
central.
n
al de la muestra y1se usa como
cuando la variable
x +medida
x 2 + ... +dexdispersión
n
x=
x i = 1 1.11
realizar
inferencias
acercaAde
los. parámetros
poblacionales
correspondientes.
A
Ejemplo
partir
de
los
10 valores
del colesterol
HDL ordenados
5de menor a
n i =1
n
mayor,
percentiles
25 y 75de
vienen
determinados
alores extremos. En tal
caso,los
suele
ir acompañado
la mediana
como por la tercera (0,87 mmol/l) y octava
continuación
se describen
principales
estimadores El
de rango
la tendencia
central de
observación
(1,53los
mmol/l),
respectivamente.
intercuartílico
se una
calcula entonces
latendencia
medida de
tendencia
central
más
utilizada
y
de
más
fácil
central. como la diferencia entre ambos percentiles, 1,53 – 0,87 = 0,66 mmol/l.
variable.
Corresponde al “centro de gravedad” de los datos de la muestra. Su
1.4.3 Coeficiente de variación
mplo 1.11 A 1.2.1
partirMedia
de los 10
valores del colesterol HDL ordenados de menor a
aritmética
ción es que estáElmuy
influenciada
por lossevalores
extremos
y, en este
coeficiente de variación
define como
el cociente
entre la desviación típica y la media aritmética,
or, los percentiles
25 yaritmética,
75como
vienen
determinados
tercera
(0,87
Laexpresado
media
denotada
por xpor
seladefine
como
suma
dey cada
de losde escala ya que,
.,Este
estimador
nolammol/l)
está
afectado
poruno
cambios
porcentaje,
100s/
ser un fiel reflejo
de
la
tendencia
central
de
la
distribución.
al multiplicar los valores de una variable por un mismo factor, tanto la media como la desviación
va observación
(1,53muestrales
mmol/l),por
respectivamente.
El
se
típica
cambian
dicho por
factor
su rango
cociente
permanece inalterable.
valores
dividida
el ynúmero
de intercuartílico
observaciones
realizadas.El
Si coeficiente
denotamosde variación
relaciona la desviación típica con la media y es útil para comparar la variabilidad de diferentes
1.4 En este y en los sucesivos ejemplos sobre estimadores muestrales, se
con distintas
por ejemplo,
unapara
desviación
típica
de 10i kg
porvariables
n el tamaño
muestralmedias.
y por xiAsí,
el valor
observado
el sujeto
i-ésimo,
= 1,en...,una
n, muestra de
adultos con un peso medio de 70 kg indicaría un mismo grado de dispersión que una desviación
los valores del colesterol HDL obtenidos en los 10 primeros sujetos del
la media vendría dada por
12
European Study on Antioxidants, Myocardial Infarction and Cancer of
x + x 2 + ... + x n
1 n
.
=
= 1
x
xyi controles
t“ (EURAMIC), un estudio multicéntrico de casos
n i =1
nrealizado
Pastor-Barriuso R.
7
realizar inferencias acerca de los parámetros poblacionales correspondientes. A
Estadística descriptiva
continuación se describen los principales estimadores de la tendencia central de una
variable.
típica de
0,5 kg en una muestra de recién nacidos con un peso medio de 3,5 kg (ambos coeficientes
de variación son 100·10/70 = 100·0,5/3,5 = 14,3%).
1.2.1 Media aritmética
Ejemplo 1.12 El coeficiente de variación de los 10 primeros valores del colesterol HDL
100·0,395/1,223
32,3%;
es decir,
en
estudio
EURAMIC
sería 100s/
Laelmedia
aritmética,
denotada
por x ,=se
define como la =suma
de cada
uno la
dedesviación
los
típica es aproximadamente un tercio de la media.
valores muestrales dividida por el número de observaciones realizadas. Si denotamos
1.5
REPRESENTACIONES
por n el tamaño muestral yGRÁFICAS
por xi el valor observado para el sujeto i-ésimo, i = 1, ..., n,
En el análisis e interpretación de los datos de un estudio, es importante no limitarse a realizar medidas
la media vendría dada por
de resumen numéricas. Las medidas de tendencia central y dispersión deben completarse con gráficos
que permitan observar directamente las características y relaciones de las variables estudiadas. En
esta sección se revisan los principales métodos
... + x n y resumir una variable.
x +para
x 2 +presentar
1 n gráficos
.
x = xi = 1
n i =1
n
1.5.1 Diagrama de barras
La media
es la medida
de tendencia
más utilizada
de más fácily cuantitativas
Los diagramas
de barras
son adecuados
para central
representar
variables ycualitativas
discretas. En estos diagramas se representan las categorías de la variable en el eje horizontal y sus
interpretación.
de gravedad”
los datos
devariable
la muestra.
Su
frecuencias
(absolutas Corresponde
o relativas) enalel“centro
eje vertical.
Para cada de
categoría
de la
se construye
un rectángulo de anchura constante y altura proporcional a la frecuencia. Los rectángulos están
principal
limitación
estádistancia
muy influenciada
porlalos
valores extremos
y, en este
separados
unos de
otros pores
la que
misma
para reflejar
discontinuidad
de la variable.
caso, puede no ser un fiel reflejo de la tendencia central de la distribución.
Ejemplo 1.13 La representación del diagrama de barras del hábito tabáquico en el grupo
control del estudio EURAMIC se ilustra en la Figura 1.1. De los 700 controles del estudio que
no habían
padecido
miocardio,
todos salvo
presentaban
información
Ejemplo
1.4 un
Eninfarto
este y agudo
en los de
sucesivos
ejemplos
sobreuno
estimadores
muestrales,
se
sobre el consumo de tabaco. De éstos, un 27,2% (190/699) eran nunca fumadores, un 35,3%
(247/699)
eran exlos
fumadores,
y elcolesterol
restante 37,5%
fumadores
actuales.
utilizarán
valores del
HDL (262/699)
obtenidoseran
en los
10 primeros
sujetos del
40
estudio
“European Study on Antioxidants, Myocardial Infarction and Cancer of
the Breast“ (EURAMIC), un estudio multicéntrico de casos y controles realizado
Frecuencia relativa (%)
30
entre
1991 y 1992 en ocho países Europeos e Israel para evaluar el efecto de los
5
20
10
0
Nunca
fumador
Ex fumador
Fumador
actual
Figura 1.1 Diagrama de barras del hábito tabáquico en el grupo control del estudio EURAMIC.Figura 1.1
8
Pastor-Barriuso R.
Representaciones gráficas
1.5.2
Histograma y polígono de frecuencias
El histograma es el principal método gráfico para la representación de variables cuantitativas
continuas. En primer lugar, los valores de la variable continua se agrupan en categorías
exhaustivas (cubren todo el rango de la variable) y mutuamente excluyentes (no se solapan). En
el eje horizontal del histograma se representan las categorías o intervalos y en el eje vertical las
frecuencias (absolutas o relativas) de cada intervalo. Posteriormente, se construye un rectángulo
para cada categoría, cuya anchura es igual a la longitud del intervalo y cuyo área es proporcional
a la frecuencia (si los intervalos tienen distinta longitud, las alturas de los rectángulos del
histograma no serán proporcionales a las frecuencias).
El polígono de frecuencias se construye uniendo con líneas rectas los puntos medios de las bases
superiores de los rectángulos que conforman un histograma. Tanto el histograma como el polígono
de frecuencias sirven para representar gráficamente la distribución de una variable continua.
Ejemplo 1.14 El histograma de la distribución del colesterol HDL en el grupo control
del estudio EURAMIC se presenta en la Figura 1.2. En este caso, se representa la
frecuencia absoluta en el eje vertical e intervalos de distinta longitud en el eje horizontal.
Para los intervalos de menor longitud (0,2 mmol/l), la altura de los rectángulos es igual a
la frecuencia; así, por ejemplo, la altura del rectángulo en el intervalo 1,2-1,4 mmol/l es
igual a los 86 sujetos con niveles del colesterol HDL dentro de este rango. Sin embargo,
para los intervalos de mayor longitud, la altura de la barra es igual a la frecuencia dividida
por el incremento relativo de la longitud del intervalo; así, por ejemplo, para el intervalo
1,4-1,7 mmol/l, cuya frecuencia es 55 y su longitud es 1,5 veces la longitud mínima, la
altura de la barra es 55/1,5 = 36,7. La Figura 1.2 se completa con el polígono de frecuencias,
que muestra una distribución del colesterol HDL aproximadamente simétrica con la cola
superior ligeramente mayor que la inferior.
150
Frecuencia absoluta
125
100
75
50
25
0
0
0,3
0,6
0,8
1
1,2
1,4
Colesterol HDL (mmol/l)
1,7
2
2,5
Figura 1.2
Figura 1.2 Histograma y polígono de frecuencias del colesterol HDL en el grupo control del estudio
EURAMIC.
Pastor-Barriuso R.
9
Estadística descriptiva
1.5.3
Gráfico de tallo y hojas
Este gráfico tiene la ventaja de reflejar los datos originales de la muestra, a la vez que permite
visualizar la distribución de frecuencias. En primer lugar, para cada observación de la variable,
se separa el último dígito significativo (hoja) de los restantes dígitos del valor de la variable
(tallo). A continuación, todos los posibles tallos se colocan ordenados en una misma columna.
Finalmente, para cada valor de la variable, se coloca su hoja a la derecha del tallo correspondiente.
Las hojas de un mismo tallo suelen colocarse en orden creciente. El resultado se conoce con el
nombre de gráfico de tallo y hojas.
Ejemplo 1.15 La Figura 1.3 muestra el gráfico de tallo y hojas del colesterol HDL en los
100 primeros controles del estudio EURAMIC con datos para esta variable. Los 2 valores
más bajos del colesterol HDL son 0,21 y 0,26 mmol/l, cuyo tallo común es 0,2 y sus
respectivas hojas son 1 y 6, que aparecen a la derecha de la primera línea del gráfico. El
siguiente tallo es 0,3, que no tiene ninguna hoja ya que no hay valores entre 0,30 y 0,39
mmol/l, y lo mismo sucede con el tallo 0,4. En el tallo 0,5 hay una hoja igual a 7, que
corresponde al valor 0,57 mmol/l. En el tallo 0,6 hay 5 hojas (35558), que corresponden a
los 5 valores del colesterol HDL entre 0,60 y 0,69 mmol/l y que son 0,63, 0,65, 0,65, 0,65 y
0,68 mmol/l. El resto de los tallos se interpreta de la misma manera. A partir de este gráfico
resulta sencillo calcular los cuantiles; así, por ejemplo, la mediana se obtendría como la
media de los valores ordenados en las posiciones 50 y 51, (1,10 + 1,12)/2 = 1,11 mmol/l.
Frecuencia
2
0
0
1
5
3
12
13
13
9
15
7
6
6
2
2
2
1
1
Tallo
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1,0
1,1
1,2
1,3
1,4
1,5
1,6
1,7
1,8
1,9
2,0
Hoja
16
7
35558
467
002344455579
0013334566779
0111123455559
023456789
000023356689999
1223778
345789
133689
44
34
36
0
9
Figura 1.3 Gráfico de tallo y hojas del colesterol HDL en los 100 primeros controles del estudio EURAMIC.
Figura 1.3
10
Pastor-Barriuso R.
Representaciones gráficas
1.5.4
Diagrama de caja
El diagrama de caja permite evaluar la tendencia central, la dispersión y la simetría de la
distribución de una variable, así como identificar valores extremos. Los límites inferior y
superior de la caja corresponden a los percentiles 25 y 75; es decir, la altura de la caja representa
el rango intercuartílico e indica la dispersión de la muestra. La línea horizontal dentro de la caja
corresponde a la mediana y representa la tendencia central de la muestra. El gráfico se completa
con barras verticales a ambos lados de la caja de longitud 1,5 veces el rango intercuartílico. Los
valores extremos, aquellos distanciados de los límites de la caja entre 1,5 y 3 veces el rango
intercuartílico, se representan con un círculo y los valores muy extremos, aquellos alejados de
la caja más de 3 veces el rango intercuartílico, se denotan mediante un asterisco.
En este gráfico, si la distribución es simétrica, los límites superior e inferior de la caja estarán
aproximadamente a la misma distancia de la mediana, mientras que si la distribución está sesgada
positivamente, el límite superior estará más alejado de la mediana que el inferior y si la distribución
está sesgada negativamente, el límite inferior estará más alejado de la mediana que el superior.
Ejemplo 1.16 La Figura 1.4 muestra el diagrama de caja del colesterol HDL en el grupo
control del estudio EURAMIC. Como puede observarse, esta distribución presenta un
leve sesgo positivo ya que el límite superior de la caja está ligeramente más alejado de la
mediana que el límite inferior.
2,5
Colesterol HDL (mmol/l)
2
1,5
1
0,5
0
Figura 1.4 Diagrama de caja del colesterol HDL en el grupo control del estudio EURAMIC.
Figura 1.4
Pastor-Barriuso R.
11
Estadística descriptiva
1.6
12
REFERENCIAS
1.
Colton T. Estadística en Medicina. Barcelona: Salvat, 1979.
2.
Glantz SA. Primer of Biostatistics, Fifth Edition. New York: McGraw-Hill/Appleton &
Lange, 2001.
3.
Pagano M, Gauvreau K. Principles of Biostatistics, Second Edition. Belmont, CA: Duxbury
Press, 2000.
4.
Rosner B. Fundamentals of Biostatistics, Sixth Edition. Belmont, CA: Duxbury Press,
2006.
Pastor-Barriuso R.
TEMA 2
PROBABILIDAD
2.1
INTRODUCCIÓN
Se denominan experimentos estocásticos, aleatorios o no determinísticos a aquellos en los
que pueden obtenerse resultados distintos cuando se repiten en idénticas circunstancias. Los
fenómenos biológicos tienen en este sentido una componente aleatoria importante. La
herramienta matemática que constituye la base para el estudio de fenómenos con una componente
aleatoria es la teoría de la probabilidad, que proporciona modelos teóricos aplicables a la
frecuencia de los distintos resultados de un experimento.
A continuación, se revisan algunos conceptos previos que van a ser necesarios para
sistematizar la noción de probabilidad.
yy Espacio muestral, denotado por W, es el conjunto de los posibles resultados de un
experimento aleatorio.
yy Se denomina suceso a cualquier subconjunto del espacio muestral W. Los sucesos pueden
ser elementos simples de W o conjuntos de elementos. Dos sucesos particulares son el
suceso seguro W, que contiene todos los elementos del espacio muestral, y el suceso
imposible o conjunto vacío ∅, que no contiene ningún elemento.
Ejemplo 2.1 Si el experimento consiste en observar el número de supervivientes a
los 6 meses de 4 pacientes con cáncer sometidos a tratamiento, el espacio muestral
será W = {0, 1, 2, 3, 4}. Si el experimento consiste en medir los niveles de colesterol HDL
de una persona, el espacio muestral será W = (0, ∞).
En el primer experimento, algunos sucesos podrían ser: no observar ningún superviviente
A = {0}, observar 1 ó 2 supervivientes B = {1, 2} u observar al menos 2 supervivientes
C = {2, 3, 4}. En el segundo experimento, algunos de los posibles sucesos incluirían:
tener un colesterol HDL ≤ 1 mmol/l A = (0, 1] o tener un colesterol HDL > 1,5 mmol/l
B = (1,5, ∞).
yy El suceso unión A∪B es el evento constituido por los elementos que pertenecen a A o B, o
a ambos a la vez.
yy El suceso intersección A∩B es el evento formado por los elementos que pertenecen
simultáneamente a A y B.
yy Sucesos disjuntos, incompatibles o mutuamente excluyentes son aquellos que no pueden
ocurrir simultáneamente; es decir, su intersección es el conjunto vacío, A∩B = ∅.
yy El suceso complementario del suceso A, denotado por Ac, es el evento que ocurre cuando
no se realiza A.
Estos sucesos están representados en los diagramas de la Figura 2.1. En general, las
operaciones entre sucesos se rigen por la teoría de conjuntos, de la cual pueden derivarse algunas
propiedades importantes como A∪(B∩C) = (A∪B)∩(A∪C), A∩(B∪C) = (A∩B)∪(A∩C),
(A∪B)c = Ac∩Bc y (A∩B)c = Ac∪Bc.
Pastor-Barriuso R.
13
Probabilidad
B
B
su intersección es
A B∩C = {2}. Al medir los niveles deAcolesterol HDL de una
persona, los sucesos
= (0, 1] y B = (1,5, ∞) son mutuamente
(a)AA∪B
(b) A∩Bexcluyentes ya que
A∩B = ∅. Asimismo, en este experimento el complementario de A es el suceso Ac
= (1, ∞).
B
En este tema se define el concepto de probabilidad y se introducen las reglas básicas
A
A
para operar con probabilidades. Estas reglas constituyen la base para el cálculo e
(c) A∩B = ∅
(d) Ac
interpretación de los procedimientos de inferencia estadística (por ejemplo, el valor P
Figura 2.1 Diagramas de los sucesos unión (a), intersección (b), sucesos mutuamente excluyentes
Figura 2.1(c) y
suceso
(d).
de un complementario
contraste de hipótesis
–véase Tema 5–) y permiten también evaluar la
sensibilidad,
especificidad
y los valoresdepredictivos
de lasa pruebas
diagnósticas.
Ejemplola 2.2
En el experimento
supervivencia
los 6 meses
de 4 pacientes con
cáncer, la unión de los sucesos B = {1, 2} y C = {2, 3, 4} es B∪C = {1, 2, 3, 4} y su
intersección es B∩C = {2}. Al medir los niveles de colesterol HDL de una persona, los
2.2 CONCEPTO
Y 1]
DEFINICIONES
PROBABILIDAD
sucesos A = (0,
y B = (1,5, ∞) sonDE
mutuamente
excluyentes ya que A∩B = ∅. Asimismo,
en este experimento el complementario de A es el suceso Ac = (1, ∞).
El concepto de probabilidad es intuitivo, tal y como se refleja en el lenguaje cotidiano:
En este tema se define el concepto de probabilidad y se introducen las reglas básicas para
operar
con probabilidades.
reglas
constituyen la
paraocurra,
el cálculo
e interpretación
de
la probabilidad
de un sucesoEstas
refleja
la verosimilitud
debase
que éste
de forma
que
los procedimientos de inferencia estadística (por ejemplo, el valor P de un contraste de hipótesis
–véase
Tema
5–)probables
y permiten
también
la sensibilidad,
especificidad
y los
los sucesos
más
se darán
con evaluar
mayor frecuencia
que loslamenos
probables.
Sinvalores
predictivos de las pruebas diagnósticas.
embargo, para abordar la probabilidad de forma sistemática, es necesaria una definición
2.2 CONCEPTO Y DEFINICIONES DE PROBABILIDAD
rigurosa, a la vez que compatible con nuestra intuición. Dos definiciones de
El concepto de probabilidad es intuitivo, tal y como se refleja en el lenguaje cotidiano: la
probabilidad de
de un
usosuceso
comúnrefleja
son: la verosimilitud de que éste ocurra, de forma que los sucesos
probabilidad
más probables se darán con mayor frecuencia que los menos probables. Sin embargo, para
• Definición frecuentista (von Mises). Al repetir un experimento indefinidamente,
abordar
la probabilidad de forma sistemática, es necesaria una definición rigurosa, a la vez que
compatible con nuestra intuición. Dos definiciones de probabilidad de uso común son:
la probabilidad de un suceso es el límite del cociente entre el número de veces que
yy Definición frecuentista (von Mises). Al repetir un experimento indefinidamente, la
probabilidad
un suceso
es el límite
del cocienterealizados,
entre el número de veces que ocurre
ocurre dicho de
suceso
y el número
de experimentos
dicho suceso y el número de experimentos realizados,
#A
,
n →∞ n
P(A) = lim
donde #A es el número de veces que se realiza A en los n experimentos.
donde #A es el número de veces que se realiza A en los n experimentos.
14
Pastor-Barriuso R.
indefinidamente los registros anuales, el límite de estos cocientes 0,4850, 0,4845,
Concepto y definiciones
de probabilidad
0,4845, ... determinaría la probabilidad de ser mujer. En la práctica,
sin embargo,
•
no es posible realizar infinitos experimentos y las probabilidades teóricas se
Ejemplo 2.3 Supongamos que se desea conocer la probabilidad de ser mujer entre todos
estiman
mediante
empíricas
obtenidas
partir de Nacional
un número
los recién
nacidos probabilidades
vivos en España.
Según los
datos dela Instituto
definito
Estadística,
se registraron 226.170 niñas de 466.371 nacimientos en 2005, 233.773 de 482.957 en
de
experimentos.
utilizando
losLa
datos
disponibles
de nacimientos
en226.170/466.371
2005–
2006
y 238.632 deAsí,
492.527
en 2007.
proporción
acumulada
de niñas es
= 0,4850 en 2005, 459.943/949.328 = 0,4845 en 2005-2006 y 698.575/1.441.855 = 0,4845
2007,
se estimaría
una probabilidad
de ser mujerlosderegistros
0,4845. anuales, el límite de estos
en 2005-2007.
Aumentando
indefinidamente
cocientes 0,4850, 0,4845, 0,4845, ... determinaría la probabilidad de ser mujer. En la
práctica, sin embargo, no es posible realizar infinitos experimentos y las probabilidades
Definición
(Kolmogorov).
La probabilidad
una función
quede
asigna
teóricas se axiomática
estiman mediante
probabilidades
empíricas es
obtenidas
a partir
un número
finito de experimentos. Así, utilizando los datos disponibles de nacimientos en 2005‑2007,
asecada
posible
suceso
de un experimento
numérico, de tal forma que se
estimaría
una
probabilidad
de ser mujerundevalor
0,4845.
cumplan losaxiomática
siguientes axiomas:
yy Definición
(Kolmogorov). La probabilidad es una función que asigna a cada
posible suceso de un experimento un valor numérico, de tal forma que se cumplan los
(i) Noaxiomas:
negatividad: P(A) ≥ 0,
siguientes
(i)(ii)No
negatividad: P(
P(A)
Normatividad:
Ω) ≥= 0,
1,
(ii) Normatividad: P(W) = 1,
, ...son
sonsucesos
sucesosmutuamente
mutuamenteexcluyentes,
excluyentes,entonces
entonces
Aditividad:SiSiAA, 1A, A, 2...
(iii)(iii)Aditividad:
1
2
∞
axiomática se derivan
de
∞ algunas propiedades importantes de la función
P Ai = P( A1 ∪ A2 ∪ ...) = P( A1 ) + P( A2 ) + ... = P( Ai ) .
axiomática se derivan
algunas propiedades importantes de la función
de
i =1
probabilidad: i =1
Notar que esta definición de probabilidad tan sólo especifica las propiedades generales
probabilidad:
∅
) tener
=esta
0, una
- P(
Notar
que
definición
probabilidad tan
especifica
las propiedades
que
debe
función de probabilidad,
perosólo
no permite
la asignación
de probabilidades
a- un
suceso
) = 0, concreto. No obstante, de la definición axiomática se derivan algunas
P(∅
1importantes
- debe
P(A),tener de
- P(Ac) =que
generales
unalafunción
propiedades
funciónde
deprobabilidad,
probabilidad:pero no permite la
c
) = 1=-0,P(A),
- P(AP(∅)
(iv)
asignación
probabilidades
a un
concreto.
No obstante, de la definición
B, suceso
entonces
P(A) ≤ P(B),
- Si A estádeincluido
en B, A ⊂
c
P(A
) =incluido
1 – P(A),
-(v)Si A
está
en B, A ⊂ B, entonces P(A) ≤ P(B),
- 0 ≤ P(A) ≤ 1,
(vi) Si A está incluido en B, A ⊂ B, entonces P(A) ≤ P(B),
- 0 ≤ P(A) ≤ 1,
- Sub-aditividad:
(vii)
0 ≤ P(A) ≤ 1, Para cualquier colección de sucesos A1, A2, ...,
4
- Sub-aditividad: Para cualquier colección de sucesos A1, A2, ...,
(viii) Sub-aditividad: Para cualquier
colección
de
sucesos
A
,
A
,
...,
1
2
∞
∞
P Ai ≤ P( Ai ) ,
i∞=1 i∞=1
P Ai ≤ P( Ai ) ,
i =1 i =1
, ...,
AkAsucesos
cualesquiera,
- Principio
de de
inclusión-exclusión:
Sean
A1,AA,2A
(ix)
Principio
inclusión-exclusión:
Sean
, ...,
sucesos
cualesquiera,
1
2
k
- Principio de inclusión-exclusión: Sean A1, A2, ..., Ak sucesos cualesquiera,
k
k
P Ai = P ( Ai ) − P( Ai ∩ A j ) + ...
ik=1 ik=1
1≤ i < j ≤ k
P Ai = P(k A
) − P( Ai ∩ A j ) + ...
+1i
k 2 ∩ ... ∩ Ak ).
i =1 + i(=−1 1) P( A1≤1 i <∩j ≤A
+ (−1) k +1 P( A1 ∩ A2 ∩ ... ∩ Ak ).
Del tercer axioma de la probabilidad se deduce que, si dos sucesos son mutuamente
Del tercer axioma
de la probabilidad
se deduce
dossus
sucesos
son mutuamente
excluyentes,
la probabilidad
de la unión
es la que,
sumasi de
probabilidades
por separado. El
Del
tercer de
axioma
de la probabilidad
se deduceeste
que,resultado
si dos sucesos
son mutuamente
principio
inclusión-exclusión
generaliza
para sucesos
no necesariamente
excluyentes, la probabilidad de la unión es la suma de sus probabilidades por separado.
excluyentes, la probabilidad de la unión es la suma de sus probabilidades por separado.
El principio de inclusión-exclusión generaliza este resultado para sucesos no
Pastor-Barriuso R.
El principio de inclusión-exclusión generaliza este resultado para sucesos no
necesariamente excluyentes: la probabilidad de la unión de dos sucesos cualesquiera es
15
El principio de
inclusión-exclusión
generaliza
este resultado
para sucesospor
no separado.
excluyentes,
la probabilidad
de la unión
es la suma
de sus probabilidades
necesariamente
excluyentes: la probabilidad
la unión
de dos
sucesos
cualesquiera
El
principio de inclusión-exclusión
generalizadeeste
resultado
para
sucesos
no
Probabilidad
es
Ejemplo 2.4 Supongamos que la probabilidad de ser bebedor en una determinada
la suma de sus probabilidades
separado, menos
la probabilidad
de lacualesquiera
intersección,es
necesariamente
excluyentes: lapor
probabilidad
de la unión
de dos sucesos
población de adultos es 0,20, la probabilidad de ser diabético es 0,03 y la
excluyentes: la probabilidad de la unión de dos sucesos cualesquiera es la suma de sus
la suma de sus probabilidades
separado,
probabilidad
de la intersección,
∪B)
= P(A) +menos
P(B)de-la
P(A
∩B).
P(Apor
probabilidades
por separado,
menos
la probabilidad
intersección,
probabilidad
de ser simultáneamente
bebedor
yladiabético
es 0,01. Si se denota por
- P(A∩B).
P(Aya∪por
B) D
= P(A)
+con
P(B)
B al suceso
ser aplicarse
bebedor
al suceso
ser
diabético,
la probabilidad
que un
Este principio
puede
colecciones
más
de dos sucesos.
Así, por de
ejemplo,
Este principio puede aplicarse a colecciones con más de dos sucesos. Así, por ejemplo, para tres
individuo
decualesquiera,
esta población
sea bebedor,
o ambos
a laAsí,
vez por
viene
para principio
tres
sucesos
cumple
quecondiabético
Este
puede
asecolecciones
más de dos
sucesos.
ejemplo,
sucesos
cualesquiera,
se aplicarse
cumple que
Ejemplo 2.4 Supongamos que la probabilidad de ser bebedor en una determinada
determinada
por
para tres
sucesos cualesquiera,
C)cumple
= P(A) que
+ P(B) + P(C)
P(A∪B∪se
población de adultos es 0,20, la probabilidad de ser diabético es 0,03 y la
- P(A∩B) - P(A∩C) - P(B∩C)
∩D)+ =P(C)
0,20 + 0,03 - 0,01 = 0,22.
P(B∪D)
B∪C)+ =P(D)
P(A)- P(B
+ P(B)
P(A=∪P(B)
probabilidad de ser simultáneamente
bebedor
y
diabético
es 0,01. Si se denota por
+ P(A∩B∩C).
- P(A∩B) - P(A∩C) - P(B∩C)
B al suceso ser bebedor y por D al suceso ser diabético, la probabilidad de que un
Ejemplo 2.4 Supongamos que la probabilidad de ser bebedor en una determinada
2.3población
PROBABILIDAD
CONDICIONAL
E INDEPENDENCIA
DE SUCESOS
de adultos
0,20, lasea
probabilidad
de ser diabético
y la probabilidad5 de
+ P(A
∩B∩diabético
C).
individuo
de esta es
población
bebedor,
o ambos aesla0,03
vez viene
ser simultáneamente bebedor y diabético es 0,01. Si se denota por B al suceso ser bebedor
La yprobabilidad
de un
puede
de laderealización
de otrode
suceso.
Así, por sea
pordeterminada
D al suceso
sersuceso
diabético,
la depender
probabilidad
que un individuo
esta población
por
5
bebedor, diabético o ambos a la vez viene determinada por
ejemplo, la probabilidad de tener un infarto
de miocardio es diferente
en los hombres
-
P(B∪D) = P(B) + P(D)
P(B∩D) = 0,20 + 0,03
0,01 = 0,22.
que en las mujeres; es decir, la probabilidad del suceso tener un infarto de miocardio
del suceso serCONDICIONAL
hombre
o ser mujer.
El concepto matemático
que
permite
2.3depende
PROBABILIDAD
EE INDEPENDENCIA
DESUCESOS
SUCESOS
2.3
PROBABILIDAD
CONDICIONAL
INDEPENDENCIA
DE
La probabilidad
de un
suceso
puede
depender de de
la realización
defunción
otro suceso.
Así,espor
ejemplo,
formalizar
cómo
se
modifica
la
probabilidad
unrealización
suceso en
de otro
la
La
probabilidad
de
un
suceso
puede
depender
de
la
de
otro
suceso.
Así,
por
la probabilidad de tener un infarto de miocardio es diferente en los hombres que en las mujeres;
es decir,
la probabilidad
del suceso
tener un
de miocardio
depende
del suceso ser hombre
probabilidad
condicional.
Entener
general,
lainfarto
probabilidad
delessuceso
B condicionada
ejemplo, la probabilidad
de
un infarto
de miocardio
diferente
en los hombresal
o ser mujer. El concepto matemático que permite formalizar cómo se modifica la probabilidad
de un
suceso
enmujeres;
función
otro la
esprobabilidad
la probabilidad
condicional.
general,
la probabilidad del
suceso
se
define
como
que
enAlas
esdedecir,
del suceso
tener unEninfarto
de miocardio
suceso B condicionada al suceso A se define como
depende del suceso ser hombre o ser mujer. El
P(concepto
A ∩ B) matemático que permite
P(B|A) =
.
( Asuceso
)
formalizar cómo se modifica la probabilidad dePun
en función de otro es la
De forma intuitiva, condicionar por el suceso A es equivalente a seleccionar por este suceso.
probabilidad condicional. En general, la probabilidad del suceso B condicionada al
Así,DeP(infarto|hombre)
es equivalente
a seleccionar
en primer
lugar a los
y
forma intuitiva, condicionar
por el suceso
A es equivalente
a seleccionar
porhombres
este
posteriormente
determinar
su
probabilidad
de
tener
un
infarto
de
miocardio.
suceso A se define como
es el riesgo arelativo
de la en
enfermedad
entre
los
no suceso.
expuestos
y RR
= P(D|E)/P(D|Eesc) equivalente
Así,
P(infarto|hombre)
seleccionar
primer lugar
a los
El concepto
de
probabilidad condicional
tiene numerosas
aplicaciones
en epidemiología
y
salud pública. Por ejemplo, si D es el sucesoP(tener
y E es el suceso estar
A ∩ Buna
) deenfermedad
expuestos
y ylosposteriormente
no expuestos.
hombres
probabilidad
tener
un infartoentre
de miocardio.
. de la
P(B|A)
expuesto
a un
factor de riesgo,determinar
P(D|E)
es su
la =probabilidad
enfermedad
los expuestos,
P
(
A
)
c
P(D|E ) es la probabilidad de la enfermedad entre los no expuestos y ψ = P(D|E)/P(D|Ec) es el
El
concepto
deenfermedad
probabilidad
condicional
tiene ynumerosas
aplicaciones en
riesgoEjemplo
relativo
de
entre
expuestos
loslanoprobabilidad
expuestos.
2.5laContinuando
con
ellos
ejemplo
anterior,
de que un
De forma intuitiva, condicionar por el suceso A es equivalente a seleccionar por este
epidemiología y salud pública. Por ejemplo, si D es el suceso tener una enfermedad y E
Ejemplo
2.5 diabético
Continuando
con como
el ejemplo anterior, la probabilidad de que un bebedor
bebedor
sea
se calcula
suceso.
Así,
P(infarto|hombre)
sea diabético
se calcula comoes equivalente a seleccionar en primer lugar a los
es el suceso estar expuesto a un factor de riesgo, P(D|E) es la probabilidad de la
hombres y posteriormente determinarPsu( Bprobabilidad
de tener un infarto de miocardio.
∩ D) 0,01
c
= 0,05
P(D|B)
=
=
de la enfermedad entre los
enfermedad entre los expuestos, P(D|E ) es la probabilidad
P( B)
0,20
El concepto de probabilidad condicional tiene numerosas aplicaciones en
6
epidemiología
y salud
Porbebedor
ejemplo,sea
si Ddiabético
es el suceso
tener una enfermedad y E
y la probabilidad
de pública.
que un no
como
16
es el suceso
Pastor-Barriuso
R.
estar expuesto a un factor de riesgo, P(D|E) es la probabilidad de la
P( B c ∩ D) P( D) − P( B ∩ D) 0,03 − 0,01
c
)
=
= 0,025.
P(D|B
= c
= de la enfermedad
entre los
enfermedad entre los expuestos,
1 −laPprobabilidad
( B)
1 − 0,20
P( B c ) P(D|E ) es
Así, el riesgo de diabetes es el doble en los bebedores que en los no bebedores,
P( B ∩ D) 0,01
PP(D|B)
(B c ∩ D
0,03 − 0,01
= ) P( D) − P
= ( B ∩ D=)0,05
c
c=
)
= 0,025.
==P2.( B)
=
P(D|B
0,20Probabilidad
c
RR = P(D|B)/P(D|B ) = 0,05/0,025
1 − P( B)
1condicional
− 0,20 e independencia de sucesos
P( B )
la probabilidad
de que
no bebedor seasidiabético
comode uno no afecta a la
Se ydice
queeldos
sucesos
sonun
independientes
la bebedores
ocurrencia
Así,
riesgo
de diabetes
es el doble en los
que en los no bebedores,
y la probabilidad de que un no bebedor sea diabético como
c A y B son independientes si P(B|A) = P(B|Ac) = P(B) o,
probabilidad
otro;
es decir,
RR =del
P(D|B)/P(D|B
P( B )c =
∩0,05/0,025
D) P( D)=−2.P( B ∩ D) 0,03 − 0,01
c
P(D|B ) =
= 0,025.
=
=
c
1 − P( B)
1 − 0,20
P( B )
c
de forma equivalente, si P(A|B) = P(A|B ) = P(A). En consecuencia, si dos sucesos son
Se dice
que dos
independientes
si la ocurrencia
unoennolos
afecta
a la
Así,
el riesgo
desucesos
diabetesson
es el
doble en los sujetos
bebedoresdeque
no bebedores,
c
independientes,
puede
probarse
que
Así,
el riesgo
de diabetes
es
el doble
ψ = P(D|B)/P(D|B
) = 0,05/0,025
= 2.en los bebedores que en los no bebedores,
probabilidad del otro; es decir, A y B son independientes si P(B|A) = P(B|Ac) = P(B) o,
RR = P(D|B)/P(D|Bc) = 0,05/0,025 = 2.
P(A∩B)
= P(A)P(B|A)
P(A)P(B).de uno no afecta a la probabilidad
Se dice que dos sucesos son
independientes
si la=ocurrencia
si dos sucesos son
de forma equivalente, si P(A|B) = P(A|Bc) = P(A). En consecuencia,
del otro; es decir, A y B son independientes si P(B|A) = P(B|Ac) = P(B) o, de forma equivalente,
c riesgo relativo es distinto de la unidad, RR = 2 ≠ 1. Esta dependencia
es=que
decir,
= P(A). son
En consecuencia,
si doslasucesos
son independientes,
puede
si P(A|B)
P(A|B
dice
dosel)sucesos
independientes
ocurrencia
de unosinolaafecta
a la probarse
PorSe
tanto,
dos sucesos
también
pueden
independientes
probabilidad
independientes,
puede
probarse
que definirse sicomo
que
c
se refleja
también
en elAhecho
de que la probabilidad
de ser= simultáneamente
P(B) o,
probabilidad
del otro;
es decir,
y B son
P(B|A
de su intersección
es igual
al producto
de independientes
la probabilidad sideP(B|A)
cada suceso
por) =
separado.
P(A∩B) = P(A)P(B|A) = P(A)P(B).
c
bebedor y diabético
no =
esP(A|B
el producto
de sus
) = P(A).
En probabilidades,
consecuencia,
si dos
son de su
de
P(A|B)
Porforma
tanto,equivalente,
dos sucesossitambién
pueden
definirse
como
independientes
si lasucesos
probabilidad
Ejemplo
2.6
A
partir
de
los
resultados
del
ejemplo
anterior,
puede
concluirse
que
Por
tanto,
dos
sucesos
también
pueden
definirse
como
independientes
si
la
probabilidad
intersección
es igual
al producto
de es
la probabilidad
cada suceso
es decir,
el riesgo
relativo
distinto de la de
unidad,
RR = 2 por
≠ 1.separado.
Esta dependencia
independientes, puede probarse
que = 0,01 ≠ 0,20⋅0,03 = P(B)P(D).
P(B∩D)
los
sucesos
padecer
diabetes
y serde
bebedor
no
son independientes
dadopor
queseparado.
la
de Ejemplo
su intersección
es
igual
al
de
probabilidad
dedecada
se refleja
el producto
hecho
quelala
probabilidad
ser suceso
simultáneamente
2.6 también
A partirende
los
resultados
del
ejemplo anterior,
puede concluirse
que los
sucesos padecer diabetes
y ser= bebedor
no son
independientes dado que la probabilidad
P(A∩B)
P(A)P(B|A)
= P(A)P(B).
probabilidad
de
ser diabético
esintersección
diferente ende
bebedores
que en no bebedores,
Notar
que
lael
la
dos
bebedor
yprobabilidad
diabético
node
esen
el
producto
probabilidades,
es
decir,
riesgo
relativo
es
distinto dede
lasus
unidad,
RR = 2cualesquiera
≠ 1. Esta dependencia
de ser
diabético
es diferente
bebedores
que
en
nosucesos
bebedores,
Ejemplo 2.6 A partir de los resultados del ejemplo anterior, puede concluirse que
es decir,
el riesgotambién
relativopueden
es distinto
de la como
unidad,
RR =c2 ≠ 1. Esta
Por tanto,
dos sucesos
definirse
independientes
si ladependencia
probabilidad
P(D|B)
=
0,05
≠
0,025
=
P(D|B
);
se refleja también en el
hecho
de
que
la
probabilidad
de
ser
simultáneamente
P(A∩B)
=
P(A)P(B|A)
P(B∩D)y=ser
0,01
≠ 0,20⋅0,03
P(B)P(D).
los sucesos padecer diabetes
bebedor
no son=independientes
dado que la
se
refleja
también
en
el
hecho
de
que
la
probabilidad
de
ser
simultáneamente
de su intersección
es igual
al producto
de lade
probabilidad
por separado.se refleja
es decir,
el riesgo
relativo
ladeunidad,
ψde= cada
2 ≠ 1.suceso
Esta dependencia
bebedor
y diabético
no es
es distinto
el producto
sus probabilidades,
probabilidad
de
ser
diabético
es
diferente
en
bebedores
que
en
no
bebedores,
no equivale
al producto
ambos sucesosbebedor
sean y diabético
también en
el hecho de sus
que probabilidades,
la probabilidad salvo
de serque
simultáneamente
bebedor
y diabético
no es el
producto
de sus de
probabilidades,
Notar
que
la
probabilidad
de
la
intersección
dos
sucesos
cualesquiera
no es el producto de sus probabilidades,
7
Ejemplo 2.6 A
de P(B∩D)
los
resultados
ejemplodeanterior,
= 0,01del
≠ 0,20⋅0,03
=
P(B)P(D).
independientes.
Enpartir
general,
para
cualquier
conjunto
sucesos
A1, A2,concluirse
..., Ak, la que
c puede
P(D|B) = 0,05 ≠ 0,025 = P(D|B );
P(B∩D) =P(A∩B)
0,01 ≠ 0,20⋅0,03
= P(B)P(D).
= P(A)P(B|A)
los sucesosdepadecer
diabetes es
y ser bebedor no son independientes dado que la
probabilidad
su intersección
Notar que la probabilidad de la intersección de dos sucesos cualesquiera
Notar
que la al
probabilidad
la probabilidades,
intersección
sucesos
cualesquiera
noprobabilidad
equivale
producto
dede
salvo
que ambos
sean
de ser diabético
es diferente de
en dos
bebedores
que
ensucesos
no bebedores,
Notar
que
probabilidad
desus
la intersección
de
dos
sucesos
cualesquiera
7
∩A
∩...∩A
)
=
P(A
)P(A
∩...∩A
|A
)
P(Ala
1
2
k
1
2
k 1
P(A)P(B|A)
independientes. En general, para P(A∩B)
cualquier= conjunto
de sucesos A1, A2, ..., Ak, la
= 0,05
≠ 0,025
= P(D|Bc);
P(A∩B)
=1)P(A
P(A)P(B|A)
= P(D|B)
P(A
1)P(A2|A
3∩...∩Ak|A1∩A2) = ...
no equivale al producto de sus probabilidades, salvo que ambos sucesos sean independientes. En
probabilidad
su intersección
es
no
equivale
alde
producto
de susde
probabilidades,
ambos sucesos sean
general,
para cualquier
conjunto
sucesos A1, A2salvo
, ..., Aque
k, la probabilidad de su intersección es
)P(A
|A
)P(A
|A
∩A
)⋅…⋅P(A
∩...∩Ak-1).
=
P(A
1
2
1
3
1
2
k|A1∩A2sean
no equivale al producto de sus probabilidades, salvo que ambos sucesos
independientes.
general,
para cualquier conjunto de sucesos A1, A2, ..., Ak, la
7
P(A1∩A2En
∩...∩A
k) = P(A1)P(A2∩...∩Ak|A1)
independientes.
En
general,
para
cualquier
conjunto
de
sucesos
A
,
A
,
...,
A
,
la
1
2
k
En el caso de que estos sucesos sean mutuamente independientes, las probabilidades
= P(Aes
probabilidad de su intersección
1)P(A2|A1)P(A3∩...∩Ak|A1∩A2) = ...
probabilidad
de su
es )P(A
condicionales
deintersección
la fórmula= anterior
se2|A
reducen
a probabilidades no condicionales y, en
P(A
1
1)P(A3|A1∩A2)⋅…⋅P(Ak|A1∩A2∩...∩Ak 1).
P(A1∩A2∩...∩Ak) = P(A1)P(A2∩...∩Ak|A1)
la
probabilidad
de la sean
intersección
es igualindependientes,
al producto de sus
Enconsecuencia,
el P(A
caso–1∩A
de2∩...∩A
que
estos
sucesos
mutuamente
las probabilidades
k) = P(A
1)P(A2∩...∩A
k|A1)
P(A )P(Ase
condicionales de la fórmula= anterior
a probabilidades
2|Areducen
1)P(A3∩...∩A
k|A1∩A2) = ... no condicionales y, en
En el caso de que estos sucesos 1sean mutuamente
independientes,
las probabilidades
probabilidades,
consecuencia,
la probabilidad
de
la
intersección
es
igual
al
producto
de sus probabilidades,
= P(A1)P(A2|A1)P(A3∩...∩Ak|A1∩A
2) = ...
= P(A
1)P(A2|A1)P(A3|A1∩A2)⋅…⋅P(Ak|A1∩A2∩...∩Ak-1).
condicionales de la fórmula
anterior
se reducen a probabilidades no condicionales y, en
k
k
= P(A1)P(A2|A1)P(A3|A1∩A2)⋅…⋅P(Ak|A1∩A2∩...∩A
k-1).
P Ai = P(A1∩A2∩...∩Ak) = P(A1)P(A2)⋅…⋅P(Ak) = ∏ P( Ai ) .
consecuencia,
la intersección
igual al producto
sus
En
el caso de que
estos
mutuamenteesindependientes,
las
probabilidades
i =1de
i =la
1 probabilidad
sucesosdesean
–
En el caso de que estos sucesos sean mutuamente independientes, las probabilidades
probabilidades,
condicionales
de la fórmula anterior se reducen a probabilidades no condicionales y, en
condicionales
la fórmula
anterior se reducen
a probabilidades no condicionales y, en
2.4 REGLAdeDE
LA PROBABILIDAD
TOTAL
consecuencia, lak probabilidad de la intersección es igual al producto de
sus Pastor-Barriuso R.
k
Pprobabilidad
Ai = P(Ade
∩...∩Ak) = P(A
)P(A2al)⋅…⋅P(A
1∩A
k) =
consecuencia, la
la2intersección
es 1igual
producto
de∏
susP( Ai ) .
i =1
i
=
1
La
probabilidad no condicional
de un suceso B se relaciona con su probabilidad
probabilidades,
17
i =1
i =1
espacio muestral; es decir, A y Ac son sucesos exhaustivos A∪Ac = Ω y mutuamente
Probabilidad
excluyentes A∩Ac = ∅.
2.4 REGLA DE LA PROBABILIDAD TOTAL
Así,
probabilidad
condicional
de B esAla
media
ponderada
de lasexhaustivos
probabilidades
y
En la
general,
para unnoconjunto
de sucesos
1, A
2, ..., A
k globalmente
2.4LaREGLA
DE
LA
PROBABILIDAD
TOTAL
probabilidad no condicional de un suceso B se relaciona con su probabilidad
descomposición
de la probabilidad
sucesoque
B en
condicionales
de B dadoque
A yformen
Ac. Estauna
partición
del espacio
muestral,
sedel
verifica
Lamutuamente
probabilidadexcluyentes
no condicional
de un suceso
B se relaciona
con su
probabilidad
condicionada
condicionada en la ocurrencia o no de otro suceso A mediante la fórmula
en la ocurrencia o nocde otro suceso A mediante la fórmula
constituyen una partición del
términos de A y A es aplicablek porque estos sucesos
k
( Ai c∩
B) == P(A)P(B|A)
P( Ai ) P( B
Ai )c,)P(B|Ac).
= +PP(A
P(B) =P(B)
P(A∩B)
∩B)
+ |P(A
c
i
i
=
1
=
1
espacio muestral; es decir, A y A son sucesos exhaustivos A∪Ac = Ω y mutuamente
Así, la probabilidad no condicional de B es la media ponderada de las probabilidades
c
c
8
= de
∅.
excluyentes
. Esta descomposición
la probabilidad
del sucesoútil
B enentérminos
condicionales
deA∩A
Bregla
dado
A ylaAprobabilidad
conocida
como
total. Esta de
fórmula
es particularmente
c
de A y A es aplicable porque estos sucesos constituyen una partición del espacio muestral; es
c
c
Ak globalmente
exhaustivos
y
En
para un
conjunto
sucesos
A∪A
= WA1y, A
mutuamente
excluyentes
A∩Aal
=dividir
∅.
decir,
A ygeneral,
Ac son sucesos
2, ...,
epidemiología,
donde
seexhaustivos
emplean de
con
frecuencia
las
particiones.
Por ejemplo,
En general, para un conjunto de sucesos A1, A2, ..., Ak globalmente exhaustivos y mutuamente
mutuamente
excluyentes
que formen
unaestán
partición
del espacio
muestral,
se verifica que
la
población
gruposuna
de edad
y sexo
empleando
categorías
globalmente
excluyentes
queenformen
partición
delseespacio
muestral, se
verifica que
exhaustivas y mutuamente excluyentes.
En general,
siempre que se divide la población
k
k
P(B) = P( Ai ∩ B) = P( Ai ) P( B | Ai ) ,
i =1
i =1
en estratos se aplica una partición
a esa población.
conocida como regla de la probabilidad total. Esta fórmula es particularmente útil en
conocida como
reglasedeemplean
la probabilidad
total. Esta
es particularmente
en
epidemiología,
donde
con frecuencia
lasfórmula
particiones.
Por ejemplo, útil
al dividir
la
Ejemplo
2.7
En
una
población
de
mayores
de
65
años,
los
individuos
con
edades
población en grupos de edad y sexo se están empleando categorías globalmente exhaustivas y
epidemiología,
donde se
frecuencia
particiones.
Por ejemplo,
al dividir
mutuamente
excluyentes.
Enemplean
general,con
siempre
que selasdivide
la población
en estratos
se aplica
entre
65–74,
75–84
y
≥
85
años
constituyen
el
60,
30
y
10%
de
la
población.
La
una partición a esa población.
la población en grupos de edad y sexo se están empleando categorías globalmente
prevalencia de la enfermedad de Alzheimer en estos grupos de edad es
Ejemplo 2.7 En una población de mayores de 65 años, los individuos con edades entre
exhaustivas
y mutuamente
general,
siempre
se divideLa
la prevalencia
población de
65-74, 75-84
y ≥ 85 añosexcluyentes.
constituyen En
el 60,
30 y 10%
de laque
población.
respectivamente de 20, 75 y 300 casos por 1000. La prevalencia global de la
la enfermedad de Alzheimer en estos grupos de edad es respectivamente de 20, 75 y 300
en casos
estratos
aplicaLa
una
partición aglobal
esa población.
porse1000.
prevalencia
de la enfermedad de Alzheimer en esta población
enfermedad de Alzheimer en esta población de mayores de 65 años se calcularía
de mayores de 65 años se calcularía
Ejemplo 2.7 En una3población de mayores de 65 años, los individuos con edades
P(A) = P( E i ) P( A | E i )
entre 65–74, 75–84i =y1 ≥ 85 años constituyen el 60, 30 y 10% de la población. La
2.5 TEOREMA DE BAYES
= 0,60⋅0,020 + 0,30⋅0,075 + 0,10⋅0,300 = 0,0645,
prevalencia de la enfermedad de Alzheimer en estos grupos de edad es
resultando 64,5 casos por 1000 personas.
El teorema de Bayes permite obtener la probabilidad condicional de A dado B a partir
respectivamente
de 20,
y 300
casos por 1000. La prevalencia global de la
resultando
64,5 casos
por75
1000
personas.
de la probabilidad de A y de las probabilidades condicionales inversas de B dado A y Ac.
2.5 TEOREMA
DEdeBAYES
enfermedad
Alzheimer en esta población de mayores de 65 años se calcularía
Aplicando
definición
de probabilidad
condicionalcondicional
y la regla dedelaAprobabilidad
total,de la
El teorema
delaBayes
permite
obtener la probabilidad
dado B a partir
3
c
probabilidad de A y de las probabilidades condicionales inversas de B dado A y A . Aplicando
9
P(A) = P( E i ) P( A | E i )
se obtienede
queprobabilidad
la definición
condicional
y la regla de la probabilidad total, se obtiene que
i =1
P( A ∩ B) 0,30⋅0,075P(+A0,10⋅0,300
) P( B | A) = 0,0645,
P(A|B) == 0,60⋅0,020 +
.
=
P( B)
P( A) P( B | A) + P( A c ) P( B | A c )
resultando
64,5secasos
porfrecuencia
1000 personas.
El teorema
de Bayes
usa con
en la evaluación de pruebas diagnósticas. Cuando
El teorema
Bayesdiagnóstica
se usa con yfrecuencia
en lasus
evaluación
de con
pruebas
diagnósticas.
se desarrolla
una de
prueba
se comparan
resultados
los de
un patrón oro
(método de referencia en el diagnóstico de la enfermedad), suelen determinarse los siguientes
Cuando se
desarrolla una propias
prueba diagnóstica
se comparan sus resultados con los de un
parámetros
o características
de la pruebaydiagnóstica:
18
patrón oro (método de referencia en el diagnóstico de la enfermedad), suelen
Pastor-Barriuso R.
determinarse los siguientes parámetros o características propias de la prueba
9
Teorema de Bayes
yy Sensibilidad es la probabilidad de obtener un resultado positivo de la prueba diagnóstica
P( D) PS(+=| P(+|D).
D)
PS
entreVP
los
enfermos,
+ =sujetos
+) =
=
,
P ( D | realmente
c
c
P( D) P(+ | D) + P( D ) P(+ | D ) PS + (1 − P)(1 − E )
yy Especificidad es la probabilidad
entre los sujetos
| D) un resultado negativo
P( D)de
P(+obtener
PS
+
=
+
=
=
,
(
|
)
VP
P
D
c
c
c
realmente sanos, E = P(–|D
P( D) P).(+ | D) + P( D ) P(+ | D ) PS + (1 − P)(1 − E )
En la aplicación clínica de una pruebaPdiagnóstica
( D c ) P(− | Dac una
) determinada población
(1 − P ) E interesa conocer,
c
= Psiguientes
( D | −) = parámetros:
=
.
VP − los
sin embargo,
c
c
+ (1 − P) E
P( D) P (−P| (DDc))+P(P+( D
| D)c P(− | D ) P(1 − S )PS
( D ) P(− | D de
) tener la =
(1 − Pentre
) E las personas
,
)=
VP + = P ( Dc | +positivo
yy Valor
laPprobabilidad
enfermedad
que
= P( D | −) = P( Des
VP −predictivo
+ (1 − P)(1 − E ) .
) P(+ | D) + P( D cc ) P(+ | D cc ) = PS
(
1
)
(
1
)
−
+
−
P
S
P
E
(
)
(
|
)
(
)
(
|
)
−
+
−
P
D
P
D
P
D
P
D
tienen un resultado positivo, VP+ = P(D|+).
P( D) P(+ | D)
PS
yy Valor
negativo
es de
la probabilidad
de nopara
tener
+ =2.8
= la enfermedad entre,las personas
)=
VPpredictivo
P( D
Ejemplo
La| +sensibilidad
la prueba ELISA
c
c detectar seropositividad
) + P( D
) Pc (+ | D ) PS + (1 − P)(1 − E )
P(negativo,
D) P(+ | DVP–
que tienen un resultado
(−P(D
| D c |–).
)
(1 − P ) E
P ( D c ) P=
c
|sensibilidad
−inmunodeficiencia
)=
= y su especificidad
VP −al=virus
P( D
Ejemplo
2.8
La
de
la
prueba
ELISA
para
seropositividad
c es del
c detectar
frente
de
humana
99%
es. del de la
Aplicando el teorema de Bayes,
los| Dvalores
función
− S ) + (1 − en
P) E
(− | D) +calcularse
) P(1predictivos
P( D) Ppueden
P( D ) P(−
prevalencia de la enfermedad en la población
y de la sensibilidad y especificidad de la prueba
c
)P
(− | D c de
)es infección
− P ) Ede es del
P( D
frente
al
virus
humana
del 99% ypor
su especificidad
cde inmunodeficiencia
96%.
En
una
población
con
una
prevalencia
el(1virus
diagnóstica,
=
.
VP − = P( D | −) =
c
c
P( D) P (− | D) + P( D ) P(− | D ) P(1 − S ) + (1 − P) E
Ejemplo
2.8 La
sensibilidad
de0,3%,
la
para
detectar
96%.
En una
población
con del
una
prevalencia
por
elseropositividad
virus
P
(prueba
D) Púnicamente
(+ |ELISA
Dde
) infección
PS de con un
inmunodeficiencia
el 6,9%
de las
personas
VP + = P ( D | + )humana
=
=
,
P( D) P(+ | D) + P( D c ) P(+ | D c ) PS + (1 − P)(1 − E )
frente al virus
de inmunodeficiencia
humana
es del
sulas
especificidad
es un
del
inmunodeficiencia
humana
del 0,3%,
únicamente
el 99%
6,9%yde
personas con
resultado
positivo
del
test ELISA
estarán
realmente
infectadas,
Ejemplo 2.8 La sensibilidad de la prueba
ELISA
para
detectar
seropositividad
P ( D c ) P(− | D c )
(1 − P ) E
c
.
VPEn
− =una
P( D
| −del
) =test
= por el virus de
96%.
población
con
una prevalencia
de infección
resultado
positivo
ELISA
estarán realmente
infectadas,
c
c
− S ) + (1 − P)es
E del
0P,003
⋅ 0,)99y Psu(1especificidad
P(PS
D) P (− | D)humana
+ P( D )es
(del
−| D
frente al virus de inmunodeficiencia
99%
VP+ =
=
= 0,069,
PShumana
+ (1 − Pdel
)(1 −0,3%,
E ) únicamente
0,003 ⋅ 0,99 el
+ 06,9%
,997 ⋅de
0,04
inmunodeficiencia
las personas con un
PS una prevalencia de
0,003
⋅ 0,99 por el virus de
96%. En una
con
infección
VP+población
=
=
= 0,069,
Ejemplo 2.8 LaPS
sensibilidad
ELISA
detectar
+ test
(1 − ELISA
P)(1de
− Elaestarán
) prueba
0,003
⋅ 0,99 +para
0infectadas,
,997
⋅ 0,04 seropositividad frente al
resultado positivo del
realmente
virus
de inmunodeficiencia
humana
del 99%
su
especificidad
esestarán
delcon
96%.
mientras
que prácticamente
todas
las es
personas
conyelresultado
inmunodeficiencia
humana del
0,3%,
únicamente
6,9%
de negativo
las personas
un En una
Ejemplo
2.8
La
sensibilidad
de
la
prueba
ELISA
para
detectar
seropositividad
población con una prevalencia de infección por el virus de inmunodeficiencia humana del
mientras
que
prácticamente
todas
las
personas
resultado
negativo
0con
,003
⋅infectadas,
0,99 positivo
0,3%,
únicamente
el
de
las personas
con
un
resultado
del estarán
test ELISA estarán
libres de
la
infección,
resultado
positivo
del6,9%
testPS
ELISA
estarán
realmente
VP+
=
=
=
0,069, es del
frente
al
virus
de
inmunodeficiencia
humana
es
del
99%
y
su
especificidad
realmente infectadas,
PS + (1 − P)(1 − E ) 0,003 ⋅ 0,99 + 0,997 ⋅ 0,04
libres de la infección,
(1 −PS
P) Euna prevalencia 00de
,,997
⋅⋅ 00,,99
96 por el virus de
003
96%. EnVPuna población
con
infección
=
=
= 1,000.
0,069,
VP+ ==
=
PPS
(1 −
−1 −P)EE
00,,003
⋅⋅ 00,,con
01 +
00,,997
⋅⋅ 00,,negativo
96
mientras que prácticamente
las
personas
resultado
estarán
+(1S(1)−−+PP()1todas
)(
)
003
99
+
997
04
E
0,997 ⋅ 0,96
inmunodeficiencia
humana del 0,3%,
VP- =
= únicamente el 6,9% de las=personas
1,000. con un
P(1 − S ) + (1todas
− P) las
E personas
0,003 ⋅ 0con
,01 +resultado
0,997 ⋅ 0,negativo
96
mientras
prácticamente
estarán libres de la
libres de que
la infección,
Sin
embargo,
en
una
población
de
alto
riesgo
con
una
prevalencia
del
virus
de
mientras
que
prácticamente
todas
las
personas
con
resultado
negativo
estarán
infección,
resultado positivo del test ELISA estarán realmente infectadas,
Sin
embargo,
en unahumana
población
de altoelriesgo
una
del virus de
(1 − Pdel
) E 10%,
0de
,997
⋅ 0sujetos
,prevalencia
96
inmunodeficiencia
73,3%con
los
con resultado
libres
de la
VPinfección,
=
=
−=
,003
,99 ⋅ 0,96 1,000.
P(1 − S ) +PS
(1 − P) E =0,003 ⋅ 0,001
+ 0⋅ ,0997
VP+
=
= 0,069,
inmunodeficiencia
humana
del
los+sujetos
positivo estarán realmente
PS
+ (1 −infectados,
P)(110%,
− E )el 73,3%
0,003 ⋅de
0,99
0,997 ⋅ con
0,04resultado
P) E
0,997 ⋅ con
0,96 una prevalencia del virus de
Sin embargo, en una(1 −población
de alto riesgo
VP- =
=
= 1,000.
inmunodeficiencia
el 073,3%
losuna
positivo
Sin embargo,
enrealmente
riesgo
con
prevalencia
del virus
de estarán
positivo
estarán
Puna
(1humana
−población
S ) + infectados,
(del
1 −10%,
Pde) Ealto
,003 ⋅ 0de
,01
+ sujetos
0,997
⋅ con
0,96resultado
PS
0
,
10
⋅
0
,
99
mientras infectados,
que prácticamente
todas las=personas con resultado negativo
realmente
VP+
=
= 0,733,estarán
+ (1 − del
P)(110%,
− E ) el 73,3%
0,10 ⋅ 0,de
99los
+ 0sujetos
,90 ⋅ 0,04
inmunodeficienciaPS
humana
con resultado
PS de alto riesgo con
0,10una
⋅ 0,99
Sin
embargo,
en=una población
prevalencia
del virus de
libres
de VP+
la infección,
=
= 0,733,
PS
+
(
1
−
P
)(
1
−
E
)
0
,
10
⋅
0
,
99
+
0
,
90
⋅
0
,
04
positivo estarán realmente infectados,
siendo muy improbable
la infección
aquellos
sujetos
con
resultado
negativo,
inmunodeficiencia
humana
del 10%,entre
el 73,3%
de los
sujetos
con
resultado
P) E
siendo muy improbable(1la−infección
entre aquellos
sujetos
0,997
⋅ 0,96 con resultado negativo,
VP=
= aquellos sujetos con resultado
= 1,000.
siendo
improbable
la) PS
infección
entre
negativo,
00,10
⋅+0,099
P
(
1
−
S
+
(
1
−
P
)
E
0
,
003
⋅
,
01
,
997
⋅
0
,
96
positivomuy
estarán
realmente
infectados,
(1 − P) E
0,90 ⋅ 0,96
VP+ =
=
= 0,733,
VP− = PS + (1 − P)(1 − E ) = 0,10 ⋅ 0,99 + 0,90 ⋅ 0,04 = 0,999.
P(1 − S ) + (1 − P) E 0,10 ⋅ 0,01 + 0,90 ⋅ 0,96
(1 −PS
P) E
0,,90
00,,96
10 ⋅⋅una
99prevalencia
Sin embargo,
en
de alto
del virus de
VP- == una población
== riesgo0con
== 0,999.
VP+
0,733,
P
(
1
−
S
)
+
(
1
−
P
)
E
0
,
10
⋅
0
,
01
+
0
,
90
⋅
0
,
96
siendo muy improbable
aquellos
PS + (1la−infección
P)(1 − E )entre
0,10
⋅ 0,99 +sujetos
0,90 ⋅ 0con
,04 resultado negativo,
inmunodeficiencia humana del 10%, el 73,3% de los sujetos con resultado
(1la−infección
P) E
0,90 ⋅ 0,96
Pastor-Barriuso
siendo
muy
improbable
entre
11 R.
positivo
estarán
infectados,
VP= realmente
= aquellos sujetos con resultado
= 0,999. negativo,
P(1 − S ) + (1 − P) E 0,10 ⋅ 0,01 + 0,90 ⋅ 0,96
11
(1 − P
)E
0,090
PS
,10⋅ 0⋅ ,096
,99
19
Como puede apreciarse, el valor predictivo positivo de esta prueba varía
Probabilidad
enormemente
función de
la prevalencia
la infección.
Como puede en
apreciarse,
el valor
predictivopoblacional
positivo dedeesta
prueba varía
enormemente en función de la prevalencia poblacional de la infección.
, A2, ..., Ak el
son
sucesos
globalmente
y mutuamente
EnComo
general,
si A1apreciarse,
puede
valor
predictivo
positivoexhaustivos
de esta prueba
varía enormemente en
función de la prevalencia poblacional de la infección.
excluyentes,
el teorema
generalizarse
como
, ...,Bayes
Ak sonpuede
sucesos
globalmente
exhaustivos y mutuamente
En general,
si A1, A2de
En general, si A1, A2, ..., Ak son sucesos globalmente exhaustivos y mutuamente excluyentes,
el teorema
degeneralizarse
BayesPpuede
generalizarse
( Ai ∩como
B)
P ( Ai )como
P( B | Ai )
elexcluyentes,
teorema de Bayes
puede
= k
P(Ai|B) =
.
P( B)
P( A ) P( B | A )
P( Ai ∩ B)
P ( Aij) P( B | Ai j)
=
1
j
= k
P(Ai|B) =
.
P( B)
P( A j ) P( B | A j )
j =1
Ejemplo 2.9 Continuando con el Ejemplo 2.7, la distribución de los casos de la
Ejemplo 2.9 Continuando con el Ejemplo 2.7, la distribución de los casos de la
enfermedad
deContinuando
Alzheimer por
por
grupo
de edad
edad
viene
dada por
por de los casos de la
Ejemplo 2.9
congrupo
el Ejemplo
2.7,
la distribución
enfermedad
de
Alzheimer
de
viene
dada
enfermedad de Alzheimer Ppor
viene
E1edad
( E1grupo
) P( A |de
)
0,60 ⋅ dada
0,020por
P(E1|A) = 3
= 0,186,
=
0,0645
PP((EE1i))PP((AA|| EE1i)) 0,60 ⋅ 0,020
P(E1|A) = i =13
=
= 0,186,
0,0645
) i ) 0,30 ⋅ 0,075
P( EP2()EPi () P
A(| A
E |2 E
i
=
1
|A)
=
= 0,349,
P(E2
=
3
0,0645
P( E i ) P( A | E i )
i =1
P( E 2 ) P( A | E 2 )
0,30 ⋅ 0,075
= 0,349,
P(E2|A) = 3
=
P( E 3 ) P( A | E 3 )
0,100,⋅0645
0,300
= 0,465.
P(E3|A) = 3 P ( E i ) P( A | E i )=
0,0645
i =1
P( E i ) P( A | E i )
i =1
P( E 3 ) P( A | E 3 )
0,10 ⋅ 0,300
Esto es, el 18,6, P(E
34,93|A)
y 46,5%
Alzheimer tienen edades
= 3 de los casos de la
= enfermedad =de0,465.
0,0645
entre 65-74, 75-84 y ≥ 85 años, (respectivamente.
( A | Ede
Esto es, el 18,6, 34,9 y 46,5%
i ) Pcasos
i ) la enfermedad de Alzheimer tienen
PdeElos
i =1
2.6
REFERENCIAS
edades
entre
65–74,
75–84
y ≥ 85
respectivamente.
Esto es,
el 18,6,
34,9
y 46,5%
de años,
los casos
de la enfermedad de Alzheimer tienen
1. Billingsley P. Probability and Measure, Third Edition. New York: John Wiley & Sons, 1995.
edades entre 65–74, 75–84 y ≥ 85 años, respectivamente.
2. Casella G, Berger RL. Statistical Inference, Second Edition. Belmont, CA: Duxbury Press, 2002.
2.6 REFERENCIAS
3.
Feller W. An Introduction to Probability Theory and Its Applications, Volume 1, Third
Edition. New York: John Wiley & Sons, 1968.
2.6
REFERENCIAS
Billingsley
P. Probability
and Measure,
Third
Edition.
New York:
John Wiley
& 2006.
4. 1.Rosner
B. Fundamentals
of Biostatistics,
Sixth
Edition.
Belmont,
CA: Duxbury
Press,
1995. P. Probability and Measure, Third Edition. New York: John Wiley &
1. Sons,
Billingsley
Sons, 1995.
12
12
20
Pastor-Barriuso R.
TEMA 3
VARIABLES ALEATORIAS Y
DISTRIBUCIONES DE PROBABILIDAD
3.1
INTRODUCCIÓN
En el tema de estadística descriptiva se revisaron las técnicas necesarias para la realización de un
análisis descriptivo de las variables recogidas en una muestra. El presente tema se centra en describir
algunos modelos teóricos de probabilidad que permiten caracterizar la distribución poblacional de
determinadas variables y que, a su vez, son aplicables a múltiples situaciones prácticas.
Cuando se realiza un estudio o un experimento aleatorio, es frecuente asignar a los resultados
del mismo una cantidad numérica. A la función que asocia un número real a cada resultado de un
experimento se le denomina variable aleatoria. Aunque el concepto de variable se ha introducido
con anterioridad, una definición más formal de variable aleatoria es, por tanto, la de una función
definida sobre el espacio muestral W que asigna a cada posible resultado de un experimento un
valor numérico. Aunque en general pueden definirse múltiples variables aleatorias para un mismo
experimento, es aconsejable seleccionar en cada caso aquellas variables que recojan las
características fundamentales del experimento. Las variables aleatorias suelen denotarse por
letras mayúsculas del final del alfabeto, tales como X, Y o Z, mientras que los valores que pueden
tomar se representan por sus correspondientes letras minúsculas, x, y o z.
Ejemplo 3.1 A continuación se definen algunas variables aleatorias para los experimentos
del Ejemplo 2.1 del tema anterior. En el experimento consistente en observar la
supervivencia a los 6 meses de 4 pacientes con cáncer sometidos a tratamiento, una
variable aleatoria X podría ser el número de supervivientes, que tomaría los valores X =
0, 1, 2, 3 ó 4 en función del número de pacientes que hayan sobrevivido a los 6 meses.
Alternativamente, podría definirse otra variable aleatoria Y como el número de muertes,
cuyos valores serían Y = 0, 1, 2, 3 ó 4 en función del número de muertes observadas. Para
el experimento de medir el colesterol HDL de una persona, la variable aleatoria X más
natural sería el nivel de colesterol HDL en mmol/l, que podría tomar cualquier valor
positivo. Si el interés se centra en saber si los niveles de colesterol HDL son superiores o
inferiores al umbral de 0,90 mmol/l, otra variable aleatoria Y podría definirse como Y = 0
si el nivel observado es inferior a 0,90 mmol/l y 1 en caso contrario. La elección de los
valores 0 y 1 es arbitraria, bastaría con asignar dos valores distintos para diferenciar
ambos tipos de resultados.
Como las variables aleatorias son funciones definidas sobre el espacio muestral, sus posibles
valores tendrán asociada una probabilidad, que corresponderá a la probabilidad del suceso
constituido por aquellos resultados del experimento que toman dichos valores. Los diferentes
valores de una variable aleatoria y las probabilidades asociadas constituyen la distribución de
probabilidad de la variable.
Ejemplo 3.2 En el primer experimento del ejemplo anterior, el número de supervivientes
es una variable aleatoria que toma los valores X = 0, 1, 2, 3 ó 4. La probabilidad asociada
al valor 0 P(X = 0) sería la probabilidad del suceso “ninguno de los 4 pacientes sobrevive
Pastor-Barriuso R.
21
Variables aleatorias y distribuciones de probabilidad
a los 6 meses”, la probabilidad asociada al valor 1 P(X = 1) sería la probabilidad del
suceso “sólo 1 de los 4 pacientes sobrevive a los 6 meses”, y así sucesivamente. En el
segundo experimento, el nivel de colesterol HDL es una variable aleatoria X que puede
tomar cualquier valor en el intervalo (0, ∞). En este caso no tiene sentido preguntarse, por
ejemplo, cuál es la probabilidad de tener exactamente un nivel de colesterol HDL de 1
mmol/l, ya que si esta variable se pudiera determinar con una precisión infinita, la
probabilidad P(X = 1) = 0. En tal caso, deberíamos preguntarnos por la probabilidad de
un determinado intervalo de valores. Así, por ejemplo, la probabilidad P(X ≤ 1) sería la
probabilidad del suceso “tener niveles de colesterol HDL menores o iguales a 1 mmol/l”.
En general, se distinguen dos grandes grupos de variables aleatorias:
yy Variables aleatorias discretas son aquellas que tan sólo puede tomar un número discreto
(finito o infinito) de valores. Cada uno de estos valores lleva asociada una probabilidad
positiva, mientras que la probabilidad de los restantes valores es 0.
yy Variables aleatorias continuas son aquellas que pueden tomar cualquier valor dentro de
un intervalo.
caso,
la probabilidad
un valor
0, porcomo
lo que las
de la
variable
discreta X de
su obtener
probabilidad
P(Xconcreto
= xi) se es
conoce
valor
xi, i = 1, 2,En...,este
probabilidades se asignan a intervalos de valores.
función
dede
probabilidad.
Esta función
debe cumplir
las=siguientes
i = masa
1, 2,se...,
la variable
discreta
X su probabilidad
P(X
xi) sealeatorias
conoce como
valor
xi, de
A
continuación
describen
las principales
características
de las
variables
discretas
y continuas, así como algunas distribuciones teóricas de probabilidad que serán aplicables a
propiedades:
la probabilidad
deutilizadas
cadaEsta
valorfunción
estar
0 y las
1, 0siguientes
< P(X = xi) ≤ 1, y la
función
de variables
masa
de aleatorias
probabilidad.
debeentre
cumplir
muchas
de las
enhalade
práctica.
suma
de las probabilidades
todosvalor
los valores
debeentre
ser igual
a 1,
propiedades:
la probabilidadpara
de cada
ha de estar
0 y 1,
0 < P(X = xi) ≤ 1, y la
3.2 DISTRIBUCIONES DE PROBABILIDAD DISCRETAS
valor xi, i = 1, 2, ..., de la variable discreta X su probabilidad P(X = xi) se conoce como
suma de las probabilidades para todos Plos
igual a 1,
( Xvalores
= x i )discreto
=debe
1. ser
Las variables aleatorias discretas toman
un
número
de
valores
con probabilidad no nula
i ≥1
función
de
masa
de
probabilidad.
Esta
función
debe
cumplir
las
siguientes
y, en consecuencia, estarán completamente caracterizadas si se conoce la probabilidad asociada
P( Xasigna
= x i ) a= cada
1. posible valor x , i = 1, 2, ..., de la
a cada uno de estos valores. La función
que
i
i
≥
1
propiedades:
la
probabilidad
deP(X
cada
ha
de estar
entre
y 1,de
0 masa
< P(Xde
= que
xprobabilidad.
1, y la
Una
vez conocida
la función
de masa
deconoce
probabilidad,
la 0probabilidad
i) ≤una
como
función
de
variable
discreta
X su
probabilidad
= valor
xi) se
Esta función debe cumplir las siguientes propiedades: la probabilidad de cada valor ha de estar
variable
aleatoria
comprendida
en cualquier
subconjunto
Ade
se
calcula
suma
las
probabilidades
todos
losde
valores
debe serlaigual
atodos
1, los
1,Xpara
yesté
la suma
de
las
probabilidades
para
valores
debe ser
entre
0Una
yde
1,vez
0 <conocida
P(X discreta
= xi)la≤función
de
masa
probabilidad,
probabilidad
que
una
igual a 1,
como
la suma
de las
probabilidades
de aquellosenvalores
xi incluidos
dentro
de calcula
ese
variable
aleatoria
discreta
X esté comprendida
subconjunto
A se
P( X = x ) =cualquier
1.
i
i ≥1
subconjunto,
como la suma de las probabilidades de aquellos valores xi incluidos dentro de ese
Una vez conocida la función de masa de probabilidad, la probabilidad de que una variable
Unadiscreta
vez conocida
función de masa
de probabilidad,
la probabilidad
que la
una
aleatoria
X esté la
comprendida
en cualquier
subconjunto
A se calculade
como
suma de
subconjunto,
P(X
∈A)
=
.
P
(
X
=
x
)
ide ese subconjunto,
dentro
las probabilidades de aquellos valores xi incluidos
xi ∈ A
variable aleatoria discreta X esté comprendida
en cualquier subconjunto A se calcula
P(X ∈A) = P( X = x i ) .
xi ∈ A
como
la suma la
defunción
las probabilidades
de aquellos
xi incluidos
dentro
dedefine
ese
En particular,
de distribución
F(x)
devalores
una variable
aleatoria
X se
En particular, la función de distribución F(x) de una variable aleatoria X se define como la
subconjunto,
como
la probabilidad
de
un valor
menor
igual
a x, aleatoria X se define
probabilidad
de observar
unobservar
valor
menor
o igual
a de
x, ouna
En particular,
la función
de distribución
F(x)
variable
F(x)P(X
= un
P(X
≤=x)menor
Xx =) .xai )x,.
como la probabilidad de observar
valor
∈A)
= P( XPo=( igual
i
xi ∈ A
xi ≤ x
F(x)variable
= P(X ≤discreta
x) = será
P ( Xuna
= xfunción
La función de distribución de una
escalonada creciente con
i ).
La
función
de
distribución
de
una
variable
discreta
xi ≤ x será una función escalonada
saltos
en
los
valores
x
con
probabilidad
no
nula.
i
En particular, la función
de distribución F(x) de una variable aleatoria X se define
creciente
con
en los valores
xi con probabilidad
nouna
nula.
La función
desaltos
distribución
de una variable
discreta será
función escalonada
como la probabilidad de observar un valor menor o igual a x,
22
Pastor-Barriuso R.
creciente con saltos en los valores xi con probabilidad no nula.
F(x) que
= P(X
x) = previos
P ( X = xse
Ejemplo 3.3 Supongamos
por≤estudios
i ) .estima que, después de 6
xi ≤ x
meses de tratamiento en 4 pacientes con cáncer, la probabilidad de que sobrevivan
0, 1, 2, 3 y 4 con probabilidad no nula.
Distribuciones de probabilidad discretas
[Tabla 3.1 aproximadamente aquí]
Ejemplo 3.3 Supongamos que por estudios previos se estima que, después de 6 meses
de tratamiento en 4 pacientes
con cáncer,
la probabilidadaquí]
de que sobrevivan 0, 1, 2, 3 ó 4
[Figura
3.1 aproximadamente
pacientes viene determinada por la segunda columna de la Tabla 3.1. Estos valores y sus
probabilidades constituyen la función de masa de probabilidad de la variable número de
supervivientes,
quedeseestadística
muestra endescriptiva,
la Figura 3.1(a).
Los valores
de la función
de distribución
En
el primer tema
se definieron
la media
y la varianza
en 0, 1, 2, 3 y 4 aparecen en la tercera columna de la Tabla 3.1; así, por ejemplo, la función
de distribución
en 1 esdeF(1)
= P(X ≤central
1) = P(X
= 0) + P(Xde= una
1) =variable
0,1296 +en0,3456
muestral
como medidas
tendencia
y dispersión
una = 0,4752.
La función de distribución de esta variable se representa en la Figura 3.1(b). Notar que
F(x) está
definida sobre
cualquier
número
real, aun
cuando
la variable
tome sólo los
muestra.
A continuación,
se definen
medidas
análogas
para
la distribución
poblacional
valores 0, 1, 2, 3 y 4 con probabilidad no nula.
de una variable aleatoria. La esperanza o media poblacional de una variable aleatoria
En el primer tema de estadística descriptiva, se definieron la media y la varianza muestral
como
medidas
de tendencia
y dispersión
de unalavariable
una
muestra.de
A continuación,
discreta
X, denotada
por μcentral
o E(X),
se define como
suma deenlos
productos
cada
se definen medidas análogas para la distribución poblacional de una variable aleatoria. La
esperanza
o media
poblacional
de=una
valor xi por
su probabilidad
P(X
xi),variable aleatoria discreta X, denotada por μ o E(X), se
define como la suma de los productos de cada valor xi por su probabilidad P(X = xi),
μ = E(X) =
x P( X = x ) .
i
i ≥1
i
Tabla
Función
masa de probabilidad y
La esperanza es la
media3.1
de los
valores xde
i ponderados por su probabilidad y representa
función de distribución del número de supervivientes
a los de
6 meses
de 4aleatoria.
pacientesNotar
con cáncer
sometidos
a se puede
así el valor promedio
la variable
que la media
muestral
tratamiento.
calcular de forma similar,
multiplicando cada
valor observado
de la variable por su
Número
Función
Función
frecuencia relativa.
de supervivientes
de masa
(x)
P(X
= x)una
La varianza poblacional de
0
2
abreviada por σ o var(X), 1se define
2
3
la variable respecto de su media,
4
0,4
como
σ 2 = var(X) = E(X - μ)2 =
0,1296
0,3456
la
esperanza
0,3456
0,1536
0,0256
=
del
0,1296
0,4752
cuadrado
0,8208
0,9744
1,0000
discreta X,
de la desviación de
(x
i
x
P( X = x i ) − μ 2 = E(X2) - μ2.
i ≥1
0,3
de distribución
F(x) = aleatoria
P(X ≤ x)
variable
i ≥1
P(X = x) 0,2
2
i
− μ ) 2 P( X = xi )
1
0,8
F(x)
0,1
0,6
0,4
5
0,2
0
0
0
1
2
3
4
0
1
2
x
x
(a)
(b)
3
4
Figura 3.1 Función de masa de probabilidad (a) y función de distribución (b) del número de supervivientes
a los 6 meses de 4 pacientes con cáncer sometidos a tratamiento.
Figura 3.1
Pastor-Barriuso R.
23
así el valor promedio de la variable aleatoria. Notar que la media muestral se puede
Variables aleatorias y distribuciones de probabilidad
calcular de forma similar, multiplicando cada valor observado de la variable por su
frecuencia relativa. La varianza poblacional de una variable aleatoria discreta X,
La esperanza
es la ponderada
media de los
xi ponderados
por su probabilidad
y representa así el
sí, la varianza resulta
ser la media
del valores
cuadrado
de las desviaciones
en los
valor promedio de la2variable aleatoria. Notar que la media muestral se puede calcular de forma
abreviada por σ o var(X), se define como la esperanza del cuadrado de la desviación de
observado
la variable
por su frecuencia relativa. La
cuadradamultiplicando
de la varianzacada
es lavalor
desviación
típica de
poblacional
σ, que
lores xi. La raízsimilar,
Así, la varianza
resulta
media ponderada
del cuadrado
de las desviaciones
en los
se define
varianza
poblacional
deser
unalavariable
aleatoria discreta
X, abreviada
por σ 2 o var(X),
la variable respecto de su media,
como ladeesperanza
delaleatoria
cuadrado
de la desviación
depoblacional.
la variable respecto de su media,
presenta la dispersión
la variable
respecto
de su media
Así,
la varianza
resulta
ser lade
media
ponderada
cuadradotípica
de laspoblacional
desviaciones
valores
x . La raíz
cuadrada
la varianza
es ladel
desviación
σ, en
quelos
i
σ 2 = var(X) = E(X − μ)2 = ( xi − μ ) 2 P( X = xi )
valores
x
.
La
raíz
cuadrada de
la varianza
esi ≥la
desviación
poblacional σ, que
i
la variable
aleatoria
respecto
detípica
su
Ejemplo 3.4 representa
A partir delalosdispersión
datos del de
ejemplo
anterior,
el 1valor
esperado
delmedia poblacional.
= xrespecto
− μmedia
= E(X
)−μ .
representa la dispersión de la variable aleatoria
de
poblacional.
i P( X = x
i ) su
número de supervivientes a los 6 meses de 4 pacientes con
i ≥1 cáncer sometidos a
Ejemplo 3.4 A partir de los datos del ejemplo anterior, el valor esperado del
2
2
2
2
varianza3.4
resulta
ser lademedia
ponderada
del cuadrado
las
desviaciones
en los valores
tratamiento Así,
seríalaEjemplo
A partir
losadatos
del
ejemplo
anterior,de
elcon
valor
esperado
del
número
de supervivientes
loses6la
meses
de 4 pacientes
cáncer
sometidos
a
cuadrada
de la varianza
desviación
típica poblacional
σ, que representa
xi. La raíz
5la
dispersión
de ladevariable
aleatoriaa respecto
de su
poblacional.
4
número
supervivientes
los 6 meses
demedia
4 pacientes
con cáncer sometidos a
tratamiento
sería
μ = kP( X = k ) = 0⋅0,1296 + 1⋅0,3456 + ... + 4⋅0,0256 = 1,60,
k = 0 Ejemplo 3.4
A partir de los datos del ejemplo anterior, el valor esperado del número de
tratamiento sería
supervivientes a4 los 6 meses de 4 pacientes con cáncer sometidos a tratamiento sería
μ = kP( X = k ) = 0⋅0,1296 + 1⋅0,3456 + ... + 4⋅0,0256 = 1,60,
y la varianza
4k = 0
μ = kP( X = k ) = 0⋅0,1296 + 1⋅0,3456 + ... + 4⋅0,0256 = 1,60,
k =0
y 4la varianza
σ =y
(k − μ ) 2 P( X = k )
la
varianza
k =0
y la varianza
2
4
2 = k)
σ 2 =+
−μ
) 2 P( X
= (0 - 1,60) 0,1296
... (+k(4
- 1,60)
0,0256 = 0,96.
2
4k = 0
σ 2 ==
(k1,60)
− μ )220,1296
P( X =+k )... + (4 − 1,60)20,0256 = 0,96.
(0 −
k =0
Es decir, el número esperado de supervivientes
a los 6 meses es 1,60 y la
Es decir, el número esperado 2de supervivientes a los 62meses es 1,60 y la desviación típica
= (0 - 1,60) 0,1296 + ... + (4 - 1,60) 0,0256 = 0,96.
= decir,
0,96 el=número
0,98.
desviación típica σEs
esperado de supervivientes a los 6 meses es 1,60 y la
Es decir, el número esperado de supervivientes a los 6 meses es 1,60 y la
σ = 0,96 = 0,98.
típica
3.2.1 desviación
Distribución
binomial
2.1 Distribución binomial
La distribución
binomial
teórico de distribución de probabilidad discreta aplicable
,96 = 0,98.
desviación
típica σes=un 0modelo
a
aquellos
experimentos
en
los
que
se
realizan
pruebas independientes,
cada una de ellas con
distribución binomial es un modelo teórico de distribución denprobabilidad
discreta
3.2.1
Distribución
binomial
sólo dos resultados posibles (éxito o fracaso) y la misma probabilidad de éxito π. En tal caso, se
dice
que la variable
aleatoria
X “número
de éxitos
en las n pruebas”
licable a aquellos
experimentos
en los
que se realizan
n pruebas
independientes,
cada sigue una distribución
3.2.1
Distribución
binomial
La
distribución
binomial
es
un
modelo
teórico
de
distribución
de
probabilidad(véase
discreta
binomial con parámetros n y π. A partir de los resultados del tema de probabilidad
Ejemplo
3.5),
puede
probarse
que
la
distribución
binomial
toma
valores
en
k
=
0,
1,
...,
n
con
probabilidad
a de ellas con sólo
dos resultados
posibleses(éxito
o fracaso)
y lademisma
probabilidad
La
distribución
binomial
un modelo
teórico
distribución
de probabilidad
discreta
aplicable
a aquellos
experimentos
en los
que se
realizan
n pruebas
independientes,
cada
n n k k
n−k n−k
= πseπ(realizan
1de
−(1πéxitos
P(XP(X
=enk)=los
se dice
que la variable
aleatoria
X=k)
“número
en, las n independientes, cada
éxito π. En tal caso,
−)fracaso)
π )n, pruebas
aplicable
a aquellos
experimentos
que
una de ellas
con sólo
dos resultados
posibles
(éxito
o
y la misma probabilidad
k k
A partir
de los y la misma probabilidad
uebas” sigue unauna
distribución
binomial
parámetros
n y π.(éxito
de ellas
con
sólo
doscon
posibles
o fracaso)
. En
tal
caso,
seresultados
dice que la
variable
aleatoria
X “número de éxitos en las n
de éxito
n π
n n! n!
= =
donde
es
número
de
de ndeelementos
tomados
de kdeenk k,
es el
el
número
de combinaciones
combinaciones
elementos
es
el
número
de
combinaciones
n elementos
tomados
encon
donde
k!tal
sultados del tema
de
probabilidad
Ejemplo
3.5),
puede probarse
que
la
kπ. kEn
−((véase
(nk!caso,
k−)!kse
dice
que
la
variable
aleatoria
X
“número
de
éxitos
en
las
n
de
éxito
n
)!
pruebas” sigue una distribución binomial con parámetros n y π. A partir de los
n! = n(n – 1)∙…∙1 y 0! = 1. Por supuesto, estas probabilidades constituyen una función de
stribución binomial
toma
valores
endistribución
k ya
= y0,que,
...,1.binomial
n con
probabilidad
partir
deque
losigual
pruebas”
sigue
una
con
npuede
y πes. A
masa
de
nparámetros
y π,
su
suma
exactamente
a 1. En la
k,
con
n! probabilidad
=n!
n(n
-tema
1)⋅…⋅1
0!1,
supuesto,
estas
probabilidades
constituyen
k, con
= n(n
- 1)⋅…⋅1
y =0!para
= Por
1. cualquier
Por
supuesto,
estas
probabilidades
constituyen
resultados
del
de probabilidad
(véase
Ejemplo
3.5),
probarse
launauna
práctica, resulta tedioso calcular las probabilidades de una distribución binomial mediante la
resultados
del
tema
de probabilidad
probabilidad
(véase
Ejemplo
puede
que
la
suma
es exactamente
función
de de
masa
de de
probabilidad
ya ya
que,
cualquier
n yprobabilidad
π,probarse
su suma
es exactamente
función
masa
para
cualquier
nπy, su
distribución
binomial
toma valores
enque,
k para
= 0,
1, ...,
n3.5),
con
24
distribución
binomial
toma
valores
en kcalcular
= 0,
1, ...,
con
probabilidad
igual
a 1.a En
la práctica,
resulta
tedioso
lasnlas
probabilidades
de de
una distribución
igual
1. En
la práctica,
resulta
tedioso
calcular
probabilidades
6 una distribución
Pastor-Barriuso R.
binomial
mediante
la fórmula
anterior.
PorPor
ello,
en en
la Tabla
1 del
Apéndice
se facilitan
binomial
mediante
la fórmula
anterior.
ello,
la Tabla
1 del
Apéndice
se facilitan
6
características sometidos a una misma terapia.
Distribuciones de probabilidad discretas
Ejemplo 3.5 En los ejemplos anteriores, se ha considerado el experimento de
observar
la Por
supervivencia
(o muerte)
en pacientes
con un determinado
cáncer binomiales
fórmula
anterior.
ello, en la Tabla
1 del Apéndice
se facilitan
las probabilidades
para n = 2, 3, ..., 20 y π = 0,05, 0,10, ..., 0,50.
sometidos al mismo tratamiento. Si por estudios previos se sabe que la
En general, la distribución binomial se aplica al estudio de observaciones repetidas e
independientes de una misma variable dicotómica (con sólo dos resultados posibles), tal como
supervivencia a los 6 meses en dichos pacientes es del 40%, el número de
el resultado de un tratamiento (éxito o fracaso) en pacientes de similares características
sometidos a una misma terapia.
supervivientes a los 6 meses en una muestra de 4 pacientes seguirá una
dado que el resultado en cada paciente es independiente y todos tienen una misma
Ejemplo 3.5 binomial
En los ejemplos
anteriores,
el experimento de observar
π considerado
= 0,4.
distribución
X de parámetros
n = se
4 yha
probabilidad
de
supervivencia
del
0,4.
En
general,
la
probabilidad
desometidos
que
la supervivencia (o muerte) en pacientes con un determinado cáncer
al mismo
tratamiento.
Si
por
estudios
previos
se
sabe
que
la
supervivencia
a
los
6
meses
en
dichos
suceso
dedeque
Utilizando
las
leyes
de la
probabilidad,
si denotamos
por Si al
dado
que
el
resultado
en
cada
paciente
es
independiente
y
todos
tienen
una
misma
sobrevivan
2
pacientes
cualesquiera
puede
descomponerse,
en
función
qué
pacientes es del 40%, el número de supervivientes a los 6 meses en una muestra de 4
pacientes seguirá
unapaciente,
distribución
binomial X de
de que
parámetros
n = 4únicamente
y π = 0,4. los
sobreviva
el i-ésimo
sobrevivan
probabilidad
de supervivencia
del 0,4. En general,
la probabilidad
de que
pacientes
sobrevivan,
como la probabilidad
Utilizando las leyes de la probabilidad, si denotamos por Si al suceso de que sobreviva el
dado
quepaciente,
el resultado
envendría
cada paciente
es
independiente
y todoslos
tienenprimeros
una misma
dos
primeros
pacientes
dada
por
i-ésimo
la probabilidad
de que
sobrevivan
únicamente
pacientes
sobrevivan
2 pacientes
cualesquiera
enc dos
función de qué
cpuede
c descomponerse,
c
P(X = 2) = P{(S1∩S2∩ S 3 ∩ S 4 )∪(S1∩ S 2 ∩S3∩ S 4 )
vendría dada por
probabilidad de supervivencia
del 0,4. En general, la probabilidad de que
c
pacientes
S 4c ) = P(S1)P(S2)P( S 3c )P( S 4c ) = 0,42(1 − 0,4)2,
P(Ssobrevivan,
1∩S2∩ S 3 ∩como
c
∪(S1∩ S 2cpuede
∩ S 3c ∩descomponerse,
S4)∪( S1c ∩S2∩Sen
3∩ S 4 )
sobrevivan 2 pacientes cualesquiera
función de qué
dado que el resultado en cada paciente es independiente
y todosctienen unac misma probabilidad
c
c
P
(
X
=
2)
=
P
{(
S
∩
S
∩
S
∩
S
)∪(
S1∩de
S2 ∩
S3∩sobrevivan
S4 )
1
2
4
de supervivencia del 0,4. En general, la 3probabilidad
que
2 pacientes
pacientes sobrevivan, como∪( S1c ∩S2∩ S 3c ∩S4)∪( S1c ∩ S 2c ∩S3∩S4)}.
cualesquiera puede descomponerse, en función de qué pacientes sobrevivan, como
∪(S1∩ S 2c ∩ S 3c ∩S4)∪( S1c ∩S2∩S3∩ S 4c )
c
c
P(Xestá
= 2)constituida
= P{(S1∩Spor
S 4c )∪(
S3∩ S 4c como
)
2∩ Sla
1∩ S 2 ∩
Esta probabilidad
unión
deStantos
sucesos
posibles 7
3∩
cc
c
c
c
c
S4)∪(
)∪(
S1c ∩SS12∩ SS32∩∩SS4c3∩
) S4)}.
∪(S∪(
1∩ S12 ∩SS23∩∩SS34∩
4
4!
24
c
c 2 en 2; es
c decir,
c
S ∩
S= )}.
combinaciones de 4 pacientes
de
=
∩
S
∩
S
∩
S
)∪(
S
∩
S
∩
∪( Stomados
2
4
3
4
1
3
1
2
2 2! (4 − 2)! 4
Esta probabilidad está constituida por la unión de tantos sucesos
como posibles
Esta probabilidad está constituida por la unión de tantos sucesos como posibles
= 6 sucesos. Además, estos sucesos son mutuamente excluyentes y todos ellos
4
4!
24
combinaciones
4 pacientes
tomados
2;es
es decir,
decir, =
=
combinaciones
de 4depacientes
tomados
dede2 2enen
2;
=6
2
2
(4 − 2)!
Esta
probabilidad
constituida
la unión
de(1tantos
2como
2!posibles
- 0,4)sucesos
. En consecuencia,
la 4
tienen
una misma está
probabilidad
de por
ocurrir
de 0,4
sucesos. Además, estos sucesos son mutuamente excluyentes y todos ellos tienen una
2 son mutuamente
2
4y! todos ellos
24 de que
= 6 probabilidad
sucesos.
Además,
estosde
sucesos
excluyentes
probabilidad
de que
sobrevivan
2 0,4
pacientes
cualesquiera
es 4 la probabilidad
(1 – 0,4)
. En consecuencia,
misma
de
ocurrir
combinaciones de 4 pacientes tomados de 2 en 2; es decir, =
=
sobrevivan 2 pacientes cualesquiera es
2 2! (4 − 2)! 4
tienen una misma probabilidad de ocurrir de 0,42(1 - 0,4)2. En consecuencia, la
4 2
0,4mutuamente
(X =sucesos
2) = son
(1 − 0,4) 2 =excluyentes
0,3456,
= 6 sucesos. Además, P
estos
y todos ellos
probabilidad de que sobrevivan
22 pacientes cualesquiera es
- 0,4)2. En
tienen
una mismaa probabilidad
dede
ocurrir
de 0,42(1 binomial
que corresponde
la probabilidad
la distribución
deconsecuencia,
parámetros n =la4 y π = 0,4
que
corresponde
a
la
probabilidad
de
la
distribución
binomial
de
parámetros n = 4
4
2
para k = 2. Aplicando esta fórmula, las probabilidades
2para k = 0, 1, 2, 3 ó 4 supervivientes
P
(
X
=
2)
=
0,4
(
1
−
0
,
4
)
=
0,3456,
probabilidad
cualesquiera
es
2 3.1(a).
aparecen en de
la que
Tablasobrevivan
3.1 y en 2lapacientes
Figura
Estas probabilidades
también pueden
π
=
0,4
para
k
=
2.
Aplicando
esta
fórmula,
las
probabilidades
para
k
=
0, 1, 2, 3
y
obtenerse directamente de la Tabla 1 del Apéndice.
4 2
n=4
que
corresponde
a
la
probabilidad
deesperanza
binomial
de
parámetros
Tabla
0,4
P
(
X
=
2)
=
(la
1 −distribución
,4)la2yFigura
=la0,3456,
ó
4
supervivientes
aparecen
en
la
3.1
y0en
3.1(a).
A partir de las fórmulas generales para
la
varianza
deEstas
una
variable aleatoria
2
discreta, puede probarse que la esperanza de una distribución binomial de parámetros n y π es
π
=
0,4
para
k
=
2.
Aplicando
esta fórmula,
las probabilidades
y
probabilidades también pueden obtenerse
directamente
de la Tabla 1para
del k = 0, 1, 2, 3
n
n
n k binomial
n=4
que correspondeEa(Xla) =
probabilidad
de
la
distribución
πy en
(
=
)
=
(1la
− πFigura
) n − k =de
nπparámetros
kP
X
k
k
a
).
Estas
ó 4 supervivientes aparecen en la Tabla 3.1
3.1(
Apéndice.
k =0
k =0 k
y π = 0,4 para k = 2. Aplicando esta fórmula, las probabilidades para k = 0, 1, 2, 3
probabilidades también pueden obtenerse directamente de la Tabla 1 del
de lasesfórmulas generales para la esperanza y la varianza de una variable
yAsupartir
varianza
ó 4 supervivientes
aparecen en la Tabla 3.1 y en la Figura 3.1(a). Estas
Apéndice.
Pastor-Barriuso R.
aleatoria discreta, puede probarse
que la esperanza de una distribución binomial de
n
probabilidades también pueden
obtenerse
directamente
de
la
Tabla
1
del
var(X) = (k − nπ ) 2 P( X = k )
A partir
las fórmulask =generales
para la esperanza y la varianza de una variable
0
n y de
π es
parámetros
Apéndice.
25
n
n
n
k =0
k =0
kP( X = k ) = k k π
Variables aleatorias y distribuciones de probabilidad
E(X) =
y su varianza es
y su varianza es
k =0
k
k
(1 − π ) n − k = nπ
Así, el número esperado de éxitos es igual al nú
probabilidad individual de éxito. La varianza n
var(X) =
n
(k − nπ )
2
P( X = k )
número de pruebas y más extrema sea la probab
que π = 0 ó 1, la varianza será 0 ya que todas la
n
IA de la enfermedad
cumplen las siguientes hipótesis
respecto2 anla
incidencia
acumulada
= (k − nπ ) π k (1 − π ) n − k = nπ(1 − π).
o éxitos.
k
k =0
(esto es, la probabilidad de desarrollar unnuevo
caso en un periodo de tiempo
k =0
Así, el número esperado de éxitos es igual al número de pruebas realizadas por la probabilidad
determinado):
Así, el de
número
de éxitos
al número
de pruebas
realizadas
la pruebas con el ejemplo
3.6por
Continuando
individual
éxito.esperado
La varianza
nπ(1 –esπ)igual
disminuye
cuanto
menor Ejemplo
sea
el número
de
y más extrema sea la probabilidad de éxito. En el caso particular de que π = 0 ó 1, la varianza
La probabilidad
de observarfracasos
un casooeséxitos.
aproximadamente
supervivientes a los 6 meses de 4 pacient
será 0•yaProporcionalidad:
que todas las pruebas
serán respectivamente
probabilidad individual de éxito. La varianza nπ(1 - π) disminuye cuanto menor sea el
proporcional al tiempo transcurrido, de tal forma que en un nintervalo
de 1,60,
tiempo
π = 4⋅0,4
la varianza nπ(1 - π) =
Ejemplo 3.6 Continuando con el ejemplo anterior, el número esperado
de=supervivientes
número
de
pruebas
y
más
extrema
sea
la
probabilidad
de
éxito.
En
el
caso
particular
de la
a los 6 meses de 4 pacientes con cáncer sometidos a tratamiento es nπ = 4∙0,4 = 1,60,
arbitrariamente corto, la probabilidad de observar un caso es muy pequeña y la
varianza nπ(1 – π) = 4∙0,4∙0,6 = 0,96 y la desviación típica nπ (1 − π ) = 0,98. Estos resultados coin
π = 0 ó 1,
la varianza
0 ya que todas
pruebas
respectivamente
fracasosse
que
resultados
coinciden
conserá
los obtenidos
en el las
Ejemplo
3.4,serán
donde
la media y la varianza
probabilidad de observar más de un caso es esencialmente nula.
calculaban a partir de las fórmulas generales para variables discretas.
3.4, donde la media y la varianza se calcu
o éxitos.
• Estacionaridad: El número de casos por unidad de tiempo permanece
para variables discretas.
3.2.2 Distribución de Poisson
t. Notar
aproximadamente
constantecon
a loellargo
de todo
el periodo
de tiempo
Ejemplo 3.6 Continuando
ejemplo
anterior,
el número
esperado
de que,
La distribución de Poisson es otro modelo teórico de distribución discreta particularmente útil
para el estudio
epidemiológico
lasubstancial
ocurrencia
Se
que
sisupervivientes
se produjera
un
cambio
dedeladeterminadas
incidencia
deenfermedades.
laDistribución
enfermedad
en
elPoisson
3.2.2
dedice
a los
6de
meses
de 4 pacientes
con cáncer
sometidos
a tratamiento
es la
variable aleatoria X “número de casos de una determinada enfermedad a lo largo de un periodo
de tiempotiempo,
tasunción
es
un la
intervalo
largo,
como
1 ótípica
10 años,
distribución
de Poisson
es otro modelo teóri
esta=
no seríadeaplicable.
nt”,
π =donde
4⋅0,4
1,60,
varianza
nπtiempo
(1 - π) arbitrariamente
= 4⋅0,4⋅0,6 =La
0,96
y la tal
desviación
sigue una distribución de Poisson si se cumplen las siguientes hipótesis respecto a la incidencia
acumulada
IA de la enfermedad
(esto es,
la probabilidad
de desarrollar
un nuevo
casoel
un epidemiológ
• Independencia:
ocurrencia
de un
caso
en un determinado
instante
aen
la
particularmente
útil
para
estudio
nπ (1 − π ) = La
0,98.
Estos resultados
coinciden
con los
obtenidos
enno
el afecta
Ejemplo
periodo de tiempo determinado):
probabilidad de La
observar
nuevosde
casos
en periodos
posteriores.
Así, por
ejemplo,
Se dice
que la variable aleatoria
yy Proporcionalidad:
probabilidad
observar
un caso
esenfermedades.
aproximadamente
proporcional
3.4, donde la media
y la varianza
se
calculaban
a partir
de las fórmulas generales
al tiempo transcurrido, de tal forma que en un intervalo de tiempo arbitrariamente corto,
enfermedad
a lo largo de un periodo de tiempo
esta hipótesis
independencia no se cumplirá en brotes
epidémicos.
la probabilidad
dede
observar
para variables
discretas.un caso es muy pequeña y la probabilidad de observar más de
un caso es esencialmente nula.
tal como 1 ó 10 años, sig
Aunque la distribución de Poisson se emplea habitualmentearbitrariamente
en el estudio delargo,
la morbiyy Estacionaridad: El número de casos por unidad de tiempo permanece aproximadamente
constante
a lo largo
todo el periodo
de tiempo
t. distribución
Notar que, siesseenprodujera
3.2.2
Distribución
dedePoisson
mortalidad
debida
a determinadas
enfermedades,
esta
general un cambio
substancial de la incidencia de la enfermedad en el tiempo, esta asunción no sería aplicable.
distribución
de La
Poisson
estiempo
otrode
modelo
teórico
de determinado
distribución
a la ocurrencia
en el
de
aleatoriosdiscreta
que satisfagan
las a la
yaplicable
yLa
Independencia:
ocurrencia
un aquellos
caso
en sucesos
un
instante
no afecta
probabilidad de observar nuevos casos en periodos posteriores. Así, por ejemplo, esta
particularmente
útil(por
paraejemplo,
el estudio
epidemiológico
deepidémicos.
la ocurrencia de determinadas
hipótesis
anteriores
accidentes
de tráfico).
hipótesis
de independencia
no selos
cumplirá
en brotes
Aunque
la distribución
de Poisson
se emplea
habitualmente
en de
elde
estudio
de
morbi-mortalidad
X “número
casos
delauna
determinada
enfermedades.
Se dice
que
variable
aleatoria
k sucesos,
k=
Bajo
estas asunciones,
se la
establece
que
la probabilidad
que
ocurran
debida a determinadas enfermedades, esta distribución es en general aplicable a la ocurrencia
en el
tiempo
sucesos
aleatorios
las hipótesis
anteriores
(por
ejemplo,
t”, donde
t es unXintervalo
tiempo
a loperíodo
largo
dedeuntiempo
periodo
deque
tiempo
t para
unasatisfagan
variable
aleatoria
que
siguedeuna
0,enfermedad
1, 2, ...,de
enaquellos
un
los accidentes de tráfico).
arbitrariamente
largo,setal
como 1que
ó 10laaños,
sigue una
Poissonk si
se 1, 2, ...,
distribución
de Poisson
es
Bajo
estas asunciones,
establece
probabilidad
dedistribución
que ocurran kdesucesos,
= 0,
en un periodo de tiempo t para una variable aleatoria X que sigue una distribución de Poisson es
9
−μ
k
e μ
P(X = k) =
,
k!
26
donde el parámetro μ es el número esperado de sucesos en el período de tiempo t. A
Pastor-Barriuso R.
diferencia de la distribución binomial, donde el número de éxitos k no puede exceder el
número finito de pruebas realizadas, en la distribución de Poisson el número de pruebas
Una característica importante de la distribución de Poisson es que tanto su media
grande, aunque
se considera infinito y el número de sucesos k puede ser arbitrariamente
Distribuciones de probabilidad discretas
como su varianza son iguales al parámetro μ,
la probabilidad P(X = k) decrecerá al aumentar k hasta hacerse esencialmente nula. Para
k
e −μ μ
donde
el parámetro
μ esμel>número
esperado
de sucesos
en el periodo
de tiempo t. A diferencia
probabilidades
son
positivas
cualquier
parámetro
kP
X
k
k
E(X)0,=estas
=
=
= μ, y suman 1, constituyendo
(
)
de la distribución binomial, donde
el
número
de
éxitos
k
no
puede
exceder
el número finito de
k!
k ≥0
k ≥0
pruebas
realizadas,
en la de
distribución
de Poisson
el número
pruebassesepresentan
consideralas
infinito y el
una función
de masa
probabilidad.
En la Tabla
2 del de
Apéndice
número de sucesos k puede ser arbitrariamente grande, aunque la− μprobabilidad
P(X = k) decrecerá
k
e μ
μ ) 2 P( X = k ) =nula.
X) hacerse
= (k −esencialmente
− μ ) 2cualquier=parámetro
μ.
(kPara
al aumentar k var(
hasta
μ > 0, estas
μ
de
0,5
a
20
en
intervalos
de
probabilidades de Poisson
para
k! 0,5.
k ≥ 0 y suman 1, constituyendo
k ≥0
probabilidades son positivas
una función
de masa de probabilidad. En
la Tabla 2 del Apéndice se presentan las probabilidades de Poisson para μ de 0,5 a 20 en
Una característica importante de la distribución de Poisson es que tanto su media
intervalos de 0,5.
Ejemplo
3.7 Según
el último
de Mortalidad
por Cáncer
en tanto
España,
tasa de
Una
característica
importante
deAtlas
la distribución
es que
su la
media
como su
μ, de Poisson
como
su varianza
son
iguales
al
parámetro
varianza son iguales al parámetro μ,
mortalidad por cáncer de vesícula en hombres es de I = 1,80 casos por 100.000
e −μ μ k
kP
X
k
k
E
(
X
)
=
=
=
= μ,
(
)
personas-año. Partiendo de esta
información, kse
pretende
k! determinar la
k ≥0
≥0
−μ
k
2 por cáncer de vesícula
2 een μ
distribución del
número
de
muertes
un
periodo
var(X) = (k − μ ) P( X = k ) = (k − μ )
= μ. de 1 ó 2
k
!
k ≥0
k ≥0
años en una población de 140.000 hombres. Las asunciones de estacionaridad e
Ejemplo 3.7 Según el último Atlas de Mortalidad por Cáncer en España, la tasa de
independencia parecen razonables por tratarse de casos de mortalidad por cáncer
mortalidad por cáncer de vesícula en hombres es de I = 1,80 casos por 100.000 personas3.7deSegún
el último Atlas
Mortalidad
por Cáncer
en España,
tasa de de
año.Ejemplo
Partiendo
esta información,
se de
pretende
determinar
la distribución
dellanúmero
en periodos cortos de tiempo. Además, como la tasa de mortalidad I es baja y se
muertes por cáncer de vesícula en un periodo de 1 ó 2 años en una población de 140.000
porrazonables
100.000 por
mortalidad
cáncer dedevesícula
en hombres
es de I = 1,80 casos
hombres.
Las por
asunciones
estacionaridad
e independencia
parecen
asume constante en el tiempo, puede probarse que la incidencia acumulada en un
tratarse de casos de mortalidad por cáncer en periodos cortos de tiempo. Además, como
personas-año.
Partiendo
de yesta
se pretende
determinar
la tasa
de mortalidad
I es baja
se información,
asume constante
en el tiempo,
puedelaprobarse que la
periodo de tiempo t es
incidencia acumulada en un periodo de tiempo t es
distribución del número de muertes por cáncer de vesícula en un periodo de 1 ó 2
IAt = 1 − exp(−It ) ≈ It;
años en una población de 140.000 hombres. Las asunciones de estacionaridad e
es decir, la probabilidad de que un individuo de esta población muera por cáncer de
es
decir,
la
derazonables
queproporcional
un individuo
esta
mueracumpliéndose
por por
cáncer
vesícula
es probabilidad
aproximadamente
aldetiempo
transcurrido,
independencia
parecen
por tratarse
de población
casos
de mortalidad
cáncerasí la
hipótesis de proporcionalidad. La incidencia acumulada en 1 año es IA1 = 0,000018 y en
de
vesícula
aproximadamente
proporcional
al tiempo
transcurrido,
0,000036.
En consecuencia,
número
de muertes
2 años
IA2 =es0,000018∙2
I es bajapor
y secáncer
en periodos
cortos de =tiempo.
Además,
como
la tasa el
de
mortalidad
de vesícula en un periodo de tiempo t seguirá una distribución de Poisson con un número
esperado
casos igual
al tiempo,
productopuede
del tamaño
poblacional
por la probabilidad
asumede
constante
en el
probarse
que la incidencia
acumulada individual
en11un
de muerte en dicho periodo, μ = 140.000∙0,000018 = 2,52 muertes esperadas en 1 año y
140.000∙0,000036
= 5,04
t es en 2 años.
periodo de tiempo
Estas distribuciones de probabilidad se muestran en la Tabla 3.2 y en la Figura 3.2. Por
ejemplo, la probabilidad de que no
IAtse= produzca
1 - exp(-Itninguna
) ≈ It; muerte por cáncer de vesícula
durante 1 año en esta población se calcula a partir de la distribución de Poisson de
parámetro μ = 2,52 como P(X = 0) = e–μμ 0/0! = e–2,52 = 0,0805. Estas distribuciones también
es decir,
la probabilidad
de que
un individuo dedeesta
población
pueden
aproximarse
mediante
las probabilidades
Poisson
de lamuera
Tabla por
2 delcáncer
Apéndice
para μ = 2,5 y 5. En la Figura 3.2 puede observarse como, al aumentar el número esperado
de vesícula
es aproximadamente
al tiempo
transcurrido,
de muertes,
la distribución
tiende a proporcional
ser más simétrica
alrededor
del valor esperado y su
varianza aumenta.
11
Pastor-Barriuso R.
27
Variables aleatorias y distribuciones de probabilidad
Tabla 3.2 Distribución de probabilidad del
número de muertes por cáncer de vesícula en
periodos de 1 y 2 años en una población de
140.000 hombres.
P(X = k)
P(X = k)
Número
de muertes (k)
1 año
2 años
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
0,0805
0,2028
0,2555
0,2146
0,1352
0,0681
0,0286
0,0103
0,0032
0,0009
0,0002
0,0001
0,0000
0,0000
0,0000
0,0000
0,0000
0,0000
0,0065
0,0326
0,0822
0,1381
0,1740
0,1754
0,1474
0,1061
0,0668
0,0374
0,0189
0,0086
0,0036
0,0014
0,0005
0,0002
0,0001
0,0000
0,25
0,25
0,2
0,2
0,15
0,15
0,1
0,1
0,05
0,05
0
0
0
5
10
15
20
0
5
10
k
k
(a)
(b)
15
20
Figura 3.2 Distribución de probabilidad del número de muertes por cáncer de vesícula en un periodo de 1
año (a) y de 2 años (b) en una población de 140.000 hombres.
Figura 3.2
28
Pastor-Barriuso R.
Este resultado es particularmente útil en la práctica, ya que el cálculo de las
probabilidades binomiales para n grande y π pequeña es muy laborioso, en cuyo caso
Distribuciones de probabilidad continuas
las probabilidades de Poisson son más fáciles de manejar y facilitan resultados
3.2.3 Aproximación
virtualmente
idénticos. de Poisson a la distribución binomial
Bajo determinadas circunstancias, la distribución de Poisson puede utilizarse como aproximación
a la distribución
binomial.
Supongamos
que,anterior
en una distribución
binomial,Xel número de pruebas
Ejemplo 3.8
Retomemos
del ejemplo
la variable aleatoria
n es grande y la probabilidad individual de éxito π es pequeña. En tal caso, el número de éxitos
de la distribución
binomial
puedede
sermuertes
muy grande
y su varianza
seráen
aproximadamente
correspondiente
al número
por cáncer
de vesícula
un periodo de 2 igual al
valor esperado, nπ(1 – π) ≈ nπ. Como se vio en el apartado anterior, estas dos características son
propias
de en
unauna
distribución
lo que sugiere
la validez del
siguienteconsistiría
resultado: si el
años
población de
de Poisson,
140.000 hombres.
El experimento
subyacente
número de pruebas n es grande y la probabilidad de éxito π es pequeña, la distribución binomial
se aproxima
a unapara
distribución
de los
Poisson
con parámetro
nπ. Por regla
general,
n = 140.000
hombres, μla =ocurrencia
o no de
una esta
en observar,
cada uno de
aproximación se considera suficientemente precisa cuando n ≥ 100 y π ≤ 0,01.
muerte
por cáncer
de vesícula durante
unpráctica,
periodo ya
de que
2 años.
El resultado
cada
Este
resultado
es particularmente
útil en la
el cálculo
de las en
probabilidades
binomiales para n grande y π pequeña es muy laborioso, en cuyo caso las probabilidades de
sujeto
independiente
y la probabilidad
de que un virtualmente
individuo promedio
de esta
Poisson
son es
más
fáciles de manejar
y facilitan resultados
idénticos.
Utilizando la aproximación de Poisson a la distribución binomial, el número de
Ejemplo 3.8
Retomemos
ejemplo en
anterior
X correspondiente
π = IA2 aleatoria
= 0,000036.
Por
población
muera
por cáncerdel
de vesícula
2 añoslaesvariable
al número de muertes por cáncer de vesícula en un periodo de 2 años en una población
muertes por cáncer de vesícula en un periodo de 2 años seguirá aproximadamente
de 140.000
hombres.
El experimento
en observar,
para cada
tanto,
el número
de muertes
por cáncersubyacente
de vesículaconsistiría
en esta población
a lo largo
de uno
de los n = 140.000 hombres, la ocurrencia o no de una muerte por cáncer de vesícula
μ =ennπcada
= 140.000⋅0,000036
= 5,04. Eny la
una distribución
dede
Poisson
conElparámetro
un periodo
2 años.
resultado
es independiente
nsujeto
= 140.000
yπ=
2durante
años seguirá
una distribución
binomial
con parámetros
probabilidad de que un individuo promedio de esta población muera por cáncer de
consecuencia,
la es
probabilidad
de observarPor
2 muertes
aproximarse
por
0,000036.
tanto,
elpuede
número
de muertes
vesícula
enAsí,
2 años
π = IAla2 =probabilidad
0,000036.
por ejemplo,
de que
ocurran
exactamente
2 por cáncer
de vesícula en esta población a lo largo de 2 años seguirá una distribución binomial con
5 , 04 por2 ejemplo, la probabilidad de que ocurran
parámetros
muertes
es n = 140.000 y π = 0,000036.
e −Así,
5,04
P
(
X
=
2)
≈
= 0,082222,
exactamente 2 muertes es
Utilizando la aproximación de Poisson a la2!distribución binomial, el número de
140.000
2
139.998
0,un
Pcáncer
(X = 2)de
= vesícula
000036
0,999964
= 0,082220.
muertes
por
en
periodo
de 2 añosbinomial
seguirá
aproximadamente
que coincide casi perfectamente
con
la
probabilidad
exacta.
2
Utilizando
la aproximación
a la μdistribución
binomial, el número
muertes
= nπ = 140.000⋅0,000036
= 5,04.deEn
una distribución
de Poisson de
conPoisson
parámetro
por cáncer de vesícula en un periodo de 2 años seguirá aproximadamente una distribución
Poisson conla parámetro
μ de
= nπ
= 140.000∙0,000036
5,04. En consecuencia,
la
3.3de
DISTRIBUCIONES
DE PROBABILIDAD
CONTINUAS
consecuencia,
probabilidad
observar
2 muertes
puede=aproximarse
por
probabilidad de observar 2 muertes puede aproximarse por
13
−5 , 04
2
Las variables aleatorias continuas son aquellas
que
pueden
tomar
cualquier
valor
dentro
5,04
e
P(X = 2) ≈
= 0,082222,
2!
de un intervalo. La probabilidad de que estas variables tomen exactamente un valor
que coincide casi perfectamente con la probabilidad binomial exacta.
que coincide
perfectamente
la probabilidad
binomial
determinado
es 0casi
y, en
consecuencia,con
carece
de sentido definir
unaexacta.
función de masa de
3.3probabilidad.
DISTRIBUCIONES
DE PROBABILIDAD
CONTINUAS
Para las variables
aleatorias continuas,
las probabilidades se asignan a
Las variables aleatorias continuas son aquellas que pueden tomar cualquier valor dentro de un
3.3intervalos
DISTRIBUCIONES
DE PROBABILIDAD
CONTINUAS
densidad
de probabilidad
denotada es 0
de valores mediante
una función
intervalo.
La probabilidad
de que estas
variablesdetomen
exactamente
un valor ,determinado
y, en consecuencia, carece de sentido definir una función de masa de probabilidad. Para las
f(x).aleatorias
Esta
función
ha de ser
negativa
valor
x, f(x) ≥de0,
y eldentro
área
Laspor
variables
aleatorias
continuas
son
aquellaspara
quesecualquier
pueden
cualquier
valor
variables
continuas,
las no
probabilidades
asignantomar
a intervalos
valores
mediante
una función de densidad de probabilidad, denotada por f(x). Esta función ha de ser no negativa
de total
uncualquier
intervalo.
La probabilidad
quefunción
estasbajo
variables
tomen
exactamente
un
bajo lavalor
curva
deladensidad
debe
ser
1, valorde densidad
para
x,definida
f(x) ≥ 0, por
y eldeesta
área
total
curva
definida
porigual
esta afunción
debe ser igual a 1,
determinado es 0 y, en consecuencia, carece
de sentido definir una función de masa de
∞
f
(
−∞ x) dx = 1.
probabilidad. Para las variables aleatorias continuas, las probabilidades se asignan a
Pastor-Barriuso R.
A partir
de la función
de densidad,
la probabilidad
una variable
aleatoria
de densidadde
deque
probabilidad
, denotada
intervalos
de valores
mediante
una función
tome valores
de cualquier
, b) puede
como el
f(x). EstaX función
ha de dentro
ser no negativa
paraintervalo
cualquier(avalor
x, f(x)calcularse
≥ 0, y el área
porcontinua
29
−∞
VariablesAaleatorias
y distribuciones
de de
probabilidad
partir de
la función
densidad,
la probabilidad de que una variable aleatoria
continua X tome valores dentro de cualquier intervalo (a, b) puede calcularse como el
A partir de la función de densidad, la probabilidad de que una variable aleatoria continua X
a ycalcularse
b,
área
bajo ladentro
función
densidad
entre los
tome
valores
de de
cualquier
intervalo
(a,puntos
b) puede
como el área bajo la función
de densidad entre los puntos a y b,
en regiones de baja probabilidad. La función debdistribución F(x) corresponde a la
P(a < X < b) = f ( x) dx .
a
probabilidad de que la variable tome un valor igual o inferior a x y, en el caso de una
Así, aun cuando la probabilidad de obtener un valor concreto es 0, la función de densidad
tomará
valores
elevados
en regiones
alta probabilidad
ydevalores
en
de
Así, aun
cuando
lacontinua,
probabilidad
de de
obtener
un
valorbajo
concreto
0,pequeños
ladefunción
deregiones
variable
aleatoria
se calcula
como
el área
la es
curva
la función
de
baja probabilidad. La función de distribución F(x) corresponde a la probabilidad de que la
variable
tome
unizquierda
valor
igual
ox, inferior
x y, en el
de una variable
aleatoria
continua, se
valores
enaregiones
decaso
alta probabilidad
y valores
pequeños
densidad
atomará
la
deelevados
calcula como el área bajo de la curva de la función de densidad a la izquierda de x,
F(x) = P(X ≤ x) =
x
−∞
14
f (t ) dt .
La función de distribución de una variable aleatoria continua es una función que, partiendo de 0,
crece
formade
continua
hasta alcanzar
el valoraleatoria
1.
La de
función
distribución
de una variable
continua es una función que,
partiendo
de 3.9
0, crece
formade
continua
hasta
alcanzar
el valorHDL
1. en hombres adultos se
Ejemplo
La de
función
densidad
para
el colesterol
representa en la Figura 3.3(a). Notar que, aunque el área bajo la curva ha de ser igual a 1, la
función de densidad puede tomar valores superiores a 1. Los niveles de colesterol HDL
Ejemplo
La función
densidad
para elprobabilidad
colesterol HDL
en hombres
adultos
próximos
a 13.9
mmol/l
son losdeque
tienen mayor
de ocurrir,
mientras
que para
niveles inferiores y superiores esta probabilidad decrece. Así, por ejemplo, la probabilidad de
a).de
Notar
que, aunque
el áreaa bajo
curva(niveles
ha de ser
en la tenga
Figuraun3.3(
queseunrepresenta
hombre adulto
nivel
colesterol
HDL inferior
0,90 la
mmol/l
bajos
según las recomendaciones del “National Cholesterol Education Program”) corresponde al
a 1, la función
de densidad
puedede
tomar
1. Los
niveles
áreaigual
sombreada
bajo la curva
a la izquierda
0,90 valores
mmol/l ysuperiores
es igual a aP(X
≤ 0,90)
= 0,3274.
esperanza
o
media
poblacional
de
una
Al
igual
que
para
variables
discretas,
la
Esta probabilidad también puede obtenerse a partir de la función de distribución del colesterol
de colesterol
HDL próximos
a 13.3(b).
mmol/lEsta
sonfunción
los quepresenta
tienen mayor
probabilidad
de de
HDL,
que se representa
en la Figura
el aspecto
característico
variable
aleatoria
representa
el valorcontinuas
promedioaproximadamente
de esa variable, ysimétricas.
se define
las funciones
decontinua
distribución
para variables
ocurrir, mientras que para niveles inferiores y superiores esta probabilidad
como
Al
igual que para variables discretas, la esperanza o media poblacional de una variable
por ejemplo,
la promedio
probabilidad
de que
un hombre
adultocomo
tenga un nivel
aleatoria decrece.
continuaAsí,
representa
el valor
de esa
variable,
y se define
∞
E(X)mmol/l
= x(niveles
f ( x) dxbajos
.
de colesterol HDL inferiorμa=0,90
según las
−∞
Program”) corresponde al
recomendaciones del “National Cholesterol Education
1,5
1
La varianza poblacional de una variable aleatoria continua es la esperanza de las
área sombreada bajo la curva a la izquierda de
0,90 mmol/l y es igual a P(X ≤
0,75
desviaciones
al cuadrado de los valores de la variable
respecto de su media, y se calcula
1
0,90) = 0,3274. Esta probabilidad también
obtenerse a partir de la función
f(x)
F(x) puede
0,5
como
0,5
de distribución del colesterol HDL, que se representa en la Figura 3.3( b). Esta
∞
0,25
σ 2 = var(X) = E(X - μ)2 = ( xde
− μ ) 2 f ( x) dx
función presenta el aspecto característico
las funciones de distribución para
−∞
0
0
∞simétricas.
variables
continuas
aproximadamente
2
2
2
2
0
0,5
1
1,5
2
2,5
=
x f ( x) dx − 0μ =0,5E(X ) 1- μ . 1,5
−∞
Colesterol HDL (mmol/l)
2
2,5
Colesterol HDL (mmol/l)
La raíz cuadrada de la varianza
es la desviación
típica poblacional
3.3 aproximadamente
aquí] σ, que
(a) [Figura
(b)representa la
Figura 3.3 Función de densidad de probabilidad (a) y función de distribución (b) del colesterol HDL en
dispersión de la variable aleatoria respecto de su media poblacional. Estas expresiones
hombres adultos.
Figura 3.3
30
para la media y la varianza poblacional de una variable continua son similares a las
Pastor-Barriuso R.
facilitadas para variables discretas, salvo que la suma sobre el número discreto de
15
−∞
∞
= x 2 f ( x) dx − μ 2 = E(X2) - μ2.
La varianza poblacional de una variable−∞aleatoria continua es la esperanza de las
σ, que representa
la continuas
La raíz cuadrada de la varianza es la desviación típica poblacionalDistribuciones
de probabilidad
cuadrado
de los
valores
de la variable
respecto deσ,su
media,
y se calcula
que
representa
la
Ladesviaciones
raíz cuadradaalde
la varianza
es la
desviación
típica poblacional
dispersión de la variable aleatoria respecto de su media poblacional. Estas expresiones
Lacomo
varianza
de una variable
continua
es la esperanza
de las desviaciones
dispersión
de poblacional
la variable aleatoria
respectoaleatoria
de su media
poblacional.
Estas expresiones
para
la media
la varianza
una variable
continua
son
similares
a las
al
cuadrado
deylos
valores depoblacional
la variablede
respecto
de su media,
y se
calcula
como
para la media y la varianza
poblacional de
2
2 una∞variable 2continua son similares a las
facilitadas para variables
discretas,
σ = var(
X ) = E(Xsalvo
μ ) que
= la( suma
x − μ )sobre
f ( x)eldxnúmero discreto de
−
Existen muchos modelos teóricos de distribuciones
continuas, cada una de ellas
−∞
facilitadas para variables discretas, salvo que la
de
∞ suma sobre el número2discreto
2
2 la integral 2sobre todos los
valores con probabilidad no nula se reemplaza
por
posibles
−
=
x
f
(
x
)
dx
−
μ
=
E
(
X
)
μ
.
caracterizada por una fórmula o expresión
−∞concreta para la función de densidad. A
valores con probabilidad no nula se reemplaza por la integral sobre todos los posibles
valores
de la variable
continua.es la desviación típica poblacional σ, que representa la dispersión
La
raíz cuadrada
de la varianza
continuación se revisa en detalle la distribución normal, que es la utilizada con mayor
de la variable aleatoria respecto de su media poblacional. Estas expresiones para la media y la
valores de la variable continua.
, que representa
la
La raíz poblacional
cuadrada de de
la varianza
es la desviación
típica
poblacional
varianza
una variable
continua son
similares
a las σ
facilitadas
para variables
t de Student,
chifrecuencia
en estadística.
Otras
distribuciones
continuas,
como la
Ejemplo
la función
de densidad
ejemplo
anterior,
el valor
discretas,
salvo3.10
que Utilizando
la suma sobre
el número
discreto del
de valores
con
probabilidad
no nula se
reemplaza
por
lalaintegral
sobre
los posibles
la variable
continua.
dispersión
de3.10
variable
aleatoria
respecto
de suvalores
media
poblacional.
Estas
Ejemplo
Utilizando
latodos
función
de densidad
del de
ejemplo
anterior,
elexpresiones
valor
decolesterol
Fisher, seHDL
discutirán
vayande
surgiendo
lo
largosería
del
texto.
cuadrado
o Fdel
esperado
en unasegún
población
hombresaadultos
paraesperado
la mediadel
y lacolesterol
varianza
poblacional
una
variable
continua
son
similares
a las esperado
Ejemplo
3.10
Utilizando
laen
función
de
densidad
del
ejemplo
anterior,
HDL
una de
población
de hombres
adultos
sería el valor
3.3.1
Distribución
normal
∞
del colesterol HDL en una población de hombres adultos sería
μ = salvo
x f ( xque
) dxla=suma
1,10 sobre
mmol/l,
facilitadas para variables discretas,
el número discreto de
0
∞
La distribución normal, también
denominada
distribución
Gaussiana,
es el modelo
μ = x f ( x) dx = 1,10 mmol/l,
0
valores con probabilidad no nula se reemplaza por la integral sobre todos los posibles
y la desviación
típica
teórico
de distribución
y la desviación
típicacontinua más utilizado en la práctica. Muchas mediciones
valores
de la variable
continua.
y la desviación
típica
1 / 2 similares al modelo teórico normal
epidemiológicas y clínicas presentan
distribuciones
∞
2
σ = ( x − 1,10) f ( x) dx
= 0,30 mmol/l.
∞0
1 / 2
2
Ejemplo
3.10colesterol
Utilizando
valor
(presión
arterial,
índice
masa
o bienanterior,
pueden el
transformarse
σ = sérico,
( xla−función
1,10
) f de
(de
x)densidad
dx corporal)
= del
0,30ejemplo
mmol/l.
0
Existen
muchosdel
modelos
teóricos
de
continuas,
cada
una demediante
ellas caracterizada
colesterol
HDL
endistribuciones
una población
de hombres
adultos
sería
para esperado
conseguir
distribuciones
aproximadamente
normales
(típicamente
por una fórmula o expresión concreta para la función de densidad. A continuación se revisa
16 en
detalle
la
distribución
normal,
que
es
la
utilizada
con
mayor
frecuencia
en
estadística.
Otras
transformaciones logarítmicas de los
∞ datos originales). No obstante, como se verá en los
16
distribuciones continuas, como laμt=de Student,
chi-cuadrado
o F de Fisher, se discutirán según
x f ( x) dx
= 1,10 mmol/l,
0
vayan
surgiendo
a
lo
largo
del
texto.
temas posteriores, la utilidad fundamental de la distribución normal surge dentro de las
y la de
desviación
típica
3.3.1
Distribución
normal
técnicas
inferencia
estadística: incluso cuando la distribución poblacional de una
La distribución normal, también denominada distribución
Gaussiana, es el modelo teórico de
2
variable diste mucho de ser normal,
puede
probarse1 / que,
bajo ciertas condiciones, la
∞
2
distribución continua más utilizado
epidemiológicas y clínicas
σ = en
( x −la1práctica.
,10) f ( xMuchas
) dx mediciones
= 0,30 mmol/l.
al0 modelo teórico normal
(presión arterial, colesterol sérico, índice
presentan distribuciones similares
distribución de los valores medios de dicha variable seguirá un modelo
de masa corporal) o bien pueden transformarse para conseguir distribuciones aproximadamente
normales (típicamente mediante transformaciones logarítmicas de los datos originales). No obstante,
aproximadamente normal.
como se verá en los temas posteriores, la utilidad fundamental de la distribución normal surge dentro
16
de las técnicas de inferencia estadística: incluso cuando la distribución poblacional de una variable
Una variable aleatoria continua X sigue una distribución normal si su función de
diste mucho de ser normal, puede probarse que, bajo ciertas condiciones, la distribución de los
valores medios de dicha variable seguirá un modelo aproximadamente normal.
densidad es
Una variable aleatoria continua X sigue una distribución normal si su función de densidad es
f (x) =
(x − μ) 2
exp −
2σ 2
2π σ
1
,
para cualquier valor x en la recta real, – ∞ < x < ∞. Esta función de densidad depende de los
parámetros
μ y σ, donde
para cualquier
valor x en la recta real, -∞ < x < ∞. Esta función de densidad depende de
yy μ representa la esperanza o media poblacional de la distribución y
σ,desviación
donde
ylos
y σ parámetros
correspondeμaysu
típica poblacional.
•
μ representa la esperanza o media poblacional de la distribución y
Pastor-Barriuso R.
17
31
Variables aleatorias y distribuciones de probabilidad
1
2π σ
•
σ corresponde a su desviación típica poblacional.
La distribución normal o Gaussiana con media μ y varianza σ 2 se denota
abreviadamente
por N(μ, σ 2). Para cualquier μ y σ > 0, la función de densidad normal
f(x)
es positiva y el área total bajo la curva es igual a 1. Esta función de densidad, que
aparece representada en la Figura 3.4, tiene forma de campana, es simétrica alrededor
• σ corresponde
típica
poblacional.
en μ + σ ya μsu- desviación
σ. Al tratarse
de una
de la media μ y tiene dos puntos de inflexión
0
Lamediana
distribución
normalElo valor
Gaussiana
con media μ y varianza σ 2 se denot
distribución simétrica, la media y la
coinciden.
más frecuente
μ - 3σ
μ - 2σ
μ-σ
μ
μ+σ
2
μ + 2σ
μ + 3σ
N(μ, σ del
). Para
μ y σ > 0, la función de de
abreviadamente
y su dispersiónpor
alrededor
valorcualquier
medio aumenta
1/( 2π σ) se alcanza en la media μ
x
Figura 3.4
positiva
yprobarse
el área total
la curva
igual
a 1. Esta función de dens
.es
Así,
puedenormal
que bajo
elμ68,27%
deles
área
bajo
al aumentar
la desviación
Figura
3.4 Función
de densidadtípica
de unaσdistribución
con media
y desviación
típica
σ. una
aparece representada
tiene
de campana, es simét
σ, la
el Figura
95,45%3.4,
entre
μ ±forma
2σ y el
función de densidad normal está comprendido
entre μ ± en
2
La distribución normal o Gaussiana con media μ y varianza σ se denota abreviadamente
μ ydetiene
dos puntos
de es
inflexión
enyμel+ área
σ y μ - σ. Al tratars
). Para
μ y σ > de
0, la
la media
función
densidad
normal
positiva
por99,73%
N(μ, σ 2entre
μ ±cualquier
3σ.
total bajo la curva es igual a 1. Esta función de densidad, que aparece representada en la
y la μmediana
Figura 3.4, tiene forma de campana, distribución
es simétricasimétrica,
alrededorlademedia
la media
y tiene coinciden.
dos puntosEl valor más fre
de inflexión en μ + σ y μ – σ. Al[Figura
tratarse3.4
deaproximadamente
una distribución simétrica,
la media y la mediana
aquí]
media
μ y μsuydispersión
alrededor del valor
se alcanza
alcanzaenenla la
media
su dispersión
coinciden. El valor más frecuente 1/( 2π σ) se
alrededor del valor medio aumenta al aumentar la desviación típica σ. Así, puede probarse
distribución
normal
con función
media
0 de
y desviación
típica 1 está
se denomina
que elLa
68,27%
del área
bajo una
densidad
normal
comprendido
μ ± σ,que el 68,27% d
σ. Así, distribución
puedeentre
probarse
al aumentar
la desviación
típica
el 95,45% entre μ ± 2σ y el 99,73% entre μ ± 3σ.
normal estandarizada, y suele denotarse por
Z o N(0, normal
1). La función
de densidadentre
de μ ± σ, el 95,45% en
de densidad
está comprendido
La distribución normal con media 0función
y desviación
típica 1 se denomina
distribución
normal
estandarizada,
y suele
denotarse
por Z o se
N(0, 1). La
función de densidad de una distribución
una distribución
normal
estandarizada
99,73%reduce
entre μa ± 3σ.
normal estandarizada se reduce a
f (z) =
1
exp − z 2 ,
2
2π
1
[Figura 3.4 aproximadamente aquí]
para cualquier – ∞ < z < ∞, que se representa en la Figura 3.5(a). Como puede observarse,
La distribución
normal
media
0 y desviación
típica
se trata
de una función
deen0.la Para
obtener
probabilidades
bajo
la 1 se denomin
∞, que sealrededor
representa
Figura
3.5(con
a).las
Como
puede
para cualquier
-∞ < z <simétrica
función de densidad normal estandarizada, no se recurre al cálculo integral, ya que estas
estandarizada
y Para
suele
denotarse
por Z facilitan
o N(0, 1). La función de
probabilidades
están
y son normal
fácilmente
accesibles.
En
general,
estas
observarse, se
tratatabuladas
de una función
simétrica
alrededor
de ,0.
obtener
lastablas
la función de distribución; es decir, la probabilidad de que la variable normal estandarizada
una
estandarizada
se
reduce
tome
un valor igual
La distribución
función
de normal
distribución
normal
estandarizada
se
probabilidades
bajoolainferior
función adez.densidad
normal
estandarizada,
no se recurre
al a
denota por F(z) = P(Z ≤ z), y se ilustra en la Figura 3.5(b). En la Tabla 3 del Apéndice se
facilita
la función
F(z) para valores
de z no negativos.
cálculo
integral,de
yadistribución
que estas probabilidades
están tabuladas
y son fácilmente
1
1
f ( z) =
exp − z 2 ,
2π la 2
accesibles. En general, estas tablas facilitan la función de distribución; es decir,
z.
probabilidad de que la variable normal
estandarizada
unque
valor
o inferior
z < ∞,
se igual
representa
en laaFigura
3.5(a). Como p
para cualquier
-∞ <tome
32
Pastor-Barriuso R.
observarse, se trata de una función simétrica alrededor de 0. Para obtene
18
Distribuciones de probabilidad continuas
f(z)
Φ(z)
1
0,5
-3
-2
-1
0
1
2
3
-3
-2
-1
0
z
z
(a)
(b)
1
2
3
Figura 3.5 Función de densidad (a) y función de distribución (b) de una variable aleatoria normal
estandarizada.
Figura 3.5
Ejemplo 3.11 La probabilidad de obtener un valor inferior a 0,50 en una distribución
normal estandarizada se obtiene directamente de la Tabla 3 del Apéndice como el valor
de la función de distribución en 0,50; es decir, P(Z ≤ 0,50) = F(0,50) = 0,6915.
Asimismo, aunque en la Tabla 3 del Apéndice no aparecen las probabilidades acumuladas
para valores negativos, la probabilidad de obtener un valor inferior a – 0,25 en una
distribución normal estandarizada puede calcularse fácilmente a partir de dicha tabla.
Como la distribución normal estandarizada es simétrica alrededor de 0, la probabilidad
a la izquierda de – 0,25 es igual a la probabilidad a la derecha de 0,25 y, en consecuencia,
P(Z ≤ – 0,25) = P(Z ≥ 0,25) = 1 – P(Z ≤ 0,25) = 1 – F(0,25) = 1 – 0,5987 = 0,4013. A
partir de los resultados anteriores, la probabilidad de que un valor de la distribución normal
estandarizada. Este resultado será particularmente útil en los temas de inferencia
estandarizada se encuentre entre – 0,25 y 0,50 viene dada por P(– 0,25 ≤ Z ≤ 0,50) = P(Z ≤
0,50)
– P(Z ≤ – 0,25) = 0,6915 – 0,4013 = 0,2902.
estadística.
El percentil 97,5 de una distribución normal estandarizada se denota por z0,975 y corresponde
al valor z que deja por debajo una probabilidad del 0,975. De la Tabla 3 del Apéndice, se
y
El
calculo
de probabilidades
cualquier
distribución
normal
con media
= 1,96. Por
tratarse
de unaμ distribución
tiene
que F(1,96)
= 0,9750 para
y, por
tanto, z0,975
simétrica en 0, el percentil 2,5 corresponde al percentil 97,5 con signo opuesto; es decir,
– z0,975 específicas,
= – 1,96. Así,sino
los que
valores
± 1,96
abarcan
el 95%
el percentil
es z0,025de= tablas
σ 2 no2,5
requiere
puede
realizarse
a partir
decentral
las de
varianza
la distribución normal estandarizada. Este resultado será particularmente útil en los temas
de inferencia
estadística.
tablas
de la distribución
normal estandarizada. Para ello, se hace uso del siguiente
resultado
la estandarización
de una distribución
normal:
si con
una variable
El cálculosobre
de probabilidades
para cualquier
distribución
normal
media μ aleatoria
y varianza σ 2
no requiere de tablas específicas, sino que puede realizarse a partir de las tablas de la distribución
X sigue
una distribución
normal
con media
y varianzaresultado
σ 2, X ~ sobre
N(μ, σla2),estandarización
entonces la de
normal
estandarizada.
Para ello,
se hace
uso delμ siguiente
una distribución normal: si una variable aleatoria X sigue una distribución normal con media μ
2
, X ~ N(μ,
la una
variable
aleatorianormal
Z = (Xestandarizada,
– μ)/σ sigue una distribución
y varianza
Z =σ(2X),-entonces
μ)/σ sigue
distribución
variable σaleatoria
normal estandarizada,
Z=
X −μ
σ
~ N(0, 1),
donde el símbolo ~ significa “estar distribuido como”. Como ya se comentó enPastor-Barriuso
el Tema R.
1, al restar a los valores de una variable su media y dividirlos por su desviación típica,
33
procedimiento de estandarización de variables normales permite utilizar las tablas
Variables aleatorias y distribuciones
de probabilidad
correspondientes
a la distribución
normal estandarizada.
3.12
Supongamos
el colesterol
HDL
en una
población
dondeEjemplo
el símbolo
~ significa
“estarque
distribuido
como”.
Como
ya se
comentó de
en hombres
el Tema 1, al restar
a los valores de una variable su media y dividirlos por su desviación típica, la variable resultante
X con media
μ = 1,10
mmol/l
y desviación
una distribución
tiene adultos
media sigue
0 y desviación
típica normal
1. El resultado
anterior
garantiza
además
que la variable
estandarizada conserva la distribución normal. Este procedimiento de estandarización de variables
σ = 0,30
mmol/l.
Utilizando
la estandarización
de variables
normales,
el
típicapermite
normales
utilizar
las tablas
correspondientes
a la distribución
normal
estandarizada.
Ejemplo 3.12
Supongamos
el colesterol
HDLniveles
en una de
población
de HDL
hombres adultos
porcentaje
de hombres
de estaque
población
que tienen
colesterol
sigue una distribución normal X con media μ = 1,10 mmol/l y desviación típica σ = 0,30
mmol/l.
la estandarización
entre
0,90Utilizando
y 1,20 mmol/l
corresponde ade variables normales, el porcentaje de hombres de
esta población que tienen niveles de colesterol HDL entre 0,90 y 1,20 mmol/l corresponde a
0,90 − 1,10 X − 1,10 1,20 − 1,10
P(0,90 ≤ X ≤ 1,20) = P
≤
≤
0,30
0,30
0,30
= P (− 0,67 ≤ Z ≤ 0,33) = P(Z ≤ 0,33) − P(Z ≤ − 0,67).
Utilizando la Tabla 3 del Apéndice, se obtiene que P(Z ≤ 0,33) = F(0,33) = 0,6293 y P(Z
20
≤ – 0,67) = F(– 0,67) = 1 – F(0,67) = 1 – 0,7486 = 0,2514. Así, resulta que P(0,90 ≤ X ≤
1,20) = 0,6293 – 0,2514 = 0,3779; es decir, el 37,79% de los hombres de esta población
tienen niveles de colesterol HDL entre 0,90 y 1,20 mmol/l.
Para obtener el percentil 90 de la distribución del colesterol HDL en esta población, se
calcula primero el percentil 90 en la distribución normal estandarizada, que corresponde
a z0,90 = 1,28, ya que F(1,28) ≈ 0,90. Para pasar este percentil estandarizado al
correspondiente percentil del colesterol HDL basta resolver z0,90 = (x0,90 – μ)/σ. Por tanto,
el percentil 90 del colesterol HDL es x0,90 = μ + z0,90σ = 1,10 + 1,28∙0,30 = 1,484 mmol/l.
3.3.2 Aproximación normal a la distribución binomial
El cálculo de las probabilidades binomiales es muy laborioso cuando el número de pruebas n en
muy elevado. Como se vio anteriormente, si n es grande y la probabilidad de éxito π es muy
pequeña, la distribución binomial puede aproximarse mediante una distribución de Poisson. En
este apartado, se revisa el comportamiento de una distribución binomial para un número de
pruebas n grande y una probabilidad individual de éxito π no excesivamente extrema. En la
Figura 3.6 se muestran las distribuciones binomiales para los parámetros π = 0,10 y n = 10, 25,
50 y 100. Al aumentar el número de pruebas, la distribución binomial tiende a ser más simétrica
y se aproxima progresivamente a una distribución normal con la misma media nπ y varianza
nπ(1 – π) que la distribución binomial (Figura 3.6(d)). En general, puede probarse que si el
número de pruebas n es elevado y la probabilidad de éxito π no es excesivamente extrema, de
forma que nπ(1 – π) ≥ 5, la distribución binomial con parámetros n y π se aproxima a una
distribución normal con media nπ y varianza nπ(1 – π).
Este resultado es un caso particular del llamado teorema central del límite, que se presentará
más adelante (véase Tema 4), y se utiliza para aproximar las probabilidades binomiales mediante
la distribución normal. Así, para una variable binomial X con parámetros n y π que cumpla las
condiciones anteriores, la probabilidad P(k1 ≤ X ≤ k2) se aproxima mediante el área bajo la curva
de la distribución normal N(nπ, nπ(1 – π)) entre k1 – 1/2 y k2 + 1/2, donde k1 ≤ k2 son números
enteros cualesquiera. Notar que, al utilizar la aproximación normal, los límites del intervalo se
amplían en 1/2 para incluir las probabilidades de obtener exactamente k1 o k2 éxitos. Este ajuste
se conoce como corrección por continuidad y se deriva del hecho de aproximar una distribución
binomial discreta mediante una distribución normal continua.
34
Pastor-Barriuso R.
extrema, de forma que nπ(1 - π) ≥ 5, la distribución binomial con parámetros n y π se
Distribuciones de probabilidad continuas
aproxima a una distribución normal con media nπ y varianza nπ(1 - π).
0,4
0,4 aquí]
[Figura 3.6 aproximadamente
0,3
0,3
Este
central del límite, que se
P(X =resultado
k) 0,2 es un caso particular del llamado teorema
0,2
0,1
0,1
presentará más
adelante (véase Tema 4), y se utiliza para
aproximar las probabilidades
0
0
binomiales mediante la distribución normal. Así, para una variable binomial X con
0
5
10
15
20
0
5
10
15
20
anteriores, la probabilidad P((b)
k1 ≤ X ≤ k2 )
parámetros n y π que cumpla las condiciones
(a)
0,4
0,4
0,3
0,3
se aproxima mediante el área bajo la curva de la distribución normal N(nπ, nπ(1 - π))
k - 1/2 y k2 + 1/2, donde k1 ≤ k2 son números enteros cualesquiera. Notar que, al
entre
P(X1= k)
0,2
0,2
0,1
0,1 se amplían en 1/2 para incluir
utilizar la aproximación
normal, los límites del intervalo
0
0
las probabilidades de obtener exactamente k1 o k2 éxitos. Este ajuste se conoce como
0
5
10
15
20
0
5
10
corrección por continuidad y se deriva
del hecho de aproximar una distribución
k
k
(c)
binomial discreta mediante una distribución normal continua.
15
20
(d)
Figura 3.6 Distribuciones binomiales con parámetros π = 0,10 y n = 10 (a), 25 (b), 50 (c) y 100 (d). En el panel d,
se representa además la función de densidad de una distribución normal con media nπ = 100∙0,10 = 10
Ejemplo
probabilidad
y varianza
nπ(1 –3.13
π) = La
100∙0,10∙0,90
= 9. de obtener entre 12 y 14 éxitos sobre un total de
100 pruebas con una probabilidad individual de éxito del 0,10 se obtiene a partir
Ejemplo 3.13 La probabilidad de obtener entre 12 y 14 éxitos sobre un total de 100
pruebas
con una binomial
probabilidad
obtiene a partir de la
X conindividual
parámetrosden éxito
= 100 del
y π 0,10
= 0,10secomo
de
la distribución
distribución binomial X con parámetros n = 100 y π = 0,10 como
P(12 ≤ X ≤ 14) =
100
0,10 k (1 − 0,10)100 − k
k =12 k
14
= 0,0988 + 0,0743 + 0,0513 = 0,2244,
cuyo cálculo es bastante laborioso. Sin embargo, como nπ(1 – π) = 100∙0,10∙0,90 = 9 ≥ 5,
una
razonable
a esta probabilidad
de la⋅0,90
distribución
nπ(1 - π)a=partir
100⋅0,10
cuyoaproximación
cálculo es bastante
laborioso.
Sin embargo,puede
comoobtenerse
normal Y con media nπ = 100∙0,10 = 10 y varianza nπ(1 – π) = 9 mediante
= 9 ≥ 5, una aproximación razonable a esta probabilidad puede obtenerse a partir
11,5 − 10 Y − 10 14,5 − 10
P(11,5 < Y < 14,5) = P
<
<
de la distribución normal Y con media nπ =3 100⋅0,103= 10 y varianza
3
nπ(1 - π) = 9
= P(0,5 < Z < 1,5) = Φ(1,5) − Φ(0,5)
mediante
= 0,9332 − 0,6915 = 0,2417.
Esta probabilidad corresponde al área sombreada en la Figura 3.6(d).
22
Esta probabilidad corresponde al área sombreada en la Figura 3.6(d).
3.3.3 Aproximación normal a la distribución de Poisson
Pastor-Barriuso R.
La distribución normal también puede emplearse como aproximación a la distribución
35
moderadamente elevado, típicamente μ ≥ 10. Así, para una variable aleatoria X que siga
Variables aleatorias y distribuciones de probabilidad
a una distribución de Poisson con parámetro μ moderadamente grande, la probabilidad
P
(k1 ≤ XAproximación
≤ k2) puede aproximarse
mediante
el áreadebajo
la curva de la distribución
3.3.3
normal a la
distribución
Poisson
La distribución normal también puede emplearse como aproximación a la distribución de Poisson
normal N(μ, μ) entre k1 - 1/2 y k2 + 1/2.
cuando el número esperado de casos μ es moderadamente grande. En la Figura 3.7 se representan las
distribuciones de Poisson con parámetros μ = 1, 2,5, 5 y 10, donde puede apreciarse que, al aumentar
el número esperado de casos, las
probabilidades
de Poisson tienden
[Figura
3.7 aproximadamente
aquí]a distribuirse de forma normal. En
términos generales, una distribución de Poisson con parámetro μ se aproxima a una distribución
normal con media y varianza iguales a μ, cuando el número esperado de casos es moderadamente
elevado, típicamente μ ≥ 10. Así, para una variable aleatoria X que siga a una distribución de Poisson
k2)largo
puededeaproximarse
con parámetro
moderadamente
la probabilidad
P(k1 ≤ X a≤ lo
Ejemploμ3.14
Si el númerogrande,
de casos
de una enfermedad
un año en mediante
el área bajo la curva de la distribución normal N(μ, μ) entre k1 – 1/2 y k2 + 1/2.
una determinada población sigue una distribución de Poisson X de parámetro μ =
Ejemplo 3.14 Si el número de casos de una enfermedad a lo largo de un año en una
determinada
población
sigue
distribución
Poisson
parámetro μ = 10, la
10,
la probabilidad
de tener
15 una
o más
casos en undemismo
añoXesde
exactamente
probabilidad de tener 15 o más casos en un mismo año es exactamente
e −10 10 k
P(X ≥ 15) =
= 0,0835,
k!
k ≥15
que puede aproximarse mediante la distribución normal Y ~ N(10, 10) como
que puede aproximarse mediante la distribución normal Y ~ N(10, 10) como
23
Y − 10 14,5 − 10
P(X ≥ 15) ≈ P(Y > 14,5) = P
>
10
10
= P(Z > 1,42) = 1 − Φ(1,42) = 1 − 0,9222 = 0,0778.
Esta aproximación corresponde al área sombreada bajo la curva normal en la Figura 3.7(d).
Esta aproximación corresponde al área sombreada bajo la curva normal en la
0,4
0,4
0,3
0,3
P(X = k) 0,2
0,2
Figura 3.7(d).
0,1
0,1
3.4 COMBINACIÓN
LINEAL DE VARIABLES ALEATORIAS
0
0
En este apartado se introducen algunas propiedades de la combinación lineal de
0
5
10
15
20
0
5
10
15
20
(a)
(b) e
variables aleatorias (discretas o continuas)
que serán útiles para la estimación
0,4
0,4
inferencia estadística.
En particular, se pretende derivar
el valor esperado y la varianza
0,3
0,3
= k) 0,2
0,2ck son constantes arbitrarias y X1,
de laP(X
combinación
lineal c1X1 + ... + ckXk, donde c1, ...,
0,1
0,1
0
0
..., Xk son variables aleatorias con esperanzas μ1, ..., μk y varianzas σ 12 , ..., σ k2 . Como el
valor esperado de la
aleatorias
0 suma 5de variables
10
15
20es igual a0la suma
5 de sus10respectivas
15
esperanzas, se tiene que
k
k
(c)
(d)
20
Figura 3.7 Distribucionesk de Poisson con
parámetros kμ = 1 (a), 2,5 (b),
5 (c) y 10 (d). En el panel d, se rek
de densidad
k de una distribución
presenta además la función
normal con media y varianza iguales a μ = 10.
36
Pastor-Barriuso R.
E c i X i = E (c i X i ) = c i E ( X i ) = c i μ i ,
i =1
i =1
i =1
i =1
ya que E(ciXi) = ciE(Xi). Es decir, la esperanza de una combinación lineal de variables
k
k 2 2
2
2
ci μ i + 2 ci c j μ i μ j
=
c
E
(
X
)
+
2
c
c
E
(
X
X
)
−
ÓN LINEAL DE VARIABLES ALEATORIAS
i
i
i j
i
j
variables aleatorias (discretas o continuas)
que serán1≤útiles
i =1
i < j ≤ k para la estimación
1≤ i < j ≤ k
i =1 e
k
Combinación lineal de variables aleatorias
introducen algunas
propiedades
de la combinación
lineal
=
cde{E ( X derivar
) − μ }el
+ valor
2 cesperado
− μi μ j }
inferencia
estadística.
En particular,
se pretende
i c j {E ( X y
i Xlaj )varianza
i =1
2
i
2
i
2
i
1≤ i < j ≤ k
(discretas o continuas)
que serán útiles
para
la estimación
2
+ c Xk,2edonde
c ,ALEATORIAS
..., ck son constantes arbitrarias y X1,
la combinación
lineal
3.4de COMBINACIÓN
k c1X1 + 2...
c i σ i2+ 2 1
c i c j {E ( X i X j ) − μ i μ j }.
k
LINEAL
DE= VARIABLES
var ci X i = E ci X i −
i =1 c i μ i
1≤ i < j ≤ k
ca. En particular,
pretende
derivar
el
esperado
varianza
i =1 variables
i =1
se introducen
valor
algunas
iy=1la
μ1, ..., μ
Ense
este
apartado
propiedades
dek ylavarianzas
combinación
lineal
variables
Xk son
aleatorias
con
esperanzas
σ 12 , ...,
σ k2 . de
Como
el
...,
aleatorias (discretas o continuas)
que serán útiles para la estimación
e
inferencia
estadística.
k
k
En
2
2 2
+ ckXk, donde
c1, ...,Así,
c
son
constantes
arbitrarias
y
X
,
lineal c1X1 + ... particular,
lac i2varianza
de
una
combinación
lineal
no
depende
sólo
de
la
varianza
específica de
kderivar
1
X
se pretende
el
valor
esperado
y
la
varianza
de
la
combinación
lineal
c
=
E
(
X
)
+
2
c
c
E
(
X
X
)
−
c
μ
+
2
c
c
μ
μ
i j
ies igual
j
i
i de sus
i j i
j1 1 + ...
a
valor esperado de la suma de ivariables
aleatorias
la suma
respectivas
i
=
1
1
≤
i
<
j
≤
k
i
=
1
1
≤
i
<
j
≤
k
+ ckXk, donde c1, ..., ck son constantes arbitrarias y X1, ..., Xk son variables aleatorias con
2
k variable σ , ...,
aleatorias con esperanzas μ11,, ..., μcada
σ 2también
el los
.. Comode
valor
esperado
de variables
sino
términos
E(Xde
) - suma
μiμj, que
se conocen como
iXjla
kk y varianzas
2
2 1
2 k
esperanzas, se tiene
que
=
c
{
E
(
X
)
−
μ
}
+
2
c
c
{
E
(
X
X
)
−
μ
μ
}
aleatorias es igual a la
suma
esperanzas,
quei j
i j sei tiene
i de sus
i respectivas
i
j
i =1
1≤ i < j ≤ k
a suma de variables aleatorias es igual
a la suma
de sus
covarianzas
entre
las respectivas
variables Xk i y Xj. En general,
la covarianza poblacional entre dos
k
k
k2 2 k
=
2 =
) i−Eμ
E c
( Xi μi )j }=. c i μ i ,
cEi c(cj {i XE (i )X=i X
i σci X+i
jc
e que
μx yi =μ1 y se define como
variables
i =1
1≤i <i =j 1≤ kX e Y con esperanzas
i =1 i =1 aleatorias
k
kk
ya que E(ciXi) = ciE(Xi). Es decir, la esperanza de una combinación lineal de variables aleatorias
2
k
k
kk i) =lineal
ksus
k
yacombinación
que E(ciX
ciuna
E(Xde
). Es
decir,
de
lineal
deespecífica
k
es
cov(
Xno
, Y2)depende
= Euna
{(Xcombinación
-sólo
μx)(Yde- la
μy)}
= E(XY
)variables
- μxμy, de
la
esperanzas.
icombinación
Así,
de
lineal
varianza
, la esperanza
E ci X i =
E (clai Xvarianza
)
=
c
E
(
X
)
=
c
μ
var
ci iX i =i E
ci iX ii − ci μ i
i
=11
i =1
i =1 A partir de
resultado,
= E(X2) – μ2, puede calcularse la varianza
ii=este
ii==11y recordando
i =1que var(X)
aleatorias
es
la
lineal
de
sus
esperanzas.
2combinación
2
2
k variable
términos
E(XiXentre
se conocen
como
cada
de
combinación
lineal
variables
aleatorias
es una
relación como
lineal
Si valores
altos (o bajos) de
j) - μ
iμj, quevariables.
ktambién
k ambas
una
σ i k,ysino
demedida
k 2dedelos
la
2−
2 2
var ci X i = E ci=X
c
μ
X i )i + i2 ci c j E ( X i X j ) − c2 i μ i 2+ 2 ci c j μ i μ j
i c i E (
E(Xi). Es decir, la esperanza
de variables
i =1 A partir
i =1 combinación
=1lineal
de
este
calcularse
la
deuna
resultado,
recordando
2
i =1 k iy
1≤ i <kj ≤ k que 2var( X) = Ei(=X
1 ) - μ , puede
será
k
X
tienden
a
asociarse
con
valores
altos
(o bajos)
depoblacional
Y1≤,i <laj ≤ kcovarianza
covarianzas
entre
las
variables
X
y
X
.
En
general,
la
covarianza
entre
dospositiva;
i
j
var kci X2i = Ek2
ci X i 2 − 2 ci μ i k 2 2
2
mbinación lineal devarianza
sus esperanzas.
=i =1
E(=X
)c+
2E (
E
X
+como
2j ) −μci μi cj }j μ i μ j
X ic)i c−j de
μi(ivariables
}=1+i X2 j )
c j {cEi (μXi i X
i i=1{
de
− caleatorias
unacicombinación
lineal
i
i
mientras
que
si
valores
altos
de
una
variable
i =1
< j≤k
i =1 define como
1se
≤ i <relacionan
j ≤k
con valores bajos de la otra
X ei =k1Y con1≤iesperanzas
μx1≤yi <μj ≤ykse
variables aleatorias
k
2
2
2
2 2
k
k X) = =
E(
X
)c2i2- Eμ2( ,X
puede
calcularse la
resultado, y recordando que var(
i ) + 2 c i c j E ( X i X j ) − c i μi + 2 c i c j μi μ j
2
2
2
c la
σ icovarianza
+ 2
c1≤i ci <cserá
E ( negativa.
X X ) − μNo
}i .μ
resulta
complicado
= ci variable,
{E=( X
jj{
i μμ
jobstante,
i =1i )i − μ
i =1j }
1≤ i < j ≤ k
i }+ 2
i≤ck j {E i( X ji X j ) −
determinar el
i =1
1≤ i <1j≤≤ik< j ≤ k
i =1
cov(
k X, Y) = E{(X - μx)(Y - μy)} = E(XY) - μxμy,
mbinación lineal de variables aleatorias
como
k
grado
deci2relación
a partir
de la magnitud de la covarianza, ya
=
{E ( X i2 )lineal
− μ i2 }entre
+ 2 doscivariables
c {E ( X i X
j ) − μ i μj }
= c i2σ i2 +
2
c
c
{
E
(
X i X j ) −1≤μ
μ
}. j
i
j
i
j
i
=
1
i
<
j
≤
k
Así, la varianza
de una1combinación
lineal no depende sólo de la varianza específica de
i =1 de la relación
≤ i < j ≤ k lineal entre ambas variables. Si valores altos (o bajos) de
y es una medida
k
que ésta
depende
de
las
unidades de medida de las variables. Una medida alternativa del
2 2
2 = c i σ i + 2 c i c j {E ( X i X j ) − μ i μ j }.
también de
los términos E(XiXj) - μiμj, que se conocen como
cada variable σ i , sino
i =1 valores altos
1≤ i < j ≤ k (o bajos) de Y, la covarianza será positiva;
tienden de
a asociarse
con
X e Ydees el coeficiente de
grado
de asociación
entresólo
dosdevariables
aleatorias
Así, laXvarianza
una combinación
lineal nolineal
depende
la varianza
específica
24
Así, covarianzas
la varianza de
una
combinación
lineal
no
depende
sólo
de
la
varianza
específica
de
entre las variables Xi y Xj. En general, la covarianza poblacional entre dos cada
2
mientras
si valores
altos
de
una variable
se
relacionan
bajos
de la otra
correlación
poblacional
ρiXxy
, que
se
como
Así, σlaique
varianza
de una
combinación
lineal
no
depende
devalores
la varianza
específica
de
, sino
también
de
los
términos
E(X
sesecon
conocen
como
covarianzas
entre
sino
también
de
los
términos
E(X
,define
quesólo
conocen
como
cada variable
iX
j)j)–-μμ
iμiμ
j, jque
covarianza
las variables
i y Xj. En general,
X e Y conlaesperanzas
μx poblacional
y μy se defineentre
comodos variables aleatorias X e Y
variablesXaleatorias
2
variable,
la
covarianza
será
negativa.
No
obstante,
resulta
determinar
el
y
μ
se
define
como
con
esperanzas
μ
los términos
E(XiXj) -poblacional
μcomplicado
conocen
cada
variable
24
iμj,Xque
x σ i y, sino
covarianzas
entre
las variables
Xitambién
y Xj. Ende
general,
la covarianza
doscomo
cov(
, Y )se entre
ρxy =
,
− μ y)}
X, Ydos
) = Evariables
{(X − μ x)(aYpartir
XYσ) x−σμyxμ yde
, la covarianza, ya
cov(
grado de relación lineal
entre
de=laE(magnitud
lasesperanzas
variables Xμi xyyXμj.yEn
general,como
la covarianza poblacional entre dos
e Y con
se define
variables covarianzas
aleatorias X entre
y es una medida de la relación lineal entre ambas variables. Si valores altos (o bajos) de X
quevariables
depende
de
unidades
delas
medida
de lasvariables.
variables.
Una
medida
alternativa
del
yésta
es una
medida
delas
la
relación
lineal
entre
Si
valores
(o
bajos)de
decorrelación
σaltos
desviaciones
típicas
X
e Y.positiva;
Elaltos
coeficiente
carece
donde
Xσ
e xYycon
esperanzas
μambas
definede
como
aleatorias
tienden
a asociarse
con valores
(o bajos)
de
covarianza
será
mientras
que si
y son
x yY,μla
y se
cov(X, Y) = E{(X - μx)(Y - μy)} = E(XY) - μxμy,
valores altos de una variable se relacionan con valores bajos de la otra variable, la covarianza
X tienden
a asociarse
conentre
valores
altos
(o bajos)
de Y, la covarianza
será
positiva; de
X etal
Y es
coeficiente
grado
de asociación
lineal
dos
variables
aleatorias
será
negativa.
No obstante,
resulta
complicado
determinar
deelrelación
dos
ρxy = 1,entre
las variables
de unidades
y toma
valores entre
-1 y 1;eldegrado
forma
que si lineal
cov(X, Y) = E{(X - μx)(Y - μy)} = E(XY) - μxμy,
y es una
medidaa de
la relación
lineal entre
ambas
variables.yaSique
valores
altos
(o bajos)
deunidades de
variables
partir
de
la
magnitud
de
la
covarianza,
ésta
depende
de
las
mientras que
si valores altos
de una
variablecomo
se relacionan con valores bajos de la otra
ρxyuna
, que
se define
correlación
medida
de laspoblacional
variables.
Una
medida
alternativa
del grado
de asociación
entre dos
las variables
presentan una
presentan
relación
lineal positiva
perfecta,
y si ρxy = -1,lineal
X tienden
a es
asociarse
con
valores
altos
(o
bajos)
de
Y
,
la
covarianza
será
positiva;
yvariable,
una
medida
de
la
relación
lineal
entre
ambas
variables.
Si
valores
altos
(o
bajos)
de
,
que
se
define
como
variables
aleatorias
X
e
Y
es
el
coeficiente
de
correlación
poblacional
ρ
xy
la covarianza será negativa. No obstante, resulta complicado determinar
el
25
cov(
X
,
Y
)
ρse
mientras que
si valores
altos
de
una
variable
relacionan
con
valores
bajos
de
la
otra
,
xy =
Xgrado
tienden
a
asociarse
con
valores
altos
(o
bajos)
de
Y
,
la
covarianza
será
positiva;
de relación lineal entre dos variables aσpartir
σ de la magnitud de la covarianza, ya
x
y
variable,
la
covarianza
será
negativa.
No
complicado
determinar
el de lacarece
mientras
que si
valores
de obstante,
una
variable
relacionan
con
valores
bajos
otra
que
las altos
unidades
de medida
variables.
Una
medida
alternativa
del de
donde
σxésta
y σdepende
desviaciones
típicas
deresulta
Xdese
elas
Y.
El coeficiente
de correlación
y son lasde
unidades
valores
entre – 1 y 1;típicas
de tal de
forma
sicoeficiente
ρxy = 1, las de
variables
presentan
una
σxyytoma
σlay son
las desviaciones
Xlaemagnitud
Yque
. El
correlación
carece
donde
gradorelación
de relación
entre
dosserá
variables
partir
devariables
la covarianza,
ya
variable,
covarianza
negativa.
obstante,
resulta
complicado
determinar
el
X ede
Y es
el
coeficiente
de negativa
grado
delineal
asociación
lineal
entre
aleatorias
–No
1, las
presentan
una
relación
lineal
lineal
positiva
perfecta,
y si dos
ρxya=variables
perfecta. Cuando ρxy = 0, se dice que las variables están incorrelacionadas. Notar que si dos
1,del
lasla
variables
de depende
unidades
yindependientes,
toma
valores
yde
1;las
dede
tal
forma
que
si ρxy = alternativa
que ésta
las
unidades
medida
variables.
Una
del
grado
dede
relación
lineal de
entre
dos
variables
aque
partir
la medida
magnitud
de
covarianza,
yauna
correlación
poblacional
ρentre
, que
se
define
como
xy
variables
son
en
el-1sentido
el de
conocimiento
valor
que toma
es=el-1,coeficiente
de presentan
grado presentan
de asociación
lineal
entre
dos
variables
aleatorias
que éstauna
depende
de las
unidades
de perfecta,
medida deyXlas
medida
alternativa
delR.
lasUna
variables
una
relación
lineal
positiva
sie ρYvariables.
Pastor-Barriuso
cov( X , Y ) xy
ρxy =
,
σ x σaleatorias
y
X e Y es el coeficiente de
grado
de asociación
lineal
variables
correlación
poblacional
ρxy, que
se entre
definedos
como
25
37
xy
implica
necesariamente
ya en
queellas
variables
correlación
se discutiránindependencia,
en mayor detalle
Tema
10. podrían presentar una
Variables aleatorias y distribuciones de probabilidad
= 0. de
Este
y otros aspectos
coeficiente de
dependencia
node
lineal
cuando ρxy
La varianza
una aun
combinación
lineal
variables
aleatoriassobre
quedaelentonces
correlación
sepor
discutirán
mayor detalle
en elelTema
variable
no aporta
ningunaeninformación
sobre
valor10.
de la otra variable, entonces están
determinada
incorrelacionadas; pero que la incorrelación no implica necesariamente independencia, ya que
La varianza
de una
combinación
lineal de variables
aleatorias
quedaρ entonces
las variables
podrían
presentar
una dependencia
no lineal
aun cuando
xy = 0. Este y otros
k
k
2
2
aspectos sobre el coeficiente
correlación
se discutirán en mayor detalle en el Tema 10.
ci X
var de
i = c i σ i + 2 c i c j cov( X i , X j )
determinada por
1≤ i < j ≤ k
i =1
i =1
La varianza de una combinación
aleatorias
queda
E(X1 - X2) lineal
= μ1k - de
μ2 variables
= 130 - 80
= 50 mm
Hg entonces determinada por
2 2
= k ci σ i + 2 ci c j σ i σ j ρ ij ,
k
i =1 2 2
i< j≤k
cμi2σ=i 130
+ 21-≤
c=i c50
X j)
var
j cov(
i ,varianza
E(X
-c iXX2)i ==μ
80variables,
mmXlaHg
1 correlación
1 - entre
y, teniendo en cuenta
la
ambas
de la
1≤ i < j ≤ k
i =1
i =1
k
2
ρij es
coeficiente
dedada
correlación
y Xcj.cEn
el caso
de que las variables
donde
presión
delelen
pulso
vendría
por
= entre
c i2σentre
+ 2Xi
y,
teniendo
cuenta
la correlación
variables,
i ambas
i j σi σ j ρla
ij , varianza de la
i =1
1≤ i < j ≤ k
sean
mutuamente
independientes
(bastaría
la condición menos restrictiva de que
2
presión
del pulso
vendría
dada2por
var(
X
1 - X2) = σ 1 + σ 2 - 2σ1σ2ρ12
donde ρij es el coeficiente de correlación entre Xi y Xj. En el caso de que las variables sean
donde
ρij esincorrelacionadas),
el coeficiente de(bastaría
correlación
entre
las que
variables
i y Xj. En el caso
estuvieran
la varianza
de laXcombinación
linealdeesque de
mutuamente
independientes
la condición
menos restrictiva
estuvieran
2
22
22
+ 10
⋅10
X1 - X2) =de20
σla1 combinación
σ 2 - 2⋅σ20
ρ⋅120,60es= 260 (mm Hg) ,
incorrelacionadas),var(
la varianza
1σ
2lineal
sean mutuamente independientes (bastaría la condición menos restrictiva de que
k
k 2 2
2
2
2
var
c
X
ci σ =
=
+=
10
-i 2⋅mm
⋅10
⋅0,60
i20
i .260 (mm Hg) ,
para una incorrelacionadas),
desviación típica= 20
260
16,1
Hg.
estuvieran
la
varianza
de
la
combinación
lineal
es
i =1
i =1
Ejemplo
3.15 Supongamos
que=kla
media
yk la desviación típica de la presión arterial
para
una desviación
típica 260
16,1
mm
para
Hg.
2 2
Lossistólica
resultados
anteriores
son
válidos
cualquier
Nomm
obstante,
población
μ1 =cvariable
130 mm aleatoria.
Hg y σ1 = 20
Hg, y la media
X1 en una determinada
var
ci X i son
=
i σi .
Ejemplo
3.15 Supongamos que
la
media
y
la
desviación
típica
de
la
presión
=
1
=
1
i
i
son
μ
=
80
mm
Hg
y σ2 = 10 mm
y la desviación típica
de
la
presión
arterial
diastólica
X
E(X1 - X2) = μ1 - μ2 = 130 - 80 = 502 mm Hg
2
X
,
...,
X
siguen
una
distribución
normal,
puede
probarse
que
la
si las
variables
1 anteriores
kademás
Supongamos
que
elμcoeficiente
de- correlación
entre
arterial sistólica
Los Hg.
resultados
son
válidos
para cualquier
aleatoria.
No obstante,
EX(X
-X
80variable
= 50son
mmμ
Hg la presión
2) =determinada
1 - μ2 = 130
población
arterial sistólica
1 1en una
1 = 130 mm Hg y σ1 = 20
El valor
esperado de la presión del
y diastólica
de los sujetos
de esta
población es
ρ12 = 0,60.
y, teniendo
enc1cuenta
correlación
entre
ambas
la varianza
de lala
X
+
...lala+diferencia
cuna
seguirá
unavariables,
distribución
normal
con
combinación
lineal
kXk también
pulso,
definida
como
la presión
arterial
diastólica,
X1, ...,
X1kSupongamos
siguen
distribución
normal,
puede sistólica
probarse
que
si
las variables
Ejemplo
3.15
queentre
la media
y la desviación
típica yde
lalapresiónsería
mm Hg,en
y la
media
la desviación
típica
de la
presión arterial
diastólica
y, teniendo
cuenta
la ycorrelación
entre
ambas
variables,
la varianza
de la X2 son μ2
E
(
X
X
μ 1 − μ 2 = 130 − 80 = 50 mm Hg
1 − dada
2 ) =por
presión
del
pulso
vendría
media y varianza
descritas
anteriormente.
Este
resultado
se utilizará en
los temas
de
c1X1 + X...
+ ckXk también
seguirá
una distribución
normal
combinación
lineal
determinada
población
son μ1 = 130
mmcon
Hg la
y σ1 = 20
arterial
sistólica
1 en una
σ2 =la10dada
mmpor
Hg. Supongamos
quelaelvarianza
coeficiente
= 80del
mm
Hgcuenta
yvendría
presión
pulso
y, teniendo
en
correlación
entre ambasademás
variables,
de de
la presión del
2
2
inferencia.
y,
teniendo
en
cuenta
la
correlación
entre
ambas
variables,
la
varianza
de
la
vendría
dada
por
var(
X
X
)
=
σ
+
σ
2
σ
σ
ρ
media ypulso
varianza
descritas
anteriormente.
Este
resultado
se
utilizará
en
los
temas
de
1
1 de
2 12
1
2 típica
mm Hg, y la media
y2 la desviación
la presión arterial diastólica X2 son μ2
correlación entre la presión2 arterial
sistólica y diastólica de los sujetos de esta
2
var(Xvendría
1 − X2) = σ 1 + σ 2 − 2σ 1 σ 2 ρ 12
presión del pulso
dada 2por 2
inferencia.
+ 10
2⋅20⋅10⋅adultas
0,60
= 260
(mm
Hg)2, sigue
20 Hg.
2 - mujeres
σ
además
coeficiente
de como
=
80
mm
Hg
y
2 = 10==
Ejemplo
3.16
El
colesterol
HDL
las
deque
una
− 2⋅20⋅10de
+ en
10Supongamos
⋅0,60
= 260
(mm
Hg)2, definida
20
El2valor
esperado
la presión
delelpoblación
pulso,
población es ρ12 = 0,60.mm
var(
X1 -laX2presión
) =
σ 12 arterial
+ σ 22 -μsistólica
21 σ
σ2ρ12ymmol/l
11,25
correlación
desería
los sujetos
deσ1esta
con
media
=
y desviación
típica
=
una
distribución
normal
1 HDL
para
una
desviación
típica
16,1
mm
Hg.
Ejemplo
3.16
Elentre
colesterol
en== las
mujeres
adultas
de
una
población
sigue
la
diferencia
entre
la Xpresión
sistólica
ydiastólica
diastólica,
260arterial
16,1
mm
2 = 16,1
2
para
una
desviación
260
Hg.
26
ρ12
=hombres
0,60.
El
valor
esperado
de
la variable
presión
del
pulso,
definida
población
+ 10para
-μde
2mm
⋅20
⋅10
⋅0,60
= 260
(mm
Hg)2distribución
,típica
20
0,35
mmol/l,
yesennormal
lostípica
adultos
dicha
población
sigue
una
X1=con
media
1,25
mmol/l
y desviación
σ1 =comosi las
una
distribución
Los
resultados
anteriores
son
válidos
cualquier
aleatoria.
No obstante,
1=
Los resultados
son válidos para cualquier variable aleatoria. No obstante,
variables
X1, ..., Xanteriores
k siguen una distribución normal, puede probarse que la combinación lineal
la
diferencia
entre
la
arterial
y diastólica,
sería
X
con
media
μ
=presión
1,10
mmol/l
ysistólica
desviación
típica
σla2 =media
0,30
mmol/l.
Así,
normal
2
2
X1 0,35
+
... mmol/l,
+ ckX
también
seguirá
una
distribución
normal
conaleatoria.
y varianza
c1Los
y en lostípica
hombres
adultos
de
dicha
población
sigue
una No
distribución
k anteriores
resultados
son válidos
para
cualquier
variable
obstante, descritas
para
una
desviación
260
=
16,1
mm
Hg.
X1, ...,resultado
Xk siguen
distribución
normal,
probarse que la
si
las variables Este
anteriormente.
seuna
utilizará
en los temas
de puede
inferencia.
26
la
diferencia
del
colesterol
HDL
entre
las
mujeres
y
los
hombres
de esta
población
X
con
media
μ
=
1,10
mmol/l
y
desviación
típica
σ
=
0,30
mmol/l.
Así,
normal
2
2
2
si las variables X1, ..., Xk siguen una distribución normal, puede probarse que la
c1XEl
...son
+ cválidos
unavariable
distribución
con
la sigue una
combinación
lineal
1 +colesterol
kXk también
3.16
HDL
enseguirá
las mujeres
adultas
de normal
una No
población
LosEjemplo
resultados
anteriores
para
cualquier
aleatoria.
obstante,
se
distribuirá
según
una
normal
con
media
media
μ1 =las
1,25
mmol/l
y desviación
típica
σpoblación
normal
X conHDL
ladistribución
diferencia
entre
mujeres
los
hombresnormal
de
estacon
c1Xcolesterol
seguirá
una ydistribución
la0,35 mmol/l,
combinación
linealdel
1 =
1 + ... 1+ ckX
k también
media
y
varianza
descritas
anteriormente.
Este
resultado
se
utilizará
en
los
temas
de2 con media
y
en
los
hombres
adultos
de
dicha
población
sigue
una
distribución
normal
si las variables X1, ..., Xk siguen una distribución normal, puede probarse que la X
= 1,10 mmol/l
y(desviación
σ=2 =1,25
0,30
Así, mmol/l
la diferencia
del colesterol
HDL
distribuirá
según
una
media
mediase
yμ2varianza
descritas
anteriormente.
resultado
utilizará
en los temas
de
E
X
X2) = μtípica
- μ2Este
- mmol/l.
1,10 se
= 0,15
1 - normal
1con
inferencia.
entre
las
mujeres
y
los
hombres
de
esta
población
se
distribuirá
según
una
normal
con
media
combinación lineal c1X1 + ... + ckXk también seguirá una distribución normal con la
inferencia.
E(X1 − X2 ) = μ 1 − μ 2 = 1,25 − 1,10 = 0,15 mmol/l
y varianza
media y varianza descritas anteriormente. Este resultado se utilizará en los temas de
Ejemplo
3.16 El colesterol HDL en las mujeres adultas de una población sigue
y varianza
2
2
2 sigue
2
y varianza
Ejemplo
3.16
ElXcolesterol
en2las mujeres
adultas
de una población
− X2) = σHDL
inferencia.
var(
1 + σ 2 = 0,35 + 0,30 = 0,213 (mmol/l) ,
X1 con
media μ1 = 1,25 mmol/l y desviación típica σ1 =
una distribución 1normal
38
media
y desviación típica
σ1 =
una distribución normal X1 con
2
2
1 = 21,25 mmol/l
var(
X2)hombres
= σ 12 + adultos
σ 22 = μ0,35
+ 0,30
= 0,213sigue
(mmol/l)
,
1 -los
0,35
mmol/l,
yElXencolesterol
dicha
población
una
distribución
enmmol/l,
las de
mujeres
adultas
de unapara
población
sigue
oEjemplo
desviación
0,213 HDL
= 0,46
ya que
los valores
distintos
Pastor-Barriuso
R. 3.16típica
0,35 mmol/l, y en los hombres adultos de dicha población sigue una distribución
X con media
μ2X=1 1,10
mmol/lμ1y =desviación
típica
σ2 = 0,30 mmol/l.
normal
con
media
y desviación
típica σ1Así,
=
una
distribución
normal
son2 independientes
y,
consecuencia,
ρmmol/l
= 0.valores
osujetos
desviación
típica
0,213
= en
0,46
mmol/l, 1,25
ya que
para distintos
12 los
y varianza
Referencias
2
2
2
var(X1 - X2) = σ + σ = 0,35 + 0,30 = 0,213 (mmol/l) ,
2
1
2
2
o desviación típica 0,213 = 0,46 mmol/l, ya
ya que
que los
los valores
valorespara
paradistintos
distintos sujetos son
independientes y, en consecuencia, ρ12 = 0.
sujetos son independientes y, en consecuencia, ρ12 = 0.
3.5 REFERENCIAS
27
1. Bickel PJ, Doksum KA. Mathematical Statistics: Basic Ideas and Selected Topics, Volume
1, Second Edition. Upper Saddle River, NJ: Prentice Hall, 2001.
2.
Casella G, Berger RL. Statistical Inference, Second Edition. Belmont, CA: Duxbury Press,
2002.
3.
Colton T. Estadística en Medicina. Barcelona: Salvat, 1979.
4.
Feller W. An Introduction to Probability Theory and Its Applications, Volume 1, Third
Edition. New York: John Wiley & Sons, 1968.
5.
Rosner B. Fundamentals of Biostatistics, Sixth Edition. Belmont, CA: Duxbury Press,
2006.
6.
Stuart A, Ord JK. Kendall’s Advanced Theory of Statistics, Volume 1, Distribution Theory,
Sixth Edition. London: Edward Arnold, 1994.
Pastor-Barriuso R.
39
TEMA 4
PRINCIPIOS DE MUESTREO
Y ESTIMACIÓN
4.1
INTRODUCCIÓN
Un primer paso en la realización de un estudio o proyecto de investigación es definir la población
de la cual se desea conocer una determinada característica o parámetro. Ocasionalmente, resulta
factible obtener información para todos los elementos de la población mediante registros o
censos. Sin embargo, en la mayoría de los estudios no es posible obtener información de toda
la población, por lo que debemos limitarnos a la recogida de datos en una pequeña fracción del
total o muestra.
La utilización de muestras presenta varias ventajas con respecto a la enumeración completa
de la población:
yy Coste reducido. Si los datos se obtienen de una pequeña fracción del total, los gastos se
reducen. Incluso si la obtención de información en toda la población es factible, suele ser
mucho más eficiente la utilización de técnicas de muestreo.
yy Mayor rapidez. Los datos pueden ser más fácilmente recolectados y estudiados si se utiliza
una muestra que si se emplean todos los elementos de la población. Por tanto, el uso de
técnicas de muestreo es especialmente importante cuando se necesita la información con
carácter urgente.
yy Mayor flexibilidad y mayores posibilidades de estudio. La disponibilidad de registros
completos es limitada. Muy a menudo, la única alternativa posible para la realización de
un estudio es la obtención de datos por muestreo.
yy Mayor control de calidad del proceso de recogida de datos. Al recoger datos en un número
menor de efectivos, resulta más fácil recoger un número mayor de variables por individuo,
así como tener un mejor control de la calidad del proceso de recogida de datos.
Si se dispone de información para todas las unidades de la población, el parámetro poblacional
de interés quedará determinado con total precisión. Sin embargo, si se emplea únicamente una
fracción del total, el parámetro poblacional desconocido ha de estimarse a partir de la muestra,
con el consiguiente error derivado tanto por el carácter parcial de la muestra como por su
posible falta de representatividad poblacional. La teoría de muestreo persigue un doble
objetivo. Por un lado, estudia las técnicas que permiten obtener muestras representativas de la
población de forma eficiente. Por otro lado, la teoría de muestreo indica cómo utilizar los
resultados del muestreo para estimar los parámetros poblacionales, conociendo a la vez el grado
de incertidumbre de las estimaciones. Así, la teoría de muestreo pretende dar respuesta a varias
preguntas de interés:
yy ¿Cómo se eligen a los individuos que componen la muestra?
yy ¿Cuántos individuos formarán parte de la muestra?
yy ¿Cómo se cuantifican las diferencias existentes entre los resultados obtenidos en la muestra
y los que hubiéramos obtenido si el estudio se hubiera llevado a cabo en toda la población?
Pastor-Barriuso R.
41
Principios de muestreo y estimación
Estas cuestiones están estrechamente relacionadas entre sí. Así, por ejemplo, al aumentar el
tamaño muestral aumenta la exactitud en las estimaciones. La determinación del tamaño
muestral se tratará más adelante (véase Tema 9). En el presente tema, se discuten los principales
tipos de muestreo probabilístico, así como la estimación en el muestreo aleatorio simple. Antes
de ello, es conveniente revisar la definición de algunos conceptos que se utilizan de forma
repetida a lo largo del capítulo:
yy Población o universo muestral es la colección de elementos o unidades de análisis
acerca de los cuales se desea información. Con frecuencia, no se puede obtener información
de toda la población, sino tan sólo de unidades que cumplen una serie de características
(criterios de inclusión/exclusión). La población marco es aquella sobre la que es posible
obtener información. La muestra se obtiene de la población marco, por lo que debe
recordarse que las conclusiones extraídas de la muestra son generalizables a la población
marco y no necesariamente a la población de inicio o universo.
yy Dentro del proceso de selección de una muestra, la población suele dividirse en unidades
de muestreo, que deben constituir una partición de toda la población. Estas unidades de
muestreo pueden coincidir con las unidades de análisis, pero también pueden estar
constituidas por un conjunto de distintas unidades de análisis.
Ejemplo 4.1 Supongamos que se desea estudiar la capacidad funcional de una población
de ancianos institucionalizados. Para ello, se dispone de un lista de residencias, algunas
de las cuales se seleccionan para el estudio. Dentro de cada residencia seleccionada, se
eligen a su vez algunos ancianos que formarán parte de la muestra definitiva. En tal caso,
la selección de la muestra se habría realizado en dos etapas: las residencias constituirían
las unidades de muestreo de primera etapa y los ancianos (unidades de análisis) serían las
unidades de muestreo de segunda etapa.
yy Muestreo probabilístico es aquel en que todas las unidades de la población tienen una
probabilidad conocida y no nula de ser seleccionadas para la muestra. El muestreo
probabilístico minimiza la probabilidad de sesgos (si el tamaño muestral no es muy
limitado, la muestra será muy probablemente representativa de la población) y permite
cuantificar el error cometido en las estimaciones como consecuencia de la variabilidad
aleatoria. La teoría del muestreo se basa fundamentalmente en el muestreo probabilístico,
ya que otros tipos de muestreo (de conveniencia, por cuotas) están sujetos a una mayor
probabilidad de sesgos y es más difícil extrapolar los resultados a la población.
yy En el muestreo con reposición, cada vez que se elige un nuevo elemento muestral se
dispone de toda la población para realizar la selección, mientras que en el muestreo sin
reposición los elementos que ya han aparecido en la muestra no están disponibles para ser
elegidos de nuevo. En el muestreo con reposición, por tanto, una unidad poblacional puede
aparecer más de una vez en la muestra. En la práctica, el muestreo suele realizarse sin
reposición. No obstante, si el tamaño de la población es muy grande con respecto al tamaño
muestral, la probabilidad de que un elemento de la población sea elegido más de una vez
en la muestra es tan pequeña que ambos tipos de muestreo son similares.
4.2
PRINCIPALES TIPOS DE MUESTREO PROBABILÍSTICO
En este apartado se describen brevemente los principales procedimientos probabilísticos de
selección de muestras, tales como los muestreos aleatorio simple, sistemático, estratificado, por
42
Pastor-Barriuso R.
Principales tipos de muestreo probabilístico
conglomerados y polietápico. Un tratamiento más extenso de estos procedimientos puede
encontrarse en los libros de muestreo referenciados al final del tema.
4.2.1
Muestreo aleatorio simple
El muestreo aleatorio simple es el más sencillo y conocido de los distintos tipos de muestreo
probabilístico. Supongamos que se pretende seleccionar una muestra de tamaño n a partir de
una población de N unidades. Un muestreo aleatorio simple es aquel en el que cualquier
subconjunto de tamaño n tiene la misma probabilidad de ser seleccionado. Puede probarse que
el muestreo aleatorio simple es un procedimiento equiprobabilístico; es decir, todas las unidades
de la población tienen la misma probabilidad n/N de ser elegidas en la muestra.
Para la selección de una muestra aleatoria simple, se enumeran previamente las unidades del
universo o población de 1 a N y a continuación se seleccionan n números distintos entre 1 y N
utilizando algún procedimiento aleatorio, típicamente mediante una tabla de números aleatorios
o un generador de números aleatorios por ordenador.
yy Las tablas de números aleatorios son tablas con los dígitos 0, 1, 2, ..., 9, donde cada dígito
tiene la misma probabilidad de ocurrir y el valor de un dígito concreto es independiente
del valor de cualquier otro dígito de la tabla. En la Tabla 4 del Apéndice se facilitan 1000
dígitos aleatorios.
yy La mayoría de los programas de análisis estadístico contienen generadores de números
aleatorios. Estos generadores producen grandes secuencias de dígitos pseudoaleatorios,
que satisfacen aproximadamente las mismas propiedades de aleatoriedad enunciadas
anteriormente.
Ejemplo 4.2 Supongamos que, en el ejemplo anterior, se dispone de una lista completa
de los N = 875 ancianos institucionalizados en dicha población, de los cuales se desean
seleccionar n = 10. La selección de una muestra aleatoria simple de este tamaño puede
realizarse a partir de la Tabla 4 del Apéndice como sigue. Comenzando en cualquier lugar
de esta tabla y leyendo grupos de 3 dígitos en cualquier dirección, seleccionar los 10
primeros números distintos entre 1 y 875. Por ejemplo, empezando en el primer dígito de
la tercera fila y de izquierda a derecha, estos números son: 339, 117, 619, 68, 440, 788,
696, 716, 183 y 546. Notar que los números 897 y 898 han sido descartados por ser
superiores a N = 875. La muestra aleatoria simple estaría así constituida por aquellos
ancianos de la población numerados previamente por estos 10 valores.
Puede probarse que, como el muestreo aleatorio simple es un procedimiento
equiprobabilístico, una media o una proporción poblacional se estiman simplemente mediante
la media o proporción muestral. La estimación de parámetros poblacionales a partir de una
muestra aleatoria simple, así como la varianza o error de las estimaciones, se discutirá en detalle
al final de este tema.
4.2.2
Muestreo sistemático
En ocasiones, la numeración consecutiva de las unidades de la población y la posterior selección
de una muestra aleatoria simple resultan muy laboriosas. En tales circunstancias, un
procedimiento alternativo más sencillo es el llamado muestreo sistemático. Bajo este
procedimiento, no siempre es necesario numerar previamente los elementos de la población,
sino que basta con disponer de alguna ordenación explícita (por ejemplo, orden de archivo de
historias clínicas o visitas sucesivas de pacientes a una consulta médica).
Pastor-Barriuso R.
43
Principios de muestreo y estimación
Para la selección de una muestra sistemática de tamaño n de una población de N unidades,
se elige aleatoriamente un número de arranque r entre 1 y k, donde k es la parte entera de N/n,
y a partir del elemento que ocupa el lugar r, se toman los restantes elementos en intervalos de
amplitud k hasta completar la muestra deseada. Así, la muestra estará constituida por los
elementos ordenados en los lugares r, r + k, r + 2k, ..., r + (n – 1)k. Como en general N no es
múltiplo de n, este método de selección no es necesariamente equiprobabilístico (si N/n no es
un número entero, las unidades comprendidas entre los lugares nk + 1 y N nunca podrán formar
parte de la muestra). Una modificación a este procedimiento, que garantiza la obtención de una
muestra equiprobabilística, consiste en seleccionar el número aleatorio de arranque r entre 1 y
N, y tomar cada k-ésima unidad a partir de ahí, continuando en el primer elemento al alcanzar
el final de la lista.
Ejemplo 4.3 Para seleccionar una muestra sistemática de tamaño n = 10 de la población
de N = 875 ancianos institucionalizados, se calcula primero la amplitud del intervalo de
selección como la parte entera de N/n = 875/10 = 87,5; es decir, k = 87. Si se seleccionara
el número de arranque r entre 1 y 87, el último anciano seleccionado ocuparía en el lugar
r + (n – 1)k = r + (10 – 1)87 = r + 783, que sería siempre inferior o igual a 870 (dado que
r ≤ 87). En consecuencia, los ancianos en los lugares 871 a 875 nunca podrían formar
parte de la muestra. Para asegurar un muestreo equiprobabilístico, el número de arranque
se selecciona aleatoriamente entre 1 y 875. Suponiendo que este número de arranque fue
r = 427 y tomando intervalos de amplitud k = 87, la muestra sistemática quedaría integrada
por aquellos ancianos en los lugares 427, 514, 601, 688, 775, 862, 74, 161, 248 y 335.
En el muestreo sistemático, la ordenación de los elementos de la población determinará las
posibles muestras. En consecuencia, este orden ha de estar exento de cualquier periodicidad
relacionada con las variables a estudio. Así, por ejemplo, si para estimar el nivel de contaminación
atmosférica en una ciudad se toma una muestra sistemática de días con k = 7, la muestra estará
formada por los mismos días de la semana y presentará un claro sesgo por falta de
representatividad. No obstante, estas periodicidades son muy infrecuentes en la práctica y
pueden solventarse con facilidad (en el ejemplo anterior, bastaría con utilizar un intervalo de
selección distinto de 7). En general, si la ordenación de las unidades de la población es
esencialmente aleatoria, la estimación de parámetros y sus correspondientes errores en un
muestreo sistemático se realiza igual que en un muestreo aleatorio simple.
4.2.3
Muestreo estratificado
En los muestreos anteriores, las muestras se seleccionan por procedimientos puramente
aleatorios. Así, si el tamaño muestral es suficientemente grande, la muestra será muy
probablemente representativa de la población. Sin embargo, no existe una garantía absoluta de
que la muestra finalmente seleccionada sea representativa para cualquier variable de interés.
Cuando se desea asegurar la representatividad de determinados subgrupos o estratos de la
población, la alternativa más sencilla es seleccionar por separado distintas submuestras dentro
de cada estrato. Este procedimiento de selección se conoce como muestreo estratificado. Los
estratos han de definir subgrupos de población que sean internamente homogéneos con respecto
a la característica o parámetro de interés y, por tanto, heterogéneos entre sí. En la práctica, los
estratos se definen en función de variables fáciles de medir previamente y relevantes para el
tema objeto de estudio (por ejemplo, edad, sexo, raza o área geográfica de residencia). En
general, el número de estratos ha de ser reducido (rara vez resulta eficiente utilizar más de 5
estratos) y el tamaño por estrato no debe ser muy pequeño.
44
Pastor-Barriuso R.
respectivamente, cuya suma será igual al tamaño total n de la muestra. La selección
dentro de cada estrato suele realizarse por muestreo aleatorioPrincipales
simple otipos
sistemático,
y el
de muestreo probabilístico
procedimiento se denomina entonces muestreo aleatorio estratificado.
Para
una muestraesestratificada
de tamañocómo
n, lasepoblación
unidades se
Enlaelselección
muestreode
estratificado,
necesario determinar
distribuyedeelNtamaño
divide en K estratos de tamaños N1, N2, ..., NK, cuya suma es igual a N. Los estratos son
mutuamente
excluyentes
exhaustivos,
de tal
formalaque
cada elemento
de la población
muestral total
n entre losy distintos
estratos;
es decir,
asignación
de los tamaños
pertenece a uno y sólo a uno de los estratos. Una vez determinados estos estratos, se selecciona
...,asignación
nK, respectivamente,
pormuestrales
separado una
de cada estrato de tamaño n1, n2,de
en función cuya
del suma
n1, nmuestra
2, ..., nK. Aunque existen distintos tipos
será igual al tamaño total n de la muestra. La selección dentro de cada estrato suele realizarse
portamaño
muestreo
aleatoriopor
simple
o sistemático,
y el procedimiento
denomina
entonces muestreo
y varianza
estrato
(véase referencias
al final del se
tema),
nos limitaremos
aquí
aleatorio estratificado.
a laelasignación
proporcional,
es el procedimiento
utilizado
con mayor
frecuencia.
En
muestreo estratificado,
esque
necesario
determinar cómo
se distribuye
el tamaño
muestral
total n entre los distintos estratos; es decir, la asignación de los tamaños muestrales n1, n2, ..., nK.
En la asignación
proporcional,
muestra total
repartedel
entre
los estratos
de forma
Aunque
existen distintos
tipos delaasignación
en se
función
tamaño
y varianza
por estrato
(véase referencias al final del tema), nos limitaremos aquí a la asignación proporcional, que es
proporcional alutilizado
tamaño de
estrato
en la población.
Así, comoproporcional,
la proporción la muestra
el procedimiento
concada
mayor
frecuencia.
En la asignación
total se reparte entre los estratos de forma proporcional al tamaño de cada estrato en la población.
en cada estrato
es Nk/N,enel cada
tamaño
muestral
k-ésimo
será del estrato
/N, estrato
el tamaño
muestral
Así,poblacional
como la proporción
poblacional
estrato
es Nkdel
k-ésimo será
nk = n
Nk
.
N
Resulta inmediato probar que esta asignación da lugar a una muestra equiprobabilística.
Resulta inmediato probar que esta asignación da lugar a una muestra equiprobabilística.
Ejemplo 4.4 La capacidad funcional de los ancianos disminuye en gran medida con la
edad. Supongamos que, de los N = 875 ancianos institucionalizados, se sabe que el 60%
Ejemplo
los ancianos
disminuye
gran
medida
525) y elderestante
40% tienen
75 o en
más
años
(N2 = 350).
tienen
menos4.4
deLa
75capacidad
años (N1 =funcional
Para simplificar la exposición, supongamos además que los ancianos menores de 75 años
institucionalizados,
con la edad.aSupongamos
los N = 875
corresponden
los primerosque,
525denúmeros
de ancianos
la lista. Así,
de los n = 10seancianos
seleccionados por muestreo aleatorio simple en el Ejemplo 4.2, la mitad resultaron ser
sabe que
75 años
(N1 = 525)aleatoria,
y el restante
40% tienen
75 años
o
mayores
de el
7560%
años.tienen
Esto menos
es, por de
simple
variabilidad
los mayores
de 75
están ligeramente sobrerrepresentados en la muestra y, en consecuencia, la capacidad
más años
(N2 =obtenida
350). Para
la exposición,
supongamos
además que
los
funcional
media
de simplificar
esta muestra
podría infraestimar
la verdadera
capacidad
funcional de los ancianos institucionalizados. Para asegurar una mejor representatividad
ancianos
de 75
años corresponden
los primeroscon
525asignación
números de
la lista.
muestral
pormenores
edad, podría
realizarse
un muestreoaestratificado
proporcional
a ambos estratos de edad. Es decir, de la muestra de tamaño n = 10, seleccionaríamos 6
muestreo
simple
en años
el (n =
Así, demenores
los n = 10
10·0,6
= 6) yaleatorio
4 mayores
de 75
ancianos
deancianos
75 años seleccionados
(n1 = nN1/N = por
2
nN2/N = 10·0,4 = 4). Utilizando un muestreo aleatorio simple dentro de cada estrato, los
Ejemplo seleccionados
4.2, la mitad resultaron
mayores
75 493,
años.24,
Esto402,
es, por
6 números
entre 1 yser
525
fueron de
505,
371simple
y 265, y los 4
números seleccionados entre 526 y 875 fueron 851, 820, 717 y 696. La muestra estratificada
variabilidad
aleatoria,
los mayores
deancianos
75 años están
ligeramentea dichos números.
proporcional
estaría
formada
por los 10
correspondientes
9
Cabe reseñar aquí dos características importantes del muestreo estratificado. Por un lado, la
asignación proporcional es la única que produce muestras equiprobabilísticas y, en consecuencia,
la media y proporción poblacional se estiman mediante la media y la proporción muestral. Para
cualquier otra asignación, la estimación de parámetros poblacionales requiere de la inclusión de
pesos para cada observación muestral (típicamente, el inverso de la probabilidad de selección).
Por otra parte, para un mismo tamaño muestral, el muestreo estratificado facilita estimaciones
ligeramente más precisas (con menor error) que el muestreo aleatorio simple. Este resultado es
debido a que, cuanto más homogéneos sean los estratos, más precisas serán las estimaciones en
dichos estratos y esto redundará en una mayor precisión de las estimaciones para toda la
población.
Pastor-Barriuso R.
45
Principios de muestreo y estimación
4.2.4
Muestreo por conglomerados
La aplicación de los diseños muestrales anteriores requiere de la enumeración u ordenación de
todos los elementos de la población. Sin embargo, a menudo no se dispone de una lista completa
o, aun disponiendo de tal lista, resulta muy costoso obtener información de las unidades
muestreadas. Por ejemplo, si se seleccionara una muestra aleatoria simple de 1000 individuos
de una gran ciudad, los individuos seleccionados estarían muy dispersos y la recogida de
información sería extraordinariamente laboriosa. En tales circunstancias, una alternativa
consiste en clasificar a la población en grupos o conglomerados, para así seleccionar una
muestra de estos conglomerados y después tomar a todas o a una parte de las unidades incluidas
dentro de los conglomerados seleccionados. Este método de selección se denomina muestreo
por conglomerados y presenta dos ventajas fundamentales:
yy Este muestreo es la única alternativa posible cuando no se dispone de una lista con todas
las unidades de la población. En el muestreo por conglomerados, únicamente es necesario
contar con listas de las unidades que integran los conglomerados seleccionados.
yy Aun cuando otras técnicas de muestreo sean posibles, con frecuencia el muestreo por
conglomerados resulta más económico, ya que las unidades muestrales están concentradas
en los conglomerados seleccionados.
Notar que, a diferencia de la estratificación, donde interesa que los estratos sean lo más
homogéneos posible, los conglomerados deben ser heterogéneos: en cada conglomerado debe
haber unidades representativas de toda la población, de lo contrario se perdería información al
seleccionar únicamente algunos de ellos. El número de conglomerados es típicamente elevado,
de los cuales suele seleccionarse un número relativamente pequeño para resolver el problema
de la dispersión muestral.
Supongamos que se pretende extraer una muestra de tamaño n a partir de una población de
N unidades agrupadas en M conglomerados de tamaños N1, N2, ..., NM. Entre los distintos
métodos de selección por conglomerados, el muestreo por conglomerados con probabilidad
proporcional a su tamaño resulta particularmente útil en la práctica. Para llevar a cabo este
muestreo, se procede como sigue:
1. Ordenar arbitrariamente los conglomerados y calcular los tamaños acumulados. Estos
tamaños acumulados delimitarán, para cada conglomerado, un rango de valores de
amplitud igual a su tamaño poblacional.
2. Si se pretende seleccionar m conglomerados, extraer una muestra sistemática de tamaño m
entre 1 y N. Los conglomerados seleccionados serán aquellos cuyo rango incluya alguno
de los valores muestreados.
3. Dentro de cada conglomerado seleccionado, obtener una muestra aleatoria simple o
sistemática de tamaño n/m.
Ejemplo 4.5 Con cualquiera de las técnicas de muestreo utilizadas en los ejemplos
anteriores, la muestra incluiría muy probablemente ancianos institucionalizados en
múltiples residencias, con el consiguiente inconveniente en la recogida de información.
Supongamos que los N = 875 ancianos institucionalizados se encuentran distribuidos en
M = 15 residencias con los tamaños especificados en la Tabla 4.1. Para optimizar el
trabajo de campo, se decide extraer la muestra de tamaño n = 10 a partir de m = 2
residencias (conglomerados) seleccionadas con probabilidades proporcionales a sus
tamaños.
46
Pastor-Barriuso R.
Principales tipos de muestreo probabilístico
Tabla 4.1 Distribución del número de ancianos institucionalizados por
residencia.
Residencia (i)
Tamaño (Ni)
Tamaño acumulado
Rango asignado
50
30
35
70
55
45
125
80
20
100
65
35
40
75
50
50
80
115
185
240
285
410
490
510
610
675
710
750
825
875
1 – 50
51 – 80
81 – 115
116 – 185
186 – 240
241 – 285
286 – 410
411 – 490
491 – 510
511 – 610
611 – 675
676 – 710
711 – 750
751 – 825
826 – 875
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
En primer lugar, se asigna a cada residencia un rango de valores de amplitud igual a su tamaño
(Tabla 4.1). A continuación, se extrae una muestra sistemática de tamaño 2 entre 1 y 875: si el
número de arranque resultó ser 316, los valores muestreados son 316 y 753 (ver apartado de
muestreo sistemático). Así, como el valor 316 está incluido dentro del rango asignado a la residencia
7 y el valor 753 en el rango de la residencia 14, resultan seleccionadas las residencias 7 y 14.
Para completar la muestra de n = 10 ancianos, se extraen finalmente muestras aleatorias
simples de tamaño n/m = 10/2 = 5 de las residencias 7 y 14. De los 125 ancianos institucionalizados
en la residencia 7, se seleccionaron los números 74, 23, 104, 111 y 57; y de los 75 ancianos de
la residencia 14, los números 38, 51, 25, 34 y 41. En conclusión, la muestra total estará
formada por los ancianos listados en los lugares 74, 23, 104, 111 y 57 de la residencia número 7,
más aquellos que ocupan los lugares 38, 51, 25, 34 y 41 de la residencia número 14.
El muestreo por conglomerados con probabilidades proporcionales a sus tamaños facilita
muestras equiprobabilísticas, así la media y la proporción poblacional pueden estimarse
mediante sus correspondientes funciones muestrales. En general, para un tamaño muestral
constante, la precisión de las estimaciones en un muestreo por conglomerados es menor que en
un muestreo aleatorio simple. Las unidades de un mismo conglomerado suelen estar
correlacionadas y, en consecuencia, aportan menos información que los elementos seleccionados
de forma más dispersa mediante un muestreo aleatorio simple.
4.2.5
Muestreo polietápico
Los diseños muestrales empleados en la práctica se realizan combinando las técnicas descritas
anteriormente. En muchas situaciones, resulta más apropiado obtener la muestra final en
diferentes etapas o pasos. En un muestreo polietápico, la población se divide en grupos
exhaustivos y mutuamente excluyentes, que constituyen las llamadas unidades de primera
etapa; cada una de ellas se desagrega a su vez en subgrupos o unidades de segunda etapa, y así
sucesivamente, hasta llegar en una última etapa a los elementos o unidades de análisis. La
selección de unidades en cada una de las etapas se realiza mediante una técnica de muestreo
diferente y la muestra final será la resultante de aplicar sucesivamente cada una de estas técnicas.
Pastor-Barriuso R.
47
Principios de muestreo y estimación
Ejemplo 4.6 En el ejemplo anterior se seleccionaron 2 de las 15 residencias y, dentro de
cada residencia seleccionada, se eligieron a su vez 5 ancianos para formar la muestra
definitiva. Este procedimiento de selección es, de hecho, un muestreo bietápico: las
residencias constituirían las unidades de muestreo de primera etapa y los ancianos serían
las unidades de muestreo de segunda etapa.
Una técnica de muestreo en etapas que se emplea con cierta frecuencia es el muestreo
estratificado polietápico. Bajo esta técnica, las unidades de primera etapa se clasifican en
distintos estratos y, dentro de cada estrato, se selecciona al menos una de sus unidades de
primera etapa. La muestra final resultará de aplicar sucesivas etapas de muestreo dentro de las
unidades de primera etapa seleccionadas en cada estrato. Este muestreo permite obtener una
mayor representatividad muestral al seleccionar unidades dentro de todos los estratos.
Ejemplo 4.7 Supongamos que, de las 15 residencias listadas en la Tabla 4.1, las
residencias 4, 7, 8, 10 y 14 son públicas, con un total de 450 ancianos (51,4%), y las
restantes 10 residencias son privadas, con un total de 425 ancianos (48,6%). En el Ejemplo
4.5, las 2 residencias seleccionadas (7 y 14) fueron públicas; es decir, la muestra final no
incluyó a ningún anciano institucionalizado en residencias privadas. Para garantizar la
representatividad de los ancianos institucionalizados tanto en residencias públicas como
privadas, bastaría con seleccionar una residencia de cada uno de estos estratos. En la
Tabla 4.2, se muestran las 15 residencias reorganizadas según su carácter público o
privado. Para las residencias públicas, se escogió aleatoriamente el número 20 entre 1 y
450, resultando así seleccionada la residencia 4, cuyo rango incluye dicho número. Para
las residencias privadas, se extrajo aleatoriamente el número 326 entre 1 y 425, resultando
seleccionada la residencia 12. A continuación, se procedería a escoger aleatoriamente 5
ancianos de estas 2 residencias. Notar que, como ambos estratos tienen aproximadamente
el mismo tamaño, la muestra resultante sería equiprobabilística.
Apuntar, por último, que en la mayoría de los muestreos polietápicos el error muestral es
sensiblemente superior al de un muestreo aleatorio simple, debido principalmente a la correlación
entre los elementos que integran las unidades de primera etapa.
Tabla 4.2 Distribución del número de ancianos institucionalizados en
residencias públicas y privadas.
Residencia (i)
Pública
4
7
8
10
14
Privada
1
2
3
5
6
9
11
12
13
15
48
Pastor-Barriuso R.
Tamaño (Ni)
Tamaño acumulado
Rango asignado
70
125
80
100
75
70
195
275
375
450
1 – 70
71 – 195
196 – 275
276 – 375
376 – 450
50
30
35
55
45
20
65
35
40
50
50
80
115
170
215
235
300
335
375
425
1 – 50
51 – 80
81 – 115
116 – 170
171 – 215
216 – 235
236 – 300
301 – 335
336 – 375
376 – 425
puede realizarse con múltiples propósitos, nos centraremos aquí en la estimación de una
media y de una proporción poblacional.
Estimación en el muestreo aleatorio simple
4.34.3.1
ESTIMACIÓN
EN EL de
MUESTREO
Estimación puntual
una media ALEATORIO
poblacional SIMPLE
Una
vez descritas
técnicas de muestreo probabilístico, nos ocuparemos a
Supongamos
que las
x1, xprincipales
2, ..., xn son los valores obtenidos en una muestra de tamaño n
continuación de la estimación de parámetros poblacionales. En adelante, se asume que la
muestra
se ha
obtenido
un muestreo
simple
a partir
de Un
una
población de
parámetro
poblacional
se le denomina
estimador,
y al resultado
de aplicar
dicha
para
una
variable
con mediante
media
poblacional
μ y aleatorio
varianza
σ 2 desconocidas.
estimador
tamaño esencialmente infinito.
función
a una
determinada
llama muestral
estimación.
cuando
muestreo
El cálculo
valorpoblacional
exactomuestra
de μ
unesse
parámetro
poblacionalAún
requiere
delelconocimiento
del
lalemedia
natural
de
ladel
media
valor de la variable objeto de estudio para todos y cada uno de los elementos de la población.
puede
con múltiples
propósitos,
centraremos
aquí en la no
estimación
de una
Como
se realizarse
ha comentado
anteriormente,
en la nos
mayoría
de las ocasiones
se dispone
de esta
n
1
1.2
MEDIDASsino
DE TENDENCIA
CENTRAL
información,
que se cuenta tan
sólo con
una
muestra.
A
la
función
de
los
valores
de una
x = xi .
media
y
de
una
proporción
poblacional.
1.2
MEDIDAS
DE
TENDENCIA
CENTRAL
n
muestra que permite hacerse una idea acerca del valor
del parámetro poblacional se le denomina
i =1
estimador,
y
al
resultado
de
aplicar
dicha
función
a una
muestra se le llama
Las medidas de tendencia central informan acerca de cuál
es eldeterminada
valor más representativo
estimación.
Aúndecuando
el muestreo
puede
concuál
múltiples
propósitos,
nos centraremos
4.3.1
Estimación
puntual
de completamente
unainforman
mediarealizarse
poblacional
Las
medidas
tendencia
central
acerca
de
esuna
el valor
más representativo
Esta
media
muestral
quedará
determinada
vez obtenida
la muestra,
aquí
en
la
estimación
de
una
media
y
de
una
proporción
poblacional.
de una determinada variable o, dicho de forma equivalente,
estimadores
indican
1.2estos
MEDIDAS
DE TENDENCIA
CENTRAL
x
,
x
,
...,
x
son
los
valores
obtenidos
en
una
muestra
de
tamaño
n
Supongamos
que
de
unaeldeterminada
o,
1variable
2
n dicho de forma equivalente, estos estimadores indican
pero
valor de la estimación
variará en función de la muestra seleccionada. Así, la
alrededor de qué valor se agrupan los datos observados. Las medidas de tendencia
4.3.1 Estimación puntual de una media poblacionalLas2medidas de tendencia central informan acerca de c
para una
variable
con media
poblacional
μuna
yobservados.
varianza
desconocidas.
Un estimador
alrededor
de quépuede
valor
se
agrupan
loscomo
datos
Las
medidas
de valor
tendencia
media
muestral
considerarse
variableσ aleatoria,
cuyo
dependerá
central
de
la
muestra
sirven
tanto
para
resumir
los
resultados
observados
como
para n para una
Supongamos que x1, x2, ..., xn son los valores obtenidosdeenuna
unadeterminada
muestra de variable
tamaño
o, dicho de forma equival
central
de
sirven tanto
para
los resultados
para
es laresumir
media
muestral
natural
dela
lamuestra
media
poblacional
Unobservados
estimador
natural
de lanmedia
variable
con
media
poblacional
μ y μvarianza
σ 2 desconocidas.
de
la muestra
finalmente
seleccionada
sobre
todas
las posibles
muestrascomo
de tamaño
de
realizar
inferencias
los parámetros poblacionales correspondientes. A
poblacional
μ es laacerca
mediade
muestral
alrededor de qué valor se agrupan los datos observado
realizar inferencias acerca de los parámetros poblacionales
correspondientes. A
n
la población
de referencia.
A la distribución
de
los
valores
de x sobre todas las posibles
1.2 MEDIDAS DE
TENDENCIA
CENTRAL
1
continuación se describen los principales estimadores
de
la
tendencia
de una
x = x i . central de la central
muestra sirven tanto para resumir los resu
n i =1
continuación se describen los principales estimadores
de la tendencia central de una
muestral de x . Las razones
muestras central
del mismo
tamaño
se lede
denomina
Las medidasvariable.
de tendencia
informan
acerca
cuál es eldistribución
valor más representativo
Esta media muestral quedará completamente determinada
una
obtenidaacerca
la muestra,
el
realizarvez
inferencias
de lospero
parámetros
poblacion
variable.
valor
de
la
estimación
variará
en
función
de
la
muestra
seleccionada.
Así,
la
media
muestral
Esta
media
muestral
quedará
completamente
determinada
una
vez
obtenida
la
muestra,
teóricas
queo,justifican
utilización
de la media
muestral como
estimador de la media
de una determinada
variable
dicho dela
forma
equivalente,
estos estimadores
indican
puede
considerarse
como una variable aleatoria, cuyo valor
dependerásededescriben
la muestra
1.2.1
Media
aritmética
continuación
losfinalmente
principales estimadores
seleccionada
de
entre
todas
las
posibles
muestras
de
tamaño
n
de
la
población
de
referencia.
1.2.1
Media
aritmética
pero
el
valor
de
la
estimación
variará
en
función
de
la
muestra
seleccionada.
Así,
la
frente
otros observados.
posibles estimadores,
se basan
en esta distribución muestral. A
alrededor de qué poblacional,
valor se agrupan
losa datos
Las medidas
de tendencia
todascomo
las posibles
muestras
delde
mismo
distribución
de los
valorespor
de x ,sobre
Lalamedia
aritmética,
denotada
se define
la suma
de
los tamaño se le
variable.cada uno
denomina
distribución
muestral
de xcomo
., Las
razones
teóricas
quede
justifican
lade
utilización
de la
La
media
aritmética,
denotada
por
se define
como
laaleatoria,
suma
cada uno
los
media
muestral
puede
considerarse
una variable
cuyo
valor
dependerá
partir
de los
resultados
el valor
esperado
central de la muestraAsirven
tanto
para
resumirdel
los Apartado
resultados3.4,
observados
como parade la distribución
media
muestral
como
estimador
de
la
media
poblacional,
frente
a
otros
posibles
estimadores,
se
valores muestrales dividida por el número de observaciones realizadas. Si denotamos
1.2.1 Media aritmética
basan
enmuestra
esta
distribución
muestral.
de la
seleccionada
sobre
las posibles
muestrasSidedenotamos
tamaño n de
valores
muestrales
dividida
por el número
de todas
observaciones
realizadas.
x finalmente
esparámetros
muestral
realizar inferencias
acerca de
de los
poblacionales correspondientes. A
por nAelpartir
tamaño
muestral
y por
el valor observado
el sujeto
i-ésimo,
i = 1,muestral
..., n, de es
de los
resultados
delxiApartado
3.4, el valorpara
esperado
de la
distribución
La media
aritmética,
denotada por
x , se define como
x sobre
todas
la población
de muestral
referencia.
A laxidistribución
de los valores
por
n el tamaño
y por
el valor observado
para el de
sujeto
i-ésimo,
i =las
1, posibles
..., n,
continuación se describen los principales estimadores de nla tendencian central de una
la media vendría dada por
1
1
dividida por el número de observac
E ( x i ) =muestrales
μ;
E( x ) = E x i = valores
lamuestras
media vendría
dadatamaño
por se le denomina
distribución
muestral de x . Las razones
del mismo
n
n
i
i
=
1
=
1
variable.
n el están
tamaño
muestralalrededor
y por xi el
x +variable
x 2 + ... +aleatoria
xpor
1 n
n
es teóricas
decir, lasque
medias
muestrales
centradas
devalor
su observado pa
justifican
laxutilización
muestral
como
estimador
de
la
media
.
= decualquier
x i n=de 1la media
... + x n
x1 +n x 2 +equivalente,
1
nxo,=i =de
1dicho
verdadera
poblacional
las medias
muestrales
1.2.1 Media aritmética
es decir, media
las medias
muestrales
cualquier
variable aleatoria
están
centradas
alrededorno
. vendría
= forma
x i de
la
media
dada
por
n
n
1
sobreestiman
nifrente
infraestiman
la media
poblacional.
En términosmuestral.
estadísticos,
poblacional,
a otros sistemáticamente
posiblesi =estimadores,
se basan
en esta distribución
es
un
estimador
centrado
o
insesgado
de
μ.
La
conveniencia
de utilizar
seLa
dice
entonces
que
La media aritmética,
denotada
por
x
,
se
define
como
la
suma
de
cada
uno
de
los
demedia
su verdadera
mediadepoblacional
o, dicho
deutilizada
forma equivalente,
las medias muestrales
es la medida
tendencia central
más
y de más fácil
estimadores
insesgados
parece
clara
ya que,
en
contrario,
del parámetro
x + x 2 + ...
1 n
A partir
de
resultados
del Apartado
3.4,caso
el valor
esperado
de
la fácil
distribución
La
media
eslos
la medida
de tendencia
central
más
utilizada
ylas
deestimaciones
más
=
x
xi = 1
poblacional
estarían
sistemáticamente
sesgadas
respecto
a
su
verdadero
valor.
Otras
medidas
valores muestrales
dividida
por
el
número
de
observaciones
realizadas.
Si
denotamos
n i =1
n
interpretación. Corresponde al “centro de gravedad” de los datos de la muestra. Su
muestrales
de
tendencia
central,
como
la
mediana
o
la
media
geométrica,
son
en
general
x
es
muestral
16
interpretación. Corresponde al “centro de gravedad” de los datos de la muestra. Su
estimadores
sesgados
de
la
media
poblacional.
por n el tamaño
muestral
y
por
x
el
valor
observado
para
el
sujeto
i-ésimo,
i
=
1,
...,
n,
i
principal limitación es que está muy influenciada por los valores extremos y, en este
La media es la medida de tendencia central más uti
principal limitación es que está muy influenciada
por
los valores extremos y, en este
n
n
1
1
la media vendría
porno ser
Supongamos
estudio
constituye toda la
Ejemplo
4.8un fiel
) que
=laEtendencia
x i control
= del
E (la
x i )distribución.
= μ EURAMIC
;
E( xde
el grupo
caso,dada
puede
reflejo
central
de
interpretación.
Corresponde
al “centro de gravedad” d
n
n
i =1
i =1
población
o
universo
a
estudio,
cuya
media
poblacional
del
colesterol
HDL
es
caso, puede no ser un fiel reflejo de la tendencia central de la distribución. μ = 1,09 mmol/l.
x + x 2 + ... + x n
1 n
principal
limitación
es que está
.
=
x
x iy=en 1los sucesivos
Ejemplo
1.4
En
este
ejemplos
sobre
estimadores
muestrales,
se muy influenciada por l
es decir, las medias
n i =1 muestrales den cualquier variable aleatoria están centradas alrededor
Ejemplo 1.4 En este y en los sucesivos ejemplos sobre estimadores muestrales, se
caso,
no ser un
fielPastor-Barriuso
reflejo
centra
R. tendencia
49
utilizarán
los valores
colesterolo,HDL
lospuede
10 primeros
sujetos
del de la
de su verdadera
media del
poblacional
dichoobtenidos
de formaen
equivalente,
las medias
muestrales
utilizarán
los valores
delmás
colesterol
HDL
La media es la medida
de tendencia
central
utilizada
y deobtenidos
más fácilen los 10 primeros sujetos del
estudio “European Study on Antioxidants, Myocardial Infarction and Cancer of
Ejemplo 1.4 En este y en los sucesivos ejemplos
realizar
inferencias
acerca
de los parámetros
se describen
los principales
estimadores
de
la tendencia
central de poblac
una
realizar continuación
inferencias acerca
de los parámetros
poblacionales
correspondientes.
A
variable.
continuación
se describen
Principios de muestreo
y estimación
continuación
principales
los principales estimadores
dese
la describen
tendencia los
central
de una estimador
variable.
variable.
1.2.1 Media aritmética
A partir de esta población, se obtienen 1000 muestras aleatorias simples de tamaño n = 10
aritmética
colesterol
HDL.
El histograma
y, en cada1.2.1
una Media
deLa
ellas,
se calcula
la media
muestral
media
aritmética,
denotada
por 1.2.1
x ,del
seMedia
define como
la suma
de cada uno de los
aritmética
de estas medias muestrales se representa en la Figura 4.1(a), que constituye una
Lapuede
media
aritmética,
denotada
x Si
, sedenotamos
define com
., Como
apreciarse,
los
valores
de los
aproximación
a lavalores
distribución
muestral
de xpor
La media
aritmética,
denotada
por
seeldefine
como
la suma de
cada
unopor
muestrales
dividida
número
de
observaciones
realizadas.
difieren entre las distintas muestras, pero su distribución conjunta está centrada alrededor
valores
muestrales
dividida
por
el número
de la verdadera
poblacional
μ por
= 1,09
mmol/l
(línea
vertical
en realizadas.
trazo
por n el
tamaño
muestral
por xi elde
valor
observado
para
eldiscontinuo).
sujeto
i-ésimo,
i =de1,observ
..., n,
valoresmedia
muestrales
dividida
elynúmero
observaciones
Si denotamos
En las Figuras 4.1(b) y (c) se presentan las distribuciones muestrales de la mediana y la
por
n el tamaño
muestral
y presentan
por xii el
valor
observado
media geométrica
para
estas
mismas
Ambas
distribuciones
media
vendría
dada
por n el la
tamaño
muestral
y muestras.
porpor
xi el valor
observado
para elmuestrales
sujeto i-ésimo,
= 1,
..., n,
un claro sesgo respecto a la media poblacional, tendiendo a infraestimar su verdadero
la media vendría dada por
valor de 1,09
mmol/l.
la media
vendría dada por
x + x + ... + x n
1 n
. práctica, se
x=
x i = 1 ya2 que, en la
Notar que el interés de este ejemplo es meramente
académico
n i =1
n
x + x2 +
desconoce la verdadera media poblacional1y nse dispone
1 n
+ ... única
+ x n muestra.
x + de
x 2 una
x = xi = 1
.
x = xi = 1
n i =1
n
n
n
La media es la medida dei =1tendencia central más utilizada y de más fácil
25
es la yde
medida
defácil
tendencia
centralSumás u
interpretación.
Corresponde
al “centro
demedia
gravedad”
datos
de la muestra.
La media
es la medida
de tendencia
centralLa
más
utilizada
delos
más
20
15
interpretación.
Corresponde
alextremos
“centro
principal
limitación es
estáde
muy
influenciada
los valores
y,gravedad”
en este
interpretación.
Corresponde
al que
“centro
gravedad”
de lospor
datos
de la muestra.
Sude
10
esde
que
está muy
po
5 caso,
puede no
ser un
reflejo
deprincipal
la tendencia
la distribución.
principal
limitación
es que
estáfiel
muy
influenciada
porlimitación
loscentral
valores
extremos
y, eninfluenciada
este
0
Frecuencia relativa (%) en muestras de tamaño 10
caso, puede
un fiel reflejo de la tendencia cen
caso, puede no ser un fiel reflejo de la tendencia
centralno
deser
la distribución.
0,7 Ejemplo
0,8
0,9
1,3 ejemplos
1,4
1,5
1.4 En 1este y1,1
en los1,2
sucesivos
sobre estimadores muestrales, s
(a) Media muestral del colesterol HDL (mmol/l)
Ejemplo
1.4estimadores
En este
y en
los
sucesivos
losyvalores
del colesterol
HDL sobre
obtenidos
en los
10muestrales,
primeros
sujetos
de
Ejemploutilizarán
1.4 En este
en los sucesivos
ejemplos
se ejemp
25
utilizarán
del colesterol
HDL
estudio
“European
Study onHDL
Antioxidants,
Myocardial
Infarction
and Cancer
of
utilizarán
los valores
del colesterol
obtenidos
enloslosvalores
10 primeros
sujetos
del obte
20
15estudio
10
5the
estudio
“European
Study
Antioxidants,
My
the Breast“ Study
(EURAMIC),
un estudio
multicéntrico
de casos
controles
“European
on Antioxidants,
Myocardial
Infarction
andyonCancer
of realizado
the Breast“
(EURAMIC),
un realizado
estudio
entre(EURAMIC),
1991 y 1992 un
en estudio
ocho países
Europeos
e Israel
para
evaluar
el efectomulticén
de los
Breast“
multicéntrico
de
casos
y controles
0
1991
y 1992
en ocho
países
e
entre 1991 y 1992 en ocho países Europeosentre
e Israel
para
evaluar
el efecto
de Europeos
los
0,7
0,8
0,9
1
1,1
1,2
1,3
1,4
1,5
(b) Mediana del colesterol HDL (mmol/l)
5
25
20
15
10
5
0
0,7
0,8
0,9
1
1,1
1,2
1,3
1,4
1,5
(c) Media geométrica del colesterol HDL (mmol/l)
Figura 4.1 Distribución muestral de la media aritmética (a), la mediana (b) y la media
Figura 4.1geométrica (c) del
colesterol HDL en 1000 muestras aleatorias simples de tamaño n = 10 obtenidas a partir del grupo control
del estudio EURAMIC. La línea vertical en trazo discontinuo corresponde a la media poblacional μ = 1,09
mmol/l de colesterol HDL.
50
Pastor-Barriuso R.
centralestándar
de la muestra
para resumir los resultados observados como para
4.3.2 Error
de la sirven
media tanto
muestral
realizar
inferencias
acerca
los parámetros
poblacionales
correspondientes.
A simple
Dado que
la media
muestral
es unde
estimador
insesgado
de la media
poblacional,
todas
Estimación
en el muestreo aleatorio
continuación
se describen
los principales
estimadores
central de una
las posibles
medias muestrales
estarán
distribuidas
alrededor de
de la
la tendencia
media poblacional.
[Figura 4.2 aproximadamente aquí]
4.3.2 Error
estándar de la media muestral
variable.
No obstante,
queda por determinar el grado de variabilidad o dispersión de estas medias
aproximadamente
aquí]
Dado que la media muestral es un estimador insesgado de la[Figura
media4.2
poblacional,
todas las
Aun
cuando
en
la
práctica
carece
de
sentido
tomar
repetidas
μ
.
La
dispersión
de
las
medias
muestrales
x
de
tamaño
n
muestrales
alrededor
de
posibles medias
muestrales
estarán distribuidas alrededor de la media poblacional. No obstante, muestras, las
1.2.1 Media
aritmética
queda por determinar el grado de variabilidad o dispersión de estas medias muestrales alrededor
xcada
pueden
utilizarse
para
cuantifica
propiedades
laseen
distribución
muestral
de
Aun
cuando
la práctica
carece
tomar
repetidas
muestras,
las
determinada
pormedias
la varianza
depor
su de
distribución
muestral,
quede
es
igual
apor
tamaño
n vendrá
determinada
lade
varianza
de vendrá
μ. La dispersión
de las
muestrales
x ,de
define
como
la suma
desentido
uno
los
La
media aritmética,
denotada
de su distribución muestral, que es igual a
utilizarse
para
cuantifi
propiedades
la distribución
de x pueden
cometido
la de
estimación
a partirmuestral
de una
única
muestra
de tamaño
n. La
desvi
valores muestrales dividida
por en
el número
de observaciones
realizadas.
Si denotamos
1 n 1 n
σ2 ,
var( x ) = var x i = 2 var( x i ) =
nde
n observado
1.2 MEDIDAS DE TENDENCIA
x esúnica
estándar
la
distribución
muestral
cometido
envalor
a partir
desujeto
una
muestra
n. La des
ix=1 el
i =1
n de
la estimación
por n el tamañoCENTRAL
muestral
y por
para el
i-ésimo,
i = 1,de
...,tamaño
n,
i
[Figura 4.2 aproximadamente
aquí] DE TENDENCIA CENTRAL
1.2 MEDIDAS
dado que los distintos valores de la muestra son independientes (véase Apartado 3.4). Puede
estándar
la es
distribución
muestral
de x es
la que
media
vendría
dadadepor
Las medidas
de
tendencia
informan
acerca
de de
cuál
valorserá
más
representativo
σ sea la
observarse
la
variabilidad
laslamedias
muestrales
tanto
mayor Apartado
cuanto mayor
dado
que
loscentral
distintos
valores
de
muestra
sonelindependientes
(véase
3.4).
x
)
=tendencia
var( x ) =
,
SE(
2
Las
medidas
de
central
de
la
variable
a
estudio.
Por
otra
parte,
esta
variabilidad
disminuye
varianza
poblacional
σ
Aun cuando en la práctica carece de sentido tomar repetidas muestras, las
n informan acerca de c
de una determinada
dicho
forma
estos
estimadores
σ las
conforme
aumentao, el
tamaño
n de equivalente,
la muestra;
es
decir,
aumentar
el tamaño
Puede variable
observarse
que
lade
variabilidad
de1lasn medias
será
tanto
mayormuestral,
cuanto
+ xal
x1 muestrales
xindican
2 + ... +SE(
n x) =
var( x ) =o, dicho
, de forma equival
.
=
=
x
x
de
una
determinada
variable
i
medias
de
las
distintas
muestras
estarán
más
próximas
a
la
verdadera
media
poblacional.
para
cuantificar
el
error
propiedades de la distribución muestral nde x pueden utilizarse
n
n de la distancia de las distintas medias muestrale
1.2 MEDIDAS
DE
TENDENCIA
CENTRAL
i =1valor promedio
facilita
alrededor de qué
valor
datosque
observados.
medidas
de tendencia
σ 2 deun
laLas
variable
a estudio.
Por otra parte, esta
mayor
seaselaagrupan
varianzalospoblacional
alrededor
de medias
qué
se
agrupan HDL
los datos observado
cometido
en4.9
la estimación
a partir
de una
de tamaño
n. valor
Ladel
desviación
En las Figuras
4.2(a),
(b)única
y (c)muestra
se presentan
las
colesterol
Ejemplo
xmedias
) se conoce
c
tamaño
n
respecto
de
la
medida
poblacional.
Esta
cantidad
que
facilita
un
valor
promedio
de
la
distancia
de
las
distintas
muestra
central de la muestra
sirven
tanto
para
resumir
los
resultados
observados
como
para
Las es
medidas
de tendencia
central
informan
acerca
esrespectivamente,
el
valor másSE(
representativo
La disminuye
media
la
medida
de
tendencia
central
de
fácil
variabilidad
conforme
aumenta
el tamaño
nmás
la10,
muestra;
es más
decir,
al
en 1000
muestras
aleatorias
simples
de
tamaño
nde= utilizada
25 de
yy cuál
100,
central de
laEn
muestra
para resumir los resu
x aproximadamente
esestudio EURAMIC.
estándar
de laadistribución
obtenidas
partir de losmuestral
controles
del
estas sirven
gráficastanto
se puede
[Figurade4.2
aquí]
x ) de
se incertid
conoce
tamaño
n
respecto
de
la
medida
poblacional.
Esta
cantidad
error
estándar
de
la
media
muestral
y
permite
cuantificar
el SE(
grado
realizar inferencias
acerca
de
los
parámetros
poblacionales
correspondientes.
A
una
determinada
variable
o,dedicho
de forma
equivalente,
estos
estimadores
indican
interpretación.
Corresponde
al
“centro
gravedad”
de las
los
datos
demás
la
muestra.
Su
aumentar
el tamaño
muestral,
las medias
las
distintas
muestras
estarán
próximas
apreciar
que,deindependientemente
deldetamaño
muestral,
medias
muestrales
están
realizar
inferencias
acercaalde
los parámetros
poblacion
centradas alrededor de la media poblacional de 1,09
mmol/l.
Sin embargo,
aumentar
el
σ
error
estándar
de
la
media
muestral
y
permite
cuantificar
el
grado
la
estimación
de
una
media
a
partir
de
una
muestra
de
tamaño
n.
continuación se
describen
los
principales
estimadores
de
la
tendencia
central
de
una
alrededor
deesqué
valor
se
agrupan
los
Las
deeste
tendencia de incer
principal
limitación
que
está
influenciada
los
valores
extremos
y, en
xde
)muy
=sentido
var(
xtomar
)substancial
= datos
,porobservados.
SE(
Aun
cuando
en
lase
práctica
carece
repetidas
muestras,
lasmedidas
a latamaño
verdadera
media
poblacional.
muestral,
observa
una
disminución
de la
variabilidad
de las
medias
n con unse
continuación
describen
principales estimadores
muestrales. Así, por ejemplo, la proporción de muestras
nivel
medio los
de colesterol
En
la
práctica,
para
poder
calcular
el
error
estándar,
estamaño
necesario
obtener
la
estimación
de
una
media
a
partir
de
una
muestra
de
variable.
central
de un
la
muestra
sirven
para
los
resultados
comon.para
caso,
puede
no
ser
fielmuestral
reflejo
de
central
de
lapara
distribución.
x tendencia
pueden
para
cuantificar
error
propiedades
de1,03
la distribución
de latanto
HDL
entre
y 1,15
mmol/l
es del
48,7%
para
n utilizarse
=resumir
10, 69,1%
n = 25observados
y el
95,4%
para
Enpromedio
las Figuras
4.2(a),
(b) y de
(c)las
se variable.
presentanmedias
las medias
del colesterol
=Ejemplo
100. un 4.9
quenfacilita
valor
de En
la distancia
distintas
muestrales
de es
la
práctica,
para
poder
calcular
el
error
estándar,
obtener
σ 2 denecesario
la variable
a estu
previamente
una
estimación
de
la
varianza
poblacional
realizar
inferencias
acerca
de
los
parámetros
poblacionales
correspondientes.
A
cometido
en
la
estimación
a
partir
de
una
única
muestra
de
tamaño
n.
La
desviación
1.2.1 Media aritmética
Ejemplo
1.4 En este
y en los
sucesivos
ejemplos
estimadores
muestrales, se
HDL
en
aleatorias
simples
decantidad
tamaño
nSE(
=sobre
10,
25
ylas
100,
Aun
cuando
en1000
la práctica
carece
de sentido
tomar
repetidas
muestras,
propiedades
de la
1.2.1 Media
x )aritmética
se
conoce
como
tamaño
n respecto
demuestras
la medida
poblacional.
Esta
σ 2 poblacional
de la variable 2a e
previamente
una
estimación
de
la
varianza
poblacional
que
este
parámetro
es
típicamente
desconocido.
La
varianza
continuación
se
describen
los
principales
estimadores
de
la
tendencia
central
x
es
estándar
de
la
distribución
muestral
de
utilizarse
para
cuantificar
error
cometido en la estimación a de una σ pu
distribución
muestralpor
de x ,pueden
La media aritmética,
denotada
se define
como la
suma
de cada el
uno
de los
utilizarán los
valores adel
colesterol
HDL obtenidos
en losEURAMIC.
10 primerosEn
sujetos del
1.2 MEDIDAS
DEúnica
TENDENCIA
respectivamente,
obtenidas
de los controles
del
partir
de una
de CENTRAL
tamaño
n.partir
La
estándar
de
laaritmética,
distribución
muestralpor
de
La media
denotada
error
estándarmuestra
de la media
muestral
y desviación
permite
cuantificar
el estudio
grado
de incertidumbre
enx ,esse define como2
que
este
parámetro
es
típicamente
desconocido.
La
varianza
poblacional σ
variable.
estimarse
a
partir
de
la
propia
muestra
mediante
la
varianza
muestral
valores muestrales dividida por el número de observaciones realizadas.
Si denotamos
σ
estudio se
“European
Study
on
Antioxidants,
Myocardial
Infarction
and Cancer
of
gráficas
puede
independientemente
tamaño
muestral,
x )que,
= de
var(
) =el
, más
SE(
valores
muestrales
dividida
por ellasnúmero de observac
Las medidas
deestas
tendencia
informan
acerca
cuálxes
valor
representativo
la estimación
de central
una media
a apreciar
partir
de
una
muestra
de
tamaño
n.del
n
estimarse
a partir
de lai-ésimo,
propia muestra
mediante la varianza muestral
por n el tamaño muestral y por
xi elMedia
valor observado
para
el sujeto
i 2= 1, ...,
1.2.1
aritmética
1 n, ny controles
2 realizado
the
Breast“
(EURAMIC),
unalrededor
estudio multicéntrico
de
casos
medias
muestrales
están
centradas
de
la
media
poblacional
1,09
s
=
(de
x i y−
x )tamaño
pores
n necesario
elmedias
tamaño
muestral
por
x. i el valor
facilita
un
valor para
promedio
de
la distancia
las estos
distintas
muestrales
de
n observado pa
de una que
determinada
variable
o, dicho
forma
equivalente,
estimadores
indican
En la práctica,
poderde
calcular
el errordeestándar,
obtener
n − 1 i =1
n
la media vendría
como
de lade los
respecto
de por
la medida
poblacional.
cantidadde
SE(
quedada
facilita
un valor
promedio
deEsta
la distancia
lasx )distintas
medias
muestrales
La media
aritmética,
denotada
por
, se conoce
define
como
la1error
sumaestándar
de de
cada2 uno
2
entre
1991
y 1992
en ocho países
Europeos
e2Israel
para
evaluar
el
efecto
de los
mmol/l.
Sin
embargo,
al
aumentar
el tamaño
muestral,
se
observa
una
s
=
(
x
−
x
)
.
i
la
media
vendría
dada
por
alrededor
de
qué
valor
se
agrupan
los
datos
observados.
Las
medidas
de
tendencia
media
muestral
y
permite
cuantificar
el
grado
de
incertidumbre
en
la
estimación
de
una
media
dado
previamente una estimación de la varianza poblacional σ de la variable
n − 1ai =estudio,
Puede
probarsepor
que
lanúmero
varianza
muestral
es un 1estimador
de la varia
a partir
de una
muestra
tamaño
n.poblacional.
x ) se conoce
como insesgado
tamaño
n respecto
dedenlamuestrales
medida
Esta
cantidad
SE(
valores
dividida
el
de
observaciones
realizadas.
Si denotamos
+ xla2 variabilidad
+ ... + x n
x1de
1
disminución
substancial
de
las
medias
muestrales.
Así,
por
2
central de que
la muestra
sirven
tanto
para
resumir
los
resultados
observados
como
para
. La varianza
= espoder
xpara
x i =calculardesconocido.
5x + x + ...
n
σ puede 1 una
parámetro
típicamente
poblacional
En laeste
práctica,
el
error estándar,
es necesario
obtener
2 previamente
1 las
2la var
nnlael
nprobarse
i=
1 tamaño
sobre
todas
sobre
todas
poblacional;
espor
decir,
el
valor
esperado
ses
Puede
que
la
varianza
muestral
un
estimador
insesgado
de posib
=
=
x
x
por
muestral
y
x
el
valor
observado
para
el
sujeto
i-ésimo,
i
=
error
estándar
de
media
muestral
cuantificar
el
grado
de
incertidumbre
en
2y permite
i
i 1, ..., n,
la variable
amedio
estudio,
dado
que este
parámetro
es
estimación
de la varianza
poblacional
σ de con
ejemplo,
la
proporción
de
muestras
un
nivel
de
colesterol
HDL
entre
n
n
i =1
realizar inferencias
acerca
parámetros
poblacionales
2
estimarse desconocido.
a partirde
delos
la propia
muestra
mediante
laσcorrespondientes.
varianza
muestralA
de la propia
típicamente
La varianza
poblacional
2
2
2 puede estimarse a partir
sobre todas
sobre
pos
poblacional;
es) decir,
el tamaño
valor
esperado
dela
s media
=σ
El
error
estándar
de
muestral
se todas
estimalas
enton
es
E(smuestra
la
media
vendría
dada
por
de
media
amuestras
partir
una
de
n.
La media
eslalaestimación
medida
tendencia
central
másdeutilizada
de .69,1%
más
fácil
muestra
mediante
launa
varianza
y de
1,15
mmol/l
esmuestral
del estimadores
48,7%
para nde=yla
10,
para
n = 25
y 95,4% para n =
continuación se1,03
describen
los
principales
tendencia
central
de
una
La media es la medida de tendencia central más uti
n 2
2
1es
2
2El
)
=
σ
.
error
estándar
de la media muestral se estima ento
muestras
E(s
En
la
práctica,
para
poder
calcular
el
error
estándar,
necesario
obtener
s/ ns . Así,
una
muestra
interpretación. Corresponde
al “centro de gravedad”
los
datos
= de
( x iseleccionada
−nde
x ) laes
. muestra.
vez
... + x n concreta, la media muestral x fa
x1 +una
x 2 +Su
100.
n − 1 i =x1 = 1 interpretación.
variable.
.
xi =
Corresponde
al “centro de gravedad” d
n i =1 σ 2 de la variable
n
a
estudio,
dado
previamente
una
estimación
de
la
varianza
poblacional
x
s/ estimación
n por
. Así,
vez seleccionada
una
muestra
concreta,
la de
media
muestral
principal limitación
es que que
está la
muy
influenciada
valores
extremos
y, en
una
insesgada
de la media
poblacional
ypoblacional;
el error
dicha
estimació
Puede probarse
varianza
muestral
eslos
ununa
estimador
insesgado
deeste
la
varianza
2
2
2
principal
limitación
es
que
está
muy
influenciada
por
l
1.2.1 Media
aritmética
es decir,
elprobarse
valor esperado
de s sobre
todas las
muestras
es E(s de
) =laσ varianza
. 2El error estándar
Puede
que la varianza
muestral
es posibles
un estimador
insesgado
18
σ ypuede
este
parámetro
esmedia
típicamente
desconocido.
La
caso, puededenoque
un fiel
reflejoLa
de
la
tendencia
central
detendencia
la
distribución.
una
estimación
de
media
poblacional
y elmuestra
error
es
la medida
de
central
másseleccionada
utilizada
deuna
más
fácil de dicha estima
Así,
unalapoblacional
vez
laser
media
muestral
se
estima
entonces
como
n ..varianza
determinado
por
s/insesgada
2
caso,
puede
no
ser
un
fiel
reflejo
deylaeltendencia centra
La media
aritmética,
denotada
por
x ,facilitará
seesperado
defineuna
como
sumatodas
de
cada
uno
de
insesgada
de
la los
media
poblacional
concreta,
la media
muestral
sobre
todas
las posibles
poblacional;
es decir,
el valor
deestimación
s lasobre
estimarse
partir
de la vendrá
propia muestra
mediante
muestralde los datos de la muestra. Su
interpretación.
Corresponde
al “centro
error
de dichaa estimación
determinado
por
n .. de gravedad”
s/la varianza
Ejemplo
1.4
En
este
y
en
los
sucesivos
ejemplos
sobre
estimadores
muestrales,
se
2
2
valores muestrales
número
de observaciones
realizadas.
σ el. El
error estándar
de la media
muestralSi
sedenotamos
estima entonces como
muestras dividida
es E(s ) =por
Ejemplo
1.4
En
este y extremos
en los sucesivos
ejemplos
principal limitación es que está
muy influenciada por los valores
y, en este
n
1
2
2
utilizarán
los valores dely colesterol
HDLobservado
en (los
10x )primeros
sujetos
sobtenidos
=
xeli −sujeto
. i-ésimo,
por
n el tamaño
porseleccionada
xi el valor
para
i = 1,del
..., n,
Pastor-Barriuso R. 51
x facilitará
s/ n . muestral
Así, una vez
una muestra
concreta,
la utilizarán
media muestral
n
−
1
los de
valores
del colesterol HDL obtenid
i
=
1
caso, puede no ser un fiel reflejo de la tendencia central
la distribución.
“European
laestudio
media vendría
dadaStudy
por on Antioxidants, Myocardial Infarction and Cancer of
una estimación insesgada de la media poblacional y el error
de dicha
estimación
vendrá
estudio
“European
Study
on Antioxidants, Myoc
Puede probarse que la varianza muestral es un estimador insesgado
de la varianza
Principios de muestreo y estimación
30
20
10
0
0,8
0,9
1
1,1
1,2
1,3
1,4
(a) Media del colesterol HDL (mmol/l) en muestras de tamaño 10
Frecuencia relativa (%)
30
20
10
0
0,8
0,9
1
1,1
1,2
1,3
1,4
(b) Media del colesterol HDL (mmol/l) en muestras de tamaño 25
30
20
10
0
0,8 de los
0,9controles
1 del estudio
1,1
1,2
1,3
1,4
Ejemplo 4.10 A partir
EURAMIC,
se ha obtenido
una
(c) Media del colesterol HDL (mmol/l) en muestras de tamaño 100
Ejemplo
4.10 A partir
de de
lostamaño
controles
se ha obtenido
una
muestra aleatoria
simple
n =del
10,estudio
cuyos EURAMIC,
valores de colesterol
HDL son
Figura
4.2
Figura 4.2 Distribución muestral de la media del colesterol HDL en 1000 muestras
aleatorias
simples de
tamañomuestra
n = 10 (a),
25
(b)
y
100
(c)
obtenidas
a
partir
del
grupo
control
del
estudio
EURAMIC.
La
línea veraleatoria
simple
de
tamaño
n
=
10,
cuyos
valores
de
colesterol
HDL
son
1,32, 1,74,corresponde
0,82, 0,92, a1,46,
1,10,
0,88, 0,97
0,63mmol/l
mmol/l.
La mediaHDL.
tical en 1,45,
trazo discontinuo
la media
poblacional
μ =y 1,09
de colesterol
52
1,45,
1,32,es1,74, 0,82, 0,92, 1,46, 1,10, 0,88, 0,97 y 0,63 mmol/l. La media
muestral
Ejemplo 4.10 A partir de los controles del estudio EURAMIC, se ha obtenido una
muestra
simple de tamaño n = 10, cuyos valores de colesterol HDL son 1,45,
muestralaleatoria
es
10
+ 1,32
+ ...
+ 0,63
1,45
1,32, 1,74, 0,82, 0,92,11,46,
1,10,
0,88,
0,97
y 0,63
mmol/l. La media muestral es
x = xi =
= 1,13 mmol/l
10 10i =1
10
1
1,45 + 1,32 + ... + 0,63
x = xi =
= 1,13 mmol/l
10 i =1
10
y la varianza muestral
y la varianza muestral
y la varianza muestral
1 n
s2 =
( xi − x ) 2
n − 1 in=1
1
2
s 2 = (1,45
x i )−2 x+)...
− 1(,13
+ (0,63 − 1,13) 2
−
1
n
i =1
=
= 0,12 (mmol/l) 2 .
9
(1,45 − 1,13) 2 + ... + (0,63 − 1,13) 2
=
= 0,12 (mmol/l) 2 .
9
Por tanto, la estimación puntual de la media poblacional del colesterol HDL es x
Pastor-Barriuso R.
Por
tanto,
la estimación
dees
la media poblacional del colesterol HDL es x
= 1,13
mmol/l
y su errorpuntual
estándar
(1,45 − 1,13) 2 +alrededor
... + (0,63 de
− 1,qué
13) 2valor se agrupan 2los datos observados. Las medidas d
=
= 0,12 (mmol/l) .
variable.
9 como para
muestra sirven tanto para resumir los resultados observados
Estimación
en
el muestreo
aleatorio
central de laDE
muestra
sirven
tanto
para
resumir
los simple
resultados observad
1.2 MEDIDAS
TENDENCIA
CENTRAL
ncias acerca de los parámetros
A 1.2.1
Por tanto,poblacionales
la estimación correspondientes.
puntual de la media
poblacional
colesterol HDL es x
Mediadel
aritmética
realizar inferencias acerca de los parámetros poblacionales correspond
Las medidas de tendencia central informan acerca de cuál es el valor más r
e describen los principales
estimadores
la tendencia
central
de La
unamedia aritmética,
Por
tanto,
la estimación
puntual
la media
poblacional
del colesterol
HDLpor
es x ,=se1,13
denotada
define como la su
= 1,13
mmol/l
y sude
error
estándardees
continuación
describen los principales estimadores de la tendencia
mmol/l y su error estándar esde una determinadasevariable
o, dicho de forma equivalente, estos estimador
valores muestrales dividida por el número de observacione
s
0,35
SE( xalrededor
) = variable.
= de qué=valor
0,11 se
mmol/l.
agrupan los datos observados. Las medidas de ten
n
10
1.2
MEDIDAS
DE
TENDENCIA
CENTRAL
por n el tamaño muestral y por xi el valor observado para e
ritmética
Frecuencia absoluta
1.2.1
Media
aritmética
Notar que, en este ejemplo ilustrativo,
error
de sirven
la estimación
muestral
es los
exactamente
central
de el
la
muestra
tanto para
resumir
resultados observados co
la
media
vendría
dada
por
mética,
xNotar
,–se
como
la
suma
de
cada
uno
de
los
μ define
=que,
1,13
–
1,09
=
0,04
mmol/l.
En
la
práctica,
sin
embargo,
el
error
exacto
no puede
Lasdenotada
medidas por
de tendencia
central
informan
acerca
de
cuál
es
el
valor
más
representativo
en este ejemplo ilustrativo, el error de la estimación muestral es
Lay,inferencias
media
aritmética,
denotada
por
sepoblacionales
define
como la
suma de cada
estimación
calcularse ya que μ es desconocido
en consecuencia,
SE( x ), como
realizar
acercase
deemplea
los parámetros
correspondiente
ralesdedividida
por el número
de
observaciones
realizadas.
Si
denotamos
del
error
promedio
que
cabría
esperar
en
similares
circunstancias
(esto
es,
en
todas
las
una determinada
variable
o,
dicho
de
forma
equivalente,
estos
estimadores
indican
n
exactamente x - μ = 1,13 - 1,09 = 0,04 mmol/l. En la práctica, sin embargo, el1
x1 + x 2 + ... + x n
x =de observaciones
xde
valores
muestrales
por
número
realizadas
posibles muestras del mismocontinuación
tamaño
obtenidas
de la dividida
población
deelreferencia).
se describen
los principales
estimadores
la tendencia
centr
i =
n i =1
n
valor
observado
para
el
sujeto
i-ésimo,
i
=
1,
...,
n,
o muestral
y por
xi elvalor
alrededor
de qué
se
agrupan
los
datos
observados.
Las
medidas
de
tendencia
error exacto no puede calcularse ya que μ es desconocido y, en consecuencia, se
por n el tamaño muestral y por xi el valor observado para el sujeto i-és
variable.
Teorema
central
del
límite los resultados observados como para
ría dada
porde la4.3.3
central
muestra
sirven
tanto
para
resumir
La media
es la medida
que cabría
esperar de
en tendencia central más utilizad
emplea SE( x ) como estimación del error promedio
la media vendría dada por
En los apartados anteriores se ha probado
paraaritmética
cualquier variable aleatoria, el valor esperado y
1.2.1 que,
Media
realizar inferencias
los
parámetros
poblacionales
correspondientes.
A respectivamente.
interpretación.
Corresponde
al tamaño
“centro
de ha
gravedad” de los
n acerca de
similares
circunstancias
(esto
es,
en
todas
las
posibles
del mismo
x 2 + ... + x n de las medias muestrales
No se
la varianza
dex1la+distribución
son μ muestras
y σ2/n,
1
. global de la distribución muestral de . Retomando
= x i sin
= embargo, el aspecto
xanalizado,
n
+ ejemplo
... + xde
x 2la+suma
La media aritmética, denotada por x , 1se define xcomo
1 el
n cada uno
ndescriben
n
i =1
continuación
se
los
principales
estimadores
de
la
tendencia
central
de
una
. por los v
=
=
x
x
principal
limitación
es
que
está
muy
influenciada
i
obtenidas
de
la
población
de
referencia).
de la distribución muestral de las medias de colesterol HDL (Figura 4.2), puede
observarse
que
la
n i =1
n
forma de esta distribución tiende a valores
aproximarse
a una dividida
distribución
conforme
aumenta el realizadas. Si d
muestrales
por normal
el número
de observaciones
caso,
puede
no
ser
un
fiel
reflejo
de la tendencia central de
s la variable.
medida de tendencia
central
más
utilizada
y
de
más
fácil
tamaño muestral. Esta característica puede resultar intuitivamente lógica, ya que la distribución
mediamuestral
esun
la aspecto
medida
de
tendencia
central
más
utilizada
de más
subyacente
del colesterol
HDL
en lapor
población
presenta
normal
n el La
tamaño
y poraproximadamente
xi el
valor observado
para(ver
el sujetoyi-ésimo,
4.3.3 Teorema
central del
límite
Corresponde
al
“centro
de
gravedad”
de
los
datos
de
la
muestra.
Su
1.2 del Tema 1). Dado que muchas de las variables utilizadas en la práctica no presentan una
1.2.1 MediaFigura
aritmética
Ejemplo 1.4alEn
este yde
engravedad”
los sucesivoslos
ejemplos
sob
interpretación.
datos de
la
distribución
poblacional
normal,
cabría
preguntarse
siCorresponde
esta
a la normalidad
la
la media
vendría
por tendencia
En los apartados
anteriores
se ha probado
que,
para dada
cualquier
variable “centro
aleatoria,
el valor de de
ación
es
que
está
muy
influenciada
por
los
valores
extremos
y,
en
este
para cualquier
tipo
de uno
variable
aleatoria.
La media aritmética,
denotada
define como
la suma de
cada
de los
distribución
muestralpor
de x ,sesemantiene
utilizarán
los
valores
obtenidos
e
principal
limitación
es
que
está
muy influenciada
porHDL
los valores
extre
2 del colesterol
esperado y la varianza de la distribución de las medias muestrales son
nμ y σ /n,
+
+
...
+
x
x
x
1
1
2
n
o servalores
un fiel muestrales
reflejo deEjemplo
ladividida
tendencia
ladedistribución.
porcentral
elEn
número
observaciones
Si denotamos
.
xde=los
x i = de
4.11
la de
Figura
4.3 se muestra realizadas.
la distribución
niveles
b-caroteno
en
estudio
“European
Study
on
Antioxidants,
Myocardia
n
n
caso,
puede
no
ser
un
fiel
reflejo
de
la
tendencia
central
=
i
1
tejido adiposo
control
estudioelEURAMIC,
que de
presenta
una distribución de la distribuc
respectivamente.
Noen
se el
hagrupo
analizado,
sindel
embargo,
aspecto global
la distribución
por n el tamaño muestral
y por xiasimétrica
el valor observado
para elde
sujeto
i-ésimo,
i =Las
1, ...,
n,
marcadamente
con una media
μ = 0,37
Figuras
4.4(a),
y (c)multicéntrico de
the mg/g.
Breast“
(EURAMIC),
un (b)
estudio
1.4 En este y en los sucesivos ejemplos sobre estimadores muestrales, se
20
La media
es la medida
tendencia
másejemplos
utilizadasobre
y de más
fácil
Ejemplo
1.4 Endeeste
y en loscentral
sucesivos
estimado
la media vendría dada por
250
entre 1991 y 1992 en ocho países Europeos e Israel p
n los valores del colesterol HDL obtenidos en los 10 primeros sujetos del
interpretación.
Corresponde
al “centro
de gravedad”
de los datos
utilizarán los valores
del colesterol
HDL obtenidos
en de
losla10mue
pri
n
+ x nCancer of
xInfarction
1
“European Study on Antioxidants,
Myocardial
1 + x 2 + ...and
200 x = x i =
.
principal
limitación
es que estáStudy
muy on
influenciada
por Myocardial
los valores extremos
estudio “European
Antioxidants,
Infarction
n i =1
n
st“ (EURAMIC), un estudio multicéntrico de casos y controles realizado
caso, puedethe
noBreast“
ser un fiel
reflejo de launtendencia
central de la distribución.
(EURAMIC),
estudio multicéntrico
de casos y co
150de tendencia central más utilizada y de más fácil
La
media
es
la
medida
91 y 1992 en ocho países Europeos e Israel para evaluar el efecto de los
entre 1991 y 1992 en ocho países Europeos e Israel para evaluar
1.4 En
y en losSu
sucesivos ejemplos sobre estimadores m
interpretación. Corresponde al “centro de gravedad”Ejemplo
de los datos
de este
la muestra.
100
5
utilizarán
los extremos
valores del
principal limitación es que está muy influenciada por
los valores
y, colesterol
en este HDL obtenidos en los 10 primero
estudio
“European
Study on Antioxidants, Myocardial Infarction and
caso, puede no ser un fiel50reflejo de la tendencia central
de la
distribución.
the Breast“ (EURAMIC), un estudio multicéntrico de casos y control
Ejemplo 1.4 En este0y en los sucesivos ejemplos sobre estimadores muestrales, se
entre 1991 y 1992 en ocho países Europeos e Israel para evaluar el ef
utilizarán los valores del colesterol
en los 10
sujetos1,6
del 1,8
0
0,2 HDL
0,4 obtenidos
0,6
0,8
1 primeros
1,2
1,4
2
β-caroteno (μg/g)
estudio “European Study on Antioxidants, Myocardial
Infarction and Cancer of
Figura 4.3
Figura 4.3
Distribución de frecuencias del nivel de β-caroteno en el grupo control del estudio EURAMIC.
the Breast“ (EURAMIC), un estudio multicéntrico de casos y controles realizado
entre 1991 y 1992 en ocho países Europeos e Israel para evaluar el efecto de los
Pastor-Barriuso R.
53
Principios de muestreo y estimación
30
20
10
0
0,1
(a)
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
Media de β-caroteno (μg/g) en muestras de tamaño 10
Frecuencia relativa (%)
30
20
10
0
0,1
(b)
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
Media de β-caroteno (μg/g) en muestras de tamaño 25
30
20
10
0
0,1
(c)
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
Media de β-caroteno (μg/g) en muestras de tamaño 100
Figura 4.4
Figura 4.4 Distribución muestral de la media de β-caroteno en 1000 muestras aleatorias simples de tamaño
n = 10 (a), 25 (b) y 100 (c) obtenidas a partir del grupo control del estudio EURAMIC. La línea vertical en
trazo discontinuo corresponde a la media poblacional μ = 0,37 μg/g de β-caroteno.
representan las medias de b-caroteno en 1000 muestras aleatorias simples de tamaño n =
10, 25 y 100, respectivamente, obtenidas a partir de los controles del estudio EURAMIC.
En estas gráficas puede observarse, de forma empírica, las siguientes propiedades:
—— Ausencia de sesgo: para cualquier tamaño muestral, el promedio de las medias
muestrales es similar a la media poblacional.
—— Disminución del error estándar: al aumentar el tamaño muestral, disminuye la
variabilidad en la distribución de las medias.
—— Aproximación a la distribución normal: al aumentar el tamaño muestral, la distribución
de las medias se aproxima a una distribución normal centrada en la media poblacional.
En los ejemplos anteriores, se ha comprobado de forma empírica que, independientemente de
la forma de la variable aleatoria en la población, la distribución de las medias muestrales tiende a
54
Pastor-Barriuso R.
estadística, conocido como teorema central del límite, formaliza esta intuición: para
Las medidas de tendencia central informan acerca de cuá
estadística, conocido como teorema central del límite, formaliza esta intuición: para
σ 2, la
distribución
de
las medias
cualquier variable aleatoria X con media μ y varianza
Estimación en
el muestreo
de una
determinada
variable
o,aleatorio
dicho simple
de forma equivalen
cualquier variable aleatoria X con media μ y varianza σ 2, la distribución de las medias
en muestras aleatorias simples de tamaño n se aproxima,
al aumentar
el tamaño
alrededor
de qué valor
se agrupan los datos observados. L
en muestras aleatorias simples de tamaño
n
se
aproxima,
al
aumentar
el tamaño
~
x → N(1,09, 0,00086).
2 tamaño de la muestra. Uno de
seguir
una distribución
normal,normal
particularmente
aumentaσ el
μ y varianza
es decir,
al aumentar
muestral,
a una distribución
con mediacuando
central
de la/n;
muestra
sirven
tantoformaliza
para resumir los resulta
losmuestral,
principales
resultados
en
estadística,
conocido
como
teorema
central
del
límite,
es decir,
al
aumentar
a una distribución normal con media μ y varianza σ 2/n;
2
, la distribución
de las
esta
paraejemplo,
cualquier
aleatoria
X con
media μdey colesterol
varianza σHDL
Así, por
la variable
probabilidad
de que
la media
endeuna
n, intuición:
realizar
inferencias
acerca
los muestral,
parámetros poblacional
medias
en
muestras
aleatorias
simples
de
tamaño
n
se
aproxima,
al
aumentar
el
tamaño
n,
decir,
al yaumentar
n, puede
a una distribución
normal
conn media
y varianza
σ 2/n; es
muestra de
tamaño
= 100 μesté
comprendida
entre
1,03
1,15 mmol/l
2 continuación se describen los principales estimadores de
σ
~ N μ,
x→
nσ 2,
~
calcularse como
,
x → N μ , variable.
n
~ significa “distribuirse
− 1,09
x − 1,09 aritmética
1,15Así,
− 1Así,
,09
1,03
aun
aun
dondeelel símbolo
símbolo P(1,03
→
donde
significa
“distribuirse
aproximadamente
como”.
cuando la
1.2.1
= P aproximadamente
≤ Mediacomo”.
≤
≤ x ≤ 1,15)
cuando
~
aproximadamente
como”.
Así,
aun
donde el símbolo
→ significa
0,029
0,029
0,029
distribución
de una variable
en la“distribuirse
población diste
mucho de
ser normal,
el teorema
central del
cuando
la distribución
de unalavariable
en la población
disteLa
mucho
de
ser
normal,
el
teorema
límite
permite utilizar
distribución
normal como
aproximación
a
la
distribución
de x ,siseeldefine como la s
media aritmética, denotada por
la distribución
variable en lagrande.
población
diste
de muestral
ser normal,
el teorema
tamaño
muestral de
es una
suficientemente
Aunque
tamaño
necesario
variará en
= P(-2,05
≤
Z ≤elmucho
2,05)
centralde
dellalímite
permite
la distribución
normal
como
aproximación
a
la
función
variable
objetoutilizar
de estudio,
esta aproximación
será
razonablemente
precisa
valores muestrales dividida por el siempre
número de observacion
del límitea permite
utilizar la distribución normal como aproximación a la
quecentral
n sea superior
50.
= 2 Φ(2,05) - 1 = 0,9596.
grande. muestral
Aunque ely tamaño
distribución de x si el tamaño muestral es suficientemente
por n el tamaño
por xi el valor observado para
~
→ N(1,09,
0,00086). HDL
el tamaño
es suficientemente
grande.
Aunque
el tamaño
distribución
media ymuestral
la xvarianza
del colesterol
en los
controles
del estudio
Ejemplo de
4.12x siLa
2 la variablelaobjeto
2
En
el
Ejemplo
4.9
se
comprobó
empíricamente
que
la
proporción
de
muestras
muestral
necesario
variará
en
función
de
de
estudio,
esta
media. vendría
dada por
Por el teorema
central delde
límite,
EURAMIC son μ = 1,09 mmol/l y σ = 0,086 (mmol/l)
muestral
necesario
variará
en
función
de
la
variable
objeto
de
estudio,
esta
laAsí,
distribución
de
las
medias
en
muestras
de
tamaño
n
=
100
será
aproximadamente
por ejemplo, la probabilidad de que la media de colesterol HDL en una
2
2
tamaño
nmedia
= razonablemente
100 μcon
un nivel
medio
de colesterol
entre 1,03
y 1,15(mmol/l)
mmol/ln es
aproximación
será
precisa
siempre
sea superior
a 50.
/n =nHDL
0,086/100
= 0,00086
,
normal
con
= 1,09
mmol/l
y varianza
σque
x1 + x 2 + ... + x
1
aproximación
será
razonablemente
precisa
siempre
que
n
sea
superior
a
50.
=
x
muestra de tamaño n = 100 esté ~
comprendida entre 1,03 y 1,15 mmol/l puede n x i =
n
del 95,4%, que coincide casi
con el resultado obtenido bajo la i =1
x perfectamente
→ N(1,09, 0,00086).
Ejemplo 4.12 La media y la varianza del colesterol HDL en los controles del
calcularse
como la probabilidad de que la media de colesterol HDL en una muestra de
Así,
por ejemplo,
Ejemplo
4.12 La
media y la varianza del colesterol HDL en los controles del
aproximación
normal.
Así, pornejemplo,
la probabilidad
que1,03
la media
demmol/l
colesterol
en una
La
media
es
laHDL
medida
de tendencia
tamaño
= 100 esté
comprendida de
entre
y 1,15
puede
calcularse
como central más utiliza
estudio EURAMIC son μ = 1,09 mmol/l y σ 2 = 0,086 (mmol/l)2. Por el teorema
2
2
σentre
=x0,086
Por el teorema
estudio EURAMIC son μ = 1,09 mmol/l
1,03 − 1y,09
−1,03
1,09y(mmol/l)
1,15
− 1.,09
muestra
de
tamaño
n
=
100
esté
comprendida
1,15
mmol/l
interpretación.
Corresponde
al “centro de gravedad” de l
≤
P
≤
≤
x
≤
1,15)
=
P(1,03
puede
Como
se
mostrará
en
los
siguientes
temas,
el
teorema
central
del
límite
central del límite, la distribución de
medias en0muestras
de
tamañoconstituye
n = 100 la
0,029
,029
0,029
las
central del
límite, la distribución de las medias
en muestras
de tamaño
nestá
= 100
como
principal
limitación
es quetanto
muy influenciada por los
2
−
=
P(
2,05
≤
Z
≤
2,05)
basecalcularse
fundamental
del
proceso
de
inferencia
estadística,
dado
que
posibilita
será aproximadamente normal con media μ = 1,09 mmol/l y varianza σ /n =la
2
1,09
mmol/l
yser
varianza
σreflejo
/n = de la tendencia central d
será aproximadamente normal
con
media−μ1 ==
=
2
Φ(2,05)
0,9596.
caso,
puede
no
un
fiel
2 1,como
construcción
de
intervalos
de
confianza
el
contraste
de
hipótesis
acerca
de la
,P 03 − 1,09 ≤ x − 1,09 ≤ 1,15 − 1,09
0,086/100P(1,03
= 0,00086
(mmol/l)
x
≤
1,15)
=
≤
2
En0,086/100
el Ejemplo= 4.9
se comprobó
proporción
de muestras
de tamaño
, 0,029 que0,la
0,00086
(mmol/l)empíricamente
029
0,029
μ. medio de colesterol HDL entre 1,03
media
n = poblacional
100 con un nivel
y
1,15
mmol/l
es
del
95,4%,
que ejemplos so
Ejemplo 1.4 En este y en los sucesivos
coincide
casi perfectamente
con el
resultado obtenido
la aproximación
normal.
En el Ejemplo
4.9 se comprobó
empíricamente
que labajo
proporción
de muestras
de
= P(-2,05
≤ Z ≤ 2,05)
22
utilizarán los valores del colesterol
HDL obtenidos
4.3.4 Estimación de una proporción poblacional
Como
se mostrará
losunsiguientes
temas,
el teorema
central
límite
constituye
la22base
tamaño
n = 100en
con
nivel medio
de colesterol
HDL
entredel
1,03
y 1,15
mmol/l es
= 2estadística,
Φ(2,05) - 1dado
= 0,9596.
fundamental
del que
proceso
de inferencia
que
posibilita
tanto la
construcción
de
estudio
“European
on Antioxidants,
Myocard
Supongamos
el interés
del estudio
se centra en estimar
la proporción
π Study
de
intervalos
de
confianza
como
el
contraste
de
hipótesis
acerca
de
la
media
poblacional
μ.
del 95,4%, que coincide casi perfectamente con el resultado obtenido bajo la
En el Ejemplo
4.9 sede
comprobó
empíricamente
que
la
proporción
decaracterística.
muestras de
thedeterminada
Breast“ (EURAMIC),
un En
estudio multicéntrico
individuos
o elementos
la población
que cumplen
una
aproximación normal.
4.3.4 tamaño
Estimación
decon
unaun
proporción
poblacional
n = 100
nivel
medio
colesterol
HDL
entre
1,03
yel1,15
es Europeos e Israel
entre
1991
y 1992
enmmol/l
ocho
tal caso, resulta
conveniente
definir
unade
variable
aleatoria
X
que
toma
valor
1 en países
los
Supongamos que el interés del estudio se centra en estimar la proporción π de individuos o
Como
se mostrará
en los siguientes
temas, el teorema
central del
límite constituye
la
del 95,4%,
que
coincide
casi
perfectamente
resultado
obtenido
bajo
lacaso,
individuos
presentan
dicha
característica
y con
0 enelquienes
no la
presentan.
media
elementos
de que
la población
que
cumplen
una determinada
característica.
En
talLa
resulta
conveniente definir una variable aleatoria X que toma el valor 1 en los individuos que presentan
base fundamental
del
proceso de inferencia estadística, dado que posibilita tanto la
aproximación
normal.
poblacional
de esta
aleatoria
es La media poblacional de esta variable
dicha
característica
y variable
0 en quienes
no discreta
la presentan.
aleatoria discreta es
construcción de intervalos de confianza como el contraste de hipótesis acerca de la
1
Como se mostrará en los siguientes temas,
el teorema central del límite constituye la
μ = k P( X = k ) = π
media poblacional μ.
k =0
base fundamental del proceso de inferencia estadística, dado que posibilita tanto la
23
4.3.4 Estimación
de una proporción
construcción
de intervalos
de confianzapoblacional
como el contraste de hipótesis acerca dePastor-Barriuso
la
R.
Supongamos
que elμ.interés del estudio se centra en estimar la proporción π de
media
poblacional
55
Si se selecciona una muestra aleatoria simple de tamaño n, en la cual k individuos
1
)
n - k individuos no la
presentan la característicaσde=interés
(k −(xπi =) 1)P(yXlos= krestantes
Principios de muestreo y estimación
2
2
k =0
y
de la proporción
poblacional es la proporción
presentan (xi = 0), el estimador natural
2
2
yLa
su varianza
varianza muestral de p=viene
•
determinada
por
π
(1
--ππ)/n;
π
(1
π
)
+
(1
π
)
π
=
π
(1
). así, al aumentar el
su varianza
• La varianza muestral de p viene determinada por π(1 - π)/n; así, al aumentar el
muestral
1
tamaño muestral, las proporciones
muestrales estarán más próximas a la verdadera
2
Si se selecciona una muestra
n, en la cual k individuos
σ 2 = aleatoria
(
k
− π )simple
P( X =dek tamaño
)
tamaño muestral, las proporciones
muestrales
estarán
más próximas a la verdadera
n
k =0
k 1
proporción poblacional.
=x.
p =(xi == 1)
x i2 restantes
y los
n - k individuos no la
presentan la característica de interés
2
proporción poblacional.= π (1 − πn) + n(1 i−=1π ) π = π (1− π ).
• Al aumentar el tamaño muestral, la distribución de las proporciones muestrales
elmuestra
estimador
naturalsimple
de la proporción
la proporción
presentan
(xi = 0),
Si
se
selecciona
una
aleatoria
de tamaño poblacional
n, en la cual es
k individuos
presentan
• Al aumentar el tamaño muestral, la distribución de las proporciones muestrales
A
partir
de
esta
notación,
es
evidente
que
una
proporción
muestral
es
un
caso
la característica
de interés
y aleatoria
los restantes
n –de
k tamaño
individuos
nolalacual
presentan
(xi = 0), el
tiende
aproximarse
amuestra
una
distribución
normal.
Esta
aproximación
es
i = 1)
Si se aselecciona
una(x
simple
n, en
k individuos
muestral
estimador
natural
de
la
proporción
poblacional
es
la
proporción
muestral
tiende
aproximarse
a una distribución
normal.
Esta aproximación
es
particular
de auna
media muestral
para una variable
dicotómica
con la codificación
arriba
π
(1
π
)
≥
5.
suficientemente
precisa
si
n
presentan la característica de interés (xi = 1) y los restantes n - k individuos no la
n
πp(1=límite
-kπ)=≥1puede
5. x i aplicarse
suficientemente
precisa
si ndel
indicada.
Así, el teorema
central
a la forma particular de esta
1 = x . poblacional
es la proporción
presentan (xi = 0), el estimador natural
n denlai =proporción
Ejemplo 4.13 En las Figuras 4.5(a), (b) y (c) se presentan las proporciones de
variable X para obtener el siguiente resultado: la distribución muestral de una
muestral
Ejemplo
4.13 Enes
lasevidente
Figurasque
4.5(a),
y (c) se presentan
lasun
proporciones
de de una
A partir
de
esta notación,
una(b)
proporción
muestral es
caso particular
A partir deactuales
esta notación,
es muestras
evidente que
una proporción
es
caso
fumadores
en 1000
aleatorias
simples demuestral
tamaño
n =un10,
25 yel teorema
media
muestral
para
una
variable
dicotómica
con
la
codificación
arriba
indicada.
Así,
proporción p se aproxima, al aumentar el tamaño muestral, a una distribución normal
fumadores
actuales
en 1000
muestras
aleatorias
simples
de tamaño
n = 10,el25siguiente
y
central del
límite puede
aplicarse
a la forma
particular
de esta
variable
X para obtener
n
1 grupo
k variable
particular
de una media muestral
para
una
dicotómica
con
la codificación
arriba
100, respectivamente,
obtenidas
apuna
partir
del
control
del
estudio
EURAMIC,
resultado:
la
distribución
muestral
de
proporción
p
se
aproxima,
al
aumentar
el
tamaño
=
=
=
.
x
x
i
con media π y varianza π(1 - π)/n,
n
n
=
1
i
respectivamente,
obtenidas
a partir
grupo control
del estudio EURAMIC,
muestral,100,
a una
distribución normal
con media
π ydel
varianza
π(1 – π)/n,
indicada.
Así,
el teorema
del límite
puede
a la forma
particular
= 0,37. Para
cualquier
tamañoden esta
donde la
proporción
decentral
fumadores
actuales
es πaplicarse
(1 −es
)π= 0,37. Para
π una
πproporción
cualquier
la
de fumadores
~ N actuales
Adonde
partir
deproporción
esta notación,
es evidente
que
muestral
es una
un tamaño
caso n
π
p
→
,
.
variable
X
para
obtener
el
siguiente
resultado:
la
distribución
muestral
de
de la muestra, las proporciones muestrales están
distribuidas
alrededor
de
la
n
de
la
muestra,
las
proporciones
muestrales
están
distribuidas
alrededor
de la arriba
particular pdeseuna
media
muestral
una
variable
dicotómica
con
la codificación
aproxima,
al aumentar
tamaño
an,una
distribución
normal
En proporción
consecuencia,
pueden
extraerse
laspara
siguientes
propiedades
una
proporción
muestral:
proporción poblacional
(ausencia
de el
sesgo).
Almuestral,
aumentarde
la distribución
En
consecuencia,
pueden extraerse
las siguientes
propiedades
una
proporción
yyindicada.
La
proporción
muestral
pcentral
es
undel
estimador
insesgado
de laa de
proporción
poblacional
π; es
(ausencia
de sesgo).
Al
aumentar
la distribución
Así,
elpoblacional
teorema
límite
puede
aplicarse
lan,forma
particular
de esta
π
y
varianza
π
(1
π
)/n,
con
media
muestral
de=laπ.proporción de fumadores actuales presenta una menor variabilidad
decir,
E(p)
muestral:
muestral
deobtener
la proporción
de fumadores
presenta
una
variabilidad
X para
el psiguiente
resultado:actuales
lapor
distribución
de una
yyvariable
La varianza
muestral
de
viene
determinada
π(1
– π)/n;muestral
así, menor
al aumentar
el tamaño
π
y se aproxima a una distribución normal
centrada
en
la
proporción
poblacional
(
1
−
)
π
π
~
muestral,
las proporciones muestrales
más .próximas
a la verdadera
proporción
• La proporción muestral p es pun
insesgado
de la proporción
poblacional
→estimador
N estarán
,
π
π
y se aproxima
a una distribución
centrada
poblacional
proporción
p se aproxima,
al aumentarnormal
el
una distribución
normal
n muestral,
poblacional.
tamaño
en la aproporción
= 0,37.
π
; es decir, E(p)
= πmuestral,
.
yy Al aumentar
tamaño
la distribución de las proporciones muestrales tiende a
= 0,37.π yelvarianza
π(1 - π)/n,
con media
aproximarse
a
una
distribución
normal.
Esta aproximación
es una
suficientemente
En consecuencia, pueden extraerse las siguientes
propiedades de
proporción precisa si
nπ(1 – π) ≥ 5.
[Figura 4.5 ~aproximadamente
π (1 − π ) aquí]
muestral:
p → N π ,
.
4.5(a),
las proporciones de fumadores
Ejemplo 4.13 En las Figuras
[Figura
4.5(b)
aproximadamente
aquí]
n presentan
y (c) se
actuales
en 1000 muestras
simples deinsesgado
tamaño nde
= 10,
25 y 100, respectivamente,
• La proporción
muestralaleatorias
p es un estimador
la proporción
poblacional
A partir
de las
propiedades
anteriores
seestudio
deduceEURAMIC,
que, para una
muestra
aleatoriadedefumadores
obtenidas
a partir
del grupo
control del
donde
la proporción
En
pueden
extraerse
las siguientes
propiedades
demuestra
una proporción
A consecuencia,
partir
deπlas
propiedades
anteriores
se deduce
que, paralasuna
aleatoria
de 24
actuales
= 0,37.
Para
tamaño
n de la muestra,
proporciones
muestrales
están
π; es es
decir,
E(p)
= π.cualquier
tamañodistribuidas
n, la proporción
muestral
p
es
un
estimador
insesgado
de
la
proporción
alrededor de la proporción poblacional (ausencia de sesgo). Al aumentar n, la
muestral:
tamaño
n, la proporción
muestral
p es un
de la proporción
distribución
muestral de
la proporción
deestimador
fumadoresinsesgado
actuales presenta
una menor variabilidad
π
y
su
error
estándar
viene
determinado
por
la
raíz
cuadrada
de la varianza
poblacional
y se aproxima a una distribución normal centrada en la proporción poblacional
π = 0,37.
•
La
proporción
muestral
p
es
un
estimador
insesgado
de
la
proporción
poblacional
poblacional π y su error estándar viene determinado por la raíz cuadrada de la varianza
muestral
dede
p, las propiedades anteriores se deduce que, para una muestra aleatoria de tamaño n,
A partir
esmuestral
decir, E(p)
muestralπ;de
p,
la proporción
p es=unπ.estimador insesgado de la proporción poblacional π y su error
estándar viene determinado por la raíz cuadrada deπ la
varianza
muestral de p,
π)
(1 −
24
,
SE(p) = var( p) =
πn (1 − π )
,
SE( p) = var( p) =
n
que
que puede
puede estimarse
estimarse aa partir
partir de la propia muestra mediante p (1 − p ) / n ..
que puede estimarse a partir de la propia muestra mediante p (1 − p ) / n .
56
Pastor-Barriuso R.
25 24
25
Estimación en el muestreo aleatorio simple
30
20
10
0
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
(a) Proporción de fumadores actuales en muestras de tamaño 10
Frecuencia relativa (%)
30
20
10
0
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
(b) Proporción de fumadores actuales en muestras de tamaño 25
30
20
10
0
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
(c) Proporción de fumadores actuales en muestras de tamaño 100
Ejemplo 4.14 A partir de una muestra aleatoria simple de n = 100 controles del
Figura 4.5
Figura 4.5 Distribución muestral de la proporción de fumadores actuales en 1000
muestras aleatorias
simples de tamaño n = 10 (a), 25 (b) y 100 (c) obtenidas a partir del grupo control del estudio EURAMIC. La
Ejemplo
4.14 discontinuo
A partir
una muestra
simple
de n =de
100
controles
del π = 0,37.
estudioenEURAMIC,
sede
obtuvieron
k a=laaleatoria
35
fumadores
actuales.
La
estimación
línea vertical
trazo
corresponde
proporción
poblacional
fumadores
actuales
estudio
se obtuvieron
k = 35
fumadores
puntual EURAMIC,
de la proporción
de fumadores
actuales
es actuales. La estimación
Ejemplo 4.14 A partir de una muestra aleatoria simple de n = 100 controles del estudio
EURAMIC,
se obtuvieron
k = 35 fumadores
puntual
de la proporción
de fumadores
actuales esactuales. La estimación puntual de la
k 35
proporción de fumadores actuales
= 0,35,
p =es =
n 100
k 35
p= =
= 0,35,
n 100
y su error estándar es
y su error estándar es
y su error estándar es
p (1 − p)
0,35(1 − 0,35)
SE(p) =
= 0,05,
=
n
100
0,35(1 − 0,35)
p (1 − p)
(p) =promedio que=cabría esperar entre
= todas
0,05, las posibles muestras de
que corresponde alSE
error
100
n
tamaño
100 de laalpoblación
a estudio.
que
corresponde
error promedio
que cabría esperar entre todas las posibles
que
corresponde
al error
que cabría
esperar entre todas las posibles
muestras
de tamaño
100 promedio
de la población
a estudio.
Pastor-Barriuso R.
muestras de tamaño 100 de la población a estudio.
En este apartado se ha discutido la estimación puntual de una proporción poblacional
57
Principios de muestreo y estimación
En este apartado se ha discutido la estimación puntual de una proporción poblacional π y su
correspondiente error estándar. No obstante, no se ha hecho un uso práctico de la aproximación
normal a la distribución muestral de p. Esta aproximación se retomará más adelante para obtener
intervalos de confianza y pruebas de hipótesis sobre la proporción poblacional π (véase Tema 7).
4.4
58
REFERENCIAS
1.
Bickel PJ, Doksum KA. Mathematical Statistics: Basic Ideas and Selected Topics.
Englewood Cliffs, NJ: Prentice Hall, 1977.
2.
Casella G, Berger RL. Statistical Inference, Second Edition. Belmont, CA: Brooks/Cole, 2001.
3.
Cochran WG. Sampling Techniques, Third Edition. New York: John Wiley & Sons, 1977.
4.
Kish L. Survey Sampling. New York: John Wiley & Sons, 1995.
5.
Lehmann EL, Casella G. Theory of Point Estimation, Second Edition. New York: Springer
Verlag, 1998.
6.
Levy PS, Lemeshow S. Sampling of Populations: Methods and Applications, Third
Edition. New York: John Wiley & Sons, 1999.
7.
Rosner B. Fundamentals of Biostatistics, Fifth Edition. Belmont, CA: Duxbury Press, 1999.
8.
Serfling RJ. Approximation Theorems of Mathematical Statistics. New York: John Wiley
& Sons, 1980.
9.
Silva LC. Diseño Razonado de Muestras y Captación de Datos para la Investigación
Sanitaria. Madrid: Díaz de Santos, 2000.
10.
Stuart A, Ord JK. Kendall’s Advanced Theory of Statistics, Volume 1, Distribution Theory,
Sixth Edition. London: Edward Arnold, 1994.
Pastor-Barriuso R.
TEMA 5
INFERENCIA ESTADÍSTICA
5.1
INTRODUCCIÓN
La teoría del muestreo aporta diversos métodos formales para seleccionar muestras a partir de
una determinada población. La información obtenida de dichas muestras puede resumirse
utilizando técnicas de estadística descriptiva. Sin embargo, cuando se trabaja con una muestra,
rara vez nos interesa la muestra como tal, sino que ésta interesa por su capacidad para aportar
información con respecto a otros sujetos o a otras situaciones.
En los estudios descriptivos, el interés radica en seleccionar una muestra representativa de la
población de referencia, o dicho más concretamente, la muestra ha de presentar el mismo grado
de diversidad que la población respecto al parámetro o característica objeto de estudio. Las
técnicas de muestreo probabilístico descritas en el tema anterior facilitan muestras que serán
muy probablemente representativas de la población si el tamaño muestral es suficientemente
grande. De esta forma, los resultados de la muestra podrán inferirse a toda población con un
grado razonable de certidumbre.
Ejemplo 5.1 En las Encuestas Nacionales de Salud, se obtiene información de una muestra
representativa a nivel provincial o nacional. Esta muestra interesa por la información que
aporta sobre toda la población. En este caso, la representatividad de la muestra es determinante
para la validez de las conclusiones derivadas del proceso inferencial.
En los estudios epidemiológicos analíticos, los resultados son interesantes porque pueden
aplicarse a situaciones de salud semejantes. En este caso, el objetivo principal del diseño es asegurar
la comparabilidad o semejanza de los grupos de estudio, más que la representatividad poblacional
de la muestra. En los ensayos clínicos randomizados, los sujetos se asignan a los distintos grupos
de tratamiento mediante algún mecanismo aleatorio (por ejemplo, mediante un muestreo aleatorio
simple). Así, si el tamaño muestral es grande, las características basales de los sujetos asignados a
los distintos grupos serán muy similares. En consecuencia, las diferencias observadas entre estos
grupos a lo largo del seguimiento podrán atribuirse al tratamiento objeto de estudio.
Ejemplo 5.2 El primer ensayo clínico publicado sobre el papel de la aspirina en la
prevención primaria de enfermedades cardiovasculares se realizó en médicos americanos
participantes en el “Physicians’ Health Study”, seleccionados además por otras
características de salud. En este caso, los sujetos a estudio no son representativos de la
población a la que se aplicarán posteriormente los resultados (población general de
hombres adultos a riesgo de padecer un primer evento cardiovascular), pero en cambio se
garantizó la comparabilidad de las personas que tomaban aspirina y quienes no la tomaban
mediante la asignación aleatoria del tratamiento y el uso de la técnica del doble ciego
(tanto el investigador como el paciente desconocían el tratamiento asignado).
La estadística inferencial aporta las técnicas necesarias para extraer conclusiones sobre el
valor poblacional de un determinado parámetro a partir de la evaluación de una única muestra.
Pastor-Barriuso R.
59
Inferencia estadística
Como se discutió en el tema anterior, las conclusiones derivadas de este proceso inferencial
siempre estarán sujetas a error como consecuencia de la variabilidad aleatoria inherente al
propio procedimiento de selección muestral. Por ello, resulta necesario disponer no sólo de una
estimación puntual, sino también de un intervalo de confianza, que facilite un rango de valores
verosímiles para el parámetro poblacional, así como de una prueba de significación estadística,
que permita determinar el grado de compatibilidad de los datos muestrales con una hipótesis
predeterminada. En este tema, se revisan los fundamentos y la interpretación de las técnicas
estadísticas de inferencia: la estimación puntual, el intervalo de confianza y el contraste de
hipótesis. Para simplificar la exposición, se asume que la muestra se obtiene por muestreo
aleatorio simple y que la población de referencia es de tamaño muy superior a la muestra.
5.2
ESTIMACIÓN PUNTUAL
Una forma natural de estimar muchos parámetros poblacionales consiste en utilizar el estadístico
muestral correspondiente. Así, la media muestral es un estimador
puntualDE
de laTENDENCIA
media poblacional
1.2 MEDIDAS
CENTRAL
yprincipales
la proporción
de
casos
de
una
enfermedad
en
la
muestra
es
un
estimador
puntual
de
la
1.2ha
MEDIDAS
DEunTENDENCIA
CENTRAL
propiedades estadísticas que
de satisfacer
buen estimador
muestral
probabilidad de tener la enfermedad en la población. No obstante, para un determinado
Las estimadores
medidas de tendencia
central
informan acerca de c
parámetro
poblacional,
pueden contemplarse distintos
alternativos.
Algunos
cabe destacar
las siguientes:
Las
medidas
de
tendencia
central
informan
acerca
de
estimadores de la media poblacional distintos de la media muestral podrían ser, por ejemplo,cuál
la es el valor m
de unadedeterminada
variable
o,
dicho de forma equival
mediana,
la media
50%Un
central
de laes
muestra
o la si
media
valores
máximo
y mínimo.
• Ausencia
de del
sesgo.
estimador
insesgado
suvariable
valorlos
medio
sobre
todas
las
de
una
determinada
o,
dicho
de
forma
equivalente,
En este apartado se presentan algunos criterios estadísticos que justifican la elección de un estos estima
alrededor de qué valor se agrupan los datos observados
determinado
a otras
posibles alternativas.
posiblesestimador
muestrasfrente
de tamaño
n coincide
parámetro
La observados. Las medidas de
alrededorcon
deelqué
valor se poblacional.
agrupan los datos
Los méritos de un estimador no se juzgan por la central
estimación
en una
muestra
de la resultante
muestra sirven
tanto
para resumir los resu
insesgadez
de
un
estimador
es
una
propiedad
deseable
ya
que
sus
estimaciones
no
concreta, sino por la distribución de todos
losde
posibles
valores
o estimaciones
a que pueda
dar
central
la muestra
sirven
tanto para resumir
los resultados
observado
lugar; esto es, por las propiedades de su distribución muestral.
Entre
las
principales
propiedades
realizar inferencias acerca de los parámetros poblacion
diferirán
delbuen
parámetro
poblacional.
estadísticas
quesistemáticamente
ha de satisfacer un
estimador
muestral
cabede
destacar
las siguientes:
realizar
inferencias
acerca
los parámetros
poblacionales correspondi
se sobre
describen
yy Ausencia de sesgo. Un estimador es insesgado si continuación
su valor medio
todaslos
lasprincipales
posibles estimadores d
continuación
se
describen
los
principales
estimadores
de la tendencia ce
muestras
de Como
tamañosenprobó
coincide
parámetro
poblacional.
La insesgadez
Ejemplo 5.3
en el con
temaelanterior,
la media
y la proporción
muestralde un
variable. no diferirán sistemáticamente
estimador es una propiedad deseable ya que sus estimaciones
variable.
del
poblacional.
sonparámetro
estimadores
insesgados de la media y la proporción poblacional,
1.2.1 Media aritmética
Ejemplo
5.3 Como
en1.2.1
el= tema
la la
media
y la proporción
muestral son
aritmética
respectivamente,
E( x se
) =probó
μ y E(p)
πMedia
. Sinanterior,
embargo,
varianza
muestral definida
estimadores insesgados de la media y la proporción
respectivamente,
E( x ), =se define como l
La poblacional,
media aritmética,
denotada por
2
2
μpor
y E(p)
la varianza
muestral
definida
por S(x
), /n
es
un estimador
La
media
aritmética,
denotada
por
seque
define
como la suma de cada u
i – x ya
Σ(xi -= xπ.) Sin
/n esembargo,
un estimador
sesgado
de
la varianza
poblacional,
valores muestrales dividida por el número de observac
sesgado de la varianza poblacional, ya que
valores muestrales dividida por el número de observaciones realizadas.
2
n
n
n
n el2 tamaño
1 por
1
1 n 2
1 muestral
y por xi el valor observado pa
2
2
E ( x i − x ) = E por
E ( x i )y−por
E x el
xi − x = nmuestral
xi observado para el sujeto i-ésim
i =1
n i =1
n i =1 n el tamaño
ni i =1valor
la media vendría dada por
n
1 n la media
1
Edada
( x i2 )por
= E ( x i2 ) − vendría
+ 2 E ( x i ) E ( x j )
2
n i =1
n i =1
1≤ i < j ≤ n
x + x 2 + ...
1 n
=
x
xi = 1
n
n
+ xn
x + x 2 n+ ...
2
n −1
1
n
i =1
= 2 E ( x i2 ) − 2 E ( x i ) E ( xxj =) x i = 1
.
n i =1
n
n i =1
n 1≤i < j ≤ n
n −1 2
n − 1 La
n −1
(σ + μ 2 ) −
μ 2 =media σes2la
; medida de tendencia central más util
n
n tendencia central más utilizada y de más fá
La media es nla medida de
interpretación. Corresponde al “centro de gravedad” de
interpretación. Corresponde al “centro de gravedad” de los datos de la m
es decir, este estadístico tiende a infraestimar la varianza poblacional σ 2 por un
principal limitación es que está muy influenciada por l
Pastor-Barriuso R.
principal limitación es que está muy influenciada por los valores extrem
factor de (n – 1)/n. Notar que este sesgo será tanto mayor cuanto menor sea el
caso, puede no ser un fiel reflejo de la tendencia centra
caso, puede no ser un fiel reflejo de la tendencia central de la distribució
tamaño muestral. En consecuencia, es preferible utilizar la varianza muestral
=
60
es decir, este estadístico tiende a infraestimar la varianza poblacional σ por un
forma, seque
tendrá
una mayor
confianza en
que
laloestimación
resultante
de la
también
las distintas
estimaciones
difieran
menos se
posible
de dicho
continuación
describen
los
principales estimadores de la t
factor de (n – 1)/n. Notar que este sesgo será tanto mayor cuanto menor sea el
Estimación puntual
DE
TENDENCIA
CENTRAL
muestra finalmente
estará
próxima
al parámetro
parámetro,
es decir, seleccionada
que1.2
la MEDIDAS
varianza
muestral
del estimador
seapoblacional.
mínima. DePor
esta
variable.
tamaño muestral. En consecuencia, es preferible utilizar la varianza muestral
ello, entre
los distintos
estimadores
insesgados
un determinado
parámetro,
es es el valor más represe
forma,
se tendrá
una mayor
confianza
que la de
estimación
resultante
de2 lade cuál
Las
medidas
deen
tendencia
central
informan
acerca
2
es decir, por
estesestadístico
la varianza
poblacional
σ por un factor
de
1.2.1
Media
aritmética
= Σ(xi - xtiende
)2/(n –a1)infraestimar
como estimador
insesgado
de la varianza
definida
(n
–
1)/n.
Notar
que
este
sesgo
será
tanto
mayor
cuanto
menor
sea
el
tamaño
muestral.
En
conveniente
seleccionar
que
presente
una menor
varianza
(o, de
forma
muestra
finalmente
seleccionada
estará
próxima
al parámetro
poblacional.
Por 2 estos estimadores ind
deaquel
una
determinada
variable
dicho
de
forma
consecuencia, es preferible
utilizar
la varianza
muestral
definida
por
s2 =equivalente,
S(x
– 1) como la sum
La
mediao,aritmética,
denotada
por
se define
i – x ), /(n
poblacional,
como
estimador
insesgado
de
la
varianza
poblacional,
equivalente,
menor alrededor
error
estándar).
general,
puede
demostrase
que, si laesLas medidas de tendenc
ello,
entre losun
distintos
estimadores
un
determinado
parámetro,
de insesgados
quéEn
valor
sedeagrupan
los
datos
observados.
valores
muestrales
dividida
por el número de observaciones
1 n
2
2
2
x. y la
varianza
muestral observados como p
distribución seleccionar
poblacional
subyacente
es normal,
la
E(s
) = que
E lapresente
x )media
σpara
=varianza
conveniente
aquel
(o,
de los
forma
( xuna
i − menor
central
de
muestra
sirven
tanto
resumir
muestral
y porresultados
xi el valor observado para el s
n − 1 i =1 por n el tamaño
los estimadores
insesgados
delos
μ yparámetros
σ 2 con menor
equivalente,
un menor error
estándar).
En
general,
puede
demostrase
que,varianza.
si la
s2 son respectivamente
realizar
inferencias
acerca
de
poblacionales
correspondientes.
A
la media
vendría
dada por
yy Mínima varianza. Además de la insesgadez
de un
estimador,
que
garantiza que
las
estimaciones
estarán centradas
alrededor
del parámetro
poblacional,
interesa
también que
x y la
varianza
muestral
distribución
subyacente
es normal,
media
π con
De la mismapoblacional
forma, la continuación
proporción
muestral
p eslaellos
estimador
insesgado
de
describen
principales
estimadores
de la que
tendencia
central de
las distintas estimaciones
difieran lo se
menos
posible de
dicho parámetro;
es decir,
la
x1 + x 2 + ... + x n
1 n
varianza
muestral del estimador sea mínima. De esta forma, se2 tendrá una mayor
confianza
.
=
x4i =
2
son respectivamente
los estimadores insesgados de μ y σ con menor xvarianza.
smenor
error estándar. variable.
n
n
i =1
en que la estimación resultante de la muestra finalmente seleccionada esté próxima
al
parámetro poblacional. Por ello, entre los distintos estimadores insesgados de un
De la misma forma, la proporción muestral p es el estimador insesgado de π con
determinado
es conveniente
seleccionar
aquel
quelapresente
una
menor
1.2.1
Media aritmética
La media
medida
de es
tendencia
central más utilizada
Ejemplo 5.4parámetro,
Para cualquier
distribución
poblacional,
la es
media
muestral
un varianza
(o, de forma equivalente, un menor error estándar). En general, puede demostrarse que, si
menor error estándar.
la define
varianza
s2 son
laestimador
distribución
poblacional
subyacente
es normal,
media
denotada
por
x ,yse
como
la suma
de cada uno
interpretación.
Corresponde
al muestral
“centro
de
gravedad”
dede
loslos
d
insesgado
deLa
la media
media aritmética,
poblacional
y sulaerror
estándar
es
2
respectivamente los estimadores insesgados de μ y σ con menor varianza. De la misma
valores
dividida
por
número
observaciones
realizadas.por
Silos
denota
forma,
la proporción
muestral
pmuestrales
es el estimador
insesgado
de π muestral
con
menor
principal
limitación
es de
que
está
muy estándar.
influenciada
val
Ejemplo
5.4 Para cualquier
distribución
poblacional,
laelmedia
es error
un
σ
.
SE( x ) =
valor
observado
para
sujeto i-ésimo,
= 1,
por
n
el
tamaño
muestral
por xla
n
i el
Ejemplo
5.4
Para
cualquier
distribución
poblacional,
media
es un
caso,
no
ser
unmuestral
fiel reflejo
deestimador
laeltendencia
centrali de
la
estimador insesgado de la media poblacional y suypuede
error
estándar
es
insesgado de la media poblacional y su error estándar es
la media vendría dada por
En el caso de que la distribución subyacente σsea normal, puede probarse que la
SE( x ) =
. Ejemplo 1.4 En este y en los sucesivos ejemplos sobre
n la media1poblacional
n
x +yxque
mediana también es un estimador insesgado de
su+ x n
2 + ...
utilizarán
losx ivalores
colesterol
. HDL obtenidos en
= 1 del
x=
En el caso de que la distribución subyacente sea normal,n puede
probarse nque la mediana
i =1
error
estándar
es
aproximadamente
En
el caso
la distribución
subyacente
sea normal,
puedey probarse
que la
también
esde
unque
estimador
insesgado
de la media
poblacional
que Study
su error
es Myocardial
estudio
“European
on estándar
Antioxidants,
aproximadamente
La media
es la medida
tendencia
centralymás
y de más fácil
mediana también es un estimador
insesgado
de lade
media
poblacional
que utilizada
su
σ Breast“ (EURAMIC), un estudio multicéntrico de c
the
SE(mediana) ≅ 1,25
.
interpretación. Corresponde nal “centro de gravedad” de los datos de la muestra. S
error estándar es aproximadamente
entre 1991 y 1992 en ocho países Europeos e Israel par
Así, aunque ambos estimadores son insesgados, el error estándar de la mediana es un 25%
principal
es que
está muy
influenciada
porestimaciones
los valores extremos y, en
mayor que el de la media
muestrallimitación
y, por tanto,
la mediana
tenderá
a facilitar
σ
.
≅ 1,25
menos precisas que la media SE(mediana)
muestral.
caso, puede no ser un fiel reflejo
de la tendencia central de la distribución.
n
yy Consistencia. Las propiedades de insesgadez y mínima varianza se refieren a la
distribución muestral del estimador para un tamaño n fijo de la muestra. La consistencia,
Ejemplo 1.4 En este y en los sucesivos ejemplos sobre estimadores muestr
sin embargo, hace referencia al comportamiento del estimador al aumentar n. Se dice
5 que
un estimador es consistente si,utilizarán
al aumentar
tamañodel
decolesterol
la muestra,
la probabilidad
que
loselvalores
HDL
obtenidos endelos
10 primeros suje
el estimador difiera del verdadero parámetro poblacional se reduce progresivamente. La
consistencia es, por tanto, un requerimiento
básico
paraon
unAntioxidants,
buen estimador
ya que bastará
estudio “European
Study
Myocardial
Infarction and Canc
con aumentar el tamaño muestral para obtener estimaciones arbitrariamente próximas
al
5
verdadero parámetro. Por supuesto,
la media,
la varianza
y la proporción
muestral
son y controles rea
the Breast“
(EURAMIC),
un estudio
multicéntrico
de casos
estimadores consistentes de sus respectivos parámetros poblacionales.
entre 1991 y 1992 en ocho países Europeos e Israel para evaluar el efecto d
Ejemplo 5.5 En el Ejemplo 4.9 se evaluó empíricamente el comportamiento de la media
muestral de colesterol HDL en muestras de tamaño n = 10, 25 y 100 obtenidas a partir
de los controles del estudio EURAMIC, donde la media poblacional del colesterol HDL
Pastor-Barriuso R.
61
Inferencia estadística
es μ = 1,09 mmol/l. La proporción de muestras con niveles medios de colesterol HDL
próximos a μ = 1,09 mmol/l, pongamos por ejemplo entre 1,03 y 1,15 mmol/l, aumentó
de un 48,7% para n = 10 a un 69,1% para n = 25 y a un 95,4% para n = 100. Este resultado
corrobora empíricamente la consistencia de la media muestral como estimador de la
media poblacional: la probabilidad de obtener estimaciones próximas al verdadero nivel
medio aumenta progresivamente conforme aumenta el tamaño muestral.
En los problemas de estimación más simples, como es el caso de una media o una proporción
poblacional, se dispone de un estimador natural que cumple las propiedades descritas
anteriormente. En otros problemas más complejos, como por ejemplo en la estimación de
parámetros en modelos de regresión, la elección de un estimador razonable no es tan directa. En
general, existen diversos métodos formales para obtener estimadores con buenas propiedades
estadísticas, entre los que destacan el método de máxima verosimilitud, el método de mínimos
cuadrados y el método de los momentos. Los métodos de mínimos cuadrados y máxima
verosimilitud se presentarán en el contexto particular de los modelos de regresión lineal (Temas
10 y 11) y logística (Tema 12), respectivamente. No obstante, los principios generales de estos
procesos de estimación y la evaluación de los estimadores resultantes pueden consultarse en los
textos de estadística matemática referenciados al final del tema.
TENDENCIA CENTRAL
5.3 ESTIMACIÓN POR INTERVALO
dencia central informan acerca de cuál es el valor más representativo
Como ya se ha comentado previamente, las estimaciones puntuales obtenidas a partir de una muestra
diferirán
del equivalente,
parámetro poblacional
y, en consecuencia,
variable o, dicho
de forma
estos estimadores
indican quedará un margen de incertidumbre que se
expresa en términos del error estándar del estimador. Así, resulta natural la pretensión de disponer de
unadatos
medida
del parámetro
poblacional
que incorpore tanto la estimación puntual como su error
or se agrupan los
observados.
Las
5.3.1
Distribución
t demedidas
Studentde tendencia
estándar. Esta medida es el intervalo de confianza, que facilita un rango de valores dentro del cual se
encontrará
ellos
verdadero
del
conde
unconfianza
cierto grado
confianza.
a sirven tanto para
resumir
resultados
comopoblacional
para
5.3.1
Distribución
tvalor
deobservados
Student
El
método
más
extendido
paraparámetro
el cálculo
de intervalos
se de
basa
en las En este
apartado se describe detenidamente el procedimiento para la construcción de un intervalo de
confianza
para
lade
media
poblacional.
principios
básicos del
cálculo
e interpretación
delímite
intervalos
acerca de los parámetros
poblacionales
correspondientes.
Adel
El
método
más
extendido
para muestral
elLos
cálculo
de estimador.
intervalos
de
confianza
secentral
basa endel
las
propiedades
la distribución
Por
el teorema
de confianza para otros parámetros son similares y se discutirán en los siguientes temas.
criben los principales
estimadores
dedistribución
la
tendencia
centralaleatoria
de
propiedades
la
muestral
deluna
estimador.
Porμelyteorema
varianzacentral
σ 2, la del límite
sabemos
que,depara
cualquier
variable
con media
5.3.1 Distribución t de Student
σ 2,media
la
sabemos
que,depara
variable aleatoria
con media μ y varianza
x es aproximadamente
normal con
μy
distribución
las cualquier
medias muestrales
El método más extendido para el cálculo de intervalos de confianza se basa en las propiedades
es aproximadamente
consabemos
media μ que,
y para
desimuestral
las
de distribución
la
distribución
delmuestrales
estimador.
Por
el teorema central
del
tica
σ 2/n
el medias
tamaño
muestral
esxsuficientemente
grande;normal
es límite
decir,
varianza
2
cualquier variable aleatoria con media μ y varianza σ , la distribución de las medias muestrales
2
, denotada por x es
, varianza
seaproximadamente
defineσcomo
decon
cada
uno es
de
los
normal
media
μ ysuficientemente
varianza σ2/n si elgrande;
tamañoes
muestral
/n silaelsuma
tamaño
muestral
decir, es suficientemente
2
σ
~ N μ,
grande; es decir,
x→
ividida por el número de observaciones realizadas. Si denotamos
n2
~ N μ , σ
x→
n, n
estral y por xi el valor observado para el sujeto i-ésimo, i = 1, ...,
o, de forma equivalente, aplicando la estandarización de una distribución normal
o, de forma equivalente, aplicando la estandarización de una distribución normal
da por
o, de forma equivalente, aplicando la estandarización de una distribución normal
x−μ ~
→ N (0, 1) .
σ
x1 + x 2 + ... + x n
1 n
.
x = xi =
x−μ
n ~
→ N (0, 1) .
n i =1
n
σ
n
Esta cantidad estandarizada depende de dos parámetros desconocidos: la media
edida de tendencia central más utilizada y de más fácil
62 Pastor-Barriuso
R.
Esta
cantidad
depende
de dos
media
poblacional
μ,estandarizada
que es el parámetro
objeto
deparámetros
inferencia, desconocidos:
y la desviaciónlatípica
esponde al “centro de gravedad” de los datos de la muestra. Su
poblacional
denecesario
inferencia,
y laconocer
desviación
típica
σ,, que
que es
es el
unparámetro
parámetroobjeto
auxiliar
para
el error
estándar en
poblacional μ
es que está muy influenciada por los valores extremos y, en este
s probabilidad en los extremos (Figura 5.1). Los grados de libertad de
la estimación de μ. Parece entonces lógico sustituir en la expresión anterior el valor
Estimación por intervalo
t de Student determinan su dispersión: al aumentar los grados de
desconocido de σ por la desviación típica muestral s. Sin embargo, como s es un
uye la variabilidad y la distribuciónt de Student se aproxima a una
a sude
vez
unparámetros
error de muestreo,
el estadístico
( xμ,-que
de σ que conlleva
Estaestimador
cantidad estandarizada
depende
dos
desconocidos:
la media resultante
poblacional
mal estandarizada.
menor
seade
el inferencia,
tamaño muestral
mayor será
es elCuanto
parámetro
objeto
y la n,
desviación
típica poblacional σ, que es un parámetro
auxiliar
para conocer
el error
estándar en
la estimación
de μ.
entonces
lógico
μ)/(s/necesario
n ) presentará
una mayor
imprecisión.
Puede
probarse que
la Parece
distribución
de este
t
de
sustituir en la expresión anterior el valor desconocido de σ por la desviación típica muestral s.
Sinestadístico
embargo, ya
como
sLa
esnormal,
un estimador
deStudent
σ que aproximadamente
conlleva
a su vez una
un
error
dealrededor
muestreo,deel0 y de aspecto
no será
sino tque
seguirá
distribución
distribución
de
es una distribución
simétrica
á una mayo estadístico resultante (x − )/(s/ n ) presentará una mayor imprecisión. Puede probarse que la
distribución
de este
ya
normal,
sino que
seguirá por
aproximadamente
una
conocida como
tparecido
deestadístico
Student
con
nno
- distribución
1será
grados
de libertad
y denotada
tn-1,
al de
una
normal
estandarizada,
aunque
menos apuntada
en el
como
t de Student
con n – 1 grados de libertad y denotada por tn–1,
ral es grande,s distribución
facilitará unconocida
estimación
precisa
deσ
centro y con más probabilidad
x − μ ~ en los extremos (Figura 5.1). Los grados de libertad de
t n −1 .
icho estadístico será aproximadamente normal. En la Tabla 5→del
s
una distribución t de Student
n determinan su dispersión: al aumentar los grados de
entan los percentiles de la distribuciónt de Student para distintos
disminuye
la variabilidad
y la alrededor
distribución
Student
separecido
aproxima a una
La distribución tlibertad,
de Student
es una distribución
simétrica
det0dey de
aspecto
ad.
al de una distribución normal estandarizada, aunque menos apuntada en el centro y con más
normal
estandarizada.
sea el tamaño
n, mayor será
probabilidad en los distribución
extremos (Figura
5.1).
Los grados de Cuanto
libertad menor
de una distribución
t demuestral
Student
determinan su dispersión: al aumentar los grados de libertad, disminuye la variabilidad y la
[Figura
5.1 aproximadamente
aquí]
distribución
t de Student se aproxima
a una distribución normal estandarizada. Cuanto menor8sea t de
el tamaño muestral n, mayor será el error de la desviación típica muestral s y, en consecuencia,
la distribución t de Student
Student otorgará
otorgará una
unamayor
mayo dispersión al estadístico (x − )/(s/ n ). Por el
contrario,
si
el
tamaño
muestral
es
grande,
s facilitará
6 De la Tabla 5 del Apéndice se obtiene que el percentil 97,5
en unauna estimación precisa de σ, de tal forma
que la distribuciónelde
dichomuestral
estadístico
será aproximadamente
normal. En
la Tabla
tamaño
es grande,
s facilitará un estimación
precisa
deσ 5 del
Apéndice
se
presentan
los
percentiles
de
la
distribución
t
de
Student
para
distintos
grados de
n t de Student con 2, 5, 10 y 30 grados de libertad es respectivamente
libertad.
distribución de dicho estadístico será aproximadamente normal. En la Tabla 5 del
303, t5;0,975 = 2,571, t10;0,975 = 2,228 y t30;0,975 = 2,042. Por tratarse de
Ejemplo 5.6 Apéndice
De la Tabla
5 del Apéndice
se obtiene
que el percentil
97,5 en
unadistintos
se presentan
los percentiles
de la distribución
t de Student
para
t decoincide
Studentcon
conel2,correspondiente
5, 10 y 30 grados de libertad es respectivamente t2;0,975 =
nes simétricas en 0, eldistribución
percentil 2,5
4,303, t5;0,975 grados
= 2,571,
t
=
2,228 y t30;0,975 = 2,042. Por tratarse de distribuciones
de libertad.
10;0,975
simétricas
0, el=percentil
2,5 coincide
con
el correspondiente percentil 97,5 con signo
-4,303, t5;0,025
= -2,571,
t10;0,025
7,5 con signo opuesto;
es decir, en
t2;0,025
opuesto; es decir, t2;0,025 = – 4,303, t5;0,025 = – 2,571, t10;0,025 = – 2,228 y t30;0,025 = – 2,042. Por
5.1 con
aproximadamente
aquí] de libertad
tanto, elel95%
central dedelaladistribución
t [Figura
de Student
2, 5, 10 y 30 grados
=
-2,042.
Por
95%
tdistribución
30;0,025
simétricatanto,
alrededor
de central
0 y de aspectodistribuciónt de
está comprendido entre ± 4,303, ± 2,571, ± 2,228 y ± 2,042, respectivamente. Así, puede
observarse
que
la comprendido
dispersión
la distribución
nl estandarizada,
2, 5, 10 y 30 grados
demenos
libertad
está
± 4,303, ± t de Student disminuye al aumentar los
aunque
apuntada
en el deentre
grados de libertad, aproximándose a una distribución normal estandarizada (95% de los
Ejemplo 5.6 De la Tabla 5 del Apéndice se obtiene que el percentil 97,5 en una
valores
entreAsí,
±de1,96,
Ejemplo
228 y ± 2,042,
respectivamente.
puede
observarse
que la
extremos
(Figura
5.1).
Los grados
libertad
de 3.11).
distribución t de Student con 2, 5, 10 y 30 grados de libertad es respectivamente
de
t
de
Student
disminuye
al aumentar
losmedia
gradospoblacional
de
an la
sudistribución
dispersión:
al
aumentar
los
grados
de
5.3.2 Intervalo de confianza
para una
t2;0,975 = 4,303, t5;0,975 = 2,571, t10;0,975 = 2,228 y t30;0,975 = 2,042. Por tratarse de
a distribuciónt de
Student
una
A partir
de se
losaproxima
resultadosa anteriores
puede construirse un intervalo de confianza para la media
poblacional. En general, la
estimación
intervaloenlleva
de
distribucionespor
simétricas
0, elasociada
percentiluna
2,5probabilidad
coincide conoelnivel
correspondiente
uanto menor sea
el tamañodenotada
muestral
n,en
mayor
será porcentuales por 100(1 – α)%, que indica la cobertura del
confianza,
términos
parámetro poblacional. Aunque
en97,5
la práctica
se utilizan
exclusivamente
los intervalos
t5;0,025 = de
-2,571, t10;0,025
percentil
con signo
opuesto;
es decir,
t2;0,025 = -4,303,
9 casi
t de nos referiremos aquí de forma genérica al intervalo de confianza
confianza al 95% (α = 0,05),
= -2,042. la
Por
tanto, el 95%
distribución
t de
= -2,228
y t30;0,025Utilizando
al 100(1 – α)% para la media
poblacional.
aproximación
t decentral
Studentdeallaestadístico
(x − )/(s/ n ), se sigue que hay una probabilidad 1 – α de que dicho estadístico esté
Student con 2, 5, 10 y 30 grados de libertad está comprendido entre± 4,303, ±
ará un estimación precisa deσ
2,571, ± 2,228 y ± 2,042, respectivamente. Así, puede observarse que la
aproximadamente normal. En la Tabla 5 del
dispersión de la distribución t de Student disminuye al aumentar los grados de
de la distribuciónt de Student para distintos
Pastor-Barriuso R. 63
libertad, aproximándose a una distribución normal estandarizada (95% de los
Inferencia estadística
valores
entre ± 1,96, Ejemplo 3.11).
libertad, aproximándose a una distribución normal estandarizada (95% de los
5.3.2 Intervalo de confianza para una media
f(x) poblacional
valores entre ± 1,96, Ejemplo 3.11).
A partir de los resultados anteriores puede construirse un intervalo de confianza para la
N(0, 1)
t
media
poblacional.
En general,para
la estimación
por
intervalo lleva asociada una 30
5.3.2 Intervalo
de confianza
una media
poblacional
t10
t5
nivel de confianza
, denotada
en términos
por 100(1
- α)%,
probabilidad
A partir de loso resultados
anteriores
puede construirse
un porcentuales
intervalo de confianza
la
t2 para
que indica
la cobertura
del parámetro
poblacional.
Aunque lleva
en la asociada
práctica se
utilizan casi
media
poblacional.
En general,
la estimación
por intervalo
una
nos referiremos
aquí
exclusivamente
los intervalos
de confianza
95%
(α = 0,05),
de confianza
, denotadaalen
términos
porcentuales
por 100(1
- αde
)%,
probabilidad
o nivel
α)% para
poblacional.
forma
genérica
al intervalo
de confianza
al 100(1 - Aunque
que
indica
la cobertura
del parámetro
poblacional.
enlalamedia
práctica
se utilizan casi
nos nreferiremos
de
exclusivamente
los intervalos
deStudent
confianza
al 95% (α (=x0,05),
- μ)/(s/
), se sigue aquí
que hay
Utilizando
la aproximación
t de
al estadístico
)% para la media
forma
genérica al1intervalo
de dicho
confianza
al 100(1
- αcomprendido
estadístico
esté
entrepoblacional.
los percentiles
una
probabilidad
- α de que
α/2 y 1 - α/2
una distribución
t de Student
con n – 1( xgrados
de libertad,
denotados
- μ)/(s/
n ), se sigue
que hay
Utilizando
la de
aproximación
t de Student
al estadístico
-3
-2
-1
0
1
2
3
y tn-1,1esto es,x esté comprendido entre los percentiles
respectivamente
α/2;estadístico
dicho
una
probabilidadpor
1 - tαn-1,deα/2que
Figura 5.1 Función de densidad
de la distribución
t de Student con
2, 5, 10 y 30 grados de libertad,
funFiguray 5.1
1.2 MEDIDAS
DE TENDENCIA
CENTRAL
ción de densidad normal estandarizada.
α/2 y 1 - α/2 de una distribución
t de Student con n – 1 grados de libertad, denotados
x − μ central informan
Las medidas
de
tendencia
acerca de cuál es el valor más representativ
P t −1α/2
< t una
,α / 2 y<1 – α/2 de
n −1,1−α
/ 2 = 1 − α .t de Student con n – 1 grados
comprendido
entre los
distribución
;
esto
es,
respectivamente
porpercentiles
tn-1,α/2 y tnn-1,1α/2 s
; esto es,
de libertad, denotados respectivamente
por tn–1,α/2
n y tn–1,1–α/2
de forma equivalente, estos estimadores indican
de
una
determinada
variable
o,
dicho
a distribución simétrica alrededor de 0 y de aspecto
los datos
el
alrededor
de qué valor
selaagrupan
observados. Las medidas de tendencia
x − μen
al estandarizada, aunque
menos se
apuntada
en
Este resultado
representa
gráficamente
Figura
Por
=1−
α .la simetría de la
P t n −1,α / 2 <
< t n −1,1−α / 2 5.2.
s
central
de
la
muestra
sirven
tanto
para
resumirpuede
los resultados
observados como para
n
anterior
extremos (Figuradistribución
5.1). Los grados
de libertad
t de Student,
tn-1,αde
=
-t
y
la
expresión
rescribirse
/2
n-1,1-α/2
Estecomo
selos
representa
gráficamente
la Figura
5.2.parámetros
Por la simetría
de la distribución
t de
realizar
inferenciasenacerca
de los
poblacionales
correspondientes.
A
nan su dispersión:
alresultado
aumentar
grados
de
Este
resultado
se
representa
gráficamente
en
la
Figura
5.2.
Por
la
simetría
de
la
Student, tn–1,α/2 = – tn–1,1–α/2 y la expresión anterior puede rescribirse como
continuación
se describen los principales estimadores de la tendencia central de una
la distribuciónt de Student se aproxima
a una
distribución t de Student, tn-1,α/2 = -tn-1,1-α/2 y la expresión anterior puede rescribirse
x−μ
Cuanto menor sea el tamaño muestral
n, variable.
mayor
P −será
t n −1,1−α / 2 <
< t n −1,1−α / 2 = 1 − α .
como
s
n
t de Media aritmética
s
s
1.2.1
=1−α .
P x − t n −1,1−α / 2
< μ < x + t n −1,1−α / 2
n de la desigualdad por el error
Para despejar la media poblacional,
se nmultiplica cada término
x − μ muestral
despejar
media
se< multiplica
término
desigualdad
n )y alacontinuación
− )/(s/
(x Para
estándar
media
resultando
que la sumapor
La poblacional,
media
denotada
se
de el
cada uno de los
1 −define
αde. lacomo
P − tse
< t n −cada
naritmética,
−1resta
,1−α / 2 la
1,por
1−α / 2 x,,=
s
n- α)% para la
media
muestrales
viene
Así, elestándar
intervalo de confianza
(IC) al
y a continuación
s 100(1
s depoblacional
xobservaciones
sedividida
resta
la por
media
muestral
, resultando
que
el número
realizadas. Si denotamos
ará un estimaciónerror
precisa deσ s/ nPvalores
x − t n −1,1−α / 2
= 1 − α .
< μ < x + t n −1,1−α / 2
n
n
determinado
pormedia
por5poblacional,
ndel
el tamaño se
muestral
y porcada
xi eltérmino
valor observado
para el sujeto
i-ésimo, i = 1, ..., n,
despejar
multiplica
de la desigualdad
por el10
aproximadamentePara
normal.
En la Tabla
Así, el intervalo de confianza (IC) al 100(1 – α)% para la media poblacional viene determinado por
intervalo dedistintos
confianzavendría
(IC) al 100(1por
- α)% spara la media poblacional viene
de la distribuciónAsí,
t de el
Student
error
estándarpara
s/ n lay media
a continuacióndada
se resta la media
muestral x , resultando que
x ± t n −1,1−α / 2
,
n
determinado por
10
x + x 2 + ... + x n
1 n
.
x = xi = 1
n i =1 del intervalo)
n como de su
64 Pastor-Barriuso
R.
que depende
tanto de la estimación puntual x (valor
s central
,
x ± t n −1,1−α / 2
.1 aproximadamente aquí]
n
error estándar s/ n . La media es la medida de tendencia central más utilizada y de más fácil
Estimación por intervalo
tn-1
1.2 MEDIDAS DE TENDENCIA CENTRAL
La distribución tLas
de Student
distribución
0 y es
deelaspecto
medidasesdeuna
tendencia
centralsimétrica
informanalrededor
acerca dedecuál
valor más representativo
1-α
parecido al de una de
distribución
normal variable
estandarizada,
menos
apuntadaestos
en elestimadores indican
una determinada
o, dichoaunque
de forma
equivalente,
a distribución simétrica alrededor de 0 y de aspecto
centro y con más probabilidad
losvalor
extremos
(Figura
grados deLas
libertad
de de tendencia
alrededor deen
qué
se agrupan
los5.1).
datosLos
observados.
medidas
al estandarizada, aunque menos apuntada en el
una distribución t de
Student
su dispersión:
alresumir
aumentar
grados de
central
de determinan
la muestra sirven
tanto para
loslos
resultados
observados como para
/2
α/2
α
extremos (Figura 5.1). Los grados de libertad de
libertad, disminuyerealizar
la variabilidad
y
la
distribución
t
de
Student
se
aproxima
a
una
inferencias acerca de los parámetros poblacionales correspondientes. A
0
tn-1,α/2grados de
tn-1,1-α/2
nan su dispersión: al aumentar los
distribución normalcontinuación
estandarizada.
Cuanto menor
seax el
tamaño
muestral
n,
mayor
será central de una
se describen
los principales
estimadores
de
la
tendencia
−μ
s
la distribuciónt de Student se aproxima a una
n
t de
variable.
Figura 5.2
uanto menor sea el tamaño muestral
n, mayor será
Figura 5.2 una
Distribución
Student otorgará
mayo muestral del estadístico (x − )/(s/ n ).
1.2.1 Media aritmética
t de
el tamaño
muestral
es media
grande,
s la
facilitará
un estimación
deσcomo
que
depende
tanto
de
estimación
puntual
(valor
central
dellaintervalo)
como
dedesulos
error
La
aritmética,
denotada
por x ,precisa
se define
suma de cada
uno
DIDAS DE TENDENCIA CENTRAL
estándar
(x − )/(s/ n .)
1.2 de
MEDIDAS
DE TENDENCIA
CENTRALnormal. En la Tabla 5 del
distribución
dicho
estadístico
será aproximadamente
valores
muestrales
dividida
por el número
observaciones
realizadas. Sieldenotamos
Los límites
del intervalo
están
determinados
por datosdemuestrales
y, en consecuencia,
intervalo
didas
deestimación
tendencia central
acerca de cuál es el valor más representativo
σ
ará un
precisainforman
de
de
confianza
variará
en
función
de
la
muestra
seleccionada.
El
principio
fundamental
de
la
estimación
ApéndiceLas
se presentan
percentiles
de la informan
distribución
t de Student
para
distintos
medidas
central
acerca
de
cuál es
elpara
valor
representativo
por de
nloseltendencia
tamaño muestral
y por xi el
valor
observado
el más
sujeto
i-ésimo, i = 1, ..., n,
por intervalo radica en que, de todas las posibles
muestras del mismo tamaño de la población de
determinada
variablenormal.
o, dichoEn
delaforma
equivalente,
estos estimadores indican
aproximadamente
delintervalos
el 100(1
–Tabla
α)% de5 los
resultantes incluirá el parámetro poblacional. Así, aunque
grados dereferencia,
libertad.
de
una determinada
variable
o, dicho
la media vendría
dada
por de forma equivalente, estos estimadores indican
no es posible saber si efectivamente un intervalo concreto incluye o no el parámetro desconocido, se
ordedelaqué
valor se agrupan
los datos
observados.
Las medidas de tendencia
distribución
t deuna
Student
paradel
distintos
tendrá
confianza
100(1 – α)% en que el único intervalo disponible esté entre aquellos que
l estudio EURAMIC.
En cada
unavalor
de las
alrededor
de qué
se agrupan los datos observados.
Las medidas de tendencia
n
+ un
x n intervalo hace referencia a
contienen dicho parámetro.
En
otras
palabras,1el nivel
dexconfianza
[Figura
5.1
aproximadamente
aquí]
1 + x 2 + ...de
de la muestra sirven tanto para resumir los resultados observados
para
.
=
x = x i como
la frecuencia con la cual el método producenintervalos
certeros
y no a la probabilidad de que el
n observados
mo
i =1 los resultados
central de la muestra sirven tanto para resumir
como para
intervalo obtenido en una muestra concreta incluya el parámetro poblacional.
inferencias acerca de los parámetros poblacionales correspondientes. A
obtenidas
a partir
de los
controles
del estudio
EURAMIC.
En cada una de
realizar
inferencias
acerca
de
los
parámetros
poblacionales
correspondientes.
A las
.1
aquí]
Ejemplo
5.6
De La
la5.7
Tabla
5
del
Apéndice
se
obtiene
que
el
percentil
97,5
en
una
s aproximadamente
s Ejemplo
media
es
la
medida
de
tendencia
central
más
utilizada
y
de
más
fácil
En la Figura
se presentan
los IC
al 95% para la media poblacional
del
= xse±describen
2,262 los, principales estimadores
ación
de 5.3
la tendencia
central
de una
10
10
colesterol
HDL
en
100
muestras
aleatorias
de
tamaño
n
=
10
obtenidas
a
partir
de
los
muestras,
el
IC
al
95%
se
calculó
como
continuación
se describen
los5,principales
estimadores
de laestendencia
central
de
una
distribución
tinterpretación.
de Student
conCorresponde
2,
10 y 30algrados
dede
libertad
respectivamente
“centro
gravedad”
de
los
datos
de
la
muestra.
Su
controles del estudio EURAMIC. En cada una de las muestras, el IC al 95% se calculó como
.
Apéndice
que típicas
el percentil
97,5 en
una = 2,228 sy t
variable.
s medias ysedesviaciones
muestrales.
t5;0,975
=limitación
2,571,
t10;0,975
= 2,042.sPor tratarse de
tobtiene
2;0,975 = 4,303,
principal
es
muy30;0,975
x ±que
t 9;0está
=influenciada
x ± 2,262 por, los valores extremos y, en este
, 975
edia aritmética
10
10
5, 10 y 30 grados
de libertad
es respectivamente
simétricas
en 0,
2,5 de
coincide
con el central
correspondiente
x 1.2.1
= 1,20
y scaso,
= aritmética
0,30,
de tal
tra se obtuvodistribuciones
puede
no
serelunpercentil
fiel reflejo
la tendencia
de la distribución.
Media
donde
s son
las correspondientes
medias
desviaciones
a aritmética, denotada
por x y, se
define
como la suma de
cada yuno
de los típicas muestrales. Así, por ejemplo,
= 2,228
y t30;0,975
= 2,042.
Por
tratarse
de
x
donde
y
s
son
las
correspondientes
medias
y
típicas
muestrales.
=
-4,303,
=de
-2,571,
testimación
percentil
97,5
con
signo
opuesto;
es
decir,
t
2;0,025
10;0,025
a0;0,975
media poblacional
de
colesterol
HDL
en la aritmética,
primera muestra
se obtuvo
1,20
y s =como
0,30,desviaciones
de
tal
forma
que
launo
La media
denotada
por x =
, se
define
lat5;0,025
suma
cada
de los puntual de la
Ejemplo
1.4
En esteHDL
yrealizadas.
enresultó
los sucesivos
ejemplos
sobre
estimadores
muestrales, se
muestrales
dividida
por
el
número
de
observaciones
Si
denotamos
media
poblacional
de
colesterol
ser
1,20
mmol/l
y
su
IC
al
95%
1,20 ± 2,262·0,30/
el percentil 2,5
coincide
con
el
correspondiente
= -2,042.
Por
tanto,
elmuestra
95%
central
de puede
la xdistribución
= -2,228
y10
tmuestrales
=afirmarse
1,20 y tsde
= 0,30,
de tal
Así,
por
ejemplo,
en
la
primera
se
obtuvo
30;0,025
= (0,99;
1,41);
es
decir,
a partir
de esta
muestra
con
confianza
del 95%
valores
dividida
por
el
número
de
observaciones
realizadas.
Siuna
denotamos
(0,99;
1,41);
es
% 1,20 ± 2,262⋅0,30/
utilizarán
los
valores
del
colesterol
HDL
obtenidos
en
los
10
primeros sujetos del
quexilaelmedia
poblacional
del colesterol
HDL
se encuentra
entre
0,99 y 1,41 mmol/l.
tamaño
muestral
y
por
valor
observado
para
el
sujeto
i-ésimo,
i
=
1,
...,
n,
= -4,303,
-2,571,
t10;0,025
o; es decir, t2;0,025
5;0,025
forma
que
puntual
de la
media
poblacional
de± colesterol
Student
2, t5,
10lay=estimación
30
grados
de
libertad
está
comprendido
entre
4,303, ± HDL
porconfianza
ncon
el tamaño
afirmarse con una
del muestral
95% queylapor xi el valor observado para el sujeto i-ésimo, i = 1, ..., n,
estudio
“European
Study
on
Antioxidants,
Myocardial
InfarctionPastor-Barriuso
and Cancer
R. of65
a tanto,
vendríaeldada
por
95%
central
de
la
distribución
t
de
2,571,
± 0,99
2,228
± 2,042,
respectivamente.
Así, puede
resultó
ser
1,20
1,20 ±observarse
2,262⋅0,30/que
10la= (0,99; 1,41); es
la media
vendría
dadammol/l
por y su IC al 95%
L se encuentra
entre
y y1,41
mmol/l.
the Breast“ (EURAMIC), un estudio multicéntrico de casos y controles realizado
n
+ ...Student
x1±+4,303,
x 2t de
s de libertaddispersión
está comprendido
entre
±+ x n disminuye al aumentar los grados de
de1la distribución
Inferencia estadística
En este ejemplo ilustrativo, donde se conoce el verdadero valor de la media poblacional
μ = 1,09 mmol/l, puede comprobarse empíricamente el significado del nivel de confianza
al 95%: 94 de los 100 intervalos calculados contienen efectivamente la media poblacional,
mientras que los 6 restantes no la contienen. Un IC particular puede o no incluir el
parámetro y, por tanto, carece de sentido decir que hay una probabilidad del 95% de que
μ se encuentre dentro de un intervalo concreto.
La estimación por intervalo facilita un rango de valores verosímiles o compatibles con la
media poblacional μ, cuya amplitud depende de:
yy El nivel de confianza 100(1 – α)%. Cuanto mayor sea la confianza deseada para un
intervalo, mayor será la amplitud del mismo.
0,6
0,8
1
1,2
1,4
1,6
Nivel medio de colesterol HDL (mmol/l)
Figura 5.3
Figura 5.3 Estimaciones puntuales (círculos) e intervalos de confianza al 95% (líneas horizontales) para
la media poblacional del colesterol HDL en 100 muestras aleatorias de tamaño n = 10 obtenidas a partir de
los controles del estudio EURAMIC. La línea vertical en trazo discontinuo corresponde al verdadero nivel
medio μ = 1,09 mmol/l de colesterol HDL.
66
Pastor-Barriuso R.
• El error estándar de la estimación SE( x ) = s/ n . Cuanto mayor sea el error de la
esto es, la media
poblacional del colesterol HDL se encuentra entre 0,89 y 1,51
MEDIDAS DE TENDENCIA
CENTRAL
se calcularía
como
Contraste
de hipótesis
estimación,
será del
la amplitud
del intervalo.
Es decir,eslamás
amplitud
deque
un el
mmol/l
con unamayor
confianza
99%. Notar
que este intervalo
amplio
medidas de tendenciaEjemplo
central informan
cuál
el valor
másanterior,
representativo
5.8 En la acerca
primerademuestra
ejemplo
s es del
0,30 el IC al 99% (α = 0,01)
x ± t 9;0aporta
= 1medida
= (0,89;
1,51);
,20 ± 3,250
intervalo de confianza
una
de la precisión
de la
estimación.
, 995
correspondiente
intervalo
al
95%
(0,99;
1,41).
10
10
na determinada variable
o,
dicho
de
forma
equivalente,
estos
estimadores
indican
se
calcularía
Ejemplo
5.8 como
En la primera muestra del ejemplo anterior, el IC al 99% (α = 0,01) se
calcularía como
Ejemplo
En observados.
una
muestraLas
aleatoria
de tamaño
n =encuentra
100 de los
controles
del
dedor de qué valor se agrupan
datos
medidas
de tendencia
esto
es,los
la5.9
media
poblacional
colesterol
se
entre
1,51
• El error estándar de la estimación
x ) = s/ 0HDL
n,30
. Cuanto
mayor sea
el 0,89
erroryde
la
s delSE(
x ± t 9;0,995
= 1,20 ± 3,250
= (0,89; 1,51);
10
x =10del
1,09
yobservados
s = 0,31,que
resultando
un IC al
para la que
media
EURAMIC
se obtuvo
ral de la muestra sirven mmol/l
tanto para resumir
los resultados
como
para
una
confianza
99%.
estedecir,
intervalo
es 95%
más de
amplio
el
estimación,con
mayor
será
la amplitud
del Notar
intervalo. Es
la amplitud
un
esto es, la media poblacional del colesterol HDL se encuentra entre 0,89 y 1,51 mmol/l
poblacional
depoblacional
izar inferencias acerca
decorrespondiente
los la
parámetros
poblacionales
correspondientes.
Amás amplio
intervalo
al
95%
(0,99;
1,41).
esto
es,
media
del
colesterol
HDL
se es
encuentra
0,89
y 1,51
con
una
confianza
del
99%.
Notar
que
este de
intervalo
que
el correspondiente
intervalo
de
confianza
aporta
una
medida
la precisión
de la entre
estimación.
intervalo al 95% (0,99; 1,41).
tinuación se describenmmol/l
los principales
estimadores
con una confianza
delde
99%.
Notar quecentral
este0,intervalo
3de1 una es más amplio que el
sla tendencia
1,09x ±) 1=,9s/84 n =
±latla
= (1,03;
1,15).
99estimación
;0,
97x
5
•Ejemplo
El error
estimación
SE(
mayor
sea
error
de la
yy El
error
estándar
dede
Cuanto
mayor
seael del
el
error
de la
5.9estándar
En una
muestra
aleatoria
=. Cuanto
100
de los
controles
100 de tamaño n 10
able.
estimación,
mayor
será la amplitud
del intervalo.
correspondiente
intervalo
al 95% (0,99;
1,41). Es decir, la amplitud de un intervalo de
confianza
aporta
una medida
de
la
de la estimación.
estimación,
mayor
será
amplitud
del intervalo.
Esun
decir,
amplitud
demedia
un
x = la1,09
y sprecisión
= 0,31,
resultando
IC alla95%
para la
EURAMIC
se obtuvo
Así,
a
partir
de
esta
muestra
de
mayor
tamaño,
se
concluye
que
la
media
1 Media aritmética
intervalo
deEn
confianza
aporta
una
precisión
de
estimación.
• El
error
estándar
de
lamuestra
estimación
SE(medida
xde
) =tamaño
s/denla. nCuanto
mayor
sea
el error
la
Ejemplo
5.9 de
una
aleatoria
= 100 de
loslacontroles
del de
EURAMIC
poblacional
poblacional
del
colesterol
HDL
se
encuentra
entre
1,03
y
1,15
mmol/l
con
un
y s =como
0,31,laresultando
un IC
al de
95%
se obtuvo
media aritmética, denotada
por x ,=se1,09
define
suma de cada
uno
lospara la media poblacional de
estimación, mayor será la amplitud del intervalo. Es decir, la amplitud de un
s Este
0,31 n = más
5.9 En
muestra
aleatoria
de tamaño
100 de
los controles
nivelelde
confianza
del
95%.
es
preciso
que los del
ores muestrales dividida Ejemplo
por
número
Simucho
denotamos
x de
±una
t observaciones
= 1realizadas.
= (1,03;
1,15).
,intervalo
09 ± 1,984
99; 0 , 975
10
intervalo de confianza aporta100
una medida de la precisión de la estimación.
intervalos
representados
en
laelFigura
para
muestras
tamaño
= 10.la media
x
=
1,09
y s = 5.3
0,31,
resultando
unde
al 95%n para
EURAMIC
se
obtuvo
sujeto
i-ésimo,
i = 1, ...,
n,IC
n el tamaño muestral y por xi el valor observado para
Así, a partir de esta muestra de mayor tamaño, se concluye que la media poblacional del
Así, a partir
de esta
muestra de
mayor
tamaño,
se concluye
la media
colesterol
HDL
se
encuentra
1,03de
y 1,15
mmol/l
con de
unque
nivel
de confianza
poblacional
5.9
Ende
una
muestra entre
aleatoria
tamaño
n = 100
los
controles
del del 95%.
media vendría dada porEjemplo
Este
intervalo
mucho
más preciso
quedelos
Figurapara
5.3 para
Como
se verá es
más
adelante,
el cálculo
losintervalos
intervalosrepresentados
de confianzaen
eslasimilar
poblacional
del
colesterol
HDL se encuentra entre 1,03 y 1,15 mmol/l con un
muestras
de
tamaño
n
=
10.
al 95% para la media
EURAMICn se obtuvo x = 1,09 ys s = 0,31, resultando
0,31unalIC100(1
+± general,
... + el
x1xEn
xt 99
x nintervalo
1
todos los parámetros.
de
confianza
- α )% para un
2 ;+
=
±
=
(1,03;
1,15).
1
,
09
1,984
0
,
975
.
= confianza
x de
x i = del 95%. Este intervalo
nivel
es
mucho
más
preciso
que los
10
100
Como
se verá
n i =1más
poblacional
de adelante,nel cálculo de los intervalos de confianza es similar para todos
poblacional
se construye
como
los determinado
parámetros. parámetro
En general,
el intervalo
de confianza
al 100(1 – α)% para un determinado
intervalos
representados
en
la
Figura
5.3
para
muestras
de tamaño n = 10.
parámetro
poblacional
seesta
construye
como
Así,
a
partir
de
muestra
de
mayor
tamaño,
se
concluye
que la media
La media es la medida de tendencia central más utilizada
y de más fácil
s
0,31
x ± t 99;0,975 estimador
= 1,09
±
=
(1,03;
1,15).
1,984
puntual ± x1–α/2 SE,
10
100
poblacional
del
colesterol
HDL
se
encuentra
entrede
1,03
y 1,15 mmol/l
conpara
un
Como
se
verá
más
adelante,
el
cálculo
de
los
confianza
es similar
rpretación. Corresponde al “centro de gravedad” de los datos
deintervalos
la muestra.
Su
donde x1–α/2 denota el percentil 1 – α/2 de la distribución muestral del estimador.
13
nivel
de confianza
delpor
95%.
Este
intervalo
essemucho
másque
preciso
que
Así,
a partir
de esta
muestra
de
mayor
tamaño,
concluye
media
α)%
paralos
un
losestá
parámetros.
En general,
el
de
confianza
al este
100(1
- la
cipal limitacióntodos
es que
muy
influenciada
losintervalo
valores
extremos
y, en
5.4 CONTRASTE DE HIPÓTESIS
intervalos
representados
en se
la
Figura
5.3como
para
de tamaño
= 10.
colesterol
HDL
seconstruye
encuentra
entremuestras
1,03 y 1,15
mmol/lncon
un
determinado
parámetro
poblacional
o, puede no ser un
fielpoblacional
reflejo
de ladel
tendencia
central
de
la
distribución.
En ocasiones, el interés de la investigación se centra no tanto en estimar un parámetro desconocido,
sino en
dilucidar
si dichodelparámetro
compatible
con unmás
valor
predeterminado.
A partir de
nivel
de confianza
95%. Esteesintervalo
es mucho
preciso
que los
estimador
puntual
±lógico,
x1α/2 SE,
Como
se
verá
más
adelante,
el
cálculo
de
los
intervalos
de
confianza
es
similar
para
conocimientos
previos
o
mediante
un
razonamiento
se
pueden
elaborar
hipótesis
o
conjeturas
Ejemplo 1.4 En este y en los sucesivos ejemplos sobre estimadores muestrales, se
sobre intervalos
el fenómeno
o parámetroen
objeto
de estudio
(pormuestras
ejemplo,deestablecer
de que la
representados
la Figura
5.3 para
tamaño nla= hipótesis
10.
α
)%
para
un
todos
los
parámetros.
En
general,
el
intervalo
de
confianza
al
100(1
media
de
una
población
toma
un
valor
determinado).
La
validez
de
estas
hipótesis
poblacionales
utilizarán los valores del colesterol HDL obtenidos en los 10 primeros sujetos del
13 ha
de ser contrastada estadísticamente a partir de la información disponible en la muestra. Las técnicas
queComo
permiten
el grado
compatibilidad
de
losCancer
datos
muestrales
con una
determinado
parámetro
poblacional
se de
construye
como
se verá
más adelante,
eldecálculo
los intervalos
de
confianza
es similar
parahipótesis
estudio “European
Study
onevaluar
Antioxidants,
Myocardial
Infarction
and
of
predeterminada se conocen genéricamente con el nombre de tests (pruebas o contrastes) de hipótesis.
todos los parámetros.
Enmulticéntrico
general,estimador
el intervalo
dey confianza
al 100(1 - α)% para un
the Breast“ (EURAMIC),
un estudio
de casos
controles
realizado
SE,
puntual
±x
1-α/2
5.4.1 Formulación de hipótesis
poblacional
se para
construye
como
entre 1991 y determinado
1992 en ochoparámetro
países Europeos
e Israel
evaluar
el efecto de los
Los tests de hipótesis parten del planteamiento de una hipótesis nula, denotada por H013
, que
representa el valor preestablecido
del
parámetro
poblacional.
Esta
hipótesis
nula
se
aceptará
si
estimador puntual ± x1-α/2 SE,
5
los datos muestrales no aportan suficiente evidencia en contra de la misma. Por el contrario, si
se cuenta con pruebas suficientes para contradecir la hipótesis nula, ésta se rechazará en favor
13 de la
de una hipótesis alternativa, denotada por H1, que corresponde generalmente a la negación
Pastor-Barriuso R.
67
tratamiento;
decir,
la presión
medialade
la población
tratada con el
Ejemplo
5.10esEn
un estudio
paraarterial
determinar
eficacia
de un fármaco
Inferencia estadística
μT es igual
a la medialade
la población
μP.deLapacientes
hipótesistratados
fármaco
antihipertensivo,
se compara
presión
arterial no
de tratada
un grupo
alternativa
sería,
el la
contrario,
que las
presiones
arteriales
medias
ambas
hipótesis
estepor
punto,
cabe
en pacientes
que el término
“aceptar”
ladehipótesis
nula no
con nula.
dichoEn
fármaco
con
de unincidir
grupo
de
tratados
con
placebo.
La
implica que dicha hipótesis sea efectivamente cierta, sino que se carece de evidencia suficiente
poblaciones
son
distintas.
eladelante,
contraste
de
hipótesis de
quedaría
formulado
como
para rechazarla.
Como
se
verá Así,
más
nunca
pueden
hipótesis nula
más
natural,
en este
caso, eslas
la hipótesis
no efecto
del ser corroboradas
completamente, quedando siempre un margen o probabilidad de error.
tratamiento; es decir, la presión arterial
de la población tratada con el
H0: μmedia
T = μP,
Ejemplo 5.10 En un estudio para determinar la eficacia de un fármaco antihipertensivo,
se
compara
la presión
arterial
grupo
de pacientes
tratados
dicho fármaco con la
μT es
igual a la
mediadedeunlaH
población
no tratada
μP. Lacon
hipótesis
fármaco
1: μT ≠ μP.
de un grupo de pacientes tratados con placebo. La hipótesis nula más natural, en este caso,
es la hipótesis
del que
tratamiento;
es decir,
la presión
media de la
alternativa
sería,depornoelefecto
contrario,
las presiones
arteriales
mediasarterial
de ambas
La
hipótesis
nula
se
aceptará
a
no
ser
que
los
resultados
del
ensayo
clínico
población tratada con el fármaco μT es igual a la media de la población no tratada μP. La
hipótesis alternativa
sería, Así,
por el contrario,
quehipótesis
las presiones
arteriales
medias
de ambas
poblaciones
son distintas.
contraste de
quedaría
formulado
como
muestren
una
gran
diferencia
entre
los
grupos
que
resulte
poco
compatible
con
poblaciones son distintas. Así, el contraste de hipótesis quedaría formulado como
H0 : μ T = μ P ,
una ausencia de efecto del tratamiento.
H1 : μ T ≠ μ P .
Supongamos hipotéticamente que el grupo control del estudio EURAMIC
La hipótesis nula se aceptará a no ser que los resultados del ensayo clínico muestren una
sentidos.
algunas
circunstancias,
donde
lascontrastar
desviaciones
la hipótesis
en de efecto
granEndiferencia
entre losa grupos
que
resulte
poco si
compatible
con unanula
ausencia
constituye
lanula
población
estudio.
Para
la de
media
poblacional
del
La
hipótesis
se
aceptará
a
no
ser
que
los
resultados
del
ensayo
clínico
del tratamiento.
algún sentido carecen de importancia o son simplemente inconcebibles, es posible
μ esdiferencia
igual a unentre
determinado
valor,
pongamos
ejemplo 1con
colesterol
HDL
Supongamos
hipotéticamente
que
ellosgrupo
control
del estudio
EURAMIC
constituye la
muestren
una
gran
grupos
que resulte
pocopor
compatible
población a estudio. Para contrastar si la media poblacional del colesterol HDL μ es igual
formular un contraste unilateral, aceptando como evidencia contra H0 únicamente las
mmol/l,
el testdedeefecto
hipótesis
se formularía
como1 mmol/l, el test de hipótesis se formularía
a un ausencia
determinado
valor,
pongamos
por ejemplo
una
del
tratamiento.
como
diferencias en un sentido.
Supongamos hipotéticamente que el H
grupo
control del estudio EURAMIC
0 : μ = 1,
H1 : μ ≠ 1.
constituye
la población
a estudio.
Para contrastar
si la antihipertensivo,
media poblacionalsedel
Ejemplo 5.11
En el estudio
de la eficacia
del fármaco
formuló
La elección entre ambas hipótesis dependerá de los resultados obtenidos en una muestra
μdelesestudio
igualbilateral
a EURAMIC.
un determinado
pongamos
ejemplo
colesterol
HDL
de los
controles
. En este
caso, sepor
admite
que 1la
una
hipótesis
alternativa
H1: μT ≠ μPvalor,
La elección entre ambas hipótesis dependerá de los resultados obtenidos en una
elen
testcontra
de hipótesis
se
como
evidencia
de la se
hipótesis
nula puede
provenir alternativa
tanto por unbilateral;
efecto nocivo
En mmol/l,
los ejemplos
anteriores,
haformularía
planteado
una hipótesis
es decir, se
muestra de los controles del estudio EURAMIC.
aceptan como evidencia contra la hipótesis nula las diferencias en ambos sentidos. En algunas
circunstancias,
donde(μlas
desviaciones
de
la hipótesis
nula (en
carecen de
del mismo
μT <algún
μP). Sisentido
en fases
del tratamiento
T>μ
P) como por la
Heficacia
0: μ = 1,
importancia
o son anteriores,
simplemente
inconcebibles,
eshipótesis
posible formular
contraste
; esunilateral,
En los ejemplos
se ha
planteado una
alternativaunbilateral
un sentido.
aceptando
como
contraseHha
previas
del evidencia
ensayo clínico
comprobado
ausencia deenefectos
secundarios
0 únicamente
1.ladiferencias
H : μ ≠las
1
decir, se aceptan como evidencia contra la hipótesis nula las diferencias en ambos
del
tratamiento,
la posibilidad
delaque
la presión
arterial media
de los tratados
sea
Ejemplo
5.11 En
el estudio de
eficacia
del fármaco
antihipertensivo,
se formuló
una
La
elección
entre
ambas
hipótesis
dependerá
de
los
resultados
obtenidos
en
una
hipótesis alternativa bilateral H1: μT ≠ μP. En este caso, se admite que la evidencia en
sentido
y sólodel
podría
superior
de los
tratados
(μT > μtanto
contra dea la media
hipótesis
nulanopuede
provenir
por unde
efecto
nocivo
tratamiento
P) carecería
15
muestra
de
los
controles
del
estudio
EURAMIC.
(μT > μP) como por la eficacia del mismo (μT < μP). Si en fases previas del ensayo clínico
explicarse
por variabilidad
aleatoria.
En talsecundarios
caso, cabríadel
plantearse
el siguiente
se ha comprobado
la ausencia
de efectos
tratamiento,
la posibilidad de
que la presión arterial media de los tratados sea superior a la media de los no tratados
En contraste
los ejemplos
anteriores,
se ha planteado una hipótesis alternativa bilateral; es
de hipótesis
de unilateral
sentido y sólo podría explicarse por variabilidad aleatoria. En tal
(μT > μP) carecería
caso, cabría plantearse el siguiente contraste de hipótesis unilateral
decir, se aceptan como evidencia contra la hipótesis nula las diferencias en ambos
H0 : μ T = μ P ,
H1 : μ T < μ P ,
15
donde sólo se considera como alternativa a H0 la posibilidad de que el tratamiento
antihipertensivo sea eficaz.
donde sólo se considera como alternativa a H0 la posibilidad de que el tratamiento
68
antihipertensivo
Pastor-Barriuso
R.
sea eficaz.
Los contrates bilaterales son más conservadores que sus correspondientes contrates
Contraste de hipótesis
1.2 MEDIDAS DE TENDENCIA CENTRAL
Las medidas de tendencia central informan acerca de cuál es el va
Los contrastes
bilateralesDE
sonTENDENCIA
más conservadores
que sus correspondientes contrastes
1.2 MEDIDAS
CENTRAL
unilaterales, dado que aquellos contemplan desviaciones de H0 en cualquier sentido. En la
de una determinada variable o, dicho de forma equivalente, estos
mayor parte de las aplicaciones
prácticas seDE
utilizan
hipótesis CENTRAL
alternativas bilaterales, ya que
1.2
MEDIDAS
TENDENCIA
Las medidas de tendencia central informan
acerca de cuál es el valor más representativo
resulta imposible excluir con absoluta certeza diferencias en alguno de los dos sentidos. Así,
alrededor de qué valor se agrupan los datos observados. Las medi
todos los contrastes de hipótesis planteados a lo largo de este texto están basados en hipótesis
de una determinada
variablede
o, tendencia
dicho de forma
estos de
estimadores
Las medidas
centralequivalente,
informan acerca
cuál es el indican
valor más represen
alternativas bilaterales.
central de la muestra sirven tanto para resumir los resultados obse
alrededor de qué
se agrupan los
datos o,
observados.
Las medidas
de tendencia
de valor
una determinada
variable
dicho de forma
equivalente,
estos estimadores indi
realizar
inferencias
acerca
de
los
parámetros
poblacionales corres
5.4.2 Contraste estadístico para la media de una población
central de la muestra
sirven
tantovalor
paraseresumir
loslos
resultados
observados
como
para de tendencia
alrededor
de qué
agrupan
datos observados.
Las
medidas
En este apartado se discuten los conceptos continuación
básicos para se
la describen
realizaciónlose principales
interpretación
de un de la tenden
estimadores
contraste de hipótesis
bilateral
sobre
una
población.
Esto
es, correspondientes.
selos
pretende
contrastar
realizar inferencias
acerca
de
los de
parámetros
poblacionales
A
central
delalamedia
muestra
sirven
tanto
para
resumir
resultados
observados
como pa
alternativa bilateral H1: μ ≠ μ0, donde μ0 es un
la hipótesis nula H0: μ = μ0 frente a la hipótesis
variable.
valor predeterminado
de laserealizar
media
poblacional.
El contraste
de otros
así
como
continuación
describen
los principales
estimadores
de parámetros,
la tendencia
central
delauna
inferencias
acerca
de
los parámetros
poblacionales
correspondientes.
A
comparación de parámetros entre distintas poblaciones, se presentará en temas posteriores.
1.2.1 Media aritmética
variable.
continuación
se describen
los principales
estimadores
de la tendencia
La elección
entre las hipótesis
nula y alternativa
dependerá
de los resultados
obtenidos
en la central de u
el valor
muestra o, más concretamente, de la compatibilidad
de la media
muestral
La media aritmética,
denotada
por x ,con
se define
como la suma de
variable.
predeterminado
. Comoaritmética
la
media muestral es un estimador sujeto a error, el objetivo es
1.2.1μ0Media
valoresconstituye
muestralesuna
dividida
por el probable
número de
observaciones
realiz
determinar si laCENTRAL
variabilidad inherente al muestreo
explicación
para
la
EDIDAS DE TENDENCIA
valorcomo
predeterminado
μ0 deuno
la de
media
diferencia observada
la media
muestral
La mediaentre
aritmética,
denotada
por x ,yseeldefine
la suma de cada
los
1.2.1
Media
aritmética
por n el de
tamaño
muestral
y por xi el
valor
observado
poblacional. Para ello, se calcula la probabilidad
que bajo
la hipótesis
nula,
una
media para el sujeto
edidas de tendencia
central
acerca
de
cuál
el
valor
más
representativo
se La
rechaza
laes
hipótesis
nula
o, de observaciones
forma
se afirma
que
inferior
oinforman
igual
que
valores
muestrales
dividida
el número
realizadas.
Si conoce
denotamos
elpor
valor
observado
de x .,equivalente,
Esta
probabilidad
se
muestral
difiera
tanto
oα más
demedia
μ0 que
aritmética,
denotada
por
se define
como
la suma
de cada uno de los
la media vendría
dada
por
como valor P del contraste de hipótesis y determina
el grado
de compatibilidad
de los datos
determinada variable
o, dicho
forma
equivalente,
indican
α 1, ..., n, Si denotam
los resultados
estadísticamente
significativos;
en
caso
contrario,
si
P
es
superior
arealizadas.
porde
nson
el
tamaño
muestral
por estimadores
xvalor
el
valor
observado
para
el
sujeto
i-ésimo,
i serán
=
valores
dividida
por
el
número
de
observaciones
muestrales
con
la
hipótesis
nula. muestrales
Si yestos
este
P
es
elevado,
los
datos
muestrales
i
compatibles con el valor μ0 de la media poblacional, careciendo así de evidencia
x1 + x 2 + ... + x n
1 n para rechazar
dor de qué valorlasehipótesis
loshipótesis
datos
observados.
Las
medidas
de
tendencia
=
x
x i =el sujeto
media
vendría
dada
por
seagrupan
aceptanula.
la
nula,
concluyendo
que
los
resultados
del
test
no
son
por
n
el
tamaño
muestral
y
por
x
el
valor
observado
para
Por el contrario, si el valor P es pequeño,i la media muestralresultará
pocoi-ésimo, i. = 1, .
n i =1
n
compatible con el valor preestablecido μ0, concluyendo entonces que los datos aportan suficiente
l de la muestra sirven
tanto
para
resumir
los
resultados
observados
como
para
estadísticamente
significativos.
la media
vendría
evidencia
para rechazar
dicha
hipótesis.
Endada
n por cuanto menor sea el valor P, menos
x + x + ... + x n
1general,
.tendencia central más utilizada y de
x =nula.
x i = 1es la 2medida de
compatibles serán los datos con la hipótesis
La
media
n calcular la probabilidad
r inferencias acerca de
losconocer
parámetros
poblacionales
correspondientes.
A
i =1tanto necesario
Para
el valor
P del contraste
es npor
+ x 2 + ...
+ xn
x umbral
1 n de un
La decisión de rechazar la hipótesis nula se basa en la definición
preestablecido
.
=
x
x i = 1 al “centro
interpretación.
Corresponde
de gravedad”
o nivel
de
significación
α, tradicionalmente
α = central
0,05. Sideeluna
valor
P es inferiorno igual
que α se de los datos
uación se describen
los
principales
estimadores
de
la
tendencia
n
=
i
1
de que las medias
de todaslalas
posibles
muestras de
tamaño
nutilizada
difieran tanto
o más
de μ0
La media
medida
de tendencia
central
yson
de estadísticamente
más
fácil
rechaza la hipótesis
nula o, es
de forma
equivalente,
se afirma
quemás
los resultados
principal
eshipótesis
que está muy
significativos; en caso contrario, si P es superior
a α limitación
se acepta la
nula,influenciada
concluyendopor los valores e
le.
x
, asumiendo
que
la media
poblacional
es datos
μ
. Bajo
que el valor
observado deCorresponde
interpretación.
al
“centro
de
gravedad”
de
los
de
la
muestra.
La
media
es
la
medida
de
tendencia
central
utilizada
y de Su
más fácil
0más
que los resultados del test no son estadísticamente significativos.
caso, puede no ser un fiel reflejo de la tendencia central de la dist
conocer
elHvalor
P
del
contraste
es
por
tanto
calcular
la probabilidad
de
que
Media aritmética Para
principal
limitación
es
que
está
muy
influenciada
por
los
valores
y, en
estela muestra. Su
interpretación.
Corresponde
al “centro
de gravedad”
lostal
datos
de
:
μ
=
μ
,
las
medias
muestrales
senecesario
distribuirán
alrededor
deextremos
μde
hipótesis
nula
0
0
0, de
las medias de todas las posibles muestras de tamaño n difieran tanto o más de μ0 que el valor
Ejemplo
1.4
En
este
endistribución.
los
sucesivos
sobre
observado
decaso,
,,asumiendo
que
lalamedia
poblacional
es
μlos
la
hipótesis
nula
Hlos
= μejemplos
dia aritmética, denotada
xsus
sedesviaciones
definenocomo
suma
de cada
uno
deestá
puede
serestandarizadas
un
fiel
reflejo
deesla
tendencia
central
dey la
principal
limitación
que
muy
influenciada
por
valores
extremos
y, estim
en e
0. Bajo
0: μ
0, las
forma por
que
medias muestrales se distribuirán alrededor de μ0, de tal forma que sus desviaciones estandarizadas
utilizarán
del colesterol
obtenidos en los 1
s muestrales dividida por el número de observaciones
Si denotamos
caso, puederealizadas.
no ser un fiel
reflejolos
de valores
la tendencia
central deHDL
la distribución.
x −sucesivos
μ0
Ejemplo 1.4 En este y en
los
ejemplos
sobre
estimadores
muestrales,
se
t=
s
estudio
“European
Study on Antioxidants, Myocardial Infar
el tamaño muestral y por xi el valor observado para el sujeto i-ésimo,
i = 1,
..., n,
n HDL
utilizarán los valores
del1.4
colesterol
obtenidos
en ejemplos
los 10 primeros
sujetos del muestra
Ejemplo
En este
y en los
sucesivos
sobre estimadores
the Breast“ (EURAMIC), un estudio multicéntrico de casos
ia vendría dadaseguirán
por
aproximadamente una distribución t de Student con n – 1 grados de libertad (Apartado
estudio
“European
Study
on
Antioxidants,
Myocardial
Infarction
and
Cancer
of
utilizarán
los
valores
colesterol
obtenidos
en los
sujet
seguirán
aproximadamente
una distribución
t de Student
con
nde- los
1 HDL
grados
de
libertad
5.3.1).
Una vez
calculado el valor
de este estadístico
tdel
a partir
datos
observados
en10
la primeros
entre 1991 y 1992 en ocho países Europeos e Israel para eva
muestra, el valor
+ x 2 + ...vendrá
+ x n determinado por el área bajo la curva de la distribución
1 n P delx1contraste
the
Breast“
(EURAMIC),
un
estudio
multicéntrico
de casos
y controles
realizadoand Cance
estudio
“European
Study
on Antioxidants,
Myocardial
. el valor de este
=
x i = Una vez calculado
5.3.1).
estadístico
t a partir
de
los
datos Infarction
tn–1 (Apartado
parax aquellos
n i =1 valores tanto
n o más distantes de 0 que el valor observado de t (esto es,
desviaciones de μ0 mayores o iguales que la observada en cualquiera de los dos sentidos). En la
1991 el
y 1992
en
ocho
países Europeos
eestudio
Israel para
evaluar
elde
efecto
los
the Breast“
(EURAMIC),
un
multicéntrico
casosde
y controles
real
observados
en laentre
muestra,
valor
Peldel
contraste
vendrá
determinado
por
eldeárea
bajo
Figura
5.4 se representa
gráficamente
cálculo
del valor
P para
este contraste
hipótesis.
media es la medida de tendencia central más utilizada y de más fácil
entreaquellos
1991 y 1992
en tanto
ocho opaíses
Europeosde
e Israel
valores
más distantes
0 que para
el evaluar el efecto de
la curva de la distribución tn-1 para
5
Pastor-Barriuso R. 69
etación. Corresponde al “centro de gravedad” de los datos de la muestra. Su
valor observado de t (esto es, desviaciones de μ0 mayores o iguales que la observada en
pal limitación es que está muy influenciada por los valores extremos y, en este
Inferencia estadística
Distribuci ón de t =
x − μ0
bajo H 0 : μ = μ 0
s
n
tn-1
1.2 MEDIDAS DE TENDENCIA CENTRAL
Las medidas de tendencia central informan
acerca de cuál es el valor más representativo
P/2
P/2
de una determinada variable o, dicho de forma equivalente, estos estimadores indican
-t
0
t
alrededor de qué valor se agrupan los datos observados. Las medidas de tendencia
(valor observado)
MEDIDAS DE TENDENCIA CENTRAL
central de la muestra
tanto
para elresumir
losbilateral
resultados
para
Figura sirven
5.4 Valor
P para
contraste
de la observados
media de unacomo
población.
Figura 5.4
medidas de tendencia central informan acerca de cuál es el valor más representativo
: μ = 1,
H0correspondientes.
realizar inferencias acerca de los parámetros poblacionales
A
Ejemplo 5.12 Supongamos que se pretende contrastar si la media poblacional del
na determinada variable o, dicho de forma equivalente, estos estimadores indican
colesterol
HDL en los
controles del
EURAMIC
es igualdea una
1 mmol/l mediante el test de
: μ ≠ 1. central
H
continuación se describen
los principales
estimadores
de la
1tendencia
hipótesis bilateral
edor de qué valor se agrupan los datos observados. Las medidas de tendencia
variable.
Para ello, se obtiene una muestra de H
tamaño
n = 10 donde la media y desviación
0 : μ = 1,
al de la muestra sirven tanto para resumir los resultados observados
H1 : μ ≠ 1. como para
1.2.1 Media aritmética
típica resultaron ser x = 1,20 y s = 0,30 mmol/l. A partir de estos datos se calcula
zar inferencias acercaPara
de los
parámetros
poblacionales
ello,
se obtiene
una muestracorrespondientes.
de tamaño n = 10Adonde la media y desviación típica
ser del
ys=
0,30lammol/l.
A cada
partiruno
de estos
La media aritmética, resultaron
denotada
por
x ,=contraste
se1,20
define
como
suma de
de losdatos se calcula el estadístico
el
estadístico
Para
ello, se obtiene
una muestra
de tamañocentral
n = 10 de
donde
nuación se describen del
los contraste
principales
estimadores
de la tendencia
una la media y desviación
valores muestrales dividida por el número de observaciones realizadas. Si denotamos
,20 − 1 A partir de estos datos se calcula
s =μ 00,301mmol/l.
típica resultaron ser x = 1,20 xy −
ble.
t=
= 2,11,
=
s
0,30 i-ésimo, i = 1, ..., n,
por n el tamaño muestral y por xi el valor observado para
el sujeto
n
el estadístico del contraste
10
Media aritmética
la media vendría dadaque
pordetermina la diferencia estandarizada (dividida por el error estándar) entre la media
x − μ 0 μ cada
− 1 de
1,20 uno
que determina
diferencia
estandariza
(dividida
porlos
el error estándar) entre la
muestral
ella
valor
predeterminado
edia aritmética, denotada
por x ,yse
define
como
= 2,11,muestral de este estadístico bajo
t =la suma de
=0. La distribución
n H : μ = 1 seguirá
s
0,30
una t de Student con 9 grados de
la hipótesis 1nula
0 x1 + x 2 + ... + xaproximadamente
n
n
.
=
=
x
x
10
x
media
muestral
y
el
valor
predeterminado
μ
.
La
distribución
este
i observaciones
es muestrales dividida
por el (n
número
Si
denotamos
0 nula
libertad
–n1
= de
10
– 1 = 9). nAsí, sirealizadas.
la hipótesis
fuera ciertamuestral
(esto es, de
si la
verdadera
i =1
media poblacional fuera 1 mmol/l), la probabilidad de obtener una muestra de 10 sujetos
el tamaño muestral ycon
poruna
xi elmedia
valor
observado
elHsujeto
i-ésimo,
=mmol/l
1,el...,
n,
μ igual
=(dividida
1 seguirá
aproximadamente
una
tdesviación
dela
estadístico
bajola
ladiferencia
hipótesispara
nula
de
colesterol
superior
a 1,20ipor
(mayor
o igual
que
0: o
que
determina
estandariza
error
estándar)
entre
La media es la medida
de tendencia
másoutilizada
mása fácil
la observada
por lacentral
derecha)
inferior oy de
igual
0,80 mmol/l (mayor o igual desviación
edia vendría dada porque
la observada
izquierda)
Student
con 9 grados
devalor
libertad
(nsería
- 1 = 10 - μ10.=La
9).distribución
Así, si la hipótesis
nula
fuera
xpor
media
muestral
y ella
predeterminado
muestral
de este
interpretación. Corresponde al “centro de gravedad” de los datos de la muestra. Su
cierta (esto
es, sixla +verdadera
1 mmol/l), la probabilidad
+ media
x 2 + ... nula
x n H0: poblacional
1 n bajo
μ = 1 seguiráfuera
aproximadamente una t de
estadístico
la1 hipótesis
principal limitación es que
muy
influenciada
por
los
valores
extremos
y,
en este
.
=
x =está
x
i
n
n
70 Pastor-Barriuso
R.
=
i
1
de obtener una muestra de 10 sujetos con una media de colesterol superior o igual
con de
9 grados
de libertad
(n de
- 1la= distribución.
10 - 1 = 9). Así, si la hipótesis nula fuera
caso, puede no ser unStudent
fiel reflejo
la tendencia
central
1,20
mmol/l (mayormás
o igual
desviación
quefácil
la observada por la derecha) o
a media es la medida ade
tendencia
utilizada
y de
más
cierta
(esto es,central
si la verdadera
media
poblacional
fuera 1 mmol/l), la probabilidad
a 1,20 mmol/l (mayor o igual desviación que la observada por la derecha) o
inferior o igual a 0,80 mmol/l (mayor o igual desviación que la observada por la
Contraste de hipótesis
izquierda) sería
P = P( x ≥ 1,20 | H0 ) + P( x ≤ 0,80 | H0 )
x − μ 0 1,20 − μ 0
x − μ 0 0,80 − μ 0
= P
≥
H 0 + P
≤
H0
s
s
s
s
n
n
n
n
≈ P(t9 ≥ 2,11) + P(t9 ≤ − 2,11) = 2P(t9 ≥ 2,11) = 0,064,
que corresponde al área bajo la curva de la distribución t9 para valores superiores a 2,11
(valor observado del estadístico) o inferiores a – 2,11. Notar que el valor exacto de P se
que
corresponde
área bajo laNo
curva
de la distribución
t9 para
ha obtenido
por alordenador.
obstante,
utilizando la
Tablavalores
5 del superiores
Apéndice, puede
S DE TENDENCIAcomprobarse
CENTRAL que el estadístico t = 2,11 está comprendido entre los percentiles t9;0,95 =
a1,833
2,11 y(valor
estadístico)
o inferiores
a -2,11.
Notar
que≥el2,11)
valor< 0,05, que
t9;0,975 observado
= 2,262, dedel
lo cual
se deduce
la desigualdad
0,025
< P(t
9
equivaleacerca
a un valor
P bilateral
comprendido
entre 0,05 < P < 0,10.
e tendencia central informan
de cuál
es el valor
más representativo
exacto de P se ha obtenido por ordenador. No obstante, utilizando la Tabla 5 del
Si se adopta el nivel de significación α = 0,05 como regla de decisión, los resultados de
inada variable o, dicho
demuestra
forma equivalente,
estos estimadores
indican
1.2 MEDIDAS
DE
TENDENCIA
CENTRAL
esta
no aportan
suficiente
evidencia
para rechazar
la hipótesis nula (P = 0,064 >
0,05), concluyendo que la verdadera media poblacional del colesterol HDL no19resulta
ué valor se agrupan los
datos observados.
Las medidas
de tendencia
significativamente
distinta
de 1demmol/l.
Las
medidas
tendencia central informan acerca de cuál es el valor más representativ
muestra sirven tantoElpara
resumir
los resultados
observados
como para
valor
P determina
la significación
estadística
deo,losdicho
resultados
de un
contraste de
hipótesis,
de
una determinada
variable
de forma
equivalente,
estos
estimadores indican
y depende tanto de la magnitud de la diferencia entre el verdadero valor del parámetro y su
ncias acerca de valor
los parámetros
poblacionales
Amuestral. Así, una pequeña diferencia puede
como
delvalor
tamaño
predeterminado
bajo
H0,correspondientes.
alrededor
de qué
se agrupan
los datos observados. Las medidas de tendencia
resultar estadísticamente significativa si el tamaño muestral es suficientemente grande y, por el
e describen loscontrario,
principales
estimadores
la tendencia
de una
:μ
Supongamos
sedeplantea
mismo
contraste
bilateral
de laestadística
hipótesis
nula
una
granque
diferencia
puede
nocentral
alcanzar
significación
si laHmuestra
es como para
0observados
central
de
laelmuestra
sirvenlatanto
para resumir
los resultados
insuficiente. En consecuencia, el valor P no debe interpretarse como una medida de la magnitud
de la diferencia
asociación
objeto
estudio.
1,09 mmol/l y correspondientes. A
= 1 a partiro de
unarealizar
muestra
de de
tamaño
n = 100
media x = poblacionales
inferencias
acerca
de con
los parámetros
Ejemplo 5.13
ejemplo
anterior
se observó
diferencia
HDL
desviación
típicaEn
s =el0,31
mmol/l.
El estadístico
del una
contraste
es en eldecolesterol
continuación
se
describen
los principales
estimadores
la tendencia
central de una
Supongamos
que
se plantea
mismo contraste
denula
la hipótesis
nula Hy0:laμ media
de
0,20 mmol/l
entre
el valoreldeterminado
bajo labilateral
hipótesis
μ0 = 1 mmol/l
mmol/l
en
una
tamaño
= 10. Los
testH no
fueron
mética, denotada por Supongamos
x ,=se1,20
define
como
laplantea
sumamuestra
deelcada
de
los−n1bilateral
que variable.
se
mismo
dexresultados
la hipótesisdel
nula
x − de
μuno
1,09
0: μ
0 contraste
=
1,09
mmol/l
y
=
1
a
partir
de
una
muestra
de
tamaño
n
=
100
con
media
=
2,90
=
t
=
estadísticamente significativos (P = 0,064) pero la magnitud de la diferencia podría ser
s
0,31
rales dividida por el número
de observaciones
realizadas.
Si denotamos
clínicamente
importante de
confirmarse
en estudios
con mayor tamaño muestral.
n
x = es
1,09 mmol/l y
=
1 a partir típica
de una1.2.1
de aritmética
tamaño
n = 10010con
Media
desviación
s muestra
= 0,31
mmol/l.
El estadístico
delmedia
contraste
Supongamos que se plantea el mismo contraste bilateral de la hipótesis nula H0: μ = 1 a
o muestral y por xi el valor observado para el sujeto i-ésimo, i = 1, ..., n,
partir
una
de
tamaño
n El
= 100
con media
mmol/l
desviación
típicauno de los
desviación
típica
s =media
mmol/l.
estadístico
del contraste
es comoy la
La
aritmética,
denotada
por
x ,=se1,09
define
suma de cada
y,
por de
tanto,
elmuestra
valor
P0,31
vendría
determinado
x − contraste
μ 0 1,09por
−1
s = 0,31 mmol/l. El estadístico
del
es
= 2,90
=
t=
ría dada por
s dividida
0,31por el número de observaciones realizadas. Si denotamos
valores muestrales
x − μ 0 1,09 −=12P(t ≥ 2,90) = 0,005.
P = P(t99 ≥ 2,90)
99
t =+ P(t99n≤ =-2,90) 10
= 2,90
0
,
31
s
n
+ xnnel tamaño muestral
x + x 2 + ...
1
por
y por
10 xi el valor observado para el sujeto i-ésimo, i = 1, ..., n,
n
.
x = xi = 1
y,
determinado
por
n iUtilizando
nvalor P vendría
laelaproximación
normal
a la distribución
t de Student con 99 grados de
=1 por tanto,
y, por tanto, el valor
P vendría
determinado
la media
vendría
dada por por
y, por tanto, el valor P vendría determinado por
libertad, el valor
P también
puede
aproximarse
partir≥de2,90)
la Tabla
3 del Apéndice
P(t99
≤ − 2,90) =a2P(t
= 0,005.
P = P(t
99 ≥ 2,90)
99
s la medida de tendencia central más
utilizada
y de+más
fácil
n
x1 + x 2 + ... + x n
1
= t 99
x2,90)
como
i =
Utilizando laPaproximación
normal
a la
de≥Student
99 grados. de libertad,
= P(t99 ≥ 2,90)
+ P(t99
≤ distribución
-2,90) =x 2P(t
=con
0,005.
n
n 99 grados de
Corresponde al “centro
de
gravedad”
de
los
datos
de
la
muestra.
Su
=
i
1
Utilizando
la aproximación
normal a laa distribución
t de Student
con
el
valor P también
puede aproximarse
partir de la Tabla
3 del Apéndice
como
ritmética
≥extremos
2,90)
≈ 2{1
Φ(2,90)}
0,004.
Ptambién
=valores
2P(t99normal
ación es que está muyUtilizando
influenciada
porPlos
y,
en− este
aproximación
a la
distribución
t de=deStudent
con del
99 grados
de
libertad,
el la
valor
puede
a partir
la Tabla
Apéndice
La media
es laaproximarse
medida de tendencia
central
más3 utilizada
y de más fácil
este caso,central
aunquedelaladiferencia
entre el valor predeterminado y la media muestral
o ser un fiel reflejo deEn
la tendencia
distribución.
libertad,
el valor P también
puede aproximarse a partir de la Tabla 3 del Apéndice
como
En
este caso,
aunque
la diferencia
entre
el valor
predeterminado
y la media
interpretación.
Corresponde
al “centro
de gravedad”
dedel
los test
datosfueron
de la muestra. Su
resultó
ser sensiblemente
menor
(0,09
mmol/l),
los
resultados
como
ser
sensiblemente
menor
(0,09
mmol/l),
resultados
del Pastor-Barriuso
test
principal
limitación
es 2{1
que
muy
por los
valores
extremos
R. 71 y, en este
-está
Φ(2,90)}
= los
0,004.
Psobre
= 2P(t
1.4 En este y en los muestral
sucesivosresultó
ejemplos
estimadores
se influenciada
99 ≥ 2,90) ≈muestrales,
fueronHDL
estadísticamente
significativos
=
0,005),
aportando
suficiente
≥ 2,90)
2{1
- Φ(2,90)}
0,004.
P =en
2P(t
caso,
puede
no
ser un≈(P
fiel
reflejo
de
la=tendencia
centralevidencia
de la distribución.
n los valores del colesterol
obtenidos
los9910
primeros
sujetos
del
En este caso, aunque la diferencia entre el valor predeterminado y la media
Inferencia estadística
estadísticamente significativos (P = 0,005), aportando suficiente evidencia para rechazar
la hipótesis nula.
La realización de una prueba de hipótesis presenta la misma estructura básica para todos los
parámetros. En general, se calcula primero un estadístico del contraste, cuyo numerador
corresponde a la diferencia entre el valor observado en la muestra y el valor esperado bajo la
hipótesis nula, y cuyo denominador representa la variabilidad o error estándar de la estimación.
El valor P se obtiene entonces como la probabilidad de obtener un valor del estadístico tanto o
más extremo que el observado en el estudio, asumiendo que la hipótesis nula es cierta.
El contraste de hipótesis para un determinado parámetro está relacionado con su
correspondiente intervalo de confianza. Si se contrasta la hipótesis nula H0: μ = μ0 frente a
la hipótesis alternativa bilateral H1: μ ≠ μ0, el resultado será estadísticamente significativo
para un nivel α = 0,05 si el IC al 95% para μ no incluye el valor μ0. Por el contrario, este
contraste no resultará estadísticamente significativo si el IC al 95% para μ contiene al valor
1.2 MEDIDAS
DEcomplementaria.
TENDENCIA CENTRAL
información
El intervalo de
μ0. No obstante, ambos métodos facilitan
confianza aporta una medida de la magnitud y precisión en la estimación del parámetro,
aunque no facilita el valor exacto de P Las
o elmedidas
grado dedecompatibilidad
coninforman
una hipótesis
tendencia central
acercanula
de cuál es el valor
de interés. El valor P sí determina la compatibilidad de los datos con una determinada
hipótesis, pero no facilita una medida de
del parámetro
asociación
objeto
de
de la
unamagnitud
determinada
variable o, odicho
de forma
equivalente,
estos esti
estudio. En general, el uso de los contrastes de hipótesis como forma exclusiva de presentar
los resultados de un estudio está siendo
ampliamente
cuestionado
enlos
la datos
actualidad.
La Las medidas
alrededor
de qué valor
se agrupan
observados.
presentación de los resultados de un estudio ha de consistir fundamentalmente en el
estimador puntual y el intervalo de confianza,
que
con el
valor los
P deresultados
la
central de
la pueden
muestra completarse
sirven tanto para
resumir
observa
hipótesis correspondiente.
realizar inferencias acerca de los parámetros poblacionales correspon
Ejemplo 5.14 En la primera muestra de tamaño n = 10 del Ejemplo 5.7 se obtuvo una
media de 1,20 mmol/l y una desviación
típica de
mmol/l,
tal formaestimadores
que el IC alde la tendencia
continuación
se0,30
describen
losde
principales
95% para la media poblacional del colesterol HDL resultó ser (0,99; 1,41). Estos mismos
datos muestrales se emplearon en elvariable.
Ejemplo 5.12 para el contraste bilateral de la hipótesis
nula H0: μ = 1, obteniendo un valor P de 0,064. Ambos resultados son consistentes dado
que el IC al 95% incluye el valor preestablecido de 1 mmol/l para la hipótesis nula y, por
1.2.1 Media aritmética
tanto, el contraste no resulta estadísticamente significativo para un nivel α = 0,05.
mmol/l
En el Ejemplo 5.9, a partir de unaLamuestra
de tamaño denotada
n = 100 con
media aritmética,
por x ,=se1,09
define
comoyla suma de cada
s = 0,31 mmol/l, se obtuvo un IC al 95% para la media poblacional del colesterol HDL de
valores muestrales
de observaciones
realizada
(1,03; 1,15). El correspondiente contraste
de H0: μ = 1dividida
frente apor
H1:elμnúmero
≠ 1 se realizó
en el
Ejemplo 5.13, resultando un valor P de 0,005. En este caso, el valor 1 mmol/l queda fuera
por ny,elen
tamaño
muestral ylos
porresultados
xi el valor observado
para el sujeto i-é
de los límites de confianza al 95%
consecuencia,
del test son
estadísticamente significativos.
la media vendría dada por
5.4.3
Errores y potencia de un contraste de hipótesis
x + x 2 + ... + x n
1 n
.
x = xi = 1
Como se comentó anteriormente, las hipótesis nunca pueden ser corroboradas
n i =1 completamente,
n
quedando siempre un margen o probabilidad de error. La elección entre las hipótesis nula y
alternativa conlleva a alguna de las situaciones presentadas en la Tabla 5.1. Si se acepta la
media la
es hipótesis
la medidanula
de tendencia
más utilizada
y de más
hipótesis nula cuando ésta es cierta, o si seLarechaza
cuando lacentral
alternativa
es
cierta, se habrá tomado una decisión correcta. Sin embargo, es posible cometer alguno de los
siguientes tipos de error en un contraste interpretación.
de hipótesis: Corresponde al “centro de gravedad” de los datos de l
principal limitación es que está muy influenciada por los valores extr
72
Pastor-Barriuso R.
caso, puede no ser un fiel reflejo de la tendencia central de la distribu
Contraste de hipótesis
P(error de tipo I) = P(rechazar H0 | H0 cierta)
P(error de tipo I) = P(rechazar H0 | H0 cierta)
cierta)
+ P(t ≤ tn-1,
= P(t ≥ tn-1,1α/2 | H0 en
/2 | H0 cierta)
Tabla 5.1 Resultados
posibles
un contraste
deαhipótesis.
==P(t
n-1,1-α/2 | H0 cierta)
/2 | H0 cierta)
t
) + P(t Realidad
≤+t P(t ≤) t=n-1,αα/2
+ α/2 = α,
P(t≥ t≥
n-1
es decir, la
n-1,1-α/2
n-1
n-1,α/2
Decisión
H0 cierta
H1 cierta
/2 +II α/2 = α,
Aceptar H0 = P(tn-1 ≥ tn-1,1-Correcto
α/2) + P(tn-1 ≤ tn-1,Error
α/2) =deαtipo
probabilidad
de
cometer
un
error
de
tipo
I
viene
determinada
de
Error de tipo I
Correcto
Rechazar H0
esantemano
decir, la probabilidad
cometer un αerror
tipo
I vienepara
determinada
. Así,depor
ejemplo,
un test condeun
por el nivel dedesignificación
yy El error de tipo I consiste en rechazar la hipótesis nula cuando ésta es, en realidad, cierta.
Como
se significación
comentó
anteriormente,
nivel
de significación
seunutiliza
para
clasificar
los
α. Así,
por
un test
con
un
antemano
por el nivel
de
α =significación
0,05, laelprobabilidad
de ejemplo,
incurrir αenpara
error
de
tipo
I
nivel de
resultados obtenidos en un test como significativos si el valor P ≤ α, en cuyo caso se
rechaza
la0,05;
hipótesis
ohipótesis
como
nonula
significativos
si Pse>rechazará
α,
caso
se acepta
la
seráde
delsignificación
esto es,nula,
es cierta,
erróneamente
αsi=la0,05,
la probabilidad
de ésta
incurrir
en en
un cuyo
error
de tipo
I
nivel
hipótesis nula. Con esta regla de decisión, puede comprobarse a partir de la Figura 5.4 que
en un
5%
de esto
los contrastes
de hipótesis
realizados
todas
las posibles
será
del
0,05;
la hipótesis
nula
es cierta, sobre
ésta se
rechazará
erróneamente
P(error
de tipoes,
I) =si P(rechazar
H
0 | H 0 cierta)
= P(t ≥ tn 1,1 α /2 | H 0 cierta) + P(t ≤ tn 1 ,α /2 | H 0 cierta)
dellos
mismo
tamaño.
enmuestras
un 5% de
contrastes
de hipótesis realizados sobre todas las posibles
EDIDAS DE TENDENCIA CENTRAL = P(tn 1 ≥ tn 1,1 α /2 ) + P(t n 1 ≤ t n 1 , α /2 ) = α /2 + α /2 = α ;
muestras
delprobabilidad
mismo tamaño.
es
decir, la
delos
cometer
un error
de tipo I viene
determinada
antemano por
Ejemplo
5.15 A partir de
controles
del EURAMIC
se obtienen
1000de
muestras
didas de tendencia central
informan
acerca
de
cuál
es
el
valor
más
representativo
el nivel de significación α. Así, por ejemplo, para un test con un nivel de significación
αaleatorias
= 0,05, la
dey,incurrir
undeerror
I será
del 0,05;deesto es, si la
deprobabilidad
tamaño
nde= los
10
en cadaen
una
ellas,desetipo
realiza
el contraste
A
partir
controles
del
EURAMIC
obtienen
1000 muestras
determinada variable
o, dicho
de
forma
equivalente,
estimadores
indican
esEjemplo
decir,
la5.15
probabilidad
de
cometer
un
error
de tipo
I se
viene
de
hipótesis
nula
es cierta,
ésta
se estos
rechazará
erróneamente
en undeterminada
5% de los contrastes
de
hipótesis
sobre
posibles muestras
del mismo
hipótesisrealizados
bilateral para
la todas
medialas
poblacional
del colesterol
HDL tamaño.
aleatorias
tamaño
n = 10 y,
enmedidas
cada una
ellas, se realiza el contraste de
or de qué valor se agrupan
losde
datos
observados.
Las
dede
tendencia
antemano por el nivel de significación α. Así, por ejemplo, para un test con un
Ejemplo 5.15 A partir de los controles del EURAMIC se obtienen 1000 muestras
= 1,09,
H0: μuna
de la muestra sirvenhipótesis
tanto
para
resumir
los nresultados
observados
como
para
bilateral
para
la=media
poblacional
delellas,
colesterol
HDLel contraste de hipótesis
aleatorias
de tamaño
10 y, en
cada
de
se realiza
α
=
0,05,
la
probabilidad
de
incurrir
en un error de tipo I
nivel
de
significación
bilateral para la media poblacional del colesterol HDL
inferencias acerca de los parámetros poblacionales correspondientes.
H1: μ ≠ 1,09, A
H0 : μ = 1,09,
será del 0,05; esto es, si la hipótesis nula es cierta, ésta se rechazará erróneamente
H1 : μ ≠central
1,09, de una
ación se describen los principales estimadores de la tendencia
mediante el estadístico
ejemplo
ilustrativo,de
la hipótesis
hipótesis nula
es ciertasobre
ya que
la media
poblacional
en En
un este
5% de
contrastes
realizados
todas
las posibles
mediante
ellos
estadístico
e.
x − 1,09
del colesterol
HDL tamaño.
en el grupo control
es efectivamente μ = 1,09
mediante
el estadístico
muestras
del
mismo
,
t = del EURAMIC
s
Media aritmética
10
mmol/l. Por lo tanto, se tomó la decisión correcta
de aceptar H0 en el 94,4% de las
x − 1,09
donde
son
lascomo
correspondientes
medias
yde
típicas muestrales.
En cada
ia aritmética, denotada
por 5.15
x ,yses A
define
la suma
de
los
t =cada
,desviaciones
Ejemplo
partir
de los
controles
deluno
EURAMIC
se obtienen
1000 muestras
s bajo
I) en
restante
5,6%,
muestras
yy se
rechazo
erróneamente
0 (error
scalcula
son
laselcorrespondientes
ydedesviaciones
muestrales.
donde x se
para valores
muestra,
valor
P como elHmedias
área
latipo
curva
de el
latípicas
distribución
t9 que
10
muestrales dividida
por
el onúmero
de observaciones
Si
denotamos
tanto
más
distantes
de
0 que
elrealizadas.
valor una
observado
de se
t, yrealiza
se decide
rechazar ladehipótesis
aleatorias
de
tamaño
n
=
10
y,
en
cada
designificación
ellas,
el contraste
= 0,05
concuerda
perfectamente
elnula
nivel
En cada
se calcula
elcon
valor
P
como
el áreaenbajo
la αcurva
la muestras (944 de
nula
si Pmuestra,
≤casi
0,05.
Así,
la hipótesis
se de
aceptó
un 94,4%
dedelas
tamaño muestral ydonde
por
xi elxyvalor
observado
el (56
sujeto
i-ésimo,
= 1, ..., n,
1000)
en
unpara
5,6%
de medias
1000). yi desviaciones
ysesrechazó
son
las
correspondientes
típicas muestrales.
hipótesis
bilateral
para
media
poblacional
del colesterol HDL
preestablecido
el la
contraste.
tanto o más distantes de 0 que el valor observado de t,
distribución t9 para valores
En este ejemplo ilustrativo, la hipótesis nula es cierta ya que la media poblacional del
a vendría dada por En cada muestra, se calcula el valor P como el área bajo la curva de la
colesterol HDL en el grupo control del EURAMIC es efectivamente μ = 1,09 mmol/l. Por
y se decide rechazar la hipótesis nula
P ≤1,09,
0,05. Así, la hipótesis nula se aceptó
H0:siμ
el 94,4%
de las muestras
y se
lo error
tanto, de
se tipo
tomóIIlaconsiste
decisiónencorrecta
de=
aceptar H
• El
aceptar
la
hipótesis
nula
en realidad,
es
0 encuando,
n
para
valores
tanto
o
más
distantes
de
0
que
el
valor
observado
de
t,
distribución
t
9
+
+
...
+
x
x
x
1
rechazó erróneamente
H0 (error
de tipo I) en el restante 5,6%, que concuerda casi
2
n
. de 1000) y se rechazó en un 5,6% (56 de 1000).
x =un 94,4%
x i =de1 las muestras
en
(944
H1: μ ≠ α1,09,
perfectamente
con
el
nivel
de
significación
=de0,05
preestablecido
para
ciertan lai =1hipótesis alternativa.
La probabilidad
cometer
un error de
tipoelIIcontraste.
se
n
y se decide rechazar la hipótesis nula si P ≤ 0,05. Así, la hipótesis nula se aceptó
yy El
errorpor
deβtipo
, II consiste en aceptar la hipótesis nula cuando, en realidad, es cierta la
denota
el estadístico
media es la medidamediante
de
tendencia
central
utilizada
de más
fácil
en
un 94,4%
de las más
muestras
(944y de
1000)
y se rechazó
un 5,6%
de 1000).
hipótesis
alternativa.
La probabilidad
de cometer
un error en
de tipo
II se (56
denota
por β,
24
etación. Corresponde al “centro de gravedad”
los datos
la muestra.
H1 cierta) = β .
P(error de tipo
II) = de
P(aceptar
H0 | Su
x − 1,09
t=
,
s
al limitación es que está muy influenciada por los valores extremos
y, en este
Pastor-Barriuso
Si la hipótesis alternativa es cierta, la probabilidad
de tomar la decisión correcta
y, R.
10
24
uede no ser un fiel reflejo de la tendencia central de la distribución.
por tanto, rechazar la hipótesis nula se conoce como potencia del test,
donde x y s son las correspondientes medias y desviaciones típicas muestrales.
73
1.2 MEDIDAS DE TENDENCIA CENTRAL
| H1 cierta) =DE
β. TENDENCIA CENTRAL
P(error de tipo II) = P(aceptar 1.2
H0 MEDIDAS
Inferencia estadística
Las medidas de tendencia central informan acerca de cuál es el valor más representativo
Si la hipótesis alternativa es cierta, la probabilidad
de tomar de
la decisión
Las medidas
tendenciacorrecta
central y,
informan acerca de cuá
de una determinada variable o, dicho de forma equivalente, estos estimadores indican
Sipor
la tanto,
hipótesis
alternativa
es cierta,
depotencia
tomar ladeldecisión
correcta
y, de
porforma equivalen
test,
rechazar
la hipótesis
nulalaseprobabilidad
conoce como
de una
determinada
variable
o, dicho
tanto,
rechazar
la
hipótesis
nula
se
conoce
como
potencia
del
test,
alrededor de qué valor se agrupan los datos observados. Las medidas de tendencia
H1 cierta)de qué valor se agrupan los datos observados.
Potencia = P(rechazar H0 |alrededor
central de la muestra sirven tanto para resumir los resultados observados como para
= 1 − P(error de tipo
II) =de1 −
.
central
laβmuestra
sirven tanto para resumir los resulta
realizar inferencias acerca de los parámetros poblacionales correspondientes. A
La probabilidad de error de tipo II β y la potencia de un contraste 1 – β no están
realizar inferencias acerca de los parámetros poblacional
predeterminadas
de
antemano
y, como
se
comprobará
a continuación,
de distintos
β
y
la
potencia
contraste
1dependen
- β de
no una
están
La
probabilidad
de
error
de
tipo
II
continuación se describen los 2principales estimadores dede
la un
tendencia
central
factores, como el N(
nivel
significación
α, lao,desviación
del verdadero
parámetro
μ0, de
σ /n)
si H0 es cierta
en caso contrario,
N(μ1,valor
σ 2/n)del
si H
aproximadamente
1 es
continuación se describen los principales
estimadores de
de
los datos σaycontinuación,
el tamaño muestral
n.
respecto
al valor nulo
μ –2 μ0, la dispersión
predeterminadas
de
antemano
y,
como
se
comprobará
dependen
2
variable.
, σ /n) side
H0 xesbajo
cierta
en caso contrario,
N(μ1, σ se/n)representa
si H1 es
aproximadamente
N(μ0muestral
laso,hipótesis
nula y alternativa
cierta. La distribución
variable.
Supongamos, para simplificar la exposición, que una variable aleatoria tiene media
de distintos factores, como el nivel
de significación α, la desviación del verdadero
laspretende
hipótesis
nula y alternativa
seno
representa
cierta.
La μaritmética
distribución
muestral
de
, xy bajo
que se
contrastar
hipótesis
nula
H0: μ = μ0
desconocida
y5.5.
varianza
conocida
σ2significación
1.2.1
α, el contraste
delahipótesis
resultará
enMedia
la Figura
Para un
nivel de
frente a la hipótesis alternativa H1: μ = μ1, donde μ1 ≠
μ
.
Por
el
teorema
central
del
límite, se
1.2.1
0 Media aritmética
μ
μ
valor
del
parámetro
respecto
al
valor
nulo
0, la dispersión de los datos σ y el
, ellacontraste
hipótesis
la Figura
5.5.
unelnivel
sabe
que
laaritmética,
distribución
dedex significación
en
deαtamaño
n será
aproximadamente
N(μ0, σ2/n)
La en
media
denotada
por
, semuestras
define como
suma
de de
cada
uno de no
losresultará
α)muestral
si
estadístico
significativo
(P >Para
si H0 es cierta o, en caso contrario, N(μ1, σ2/n) si H1 esLa
cierta.
Laaritmética,
distribución
muestralpor
de x ,bajo
media
denotada
se define como la
tamaño muestral n.
α) si elpor
estadístico
significativo
>alternativa
valores
muestrales
número deen
observaciones
Si denotamos
las
hipótesis
nula(Pydividida
seelrepresenta
la Figura 5.5.realizadas.
Para un nivel
de significación α,
x − μ(P
0 valores
el contraste de hipótesis no resultará-zsignificativo
si elmuestrales
estadísticodividida por el número de observacio
<> zα)
1-α/2 <
1-variable
α/2
Supongamos, para simplificar la exposición,
que
una
aleatoria tiene media
σ
por n el tamaño muestral y por xi el valor observado
para el sujeto i-ésimo, i = 1, ..., n,
x − μn0
<por
z1−αn/2el tamaño muestral y por xi el valor observado para
− z12− α /2 <
μ y varianza
contrastar la hipótesis nula H0:
desconocida
la
media vendría
dada por conocida σ , y queσse pretende
n
la media vendría dada por
de forma equivalente, si
μ =deo,μforma
0 frente a la hipótesis alternativa H1: μ = μ1, donde μ1 ≠ μ0. Por el teorema central
o,
equivalente, si
x + x 2 + ... + x n
1 n
o, de forma equivalente, six = x i = 1
.
n
del límite, se sabe que la distribución
μ 0 − z1n− αi/2=1σmuestral
/ n < xde< nμx 0 en
+ zmuestras
; tamaño n seráx = 1 x = x1 + x 2 + ... +
1−α /2 σ / nde
i
n i =1
n
μ0 - z1-α/2σ/ n < x < μ0 + z1-α/2σ/ n ;
Distribuci
ón de x bajo
Distribuci
ónyde
bajo
La
media la
eshipotes
la medida
central
más
utilizada
dex más
1
0
es decir,
nuladesetendencia
aceptará
enHtodas
aquellas
muestras
conHfácil
una
media x 25
La
media
es
la
medida
de tendencia central más utiliz
2
2
N(μ1, σ /n)
N(μ0, σ /n)
es decir, la hipotes
nula se
aceptará
en
todas
aquellas
muestras
con
una
mediaSux
interpretación.
Corresponde
al
“centro
de
gravedad”
de
los
datos
de
la
muestra.
comprendida en la región μ0 ± z1-α/2σ/ n , que se denomina comúnmente como región
interpretación. Corresponde al “centro de gravedad” de l
principal
limitación
que está
por
los valorescomúnmente
extremos y, como
en esteregión
μ0 muy
± z1-αinfluenciada
σ
/
n
,
que
se
denomina
comprendida
en laesregión
de aceptación. Así, la probabilidad/2 de un error de tipo I α está determinada por el área
principal limitación es que está muy influenciada por los
caso,
puede
no
ser
un
fiel
reflejo
de
la
tendencia
central
la está
distribución.
determinada por el área
de
aceptación.
Así,Hla probabilidad
de un error de tipodeI α
bajo
la curva para
0 situada fuera de la región de aceptación (área en gris oscuro de la
caso, puede no ser un fiel reflejo de la tendencia central
de laderegión
(árealaencurva
gris oscuro
la
bajo
la curva
H0 situada fuera
β aceptación
por
el área
bajo
para H1de
Figura
5.5),1.4
ypara
laEn
probabilidad
error
tipo
IIde
Ejemplo
este y en losdesucesivos
ejemplos
sobre
estimadores
muestrales,
se
Ejemplo 1.4 En este y en los sucesivos ejemplos so
β por
áreade
bajo Figura
la curva5.5).
para H1
Figura
5.5),
y ladeprobabilidad
de
error de tipo
IIen
situada
dentro
la región
aceptación
(área
grisel
claro
utilizarán
los valores
del de
colesterol
HDL
obtenidos
en
los 10laprimeros
sujetos del
utilizarán los valores del colesterol HDL obtenidos
β en gris claro
situada dentro de la región de aceptación (área
de la Figura 5.5).
estudio “European Study on Antioxidants,
Myocardial
Infarction and Cancer
of
α
/2
α/2
[Figura 5.5 aproximadamente
aquí]
estudio “European Study on Antioxidants, Myocar
the Breast“ (EURAMIC),[Figura
un
estudio
multicéntrico
de
y controles realizado
μ1
μaquí]
5.5 aproximadamentecasos
0
the Breast“ (EURAMIC), un estudio multicéntrico
El balance
de un error
de tipo
I yevaluar
tipo II el
puede
observarse
entre
1991 yentre
1992las
enprobabilidades
ocho países
Europeos
e
Israel
para
efecto
los en
μ0 − z1−α / 2σ / n
μ0 + z1−αde
/ 2σ / n
entre 1991IIypuede
1992 observarse
en ocho países
Europeos e Israe
El balance
probabilidades
de undeerror
(esto es, se aumenta
la en
la Figura
5.5. entre
Si se las
reduce
la probabilidad
errordedetipo
tipoI Iyαtipo
5
Región de aceptación de H0
α
(esto
es,
se
aumenta
la
la
Figura
5.5.
Si
se
reduce
la
probabilidad
de
error
de
tipo
I
región de aceptación), aumenta la probabilidad de error de tipo II β, mientras que si α
Figura 5.5 Errores de tipo I y II para el contraste bilateral de la hipótesis nula H0: μ = μ0 frenteFigura
la5.5hipóque sia α
región
de aceptación),
la probabilidad
de error
de tipo
II β,αmientras
tesisaumenta,
alternativadisminuye
H1: μ = μ1 en
una
con
varianza conocida.
β.aumenta
En distribución
la práctica,
la estrategia
habitual
es fijar
en el nivel
74
β. En la práctica,
habitual esβ fijar
en el nivel
aumenta, disminuye
α = 0,05)laeestrategia
intentar minimizar
o, deαforma
equivalente,
(típicamente
predeterminado
Pastor-Barriuso
R.
α =contraste.
0,05) e intentar
β o, dedeforma
equivalente,
predeterminado
(típicamente
Para α minimizar
fijo, la potencia
1 - β depende
de la
maximizar la potencia
1 - β del
TENDENCIA CENTRAL
μ0 -de
z1-cuál
< x <más
μ0 +
z1-αvariable.
α/2σ/es n
/2σ/ n ;
dencia central informan acerca
el valor
representativo
Contraste de hipótesis
1.2.1 Media aritmética
variable o, dicho de forma equivalente, estos estimadores indican
es decir, la hipotes nula se aceptará en todas aquellas muestras con una media x
es decir,
la hipotesis nula
se aceptará
todas
muestras con
una media
se define como la suma de
Laaquellas
media aritmética,
denotada
por x ,comprendida
or se agrupan los
datos observados.
Las medidas
de en
tendencia
comprendida en la región
región μ0 ± z1 α/2σ/ n , que se denomina comúnmente como región de aceptación. Así, la
valores muestrales
dividida
el número
observaciones realiz
probabilidad
deresultados
un error de
tipo I α está
determinada
por el área
bajo lapor
curva
para H0 de
situada
a sirven tanto para resumir los
observados
como
para
región de aceptación
(área
grisI oscuro
la Figura 5.5),
probabilidad de error
α está de
determinada
poryellaárea
de aceptación.fuera
Así, de
la la
probabilidad
de un error
deen
tipo
por
n
el
tamaño
muestral
y
por
xi el valor observado
(área en para el sujeto
de tipo II poblacionales
β por el área bajo
la curva para HA1 situada dentro de la región de aceptación
acerca de los parámetros
correspondientes.
gris claro de la Figura 5.5).
(área en gris oscuro de la
bajo la curva para H0 situada fuera de la región de aceptación
la media vendría dada por
criben los principales
estimadores
tendencia central
El balance
entredelasla probabilidades
de de
ununa
error de tipo I y tipo II puede observarse en la
5.5. Si se de
reduce
deelerror
tipolaI curva
α (estopara
es, se
la región de
áreade
bajo
H1aumenta
Figura 5.5), y Figura
la probabilidad
errorladeprobabilidad
tipo II β por
n
x + xβ.
1 disminuye
aceptación), aumenta la probabilidad de error de tipo II β; mientras que si α aumenta,
2 + ... + x n
.
x = xi = 1
la estrategia
habitual
es fijar
en undenivel
predeterminado
(típicamente
α = 0,05)n
n i =1
situada dentroEn
delalapráctica,
región de
aceptación
(área en
gris αclaro
la Figura
5.5).
e intentar minimizar β o, de forma equivalente, maximizar la potencia 1 – β del contraste. Para
tica
α fijo, la potencia 1 – β depende de la superposición de las distribuciones nula y alternativa de
media
es la medida de tendencia central más utilizada y de
está a como
su[Figura
vezladeterminada
poruno
losde
siguientes
factores:
, denotada por x ,, que
se define
suma
cada
los La
5.5 de
aproximadamente
aquí]
yy La diferencia subyacente μ1 – μ0. La potencia
para detectar
una hipótesis
alternativa
cierta de los datos
interpretación.
Corresponde
al “centro
de gravedad”
ividida por el número de observaciones realizadas.
Si denotamos
será tanto mayor cuanto mayor sea la diferencia entre el verdadero valor del parámetro μ1 y
El balance entreellas
probabilidades
de un error
de tipo
tipo II5.6(a),
puededonde
observarse
en un incremento
valor
nulo μ0. Esta situación
se ilustra
enIlayFigura
se observa
estral y por xi el valor observado para
el sujeto i-ésimo, i = 1,principal
..., n, limitación es que está muy influenciada por los valores
de la potencia como consecuencia de una mayor diferencia entre μ1 y μ0.
(estono
es,ser
se un
aumenta
la de la tendencia central de la dist
la por
Figura 5.5. Si se reduce la probabilidad de error de tipo
I αpuede
caso,
fiel reflejo
da
~ N ( μ , σ 2 / n)
H0 : x →
0
~ N ( μ , σ 2 / n)
H1 : x →
1
región de aceptación),
aumenta la probabilidad de error de tipo II β, mientras que si α
n
x + x 2 + ... + x n
Ejemplo 1.4 En este y en los sucesivos ejemplos sobre estim
1
.
xi = 1
n i =1
β. En lan práctica, la estrategia habitual esutilizarán
fijar α en
nivel del colesterol HDL obtenidos en los 1
aumenta, disminuye
loselvalores
x=
edida
de tendencia(típicamente
central más utilizada
más fácil
α = 0,05)y edeintentar
minimizar βestudio
o, de forma
equivalente,
predeterminado
“European
Study on Antioxidants, Myocardial Infar
esponde
al “centro
de gravedad”
los datos Para
de la α
muestra.
the Breast“
(EURAMIC),
fijo, laSu
potencia
de 1 - β
depende de un
la estudio multicéntrico de casos
maximizar
la potencia
1 - β deldecontraste.
α/2 β
α/2
es que está muy influenciada por los valores extremos y, en este entre 1991 y 1992 en ocho países Europeos e Israel para ev
μ0 − z
σ/ n
μ0 + z
σ/ n
μ
μ
1−α / 2
1
n fiel reflejo de la tendencia central de la distribución.
1−α / 2
0
(a)
~ N ( μ , σ 2 / n)
H1 : x →
1
26
~ N ( μ , σ 2 / n)
H0 : x →
0
n este y en los sucesivos ejemplos sobre estimadores muestrales, se
valores del colesterol HDL obtenidos en los 10 primeros sujetos del
pean Study on Antioxidants, Myocardial Infarction and Cancer of
URAMIC), un estudio multicéntrico de casos y controles realizado
992 en ocho países Europeos e Israel para evaluar el efecto de los
α/2
β
μ1 μ0 − z1−α / 2σ / n5
α/2
μ0
μ0 + z1−α / 2σ / n
(b)
Figura 5.6 Errores de tipo I y II para una mayor diferencia μ0 – μ1 (a) y para un mayor
tamaño muestral n (b).
Figura 5.6
Pastor-Barriuso R.
75
S DE TENDENCIA CENTRAL
Inferencia estadística
superposición
las distribuciones
nula ymás
alternativa
de x , que está a su vez
e tendencia central
informan de
acerca
de cuál es el valor
representativo
por los
siguientes factores:
nada variable determinada
o, dicho de forma
equivalente,
estos estimadores indican
Tabla 5.2 Porcentaje de muestras de tamaño n = 10, 25 y 100 con
significativos
(P
≤tendencia
0,05) para
el contraste
bilateral de
• los
La diferencia
subyacente
para detectar
una hipótesis
ué valor se agrupan
datosresultados
observados.
Las μmedidas
depotencia
1 - μ0. La
las hipótesis nulas H0: μ = 1 y 1,05 mmol/l sobre la media poblacional
del
colesterol
HDLobservados
en los cuando
controles
del estudio
EURAMIC.
uestra sirven tanto para
resumircierta
los resultados
como
para
alternativa
será tanto
mayor
mayor
sea la diferencia
entre el
Hipótesis nula H0: μ = μ0
ncias acerca de los parámetros
correspondientes.
μ1 y el valorAnulo μ0. Esta situación se ilustra en la
verdadero poblacionales
valor del parámetro
Tamaño muestral (n)
μ0 = 1
μ0 = 1,05
10 tendencia central de una
5,0
e describen los principales
Figura estimadores
5.6(a), dondedesela
observa un incremento11,2
de la potencia como
consecuencia
25
100
de una mayor diferencia entre μ1 y μ0.
26,9
85,7
8,0
23,0
el el
error
estándar de la
σ / n . Al
Al aumentar
aumentareleltamaño
tamañomuestral
muestraln,n,disminuye
disminuye
error
media muestral y, en consecuencia, la variabilidad de las distribuciones nula y alternativa de
para
nivellamuestral
de
significación
α predeterminado,
la potencia
mética, denotada por estándar
x .,Así,
se define
como
suma
de y,
cada
uno
de los
de laun
media
en consecuencia,
la variabilidad
de del
las contraste aumenta
conforme aumenta el tamaño de la muestra (Figura 5.6(b)). Esta relación puede utilizarse
ales dividida por el número
de observaciones
realizadas.
denotamos
tanto para
calcular
potencia
de
vez determinado
el tamaño
muestral,
xSi
.contraste
Así,
parauna
un nivel
de significación
α
distribuciones
nula ylaalternativa
deun
como para estimar a priori el tamaño muestral necesario para una determinada potencia.
valorúltimo
observado
el sujeto
i-ésimo,
= 1, ...,enn,conforme
o muestral y por xi elpredeterminado,
Este
puntolapara
se
discutirá
mayoridetalle
el Tema 9 aumenta
de determinación
potencia
delcon
contraste
aumenta
el tamañodel tamaño
muestral.
ía dada por
de la muestra (Figura 5.6(b)). Esta relación puede utilizarse tanto para calcular la
Ejemplo 5.16 A partir de los controles del EURAMIC se obtienen 1000 muestras
n
potencia
un
contraste
vez25determinado
tamaño
para el contraste
+ ... + x nn una
xde+de
x 2 tamaño
1 aleatorias
= 10,
y 100 y, enelcada
unamuestral,
de ellas, como
se realiza
.
x = xi = 1
de lasn hipótesis nulas H0: μ = 1 y 1,05 mmol/l para la media poblacional del
n i =bilateral
1
estimar
a
priori
el Para
tamaño
muestral
paraeluna
determinada
potencia.
colesterol HDL.
cada
muestranecesario
y contraste,
valor
P se calcula
según Este
los métodos
del Apartado 5.4.2 y la hipótesis nula se rechaza si P ≤ 0,05. En la Tabla 5.2 se presenta
último
puntomás
se discutirá
con
detalle en significativos
el Tema 9 de determinación
del tamaños
la medida de tendencia
central
utilizada
y demayor
más resultados
fácil
el porcentaje
de
muestras
con
para los distintos
muestrales e hipótesis nulas.
tamaño
muestral. de los datos de la muestra. Su
Corresponde al “centro
de gravedad”
En este caso, ambas hipótesis nulas son falsas dado que la verdadera media del colesterol
en los controles
del estudio
EURAMIC
es 1,09 mmol/l. Así, los porcentajes de la
ación es que está muyHDL
influenciada
por los valores
extremos
y, en este
Tabla 5.2 representan [Figura
valores empíricos
de la potenciaaquí]
de cada contraste. Para una desviación
5.6 aproximadamente
=
1,09
–
1
=
0,09
mmol/l
entre
el
verdadero nivel medio de colesterol
subyacente
de
μ
–
μ
ser un fiel reflejo de la tendencia central0 de la distribución.
HDL y el valor nulo, la potencia resultó ser del 11,2% para n = 10, 26,9% para n = 25 y
85,7% para n = 100. Para una desviación de μ – μ0 = 1,09 – 1,05 = 0,04 mmol/l, la potencia
Ejemplo
A 5,0%
partir
de los
controles
del
EURAMIC
obtienen
muestras
1.4 En este y en los sucesivos
ejemplos
sobre
estimadores
muestrales,
se yse
se redujo5.16
a un
para
n=
10, 8,0%
para
n = 25
23,0%
para1000
n = 100.
Como puede
apreciarse, sólo se alcanza una potencia aceptable para detectar una diferencia de 0,09
aleatorias
de obtenidos
tamaño
n en
= muestral
10,
100100,
y, enmientras
cada una
desería
ellas,necesaria
se realizauna
el muestra mayor
n los valores del colesterol
HDL
los25
10yprimeros
sujetos
del
mmol/l
con
un tamaño
de
que
para poder detectar una diferencia de 0,04 mmol/l.
y 1,05 mmol/l para la media
contraste
bilateral
de las hipótesis
nulas
0: μ = 1of
European Study on Antioxidants,
Myocardial
Infarction
andHCancer
Elerror
error estándar
estándar
• yyEl
ritmética
5.5 REFERENCIAS
del colesterol
HDL.yPara
cada muestra
st“ (EURAMIC), unpoblacional
estudio multicéntrico
de casos
controles
realizadoy contraste, el valor P se
1. Bickel PJ, Doksum KA. Mathematical Statistics: Basic Ideas and Selected Topics.
calcula
según los
métodos
Apartado
5.4.2de
y la
91 y 1992 en ocho países
Europeos
e Israel
paradel
evaluar
efecto
loshipótesis nula se rechaza si P ≤
Englewood
Cliffs,
NJ: Prentice
Hall,el1977.
76
2.
Casella G, Berger RL. Statistical Inference, Second Edition. Belmont, CA: Brooks/Cole,
5
2001.
3.
Colton T. Estadística en Medicina. Barcelona: Salvat, 1979.
Pastor-Barriuso R.
27
Referencias
4.
Lehmann EL. Testing Statistical Hypotheses, Second Edition. New York: Springer Verlag,
1997.
5.
Lehmann EL, Casella G. Theory of Point Estimation, Second Edition. New York: Springer
Verlag, 1998.
6.
Rosner B. Fundamentals of Biostatistics, Fifth Edition. Belmont, CA: Duxbury Press, 1999.
7.
Rothman KJ, Greenland S, Lash TL. Modern Epidemiology, Third Edition. Philadelphia:
Lippincott Williams & Wilkins, 2008.
8.
Snedecor GW, Cochran WG. Statistical Methods, Eighth Edition. Ames, IA: Iowa State
University Press, 1989.
9.
Stuart A, Ord JK, Arnold S. Kendall’s Advanced Theory of Statistics, Volume 2A, Classical
Inference and the Linear Model, Sixth Edition. London: Edward Arnold, 1999.
Pastor-Barriuso R.
77
TEMA 6
INFERENCIA SOBRE MEDIAS
6.1
INTRODUCCIÓN
En el presente tema se revisan las técnicas básicas de inferencia a partir de datos de carácter
cuantitativo. En la mayor parte de las ocasiones, la inferencia sobre variables cuantitativas se
centra en el estudio de parámetros subyacentes tales como la media y la varianza poblacional.
A partir de los datos obtenidos en muestras aleatorias y utilizando los principios de inferencia
descritos en el tema anterior, se pretende dar respuesta a los siguientes tipos de problemas:
yy La estimación de la media y la varianza de una población.
Ejemplo 6.1 Supongamos que los controles del estudio EURAMIC constituyen una
muestra representativa de la población de referencia del estudio. A partir de los valores de
colesterol HDL obtenidos en los controles, ¿cuál es la estimación y el intervalo de
confianza al 95% para la media y la varianza del colesterol HDL en la población de
referencia? ¿Son estos datos muestrales compatibles con una verdadera media poblacional
de 1 mmol/l?
yy La comparación de medias y varianzas poblacionales a partir de dos muestras
independientes.
Ejemplo 6.2 En el estudio EURAMIC se comparan dos muestras independientes: una
muestra de casos de infarto de miocardio, recogida de las unidades de cuidados intensivos,
y una muestra independiente de controles, representativos de la población de la que
proceden los casos. ¿Cuál es entonces la estimación y el intervalo de confianza al 95%
para la diferencia en los niveles medios de colesterol HDL entre los casos de infarto y los
sujetos libres de la enfermedad? ¿Es esta diferencia estadísticamente significativa?
En un ensayo clínico para evaluar la eficacia antihipertensiva de un nuevo medicamento,
se asignaron aleatoriamente 100 pacientes hipertensos a uno de los dos grupos de
tratamiento: un grupo que toma la medicación a estudio y otro que toma un placebo.
Después de 4 semanas de tratamiento, se compararon las medias de presión arterial
sistólica entre ambos grupos como medida de la eficacia de dicho medicamento. ¿Cuál es
la estimación puntual y el intervalo de confianza al 95% para la reducción en el nivel
medio de presión arterial sistólica? ¿Cómo se determina si esta reducción es efecto del
tratamiento o se debe a simple variabilidad aleatoria?
yy La comparación de medias poblacionales a partir de dos muestras dependientes.
Ejemplo 6.3 En un estudio de casos y controles sobre el efecto del colesterol HDL en
el riesgo de desarrollar infarto de miocardio, cada caso se emparejó por grupo de edad y
sexo a un control libre de la enfermedad. En este caso, las medias de colesterol HDL de
los casos y de los controles no pueden analizarse como medidas procedentes de muestras
independientes, ya que es esperable un cierto grado de correlación entre los valores de
Pastor-Barriuso R.
79
Inferencia sobre medias
colesterol HDL en cada pareja caso-control. ¿Cómo contrastar entonces si existe una
asociación significativa entre el nivel de colesterol HDL y la ocurrencia de un infarto de
miocardio?
Para evaluar la eficacia de un fármaco antihipertensivo, se seleccionaron 50 pacientes
hipertensos y se administró a todos ellos dicho fármaco durante 4 semanas. La presión
arterial sistólica de cada paciente se determinó tanto al comienzo del estudio como
después de las 4 semanas de tratamiento. En tal caso, los valores medios de presión arterial
antes y después del tratamiento no son independientes, ya que los datos recogidos en un
mismo paciente están correlacionados. En estas circunstancias, ¿cómo estimar la reducción
media de presión arterial sistólica al administrar dicho tratamiento?
1.2 MEDIDAS DE TENDENCIA CENTRAL
Para cada uno de estos problemas, se facilitan las técnicas de inferencia apropiadas para
Las medidas
de tendencia
central objeto
informan
acerca deasícuál es el valor
obtener estimaciones puntuales y por intervalo
del parámetro
poblacional
de estudio,
como para el contraste de hipótesis preestablecidas. Estos procedimientos van a permitir inferir
de una determinada
variable
o, dicho de forma equivalente, estos estim
los resultados del estudio al ámbito poblacional
de forma clara
y sucinta.
alrededor de qué valor se agrupan los datos observados. Las medidas
6.2 INFERENCIA SOBRE UNA MEDIA Y VARIANZA POBLACIONAL
central de la muestra sirven tanto para resumir los resultados observad
La media y la varianza poblacional son parámetros que representan la tendencia central y
dispersión de la distribución subyacente
de una
variableacerca
aleatoria.
parámetros
son
realizar
inferencias
de losEstos
parámetros
poblacionales
correspon
típicamente desconocidos y, en consecuencia, han de ser estimados a partir de los valores
observados de dicha variable en una muestra.
En esta
sección, selospresentan
losestimadores
métodos dede la tendencia
continuación
se describen
principales
estimación y contraste para la media y la varianza de una distribución poblacional.
variable.
6.2.1
Inferencia sobre la media de una población
1.2.1 Media aritmética
La estimación e inferencia de una media poblacional µ se discutió en el tema anterior. Para
Utilizando
lasaleatoria,
propiedades
distribución
muestral
de
la muestral
media,
obtener
La media aritmética,
denotada
poresxposible
,es
se un
define
como la suma de cada
estimador
cualquier
variable
se de
ha lacomprobado
que
la media
insesgado y consistente de µ y que, en el caso de distribuciones normales, es el estimador con
un intervalo
de confianza
100(1 - αvalores
)% para
la media
poblacional
menor
error estándar.
Estas alcaracterísticas
hacen
de la media
muestral
un buendeestimador
muestrales
dividida
porμelcomo
número
observaciones realizada
Utilizando las propiedades de la distribución muestral de la media, es posible obtener
puntual de la media poblacional.
por n el tamaño
y por xiesel posible
valor observado
para el sujeto i-és
s muestral
Utilizando
la distribución
muestral
de la media,
obtener un
la
media
μ como
un
intervalolas
de propiedades
confianza al de
100(1
- xα)%
± t npara
. poblacional
−1,1−α / 2
intervalo de confianza al 100(1 – α)% para la media poblacional
µ como
n
la media vendría dada por
s
x ± t n −1,1−α / 2
.
alternativa
A su vez, el contraste de la hipótesis nula H0: μ = μ
n 0 frente a la hipótesis
x + x 2 + ... + x n
1 n
.
x = xi = 1
n
n
A su
vez,
el
contraste
de
la
hipótesis
nula
H
:
μ
=
μ
frente
a
la
hipótesis
alternativa
bilateral
H
:
=
i
1
0
1
bilateral H1: μ ≠ μ0 puede realizarse mediante
el0 estadístico
realizarse
el estadístico
μ ≠Aμ0supuede
vez, el
contrastemediante
de la hipótesis
nula H0: μ = μ0 frente a la hipótesis alternativa
80
Laxmedia
es la medida de tendencia central más utilizada y de más
− μel0 estadístico
bilateral H1: μ ≠ μ0 puede realizarse mediante
t=
.
s
interpretación.
Corresponde al “centro de gravedad” de los datos de la
n
x − μ0
t = aproximadamente
.
Bajo la hipótesis nula, este estadístico seguirá
una distribución t de Student
principal
s limitación es que está muy influenciada por los valores extre
Bajo
la
hipótesis
nula,
este
estadístico
seguirá
aproximadamente
una puede
distribución
t de como
con n – 1 grados de libertad y, en consecuencia, elnvalor P del contraste
calcularse
el área bajo la curva de esta distribucióncaso,
para aquellos
tanto
o másdedistantes
de 0 que
el de la distribu
puede novalores
ser un fiel
reflejo
la tendencia
central
Student
con
n
1
grados
de
libertad
y,
en
consecuencia,
el
valor
P
del
contraste
puede
valor observado de t. En general, el planteamiento de una determinada hipótesis nula puede
Bajo lade
hipótesis
nula,
este estadístico
seguirá
aproximadamente
unacomportamiento
distribución t dede las
proceder
estudios
previos
o de hipótesis
biológicas
respecto al
calcularse como el área bajo la curva de esta
distribución
tanto
o
Ejemplo
1.4 Enpara
esteaquellos
y en losvalores
sucesivos
ejemplos
sobre estimado
Student
con
n
1
grados
de
libertad
y,
en
consecuencia,
el
valor
P
del
contraste
puede
Pastor-Barriuso R.
más distantes de 0 que el valor observado de
t. En general,
el planteamiento
deHDL
una obtenidos en los 10 pr
utilizarán
los valores
del colesterol
calcularse como el área bajo la curva de esta distribución para aquellos valores tanto o
determinada hipótesis nula puede proceder estudio
de estudios
anteriores
o de
“European
Study
onhipótesis
Antioxidants, Myocardial Infarctio
n
539
media poblacional los contrastes
de
hipótesis
pueden
resultar
un tanto artificiales.
realizar inferencias acerca de los parámetros
poblacionales correspondientes. A
Inferencia sobre una media y varianza poblacional
cuya distribución bajo la hipótesis nula será t538 o, de forma equivalente, normal
continuación se describen los principales estimadores de la tendencia central de un
Ejemplo 6.4 Entre los n = 539 controles del estudio EURAMIC con
estandarizada. De la Tabla 3 del Apéndice se desprende que la probabilidad de
variables, aunque en el casovariable.
de una única media poblacional los contrastes de hipótesis pueden
determinaciones
del colesterol HDL, la media y desviación típica fueron x = 1,09
resultar
un
tanto
artificiales.
obtener valores superiores a 7,21 en una distribución normal estandarizada es
1.2.1 Media aritmética
y s = 0,29 mmol/l. Así, el IC al 95% para la media de colesterol HDL en la
Ejemplo
6.4 Entre
539elcontroles
del estudio
con determinaciones
virtualmente
nula, los
pornlo=que
valor P bilateral
seráEURAMIC
inferior a 0,001.
En
mediay aritmética,
por x ,=se1,09
define
como
suma de
cada uno de los
ys=
0,29lammol/l.
Así,
del colesterol HDL, laLamedia
desviacióndenotada
típica fueron
población de referencia resultó ser
el IC
al 95% para
la media
población
de difiere
referencia resultó ser
conclusión,
el nivel
mediodedecolesterol
colesterolHDL
HDLenenlaesta
población
valores muestrales dividida por el número de observaciones realizadas. Si denotam
0,29 (P < 0,001). De hecho, la media poblacional de
significativamente
1 mmol/l
1,09 ± t 538de
= 1,09 ± 1,96⋅0,012 = (1,07; 1,11).
; 0 , 975
por n el 539
tamaño muestral y por xi el valor observado para el sujeto i-ésimo, i = 1, ..
colesterol HDL se estimó en 1,09 mmol/l, con un intervalo de confianza al 95%
Estos datos muestrales
también
se emplearon
la media
vendría
dada porpara el contraste bilateral de la hipótesis
Estos
también
se mmol/l.
emplearon
paradel
el contraste bilateral de la
nula
Hdatos
1. Para
ello,
seycalculó
el estadístico
0: μ =muestrales
comprendido
entre
1,07
1,11
n
x1 + x 2 + ... + x n
x − μ0
1,09 − 1 x = 1
hipótesis nula H0: μ = 1. Para
contraste
.
xdel
= 7,21,
t = ello, se=calculó el estadístico
i =
n i =1
n
0,29
s
6.2.2 Inferencia sobre la varianza de
n una población
539
distribución
la media
hipótesis
ttendencia
o, dedecentral
forma
equivalente,
normal
La
es lanula
medida
dela
más
utilizada
En cuya
ocasiones,
el interésbajo
se centra
en estimar
noserá
sólo
una variable
aleatoria
538media
4y de más fácil
cuya distribución
la hipótesis
nula seráset538desprende
o, de forma
normal
estandarizada.
De bajo
la Tabla
3 del Apéndice
queequivalente,
la probabilidad
de obtener
valoressino
superiores
7,21
en unapoblacional.
distribución
normal
estandarizada
virtualmente
interpretación.
Corresponde
al se
“centro
deen
gravedad”
de los
de la muestra. Su
continua,
tambiéna su
varianza
Como
mostró
el es
Apartado
5.2datos
delnula,
estandarizada.
De
la
Tabla
3
del
Apéndice
se
desprende
que
la
probabilidad
de
por lo que el valor P bilateral será inferior a 0,001. En conclusión, el nivel medio de
principal
limitación
es que estáinsesgado
muy influenciada
por
valoresDe
extremos y, en es
tema
anterior,HDL
la varianza
muestral
s2difiere
es un estimador
de
la
colesterol
en esta
población
significativamente
dey 1consistente
mmol/l
(Plos
< 0,001).
obtener
valores
superiores
a
7,21
en
una
distribución
normal
estandarizada
es
hecho, la media poblacional de colesterol HDL se estimó en 1,09 mmol/l, con un intervalo
caso,
puede novariable
ser un
fiel
de la tendencia
de la distribución.
varianza
poblacional
σ 2comprendido
de cualquier
aleatoria,
siendo
además elcentral
estimador
de confianza
al 95%
entre
1,07
y reflejo
1,11 mmol/l.
virtualmente nula, por lo que el valor P bilateral será inferior a 0,001. En
insesgado con menor error estándar para distribuciones normales.
6.2.2 conclusión,
Inferenciaelsobre
varianza
de una
Ejemplo
1.4 población
En
esteenyesta
en los
sucesivos
ejemplos sobre estimadores muestral
nivellamedio
de colesterol
HDL
población
difiere
Al igual que ocurría en el caso de una media, los intervalos de confianza y las
En ocasiones,
el interés sedecentra
en estimar
no valores
sóloDe
la media
de
variable
aleatoria
continua,
utilizarán
los
del colesterol
HDL
obtenidos
los 10 primeros sujeto
significativamente
1 mmol/l
(P < 0,001).
hecho,
la una
media
poblacional
deen
sino también su varianza poblacional. Como se mostró en
2 el Apartado 5.2 del tema anterior, la
pruebas de hipótesis
sobre la varianza poblacional σ se basan en la distribución
varianza
muestral
s2 esseun
estimador
insesgado
ycon
consistente
de la
poblacional
σ 2 de
estudio
“European
Study
on Antioxidants,
Myocardial
and Cance
colesterol
HDL
estimó
en
1,09
mmol/l,
un intervalo
devarianza
confianza
al 95% Infarction
cualquier variable
aleatoria,
siendo
además
el
estimador
insesgado
con
menor
error
estándar
muestral de s2. Si la distribución subyacente de la variable es normal, puede probarse
para distribuciones
the Breast“
comprendido normales.
entre 1,07 y 1,11
mmol/l.(EURAMIC), un estudio multicéntrico de casos y controles reali
2 de
Al igual
que ocurría(nen– el1)s
caso
una media,
los intervalos
de confianza
y las pruebas de
hipótesis
que
el estadístico
/σ 2 sigue
una distribución
denominada
chi-cuadrado
con
n1991en
y 1992
en ocho países
Europeos
para evaluar el efecto de
sobre la varianza poblacional σ 2 entre
se basan
la distribución
muestral
de s2. eSiIsrael
la distribución
2 población
subyacente
de
variable
es normal,
probarse que el estadístico (n – 1)s2/σ2 sigue una
6.2.2
Inferencia
sobre
varianza
depuede
1 grados
de la
libertad
yladenotada
por
χuna
n −1 ,
distribución denominada chi-cuadrado con n – 1 grados de libertad y denotada por χ2n–1,
En ocasiones, el interés se centra en estimar no sólo la media de una variable aleatoria
(n − 1) s 2 χ 2
~ n −1 .
continua, sino también su varianza poblacional.
Como
se mostró en el Apartado 5.2 del
σ2
Como
puede
en la Figura
6.1,
la distribución
chi-cuadrado
sólo
valores
tema
anterior,
la apreciarse
varianza muestral
s2 es un
estimador
insesgado
y consistente
de toma
la
positivos y está sesgada a la derecha. Los grados de libertad de una distribución chi-cuadrado
determinan
su tendencia
central,
dispersión
asimetría:siendo
al aumentar
grados de libertad,
varianza poblacional
σ 2 de
cualquier
variableyaleatoria,
además los
el estimador
5 6
aumenta la media y la varianza de la distribución y disminuye su sesgo a la derecha. En la Tabla
del Apéndice se presentan los percentiles de la distribución chi-cuadrado para distintos grados
insesgado con menor error estándar para distribuciones normales.
de libertad.
Al igual que ocurría en el caso de una media, los intervalos de confianza y las
pruebas de hipótesis sobre la varianza poblacional σ 2 se basan en la distribución
muestral de s2. Si la distribución subyacente de la variable es normal, puede probarse
Pastor-Barriuso R.
que el estadístico (n – 1)s2/σ 2 sigue una distribución denominada chi-cuadrado con n -
81
Inferencia
sobre medias
Como
puede
apreciarse en la Figura 6.1, la distribución chi-cuadrado sólo toma
Como puede apreciarse en la Figura 6.1, la distribución chi-cuadrado sólo toma
valores positivos y está sesgada a la derecha. Los grados de libertad de una distribución
valores
y está sesgada
la derecha.
grados dechi-cuadrado
libertad de una
Comopositivos
puede
apreciarse
en la aFigura
6.1, laLos
distribución
sólodistribución
toma
0,6 determinan su tendencia central, dispersión y asimetría: al
chi-cuadrado
χ 21aumentar los
χ2
2
chi-cuadrado
determinan
su tendencia
central,Los
dispersión
y asimetría:
aluna
aumentar
los
valores
positivos
está sesgada
a la derecha.
grados
de
libertad de
distribución
2
grados de
libertad,y aumenta
la media
y la varianza
de la distribución
yχdisminuye
su
3
0,5
χ2
5
grados
de libertad,
aumenta
media ycentral,
la varianza de la distribución
yaldisminuye
su
chi-cuadrado
determinan
su la
tendencia
y asimetría:
aumentar
sesgo a la derecha.
En la Tabla
6 del Apéndicedispersión
se presentan
los percentiles
de la los
0,4
sesgo
ade
la libertad,
derecha. aumenta
En la Tabla
6 del Apéndice
se presentan
los percentiles
de la su
grados
la media
y lagrados
varianza
de la distribución
y disminuye
distribución
chi-cuadrado para
distintos
de libertad.
f(x)a la 0,3
distribución
chi-cuadrado
para distintos
grados se
de presentan
libertad. los percentiles de la
sesgo
derecha.
En la Tabla
6 del Apéndice
[Figura 6.1 aproximadamente aquí]
distribución
chi-cuadrado
para
distintos grados de libertad.
0,2
[Figura 6.1 aproximadamente aquí]
A partir de la distribución χ n2−1 del estadístico (n – 1)s2/σ 2 resulta sencillo calcular
[Figura 6.1 aproximadamente aquí]
0,1
A partir de la distribución χ n2−1 del estadístico (n – 1)s2/σ 2 resulta sencillo calcular
un intervalo de confianza para la varianza poblacional. El 100(1 - α)% de la
2
2
partir 0dedelaconfianza
distribución
del estadístico
(n – 1)s
/σ 2 resulta
de la calcular
un A
intervalo
paraχlan −1varianza
poblacional.
El 100(1
- α)%sencillo
distribución muestral de este estadístico está comprendido entre los percentiles α/2 y 1 -
0
2
4
6
8
10
12
de la α/2
un intervalo muestral
de confianza
paraestadístico
la varianza
poblacional.
El 100(1
- α)%
distribución
de este
está
comprendido
entre los
percentiles
y12
α/2 de la distribución chi-cuadrado con n - 1 grados
x de libertad, denotados por χ n −1,α / 2
2 Figura 6.1
distribución muestral de este estadístico está comprendido entre los percentiles α/2
y1y χ n −1,1−α / 2 ,
1.2 MEDIDAS DE TENDENCIA CENTRAL
/2 2de la distribución
chi-cuadrado
con n - 1 grados 2de2 libertad, denotados por χ n2−1,α / 2
2
,
yα
Aχ
partir
de
la
distribución
χ
del
estadístico
(n – 1)s /σ resulta sencillo calcular un intervalo
n −1,1−α / 2
n–1
2
Las medidas
de
tendencia
central
acerca
de cuáldeeseste
el valor más repre
de confianza para la varianza
– α)%
distribución
muestral
de lainforman
poblacional.
(n − 1El
) s 100(1
2
2
2
.
P
χ
χ
=
1
−
α
<
<
y
χ
,
−
α
−
−
α
n
1
,
/
2
n
1
,
1
/
2
estadístico
y 1 – α/2 de la distribución chi-cuadrado
entre los percentiles
n −1,1−αestá
/ 2 comprendido
σ12)2s 2 α/2
o,, dicho de forma equivalente, estos estimadores i
denotados
(npor
−
variable
2de una determinada
2χ2
con n – 1 grados de libertad,
χ
y
P χ n −1,α / 2 <
< χ n −1,n–1,1–α/2
n–1,α/2
1−α / 2
2
=1−α .
σ 2
2alrededor
n
s
−
(
1
)
2 se agrupan
de
qué
valor
los datos observados. Las medidas de tenden
Manipulado esta desigualdad
para
despejar
la
varianza
poblacional,
P χ n −1, α / 2 <
< χ n −1,1−α / 2 = 1 − α . se obtiene que
2
σ
Manipulado esta desigualdad
para despejar
la varianza
se obtiene
que
central
de la muestra
sirvenpoblacional,
tanto para resumir
los resultados
observados como
2
2poblacional,
Manipulando esta desigualdad (para
despejar
la
varianza
se
obtiene
que
(n − 1) s
n − 1) s
< σ 2 <la varianza
=1−α ;
P para
2
2
Manipulado esta desigualdad
despejar
se obtiene
que
realizar
poblacional,
inferencias
acerca
los parámetros
poblacionales
correspondientes. A
2 de
χ
n
1
,
/
2
−
α
(
1
)
n
s
−
(χnn −−1,11−)αs/22
2
=1−α ;
P 2
<σ < 2
χ
χ
n
1
,
1
/
2
n
1
,
/
2
−
−
α
−
α
continuación
se
describen
los
estimadores de la tendencia central d
2
2
principales
−
−
(
1
)
(
1
)
n
s
n
s
2
2
para la varianza
=21σ− αviene
determinado por
es decir, el IC al 100(1 - α
< σ < poblacional
P)%
;
2 la varianza poblacional
2
es decir, el IC al 100(1 – α)%
para
σ viene determinado por
χ
χ
variable.
n −1,α / 2
n −1,1−α / 2
es decir, el IC al 100(1 - α)% para la varianza poblacional σ 2 viene determinado por
2 2
2
2
2
intervalos de confianza para
no/ χson
alrededor
[(n –σ1)s
/ χ n2−1,α de
/ 2 ],s , particularmente
n −1,1simétricos
−α / 2 , (n – 1)s
2
1.2.1
aritmética
para2Media
la varianza
poblacional
σ viene determinado por
es decir, el IC al 100(1 - α)%
2
/ χ n2de
(n – 1)s
/ χ n2−1,α / 2en
], la muestra. A diferencia de
[(n – a1)s
−1,1−los
α / 2 ,datos
cuyos
límites
pueden
calcularse
partir
observados
cuando el tamaño muestral es reducido.
cuyos
límites
pueden
calcularse
a
partir
de
los
datos
observados
muestra.
A confianza
media
aritmética,
por
,los
selaintervalos
define
como
la suma de cada uno de l
los intervalos de confianza paraLa
μ, que
están
centradosdenotada
alrededor
de x ,en
de
2
2
2
2
2
2α / 2 , (n – 1)s / χ n −1,α / 2 ],
/
χ
[(n
–
1)s
2
2
1
,
1
n
−
−
para
σDeno
sonforma,
simétricos
alrededor
de determinada
sde, particularmente
cuando
σtamaño
= σ 0 Amuestral
frente a es
igual
el calcularse
contraste
de
una
nulaenHla0el: muestra.
cuyos
límites
pueden
a partir
los datoshipótesis
observados
, que están
de x , losrealizadas. Si deno
diferencia de los intervalos de
confianza
para μdividida
valores
muestrales
porcentrados
el númeroalrededor
de observaciones
reducido.
α/2 6.1
de laFunción
distribución
chi-cuadrado
con n - 1chi-cuadrado
grados de libertad,
porlibertad.
χ n −1,α / 2
Figura
de densidad
de la distribución
con 1, 2, 3denotados
y 5 grados de
2
2 datos observados en2 la muestra.
cuyos
límites
pueden
calcularse
a 1partir
Ala xhipótesis
μ,hipótesis
que realizarse
estánnula
centrados
, los
diferencia
dealternativa
los
de una
confianza
para
σ02 el
frente
ade
Dehipótesis
igual
forma,
elintervalos
contraste
determinada
Hmediante
la
bilateral
H
: tamaño
σ 2 ≠de
σlos
estadístico
0 puede
0: σ =alrededor
por
n
el
muestral
y
por
x
el
valor
observado
para el sujeto i-ésimo, i =
i
2
2
alternativa bilateral H1: σ ≠ σ0 puede realizarse mediante el estadístico
están centrados alrededor de x , los
diferencia de los intervalos de confianza para μ, que
la media vendría
(n dada
− 1) s 2por
2
6
χ =
,
2
σ
82
0
x + x 2 + ... + x n 6
1 n
.
x = xi = 1
n i =1 de libertad. Así,
n el
que
bajo
H
sigue
una
distribución
chi-cuadrado
con
n
1
grados
Pastor-Barriuso R. 0
6
valor P del test se obtiene como
doblees
dellaárea
a la de
izquierda
de este
estadístico
bajo y de más fácil
Laelmedia
medida
tendencia
central
más utilizada
2
s2 > σ 02 . Eslaimportante
notar
subyacente dista mucho de ser
χ n2−1que,
, si ssi2 ≤la σdistribución
distribución
0 , o como el doble del área a la derecha del estadístico, si
menos fiables que para la media, en cuyo caso conviene proceder con cautela.
Comparación
de medias
en dos muestras independientes
normal, los 2intervalos
de confianza y los contrastes para la varianza
poblacional
son
s > σ 02 . Es importante notar que, si la distribución subyacente dista mucho de ser
6.5 Utilizando
desviación
menos fiables que para la media, en cuyoEjemplo
caso conviene
procederlacon
cautela. típica s = 0,29 mmol/l del colesterol HDL
normal, los intervalos de confianza y los contrastes para la varianza poblacional son
que bajo H0 sigue una distribución chi-cuadrado con n – 1 grados de libertad. Así, el valor P del
en los n = 539 controles del EURAMIC, el IC al 95% para la varianza poblacio
test se obtiene como el doble del área a la izquierda de este estadístico bajo la distribución χ2n–1,
menos
fiables
que paradesviación
la media, típica
en cuyo=caso
proceder
con cautela.
Ejemplo
0,29conviene
mmol/l
del
colesterol
2
si s2 6.5
≤ σ0Utilizando
, o como elladoble
del área a la sderecha
del estadístico,
si s2 >HDL
σ02 . Es importante notar
viene determinado por
que, si la distribución subyacente dista mucho de ser normal, los intervalos de confianza y los
en loscontrastes
n = 539 controles
del EURAMIC,
el ICson
al 95%
parafiables
la varianza
poblacional
para6.5
la Utilizando
varianza
poblacional
menos
que para
la media, HDL
en cuyo caso
Ejemplo
la desviación
típica
s =2 0,29
mmol/l
del colesterol
2
2
2
(538⋅0,29
/
χ
,
538⋅0,29
/
χ
538; 0 , 975
538; 0 , 025 )
conviene proceder con cautela.
viene determinado por
en los n = 539 controles del EURAMIC, el IC al 95% para la varianza poblacional
45,25/475,62)
= (0,075;
Ejemplo 6.5 Utilizando la desviación típica s==(45,25/604,16;
0,29 mmol/l del
colesterol HDL
en los0,095),
2
2
2
2
/ χ 538;0,975por
, 538⋅0,29
/ χ 538;0el
) al 95% para la varianza poblacional viene
n(538⋅0,29
= 539
controles
del
EURAMIC,
, 025IC
viene
determinado
determinado por
ya que los percentiles 2,5 y 97,5 de la distribución chi-cuadrado con 538 grado
= (45,25/604,16;
45,25/475,62)
2
2 =2(0,075; 0,095),
2
(538⋅0,29 / χ 538;0,975 , 538⋅0,29 / χ 538;0,025 )
2
2
de libertad son respectivamente χ 538
; 0 , 025 = 475,62 y χ 538; 0 , 975 = 604,16. Así, el
= (45,25/604,16; 45,25/475,62) = (0,075; 0,095),
ya que los percentiles 2,5 y 97,5 de la distribución chi-cuadrado con 538 grados
95% de
para
la desviaciónchi-cuadrado
típica del colesterol
HDL endelalibertad
población de referenc
ya que los percentiles 2,5aly 97,5
la distribución
con 538 grados
2
2
de libertad son
son respectivamente χ 538
=
475,62
y
χ
=
604,16.
Así,
el
IC
el
IC
al
95%
para
la
; 0 , 025
538; 0 , 975
ya que los percentiles 2,5esy 97,5 de la distribución chi-cuadrado con 538 grados
desviación típica del colesterol HDL en la población de referencia es
Para
determinartípica
si los del
niveles
de colesterol
en los2controles
del EURAMIC
al 95% para
la desviación
colesterol
la población
de referencia
2 HDL enHDL
de libertad son respectivamente χ 538
025 = 475,62 y χ 538; 0 , 975 = 604,16. Así, el IC
( 0,075 ; 0;0,,095
) = (0,27; 0,31).
son compatibles con una desviación típica poblacional de 0,30 mmol/l, se
es
Para
determinar
si los niveles
controles de
delreferencia
EURAMIC son
al
95%
para la desviación
típicade
delcolesterol
colesterolHDL
HDLen
enlos
la población
compatibles con una desviación típica poblacional
2
2 de 0,30 mmol/l, se contrastó
( 0,075 ; contrastó
0,095 ) =bilateralmente
(0,27; 0,31). la hipótesis nula H0: σ = 0,30 mediante el estadístico
bilateralmente la hipótesis nula H0: σ2 = 0,302 mediante el estadístico
es
(n − 1) s 2 538 ⋅ 0,29 2
( 0,075 ; 0,095 ) = (0,27;
χ 2 = 0,31).
=
= 502,73.
σ 02
0,30 2
1.2 MEDIDAS
1.2 MEDIDAS
DE TENDENCIA
DE TENDENCIA
CENTRAL
CENTRAL
7
2
Como s < σ0, el valor P corresponde a 2P(χ
≤ 502,73)
=DE
2∙0,140
= 0,280; es
decir,
el
1.2538
MEDIDAS
1.2
MEDIDAS
TENDENCIA
DE TENDENCIA
CENTRAL
CENTRAL
2
contraste
estadísticamente
significativo,
careciendo
entonces
de
evidencia
para
Como
s <no
σ 0resultó
, Las
el valor
P
corresponde
a
2P(
χ
≤
502,73)
=
2⋅0,140
=
0,280;
es
538
medidas
Las medidas
de tendencia
de tendencia
central
central
informan
informan
acerca
acerca
de cuál
de cuál
es el es
valor
el valor
más más
representativo
representat
7
rechazar la hipótesis nula. La conclusión de este contraste es consistente con el intervalo
Las
medidas
Las medidas
de
tendencia
de
tendencia
central
central
informan
informan
acerca
acerca
de cuál
de cuá
es
0,30
mmol/l.
de confianza
para
σ,
queestadísticamente
éstevariable
incluye
el
nulo
σde
de una
dedado
determinada
una determinada
variable
o, valor
dicho
o, dicho
de forma
forma
equivalente,
equivalente,
estosestos
estimadores
estimadores
indican
indican
decir,
el contraste
no
resultó
significativo,
careciendo
entonces
0 =
de una
de determinada
una determinada
variable
variable
o, dicho
o, dicho
de forma
de forma
equivalente,
equivalene
alrededor
alrededor
de qué
valor
qué valor
senula.
agrupan
se agrupan
los datos
los datos
observados.
observados.
Las medidas
Las
de tendencia
de tendencia
de evidencia para
rechazar
lade
hipótesis
La conclusión
de este
contraste
es medidas
6.3 COMPARACIÓN DE MEDIAS EN DOS
MUESTRAS
alrededor
alrededor
de qué
deINDEPENDIENTES
valor
qué valor
se agrupan
se agrupan
los datos
los datos
observados.
observados.
Las m
L
central
de lade
muestra
muestra
sirven
sirven
tantoσtanto
para
resumir
losincluye
resultados
los resultados
observados
observados
comocomo
para para
consistente concentral
el intervalo
delaconfianza
para
,para
dado
queresumir
éste
el valor
Hasta ahora se han revisado las técnicas estadísticas para realizar inferencias sobre el valor de
central
central
de lademuestra
la muestra
sirven
sirven
tantotanto
parapara
resumir
resumir
los resultados
los resulta
un parámetro
unarealizar
población.
Sin
embargo,
una
situación
muchopoblacionales
máspoblacionales
frecuente
en correspondientes.
la práctica A A
realizar
inferencias
inferencias
acerca
acerca
de los
deparámetros
los parámetros
correspondientes.
= 0,30
mmol/l.
nulo σ 0 en
es la comparación de un determinado parámetro entre dos poblaciones distintas. En este apartado
realizar
realizar
inferencias
inferencias
acerca
acerca
de los
deparámetros
los parámetros
poblacionales
poblacionale
co
se presentan los métodos
para comparar
la media
poblacional
deestimadores
una variable
cuantitativa
acentral
continuación
continuación
se describen
se describen
los principales
los
principales
estimadores
de lade
tendencia
la tendencia
central
de una
de una
partir de dos muestras independientes, donde las observaciones de una muestra no están
continuación
continuación
se describen
se describen
los principales
los principales
estimadores
estimadores
de ladete
relacionadas
o emparejadas
con las observaciones
de la otra muestra.
6.3
COMPARACIÓN
DE
MEDIAS
EN DOS MUESTRAS
INDEPENDIENTES
variable.
variable.
En adelante, la media y la varianza de la variable
aleatoria
variable.
variable.en la primera población se denotan
Hasta
revisado
lasMedia
técnicas
realizar
inferencias
sobrelaeldiferencia
y σ12, yseenhan
la segunda
población
porestadísticas
μ2 y σ22. Elpara
objetivo
se centra
en estimar
por μ1 ahora
1.2.11.2.1
Media
aritmética
aritmética
entre ambas medias poblacionales μ1 – μ2 a partir de dos muestras independientes de dichas
1.2.11.2.1
Media
Media
aritmética
aritmética2
valor
de un parámetro
una
población.
Sin
embargo,
situación
mucho
Laen
media
media
aritmética,
aritmética,
denotada
denotada
por una
xpor
, se
xdefine
, se define
como
como
la más
suma
la 2suma
de cada
de cada
uno de
unolos
de los
poblaciones
de tamaños
nLa
1 y n2 con medias respectivas 1 y 2 y varianzas s1 y s2 .
media
La media
aritmética,
aritmética,
denotada
denotada
por por
x 1,–sex 2define
, se
comocomo
la suma
la s
quedefine
Como cabría esperar, el estimador puntual es laLa
diferencia
de las
medias
muestrales
frecuente en la práctica
es
lamuestrales
comparación
dedividida
unpor
determinado
parámetro
entre dosrealizadas.
valores
valores
muestrales
dividida
elpor
número
el número
de observaciones
de observaciones
realizadas.
Si denotamos
Si denotamos
representa además un estimador insesgado y consistente de la diferencia subyacente μ1 – μ2 en la
valores
valores
muestrales
muestrales
dividida
dividida
por el
por
número
elnecesario
número
de observaciones
de observacion
r
población. Para
realizar
inferencias
sobre
esta
diferencia
de medias
poblacionales,
es
poblaciones
distintas.
este
semuestral
presentan
los
para
comparar
media
porEnnpor
el tamaño
n apartado
el tamaño
muestral
y poryxpor
xvalor
observado
observado
para para
el la
sujeto
el
sujeto
i-ésimo,
i-ésimo,
i = 1,i ...,
= 1,n,..., n
i el métodos
i el valor
por npor
el ntamaño
el tamaño
muestral
muestral
y pory xpor
el xvalor
observado
observado
parapara
el su
i el valor
poblacional de una variable
cuantitativa
a dada
partir
de dos muestras independientes, idonde
la media
la media
vendría
vendría
dada
por por
Pastor-Barriuso R.
la media
la media
vendría
vendría
dadadada
por por
las observaciones de una muestra no están relacionadas no emparejadas
con las
n
x1 + x12 ++ x...2 ++ x...n + x n
1 1
.
.
= x i
= xi =
x = x
83
continuación
continuación
se describen
seaproximadamente
describen
los principales
los
principales
estimadores
estimadores
de la tendenc
de la ten
distribuciones
normales
N(μ1, muestrales
σn12 /n
, σx222 /n
Así,
allas
tratarse
1) y N(xμ
2), respectivamente.
centraltamaños
del límite),
las medias
seguirán
1 2y
y
son
suficientemente
grandes
(recuérdese
el la
teorema
ambos
muestrales
n
1
2
de muestras independientes (véase Apartado 3.4), la distribución
muestral de
variable.
variable.
variable.
variable.
Inferencia
sobre medias
de
muestras
independientes
Apartado
la2),
distribución
muestral de la
σ 12 /n
σx 222 /n
respectivamente.
distribuciones
normales
N(μ(véase
1,muestrales
1) y N(
x1μ2y,3.4),
seguirán
aproximadamente
central
del de
límite),
lastambién
medias
diferencia
medias
será
aproximadamente
normal
con media Así, allastratarse
1.2.11.2.1
Media
Media
aritmética
aritmética
diferencia
de
medias también(véase
será aproximadamente
normal
con media
1.2.1 Media
1.2.1
aritmética
2 Media
de muestras independientes
3.4),
laaritmética
distribución
muestral de la
μ1x, σ-12 x/nApartado
distribuciones
normales N(E(
1) y N(μ2, σ 2 /n2), respectivamente. Así, al tratarse
)
=
E(
x
)
E(
x
)
=
μ
μ
2x define
1como
x 1,–se
,2. Si
se ambos
define
como
la2suma
lamuestrales
suma
uno
de
los
de los
Laconocer
media
La media
aritmética,
aritmética,
denotada
denotada
por
1de cada
2de cada
la
distribución
muestral
de1por
tamaños
n1 y nuno
2 son suficientemente
La
media
La
media
aritmética,
aritmética,
denotada
denotada
por
x
, se xdefine
, se define
como como
la suma
la suma
de ca
grandes
(recuérdese
el
teorema
central
del
límite),
las
medias
muestrales
1 y
2 seguirán
diferencia
deindependientes
medias también
media depor
E((véase
x1será
- x 2aproximadamente
) = E( x1 )3.4),
- E(2la
x 2 distribución
)normal
= μ1 - μcon
2 2 muestral
de
muestras
Apartado
la
valores
valores
muestrales
muestrales
dividida
dividida
por el
pornúmero
elnormales
número
de observaciones
de observaciones
realizadas.
realizadas.
Si denotamos
Si denotamos
aproximadamente
las distribuciones
N(μ
1, σ1 /n1) y N(μ2, σ2 /n2), respectivamente. Así, al
y varianza
valores
valores
muestrales
muestrales
dividida
dividida
por
el
por
número
el número
observaciones
de observaciones
realizad
re
tratarse de muestras independientes (véase Apartado 3.4), la distribución muestral
de
la de
diferencia
diferencia
de
medias
también
será
aproximadamente
normal
con
media
E(
x
x
)
=
E(
x
)
E(
x
)
=
μ
μ
1
2
1
2
1
2
yelvarianza
por
ntamaño
el también
tamaño
muestral
muestral
y pory xpor
observado
observado
para
para
el sujeto
el sujeto
i-ésimo,
i-ésimo,
i = 1,i =...,1,n,..., n,
i elxvalor
i el valor
denpor
medias
será aproximadamente
normal
con
media
2
2
var( x1 - x 2 ) = var( xpor
)
+
var(
x
)
=
σ
/n
+
σ
/n
.
el valor
observado
observado
para elpara
sujeto
el su
i
n
por
el
tamaño
n
el
tamaño
muestral
muestral
y
por
y
x
xi el valor
1
2
1
2
1
2 i por
la media
lay media
vendría
vendría
dadadada
por por E( x1 − x 2 ) = E( x1 ) − E( x 2 ) = μ2 1 − μ 2 2
varianza
var( x1 - x 2 ) = var( x1 ) + var( x 2 ) = σ 1 /n1 + σ 2 /n2.
la media
la media
vendría
vendría
dada por
dada por
En
consecuencia,
se
tiene que
y varianza
n
x n+ x2n/n + σ 2 /n .
1 n xx1 )++xx1var(
2++x...
2x +)...
yEn
varianza
var(
x1x−=
x1x2 )
1
2 = σ
2
2
. 1 .1
== xvar(
consecuencia, se
tiene
que
i = xi =
1 n 1 n x1 + xx2 1++...x 2+ +x n... + x n
n i =1n i =1
n n 2
2
.
.
=
= xi =
x
x=x i
σ
σ
~ Nμ − μ , 1 + 2
En consecuencia, se tiene que x1 − x 2 →
n i =1 n i =1
n
n
1
2
2
2
x1 - que
x 2 ) = var( x1 ) + var( x 2 )n=
2 σ 1 n/n
2 + σ 2 /n2.
En consecuencia, var(
se tiene
σ 11
σ 22 1
~
μutilizada
→N
+ y deymás
La media
La media
es laesmedida
la medida
de tendencia
dextendencia
central
de más
fácilfácil
1 − x 2 central
1 − más
2 , utilizada
μmás
n
nmedida
1
2
La media
La media
es
la
es
la
medida
de
tendencia
de tendencia
centralcentral
más utilizada
más utilizada
y de my
2
2
En
consecuencia,
se tiene que de una
σ
σ
o,
aplicando
la
estandarización
distribución
normal,
1
2
~
interpretación.
Corresponde
al “centro
“centro
gravedad”
de gravedad”
de los
de+datos
los datos
la muestra.
Su Su
de lademuestra.
xal
x 2de
N
→
− μ normal,
o, interpretación.
aplicando laCorresponde
estandarización
de
distribución
1 −una
2,
μ1 interpretación.
n
n
interpretación.
Corresponde
Corresponde
al
“centro
al
“centro
de gravedad”
de gravedad”
de losde
datos
los da
de
1
2
o, aplicando la estandarización de una distribución
normal,
2
2
principal
principal
limitación
limitación
es que
es que
está está
muy
los
por valores
losσvalores
extremos
y, eny,este
en este
2 extremos
x1 muy
−influenciada
x ~influenciada
− ( μ1 − μpor
2 ) ~σ 1
μ1 −principal
μ 2limitación
, N (+limitación
x1 −
x 2 2→
Nprincipal
. queesestá
0, 1)es
→
que
muy
está
influenciada
muy
influenciada
por lospor
valores
los valo
ex
2
n2
1
σ1 22− μ 2 ) ~nnormal,
σ
o,
aplicando
la
estandarización
de
una
distribución
1
μ
x
−
x
−
(
1
2
caso,caso,
puede
puede
no ser
no un
serfiel
un reflejo
fiel reflejo
de ladetendencia
la tendencia
central
central
+
→ de
N (la
0de
, distribución.
1)la. distribución.
2 caso,
2 puede
n
n
1
2
caso,
puede
no
ser
no
unser
fielunreflejo
fiel reflejo
de la tendencia
de la tendencia
centralcentral
de la distrib
de la
σ1 σ 2
+
o,
aplicando
la estandarización
normal,
μ 2 )la~comparación
x1 de
− xuna
− distribución
( μ1n 2−para
2n la
Esta
distribución
muestral constituye
de dos medias poblacionales
1 base
→sobre
N (sobre
0,estimadores
1) . estimadores
Ejemplo
Ejemplo
1.4 En
1.4este
En este
y enylos
en sucesivos
los sucesivos
ejemplos
ejemplos
muestrales,
muestrales,
se se
2
2
a partir
de muestras
independientes.
No
para
hacer
uso de este de
resultado,
es necesario
Esta
distribución
muestral constituye
la
para
la1.4
comparación
dos
medias
σ 1obstante,
σ 2base
Ejemplo
Ejemplo
En
1.4
este
En
y
este
en
los
y
en
sucesivos
los
sucesivos
ejemplos
ejemplos
sobre sobre
estimae
+
2
2
estimar
previamente
las
varianzas
desconocidas
σ
de
ambas
poblaciones.
La
estimación
x
x
1 −
2n− ( μ 1n− μ σ
2 1) y
~
2
utilizarán
utilizarán
los valores
los valores
del colesterol
delconstituye
colesterol
HDL
en
losprimeros
10 primeros
sujetos
sujetos
del del
1HDL
2obtenidos
Esta
distribución
muestral
la
baseobtenidos
para
la
comparación
de 2dos
medias
→No
Nen
(0obstante,
,los
1) .10
2
poblacionales
a partir desimuestras
para
deHDL
esteHDL
se simplifica
notablemente
se asumeindependientes.
varianzas
iguales
σcolesterol
= σuso
cuyo
caso obtenidos
2
1 del
2 , en
utilizarán
utilizarán
losson
valores
los
valores
delhacer
colesterol
obtenidos
en losen
10lo
σ 1que
σlas22 dos
+
es posible
obtener
una
estimación
combinada
de
la
varianza
común
para
ambas
poblaciones.
estudio
estudio
“European
“European
on Antioxidants,
on Antioxidants,
Myocardial
Myocardial
Infarction
Infarction
and
and
Cancer
Cancer
of
of
poblacionales
a partirStudy
de2 Study
muestras
independientes.
Nolaobstante,
para
hacer
de
n1 poblacional
nla2 base
2 uso
2 este
distribución
para
comparación
de
medias
σ2estimar
, cadaconstituye
varianza
deberá
estimarse
por
separado,
Porresultado,
elEsta
contrario
si σ12 ≠muestral
es necesario
previamente
las
varianzas
desconocidas
σdos
yon
σAntioxidants,
1Antioxidants,
2 de siendo
estudio
estudio
“European
“European
Study Study
on
Myocardial
Myocardial
InfarctI
entonces
más
impreciso
el
proceso
de
inferencia.
Parece
razonable
pensar
que
la
comparación
2
2
the Breast“
the Breast“
(EURAMIC),
(EURAMIC),
un estudio
un estudio
multicéntrico
multicéntrico
de casos
de
casos
y controles
y controles
resultado,
necesario
estimar
previamente
las
desconocidas
σrealizado
y realizado
σde
1 uso
2 de
poblacionales
acomplicada
partir
de
muestras
independientes.
No obstante,
para
hacer
este
de ambas
medias
es es
más
enconstituye
distribuciones
convarianzas
distinta
variabilidad
que
enmedias
distribuciones
La
estimación
se simplifica
notablemente
si
se asume
lasestudio
dos
Estapoblaciones.
distribución
muestral
la base
para
comparación
de
dosque
the
Breast“
thelaBreast“
(EURAMIC),
(EURAMIC),
un
estudio
un
multicéntrico
multicéntrico
de casos
de ca
y
con entre
una entre
misma
varianza.
La
igualdad
de
varianzas
no
es
una
asunción
puramente
teórica,
sino
1991
1991
y 1992
y 1992
en
en ocho
países
países
Europeos
Europeos
e Israel
e Israel
parapara
evaluar
evaluar
efecto
el efecto
de los
de
los
2que
2 dos
ambas
poblaciones.
La ocho
estimación
se
simplifica
notablemente
si seelasume
resultado,
es necesario
previamente
las
varianzas
desconocidas
σ
y países
σlas
quepoblacionales
tiene implicaciones
como
puede
apreciarse
el
siguiente
ejemplo.
1 uso
2 de
a partirprácticas
deestimar
muestras
independientes.
No en
obstante,
para
hacer
de
este
entre
1991
entre
y1991
1992
y en
1992
ocho
en
países
ocho
Europeos
Europeos
e Israel
e Israel
para evalu
para
9
2 dos
ambas
poblaciones.
estimación
se simplifica
notablemente
si se asume
las
Ejemplo
EnLa
elestimar
ensayo previamente
clínico
del Ejemplo
6.2 sedesconocidas
pretende
comparar
resultado,
es6.6
necesario
las varianzas
σ 12 que
y σlas
de5 5 de
2 medias
9
presión arterial sistólica entre el grupo placebo y el grupo bajo tratamiento antihipertensivo.
Si este
tratamiento
unasereducción
nivel de presión
ambas
poblaciones.
Laprodujera
estimación
simplificadel
notablemente
si searterial
asume aproximadamente
que las dos
igual en todos los pacientes, cabría esperar que la distribución de la presión arterial en9los
tratados presentara un nivel medio inferior que en el grupo placebo manteniendo
inalterable la variabilidad. En tal caso, estaríamos ante una comparación de medias
9 en
distribuciones con igual varianza (Figura 6.2(a)). En caso contrario, si el tratamiento
produjera una disminución de la presión arterial sistólica proporcional al nivel basal de
cada paciente (esto es, mayor reducción en los sujetos con niveles más altos), la presión
arterial en el grupo tratado tendría menor nivel medio y dispersión que en el grupo placebo.
Bajo esta circunstancia, nos encontraríamos con una comparación de medias en
distribuciones con distinta varianza (Figura 6.2(b)).
84
Pastor-Barriuso R.
Comparación de medias en dos muestras independientes
Tratamiento
Placebo
μ trat
μ plac
(a) Efecto constante
Tratamiento
Placebo
6.3.1 Comparación de medias en distribuciones con igual varianza
Si se asume que las varianzas poblaciones son iguales σ 12 = σ 22 , resulta natural estimar
una única varianza combinada a partir de la información disponible en ambas muestras.
μ trat
μ plac
Así, se obtendrá un estimador más estable
de la varianza
poblacional, lo que redundará
(b) Efecto proporcional
en una mayor precisión de la estimación de la diferencia de medias y en una mayor
Figura 6.1
Figura 6.2 Distribución de la presión arterial sistólica en los grupos placebo y tratamiento de un hipotético
ensayo clínico asumiendo un efecto constante (a) o proporcional (b) del tratamiento antihipertensivo.
potencia del contraste.
6.3.1 LaComparación
de mediasmuestrales
en distribuciones
igual
varianza
s12 y s 22 con
podría
utilizarse
como estimador
media de las varianzas
Si se asume que las varianzas poblacionales son iguales σ12 = σ22, resulta natural estimar una
combinado
la varianza.
Esta media
sin embargo,
ineficiente
que otorga
el Así, se
única
varianzade
combinada
a partir
de la es,
información
disponible
en ya
ambas
muestras.
obtendrá un estimador más estable de la varianza poblacional, lo que redundará en una mayor
mismo peso a ambas varianzas muestrales, aun cuando la varianza estimada a partir de
precisión de la estimación de la diferencia de medias y en una mayor potencia del contraste.
s22 podría
s12 ydar
utilizarse
como estimador
combinado
de
La
de las
varianzas
muestrales
unamedia
muestra
mayor
sea más
fiable. Para
más peso
a los resultados
obtenidos
con
la varianza. Esta media es, sin embargo, ineficiente ya que otorga el mismo peso a ambas
varianzas
muestrales,
aun cuando
la varianza
estimada
de una
muestracomo
mayorlasea más
mayor tamaño
muestral,
la estimación
combinada
dealapartir
varianza
se obtiene
fiable. Para dar más peso a los resultados obtenidos con mayor tamaño muestral, la estimación
2
2 varianza
2
ponderada
por sus correspondientes
combinada
se obtiene como la media de s12 y s2grados
media dedesla
de libertad
1 y s 2 ponderada por sus correspondientes
grados de libertad
s2 =
=
(n1 − 1) s12 + (n 2 − 1) s 22
n1 + n 2 − 2
n1
n2
i =1
j =1
( xi − x1 ) 2 + ( x j − x 2 ) 2
n1 + n 2 − 2
.
El numerador de s2 es simplemente la suma de las desviaciones al cuadrado respecto de la
El numerador
de s2 yeselsimplemente
la corresponde
suma de las desviaciones
cuadrado
respectopara
de el
media
de cada grupo,
denominador
al número dealgrados
de libertad
cálculo de este estimador: n1 – 1 grados de libertad en la primera muestra y n2 – 1 en la segunda,
media
y el denominador corresponde al número de grados de libertad
(n1 la
– 1)
+ (n2de– cada
1) = ngrupo,
1 + n2 – 2.
para el cálculo de este estimador: n1 – 1 grados de libertad en la primera muestra y n2 –
1 en la segunda, (n1 – 1) + (n2 – 1) = n1 + n2 – 2.
Pastor-Barriuso R.
En la distribución muestral de la diferencia de medias, las varianzas desconocidas
85
A partir
de esteyaresultado,
y siguiendo
un procedimiento
análogo al utilizado
para una
de la diferencia
de medias
no será normal,
sino que
seguirá aproximadamente
una
Inferencia sobre medias
un intervalo
de confianza
al 100(1 - α)% para
distribución media
t de
con n5.3.2),
+ medias
n2 puede
– 2 grados
de libertad,
1de
deStudent
la(Apartado
diferencia
yaderivarse
no será
normal,
sino que
seguirá aproximadamente
una
la diferencia
detmedias
poblacionales
2 comode libertad,
distribución
de
+ n~μ
2 1– -2μgrados
x1 Student
−muestral
x 2 − ( μcon
En la distribución
denμ1la
de medias, las varianzas desconocidas σ12 y σ22
1 −
2 ) diferencia
→ t n1 + n2 − 2 .
pueden
entonces sustituirse
combinada
la varianza
s2. Sin embargo,
de la diferencia
de medias
ya
noestimación
será normal,
sino quede
seguirá
aproximadamente
unacomo
1 por
1 la
2
s
+
esta estimación s está sujeta al error
del muestreo, la~1distribución
de la diferencia de medias ya
1
n1 x1n−2 xx12 −± xt 2n1 +−n2(−μ2,11−−α /μ2 2s) →
t
n1 + n2 − 2, .
+
nodistribución
será normal,t de
sinoStudent
que seguirá
una
distribución
t de Student con n1 + n2 – 2
grados
de
conMEDIDAS
naproximadamente
1.2
1 + n2 –
1 2 DE
1 TENDENCIA
n1libertad,
n 2 CENTRAL
s
+
grados
de
libertad,
1.2 MEDIDAS DE TENDENCIAn1CENTRAL
n2
A partir de este resultado, y siguiendo un procedimiento
análogo
al1.2
utilizado
para
una
1.2 MEDIDAS
MEDIDAS
DE TENDENCIA
DE TENDENCIA
informan
acerca
de cuál CENTRAL
es el CENTRAL
valor más represen
− x 2 −de( μtendencia
− medias
μ 2 ) ~central
1de
que está centrado alrededorLas
de medidas
lax1diferencia
muestrales
y
cuya
amplitud
→
t
n1 + n2 − 2 .
Las
medidas
de
tendencia
central
informan
cuál es
valor más representativo
media (Apartado
5.3.2),
derivarse
un
intervalo
de confianza
- αel
)%
1 un
1 acercaalde100(1
A partir
depuede
este resultado,
y siguiendo
procedimiento
análogo
al para
utilizado para una
de una determinada
o, dicho
detendencia
forma
equivalente,
estos estimadores
indic
+ variable
s
Las
medidas
Las
medidas
de
de
tendencia
central
informan
acerca
acerca
de cuál
de es
c
intervalo
es informan
depende de su error estándar SE( x1 - xn2 1) = sn 2 1 / n1 + 1 / n 2 . Notar que este central
de una determinada variable o, dicho de forma equivalente, estos estimadores indican
la diferencia demedia
medias
poblacionales
(Apartado
5.3.2),μalrededor
puede
derivarse
un
intervalo
de confianza
alobservados.
100(1 - α)%
para
1 - μ2 como
de un
quéprocedimiento
valor
se una
agrupan
los
datos
Las
medidas
de
tendencia
de
dedeterminada
una
determinada
variable
variable
o,
dicho
o,
dicho
de
forma
de forma
equivalente,
equivale
A
partir
de
este
resultado,
y
siguiendo
análogo
al
utilizado
para
una
media
una generalización
bastante
natural
del
intervalo
para
la
media
de
una
poblacional.
alrededor
de puede
qué valor
se
agrupan
los
datos
medidas
tendencia
(Apartado
5.3.2),
derivarse
un intervalo
deobservados.
confianzaanálogo
alLas
100(1
α)%depara
la diferencia
Alapartir
de
este
y siguiendo
procedimiento
al– utilizado
para
una
diferencia
deresultado,
medias
poblacionales
μun
1 - μ2 como
central
de
la
muestra
sirven
tanto
para
resumir
los
resultados
observados
como Las
par
alrededor
alrededor
de
qué
de
valor
qué
valor
se
agrupan
se
agrupan
los datos
los datos
observados.
observados
1
de medias poblacionales μ1 – μ2 como 1
x
x
t
s
−
±
+
,
n
+
n
−
−
α
1
2
2
,
1
/
2
1
2
central de la muestra sirven tanto para
resumir
los resultados observados como para
n1 un
nla2intervalo
Ejemplo
6.7 En
el estudio
media y la
del - α)% para
media
(Apartado
5.3.2),
puedeEURAMIC,
derivarse
dedesviación
confianza típica
al 100(1
realizar inferencias acerca
de
parámetros
poblacionales
central
central
de la
muestra
la muestra
sirven
sirven
tantotanto
paracorrespondientes.
resumir
para resumir
los resultados
los A
resul
1los
1de
x 2 ±parámetros
t n1 + n2 − 2,1−α / poblacionales
+
, correspondientes. A
2 s
realizar inferencias acercax1de− los
infarto
miocardio
fueron x ca =
colesterol HDL
entrepoblacionales
los nca = 462 μcasos
ncuya
la diferencia
- μ2decomo
1 de n
2
continuación
se1muestrales
describen
los
principales
estimadores
la
central
de unc
que está centrado
alrededorde
demedias
la diferencia
de medias
yrealizar
amplitud
realizar
inferencias
inferencias
acerca
acerca
de losdeparámetros
lostendencia
parámetros
poblacionales
poblacion
continuación
se
describen
los
principales
estimadores
de
la
tendencia
central
de
una
que está centrado alrededor de la diferencia de medias muestrales y cuya amplitud depende de
0,98 y sca = 0,25 mmol/l,
y entre los nco = 539
controles
fueron
co = 1,09 y sco =
continuación
continuación
describen
seyxdescriben
los
principales
los principales
estimadores
estimadores
de la dt
que está
centrado
medias
cuya
amplitud
x1 − xvariable.
s la1 /diferencia
n1 + 1 / n 2 de
. Notar
SE(alrededor
depende de su error
estándar
que
este
intervalo
es una
generalización
2 ) =de
1 muestrales
1 se
x
x
t
s
−
±
+
,
variable.
n1 + nde
1
1−α / 2población.
2 − 2 ,una
bastante natural del intervalo para
la2media
n1 n 2 puntual de la diferencia
0,29 mmol/l. De estos datos se deduce que la
estimación
variable.
xpara
xla
= s variable.
1 de
/ n1una
+ 1 /poblacional.
n 2 . Notar que este intervalo es
depende
de sunatural
error estándar
SE(
una generalización
bastante
del1.2.1
intervalo
Media
1 - aritmética
2 ) media
Ejemplo
6.7medio
En el
EURAMIC,
desviación
colesterol
1.2.1
aritmética
x camedia
- x co y=la0,98
- 1,09 =típica
-0,11del
mmol/l.
Si HDL
en el Media
nivel
deestudio
colesterol
HDL es la
que
está
centrado
alrededor
de
la
diferencia
de
medias
muestrales
y
cuya
amplitud
La
media
aritmética,
denotada
por
x
,
se
define
como
la
suma
de cada
entre
los
n
=
462
casos
de
infarto
de
miocardio
fueron
=
0,98
y
s
=
0,25
mmol/l,
y uno de los
1.2.1
1.2.1
Media
Media
aritmética
aritmética
una generalización
bastante natural del intervalo
para
la media
una poblacional.
ca
ca de
ca
Ejemplo 6.7La
En
el
estudio
EURAMIC,
la
media
y
la
desviación
típica
del
media
denotada
por x co, se
define
la suma
de De
cada
unodatos
de los
entre
los naritmética,
= 539 controles
fueron
= 1,09
y scomo
= 0,29
mmol/l.
estos
se deduce
asumimoscouna misma variabilidad del
colesterolco HDL en casos y controles, la
valores
muestrales
dividida
por
el
número
de
observaciones
realizadas.
Si denotam
media
aritmética,
denotada
denotada
por
xdefine
, se
como
como
la sum
l
que ladeestimación
puntual de
el
colesterol
HDL
es xpor
– es
= define
s La
1 /nivel
nmedia
+ 1medio
/ aritmética,
n 2 . de
Notar
que
este
intervalo
depende
su error estándar
SE(laxdiferencia
1 La
1 - x 2 ) = en
ca, se
co
=
462
casos
de
infarto
de
miocardio
fueron
x
=
colesterol HDL
entre
los
n
cammol/l,
Ejemplo
6.7
Endividida
elmmol/l.
estudio
EURAMIC,
la
media
y lavariabilidad
desviación
típica
del
ca0,11
valores
muestrales
por
el
númeroesde
observaciones
realizadas.
Si
denotamos
0,98
–
1,09
=
–
Si
asumimos
una
misma
del
colesterol
HDL
en
es
decir,
la
desviación
típica
combinada
s
=
0
,
074
=
0,272
cuyo
varianza combinada de ambas muestras vendría determinado por
por natural
n el combinada
tamaño
muestral
y por
ximedia
el muestrales
valor
para
elpor
sujeto
i = 1, ..
valores
valores
muestrales
dividida
dividida
por
elpor
número
el
número
dei-ésimo,
observaciones
de observaci
y controles,
la varianza
de ambas
muestras
vendría
una casos
generalización
bastante
del intervalo
para
la
deobservado
unadeterminado
poblacional.
0,98 y sca =por
0,25
y entre
los nalos
=ndesviación
539
controles
fueron
xpara
=enel
1,09
y scoi-ésimo,
=fueron
casos
de
infarto
miocardio
x=ca1,=..., n,
colesterol
HDL
entre
n mmol/l,
elestá
tamaño
muestral
ycolapor
x=i el462
valor
observado
sujeto
code
ca
valor
más
próxima
típica
observada
los
controles
quei en
2
2
la
media
vendría
dada
por
(n ca − 1) s ca + (n co − 1) s conpor
el tamaño
n el tamaño
muestral
muestral
y poryxpor
xi el valor
observado
observado
para el
pa
i el valor
s2 =
la De
media
vendría
dada
por
0,29 mmol/l.
estos
datos
se
deduce
que
la
estimación
puntual
de
la
diferencia
0,98
y
s
=
0,25
mmol/l,
y
entre
los
n
=
539
controles
fueron
x
=
1,09
y
s
=
co
los
casos ca
(mayor
muestral
el error estándar
la co
− co
2primeros).
n ca + de
n colos
Ejemplo
6.7 En tamaño
el estudio
EURAMIC,
la media Así,
y la desviación
típicadedel
la
media
vendría
dada
dada
por
por
es decir, la desviación típica combinada es sla=media
0,074
=
0,272
mmol/l,
cuyo
n vendría
x + x 2 + ... + x n
12
2
(462
−ca1se
)-0x,deduce
25
+0,98
(539
−
1estimación
) 0x=,=
29
= 1 Si
xpuntual
x
1,09
-0,11
mmol/l.
en el nivel medio
demmol/l.
colesterol
HDL
es
diferencia
de
medias
puede
calcularse
como
n =
co
0,29
Deentre
estos
datos
que
la
la diferencia
i
=
462
casos
de
infarto
de
miocardio
fueron
x ca .=
colesterol
HDL
los
n
x1 + x 2 + ... +n xi==n1 0,074; de
=
ca 1
n
= −2
x = 462
+xi539
valor está más próxima a la desviación
en.los controles que 1enn 1 n x1 + xx21 + ...
x 2++x...
n +
n i =1 típica observada
n
.
= x
= xSi
= xi =
xmmol/l.
asumimos una0,98
misma
variabilidad
del
colesterol
HDL
en
la
x
x
0,98
1,09
=
-0,11
en
ely nivel
medio
de
colesterol
HDL
es
i
cacasos
co y=controles,
=
0,25 mmol/l,
ycombinada
entre
controles
fueron
x co = cuyo
1,09
sn =
1 los1nco
1 =10,272
ca desviación
n yivalor
n
n
es
típica
es=s 539
es decir,
decir,sla
la
desviación
típica
combinada
=
0
,
074
mmol/l,
=1 co
i =está
1
)muestral
=media
+lalos
= 0,272
+ el error
= 0,017.
s
SE( xtamaño
La
es
medida
de tendencia
central
más utilizada
ca - x co
los casos (mayor
de
primeros).
Así,
estándar
de la y de más fácil
más
próximo
a
la
desviación
típica
en
los
controles
que
en
los
casos (mayor
462
539
n
n
ca observada
co
varianza combinada
de ambas
muestras
determinado
La
media
esuna
la medida
de vendría
tendencia
central
máspor
utilizada
de más
fácil
asumimos
misma
variabilidad
del
colesterol
HDL en ycasos
y controles,
la
0,29 está
mmol/l.
De
datos
se deduce
que observada
laestándar
estimación
puntual
de de
laque
diferencia
tamaño
muestral
deestos
los
primeros).
Así,
eltípica
error
de
lalos
diferencia
medias
puede
valor
más
próxima
a
la
desviación
en
controles
en
12
interpretación.
Corresponde
al
“centro
de
gravedad”
de
los
datos
decentral
lamás
muestra.
Su
La media
es la es
medida
la medida
de tendencia
de tendencia
central
utilizada
más util
diferencia de medias puede calcularse como La media
calcularse
como
interpretación.
Corresponde
al
“centro
de gravedad”
deerror
los datos
de la
muestra. Su
Avarianza
partir decombinada
diferencia
medias
y de su
estándar,
y teniendo
ambas
muestras
vendría
determinado
por
2 de
2 muestrales
(nlamedio
) sde
(de
nmuestral
ca − 1tamaño
ca +
co − 1) sHDL
code los
x
=
0,98
1,09
=
-0,11
mmol/l.
Si extremos
encasos
els nivel
colesterol
es
2 (mayor
ca - x co Así,
los
primeros).
el
error
estándar
lavalores
principal
limitación
es
que
está
muy
influenciada
por
losal
y,
=
interpretación.
interpretación.
Corresponde
Corresponde
al de
“centro
“centro
de gravedad”
de gravedad”
deen
loses
ded
1
1
1
1
n
+
n
−
2
ca
co
t
de
Student
con
n
+
n
–
2
=
999
grados
de
en cuenta
que
la
distribución
principal
limitación
es
que
está
muy
influenciada
por
los
valores
extremos
y,
en
este
ca
co
2
SE( x ca − x co ) =
= 0−,272
+
= 0,017.
(n cascalcularse
−n1cano
) s+ca2ser
+cocomo
(un
ncolesterol
1reflejo
) sprincipal
co
co 462
diferencia
medias
puede
asumimosdeuna
misma
HDL
en
casos
y es
controles,
2 variabilidad
ndel
539
caso,
de
la
tendencia
central
de la
la
distribución.
2 puede
2fiel
principal
limitación
limitación
es que
está
que muy
está
muy
influenciada
influenciada
por los
porval
lo
s
=
(462 − 1) 0,25 + (539 − 1) 0,29
n
+
n
−
2
libertad
virtualmente
acauna
distribución
normal
co
=es no
= 0,074
; de estandarizada,
caso,
puede
ser un fielidéntica
reflejo de
la tendencia
central
la distribución.el IC al
Avarianza
partir de combinada
la diferencia
de
medias
muestrales
y de su
error estándar,
y teniendo en cuenta
462
+ambas
539
− 2muestras
de
vendría
determinado
por
caso,caso,
puede
puede
no2 ser
nounser
fiel
unreflejo
fiel reflejo
de la de
tendencia
la tendencia
central
centra
de l
2
1) muestrales
1
1
1
A
partir
de
la
diferencia
de
medias
y
de
su
error
estándar,
y teniendo
que
la
distribución
t
de
Student
con
n
+
n
–
2
=
999
grados
de
libertad
es virtualmente
(
462
−
0
,
25
+
(
539
−
1
)
0
,
29
ca En=
coeste
y en los +sucesivos
ejemplos
sobre estimadores muestral
95% para μSE(
xcoca viene
- x co=)dado
=Ejemplo
0,272
= 0,017.
s por +1.4
ca - μ
=
0
,
074
;
idéntica
a una distribución
alsobre
95%
para μca – μcomuestrales,
viene dado se
por
n caestandarizada,
n co+ 539ejemplos
462
539estimadores
462
− 2el2 IC
Ejemplo
1.4 En este ynormal
en los
sucesivos
2
(
n
−
1
)
s
+
(
n
−
1
)
s
en cuenta que la distribución
t
de
Student
con
n
+
n
–
2
=
999
grados
de
ca
ca
co
co
ca
co
2
utilizarán los valores del
colesterol
obtenidos
lossucesivos
10 primeros
sujeto
Ejemplo
Ejemplo
1.4 HDL
En
1.4este
En
yeste
en los
y enen
sucesivos
los
ejemplos
ejemplos
sobre
x ca s− x=co ± t999;0,975
SEn( x ca− −2 x co )
12
n
+
ca
co HDL obtenidos en los 10 primeros sujetos del
utilizarán
los
valores
del
colesterol
A partiresdevirtualmente
la diferenciaidéntica
de =
medias
muestrales
y =de(−normal
su
error
estándar, y teniendo
libertad
a una
distribución
IC al
− 0,11
± 1,96⋅0,017
0,14;
0,08).
−estandarizada,
estudio
“European
Study
onutilizarán
Antioxidants,
Myocardial
Infarction
andobtenid
Cancer
utilizarán
los valores
delelcolesterol
del
colesterol
HDLHDL
obtenidos
en
2
2 los valores
(
462
−
1
)
0
,
25
+
(
539
−
1
)
0
,
29
12
estudio
“European
Study
on
Antioxidants,
Myocardial
Infarction
and
Cancer
of
=
0,074
;
t de Student con nca + nco – 2 == 999
grados
de
en cuenta
la distribución
95%
para μque
ca - μco viene dado
462(EURAMIC),
+ 539 − 2estudio
the por
Breast“
un
estudio
multicéntrico
casos
y controles
reali
estudio
“European
“European
StudyStudy
on de
Antioxidants,
on
Antioxidants,
Myocardial
Myoca
De los
del estudio
EURAMIC
puede
entonces
concluirse
el nivel
theresultados
Breast“
(EURAMIC),
una estudio
multicéntrico
de
casos
y que
controles
realizado
libertad
es
virtualmente
idéntica
una distribución
normal
estandarizada,
el IC
al
86 Pastor-Barriuso R.
entre
1991
y
1992
en
ocho
países
Europeos
e
Israel
el
efecto de
the Breast“
(EURAMIC),
(EURAMIC),
un para
estudio
un evaluar
estudio
multicéntrico
multicéntric
x ca - x co ± t999;0,975 SE( x ca - x co )the Breast“
medio de 1991
colesterol HDL
en
los países
casos de
infarto es
inferiorpara
en 0,11
mmol/l
al de los
ocho
Europeos
e Israel
evaluar
el efecto
95% entre
para μca - μyco1992
vieneendado
por
12 Europeos
entre
1991
1991
y 1992
y 1992
en ocho
en ocho
paísespaíses
Europeos
e Israel
e Isra
pa
= -0,11 ± 1,96⋅0,017 =entre
(-0,14;
-0,08).
medio de colesterol HDL en los casos de infarto es inferior en 0,11 mmol/l al
Comparación de medias en dos muestras independientes
nivel medio de los sujetos libres de la enfermedad,
estando esta diferencia
que sigue aproximadamente una distribución t de Student con n1 + n2 - 2 grados de
comprendida entre 0,08 y 0,14 mmol/l con una confianza del 95%.
De los resultados del estudio EURAMIC puede entonces concluirse que el nivel medio de
libertad si la hipótesis nula H0: μ1 = μ2 es cierta. Por tanto, el valor P se obtiene como el
colesterol HDL en los casos de infarto es inferior en 0,11 mmol/l al nivel medio de los
En
el caso
de la
de medias
poblaciones,
la hipótesis
sujetos
libres
decomparación
la enfermedad,
estandoentre
esta dos
diferencia
comprendida
entrenula
0,08más
y 0,14
área bajo
la
distribución
t
n1 +n2 − 2 para valores más extremos que el valor observado de t.
mmol/l con una confianza del 95%.
natural es la igualdad de ambas medias poblacionales. Para realizar el contraste de esta
Esta prueba de hipótesis se conoce genéricamente como el test de la t de Student para
En el caso de la comparación de medias entre dos poblaciones, la hipótesis nula más natural
hipótesis nula H0: μ1 = μ2 frente a la hipótesis alternativa bilateral H1: μ1 ≠ μ2 a partir de
es
la
igualdad
de ambas medias
poblacionales.
muestras
independientes
con igual
varianza. Para realizar el contraste de esta hipótesis nula
H0: μ1 = μ2 frente a la hipótesis alternativa bilateral H1: μ1 ≠ μ2 a partir de dos muestras
dos muestras independientes de igual varianza, se emplea el siguiente test estadístico
independientes de igual varianza, se emplea el siguiente test estadístico
Ejemplo 6.8 Un nivel medio de colesterol HDL significativamente más bajo en
x1 − x 2
x1 − x 2
t=
=
,
( x1 − libres
x 2 ) de enfermedad
los casos de infarto que en losSE
sujetos
sería compatible con
1
1
que sigue aproximadamente una distribución t de Student con ns 1 + n+
2
grados
de
n1 2 n 2
la hipótesis de que el colesterol HDL es un factor protector en el infarto de
libertad si laque
hipótesis
nula H0: μ1 = μ2 esuna
cierta.
Por tanto,t de
el valor
P secon
obtiene
el
sigue aproximadamente
distribución
Student
n1 + ncomo
2 – 2 grados de libertad si
la hipótesis
nula En
H0:este
μ1 =ejemplo,
μ2 es cierta.
Por tanto,
el valor
se obtiene
comode
el los
área bajo la
miocardio.
se pretende
contrastar
estaP hipótesis
a partir
valores más
másextremos
extremosque
queelelvalor
valor
observado
área bajo la distribución t n1 +n2 − 2 para valores
observado
de de
t. t. Esta prueba de
13
niveles
de colesterol
HDL observados
y controles
del estudio
hipótesis
se conoce
genéricamente
como el testendelos
la tcasos
de Student
para muestras
independientes
igual varianza.
Esta prueba con
de hipótesis
se conoce genéricamente como el test de la t de Student para
EURAMIC. El resultado de este contraste, junto con la estimación puntual y por
muestras independientes
varianza.
Ejemplo con
6.8 igual
Un nivel
medio de colesterol HDL significativamente más bajo en los
intervalo
obtenida
en
ejemplo
evaluar
nocompatible
sólo la
casos de infarto que enellos
sujetosanterior,
libres depermiten
enfermedad
sería
con la hipótesis
de que el colesterol HDL es un factor protector para el infarto de miocardio. En este
Ejemplo 6.8significación
Un nivelse
medio
de colesterol
HDL
máslos
en pública
estadística
sino también
la relevancia
clínica
y bajo
deniveles
salud
del HDL
ejemplo,
pretende
contrastar
estasignificativamente
hipótesis
a partir
de
de colesterol
observados en los casos y controles del estudio EURAMIC. El resultado de este contraste,
los casos dehallazgo.
infarto
que
los sujetos
libresyde
enfermedad
sería compatible
con anterior, permiten
junto
con
la en
estimación
puntual
por
intervalo obtenidas
en el ejemplo
evaluar no sólo la significación estadística sino también la relevancia clínica y de salud
la hipótesis Asumiendo
de
que eldel
colesterol
es un factor
protector enelelcontraste
infarto de
igualdadHDL
de varianzas
poblacionales,
bilateral de la
pública
hallazgo.
Asumiendo
igualdad
de varianzas
poblacionales,
contraste
miocardio. En
este ejemplo,
contrastar
esta hipótesis
a partir bilateral
de los de la hipótesis nula
H0se
: μpretende
realiza
mediante
elelestadístico
hipótesis
nula
ca = μco se
H0: μca = μco se realiza mediante el estadístico
niveles de colesterol HDL observados en los casos y controles del estudio
x ca − x co
− 0,11
= − 6,35.
t=
=
SE (junto
x ca − con
x co ) la estimación
0,017
EURAMIC. El resultado de este contraste,
puntual y por
Si ambas medias poblacionales fueran iguales, la distribución de este estadístico sería t999 o
intervalo obtenida
en medias
el ejemplo
anterior, permiten
evaluar la
nodistribución
sólo la
Si
ambas
poblacionales
fueran El
iguales,
de este
estadístico
aproximadamente
normal estandarizada.
valor P bilateral
se obtiene
entonces
como el doble
de la probabilidad a la izquierda de – 6,35 en la distribución normal estandarizada, que corresponde
significaciónsería
estadística
sino también la relevancia
clínica y de salud
pública
del se obtiene
normal
estandarizada.
El muy
valor
P bilateral
a P < t0,001.
Así, puede concluirse
que existen
diferencias
significativas
en el nivel medio
999 o aproximadamente
de colesterol HDL entre los infartados y los sujetos libres de enfermedad. Esta diferencia
hallazgo. entonces como el doble de la probabilidad a la izquierda de -6,35 en la
significativa es perfectamente consistente con el intervalo de confianza calculado en el ejemplo
anterior,
que éstepoblacionales,
no contenía al cero
(valor nulo
para la de
diferencia
medias).
Asumiendo distribución
igualdadpuesto
de varianzas
el corresponde
contraste
bilateral
la Así,depuede
normal estandarizada,
que
a P < 0,001.
métodos
en este apartado
extenderse a la comparación de tres o más medias
hipótesis Los
nula
H0: μca descritos
=que
μco existen
se realiza
mediantepueden
el estadístico
concluirse
diferencias
muy
significativas
el nivelindependientes
medio de
poblacionales. Las técnicas para comparar medias en múltiplesen
muestras
se conocen
con el nombre de análisis de la varianza de una vía y pueden consultarse en los libros referenciados
colesterol
HDL
entre
los
y los sujetos
enfermedad. Esta
x ca estos
− x coinfartados
- 0,11
al final
del tema.
procedimientos
no selibres
tratandeexplícitamente
en este texto, la
t Aunque
=
=
= -6,35.
comparación de múltiples
de datos independientes también puede abordarse mediante
SE (medias
x ca − xacopartir
) 0,017
los modelos de regresión lineal que se presentarán más adelante (Temas 10 y 11).
14
Si ambas medias poblacionales fueran iguales, la distribución de este estadístico
sería t999 o aproximadamente normal estandarizada. El valor P bilateral se obtiene
entonces como el doble de la probabilidad a la izquierda de -6,35 en la
Pastor-Barriuso R.
87
para contrastar estadísticamente la hipótesis de homogeneidad de varianzas en dos
Inferencia sobre medias
muestras independientes.
6.3.2
El test para la igualdad de varianzas poblacionales se basa en la comparación de las
Contraste para la igualdad de varianzas
varianzas muestrales s12 y s 22 . Como se apuntó anteriormente (Apartado 6.2.2), si la
La comparación de medias
presentada en el apartado anterior se fundamenta en la asunción de
igualdad de varianzas. Esta asunción es determinante para poder calcular una estimación
distribución
de En
la variable
es normalseenpresentan
ambas poblaciones,
los estadísticos
combinada
de subyacente
la varianza.
este apartado
los métodos
para contrastar
estadísticamente
la hipótesis de homogeneidad de varianzas en dos muestras independientes.
(n1 – 1) s12 / σ 12 y (n2 – 1) s 22 / σ 22 se distribuyen como una chi-cuadrado con n1 - 1 y n2 El test para la igualdad de varianzas poblacionales se basa en la comparación de las varianzas
2
s22. Como
se apuntó anteriormente
(Apartado
6.2.2), si ladedistribución
subyacente
muestrales
1 gradoss1deylibertad,
respectivamente.
Combinando
la distribución
estos
estadísticos
2
2
de la variable es normal en ambas poblaciones, los estadísticos (n1 – 1)s1 /σ1 y (n2 – 1)s22/σ22 se
distribuyen
una independientes,
chi-cuadrado con
n2 – 1 grados de libertad, respectivamente.
1 – 1 yque
en ambascomo
muestras
se nobtiene
Combinando
la distribución
de estosseestadísticos
en ambas
independientes,
se obtiene
A la derecha
de esta expresión
tiene el cociente
de muestras
dos variables
independientes
chi- que
A la derecha de estacuadrado
expresión
se tiene por
el cociente
de
χ n2 −1de
/(independientes
nlibertad,
s12 dos
/ σ 12variables
1 − 1)
divididas
sus respectivos
grados
que sechiconoce como la
1
.
~
2
2
2
s 2 / σ 2 χ n2 −1 /(n 2 − 1)
uadrado divididas distribución
por sus respectivos
grados
de
libertad,
que de
se libertad
conoce como
la
F de Fisher con n1 - 1 grados
en el numerador
y n2 - 1 en el
A la derecha de esta expresión se tiene el cociente de dos variables independientes chiistribución F decuadrado
Fisher con
n1 - 1 grados
libertad en el numerador
y n2 que
- 1 en
2 el
2
2como
2 la distribución
divididas
pordenota
susderespectivos
de libertad,
se
conoce
15
denominador,
y se
por Fn1 −1, n2grados
−1 . Así, la razón entre s1 / σ 1 y s 2 / σ 2 sigue una
F de Fisher con n1 – 1 grados de libertad en el numerador y n2 – 1 en el denominador, y
2
2
enominador, y se denota
/ σ1212y ys22s/σ22 2/2σsigue
2 sigue
denota por
por Fn1 −1, n2 −1 . Así, la razón entre ss112/σ
unauna
distribución F con n1 – 1 y
distribución F con n1 - 1 y n2 - 1 grados de
libertad,
n2 – 1 grados de libertad,
istribución F con n1 - 1 y n2 - 1 grados de libertad,
s12 / σ 12
~ Fn1 −1, n2 −1 .
2
2
2
2
σ
s
/
2
2
s1 / σ 1
~ Fn1 −1, n2 −1 .
2
2
s 2 de
/ σFisher
La distribución F
toma sólo valores positivos y está sesgada positivamente con un
2
F de Fisher
toma
valores
positivos
sesgada
positivamente
valor La
másdistribución
frecuente (moda)
menor
de 1sólo
y una
media
mayor ydeestá
1. Al
aumentar
los grados de
libertad del numerador y denominador, tanto la media como la moda se aproximan al valor 1
La distribución Fcon
de Fisher
toma sólo
valores
positivos
y está
positivamente
valor
frecuente
menor
deF1sesgada
una media
de grados
1. Al aumentar
(Figuraun
6.3).
Losmás
percentiles
de(moda)
la distribución
dey Fisher
paramayor
distintos
de libertad del
numerador y denominador se presentan en la Tabla 7 del Apéndice.
on un valor más frecuente
(moda)
menordel
de numerador
1 y una media
mayor de 1. Al
aumentar
los grados
de libertad
y denominador,
tanto
la media como la moda se
os grados de libertad
del0,8
numerador
la
media como
moda se F de Fisher para F
0,8lala
F
aproximan
al valory 1denominador,
(Figura 6.3). tanto
Los percentiles
de
distribución
5,5
5,5
F5,10
F10,5
proximan al valor distintos
1 (Figuragrados
6.3). Los
percentiles
de
la
distribución
F
de
Fisher
para
F
F30,5
de libertad del numerador5,30y denominador se presentan en la Tabla 7 del
0,6
0,6
istintos grados de libertad
del numerador y denominador se presentan en la Tabla 7 del
Apéndice.
f(x)
Apéndice.
0,4
0,4
[Figura 6.3 aproximadamente
aquí]
0,2
0,2
[Figura 6.3 aproximadamente aquí]
0
0
Ejemplo 6.9 Utilizando la Tabla 7 del Apéndice, el percentil 97,5 de una
0
1
2
3
0
1
2
Ejemplo 6.9 Utilizando
la TablaF7de
delFisher
Apéndice,
percentil
97,5 de en
unael numerador y denominador
distribución
con 5elgrados
de libertad
x
x
distribución F de Fisher
grados
libertad
en el numerador
7,15, de
y (a)
para
30 grados
de libertadyendenominador
ambos es F
es F con 5 =
5;5;0,975
3
(b)
30;30;0,975
= 2,07.
Función
de densidad
de la distribución
al aumentar los grados de libertad del de= 7,15,6.3yAunque
para
30esta
grados
libertad
ambos Fesdeinferiores,
FFisher
es F5;5;0,975Figura
30;30;0,975 = 2,07.
tabladeno
facilitaenpercentiles
puede comprobarse que el
nominador (a) y del numerador (b).
Figura 6.1
Aunque esta tabla no facilita percentiles inferiores, puede comprobarse que el
percentil α en una distribución F con d1 y d2 grados de libertad es igual al inverso
88
Pastor-Barriuso R.
percentil α en una distribución F con d1 y d2 grados de libertad es igual al inverso
del percentil 1 - α en una distribución F con d2 y d1 grados de libertad, Fd1 , d 2 ,α =
del percentil 1 - α en una distribución F con d2 y d1 grados de libertad, Fd1 , d 2 ,α =
or y denominador, la distribución F
rica alrededor del valor 1.
distribución F de Fisher con 5 grados de libertad en el numerador y d
Comparación
medias
en dosde
muestras
independientes
es F5;5;0,975 = 7,15,
y parade30
grados
libertad
en ambos es F30;30;0,975
distribución F30,30 entre 0,48 y 2,07.
Puede
que, al aumentar
Aunque
estaentonces
tabla no observarse
facilita percentiles
inferiores, puede comprobar
2
cociente entre s12 / σ 12Ejemplo
y s 22 / σ 26.9
,
Tabla 7del
delnumerador
Apéndice, yeldenominador,
percentil 97,5ladedistribución
una distribución
F
el número deUtilizando
grados delalibertad
F
α en una ydistribución
F con
grados
1 y d2 =
de Fisher con 5 grados de libertadpercentil
en el numerador
denominador
es Fd5;5;0,975
7,15, de
y libertad es igu
para
grados
de libertad
en ambosy más
es F30;30;0,975
= alrededor
2,07. Aunque
esta 1.
tabla no facilita
ara la razón de dos varianzas
de30
Fisher
se hace
menos dispersa
simétrica
del valor
α
en
una
distribución
F con dF
d1 grados
de libertad
del
percentil
1
2 ycon
percentiles inferiores, puede comprobarse que el percentil α en una distribución
d1
y d2 grados de libertad es igual al inverso del percentil 1 – α en una distribución F con d2
utilidad práctica, nos centraremos
2 en
Fnd1 −2 1,d, n12,1−−1entonces
. Así,
el
percentil
distribuciones
anteriores es F5;
y dpartir
libertad, Fmuestral
elobservarse
percentil
en2las
las
α del
d1 , d 2 ,α = 1/F
1 grados
cociente
entre 2,5
s2,5
s 22distribuciones
/ σ 22 ,
A
de lade
1 / σ 1al y
y 2,07. Puede
que,
aumentar
distribución
Fdistribución
30,30 entre 0,48
anteriores
es
F
=
1/F
=
1/7,15
=
0,14
y
F
=
1/F
=
1/2,07
=
0,48.
traste bilateral de la hipótesis nula 5;5;0,025
5;5;0,975
30;30;0,025
30;30;0,975
Por
tanto,
el
95%
central
de
la
distribución
F
está
comprendido
entre
0,14
y 30;30;0,975
7,15,
y de
1/F
=
1/7,15
=
0,14
y
F
= 1/F
= 1/2,07 = 0,48.
5;5;0,975 5,5 para
30;30;0,025
el número
decalcular
grados de
y denominador,
distribución
F
resulta
sencillo
un libertad
intervalodel
denumerador
confianza
la razón de la
dos
varianzas
e basa en la razón de la
lasdistribución
varianzas F30,30 entre 0,48 y 2,07. Puede entonces observarse que, al aumentar el
número
del ynumerador
y de
denominador,
la valor
distribución
F de Fisherentre 0,14 y 7,15
95%
la
distribución
F5,5 está
2
2 de libertad
de Fisherdesegrados
menos
dispersa
máscentral
simétrica
alrededor
del
1. comprendido
σhace
poblacionales
1 / σ 2 . No obstante, por su mayor utilidad práctica, nos centraremos
se hace menos dispersa y más simétrica alrededor del valor 1.
aquí en el test para la igualdad de varianzas. El contraste bilateral
de la hipótesis
nula
2 2 2 2 22
2
A partir de la
del cociente
cociente entre
entre ss121/σ
/1σ y1 sy2/σs 22,/ σ
resulta
sencillo
la distribución
distribución muestral
muestral Fn1 −1, n2 −1 del
2 ,
2 2
2 intervalo
2
calcular
de confianza para la razón2 de dos2 varianzas poblacionales σ1/σ2 . No obstante,
H0: σun
1 = σ 2 frente a la alternativa H1: σ 1 ≠ σ 2 se basa en la razón de las varianzas
por
su
mayor
utilidad
práctica,
nos centraremos
aquí
en la
el razón
test para
la igualdad
de varianzas. El
resulta sencillo calcular
un intervalo
de confianza
para
de dos
varianzas
2
2
2
contraste bilateral de la hipótesis nula H0: σ1 = σ2 frente a la alternativa H1: σ1 ≠ σ22 se basa en la
muestrales 2 2
razón de las varianzas
σ 1 / σ 2 muestrales
. No obstante, por su mayor utilidad práctica, nos centraremos
σ 22 es cierta, lapoblacionales
razón
s12
aquí en el test para la igualdad de varianzas.F El
contraste
bilateral de la hipótesis nula
= 2.
que este estadístico se distribuirá
s2
H0: σ 12 = σ 22 frente a la alternativa H1: σ 12 ≠ 2σ 22 se
basa en la razón de las varianzas
en el numerador
- 1 en elnula de igualdad de varianzas σ1 = σ22 es cierta, la razón (s12/σ12)/(s22 /σ22 ) se reduce
Siylan2hipótesis
2
a s12Si
/s22la
, de
tal forma
que
estadístico
se distribuirá
una F de
Fisher con n1 – 1 grados
hipótesis
nula
deeste
igualdad
de varianzas
σ 12 = σsegún
la razón
2 es cierta,
muestrales
tonces como el de
doble
de
la
libertad en el numerador y n2 – 1 en el denominador. El valor P del contraste se calcula
2
2
2
2
entonces
de la probabilidad
a la izquierda de este estadístico bajo la distribución
( s12 / σ 1como
)/( 2s 22el/ σdoble
2 ) se reduce a s1 / s 2 , de tal forma que este estadístico se distribuirá
2
2 2
s2, so2 como
el doble del área a sla12 derecha del estadístico, si s12 > s22.
la distribución Fn1 −1, n2 −1, si ss1 1≤ ≤
,
F=
.
según una F de Fisher con n1 - 1 grados des 22libertad en el numerador y n2 - 1 en el
2
2
Ejemplo 6.10 En los Ejemplos 6.7 y 6.8 se comparó la media del colesterol HDL entre s ca 0,25
o, si s12 > s 22 .
F= 2 =
los casos y El
controles
la asunción
decomo
homogeneidad
denominador.
valor Pdel
delEURAMIC
contraste sebajo
calcula
entonces
el doble dede
la varianzas. La s co 0,29 2
2
2
Si la hipótesis
nula
deresultados
igualdad de
varianzasdelσ cumplimiento
la razón
1 = σ 2 es cierta,
validez de
estos
dependerá
de dicha
hipótesis. Para contrastar
2
2
2
2
bilateralmente
la
hipótesis
nula
H
:
σ
=
σ
,
se
calcula
el
test
estadístico
omparó la media del
colesterol
HDL
probabilidad a la izquierda de este estadístico
0
ca
cobajo la distribución Fn1 −1, n2 −1 , si s1 ≤ s 2 ,
que
sigue
una
distribución
F con nca – 1 = 461
2
2
2
2
2
2
( s1 / σ 1 )/( s 2 / σ 2 ) se reduce a s1 / s 2 , de tal forma que este estadístico se distribuirá
s ca2
0,25 2
jo la asunción de homogeneidad de
s 22 . H0. Como sca < sco, el valor P es igual a 2
o como el doble del área a la derecha
estadístico,
si s12 > bajo
=
= 0,74,
F = del
2 libertad
2 en el numerador
y n2 - 1 en el
según una F de Fisher con n1 - 1 grados sde
0,29
co
enderá del cumplimiento de dicha
0,001.
Notar
este valor
P0.sería idéntico si
que sigueEluna
distribución
F conse
ncacalcula
– 1 = 461
y nco –como
1 = 538
grados
de
libertad
bajo H
denominador.
valor
P del
contraste
entonces
el
doble
decolesterol
laque
Ejemplo
6.10
En
los
Ejemplos
6.7
y
6.8,
se
comparó
la
media
del
HDL
2 Como
2
con naca2P(F
–1=
461≤y0,74)
nco – =1 2∙0,0005
= 538 grados
de libertad
sco,distribución
el valor P esFigual
= 0,001.
Notar que este
ca <una
461,538
pótesis nula H0: σ ca =que
σ cosigue
, sse
2
2
F
=
s
valor
P
sería
idéntico
si
se
hubiera
utilizado
el
estadístico
inverso
co /2 s ca =2 1,35. En tal caso, el val
probabilidad
alos
la izquierda
de este estadístico
bajo la
distribución
Fnde
1 −1, n
2 −1 , si s1 ≤ s 2 ,de
entre
casos
y
controles
del
EURAMIC
bajo
la
asunción
homogeneidad
bajocaso,
H0. Como
, el valoraPpartir
es igual
a 2P(F
0,74)
2⋅0,0005
tal
el valorscaP<sesco
obtendría
de la
distribución
2P(F=538,461 ≥ 1,35)
461,538 ≤ F
538,461=como
= 2∙0,0005 = 0,001.
distribución F538,461 como 2P(F538,461 ≥ 1,35)
La
validez
de estosdel
resultados
dependerá
de dicha
s12 > del
s 22utilizado
.cumplimiento
o como
elvarianzas.
doble
delque
área
a lavalor
derecha
estadístico,
sihubiera
0,001.
Notar
este
P
sería
idéntico
si
se
el estadístico
La variabilidad del colesterol HDL resulta significativamente menor
entre los casos de
Lalovariabilidad
colesterollaHDL resulta sig
2delaceptarse
infarto
que entre
los
individuos libres de la enfermedad, con
cual2no puede
hipótesis.
Para
2
2contrastar bilateralmente la hipótesis nula H0: σ ca = σ co , se
inverso
F
=
s
/
s
=
1,35.
En
tal
caso,
el
valor
P
se
obtendría
a
partir
de
la
co
ca
hipótesis 6.10
de igualdad
de varianzas.
consecuencia,
procedimientos
utilizados
Ejemplo
En los
Ejemplos
6.7 yEn6.8,
se comparó los
la media
del colesterol
HDL en los
17
casos
de
infarto
que
entreHDL
los individuos libre
Ejemplos
y 6.8
son inadecuados para comparar los niveles medios de colesterol
calcula 6.7
el test
estadístico
distribución
como 2P(F
= 2⋅0,0005
= 0,001.
538,461
538,461 ≥ 1,35)
entre
casos
yFcontroles.
entre
los
casos
y controles
del EURAMIC
bajo
la asunción
de homogeneidad de
puede aceptarse la hipótesis de igualdad de va
La variabilidad
del colesterol
resultadependerá
significativamente
menor entre
los
varianzas.
validez
de
estos HDL
resultados
del cumplimiento
de dicha
Existen
otrasLatécnicas
estadísticas
para la comparación
de varianzas
en muestras
procedimientos
utilizados
en los Ejemplos 6.7
.
En
general,
estas
técnicas
independientes,
tales
como
el
test
de
Bartlett
o
la
prueba
de
Levene
17
casos de infarto
que entre bilateralmente
los individuos la
libres
de la nula
enfermedad,
2 con lo
hipótesis.
Para contrastar
hipótesis
H
σ co2 niveles
,cual
se nomedios
0: σ ca = los
comparar
de colesterol HD
puede aceptarse la hipótesis de igualdad de varianzas. En consecuencia, losPastor-Barriuso R. 89
calcula el test estadístico
otras técnicas
procedimientos utilizados en los Ejemplos 6.7 y 6.8 sonExisten
inadecuados
para estadísticas para la compa
Así, sustituyendo σ 12 por s12 y σ 22 por s 22 en la distribución muestral de la
Inferencia sobre medias
diferencia de medias, se obtiene el estadístico
permiten comparar varianzas entre dos
y, en el caso del test de Levene, la
x1 − ox 2más
− ( μgrupos
1 − μ2 )
. la variable sea normal. Los lectores
comparación no requiere que la distribución subyacente de
2
2
s
s
1
2
interesados pueden consultar estos procedimientos
+ en las referencias incluidas al final del tema.
n1 n 2
2
6.3.3 Así,
Comparación
distinta varianza
sustituyendode
σ 1medias
por s12eny distribuciones
σ 22 por s 22 en lacon
distribución
muestral de la
Aunque resulta complicado derivar la distribución exacta de este estadístico, existen
Cuando las varianzas poblacionales son distintas, carece de sentido calcular una estimación
diferencia de medias, se obtiene el estadístico
combinada
la varianza, yaque
quefuncionan
ésta infraestimará
o sobreestimará
la variabilidad
específica
diversas de
aproximaciones
bien en la
práctica. El método
más utilizado
es de
cada población. En este caso, aun perdiendo algo de precisión, es preferible estimar por separado las
2
Así,poblacionales
sustituyendo
s12 permite
y xσ1 22−sus
por
muestral
la s12 y s22 .
xaproximar
−s(22μen
μla2distribución
)distribución
2 correspondientes
1 −la
varianzas
σσ121y por
σ22que
mediante
varianzas
la aproximación
de Welch,
demuestrales
este de
estadístico
.
2
s 22
muestral de la diferencia de medias,
Así, sustituyendo σ12 por s12 y σ22 por s22 en sla1 distribución
+
diferenciauna
de medias,
se obtiene
estadísticogrados de libertad
mediante
t de Student
con loselsiguientes
se obtiene
el estadístico
n1 n 2
x1 (−s 2x 2/ n− (+μ s1 2−/μn2 )) 2
1
1
2
2 .
Aunque resulta complicado
la distribución
exacta
de este estadístico,
existen
d = derivar
.
2
2 2
2
2
s
s
1
2
( s1 / n1 ) /(n1 − 1)++ ( s 2 / n 2 ) 2 /(n 2 − 1)
n1 enn 2la práctica. El método más utilizado es
diversas aproximaciones que funcionan bien
Aunque
complicado
la distribución
exacta
Puederesulta
comprobarse
que dderivar
es siempre
inferior o igual
a nde
n2 –estadístico,
2; es decir, existen
esta diversas
1 +este
la aproximación de Welch, que permite aproximar la distribución
de este estadístico
Aunque resulta
complicado
exacta de
este
estadístico,
aproximaciones
que
funcionan derivar
bien en la
la distribución
práctica. El método
más
utilizado
es laexisten
aproximación
t de Student
será más
dispersa quede
la este
empleada
en el mediante
caso de igualdad
de distribución
Welch, que permite
aproximar
la distribución
estadístico
una t dede
Student
mediante una t de Student con los siguientes grados de libertad
diversas
aproximaciones
que
funcionan
bien
en
la
práctica.
El
método
más
utilizado
es
con los siguientes grados de libertad
varianzas. Esto es lo que cabría esperar ya que, al estimar por separado las varianzas, la
2
la aproximación de Welch, que permite
de este estadístico
( s12 aproximar
/ n1 + s 22 / nla2 )distribución
d
=
.
distribución resultante ha de
conllevará una
( s12reflejar
/ n1 ) 2 /(mayor
n1 − 1)incertidumbre.
+ ( s 22 / n 2 ) 2 /(nEsto
2 − 1)
mediante una t de Student con los siguientes grados de libertad
disminución
tantoque
en la
precisión
los intervalos
en la
potencia
de t
Puede
comprobarse
d es
siempredeinferior
o igual de
a nconfianza
es decir,
esta
distribución
1 + n2 – 2; como
que d que
es siempre
inferior
o
igual
a
n
+
n
–
2;
es
decir,
esta
de Puede
Studentcomprobarse
será más dispersa
la empleada
en
el
caso
de
igualdad
de
varianzas.
Esto
es
lo que
1
2
( s12 / n1 + s 22 / n 2 ) 2
los contrastes.
cabría
esperar ya que, al destimar
la distribución
resultante ha de
= 2 por 2separado las varianzas,
.
s 22disminución
( sEsto
/ n1 conllevará
)dispersa
/(n1 − 1que
) +una
(la
/ n 2 ) 2 /(n 2en− tanto
1) casoendelaigualdad
distribución
de Student será
empleada
el
de de los
1 más
reflejar
mayor tincertidumbre.
precisión
En eldecaso
de distribuciones
distinta
el intervalo de confianza al 100(1 intervalos
confianza
como en lacon
potencia
devarianza,
los contrastes.
varianzas. Esto es lo que cabría esperar ya que, al estimar por separado las varianzas, la
Puede
comprobarse
que d es con
siempre
inferior
o igual
n1 + n2 –de2;confianza
es decir, esta
En el caso
de distribuciones
distinta
varianza,
el aintervalo
al 100(1 – α)%
α)% para la diferencia de medias poblacionales μ1 - μ2 vendrá determinado por
μ2 vendrá determinado
por
para
la diferencia
de medias
μ1 –incertidumbre.
distribución
resultante
ha poblacionales
de reflejar mayor
Esto conllevará
una
distribución t de Student será más dispersa que la empleada en el caso de igualdad de
2
90
2
s2
disminución tanto en la precisión de los intervaloss1de confianza
como en la potencia de
− x 2 ± ya
+
,por separado las varianzas, la
t d ,1−que,
varianzas. Esto es lo que cabríax1esperar
α / 2 al estimar
n1 n 2
los contrastes.
distribución
de reflejar
mayor incertidumbre.
Esto
conllevará
una forma, para
donde
d son losresultante
grados dehalibertad
calculados
según la fórmula
anterior.
De igual
donde
dlason
los
según
laelfórmula
De de
igual
forma,
contrastar
hipótesis
nulade
H0libertad
: µ1 =con
µ2calculados
frente
alternativa
H1: μ1 anterior.
≠ de
μ2 aconfianza
partir
dos
muestras
En el
caso
degrados
distribuciones
distintaa la
varianza,
intervalo
al 100(1
disminución
tanto
en
la
precisión
de
los
intervalos
de
confianza
como
en
la
potencia
de
independientes con distinta varianza, se emplea el estadístico
H1: μ1 ≠ μpor
para
contrastar
la hipótesis
nula Hpoblacionales
0: μ1 = μ2 frente
2 a partir de
α
)%contrastes.
para la diferencia
de medias
μ1 a- la
μ2alternativa
vendrá determinado
los
x1 − x 2
,
t=
dos muestras independientes con distinta varianza,
el estadístico
s12 s 22 2se emplea
En el caso de distribuciones con distinta varianza,
+ s1 els 22intervalo de confianza al 100(1 ,
x1 − x 2 ± t d ,1n−α1 / 2 n 2 +
n1 n 2
)% para
la diferencia
poblacionales
μ1 - μ2 vendrá
determinado
porcon d grados
queαbajo
la hipótesis
nula,de
se medias
distribuye
aproximadamente
según una
t de Student
19
bajo Así,
la hipótesis
se distribuye
según una
t de más
Student
con d que
de que
libertad.
el valor nula,
P viene
dado por laaproximadamente
probabilidad de obtener
valores
extremos
dondeobservado
d son los de
grados
calculados
la fórmula
anterior.
igual forma,
el valor
t bajodelalibertad
distribución
td. Estesegún
contraste
se conoce
con elDe
nombre
de test de
s12 s 22
grados
de
libertad.
Así,
el
valor
P
viene
dado
por
la
probabilidad
de
obtener
valores
más
−
±
+
,
x1 x 2 t d ,1−α / con
la t de Student para muestras independientes
distinta varianza.
2
2
H1: μ1 ≠ μ2 a partir de
para contrastar la hipótesis nula H0: μ1 = μ2 frentena1 la nalternativa
extremos R.que el valor observado de t bajo la distribución td. Este contraste se conoce
Pastor-Barriuso
dos
muestras
independientes
con distinta
varianza,
estadístico
donde
d son los
grados de libertad
calculados
segúnselaemplea
fórmulaelanterior.
De igual forma,
con el nombre de test de la t de Student para muestras independientes con distinta
Ejemplo 6.11 En el Ejemplo 6.10 se contrastó que
HDL difiere significativamente entre los casos de infarto y los sujetos libres de la
independientes con distinta varianza. La estimación puntual
de la significativamente
diferencia de
HDL difiere
entre los casos de i
enfermedad. Por ello, la comparación del nivel medio
de colesterol
entreindependientes
Comparación
de medias en HDL
dos muestras
medias es x ca - x co = 0,98 - 1,09 = -0,11 mmol/l, cuyo
error estándar
se estima
enfermedad.
Por ello,
la comparación del nivel med
casos y controles ha de realizarse mediante la prueba t de Student para muestras
directamente
casos
y controlesdel
ha colesterol
de realizarse
mediante la prue
Ejemplo
6.11porcon
En el
Ejemplo
6.10 seLacontrastó
quepuntual
la variabilidad
HDL
independientes
distinta
varianza.
estimación
de la diferencia
de
difiere significativamente entre los casos de infarto y los sujetos libres de la enfermedad.
conydistinta
varianza.
Por ello, la comparación del nivel2 medio2 de colesterol
HDL2 entre casos
controles
ha de La estimación
2 independientes
medias es x ca - x co = 0,98 - 1,09
0,25 cuyo
0,error
29 estándar se estima
s ca= -0,11
s co mmol/l,
realizarse mediante
t
de
Student
para
muestras
independientes
con
distinta
SE( x ca la
- xprueba
)
=
+
=
+
=
0,017.
co
462de medias
539 es x ca − x co == 0,98 –- 1,09
co
1,09 ==-0,11 mmol/l, c
varianza. La estimación puntualn cade landiferencia
directamente por
– 0,11 mmol/l, cuyo error estándar se estima directamente por
directamente
En el caso de varianzas heterogéneas, los grados de libertad
para lapor
distribución
2
2
2
2
0,25
0,29
s ca s co
+
=
+
= 0,017.
SE( x ca − x co ) =
de la diferencia de medias vienen
por la aproximación
de Welch, a
462
539
n cadeterminados
n co
0,25 2
s ca2
s co2
+
=
SE( x ca - x co ) =
462
n cala n co
En
el caso de varianzas heterogéneas, los grados de libertad para la distribución de
saber
En el caso de
de medias
varianzas
heterogéneas,
los grados
de libertad para
distribución
diferencia
vienen
determinados
por la aproximación
delaWelch
En el caso de varianzas heterogéneas, los grados de
( s ca2vienen
/ n ca +determinados
s co2 / n co ) 2 por la
de la diferencia de medias
aproximación de Welch, a
d
=
2
2
2 de libertad
2
Notar que, en(este
ejemplo,
los
grados
son
casi
s ca / n ca ) (n ca − 1) + ( s co / n co ) (n co − 1) iguales a los obtenidos
de la diferencia de medias vienen determinados po
saber
2
2
2
bajo
asunción
de igualdad
de grados
(nca/ +
ncoson
= 999).
A partir
de estos
(0,25
/varianzas
462 + de
0,29
539
) – 2casi
Notarlaque,
en
los
libertad
iguales
a los,97
obtenidos
= este ejemplo,
=
998
.
saber
2
2
2 / 539)
(0,25 2 / 462( s) 22 /(462
− s1)2 +/ n(0,29
(539 − 1)
n
+
)
ca
ca IC co
co para μca - μco como
resultados,
calcular
al 95%
bajo la asunción
de igualdad
deunvarianzas
(nca2 + nco – 2 = 999). A partir de estos
d es
= posible
2
2
2
Notar que, en (este
ejemplo,
los
grados
de
son− 1casi
(n co
) iguales a los obtenidos
s ca / n ca ) (n ca − 1) + ( s co / nlibertad
co )
( s ca2 / bajo
n ca +las co2 / n co ) 2
d = de estos resultados es
asunción
de varianzas
(nca 95%
+ ncopara
– 2 μ= 999).
A partir
resultados,deesigualdad
posible
2un IC alSE
x ca - calcular
x co(0±,25
t998,97;0,975
(29
x ca2 /-539
x co)ca
)2 - μco como ( s ca2 / n ca ) 2 (n ca − 1) + ( s co2 / n co ) 2 (n co
/
462
+
0
,
posible calcular
para μca – μco como
= un 2IC al 95%
= 998,97.
2
(0,25 / 462) (462 − 1) + (0,29 2 / 539) 2 (539 − 1)
20 2 / 462 + 0,29 2 / 539)
(0,25
-0,11 ± 1,96⋅0,017
=)(-0,14; -0,08),=
x ca − x co ± =
t998,97;0,975
SE ( x ca − x co
(0,25 2 / 462) 2 (462 − 1) + (0,29 2 / 539
= − 0,11 ± 1,96⋅0,017 = (−0,14; −0,08),
y contrastar la hipótesis nula H0: μca = μco mediante el estadístico
y contrastar la hipótesis nula H0: μca = μco mediante el estadístico
20
y contrastar la hipótesis nula Hx0ca: μ−cax=co μco mediante
− 0,11 el estadístico
= −6,44,
t=
=
SE ( x ca − x co ) 0,017
− x co estandarizada,
- 0,11
que bajo la distribuciónt t=998,97 xocanormal
corresponde a un valor P menor
=
= -6,44,
SE
x
−
x
(
)
0,017
ca
co
que bajo
0,001.
Así,
se
pone
de
manifiesto
que
los
casos
de
infarto presentan
un nivel
a un valor
P medio
la distribución t998,97 o normal estandarizada, corresponde
de colesterol HDL significativamente inferior que los sujetos libres de la enfermedad
(P
0,001),
con una
estimada
en 0,11
mmol/l
(IC
95%
0,08-0,14
mmol/l).
menor
que
Así,diferencia
set poneode
manifiesto
que los
casos
de al
infarto
presentan
normal
estandarizada,
corresponde
a un
valor Pun
que<bajo
la 0,001.
distribución
998,97
En este caso, los resultados obtenidos asumiendo homogeneidad o heterogeneidad de
varianzas
idénticos
debido, que
en parte,
a que
tamaños
muestrales
nivel
devirtualmente
colesterol
HDL
significativamente
inferior
que
los sujetos
libres
menormedio
queson
0,001.
Así, se pone
de
manifiesto
los
casos
de ambos
infarto
presentan
un
no difieren sustancialmente.
de
la enfermedad
(P < 0,001),
una diferencia estimada
en 0,11
mmol/llibres
(IC al
nivel
medio de colesterol
HDLcon
significativamente
inferior que
los sujetos
En resumen, la comparación de medias en muestras independientes requiere contrastar en
mmol/l).
En este
resultados
obtenidos
asumiendo
delugar
la 0,08−0,14
enfermedad
(Pde
< 0,001),
concaso,
una los
diferencia
estimada
en 0,11
mmol/l
(IC de
al la t de
primer95%
la igualdad
varianzas,
para
después
utilizar
según
proceda
el test
Student con igual o distinta varianza. Esta distinción no es meramente académica: si la
homogeneidad
ommol/l).
heterogeneidad
varianzas
son virtualmente
debido,
variabilidad
difiere entre
ambas
procedimientos
estimación
y contraste
95% 0,08−0,14
Enpoblaciones,
este de
caso,
loslos
resultados
obtenidosdeidénticos
asumiendo
asumiendo igualdad de varianzas pueden ser muy engañosos, particularmente en muestras
en
parte,
a que ambos
no difieren
sustancialmente.
n2 difieran
sustancialmente.
pequeñas
o moderadas
cuyostamaños
tamañosmuestrales
nde
homogeneidad
o heterogeneidad
son
virtualmente
idénticos debido,
1 yvarianzas
en parte, a que ambos tamaños muestrales no difieren sustancialmente.
En resumen, la comparación de medias en muestras independientes requiere
contrastar
en primer
lugar la igualdad
de varianzas,
paraindependientes
después utilizar
según proceda
En resumen,
la comparación
de medias
en muestras
requiere
el
test de laent de
Student
con
o distinta
varianza.
Esta
distinción
no es
meramente
contrastar
primer
lugar
la igual
igualdad
de varianzas,
para
después
utilizar
según
proceda
Pastor-Barriuso R.
académica:
la Student
variabilidad
difiere
entre ambas
poblaciones,
los procedimientos
de
el test de la si
t de
con igual
o distinta
varianza.
Esta distinción
no es meramente
91
Inferencia sobre medias
6.4
COMPARACIÓN DE MEDIAS EN DOS MUESTRAS DEPENDIENTES
Los datos dependientes surgen cuando las observaciones recogidas en el estudio están
correlacionadas entre sí. A continuación se presentan algunos mecanismos y diseños
epidemiológicos que generan datos dependientes:
yy La obtención de dos o más determinaciones de la misma variable en un mismo sujeto da
lugar a datos dependientes, que pueden presentarse como:
Diferentes medidas de la misma variable en un momento determinado, habitualmente
para aumentar la fiabilidad del instrumento de medida.
Determinaciones de la misma variable en diferentes localizaciones anatómicas.
Medidas repetidas en el mismo sujeto a lo largo del tiempo, bien sea en comparaciones
antes y después de un tratamiento, en ensayos clínicos cruzados o en estudios de medidas
repetidas con visitas sucesivas.
yy La selección de los participantes en un estudio emparejándolos por determinadas
características pronósticas genera datos dependientes entre los sujetos emparejados. El
ejemplo más habitual es el emparejamiento en el diseño de los estudios de casos y controles.
yy Los datos de estudios procedentes de sujetos de una misma familia o de animales
pertenecientes a la misma camada suelen ser también dependientes.
En todos estos casos, la correlación se limita a los grupos específicos donde se genera la
dependencia, que suelen ser habitualmente parejas. Así, en un estudio de casos y controles
emparejados, los datos de cada pareja son dependientes, pero los datos de las distintas parejas
son independientes entre sí. Igualmente, en un estudio de medidas repetidas, los datos de un
mismo individuo son dependientes, mientras que los resultados en diferentes individuos son
independientes entre sí.
Las muestras dependientes están constituidas por observaciones en los mismos sujetos o en
distintos sujetos emparejados según ciertas características pronósticas de interés. De esta forma,
la distribución de dichas características será similar en ambas muestras, eliminando así la
posibilidad de que estos factores influyan en la comparación objeto de estudio. En general, el
emparejamiento es una técnica frecuentemente utilizada en el diseño de estudios clínicos o
epidemiológicos con el propósito de controlar por determinados factores de confusión (ver
textos de método epidemiológico referenciados al final del tema). Estos diseños requieren de
técnicas específicas de análisis que preserven el emparejamiento. En este apartado se revisan
los métodos estadísticos para el tratamiento de un caso específico de dependencia, en el que se
dispone de dos determinaciones de una variable continua para cada pareja de datos dependientes.
Ejemplo 6.12 Supongamos que en el estudio EURAMIC se seleccionan
aleatoriamente 50 casos de infarto de miocardio. Como la edad es un importante factor
pronóstico de enfermedades coronarias, cada uno de estos casos se emparejó por grupos
quinquenales de edad a un control libre de la enfermedad. Así, por ejemplo, para un caso
de 62 años de edad se seleccionó aleatoriamente un control entre todos los controles
disponibles con edades comprendidas entre 60 y 64 años. La muestra resultante de aplicar
este procedimiento constituiría un estudio de casos y controles emparejados. En este
estudio, cabría esperar un cierto grado de correlación en la información recogida para
cada pareja, dado que tanto el caso como el control se encuentran en el mismo rango de
edad. En la Tabla 6.1 se presentan los niveles de colesterol HDL en las 50 parejas de casos
y controles.
92
Pastor-Barriuso R.
Comparación de medias en dos muestras dependientes
Tabla 6.1 Colesterol HDL en 50 casos y controles del estudio EURAMIC emparejados
según grupos quinquenales de edad.
Colesterol HDL (mmol/l)
Pareja
1
Colesterol HDL (mmol/l)
Caso
Control
d*
Pareja
0,81
0,63
0,18
26
2
0,91
0,91
0,00
27
3
0,98
0,76
0,22
28
4
0,91
1,19
– 0,28
29
5
0,55
0,99
– 0,44
30
6
0,62
1,14
– 0,52
31
7
0,79
0,73
0,06
32
8
0,89
1,08
– 0,19
33
9
1,24
0,87
0,37
34
10
1,76
1,04
0,72
35
11
1,35
1,03
0,32
36
12
0,72
1,09
– 0,37
37
13
0,94
1,12
– 0,18
38
14
1,01
1,20
– 0,19
39
15
0,98
1,62
– 0,64
40
16
0,92
1,25
– 0,33
41
17
0,68
1,31
– 0,63
42
18
1,48
1,00
0,48
43
etar el problema, supongamos
que
se
dispone
de
n
pares
de
observaciones
19
1,23
0,78
0,45
44
20
0,83
0,95
– 0,12
45
e aleatoria continua. 21
En cada pareja
de datos1,13
dependientes,
una 46
0,92
– 0,21
22
0,82
0,97
– 0,15
47
corresponde a la primera muestra y la otra observación x2 a la segunda
23
1,21
0,74
0,47
48
24
0,78
0,88
– 0,10
49
jetivo se centra en comparar las medias poblacionales μ1 y μ2 a partir de
25
0,88
1,14
– 0,26
50
Control
d*
0,96
1,29
– 0,33
1,33
0,93
0,32
0,86
0,93
1,40
1,50
0,92
0,88
0,82
1,52
1,68
0,81
0,60
1,16
0,75
0,96
1,46
0,76
0,76
1,12
1,01
0,99
0,75
0,72
1,04
1,54
1,08
1,12
1,75
1,29
1,17
0,93
0,88
0,74
1,45
1,02
1,15
1,49
0,98
1,31
1,15
1,51
1,01
1,26
0,91
1,63
1,45
0,61
– 0,11
– 1,22
– 0,22
– 0,19
– 0,35
0,21
– 0,25
– 0,05
– 0,06
0,78
0,23
– 0,21
– 0,55
– 0,33
– 0,23
– 0,35
0,31
– 0,75
– 0,25
– 0,14
0,10
– 0,64
– 0,70
Caso
* Diferencia de colesterol HDL entre caso y control.
stras dependientes.
imientos desarrollados en el Apartado 6.3 no pueden aplicarse a esta
Para concretar el problema supongamos que se dispone de n pares de observaciones de una
variable
En cada pareja de
dependientes,
una observación x1 corresponde
ue las medias de ambasaleatoria
muestrascontinua.
no son independientes
pordatos
provenir
de
a la primera muestra y la otra observación x2 a la segunda muestra. El objetivo se centra en
comparar
las medias
poblacionales
μ1 y μ2 a partir
de estas dos muestras dependientes.
correlacionadas.
Sin embargo,
la comparación
se simplifica
notablemente
Los procedimientos desarrollados en el Apartado 6.3 no pueden aplicarse a esta situación, ya
las diferencias dque
= x1las
- x2medias
en cadadeuna
de lasmuestras
n observaciones
ambas
no son emparejadas.
independientes por provenir de observaciones
correlacionadas. Sin embargo, la comparación se simplifica notablemente si se calculan las
omo las distintas
parejas nodestán
entre
diferencias emparejadas. Por un lado, como las
x2 en cada una
desí,lasestas
n observaciones
diferencias
= x1 –relacionadas
distintas parejas no están relacionadas entre sí, estas diferencias son independientes. Por otro
lado, la
la media
media de
de las
las diferencias
diferencias d coincide
entes. Por otro lado,
coincide con
con la
la diferencia de medias muestrales,
medias muestrales,
d=
=
1 n
1 n
=
d
( x i1 − x i 2 )
i
n
n i =1
i =1
1
1
x i1 − xi 2 = x1 − x 2
n i =1
n i =1
n
n
Pastor-Barriuso R.
93
n
i =1
n
i =1
n
son independientes.
otro lado,
la
media1den las diferencias d coincide con la
rrollados en el Apartado
6.3 no puedenPor
aplicarse
a 1esta
=
x i1 − xi 2 = x1 − x 2
Inferencia sobre medias
n i =1
n i =1
diferencia
de medias muestrales,
de ambas muestras
no son independientes
por provenir de
donde sd es la desviación típica de las diferencias observadas. De igual forma, la
consecuencia,
d es un estimador
insesgado
de la diferencia de medias
das. Sin embargo, y,
la en
comparación
se simplifica
notablemente
1 n
1 n
= d i = H: (μx i1=−μx i 2puede
)
hipótesis de igualdad de mediasdpoblacionales
contrastarse frente a la
0
1
2
n i =1 de la
n comparación
i =1
poblacionales
de medias en dos muestras
1 - μ2. Así, el problema
s d = x - x en cada
una de las n μobservaciones
emparejadas.
1
2
1 n el estadístico
1 n
hipótesis alternativa H1: μ1 ≠ μ2 mediante
x i1 − inferencia
x1 − xla
dependientes
a=una
simple
2 media de una única
tas parejas no están
relacionadasqueda
entrereducido
sí, estas diferencias
xi 2 = sobre
n i =1
n i =1
muestra
de n diferencias
independientes.
d de la diferencia de medias poblacionales μ1 – μ2.
d es
coincide
con la insesgado
o lado, la mediay,deen
las
diferencias
consecuencia,
un estimador
.
t=
s d en dosde
Así,y,elenproblema
de la comparación
de medias
muestras
dependientes
queda reducido a
consecuencia,
d es un estimador
insesgado
la diferencia
de medias
Los métodos
delsobre
Apartado
6.2.1de
para
media
de unade
muestra
pueden independientes.
entonces
n muestra
rales,
una simple
inferencia
la media
unalaúnica
n diferencias
poblacionales
μ1 -Apartado
μ2. Así, el6.2.1
problema
demedia
la comparación
de medias
en dos
muestras
Los
métodos
para
de
muestra
pueden
entonces
utilizarse
utilizarse
paradel
calcular un intervalo
de la
confianza
al una
100(1
- α)% para
μ
1 - μ2 como
n
n
la hipótesis
nula, las de
diferencias
distribuirían
para calcular
un intervalo
confianzaobservadas
al 100(1 – se
α)%
para μ – μaleatoriamente
1
1Bajo
2 como
d = di =
( x i1 − x i 2 ) queda reducido a una simple inferencia sobre1 la media
dependientes
de una única
n i =1
n i =donde
1
la desviación
típica de
diferenciassobservadas.
Dedistribución
igual forma,t de
la
d esvalor
d seguiría una
alrededor sdel
0, de tal forma
quelas
deste
± testadístico
,
n −1,1−α / 2
n
nmuestra de n diferencias independientes.
1
1
n
= x i1 − Student
= x1de
−- igualdad
xi 2 con
x12 grados de
contrastarse
frente a la
hipótesis
medias
poblacionales
H0: μ1 = μ2 puede
n
de
liberad.
El
valor
P
corresponderá,
por tanto,
a la
n i =1
n i =1
donde
sd esmétodos
la desviación
típica de
las para
diferencias
observadas.
De igual
forma,
la hipótesis de
Los
del Apartado
6.2.1
la media
de una muestra
pueden
entonces
igualdad
de medias
µ1 =valores
µ2 el
puede
contrastarse
frente
la hipótesis
alternativa
hipótesis
alternativa
H1: μ1 ≠ μt2H
mediante
estadístico
0:para
probabilidad
bajo lapoblacionales
distribución
más
extremos que
el avalor
observado
n-1
H
:
µ
≠
µ
mediante
el
estadístico
para calcular
un intervalo de confianza al 100(1 - α)% para μ1 - μ2 como
1 utilizarse
1 de 2la diferencia
n estimador insesgado
de medias
24
de t. Esta prueba se denomina habitualmente como el test de la t de Student para
d
.s d
el problema de la comparación de medias en dos muestrast =
s
d
d
t
±
,
n −1,1−α / 2
muestras dependientes.
n n
o a una simple inferencia sobre la media de una única
Bajo la hipótesis nula, las diferencias observadas se distribuirían aleatoriamente alrededor del
Ejemplo
6.13 nula,
Para
preservar
el emparejamiento
entre
los casos
yStudent
controles
Bajo
la
las diferencias
observadas
distribuirían
aleatoriamente
0,
dehipótesis
tal forma
que este
estadístico
seguiría
unase
distribución
t de
conde
n –la1 grados
dependientes. valor
libertad. Elque
valor
corresponderá,
a la probabilidad bajo la distribución tn–1 para
ar el problema,de
supongamos
se P
dispone
de n parespor
detanto,
observaciones
d = xca una
-sexcodenomina
en cada pareja.
Tabla
6.1,
se
calcula
la
diferencia
de
colesterol
alrededor
del
valor
0,
de
tal
forma
que
este
estadístico
distribución
t de 24
do 6.2.1 para la valores
media demás
unaextremos
muestra pueden
que el entonces
valor observado de t. HDL
Estaseguiría
prueba
habitualmente
comoEn
el cada
test de
la t de
para muestras
aleatoria continua.
pareja
de Student
datos dependientes,
una dependientes.
Como
puede
apreciarse,
predominan
las
parejas
donde el caso
un nivel
Student
con
n
1
grados
de
liberad.
El
valor
P corresponderá,
porpresenta
tanto, a la
ntervalo de confianza al 100(1 - α)% para μ1 - μ2 como
Ejemplo
6.13y laPara
el emparejamiento
corresponde a la primera
muestra
otrapreservar
observación
x2 a la segundaentre los casos y controles de la Tabla 6.1,
inferior debajo
colesterol
HDL quetn-1
supara
correspondiente
control
(diferencias
negativas).
probabilidad
la distribución
valores
extremos
que el
valor
observado
se
calcula
la
diferencia
de
colesterol
HDL
d = xca –más
xco en
cada pareja.
Como
puede
apreciarse,
sd
d
t
±
,
n −1en
,1−α comparar
/ 2 predominan
las parejas
donde el caso
presenta
undenivel inferior de colesterol HDL que su
μ1 y μ
etivo se centra
las medias
poblacionales
2 a partir
hecho,
la media
de estashabitualmente
diferencias
nEsta
de tDe
.correspondiente
prueba
secontrol
denomina
como
el hecho,
test delalamedia
t de Student
(diferencias negativas). De
de estas para
diferencias
tras dependientes.
muestras dependientes. 1 50
0,18 + 0,00 + ... − 0,70
d=
di =
= −0,12
mientos desarrollados en el Apartado 6.3 no50
pueden
aplicarse a esta
50
i =1
24
Ejemplo
6.13 Para
el en
emparejamiento
entre los casos y controles de la
es muestras
una
estimación
lapreservar
diferencia
nivel medio
ue las medias de ambas
no sonde
independientes
porelprovenir
de de colesterol HDL entre los casos de
50
es
una estimación
la1diferencia
en el nivelLa
medio
de colesterol
HDL entre
losdada por
infarto
y los sujetos2delibres
de la enfermedad.
varianza
de las diferencias
viene
(d i − d ) 2de colesterol HDL d = xca - xco en cada pareja.
s d = la
Tabla 6.1, se calcula
diferencia
49 ise
correlacionadas. Sin embargo, la comparación
=1 simplifica notablemente
1 50 libres de2 la enfermedad. La varianza de las
casos de infarto y los
sujetos
2
(d i − d2 ) las parejas donde2 el caso presenta un nivel
sd =
Como puede apreciarse,
predominan
(n49
0observaciones
,18
+ (−0,70 + 0,12)
i =1+ 0,12) + ...
as diferencias d = x1 - x2 en cada una de las
emparejadas.
=
= 0,16,
diferencias viene dada por
49
2
2
inferior de colesterol
control
(diferencias negativas).
(0HDL
,18 + 0que
,12)su +correspondiente
... + (−0,70 + 0,12
)
mo las distintas parejas no están relacionadas
= entre sí, estas diferencias
= 0,16,
49
De el
hecho,
media de estas
luego
error la
estándar
d es diferencias
error
de d es
ntes. Por otro lado, laluego
mediaelde
las estándar
diferencias
coincide con la
luego el error estándar de d es
1 50
,00 + ... − 0,70
s0d,18 +0,040
medias muestrales,
d = SE
(dd)i ==
=
= 0,057 . = −0,12
50 i =1
n
50 50
sd
0,40
SE (d ) =
=
= 0,057 .
25
1 n
1 n
n
50
d = d i = ( x i1 − x i 2 )
es
una
estimación
de
la
diferencia
en
el
nivel
medio
de
colesterol
HDL
entre
los
elR.
94 Pastor-Barriuso
n i =Así,
nICi =1al 95% para la diferencia de medias poblacionales μca - μco se obtiene
1
=
n
1 ncomo
μca - μco de
se las
obtiene
Así,
el 1ICde
alinfarto
95% para
diferencia
dede
medias
poblacionales
casos
y loslasujetos
libres
la enfermedad.
La varianza
−
x
xi 2 = x1 − x 2
1
i
n i =1
n i =1
SE (d ) =
=
= 0,057 .
n
50
Así, el IC al 95% para la diferencia de medias poblacionales μca - μco se obtiene
Así, el IC al 95% para la diferencia de medias poblacionales μca - μco se obtiene
como
Referencias
como
Así, el IC al 95% para
d ± la
t diferencia
SE( d de
) medias poblacionales μca – μco se obtiene como
49;0,975
d ± t49;0,975
SE( d±) 2,01⋅0,057 = (-0,23; -0,01),
= -0,12
= −0,12 ± 2,01⋅0,057 = (− 0,23; − 0,01),
y la hipótesis nula H0: μca = μco se contrasta mediante el test estadístico
y la hipótesis nula H0: μca = μco se contrasta mediante el test estadístico
y la hipótesis nula H0: μca = μco se contrasta mediante el test estadístico
d
− 0,12
t=
= − 2,13,
=
SE (d ) 0,057
d
− 0,12
t=
=
= -2,13,
cuyo valor P asociado en la distribución
es P = 2P(t49 ≤ – 2,13) = 2∙0,019 = 0,038. De
SE (d ) t049,057
cuyoestudio
valor Pdeasociado
la distribución
t49 espuede
P = 2P(t
= 2⋅0,019
este
casos y en
controles
emparejados
entonces
concluirse
que =la media del
49 ≤ -2,13)
colesterol HDL en los casos de infarto es inferior en 0,12 mmol/l al nivel medio de
= 2P(t49
≤ -2,13)
= 2⋅0,019
=
cuyo
valor P asociado
en la0,01-0,23
distribución
t49 es Psiendo
0,038.
los
controles
(IC al 95%
mmol/l),
esta
diferencia
estadísticamente
significativa (P = 0,038). Esta conclusión es consistente con la obtenida en el Ejemplo
0,038.
De
este
de casos
y controles
emparejados, de
puede
concluirse
que cabe
6.11
paraestudio
las muestras
completas
e independientes
casosentonces
y controles.
No obstante,
destacar las siguientes particularidades. Por un lado, esta estimación está sujeta a mayor
este estudio
de casos
y controles
emparejados,
puede
entonces
concluirse
laDemedia
del aleatoria
colesterol
en los
de50
infarto
es de
inferior
en
0,12
mmol/l
al
variabilidad
yaHDL
que
tan
sólocasos
utiliza
parejas
casos
y controles.
Porque
otro lado,
el diseño emparejado permite comparar casos con controles de similar edad y, en
la media
delde
colesterol
HDL(IC
en los
casos0,01−0,23
de infartommol/l),
es inferior
en 0,12
al
nivel
medio
losestimación
controles
95%
siendo
estammol/l
diferencia
consecuencia,
la
seráal menos
propensa a posibles
sesgos
derivados de la
diferencia de edad entre casos y controles.
nivel medio de los
controles (IC
95% 0,01−0,23
mmol/l),essiendo
esta diferencia
estadísticamente
significativa
(P =al0,038).
Esta conclusión
consistente
con la
Los procedimientos presentados en este apartado se limitan a la comparación de una variable
estadísticamente
significativa
(P las
= 0,038).
Esta conclusión
es consistente con
obtenida
Ejemplo
6.11emparejadas
para
muestras
independientes
de la de dos
continua
a partirendeeldos
muestras
sujeto acompletas
sujeto. Eleanálisis
de la varianza
vías permite extender esta comparación a casos más generales de dependencia, tales como el
obtenida
en el Ejemplo
6.11 para lasdestacar
muestraslascompletas
e independientes dePor
y controles.
siguientes
diseñocasos
de parejas
con másNo
deobstante,
un sujetocabe
por muestra (por
ejemplo, unparticularidades.
estudio de casos y controles
donde cada caso se empareja con 2 controles) o la comparación de tres o más muestras
casos
y controles.
No obstante,
cabe
destacar
las siguientes
particularidades.
Por
un
lado,
estaejemplo,
estimación
sujeta
a mayor
variabilidad
aleatoria
que tantratamientos
solo
dependientes
(por
un está
ensayo
clínico
donde
cada paciente
recibeya
diversos
alternativos). Los métodos de análisis de la varianza de dos vías pueden consultarse en los
un lado,
estimación
está
sujeta a mayor
variabilidad
aleatoria
ya que tan solo
50esta
parejas
de acasos
y controles.
Por otro
lado, el diseño
emparejado
textosutiliza
estadísticos
citados
continuación.
utiliza 50 parejas de casos y controles. Por otro lado, el diseño emparejado
6.5
REFERENCIAS
26
1. Armitage P, Berry G, Matthews JNS. Statistical Methods in Medical Research, 26
Fourth
Edition. Oxford: Blackwell Science, 2001.
2. Bickel PJ, Doksum KA. Mathematical Statistics: Basic Ideas and Selected Topics.
Englewood Cliffs, NJ: Prentice Hall, 1977.
3. Breslow NE, Day NE. Statistical Methods in Cancer Research, Volume 1, The Analysis of
Case-Control Studies. Lyon: International Agency for Research on Cancer, 1980.
4. Casella G, Berger RL. Statistical Inference, Second Edition. Belmont, CA: Brooks/Cole,
2001.
5. Colton T. Estadística en Medicina. Barcelona: Salvat, 1979.
6. Fleiss JL. The Design and Analysis of Clinical Experiments. New York: John Wiley &
Sons, 1986.
Pastor-Barriuso R.
95
Inferencia sobre medias
7. Kleinbaum DG, Kupper LL, Morgenstern H. Epidemiologic Research: Principles and
Quantitative Methods. New York: John Wiley & Sons, 1982.
8. Kleinbaum DG, Kupper LL, Muller KE, Nizam A. Applied Regression Analysis and Other
Multivariable Methods, Third Edition. Belmont, CA: Duxbury Press, 1998.
9. Rosner B. Fundamentals of Biostatistics, Fifth Edition. Belmont, CA: Duxbury Press,
1999.
10. Rothman KJ, Greenland S, Lash TL. Modern Epidemiology, Third Edition. Philadelphia:
Lippincott Williams & Wilkins, 2008.
11. Snedecor GW, Cochran WG. Statistical Methods, Eighth Edition. Ames, IA: Iowa State
University Press, 1989.
12. Stuart A, Ord JK, Arnold S. Kendall’s Advanced Theory of Statistics, Volume 2A, Classical
Inference and the Linear Model, Sixth Edition. London: Edward Arnold, 1999.
96
Pastor-Barriuso R.
7.1 INTRODUCCIÓN
En el análisis de datos epidemiológicos es frecuente el estudio de variables dicotómicas,
que reflejan la presencia o ausencia deTEMA
una determinada
7 característica en los miembros
de una población. El interés radica fundamentalmente en estimar la proporción de
INFERENCIA SOBRE PROPORCIONES
individuos o elementos de la población que presentan dicha característica.
Esta proporción poblacional es un parámetro desconocido que se estima mediante
7.1 INTRODUCCIÓN
la proporción muestral p = k/n, donde k es el número observado de individuos que
En el análisis de datos epidemiológicos es frecuente el estudio de variables dicotómicas, que
reflejan
la presencia
o ausencia
de unaendeterminada
en losn.miembros
de una
presentan
la característica
de interés
una muestra característica
aleatoria de tamaño
La
población. El interés radica fundamentalmente en estimar la proporción π de individuos o
elementos
de lamuestral
población
dicha
característica.
distribución
deque
unapresentan
proporción
ya se
discutió en el Apartado 4.3.4.
Esta proporción
π eesindependientes.
un parámetro Para
desconocido
que sedeestima
mediante la
partir
de muestraspoblacional
dependientes
cada problema
inferencia
Brevemente,
recordamos
una
muestral
p tiende
distribuirse
depresentan
forma
proporción
p = k/n,que
donde
kproporción
esproblema
el número
de aindividuos
que
la
de muestras dependientes
emuestral
independientes.
Para
cada
de observado
inferencia
sobre
proporciones
se
presentará
un
estimador
puntual
del
parámetro
poblacional
objeto
característica de interés en una muestra aleatoria de tamaño n. La distribución muestral de una
normal con
y varianza
(1parámetro
- )/n,
ya
se
discutió
en el Apartado
4.3.4. poblacional
Brevemente,objeto
recordamos que una proporción
proporciones seproporción
presentará
unmedia
estimador
puntual
del
de
estudio,
un
intervalo
de
confianza
y
una
prueba
de
significación.
muestral p tiende a distribuirse de forma normal con media π y varianza π(1 – π)/n,
partir de muestras dependientes e independientes. Para cada problema de inferencia
udio, un intervalo de confianza y una prueba de significación.
~ N , (1 ) ,
p
del parámetro poblacional objeto
sobre
proporciones
se
presentará
un
estimador
puntual
n POBLACIONAL
7.2 INFERENCIA SOBRE UNA PROPORCIÓN
NFERENCIA SOBRE
UNA
PROPORCIÓN
POBLACIONAL
cuando
el tamaño
muestral
suficientemente
grande
y la proporción poblacional no es
de estudio,
un
intervalo
de es
confianza
y una prueba
de significación.
Con frecuencia
se muestral
desea
conocer
la
lade
individuos
unaaproximación
cierta
cuando
el tamaño
es suficientemente
y la proporción
no es
excesivamente
extrema,
de tal
forma
queproporción
se cumplagrande
condición
nπ(1que
– π)poseen
≥poblacional
5. Esta
se utilizará
de esteque
tema
de inferencia
sobre datos de carácter binario o
recuencia se desea
conocerrepetidamente
la proporción alo
delargo
individuos
poseen
una cierta
característica
enextrema,
la población.
Como
ya
enlaPOBLACIONAL
elcondición
Apartado n5.2,
dicotómico.
7.2 INFERENCIA
SOBRE
PROPORCIÓN
(1 la
- proporción
) 5. Esta
excesivamente
de talUNA
forma
queseseapuntó
cumpla
erística en la población.
Como
el Apartado
5.2,medias,
la proporción
Al igual
que ya
en se
el apuntó
tema deeninferencia
sobre
este capítulo aborda la estimación de
muestral p es un
buen
estimador
puntual adelolalargo
proporción
poblacional,
ya quesobre
p es el
aproximación
se
utilizará
repetidamente
de
estaproporciones
tema que
de inferencia
unaCon
proporción
poblacional,
así como
la comparación
de
a partir
muestras
frecuencia
se desea conocer
la proporción
de individuos
poseen
una de
cierta
ral p es un buendependientes
estimador puntual
de la proporción
ya quede
p es
el
e independientes.
Parapoblacional,
cada problema
inferencia
sobre proporciones se
estimador
insesgado
ypuntual
consistente
de con menor
error estándar.
datos
deun
carácter
binario
o dicotómico.
presentará
estimador
del
parámetro
poblacional
objeto de
estudio,
un intervalo de
característica
en la población.
Como
ya se apuntó
en el Apartado
5.2,
la proporción
ador insesgado confianza
y consistente
de prueba
con menor
error estándar.
y una
de significación.
Al
igual quelaen
el tema de inferencia
sobre
medias, este
capítulo
aborda
la la
Utilizando
aproximación
normal a la
distribución
muestral
de p,
se tiene
muestral p es un buen estimador puntual de la proporción poblacional, ya que p es el
lizando la aproximación
normal a la distribución
muestral
de p, se tiene
la
7.2estimación
INFERENCIA
SOBRE UNA
PROPORCIÓN
de una proporción
poblacional,
así comoPOBLACIONAL
la comparación de proporciones a
siguiente relación
estimador insesgado y consistente de con menor error estándar.
nte relación Con frecuencia se desea conocer la proporción π de individuos que poseen una cierta característica
en la población. Como ya se apuntó en el Apartado 5.2, la proporción muestral p es un buen
Utilizando la aproximación
normal apladistribución
de p, se tiene la
ya que p esmuestral
estimador puntual de la proporción
estimador insesgado y consistente
P z1 / 2poblacional,
z1 / el
1
2 1 ,
(1 ) / n
p estándar.
de π con menor error
relación
Psiguiente
z
z1 / 2 1 ,
1 / 2
(1 ) / n normala la distribución muestral de p, se tiene la siguiente relación
Utilizando
la aproximación
donde z1-/2 es el percentil
normal
1 - /2 de la distribución
estandarizada. El método
p
z1 / 2
P
z
/2 1 ,
z1-/2 es el percentil 1 - /2 de la distribución
El1método
normal estandarizada.
(
1
)
/
n
un intervalo de confianza consiste
en sustituir el error
más sencillo para obtener
encillo para obtener
intervalo
confianza
en distribución
sustituir el error
dondeunz1–α/2
es el de
percentil
1 –consiste
α/2 de la
normal estandarizada. El método más
estándar
de
p
por
su
estimación
p
(
1
p
)
/
n
y
despejar
la estandarizada.
proporción
sencillo
un intervalo
consistenormal
en sustituir
el error poblacional
estándar
de p por su
dondepara
z1-/2obtener
es el percentil
1 - de
/2 confianza
de la distribución
El método
estimación p (1 p ) / n yy despejar
dar de p por su estimación
despejar la
la proporción
proporción poblacional
poblacional
más sencillo para obtener un intervalo de confianza consiste en sustituir el error
p (1 p)
p(1 p)
1 .
p z1 / 2
P p z1 / 2
n
n
(
1
)
(
1
)
p
p
p
p
de
p
por
su
estimación
p
(
1
p
)
/
n
y
despejar
la
proporción
poblacional
1
p
z
P p z1estándar
.
/2
1 / 2
n
n
R.
Pastor-Barriuso
viene
Así, el intervalode confianza al 100(1 - )% para la proporción poblacional
p (1 p)
p(1 p)
zpara
poblacional
p z1 / 2 viene
1 / 2la proporción
l intervalo de confianza al 100(1P- p)%
1 .
n
n
dado por
97
zn
0 (1 0 )
,
n
n
Así, el intervalo de confianza al 100(1 - )% para la proporción poblacional viene
Inferencia sobre proporciones
cuya
distribución
será aproximadamente N(0, 1) si la hipótesis nula H0: = 0 es cierta.
dado
por
Así, el intervalo de confianza al 100(1 – α)% para la proporción poblacional π viene dado por
El valor P del test corresponde entonces a la probabilidad bajo la distribución normal
p(1 p )
p z1 / 2
.
estandarizada para valores más alejados de 0 que el nvalor observado de z.
Para realizar el contraste de la hipótesis nula H0: π = π0 frente a la alternativa bilateral H1: π ≠ π0,
puedeEjemplo
emplearse
el A
estadístico
Para
realizar
el
contraste
de controles
la hipótesis
H0:
= 0 frente se
a la
alternativa
7.1
partir
de los
delnula
estudio
EURAMIC,
pretende
estimar
p 0
z el estadístico ,
puede emplearse
bilateral
H1:
la proporción
de0, individuos
en la población
de dicho estudio que
0 (1 de
0referencia
)
n
presentan niveles de colesterol HDL inferiores o iguales a 0,90 mmol/l (niveles
2
cuya distribución será aproximadamente N(0, 1) si la hipótesis nula H0: π = π0 es cierta. El
bajos
según
el “National
Cholesterol
Education
Program”).
En kH=0normal
los
n=
valor
P
del
test
corresponde
entonces
a la probabilidad
la distribución
:158
=de
0estandarizada
es cierta.
cuya
distribución
será aproximadamente
N(0, 1) si bajo
la
hipótesis
nula
para valores más alejados de 0 que el valor observado de z.
539 controles
observaron entonces
valores inferiores
o igualesbajo
a este
El valor
P del testsecorresponde
a la probabilidad
la umbral,
distribución normal
Ejemplo 7.1 A partir de los controles del estudio EURAMIC, se pretende estimar la
obteniéndose
proporción
muestral
estandarizada
valores
más
de 0 que
el valor observado
z.
proporción para
deuna
individuos
enalejados
la población
de referencia
de dichode
estudio
que presentan
niveles de colesterol HDL inferiores o iguales a 0,90 mmol/l (niveles bajos según el
“National Cholesterol Education
k = 158 de los n = 539 controles se
p = k/nProgram”).
= 158/539 =En
0,293.
Ejemplo
7.1
A
partir
de
los
controles
del
estudio
EURAMIC,
se pretende
observaron valores inferiores o iguales a este umbral,
obteniéndose
una estimar
proporción
muestral
Dado
que np(1 - p)
111,7 5,enpuede
emplearse
aproximación
normal
paraque
la proporción
de =individuos
la población
de la
referencia
de dicho
estudio
p = k/n = 158/539 = 0,293.
presentan
colesterol
HDL inferiores
olaiguales
a 0,90 mmol/l
como
calcular
unnp(1
ICniveles
al– 95%
la≥proporción
poblacional
Dado
que
p) =depara
111,7
5, puede
emplearse
aproximación
normal(niveles
para calcular
un IC al 95% para la proporción poblacional π como
bajos según el “National Cholesterol Education Program”). En k = 158 de los n =
0,293(1 0,293)
0,293 z 0,975
539 controles se observaron valores539
inferiores o iguales a este umbral,
= 0,293 1,960,020 = (0,255; 0,332);
obteniéndose una proporción muestral
es decir, la proporción poblacional de sujetos con niveles bajos de colesterol HDL está
comprendida entre el 25,5 y el 33,2%
con=una
confianza
del 95%. Asimismo, para determinar
p = k/n
158/539
0,293.
es decir, la proporción poblacional
de sujetos
con=niveles
bajos de colesterol HDL
si los datos muestrales son compatibles con una proporción subyacente del 30%, se
contrastó la hipótesis H0: π = 0,30 versus H1: π ≠ 0,30 mediante el estadístico
estáDado
comprendida
25,5 y 5,
el puede
33,2% emplearse
con una confianza
del 95%.normal
Asimismo,
que np(1 entre
- p) =el111,7
la aproximación
para
p 0
0,293 0,30
z=
= 0,35,
para
determinar
datos
muestrales
son
compatibles
una proporción
para
0,30
(1 0,30) con
0 (1
0)
como
calcular
un ICsiallos
95%
laproporción
poblacional
n
539
subyacente del 30%, se contrastó la hipótesis H0: = 0,30 versus H1: 0,30
que corresponde a un valor P = 2P(Z
≤ –0,35)
= 2{1
0,293
(1 0,293
) – Φ(0,35)} = 0,726 en las tablas de
0
,
293
z
0 , 975
la distribución
normal
estandarizada
Apéndice).
Por= tanto,
que
corresponde
a un valor
P = 2P(Z (Tabla
-0,35)
= 2{1
- (0,35)}
0,726 puede
en las concluirse
mediante
el estadístico
5393 del
que la prevalencia poblacional de niveles bajos de colesterol HDL no es significativamente
distintadedel
tablas
la 30%.
distribución normal=estandarizada
(Tabla=3(0,255;
del Apéndice).
0,293 1,960,020
0,332); Por tanto,
concluirse que
prevalencia
poblacional
niveles
bajosasumen
de colesterol
Lospuede
procedimientos
de la
inferencia
presentados
en de
este
apartado
que el tamaño
es
decir,
la
proporción
poblacional
de
sujetos
con
niveles
bajos
de
colesterol
HDL
3 ha de
muestral es suficientemente grande para aplicar la aproximación normal; es decir,
HDLelnorequerimiento
es significativamente
distinta
del 30%.
cumplirse
mínimo de
que nπ(1
– π) ≥ 5. No obstante, en el Apéndice de este
está
comprendida
entre
el
25,5
y
el
33,2%
unamétodos
confianza
95%. Asimismo,
tema (Apartado 7.8) se facilitan correcciones de con
estos
quedelpermiten
aumentar la
cobertura de los intervalos de confianza y reducir la probabilidad de un error de tipo I en los
para
determinardesiinferencia
los datoselmuestrales
son
con
proporción
Los procedimientos
presentados
en compatibles
este
asumen
que el
tamaño
contrastes,
particularmente
cuando
tamaño muestral
es apartado
moderado
o una
pequeño.
Esta
corrección
98
muestral subyacente
es suficientemente
para aplicar
la aproximación
normal;
de
versusesHdecir,
0,30
del 30%,grande
se contrastó
la hipótesis
H0: = 0,30
1: ha
Pastor-Barriuso R.
el estadístico
cumplirsemediante
el requerimiento
mínimo de que n(1 - ) 5. No obstante, en el Apéndice de
Comparación de proporciones en dos muestras independientes
de la aproximación normal se conoce como corrección por continuidad y es aplicable a la
mayoría de los procedimientos estadísticos descritos en este tema. En adelante, se tratarán los
métodos de inferencia sin corrección por continuidad. Las correspondientes versiones con
corrección se presentan en el Apéndice al final del tema.
7.3 COMPARACIÓN DE PROPORCIONES EN DOS MUESTRAS INDEPENDIENTES
Supongamos ahora que el interés radica en comparar la proporción de sujetos con una
determinada característica en dos muestras independientes. Este planteamiento general es
aplicable a las comparaciones realizadas en cualquiera de los siguientes diseños de un estudio:
yy Un estudio prospectivo es aquel en el que n1 individuos expuestos a una intervención
(ensayo clínico) o a un potencial factor de riesgo (estudio de cohortes) y n2 individuos no
expuestos son seguidos a lo largo de un periodo de tiempo para determinar cuántos
desarrollan la enfermedad. Los tamaños muestrales de ambos grupos n1 y n2 están fijados
de antemano y, en el caso de un ensayo clínico, la intervención se asigna de forma aleatoria
a cada sujeto. El objetivo se centra en comparar la proporción de sujetos que desarrollan
la enfermedad entre los expuestos y los no expuestos.
yy Un estudio retrospectivo (estudio de casos y controles) es aquel en el que m1 sujetos con
la enfermedad (casos) y m2 sujetos libres de ella (controles) son examinados para determinar
cuántos han estado previamente expuestos al potencial factor de riesgo. Bajo este diseño,
el número de casos y controles está predeterminado y, en consecuencia, ha de compararse
la proporción de expuestos entre los sujetos con y sin la enfermedad.
yy Un estudio transversal es aquel en el que se selecciona un total de n individuos en un
instante determinado para establecer en cada sujeto la presencia o ausencia de la exposición
y la enfermedad. A diferencia de los estudios prospectivos, donde se compara la incidencia
de nuevos casos de la enfermedad, los estudios transversales comparan la prevalencia de
la enfermedad en un instante determinado entre expuestos y no expuestos.
Ejemplo 7.2 En el “Second National Health and Nutrition Examination Survey”
(NHANES II), una encuesta llevada a cabo entre 1976 y 1980 en Estados Unidos, se
recogieron datos del nivel de colesterol sérico total en una muestra representativa
de 7.712 sujetos entre 30 y 74 años de edad sin diagnóstico previo de enfermedad
cardiovascular o cáncer. Tras un seguimiento medio de 15 años, se determinó el estatus
vital de cada sujeto y, en su caso, la causa de muerte. Así, en este estudio de cohortes
prospectivo se registraron 254 muertes por enfermedad cardiovascular entre los 2.713
participantes con niveles de colesterol total superiores o iguales a 6,20 mmol/l (niveles
altos según el “National Cholesterol Education Program”) y 309 muertes por enfermedad
cardiovascular entre los 4.999 participantes con niveles de colesterol total inferiores
a 6,20 mmol/l.
Ejemplo 7.3 En el estudio de casos y controles EURAMIC, se clasificó a los sujetos
según tuvieran valores superiores o inferiores al umbral de 0,90 mmol/l de colesterol HDL.
De los 462 casos de infarto de miocardio con datos disponibles, 193 tuvieron valores de
colesterol HDL inferiores o iguales a 0,90 mmol/l; mientras que de los 539 controles
libres de la enfermedad, 158 presentaron valores de colesterol HDL inferiores a dicho
umbral.
Pastor-Barriuso R.
99
valores de colesterol HDL
valores
inferiores
de colesterol
a dicho HDL
umbral.
inferiores a dicho umbral.
Inferencia sobre proporciones
n general, los resultados
Ende
general,
la comparación
los resultados
de una
devariable
la comparación
dicotómica
de una
en dos
variable dicotómica en dos
tras independientesmuestras
suelen organizarse
independientes
en una
suelen
tablaorganizarse
22 (Tabla en
7.1).
unaEntabla
este22 (Tabla 7.1). En este
Tabla 7.1 Tabla 2×2 genérica de la
2(1 - 2)/n2). Además, como ambas muestras son
asociación entre exposición y enfermedad.
ado suponemos queapartado
se analizan
suponemos
datos deque
un estudio
se analizan
prospectivo,
datos de un
en el
estudio
que seprospectivo, en el que se
Enfermedad
4), se tiene que
~ N( , (1 - )/n ). Además, como ambas muestras son
1, en
) ydiferencia
p2 de
N(
Exposición
1(1estimar
1)/n1la
2 la2 proporción
2 expuestos
2 de No
nde estimar la diferencia
pretende
la- proporción
enfermos
en
entreSí
enfermos
y no Total
entre expuestos y no
Sí
a
b
n1
1 (1 1 ) 2 (1 2 )
. métodos
estos.
pueden aplicarse
(véase
1 Estos
2,
independientes
Apartado
se tiene
que d a estudios
métodos
expuestos.
Estos
igualmente
a3.4),
estudios
aplicarse
igualmente
peron
retrospectivos, pero
No pueden
c retrospectivos,
n1
n2
Total
m1
m2
2
n
arando la proporción
comparando
de expuestos
la proporción
entre casosdey expuestos
controles (ver
entre
controles
Ejemplo 7.5).
1Ejemplo
(1casos
2 (1 (ver
1 )y 7.5).
2)
~
p1 de
p 2de
p1 - p2 es un estimador
puntuallos
insesgado
lalaN comparación
.
1 2 ,
En general,
resultados
de
en dos muestras
n1 una variable
n 2 dicotómica
~
independientes
suelen
organizarse
en
una
tabla
2×2
(Tabla
7.1).
En
este
apartado
suponemos
1(1 - 7.1
2, aquí]
- aproximadamente
2)/n2). Además, como
ambas muestras son
N(1,[Tabla
1)/n
1) y p2 N(
2(1
aproximadamente
[Tabla
7.1
aquí]
y
no
expuestos,
E(p
p
)
=
1 - 2 entre expuestos
1
2
1
que se analizan datos de un estudio prospectivo, en el que se pretende estimar la diferencia en
De este resultado
se desprende
que p1 - p2 yesno
unexpuestos.
estimador puntual
insesgado
de la aplicarse
la independientes
proporción
de enfermos
entre expuestos
Estos métodos
pueden
(véase Apartado
3.4), se tiene que
0(1 - )% para igualmente
se
obtiene
siguiendo
el
mismo
estudios retrospectivos, pero comparando la proporción
de expuestos entre= casos
1
2
proporción de enfermos
La proporción
ena la
muestra
de de
enfermos
sujetosen
expuestos
la muestra
viene
de sujetos
dada por
expuestos
p1 =
viene
dada por p1
1 - 2 entre expuestos y no
expuestos, E(p1 - p2) = 1 diferencia(ver
de Ejemplo
riesgos subyacente
y controles
7.5).
1 (1 1 ) 2 (1 2 )
roporción como
y en la muestra de N(
sujetos
=~ la
c/n
y22,)/n
nsujetos
son
psuficientemente
= c/n2como
. Siviene
n1ambas
y ndada
suficientemente
a/n
a/n1 y en la
La
de 1enfermos
por
p1 = son
p~p22en
n-1 de
proporción
(1la-expuestos
muestra
) ypde
p2sujetos
N(
Nno
,2.expuestos
). Además,
muestras
2. son
1por
1(1
2 2por
2expuestos
1,yen
1no
1)/n
2muestra
2Si
.
El
intervalo
de
confianza
al
100(1
)%
para
siguiendo
el
mismo
n
n
2
1 1 - 2 se obtiene
2
muestra de sujetos no expuestos por p2 = c/n2. Si n1 y n2 son suficientemente grandes, estas
~ N(π
~ N(π ,
des, estas
proporciones
grandes,
tenderán
a distribuirse
muestrales
tenderán
forma
anormal,
distribuirse
pp11
de forma
normal,
π1)/n1) ypp12
proporciones
tenderán
a distribuirse
de
forma
p1 (1 p1 ) independientes
p 2 (1muestrales
pestas
) proporciones
(véase
Apartado
3.4), sede
tiene
quenormal,
2muestrales
1, π1(1 –
2
,
procedimiento
utilizado
para
unamuestras
proporción
como
/ 2
π
(1
–
π
)/n
).
Además,
como
ambas
son
independientes
(véase
Apartado
3.4),
se
tiene
que
2 De este
2n 2 2resultado se desprende que p1 - p2 es un estimador puntual insesgado de la
n1
~ , 1 (1 1 ) 2 (1 2 ) .
-1 entre
1 p 2 N
2p1 (1 expuestos
p1 ) p 2y(1no
expuestos,
p2 )
E(p1 - p2) = 1 diferencia de riesgospsubyacente
n1
n2 6 ,
p1 amplitud
p 2 z11 / 22
erencia de proporciones muestrales con una
6
n1
n2
Deeste
p1 – p2- es
un para
estimador
insesgado
de laeldiferencia
intervalosededesprende
confianzaque
al 100(1
)%
1 - puntual
siguiendo
mismo de
2. Elresultado
2 se obtiene
mación de su error estándar.
De este
resultadoπse
que p1 - py2 no
es un
estimador
puntual
insesgado
deintervalo
la
riesgos
subyacente
π2 entre expuestos
expuestos,
E(p
π1 – π2. El
de
1 –desprende
1 – p2) =
que es simétrico
deπuna
la–diferencia
decomo
proporciones
muestrales
con una amplitud
π
se
obtiene
siguiendo
el
mismo
procedimiento
utilizado
confianza
al 100(1utilizado
–alrededor
α)% para
procedimiento
para
proporción
1
encias en la probabilidad subyacente de desarrollar
la2
para
una proporción
como
diferencia
de riesgos
subyacente 1 - 2 entre expuestos y no expuestos, E(p1 - p2) = 1 directamente proporcional a la estimación de su error estándar.
stos y no expuestos, se contrasta la hipótesis nula H0:
p1 (1 p1 ) p 2 (1 p 2 )
2. El intervalo de confianza
100(1
p1 pal
z1 / 2- )% para 1- 2 se obtiene
, siguiendo el mismo
2
Para determinar si existen diferencias en lan1probabilidadn 2subyacente de desarrollar la
tiva bilateral H1: 1 2. Bajo la hipótesis nula de
utilizado
para
una
proporcióndecomo
queprocedimiento
es simétrico
alrededor
de expuestos
la diferencia
proporciones
muestrales
con una
amplitud
enfermedad
entre
los sujetos
y no expuestos,
se contrasta
la hipótesis
nula
H0:
directamente
proporcional
a
la
estimación
de
su
error
estándar.
que
es
simétrico
alrededor
de
la
diferencia
de
proporciones
muestrales
con
una
amplitud
2 = , se cumple que
Para
hipótesis
2 (12.Bajo
de
pen
H
pprobabilidad
psubyacente
existenalternativa
diferenciasbilateral
de nula
desarrollar
la
1 = determinar
2 frente a la si
1 (1la
11): 1 p
2 ) la hipótesis
p1 a pla2 estimación
z1 / 2
estándar. ,
directamente
proporcional
de
su
error
enfermedad
se contrasta
la hipótesis nula H0: π1 = π2
n1
n2
1 entre los sujetos expuestos y no expuestos,
~ N 0, (1 ) 1igualdad
,
:
=
=
,
se
cumple
que
de
proporciones
H
frente
a la hipótesis alternativa
H1: π1 ≠ π2. Bajo la hipótesis nula de igualdad de
0 bilateral
1
2
diferencias en
la probabilidad subyacente de desarrollar la
n 2 determinar
n1 Para
H : π = πsi existen
proporciones
=
π,
se
cumple
que
0
1
2
que es simétrico alrededor de la diferencia de proporciones muestrales con una amplitud
enfermedad entre los sujetos expuestos
expuestos,
la hipótesis nula H0:
1 se1contrasta
~ N y0no
p1 p 2
,
,
(
1
)
dad de enfermar común
para
expuestos
y
no
de su error
directamente proporcional a la estimación
n 2
n1estándar.
1 = 2 frente a la hipótesis alternativa bilateral H1: 1 2. Bajo la hipótesis nula de
su
valor
puedea estimarse
ad es desconocida,
dondePara
π corresponde
lasiprobabilidad
de enfermar
común
para expuestos
y no expuestos.
Aunque
determinar
existen diferencias
en la
probabilidad
subyacente
de desarrollar
la esta
probabilidad
π
es
desconocida,
su
valor
puede
estimarse
mediante
la
proporción
combinada
de
enfermos
donde
corresponde
a
la
probabilidad
de
enfermar
común
para
expuestos
y
no
igualdad de proporciones H0: 1 = 2 = , se cumple que
p =los
=(a(asujetos
c)/(1nexpuestos
de enfermos enenambas
muestras
++c)/(n
+1 +
n2) = m1/n.
el estadístico
este test nula
es H0:
ambas
muestras
enfermedad
entre
y Así,
no expuestos,
se propuesto
contrasta para
la hipótesis
p
p
1
2
su valor puede estimarse
expuestos. Aunque esta probabilidad es desconocida,
,1
z ~
1
uesto para este testes
H)1: 11
1 = 2 frente a la hipótesis
p1alternativa
, la hipótesis nula de
0, (11
p 2 N bilateral
2. Bajo
(1 p ) enambas
n1 n muestras
2
p = (a + c)/(n1 +
mediante la proporción combinada depenfermos
n1 n 2
igualdad de proporciones H0: 1 = 2 = , se cumple que
quen2bajo
aproximadamente
una distribución
normal
estandarizada, lo que permitirá
) = mH1/0corresponde
n.sigue
Así, el
estadístico
propuesto
este test
es para
donde
a la probabilidad
depara
enfermar
común
expuestos y no
determinar
estadística deuna
la distribución
diferencia entre
proporciones.
que bajo la
H0significación
sigue aproximadamente
normal
estandarizada, lo que
~ N 0, (1 ) 1 1 ,
p1 p 2
puede estimarse
es desconocida,
sun valor
expuestos.
Aunque
esta
probabilidad
permitirá determinar la significación estadística
delan1diferencia
entre proporciones.
2
7
100
Pastor-Barriuso R.
mediante la proporción combinada de enfermos en ambas muestras p = (a + c)/(n1 +
dondeEjemplo
corresponde
probabilidad
de enfermar
común
expuestos
y no
7.4 EnalalaTabla
7.2 se presenta
el número
depara
muertes
por enfermedad
7
n ) = m /n. Así, el estadístico propuesto para este test es
permitirá determinar la significación estadística de la diferencia entre proporciones.
p2 es un estimador puntual insesgado de la
que bajo H0 sigue aproximadamente una distribución
normal estandarizada, lo que
Comparación de proporciones en dos muestras independientes
entre expuestos y no Ejemplo
expuestos,
- pTabla
- se presenta el número de muertes por enfermedad
2) = 17.2
7.4E(p
En1 la
permitirá determinar la significación estadística de la diferencia entre proporciones.
)% para 1 - 2 se obtiene
siguiendoobservadas
el mismo durante el seguimiento del estudio NHANES II entre
cardiovascular
Tabla 7.2 Muertes por enfermedad cardiovascular
durante
el seguimiento
del estudio
Ejemplo
7.4con
En(ECV)
la Tablaaltos
7.2 ysemoderados-bajos
presenta
el número
muertes
por enfermedad
rción como
los sujetos
niveles
de de
colesterol
sérico
total (Ejemplo
NHANES II según niveles del colesterol sérico total.
cardiovascular
observadas
durante
seguimiento
del
II entre
Mortalidad
por
ECVestudio NHANES
7.2). La proporción
de muertes
porelenfermedad
cardiovascular
es p1 = 254/2.713
Colesterol
p1 (1 p1 ) p 2 (1 p 2 )
,
total (mmol/l)
Sí
No
Total
n1
n 2 los
sujetos
niveles altos ycon
moderados-bajos
de colesterol
sérico total
(Ejemplo
= 0,094
en con
los participantes
niveles de colesterol
total superiores
a 6,20
cia de proporciones
≥ 6,20
254
2.459
2.713
< 6,20
309
4.690
4.999
254/2.713
7.2).
La yproporción
de muertes
porenenfermedad
cardiovascular
es p1a=6,20
pcon
309/4.999
= 0,062
aquellos
con
niveles inferiores
mmol/l.
mmol/l
2 = una
muestrales
amplitud
Total
563
7.149
7.712
=Por
0,094
enlalosestimación
participantes
con niveles
de colesterol
total superiores
6,20
p - p2 =
tanto,
puntual
de la diferencia
de riesgos
subyacentea es
ón de su error estándar.
Ejemplo 7.4 En la Tabla 7.2 se presenta el número de muertes por1 enfermedad
cardiovascular
observadas=durante
el aquellos
seguimiento
estudio NHANES II entre los sujetos
p2 = =309/4.999
0,062 en
con del
niveles
mmol/l
0,094 - y0,062
0,032 y su
de confianza
al 95% inferiores a 6,20 mmol/l.
s en la probabilidad subyacente
desarrollar
la intervalode
con nivelesde
altos
y moderados-bajos
colesterol sérico total (Ejemplo 7.2). La proporción
= 254/2.713
= 0,094 eneslos
de muertes
enfermedad
cardiovascular
es p1 de
p1 participantes
- p2 =
Por
tanto, lapor
estimación
puntual
de la diferencia
riesgos subyacente
y no expuestos, se contrasta
la hipótesis
nula total
H0:0,superiores
094(1 0,094
) mmol/l
0,062(1yp02 ,=062
)
con niveles
de colesterol
a 6,20
309/4.999
= 0,062 en aquellos
0,032 z 0,975
con niveles
6,20
mmol/l.
tanto, laalestimación
puntual de la diferencia de
2.713
495%
.999
0,094
- 0,062inferiores
= 0,032 ya su
intervalo
dePor
confianza
bilateral H1: 1 2. Bajo
la hipótesis
nula
riesgos
subyacente
es de
p1 – p2 = 0,094 – 0,062 = 0,032 y su intervalo de confianza al 95%
cardiovascular en los sujetos con=niveles
de colesterol
total0,045).
excedió en 32
0,032 altos
1,960,007
= (0,019;
0,094(1 0,094) 0,062(1 0,062)
, se cumple que
0,032 z 0,975
2.713 con niveles4más
.999bajos (IC al 95% entre 19
casos por 1.000 a la de los participantes
Para el contraste bilateral de la hipótesis nula de igualdad de proporciones
1
1
= diferencia
0,032 1,960,007
= (0,019;(0,045).
0, (1 ) y ,45 casos por 1.000), siendo esta
P < 0,001).
muy significativa
n
n
2 poblacionales
1
Para el contraste
H0:bilateral
1 = 2 de
se emplea
el
estadístico
la hipótesis nula de igualdad de proporciones poblacionales
H0: πel
π2 se emplea
el estadístico
1 =contraste
Para
bilateral
de la hipótesis nula de igualdad de proporciones
0,032
de enfermar común para expuestos y no
z = [Tabla 7.2 aproximadamente aquí]= 5,13,
poblacionales H0: 1 = 2 se emplea el estadístico
1
1
0,073(1 0,073)
es desconocida, su valor puede estimarse
2.713 4.999
0la,032
Ejemplo
La
casos
de infarto
de miocardio
y lospor enfermedad
donde p 7.5
0,073 eslos
proporción
global
muertes
= (563/7.712
a +Tabla
cz)/(=n17.3
+= muestra
nfermos en ambas muestras
= de
5,13,
1 NHANES
1 de
donde p = 563/7.712
0,073
es la proporción
global
porP enfermedad
cardiovascular
en todos= los
participantes
El valor
del test se obtiene
del
II.muertes
0,073
(1valores
) colesterol
0,073de
HDL superiores o inferiores a
controles
del
EURAMIC
con
como
2P(Z
≥
5,13)
=
2{1
–
Φ(5,13)}
<
0,001.
En
resumen,
después
de 15 años de
para este test es
2.713 4.999
seguimiento,
incidencia
de del
muertes
por enfermedad
P del test se en los
cardiovascularlaen
todos losacumulada
participantes
NHANES
II. El valor cardiovascular
0,90
mmol/l.
A partiraltos
de esta
tabla 22, total
se pretende
la proporción
sujetos
con niveles
de colesterol
excediócomparar
en 32 casos
por 1.000dea la de los
donde
= 563/7.712
= 0,073
es la- (IC
proporción
global
de
muertes
enfermedad
participantes
con
más
al 95%< entre
19En
y 45
casos por
por
1.000),desiendo
Z 5,13)
= bajos
2{1
(5,13)}
0,001.
resumen,
después
15 esta
obtienepcomo
2P(niveles
sujetos
conmuy
niveles
bajos de colesterol
HDL ( 0,90 mmol/l) entre casos p1 = c/m1
diferencia
significativa
(P < 0,001).
P del test se
cardiovascular
en
todos
los
participantes
del NHANES
II. por
El valor
años de seguimiento, la incidencia acumulada
de muertes
enfermedad
p2 = dlos
/m2 casos
= 158/539
= 0,293.
La diferencia
=
193/4627.5
= 0,418
y controles
Ejemplo
La Tabla
7.3 muestra
de infarto
de miocardio
y losdecontroles del
7= 2{1 - (5,13)} < 0,001. En resumen, después de 15
P
(
Z
5,13)
obtiene
como
2
EURAMIC con valores de colesterol HDL superiores o inferiores a 0,90 mmol/l. A8 partir
p2 = 0,418la- 0,293
= 0,125
el IC alcon
95%niveles
para bajos
proporciones
es p1 - comparar
de esta tabla muestrales
2×2, se pretende
proporción
deysujetos
de
1años
de
seguimiento,
la
incidencia
acumulada
de
muertes
por
enfermedad
colesterol HDL (≤ 0,90 mmol/l) entre casos p1 = c/m1 = 193/462 = 0,418 y controles p2 =
d/m
dado por= 0,293. La diferencia de proporciones muestrales es p1 – p2 = 0,418 –
2 viene
2 = 158/539
8
0,293 = 0,125 y el IC al 95% para π1 – π2 viene dado por
p1 p 2 z 0,975
p1 (1 p1 ) p 2 (1 p 2 )
m1
m2
= 0,125 1,96
0,418(1 0,418) 0,293(1 0,293)
462
539
= 0,125 1,960,030 = (0,065; 0,184).
Pastor-Barriuso R.
El estadístico para el contraste bilateral de la hipótesis nula H0: 1 = 2 se calcula
101
viene dado por
p1 (1 p1 ) p 2 (1 p 22 )
,
Inferencia
n1
n 2 sobre proporciones
p1 (1 p1 ) p 2 (1 p 2 )
z 0,975
= 0,351
es la proporción total de sujetos con niveles
donde p p=1 n2/pn2=351/1.001
m1
m2
ia de proporciones muestrales con una amplitud
Tabla 7.3 Colesterol HDL en los casos de infarto
bajos de colesterol
HDL.
La significación
estadística del
es por tanto P =
agudo de
miocardio
y (los
del(contrate
0,418
1 0controles
,418) 0,293
1estudio
0,293)
n de su error estándar.
= 0,125 1,96
EURAMIC.
539 son
2{1 - (4,12)} < 0,001. Así, los casos 462
de infarto de miocardio
Infarto
de
miocardio
en la probabilidad subyacente de desarrollar
la
Colesterol
HDL
= (mmol/l)
0,125
1,960,030
= (0,065;
0,184).bajosTotal
Caso
Control
significativamente
más propensos
a presentar
niveles
de colesterol HDL que
y no expuestos, se contrasta la hipótesis nula H0:
> 0,90
269
381
650
0,001),
con nula
una diferencia
los sujetos para
libres
la enfermedad
(Pde< la
≤ 0,90
193
158
H0351
: 1 = de
El estadístico
elde
contraste
bilateral
hipótesis
2 se calcula
ilateral H1: 1 2. Bajo
la hipótesis nula
de
Total
462
539
1.001
, se cumple que
proporciones del 12,5% (IC al 95% 6,518,4%).
como
El estadístico para el contraste bilateral de la hipótesis nula H0: π1 = π2 se calcula como
p1 p 2
1
z [Tabla 7.3 aproximadamente aquí]
1
0, (1 ) ,
1
1
n1 n 2
p (1 p )
m1 m 2
0,125
e enfermar común 7.4
paraASOCIACIÓN
expuestos y no ESTADÍSTICA EN
UNA TABLA DE
4CONTINGENCIA
,12,
1
1
0,351(1 0,351)
s desconocida, su valor puede estimarse
462 539 estadística para evaluar de
En este apartado se presenta una prueba de significación
donde p == n(a/n+ =c)/(
351/1.001
= 0,351 es la proporción total de sujetos con niveles bajos de
n1 +
fermos en ambas muestras
forma genérica 2la presencia o ausencia de asociación entre las variables dicotómicas
colesterol HDL. La significación estadística del contraste es por tanto P = 2{1 – Φ(4,12)} <
9
0,001. Así, los casos de infarto de miocardio son significativamente más propensos a presentar
para este test es
representadas en una tabla 22. Este procedimiento no facilita estimaciones de efecto,
niveles bajos de colesterol HDL que los sujetos libres de la enfermedad (P < 0,001), con
una diferencia de proporciones del 12,5% (IC al 95% 6,5-18,4%).
sino únicamente valores P, y es aplicable a estudios prospectivos (marginales n1 y n2
y m2UNA
fijos)TABLA
y transversales
(tamaño muestral n fijo).
retrospectivos
(marginales m1 EN
7.4fijos),
ASOCIACIÓN
ESTADÍSTICA
DE CONTINGENCIA
En este
apartado
se presenta
una
significación
estadística para
de las
forma
Para
contrastar
si las variables
de unadetabla
22 son independientes,
se evaluar
comparan
7 prueba
genérica la presencia o ausencia de asociación entre las variables dicotómicas representadas en
unafrecuencias
tabla 2×2. observadas
Este procedimiento
no celda
facilita(i,estimaciones
sino únicamente
valores
Oij en cada
j) de la tabla de
conefecto,
sus frecuencias
esperadas
P, y es aplicable a estudios prospectivos (marginales n1 y n2 fijos), retrospectivos (marginales
y ijmbajo
y transversales
muestraldonde
n fijo).i = 1, 2 denota la fila y j = 1, 2 la
m1 E
la hipótesis
nula de(tamaño
independencia,
2 fijos)
Para contrastar si las variables de una tabla 2×2 son independientes, se comparan las
Eij j)sede
calculan
el producto
de esperadas
sus
columna.observadas
Estas frecuencias
esperadas
celda (i,
la tablacomo
con sus
frecuencias
Eij bajo
frecuencias
Oij en cada
la hipótesis nula de independencia, donde i = 1, 2 denota la fila y j = 1, 2 la columna. Estas
ni y mcomo
por el tamaño
muestral total n, marginales n
correspondientes
marginales
j, dividido
frecuencias
esperadas
Eij se calculan
el producto
de sus correspondientes
i
y mj, dividido por el tamaño muestral total n,
nm
Eij = i j .
n
Así, por ejemplo, si en un estudio prospectivo no hubiera asociación entre exposición y
Así, por ejemplo,
si en un
estudiode
prospectivo
asociación
entre exposición
y al
enfermedad,
la frecuencia
esperada
expuestos no
quehubiera
desarrollan
la enfermedad
sería igual
producto del número de expuestos n1 por la proporción combinada de enfermos m1/n, E11 =
la frecuencia esperada de expuestos que desarrollan la enfermedad sería
n1menfermedad,
1/n. Igualmente, en un estudio retrospectivo la frecuencia esperada de casos que han estado
expuestos al factor de riesgo correspondería al producto del número de casos m1 por la proporción
n1 por la proporción
combinada
de enfermos
igual al producto
del número
m1n1/n. Asimismo,
en un estudio
transversal
la frecuencia
combinada
de expuestos
n1/n, E11de=expuestos
esperada de sujetos a la vez expuestos y enfermos sería igual al producto del número total de
10
102
Pastor-Barriuso R.
Ejemplo 7.6 La Tabla 7.2 muestra los valores observados de la asociación entre la
mortalidad por enfermedad cardiovascular y el colesterol
total en el estudio
Asociación estadística en una tabla de contingencia
prospectivo NHANES II. Si ambas variables fueran independientes, la
sujetosprobabilidad
n por las proporciones
expuestoscardiovascular
n1/n y de enfermos
m1/n,enElos
n(n1/n)(m1/n) =
11 =sujetos
de morir por de
enfermedad
sería igual
n1m1/n. Notar, por tanto, que los valores esperados bajo la hipótesis nula de independencia
coinciden
en los distintos
tipos de
de colesterol
diseño. total. Esta probabilidad podría entonces
con niveles
altos y bajos
Ejemplo
La Tabla
7.2 muestra
los valores
observados
de lamuestras
asociación entre la
estimarse7.6
mediante
la proporción
combinada
de muertes
en ambas
mortalidad por enfermedad cardiovascular y el colesterol total en el estudio prospectivo
NHANES
Si ambas
variables
fueran
independientes,
la probabilidad
563/7.712 =II.0,073.
Así, entre
los 2.713
participantes
con niveles
altos de de morir por
enfermedad cardiovascular sería igual en los sujetos con niveles altos y bajos de
colesterol total,
total.cabría
Esta probabilidad
podría =entonces
estimarse
mediante la proporción
esperar 2.7130,073
198,1 muertes
por enfermedad
combinada de muertes en ambas muestras 563/7.712 = 0,073. Así, entre los 2.713
participantes
altos de
total, cabría
esperar este
2.713·0,073
cardiovascularcon
bajoniveles
la hipótesis
nulacolesterol
de independencia.
Aplicando
mismo = 198,1
muertes por enfermedad cardiovascular bajo la hipótesis nula de independencia.
Aplicando
estelosmismo
los valores
esperados
en por
cada celda vendrían
razonamiento,
valoresrazonamiento,
esperados en cada
celda vendrían
dados
dados por
2.713 563
Estos valores esperados se
en la=Tabla
E11representan
=
198,1,7.4. Notar que los marginales
7.712
de la tabla de frecuencias observadas
2.713 7(Tabla
.149 7.2) y esperadas (Tabla 7.4)
= 2.514,9,
E12 =
7
.
712
coinciden. De hecho, una vez calculado el valor esperado en una cualquiera de las
4.999 563
=
E21esperados
= 364,9,
celdas, los restantes valores
7.712de la tabla 22 quedan determinados por
dichos marginales.
E22 =
4.999 7.149
= 4.634,1.
7.712
Estos valores esperados se representan en la Tabla 7.4. Notar que los marginales de la
[Tabla
7.4 aproximadamente
aquí] 7.4) coinciden. De hecho,
tabla de frecuencias observadas
(Tabla
7.2) y esperadas (Tabla
una vez calculado el valor esperado en una cualquiera de las celdas, los restantes11
valores
esperados de la tabla 2×2 quedan determinados por dichos marginales.
Para evaluar la independencia de las variables de una tabla 22, se comparan las
Para
evaluarobservadas
la independencia
de las mediante
variables el
deestadístico
una tabla 2×2, se comparan las frecuencias
frecuencias
y esperadas
observadas y esperadas mediante el estadístico
2 =
(Oij E ij ) 2
Eij .
i 1 j 1
2
2
Cuanto mayor seaTabla
la diferencia
entre los valores
observados
esperados, mayor será la
7.4 Frecuencias
esperadas
bajo layhipótesis
de independencia entre la mortalidad por
magnitud del estadístico
y, en consecuencia,
se tendrá
evidencia en contra de la
enfermedad
cardiovascular
(ECV)mayor
y el colesterol
total en el estudio NHANES II.
hipótesis nula de independencia. En particular, puede probarse que si las variables de la
Colesterol
total (mmol/l)
Mortalidad por ECV
Sí
No
Total una distribución
tabla 22 son independientes, este estadístico
sigue aproximadamente
chi-cuadrado con 1
≥ 6,20
< 6,20 de
grado
Total
libertad
198,1
364,9
(sólo
una
563
2.514,9
4.634,1
frecuencia
7.149
2.713
4.999de
esperada
7.712
la tabla 22 es
independiente). El valor P del contraste corresponde entonces a la probabilidad a la
el nombre R.
derecha del estadístico 2 bajo la distribución 12 . Esta prueba se conoce conPastor-Barriuso
de test chi-cuadrado de independencia o asociación de Pearson, y puede aplicarse
103
Inferencia sobre proporciones
Cuanto mayor sea la diferencia entre los valores observados y esperados, mayor será la magnitud
del estadístico y, en consecuencia, se tendrá mayor evidencia en contra de la hipótesis nula de
independencia. En particular, puede probarse que si las variables de la tabla 2×2 son
independientes, este estadístico sigue aproximadamente una distribución chi-cuadrado con 1
grado de libertad (sólo una frecuencia esperada de la tabla 2×2 es independiente). El valor P del
contraste corresponde entonces a la probabilidad a la derecha del estadístico χ 2 bajo la
distribución χ 21. Esta prueba se conoce con el nombre de test chi-cuadrado de independencia
o asociación de Pearson, y puede aplicarse siempre que los marginales de la tabla sean
suficientemente grandes, de tal forma que todas las frecuencias esperadas sean superiores o
iguales a 5.
Ejemplo 7.7 A partir de los valores observados y esperados bajo la hipótesis de
independencia entre la mortalidad por enfermedad cardiovascular y el colesterol sérico
total, se obtiene el test estadístico
(254 198,1) 2 (2.459 2.514,9) 2
=
198,1
2.514,9
2
(309 364,9) 2 (4.690 4.634,1) 2
364,9
4.634,1
= 15,80 + 1,24 + 8,58 + 0,68 = 26,30.
Como las frecuencias esperadas son claramente superiores a 5, este estadístico se
Como
las frecuencias
esperadas
son claramente
superiores
este estadístico
se bajo la
distribuirá
aproximadamente
como
una chi-cuadrado
cona15,grado
de libertad
hipótesis nula de independencia. Utilizando la Tabla 6 del Apéndice, puede comprobarse
2 libertad bajo
distribuirá
como una
chi-cuadrado
1 gradoχde
que el valoraproximadamente
calculado del estadístico
es muy
superior con
al percentil
1;0,995 = 7,88, de lo cual
2
se deduce que P = P(χ 1 ≥ 26,30) < 0,005. Así, los niveles altos de colesterol total están
la
hipótesis nula deasociados
independencia.
Tabla
6 del Apéndice,
puede
significativamente
con laUtilizando
mortalidadlapor
enfermedad
cardiovascular.
comprobarse que el valor calculado del estadístico es muy superior al percentil
La hipótesis nula de independencia entre las variables de una tabla 2×2 equivale a la
igualdad
dos proporciones poblacionales. De hecho,2 puede probarse que el estadístico χ 2 de
12;0de
, 995 = 7,88, de lo cual se deduce que P = P( 1 26,30) < 0,005. Así, los
Pearson es igual al cuadrado del estadístico z de la comparación de proporciones en muestras
independientes, de tal forma que los valores P resultantes de ambos procedimientos son
niveles altos de colesterol total están significativamente asociados con la
idénticos (la distribución chi-cuadrado con 1 grado de libertad es, por definición, igual al
cuadrado de una distribución normal estandarizada). Cabría preguntarse entonces cuál es la
mortalidad por enfermedad cardiovascular.
aportación del test de independencia de Pearson. En primer lugar, los cálculos de este test no
dependen del diseño utilizado para generar los datos. En segundo lugar, esta prueba puede
generalizarse de forma sencilla a la comparación de múltiples proporciones en una tabla con r
La hipótesis nula de independencia entre las variables de una tabla 22 equivale a la
filas y c columnas.
igualdad
de dos proporciones
poblacionales.
De hecho,
puede probarse
Para contrastar
la independencia
de dos variables
categóricas
en una que
tablaelr×c, se calcula el
estadístico
estadístico 2 de Pearson es igual al cuadrado del estadístico z de la comparación de
r
c
(Oij E ij ) 2
2 =
,
proporciones en muestras independientes,
de tal forma
E ij que los valores P resultantes de
i 1 j 1
104
ambos procedimientos son idénticos (la distribución chi-cuadrado con 1 grado de
donde las frecuencias esperadas Eij = nimj/n se calculan de la misma forma que en una
libertad es, por definición, igual al cuadrado de una distribución normal estandarizada).
tabla 22.R.Bajo la hipótesis nula de independencia, dicho estadístico se distribuye
Pastor-Barriuso
Cabría preguntarse entonces cuál es la aportación del test de independencia de Pearson.
aproximadamente según una chi-cuadrado con (r - 1)(c - 1) grados de libertad. Los
En primer lugar, los cálculos de este test no dependen del diseño utilizado para generar
celdas tengan valores esperados inferiores a 5.
Asociación estadística en una tabla de contingencia
Ejemplo 7.8 La Tabla 7.5 muestra las muertes por enfermedad cardiovascular
donde las frecuencias
Eij =del
nimestudio
de laIImisma
que en
una tabla
j/n se calculan
entre los esperadas
participantes
NHANES
con unforma
colesterol
sérico
total 2×2.
Bajo la hipótesis nula de independencia, dicho estadístico se distribuye aproximadamente según
una chi-cuadrado
cona(r5,20
– 1)(c
– 1) (nivel
gradosdeseable),
de libertad.
Los5,20
grados
de libertad
corresponden
inferior
mmol/l
entre
y 6,19
mmol/l (nivel
limítrofeal
número de frecuencias esperadas independientes para el cálculo del estadístico, una vez
determinadosalto)
los marginales
la tabla
r×c.mmol/l
La aproximación
chi-cuadradoPara
a la determinar
distribuciónsidel
y superior de
o igual
a 6,20
(hipercolesterolemia).
la
estadístico será válida si el tamaño muestral es suficientemente grande. En concreto, el criterio
más aceptadoincidencia
para aplicar
test es
ningún valor
esperado sea
inferior
a 1los
y que
más
de este
muertes
porque
enfermedad
cardiovascular
difiere
entre
tres no
grupos,
del 20% de las celdas tengan valores esperados inferiores a 5.
se calculan en primer lugar las frecuencias esperadas mediante el producto de sus
Ejemplo 7.8 La Tabla 7.5 muestra las muertes por enfermedad cardiovascular entre los
participantes
del estudio NHANES
con un colesterol
sérico
total inferior
a 5,20 mmol/l
correspondientes
marginalesIIdividido
por el tamaño
muestral
total. Estas
(nivel deseable), entre 5,20 y 6,19 mmol/l (nivel limítrofe alto) y superior o igual a 6,20
mmol/lfrecuencias
(hipercolesterolemia).
Para
determinar
la incidencia
muertes
por
esperadas se
presentan
entresiparéntesis
en de
la Tabla
7.5.
Aenfermedad
cardiovascular difiere entre los tres grupos, se calculan en primer lugar las frecuencias
esperadas
mediante el
producto de
correspondientes
marginales
divididoel por el
continuación,
se comparan
los sus
valores
observados y esperados
mediante
tamaño muestral total. Estas frecuencias esperadas se presentan entre paréntesis en la
Tabla 7.5.
A continuación, se comparan los valores observados y esperados mediante el
estadístico
estadístico
2 =
(254 198,1) 2 (2.459 2.514,9) 2
198,1
2.514,9
(174 175,8) 2 (2.234 2.232,2) 2
175,8
2.232,2
(135 189,1) 2 (2.456 2.401,9) 2
189,1
2.401,9
14
= 15,80 + 1,24 + 0,02 + 0,00 + 15,50 + 1,22 = 33,79.
Dado que las frecuencias esperadas son superiores a 5, puede utilizarse la distribución
chi-cuadrado
conlas
(3frecuencias
– 1)(2 – 1)esperadas
= 2 grados
libertad a(Tabla
6 del
Apéndice)
Dado que
son de
superiores
5, puede
utilizarse
la para
2
obtener un valor P = P(χ 2 ≥ 33,79) < 0,005. Esto es, la incidencia de muertes por
enfermedad
cardiovascular
difierecon
significativamente
losde
tres
grupos,
obteniéndose
distribución
chi-cuadrado
(3 - 1)(2 - 1) = 2entre
grados
libertad
(Tabla
6 del
una incidencia acumulada en los 15 años de seguimiento de 52, 72 y 94 muertes por
cada 1.000
participantes
con niveles
altoses,
delacolesterol
33,79) <altos
0,005.y Esto
Apéndice)
para obtener
un valordeseables,
P = P( 22 limítrofes
total, respectivamente.
incidencia de muertes por enfermedad cardiovascular difiere significativamente
Tabla 7.5 Frecuencias observadas (esperadas) de
entre
los tres por
grupos,
obteniéndose
una incidencia
acumulada
muertes
enfermedad
cardiovascular
(ECV)
entre en
loslos 15 años de
participantes del NHANES II con niveles de colesterol
seguimiento
de 52,
72 y 94ymuertes
por cada 1.000 participantes con niveles
total < 5,20,
5,20-6,19
≥ 6,20 mmol/l.
Mortalidad por ECV
Colesterol
deseables,
limítrofes altos y altos
de colesterol total, respectivamente.
total (mmol/l)
≥ 6,20
5,20-6,19
< 5,20
Total
Sí
254 (198,1)
174 (175,8)
[Tabla
7.5
135 (189,1)
563
No
2.459 (2.514,9)
2.234 (2.232,2)
aproximadamente
2.456 (2.401,9)
7.149
Total
2.713
2.408
aquí]
2.591
7.712
7.5 TEST DE TENDENCIA EN UNA TABLA r2
Pastor-Barriuso R.
A partir de una tabla r2, el test chi-cuadrado de Pearson permite contrastar la hipótesis
105
p1se
(1 desprende
p1 )que pp21que
(-1 p2ppes
De este
Deresultado
este resultado
se desprende
p2 estimador
es un estimador
puntual
puntual
insesgado
insesgado
de la de la
1 2-)un
p1 p 2 z1 / 2
,
n
n
1
2
Inferencia sobre proporciones
1 - 2entre
entre expuestos
y no expuestos,
y no expuestos,
E(p1 -E(p
p2)1=- p12)- = 1 diferencia
diferencia
de riesgos
de riesgos
subyacente
subyacente
1 - 2 expuestos
e es simétrico alrededor de la diferencia de proporciones muestrales con una amplitud
. El intervalo
de confianza
de confianza
al 100(1
al 100(1
- )%-para
)%para
2 se obtiene
siguiendo
siguiendo
el mismo
el mismo
2. El intervalo
1 - 2se
1 - obtiene
7.52 TEST
DE TENDENCIA EN UNA TABLA r×2
ectamente proporcional a la estimación de su error estándar.
utilizado
utilizado
para
para
proporción
una proporción
como
comopermite contrastar la hipótesis nula de
Aprocedimiento
partirprocedimiento
de una tabla
r×2,
el
testuna
chi-cuadrado
de
Pearson
π1 = π2 = ... =subyacente
πr frente a de
la hipótesis
alternativa
H1: πi ≠ πj, donde
de diferencias
proporciones
Para determinarigualdad
si existen
en H
la0:probabilidad
desarrollar
la
i y j son 2 muestras cualesquiera. Un resultado
indicaría que al
p1 (1 ppsignificativo
) pp12)(1 ppde
) esta
p 2 prueba
)
1 1(1
2 2(1
p
z
p
,
,
menos
2
de
las
r
proporciones
En
el
caso
de
que
los grupos o
1 pp2poblacionales
1
12
/ 2 z1 / 2son heterogéneas.
fermedad entre los sujetos expuestos y no expuestos, se contrasta
lanhipótesis
nula
H0:
n
n
n
1los grupos.
1
2
2
simplemente tomar
los
valores
1,
2,
...,
r
indicando
el
orden
de
A
muestras estén intrínsecamente ordenados, cabría preguntarse además si estas proporciones
siguen
alguna
tendencia
determinada
largo la
dehipótesis
los grupos.
= 2 frente a la
hipótesis
alternativa
bilateral
H1: 1 alo
nulaEndeeste apartado se presenta un
2.pBajo
con
sus
correspondientes
continuación,
setest
relacionan
las
proporciones
observadas
i
específico
para
detectar
gradiente
omuestrales
componente
(creciente
o
que
esque
simétrico
es simétrico
alrededor
alrededor
delalaexistencia
diferencia
de2,la...,
diferencia
deun
proporciones
de
proporciones
muestrales
conlineal
una
una amplitud
simplemente
tomar
los
valores
1,
r de
indicando
el orden
de los
grupos.
Aconamplitud
decreciente) entre las proporciones de los sucesivos grupos.
ualdad
de proporciones
H0el: estadístico
1 = 2 = , se cumple que
puntuaciones
si mediante
directamente
directamente
proporcional
proporcional
a lalas
estimación
a puntuación
la estimación
de su
error
de su estándar.
errorpiestándar.
continuación,
se relacionan
proporciones
con sus correspondientes
En primer
lugar,
se asigna
una
sobservadas
i a cada una de las muestras ordenadas. Esta
puntuación puede representar un atributo numérico del grupo (ver Ejemplo 7.9), o simplemente
2
1 en
1 diferencias
r ...,
Para
Para determinar
si
existen
si el
existen
diferencias
la probabilidad
en la probabilidad
subyacente
subyacente
de desarrollar
de desarrollar
la
la
estadístico
puntuaciones
s~i1,mediante
tomar
lospdeterminar
valores
2,
, de los grupos. A continuación, se relacionan las
0n, (r(p1indicando
p))( s
els )orden
1 p 2 N
n1i correspondientes
n2
proporciones observadas
puntuaciones si mediante el estadístico
i pi i con sus
i 1
2
enfermedad
enfermedad
entre
los
entre
sujetos
los
sujetos
expuestos
expuestos
y
no
expuestos,
y
no
expuestos,
se contrasta
la hipótesis
la hipótesis
nula Hnula
H0:
0:
=
,
2 se contrasta
r
r 2
p (1 p ) ni ( s i
s ) ni ( p i p )( s i s )
nde corresponde
de
común
para expuestos
1 a=la2probabilidad
= 2 frente
a la hipótesis
a laenfermar
hipótesis
bilateral
H1: 1Hy1:no
2.1 Bajo
2. la
Bajo
hipótesis
la hipótesis
nula de
nula de
ialternativa
1
i 1bilateral
1frente
2 alternativa
=
,
r
2
p (1valor
ni (cumple
sestimarse
i s)
es desconocida,
puede
puestos. Aunque igualdad
esta probabilidad
,2sep=)cumple
,
se
que
que
igualdad
de proporciones
de proporciones
H0: 1H=0:2su
1==
1 proporción
donde ni es el tamaño de cada muestra, n = ni, p = nipi/n esi la
dondecombinada
ni es el tamaño
de cadaenmuestra,
n = ∑ni, p == ∑n
/n)/(es
(a +
n1 la
+ proporción combinada en
diante la proporción
de enfermos
ambas muestras
ipic
1
1
1
1
~puntuación
combinada en todas
las
yy s ==∑n
n
esla
lapuntuación
Notar
si las
todas
lasmuestras
muestras
/n
Notar
si las
i/nes
deispiiscada
muestra,
, )(p1 =
/nque
la
donde
ni es el tamaño
i
i
pN2
media.
n
,es
,proporciones observadas
0~n, =N(1n
0,media.
) ipque
proporción
1 pp
21
tienden
a
aumentar
o
disminuir
con
las
puntuaciones,
el
numerador
del
n
n
n
n
1 21 2 estadístico será grande.
= m1/n. Así, el estadístico propuesto para este test es
Si, por el tienden
contrario,
las proporciones
no varían
en función de laelpuntuación de cada grupo, el
proporciones observadas
a aumentar
o disminuir
combinada en todas
las muestras
y s =con
nilas
si/npuntuaciones,
es la puntuación media. Notar que si las
numerador estará próximo a 0. Bajo la hipótesis
nula de ausencia de una componente lineal en
donde
corresponde
grande.
corresponde
aSi,
la por
probabilidad
a la
de enfermar
de
enfermar
comúncomún
para
expuestos
para
expuestos
y no chi-cuadrado
y no
ladonde
tendencia,
estadístico
anterior
seguirá
aproximadamente
una
distribución
numerador del estadístico
seráel
el probabilidad
contrario,
las
proporciones
no varían
en
proporciones
observadas
tienden
a
aumentar
o
disminuir
con
las
puntuaciones,
el
con 1 grado de libertad. Esta prueba se conoce genéricamente como test chi-cuadrado
de
es
desconocida,
es
desconocida,
su
valor
su
puede
valor
puede
estimarse
estimarse
expuestos.
expuestos.
Aunque
Aunque
esta
probabilidad
esta
probabilidad
tendencia
y,
a
diferencia
del
test
de
independencia
o
asociación,
puede
aplicarse
incluso
unción de la puntuación de cada grupo, el numerador estará próximo a 0. Bajo la
numerador
del=muestras
estadístico
grande.
porreducido,
el
proporciones
no varían
cuando
algunas
un tamaño
bastalascon
que lademuestra
totalensea
=será
174/2.408
=Si,
0,072
y pcontrario,
= 0,094
las
135/2.591
0,052, p2tengan
3 = 254/2.713
ycombinada
la proporción
muy
extrema,
n7p(1=–(ap)+=
≥c)/(
5.
(a nFinalmente,
+1 c+)/(n1 +
mediante
mediante
la
lacomponente
proporción
combinada
enfermos
enfermos
ennoambas
en
ambas
muestras
muestras
hipótesis nula desuficientemente
ausencia
deproporción
unagrande
linealde
encombinada
la de
tendencia,
el
estadístico
función
de
la
puntuación
de
cada
grupo,
el
numerador
estará
próximo
a
0.
Bajo
la
cabe reseñar
quecategorías
el test de(Figura
tendencia
noPara
permite
contrastar
la tendencia
idoneidadcreciente
de la relación
lineal;
sucesivas
7.1).
contrastar
si esta
es
este
test
únicamente
determina
la
existencia
de
una
componente
lineal
significativa,
anterior seguirá aproximadamente
una
distribución
chi-cuadrado
con
1es
grado
n2) = m
n21)/n=. Así,
m1/n.elAsí,
estadístico
el
estadístico
propuesto
propuesto
para este
para
test
este
test esde
hipótesis
nula
dese
ausencia
de
componente
ensla=tendencia,
estadístico
independientemente
deasignan
cuál sea
lapuntuaciones
relación
subyacente.
= 4,65,
5,72 y s3 =el6,90
significativa,
lasuna
s1lineal
2
ibertad. Esta prueba se conoce genéricamente como test chi-cuadrado de tendencia y,
anterior
seguirá aproximadamente
unacolesterol
distribución
con 1 grado
de
correspondientes
medianaanterior
del
totalchi-cuadrado
dediferencias
cada categoría.
Aunque
Ejemplo 7.9 Enaellaejemplo
se detectaron
significativas
en el riesgo
muerte por enfermedad
cardiovascular
entre
los participantes
del NHANES II con
a diferencia del test dedeindependencia
o asociación,
puede aplicarse
incluso
cuando
test chi-cuadrado
de
tendencia
y, un
libertad.
Esta
prueba
se conoce
podrían
asignarse
las
puntuaciones
1, 2 y 3, como
esy preferible
utilizarDe
una
medida
niveles
de
colesterol
total < genéricamente
5,20, 5,20-6,19
≥ 6,20
mmol/l.
hecho,
se de
observa
claro
en las incidencias
acumuladas
p1total
= 135/2.591
= 0,052, p2 = 174/2.408 =
algunas muestras tengan
unincremento
tamaño reducido,
basta con que
la muestra
sea
a diferencia
del
test
de
independencia
o
asociación,
puede
aplicarse
incluso
cuando
7 si7
tendencia
de cada
categoría
(media
o mediana)
para(Figura
preservar
distancia
0,072 y p3 central
= 254/2.713
= 0,094
de las
sucesivas
categorías
7.1).laPara
contrastar
esta
tendencia
creciente
es significativa,
se asignan
s1 = 4,65, s2 = 5,72
suficientemente grande
y la
proporción
combinada
no muy
extrema,
n con
p (1las
- puntuaciones
p la
) muestra
5.
algunas
muestras
tengan
un
tamaño
reducido,
basta
que
total
sea
y s3 =las
6,90
correspondientes
a la mediana
del colesterol
total
cada categoría.
Aunque
entre
mismas.
Así, el numerador
del estadístico
del test
de de
tendencia
vendría
podrían asignarse las puntuaciones 1, 2 y 3, es preferible utilizar una medida de tendencia
Finalmente, cabe reseñar
que el testgrande
de tendencia
no permite
contrastarnolamuy
idoneidad
de n p (1 - p ) 5.
suficientemente
y la proporción
combinada
extrema,
central
de cada categoría
(media o mediana)
para preservar
la distancia
entre las mismas.
dado
por
Así, el numerador del estadístico del test de tendencia vendría dado por
a relación lineal; este test únicamente determina la existencia de una componente lineal
Finalmente, cabe reseñar que el test de tendencia no permite contrastar la idoneidad de
N = {2.591(0,052 0,073)(4,65 5,78)
significativa, independientemente de cuál
sea la relación
subyacente. 5,78)
0,073)(5,72
2.408(0,072
la relación lineal; este+test
únicamente
determina la existencia de una componente lineal
+ 2.713(0,094 0,073)(6,90 5,78)}2 = 15.364,56
significativa,
independientemente
de diferencias
cuál sea la relación
subyacente.
Ejemplo 7.9 En el ejemplo anterior se detectaron
significativas
en el
riesgo de muerte por enfermedad cardiovascular entre los participantes del
7.9 Enpor
el ejemplo anterior se detectaron diferencias significativas en el
y elEjemplo
denominador
106 Pastor-Barriuso R.
NHANES II con niveles
< 5,20, 5,206,19
y 6,20
mmol/l.
De
riesgo de
de colesterol
muerte portotal
enfermedad
cardiovascular
entre
los participantes
del
D = 0,073(1 - 0,073){2.591(4,65 - 5,78)2
n1
n2
p2 es un estimador puntual insesgado de la
Medidas de efecto en una tabla de contingencia
entre expuestos y no expuestos, E(p1 - p2) = 1 -
135/2.591
0,1 = 0,052, p = 174/2.408 = 0,072 y p3 = 254/2.713 = 0,094 de las
2
)% para 1 - 2 se obtiene siguiendo el mismo
Incidencia acumulada de muertes por ECV
sucesivas categorías (Figura 7.1). Para contrastar si esta tendencia creciente es
rción como
0,08
significativa, se asignan las puntuaciones s1 = 4,65, s2 = 5,72 y s3 = 6,90
p1 (1 p1 ) p 2 (1 p 2 )
, 0,06
a la mediana del colesterol total de cada categoría. Aunque
n1
n 2 correspondientes
podrían asignarse las puntuaciones 1, 2 y 3, es preferible utilizar una medida de
cia de proporciones muestrales
0,04con una amplitud
tendencia central de cada categoría (media o mediana) para preservar la distancia
ón de su error estándar.
entre las
0,02mismas. Así, el numerador del estadístico del test de tendencia vendría
s en la probabilidad subyacente de desarrollar la
dado por
y no expuestos, se contrasta la 0hipótesis nula H0:
simplemente tomar los valores 1, 2, ..., r indicando el orden de los grupos. A
N = {2.591(0,052 - 0,073)(4,65 - 5,78)
bilateral H1: 1 2. Bajo la hipótesis4,5
nula de continuación,
5
6 proporciones
6,5 observadas
7 pi con sus correspondie
se5,5
relacionan las
+ 2.408(0,072 - 0,073)(5,72 - 5,78)
total (mmol/l)
, se cumple que
puntuaciones sColesterol
i mediante el estadístico
Figura 7.1
2
Figura 7.1 Incidencia acumulada
de muertes
por enfermedad
= 15.364,56(ECV) en 15 años de
+ 2.713(0,094
- 0,073)(6,90
- 5,78)}cardiovascular
seguimiento del estudio NHANES II según niveles de colesterol total < 5,20, 5,20-6,19 y ≥ 6,20 mmol/l.
1
1
0, (1 )
n1 n 2
,
y el denominador por
y el denominador por
2
r
ni ( p i p )( s i s )
,
2 = i 1
r
2
p (1 p ) ni ( s i s ) 2
de enfermar común para expuestos y D
no= 0,073(1 0,073){2.591(4,65 5,78)
i 1
+ 2.408(5,72 5,78)2
es desconocida, su valor puede estimarse
+ 2.713(6,90 5,78)2} = 454,78,
donde ni es el tamaño de cada muestra, n = ni, p = nipi/n es la proporción
donde p = (563/7.712
a + c)/(n1 += 0,073 es la proporción global de muertes por enfermedad
nfermos en ambas muestras
en todas
muestras
nisi/n es la+puntuación
cardiovascular en todos combinada
los participantes
del las
NHANES
II yy s == (2.591∙4,65
2.408∙5,72 media. Notar q
donde
p
=
563/7.712
=
0,073
es
la
proporción
global
de
muertes
por
enfermedad
+ 2.713∙6,90)/7.712 = 5,78 es la puntuación media. El estadístico resulta entonces χ 2 =
para este test es
proporciones
observadas
conchilas puntuaciones,
N/D = 33,78, que corresponde
a un valor
P = P(χ 21 tienden
≥ 33,78)a<aumentar
0,005 en oladisminuir
distribución
cuadrado
con 1 en
grado
delos
libertad
(Tabla 6del
delNHANES
Apéndice).II Este
confirma
que el
cardiovascular
todos
participantes
y s resultado
= (2.5914,65
+
numerador
del estadístico
será grande.
Si, por
el contrario, las al
proporciones no
riesgo de mortalidad por
enfermedad
cardiovascular
aumenta
significativamente
aumentar
de colesterol total.
2.4085,72el+nivel
2.7136,90)/7.712
= 5,78 es la puntuación media. El estadístico
función de la puntuación de cada grupo, el numerador estará próximo a 0. Bajo
resulta entonces 2 = N/D7= 33,78, que corresponde a un valor P = P( 12 33,78)
hipótesis
nulaTABLA
de ausencia
de una componente lineal en la tendencia, el estadíst
7.6 MEDIDAS DE EFECTO
EN UNA
DE CONTINGENCIA
< 0,005 en la
distribución
chi-cuadrado
con
1 grado
de en
libertad
(Tabla
delchi-cuadrado
En epidemiología
y en
otras aplicaciones
del análisis
de datos
salud
pública,6 no
sólo interesa con 1 grado d
anterior
seguirá
aproximadamente
una distribución
determinar el grado de significación estadística sino también obtener estimadores de efecto o
Apéndice).
Este resultado
confirma
que
el riesgo
detabla
mortalidad
por enfermedad
medidas
de la magnitud
de la libertad.
asociación.
A
partir
de
2×2 pueden
obtenerse
chi-cuadrado de tend
Esta
prueba
seuna
conoce
genéricamente
como testdistintas
medidas de efecto, tales como la diferencia de riesgos, el riesgo relativo y el odds ratio. La
cardiovascular
al
el nivel
de
colesterol
total.
diferencia
de riesgosaumenta
o proporciones,
que ya
discutió
en el Apartado
7.3,
permitepuede
determinar
asignificativamente
diferencia
delsetest
deaumentar
independencia
o asociación,
aplicarse incluso cua
la diferencia en la tasa de incidencia o prevalencia de la enfermedad entre los sujetos expuestos
y no expuestos en un estudio algunas
prospectivo
o transversal,
estecon
apartado
muestras
tengan unrespectivamente.
tamaño reducido,Enbasta
que lase
muestra total sea
revisan los métodos de inferencia sobre el riesgo relativo y el odds ratio, así como sus respectivos
[Figura 7.1 aproximadamente aquí]
ámbitos de aplicación.
suficientemente grande y la proporción combinada no muy extrema, n p (1 - p
17 R. 107
Pastor-Barriuso
Finalmente, cabe reseñar que el test de tendencia no
permite contrastar
la idone
la relación lineal; este test únicamente determina la existencia de una componen
Riesgo
> 1 indica
una mayor probabilidad de desarrollar la enfermedad en expuestos
7.6.1
relativo
Inferencia sobre proporciones
El riesgo
o razón dePor
riesgos
es lasimedida
de efecto
más utilizada
estudios
querelativo
en no expuestos.
ejemplo,
= 1,25,
los sujetos
expuestosentienen
1,25
prospectivos
parariesgo
comparar
incidencia
la enfermedad
entre expuestos
y no que los
veces más
o sonlaun
25% másdepropensos
a desarrollar
la enfermedad
7.6.1
Riesgo
relativo
expuestos,
y seodefine
como
El riesgo
relativo
razón
de
riesgos
la medida- 1)
de =
efecto
más utilizada en estudios prospectivos
- 1) =es100(1,25
25%).
no
expuestos
(100(
para comparar la incidencia de la enfermedad entre expuestos y no expuestos, y se define como
< 1 indica una menor probabilidad
D | E ) la enfermedad en expuestos que
1 deP(contraer
=
,
2 P( D | E c )
en no expuestos. Por ejemplo, si = 0,80, los sujetos expuestos son un 20%
donde π1 = P(D|E) y π2 = P(D|Ec) representan la probabilidad de desarrollar la enfermedad D
c
entre
los sujetos
expuestos
no expuestos
Ec, respectivamente.
Así,
el
riesgo (100(0,80
relativo
donde
1 = P(D|E)
y 2 E=a ydesarrollar
P(D|E
) representan
la probabilidad
de
desarrollar
la determina
menos
propensos
la enfermedad
que los no
expuestos
- 1)
cuántas veces es más frecuente la enfermedad en expuestos que en no expuestos. Se trata, por
c
tanto,
de =una
medida
efecto
multiplicativa
tomarEcualquier
valor no negativo,
-20%).
, respectivamente.
Así, el de
enfermedad
D entredelos
sujetos
expuestos Eque
y nopuede
expuestos
tal forma que:
riesgo
relativo
veces
es más
frecuente
la enfermedad
en expuestos
valordetermina
de
y su cuántas
inverso
1/
representan
el mismo
nivel de
asociación,
pero
en =
yy ψ =Un
1 indica
la
misma
probabilidad
de
enfermar
en expuestos
y no
expuestos
P(D|E)
P(D|Ec); es decir, la exposición y la enfermedad son independientes. Cuanto más alejado
queesté
ensentido
nodeexpuestos.
SePor
trata,
por tanto,
una
efecto
multiplicativa
que
opuesto.
ejemplo,
si de
=será
4,
los
sujetosdeexpuestos
son 4 veces
ψ
1 en
cualquier
sentido,
mayor
lamedida
magnitud
de la asociación
entremás
exposición
y enfermedad.
puede propensos
tomar cualquier
valor nolanegativo,
de tal
a desarrollar
enfermedad
queforma
los noque:
expuestos, o equivalentemente
yy ψ > 1 indica una mayor probabilidad de desarrollar la enfermedad en expuestos que en no
expuestos.
Por ejemplo,
siprobabilidad
ψ = 1,25, losdesujetos
expuestos
tienen 1,25
más riesgo o
1 indica
la misma
enfermar
expuestos
y no veces
expuestos
los= no
expuestos
son un
75% menos propensos
aen
contraer
la enfermedad
que los
son un 25% más propensos a desarrollar la enfermedad que los no expuestos (100(ψ – 1)
c
= 100(1,25
1) = 25%).
);es- decir,
la exposición
la enfermedad son independientes.
P(D|E)
=– P(D|E
1) = 100(0,25
- 1) =y-75%).
expuestos
(100(1/
yy ψ < 1 indica una menor probabilidad de contraer la enfermedad en expuestos que en no
expuestos.
Pordeejemplo,
si ψ = 0,80,
losaplicarse
sujetos expuestos
un 20% menos
propensos a
Esta medida
efecto también
puede
a estudiosson
transversales
en términos
18
desarrollar la enfermedad que los no expuestos (100(0,80 – 1) = –20%).
la razón
y aleligual
quenivel
ocurría
la diferencia
de sentido
yde
y Un
valor de
de prevalencias.
ψ y su inversoSin
1/ψembargo,
representan
mismo
de con
asociación,
pero en
opuesto. Por ejemplo, si ψ = 4, los sujetos expuestos son 4 veces más propensos a
riesgos,
el riesgo
relativo no que
es directamente
estimable
a partir de estudios
desarrollar
la enfermedad
los no expuestos,
o equivalentemente
los no expuestos son
un 75% menos propensos a contraer la enfermedad que los expuestos (100(1/ψ – 1) =
retrospectivos
la proporción de casos está predeterminada por el propio diseño
100(0,25 – 1)ya=que
–75%).
Esta
medida de efecto también puede aplicarse a estudios transversales en términos de la
del estudio.
razón de prevalencias. Sin embargo, y al igual que ocurría con la diferencia de riesgos, el riesgo
relativo
es directamente
estimable a en
partir
estudios
retrospectivos
que la proporción
A no
partir
de los datos observados
unade
tabla
22 (Tabla
7.1), un ya
estimador
puntual de
casos está predeterminada por el propio diseño del estudio.
delpartir
riesgoderelativo
viene
determinado
por tabla 2×2 (Tabla 7.1), un estimador puntual del
A
los datos
observados
en una
riesgo relativo viene determinado por
RR =
p1 a / n1
,
p 2 c / n2
que corresponde al cociente entre la proporción de enfermos en la muestra de sujetos expuestos
p1 = a/n1 y no expuestos p2 = c/n2.
19
Ejemplo 7.10 De la Tabla 7.2 se desprende que la proporción de muertes por enfermedad
cardiovascular es p1 = 254/2.713 = 0,094 en los participantes del estudio NHANES II con
niveles de colesterol total superiores a 6,20 mmol/l y p2 = 309/4.999 = 0,062 en aquellos
con niveles inferiores a 6,20 mmol/l. Así, la estimación puntual del riesgo relativo es
RR = 0,094/0,062 = 1,51;
108
Pastor-Barriuso R.
El cálculo de un intervalo de confianza y un test de hipótesis para no resulta
Medidas de efecto en una tabla de contingencia
sencillo ya que la distribución muestral de su estimador RR
es muy asimétrica,
particularmente cuando el riesgo relativo subyacente dista mucho del valor nulo 1. Para
es decir, la incidencia acumulada de muertes por enfermedad cardiovascular en 15 años
de seguimiento
es un de
51%
superior en
los sujetostrabajar
con niveles
altos
de colesterol
solventar
este problema
inferencia,
es preferible
con el
logaritmo
naturaltotal
del que
en quienes tienen niveles más bajos.
riesgo relativo, cuya distribución presenta una mayor simetría. De hecho, puede
El cálculo de un intervalo de confianza y un test de hipótesis para ψ no resulta sencillo ya
queprobarse
la distribución
muestral
dede
su ambas
estimador
RR esson
muy
asimétrica, particularmente
- 1) el
que si los
tamaños
muestras
suficientemente
grandes n11(1cuando
riesgo relativo subyacente dista mucho del valor nulo 1. Para solventar este problema de
inferencia,
preferible
contiende
el logaritmo
naturalde
delforma
riesgo
relativo,
distribución
5 y n2es
- 2) 5,trabajar
el log(RR)
a distribuirse
normal
concuya
media
log()
2(1
presenta una mayor simetría. De hecho, puede probarse que si los tamaños de ambas muestras
y 2n, 2π2(1 – π2) ≥ 5, el log(RR) tiende a distribuirse
sonysuficientemente
grandes
+ π1/c
1/n
varianza aproximada
1/an-1π1/n
1(11 –
1) ≥- 5
de forma normal con media log(ψ) y varianza aproximada 1/a – 1/n1 + 1/c – 1/n2,
~ N log( ), 1 1 1 1 .
log( RR)
a n1 c n 2
Frecuencia relativa (%) en muestras de tamaño 500
Ejemplo 7.11 En las Figuras 7.2(a) y (b) se presentan las distribuciones muestrales
delEjemplo
RR y del7.11
log(RR)
deFiguras
mortalidad
poryenfermedad
cardiovascular
entre los sujetos con
En las
7.2(a)
(b) se presentan
las distribuciones
un colesterol total ≥ 6,20 y < 6,20 mmol/l obtenidos a partir de 1000 muestras aleatorias
simples
de tamaño
estudio
NHANES por
II. enfermedad
Como puede
observarse, ambas
muestrales
del RR 500
y deldel
log(RR)
de mortalidad
cardiovascular
distribuciones están centradas alrededor de los parámetros subyacentes 1,51 y log(1,51)
= 0,42 en todos los participantes del estudio. Sin embargo, la distribución muestral del
20
RR presenta una clara asimetría, mientras que el log(RR) se distribuye de forma
aproximadamente normal.
25
25
20
20
15
15
10
10
5
5
0
0
0
1
2
(a)
3
4
-1
RR
(b)
25
25
20
20
15
15
10
10
5
5
0
0
0
1
2
(c)
OR
0
3
4
-1
2
1
2
log(RR)
0
(d)
1
log(OR)
Figura 7.2
Figura 7.2 Distribución muestral del RR (a), log(RR) (b), OR (c) y log(OR) (d) de mortalidad por enfermedad
cardiovascular entre los sujetos con un colesterol total ≥ 6,20 y < 6,20 mmol/l en 1000 muestras aleatorias
simples de tamaño n = 500 obtenidas a partir del estudio NHANES II. Las líneas verticales en trazo discontinuo
corresponden a los parámetros subyacentes ψ = 1,51, log(ψ) = 0,42, ω = 1,57 y log(ω) = 0,45.
Pastor-Barriuso R.
109
1 / 2
a normal
n1 cdel log(RR),
n2
En base a la distribución aproximadamente
[Figura 7.2 aproximadamente
aquí] puede obtenerse un
) como
al 100(1 logarítmica
- )% para el
Deshaciendo la transformación
enlog(
ambos
límites de este intervalo, el IC al
En base a la distribución aproximadamente normal del log(RR), puede obtenerse un
para
el riesgo relativouna
subyacente
determinado
por
sigue
aproximadamente
distribución
estandarizada.
Conviene
que100(1
bajo -H0 )%
1 queda
1normal
1 entonces
1
el log(
)como
intervalo
confianza alaproximadamente
100(1
- ) )%
En base ade
la distribución
log(RR),
log( RR
zpara
del
. puede obtenerse un intervalo
1 / 2 normal
n1 c n 2
de
confianza
al 100(1
– α)%nula
paraHel:
log(ψ)
comoa con
=
1
coincide
la hipótesis H : = 2 de la
destacar
que esta
hipótesis
0
1 1 1 1 0 1
explog( RR) z1 / 2 1 1 1 1 .
aambos
c nde
log(
)muestras
z1 / 2 en
n1 límites
RR
2. este intervalo, el IC al
Deshaciendo
transformación
logarítmica
en dos
comparación
de la
proporciones
independientes,
a n1 c n 2así como con la hipótesis
Inferencia
sobre proporciones
intervalo
de confianza
2
el del
riesgo
relativo
subyacente
queda
entonces
determinado
por
100(1
- )%
Deshaciendo
la para
transformación
enenambos
límites
deEste
este
intervalo,
el
IC un
al 100(1
de Pearson
una
tabla
22.
test
es, por
nula
de independencia
Notar
que por
tratarse
detest
unalogarítmica
medida
de efecto
multiplicativa,
el intervalo
detanto,
confianza
Deshaciendo
la
transformación
logarítmica
en
ambos
límites
de
este
intervalo,
el
IC
–
α)%
para
el
riesgo
relativo
subyacente
ψ
queda
entonces
determinado
por
que bajo H0 sigue aproximadamente una distribución normal estandarizada. Conviene al
procedimiento
alternativo
para
la misma
hipótesis
nula,quelaarroja
resultados
no es simétrico
alrededor
de contrastar
la estimación
puntual
RR.
hipótesis
nula de
1 queda
1 Asimismo,
1entonces
1 determinado
100(1
)%
para
el
riesgo
relativo
subyacente
. 0: 1 = 2 depor
lahipótesis
H
1 / 2
destacar que esta hipótesisexp
nula
H0: RR
=) 1 zcoincide
con
la
log(
a No
n1 obstante,
c n 2 si la muestra es
muy
similares
cuando
el
tamaño
muestral
es
grande.
no efecto H0: = 1 puede contrastarse frente a la hipótesis alternativa bilateral H1:
comparación
proporciones
dos muestras
como condela confianza
hipótesis no es
Notar que pordetratarse
de una en
medida
de efectoindependientes,
multiplicativa,
el
1 1 1 así
1 intervalo
moderada
o
pequeña,
el
valor
P
de
este
test
puede
resultar
algo
impreciso,
en
cuyo
exp
RRpuntual
) dez1efecto
la hipótesis
RR.
/2
.intervalo
log(
1Notar
mediante
el estadístico
simétrico
alrededor
de la de
estimación
Asimismo,
nulade
deconfianza
nocaso
efecto H0:
que
por
tratarse
una
medida
multiplicativa,
el
a
n
c
n
1
2
2
Pearson
en una tabla
22. H
Este
test es, por tanto, 2un
nula
independencia
test ala de
ψ = 1de
puede
contrastarsedel
frente
hipótesis
alternativa
bilateral
1: ψ ≠ 1 mediante el estadístico
es preferible
utilizar
los
contrates
basados
en
la
diferencia
de
proporciones
o el test
no es simétrico alrededor de la estimaciónlog(
puntual
RR) RR. Asimismo, la hipótesis nula de
procedimiento
alternativo
para
mismamultiplicativa,
hipótesis
arroja resultados
z delaefecto
, nula,elque
Notar que por
tratarse de
unacontrastar
medida
intervalo
de confianza
1
1
1
1
de no
Pearson.
a la hipótesis alternativa bilateral H1:
efecto H0: = 1 puede contrastarse frente
aes grande.
npuntual
c No
n 2obstante,
muy
cuando
el tamaño
si lalamuestra
esnula de
1
nosimilares
es simétrico
alrededor
de lamuestral
estimación
RR.
Asimismo,
hipótesis
mediante
el estadístico
que1 bajo
H0 sigue
aproximadamente
una distribución
estandarizada.
Conviene
Ejemplo
7.12
Retomando
de este
nuevo
datosresultar
delnormal
NHANES
II presentados
encaso
la destacar
moderada
o
pequeña,
elpuede
valor contrastarse
P de
testlos
puede
algoalternativa
impreciso,
en cuyo
:
=
1
frente
a
la
hipótesis
bilateral
H
no
efecto
H
0
1: de
que esta hipótesis nula H : ψ = 1 coincide con la hipótesis H : π = π de la comparación
0
0
1
2
proporciones
en dos
muestras
independientes,
asíRR
como
log(
) con la hipótesis nula de independencia
2
) resulta
ser
Tabla 7.2,
el IClos
al contrates
95% para
el log(en
es preferible
utilizar
basados
la diferencia
z
,de proporciones o el test
1
mediante
el
estadístico
2
test
es,
por
tanto,
un
procedimiento
alternativo
para
del test χ de Pearson en una tabla 2×2. Este
1 1 1 1
resultados
contrastar la misma hipótesis nula, que arroja
muy similares cuando el tamaño
21
de Pearson.
a 1n1 c 1 n 2 1
1 muestra
muestral es grande.
No
obstante,
si
la
es
moderada
o
pequeña,
el
valor
P
de
este
test
log(
RR
)
log(1,51) z 0,975 z
254 caso
2.713
309 4,utilizar
.999 los contrastes basados en la
puede resultar algo impreciso, en cuyo
es
preferible
1 1 1 1
diferencia
de proporciones
o el test
χ 2 de Pearson.
Ejemplo
7.12 Retomando
de nuevo
II presentados en la
alos datos
n
cdel nNHANES
2
= 0,415 1 1,960,081
= (0,256; 0,574).
Ejemplo
Retomando
nuevo
los datos
) resulta
ser del NHANES II presentados en la
Tabla
7.2,7.12
el IC al
95% para eldelog(
Tabla
7.2,
el
IC
al
95%
para
el
log(ψ)
resulta
ser
21
Aplicando la exponencial a ambos límites del intervalo,
el IC al 95% para
vendría dadolog(
por1,51) z 0,975
1
1
1
1
254 2.713 309 4.999
21
= 0,415
1,960,081
= (0,256;
(exp{0,256},
exp{0,574})
= (1,29;
1,78), 0,574).
Aplicando la exponencial a ambos límites del intervalo, el IC al 95% para ψ vendría dado por
que es ligeramente
asimétrico
respecto
a ladel
estimación
puntual
= 1,51.
El
Aplicando
la exponencial
a ambos
límites
intervalo,
el IC alRR
95%
para
(exp{0,256},
exp{0,574})
= (1,29; 1,78),
que
es ligeramente
asimétrico respecto a la estimación puntual RR = 1,51. El estadístico
estadístico
para
vendría
dado
porel contraste de la hipótesis de no efecto H0: = 1 es
para el contraste de la hipótesis de no efecto H0: ψ = 1 es
110
log(1,51)
exp{0,574})
= (1,29; =1,78),
z(exp{0,256},
=
5,11,
1
1
1
1
254 respecto
2.713 a la
309
4.999 puntual RR = 1,51. El
que es ligeramente asimétrico
estimación
que corresponde a un valor P bilateral 2P(Z ≥ 5,11) = 2{1 – Φ(5,11)} < 0,001. Como cabía
:-
= nulo
1 es ψ<=0,001.
estadístico
la hipótesis
efecto
H
esperar,
estepara
test el
arroja
un resultado
significativo
dado
que
el0valor
1 queda fuera de
que corresponde
a contraste
un valor
Pdebilateral
2P(Zde no
5,11)
=
2{1
(5,11)}
los límites del intervalo de confianza. Así, se concluye que los sujetos con niveles de colesterol
total
superiores
a 6,20este
mmol/l
(IC
al 95% 29-78%;
< 0,001)
más riesgo
Como
cabía esperar,
test presentan
arrojalog(
un1un
resultado
significativo
dadoPque
el valor
,5151%
)
=
5,11,
z
=
de morir por enfermedad cardiovascular que quienes tienen niveles inferiores a este umbral.
1
1
1
1
22
254 2.713 309 4.999
Pastor-Barriuso R.
que corresponde a un valor P bilateral 2P(Z 5,11) = 2{1 - (5,11)} < 0,001.
,
medirse
mediante
7.6.2 Odds
ratio la probabilidad P(D|E)
P( D c de
| Eque
) un sujeto de la población expuesta
vendría dada por
presente
o desarrolle
enfermedad.
Otrapoblación
medida de
frecuencia
de
la
Medidas adeun
efecto
en enfermedad
una
de contingencia
La frecuencia
de una dicha
enfermedad
D en una
expuesta
factor
Etabla
suele
entre
los
expuestos
y
puede
estimarse
que se conoce como el odds de estar enfermo
P( D | E )
,
vendría
por la probabilidad P(D|E)
medirse dada
mediante
P( D c de
| Eque
) un sujeto de la población expuesta
mediante
7.6.2 Odds ratio
presente o desarrolle dicha enfermedad.POtra
de frecuencia de la enfermedad
( D | medida
E)
,
odds
de
estar
enfermo
entre
los
expuestos
estimarse
que
se
conoce
como
el
La frecuencia de una enfermedad D ena /una
expuesta ya puede
un factor
E suele medirse
n1( Dpoblación
ca
P
| .E )
vendría
dada
por
mediante la probabilidad P(D|E) de quebun
/ nsujeto
b de la población expuesta presente o desarrolle
1
mediante
dicha enfermedad. Otra medida de frecuencia de la enfermedad vendría dada por
que se conoce como el odds de estar enfermo
P( D | Eentre
) los expuestos y puede estimarse
,
a / n1 por
ca
Ejemplo 7.13 La proporción de muertes
enfermedad
cardiovascular entre los
P
(
D
|
E
)
.
mediante
b / n1 b
que se conoce como el odds de estar enfermo entre los expuestos y puede estimarse mediante
participantes del NHANES II con niveles de colesterol total 6,20 mmol/l es
que se conoce como el odds de estar enfermo
a / n1 entre
a los expuestos y puede estimarse
.
b / n1poraltos
b de colesterol
Ejemplo
7.13
proporción
decon
muertes
cardiovascular
entre los
esto es,
porLa
cada
10 sujetos
que no fallezcan
por
a niveles
254 enfermedad
mediante
0,094 ;
n1de muertes
2.713 por enfermedad cardiovascular entre los
Ejemplo
La
proporción
participantes
NHANES
II con
niveles
de
colesterol
total
que
6,20no
mmol/l
enfermedad
cardiovascular,
habrá
aproximadamente
1 muerte
por
dicha es
causa
esto
es,7.13
pordel
cada
10
sujetos
con
niveles
altos
de colesterol
fallezcan
por a
a
/
n
1 deacolesterol total ≥ 6,20 mmol/l es
participantes
del
NHANES
II
con
niveles
Ejemplo 7.13 La proporción de muertespor. enfermedad cardiovascular entre los
es decir,
1 dehabrá
cada 11
altosambas
de colesterol
/ nla
b con niveles
1sujetos
los 15aproximadamente
años de
seguimiento.
Aunque
interpretación
medidas
enfermedad
cardiovascular,
1difiere,
muerte
por
dicha
causade
a
a baproximadamente
254
;
niveles
0de
,094
participantes del NHANES IIn con
colesterol
total
6,20
mmol/l
es
2.713
1
fallecerá
cardiovascular
los
15deaños
dedifiere,
seguimiento.
Por
otraporde
frecuencia
facilitan
misma
información.
esto
es,por
porenfermedad
cada
10 la
sujetos
con
niveles
altos
colesterol
queambas
no fallezcan
los
15
años
de
seguimiento.
Aunque
laa interpretación
medidas
es decir,
aproximadamente
1 dede
cada
11 sujetos
con nivelescardiovascular
altos de colesterol
Ejemplo
7.13 La proporción
muertes
por enfermedad
entrefallecerá
los
a
254
parte,
el
odds
de
morir
por
enfermedad
cardiovascular
entre
estos
sujetos
es
por
enfermedad
cardiovascular
a
los
15
años
de
seguimiento.
Por
otra
parte,
el odds
es decir,
aproximadamente
1 dehabrá
cada
11
altos por
de colesterol
; 1 muerte
sujetos
0con
,094niveles
enfermedad
cardiovascular,
aproximadamente
dicha causa
a de
frecuencia
facilitan
la misma
información.
n
2
.
713
1 entre
Departicipantes
forma
equivalente,
el odds II
decon
estar
enfermo
entre
loses
no
expuestos
se define
morir
por enfermedad
cardiovascular
estos
sujetos
del NHANES
niveles
de colesterol
total
6,20 mmol/l
es
fallecerá
cardiovascular
a
los
15
años
de
seguimiento.
Por
otra
los 15 por
añosenfermedad
de seguimiento.
Aunque
la
interpretación
difiere,
ambas
medidas
de
a
254
enfermo
0,103
; los no expuestos se define
como
Dees
forma
equivalente,
el
odds
de
estar
entre
decir, aproximadamente 1 bde cada
11 sujetos con niveles altos de colesterol
a2.459
254
parte,
el odds facilitan
de morir la
por
enfermedad
cardiovascular
frecuencia
misma
información.
0,094 ; entre estos sujetos es
estofallecerá
es, por cada
10
sujetos
con
niveles
altos
de
colesterol que no fallezcan por enfermedad
n
2
.
713
como
1
c
por enfermedad cardiovascular
23
P( D | Ea )los 15 años de seguimiento. Por otra
cardiovascular, habrá aproximadamente 1 muerte
por dicha causa a los 15 años de
,
c
a P254
| E 0c ,)103
seguimiento.
Aunque
lael interpretación
difiere,
ambas
medidas
de frecuencia
( Denfermo
; los
De
formaelequivalente,
odds
de estar
entre
no
expuestos
se define
c
parte,
odds
de
morir
por
enfermedad
entre
estos
sujetos
esfacilitan la
es decir, aproximadamente 1 bde cada
sujetos
con niveles
altos
de
colesterol
P
D11
| Ecardiovascular
)
2.(459
misma información.
,
P( D c | E c )
como
y el odds
ratio opor
razón
de odds entre
expuestos
no15
expuestos
entonces
fallecerá
enfermedad
cardiovascular
los
años de queda
seguimiento.
Por otra
23
254ayentre
De forma equivalente, el odds de estaraenfermo
los
no
expuestos
se define como
0,103 ;
b 2.459c
ydeterminado
el odds
ratio
o razón
odds
expuestos
y) no expuestos
queda
entonces
parte,
elpor
odds
de de
morir
porentre
enfermedad
entre
estos
sujetos es
P( D | Ecardiovascular
,
c
c
23
P( D | E )
determinado por
c
c
c
)
(D | E )
P( D | E ) / P( D
P( D | E ) Pqueda
a | E254
y el odds ratio o razónde= odds entre expuestos
entonces
determinado por
yc no
0,103
;
expuestos
,
c
c
c
c
b
2
.
459
(
|
)
/
(
|
)
(
|
)
(
|
)
P
D
E
P
D
E
P
D
E
P
D
E
y el odds ratio o razón de odds entre expuestos
y no expuestos cqueda
entonces
P( D | E ) / P( D c | E )
P( D | E ) P( D | E c )
,
=
c
c
c
c
c
23
determinado
por puntualP( D | E ) / P ( D | E ) P( D | E ) P( D | E )
cuya estimación
cuya estimación puntual
c
cuya estimación puntual P( D | E ) / P ( D
) d / nP2()D | ad
E ) P( D c | E c )
(a / |nE1 )(
=
,
c
OR = c c
c
|
)
(
|
)
(
|
)
P( D | E c ) / P( D
E
P
D
E
P
D
E
(b / n1 )(c / n 2 ) bc
(a / n1 )(d / n 2 ) ad
=
coincide con la razón del productoOR
cruzado
de las celdas de una tabla 2×2.
(b / n1 )(c / n 2 ) bc
cuya
estimación
puntual
coincide
conellariesgo
razón relativo,
del producto
cruzado
deuna
las celdas
tabla
22.
Al
igual que
el odds
ratio es
medidadedeuna
efecto
multiplicativa
que toma
valores no negativos. Si ω = 1, las probabilidades de enfermar en expuestos y no expuestos
c relativo,
Al igual
elP(D|E
riesgo
elcruzado
odds
detabla
efecto
multiplicativa
coincide
conque
la=razón
del
ded las
celdas
22.
(a / nratio
/es
n 2una
) medida
ad de una
1 )(
), producto
indicando
coinciden
P(D|E)
OR = independencia entre
exposición y enfermedad. Si por el
contrario ω > 1, la probabilidad de contraer
(b / nla1 )(enfermedad
c / n 2 ) bcserá mayor en expuestos que en no
odds
= 1, las
probabilidades
en expuestos
y en
queAltoma
valores
no
negativos.
igual
que elque
riesgo
ratio
es
medidadede
efecto multiplicativa
expuestos;
mientras
si ωrelativo,
< 1, Si
la el
probabilidad
deuna
desarrollar
laenfermar
enfermedad
será menor
expuestos que en no expuestos. Resulta sencillo probar que el odds ratio estará siempre más
c
coincide
lacoinciden
razón
delP(D|E)
producto
de
las celdas
de de
unaenfermar
tablaentre
22.
independencia
no expuestos
= P(D|E
cruzado
= 1, ),lasindicando
probabilidades
enexposición
expuestos yy
que
tomacon
valores
no negativos.
Si
Pastor-Barriuso
Al
igual que
el
relativo,
el
odds
ratio
es unaindependencia
medida
de efecto
multiplicativa
> 1,
lac),probabilidad
de contraer
laentre
enfermedad
seráy R.
enfermedad.
Si
porriesgo
el contrario
indicando
exposición
no
expuestos
coinciden
P(D|E)
=P(D|E
= la
1, probabilidad
las
probabilidades
enfermar
en expuestos
que
toma
noelque
negativos.
Si
> 1,
enfermedad
será y
enfermedad.
Si por
contrario
mayor
en valores
expuestos
en no expuestos;
mientras
quedesicontraer
de
< 1,
lalaprobabilidad
de
111
254 4.690
= 1,57.
2.459 309
Inferencia sobre proporciones
y no expuestos, de tal forma que P(Dc|E) y P(Dc|Ec) estén próximas a 1, el odds ratio
Por tanto, el odds de mortalidad por enfermedad cardiovascular es un 57%
será
entonces
aproximadamente
igualrelativo.
al riesgo
relativo.si la probabilidad de enfermar es baja en
alejado del valor
nulo 1 que el riesgo
Además,
c
superior
en los
sujetos
con niveles
de colesterol
a 6,20próximas
mmol/l que
|E) ysuperiores
P(Dc|Ec) estén
a 1, el
los sujetos
expuestos
y no
expuestos,
de tal forma
que P(Dtotal
odds ratio
será entonces
aproximadamente
igual alenriesgo
relativo.
Ejemplo
7.14 Acon
partir
de datos
observados
el estudio
7.2),
en aquellos
niveles
inferiores
a 6,20 mmol/l.
Este NHANES
odds ratio II
es(Tabla
ligeramente
OR =
Ejemplo
7.14 A partir
deodds
los datos
observados en el estudio NHANES II (Tabla 7.2), la
la estimación
ratio
mayor que puntual
el riesgodel
relativo
RR =es1,51 estimado en el Ejemplo 7.10, aunque la
estimación puntual del odds ratio es
diferencia no es muy grande porque
acumulada es relativamente baja
254 la4.incidencia
690
= 1,57.
OR =
2.459 309
tanto en expuestos 254/2.713 = 0,094 como en no expuestos 309/4.999 = 0,062.
Por tanto, el odds de mortalidad por enfermedad cardiovascular es un 57% superior en los
sujetos
conelniveles
demortalidad
colesterol total
superiores a cardiovascular
6,20 mmol/l queesen
Por tanto,
odds de
por enfermedad
unaquellos
57% con niveles
inferiores
a 6,20
mmol/l.
Este
odds obvio
ratio es
el riesgo
relativo
, resulta
queligeramente
el odds ratiomayor
puedeque
estimarse
a partir
De la propia
definición
de
superior
los sujetos
niveles 7.10,
de colesterol
total
superiores
a 6,20
RR
= 1,51enestimado
en con
el Ejemplo
aunque la
diferencia
no es
muymmol/l
grande que
porque la
incidencia
acumulada
es
relativamente
baja
tanto
en
expuestos
254/2.713
=
0,094
de estudios prospectivos y transversales, ya que ambos diseños facilitan estimaciones como
de
aquellos
con niveles
inferiores
a 6,20 mmol/l. Este odds ratio es ligeramente
en no
expuestos
309/4.999
= 0,062.
las probabilidades de enfermar P(D|E) y P(D|Ec). Aplicando la definición de
que definición
el riesgo relativo
RR = 1,51
estimado
el Ejemplo
7.10,estimarse
aunque laa partir de
Demayor
la propia
de ω, resulta
obvio
que el en
odds
ratio puede
estudios
prospectivos
y transversales,
ya elque
ambos
diseñosexpresarse
facilitan aestimaciones
probabilidad
condicional
(ver Tema 2),
odds
ratio puede
su vez en de las
c
diferencia de
no es
muy grande
porque
la incidencia
acumulada
es relativamente
baja
). Aplicando
la definición
de probabilidad
probabilidades
enfermar
P(D|E)
y P(D|E
condicional
2), el odds
expresarse
a su vez
enenfermos
términos de
la probabilidad
términos (ver
de laTema
probabilidad
de ratio
estarpuede
expuesto
en enfermos
y no
como
tanto
en expuestos
254/2.713
0,094 como
de estar
expuesto
en enfermos
y no =
enfermos
comoen no expuestos 309/4.999 = 0,062.
P( D | E ) P( D c | E c ) P( D E ) P( D c E c )
c
c
a partir
De la propia definición Pde( Dc, |resulta
( Dodds
) P(puede
D Eestimarse
)
E ) P ( Dobvio
| E c )quePel
Eratio
c
( E | D) P( E c ya
| D que
) ambos diseños facilitan estimaciones de
de estudios prospectivos yPtransversales,
,
P( E | D c ) P( E c | D)
las probabilidades de enfermar P(D|E) y P(D|Ec). Aplicando la definición de
de donde
se desprende
queodds
el odds
ratio
también
estimable a partir
de estudios
retrospectivos,
estimación
puntual del
ratio
en es
estudios
retrospectivos
coincide
con la razón
del
aun
diseños (ver
no
información
alguna
sobre
las
probabilidades
decuando
dondeestos
se
desprende
quefacilitan
el odds2),
ratio
es también
estimable
a partir
devez
estudios
probabilidad
condicional
Tema
el odds
ratio
puede
expresarse
a su
en absolutas de
enfermar
en cruzado
expuestos y no expuestos. Por supuesto, la estimación puntual del odds ratio en
producto
estudios
retrospectivos
coincide
condiseños
la razónnodel
producto
cruzado
retrospectivos,
aun cuando
información
alguna
sobre las
términos
de la probabilidad
deestos
estar
expuesto
enfacilitan
enfermos
y no enfermos
como
(a / mexpuestos
ad
1 )( d / m 2 )y no
probabilidades absolutas de enfermar
Por supuesto, la
expuestos.
.
OR =c en
c
P( D | E ) P( D | E
)m 2 P
(cD/ m
(D c E c )
1 )E ) Pbc
(
b
/
)(
P( D c | E ) P( D | E c ) P( D c E ) P( D E c )
Los estudios retrospectivos suelen conducirse en enfermedades de baja incidencia, para las
c
c
cualesLos
la obtención
de un
suficiente
de estudios
estudios retrospectivos
en requeriría
enfermedades
de baja prospectivos
incidencia, 25con
P( Enúmero
| D) Psuelen
(E
| Dconducirse
) de casos
y amplio
, En tales circunstancias, si la incidencia de la
gran tamaño muestral
c seguimiento.
c
(
|
)
(
|
)
P
E
D
P
E
D
enfermedad
es bajalayobtención
el diseño de
delun
estudio
retrospectivo
(esto es,
incidentes
para las cuales
número
suficientes es
de adecuado
casos requeriría
decasos
estudios
y controles representativos del nivel de exposición en la población libre de enfermedad), el
odds
ratioseconstituye
una
buena
aproximación
al riesgo
relativo
subyacente.
En adelante,
con gran
tamaño
amplio
seguimiento.
En
tales
circunstancias,
si el
de prospectivos
donde
desprende
que
el oddsmuestral
ratio es ytambién
estimable
a partir
de estudios
odds ratio se utilizará e interpretará como estimación del riesgo relativo, asumiendo que se
cumplen
las condiciones
citadas
la incidencia
de la
enfermedad
es baja no
y elfacilitan
diseño información
del estudio retrospectivo
retrospectivos,
aun
cuando
estos anteriormente.
diseños
alguna sobrees
lasadecuado
(esto
es, casos
incidentes
y controles
nivel
dePor
exposición
probabilidades
absolutas
enfermar
enrepresentativos
expuestos
y no del
expuestos.
supuesto,
lala
Ejemplo
7.15
En de
el estudio
EURAMIC
se obtuvo
una
muestra
de casosenincidentes
de
infarto de miocardio procedentes de las unidades de cuidados intensivos y una muestra
población
de enfermedad),
el oddsaratio
constituye
una buena
aproximación
al
aleatorialibre
de controles
seleccionados
partir
de la población
de referencia.
El número
de
casos y controles con valores de colesterol HDL superiores o inferiores a 0,90 mmol/l
se
25
riesgo
relativo
subyacente.
En adelante,
el odds
ratio se utilizará
e interpretará
como
presenta
en la
Tabla 7.3. Aunque
el diseño
retrospectivo
del estudio
no permite
conocer la
112
estimación
Pastor-Barriuso
R.
del riesgo relativo, asumiendo que se cumplen las condiciones citadas
anteriormente.
retrospectivo
delhombres
estudio no
permite
la incidencia
de infartoscomo
entreun
losriesgo
población de
adultos,
esteconocer
odds ratio
puede interpretarse
con un colesterol HDL inferior a 0,90 mmol/l (100(0,58 - 1) = -42%).
Medidas
de efecto
enauna
tabla
de contingencia
sujetos
con
altos
bajos
de
colesterol
HDL, síes
es
posible
obtener
una
relativo
concluir
que
sujetos
condeunmiocardio
colesterol
HDL
superior
0,90
mmol/l
Como
layvalores
incidencia
deylos
infarto
agudo
relativamente
baja
en
la
El
odds
ratio un
es
de
efecto
cuya
distribución
muestral
medida
relativa
de
lamedida
asociación
entre
el
colesterol
HDL
yde
elmiocardio
riesgo de
infarto
dees
presentan
42%
menos
riesgo
de multiplicativa
padecer
un puede
infarto
que
aquellos
población
de una
hombres
adultos,
este
odds
ratio
interpretarse
como
un riesgo
incidencia de infartos entre los sujetos con valores altos y bajos de colesterol HDL, sí es
notablemente
asimétrica
7.2(c)),
mientras
que
suentre
transformación
miocardio
mediante
el(Figura
odds
ratio
con
un
colesterol
HDL
inferior
a 0,90
(100(0,58
- superior
1)colesterol
= -42%).
posible
obtener
una medida
relativa
de
lammol/l
asociación
HDLmmol/l
y el riesgo
relativo
y concluir
que
los
sujetos
con
un
colesterol
HDLel
alogarítmica
0,90
de infarto de miocardio mediante el odds ratio
log(OR)
tiende aun
distribuirse
normalmente
(Figuraun
7.2(d))
varianza
presentan
42% menos
riesgo de
padecer
infartocon
deuna
miocardio
que aquellos
158
269
El odds ratio es una medida deOR
efecto
= multiplicativa
= 0,58.cuya distribución muestral es
381
193 de las frecuencias de una tabla 22
aproximadamente
igual HDL
a la suma
de los
inversos
con un colesterol
inferior
a 0,90
mmol/l (100(0,58 - 1) = -42%).
notablemente
asimétricade(Figura
mientras
que es
su relativamente
transformaciónbaja
logarítmica
Como la incidencia
infarto7.2(c)),
agudo de
miocardio
en la población
de hombres adultos, este odds ratio puede interpretarse
como
un
riesgo
relativo
y concluir
1 1 1 1
log(OR)
tiende
distribuirse
normalmente
con
unapresentan
varianza
var{log(OR)}
(Figura
7.2(d))
cuya
. distribución
que
los
sujetos
con
colesterol
HDLmultiplicativa
superior
a 0,90
mmol/l
un 42%
El odds
ratioaes
una un
medida
de efecto
muestral
esmenos
c d con un colesterol HDL26
riesgo de padecer un infarto de miocardioa queb aquellos
inferior
aproximadamente
igual a(Figura
la –suma
de
los inversos
lassufrecuencias
de una
tabla 22
a 0,90 mmol/l
(100(0,58
1) =7.2(c)),
–42%).
notablemente
asimétrica
mientrasde
que
transformación
logarítmica
Utilizando esta aproximación normal a la distribución muestral del log(OR) y
log(OR)
normalmente
unadistribución
varianza
El
odds tiende
ratio aesdistribuirse
una medida
de efecto(Figura
multiplicativa
cuya
muestral es
1 1 7.2(d))
1 1con
var{log(OR)}
.
deshaciendoasimétrica
a continuación
la 7.2(c)),
transformación
se obtiene ellogarítmica
intervalo delog(OR)
notablemente
(Figura
mientraslogarítmica,
que su transformación
a b c d
aproximadamente
igual
a
la
suma
de
los
inversos
de
las
frecuencias
de
una
tabla 22
tiende a distribuirse normalmente (Figura 7.2(d)) con una varianza aproximadamente
igual a la
)%frecuencias
para el oddsderatio
confianza
al 100(1de
- las
suma
de los inversos
una subyacente
tabla 2×2
Utilizando esta aproximación normal a la distribución muestral del log(OR) y
1 1 1 1
var{log(OR)} .
transformaciónalogarítmica,
1 b 1 c 1 dse1 obtiene
deshaciendo a continuación
el intervalo de
,
explalog(
OR) z1 / 2
a bmuestral
c d del log(OR) y deshaciendo a
Utilizando esta aproximación normal
a la distribución
el odds aratio
subyacente
confianza
100(1
- )% para
continuación
laesta
transformación
logarítmica,
obtiene el intervalo
de
Utilizandoal
aproximación
normal
lasedistribución
muestral
delconfianza
log(OR) yal 100(1 – α)%
para el odds ratio subyacente ω
que no es simétrico alrededor de la estimación puntual OR. De forma análoga, la
deshaciendo a continuación la transformación logarítmica, se obtiene el intervalo de
con el ejemplo anterior,
1 1 el1 IC 1al95% para el odds
Ejemplo 7.16 Continuando
z1 / 2 de la
nula
log(OR) bilateral
, H0: = 1 se obtiene
significación estadística exp
del contraste
a bhipótesis
el odds ratio subyacente
c d
confianza al 100(1 - )% para
ratio de infarto agudo de miocardio entre los sujetos con niveles altos y bajos de
quea no
es simétrico
alrededor de la estimación puntual OR. De forma análoga, la significación
partir
del estadístico
quecolesterol
no es
alrededor
estimación
puntual
De
la estadístico
estadística
delsimétrico
contraste
bilateral de la hipótesis
nula
=11 se
a partir del
forma análoga,
1 H0:1ωOR.
1 obtiene
HDL es
,
explog(OR) z1 / 2
log(ORa) b c d
,
z bilateral de la hipótesis
significación estadística del contraste
nula H0: = 1 se obtiene
11 1 1 1 11
1
exp log(0,58) z 0,975
al 95% para el odds
Ejemplo
7.16 Continuando
con el 269
ejemplo
anterior,
el158
ICDe
a b381
c 193
d OR.
aque
partir
delsimétrico
estadístico
no es
puntual
alrededor de la estimación
forma análoga, la
que bajo H0 sigue aproximadamente una distribución normal estandarizada.
ratio de infarto
agudodel
de miocardio
entre losdesujetos
con niveles
de
: =y 1bajos
se obtiene
significación
estadística
contraste
bilateral
nula
Haltos
00,75).
aproximadamente
una
distribución
normal=estandarizada.
que
bajo H0 sigue
log(OR
) la hipótesis
= exp(-0,55
1,960,134)
(0,44;
,
z
Ejemplo
7.16
Continuando
con el 1ejemplo
el IC al 95% para el odds ratio de
1 1anterior,
1
colesterol
HDL
es
a partir
del
estadístico
infarto
agudo
de miocardio
entreuna
losconfianza
sujetos
niveles
altoslos
y bajos
decon
colesterol
Por tanto,
puede
afirmarse con
sujetos
nivelesHDL es
a b con
cdel
d95% que
1 log(
1OR) 56%
1 menos
1 riesgo de padecer un
altos de colesterol
expaproximadamente
log(HDL
0,58)tienen
z 0,975zentre
25 y un
,
unaun
estandarizada.
distribución
normal
que bajo H0 sigue
27
269
1 1381 1 193
1 158
infarto de miocardio que quienes
tienen
niveles
más
- 1) = -25% y
a0,55
b c1,960,134)
d bajos=(100(0,75
= exp(
(0,44; 0,75).
100(0,44
1) = -56%).
Asimismo,
contrastedelbilateral
delos
la hipótesis
de niveles
no
Por
tanto, -puede
afirmarse
con una el
confianza
95% que
sujetos con
altos de
que bajo H0 sigue aproximadamente una distribución normal estandarizada.
colesterol HDL tienen entre un 25 y un 56% menos riesgo de padecer un infarto de miocardio
Por tanto,
afirmarse el
con
una confianza del 95% que los sujetos con niveles 27
tienen
= 1 mediante
estadístico
efecto
H0: puede
que
quienes
niveles más
bajos (100(0,75 – 1) = –25% y 100(0,44 – 1) = –56%).
Asimismo, el contraste bilateral de la hipótesis de no efecto H0: ω = 1 mediante el estadístico
altos de colesterol HDL tienen entre un 25 y un 56% menos riesgo de padecer un
log(0,58)
z=
= − 4,10
infarto de miocardio que quienes
más
1 tienen
1 niveles
1
1 bajos (100(0,75 - 1) = -25% y 27
269 381 193 158
100(0,44 - 1) = -56%). Asimismo, el contraste bilateral de la hipótesis de no
R.
arroja
muy significativo
P = 2P(Z -4,10) = 2{1 - (4,10)} <Pastor-Barriuso
0,001.
efecto un
H0:resultado
= 1 mediante
el estadístico
Notar que este test es equivalente al contraste de hipótesis realizado en el Ejemplo
log(0,58)
113
Inferencia sobre proporciones
arroja un resultado muy significativo P = 2P(Z ≤ –4,10) = 2{1 – Φ(4,10)} < 0,001. Notar
que este test es equivalente al contraste de hipótesis realizado en el Ejemplo 7.5 sobre la
igualdad en la proporción de sujetos con niveles bajos de colesterol HDL entre los casos
de infarto y los sujetos libres de la enfermedad, de tal forma que los valores P resultantes
de ambos procedimientos son virtualmente idénticos.
7.7
COMPARACIÓN DE PROPORCIONES EN DOS MUESTRAS DEPENDIENTES
Hasta este punto se han presentado distintos métodos para la comparación de proporciones a
partir de muestras independientes. Con cierta frecuencia, sin embargo, suelen emplearse
muestras dependientes, que surgen tanto de observaciones tomadas en los mismos sujetos como
en distintos sujetos emparejados de acuerdo a determinados factores pronósticos. En el Apartado
6.4 del tema anterior, se presentaron diversos diseños o mecanismos de generación de datos
dependientes. En general, el propósito de los diseños emparejados es aumentar la precisión de
las comparaciones y, en mayor medida, mejorar la validez de las inferencias al controlar por
posibles factores de confusión. En este apartado se aborda el tratamiento estadístico de datos
binarios o dicotómicos procedentes de parejas dependientes.
La muestra consiste en n parejas dependientes o correlacionadas, donde cada pareja está
compuesta por dos observaciones de una variable dicotómica procedentes de distintas poblaciones.
Así, por ejemplo, en comparaciones antes y después de un tratamiento, cada pareja de datos está
constituida por la respuesta en un mismo sujeto antes y después de dicho tratamiento. Igualmente,
en un estudio de casos y controles emparejados, cada pareja de observaciones está formada por
la presencia o ausencia de exposición en cada caso y su correspondiente control. Para simplificar
la presentación, nos centraremos en adelante en un estudio de casos y controles emparejados.
Para preservar el emparejamiento muestral, la unidad de análisis será cada pareja y no cada
individuo. Así, la organización de los datos por individuo mediante la Tabla 7.1 no resulta adecuada
ya que se pierde la información relativa al emparejamiento. La forma apropiada de presentar los
datos se muestra en la Tabla 7.6. Cada unidad de esta tabla representa una pareja, de tal forma que
hay a parejas donde ambos caso y control están expuestos al factor de riesgo, b parejas donde el
caso está expuesto y el control no, c parejas donde el control está expuesto y el caso no, y d parejas
donde ninguno está expuesto. Las a + d parejas donde ambos o ninguno de los miembros están
expuestos se denominan parejas concordantes, mientras las restantes b + c parejas son discordantes.
Ejemplo 7.17 En el Ejemplo 6.12 se seleccionaron 50 casos de infarto de miocardio y 50
controles del estudio EURAMIC emparejados por grupos quinquenales de edad. A partir de sus
valores del colesterol HDL (Tabla 6.1), se desprende que hay 23 parejas donde el caso de infarto
y su correspondiente control presentan niveles altos de colesterol HDL (superior a 0,90 mmol/l),
6 parejas donde el caso tiene un nivel alto y el control bajo, 17 parejas donde el caso tiene un
nivel bajo y el control alto, y 4 parejas donde ambos presentan niveles bajos de colesterol HDL.
Los datos de este estudio de casos y controles emparejados se resumen en la Tabla 7.7.
Tabla 7.6 Tabla de contingencia en un estudio de casos
y controles emparejados.
Controles
Casos
Expuestos
No expuestos
Total
114
Pastor-Barriuso R.
Expuestos
No expuestos
Total
a
c
a+c
b
d
b+d
a+b
c+d
n
Comparación deaquí]
proporciones en dos muestras dependientes
[Tabla 7.7 aproximadamente
Con objeto de evaluar la asociación entre exposición y enfermedad controlando por
Tabla 7.7 Colesterol HDL en 50 casos de infarto de miocardio y 50
controles del estudio EURAMIC emparejados por grupos quinquenales
aquellos factores de confusión utilizados en el emparejamiento, cada caso ha de ser
de edad.
comparado con su correspondiente control; esControles
decir, las comparaciones deben estar
donde la última igualdad refleja su relación con el odds ratio subyacente . Despejando
Casos
HDL > 0,90 mmol/l
HDL ≤ 0,90 mmol/l
Total
17
4
21
condicionadas
a cada pareja. Por ello,23los pares concordantes,6donde ambos miembros
HDL
> 0,90 mmol/l
29
de esta
expresión,
se tiene que
HDL ≤ 0,90 mmol/l
están o Total
no expuestos, no aportan información
sobre la asociación
a estudio y,50
en
40
10
a las. parejas discordantes. La probabilidad
consecuencia, el análisis estadístico se limita
1
Con objeto de evaluar la asociación entre exposición y enfermedad controlando por aquellos
factores
de confusión
utilizados
en elexpuesto
emparejamiento,
cadanocaso
ha de viene
ser comparado
de observar
una pareja
con el caso
y el control
expuesto
dada por con su
puede
mediante deben
la proporción
observada b/(b
+ c) pareja.
de
Como la probabilidad
correspondiente
control; es
decir, estimarse
las comparaciones
estar condicionadas
a cada
c c
PorP(E|D)P(E
ello, los pares
concordantes,
ambos de
miembros
están
o nocon
expuestos,
|D ), mientras
que ladonde
probabilidad
obtener una
pareja
el controlno aportan
parejas discordantes
donde el acaso
está y,
expuesto,
la estimación
puntualestadístico
del odds ratio
de a
información
sobre la asociación
estudio
en consecuencia,
el análisis
se limita
c
c
lasexpuesto
parejas discordantes.
La probabilidad
observar
unadado
pareja
casoesexpuesto y el
)P(E
|D). Así,
que con
una el
pareja
y el caso no expuesto
es P(E|Dde
. Despejando
dondenolaexpuesto
última
igualdad
refleja
suP(E|D)P(E
relación
ratioque
subyacente
c
enfermar
entre expuestos
y nopor
expuestos
es con
|Dcel
), odds
mientras
la probabilidad
de obtener
control
viene dada
c
c
de quey el
expuesto es P(E|D )P(E |D). Así, dado que
unadiscordante,
pareja con la
el probabilidad
control expuesto
el caso
casoesté
no expuesto
de
esta
expresión,
se
tiene
que
una pareja es discordante, la probabilidad
c)estéb expuesto es
b /(b de
c) quebel/(bcaso
OR =
,
Psu
)b cratio
. Despejando
(cEcon
1(Erelación
/(b) P
)c | D
) c subyacente
b| D
cel/(codds
donde la última
igualdad
refleja
,
c
c
c
c
P( E | D) P( E | D ) P ( E | D
. ) P( E | D) 1
1
dela
esta
expresión,
se refleja
tiene
que
que
coincide
con
la razón
entre
tipos
Si elω.
número
de
donde
última
igualdad
suambos
relación
condeelpares
oddsdiscordantes.
ratio subyacente
Despejando
ω de
esta expresión, se tiene que
puede
estimarse
mediante
la proporción
Como ladiscordantes
probabilidadb con
parejas
el caso
expuesto
es superior
al númeroobservada
de parejasb/(b + c) de
.
1
parejas discordantes
caso está el
expuesto,
la estimación
odds ratio de
discordantes
c con eldonde
controlelexpuesto,
odds ratio
será mayor puntual
de 1 y ladel
exposición
30
Como la probabilidad π puede estimarse mediante la proporción observada b/(b + c) de parejas
enfermar
entre
y no
expuestos
es
discordantes
dondeexpuestos
el caso
expuesto,
la estimación
delsiodds
deb/(b
enfermar
está
puede
estimarse
mediante
lapuntual
proporción
Como
la probabilidad
estará
directamente
asociada
con
la enfermedad;
mientras
que
bobservada
es ratio
inferior
a c,+elc) deentre
expuestos y no expuestos es
odds ratio
será menordonde
de 1 yellacaso
exposición
conodds
la ratio de
parejas
discordantes
expuesto,
labestimación
puntual del
bestá
/(b
c)estaráb inversamente
/(
c) b asociada
,
OR =
1 b /(b c) c /(b c) c
enfermedad.
enfermar
entre expuestos y no expuestos es
que coincide con la razón entre ambos tipos de pares discordantes. Si el número de parejas
igualbque
independientes,
el log(OR)
también se Si
distribuye
de de
forma
queAlcoincide
conenel
lamuestras
razónexpuesto
entre
ambos
tipos
pares
el número
discordantes
con
caso
discordantes
c con el
c) de al
bes/(bsuperior
b /(número
b discordantes.
c) deb parejas
exposiciónestará
, directamente asociada con
= mayor de 1 y la
control expuesto, el odds ratioOR
será
1 b /(dependientes,
b c) c /(b con
c) media
c
) ydevarianza
aproximadamente
normal
parejas discordantes
bque
conen
caso
expuesto
eselsuperior
al número
deparejas
la enfermedad;
mientras
sielbmuestras
es inferior
a c,
odds ratio
será log(
menor
1 y la exposición
estará inversamente asociada con la enfermedad.
discordantes
ccon
con
elrazón
control
expuesto,
el odds
será
mayor
de Si
1 el
yella
exposición
aproximada
+la1/c.
El intervalo
de confianza
al 100(1
- )% para
odds
ratiode
que
coincide1/b
entre
ambos
tipos
de ratio
pares
discordantes.
número
Al igual que en muestras independientes, el log(OR) también se distribuye de forma
estará directamente
asociada
enfermedad;
mientras
que
si byde
esvarianza
inferioraproximada
a c, el
aproximadamente
normal
en
dependientes,
con
media
log(ω)
1/b
subyacente
resulta
parejas
discordantes
bentonces
conmuestras
el con
casolaexpuesto
es superior
al número
parejas
+ 1/c. El intervalo de confianza al 100(1 – α)% para el odds ratio subyacente ω resulta entonces
odds ratio será
menor
de 1 y la
exposición
estará
inversamente
la
discordantes
c con
el control
expuesto,
el odds
ratio
será mayorasociada
de 1 y la con
exposición
1 1
explog(OR) z1 / 2
.
enfermedad.
b c que si b es inferior a c, el
estará directamente asociada conla enfermedad; mientras
Alratio
igual quemenor
en muestras
el log(OR)
tambiénasociada
se distribuye
odds
y independientes,
la exposición
estará
inversamente
con sólo
lade forma
Ejemploserá
7.18 Ende
la 1Tabla
7.7 se tienen
6 parejas
discordantes
donde
el caso de
infarto
tiene7.18
un nivel
de7.7
colesterol
HDL
y 17discordantes
parejas discordantes
donde
sólo el
Ejemplo
En la alto
Tabla
se tienen
6 parejas
donde
sólo
el caso
) y varianza
aproximadamente
normal
en muestras
dependientes,
con media log(
enfermedad.
de infarto tiene un nivel alto de colesterol HDL y 17 parejas discordantes donde
aproximada
1/b en
+ 1/c.
El intervalo
de confianza
al 100(1también
- )% para
el odds ratio
Pastor-Barriuso
Al igual que
muestras
independientes,
el log(OR)
se distribuye
de forma R.
aproximadamente
normal
en muestras dependientes, con media log() y varianza
subyacente resulta
entonces
115
sólo el control presenta un nivel alto, de lo cual se deduce que la estimación
Inferencia sobre proporciones
sólo el control
puntual
del oddspresenta
ratio es un nivel alto, de lo cual se deduce que la estimación
puntual
del odds un
ratio
es alto, de lo cual se deduce que la estimación puntual del odds
control presenta
nivel
6
OR =
= 0,35,
ratio es
17
6
OR =
= 0,35,
17
y su IC al 95%
y su IC al 95%
y su IC al 95%
1 1
explog(0,35) z 0,975
6 17
1 1
explog(0,35=)exp(
z 0,975
1,04 1,960,475)
= (0,14; 0,90).
6 17
Por tanto, el riesgo de infarto agudo de miocardio es inferior en un 65% (IC al 95%
= exp(-1,04
1,960,475) =
0,90). respecto a aquellos
10-86%)
los sujetos
con niveles
> (0,14;
0,90enmmol/l
Por
tanto, en
el riesgo
de infarto
agudo de
de colesterol
miocardioHDL
es inferior
un 65% (IC al
con niveles ≤ 0,90 mmol/l. La conclusión de este estudio emparejado es consistente con
la obtenida
los Ejemplos
y 7.16
en la muestra
completa eunindependiente
Por
tanto,
elenriesgo
infarto7.15
agudo
de miocardio
es inferior
65% (IC al de casos
95%
1086%)
en losdesujetos
con
niveles
de colesterol
HDL >en
0,90 mmol/l
y controles del estudio EURAMIC. Aunque esta estimación de efecto es más imprecisa
por disponer
únicamente
de 50 parejas,
será
menos propensa
a0,90
posibles
sesgos derivados
95%
1086%)
en los
niveles
de colesterol
HDL >de
respecto
a aquellos
consujetos
nivelescon
0,90
mmol/l.
La conclusión
estemmol/l
estudio
de la diferencia de edad entre casos y controles.
2
b c La conclusión de este estudio
respecto
a
aquellos
con
niveles
0,90
mmol/l.
emparejado es consistente con la 2obtenida
y 7.16 en la
b en los Ejemplos 7.15
El método más extendido
entre exposición
Econtrastar
{bpara
(b)}
(b de
)2
cindependencia
2 nula
la hipótesis
2
=
.
y enfermedad
en un
estudio
emparejado
en
la
frecuencia
b de
emparejado
es consistente
con
los comparar
Ejemplos
7.15
y 7.16
enobservada
la
b en
var(
b) la obtenida
b del
c estudio
muestra
completa
e independiente
deconsiste
casos
yccontroles
EURAMIC.
pares discordantes donde el caso está expuesto4con su frecuencia esperada bajo la hipótesis
nula. Aunque
Si
no hubiera
asociación
exposición
yy enfermedad,
frecuencia
esperada
sería
muestra
completa
e independiente
casos
controles
delesta
estudio
EURAMIC.
esta
estimación
deentre
efecto
esdemás
imprecisa
por disponer
únicamente
de
simplemente la mitad del número total de parejas discordantes (b + c)/2, con lo cual el estadístico
Bajocontraste
la
hipótesis
nula
de no efecto,
este
estadístico
siguederivados
aproximadamente
una de
del
viene
determinado
Aunque
esta
estimación
depor
efecto
es
más imprecisa
por disponer
de
50
parejas,
será
menos
propensa
a posibles
sesgos
de la únicamente
diferencia
2
b c permite obtener el valor P
sesgos
distribución
chi-cuadrado
conpropensa
1 grado adeposibles
libertad,
50 parejas,
será menos
la diferencia de
edad
entre
casos
y controles.
b lo que
derivados de
2
(b c) 2
{b E (b)}
2
2
=
. 2
1 . Este
como edad
la probabilidad
derechavar(
delbestadístico
b 2 en
c la distribución
)
bc
entre casosaylacontroles.
El método más extendido para contrastar la hipótesis
4 nula de independencia entre
contraste
se conoce
como
el test
de McNemar
y se aplica
cuando la varianzauna
de bdistribución
bajo
Bajo
hipótesis
de no
efecto,
este estadístico
sigue
aproximadamente
El la
método
másnula
extendido
para
contrastar
la hipótesis
nula
independencia
entre
exposición
y enfermedad
en un
estudio
emparejado
consiste
endecomparar
la frecuencia
chi-cuadrado
con 1 grado
libertad,
que
permite obtener
el valor P como la
Bajo la hipótesis
nula dedeno
efecto, lo
este
estadístico
sigue aproximadamente
unaprobabilidad
la
hipótesis
nula
es
var(b)
=
(b
2 + c)(1 - ) = (b + c)/4
2 5; es decir, cuando el número
la distribución χ consiste
se conoce
como el test
a la derechay del
estadístico
χ en
1 . Este contraste
exposición
en un
estudio
encon
comparar
la frecuencia
observada
b deenfermedad
pares discordantes
dondeemparejado
el caso está expuesto
su frecuencia
de distribución
McNemar ychi-cuadrado
se aplica cuando
varianza
de b bajo
la hipótesis
nula eselvar(b)
= (b + c)
con 1 la
grado
de libertad,
lo que
permite obtener
valor P
de
parejas
discordantes
es
superior
o
igual
a
20.
π(1 – π) = b(bde+pares
c)/4 ≥
5; es decir,donde
cuando
el número
de parejas
es superior o
observada
discordantes
el caso
está expuesto
con discordantes
su frecuencia
esperada
bajo la hipótesis
nula. Si no hubiera
asociación
entre exposición
y enfermedad,
2
2
igual
a
20.
como la probabilidad a la derecha del estadístico en la distribución 1 . Este
esperada
bajo laesperada
hipótesis
nula.
Si del
no hubiera
asociación
exposición
y enfermedad,
esta
frecuencia
sería
simplemente
la McNemar
mitad
del número
total7.7
de toma
parejas
Ejemplo
7.19
El estadístico
test de
enentre
la Tabla
el valor
contraste
se 7.19
conoceElcomo
el test del
de McNemar
y se aplica
la varianza
de b bajo
Ejemplo
estadístico
test de McNemar
en lacuando
Tabla 7.7
toma el valor
esta frecuencia
simplemente
la mitad
del número
total
de parejas por
discordantes
(b +esperada
c)/2, consería
lo cual
el estadístico
del2 contraste
viene
determinado
= )(b += c)/4
la hipótesis nula es var(b) = (b + c)2=(1(-6)17
5,26. 5; es decir, cuando el número
6 17del contraste viene determinado por
discordantes (b + c)/2, con lo cual el estadístico
de A
parejas
es superior
o igual acon
20.1 grado de libertad (Tabla 6 del Apéndice),
partir discordantes
de la distribución
chi-cuadrado
116
A partircomprobarse
de la distribución
con 1está
gradocomprendido
de libertad (Tabla
puede
que chi-cuadrado
este estadístico
entre6 del
los percentiles
2
2
χ 1 Ejemplo
y χEl1 ;0,99
= 6,63, de
lo cual
se
tiene queen0,01
< P <7.7
0,025.
Así,
el riesgo de
;0,975 = 5,02
7.19
estadístico
del
deestadístico
McNemar
la
Tabla
toma
ellos
valor
Apéndice),
puede
comprobarse
quetest
este
está entre
comprendido
entre
infarto
agudo
de miocardio
difiere
significativamente
los sujetos
con
niveles
de
32
colesterol HDL superiores e inferiores a 0,90 mmol/l.
percentiles 12;0,975 = 5,02 y 12;0,99 2= 6,63,
(6 de
17lo
) 2 cual se tiene que 0,01 < P <
32
=
= 5,26.
6 17
0,025. Así, el riesgo de infarto agudo de miocardio difiere significativamente
Pastor-Barriuso R.
A partir de la distribución chi-cuadrado con 1 grado de libertad (Tabla 6 del
entre los sujetos con niveles de colesterol HDL superiores e inferiores a 0,90
Apéndice), puede comprobarse que este estadístico está comprendido entre los
siguen
argumentos
similares a los descritos en este apartado y pueden consultarse en los
CE: CORRECCIÓN
POR
CONTINUIDAD
libros de análisis de datos categóricos referenciados en este tema.Apéndice: corrección por continuidad
ice se derivan las versiones
con corrección
porun
continuidad
del intervalo
cada paciente
que conforma
grupo de emparejamiento).
Estas generalizaciones
. Si kCONTINUIDAD
es
número
y del test de hipótesis
para
una proporción
poblacional
7.8
APÉNDICE:
CORRECCIÓN
POR
siguen
argumentos
similares
a los descritos
en el
este
apartado y pueden consultarse en los
La inferencia sobre proporciones puede extenderse a estudios donde se empareja más de un
poraleatoria
muestra de
(por
ejemplo,
unintervalo
estudio dedecasos
y controles
donde cada caso está emparejado
eventos en una sujeto
muestra
tamaño
el
confianza
libros
deapéndice
análisis se
de
datos n,
categóricos
referenciados
enaleste
tema.
En
este
derivan
las
versiones
con
corrección
por
continuidad
del intervalo
con múltiples controles, o un ensayo clínico donde cada paciente que
recibe un nuevo
tratamiento
está
emparejado
con
varios
pacientes
bajo
tratamiento
estándar),
así
como
a
estudios
donde se
para vendrá determinado
por aquellos
valores
( inf, para
que proporción
verifiquen poblacional . Si k es el número
sup) una
de
confianza
y
del
test
de
hipótesis
comparan
más de dosCORRECCIÓN
muestras dependientes
(por ejemplo, un ensayo clínico donde se asignan
7.8 APÉNDICE:
POR CONTINUIDAD
aleatoriamente distintos tratamientos a cada paciente que conforma un grupo de emparejamiento).
observado
muestra aleatoria
de atamaño
n, el intervalo
confianza
al
P(Xgeneralizaciones
k | de
= eventos
en
/2, unaargumentos
Estas
similares
los descritos
en este de
apartado
y pueden
inf) = siguen
En este apéndice
se derivan
las versiones
con corrección
por continuidad
intervalo
consultarse
en los libros
de análisis
de datos categóricos
referenciados
en estedel
tema.
)%
para
vendrá
determinado
por
aquellos
valores
(
,
)
que
verifiquen
100(1
inf
sup
P(X k | = sup) = /2,
de confianza y del test de hipótesis para una proporción poblacional . Si k es el número
7.8 APÉNDICE: CORRECCIÓN POR CONTINUIDAD
P(X
k | = en
infel) = /2,
a distribución binomial
de parámetros
n en
y una
. Como
se discutió
de eventos
aleatoria
de tamaño por
n, elcontinuidad
intervalo de del
confianza
al de
En observado
este apéndice
se derivan
lasmuestra
versiones
con corrección
intervalo
confianza y del test de hipótesis para
una proporción
π. Si k es el número observado
P(X
k | aproximarse
= sup)poblacional
= /2,
2, si n(1 - ) 5,100(1
estas probabilidades
binomiales
pueden
)%
para
vendrá
determinado
por
aquellos
valores
(
infconfianza
, sup) quealverifiquen
de eventos en una muestra aleatoria de tamaño n, el intervalo de
100(1 – α)%
para π vendrá determinado por aquellos valores (πinf, π sup) que verifiquen
istribución normaldonde
estandarizada
como
X es unaZdistribución
binomial de parámetros n y . Como se discutió en el
P(X k | = inf) = /2,
P(X k | = sup) = /2,
Apartado 3.3.2,k si
n/2(1-n) 5,
estas probabilidades binomiales pueden aproximarse
1
inf
= /2,
P(X k | = inf) P Z
distribución
de parámetros n y π. Como se discutió en el Apartado 3.3.2,
donde X es una
binomial
n
(
1
)
inf
inf
la distribución
mediante
normal
estandarizada
Z como aproximarse mediante la distribución
si nπ(1 – π) ≥ 5, estas probabilidades
binomiales pueden
donde
X
es
una
distribución
binomial
de
parámetros
n y . Como se discutió en el
normal estandarizada Z como
k 1 / 2 n sup
3.3.2,
n inf pueden aproximarse
P(X k | = Apartado
= )/2.probabilidades
siP(X
sup) P Z
n(1 -k|)=5,estas
Z k 1 / 2binomiales
P
= /2,
inf
n sup (1 sup )
n
(
1
)
inf
inf
mediante la distribución normal estandarizada Z como
k 1 / 2 n sup
=añade
sup)aambas
P(X k | se
P Z expresiones
= /2.
érmino 1/2 de la corrección por continuidad
n
(
1
)
sup
sup
k 1 / 2 n inf
incluir la probabilidad de observar exactamente
k
eventos.
Para
= /2,
P(X k | = inf) P Z
ncontinuidad
infañade
) a ambas expresiones con
k 1 / 2 por
Notar que el término 1/2 de la corrección
inf n inf (1 se
= z1-/2,
objeto de incluir
de observar
exactamente
k eventos. Para simplificar los
s cálculos, las desviaciones
típicasladeprobabilidad
estas distribuciones
normales
se
np
p
(
1
)
Notar
que
el
término
1/2
de
la
corrección
por
continuidad
se
a ambaspor
expresiones
cálculos, las desviaciones típicas de estas distribuciones normalesañade
se sustituyen
la estimación
k 1 / 2 n sup
ksup)1/de2P
P(Xseladeduce
k | = que
Z
= /2.
(1 objeto
p) , dedeloincluir
cual
la estimación np
con
probabilidad
observar
n sup n=exactamente
1/2. sup )k eventos. Para
sup1-(
-z
k np
1 / (21
np) inf = z
1/2,
simplificar los cálculos, las desviaciones
np(1 típicas
p) de estas distribuciones normales se
Notar que el término 1/2 de la corrección por continuidad se añade a ambas expresiones
1se/p2obtiene
n lo
Finalmente,
despejando
inf y npksup(
intervalo
de confianza
al 100(1 - )%
supel
sustituyen por
la estimación
1,
) , de
cual
deduce
que
= zse
1/2.
con objeto de incluir la probabilidadnpde(1observar
exactamente k eventos. Para
p)
para
34
simplificar
los
cálculos,
las
desviaciones
típicas
de
estas
normales
separa π
Finalmente, despejando π inf y π sup, se obtiene el intervalo de distribuciones
confianza al 100(1
– α)%
al 100(1 - )%
Finalmente, despejando inf y sup, se obtiene
pintervalo
p(1 el
)
1 de confianza
que
sustituyen por la estimación pnp
(1z1p/)2 , de lo cual se deduce
.
n
2n
34
para
Este intervalo de confianza difiere de la versión sin corrección presentada en el Apartado 7.2 en
que ambos
límites del
amplían
cantidad
1/(2n) inversamente
al
Este intervalo
deintervalo
confianzasedifiere
deen
la una
versión
sin corrección
presentadaproporcional
en el
p
(
1
p
)
1
tamaño muestral. La utilización de
esta
se fundamenta
z1corrección
. en el hecho de aproximar una
p
/ 2
n se amplían
2n encontinua.
distribución
discreta
una
distribución
normal
Cuanto
menor sea el
Apartado binomial
7.2 en que
ambosmediante
límites del
intervalo
una cantidad
1/(2n)
tamaño muestral, más imprecisa será la aproximación normal y, en consecuencia, la corrección
34por
inversamente proporcional al tamaño muestral. La utilización de esta corrección se
Este intervalo de confianza difiere de la versión sin corrección presentada en el
Pastor-Barriuso
fundamenta en el hecho de aproximar una distribución binomial discreta mediante
una R.
Apartado 7.2 en que ambos límites del intervalo se amplían en una cantidad 1/(2n)
distribución normal continua. Cuanto menor sea el tamaño muestral, más imprecisa será
inversamente proporcional al tamaño muestral. La utilización de esta corrección se
117
la aproximación normal y, en consecuencia, la corrección por continuidad 1/(2n) ha de
ser mayor. Por el contrario, si el tamaño muestral es grande, la distribución binomial
k n 0 1 / 2
P = 2P(X k | H0) 2 P Z
la corrección
estará muy próxima a la normal, por lo que
n 0 (1 1/(2n)
0 ) será insignificante.
continuidad
1/(2n)
ha de
mayor. bilateral
Por el contrario,
si el tamaño
es grande,
la distribución
El valor
P para
el ser
contraste
de la hipótesis
nulamuestral
H0: =
0 puede obtenerse a
binomial estará muy próxima a la normal, por lo
que
la
corrección
1/(2n)
será
insignificante.
n 0 k 1 / 2
,
= 2 P Z
partir
de Plapara
aproximación
normal
a lade
distribución
nbinomial
nula
0:0como
)π = π0 puede obtenerse a partir
El
valor
el contraste
bilateral
la hipótesis
0 (1 H
de la aproximación normal a la distribución binomial como
Inferencia sobre proporciones
118
k n 0 1 / 2
resultados,
al doble de
si p 0. Combinando ambos
P = 2P(X
k | H0)setiene
,
el valor P corresponde
2 P Zque
k nn0 (011/ 02)
= 2P(X k | aHla0) derecha
2 PZdel
test estadístico
la probabilidad normal P
estandarizada
n 0 (1 0 )
si la proporción observada p > π0, o alternativamente
como
si la proporción observada p > 0, o alternativamente como
1
Z nk0| 0nk0 11// 22
P = 2P(X
k
|
H
0) 2 P| p
| k n 0 | 1 =
/ 22 P Z n 2(n1 ) ,
0
. 0
z
0 (1 n00()1 0 )
n 0 (1 0 )
nn 0 k 1 / 2
,
= 2 P Z
quenel
valor
P
corresponde
al doble de
si p 0. Combinando ambos resultados, se tiene
(
1
)
0
0
El test con corrección por continuidad incorpora el término -1/(2n) en el numerador
normal
estandarizada
a lasederecha
del el
test
estadístico
si pla≤probabilidad
π0. Combinando
ambos
resultados,
tiene que
valor
P corresponde al doble de la
probabilidad
normal
estandarizada
a
la
derecha
del
test
estadístico
del si
estadístico,
de tal formaambos
que elresultados,
valor P será
mayorPque
el obtenido
el 35
se ligeramente
tiene que el valor
corresponde
al en
doble
de
p 0. Combinando
1
| p 0(Apartado
|
correspondiente
contraste
sin
corrección
por
continuidad
7.2). Esta
la probabilidad normal estandarizada
la1derecha
del test estadístico
| k n 0 a|
/2
2n .
z
0 ) seael0 (tamaño
0 (1reducido
1 0 ) muestral.
corrección será tanto mayor cuantonmás
1
| p n0 |
| k n 0 | 1 / 2
2n .
el término
z continuidad
El Ejemplo
test con corrección
por
incorpora
–1/(2n)
en EURAMIC
el numerador del
7.20 En el Ejemplo 7.1
los controles
estudio
incorpora
0 ) del
n 0se(1utilizaron
0)
0 (1
El
test
con
corrección
por
continuidad
el
término
-1/(2n)
en
el
estadístico, de tal forma que el valor P será ligeramente mayor que el numerador
obtenido en el
n
correspondiente
contraste
sin corrección
por continuidad
(Apartado
7.2). Estaadultos
corrección será
de hombres
para realizar
inferencias
sobre la prevalencia
poblacional
delmayor
estadístico,
tal forma
quesea
el valor
P será
ligeramente mayor que el obtenido en el
tanto
cuantodemás
reducido
el tamaño
muestral.
El test
con corrección
por continuidad
incorpora
el término
-1/(2n) ense
el calculan
numerador
con
niveles
bajos
de colesterol
HDL (
0,90
mmol/l).
A
continuación
correspondiente
contraste
sin
corrección
por
continuidad
(Apartado
7.2).
Esta
Ejemplo 7.20 En el Ejemplo 7.1 se utilizaron los controles del estudio EURAMIC para
inferencias
sobre
la prevalencia
poblacional
π de
hombres
adultos
delrealizar
estadístico,
de tal forma
que
elde
valor
P será
ligeramente
mayor
que el
obtenido
el
los
correspondientes
intervalos
confianza
y sea
test el
detamaño
hipótesis
utilizando
la conenniveles
corrección
será
tanto
mayor
cuanto
más
reducido
muestral.
bajos de colesterol HDL (≤ 0,90 mmol/l). A continuación se calculan los correspondientes
intervalos
ysintest
utilizando
la (Apartado
corrección
por continuidad.
El IC
correspondiente
contraste
corrección
porpara
continuidad
Esta
vendría
dado por7.2).
correcciónde
porconfianza
continuidad.
EldeIChipótesis
al 95%
al 95% para π vendría dado por
Ejemplo 7.20 En el Ejemplo 7.1 se utilizaron los controles del estudio EURAMIC
corrección será tanto mayor cuanto más reducido sea el tamaño muestral.
0,293(1 0,293)
1
de hombres adultos
para realizar
inferencias
0,293
z 0,975 sobre la prevalencia
poblacional
539
2 539
Ejemplo 7.20 En el Ejemplo 7.1 se utilizaron los controles del estudio EURAMIC
con niveles bajos de colesterol HDL ( 0,90 mmol/l). A continuación se calculan
= 0,293 (1,960,020 + 0,001) = (0,254; 0,333),
para realizar inferencias sobre la prevalencia poblacional de hombres adultos
correspondientes
de confianza
y test
hipótesis nula
utilizando
la0,30 sería
y ellos
estadístico
corregidointervalos
para el contraste
bilateral
de de
la hipótesis
H0: π =
niveles bajos
de colesterol
HDL ( bilateral
0,90 mmol/l).
A continuación
y elcon
estadístico
corregido
para el
de la1 hipótesis
nula H0se
: calculan
=
1 contraste
vendría
dado
por
corrección por continuidad.
El
IC
al
95%
para
| p 0 |
| 0,293 0,30 |
539
2n de confianza y test2 de
correspondientes
intervalos
hipótesis
= 0,30,utilizando la
z=
0,30lossería
0,30(1 0,30)
0 (1 0 )
0,293(1 0,293)
1
0,293
z 0,n975 El IC al 95% para
vendría
dado por
corrección por
continuidad.
539
539
2 539
36
con un valor P asociado en las tablas de la distribución normal estandarizada P = 2P(Z ≥
con un= valor
asociado=
las tablas
estandarizada
=
en0,293
0Como
,293
(de
1cabría
la0,distribución
293
)+ 0,001)
1elnormal
0,30)
2{1 –PΦ(0,30)}
esperar,
intervalo
confianzaPcorregido
(1,960,020
=(0,254; de
0,333),
0,293 z=0,764.
0 , 975
539
2 539
2P(Z 0,30) = 2{1 - (0,30)}
= 0,764. Como cabría esperar,
el intervalo de
Pastor-Barriuso R.
y el estadístico corregido para el contraste bilateral de la hipótesis nula H0: =
= 0,293 (1,960,020
0,001) = (0,254;
0,333),
confianza corregido por continuidad
(IC al 95%+25,433,3%)
es ligeramente
más
0,30 sería
p(1 p ) p1 (p1 (1p1 )p ) p 2 (11 1p 2 ) 1 1 1
―
Test de McNemar
Test
McNemar
Test
de de
McNemar
2
―
* La corrección por continuidad no se aplica al test χ 2 de Pearson en tablas de contingencia mayores de 2×2.
** La
corrección
por
se
test
de
Pearson
tablas
mayores
La corrección
corrección
por
continuidad
no se
se aplica
aplica no
al test
test
22 de
de al
Pearson
en
tablas
de en
contingencia
mayores de
de 22.
22.
Lapor
corrección
por continuidad
continuidad
no
se aplica
aplica
al
test
2en
detablas
Pearson
en
tablas de
de contingencia
contingencia
mayores de
de 22.
22.
** La
continuidad
no
al
Pearson
de
contingencia
mayores
2
2 de Pearson*
Test
χ 2 de2 Pearson*
Test
deTest
Pearson*
2
1
1 1
11 1
| p11 p 22|
| p11 p22 |
2 n n22
2 n11 n22 11
zz
z
1
1 1
1
p (1 p ) p (1 p)
n11 n 22 n11 n 22
Eijij
2
2
( | b c2 | 1( )| 22b c | 1 ) 2
bc
bc
ii 11
jj 11 ijij
E
2
46
22 ( | b c22 | 1()| b c | 1 )
bc
ii 11
jj 11
2
2
46
2
2
2 (||
22 22 (2| O 2 E
O1ijij/ 2)E
ijij | 1 / 2)
2
ijij
ijij
2 2
E
p11 ) p11 (p122(1p11 )p22 ) p22 (11 1p22 ) 1 1 1 1
Dos
muestras independientes
independientesp11 p 22 ppz1111
//pp22 22
p11 (zz111
Dos
muestras
independientes
Dos
muestras
Dos
muestras
independientes
n
// 22
n11 n22
2nn22 n11 n22 22 nn11 nn22
n11
Una muestra
muestra
Una
Una
muestra
Una
muestra
1
1
| p 00 | | p 00 |
2
n
2n
zz
z
00 (1 00 ) 00 (1 00 )
nn
n
p(1 p )
1
p(1zz11p// 22) 1
p z11 // 22pp
22nn
2nnn
n
Test estadístico
Test estadístico
Test estadístico
IC al 100(1 – α)%
100(1 - )%
)%
IC al 100(1IC- al
1
Intervalos de confianza (IC) y tests de hipótesis con corrección por continuidad.
7.8 Intervalos
de confianza
y tests decon
hipótesis
con corrección
por continuidad.
Tabla 7.8 Tabla
Intervalos
de confianza
(IC) y tests(IC)
de hipótesis
corrección
por continuidad.
Tabla 7.8
Apéndice: corrección por continuidad
Pastor-Barriuso R.
119
Inferencia sobre proporciones
por continuidad (IC al 95% 25,4-33,3%) es ligeramente más amplio que su correspondiente
intervalo sin corrección (25,5-33,2%, Ejemplo 7.1), y el valor P aumenta al aplicar dicha
corrección (P = 0,764 versus 0,726, Ejemplo 7.1). No obstante, los resultados con y sin
corrección son muy similares dado que el tamaño muestral utilizado en este ejemplo es
moderadamente grande.
La corrección por continuidad también se aplica a la comparación de proporciones en muestras
independientes o dependientes y al test chi-cuadrado de asociación en una tabla 2×2, ya que estos
métodos de inferencia utilizan una distribución continua (normal o chi-cuadrado) para representar
una distribución de frecuencias discreta. Las versiones corregidas de estos procedimientos, cuya
derivación es similar al caso de una proporción, se presentan en la Tabla 7.8. En general, la
utilización de la corrección por continuidad da lugar a resultados más conservadores; esto es,
intervalos de confianza más amplios y mayores valores P de los contrastes. El principal objetivo
de esta corrección es aumentar la cobertura de los intervalos de confianza y reducir la probabilidad
de un error de tipo I en los contrastes, especialmente cuando el tamaño muestral es reducido.
7.9
120
REFERENCIAS
1.
Agresti A. Categorical Data Analysis, Second Edition. New York: John Wiley & Sons,
2002.
2.
Armitage P, Berry G, Matthews JNS. Statistical Methods in Medical Research, Fourth
Edition. Oxford: Blackwell Science, 2001.
3.
Breslow NE, Day NE. Statistical Methods in Cancer Research, Volume 1, The Analysis of
Case-Control Studies. Lyon: International Agency for Research on Cancer, 1980.
4.
Breslow NE, Day NE. Statistical Methods in Cancer Research, Volume 2, The Design and
Analysis of Cohort Studies. Lyon: International Agency for Research on Cancer, 1987.
5.
Collett D. Modelling Binary Data, Second Edition. London: Chapman & Hall, 2002.
6.
Colton T. Estadística en Medicina. Barcelona: Salvat, 1979.
7.
Fleiss JL, Levin B, Paik MC. Statistical Methods for Rates and Proportions, Third Edition.
New York: John Wiley & Sons, 2003.
8.
Hennekens CH, Buring JE. Epidemiology in Medicine. Boston: Little, Brown and
Company, 1987.
9.
Kleinbaum DG, Kupper LL, Morgenstern H. Epidemiologic Research: Principles and
Quantitative Methods. New York: John Wiley & Sons, 1982.
10.
Rosner B. Fundamentals of Biostatistics, Fifth Edition. Belmont, CA: Duxbury Press,
1999.
11.
Rothman KJ, Greenland S, Lash TL. Modern Epidemiology, Third Edition. Philadelphia:
Lippincott Williams & Wilkins, 2008.
Pastor-Barriuso R.
TEMA 8
MÉTODOS NO PARAMÉTRICOS
8.1
INTRODUCCIÓN
En los temas anteriores se han presentado distintos métodos de inferencia para datos de carácter
continuo (Tema 6) y categórico (Tema 7). Estos procedimientos se conocen como métodos
paramétricos y asumen que los datos proceden de una población cuya distribución de probabilidad
es conocida (normal o binomial), o que al menos la distribución de los estadísticos empleados
puede aproximarse mediante el teorema central del límite. Así, las inferencias se fundamentaban
en la aproximación normal a la distribución de las medias y proporciones muestrales. Aunque en
la mayoría de las ocasiones estas asunciones son razonables, pudiera ocurrir que no se cumplan
las condiciones necesarias para la realización de análisis paramétricos, especialmente cuando los
tamaños muestrales son muy reducidos. En tales circunstancias, es posible utilizar métodos
alternativos que realizan asunciones mínimas acerca de la distribución de la variable a estudio, y
que reciben colectivamente el nombre de métodos no paramétricos o de distribución libre.
Antes de proceder a la descripción de los métodos no paramétricos más utilizados, conviene apuntar
sus principales ventajas e inconvenientes. Entre las ventajas fundamentales cabe destacar que:
yy Los métodos no paramétricos son muy robustos y, en consecuencia, pueden aplicarse a
situaciones donde la utilización de pruebas paramétricas es cuestionable. Así, por ejemplo,
la comparación de medias en dos muestras independientes requiere de tamaños muestrales
suficientemente grandes para aplicar el teorema central del límite y de una varianza
homogénea en ambas poblaciones, mientras que su equivalente no paramétrico permite
contrastar globalmente la igualdad de distribuciones bajo la única asunción de que ambas
distribuciones sean continuas.
yy Como se verá más adelante, la propia naturaleza de las pruebas no paramétricas las hace
particularmente útiles para comparar variables cualitativas ordinales, cuyo tratamiento
mediante métodos paramétricos clásicos entraña problemas conceptuales ya que estas variables
carecen de interpretación numérica (ver definición de tipos de variables en el Tema 1).
Sin embargo, los métodos no paramétricos presentan una serie de limitaciones que impiden
su uso generalizado:
yy Los métodos no paramétricos se emplean casi exclusivamente para determinar la
significación estadística de la comparación entre grupos. Aunque existen procedimientos
no paramétricos para obtener estimadores de efecto e intervalos de confianza, éstos
requieren de asunciones adicionales y su aplicación es más compleja.
yy Si se cumplen las condiciones de aplicación de las pruebas paramétricas, el uso de métodos no
paramétricos es un tanto ineficiente, lo que conlleva una leve pérdida de potencia en el análisis.
Estudios de simulación bajo la asunción de normalidad han mostrado una perdida de potencia
aproximada del 5% de las pruebas no paramétricas respecto a sus equivalentes paramétricos.
yy Los métodos paramétricos pueden extenderse fácilmente al análisis multivariante de
situaciones más complejas. Aunque en la actualidad los métodos no paramétricos han
experimentado un fuerte desarrollo, su utilización es aún limitada por la mayor complejidad
y menor disponibilidad en los programas de análisis estadístico de uso rutinario.
Pastor-Barriuso R.
121
Métodos no paramétricos
En general, los métodos no paramétricos se emplean como complemento o alternativa a las
pruebas paramétricas cuando no se cumplen las condiciones mínimas para la aplicación de estas
últimas. En este tema se revisan los métodos no paramétricos de uso más frecuente, tales como
el test de la suma de rangos de Wilcoxon, el test de los rangos con signo de Wilcoxon y el test
exacto de Fisher.
la variable (empates), se asigna a cada una de ellas la media de los rangos
correspondientes.
Finalmente,
seRANGOS
suman los DE
rangos
de una cualquiera de las dos
8.2variable
TEST(empates),
DE LA
SUMA
DE
WILCOXON
la
se asigna
a cada una de
ellas
la media de los rangos
muestras,
seleccionemos
ejemplo la
muestra,de variables continuas en dos muestras
En el Apartado
6.3 se tratópor
el problema
deprimera
la comparación
correspondientes. Finalmente, se suman los rangos de una cualquiera de las dos
independientes. Si ambos tamaños muestrales n1 y n2 son suficientemente grandes para aplicar
el teorema central del límite, el test de la t den1 Student permite realizar inferencias acerca de la
muestras, seleccionemos por ejemplo la primera
muestra,
U = rSin
diferencia de medias entre ambas poblaciones.
i . embargo, si la distribución subyacente dista
1
mucho de ser normal y las muestras son muyi =pequeñas,
las medias muestrales no se distribuirán
n1
de forma normal y la anterior prueba paramétrica no será aplicable. Bajo estas circunstancias,
U = ri .
ha estadístico
de utilizarse
el equivalente
al test de la t de Student para muestras
El
del test
de Wilcoxonnose paramétrico
basa en
i =1 esta suma de rangos.
independientes, que se conoce como el test de la suma de rangos de Wilcoxon. Este procedimiento
permite contrastar globalmente la igualdad de distribuciones bajo la única asunción de que la
El
estadístico
del
de una
Wilcoxon
en esta
suma
de nrangos.
variable
a estudio
tenga
distribución
subyacente
continua.
Ejemplo
8.1test
Supongamos
queselabasa
muestra
consiste
en
1 = 10 casos de infarto de
Si no se asume nada sobre la forma de la distribución, parece razonable basar el contraste en
miocardio
y n2 = 10secontroles
del estudio
la variable
asigna
a seleccionados
cada
una deconsiste
ellas
media
de
rangos
el orden
de las(empates),
observaciones
deque
ambas
muestras
yaleatoriamente
nolaen
sus
valores.
Ejemplo
8.1
Supongamos
la
muestra
en
n1 =verdaderos
10 los
casos
de
infartoPara
de ello, se
combinan las dos muestras ordenando los valores de menor a mayor. A continuación, se asigna
EURAMIC.
LaFinalmente,
Tabla
8.1 muestra
los los
niveles
de de
β-caroteno
en tejido
correspondientes.
se seleccionados
suman
rangos
una
cualquiera
de adiposo
las dos para
que
ocupa
cada
observación
dentro
de la
muestra
combinada.
Si existen
el rango
ri o posición
miocardio
y n2 =
10 controles
aleatoriamente
del estudio
varias observaciones con el mismo valor de la variable (empates), se asigna a cada una de ellas
muestras,
seleccionemos
por ejemplo
la
primera
muestra,
estos
sujetos.
Al
menor
valor delos
ambas
muestras
0,04 μg/g
se
le asigna
la media
de20
los
rangos
correspondientes.
Finalmente,
suman
losen
rangos
deadiposo
unael
cualquiera
de
EURAMIC.
La Tabla
8.1 muestra
niveles
deseβ-caroteno
tejido
para
las dos muestras, seleccionemos por ejemplo la primera muestra,
rango20
1, sujetos.
al siguiente
valor 0,05
se le notorga
el rango
2 y así
1
estos
Al menor
valorμg/g
de ambas
muestras
0,04 μg/g
se sucesivamente
le asigna el
U = ri.
i =1
hasta asignar
el rangovalor
20 al0,05
mayor
valorle0,57
μg/g. rango
A los dos
sujetos
con idéntico
rango
1, del
al siguiente
otorga
2 y así
sucesivamente
El estadístico
test de Wilcoxon
se μg/g
basa se
en esta
sumaelde
rangos.
El nivel
estadístico
del test
de Wilcoxon
basa en esta suma
de rangos.
0,13
μg/g
de
β-caroteno
lessecorresponden
las posiciones
7 y 8 y,con
en idéntico
hasta
asignar
rango
20 al mayor
valor
0,57 μg/g.
A los
Ejemplo
8.1 el Supongamos
que la
muestra
consiste
endos
n1 sujetos
= 10 casos
de infarto de
=
10
controles
seleccionados
aleatoriamente
del
estudio
EURAMIC.
La
miocardio
y
n
consecuencia, 2se asigna el rango medio (7 + 8)/2 = 7,5 a ambas observaciones.
nivel
0,13
μg/g
de
β-caroteno
les
corresponden
las
posiciones
7
y
8
y,
en
Tabla
8.1 muestra
los nivelesque
de la
β-caroteno
en tejidoenadiposo
20 sujetos.
Ejemplo
8.1 Supongamos
muestra consiste
n1 = 10para
casosestos
de infarto
de Al
menor
valor
de
ambas
muestras
0,04
μg/g
se
le
asigna
el
rango
1,
al
siguiente
valor
0,05
Así, la suma de rangos en los casos de infarto es
consecuencia,
se
asigna
el
rango
medio
(7
+
8)/2
=
7,5
a
ambas
observaciones.
μg/g
se le otorga
2 y así sucesivamente
hasta asignar eldel
rango
20 al mayor valor
miocardio
y n2el=rango
10 controles
seleccionados aleatoriamente
estudio
0,57 μg/g. A los dos sujetos con idéntico nivel 0,13 μg/g de β-caroteno les corresponden
10
Así,
la suma de7La
rangos
en8.1
los
casos de infarto
es el β-caroteno
las EURAMIC.
posiciones
y 8Tabla
y, en
consecuencia,
asigna
rango medio
+ 8)/2
= 7,5 apara
ambas
muestra
en(7tejido
adiposo
ri = 1 +los
9 se
+niveles
...
+ 19de
= 96,5
observaciones. Así, la sumai =1de rangos en los casos de infarto es
10 valor de ambas muestras 0,04 μg/g se le asigna el
estos 20 sujetos. Al menor
ri = 1 + 9 + ... + 19 = 96,5
y en los controles
i =1
rango 1, al siguiente valor 0,05 μg/g se le otorga el rango 2 y así sucesivamente
y en los controles
10
y enhasta
los controles
asignar el rango 20 al
A los dos sujetos con idéntico
= 13 +valor
2 + ...0,57
+ 6 μg/g.
= 113,5.
r j mayor
j =1
nivel
0,13
de β-caroteno
corresponden
las posiciones
7 y 8 y,
Notar
que
la μg/g
elección
entre una les
u otra
suma de rangos
es arbitraria.
Laensuma total de
r j = 13 + 2 + ... + 6 = 113,5.
rangos
en
ambas
muestras
es
(n
+
n
)(n
+
n
+
1)/2
=
20⋅21/2
=
210,
de
forma que una
2 suma
1
2de rangos es irrelevante. Latal
Notar que la elección entrej =1una1u otra
suma
se asigna
el rango
medio
+ 8)/2 =muestra,
7,5 a ambas
observaciones.
vezconsecuencia,
calculada la suma
de rangos
96,5
en la(7primera
la otra
queda determinada
por
210
–
96,5
=
113,5.
total de rangos en ambas muestras es (n1 + n2)(n1 + n2 + 1)/2 = 20⋅21/2 = 210, de
Notar
la elección
entreen
una
otra suma
de rangos
Así,que
la suma
de rangos
losucasos
de infarto
es es irrelevante. La suma
10
122
Pastor-Barriuso
R.
tal forma
que una vez calculada la suma de rangos 96,5 en la primera muestra, la
total de rangos en ambas muestras
es (n1 + n2)(n1 + n2 + 1)/2 = 20⋅21/2 = 210, de
10
r
= 1 + 9 + ... + 19 = 96,5
otra queda determinada por 210
- i96,5 = 113,5.
i
=
1
tal forma que una vez calculada la suma de rangos 96,5 en la primera muestra, la
Test de la suma de rangos de Wilcoxon
Tabla 8.1
β-caroteno
en tejidoenadiposo
en 10 casos
infarto
miocardio
y 10 y 10
Tabla
8.1 β-caroteno
tejido adiposo
en 10decasos
de de
infarto
de miocardio
Tabla 8.1 β-caroteno en tejido adiposo en 10 casos de infarto de
controles
seleccionados
del
EURAMIC.
[Tablaseleccionados
8.1estudio
aproximadamente
aquí] del estudio
controles
seleccionados
aleatoriamente
del estudio
EURAMIC.
miocardio
yaleatoriamente
10 controles
aleatoriamente
EURAMIC.
Caso Caso
ControlControl
El objetivo es contrastar
ambas poblaciones son
Casosi las distribuciones F1 y F2 en Control
(μg/g) (μg/g)aquí]
RangoRango
(r
(μg/g) (μg/g)
Rango (r
)
β-caroteno
Rango
(rj)
β-caroteno
Rango
(r ) β-caroteno
[Tablaβ-caroteno
8.1 aproximadamente
i)
β-caroteno (μg/g)
(r ) i
β-caroteno (μg/g)
Rango (rj) j
esta
iguales H0: F1 = F2 frente a la hipótesisi alternativa bilateral H1: F1 ≠ F2. Bajo
0,04
1
0,25
13
0,04 0,04
1
0,25
13
1
0,25
13
0,14
9
0,05
2
s contrastar si las distribuciones
F
y
F
en
ambas
poblaciones
son
hipótesis
nula,
la
suma
de
rangos
esperada
en
la
primera
muestra
sería
igual
a
la
suma
1
2
0,14 0,14
9
0,05 0,05
2
9
2
0,20
11
0,36
17
aquí]
0,20 0,20
11[Tabla118.1 aproximadamente
0,36 0,36
17
17
0,08
323. Bajo en
0,09 0,09
44
total dealternativa
rangos 0,08
porbilateral
la proporción
deFsujetos
muestra,
= F2 frente a la hipótesis
H1:3F1 ≠
estadicha0,09
0,08
4
0,21
12
0,33 0,33
1616
aquí]
0,21 0,21
12[Tabla
0,33
128.1 aproximadamente
16
El objetivo
es
contrastar
si las distribuciones
F1 y0,37
F2 en ambas poblaciones
son
0,10 muestra
5igual
a suma de rangos esperada
en la primera
0,10
0,10
5 a la suma
18
n1 + n 2 + 1) 1818
(n1 + 5nsería
n1 0,37n1 (0,37
2 )( n1 + n 2 + 1)
.
E(U)
=
= 0,13
0,28
14
0,13
7,5
0,28 0,28
14
0,13
7,5
14
7,5
n1F+1 nybilateral
2
2: F1poblaciones
2F en ambas
El objetivo
es
contrastar
si
las
distribuciones
son
:
F
=
F
frente
a
la
hipótesis
alternativa
H
≠
F
.
Bajo
esta
iguales
H
2
0
1
2
1
2
por la proporción de
sujetos
en
dicha
muestra,
0,29 0,29
15
0,17
15
10
0,29
15
0,17 0,17
1010
[Tabla7,5
8.1 aproximadamente
aquí]
0,13 0,13
7,5
0,57
7,5
20
0,13
0,57 0,57
2020
:
F
=
F
frente
a
la
hipótesis
alternativa
bilateral
H
:
F
≠
F
.
Bajo
esta
iguales
H
hipótesis
nula,
la
suma
de
rangos
esperada
en
la
primera
muestra
sería
igual
a
la
0
1
2
1
1
2
0,12
la primera
19
0,12 muestra,6 6el valorsuma
6
0,48 la
0,12
n1 +tanto,
n 2 0,48
+ 1si
n1suma
n 2 rangos
(n1 + n 2 )(Por
) u denota
(n1 +19de
) observada en
+ 119
n0,48
1
E(U) =
.
=10
10
10
n1 es
+la
ncontrastar
2 Elde
2 la proporción
objetivo
si102las por
distribuciones
Fprimera
F2 en
ambas
poblaciones
son
1 y muestra,
total
rangos
por
de
sujetos
enladicha
hipótesis
nula,
suma
de
rangos
esperada
en
muestra
sería
igual
suma
exacto
de
P vendría
determinado
la
probabilidad
bajo
H
de
obtener
de
0
r
=
96,5
r
=
113,5
r
=
96,5
r j asuma
=la113,5
i
j
i
una
i =1
i =1
j =1
j =1
iguales
H0: Fo1más
=
F2distante
frente
a la muestra,
hipótesis
bilateralu;Hes
: F1 ≠ F2. Bajo esta
total de
rangos
por
la
proporción
de que
sujetos
en dicha
rangos
tanto
elvalor
valor
observado
enota la suma de rangos
observada
en
la
primera
elalternativa
+ nE(U)
n1 (n1 1+ ndecir,
(n1 de
n1 muestra,
2 )( n1 + n 2 + 1)
2 + 1)
E(U) =
.
=
n
+
n
2
2
1
2
hipótesis
nula,
suma
rangos
esperada
en laFde
primera
muestra
igual a lason
suma
El
objetivo
es la
contrastar
distribuciones
y F en
ambassería
poblaciones
iguales
delas
obtener
dría determinado por
la probabilidad
bajo de
H(n0si
+una
n 2 +suma
1≥) u |n1H1 0), 2 n1 (n1 + n 2 + 1)
1 + n 2 )( n
1=
P
2P(U
E(U)
=
.
=
H0: F1 = F2 frente a la hipótesis alternativa bilateral H1: F1 ≠ F2. Bajo esta hipótesis nula, la suma
1 + n 2muestra, 2
total
deelesperada
rangos
por
proporción
de2 sujetos
en ndicha
de rangos
en la primera
sería
igual
a la
total de
rangos el
porvalor
la proporción
Por
tanto,
si u denota
la suma
de
rangos
observada
ensuma
la primera
muestra,
más distante de E(U)
que
valor
observado
u; esmuestra
decir,
de si
sujetos
en dicha
muestra,
u > E(U),
o alternativamente
una
suma de
exacto
de
P
vendría
por
H0 1de
Por tanto, si u denotadeterminado
la suma
observada
la nprimera
el valor
(n1 + nde2 )(rangos
n1 +lanprobabilidad
nmuestra,
+ obtener
n1 enbajo
1 (n
2 + 1)
2 + 1)
P = 2P(U ≥ u | HE(U)
0), =
.
=
2 = 2P(U ≤ nu1 | +Hn0),2
2
P
rangos
tanto
o más distante
de E(U)
el valor observado
esobtener
decir, una suma de
exacto de
P vendría
determinado
porque
la probabilidad
bajo Hu;
0 de
ternativamente Por tanto, si u denota la suma de rangos observada en la primera muestra, el valor exacto de P
Por
tanto,
si Esta
uo denota
lalasuma
rangos
observada
en la primera
muestra,
el la
valor
vendría
determinado
por
probabilidad
bajo
H de
obtener
suma
debajo
rangos
tanto o más
si
u≤
E(U).
probabilidad
puede
calcularse
teniendo
enuna
cuenta
que
hipótesis
rangos
tanto
más
distante
dede
E(U)
que
el valor
observado
u;
es
decir,
P = 2P(U ≥0 u | H0),
distante de E(U) que el valor observado u; es decir,
P = 2P(U
u | H0), determinado por la probabilidad bajo H de obtener una suma de
exacto
P≤ vendría
nula
dede
igualdad
de distribuciones, cualquier combinación de0 rangos en la primera
P = 2P(U ≥ u | H0),
si u > E(U), o alternativamente
rangos
tanto
oteniendo
más distante
de E(U)
ellavalor
observado
u; es decir, de los n1 + n2
eso igualmente
probable.
Así,
como
elhipótesis
número
de combinaciones
si umuestra
> calcularse
E(U),
alternativamente
a probabilidad puede
en
cuenta
queque
bajo
si u > E(U), o alternativamente
P = 2P(U ≤ u | H0),
n1 +≥n 2u| H0),
de distribuciones, cualquier combinación de rangos Pen=la2P(U
primera
, la probabilidad
tomados depuede
n1 en calcularse
n1 es
si uposibles
≤ E(U). rangos
Esta probabilidad
en cuenta quebajo
bajoHla0 para
hipótesis nula de
nteniendo
P = 2P(U
1≤ u| H0),
si
u
≤
E(U).
Esta
probabilidad
puede
calcularse
teniendo
en
cuenta
que
bajo
laeshipótesis
igualdad
de
distribuciones,
cualquier
combinación
de
rangos
en
la
primera
muestra
igualmente
mente probable. Así, como el número de combinaciones de los n1 + n2
si u > E(U),
o alternativamente
probable.
Así, como
el número de combinaciones de los n1 + n2 posibles rangos tomados de n1
cualquier
combinación
r1, ..., rpuede
dada por
n1 viene
si u ≤de
E(U).
Esta
probabilidad
calcularse
teniendo endecuenta
que
la hipótesis
nula
igualdad
de
distribuciones,
cualquier
combinación
rangos
enbajo
la primera
n1 + n 2
tomados de n1 en
n
es
,
la
probabilidad
bajo
H
para
en n11
bajo H00 para cualquier combinación r1, ..., rn viene dada por
P = 2P(U ≤ u | H0),
n1
muestra
es
igualmente
probable.
Así,
como1elcombinación
número de combinaciones
los n1 + n2
nula de igualdad de distribuciones,
cualquier
de rangos en ladeprimera
.
n1 + n 2
nación r1, ..., rn1 viene
si
u ≤dada
E(U).
Esta probabilidad
puede
cuenta que bajo
la hipótesis
n1 +elnnúmero
muestra
espor
igualmente
probable.
Así, calcularse
como
de en
combinaciones
de los
n1 + n2
2teniendo
posibles rangos tomados de n1 en n1 es n1 , la probabilidad bajo H0 para
n1 combinación
nula
de
igualdad
de
distribuciones,
cualquier
de rangos en la primera
n2
nel
1 +siguiente
1
El cálculo
del
valor
exacto
de
P
se
ilustra
en
ejemplo.
, la probabilidad
posibles rangos. tomados de n1 en n1 es
bajo H0 para
n
El
cálculo
del
de
P
se
ilustra
en
el
siguiente
ejemplo.
1por
n1 +combinación
n 2 valor exacto
cualquier
r
,
...,
r
viene
dada
n
1
1
muestra
probable.
Así, como el número de combinaciones de los n1 + n2
es igualmente
n
1
27
27
cualquier combinación r1, ..., rn1 viene dada
n2
n1 1+por
., la probabilidad bajo H0 para
posibles rangos tomados de n1 en n1 es
Pastor-Barriuso
n1 +n1n 2
5 R. 123
alor exacto de P se ilustra en el siguiente ejemplo.
1
n1 .
n1 + por
n2
cualquier combinación r1, ..., rn1 viene dada
1
Ejemplo 8.2 Si la distribución del β-caroteno fuera igual en los casos de infarto y
10(10 + 10 + 1)
E(U) =
= 105.
2suma de rangos esperada en los 10 casos
en
los
controles
libres
de
enfermedad,
la
Como el valor observado de esta suma de rangos u = 96,5 es inferior al esperado,
Métodos no paramétricos
Ejemplo 8.2 Si la distribución del β-caroteno fuera igual en los casos de infarto y
de
infarto
del
ejemplo
anterior
sería
igual
a
u = 96,5 es inferior al esperado,
Como
el Pvalor
observado
de esta
suma
de rangos
se obtiene
mediante
el valor
en los controles libres de enfermedad, la suma de rangos esperada en los 10 casos
Ejemplo
Si la distribución
fuera igual en los casos de infarto y en los
se obtiene
mediante del10b-caroteno
el
valor P8.2
(10 de
+ 10
+961) esperada en los 10 casos de infarto del
controles
de enfermedad,
la
suma
rangos
de infartolibres
del ejemplo
anterior
sería
igual
a
= | H0) = 2 P=(U105.
P = 2PE(U)
(U ≤ 96,5
= k | H0).
2 k =55
ejemplo anterior sería igual a
96
P = 2P(U ≤ 96,5
10| (H
100)+=102 +
1)P(U = k | H 0 ) .
E(U)
=
k
=
55
u==105.
96,5
Como
el valor
observado
sumamínimo
de rangos
Notar que
la suma
arrancadeenesta
el valor
posible
1 + 2es+inferior
... + 10al= esperado,
55 y sólo
2
Como
elPvalor
observado
de
sumamínimo
de rangos
u = 96,5
es
el valor
se suma
obtiene
mediante
el
valor
Notar
que
la
arranca
enesta
el valor
posible
1 + facilitar
2 +inferior
... + los
10alcálculos).
=esperado,
55 y sóloLa
toma
valores
enteros
(se excluyen
posibles empates
para
Como
el valor
observado de esta suma de rangos u = 96,5 es inferior al esperado,
P
se obtiene
mediante
96
toma
valores enteros
excluyen
posibles
empates
facilitar
cálculos).
La
para
cualquier
combinación
depara
rangos
en lalos
primera
muestra
probabilidad
bajo H0(se
el valor P se obtiene
P mediante
= 2P(U ≤ 96,5 | H0) = 2 P(U = k | H 0 ) .
k = 55
probabilidad
bajo H0 para cualquier combinación de rangos en la primera muestra
es
Notar que la suma arranca en el valor mínimo96posible 1 + 2 + ... + 10 = 55 y sólo toma
P = 2P(en
Uposibles
≤el96,5
H
P(facilitar
U =1 k+| 2Hlos
. + 10 = 55
0) = 2
Notar que
la suma
valor| empates
mínimo
posible
+0 )...
sólo
valores
enteros
(se arranca
excluyen
para
cálculos).
Layprobabilidad
es
10! (20 − 10)!k =55 1
1
bajo H0 para cualquier combinación
, muestra es
= de rangos en
= la primera
20! empates
184para
.756 facilitar los cálculos). La
20
toma valores enteros (se excluyen
1 10posibles
! (20 − 10)!
1
Notar que la suma arranca 10
en el= valor mínimo =posible 1 +, 2 + ... + 10 = 55 y sólo
20
20!
184
combinación
de.756
rangos en la primera muestra
probabilidad bajo H0 para cualquier
toma valores enteros (se excluyen
posibles
empates
para
facilitar los cálculos). La
10
de
lo
cual
se
sigue
que
es
de
lo cual se sigue
probabilidad
bajo Hque
0 para cualquier combinación de rangos en la primera muestra
de lo cual se sigue que
P(U = 55 | H0) = P(1,
3,! 4,
(205,−6,107,
)! 8, 9, 10
1 2,10
1 | H0) = 1/184.756,
es
,
=
=
P(U = 56 | H0) =P(1,
5,!6, 7, 8, 184
9, 11
| H0) = 1/184.756,
20 2, 3, 4,20
.756
P(U = 55 | H0) = P(1, 2, 3, 4, 5, 6, 7, 8, 9, 10 | H0) = 1/184.756,
3, 4, 5, 6, 7, 8, 9, 12 | H )
10
P(U = 57 | H0) =P(1,
0
! (20 − 10)!
1 2,10
1
,
=
=
2, 3, 4, 5,
| H ) = 1/184.756,
P(U = 56 | H0) =+P(1,
5,!6,
6,7,
7,8,
8,9,
10,11.11
20 2, 3, 4,20
184
756| 0H0) = 2/184.756
P(1,
de lo cual se sigue que 10
)
=
2, 3,
4, 5, 6,el7,procedimiento
8, 9, 12 | H0) resulta muy laborioso incluso
P(U
=
57
|
H
0
y así sucesivamente. ComoP(1,
puede
intuirse,
para estas pequeñas muestras de tamaño 10, ya que requiere determinar el número de
P(U = con
55 | igual
H0) =
P(1, 2,
4, 5, 6, 7, 8, 9,
H
2/184.756
+suma
10,10
11|múltiples
|H
0)0)==1/184.756,
combinaciones
de3,rangos.
de
cálculos,
se tiene que
de
lo sucesivamente.
cual se sigue
queComo
y así
puede
intuirse,Después
el procedimiento
resulta
muy laborioso
96
5, 6,
8,29,+ 11
P(U
| HP0()U= =P(1,
0) = 1/184.756,
P = 256
| H2,0 3,
)intuirse,
=4,2(1
+ el
17,+
...ya
+| H
4.397)/184.756
yincluso
así sucesivamente.
Como kpuede
procedimiento
resulta
muydeterminar
laborioso
para
muestras
tamaño
10,10
que
se
requiere
P(Uestas
= 55k =pequeñas
|55H0) = P(1,
2, 3, 4, de
5, 6,
7, 8, 9,
|H
0) = 1/184.756,
4, 5, 6, 7, 8, 9, 12 | H0)
P(U =
= 97.708/184.756
57 | H0) = P(1, 2,= 3,
0,529.
incluso
paradeestas
pequeñas muestras
de tamaño
10, ya que
se requiere
determinar
el número
igual
de múltiples
2, 3,
4, 5,suma
6, 7,de
8, rangos.
9, 11 | HDespués
P(U =combinaciones
56 | H0) = P(1,con
0) = 1/184.756,
Aunque los casos de infarto
muestran
inferiores
que los controles
= 2/184.756
+ P(1,
2, 3, 4, niveles
5, 6, 7, 8,
10, 11 | de
H0)b-caroteno
el
númerose
detiene
combinaciones
con igual suma de rangos. Después
de múltiples
cálculos,
que
(la suma P(U
de rangos
observada
en3,los
casos
4, 5,
6, 7,es8,menor
9, 12 | que
H0) la esperada), no se alcanzan
= 57 | H
0) = P(1, 2,
Aunque
los casos
de infarto muestran
niveles inferiores
de β-caroteno
los
diferencias
estadísticamente
significativas.
No obstante,
dado el que
reducido
tamaño
y así sucesivamente.
cálculos,
se tiene que Como puede intuirse, el procedimiento resulta muy laborioso6
muestral, cabe esperar que
la potencia
sea
muy
pequeña para detectar
2/184.756
+ P(1,
2, 3, 4, 5,de6,este
7, 8,contraste
10, 11 | H
0) =
controles
sumadiferencia
de rangos en
observada
en los
casos es menor
que la esperada),
cualquier (la
posible
los niveles
subyacentes
de b-caroteno
entre los no
casos
de
6
incluso para estas pequeñas muestras de tamaño 10, ya que se requiere determinar
infarto y los sujetos libres de la enfermedad.
y así
sucesivamente.
Como
puede intuirse,
el procedimiento
resulta muy
se
alcanzan
diferencias
estadísticamente
significativas.
No obstante,
dadolaborioso
el
el número de combinaciones con igual suma de rangos. Después de múltiples
Para
simplificar
los cálculos
decabe
esteesperar
test, la
Tabla
del
losdeterminar
percentiles
incluso
para
estas
pequeñas
muestras
deque
tamaño
10,Apéndice
ya que
sefacilita
requiere
reducido
tamaño
muestral,
la8potencia
de este
contraste
sea muy de la
distribución
de
la
suma
de
rangos
de
Wilcoxon
bajo
la
hipótesis
nula
de
igualdad
de
distribuciones,
cálculos, se tiene que
cuando
menor
las doscualquier
muestras
es desuma
tamaño
inferior
o igualsubyacentes
a múltiples
8. Para un
el la
número
dede
combinaciones
conposible
igual
de rangos.
de
pequeña
para
detectar
diferencia
en losDespués
niveles
de nivel de
6 de
significación α bilateral, la hipótesis nula se rechazará si la suma de rangos en la muestra
menorβcálculos,
tamaño es
inferior
al
percentil
α/2 oysuperior
al percentil
α/2 de dicha tabla.
seentre
tienelos
que
-caroteno
casos
de infarto
los sujetos
libres de1la– enfermedad.
6
Para simplificar los cálculos de este test, la Tabla 8 del Apéndice facilita los
124
Pastor-Barriusode
R. la distribución de la suma de rangos de Wilcoxon bajo la hipótesis nula
percentiles
de igualdad de distribuciones, cuando la menor de las dos muestras es de tamaño
Ejemplo 8.3 En un estudio hipotético a partir de dos muestras independientes de
Test de la suma de rangos de Wilcoxon
tamaños n1 = 5 y n2 = 10, la suma de rangos en la muestra más pequeña es 23.
Ejemplo
8.3 En unbajo
estudio
partir es
de simétrica
dos muestras
independientes
de
la suma dea rangos
alrededor
de E(U)
Como la distribución
H0 dehipotético
tamaños
= que
5 y nambos
=
10,
la
suma
de
rangos
en
la
muestra
más
pequeña
es
23.
Como
la
En
el cason1de
tamaños
muestrales
sean
superiores
a
8,
puede
emplearse
el
2
distribución
H0=de5(5
la +
suma
rangos
esse
simétrica
alrededor de E(U) = n1(n1 + n2 + 1)/2
+ 1)/2
10 +de1)/2
= 40,
tiene que
= n1(n1 + n2 bajo
el +
caso
que
8, puede
emplearse
=En5(5
10 de
+ 1)/2
=ambos
40, setamaños
tiene
quemuestrales
siguiente
método
aproximado.
Como
el contrastesean
parasuperiores
la igualdada de
distribuciones
se el
En el caso
de que ambos
muestrales
sean
emplearse el
P =tamaños
2P(U
≤ 23
H0) = 2P(U
57igualdad
| H ). a 8,
siguiente
Como
el |contraste
para≥superiores
la
depuede
distribuciones
basa
en el método
rango o aproximado.
posición de las
observaciones,
resulta
lícito0 sustituir
los valores se
En
el caso de
que
ambos
muestrales
emplearse
Utilizando
la Tabla
8 del tamaños
Apéndice
n1 = 5sean
ypara
n2 superiores
=la10,
puedea 8,
comprobarse
que el
valor
siguiente
aproximado.
Como
elcon
contraste
igualdad
depuede
distribuciones
seel
basa
en elmétodo
rango
o
posición
de
las
observaciones,
resulta
lícito
sustituir
los
valores
Utilizando
la
Tabla
8
del
Apéndice
con
n
=
5
y
n
=
10,
puede
comprobarse
que
observados
x
por
sus
correspondientes
rangos
r
en
el
estadístico
de
la
t
de
Student
para
1
2
i u0,975
u = 57 estái comprendido entre los percentiles
56 y u0,99 = 58, de lo cual se deduce
siguiente
método
aproximado.
Como
el
contraste
para
la
igualdad
distribuciones
la en
desigualdad
< P(U
57observaciones,
| H0) < 0,025, que
corresponde
ade0,02
< Pvalores
< 0,05.se
basa
el rango
o0,01
posición
de≥las
resulta
lícito sustituir
observados
rangos
ri en
el estadístico
tlos
de
Student
i por
u0,975 obteniéndose
= 56dey la
u0,99
= 58,
de lo para
el valor
ux=
57 sus
estácorrespondientes
comprendido
entre
los(Apartado
percentiles
muestras
independientes
con igual varianza
6.3.1),
basa
en el rango
posición
de las observaciones,
resulta
lícito sustituir
correspondientes
rangos
ri en
el estadístico
de la tlos
de valores
Student para
observados
xi poro sus
muestras
independientes
con
igual
varianza
(Apartado
6.3.1),
obteniéndose
En
el
caso
de
que
ambos
tamaños
muestrales
sean
superiores
a
8,
puede
emplearse
elasiguiente
≥
57
|
H
)
<
0,025,
que
corresponde
cual se deduce la desigualdad 0,01 < P(U
0
r1 igualdad
− r2
método
aproximado.
Como
el
contraste
para
la
de
distribuciones
se
basa
en
rango o
z = rangos
observados
xi por sus correspondientes
ri en el, estadístico
de la t de Studentelpara
muestras independientes
con igual varianza
(Apartado
6.3.1), obteniéndose
1
1
posición
observaciones, resulta lícito
los valores observados xi por sus
0,02de
< Plas< 0,05.
s r r1 −sustituir
+r2
z
=
,
correspondientes
rangos ri encon
el estadístico
de lan(Apartado
t denStudent
paraobteniéndose
muestras independientes con
muestras independientes
igual varianza
6.3.1),
11− r 12
7
r
igual varianza (Apartado 6.3.1), obteniéndose
1
2
s
+
z = r n1 n 2 ,
donde la diferencia de rangos medios ess r r1 1− r+2 1
z=
n1 n 2 ,
1
1
donde la diferencia de rangos medios ess r
+
n1
n2
n1 n 2
1
1
r
r
r
r
−
=
−
i
j
1
2
donde la diferencia de rangos
n1 i =medios
n 2esjn=21
n11
1
donde la diferencia de rangos medios
es 1
ri − es r j
− rrangos
2 =
donde la diferenciar1 de
medios
n
1
n11 in=11
n12 nj (=2 1n1 + n 2 )(n1 + n 2 + 1) n1
1
1
r
=
−
− ri
r1 − r2 = n
rii − n r j
2
1
2
=
1
i
n
1
n11 in=11
n12 nj =2(1n1 + n 2 )(n1 + n 2 + 1) i =n11
1
1
r
=
−
− ri
r1 − r2 =
rii − n1
rj
+21 n+2 n+21+
) 1) in=11
nn1111 ii=n=111 1 nn122 j =(1n1 +n1n(2n)(
1 n
== + ri − ri −
− ri
n 2 ni2=n11
2
nn111
1 in=11 1 1 (n1 +nn1 (2n)(1 n2+1 n+2n+2 1+)1) in=11
− ri
== n+rin − ri −
2
111i =1 12 n2in=11
n
2
i =1
n1 (n1 + n 2 + 1)
y, si no hay empates, la varianza
ri − en la muestra combinada es
= + de los
rangos
n
n
2
n1 (n1 + n 2 + 1)
11 12 in=11
y, si no hay empates, la =
varianza
ri − en la muestra combinada es
rangos
+ delos
n1 + n2
2
21
2 n1 de nlos
i =1
y, si no hay empates, la varianza
rangos
en la muestra
combinada
es
s
=
(ri en
− rla) 2muestra combinada es
r
y, si no hay empates, la varianza
de
los
rangos
n1 + n 2 − 1 ni1=+1n2
1
2
2
s
=
(ren
r )muestra
r
i − la
y, si no hay empates, la varianza
de
los
rangos
es
2
n
+
n
1
2
n1 + 1n 2 − 1 n1i+=n12 n1 + n 2 + 1combinada
1
s r2 == n + n − 1
(rii −− r ) 2 2
1
2
i
1
=
n
+
n
1
2
n1 + 1n 2 − 1 n1i+=n12 n1 + n 2 + 1 2
1
(r i −− r ) 2
s r2 == (n + n )(n
n111++ nn222−−111n1ii=++=1n12n2i + 1) 2
2
n
1
=
n1. + n 2 + 1
=
12 i −
2
n(n1 1++nn2 2−)(1nn11i+=+n12 n2 + 1) 2
1
n1 .+ n 2 + 1
=
=
12 i −
n(n1 1++nn2 2−se
)(1ntiene
2 + 1) 2
1i =+
1 n
Sustituyendo en la expresión=anterior,
.
Sustituyendo en la expresión anterior, se tiene
12
(n1 + n 2 )(sen1tiene
+ n 2 + 1)
Sustituyendo en la expresión= anterior,
.
n1
n1 (n12
1 + n 2 + 1)
ri − se tiene
Sustituyendo en la expresión
anterior,
U − E (U )
2
i =n11
n1 (n1 + n 2 + 1) =
,
z=
SE (U )
nri1 n−2 (n1se+tiene
n 2 + 1)
Sustituyendo en la expresión
anterior,
U − E (U )
2
n1 (12
n1 + n 2 + 1) =
,
z = in=11
rni 1−n 2 (n1 + n 2 + 1)
SE (U )
U − E (U )
2
n1 (n12
,
z = in=11
1 + n 2 + 1) =
rni 1−n 2 (n1 + n 2 + 1)
SE (U )
U − E (U )
2
,
z = i =1
=
12
Pastor-Barriuso R.
SE (U )
n1 n 2 (n1 + n 2 + 1)
8
12
8
125
Las medidas
Las medidas
de tendencia
de tendencia
central
central
informan
informan
acercaacerca
de cuál
de es
cuál
el valor
es el valor
más representati
más represe
Métodos no paramétricos
de una
dedeterminada
una determinada
variable
variable
o, dicho
o, dicho
de forma
de forma
equivalente,
equivalente,
estos estos
estimadores
estimadores
indican
ind
alrededor
alrededor
de qué
devalor
qué valor
se agrupan
se agrupan
los datos
los datos
observados.
observados.
Las medidas
Las medidas
de tendencia
de tendenc
que corresponde simplemente a la suma de rangos estandarizada; es decir, la diferencia entre la
central
central
de la de
muestra
sirvensirven
tanto tanto
para
resumir
para resumir
lossuresultados
los resultados
observados
observados
comocomo
para p
suma de rangos observada
y esperada
enlalamuestra
primera
muestra
dividida
por
error
estándar
bajo
la hipótesis nula de igualdad de distribuciones. Bajo H0, este estadístico seguirá aproximadamente
realizar
inferencias
inferencias
acerca
de
losdeparámetros
los en
parámetros
poblacionales
poblacionales
correspondientes.
correspondientes.
A A
una distribución normalrealizar
estandarizada
si n1,acerca
n2 > 8.
Notar
que,
general,
este
tamaño
muestral
es muy inferior al que se requeriría para aplicar la prueba paramétrica de la t de Student en dos
continuación
continuación
se describen
se describen
los principales
los principales
estimadores
estimadores
de la de
tendencia
la tendencia
central
central
de una
de
muestras independientes.
variable.
variable.
Ejemplo 8.4 A partir
del estudio EURAMIC, se seleccionan 1000 muestras aleatorias
simples de n1 = 10 casos de infarto de miocardio y n2 = 10 controles. En cada una de estas
muestras, se calcula1.2.1
la diferencia
de niveles
medios de b-caroteno entre casos y controles, así
1.2.1
Media
Media
aritmética
aritmética
como la suma de rangos para los casos de infarto. Las Figuras 8.1(a) y (b) presentan las
La media
Lade
media
aritmética,
aritmética,
denotada
por xpor
se xdefine
sede
define
como
como
la suma
suma
de cada
de
cadade
uno
losde los
la suma
delarangos
U,uno
distribuciones muestrales
la diferencia
dedenotada
medias
1, –
2, y
respectivamente. Como la distribución poblacional del b-caroteno es marcadamente asimétrica
(ver Figura 4.3) yvalores
las muestras
son muy
pequeñas,
lanúmero
diferencia
dedemedias
muestrales
se Si denotamos
valores
muestrales
muestrales
dividida
dividida
por elpor
el número
de observaciones
observaciones
realizadas.
realizadas.
Si denota
distribuye de forma asimétrica alrededor de la diferencia subyacente μ1 – μ2 = – 0,09 mg/g, de
npor
el tamaño
el tamaño
muestral
muestral
y poryxipor
elnecesaria
valor
xi el valor
observado
observado
paraelel
para
sujeto
el la
sujeto
i-ésimo,
i = 1,i...,
= 1,
n
tal forma que no sepor
cumple
lan condición
de
normalidad
para
aplicar
test
de
t de i-ésimo,
Student. Por el contrario, la suma de rangos sí se distribuye de forma aproximadamente normal
media
la media
vendría
vendría
dada
dada
por E(U)
por = 96,9. Así, aun cuando se disponga de
en torno a su valorlaesperado
en esta
población
muestras tan reducidas, se podría aplicar la aproximación normal al test de la suma de rangos
de Wilcoxon.
x 2++x...
1 n 1 n x1 + xx21 ++ ...
n + xn
.
.
= xi
= xi =
x = x
n i =1 n i =1
n
n
Frecuencia relativa (%)
30
30
La media
La media
es la medida
es la medida
de tendencia
de tendencia
central
central
más utilizada
más utilizada
y de más
y defácil
más fácil
25
5
25
1.2 MEDIDAS
1.2 MEDIDAS
DE TENDENCIA
DE TENDENCIA
CENTRAL
CENTRAL
interpretación.
interpretación.
Corresponde
Corresponde
al “centro
al “centro
de gravedad”
de gravedad”
de losdedatos
los datos
de la de
muestra.
la muestra.
Su S
20
Las medidas
Las medidas
de tendencia
de tendencia
centralcentral
informan
informan
acercaacerca
de cuál
dees
cuál
el valor
es el valor
más repres
más
15
principal
principal
limitación
limitación
es quees
está
quemuy
está influenciada
muyvariable
influenciada
por
los
porvalores
losequivalente,
valores
extremos
extremos
y,
enestimado
y,
este
enin
de unadedeterminada
una determinada
variable
o, dicho
o, dicho
de forma
de forma
equivalente,
estos estos
estimadores
10
de qué
valor
qué
setendencia
agrupan
secentral
agrupan
los central
datos
los
observados.
observados.
Las medidas
Las medidas
de tenden
de te
caso, caso,
puedepuede
no sernounser
fielunalrededor
reflejo
fielalrededor
reflejo
de
ladede
tendencia
lavalor
dedatos
la de
distribución.
la distribución.
5
0
centralcentral
de la muestra
de la muestra
sirvensirven
tanto tanto
para resumir
para resumir
los resultados
los resultados
observados
observados
como c
0
20
15
10
-0,9
-0,6
Ejemplo
Ejemplo
1.4 En
1.4este
Enrealizar
yeste
enrealizar
los
y ensucesivos
los sucesivos
ejemplos
ejemplos
sobre
estimadores
estimadores
muestrales,
muestr
inferencias
inferencias
acercaacerca
de losde
parámetros
los sobre
parámetros
poblacionales
poblacionales
correspondientes.
correspondien
A
-0,3
0
0,3
0,6
50
70
90
110 130 150
continuación
continuación
se describen
se describen
los principales
los principales
estimadores
estimadores
de la tendencia
de la tendencia
centralcent
de
utilizarán
los valores
los valores
del colesterol
del colesterol
HDL HDL
obtenidos
en losen10los
primeros
10 primeros
sujetos
suje
d
xutilizarán
U obtenidos
1 − x2
variable.
variable.
estudio
“European
“European
StudyStudy
on Antioxidants,
on Antioxidants,
Myocardial
Infarction
Infarction
and Cancer
and Canc
of
(a) estudio
(b) Myocardial
1.2.1 1.2.1
MediaMedia
aritmética
aritmética
the Breast“
the Breast“
(EURAMIC),
(EURAMIC),
un estudio
un estudio
multicéntrico
multicéntrico
de casos
de casos
y controles
y controles
realizad
rea
, se xdefine
, se define
como como
la suma
la suma
de cada
de uno
cadadeuno
lo
La media
La medios
media
aritmética,
aritmética,
denotada
por xpor
Figura 8.1 Distribución muestral de la diferencia de niveles
de denotada
β-caroteno
1 –
2 entre casos y
controles (a) y de la suma de rangos U en los casos de infarto (b) en 1000 muestras aleatorias Figura
simples
8.1 de
valores
valores
muestrales
muestrales
dividida
dividida
por el
número
elenúmero
de observaciones
de
observaciones
realizadas.
Si deno
Sid
entre
1991 1991
y 1992
y 1992
en
ocho
en
ocho
países
países
Europeos
Europeos
e por
Israel
Israel
para
evaluar
para
evaluar
elrealizadas.
efecto
el efecto
de
los
n1 = 10 casos de infarto de miocardio
y nentre
2 = 10 controles obtenidos a partir del estudio EURAMIC. Las líneas
verticales en trazo discontinuo corresponden a los parámetros subyacentes μ1 – μ2 = – 0,09 μg/g y E(U) = 96,9.
por n por
el tamaño
n el tamaño
muestral
muestral
y por yxi por
xi el valor
el valor
observado
observado
para elpara
sujeto
el sujeto
i-ésimo,
i-ésimo
i=1
la media
la media
vendría
vendría
dada por
dada por
1 n 1 n x1 + xx21 ++...x 2+ +x n... + x n
.
.
= xi =
x = x= x i
n i =1 n i =1
n
n
La media
La media
es la medida
es la medida
de tendencia
de tendencia
centralcentral
más utilizada
más utilizada
y de más
y defácil
más fáci
interpretación.
interpretación.
Corresponde
Corresponde
al “centro
al “centro
de gravedad”
de gravedad”
de losde
datos
los datos
de la muestra.
de la mu
126
Pastor-Barriuso R.
principal
principal
limitación
limitación
es queesestá
quemuy
estáinfluenciada
muy influenciada
por los
por
valores
los valores
extremos
extremos
y, en
caso, caso,
puedepuede
no serno
unser
fielunreflejo
fiel reflejo
de la tendencia
de la tendencia
centralcentral
de la distribución.
de la distribución
Si se producen empates en la asignación
de rangos en la muestra combinada, la
T
t i (t i + 1)(t i − 1)
Test de combinada,
la
de rangos
de Wilcoxon
varianza
de
la
suma
de
rangos
es
menor
que la obtenida en ausencia
desuma
empates
y el
i
1
=
Si se producen empates
la
,
f = en la asignación de rangos en la muestra
(n1 + n 2 )(n1 + n 2 + 1)(n1 + n 2 − 1)
estadístico
del
test
de
la
suma
rangos
Wilcoxonenresulta
varianza de la suma de rangos de
es los
menor
que de
la obtenida
ausencia de empates y el
Sit se
producendeempates
enpara
la asignación
de rangos
la muestra
combinada,
varianza de
empates
el valor
i-ésimo
de
laen
variable.
Notar
que, si nolahay
conestadístico
i el número
del test
de la suma
de
losn1 rangos
de
Wilcoxon
resulta
la suma de rangos
es menor
que la
obtenida
en
ausencia
de
empates
y
el
estadístico
del test de
n1 (n1 + n 2 + 1)
r
−
i
la suma de
de Wilcoxon
resulta al citado anteriormente.
2
empates,
f =los
0 yrangos
este estadístico
se reduce
Finalmente, como la
,
z = in=11
n
n
+
n
+
(
1
)
n1 nr2i (−n1 +1 n 21 + 1)(2 1 − f )
suma de rangos es un variable discreta
que se aproxima
mediante una distribución
12 2
,
z = i =1
n1 n 2 (n1 + n 2 + 1)(1 − f )
normal continua, es frecuente aplicar la corrección por continuidad a estos estadísticos.
12
donde
La
versión con corrección por continuidad del test de la suma de rangos de Wilcoxon
donde
donde
T
(con o sin empates) se presenta en la Tabla
t8.2.
i (t i + 1)(t i − 1)
i =1
,
f =
T
(n1 + n 2 )(nt1i (+t i n+2 1+)(1t)(
n
+
n
−
1
)
1
2
i − 1)
[Tabla 8.2 aproximadamente
aquí]
i =1
,
= el valor i-ésimo de la variable. Notar
con ti el número de empates fpara
que, si no hay empates,
(
n
1 + n 2 )( n1 + n 2 + 1)( n1 + n 2 − 1)
f =con
0 y teste
estadístico
se reducepara
al citado
anteriormente.
como
la si
suma
de rangos
de empates
el valor
i-ésimo de la Finalmente,
variable. Notar
que,
no hay
i el número
es una variable discreta que se aproxima mediante una distribución normal continua, es frecuente
aplicar
por
a estos
estadísticos.
versión
con
empates,
f = 8.5
0 y Como
este
estadístico
al
citado
Finalmente,
Ejemplo
lacontinuidad
muestra
dereduce
casos
y controles
laLa
Tabla
8.1
es
n1 =sicorrección
nno
=hay
10 la por
tilael corrección
número
de empates
paraseel
valor
i-ésimo
deanteriormente.
lade
variable.
Notar
que,
con
2como
continuidad del test de la suma de rangos de Wilcoxon (con o sin empates) se presenta en la
Tabla
suma
rangos
unestadístico
variable
discreta
que
aproxima
mediante
una
>8.2.
8,depuede
la aproximación
normal
a laanteriormente.
suma
de rangos
Udistribución
= 96,5 en
los la
empates,
f = 0 aplicarse
y es
este
se reduce
alsecitado
Finalmente,
como
normal
frecuente
aplicar
lacasos
corrección
por continuidad
a8.1
estos
casos
de infarto.
Bajo
hipótesis
de
misma
distribución
del
β-caroteno
Ejemplo
8.5 eses
Como
lalamuestra
denula
controles
de
la Tabla
es
nestadísticos.
suma
decontinua,
rangos
un
variable
discreta
que
seyuna
aproxima
mediante
una
distribución
1 = n2 = 10 > 8,
puede aplicarse la aproximación normal a la suma de rangos U = 96,5 en los casos de
La en
versión
con
corrección
continuidad
lacontinuidad
suma
rangos
de estadísticos.
Wilcoxon
infarto.
Bajo
la
dela+una
misma
distribución
en casos y
normal
continua,
es hipótesis
frecuente
aplicar
corrección
por
ab-caroteno
estos
casos
y controles,
el por
valor
esperado
de
de
rangos
sería
10nula
⋅ 10
(10
10
+del
1esta
)(test
1 −suma
0de
,00075
) dedel
var(U)
=
=
174,87,
controles, el valor esperado de esta suma
12de rangos sería
(con
o sin empates)
se presenta
en la Tabladel
8.2.test de la suma de rangos de Wilcoxon
La
versión
con corrección
por continuidad
10(10 + 10 + 1)
E(U) =
= 105
2
(condonde
o sin empates) se presenta
en
la
Tabla
8.2.
10 ⋅ 10(10 + 10 + 1)(1 − 0,00075)
= 174,87,
y su varianza var(U) = [Tabla 8.2 aproximadamente aquí]
12
y su varianza
(2 ++ 110
)(2+−1)(
1)1 − 0,00075)
⋅ 102(10
f = = 10
= 0,00075
[Tabla 8.2 aproximadamente aquí]
var(U)
(10 + 10)(10 + 10 +12
1)(10 + 10 − 1) = 174,87,
10
donde
Ejemplo 8.5 Como la muestra de casos y controles de la Tabla 8.1 es n1 = n2 = 10
donde
es el
factor
deaplicarse
corrección
de
la 2varianza
debido
aa la
de t1 =U2 = 96,5 en los
donde
(2de+ casos
1)(2normal
−y1)controles
> 8,
puede
lamuestra
aproximación
la presencia
suma
deTabla
rangos
Ejemplo
8.5 Como
la
de
la
f=
= 0,00075 8.1 es n1 = n2 = 10
(10 + 10)(10 + 10 + 1)(10 + 10 − 1)
g/g.misma
Por tanto, el estadístico
la
observaciones
empatadas
para
casos
de infarto.
Bajolalaaproximación
hipótesis
βde
-caroteno
2el(2valor
+ 1nula
)(20,13
−de
1)μuna
>
8, puede
aplicarse
normal
a la sumadistribución
de rangos Udel
= 96,5
en los
f
=
=
0,00075
es el factor de corrección de la varianza debido a la presencia de t1 = 2 observaciones
(10 + 10)(con
10 +corrección
10 + 1)(10 por
+ 10continuidad
− 1)
suma
de rangos
de
es
empatadas
para
el Wilcoxon
valorel0,13
mg/g.
Pordebido
tanto,
elsuma
estadístico
de tsería
de rangos de
2 β-caroteno
es casos
el factor
de
corrección
de
la
varianza
a
la
presencia
de
1la=suma
en
casos
y
controles,
valor
esperado
de
esta
dedistribución
rangos
de infarto. Bajo la hipótesis nula una misma
del
Wilcoxon con corrección por continuidad es
tanto, elde
estadístico
de la
observaciones
empatadas
para
el
valor
0,13
t1 = 2
es
el
corrección
la| varianza
debido
laPor
presencia
96
,5 −10
105
| −+1μesta
/g/g.
2a+suma
enfactor
casos de
y controles,
elde
esperado
(10de
10
1)0,60,de rangos sería
zvalor
=E(U
=
) = 174,87
= 105
2por
suma de rangosempatadas
de Wilcoxon
corrección
g/g.continuidad
Por tanto, elesestadístico de la
observaciones
paracon
el valor
0,13 μ
10(10 + 10 + 1)
que corresponde a un valor PE(=U2P(Z
F(0,60)} = 0,549 a partir de la
) = ≥ 0,60) = 2{1=–105
2por
suma
rangos
de
Wilcoxon
continuidad
esEste
distribución
normal
estandarizada
de
la
Tabla
3
del
Apéndice.
valor
aproximado
de
=| 96
2Pcorrección
(
Z
≥
0,60)
=
2{1
Φ
(0,60)}
= 0,549
a partir
de
quey corresponde
a un
valor P con
sudevarianza
,5 − 105 | −1 / 2
z
=
=
0,60,
P es muy similar al valor exacto calculado en el Ejemplo 8.2, no habiendo así suficiente
10
174
,87
evidencia
para rechazar
la hipótesis
igualdad
distribuciones
del nivel
la distribución
normal estandarizada
la| Tabla
3 del
Apéndice. Este
valorde b-caroteno
y su varianza
| 96,5 de
−de
105
−1 / 2de
z=
0,60,de la enfermedad.
en los casos de infarto de miocardio
y los sujetos =libres
174
,
87
10
similar
exacto
calculado
en el=Ejemplo
aproximado
de P aesunmuy
P = 2al
P(valor
Z ≥ 0,60)
= 2{1
- Φ(0,60)}
0,549 a 8.2,
partirnode
que corresponde
valor
habiendo
así suficiente
evidencia
la3 hipótesis
de igualdad
la distribución
normal
estandarizada
la Tabla
del
Este valor
P = 2Ppara
(Z de
≥rechazar
0,60)
= 2{1
- ΦApéndice.
(0,60)}
= 0,549
ade
partir de
que
corresponde
a un valor
Pastor-Barriuso R.
β-caroteno
casos
de infarto
miocardio
y los
distribuciones
nivel
desimilar
P es
muy
al valor
exacto
calculado
en de
el Ejemplo
8.2,
no
aproximado
dedel
la
distribución
normal
estandarizada
deenlalos
Tabla
3 del
Apéndice.
Este valor
sujetos
libres
dePlaesenfermedad.
habiendo
asíde
suficiente
rechazar
hipótesisendeeligualdad
muyevidencia
similar alpara
valor
exacto la
calculado
Ejemplode
8.2, no
aproximado
127
128
Pastor-Barriuso R.
TestTest
deTest
los
con
signo
de
rangos
signo
derangos
loslos
rangos
concon
signo
Test
rangos
signo
Test
de de
los
rangos
concon
signo
Test
de los
los
rangos
con
signo
Test
la suma
rangos
Test
de de
la suma
de de
rangos
TestTest
deTest
ladesuma
rangos
de
la
la
de de
rangos
Test
desuma
ladesuma
suma
de rangos
rangos
1
1
1 2
2
n nn2n(11nn212(+
(nn1n+2++nn21)++11))
n nn2 1(n21 (+n11n+2 +n221)+ 1)
12 12
12
12 12
m
m
mm
n(nnn+((n1n)++11))1 11
m
−−(nn+(n1)+−1) 1−− 1
r
i −rriin
=i=11−ri − 4 4
ir
=1
i
4 − 2− 22
i
z =zz ==
4 4 2 2
i =1 i =1
z =z = n(nnn+((n1n)(
++211)(
n)(2+2n1n)++11))
+ 21)(
n(nn+(n1)(
n 2+n1)+ 1)
24 24
24
24 24
z =z =
+ n +−1) − 1
r−rrn−−(nn ((+nnn+
+n 1)+ 1) 1− 1
r −r − 2 22
− 2− 22
z =zz =
2 2
2 2
=
n1 nn11
n1 n1
ii
i
i =1 ii=i=11 i
i =1 i =1
1
1
n1 (n11(+n1n1 +2 +n212)+ 1) 1 1
empates
SinSin
empates
Sin
empates
empates
SinSin
empates
1 2
2
iii
ii
i
ii
T
T
TT
T
++t11i)()(−tti1i )−−11))
t
i (tttiii(+
(tti1i )(
t i1)(
+ t1i)(−t i1)− 1)
t
ii=i=11(ttii (+
=1
i
concon
f =ff =
con
=1 i =1
i=
2 22
concon
f =f =
2 2
m
m
mm
n(nn+(n1)+ 11))1 11
m−r − n( n +−
r
i
riin−(nn+(n1)+ 1) 1−− 1
iri=i=11−ri − 4 4
=1
4 − 2− 22
z =zz ==i
4 4 2 2
i =1 i =1
z =z =n(nnn+((nn1)(
++211)(
n)(2+2nn1)++−11))f−− ff
+ 21)(
n(nn+(n1)(
n 2+n1)+−1)f− f
24 24
24
24 24
28 28
28
28 28
i
ii i
i
concon
f =ff ==
con
nnn)()(+nn11n++
++n11)(
nn11n++
+n221)(
−n21)−−11))
concon
f =f(n=1((+nn n++)(
2 n
1)(+
2 n
n n+ )(
n n)(+
n1n+2 n+21)(
+ n1)(
n1n+2 n−221)− 1)
(n1(+
1 +
++t11)()(−tt1)−−11))
t
(ttt (+(tt1)(
+ t1)(−t 1)− 1)
t (tt (+t 1)(
T
T
TT
T
i
i =1 ii=i=11
i =1 i =1
11 2 221
1 2 21
++111)(
z =z =n nnn(nn (+
−)(11f−−) ff ))
(nn1n+2++nn21)(
+11)(
n nn(n (+n11n+2 +n221)(
−1f−) f )
12 12
12
12 12
1
n (n11(+n1n1 +2 +n212)+ 1) 1 1
n1 nn11
1
n1 n1
ii 1
i
i =1 ii=i=11 i
i =1 i =1
1 2 11 212
1 2 1 21
+ n +−1) − 1
r−rrn−−(nn ((+nnn+
+n 1)+ 1) 1− 1
r −r − 2 22
− 2− 22
z =zz =
2 2
2 2
=
Con empates
Con
empates
Con
empates
Con
empates
Con
empates
Con
empates
Tabla
Estadísticos
para
el test
la suma
rangos
y de
rangos
signo
Wilcoxon
corrección
continuidad.
Tabla
8.28.2
Estadísticos
para
el test
de de
la suma
de de
rangos
y de
loslos
rangos
concon
signo
de de
Wilcoxon
concon
corrección
porpor
continuidad.
Tabla
8.2
Estadísticos
para
test
la de
suma
deyrangos
y rangos
de
los
rangos
signo con
decon
Wilcoxon
con
corrección
Tabla
Estadísticos
para
el
de
la
de
yy de
signo
de
corrección
por
continuidad.
Tabla
8.28.2
Estadísticos
para
el test
de
la
suma
rangos
de
los
rangos
concon
signo
decon
Wilcoxon
corrección
por
continuidad.
Tabla
8.2
Estadísticos
para
eleltest
test
dede
la suma
suma
de rangos
rangos
de los
los
rangos
con
signo
de Wilcoxon
Wilcoxon
con
corrección
por
continuidad.por continuidad.
Métodos no paramétricos
Test de los rangos con signo de Wilcoxon
El test de la suma de rangos de Wilcoxon es también conocido como el test de MannWhitney. Aunque este último se deriva siguiendo un procedimiento distinto, ambas pruebas de
hipótesis son completamente equivalentes, obteniéndose el mismo valor P con cualquiera de
ellas. La comparación no paramétrica de distribuciones continuas en más de dos muestras
independientes se conoce como el test de Kruskal-Wallis. Este procedimiento es una
generalización del test de la suma de rangos de Wilcoxon y puede consultarse en los textos
sobre métodos no paramétricos referenciados en este tema.
8.3 TEST DE LOS RANGOS CON SIGNO DE WILCOXON
En este apartado se describe el procedimiento de contraste no paramétrico equivalente al test de
la t de Student para muestras dependientes. Como se discutió en el Apartado 6.4, la prueba t
para datos emparejados permite comparar dos medias poblacionales a partir de las diferencias
observadas en cada pareja de datos dependientes. Esta prueba paramétrica requiere que el
número de parejas sea suficientemente grande para asegurar que la media de las diferencias se
distribuya de forma normal. En aquellas circunstancias donde se produzcan violaciones claras
de este supuesto de normalidad (particularmente cuando el número de parejas sea muy reducido),
resulta más apropiado utilizar el test no paramétrico de los rangos con signo de Wilcoxon. Bajo
la asunción de que la variable a estudio sea continua, este procedimiento permite contrastar si
las diferencias se distribuyen simétricamente alrededor de 0. La hipótesis nula establece, por
tanto, que las diferencias de cualquier magnitud a favor de los sujetos de una población son
igualmente probables que a favor de los sujetos de la otra población.
Con objeto de preservar el emparejamiento, se calculan las diferencias di en cada pareja de
datos dependientes. La asignación de rangos a estas diferencias se realiza mediante el siguiente
procedimiento. En primer lugar, se excluyen las parejas donde di = 0 y se asignan rangos ri a las
restantes n diferencias no nulas, comenzando en 1 para la diferencia con menor valor absoluto
hasta n para aquella con mayor valor absoluto. Si existen diferencias con el mismo valor
absoluto (empates), se asigna a cada una de ellas la media de los rangos correspondientes.
Finalmente, a cada rango se le otorga el signo correspondiente a su diferencia. Estos rangos
con signo constituyen así una representación estandarizada de las diferencias, que preserva
tanto el orden de magnitud como el signo de las mismas. El test de los rangos con signo de
Wilcoxon se basa en la suma de los rangos positivos (o, equivalentemente, de los rangos
negativos)
W=
m
r,
i
i =1
donde m denota el número de rangos positivos.
donde m denota el número de rangos positivos.
Ejemplo 8.6 A partir del estudio EURAMIC, se seleccionan aleatoriamente 20 casos
de infarto de miocardio y 20 controles emparejados por grupos quinquenales de edad.
A partir delpara
estudio
EURAMIC,
aleatoriamente
20 en la
LosEjemplo
niveles 8.6
de b-caroteno
estas
20 parejas se
deseleccionan
casos y controles
se presentan
Tabla 8.3. Una vez excluida la pareja con di = 0, el número efectivo de parejas es n = 19.
casosde
deestas
infarto
de miocardio
y 20 controles
por grupos
A partir
parejas
con diferencias
no nulas, emparejados
se asignan rangos
del 1 al 19 comenzando
en la menor diferencia absoluta 0,01 mg/g hasta la mayor diferencia absoluta 1,00 mg/g. A las
de edad. Los
niveles
β-caroteno
para estas
20 parejas
dosquinquenales
parejas con diferencia
absoluta
0,27demg/g
se les otorga
el rango
medio (9de+casos
10)/2 y= 9,5,
y a otras dos parejas con diferencia absoluta 0,38 mg/g se les asigna su rango medio
presentan
en la Tabla
8.3. un
Una
vez positivo
excluidaalalos
pareja
concorrespondientes
di = 0, el
(12controles
+ 13)/2 =se12,5.
Finalmente,
se otorga
signo
rangos
número efectivo de parejas es n = 19. A partir de estas parejas con diferencias no
nulas, se asignan rangos del 1 al 19 comenzando en la menor diferencia Pastor-Barriuso
absoluta R.
0,01 μg/g hasta la mayor diferencia absoluta 1,00 μg/g. A las dos parejas con
129
otras dos parejas con diferencia absoluta 0,38 μg/g se les asigna su rango medio
(12 + 13)/2 = 12,5. Finalmente, se otorga un signo positivo a los rangos
(12 + 13)/2 = 12,5. Finalmente, se otorga un signo positivo a los rangos
correspondientes
Métodos no
paramétricos
a diferencias positivas y un signo negativo a los rangos
correspondientes
diferenciasnegativas.
positivas La
y un
signo
a los rangos
correspondientes aa diferencias
suma
de negativo
rangos positivos
resulta
correspondientes
a diferencias
negativas.
La asuma
de rangos
positivos resulta
a diferencias positivas
y un
signo
negativo
los rangos
correspondientes
a diferencias
9
negativas. La suma de rangos
positivos
resulta
ri = 17 + 12,5 + ... + 3 = 91
i =91
r
i
= 17 + 12,5 + ... + 3 = 91
i =1
y la suma de rangos negativos
y la suma de rangos negativos
y la suma de rangos negativos
10
r
j
= (− 4) + (− 14) + ... + (− 9,5) = − 99.
j =1
10
r j = de
(-4)los
+ (-14)
... + (-9,5)es= n(n
-99.+ 1)/2 = 19∙20/2 = 190. Así,
En este ejemplo la suma
total
rangos+ absolutos
j
=
1
En vez
este determinada
ejemplo la suma
total de
rangos
absolutos91,
es la
n(nsuma
+ 1)/2
19⋅20/2negativos
=
una
la suma
delos
rangos
positivos
de=rangos
viene
dada por 91 – 190 = – 99.
190. Así, una vez determinada la suma de rangos positivos 91, la suma de rangos
En este ejemplo la suma total de los rangos absolutos es n(n + 1)/2 = 19⋅20/2 =
negativos
dada por 91
-tejido
190 = -99.
Tabla
8.3viene
β-caroteno
adiposo
eny20
casos y controles
del estudio
Tabla
8.3Así,
β-caroteno
tejidoen
adiposo
en
20decasos
controles
190.
una vezen
determinada
la suma
rangos
positivos del
91,estudio
la sumaEURAMIC
de rangos
EURAMIC
según grupos
quinquenales de edad.
emparejados
segúnemparejados
grupos quinquenales
de edad.
negativos viene dada por 91
- 190 = (μg/g)
-99.
β-caroteno
β-caroteno (μg/g)
Pareja
Pareja
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
Caso
Control
Caso0,47
0,470,75
0,750,78
0,780,66
0,660,09
0,090,20
0,200,08
0,08
0,08
0,08
0,310,31
0,300,30
0,160,16
0,130,13
0,060,06
0,250,25
0,390,39
0,950,95
0,330,33
0,530,53
0,160,16
0,230,23
0,55
Control
0,09
0,55
0,40
0,09
0,40
0,13
0,13
0,49
0,49
0,31
0,31
0,28
0,28
0,46
0,46
0,16
0,16
0,87
0,87
1,16
1,16
0,13
0,13
0,37
0,37
0,04
0,04
0,37
0,37
0,14
0,14
0,06
0,06
0,50
0,50
0,17
0,17
0,50
0,50
Diferencia
(di)
Diferencia
absoluta
Diferencia Diferencia
– 0,08
0,08
(di)
absoluta
0,66
0,66
-0,08
0,08
0,38
0,38
0,66
0,66
0,38
0,38
0,53
0,53
0,53
0,53
– 0,40
0,40
-0,40
0,40
– 0,11
0,11
0,11
–-0,11
0,20
0,20
-0,20
0,20
– 0,38
0,38
-0,38
0,38
0,15
0,15
0,15
0,15
– 0,57
0,57
-0,57
0,57
–-1,00
1,00
1,00
1,00
00
00
–-0,31
0,31
0,31
0,31
0,21
0,21
0,21
0,21
0,02
0,02
0,02
0,02
0,81
0,81
0,81
0,81
0,27
0,27
0,27
0,27
0,03
0,03
0,03
0,03
-0,01
0,01
– 0,01
0,01
-0,27
0,27
– 0,27
0,27
Rango
absoluto
Rango
4
absoluto
17 4
12,5
17
1512,5
1415
514
75
7
12,5
12,5
6
6
16
16
1919
—−
1111
88
22
1818
9,59,5
3 3
11
9,5
9,5
Rango con
13
signo (ri)
Rango con
– 4 (ri)
signo
17-4 13
12,5
17
1512,5
– 1415
–-14
5
– 7-5
-7
– 12,5
-12,5
6
6
– 16
-16
– 19
-19
—−
– 11
-11
88
22
1818
9,59,5
33
– 1-1
-9,5
– 9,5
99
de rangos
positivos rrii ==9191
SumaSuma
de rangos
positivos
ii ==11
10
10
– 99
de rangos
negativos rrjj= =
SumaSuma
de rangos
negativos
-99
=1
jj =
1
130
Pastor-Barriuso R.
de 0, se esperaría la misma suma
de rangos
positivos que negativos
[Tabla
8.3
aquí] y, por consiguiente,
2 aproximadamente
2
4
la suma esperada de rangos positivos sería
de rangos absolutos
1) n(de
n +la1suma
) Testtotal
1 n(nla+ mitad
losapartado
rangos con signo
de Wilcoxon
E(W)
donde
indica
el número
deque
diferencias
no nulas.
igual ,que
endeel
anterior,
Bajon la
hipótesis
nula de
las =diferencias
se= Al
distribuyen
simétricamente
alrededor
2
2
4
1 n(n + 1) n(n + 1)
el
de la
P misma
para el suma
contraste
bilateral
vendrá
dadonegativos
bajo H0
E(W)de=rangos
= que
,por la probabilidad
devalor
0, se exacto
esperaría
positivos
y, por consiguiente,
2
2
4
donde
n
indica
el
número
de
diferencias
no
nulas.
Al
igual
que
en
el
apartado
anterior,
Bajo la hipótesis nula de que las diferencias se distribuyen simétricamente alrededor de 0, se
de
obtener
una suma
de
positivos
tanto
o másdedistante
detotal
E(W)
susuma
valor
la suma
de rangos
positivos
sería
la negativos
mitad
la
deque
rangos
absolutos
esperaría
laesperada
misma
suma
de rangos
rangos
que
y, suma
por consiguiente,
la
esperada
el
valor
exacto
de
P
para
el
contraste
bilateral
vendrá
dado
por
la
probabilidad
bajo
H0
de rangos
la mitad
de la sumanototal
de Al
rangos
donde npositivos
indica elsería
número
de diferencias
nulas.
igualabsolutos
que en el apartado anterior,
observado w; esto es, si w > E(W),
1 n(n + 1) n(n + 1)
devalor
obtener
una de
suma
de rangos
positivos
tanto vendrá
o=más distante
que su valor
E(W)
= bilateral
el
exacto
P para
el contraste
dado, pordelaE(W)
probabilidad
bajo H0
2
2
4
P = 2P(W ≥ w | H0)
observado
es,de
siderangos
w diferencias
> E(W),
de
obtener
una
suma
positivos
tanto oAlmás
distante
que anterior,
su valor el valor
donde
n indicaw;
elesto
número
no nulas.
igual
que endeelE(W)
apartado
donde
n
indica
el
número
de
diferencias
no
nulas.
Al
igual
que
en
el
apartado
obtener una
exacto de P para el contraste bilateral vendrá dado por la probabilidad bajo H0 deanterior,
y,
sidew rangos
≤ E(W),
observado
w; esto
es, si w
> E(W),
suma
positivos
tanto
o más
distante
de
E(W)
que
su
valor
observado
w; esto es,
P = 2P(W ≥ w | H0)
el
valor
exacto
de
P
para
el
contraste
bilateral
vendrá
dado
por
la
probabilidad
bajo
H0
preestablecido,
la hipótesis nula se rechazará si la suma de rangos positivos es inferior
si w
> E(W),
PP == 2P(W
H00).)
2P(W ≤≥ ww || H
y, percentil
si
w ≤ E(W),
de
obtener
una
de rangos
positivos
al
α/2 suma
o superior
al percentil
1 - tanto
α/2. o más distante de E(W) que su valor
y, si w ≤ E(W),
Bajo
dicha
hipótesis
observado
w;
esto es,nula,
si w cualquier
> E(W), combinación de un número arbitrario de rangos
y, si w
≤ E(W),
P = 2P(W ≤ w | H0).
Ejemplo 8.7 Como ilustración, supongamos que la suma de rangos positivos es w
es igualmente
y su probabilidad
determinada
porpositivos
positivos
r1, ..., rm nula,
Bajo
dicha hipótesis
cualquierprobable
combinación
de un númeroviene
arbitrario
de rangos
)
P=
2P(W ≤≥ w | de
H00).
Bajo
dicha
hipótesis
nula,
cualquier
combinación
un
número
arbitrario
de
rangos
r1, ..., rm =
es25
igualmente
y su probabilidad
viene determinada
por
a partir deprobable
n = 12 parejas
de datos dependientes
con diferencias
no nulas. La
1
, ..., rm bajo
es nula,
igualmente
probable
y nsu, probabilidad
viene
determinada
por
positivos
r1hipótesis
y,
si wdicha
≤ E(W),
Bajo
cualquier
combinación
de un número
arbitrario
de rangos
distribución
H0 de
la suma
de rangos
positivos
es simétrica
alrededor
de
2
preestablecido, la hipótesis nula se rechazará si la suma de rangos positivos es inferior
donde
2nE(W)
es el
deigualmente
subconjuntos
de=cualquier
que
pueden
obtenersepor
a partir de
...,
y1su
viene
determinada
positivos
r1,=número
n(nrm+es1)/4
= 12(12 +probable
1)/4
39,
deprobabilidad
lo tamaño
cual se deduce
que
P
=
2P(W
≤
w
|
H
).
n
0
α/2
superiordealsubconjuntos
percentil
- αde
/2.cualquier
, de tamaño
lasaldonde
npercentil
parejas
con
no
nulas. 1Haciendo
uso
este resultado,
la Tabla
9 del Apéndice
el odiferencias
número
que pueden
obtenerse
a
2 es
n
2
facilita los percentiles de la distribución de la suma de rangos positivos bajo la hipótesis nula de
w0,05 = n(n + 1)/21 - w0,95 = 78 – 60 = 18,
quepartir
las diferencias
se distribuyen
simétricamente
alrededor
0, cuando
número
deladiferencias
de lashipótesis
n parejas
con diferencias
no nulas.
uso
de arbitrario
esteelresultado,
Tabla
, Haciendo
Bajo
dicha
nula,
cualquier
combinación
de unde
número
de rangos
n
n
Ejemplo
8.7
Como
ilustración,
supongamos
que
la
suma
de
rangos
positivos
es
w
2
no nulas
≤ 16.
Para unde
nivel
de significación
α preestablecido,
la pueden
hipótesis
nula se rechazará
el número
subconjuntos
de cualquier
tamaño que
obtenerse
a
dondees2 nes
donde
w
=
60
se
obtiene
de
la
Tabla
9
del
Apéndice
para
n
=
12.
Como
la
suma
9positivos
del
Apéndice
facilita
los
percentiles
de
la
distribución
de
la
suma
de
rangos
positivos
si la
suma
derrangos
positivos
es
inferior
al
percentil
α/2
o
superior
al
percentil
1
–
α/2.
0,95
,
...,
r
es
igualmente
probable
y
su
probabilidad
viene
determinada
por
= 25n a1partir mde n = 12 parejas de datos dependientes con diferencias no nulas. La
partir de
n parejas
diferencias nodenulas.
Haciendo
usoque
de pueden
este resultado,
la Tabla
es el
númerocon
de subconjuntos
cualquier
tamaño
obtenerse
a
donde
2 las
bajoEjemplo
laobservada
hipótesis
nula
de
que
las
diferencias
se
distribuyen
simétricamente
alrededor
w
=
25
>
w
=
18,
se
sigue
que
P(W
≤
25
|
H
)
>
0,05.
Así,
el
0,05
0
8.7 bajo
Como
ilustración,
que la
de rangos
positivos
es de
w = 25
distribución
H0 de
la suma desupongamos
rangos1 positivos
es suma
simétrica
alrededor
de
9 del
Apéndice
losdiferencias
percentiles
de nulas.
la distribución
de
la
suma
de
rangos
positivos
,
partir
de lasdennparejas
con
no
Haciendo
uso
de
este
resultado,
la
Tabla
a partir
=facilita
12 parejas
de datos dependientes
con
diferencias
no
nulas.
La
distribución
n
20,10.
≤ 16.
Para
unque
niveldedeE(W)
significación
α =
0, cuando
número
diferencias
no
nulas
es
ncual
contraste
arroja
valor
P >de
labilateral
rangos
positivos
es
alrededor
= n(n + 1)/4
bajo
H0el
E(W)
=de
n(n
+suma
1)/4de=de
12(12
+un1)/4
= 39,
lo simétrica
se deduce
laApéndice
hipótesis
delos
que
las se
diferencias
se distribuyen
alrededor
de
9bajo
del
percentiles
de laque
distribución
desimétricamente
la suma de rangos
positivos
12(12
+ 1)/4 facilita
=nula
39, de
lo
cual
deduce
n
donde 2 es el número de subconjuntos de cualquier tamaño que pueden obtenerse a
w0,05 = el
n(n
+ 1)/2 –dewdiferencias
18, sea superior a 16,
0,95 = 78 – 60
Enlaaquellas
muestras
donde
número
no=simétricamente
nulas
un nivel de significación
α
0, cuando
el número
no nulasse
es
n ≤ 16. Para
bajo
hipótesis
nulade
dediferencias
que las diferencias
distribuyen
alrededor de
partir
de las
con diferencias
no9nulas.
Haciendo
uso
este
resultado,
Tabla
donde
w0,95n =parejas
60 se obtiene
de la Tabla
del Apéndice
para
n =de12.
Como
la sumalaobservada
puede
siguiente
aproximación
Dado
queAsí,
los
rangos
conlasigno
=la=60
se
obtiene
deque
la no
Tabla
9normal.
del
Apéndice
para
n nivel
=el
12.
Como
suma α
≤
16.
Para
un
de
significación
0, cuando
número
de
diferencias
nulas
es
n
w donde
=utilizarse
25 el
>w0,95
w
18,
se
sigue
P(W
≤
25
|
H
)
>
0,05.
contraste
bilateral
arroja
0,05
0
14
9 del
un Apéndice
valor P > facilita
0,10. los percentiles de la distribución de la suma de rangos positivos
observada
= 25 > w0,05 = 18,
se sigue quede
P(W
25 | H0) > 0,05.
Así, el en cada
constituyen
unawrepresentación
estandarizada
las≤diferencias
observadas
bajo la hipótesis nula de que las diferencias se distribuyen simétricamente alrededor de14
contraste
bilateral
arroja
P
> 0,10.
pareja
de datos
dependientes,
construirse
un estadístico
sustituyendo
las a 16, puede
En aquellas
muestras
dondeunpodría
elvalor
número
de diferencias
no nulas
sea superior
utilizarse
la siguiente
Dado
rangos
con de
signo
constituyen
≤ 16.los
Para
un nivel
significación
α una
0, cuando
el númeroaproximación
de diferenciasnormal.
no nulas
es n que
14
loslas
rangos
con signo
ri en el en
testcada
de la
t de Student
diferencias no
nulas di porde
representación
estandarizada
diferencias
observadas
pareja
de datospara
dependientes,
En aquellas muestras donde el número de diferencias no nulas sea superior a 16,
podría construirse un estadístico sustituyendo las diferencias no nulas di por los rangos con
muestras
(Apartado
6.4).
Así, eldependientes
estadístico resulta
signo
r en eldependientes
test de la t de Student
para
muestras
(Apartado 6.4). Así, el estadístico
puedei utilizarse la siguiente aproximación normal. Dado que los rangos con signo
resulta
constituyen una representación estandarizada de rlas diferencias observadas en cada
z=
,
sr
14
pareja de datos dependientes, podría construirse unnestadístico sustituyendo las
diferencias no nulas di por los rangos con signo ri en el test de la t de Student para
donde la media de los m rangos positivos y n - m rangos negativos es
muestras dependientes (Apartado 6.4). Así, el estadístico resulta
Pastor-Barriuso R.
z=
sr
r
,
131
Métodos no paramétricos
n−m
1 n
1 m
r = 1
n ri =
m ri +
n−m r j
1 i =1
i =1 ri = n
j =1 r j
ri +
r =n
n i =1 y n – im
donde la media de los m rangos positivos
es
=1 rangos
j =1 negativos
nn(−nm + 1)
1 n m
mm
= 11
m ri +1
m ri −
n(n + 1)
= n
r=
1 riri −+ 2r j
i =1riri=+
i =
n
j =12
nn i =i1=1
i =i1=1
n(n + 1)
2 m
m ri −
= 21
m
(mn4+ 1) n(n + 1)
+ n
ri −
i =1 rii −
= n
n ii==11
i =14 2
y, en el caso de que no haya empates,
n(n + 1)bajo
2 m la varianza
H0 de los rangos con signo se
=
rla
i −
y, en el caso de que no haya empates,
varianza
bajo
4 H0 de los rangos con signo se
n i =1
estima mediante
estima
mediante
el problema,
supongamos
que se dispone
pares
de observaciones
y, Para
en
elconcretar
caso
de que
no haya empates,
la varianza
bajo H0deden los
rangos
con signo se estima
H
de
los
rangos
con signo se
y, en el caso de que no haya empates,
la
varianza
bajo
mediante
0
1 n 2 1 n 2 (n + 1)(2n + 1)
2
de una variable aleatoria continua.
En
dependientes, una
sr = 1
= (datos
n rcada
n i de
i = pareja
n + 1)(62n + 1) .
1
2
2
2
n
n
i
i
=
1
=
1
estima mediante
s r = ri = i =
.
n i =1 muestra
n i =1 y la otra observación
6
observación x1 corresponde a la primera
x2 a la segunda
n
n
Aplicando ambas resultados,
se
el 1estadístico
(n + 1)(2n + 1)
1 tiene
2 se tiene
2 estadístico
Aplicando
ambos
resultados,
el
muestra.
El
objetivo
se
centra
en
comparar
las
medias
s
=
r
=
i 2 = poblacionales. μ1 y μ2 a partir de
r
i
Aplicando ambas resultados, se
tiene el estadístico
6
n i =1
n i =1
m
estas dos muestras dependientes. m ri − n(n + 1)
n(n4+ 1)
W − E (W )
i =tiene
1 ri −el estadístico
Aplicando ambas resultados,
se
z=
= W − E (W ) ,
4
Los procedimientos desarrolladosin=1(en
el
Apartado
6.3
no(pueden
W ) , aplicarse a esta
n + 1)(2n + 1) = SE
z=
SE (W )
nm (n + 124
)(2n + 1)
n(n +no
1) son independientes por provenir de
situación, ya que las medias de ambas rmuestras
i − 24
− E (W )de la suma de rangos positivos,
que representa
la diferencia
entrey,elen
observado
yW
esperado
4
i =valor
1 consecuencia,
distribución
asimétrica
=la utilización, de la prueba de la t de
z=
dividida
por sucorrelacionadas.
error
estándar bajo
diferencias
node
nulas
es n > 16,
que representa
la diferencia
entre
y esperado
de la suma
rangos
observaciones
SinHembargo,
la
se
notablemente
SE
(Wcon
) simplifica
+el1)(número
n0.(elnSivalor
2observado
n +comparación
1)de parejas
que
representa
la
diferencia
entre
el
valor
observado
y
esperado
de
la
suma
de
rangos
este estadístico
una distribución
normal estandarizada bajo la hipótesis
Studentsigue
para aproximadamente
muestras dependientes
24 resulta cuestionable. Sin embargo, a pesar de
Si las
el número
de parejasemparejadas.
con diferencias
de simetría
las por
diferencias
de 0.
dividida
su derror
estándar
bajo
H0.de
- x2 en cada
una
n observaciones
sinula
sepositivos,
calculan
las de
diferencias
= x1alrededor
.
Si
el
número
de
parejas
con positivos
diferencias
positivos,
dividida
por
su
error
estándar
bajo
H
0
contar únicamente con 20 parejas, la distribución
de la suma de rangos
que
representa
diferencia
entre
elsigue
valor
observado
y esperado
deestas
la
suma
de
rangos de 20
es
n8.8
> la
16,
este
aproximadamente
una1000
distribución
normal
Porno
unnulas
lado,
como
las
distintas
no
están
relacionadas
entre
sí,
diferencias
Ejemplo
A
partirestadístico
delparejas
estudio
EURAMIC,
se seleccionan
muestras
aleatorias
no parejas
nulas
es
n
>
16,
este
estadístico
sigue
aproximadamente
una
distribución
normal
presenta
un aspecto
mucho
más normal,
asíedad.
el usoLadeFigura
la aproximación
de casos
y controles
agrupados
según permitiendo
quinquenios de
8.2 presenta la
.
Si
el
número
de
parejas
con
positivos,
dividida
por
su
error
estándar
bajo
H
estandarizada
bajo
la
hipótesis
nula
de
simetría
de
las
diferencias
alrededor
de
0. así como
0
casoscon
y controles,
distribución muestral
delado,
la diferencia
b-caroteno d entre
son independientes.
Por otro
la mediamedia
de lasdediferencias
coincide
la diferencias
estandarizada
bajo
la
hipótesis
nula
de
simetría
de
las
diferencias
alrededor
de
0.
normal al test
de los de
rangos
conde
signo
de Wilcoxon.
la distribución
muestral
la suma
rangos
positivos W (esto es, la suma de rangos
en las
no
nulas
es
n
>
16,
este
estadístico
sigue
aproximadamente
una
distribución
normal
diferencia
de medias
muestrales,
parejas
donde el
caso presenta un nivel superior de b-caroteno que el control). Debido al
Ejemplo
8.8 Adepartir
dellaestudio
EURAMIC,
se seleccionan
muestras
reducido
número
parejas,
media de
las diferencias
de b-caroteno1000
presenta
una distribución
Ejemplo
8.8
A
partir
del
estudio
EURAMIC,
se
seleccionan
1000
muestras
estandarizada
bajo
la
hipótesis
nula
de
simetría
de
las
diferencias
alrededor
de
0. muestras
asimétrica y, en consecuencia,n la utilización
de la prueba de la t de Student para
n
aleatorias de 20 parejas1[Figura
de casos8.2
y1 controles
agrupadosaquí]
según quinquenios de
aproximadamente
dependientes resulta cuestionable.
de contar únicamente con 20 parejas,
= embargo,
d = d i Sin
( x i1 −axpesar
i2 )
aleatorias de 20 parejas de
casos ny
controles
agrupados
según quinquenios de
i =1 rangos
ipositivos
=1
la distribución de la suman de
presenta un aspecto mucho más normal,
Ejemplo
8.8 A partir
del estudio
EURAMIC,muestral
se seleccionan
1000 muestras
edad.
La Figura
8.2depresenta
la distribución
de la diferencia
media de βpermitiendo
así el uso
la aproximación
n
n normal al test de los rangos con signo de Wilcoxon.
1
1
En edad.
el caso
de
existir
diferencias
con
el
mismo
valor
absoluto,
ha
de
utilizarse
La Figura 8.2 presenta
distribución
de la diferencia medialade β= xla
xi 2 = xmuestral
1 − x2
i1 −
aleatoriasddeentre
20 parejas
casos yn controles
agrupados según quinquenios de
=1
1 como la distribución muestral de la suma
i =así
casosnydei controles,
caroteno
siguiente
versión
corregida
del
estadístico
del
test
de
rangos ha
conde
signo
En el caroteno
caso de existir
diferencias
con el mismo
valorlalos
absoluto,
utilizarse
siguiente
d entre
casos y controles,
así como
distribución
muestral
de lalasuma
edad.
La
Figura
8.2
presenta
la
distribución
muestral
de
la
diferencia
media
de
versión corregida
del
estadístico
del
test
de
los
rangos
con
signo
de rangos positivos W (esto es, la suma de rangos en las parejas donde el caso βy, en consecuencia,
d es un estimador
derangos
la diferencia de medias
de rangos positivos
W (esto es,insesgado
lamsuma nde
(n + 1) en las parejas donde el caso
riasí
− como
d nivel
entre superior
casos y controles,
distribución
muestral
de la suma
caroteno un
que
Debido
al reducido
presenta
de β-caroteno
4 ellacontrol).
ila
=1 comparación
poblacionales
μ
μ
.
Así,
el
problema
de
de
medias
en
dos
muestras
1
2
,
z
=
presenta un nivel superior de β-caroteno que el control). Debido al reducido
nla
+ 1)(2de
n +rangos
(nsuma
1) − f en las parejas donde el caso
de rangos
(esto es,
número
depositivos
parejas, laWmedia
de las
diferencias
de β-caroteno presenta una
dependientes
queda
a una
simple
media depresenta
una única
24 sobre
una
número
dereducido
parejas, la
media
de lasinferencia
diferencias
de βla-caroteno
16
presenta un nivel superior de β-caroteno que el control). Debido al reducido
muestra de n diferencias independientes.
16
cuya varianza incluye el término de corrección por empates
número de parejas, la media de las diferencias de β-caroteno presenta una
Los métodos
132 Pastor-Barriuso
R. del Apartado 6.2.1 para la media de una muestra pueden entonces
T
16
t i (t i +al1)(100(1
t i − 1)- α)% para μ - μ como
utilizarse para calcular un intervalo de confianza
1
2
f = i =1
,
distribución asimétrica y, en consecuencia, la utilización de la prueba de la t de
TestSin
de los
rangos conasigno
de Wilcoxon
Student para muestras dependientes resulta cuestionable.
embargo,
pesar
de
Frecuencia relativa (%)
contar únicamente con 20 parejas, la distribución de la suma de rangos positivos
Para concretar el problema, supongamos que se dispone de n pares de observaciones
25
25
presenta
un aspecto mucho más normal, permitiendo
así el uso de la aproximación
de una variable aleatoria continua. En cada pareja de datos dependientes, una
20
20
normal
al test de
los rangosacon
signomuestra
de Wilcoxon.
la primera
y la otra observación x2 a la segunda
observación
x1 corresponde
15
15
muestra. El objetivo se centra en comparar las medias poblacionales μ1 y μ2 a partir de
10 estas dos muestras dependientes.
[Figura 8.2
5
10
aproximadamente aquí]
5 6.3 no pueden aplicarse a esta
Los procedimientos desarrollados en el Apartado
En el0caso
de existir
el muestras
mismo valor
ha de
0 son absoluto,
situación,
ya quediferencias
las medias decon
ambas
no
independientes
porutilizarse
provenir dela
observaciones
correlacionadas.
la comparación
-0,6
-0,3
0 Sin embargo,
0,3
0 rangos
30se simplifica
60 signo
90notablemente
120 150
siguiente versión
corregida
del estadístico
del test
de los
con
180
si se calculan las diferencias
d = x1 - x2 en cada una de las n observaciones
d
W emparejadas.
m
n(n + 1)
4
Por un lado, como las
(a)distintas parejasrino−están relacionadas entre sí, estas
(b)diferencias
z=
i =1
,
Figura 8.2 Distribución
muestralPor
deotro
la diferencia
casos
controles (a) y de la
son independientes.
lado,
las1β-caroteno
d entre
coincide
cony la
n(lan media
+ media
n de
+
− f
1)(2de
)diferencias
suma de rangos positivos W (b) en 1000 muestras aleatorias de n = 20 parejas de casos y controles agrupados
24
Figura 8.2
según quinquenios
de edad
a partir
del estudio EURAMIC.
Las líneas verticales en trazo discontinuo
diferencia
de medias
muestrales,
corresponden a los parámetros subyacentes μ1 – μ2 = – 0,09 μg/g y E(W) = 80,3.
1 n
1 npor empates
cuya varianza incluye el término de
d =corrección
di =
( x i1 − x i 2 )
n i =1
n ni =1=
Ejemploincluye
8.9 En el
la término
Tabla 8.3desecorrección
obtuvieron
19 > 16 parejas de casos y
cuya varianza
por
empates
1T
n
1
n
= de
2
x(i1t i−+n1
controles con diferencias no nulas
puede
)(txii 2−=y,1x)1en− xconsecuencia,
n t iβ-caroteno
i =1
i =1
i =1
,
f =
2 de rangos positivos W = 91. Bajo la
utilizarse la aproximación normal a la suma
y, 8.9
en consecuencia,
es un
insesgado
de >
la 16
diferencia
medias
Ejemplo
En la Tablad 8.3
seestimador
obtuvieron
n = 19
parejasdede
casos y
donde ti es el número de empates para la i-ésima diferencia absoluta. Esta corrección conlleva
hipótesis
nula
de simetría
deefecto
las
diferencias
alrededor
de
0, apreciable
el valor
esperado
de
μ1 -empates
μy
Así,
el
problema
deel
lanestadístico
comparación
de
medias
en casos
dos
muestras
2. 8.3
unadonde
reducción
la varianza
su
sobre
será
cuando
el la
número
elde
número
para
la i-ésima
absoluta.
Esta
corrección
ti espoblacionales
Ejemplo
8.9
la de
Tabla
se
obtuvieron
=diferencia
19y,> en
16consecuencia,
parejas
de
y
controles
conEn
diferencias
no nulas
de β-caroteno
puede
de empates sea elevado (tal es el caso de las variables cualitativas ordinales). Dado el carácter
dependientes
queda reducido
a una simple inferencia sobre la media de una única
suma
de
positivos
es
discreto
de una
la rangos
suma
de
rangos
y nulas
el reducido
tamaño
inherente
aapreciable
las pruebas no
conlleva
reducción
de la no
varianza
y su
efecto
sobre
estadístico
será
controles
con
diferencias
de
β-caroteno
y,muestral
enelconsecuencia,
puede
utilizarse
la
aproximación
normal
a
la
suma
de
rangos
positivos
W
=
91.
Bajo
la
paramétricas, la aproximación normal a estos estadísticos suele incorporar además la corrección
muestra de n diferencias independientes.
porcuando
continuidad
la de
Tabla
8.2 para
la
de
incurrir
en=un
error
I.
el número
empates
sea reducir
elevado
(tal
caso de
las
variables
cualitativas
(probabilidad
19es
+de1el)rangos
utilizarse
ladeaproximación
normal
a =la19
suma
positivos
W
91.
Bajode
latipo
hipótesis
nula
de simetría
de
las
diferencias
alrededor
de
0, elpueden
valor
esperado
de
la
E(W)
95 muestra
Los métodos
del Apartado
6.2.1
para la media
de=una
entonces
4
ordinales).
Dado
el
carácter
discreto
de la sumaalrededor
y 0,
el reducido
tamaño
Ejemplo
8.9
En
la
Tabla
8.3
se
obtuvieron
nde=alrangos
19
> 16
casos
y controles
hipótesis
nula
de
simetría
de
las
diferencias
de
valor
esperado
de la con
calcular es
un intervalo de confianza
100(1
- αparejas
)% el
para
μde
1 - μ2 como
suma deutilizarse
rangospara
positivos
diferencias no nulas de b-caroteno y, en consecuencia, puede utilizarse la aproximación
y la varianza
muestral
inherente
apositivos
las
no paramétricas,
aproximación
a estos
suma de
es positivos
normal
arangos
la suma
de pruebas
rangos
W = 91.la
la hipótesisnormal
nula de
simetría de las
sBajo
d
d
t
±
,
19
(
+
n19
/ 21)
−1,1−α
diferencias alrededor de 0, el E(W)
valor esperado
de la
=
95 de rangos positivos es
n= suma
estadísticos suele incorporar además
19(19la+corrección
1)(2 ⋅419 + 1por
) − 6continuidad de la Tabla 8.2 para
= 617,25,
var(W) =
19(19 + 1)
E(W) = 24
= 95
reducir la probabilidad de incurrir en un error4de tipo I.
y la varianza
24
ydonde
la varianza
el término de corrección de la varianza por los t1 = 2 empates con
y la varianza
19(19 + 1)(2 ⋅ 19 + 1) − 6
) = y los t2 = 2 empates con=diferencia
617,25, absoluta 0,38
diferencia absoluta var(
0,27Wμg/g
24
19(19 + 1)(2 ⋅ 19 + 1) − 6
= 617,25,
var(W) =
donde
el
término
de
corrección
de la varianza
por los t1 = 2 empates con diferencia
17
μg/g es
24
con es
donde el 0,27
término
de la varianza
por los tabsoluta
absoluta
mg/gdey corrección
los t2 = 2 empates
con diferencia
0,38 mg/g
1 = 2 empates
con 0,38
donde el término
de0,27
corrección
2(2 + 1de
)(2la−varianza
1) + 2(2 +por
1)(los
2 −t11)= 2 empates
absoluta
diferencia
absoluta
f =μg/g y los t2 = 2 empates con diferencia
= 6.
2
diferencia absoluta 0,27 μg/g y los t2 = 2 empates con diferencia absoluta 0,38
μg/g es
Pastor-Barriuso R.
Aplicando la corrección por continuidad, el test estadístico de los rangos con
μg/g es
2(2 + 1)(2 − 1) + 2(2 + 1)(2 − 1)
f = entonces
= 6.
signo de Wilcoxon resulta
2
133
f=
2(2 + 1)(2 − 1) + 2(2 + 1)(2 − 1)
= 6.
2
Métodos no paramétricos
Aplicando la corrección por continuidad, el test estadístico de los rangos con
signo de Wilcoxon
resultapor
entonces
Aplicando
la corrección
continuidad, el test estadístico de los rangos con signo de
Wilcoxon resulta entonces
z=
| 91 − 95 | −1 / 2
617,25
= 0,14,
con un valor P = 2P(Z ≥ 0,14) = 2{1 – F(0,14)} = 0,889. Notar que el resultado del test
sería
idéntico
suma
de rangos
negativos
W =Notar
– 99, que
ya que
su valor esperado
con un
valor Pde= utilizar
2P(Z ≥ la
0,14)
= 2{1
- Φ(0,14)}
= 0,889.
el resultado
es E(W) = – 95 y su varianza coincide con var(W) = 617,25. Así, una vez controladas las
diferencias
edad, las
de b-caroteno
favor de W
los=casos
deque
infarto
-99, ya
su no son
del test seríadeidéntico
dediferencias
utilizar la suma
de rangosanegativos
significativamente distintas de las diferencias a favor de los sujetos libres de la enfermedad.
valor esperado es E(W) = -95 y su varianza coincide con var(W) = 617,25. Así,
La comparación no paramétrica de una variable continua en más de dos muestras dependientes
vez controladas
diferencias
de edad,Bajo
las diferencias
dede
β-caroteno
a favorsigue la
puedeuna
realizarse
mediante las
el test
de Friedman.
la asunción
que la variable
misma distribución continua excepto posibles diferencias de localización (traslaciones), esta
prueba permite contrastar la hipótesis nula de una misma localización de la variable en cada una
de las poblaciones. Este procedimiento también se fundamenta en la definición de rangos y
puede consultarse en los libros específicos de métodos no paramétricos.
18
8.4 TEST EXACTO DE FISHER
En el Apartado 7.4 se presentó el test χ2 de Pearson como un procedimiento general para evaluar
la asociación estadística entre las variables de una tabla 2×2. Esta prueba se basa en la asunción
de que el tamaño muestral es suficientemente grande para justificar la aproximación chicuadrado a la distribución nula del estadístico χ2 de Pearson. En concreto, si los marginales de
la tabla son pequeños, de tal forma que la frecuencia esperada en alguna de las celdas sea
inferior a 5, esta aproximación puede resultar imprecisa. En tales circunstancias, es preferible
utilizar métodos alternativos basados en la distribución exacta de las frecuencias de las celdas
de una tabla 2×2. En este apartado se describe el más conocido de estos procedimientos, el test
exacto de Fisher.
Ejemplo 8.10 La Tabla 8.4 presenta el número de sujetos con niveles de b-caroteno
Ejemplo
Bajo la hipótesis
de independencia
de β-caroteno
y el
superiores8.1.
e inferiores
a 0,30 mg/g
entre los 10 entre
casoseldenivel
infarto
y los 10 controles
del
estudio EURAMIC seleccionados de forma independiente en el Ejemplo 8.1. Bajo la
riesgo
de de
infarto
de miocardio,
esperada en
celda
sería de miocardio,
hipótesis
independencia
entrelaelfrecuencia
nivel de b-caroteno
y elcada
riesgo
de infarto
la frecuencia esperada en cada celda sería
E11 = E12 =
5⋅10
= 2,5,
20
E21 = E22 =
15 ⋅ 10
= 7,5.
20
Como los valores esperados en dos de las cuatro celdas son inferiores a 5, la prueba χ2 de
Pearsonlosnovalores
será aplicable
a esta
tablade2×2
la asociación
ha de
contrastarse
mediante otro
Como
esperados
en dos
lasycuatro
celdas son
inferiores
a 5, la
procedimiento.
prueba χ 2 de Pearson no será aplicable a esta tabla 2×2 y la asociación ha de
contrastarse mediante otro procedimiento.
134
Pastor-Barriuso R.
[Tabla 8.4 aproximadamente aquí]
Test exacto de Fisher
Tabla 8.4 β-caroteno en tejido adiposo en
10 casos de infarto de miocardio y 10 controles
seleccionados aleatoriamente del estudio
EURAMIC.
β-caroteno
(μg/g)
> 0,30
≤ 0,30
Total
Infarto de miocardio
Caso
Control
Total
1
9
10
4
6
10
5
15
20
El test exacto de Fisher se basa en determinar la probabilidad exacta de observar una tabla
cualquiera con frecuencias a, b, c y d, bajo la hipótesis nula de independencia y asumiendo que
todos los marginales n1, n2, m1 y m2 son fijos (Tabla 7.1). La condición de marginales fijos se
impone por conveniencia matemática, ya que los cálculos se simplifican notablemente y los
marginales contienen poca información sobre la asociación a estudio. Bajo H0, la probabilidad
de enfermar π es común en los sujetos expuestos y los no expuestos. Así, el número de enfermos
entre los expuestos sigue una distribución
de parámetros
n1 y π, mientras que entre los
n1 binomial
a
n1 − a n 2
c
n2 − c
)
=
π
(
1
−
π
)
π
(
1
π )Como
P(a,
b,
c,
d
|
H
0
no expuestos sigue una distribución binomial
de parámetros
las muestras de
a
c n2 y− π.
expuestos y no expuestos son independientes,
la probabilidad
de obtener una tabla con
frecuencias a, b, c y d es el producto de las probabilidades binomiales de observar a sujetos
n1 n 2 m1
los
enfermos entre los expuestos y c entre
no expuestos,
π (1 − π ) m2 .
=
na1 m1 − a
n2
P(a, b, c, d | H0) = π a (1 − π ) n1 − a π c (1 − π ) n2 − c
a
c
Para marginales n1, n2, m1 y m2 fijos, el rango de valores posibles k para el número de
n1 n 2 m1
m - n ) y π
(1min(n
− π ) m,2 m
. ). Por tanto, la
=
k
=
casos expuestos varía entre k1 = max(0,
1
2
2
1
1
a
m
−
a
1
Para
marginales de
n1,obtener
n2, m1 yuna
m2tabla
fijos,con
el rango
de valores
k para ela unos
número de casos
probabilidad
frecuencias
a, b, cposibles
y d condiciona
expuestos
varía
entre
k
=
max(0,
m
–
n
)
y
k
=
min(n
,
m
).
Por
tanto,
la
probabilidad
1
1 posibles
1
Para marginales n1, n1 2, m1 y m2 fijos,
el2 rango2 de valores
k para el número
de de
obtener
una tabla
frecuencias
b, c ydada
d condicionada
a unos marginales n1, n2, m1 y m2 fijos
marginales
n1, con
n2, m
por
1 y m2 fijosa,viene
viene
dada
por
casos expuestos varía entre k = max(0, m - n ) y k = min(n , m ). Por tanto, la
1
1
2
2
1
1
n1 n 2 m1
a, b, c y dπ condiciona
(1 − π ) m2 a unos
probabilidad de obtener una tabla con frecuencias
−
a
m
a
1
P(a, b, c, d | n1, n2, m1, m2; H0) = k
2
marginales n1, n2, m1 y m2 fijos viene dada por n1 n 2 π m1 (1 − π ) m2
k = k1 k m1 − k
nn1 nn2 m1 n m2 n
2
2
1
π (1 −1 π
)
aa m
1 − a
m1 − a
a m1 − a
P(a, b, c, d | n1, n2, m1, m2; H0) ==
,
k2
nn2 =m1 n + mn2
1
k2 n
n
1
2
1π ) 2
π
(
1
−
k m − k
k
= k1
1
k = k1 k m1 − k
m1
n 2 las propiedades
n1 de
n1 nde
coeficientes
2 los
donde el denominador de la última igualdad se obtiene
binomiales.
Esta distribución
probabilidades
entre
donde el denominador
de ladeúltima
igualdad se
delas
propiedades
m1 −deacon
a todas
m1 −
alas
obtiene
posibles
a tablas
loslos mismos
=
,
=
marginales se conoce como distribución hipergeométrica
y
determina
la
distribución
bajo H0
k2
n1 n 2
n1 + n 2
entre todas
coeficientes binomiales. Esta distribución de
probabilidades
lasposibles
k = k1 k m1 − k
m1
Pastor-Barriuso
R.
tablas con los mismos marginales se conoce como distribución hipergeométrica
y
donde el denominador de la última igualdad se obtiene de las propiedades de los
determina la distribución bajo H0 del número de casos expuestos y no expuestos en una
135
Métodos no paramétricos
del número de casos expuestos y no expuestos en una muestra de m1 casos obtenidos a partir de
un total de n1 sujetos expuestos y n2 sujetos m
no expuestos. Notar que esta probabilidad depende
1 m 2 n1 n 2
dado
que una vez
conocido
a las frecuencias de
únicamente del número a de casos expuestos,
a la
1 − a
1 − a
a los
nmarginales
de
mtabla.
las restantes celdas
quedan
determinadas
por
Cabe
destacar también
P(a | n1, n2, m1, m2; H0) =
=
m2
que aunque los cálculos se han derivado de
prospectivo,
mun
n1 + n 2 se obtendría el mismo
1 + estudio
resultado a partir de un estudio retrospectivoen términos
del
número
de
sujetos expuestos entre
n1
m1
casos y controles,
n1 !nm2 !1 m
1 ! mm2 2! n1 n 2
=
,
n! aa! b! c!nd1!− a a m1 − a
P(a | n1, n2, m1, m2; H0) =
=
m1 + m 2
n1 + n 2
lo cual confirma que la probabilidad condicional
tabla no
n1 a una determinada
m1
asociada
varía en función del diseño prospectivo o retrospectivo
del
n1 ! n 2 ! m1 ! m
2 ! estudio.
=,
n! a! b! c! d!
lo cualEjemplo
confirma
queBajo
la probabilidad
asociada a una
no varía en
8.11
la hipótesis condicional
nula de independencia
entredeterminada
el nivel de βtabla
-caroteno
función
del
diseño
prospectivo
o
retrospectivo
del
estudio.
lo cual confirma que la probabilidad condicional asociada a una determinada tabla no
y el riesgo de infarto agudo de miocardio, la probabilidad exacta de obtener la
Ejemplo
8.11 delBajo
la hipótesis
nulaode
independencia
entre el nivel de b-caroteno y el
varía
en función
diseño
prospectivo
retrospectivo
del estudio.
riesgo 8.4
de manteniendo
infarto agudolosdemarginales
miocardio,fijos
la probabilidad
exacta de obtener la Tabla 8.4
Tabla
es
manteniendo los marginales fijos es
Ejemplo 8.11 Bajo la hipótesis nula de independencia entre el nivel de β-caroteno
10 10
1
4
5!15!10!10!exacta de obtener la
y el riesgo
de| infarto
agudo
P(1
5, 15, 10,
10; de
H0)miocardio,
= la probabilidad
= 0,136,
=
20!1! 4! 9! 6!
20
es
Tabla 8.4 manteniendo los marginales fijos
5
que corresponde a la probabilidad de que, de los 5 sujetos observados con niveles de
10 y10
b-caroteno
superiores
a 0,30 mg/g,de
1 sea
restantes
4 sean controles.
Notar que
que
corresponde
a la probabilidad
que,caso
de loslos
5 sujetos
observados
con niveles
1 4
!15!la10primera
!10!
la tabla se refiere por la frecuencia a = 1 observada
celda, dado que las
5en
= 0,136,
P(1 | 5, 15, 10, 10; H0) =
=
demás
frecuencias
b = 4, ac 0,30
= 9 yμdg/g,
= 61vienen
entonces
dadas
por
los
marginales.
β-caroteno
superiores
sea caso
y
los
restantes
4
sean
controles.
de
20
20!1! 4! 9! 6!
5
Notar
que
la
tabla
se
refiere
por
la
frecuencia
a =de1 una
observada
en la
celda,
Para contrastar la independencia entre las variables
tabla 2×2,
el primera
test exacto
de Fisher
consiste en enumerar todas las posibles tablas con los mismos marginales que la tabla observada,
las demás
b = 4,de
cexacta
=que,
9 yde
d =los
6 vienen
entonces
por
losbajo la
queque
corresponde
afrecuencias
lalaprobabilidad
5 sujetos
observados
con
niveles
para adado
continuación
calcular
probabilidad
asociada
a cada
una dedadas
estas
tablas
hipótesis nula de independencia. El valor P bilateral del test exacto de Fisher corresponde
marginales.
β-caroteno
a 0,30para
μg/g,
1 seaaquellas
caso y los
restantes
4 sean controles.
de
entonces
a la
suma de superiores
probabilidades
todas
tablas
con probabilidad
inferior o
igual a la de la tabla observada (esto es, la suma de probabilidades de las tablas tanto o menos
Notar
la tabla senula
refiere
la frecuencia
a = 1 observada en la primera celda,
compatibles
conque
la hipótesis
quepor
la tabla
observada).
Para contrastar la independencia entre las variables de una tabla 2×2, el test exacto
dado que
demás
frecuencias
b =todas
4, c =
y d = 6 vienen
entonces
dadas marginales
por los
Ejemplo
8.12las La
Tabla
8.5 presenta
las9 posibles
tablas con
los mismos
de Fisher consiste en enumerar todas las posibles tablas con los mismos marginales que
n1 = 5, n2 = 15, m1 = 10 y m2 = 10 observados en la Tabla 8.4 para la asociación entre el
marginales.
b-caroteno
y el
infarto
de miocardio.
Bajo la
nulaexacta
de independencia
entre ambas
la tabla
observada,
para
a continuación
calcular
la hipótesis
probabilidad
asociada a cada
variables, la probabilidad exacta asociada a cada tabla viene dada por la distribución
una dehipergeométrica
estascontrastar
tablas bajo
la hipótesis nula
de independencia.
valor
P bilateral
delexacto
test
Para
la independencia
entre
las variables deEluna
tabla
2×2, el test
exacto
de Fisher
corresponde
entonces
la suma
de probabilidades
para todas
aquellas que
de Fisher
consiste
en enumerar
todasa las
posibles
tablas con los mismos
marginales
136
la tabla observada, para a continuación calcular la probabilidad exacta asociada a cada
Pastor-Barriuso R.
22
una de estas tablas bajo la hipótesis nula de independencia. El valor P bilateral del test
Test exacto de Fisher
tablas con probabilidad inferior o igual a la de la tabla observada (esto es, la suma de
probabilidades de las tablas tanto o menos compatibles con la hipótesis nula que la tabla
Tabla 8.5 Todas las posibles tablas con los mismos
marginales que la Tabla 8.4, junto con sus probabilidades
observada).
tablas con probabilidad
inferior
o igual
a la de nula
la tabla
observada (esto es, la suma de
asociadas
bajo
la hipótesis
de independencia.
Tabla
Probabilidad
bajo Hcon
Odds rationula que la tabla
0
probabilidades
lasLa
tablas
o menos
compatibles
latablas
hipótesis
Ejemplo de
8.12
Tablatanto
8.5 presenta
todas
las posibles
con los mismos
0
5
1
4
observada).
0 la Tabla 8.4 para la
5, n2 = 15,5 m1 = 10 y m0,016
marginales n1 = 10
2 = 10 observados en
9 β-caroteno
6
0,136
0,17la hipótesis nula de
asociación entre el
y el infarto
de miocardio. Bajo
Ejemplo 8.12 La Tabla 8.5 presenta todas las posibles tablas con los mismos
2
8
entre
3
7
ambas
independencia
variables, la0,348
probabilidad exacta0,58
asociada a cada tabla
marginales n1 = 5, n2 = 15, m1 = 10 y m2 = 10 observados en la Tabla 8.4 para la
3
2
7
8
la distribución
0,348
1,71
viene dada por
hipergeométrica
asociación entre el β-caroteno y el infarto de miocardio. Bajo la hipótesis nula de
4
6
1
9
0,136
6
15!10!10! exacta asociada a cada tabla
independencia entre ambas
variables, la5!probabilidad
P(0)
= 0,016,
5
0 = P(5) =
200,016
! 0! 5!10! 5!
5
10
∞
viene dada por la distribución hipergeométrica
5!15!10!10!
P(1) = P(4) =
= 0,136,
520
!1!51!!140!!91!06!!
P(0) = P(5) =
= 0,016,
20! 0! 5!10! 5!
5!15!10!10!
P(2) = P(3) = 5!15!10!10! = 0,348,
P(1) = P(4) = 20! 2! 3! 8! 7! = 0,136,
20!1! 4! 9! 6!
5!15!10!10! tablas con a = 0, 1, 4 y 5
cuya suma de probabilidades
igual
P(2) =es
P(3)
= a 1. Como las
= 0,348,
20! 2! 3! 8! 7!
tienen asociadas probabilidades menores o iguales que la probabilidad P(1) =
cuya suma de probabilidades es igual a 1. Como las tablas con a = 0, 1, 4 y 5 tienen
asociadas
menores
o iguales
quedel
la probabilidad
= 0,136
P bilateral
test exacto deP(1)
Fisher
es de la tabla
0,136 de laprobabilidades
tabla observada,
el valor
a
=
0,
1,
4
y5
cuya
suma
de
probabilidades
es
igual
a
1.
Como
las
tablas
con
observada, el valor P bilateral del test exacto de Fisher es
P = P(0) + Pmenores
(1) + P(4)o +iguales
P(5) que la probabilidad P(1) =
tienen asociadas probabilidades
= 0,016 + 0,136 + 0,136 + 0,016 = 0,304.
0,136 de la tabla observada, el valor P bilateral del test exacto de Fisher es
Notar que se obtendría el mismo valor P si se sumaran las probabilidades asociadas a
todas
tablas con
un
oddsvalor
ratio Ptanto
osumaran
más alejado
del valor nulo 1 que el OR =
Notaraquellas
que se obtendría
mismo
las probabilidades
P = Pel(0)
+ P(1)
+ P(4)si+seP(5)
1∙6/(4∙9) = 0,17 de la tabla observada; es decir, las probabilidades de las tablas con OR ≤ 0,17
oasociadas
OR ≥ 1/0,17
= 6. aquellas
Así,= a0,016
partir
esta
muestra
reducida,
no puede
concluirse
que exista
a todas
tablas
con un
odds tan
ratio
tanto
o más
alejado
del valor
+de0,136
+ 0,136
+
0,016
= 0,304.
una asociación significativa entre el nivel de b-caroteno y el riesgo de infarto de miocardio.
nulo 1 que el OR = 1⋅6/(4⋅9) = 0,17 de la tabla observada; es decir, las
P si el
se número
sumarande
lasposibles
probabilidades
Notar
se obtendría
el es
mismo
Cuando elque
tamaño
muestral
muy valor
pequeño,
tablas con los mismos
marginales
será
muy
reducido,
de
tal
forma
que
el
valor
P
del
test
exacto
Fisherde
podrá
probabilidades de las tablas con OR ≤ 0,17 ó OR ≥ 1/0,17 = 6. Así,dea partir
esta tomar
asociadas
a
todas
aquellas
tablas
con
un
odds
ratio
tanto
o
más
alejado
del
valor
muy pocos valores, siendo así particularmente difícil obtener resultados significativos. Para un
nivel de
significación
α preestablecido,
el test exacto
de Fisher
tenderá a ser
conservador con
muestra
tan reducida,
no puede concluirse
que exista
una asociación
significativa
OR
=
1
⋅
6/(4
⋅
9)
=
0,17
de
la
tabla
observada;
es
decir,
las
nulo
1
que
el
una verdadera probabilidad de error de Tipo I menor que el valor nominal α. Un contraste
alternativo
consiste
en calcular
el valor
mid-P bilateral, que se define como
y el riesgo
de infarto
de miocardio.
entremenos
el nivelconservador
de β-caroteno
probabilidades
de
las
tablas
con
OR
≤
0,17
ó
OR
≥
1/0,17
= 6.menos
Así, a verosímiles
partir de esta
la probabilidad de la tabla observada más la probabilidad de las tablas
bajo H0.
Este valor mid-P será siempre inferior o igual al valor exacto de P, obteniéndose resultados
23
muestra tan
no puedeesconcluirse
muy similares
si elreducida,
tamaño muestral
grande. que exista una asociación significativa
entre el nivel de β-caroteno y el riesgo de infarto de miocardio.
Pastor-Barriuso R.
23
137
Métodos no paramétricos
Ejemplo 8.13 De todas las posibles tablas enumeradas en la Tabla 8.5, sólo las tablas
con a = 0 y 5 tienen probabilidades bajo H0 menores que la probabilidad P(1) = 0,136 de
la tabla observada, así que el valor mid-P bilateral se calcula como
mid-P = P(0) + P(1) + P(5) = 0,016 + 0,136 + 0,016 = 0,168,
que es considerablemente menor que el valor exacto de P = 0,304 calculado en el ejemplo
anterior. No obstante, ambos valores de P arrojan resultados no significativos para el
nivel de significación estándar α = 0,05.
El test exacto de Fisher puede generalizarse para evaluar la asociación estadística entre las
variables categóricas de una tabla r×c, cuando algunas frecuencias esperadas sean muy bajas y
no pueda aplicarse el test χ2 de Pearson. Aunque el valor P del test exacto de Fisher para tablas
mayores de 2×2 se define igualmente como la suma de probabilidades para aquellas tablas tanto
o menos probables que la tabla observada, su cálculo requiere de algoritmos de computación
dado el elevado número de posibles tablas con los mismos marginales.
8.5
138
REFERENCIAS
1.
Agresti A. Categorical Data Analysis, Second Edition. New York: John Wiley & Sons, 2002.
2.
Bickel PJ, Doksum KA. Mathematical Statistics: Basic Ideas and Selected Topics.
Englewood Cliffs, NJ: Prentice Hall, 1977.
3.
Breslow NE, Day NE. Statistical Methods in Cancer Research, Volume 1, The Analysis of
Case-Control Studies. Lyon: International Agency for Research on Cancer, 1980.
4.
Colton T. Estadística en Medicina. Barcelona: Salvat, 1979.
5.
Conover WJ. Practical Nonparametric Statistics, Third Edition. New York: John Wiley
& Sons, 1998.
6.
Fleiss JL. The Design and Analysis of Clinical Experiments. New York: John Wiley &
Sons, 1986.
7.
Fleiss JL, Levin B, Paik MC. Statistical Methods for Rates and Proportions, Third Edition.
New York: John Wiley & Sons, 2003.
8.
Hollander M, Wolfe DA. Nonparametric Statistical Methods, Second Edition. New York:
John Wiley & Sons, 1999.
9.
Lehmann EL. Nonparametrics: Statistical Methods Based on Ranks. San Francisco:
Holden and Day, 1975.
10.
Rosner B. Fundamentals of Biostatistics, Fifth Edition. Belmont, CA: Duxbury Press,
1999.
11.
Snedecor GW, Cochran WG. Statistical Methods, Eighth Edition. Ames, IA: Iowa State
University Press, 1989.
Pastor-Barriuso R.
TEMA 9
DETERMINACIÓN DEL TAMAÑO MUESTRAL
9.1
INTRODUCCIÓN
Las inferencias poblacionales derivadas a partir de una muestra conllevan indefectiblemente un
margen de error. Así, en el diseño de un estudio epidemiológico o clínico, es necesario plantearse
de antemano el número de sujetos que deben ser estudiados para responder a la pregunta de
investigación con un grado razonable de certidumbre. La determinación a priori del tamaño
muestral es una parte importante del diseño de un estudio por distintos motivos:
yy Permite concretar la hipótesis de trabajo. El investigador ha de precisar la hipótesis
principal del estudio y, en función de su experiencia, investigaciones previas o estudios
piloto, especificar la magnitud de efecto clínica o biológicamente relevante que se pretende
detectar.
yy Permite evaluar la factibilidad del estudio. Una de las limitaciones más frecuentes en los
estudios epidemiológicos es la imposibilidad de reclutar un número suficiente de pacientes,
bien sea por limitaciones en los recursos económicos, en el número de pacientes disponibles
o en el tiempo de duración del estudio.
yy Previene la obtención de resultados no concluyentes. Como se describió en el Tema 5, la
precisión de una estimación y la potencia estadística de un contraste de hipótesis aumentan
conforme aumenta el tamaño muestral, de tal forma que una muestra insuficiente dará
lugar a estimaciones imprecisas y contrastes de baja potencia.
Desde un punto de vista puramente teórico, basta con aumentar el tamaño muestral para
obtener estimaciones arbitrariamente precisas o para detectar como estadísticamente significativo
cualquier efecto por pequeño que sea. Aun cuando esto sea posible en la práctica, la utilización
de muestras excesivamente grandes es ineficiente, ya que la posible detección de efectos
trivialmente pequeños y de escasa utilidad práctica no justificaría los recursos empleados. En
último término, el objetivo de la determinación a priori del tamaño muestral consiste en estimar
la muestra mínima necesaria para asegurar estimaciones razonablemente precisas o para tener
una potencia suficiente en la detección de efectos clínicamente relevantes.
Con cierta frecuencia, el número de sujetos disponibles para un estudio viene dictado de
antemano por las limitaciones económicas o temporales. En tales circunstancias, es importante
determinar qué magnitudes de efecto tendrían una probabilidad razonable de ser detectadas con
la muestra disponible, para contar así con una idea aproximada de las posibilidades que ofrecería
la realización de dicho estudio.
Como se verá a continuación, el cálculo del tamaño muestral requiere de información previa
a la realización del estudio. Estos datos suelen proceder de investigaciones previas relacionadas
y, en la medida de lo posible, han de ajustarse a unas hipótesis de trabajo verosímiles. En
cualquier caso, las asunciones realizadas en el cálculo del tamaño muestral pueden diferir de los
resultados posteriores del estudio y, en consecuencia, estas determinaciones deben servir como
guía orientativa más que como norma rígida para la estimación del tamaño muestral. Conviene
apuntar también que la muestra resultante se refiere al número de sujetos necesarios para el
Pastor-Barriuso R.
139
ación de tamaño esencialmente infinito. La corrección de las fórmulas del tamaño
Determinación
del tamañoymuestral
tral para otros tipos
de muestreo
para poblaciones finitas puede consultarse en
bros sobre muestreos complejos citados al final del tema.
análisis y no a los inicialmente incluidos. Así, la muestra estimada ha de incrementarse en
previsión de las posibles pérdidas de sujetos que pudieran ocurrir en el estudio.
TAMAÑO MUESTRAL PARA LA ESTIMACIÓN DE UN PARÁMETRO
En este tema se revisan las fórmulas del tamaño muestral más frecuentemente utilizadas en
LACIONAL el diseño de estudios epidemiológicos y clínicos, tanto para la estimación de una media y una
proporción en una única muestra, como para la comparación de medias y proporciones en muestras
dependientes e independientes. En adelante, se asume que las muestras se obtienen mediante un
1.2 MEDIDAS
sta sección se presentan las fórmulas para determinar el tamaño muestral
necesarioDE TENDENCIA CENTRAL
muestreo aleatorio simple a partir de una población de tamaño esencialmente infinito. La
corrección de las fórmulas del tamaño muestral para otros tipos de muestreo y para poblaciones
obtener estimaciones fiables de un parámetro poblacional (típicamente
la mediadedetendencia central informan acerca de cuál e
Las medidas
finitas puede consultarse en los libros sobre muestreos
complejos
citados al final del tema.
variable continua o la proporción de sujetos con una determinada característica)
a
de una determinada
variable o, dicho de forma equivalente
9.2 TAMAÑO MUESTRAL PARA LA ESTIMACIÓN DE UN PARÁMETRO
r de una única muestra. Esta situación concierne esencialmente a los
estudiosde qué valor se agrupan los datos observados. La
alrededor
POBLACIONAL
iptivos o transversales.
El objetivo
se centra las
en calcular
tamaño
muestral
En esta sección
se presentan
fórmulaselpara
determinar
necesario
para los resultado
central
deellatamaño
muestramuestral
sirven tanto
para resumir
obtener estimaciones fiables de un parámetro poblacional (típicamente la media de una variable
mo necesario para
estimar
con un
de
continua
o el
la parámetro
proporciónpoblacional
de sujetos con
unadeterminado
determinada
característica)
a partir
de parámetros
una única poblacionales
realizargrado
inferencias
acerca
de los
muestra. Esta situación concierne esencialmente a los estudios descriptivos o transversales. El
sión, que puedeobjetivo
cuantificarse
mediante
la amplitud
del intervalo
confianza.
se centra
en calcular
el tamaño
muestral de
mínimo
necesario
para estimar
el parámetro
continuación
se describen
los principales
estimadores de la
poblacional con un determinado grado de precisión, que suele cuantificarse mediante la amplitud
del intervalo
confianza.de una media
variable.
Tamaño muestral
para la de
estimación
tamaño de una muestra precede a su selección y, en consecuencia, no se dispone de
rtir de la aproximación normal N(μ, σ 2/n) a la distribución de una1.2.1
mediaMedia
muestral
aritmética
9.2.1 Tamaño muestral para la estimación de una media
tamaño
de
una
muestra
precede
a
su
selección
y,
en
consecuencia,
no se
dispone de por
información muestral. La precisión de la estimación δ queda entonces
determinada
2
uede construirseAun
intervalo
de confianza al
100(1N(μ,
- α)%
paraa la
media
partir
de la aproximación
normal
σ /n)
la distribución
de una media
muestral
La media aritmética,
denotada
por x ,, puede
se define como la su
información
muestral.
La
precisión
dealo,
la100(1
estimación
δ queda
entonces
determinada
por
construirse
un del
intervalo
dede
confianza
– α)%
para la
media
poblacional
μ como
la amplitud
intervalo
confianza
más
concretamente,
por
la distancia
del centro
valores
muestrales
dividida
por
el
número
acional μ como x ± z1 – α /2 σ / n . Notar que este intervalo incluye
incluye la
la desviación
desviación típica poblacional σ en lugar dede observacione
amplitud
confianza
o, más concretamente,
poruna
la distancia
centroa su
su la
muestral,
ya de
que
la determinación
del tamaño de
muestradel
precede
aestimación
los
límitesdel
delintervalo
intervalo
por
n
el
tamaño
muestral
y
por
x
para e
i el valor
consecuencia,
no seyadispone
de información
de observado
la
en lugar dey, suenestimación
muestral,
que la determinación
del muestral. La precisión
a poblacional σselección
a los límites
del intervalo
estimación
δ queda
entonces determinada por la amplitud del intervalo de confianza o, más
σ media vendría dada por
la
concretamente, por la distancia del centro
z1−αlímites
δ =a los
, del intervalo3
/2
n
σ
δ = z1−α / 2
,
x1 + x 2 + ... + x n
1 n
n
=
=
x
x
i
de donde puede despejarse el tamaño muestral n para obtener
n i =1
n
de donde puede despejarse el tamaño muestral n para obtener
de donde puede despejarse el tamaño muestral n para obtener
z 2 σ 2 La media es la medida de tendencia central más utilizad
n = 1−α / 2
.
2
z2 δ σ 2
n = 1−α / 22 interpretación.
.
Corresponde al “centro de gravedad” de los
δ muestral para la estimación de una media
De esta expresión se desprende que el tamaño
De estadepende
expresión
desprende
queque
el tamaño
muestral
para la estimación
de una
poblacional
de se
tres
elementos,
debenprincipal
ser
determinados
parainfluenciada
poder
limitaciónde
es antemano
que está muy
por los v
aplicarDe
la esta
fórmula:
expresión
se desprende
el tamaño
para
la estimación
una
media poblacional
depende
de tres que
elementos,
quemuestral
deben ser
determinados
dede
antemano
caso,
puede
no
ser
un
fiel
reflejo
de lamayor
tendencia central de
yy El nivel de confianza 100(1 – α)%. Cuanto mayor sea este nivel de confianza,
media
poblacional
depende
de
elementos,
queutilizarse
deben serpor
determinados
de confianza
antemano del
será
el tamaño
En tres
la práctica,
suele
convenio una
para
poder
aplicarmuestral.
la
fórmula:
95% (α = 0,05), de tal forma que el percentil de la distribución normal estandarizada es
Ejemplo 1.4 En este y en los sucesivos ejemplos sob
para
poder
aplicar
la fórmula:100(1 - α)%. Cuanto mayor
z0,975
= 1,96.
z•1–α/2
El=nivel
de
confianza
sea este nivel de confianza,
140
yy La varianza poblacional σ 2. Cuanto más dispersa sea
una variable,
mayordel
será
la muestra
utilizarán
los valores
colesterol
HDL obtenidos e
• El nivel de confianza 100(1 - α)%. Cuanto mayor sea este nivel de confianza,
mayorpara
será describirla
el tamaño muestral.
En la práctica,
suelepor
utilizarse
porunconvenio
una
necesaria
aceptablemente.
Se requiere,
tanto, de
valor aproximado
estudio
“European
Study on una
Antioxidants, Myocardia
mayor
serádel
el tamaño
muestral.
Entallaforma
práctica,
suele
utilizarse
por
convenio
confianza
95%
(
α
=
0,05),
de
que
el
percentil
de
la
distribución
Pastor-Barriuso R.
the Breast“ (EURAMIC), un estudio multicéntrico de
confianza
del 95% (α es
= 0,05),
tal forma
normal estandarizada
z1-α/2 =dez0,975
= 1,96.que el percentil de la distribución
entre 1991 y 1992 en ocho países Europeos e Israel p
Ejemplo 9.1 En un pequeño estudio piloto realizado en personas adultas de una
Tamañopara
muestral
para la estimación
de un parámetro
precisión de un kilogramo puede ser aceptable
estimar
el peso medio
en poblacional
determinada población, la media y la desviación típica de la presión arterial
personas adultas, pero resulta claramente insuficiente en recién nacidos.
sistólica
resultaron
ser 130 ay estudio,
20 mm Hg,
esta similares ya
de
la varianza
de la variable
que respectivamente.
suele obtenerse a Utilizando
partir de trabajos
realizados o de un estudio piloto.
información
preliminar,
se planea
muestra
Ejemplo
9.1 En
un pequeño
estudioobtener
piloto una
realizado
en aleatoria
personas simple
adultasde
demayor
una
yy La precisión deseada δ. El tamaño muestral será tanto mayor cuanto mayor sea la precisión
exigida
la estimación
es,medio
cuanto
menor
seaarterial
δ).
El criterio
para
la precisión
tamañoapara
estimar el(esto
nivel
presión
sistólica
conestablecer
una
precisión
determinada
población,
la media
y ladedesviación
típica
de la presión
arterial
de una estimación ha de fundamentarse en el conocimiento previo sobre la magnitud
aproximada
del Asumiendo
parámetro.
Así,
por de
ejemplo,
unadel
precisión
de un
kilogramo
puede ser
Hg.
confianza
95% yUtilizando
una
desviación
de ±2 mm
sistólica
resultaron
ser 130 yun
20nivel
mm
Hg,
respectivamente.
esta típica
aceptable para estimar el peso medio en personas adultas, pero resulta claramente
insuficiente
recién
nacidos.
información
preliminar,
se planea
obtener una muestra aleatoria simple de mayor
similar a la en
del
estudio
piloto,
se tiene
Ejemplopara
9.1estimar
En unel nivel
pequeño
estudio
piloto
realizado
en personas
adultas de una
tamaño
medio
de2presión
arterial
sistólica
con una precisión
2
1
,
96
20
determinada población, la media
típica de la presión arterial sistólica
n = y la2 desviación
= 384,16;
2
resultaron
ser
130
y
20
mm
Hg,
respectivamente.
Utilizando
estadesviación
información
preliminar,
típica
de ±2 mm Hg. Asumiendo un nivel de confianza del 95% y una
se planea obtener una muestra aleatoria simple de mayor tamaño para estimar el nivel
medio
de
presión
arterial
sistólica
con una385
precisión
±2 estimar
mm Hg.laAsumiendo
similar
a la
del
estudio
piloto,
se tiene
es decir,
se
requerirían
aproximadamente
sujetosde
para
presión un nivel
de confianza del 95% y una desviación típica similar a la del estudio piloto, se tiene
arterial sistólica media de esta población
1,96 2 20 2con una precisión de ±2 mm Hg.
n=
= 384,16;
2
2
Obsérvese que el tamaño muestral aumenta de forma cuadrática con la precisión
es decir, se requerirían aproximadamente 385 sujetos para estimar la presión arterial
sistólica
media
de estaque
población
con una
precisión
de
mm
Obsérvese que el
es
decir, se
aproximadamente
sujetosδpara
estimar
laelpresión
= 1±2
mm
Hg,Hg.
tamaño
deseada,
derequerirían
tal forma
para el doble
de385
precisión
tamaño muestral aumenta de forma cuadrática con la precisión deseada, de tal forma que
para
el doble
de precisión
=sería
1 población
mm
Hg, elveces
tamaño
muestral
necesario
Hg. sería cuatro
arterial
sistólica
media
deδesta
con
una
precisiónmínimo
de ±2 mm
muestral
mínimo
necesario
cuatro
mayor
veces mayor
Obsérvese que el tamaño muestral2 aumenta
de forma cuadrática con la precisión
1,96 20 2
n=
= 1.536,64 ≈ 1.537.
2
deseada, de tal forma que para el1doble de precisión δ = 1 mm Hg, el tamaño
muestral
necesario
cuatro
veces
mayor
mediante
p ±mínimo
zmuestral
− π ) /lansería
.estimación
Así,
la precisión
δ proporción
en la estimación de una proporción
9.2.2
Tamaño
de una
1-α/2 π (1para
9.2.2 Tamaño muestral para la estimación de una proporción
2 la2 precisión
Siguiendo
unpargumento
apartado
anterior,
puede
utilizarse ladeaproximación
normal
mediante
±viene
z1-α/2 determinada
π similar
(1 − π ) al
/ ndel
Así,
δ en
la estimación
una proporción
1.,96
20
poblacional
por
Siguiendo
un
argumento
similar
al
del
apartado
anterior,
puede
utilizarse
la
n
=
=
1.536,64
≈
1.537.
N(π, π(1 – π)/n) a la distribución de una
proporción muestral p para obtener un intervalo de
12 poblacional π mediante
confianza
al
100(1
–
α)%
para
la
proporción
mediante p ± z1–α/2 π (1 − π ) / n . Así,
Así, la precisión δ
poblacional viene determinada por
aproximación
normal
N
(
π
,
π
(1
π
)/
n
)
a
la
distribución
de
una
proporción
muestral
p
π (1 − π )
la precisión δ en la estimación de unaδ proporción
viene determinada por
= z1−α / 2 poblacional
,
n
poblacional viene determinada por
9.2.2
Tamañounmuestral
la estimación
de π-una
para obtener
intervalopara
de confianza
al 100(1
α
−proporción
πpara
(1)%
) la proporción poblacional π
δ = z1−α / 2
,
n
y el tamaño
muestral mínimo
para alcanzar
Siguiendo
un argumento
similar necesario
al del apartado
anterior, dicha
puedeprecisión
utilizarseesla
π (1 − π
δ = z1−α / 2
y el tamaño muestral mínimo necesario para alcanzar dicha precisión es
n
y el tamañonormal
muestral
para
alcanzardedicha
precisión esmuestral p
2
N(mínimo
π, π(1 - necesario
π)/n) a lazdistribución
una
proporción
aproximación
π (1 − π )
n = 1−α / 2 2
.
δ
y el
muestral
mínimoπnecesario
para alcanza
5
2
para obtener un intervalo de confianza al 100(1
la tamaño
proporción
poblacional
z1−α / 2π-(α
1 )%
− π para
)
n =la estimación
El cálculo del tamaño muestral para
de. una proporción precisa, por tanto, de
2
δ
los siguientes
elementos:
El cálculo del tamaño muestral para la estimación de una proporción precisa, por
z 2 π (1 − π
n = 1−α / 2 2
yy El nivel de confianza 100(1 – α)%, que se establece habitualmente en el 95%.
δ
tanto,
de los siguientes
El cálculo
del tamañoelementos:
muestral para la estimación de una proporción precisa, por
yy La proporción poblacional π.
5 para la estimación
Elhabitualmente
cálculo
del tamaño
muestral
tanto,
de nivel
los siguientes
elementos:
• precisión
El
dedeseada
confianza
)%, queque
se establece
en el 95%.
yy La
δ o 100(1
el error- α
absoluto
se considere
aceptable.
•
tanto,
de los siguientes
El
de confianza
100(1 π- .α)%, que se establece
habitualmente
en elelementos:
95%.
La nivel
proporción
poblacional
•
• El nivel de confianza 100(1 - α)%, que se est
La proporción
poblacional
. absoluto que se considere
precisión deseada
δ o el πerror
aceptable.
Pastor-Barriuso R.
• La objeto
proporción
poblacional
π.
La precisión
deseada
δ o elaproximado
error absoluto
que
se considere
aceptable.
El •conocimiento
previo
del valor
de la
proporción
de estudio
es
141
Determinación del tamaño muestral
El conocimiento previo del valor aproximado de la proporción objeto de estudio es necesario
no sólo para sustituirlo explícitamente en la fórmula, sino también para establecer la precisión
deseada en la estimación. Por ejemplo, un error absoluto del ±5% podría ser admisible en la
estimación
de una proporción
mientras
que este
error
información,
se pretendepróxima
realizar al
un50%,
estudio
transversal
paramismo
estimar
la sería claramente
inaceptable para una proporción pequeña, pongamos del 5% (o equivalentemente para una
proporción muy grande, ya que cuando se estima una proporción también se está estimando su
prevalencia de hipertensión en esta población con un error absoluto del ±3%
complementario). Así, para determinar de antemano qué error se considera admisible, ha de
contarse con alguna información sobre la magnitud de π, bien sea a través de investigaciones
±10%).
Asumiendo
el niveltransversal
de confianza
información,
sedel
pretende
realizar
un estudio
paraestándar
estimar del
la 95%, π =
previas(error
o, enrelativo
su defecto,
de un estudio
piloto.
se necesitaría
una
mínima
deerror absoluto del ±3%
0,30
y δ = 0,03,
prevalencia
hipertensión
estamuestra
población
conanterior,
un
Ejemplo
9.2de En
el estudioenpiloto
del ejemplo
la proporción de hipertensos
(presión arterial sistólica ≥ 140 mm Hg) fue del 30%. En base a esta información, se
π=
(error relativo
delun
±10%).
nivel
de confianza
estándar del
2
pretende
realizar
estudio
la prevalencia
de 95%,
hipertensión
en
1,Asumiendo
96transversal
0,30(1 −el
0,para
30
) estimar
=
896,37
≈
897.
n
=
esta población con un error absoluto
0,03 2 del ±3% (error relativo del ±10%). Asumiendo el
0,03, se necesitaría
una
muestra
0,30 ydeδ =confianza
nivel
estándar del
95%,
π = mínima
0,30 y δde= 0,03, se necesitaría una muestra
mínima de
Si, por el contrario, el estudio 2se diseñara para estimar la prevalencia de diabetes,
1,96 0,30(1 − 0,30)
n=
= 896,37 ≈ 897.
03 2error absoluto del ±1% (error relativo del
que se asume próxima al 5%, con0,un
Si, por el contrario, el estudio se diseñara para estimar la prevalencia de diabetes, que se
±20%),
requeriría
tamaño
considerablemente
mayor
asume
al 5%,
con un
error
absoluto
del ±1%
(error
relativo
del ±20%), se
Si, por próxima
elsecontrario,
elunestudio
semuestral
diseñara
para estimar
la prevalencia
de diabetes,
requeriría un tamaño muestral considerablemente mayor
que se asume próxima al1,96
5%,
2 con un error absoluto del ±1% (error relativo del
0,05(1 − 0,05)
= 1.824,76 ≈ 1.825.
n=
0,012
±20%), se requeriría un tamaño muestral considerablemente mayor
Como se desprende de este ejemplo, para estimar fiablemente una proporción extrema
(muy
o muy
se necesitará
una fiablemente
muestra mayor
que para estimar una
Comopequeña
se desprende
de grande)
este ejemplo,
para estimar
una proporción
1,96 2 0,05(1 − 0,05)
proporción cercana nal=50%.
= 1.824,76 ≈ 1.825.
0,012 se necesitará una muestra mayor que para
extrema (muy pequeña o muy grande)
La fórmula del tamaño muestral presentada en este apartado se basa en la aproximación
normal
a laseuna
distribución
una
Aunqueunaesta
aproximación es
estimar
proporción
cercana
alde50%.
Como
desprende
demuestral
este
ejemplo,
para proporción.
estimar fiablemente
proporción
razonable en la mayoría de las circunstancias, existen fórmulas alternativas, tales como
las basadas
en (muy
la aproximación
normal
con corrección
poruna
continuidad
o en la
aproximación
extrema
pequeña o muy
grande)
se necesitará
muestra mayor
que
para
La
fórmula
del
tamaño
muestral
presentada
en
este
apartado
se
basa
en
la
de Poisson, que pueden ser útiles cuando se prevé trabajar con muestras de reducido
tamaño
o conuna
proporciones
extremas.
estimar
proporciónmuy
cercana
al 50%.Una descripción y comparación más detallada
aproximación
normal
a
la
distribución
de una proporción.
Aunque esta
de los distintos métodos de cálculo delmuestral
tamaño muestral
puede encontrarse
en la bibliografía
de este tema.
aproximación
en la mayoría
de lasen
circunstancias,
La fórmula es
delrazonable
tamaño muestral
presentada
este apartado existen
se basa fórmulas
en la
alternativas,
tales
como
lasdistribución
basadas
en muestral
la
normal DE
conMEDIAS
corrección
9.3
TAMAÑO
MUESTRAL
PARA
LAaproximación
COMPARACIÓN
aproximación
normal
a la
de una proporción.
Aunque
estapor
Muchos
diseños
bien
sean
defórmulas
cohortes
o de casos y
continuidad
o en
la aproximación
de
Poisson,
que
pueden ser(estudios
útiles
cuando
se prevé
aproximación
esepidemiológicos,
razonable
en la mayoría
deobservacionales
las
circunstancias,
existen
controles) o experimentales (ensayos clínicos), se realizan con un afán comparativo, donde el
objetivo
no es
tanto
estimar
la magnitud
de
un determinado
parámetro
poblacional,
trabajar
con
muestras
delas
reducido
tamaño
o con
proporciones
muy
Una
alternativas,
tales
como
basadas
en la aproximación
normal
conextremas.
corrección
por sino más
bien comparar parámetros entre distintas poblaciones. En tales diseños, el problema radica en
determinar
muestral
necesario
en
cada métodos
grupo
dedecomparación,
de tal forma
descripción
comparación
másmínimo
detallada
de los
distintos
cálculosedel
tamaño
continuidadelyotamaño
en la aproximación
de Poisson,
que
pueden
ser útiles
cuando
prevé
que el contraste de hipótesis que se pretende realizar tenga una potencia suficiente para detectar
posibles
diferencias
clínica
o epidemiológicamente
En extremas.
este apartado
muestral
puede
encontrarse
en
la bibliografía
de proporciones
esterelevantes.
tema. muy
trabajar con
muestras
de reducido
tamaño o con
Una se presentan
descripción y comparación más detallada de los distintos métodos de cálculo del tamaño
142
Pastor-Barriuso R.
muestral puede encontrarse en la bibliografía de este tema.
7
determinada
minada variable
variable
o, dicho
o, dicho
de forma
de forma
equivalente,
equivalente,
estosestos
estimadores
estimadores
indican
indican
independientes
orqué
de valor
qué valor
se agrupan
se agrupan
los datos
los datos
observados.
observados.
Las medidas
Las medidas
de tendencia
de tendencia
Tamaño muestral para la comparación de medias
Supongamos
quelos
se resultados
pretende
contrastar
la hipótesis
de
muestra
la muestra
sirven
sirven
tanto
tanto
para para
resumir
resumir
los resultados
observados
observados
comocomo
paranula
paraH0: μ1 = μ2 de igualdad de
μ1 ≠ μ2 enendos
conde una
medias
frente
la hipótesis
alternativa
bilateralAHdiferencias
1: A
laslos
fórmulas
del apoblacionales
tamaño
muestral
para
contrastar
losdistribuciones
niveles medios
rencias
inferencias
acerca
acerca
de
de
parámetros
los parámetros
poblacionales
correspondientes.
correspondientes.
variable cuantitativa a partir de dos muestras dependientes o independientes.
2
2
2
nación
se describen
se describen
los principales
los principales
estimadores
tendencia
la tendencia
central
central
de una
de
σestimadores
= la
σde
. Según
los
resultados
deluna
Apartado 6.3, la distribución
igual
varianza
1 = σ 2de
9.3.1 Tamaño muestral para la comparación de medias en dos muestras independientes
muestral de la diferencia de medias x1 - x 2 en muestras independientes de tamaño n1 y
Supongamos que se pretende contrastar la hipótesis nula H0: μ1 = μ2 de igualdad de medias
n2 será
normal
con H
media
μμ2- en
μ2 dos
= 0 bajo
H0 y μ1 - μcon
0 bajovarianza
H1, y σ12
edia
aritmética
aritméticafrente
distribuciones
a la aproximadamente
hipótesis alternativa
bilateral
2 ≠ igual
1: μ1 ≠ 1
= σ22 = σ2. Según los resultados del Apartado 6.3, la distribución muestral de la diferencia de
2
tmética,
a aritmética,
denotada
denotada
por por
x 1, –seσ
x define
se
define
suma
de
uno
de
unolos
den9.1).
de
y nPara
aproximadamente
normal con
medias
/n1muestras
+como
σ 22 /como
n2laindependientes
=suma
σla2(1/
n1 cada
+de
1/ncada
(Figura
una probabilidad
varianza
2) tamaño
21, en
1los
2 seráasegurar
media μ1 – μ2 = 0 bajo H0 y μ1 – μ2 ≠ 0 bajo H1, y varianza σ12/n1 + σ22/n2 = σ 2(1/n1 + 1/n2) (Figura
strales
muestrales
dividida
dividida
porαel
por
elasegurar
número
deunobservaciones
de
observaciones
Si denotamos
Si
9.1).
Para
una
probabilidad
de cometer
undenotamos
error
de tipo I,sólo
la hipótesis
nula se rechazará
denúmero
cometer
error
de tipo realizadas.
I, laα realizadas.
hipótesis
nula
se rechazará
si el estadístico
sólo si el estadístico
valor
observado
observado
para para
el sujeto
el sujeto
i-ésimo,
i-ésimo,
i = 1,i =
...,1,n,..., n,
año
tamaño
muestral
muestral
y pory xpor
i el x
i el valor
x1 − x 2
x1 − x 2
≤ z1α /2 ó
≥ z1α /2
adría
vendría
dadadada
por por
11-/ nα /21 σ+ 11/ n/ n2 + 1 / n ó xσ1 -1x/ 2n1≥+z11- α/ /2n 2σ 1 / n + 1 / n .
x1 - x 2 σ≤ -z
.
1
2
1
2
o, equivalentemente,
si la diferencia de medias
x...2 ++ x...n + x n
1 n 1 n x1 + x12 ++ si
o,
equivalentemente,
la diferencia
de medias
bajo
la
del test para detectar una diferencia
.
.la potencia
= x
= x i
= xxhipótesis
= x ≤ alternativa,
x Así,
i
2 n z1
n i =1 n i =1 1
nα /2 σ 1 / n1 + 1 / n 2 ó x1 x 2 ≥ z1α /2 σ 1 / n1 + 1 / n 2 .
subyacente
μ1 - μ2 vendrá
dada la
porpotencia del test para detectar una diferencia subyacente
Así,
bajo la hipótesis
alternativa,
–de
μ2tendencia
vendrá
por más
Así,
bajocentral
ladada
hipótesis
alternativa,
potencia
del test para detectar una diferencia
edia
es laes
medida
la medida
deμ1tendencia
central
más
utilizada
utilizada
y delaymás
de más
fácilfácil
8
=dada
P(
x1por
x 2 la
≤de
zla
1 / n1Su
+ 1 / n 2 | H1 )
1 deβ los
muestra.
μde
μ2 vendrá
datos
tación.
n. Corresponde
Corresponde
al subyacente
“centro
al “centro
de gravedad”
de
datos
los
de
1α muestra.
/2 σ Su
1 - gravedad”
x1 extremos
x 2 ≥extremos
z1 α y,
1este
/en
n1 este
+ 1 / n 2 | H1 ).
P( valores
mitación
l limitación
es que
es está
que está
muymuy
influenciada
influenciada
por los
por+valores
los
/2 σeny,
1 - β = P( x1 - x 2 ≤ -z1- α /2 σ 1 / n1 + 1 / n 2 | H1 )
no
edeser
noun
serfiel
un reflejo
fiel reflejo
de lade
tendencia
la tendencia
central
central
de lade
distribución.
la distribución.
Asumiendo sin pérdida de generalidad que μ1 < μ2 (Figura 9.1), la segunda probabilidad
+ P( x1 - x 2 ≥ z1- α /2 σ 1 / n1 + 1 / n 2 | H1 ).
H1: μ1 ≠ μ2
H0: μ1 = μ2
x1 se
sea apreciablemente mayor
lasucesivos
expresión
anterior,
que representa
el evento
de que
lo
emplo
1.4 En
1.4este
En este
y ende
ylos
en
los sucesivos
ejemplos
sobre
sobre
estimadores
estimadores
muestrales,
muestrales,
~ejemplos
~se
x1 − x2 →
N ( μ1 − μ 2 , σ 2 (1 / n1 + 1 / n2 ))
x1 − x2 →
N (0, σ 2 (1 / n1 + 1 / n2 ))
Asumiendo sin pérdida de generalidad que μ1 < μ2 (Figura 9.1), la segunda probabilidad
rán
ilizarán
los valores
los valores
delque
colesterol
del xcolesterol
HDL
HDL
obtenidos
obtenidos
en los
en
los
primeros
10 primeros
sujetos
del
del a
virtualmente
cero.
La10
potencia
sesujetos
reduce
entonces
2 , será
de la expresión anterior, que representa el evento de que x1 sea apreciablemente mayor
otudio
“European
“European
StudyStudy
on Antioxidants,
on Antioxidants,
Myocardial
Myocardial
Infarction
Infarction
and Cancer
and Cancer
of of
1 - β = P( x1 - x 2 ≤ -z1- α /2 σ 1 / n1 + 1 / n 2 | H1 )
que x 2 , será virtualmente cero. La potencia se reduce entonces a
east“
e Breast“
(EURAMIC),
(EURAMIC),
un estudio
un estudio
multicéntrico
multicéntrico
de casos
de casos
y controles
y controles
realizado
realizado
x − x 2 − ( μ 1 − μ 2 ) − z1−α / 2 σ 1 / n1 + 1 / n 2 − ( μ 1 − μ 2 )
P x1e1 -Israel
≤
H
1 Europeos
- β =Europeos
P(
x1e2- βIsrael
≤ para
-z1- α para
σ 1evaluar
/ nel
+
1
/
n
|
H
)
tre
9911991
y 1992
y 1992
en ocho
en ocho
países
países
evaluar
efecto
el
efecto
de
los
de
los
/2
1
1
1
2
σ 1/ n + 1/ n
σ 1 / n1 + 1 / n 2
1
2
x − x 2 − ( μ 1 − μ 2 ) − z1−α / 2 σ 1 / n1 +5 1 / n52 − ( μ 1 − μ 2 )
= P 1
≤ |
H1
μ
μ
|
−
, σ 1 / n1 + 1 / n 2
= Φ − σz1−α1/ 2/ n+1 + 1 / n12 α/2 2
α/2
σ 1 / n1 + 1 / n 2
μ1 - μ2
0
| μ 1 − μ 2 |
− z
,
=
Φ
+
donde la última igualdad
de la distribución normal de x1 - x 2 bajo la hipótesis
1−α / 2se deriva
σ − 1z / n1σ+ 11//nn+2 1/ n
z1−α / 2σ 1 / n1 + 1 / n2
1−α / 2
1
2
μ2. Esta
expresión
alternativa.
Notar que sedealcanzaría
mismo
resultado
si μde1 >medias
Figura
9.1 Representación
la potenciaeldel
contraste
bilateral
a partir
de dos
muestras
Figura
9.1
donde la última igualdad se deriva de la distribución normal de x1 - x 2 bajo la hipótesis
independientes.
permite determinar a posteriori la potencia de un contraste para detectar una diferencia
alternativa. Notar que se alcanzaría el mismo resultado si μ1 > μ2. Esta expresión
Pastor-Barriuso R.
n1 y
de medias subyacente μ1 - μ2 a partir de dos muestras independientes de tamaños
permite determinar a posteriori la potencia de un contraste para detectar una diferencia
n2.
143
+ P(
1 - x 2 ≥ z1- α /2 σ 1 / n1 + 1 / n 2 | H1 ).
continuación
sexdescriben
los principales
continuación
estimadores
se describen
de la tendencia
los principales
central deestimadores
una
Las medidas
Las medidas
de tendencia
de tendencia
central
central
informan
informan
acercaacerca
de cuál
dees
cuál
el valor
es el valor
más rem
variable.
Asumiendo sin pérdida de generalidad que μ1 < μ2 (Figura
9.1), la segunda probabilidad
de unadedeterminada
una determinada
variable
variable
o, dicho
o, dicho
de forma
de forma
equivalente,
equivalente,
estos estos
estimadore
estim
1.2.1 Media
aritméticael evento de que
1.2.1x1Media
aritmética
sea apreciablemente
mayor
de la expresión anterior,
que representa
Asumiendo sin pérdida de generalidad
que de
μ1 <
μde
(Figura
9.1),
segunda
de
2 valor
alrededor
alrededor
qué
qué valor
se agrupan
se la
agrupan
los datos
losprobabilidad
datos
observados.
observados.
Laslamedidas
Las medidas
de tend
La
media
aritmética,
denotada
por
La
media
aritmética,
denotada
por
x
,
se
define
como
la
suma
de
cada
uno
x
,
de
se
los
define
como
expresión
anterior,
que
representa
el
evento
de
que
sea
apreciablemente
mayor
que
que x 2 , será virtualmente cero. La potencia se reduce1 entonces a
2
será virtualmente cero. La potencia
se reduce
a
central
central
de laentonces
de
muestra
la muestra
sirven
sirven
tanto tanto
para resumir
para resumir
los resultados
los resultados
observados
observad
co
valores muestrales dividida por el número
valores
demuestrales
observaciones
dividida
realizadas.
por el número
Si denotamos
de observa
1 − β = P( x1 − x 2 ≤ − z1−realizar
1 /inferencias
n1 + 1inferencias
/ n 2 |acerca
H1 ) acerca
α /2 σ realizar
de losdeparámetros
los parámetros
poblacionales
poblacionales
correspondientes
correspond
por n el tamaño muestral y por xi el valor
por nobservado
el tamañopara
muestral
y pori-ésimo,
xi el valor
el sujeto
i = observado
1, ..., n, p
x − x 2 − ( μ 1 − μ 2 ) − z1−α / 2 σ 1 / n1 + 1 / n 2 − ( μ 1 − μ 2 )
aleatoriamente
hipertensos
al
de monoterapia
estándar
otros de la de
continuación
continuación
segrupo
describen
se describen
los principales
los principales
estimadores
tendencia
la tendencia
centrac
= P 501 pacientes
≤
Hyestimadores
1
la media
por
la
media
vendría
dada
por
σ 1 /vendría
n1 + 1 / ndada
σ
1
/
n
+
1
/
n
2
1
2
50 pacientes de similares características
variable.
variable.al grupo de tratamiento combinado con el
| μ 1 − μ 2 |
− z
x1 + x 2 + ... + x n
x + x2 + .
1 n
=
, 1 n
Φ
+
1
/
2
−
α
nuevo fármaco. Después de
4
semanas
de
tratamiento,
la
media
y
la
desviación
.
=
=
=
x
x
x
xi = 1
i
σ
1
/
n
+
1
/
n
1
2aritmética
1.2.1 1.2.1
Media
Media
aritmética
n i =1
n
n i =1
n
típica de la presión
arterial sistólica
fueron
155 y de
22 monoterapia
mm Hg en elestándar
grupo dey otros
aleatoriamente
50 pacientes
hipertensos
al grupo
La media
aritmética,
aritmética,
denotada
denotada
por xpor
se xdefine
se define
como
como
la suma
la suma
de cada
de uno
cadad
donde la última igualdad se deriva
deLalamedia
distribución
normal
de
la hipótesis
1, –
2, bajo
La media es la medida de tendencia central
La media
másesutilizada
la medida
y de
de más
tendencia
fácil central más ut
alternativa.
Notar que
se yalcanzaría
si μ1 > combinado.
μ2. combinado
Esta expresión
permite
monoterapia,
y 150
18 mm
Hgelenmismo
el grupo
de tratamiento
Como
50
pacientes
de
similares
características
al resultado
grupo
de tratamiento
con el
valores
valores
muestrales
muestrales
dividida
dividida
por
el
por
número
el
número
de
observaciones
de
observaciones
realizadas
Si d
donde
la
última
igualdad
se
deriva
de
la
distribución
normal
de
x
x
bajo
la
hipótesis
1
2
determinar a posteriori la potencia de un contraste para detectar una diferencia de mediasrealizadas.
interpretación. Corresponde al “centro
interpretación.
de gravedad”Corresponde
de los datos de
al “centro
la muestra.
de gravedad”
Su
a la
partir
de dos
independientes
n2.
subyacente
μfármaco.
paso previo
comparación
medias,
contrastade
lalatamaños
igualdad
varianzas
1 – μ2 a
1laydesviación
nuevo
Después
demuestras
4 de
semanas
desetratamiento,
media ynde
por
n
por
el
tamaño
n
el
tamaño
muestral
muestral
y
por
y
x
por
el
valor
x
el
valor
observado
observado
para el
para
sujeto
el sujeto
i-ésimo,
i-ési
i
i
alternativa. Notar que se alcanzaría el mismo resultado si μ1 > μ2. Esta expresión
principal limitación es que está muy influenciada
principal limitación
por los es
valores
que está
extremos
muy influenciada
y, en este por
mediante
estadístico
típica
de 9.3
laelpresión
fueron
155 yla22eficacia
mm Hgantihipertensiva
en el grupo de de un nuevo
Ejemplo
En unarterial
ensayosistólica
para
evaluar
laclínico
media
la media
vendría
vendría
dada
por
dada por
permite
determinar
a
posteriori
la
potencia
de
un
contraste
para
detectar
una
fármaco en combinación
conserununtratamiento
se asignaron
aleatoriamente
caso, puede no
fiel reflejo estándar,
de lacaso,
tendencia
puede
central
no ser un
de
fiel
ladiferencia
distribución.
reflejo de50
la tendencia cent
2
monoterapia,
y
150
y
18
mm
Hg
en
el
grupo
de
tratamiento
combinado.
Como
2
pacientes hipertensos al grupo de monoterapia
estándar y otros 50 pacientes de similares
s
22muestras
μ1 - de
μ2 atratamiento
partir
independientes
de características
medias subyacente
1x y
=combinado
F = de12 dos
=
1,49,
+x
x1 + Después
xx21 ++n...
x...
1 n fármaco.
1den tamaños
al grupo
con
el nuevo
2++de
n 4
2
. n.
=
=
=
=
x
x
x
x
18
s
i
i
2
Ejemplo
1.4
En
este
y
en
los
sucesivos
Ejemplo
ejemplos
1.4
sobre
En
este
estimadores
y
en
los
sucesivos
muestrales,
ejemplo
se
paso
previo
a
la
comparación
de
medias,
se
contrasta
la
igualdad
de
varianzas
semanas de tratamiento, la media y la desviación típica de nlai =presión
arterial
n sistólica
n
1 n i =1
n2.fueron 155 y 22 mm Hg en el grupo de monoterapia, y 150 y 18 mm Hg en el grupo de
utilizarán
valores
HDL
utilizarán
obtenidos
los valores
en se
loscontrasta
10
delprimeros
colesterol
HDL obten
del
mediante
estadístico
tratamiento
combinado.
Como
paso
previo
acolesterol
la comparación
de medias,
la sujetos
que bajo laeldistribución
F
de los
Fisher
con
ndel
1 – 1 = 49 y n2 – 1 = 49 grados de
La
media
La
media
es
la
medida
es
la
medida
de
tendencia
de
tendencia
central
central
más
utilizada
más
utilizada
y
de
más
y
de
fácil
más
igualdad de varianzas mediante el estadístico
[Figura
9.1
aproximadamente
aquí]
estudio
“European
Study
on Antioxidants,
estudio
Myocardial
“EuropeanInfarction
Study on and
Antioxidants,
Cancer ofMyo
22P(F
libertad, corresponde
a un valor
P bilateral
49,49 ≥ 1,49) = 2⋅0,082 = 0,164.
s12 22Corresponde
interpretación.
interpretación.
Corresponde
al
“centro
al
“centro
de
gravedad”
de
gravedad”
de
los
de
datos
los
datos
de la de
mues
la
F = 2 = 2 = 1,49,
s 2 18 un estudio the
(EURAMIC),
multicéntrico
Breast“
(EURAMIC),
de casos y controles
un estudio
realizado
multicéntr
Así, la comparaciónthe
delBreast“
nivel
medio
de
presión
arterial
sistólica
entre
ambos
principal
principal
limitación
limitación
es
queesestá
quemuy
está influenciada
muy influenciada
por los
porvalores
los valores
extremos
extrey
9.3 En un ensayo
paranevaluar
la eficacia antihipertensiva de un
queEjemplo
bajo la distribución
F de clínico
Fisher con
1 – 1 = 49 y n2 – 1 = 49 grados de libertad,
entremediante
1991 y 1992
en ocho
países
Europeos
entre muestras
1991
e Israel
y 1992
paraenevaluar
ocho países
el efecto
Europeos
de los e Is
grupos
la con
prueba
deun
–t1,49)
1no
=Student
49
y reflejo
nfiel
– 1reflejo
49
de
que
bajopuede
la distribución
decaso,
Fisher
n1≥ser
= un
2∙0,082
==de0,164.
Así,
la comparación
corresponde
a realizarse
un valor PF
bilateral
2P(F
2 para
49,49
caso,
puede
puede
no
ser
fiel
la grados
de
tendencia
la tendencia
central
central
de la de
distribución.
la distribuc
fármaco
en combinación
con un tratamiento
se asignaron
del nuevo
nivel medio
de presión
arterial sistólica
entre ambosestándar,
grupos puede
realizarse mediante
independientes
asumiendo
igualdad
deindependientes
varianzas,
cuyo
estadístico
resulta
≥asumiendo
1,49)
= 2⋅0,082
= 0,164.
libertad,
a para
un valor
P bilateral
2P(F49,49
la
pruebacorresponde
t de Student
muestras
igualdad
de varianzas,
5
cuyo estadístico resulta
Ejemplo
Ejemplo
1.4 En1.4
este
Enyeste
en los
y ensucesivos
los sucesivos
ejemplos
ejemplos
sobresobre
estimadores
estimado
m
9
Así, la comparación del nivel
medio
de
presión
arterial
sistólica
entre
ambos
x1 − x 2
155 − 150
t=
= utilizarán
=del
1,24,
utilizarán
los valores
los valores
colesterol
del colesterol
HDL HDL
obtenidos
obtenidos
en losen10los
primeros
10 prim
1
1
1
1
grupos puede realizarse mediante
la
prueba
t
de
Student
para
muestras
s
+
+
20,1
n1 nestudio
50“European
50StudyStudy
2
estudio
“European
on Antioxidants,
on Antioxidants,
Myocardial
Myocardial
Infarction
Infarction
and
independientes asumiendo igualdad
de
varianzas,
cuyo
estadístico
resulta
donde la varianza combinada es s2 = {(50 – 1)222 + (50 – 1)182}/(50 + 50 – 2) = 404.
the Breast“
the Breast“
(EURAMIC),
un2 estudio
undeestudio
multicéntrico
multicéntrico
de casos
de casos
y controle
y co
2 (EURAMIC),
– (50
2 = -98
grados
Utilizando
la distribución
t de es
Student
con
-n1)22
1)18
}/(50
+libertad,
50 - 2) =el valor P
donde la varianza
combinada
s2 = {(50
1 + n2 +
x1 − x 2 = 0,216;
155
150 los resultados del estudio no aportan
es−decir,
bilateral es 2P(t98 ≥ 1,24) = 2∙0,108
1,24,
= entre
t=
entre
1991
1991
y 1992
y 1992
en=ocho
en ocho
paísespaíses
Europeos
Europeos
e Israel
e Israel
para evaluar
para evaluar
el efe
suficiente
evidencia
para afirmar
que
el
tratamiento
es
más
– 2 = 98 grados
de eficaz que la
404. Utilizando
la distribución
t
de
Student
con
1
1
1 n1 +
1 n2combinado
s
+
+
20,1
monoterapia.
n1 n 2
50 50
≥ 1,24) = 2⋅0,108
= 0,216; ambos
es decir,
los
libertad,
el valor
bilateral escabría
2P(t98preguntarse
A
partir de
estosPresultados
si en realidad
tratamientos
son
variable.
Determinación del tamaño muestral
igualmente eficaces o si, por el contrario,
el estudio
carece de
potencia suficiente para
2
2
2
resultados
del
estudio
no
aportan
suficiente
evidencia
para
afirmar
que
el - 2)en= términos
donde
la
varianza
combinada
es
s
=
{(50
1)22
+
(50
1)18
}/(50
+ 50
detectar una diferencia que, aun siendo moderada o pequeña, sea importante
clínicos. Si se considera clínicamente relevante una diferencia absoluta de |μ1 – μ2| = 5
tratamiento
es mássistólica
eficaz
que
lacon
monoterapia.
grados
de
404.
Utilizando
la distribución
t de Student
n 1 + n2 – 2 =
mm
Hg
en lacombinado
presión
arterial
media,
y asumiendo
un98
nivel
de significación
α=
144
A partir de
estos P
resultados
en realidad
ambos
tratamientos
2⋅0,108
= 0,216;
es decir,
los
libertad,
el valor
bilateral cabría
es 2P(tpreguntarse
98 ≥ 1,24) = si
Pastor-Barriuso R.
son igualmente
eficaces
si, por el
contrario,
el estudio
carece
de potencia
resultados
del estudio
nooaportan
suficiente
evidencia
para
afirmar
que el
1
2
Por tanto, no
es sorprendente
que elsignificativa
estudio anterior
arrojara unreal
resultado
noHg.
detectarían
como
estadísticamente
una diferencia
de 5 mm
α =diferencia
0,05 y una
desviación
σmagnitud
= 20 mm
asumiendo
un nivel
de
significación
significativo,
aunsorprendente
cuando
exista
subyacente
detípica
dicha
Por
tanto, no es
queuna
el estudio
anterior
arrojara
un
resultado
no de medias
Tamaño
muestral
para
la comparación
Hgentre
en ambos
la potencia para detectar dicha diferencia en un estudio con
ambosgrupos,
tratamientos.
significativo,
aun cuando exista una diferencia subyacente de dicha magnitud
0,05
típica σ = 20 mm Hg en ambos grupos, la potencia para detectar
= 50desviación
sería
n1 = ny2una
entre ambos tratamientos.
n2 = 50de
sería
dicha
diferencia
en
un
estudio
conenn1el= diseño
Como ilustra el ejemplo anterior,
un estudio es importante determinar
5
βmuestral
= Φ −anterior,
1el− ejemplo
1,será
96 +necesario
=estudio
Φ(−de
0,71)
0,239. para
a priori
tamaño
en cada
grupo
comparación
evitar la
Comoqué
ilustra
en el diseño
de un
es =importante
determinar
20 1 / 50 + 1 / 50
resultados
no 23,9%
concluyentes
poren
falta
degrupo
potencia.
Supongamos,
en el
casocomo
aobtención
priori
quédetamaño
muestral
será necesario
cada
de comparación
para
evitar
la
Es decir,
únicamente
un
de los estudios
con
este tamaño
muestral detectarían
estadísticamente
significativa
unadediferencia
realcon
de 5este
mmtamaño
Hg. Pormuestral
tanto, no es sorprendente
Es decir, únicamente
un 23,9%
los estudios
másque
general,
que
se
pretende
asignar
distinto
tamaño
a
ambas
muestras
2 = kn
obtención
de
resultados
no
concluyentes
por
falta
de
potencia.
Supongamos,
en1,eldonde
caso una
el estudio anterior arrojara un resultado no significativo, aunncuando
exista
diferencia
de dicha magnitud
entre ambos
tratamientos.
detectaríansubyacente
como estadísticamente
significativa
una diferencia
real de 5 mm Hg.
k es un
número
prefijado.
A partir
detamaño
la fórmula
de la muestras
potencia ncon
2=
1, y
kn
donde
más
general,
quepositivo
se pretende
asignar
distinto
a ambas
2 =n
1, kn
Como
anterior, que
en eleldiseño
deanterior
un estudio
es importante
determinar
a priori
Porilustra
tanto, el
noejemplo
es sorprendente
estudio
arrojara
un resultado
no
)
=
1
β
,
se
sigue
que
recordando
que
Φ(z
=
kn
,
k
es
un
número
positivo
prefijado.
A
partir
de
la
fórmula
de
la
potencia
con
n
1β
1 y
qué tamaño muestral será necesario en cada grupo de comparación para evitar la2 obtención
de
resultados
no concluyentes
por falta
potencia.
Supongamos,
caso magnitud
más general, que se
significativo,
aun cuando
existadeuna
diferencia
subyacenteendeeldicha
, se sigue
que n2|=μkn−1, μdonde
recordando
Φ(z1-tamaño
β) = 1 - aβambas
k es un número positivo prefijado.
pretende
asignarque
distinto
muestras
1
2 |
z1− β con
= − zn12−α=/ 2kn+1, y recordando
, que Φ(z1–β) = 1 – β, se sigue que
A partir
de laambos
fórmula
de la potencia
entre
tratamientos.
1
1
σ | μ −+μ |
2
n1 1 kn
z1− β = − z1−α / 2 +
1 ,
1 estudio
1
Como ilustra el ejemplo anterior, en el diseñoσde un
es importante determinar
+
n1 kn1
de donde
puede despejarse
n1 para
obteneren cada grupo
a priori
qué tamaño
muestral será
necesario
de comparación para evitar la
de donde puede despejarse n1 para obtener
de dondedepuede
despejarse
n1 para obtener
2
2 Supongamos, en el caso
obtención
resultados
no concluyentes
de potencia.
(k + en
1por
)( la
z1falta
que corresponde
al tamaño
necesario
y n2 = kn1 al de la segunda
−primera
α / 2 + z 1−muestra
β ) σ
n1 =
,
2
k ( μtamaño
1 − μ 2 )a ambas
2 muestras n2 = kn1, donde
másmuestra.
general,En
que
pretende
asignar
distinto
el se
caso
particular
de que
se
desee
un
mismo
muestral en ambos
(k + 1)( z1−α / 2 + z1− β ) 2 σ tamaño
n
=
,
que corresponde al tamaño necesario
en la primera muestra
y n = kn1 al de la segunda muestra.
1
kde
( μla
μ 2 ) 2 de la 2potencia
1 −fórmula
, y= 1, éste
k esgrupos
número
prefijado.
A partir
con ngrupos
2 = kn1k
En
eluncaso
de que
se desee
un mismo
tamaño
muestral en ambos
kparticular
= 1,positivo
éste vendrá
determinado
por
11
vendrá determinado por
recordando que Φ(z1-β) = 1 - β, se sigue que
2( z1−α / 2 + z1− β ) 2 σ 2
11
n1 = n 2 =
.
2
( μ| μ1 −−μμ2 ) |
1
2
z1− β = − z1−α / 2 +
,
La asignación de igual tamaño a ambas muestras
1 es,1 en general, más eficiente ya que da
+ es,
lugar aLaunasignación
menor tamaño
totaltamaño
del estudio.
Noσ
obstante,
hayensituaciones
prácticas
en ya
lasque
que es
de igual
a ambas
muestras
general, más
eficiente
n1 kn
1
preferible seleccionar muestras de distinto tamaño, aun cuando ello conlleve un aumento de la
muestra
totalapara
alcanzar
la misma
tal esNo
el caso
de loshay
estudios
donde la
disponibilidad
da lugar
un menor
tamaño
totalpotencia;
del estudio.
obstante,
situaciones
prácticas
en
de sujetos
donde puede
despejarse
n1 entre
para obtener
de
o los costes
difieren
los grupos, o cuando se requieren estimaciones más precisas
en uno
de los
grupos. Además
de estas
consideraciones,
el cálculo
del tamaño
las que
es preferible
seleccionar
muestras
de distinto en
tamaño,
aun cuando
ellomuestral
conlleve para
la comparación de medias es necesario determinar previamente
los siguientes elementos:
(k + 1)( z1−α / 2 + z1− β ) 2 σ 2
un
aumento
de
la
muestra
total
para
alcanzar
la
misma
potencia;
tal es ellacaso
de los
n1 =α del contraste bilateral,
,
yy El nivel de significación
que
representa
probabilidad
de
2
k (μ − μ )
rechazar erróneamente la hipótesis nula1 y se2establece usualmente en α = 0,05.
estudios donde la disponibilidad de sujetos o los costes difieren entre los grupos, o
yy La potencia 1 – β del contraste, que determina la probabilidad de detectar hipótesis
alternativas
ciertasestimaciones
y se fija habitualmente
en en
1 –uno
β =de
0,80
0,90. Además de estas
cuando
se requieren
más precisas
losógrupos.
11
2
yy La varianza poblacional σ . En la determinación del tamaño muestral suele asumirse que
consideraciones,
en el cálculo
del tamaño
muestral
la comparación
de medias
es
la varianza es común
para ambos
grupos,
ya que para
generalmente
se carece
de información
previa suficiente para determinar una varianza específica en cada uno de los grupos.
necesario determinar previamente los siguientes elementos:
yy La diferencia mínima detectable |μ1 – μ2|. El tamaño muestral será tanto mayor cuanto
menor
sea la diferencia que se pretende detectar. La magnitud de esta diferencia debe ser
• El nivel de significación α del contraste bilateral, que representa la probabilidad
de rechazar erróneamente la hipótesis nula y se establece usualmente en α = 0,05.
Pastor-Barriuso R.
•
La potencia 1 - β del contraste, que determina la probabilidad de detectar
145
β = 0,80 para detectar posibles diferencias de dicha magnitud. Asumiendo que se
potencia suficiente para detectar una diferencia subyacente de 5 mm Hg en la
pretende
asignar
el mismo
Determinación
del tamaño
muestral
número de pacientes a ambos brazos del ensayo
presión arterial sistólica media de los hipertensos bajo monoterapia y tratamiento
clínico, un nivel de significación α = 0,05 y una desviación típica σ = 20 mm Hg
combinado, se planea realizar un nuevo ensayo clínico que tenga una potencia 1 un valor plausible basado en conocimientos previos, o bien relevante desde el punto de
similar
a la del
estudio anterior, el tamaño muestral necesario en cada uno de los
vista
clínico
epidemiológico.
β = 0,80
parao detectar
posibles diferencias de dicha magnitud. Asumiendo que se
grupos
sería
Ejemplo
9.4 Dado
que elnúmero
estudiodedescrito
en aelambos
ejemplo
anterior
carecía de potencia
pretende asignar
el mismo
pacientes
brazos
del ensayo
suficiente para detectar una diferencia subyacente de 5 mm Hg en la presión arterial
2
2
2
sistólica
media
hipertensos
tratamiento
se planea
zsignificación
2(los
αbajo
= 0,05
típica σcombinado,
= 20 mm Hg
clínico, un
niveldede
2monoterapia
(1,y96una
+ 0desviación
,84)y2 20
0 , 975 + z 0 ,80 ) σ
=
n
=
≈ 251,
n
=
1 nuevo
2
realizar un
ensayo clínico2 que tenga una potencia
1 – β==250,88
0,80 para
detectar posibles
2
(μ 1 − μ 2 )
5
diferencias
magnitud.
que se pretende
asignar
el uno
mismo
número de
similar a la de
deldicha
estudio
anterior,Asumiendo
el tamaño muestral
necesario
en cada
de los
pacientes a ambos brazos del ensayo clínico, un nivel de significación α = 0,05 y una
desviación
típica total
σ = de
20 251
mm+Hg
la del estudio
anterior,por
el el
tamaño muestral
para
unasería
muestra
251similar
= 502 apacientes.
Supongamos,
grupos
necesario en cada uno de los grupos sería
contrario, que el tratamiento combinado
con el nuevo 2fármaco
es muy costoso y
que se dispone de n pares de observac
2( z 0,975 Para
) 2 σ 2 2el(1problema,
+ z 0,80concretar
,96 + 0,84)supongamos
20 2
n1 = n2 =
=
250,88
≈ 251,
=
2
52
− μ 2 ) de
que se decide estudiar( μla1 mitad
sujetos bajo tratamiento
combinado que bajo
de una variable aleatoria continua. En cada pareja de datos dependientes, una
9.3.2 Tamaño muestral para la comparación de medias en dos muestras
para una muestra
total esto
de 251
= 502
pacientes.
por el contrario, que
= 0,5n
tal caso, Supongamos,
el tamaño muestral
monoterapia
estándar;
es, +n2251
1. En
laSupongamos,
primera
yella
otra observación
x2 a la segu
x1=corresponde
para
una muestra
totalobservación
de 251
502
pacientes.
porse
el
tratamiento
combinado
con +el251
nuevo
fármaco
esamuy
costosomuestra
y que
decide
estudiar
dependientes
la mitad de
bajo
que bajo monoterapia estándar; esto es,
necesario
ensujetos
el grupo
de tratamiento
monoterapiacombinado
sería
9.3.2
Tamaño
muestral
para
lacombinado
comparación
de
medias
en
muestras
que
el
tratamiento
con
elcentra
nuevo
fármaco
es
muy
costoso
y sería
muestra.
El muestral
objetivo
se
enen
comparar
las
medias
poblacionales
μ1 y μ2 a par
=
0,5n
.
En
tal
caso,
el
tamaño
necesario
el dos
grupo
de
monoterapia
ncontrario,
2
1
Supongamos
que se planea seleccionar n parejas de datos dependientes procedentes de
2
dependientes
(0,mitad
5 +dos
1)(1de
,96sujetos
+ 0,84dependientes.
) 2 20tratamiento
que se decide estudiarestas
la
bajo
combinado que bajo
muestras
=
=μ376,32
≈ 377a la hipótesis
n
1
2
:
=
μ
frente
dos poblaciones para contrastar la hipótesis
nula
H
0
1
2
0,5 ⋅ 5
Supongamos
queestándar;
se planeaesto
seleccionar
n parejas
de caso,
datos el
dependientes
procedentes
tal
tamaño
monoterapia
es,procedimientos
n2 = 0,5n
Los
en el muestral
Apartado
6.3 node
pueden aplicarse a est
1. En desarrollados
y
en
el
grupo
de
tratamiento
combinado
n
=
0,5∙376,32
=
188,16
≈
189.
El
número
en el Apartado 6.4, la media de las total
alternativa bilateral H1: μ1 ≠ μ2. Como se discutió
2
de
pacientes
necesarios
para
el
estudio
sería
entonces
+ 189
= no
566;
decir, 64
= 0,5⋅376,32
188,16
≈ 189.
El
en el grupo
degrupo
tratamiento
combinado
nnula
μ2=377
frente
a la
hipótesis
dosynecesario
poblaciones
para
contrastar
la hipótesis
H0: μde
2 medias
en el
de
monoterapia
situación,
ya quesería
las
muestras
sonesindependientes
por proven
1 =ambas
pacientes
más
de
los
requeridos
en
el
caso
de
igual
tamaño
muestral
para
alcanzar
una
diferencias en cada pareja d se distribuirá de forma aproximadamente normal N(0,
misma potencia.
número
total de pacientes
necesarios
para
el2 estudio
sería
377
+ 189
correlacionadas.
Sin entonces
embargo,
lamedia
comparación
discutió
en
6.4, la
de=las se simplifica notabl
alternativa
bilateral
H1: μobservaciones
1≠μ
2. Como se
2 el Apartado
(
0
,
5
+
1
)(
1
,
96
+
0
,
84
)
20
376,32
≈ 377 de las diferencias.
σ d2 /n) bajo H0 y N(μ1n1- =μ2, σ d2 /n) bajo
H12, donde σ d2= es
la varianza
0
,
5
⋅
5
566;
es
decir,
64
pacientes
más
de
los
requeridos
en
el
caso
de
igual
tamaño
si
se
calculan
las
diferencias
d
=
x
x
cadanormal
unadependientes
deN(0,
las n observaciones empar
1 dos
2 en
diferencias
en muestral
cada pareja
d se
distribuirá de forma
aproximadamente
9.3.2
Tamaño
para
la comparación
de medias
en
muestras
α
preestablecido,
el contraste
arrojará
un resultado
Para
un nivelpara
de significación
muestral
alcanzarPor
unaun
misma
potencia.
2
lado,
distintas
parejas
no están
relacionadas
Supongamos
que
nHparejas
deσ datos
dependientes
procedentes
deentre
dos sí, estas diferen
σ d2 y/n)enbajo
H0 yseN(
μtratamiento
σ d2 /n)
bajocomo
de
las
diferencias.
= 188,16
≈ 189.
El
el grupo
deplanea
combinado
nlas
1 - μ2,seleccionar
1, donde
2 = 0,5⋅376,32
d es la varianza
poblaciones para contrastar la hipótesis nula H0: μ1 = μ2 frente a la hipótesis alternativa bilateral
cuando
la media
deApartado
las diferencias
: μ1 número
≠ μ . Como
se discutió
en independientes.
el
6.4, el
la estudio
media
de
lasladiferencias
en+diferencias
cada
H1significativo
son
Por
otro lado,
media de377
las
coincide con la
total
pacientes
necesarios
para
sería
entonces
189pareja
= 13 d se
α preestablecido,
el contraste
arrojará
un resultado
Para un2 nivel
de de
significación
2
2
distribuirá de forma aproximadamente normal N(0, σd /n) bajo H0 y N(μ1 – μ2, σd /n) bajo H1,
varianza
las
Para
significación
α preestablecido, el
donde
σd2 esesladecir,
ddiferencia
≤diferencias.
-z
σde
/medias
nrequeridos
ó un
dmuestrales,
≥nivel
z1-en
σdcaso
/ n de
. igual tamaño
566;
64 pacientes
más
el
1-las
α/2de
dlos
α/2de
significativo
cuando
lademedia
de
diferencias
contraste arrojará un resultado significativo cuando la media de las diferencias
muestral para alcanzar una misma potencia.
1 nμ , la potencia
1 n
Por tanto, asumiendo como
apartado anterior que μ
=d1 /<
− x i 2detectar
)
d ≤en
n2d. i = ( x i1para
− zel
1−α/2σ d / n ó d ≥ z1−αd/2σ
n i =1
n i =1
13 una
Por
tanto,
asumiendo
como μen
anterior que μ1 igual
< μ2n, ala potencia
para detectar
μ2apartado
será aproximadamente
una
diferencia
de medias
n
1 -el
1
1
Por tanto,
enaproximadamente
el apartado anterior
queaμ=1 < μ2,xla
μ2 será
igual
diferencia
deasumiendo
medias μ1 –como
= x1detectar
− x2
i1 −potencia
xi 2para
n i =1
n i =1
= P( d μ≤1 −- μ
z12−αserá
/ n | H1 )
− βmedias
igual a
una diferencia1de
/2 σ d aproximadamente
146
dy,−en( μconsecuencia,
de la diferencia de medias
− z1d−α / es
μ2)
n − ( μ 1 −insesgado
d / estimador
2 σun
1 − μ2 )
≤
= P
H1
1 - β = P(d ≤σ-zd 1-/α/2σ
σd / n
n d / n | H1)
poblacionales μ1 - μ2. Así, el problema de la comparación de medias en dos mues
| μ − μ |
= Φ d− z−1−(αμ/ 12 −+ μ 2 )1 − 2z1−α ./ 2σ d / n − ( μ 1 − μ 2 )
≤/ n reducido
= P dependientes
H1
queda
a
una
simple
inferencia
sobre la media de una única
σ
σ / n d
σd / n
d
muestra de n diferencias independientes.
| μ 1 − μ 2 |
Pastor-Barriuso R.
+
.
= Φ − z1Los
−α / 2 métodos del Apartado
6.2.1 para la media de una muestra pueden entonces
/ n que
Como por definición Φ(z
1-β) = 1 - β,σsed sigue
utilizarse para calcular un intervalo de confianza al 100(1 - α)% para μ1 - μ2 com
| μ − μ 2 |
.
= Φ − z1−α / 2 + 1
σ d / n
Tamaño muestral para la comparación de medias
( z1−α / 2 + z1− β ) 2 σ d2
n=
.
( μ 1 −que
μ 2) 2
Como por definición Φ(z1-β) = 1 - β, se sigue
+ z1− β ) 2 σ d2
z1−α / 2que
Como por definición Φ(z1–β) = 1 – β, se (sigue
n=
.
( μ 1 directamente
− μ 2) 2
En la práctica, resulta difícil determinar
| μ − μ 2 | la varianza de las diferencias
z1− β = − z1−α / 2 + 1
,
σd / n
2
σ dEnyalaque
los datos
de una
misma
pareja están
correlacionados.
Asumiendo
igual
práctica,
resulta
difícil
determinar
directamente
la varianza
de las diferencias
de donde puede despejarse n para obtener el número mínimo de parejas que serán necesarias
2 donde puede
2
despejarse
nmisma
para obtener
el
número
mínimo
de
que
μestán
unade
potencia
1 –parejas
β,ρ entre
parade
detectar
subyacente
1 –coeficiente
2 concorrelacionados.
σvarianza
los
datos
depoblaciones
una
pareja
Asumiendo
igual
σuna
endiferencia
ambas
y μun
correlación
losserán
valores de
d ya que
2
2
( z1−α / 2 + z1− β ) σ d
μ1 -determinada
μ. 2 con una potencia
1 -resultados
β,
necesarias
detectar
una diferencia
subyacente
2para
=
n
una
misma
pareja,
la
varianza
de
las
diferencias
viene
según los
coeficiente
varianza σ en ambas poblaciones y un
( μ − μ ) 2 de correlación ρ entre los valores de
1
2
dellaApartado
3.4
por
En
práctica,
resulta
difícil determinar
directamente
varianza de según
las diferencias
σd2 ya que
una
misma
pareja,
la varianza
de las diferencias
vieneladeterminada
los resultados
2
En la
resulta
difícil
determinar
directamente
la varianza
las diferencias
los datos
depráctica,
una misma
pareja
están
correlacionados.
Asumiendo
igualdevarianza
σ en ambas
2
2
2
2
2
poblaciones
y un3.4
coeficiente
deσ correlación
ρ entre los valores de una misma pareja, la varianza
del Apartado
por
14
d = σ + σ - 2σ ρ = 2σ (1 - ρ ).
de las
viene de
determinada
resultados
del Apartado
3.4 por igual
σ d2 diferencias
ya que los datos
una mismasegún
parejalos
están
correlacionados.
Asumiendo
2
2
2
2
2
σ d = σ + σ − 2σ ρ = 2σ (1 − ρ ).
2
Así,
el
número
de
parejas
necesarias
también
puede
expresarse
como
ρ entre los valores de
varianza σ en ambas poblaciones y un coeficiente de correlación
Así, el número de parejas necesarias también puede expresarse como
2
2expresarse
Así, misma
el número
de parejas
necesarias
también
puede
como
una
pareja,
la varianza
de 2las
viene
determinada
según los resultados
( z1diferencias
−α / 2 + z1− β ) σ (1 − ρ )
n=
(μ 1 − μ 2 ) 2
del Apartado 3.4 por
2( z1−α / 2 + z1− β ) 2 σ 2 (1 − ρ )
n=
que, además
de
los parámetros
descritos
en
depende
de la correlación
ensayo
clínico
emparejado
donde,
enel
distintos
pacientes
a ambos entre
(lugar
μapartado
− de
μ 2 asignar
) 2anterior,
2 en1 el 2apartado
2 anterior, depende de la
que,
además
de
los
parámetros
cada pareja de datos. Si el emparejamiento
que ρ está próximo a 0, el
σ 2 =descritos
σ 2 + σno
- es
2σefectivo,
ρ = 2σ de
(1tal
- ρforma
).
d
número
de parejas
necesarias
un estudio
aproximadamente
igual al número
grupos,
cada
paciente
espara
sometido
a laSiemparejado
monoterapiaserá
estándar
durante
un primer
correlación
entre
cada
de
datos.
no
es efectivo,
que,
además
de
lospara
parámetros
descritos
enelelemparejamiento
apartado
anterior,
depende
de sujetos
por grupo
unpareja
estudio
con
muestras
independientes
(notar
que sideρ la
=de0,tal
la fórmula
Así,
el
número
de
parejas
necesarias
también
puede
expresarse
como
anterior
se reduce
la obtenida
el caso de muestras
independientes
mismodurante
tamaño). Si, por
periodo
de 4a semanas
y alentratamiento
combinado
con el nuevodel
fármaco
está próximo
a 0,es
elefectivo,
número
necesarias
un estudio
forma queelρ entre
correlación
cada pareja
de
datos.
Side
el parejas
emparejamiento
nopara
es efectivo,
de tal
el contrario,
emparejamiento
los
datos de
cada pareja
estarán
correlacionados
2
2
positivamente
y, enperiodo
consecuencia,
será
inferior
un segundo
de igualelduración.
asume
que
laρ )desviación típica
de la al número
2número
( z1−α / 2 de
+Sezparejas
(1 −substancialmente
1− β ) σ de
emparejado
aproximadamente
al número
sujetos bajo
por
grupo
para un
estudio
de forma
sujetos
requeridos
en cadaagrupo
deigual
un estudio
independiente
las
mismas
condiciones.
ρ será
está próximo
0,n el
de
parejas
necesarias
para
un
estudio
que
= número
(μ1 − μ 2 ) 2
presión arterial sistólica bajo ambos tratamientos es 20 mm Hg, y que el
=comparabilidad
0, la de
fórmula
anterior
sepacientes
reduce
a hipertensos
la
conEjemplo
muestrasserá
independientes
que sialρla
emparejado
aproximadamente
igual
número
sujetos
por
grupo
para un
estudio
9.5
Con objeto (notar
de asegurar
de los
bajo
monoterapia
y tratamiento
combinado,
decide diseñar
undepende
ensayo
clínico
emparejado
coeficiente
correlación
entre
las determinaciones
tomadas
en
un mismo
que,
además
dedelos
parámetros
descritos
en el se
apartado
anterior,
de lasujeto
obtenida
en
el
caso
de
muestras
independientes
del
mimo
tamaño).
Si,
por
el
contrario,
en lugar
de asignar (notar
distintos
grupos,
cada
fórmula
anterior
se paciente
reduce aes
la sometido
condonde,
muestras
independientes
quepacientes
si ρ = 0, alaambos
a
la
monoterapia
estándar
durante
un
primer
periodo
de
4
semanas
y
al
tratamiento
con un intervalo
de 4pareja
semanas
es aproximadamente
0,50. Para
unade tal
correlación
entre cada
de datos.
Si el emparejamiento
no esdetectar
efectivo,
el emparejamiento
efectivo,
los
datos
de cada
pareja
estarán
correlacionados
combinado
fármaco
durante
un segundo
periodo
de igual
duración.
Se asume
obtenida
en el con
casoeles
denuevo
muestras
independientes
del
mimo
tamaño).
Si, por
el contrario,
que
la
desviación
típica
de
la
presión
arterial
sistólica
bajo
ambos
tratamientos
es
diferencia
subyacente
5 mm
Hg en de
la presión
sistólica
media
al final de20 mm
próximode
a 0,
el número
parejas arterial
necesarias
para un
estudio
forma
que ρ está
positivamente
y,
en
consecuencia,
el
número
de
parejas
será
substancialmente
inferior
Hg, y que el coeficiente
de correlación
determinaciones
tomadas en
un mismo
el emparejamiento
es efectivo,
los datos deentre
cada las
pareja
estarán correlacionados
sujeto
con
un
intervalo
de
4
semanas
es
aproximadamente
0,50.
Para
detectar
ambos tratamientos
con una potencia
0,80 y undenivel
de significación
deun
0,05,
emparejado
será aproximadamente
igual de
al número
sujetos
por grupo para
estudiouna
al
número
de
sujetos
requeridos
en
cada
grupo
de
un
estudio
independiente
bajo
las
diferencia subyacente
de 5 mm Hg
en la presión
arterial
media al final
de ambos
positivamente
y, en consecuencia,
el número
de parejas
serásistólica
substancialmente
inferior
tratamientos
con
una
potencia
de
0,80
y
un
nivel
de
significación
de
0,05,
el
número
de
elmuestras
número de
sujetos necesarios
este
sería se reduce a la
= 0, laemparejado
fórmula anterior
con
independientes
(notaren
que
si ρestudio
mismas
condiciones.
parejas necesarias
sería
al número
de sujetos requeridos
en cada grupo de un estudio independiente bajo las
obtenida en el caso de muestras
2(1,96 + independientes
0,84) 2 20 2 (1 − 0del
,50)mimo tamaño). Si, por el contrario,
mismas condiciones.
126;pacientes
n
=
= 125,44de
≈ los
Ejemplo 9.5 Con objeto de asegurar
la comparabilidad
52
el emparejamiento es efectivo, los datos de cada pareja estarán correlacionados
es decir,
la mitad
demonoterapia
los sujetos
que
serían
necesarios
en de
cada
uno
dediseñar
los grupos
hipertensos
y tratamiento
combinado,
selos
decide
un de un
Ejemplo
9.5bajo
Con
objeto
de asegurar
la comparabilidad
pacientes
es decir,nolaemparejado
mitad
de los(Ejemplo
sujetos el
que
serían de
necesarios
en cada
uno de los grupos
de
positivamente
y, en consecuencia,
número
parejas será
substancialmente
inferior
diseño
9.4).
hipertensos bajo monoterapia y tratamiento combinado, se decide diseñar un
un
diseño
emparejado
9.4).
al
de no
sujetos
en cada
grupo
de un estudio
lasmuestras
15
Lanúmero
determinación
del requeridos
tamaño (Ejemplo
muestral
para
la comparación
de independiente
medias en más bajo
de dos
dependientes o independientes sigue argumentos similares a los descritos en este apartado. No
mismas condiciones.
La determinación del tamaño muestral para la comparación de medias en más de dos 15
Pastor-Barriuso R.
muestrasEjemplo
dependientes
o independientes
siguelaargumentos
similares
a los
descritos en
9.5 Con
objeto de asegurar
comparabilidad
de los
pacientes
147
aproximación
la fórmulas
distribución
muestral
de una proporción
y, en consecuencia,
en el Apartadonormal
9.2.2, alas
descritas
a continuación
se fundamentan
en la
π(1 - π) ≥ 5 muestral
en ambosdegrupos
de comparación.
En las
serán
válidas
siempre
aproximación
normal
a landistribución
una proporción
y, en consecuencia,
Determinación
del tamaño
muestralque
referencias
de siempre
este temaque
pueden
otros métodos
alternativos
de cálculo
π) ≥ 5 en ambos
grupos de
comparación.
En las del
serán válidas
nπ(1 -consultarse
obstante, para preservar la incertidumbre global del proceso de inferencia, es necesario utilizar
tamaño
muestral
particularmente
útiles para laotros
comparación
de proporciones
muy del
referencias
de este
tema
pueden
consultarse
métodos
de cálculo
técnicas
de corrección
por las
múltiples
comparaciones
que se alternativos
pretendan realizar
en el análisis
(por ejemplo, un ensayo clínico en el que se comparan varios tratamientos frente a placebo). Estos
extremas
en muestras
reducidas. útiles para la comparación de proporciones muy
tamaño
muestral
particularmente
métodos
pueden
consultarse
en los libros de tamaño muestral referenciados al final del tema.
extremas
en muestras
reducidas.
9.4.1
Tamaño
muestral
para la comparación de proporciones en dos muestras
9.4 TAMAÑO MUESTRAL PARA LA COMPARACIÓN DE PROPORCIONES
independientes
9.4.1 Tamaño muestral para la comparación de proporciones en dos muestras
En esta sección se aborda el problema de la determinación del tamaño muestral en estudios
observacionales
o ensayos
donde
se pretende
diferencias
entre proporciones
El
propósito se
centra enclínicos
contrastar
la hipótesis
nulacontrastar
de igualdad
de proporciones
independientes
a partir de dos muestras dependientes o independientes. Al igual que en el Apartado 9.2.2, las
fórmulas
descritas
sea fundamentan
en
la aproximación
distribución
: continuación
π1 = en
π2 frente
la la
hipótesis
alternativa
bilateral de
Hnormal
: π1 ≠ πa2laa partir
de
poblacionales
Ha0centra
El propósito
se
contrastar
hipótesis
nula
de igualdad
1proporciones
muestral de una proporción y, en consecuencia, serán válidas siempre que nπ(1 – π) ≥ 5 en
ambos
grupos deindependientes
comparación.
En
este tema bilateral
pueden
7.3consultarse
se1:desprende
quemétodos
lade
dos
muestras
delas
tamaños
n1 y nde
a referencias
la hipótesis
alternativa
H
π1 ≠ π2otros
a partir
poblacionales
H0: π1 = π2 frente
2. Del Apartado
alternativos de cálculo del tamaño muestral particularmente útiles para la comparación de
proporciones
muy
extremas enmuestrales
muestras
reducidas.
una distribución
diferencia
de
proporciones
p1 -np12yseguirá
n2. Delaproximadamente
Apartado 7.3 se desprende
que la
dos muestras
independientes
de tamaños
(1
- π)(1/npara
bajo H
π1 -proporciones
π2, aproximadamente
π1(1 - π1)/n
π2(1
- πdistribución
normal
N(0,deπmuestral
una
diferencia
proporciones
muestrales
p10 -ypN(
1 + 1/n
2)/n2) bajo
2 seguirá
9.4.1 Tamaño
la2))
comparación
de
en1 +
dos
muestras
independientes
(11-π1π)(1/n
1/n
y N(π1 - π2,combinada
π1(1 - π1)/nque
π2(1
- π2)/n
N(0,
π =π(n
+ n2π12+
)/(n
la0proporción
asume
común
a
Hnormal
2))nbajo
1 + se
2) bajo
1, donde
1+
2) es H
El propósito se centra en contrastar la hipótesis nula de igualdad de proporciones poblacionales
donde
π =bajo
(na1πla
nEl2πcontraste
+ n2resultará
) es la proporción
que
seαasume
común
a
Hπ11, =
significativo
un
cuando
lamuestras
H
πgrupos
bilateral
Hcombinada
partir
de dos
H0:ambos
1+
2)/(n1 alternativa
0.hipótesis
2 frente
1: πpara
1 ≠ π
2 anivel
independientes de tamaños n1 y n2. Del Apartado 7.3 se desprende que la diferencia de
– pcontraste
una distribución
N(0,laπ(1 – π)
proporciones
muestrales
diferencia
de
proporciones
muestrales
resultará significativo
para un nivelnormal
α cuando
ambos grupos
bajo Hp0.1 El
2 seguirá aproximadamente
(1/n1 + 1/n2)) bajo H0 y N(π1 – π2, π1(1 – π1)/n1 + π2(1 – π2)/n2) bajo H1, donde π = (n1π1 + n2π2)/
n2) es la proporción
combinada
que se asume común a ambos grupos bajo H0. El contraste
(n1 +diferencia
de proporciones
muestrales
p
≤
-z
π (la
1 −diferencia
π )(1 / n1 +de
1 /proporciones
n2 )
p
1
2
1-α /2
resultará significativo para un nivel α cuando
muestrales
o
p1 − p2 ≤ − z1− α /2 π (1 − π )(1 / n1 + 1 / n 2 )
o
o
p1 − p2 ≥ z1−α /2 π (1 − π )(1 / n1 + 1 / n 2 ) .
Así, asumiendo sin pérdida de
π21, /lan1potencia
detectar una diferencia
- p2 ≥ z1-α/2 que
π (1π−1 <
π )(
+ 1 / n 2 ) para
.
p1generalidad
Así,
asumiendo
sin
pérdida
de
generalidad
que
π
<
π
,
la
potencia
para
detectar una
1
2
de proporciones subyacente π1 – π2 vendrá determinada por
Así, asumiendo
de generalidad
π1 < πdeterminada
para detectar una
π1 - πque
diferencia
subyacente
2, la potenciapor
2 vendrá
− βproporciones
1de
= sin
P( ppérdida
1 − p2 ≤ − z1 − α /2 π (1 − π )(1 / n1 + 1 / n 2 ) | H1 )
psubyacente
diferencia de proporciones
1 − p 2 − (π π
1 1−-ππ22 )vendrá determinada por
= P
π (1 − π ) / n + π (1 − π ) / n
1
1
2
2
2
1
≤
− z1−α / 2 π (1 − π )(1 / n1 + 1 / n 2 ) − (π 1 − π 2 )
α
/
2
π 1 (1 − π 1 ) / n1 + π 2 (1 − π 2 ) / n 2
H1
| π − π 2 | − z1−α / 2 π (1 − π )(1 / n1 + 1 / n 2 )
.
= Φ 1
π 1 (1 − π 1 ) / n1 + π 2 (1 − π 2 ) / n 2
148
Pastor-Barriuso
R.
Si las limitaciones
prácticas determinan de antemano el tamaño muestral disponible
para un estudio o si el estudio ya ha sido llevado a cabo, la fórmula anterior permitirá
17
17
Tamaño muestral para la comparación de proporciones
Si las limitaciones prácticas determinan de antemano el tamaño muestral disponible para un
estudio o si el estudio ya ha sido llevado a cabo, la fórmula anterior permitirá calcular la potencia
estadística que tendría dicho estudio con la muestra disponible para detectar diferencias de una
determinada magnitud.
Ejemplo 9.6 Se planea realizar un estudio de cohortes para evaluar la asociación entre
el =
uso
de anticonceptivos
de cáncer
de (véase
mama Apartado
en mujeres2.4),
entre
0,00750.
Aplicando laorales
regla ydeellariesgo
probabilidad
total
la 40 y 49
años. Para ello, se dispone de una cohorte de 6.000 mujeres en este rango de edad sin
evidencia
cáncer
de mama,combinada
que serán seguidas
un en
periodo
decohorte
5 años para
relaciónbasal
entrede
esta
probabilidad
de cáncerdurante
de mama
toda la
determinar casos incidentes de la enfermedad. Se estima que un 40% de estas mujeres han
utilizado
regularmente específicas
anticonceptivos
oralesdeyexposición
que la tasavendrá
de incidencia
y las probabilidades
por grupo
dada porde cáncer de
mama en este grupo de edad es de I = 150 casos por 100.000 personas-año. Para un nivel
de significación α = 0,05, ¿cuál sería la potenciacde este estudio
para detectar un hipotético
c
π
=
P(D)
=
P(E)P(D|E)
+
P(E
)P(D|E
)
aumento del riesgo de cáncer de mama del 50% entre las usuarias de anticonceptivos
orales?
= 0,40π 1 + 0,60π 2 = 0,40⋅1,50π 2 + 0,60π 2 = 1,20π 2 ,
Asumiendo
una tasa delaincidencia
en los
5 años
deApartado
seguimiento,
= 0,00750. Aplicando
regla de laconstante
probabilidad
total
(véase
2.4),lalaincidencia
acumulada o probabilidad de desarrollar un cáncer de mama en esta cohorte durante los
ya queentre
se
que aproximadamente
un 40% de
las mujeres
son
usuarias
de anticonceptivos
=
Aplicando la
próximos
5 estima
años
π de
= IA
5 = 0,00150∙5
relación
estasería
probabilidad
combinada
cáncer
de mama
en0,00750.
toda la cohorte
regla de la probabilidad total (véase Apartado 2.4), la relación entre esta probabilidad
detoda
padecer
un
cáncer
devendrá
mama dada
entrepor
lasespecíficas
usuarias es por
orales
y que
la probabilidad
combinada
de cáncer
de mamaπ1por
en
lade
cohorte
y las
probabilidades
y las
probabilidades
específicas
grupo
exposición
grupo de exposición vendrá dada por
Así, la probabilidad de
un 50% superior a la probabilidad π2 entre clas no usuarias.
c
π = P(D) = P(E)P(D|E) + P(E )P(D|E )
desarrollar un cáncer
mama en los 5 años de seguimiento sería π2 = π/1,20 =
= 0,40πde
1 + 0,60π 2 = 0,40⋅1,50π 2 + 0,60π 2 = 1,20π 2 ,
ya0,00750/1,20
que se estima=que
un 40%
de las mujeres
sonyusuarias
deπanticonceptivos
y que
π1 = 1,50
=
0,00625
entre
no usuarias
2 = 1,50⋅0,00625orales
la
de padecer
de mama
entre lasde
usuarias
es un 50% superior a
yaprobabilidad
que se estimaπ1que
un 40% un
de cáncer
las mujeres
son usuarias
anticonceptivos
entre
las
no
usuarias.
Así,
la
probabilidad
de
desarrollar
cáncer de
la 0,00938
probabilidad
π
2
entre las
usuarias de anticonceptivos orales. Como se espera que un
n1 =
π/1,20 de
= 0,00750/1,20
= 0,00625
mama
los la
5 años
de seguimiento
sería πun
2 = cáncer
π1 de padecer
mama entre las
usuariasentre
es las
orales en
y que
probabilidad
= 1,50π
=
1,50∙0,00625
=
0,00938
entre
las
usuarias
de
anticonceptivos
no0,40⋅6.000
usuarias y =π12.400
2
mujeres
de la muestra sean usuarias de estos anticonceptivos y
orales. Como se espera que n1 = 0,40∙6.000 = 2.400 mujeres de la muestra sean usuarias
un 50% superior a la probabilidad π2 entre las no usuarias. Así, la probabilidad de
= 0,60∙6.000
= 3.600denoeste
usuarias,
potencia
delas
estos
anticonceptivos
y las restantes
n2 usuarias,
= 3.600 no
la potencia
estudiolasería
restantes
n2 = 0,60⋅6.000
de este estudio sería
desarrollar un cáncer de mama en los 5 años de seguimiento sería π2 = π/1,20 =
| 0,00938 − 0,00625 | −1,96 0,00750(1 − 0,00750)(1 / 2.400 + 1 / 3.600)
0,00750/1,20
1 − β = Φ= 0,00625 entre las no usuarias y π1 = 1,50π2 = 1,50⋅0,00625 =
0
,
00938
(
1
−
0
,
00938
)
/
2
.
400
+
0
,
00625
(
1
−
0
,
00625
)
/
3
.
600
0,00938 entre las usuarias de anticonceptivos orales. Como se espera que n1 =
0,00313 − 1,96 ⋅ 0,00227
= Φ
= Φ(− 0,56) = 0,287;
0
,
00237
sean usuarias de estos anticonceptivos y
0,40⋅6.000 = 2.400 mujeres de la muestra
es decir, la probabilidad de detectar un hipotético incremento del riesgo de cáncer de
las restantes n = 0,60⋅6.000 = 3.600 no usuarias, la potencia de este estudio sería
mama del 50%2 entre las usuarias y no usuarias de anticonceptivos orales sería únicamente
es decir, la probabilidad de detectar un hipotético incremento del riesgo de cáncer
del 28,7% a partir de una cohorte de 6.000 mujeres seguidas durante 5 años.
| 0,00938 − 0,00625 | −1,96 0,00750(1 − 0,00750)(1 / 2.400 + 1 / 3.600)
1de- βmama
= Φdel 50% entre las usuarias y no usuarias de anticonceptivos orales sería
La expresión anterior
de,00938
la potencia
permite
asimismo
determinar
a priori) /la3.muestra
mínima
0
(
1
−
0
,
00938
)
/
2
.
400
+
0
,
00625
(
1
−
0
,
00625
600
que seráúnicamente
necesaria endel
cada
uno de
los grupos
alcanzar
una potencia
1 –5β en
28,7%
a partir
de unapara
cohorte
de 6.000
mujeres preestablecida
seguidas durante
la detección de una diferencia subyacente de proporciones π1 – π2. En general, si se prevé asignar
0,00313 − 1,96 ⋅ 0,00227 sigue a partir de la fórmula de la potencia que
distinto años.
tamaño
= Φ(-0,56) = 0,287;
= Φaambas muestras n2 = kn1, se
0,00237
La expresión anterior de la potencia permite asimismo determinar a priori laPastor-Barriuso
muestra R.
es decir, la probabilidad de detectar un hipotético incremento del riesgo de cáncer
mínima que será necesaria en cada uno de los grupos para alcanzar una potencia
de mama del 50% entre las usuarias y no usuarias de anticonceptivos orales sería
149
2
1
| π 1 − π 2 | − z1−α / 2 π (1 − π ) +
n1 kn1
z1- β = asignar distinto tamaño a ambas muestras n = kn , se sigue a
π2. Endegeneral,
si sedeprevé
partir
la fórmula
la potencia que
2
1
π 1 (1 − π 1 ) π 2 (1 − π 2 )
Determinación del tamaño muestral
+
n
kn1
partir de la fórmula de la potencia que 1
1
1
| π 1 − π 2 | − z1−α / 2 π (1 − π ) +
(k + 1)π (1n−1 π ) kn1
z1- β = | π 1 − π 2 | − z1−α / 2
1
1
kn
| π 1 − π 2π|1−(1z−
π−)1π 2 ) +
(
1
1−απ /12) π π(12−
=
, 1
n1 kn
+
kπ 1 (1 −nπ1 1 ) + π 2 (1 −kn
π12 )
z1−β =
π 1 (1 − πkn
π 2 (1 − π 2 )
1)
1 +
n1
kn
(k + 1)π (11 − π )
| π 1 − π 2 | − z1−α / 2
de tal forma que el tamaño muestral requerido será
(k + 1kn
)π1(1 − π ) ,
= | π −π | −z
1
2
1−α / 2
kπ 1 (1 − π 1 ) + π 2 (1 −kn
π 21 )
=
,
2
( z1−α / 2 (k + 1)π (1kπ−1π(1) −+πz1kn
(
1
−
)
+
π
π
1 π kπ(11 −
π
)
1)− β+
1
2 (1 − π 2 ) )
2
2
n1 =
k (π 1kn−1π 2 ) 2
de tal forma que el tamaño muestral requerido será
de en
tal la
forma
que muestra
el tamaño
requerido será
primera
y nmuestral
2 = kn1 en la segunda muestra, donde la proporción combinada
de tal forma que el tamaño
muestral requerido será
( z1−α / 2 (k + 1)π (1 − π ) + z1− β kπ 1 (1 − π 1 ) + π 2 (1 − π 2 ) ) 2
n1 = viene dada por π = (n1π1 + n2π2)/(n
+ n2) = (π1 + kπ2)/(1 + k). En el
en ambas muestras
k (π 1 − π 2 ) 2 1
( z1−α / 2 (k + 1)π (1 − π ) + z1− β kπ 1 (1 − π 1 ) + π 2 (1 − π 2 ) ) 2
n1 =
de asignar
igualytamaño
grupos de
comparación k = 1, el tamaño muestral
en caso
la primera
muestra
n2 = kna1 ambos
en la segunda
k (π 1 muestra,
− π 2 ) 2 donde la proporción combinada en
π
+
n
π
)/(n
= (π1 +lakπ
En el caso de
ambas
muestras
viene
dada
por
π
=
(n
en la primera muestra y n2 = kn1 en la
proporción
1 1segunda
2 2 muestra,
1 + n2) donde
2)/(1 + k). combinada
en cada
una
de las amuestras
se reduce
a
asignar
igual
tamaño
ambos grupos
de comparación
k = 1, el tamaño muestral en cada una de
las en
muestras
se
reduce
a
enambas
la primera
muestra
y ndada
π la
= segunda
(n1π1 + nmuestra,
n2) = la
(π1proporción
+ kπ2)/(1 +combinada
k). En el
muestras
viene
por
2 = kn
1 en
2π2)/(n1 +donde
2
( z1−α / 2 2π (1 − π ) + z1− β π 1 (1 − π 1 ) + π 2 (1 − π 2 ) ) 2
(n1π1 +den2comparación
π2)/(n1 + n2) =k =(π1,
π2)/(1
k). En el
en ambas
muestras
dada
por π =grupos
caso
de asignar
a ambos
1 +elktamaño
, + muestral
n1 =igual
n 2 viene
=tamaño
(π 1 − π 2 ) 2
caso
de una
asignar
igual
tamañoseareduce
ambosagrupos de comparación k = 1, el tamaño muestral
en
cada
de las
muestras
donde la proporción combinada es π = (π1 + π2)/2. Como se comentó anteriormente, la asignación
de donde
igual tamaño
a las dos
muestras
eficiente
al requerir
un menor
tamaño total
la proporción
combinada
es es
π =más
(π +
π2)/2. Como
se comentó
anteriormente,
la del
en cada una de las muestras se reduce a 1
2
estudio para alcanzar una (misma
estudios
z1−α / 2 potencia.
2π (1 − π )Sin
+ zembargo,
− πel1 )diseño
+ π 2 (1de
− πdeterminados
π 1 (1 en
1− β
2) )
n1igual
= n 2 tamaño
= la aselección
(verasignación
ejemplos de
posteriores),
de muestras
de2 eficiente
distinto al
tamaño
puede
resultar más
las dos muestras
es más
requerir
un, menor
(π pacientes.
1 −π 2)
factible en términos de coste
de
En cualquier caso, 2la determinación
( z1o−αdisponibilidad
/ 2 2π (1 − π ) + z1− β π 1 (1 − π 1 ) + π 2 (1 − π 2 ) )
n1 =estudio
npara
deltamaño
tamañototal
muestral
comparación
de proporciones
en muestras
independientes
2 = lapara
del
alcanzar una
misma potencia.
Sin embargo,
en ,el diseñoprecisa
(π 1 − π 2 ) 2
de los
siguientes
elementos:
donde
la proporción
combinada es π = (π1 + π2)/2. Como se comentó anteriormente, la
de
determinados
estudios
(ver
ejemplos
posteriores),
la selección
de muestras
yy El nivel de significación
α del
contraste
bilateral, que
suele establecerse
pordeconvenio en
= (π1 + πes
Como
se comentó
anteriormente,
donde
la proporción
combinada
asignación
de igual tamaño
a las es
dosπ muestras
más
eficiente
al requerir
un menor la
2)/2.
α = 0,05.
distinto tamaño puede resultar más factible en términos de coste o disponibilidad de
yy La potencia 1 – β para detectar hipótesis alternativas ciertas. La mayoría de los estudios
asignación
tamaño
las dos muestras
es potencia.
más eficiente
al requerirenunelmenor
tamaño
totalde
deligual
estudio
paraaalcanzar
una misma
Sin embargo,
diseño
se diseñan con una potencia 1 – β = 0,80 ó 0,90.
yde
y Las
proporciones
poblacionales
π1 una
yposteriores),
π2misma
. A diferencia
de Sin
la comparación
medias, no
tamaño
total del estudios
estudio
para
potencia.
embargo,
en de
eldediseño
determinados
(ver alcanzar
ejemplos
la selección
de muestras
es suficiente con determinar la diferencia de proporciones que se pretende detectar, sino
estamaño
necesario
especificar
magnitud
aproximada
esta
en cada
grupo
deque
determinados
estudios
(verla
ejemplos
posteriores),
lade
selección
muestras
de de
distinto
puede
resultar
más
factible
en términos
de
costeproporción
o de
disponibilidad
20 de
comparación, para contar así con un valor aproximado de las varianzas poblacionales
π1) y π2(1
– π2).resultar más factible en términos de coste o disponibilidad de
π1(1 – tamaño
distinto
puede
Ejemplo 9.7 Como se vio en el ejemplo anterior, una cohorte de 6.000 mujeres carece
de potencia suficiente para detectar un hipotético incremento del 50% en la incidencia
20
acumulada de cáncer de mama en 5 años entre las mujeres usuarias y no usuarias de
anticonceptivos orales. Según los cálculos del ejemplo anterior, la incidencia acumulada
20
en este periodo en una cohorte de mujeres entre 40 y 49 años será aproximadamente
π = 0,00750, siendo π1 = 0,00938 y π2 = 0,00625 las respectivas incidencias acumuladas
150
Pastor-Barriuso R.
años será aproximadamente π = 0,00750, siendo π1 = 0,00938 y π2 = 0,00625 las
mujeres usuarias de estos anticonceptivos y n2 = 1,5⋅10.202,55 = 15.303,82 ≈
respectivas incidencias acumuladas en usuarias y no usuarias. Como se prevé que
Tamaño muestral para la comparación de proporciones
15.304 no usuarias. Así, para detectar un aumento subyacente del riesgo de cáncer
la cohorte esté compuesta de un 40% de mujeres usuarias de anticonceptivos
de mama del 50% entre las usuarias de anticonceptivos orales con una potencia de
en
usuarias
y no de
usuarias.
Comosesetiene
prevé
que
cohorte
esté compuesta
de de
un 40% de
= 1,5n
un nivel
orales
y un 60%
no usuarias,
que
n2 la
1. Asumiendo
mujeres
usuarias
de
anticonceptivos
orales
y
un
60%
de
no
usuarias,
se
0,80, se precisaría de una cohorte inicial de 25.507 mujeres seguidas durante untiene que
nivel
de significación
α =se0,05
y una potencia 1 – β = 0,80, se
nsignificación
α = 0,05 un
y una
potencia
1 - β = 0,80,
necesitarían
2 = 1,5n1. Asumiendo
necesitarían
periodo de 5 años.
(1,96 2,5 ⋅ 0,00744 + 0,84 1,5 ⋅ 0,00929 + 0,00621 ) 2
n
=
El tamaño necesario
de la cohorte se reduciría si el seguimiento
del estudio se
1
1,5(0,00938 − 0,00625) 2
extendiera, por ejemplo,
hasta
los 10 años, ya que el número esperado de eventos
= 10.202,55
≈ 10.203
mujeres usuarias de estos anticonceptivos y n2 = 1,5∙10.202,55 = 15.303,82 ≈ 15.304 no
aumentaría
considerablemente.
Siguiendo
argumentos
similares
a los del
usuarias. Así,
para detectar un aumento
subyacente
del riesgo
de cáncer
deejemplo
mama del 50%
entre las usuarias de anticonceptivos orales con una potencia de 0,80, se precisaría21de una
anterior,
la incidencia
acumulada
toda ladurante
cohorteun
durante
10 de
años
sería π =
cohorte inicial
de 25.507
mujeresen
seguidas
periodo
5 años.
El tamañoy necesario
de la cohorte
se reduciría
si elentre
seguimiento
del estudio
se extendiera,
0,01500,
las incidencias
acumuladas
específicas
las usuarias
y no usuarias
por ejemplo, hasta los 10 años, ya que el número esperado de eventos aumentaría
considerablemente.
Siguiendo
argumentos
similares
los del ejemplo
anterior, la incidencia
π1 = 0,01875
y π2 =a 0,01250,
respectivamente.
La
de
anticonceptivos orales
serían
acumulada en toda la cohorte durante 10 años sería π = 0,01500, y las incidencias
acumuladas
específicas
entreentonces
las usuarias
cohorte
necesaria
consistiría
en y no usuarias de anticonceptivos orales serían
π1 = 0,01875 y π2 = 0,01250, respectivamente. La cohorte necesaria consistiría entonces en
n1 =
(1,96 2,5 ⋅ 0,01478 + 0,84 1,5 ⋅ 0,01840 + 0,01234 ) 2
1,5(0,01875 − 0,01250) 2
= 5.061,27 ≈ 5.062
usuarias de anticonceptivos orales y n2 = 1,5∙5.061,27 = 7.591,90 ≈ 7.592 no usuarias; es
decir, 12.654 mujeres seguidas a lo largo de 10 años.
usuarias de anticonceptivos orales y n2 = 1,5⋅5.061,27 = 7.591,90 ≈ 7.592 no
de la población de referencia, la proporción de utilización de anticonceptivos
Dado
que la
realización
de un
prospectivo
Ejemplo es
9.8decir,
usuarias;
12.654
mujeres
seguidas
a loestudio
largo de
10 años. requeriría de una gran
= 0,40. Ade casos de
orales
entre
las
mujeres
del
grupo
control
será
aproximadamente
cantidad de personas-año de seguimiento para obtener un númeroπ2suficiente
de la población
referencia,
proporción
utilización
de anticonceptivos
cáncer
de mama,deresultará
máslaviable
llevar adecabo
un estudio
de casos y controles. En tal
partir
de
la
expresión
del
odds
ratio
en
estudios
de
casos
y
controles
(véase
caso, el propósito se centrará en seleccionar un número suficiente de
casos y controles
Ejemplo
9.8 las
Dado
queratio
ladel
realización
de
estudio
requeriría
deyAuna
πusuarias
=
0,40.
oralesdetectar
entre
grupo
control
será
aproximadamente
para
unmujeres
odds
de
cáncer
deun
mama
ω =prospectivo
1,50 entre las
no usuarias
2
Apartado
7.6.2),
se
tiene
que
de anticonceptivos orales con una potencia 1 – β = 0,80. Si los controles seleccionados
gran
de personas-año
de
seguimiento
para
obtener
un
número
suficiente
constituyen
una
muestra
representativa
de la población
referencia,
la proporción de
partircantidad
de la expresión
del odds
ratio
en estudios
de casos
ydecontroles
(véase
utilización de anticonceptivos
π 1 (1mujeres
− π 2 ) del grupo control será
) P( E c | entre
P( E | Dorales
D c ) las
, ratio
de
casos
de
cáncer
de
mama,
resultará
más
viable
llevar
aodds
cabo
un estudio
de de casos y
ω
=
=
=
0,40.
A
partir
de
la
expresión
del
en estudios
aproximadamente
π
Apartado 7.6.2), se 2tiene que
P( E | D c ) P( E c | D) π 2 (1 − π 1 )
controles (véase Apartado 7.6.2), se tiene que
casos y controles. En tal caso, el propósito
se centrará en seleccionar un número
P( E | D) P( E c | D c ) π 1 (1 − π 2 ) ,
ω = la proporción
=
de donde puede despejarse
π1 de mujeres
que han usado
π 2 (ratio
1 − π 1de
) cáncer de mama ω =
| D c detectar
) P( E c | D
P( Epara
suficiente de casos y controles
un) odds
anticonceptivos
entre la
losproporción
casos de cáncer
mamaque
como
de donde puede orales
despejarse
π1 de de
mujeres
han usado anticonceptivos
1,50 entre las usuarias y no usuarias de anticonceptivos
orales con una potencia 1
orales
entre
los casos
de cáncer
de mama πcomo
de donde
puede
despejarse
la proporción
1 de mujeres que han usado
ωπ 2
1,50 ⋅ 0,40 una muestra representativa
seleccionados
constituyen
- β = 0,80. Si los controles
π 1 =entre
= 0,50.
= cáncer
anticonceptivos orales
los
casos
de
1 + ( ω − 1)π 2 1 + 0,50de
⋅ 0,mama
40 como
22
ωπ2
1,50 ⋅ 0,40
π1 =
= 0,50.la selección del
Para un nivel de significación
estándar =α = 0,05 y asumiendo
1 + (ω − 1)π 2 1 + 0,50 ⋅ 0,40
mismo número de casos que controles, de tal forma que la proporción combinada
Pastor-Barriuso R.
Para un nivel de significación estándar α = 0,05 y asumiendo la selección del
π = (π1 + π2)/2 = (0,50 + 0,40)/2 = 0,45, el número necesario de casos y controles
mismo número de casos que controles, de tal forma que la proporción combinada
151
Para un nivel de significación estándar α = 0,05 y asumiendo la selección del
Determinación
del número
tamaño muestral
mismo
de casos
que controles, de tal forma que la proporción combinada
π = (π1 + π2)/2 = (0,50 + 0,40)/2 = 0,45, el número necesario de casos y controles
Para un nivel de significación estándar α = 0,05 y asumiendo la selección del mismo
sería
número de casos que controles, de tal forma que la proporción combinada π = (π1 + π2)/2
= (0,50 + 0,40)/2 = 0,45, el número necesario de casos y controles sería
n1 = n2 =
(1,96 2 ⋅ 0,45(1 − 0,45) + 0,84 0,50(1 − 0,50) + 0,40(1 − 0,40) ) 2
(0,50 − 0,40) 2
= 386,90 ≈ 387,
para una muestra total de 774 mujeres.
Supongamos
que,total
dadadela774
bajamujeres.
incidencia de cáncer de mama, la disponibilidad de casos
para
una muestra
incidentes de esta enfermedad en la población es limitada y, por tanto, se decide reclutar el
la proporción
combinada
será π = (π
doble de controles
que de
Así, n2 = 2n
Supongamos
que, dada
lacasos.
baja incidencia
de1 ycáncer
de mama,
la disponibilidad
de1 + kπ2)/
(1 + k) = (0,50 + 2∙0,40)/3 = 0,43. La muestra necesaria estaría entonces compuesta por
casos incidentes de esta enfermedad en la población es limitada y, por tanto, 2se
(1,96 3 ⋅ 0,43(1 − 0,43) + 0,84 2 ⋅ 0,50(1 − 0,50) + 0,40(1 − 0,40) )
n1 =
2
(0,50
0,40)Así,
decide reclutar el doble de controles 2que
de −casos.
n2 = 2n1 y la proporción
= 289,17 ≈ 290
combinada será π = (π1 + kπ2)/(1 + k) = (0,50 + 2⋅0,40)/3 = 0,43. La muestra
casos de cáncer de mama y n2 = 2∙289,17 = 578,33 ≈ 579 controles libres de la enfermedad.
necesaria
estaría
entonces
compuesta
pores decir, 95 mujeres más de las requeridas en un
El
tamaño
total sería
290 y+
= 869;
casos
de cáncer
de mama
n579
2 = 2⋅289,17 = 578,33 ≈ 579 controles libres de la
estudio con el mismo número de casos que controles.
enfermedad. El tamaño total sería 290 + 579 = 869; es decir, 95 mujeres más de
9.4.2 Tamaño muestral para la comparación de proporciones en dos muestras dependientes
23
las requeridas en un estudio con el mismo número de casos que controles.
Supongamos que se pretende contrastar la hipótesis nula H0: π1 = π2 frente a la hipótesis alternativa
n parejas de datos dependientes. Para simplificar la exposición,
bilateral H1: π1 ≠ π2 a partir
var( pde
b - pc ) = var( pb ) + var( pc) - 2 cov( pb , pc )
supondremos además que se trata de un estudio de casos y controles emparejados uno a uno,
9.4.2 Tamaño
muestrallas
para
la comparación
de proporciones
enexpuestos
dos muestras
respectivas
a un determinado
donde
π1 y π2 representan
πproporciones
πpoblacionales
2de
πb πc
b (1 − π b )
c (1 − π c )
+
=
factor antecedente entre casos y controles.
Como+las parejas concordantes
reflejan una misma
n proporciones
n en un diseño emparejado
dependientes
exposición
en caso y control, la hipótesis nulan de igualdad de
discordantes con el caso expuesto
es equivalente a H0: πb = πc, donde πb es la proporción de parejas
2
Supongamos
que
se
pretende
contrastar
la
hipótesis
nula
H
:
π
la hipótesis
(
π
+
π
)
−
(
π
−
π
)
0
1=π
2 frente
b
c
b
c
y πc es la proporción de parejas discordantes
con el control expuesto.
Según
la anotación
de la Tabla
=
,
n pares discordantes serán pb = b/n y pc = c/n.
7.6, las proporciones muestrales de ambos tipos de
≠ π2 a partir correlacionadas,
de n parejas de datos
Para esperado de la
alternativa
bilateralestarán
H1: π1 obviamente
Estas
proporciones
de taldependientes.
forma que el valor
= πb – πcentre
y su varianza
(véase
Apartado
3.4) , p ) = -π π /n. Así, la
diferencia
será
E(pb – pc)negativa
y pc viene
pordecov(p
donde la
b
c
c
simplificar
lacovarianza
exposición,
supondremospbademás
que dada
se trata
un estudio
de bcasos
y
var( pb − pc ) = var( pb ) + var( pc) − 2cov( pb , pc )
diferencia
en la proporción
muestral
de parejas
discordantes
pb - pc seguirá
y ππ2 )representan
controles
emparejados
uno a uno,
donde
π bπ(11 −
π c (1 − π c las
) respectivas
2π π
b
+
+ b c
=
n
nH y N(π - π , {(π +
bajo
aproximadamente
una distribución
normal
(πb +nπc)/n)
0
b entre
c
b
proporciones
poblacionales
de expuestos
a un N(0,
determinado
factor
antecedente
2
(π + π c ) − (π b − π c )
= b
,
2
π
)
(
π
π
)
}/n)
bajo
H
.
b
c
casosc y controles.
Como las 1parejas concordantesnreflejan una misma exposición en
152
dondePara
la covarianza
negativa
entre pbαy, pelc viene
dadaarrojará
por cov(p
, pc) = – πbπsignificativo
/n. Así, la diferencia
contraste
un
un nivel
de
significación
caso y control,
la hipótesis
nula de igualdad
de proporciones
enb resultado
un diseño cemparejado
en la proporción muestral de parejas discordantes pb – pc seguirá aproximadamente una
por cov(p
donde la covarianza
negativa
entre
pbHy pyc viene
b, pc) = -πb2πc/n. Así, la
+ πc)/n)
bajo
N(πb –dada
πc, {(π
distribución
N(0, (π
0
b + πc) – (πb – πc) }/n) bajo H1.
cuando normal
πb es la proporción
de parejas
discordantes con el
es equivalente
a H0: πb = πcb, donde
Para
un nivelen
delasignificación
α, el contraste
arrojará
un resultado
cuando
diferencia
proporción muestral
de parejas
discordantes
pb - psignificativo
c seguirá
proporción
el
expuesto.
caso expuesto y π
(π bde+ parejas
π c ) / n discordantes
ó pb − pc ≥ z1−con
(π control
pbc −espla
c ≤ − z1− α /2
α /2
b +π c)/n .
aproximadamente una distribución normal N(0, (πb + πc)/n) bajo H0 y N(πb - πc, {(πb +
Según la notación de la Tabla 7.6, las proporciones muestrales de ambos tipos de pares
Pastor-Barriuso
πc) - (πR.b - sin
πc)2pérdida
}/n) bajodeHgeneralidad
1.
Asumiendo
que πb < πc, la probabilidad del segundo evento
discordantes serán pb = b/n y pc = c/n. Estas proporciones estarán obviamente
, el contraste
unpodrá
resultado
significativo
Para un nivelbajo
de significación
será despreciable
la hipótesis α
alternativa
y laarrojará
potencia
entonces
aproximarse
correlacionadas, de tal forma que el valor esperado de la diferencia será E(p - p ) = π -
Asumiendo sin pérdida de generalidad que πb < πc, la
probabilidad del segundo evento
Tamaño muestral para la comparación de proporciones
será despreciable bajo la hipótesis alternativa y la potencia podrá entonces aproximarse
Asumiendo
mediante sin pérdida de generalidad que πb < πc, la probabilidad del segundo evento será
despreciable bajo la hipótesis alternativa y la potencia podrá entonces aproximarse mediante
1 − β = P( pb − pc ≤ − z1−α / 2 (π b + π c ) / n | H1)
− z1−α / 2 (π b + π c ) / n − (π b − π c )
p b − p c − (π b − π c )
= P
H1
≤
{(π + π ) − (π − π ) 2 } / n
{(π b + π c ) − (π b − π c ) 2 } / n
b
c
b
c
| π b − π c | − z1−α / 2 (π b + π c ) / n
.
= Φ
{(π + π ) − (π − π ) 2 } / n
b
c
b
c
A partir de esta expresión, se sigue que el número total de parejas necesarias para alcanzar una
potencia 1 – β es
A partir de esta expresión, se sigue que el número total de parejas necesarias para
( z1−α / 2 π b + π c + z1− β (π b + π c ) − (π b − π c ) 2 ) 2
,
n
=
alcanzar una potencia 1 - β es
(π − π ) 2
b
c
para cuyo cálculo se precisa de una idea aproximada de las probabilidades de obtener ambos
paradecuyo
cálculo
se precisa de
aproximada
de las
de obtener
y πcidea
. Aunque
son pocos
losprobabilidades
diseños emparejados
donde se
tipos
parejas
discordantes
πb una
cuenta con información a priori de estas probabilidades, las siguientes consideraciones generales
pueden
resultar
útiles
en ladiscordantes
práctica. Si elπbemparejamiento
fueralos
efectivo,
ambos
tipos de
parejas
y πc. Aunque sonnopocos
diseñospongamos por
25
ejemplo un estudio de casos y controles donde las variables de emparejamiento no estuvieran
asociadas
con la
exposición
principal,
el nivel ade
exposición
entonces virtualmente
emparejados
donde
se cuenta
con información
priori
de estas sería
probabilidades,
las
independiente entre caso y control, de tal forma que la proporción esperada de parejas con el
π1(1 – útiles
π2) y con
control expuesto
y el caso
caso
expuestoconsideraciones
y el control no expuesto
πb =resultar
siguientes
generalessería
pueden
en laelpráctica.
Si el
no expuesto πc = π2(1 – π1), para una proporción total de pares discordantes πb + πc = π1(1 – π2)
+ πemparejamiento
probarse
quepor
el ejemplo
número un
necesario
parejas
no caso,
fuera puede
efectivo,
pongamos
estudio de casos
y coincidiría
2(1 – π1). En tal
aproximadamente con el número de sujetos por grupo en un estudio de casos y controles
independientes;
resultado
esperable
siempre que seno
empareje
porasociadas
características
controles donde
las variables
de emparejamiento
estuvieran
con lairrelevantes.
Por el contrario, si el emparejamiento fuera efectivo, esto es, si los factores pronósticos
empleados
en principal,
el emparejamiento
asociados
con la exposición
estudio, los casos y
exposición
el nivel deestuvieran
exposición
sería entonces
virtualmentea independiente
controles se asemejarían en su nivel de exposición, induciendo así una correlación positiva en
entre caso ydecontrol,
de taldeforma
la proporción
esperada
de parejas
con entonces
el caso menos
la exposición
cada pareja
caso que
y control.
Las parejas
discordantes
serían
probables πb + πc < π1(1 – π2) + π2(1 – π1) y, en consecuencia, para obtener un número suficiente
de expuesto
pares discordantes
para
análisis, sería
el número
de ser
superiory al
πb = πtotal
π2parejas
) y con habría
el control
expuesto
el número
y el control
noelexpuesto
1(1 -de
de sujetos por grupo en un estudio independiente. En general, la comparación de proporciones
en caso
muestras
emparejadas
menor
potencia
que la comparación
cruda
de proporciones
πc = πtiene
una proporción
total de pares
discordantes
πb + πc en
no expuesto
2(1 - π
1), para
muestras independientes, pero mayor validez interna al controlar los posibles sesgos derivados
de =losπ1factores
utilizados en el emparejamiento.
(1 - π2) +deπconfusión
2(1 - π1). En tal caso, puede probarse que el número necesario de parejas
y de
controles
ejemplo
anterior,
Ejemploaproximadamente
9.9 En el estudio
coincidiría
condeel casos
número
sujetos independientes
por grupo en undel
estudio
de casos
cabría esperar que la edad media de los casos sea superior a la de los controles ya que la
incidencia
de cáncer de mama
aumenta
con la edad.
Además,
como
la edadpor
está inversamente
y controles
independientes;
resultado
esperable
siempre
que se
empareje
relacionada con el uso de anticonceptivos orales, esta variable podría provocar una
confusión negativa
en la asociación
a estudio,
tal forma que elfuera
oddsefectivo,
ratio obtenido
de la
características
irrelevantes.
Por el contrario,
si elde
emparejamiento
esto es,
comparación cruda de casos y controles independientes tendería a infraestimar el potencial
efecto
nocivo
del uso deempleados
anticonceptivos
orales en el riesgo
de cáncerasociados
de mama.con la
si los
factores
pronósticos
en el emparejamiento
estuvieran
exposición a estudio, los casos y controles se asemejarían en su nivel de exposición,
Pastor-Barriuso R.
induciendo así una correlación positiva en la exposición de cada pareja de caso y
control. Las parejas discordantes serían entonces menos probables πb + πc < π1(1 - π2) +
153
Determinación del tamaño muestral
Para evitar esta posible confusión, se decide diseñar un estudio de casos y controles
emparejados, donde cada caso de cáncer de mama se empareja aleatoriamente con un
control de su misma edad. Como consecuencia de este emparejamiento por edad, se
induciría un cierto grado de correlación positiva en la utilización de anticonceptivos de
cada pareja. Así, la proporción esperada de pares discordantes sería inferior a π1(1 – π2) +
π2(1 – π1) = 0,50(1 – 0,40) + 0,40(1 – 0,50) = 0,50, donde π1 = 0,50 y π2 = 0,40 son las
proporciones poblacionales de usuarias de anticonceptivos orales entre casos y controles
obtenidas del ejemplo anterior. Asumiendo una correlación moderada, podría establecerse
a priori una proporción aproximada de parejas discordantes πb + πc = 0,40. Para un
hipotético odds ratio de cáncer de mama ω = πb/πc = 1,50, se esperaría entonces una
proporción
de parejas
condicho
el control
depotencia
anticonceptivos
orales
y elnivel
caso de
no usuario
y un
necesarias para
detectar
efectousuario
con una
1 - β = 0,80
πc = (πb + πc)/(ω + 1) = 0,40/2,50 = 0,16, y con el caso usuario y el control no usuario
= 0,24.
πsignificación
α = 0,05
sería Así, el número total de parejas necesarias para detectar dicho
b = ωπc = 1,50∙0,16
efecto con una potencia 1 – β = 0,80 y un nivel de significación α = 0,05 sería
n=
(1,96 0,24 + 0,16 + 0,84 (0,24 + 0,16) − (0,24 − 0,16) 2 ) 2
(0,24 − 0,16) 2
= 487,64 ≈ 488,
con lo que se tendrían aproximadamente 0,40∙488 = 195 pares discordantes para el análisis.
Notar que el número de parejas requeridas para este estudio sería mayor que los 387 casos
ycon
controles
en el correspondiente
estudio
independiente
(Ejemplo
lo que senecesarios
tendrían aproximadamente
0,40⋅488
= 195
pares discordantes
para9.8). No
obstante, el análisis emparejado de casos y controles de igual edad eliminaría la posibilidad
de
sesgos por
diferencias
de edadde
entre
casos
y controles.
el análisis.
Notar
que el número
parejas
requeridas
para este estudio sería
El cálculo
del tamaño
puede extenderse
a laen
comparación
de tres oestudio
más proporciones
mayor que
los 387 muestral
casos y controles
necesarios
el correspondiente
en muestras dependientes o independientes. Aunque las fórmulas se derivan siguiendo
procedimientos
similares
a los 9.8).
aquí descritos,
suelen
emplearse
métodos de
de casos
corrección
del nivel
independiente
(Ejemplo
No obstante,
el análisis
emparejado
y
de significación α para preservar la probabilidad global de obtener un resultado significativo
entre las
múltiples
comparaciones
que selapretendan
realizar
(ver referencias
bibliográficas).
controles
de igual
edad eliminaría
posibilidad
de sesgos
por diferencias
de edad
9.5
1.
REFERENCIAS
entre casos y controles.
Breslow NE, Day NE. Statistical Methods in Cancer Research, Volume 2, The Design and
Lyon:
International
for Research
on Cancer,
ElAnalysis
cálculo of
delCohort
tamañoStudies.
muestral
puede
extenderse Agency
a la comparación
de tres
o más 1987.
2. Cochran WG. Sampling Techniques, Third Edition. New York: John Wiley & Sons, 1977.
proporciones
enRaghavarao
muestras dependientes
o independientes.
fórmulas
se 1990.
3.
Desu MM,
D. Sample Size
Methodology. Aunque
Boston: las
Academic
Press,
4. Fleiss JL. The Design and Analysis of Clinical Experiments. New York: John Wiley &
derivan siguiendo procedimientos similares a los aquí descritos, suelen emplearse
Sons, 1986.
5.
FleissdeJL,
Levin B, del
Paiknivel
MC.deStatistical
Methods
forpreservar
Rates andlaProportions,
Edition.
α para
probabilidadThird
global
métodos
corrección
significación
New York: John Wiley & Sons, 2003.
6.
Lemeshow
S, Hosmer
DW, Klar J,entre
Lwanga
SK. Adequacy
of Sampleque
Sizese
in Health Studies.
de obtener
un resultado
significativo
las múltiples
comparaciones
New York: John Wiley & Sons, 1990.
pretendan
realizar
(ver referencias
bibliográficas).
7.
Levy PS,
Lemeshow
S. Sampling
of Populations: Methods and Applications, Third Edition.
New York: John Wiley & Sons, 1999.
8.
Rosner B. Fundamentals of Biostatistics, Fifth Edition. Belmont, CA: Duxbury Press, 1999.
9.5 REFERENCIAS
9. Silva LC. Diseño Razonado de Muestras y Captación de Datos para la Investigación
Sanitaria. Madrid: Díaz de Santos, 2000.
1. Breslow NE, Day NE. Statistical Methods in Cancer Research, Volume 2, The
154
Pastor-Barriuso R.
Design and Analysis of Cohort Studies. Lyon: International Agency for Research
on Cancer, 1987.
TEMA 10
CORRELACIÓN Y
REGRESIÓN LINEAL SIMPLE
10.1
INTRODUCCIÓN
En el Tema 6 se discutieron las técnicas estadísticas adecuadas para comparar los niveles medios
de una variable continua en dos grupos de sujetos definidos según la presencia o ausencia de
una determinada característica dicotómica; esto es, la dependencia entre una variable continua
y otra dicotómica. Asimismo, en el Tema 7 se presentaron distintos procedimientos para
determinar la existencia o no de asociación entre dos variables dicotómicas. Queda pendiente,
por tanto, describir los métodos necesarios para evaluar la relación entre dos variables continuas.
En este tema se presentan el coeficiente de correlación y la regresión lineal simple como las
dos técnicas estadísticas más utilizadas para investigar la relación entre dos variables continuas
X e Y. Como veremos más adelante, ambos procedimientos están estrechamente relacionados,
aunque obedecen a estrategias de análisis un tanto diferentes. Por un lado, el coeficiente de
correlación determina el grado de asociación lineal entre X e Y, sin establecer a priori ninguna
direccionalidad en la relación entre ambas variables. Por el contrario, la regresión lineal simple
permite cuantificar el cambio en el nivel medio de la variable Y conforme cambia la variable X,
asumiendo
implícitamenteDE
queCORRELACIÓN
X es la variable explicativa o independiente e Y es la variable
10.2 COEFICIENTE
respuesta o dependiente.
Como ya se anticipó en el Apartado 3.4, el parámetro más utilizado para medir la
10.2 COEFICIENTE DE CORRELACIÓN
asociación lineal entre dos variables aleatorias X e Y es el coeficiente de correlación
Como ya se anticipó en el Apartado 3.4, el parámetro más utilizado para medir la asociación
ρxy, que sealeatorias
define como
poblacional
lineal
entre dos variables
X e Y es el coeficiente de correlación poblacional ρxy, que
se define como
ρ xy =
cov( X , Y )
σx σ y
=
E{( X − μ x )(Y − μ y )}
σx σy
,
donde μx y μy son las respectivas medias poblacionales de X e Y y σx y σy son sus correspondientes
desviaciones
El numerador
del coeficiente
cov(X, Y) =
μy son poblacionales.
las respectivas medias
poblacionales
de X e Y de
y σcorrelación
donde μx ytípicas
x y σy son sus
E{(X – μx)(Y – μy)} es la covarianza poblacional entre ambas variables y se define como la
esperanza
del producto
de las desviaciones
de cada variable
respecto de del
su media.
Así, sidevalores
correspondientes
desviaciones
típicas poblacionales.
El numerador
coeficiente
altos (o bajos) de X tienden a asociarse con valores altos (o bajos) de Y, el producto de las
– μ=y)E{(X
tenderá
ser-positivo
y la
covarianzapoblacional
será positiva.
Por ambas
el contrario,
desviaciones
– μx)(yY)
μy)} es la
covarianza
entre
correlación(xcov(X,
- μxa)(Y
si valores altos de una variable se relacionan con valores bajos de la otra variable, el producto
de variables
las desviaciones
tenderá
seresperanza
negativo del
y laproducto
covarianza
serádesviaciones
negativa. Nodeobstante,
resulta
y se define
comoa la
de las
cada
complicado determinar el grado de asociación lineal entre dos variables a partir de la magnitud
de variable
la covarianza,
ya que
depende
las unidades
de bajos)
medidadedeX las
variables.
respecto
de suésta
media.
Así, de
si valores
altos (o
tienden
a asociarse
Al dividir la covarianza por el producto de las desviaciones típicas de X e Y, el coeficiente de
- μy) tenderá
a o
con valores
altos (o bajos)
el producto
de las desviaciones
- μx)(y
correlación
poblacional
carecededeY,unidades
y permanece
inalterable(xante
cambios
de origen
escala en cualquiera de las dos variables. Puede comprobarse, además, que la covarianza entre
positivo
y lavalor
covarianza
Por de
el contrario,
si valores
altosy,de
X eser
Y es
menor en
absolutoserá
quepositiva.
el producto
sus desviaciones
típicas
en una
consecuencia,
variable se relacionan con valores bajos de la otra variable, el producto de las
Pastor-Barriuso R.
desviaciones tenderá a ser negativo y la covarianza será negativa. No obstante, resulta
155
comprendido entre -1 y 1. En el caso extremo de que ρxy = 1, las variables
Correlación y regresión lineal simple
estandarizadas Zx = (X -
μx)/σx y Zy = (Y - μy)/σy verifican que (véase Apartado 3.4)
comprendido entre -1 y 1. En el caso extremo de que ρxy = 1, las variables
var(Zx)está
+ var(Z
ρxyel) =caso
0; extremo de que
x - Zy) =
y) - 2cov(Z
x, Zy)–=
el coeficiente de var(Z
correlación
siempre
comprendido
entre
1 2(1
y 1. -En
(X - μx)/σx y ZyZ=x =
(Y(X
- μ–y)/μσxy)/σ
verifican
que (véase Apartado 3.4)
Zx =estandarizadas
ρxy estandarizadas
= 1, las variables
x y Zy = (Y – μy)/σy verifican que (véase
Apartado
3.4)
es decir,
Zx - Zy es una variable aleatoria degenerada (constante) en su valor esperado, Zx
var(Zx − Zy ) = var(Zx ) + var(Zy ) − 2cov(Zx , Zy ) = 2(1 − ρ xy ) = 0;
- Zy = E(Zx - Zy) = 0, lo que implica que las variables X e Y presentan una relación lineal
es decir, Zx – Zy es una variable aleatoria degenerada (constante) en su valor esperado, Zx – Zy =
Zy que
esYuna
degenerada
en su
valor esperado,
Zx
es
decir, perfecta,
Z0,
x - lo
quealeatoria
las variables
X e Y (constante)
presentan una
relación
lineal positiva
E(Zpositiva
μvariable
=implica
x – Zy) =
y + σy/σx(X - μx). De igual forma, si ρxy = -1, se cumple que
perfecta, Y = μy + σy/σx(X – μx). De igual forma, si ρxy = – 1, se cumple que
- Zy = E(Zx - Zy) = 0, lo que implica que las variables X e Y presentan una relación lineal
var(Zx + Zy ) = var(Zx ) + var(Zy ) + 2cov(Zx , Zy ) = 2(1 + ρ xy ) = 0
+ σy/σx(X
- μx). De
igual forma,
ρxyvalor
= -1,esperado,
se cumpleZque
positiva
= μyvariable
y, por
tanto,perfecta,
Z + Z esY una
aleatoria
constante
igual si
a su
+ Z = E(Z
x
y
x
y
x
una variable
igual a su
valor
esperado,
+ Zy
por tanto, Zx + Zsey es
deduce
que lasaleatoria
variablesconstante
X e Y presentan
una
relación
linealZxnegativa
+ Zy,
y) = 0, de donde
– σy/σ
(XZy–) =μxvar(Z
). Cuando
ρxy =y) 0,
se dicex, que
variables
linealmente
perfecta, Y = μy var(Z
+ 2cov(Z
Zy) =las2(1
+ ρxy) = están
0
x x+
x) + var(Z
de que
donde
deduce
que laslineal
variables
e Y presentan
unaNotar
relación
= E(Zx + Zy) = 0, ya
incorrelacionadas
noseexiste
relación
entreXambas
variables.
que si dos
variables son estadísticamente independientes, en el sentido de que el conocimiento del valor
+ Zyno
esaporta
una
aleatoria
igual
a su
esperado,
Zentonces
y,toma
por negativa
tanto,
Zx perfecta,
x + Zy
μninguna
(X - μx).constante
Cuando
= 0,
se
dice
que
las variables
Y =variable
quelineal
una variable
sobreρ
el
devalor
la otra
variable,
y - σy/σxinformación
xy valor
están incorrelacionadas; pero que la incorrelación no implica necesariamente independencia, ya
=las
E(Zvariables
x + Zy) = 0, de donde se deduce que las variables X e Y presentan una relación
0.
queestán
podrían
presentar una dependencia
no lineal
aun cuando
ρxy =ambas
incorrelacionadas
ya que no existe
relación
lineal entre
linealmente
El
coeficiente
de
correlación
por
cuantificar
de asociación
lineal
μypermite,
- σy/σson
- μtanto,
= 0,elsegrado
dice que
laselvariables
lineal
negativa
perfecta,
Y =variables
x(X estadísticamente
x). Cuando ρxy independientes,
variables.
Notar
que
si
dos
en
sentido
entre dos variables, de tal forma que cuanto más próximo esté el coeficiente de correlación a 1
ó –están
1, mayor
será la dependencia
lineal positiva
negativa
entre lineal
las variables.
Este hecho se
incorrelacionadas
ya queuna
noovariable
existe
relación
entre información
ambas
linealmente
de
que
el
conocimiento
del
valor
que
toma
no
aporta
ninguna
ilustra en los diagramas de dispersión de la Figura 10.1, donde se representan los valores de
la variable
X en
el eje
horizontal
y los correspondientes
valoresindependientes,
de Y en el eje vertical.
A medida
variables.
Notar
que
si dos
variables
son estadísticamente
en la
el sentido
sobre
el
valor
de
la
otra
variable,
entonces
están
incorrelacionadas;
pero
que
que los puntos del diagrama de dispersión se desvían de una línea recta perfecta con pendiente
positiva
negativa,
el coeficiente
de que
correlación
sevariable
aleja de no
1 óaporta
– 1. Aunque la interpretación
de
de queo el
conocimiento
valor
toma
una
información
incorrelación
no implicadel
necesariamente
independencia,
ya que lasninguna
variables
podrían
la magnitud del coeficiente de correlación depende del contexto particular de aplicación, en
términos
generales
que una
correlación
baja por debajo depero
0,30que
en valor
sobre el
valor
deselaconsidera
otra variable,
entonces
están es
incorrelacionadas;
la absoluto,
ρ
=
0.
presentar
una
dependencia
no
lineal
aun
cuando
xy
moderada entre 0,30 y 0,50, y alta por encima de 0,50.
incorrelación
no implica
ya que
las
variables
podrían
Notar,
por último,
ennecesariamente
la interpretación
coeficiente
de elcorrelación
hay
dos errores
El coeficiente
deque
correlación
permite, independencia,
pordel
tanto,
cuantificar
grado
de asociación
frecuentes que deben ser evitados:
ρxymás
= 0.próximo esté el coeficiente de
presentar
una
dependencia
notal
lineal
aunque
cuando
entre
dos
variables,
de
forma
cuanto
ylineal
y El coeficiente
de correlación
entre
X e Y no
es una
medida de la magnitud de la pendiente
de la recta de regresión entre ambas variables. El coeficiente de correlación determina el
El coeficiente
de correlación
permite,
por tanto,
cuantificar
grado deentre
asociación
correlación
1 ó -1,
mayor de
serálos
la dependencia
lineal
positiva
oelnegativa
grado de aaproximación
puntos del diagrama
de dispersión
a una las
línea recta,
independientemente de cuál sea la magnitud de la pendiente de dicha recta. Como se
lineal entreEste
dos variables,
de tal formadiagramas
que cuanto más
próximo esté
coeficiente
de
dispersión
laelFigura
10.1,
variables.
seailustra
ilustra en los hecho
paneles
y b deenlalos
Figura 10.2, el de
coeficiente
de de
correlación
es
mayor en el
panel a, a pesar de que la pendiente de la recta de regresión es mayor en el panel b. La
correlación
a 1 ó -1, mayor
será ladedependencia
positiva
o negativa
las
donde
se representan
losdevalores
la
Xlineal
en el
eje horizontal
y losentre
pendiente
de la recta
regresión
novariable
se determina
mediante
el coeficiente
de correlación,
sino mediante las técnicas de regresión lineal simple que se discutirán en la segunda parte
variables. Este hecho
se ilustra en los diagramas de dispersión de la Figura 10.1,
correspondientes
de este tema. valores de Y en el eje vertical. A medida que los puntos del diagrama
yde
y El
coeficiente
de correlación
no la
esrecta
unaperfecta
medida
deeje
la
idoneidad
lineal.
donde
se representan
los de
valores
de
variable
X en con
el
horizontal
ydel
losmodelo
dispersión
se desvían
una línea
pendiente
positiva
o negativa,
el El
coeficiente de correlación sólo determina la existencia de una componente lineal en la
relación entre
dos
variables,
independientemente
dela
lainterpretación
forma
demagnitud
dicha
relación.
correspondientes
valores
de
en eldeeje1 vertical.
A medida
que subyacente
los puntos
del
diagrama
coeficiente
de correlación
seYaleja
ó -1. Aunque
de la
Así, por ejemplo, el coeficiente de correlación es mayor en el panel d que en el panel c de
Figura 10.2,
aun cuando
relación
subyacente
entre las variables
panel el
d es
deladispersión
se desvían
de una la
línea
recta perfecta
con pendiente
positiva o del
negativa,
3
claramente no lineal (en este caso, cuadrática). Por ello, antes de analizar el grado de
asociacióndelineal
entre se
dosaleja
variables,
es Aunque
aconsejable
inspeccionardelalanaturaleza
coeficiente
correlación
de 1 ó -1.
la interpretación
magnitud de la
relación mediante un diagrama de dispersión.
3
156
Pastor-Barriuso R.
Coeficiente de correlación
y
(a) ρxy = 0,70
(b) ρxy = 0,50
(c) ρxy = 0,30
x
x
x
(d) ρxy = -0,70
(e) ρxy = -0,50
(f) ρxy = -0,30
y
Figura 10.1
Figura 10.1 Diagramas de dispersión entre dos variables aleatorias X e Y con coeficientes de correlación
positivos ρxy = 0,70 (a), 0,50 (b) y 0,30 (c), así como con coeficientes de correlación negativos ρxy = – 0,70 (d),
– 0,50 (e) y – 0,30 (f).
y
(a) ρ xy = 0,70
(b) ρxy = 0,50
x
x
(c) ρxy = -0,70
(d) ρxy = -0,80
y
Figura 10.2
Figura 10.2 Diagramas de dispersión, coeficientes de correlación y rectas de regresión entre dos variables
aleatorias X e Y con distintas pendientes de la recta de regresión (paneles a y b) y distintas formas de la
relación subyacente (paneles c y d).
Pastor-Barriuso R.
157
Una vez descritas las propiedades e interpretación del coeficiente de correlación
poblacional, en este apartado se presentan los métodos para estimar el coeficiente de
Correlación y regresión lineal simple
AS DE TENDENCIA
CENTRAL
correlación entre dos variables X e Y a partir de los valores observados de ambas
de tendencia central informan acerca de cuál es el valor más representativo
una
muestra demuestral
n sujetos de
mutuamente
variables
(xi, yi) ende
10.2.1
Coeficiente
correlación
Pearson independientes, i = 1, ..., n.
minada variableUna
o, dicho
de forma las
equivalente,
estos
estimadores indican
vez
descritas
propiedades
e interpretación
del coeficiente
de correlación
El estimador
muestral
más utilizado
para evaluar
la dependencia
lineal entrepoblacional,
dos
en este apartado se presentan los métodos para estimar el coeficiente de correlación entre dos
qué valor se agrupan
los X
datos
medidas
de tendenciaambas variables (x , y ) en una muestra de
variables
eXYeaobservados.
losLas
valores
variables
Ypartir
es el de
coeficiente
de observados
correlación de
muestral de Pearson, que
i
i se denota por
n sujetos mutuamente independientes, i = 1, ..., n.
muestra sirven tanto para resumir los resultados observados como para
o simplemente
por más
r, y se
define para
comoevaluar
la covarianza
muestrallineal
entreentre
X e Ydos
dividida
rEl
xy,estimador
muestral
utilizado
la dependencia
variables X
Y esparámetros
el coeficiente
de correlación
muestral de Pearson,
que se denota por rxy, o simplemente
encias acerca dee los
poblacionales
correspondientes.
A
producto
sus la
desviaciones
muestrales,
porpor
r, yel se
define de
como
covarianzatípicas
muestral
entre X e Y dividida por el producto de sus
muestrales,
se describen losdesviaciones
principales típicas
estimadores
de la tendencia central de una
n
1 n
(
x
−
x
)(
y
−
y
)
( x i − x )( y i − y )
i
i
n − 1 i =1
i =1
,
r=
=
n
n
sx s y
( xi − x ) 2 ( y i − y ) 2
aritmética
i =1
i =1
mética, denotada
por x ,ysesxdefine
la ysuma
de cada uno
de los
donde
son lacomo
media
la desviación
típica
muestral de X y y y sy son la media y la
donde xtípica
y sx son
la media
y la
desviación
típicademuestral
de Xmuestral
y y y syde
son
la media
y
desviación
muestral
de Y.
Así,
el coeficiente
correlación
Pearson
se define
trales dividida por
el número
de observaciones
Si denotamos
de forma
análoga
al coeficiente realizadas.
de correlación
poblacional, reemplazando la covarianza y las
desviaciones
típicas
poblacionales
suselcorrespondientes
estimadores
muestrales.
. Así,
coeficiente de correlación
muestral
de Al igual
la desviación
típica
muestral de Ypor
quexielelcoeficiente
de correlación
poblacional,
de correlación muestral siempre
ño muestral y por
valor observado
para el sujeto
i-ésimo, iel= coeficiente
1, ..., n,
1 yforma
1, de análoga
tal formaal que
cuanto más
se aproxime
a 1 ó – 1, mayor será la
toma
valores
Pearson
se entre
define– de
coeficiente
de correlación
poblacional,
dría dada por dependencia lineal positiva o negativa entre las variables.
reemplazando la covarianza y las desviaciones típicas poblacionales por sus
Ejemplo 10.1 En la Figura 10.3 se presenta el diagrama de dispersión entre el índice de
x + x 2 + ... + x n
1 n
masa
medida de. obesidad
queAl
se igual
obtiene
el peso
kilogramos por la
= 1
x =correspondientes
x i corporal,
estimadores
muestrales.
quedeeldividir
coeficiente
deencorrelación
n i =1
n
Colesterol HDL (mmol/l)
poblacional, el coeficiente de correlación muestral siempre toma valores entre -1 y 1, de
2,25
es la medida de tendencia central
más utilizada y de más fácil
tal forma que cuanto más se aproxime a 1 ó -1, mayor será la dependencia lineal
2
n. Corresponde al “centro de gravedad”
de los datos de la muestra. Su
positiva o negativa entre las variables.
itación es que está muy influenciada por los valores extremos y, en este
1,5
10.1
En lade
Figura
10.3 se presenta el diagrama de dispersión entre el
no ser un fiel reflejo de laEjemplo
tendencia
central
la distribución.
índice de masa corporal, medida de obesidad que se obtiene de dividir el peso en
o 1.4 En este y en los sucesivos ejemplos sobre estimadores muestrales, se
1
án los valores del colesterol HDL obtenidos en los 10 primeros sujetos del
5
“European Study on Antioxidants,
Myocardial Infarction and Cancer of
0,5
ast“ (EURAMIC), un estudio
0,25multicéntrico de casos y controles realizado
991 y 1992 en ocho países Europeos e20Israel para evaluar
el efecto de
24
28 los
32
36
Indice de masa corporal (kg/m²)
5
Figura 10.3
Figura 10.3 Diagrama de dispersión entre el índice de masa corporal y el colesterol HDL en el grupo
control del estudio EURAMIC.
158
Pastor-Barriuso R.
que indica una asociación lineal negativa moderada entre el índice de masa
controles del estudio EURAMIC con valores para ambas variables. A simple
corporal y el colesterol HDL.
Coeficiente de correlación
vista, se aprecia un cierto grado de dependencia lineal negativa entre ambas
variables; esto es, el colesterol HDL tiende a decrecer conforme aumenta el índice
altura en metros al cuadrado,
el colesterol
HDL enaquí]
los 533 controles del estudio
[Figura y10.3
aproximadamente
de masa corporal.
Esta apreciación
se confirma
mediante
cálculoundelcierto grado
EURAMIC
con valores
para ambasvisual
variables.
A simple
vista, seelaprecia
de dependencia lineal negativa entre ambas variables; esto es, el colesterol HDL tiende a
coeficiente
de de
correlación
de
decrecer
conforme
aumentamuestral
elríndice
dePearson,
masa
corporal.
Esta apreciación
visual
se confirma
de Pearson
tiene
una distribución
muestral
tanto
más
El coeficiente
correlación
mediante el cálculo del coeficiente de correlación muestral de Pearson,
asimétrica cuanto más distante
1 533 esté la correlación subyacente ρ del valor 0. Cuando ρ
( xi − x )( y i − y ) − 0,285
532 i =1
está relativamenterpróximo
a 1 ó -1, las estimaciones
muestrales
del coeficiente de
=
=
= − 0,276,
sx s y
3,50 ⋅ 0,295
en la de
cola
que corporal
no está y el
correlación
tenderán
por fuerza
a desviarse
del parámetro
que indica
una asociación
lineal
negativamás
moderada
entre el ρíndice
masa
que indicaHDL.
una asociación lineal negativa moderada entre el índice de masa
colesterol
limitada por el rango [-1, 1] de valores posibles de r, resultando en una distribución con
El coeficiente
decolesterol
correlación
r de Pearson tiene una distribución muestral tanto más asimétrica
corporal y el
HDL.
un marcado
sesgoesté
negativo
o positivo.
Por ello, el
intervalo
de confianza
cuanto
más distante
la correlación
subyacente
ρ cálculo
del valorde0.unCuando
ρ está
relativamente
próximo a 1 ó – 1, las estimaciones muestrales del coeficiente de correlación tenderán por fuerza
realizarse
a partir
de la por
distribución
r,
y un test más
de hipótesis
para ρρno
a desviarse
del parámetro
ensuele
la cola
que no está
limitada
el rango muestral
[– 1, 1] dedevalores
10.3 aproximadamente
aquí]sesgo negativo o positivo. Por
posibles de r, resultando en[Figura
una distribución
con un marcado
z de Fisher
sino
mediante
ello,
el cálculo
delauntransformación
intervalo de confianza
y un test de hipótesis para ρ no suele realizarse a
partir de la distribución muestral de r, sino mediante la transformación z de Fisher
El coeficiente de correlación r de Pearson tiene una distribución muestral tanto más
1
1 + r
z = log
,
2no es
− r pequeño,
ρ del
valor 0. Cuando
asimétrica
cuanto
másydistante
estémuestral
la correlación
subyacente
1muy
del modelo
normal
el tamaño
típicamente
n > 50, ρla
cuya distribución muestral presenta una mayor simetría para cualquier valor de ρ. Puede
estátransformación
relativamente
a 1seódistribuye
-1,poblacionales
las estimaciones
muestrales
del
de mucho del
de
Fisher
forma
aproximadamente
con
probarse
que si laszpróximo
distribuciones
de
las
variables
X coeficiente
e Ynormal
no
distan
. Puede
cuya distribución
muestral
presenta
una de
mayor
simetría
para cualquier
valor
de ρmedia
modelo normal y el tamaño muestral no es muy pequeño, típicamente n > 50, la transformación
en la cola
que+no
está– ρ)}/2 y
tenderán
porde
a desviarse
parámetro
ρque
)/(1
ρ)}/2
yfuerza
varianza
1/(n
- 3),más del
zcorrelación
delog{(1
Fisher+se
distribuye
forma
aproximadamente
normal
conρ media
ρ)/(1
probarse
si- las
distribuciones
poblaciones
de las
variables
X e Y log{(1
no distan
mucho
varianza 1/(n – 3),
limitada por el rango [-1, 1] de valores posibles de r, resultando en una distribución con 6
~ N 1 log 1 + ρ , 1 .
z→
1el
2 ello,
ρ n − de
3 un intervalo de confianza
un marcado sesgo negativo o positivo. Por
− cálculo
Notar
quedelahipótesis
varianza para
de z es
inversamente
proporcional
al la
tamaño
muestral
e independiente
de
ρ no
suele realizarse
a partir de
distribución
muestral
de r,
y un test
Notar que lasubyacente
varianza de
la correlación
ρ. z es inversamente proporcional al tamaño muestral e
sino mediante la transformación z de Fisher
independiente
de laLas
correlación
subyacente
Ejemplo 10.2
Figuras 10.4(a)
y (b)ρ.muestran las distribuciones del coeficiente de
correlación r de Pearson y de la transformación z de Fisher entre el índice de masa corporal
1
1 + r simples de tamaño 50 obtenidas a partir
y el colesterol HDL en 1000 muestras
z = logaleatorias
muestran
,
10.2 del
Lasestudio
FigurasEURAMIC.
10.4(a)
las distribuciones
coeficiente
de Ejemplo
los controles
muestral de rdel
presenta
un leve
2 y (b)
1 La
− r distribución
sesgo positivo ya que el percentil 75 (– 0,18) está ligeramente más alejado de la mediana
de correlación
r de Pearson
y de la
transformación
de Fisher
entrelaeltransformación
índice de
(– 0,28)
que el percentil
25 (– 0,36).
Para
corregir esta zleve
asimetría,
z
Puede de la
cuya distribución
muestral
presenta
una
mayor
simetría
para
cualquier
valor
de
de Fisher aumenta la dispersión de los valores de r más distantes de 0 (colaρ.inferior
masa corporal
y el colesterol
HDL constantes
en 1000 muestras
aleatorias
simples
de tamaño
distribución)
y mantiene
virtualmente
los valores
próximos
a 0 (cola
superior),
probarse
que
si
las
distribuciones
poblaciones
de
las
variables
X
e
Y
no
distan
mucho
dando lugar así a una distribución sensiblemente más simétrica.
50 obtenidas a partir de los controles del estudio EURAMIC. La distribución
6
En este ejemplo, la distribución muestral del coeficiente de correlación r de Pearson
presenta
unade
leve
asimetríaunyaleve
quesesgo
la correlación
– 0,276 en
losestá
controles
muestral
r presenta
positivo subyacente
ya que el percentil
75 todos
(-0,18)
del estudio EURAMIC es moderadamente baja. En otras situaciones donde la correlación
subyacente
ρ sea
la distribución
muestral
r será
notablemente
asimétrica
ligeramente
másalta,
alejado
de la mediana
(-0,28)deque
el percentil
25 (-0,36).
Para y, en
consecuencia, el efecto normalizador de la transformación z de Fisher será mucho más
marcado.
corregir esta leve asimetría, la transformación z de Fisher aumenta la dispersión
de los valores de r más distantes de 0 (cola inferior de la distribución) y Pastor-Barriuso
mantiene R.
virtualmente constantes los valores próximos a 0 (cola superior), dando lugar así a
159
Correlación y regresión lineal simple
Frecuencia relativa (%)
20
15
20
[Figura 10.4 aproximadamente
aquí]
15
10
10
5
5
En base a la distribución muestral de la transformación z de Fisher, el intervalo de
confianza al 100(1 - α)% para el parámetro log{(1 + ρ)/(1 - ρ)}/2 viene dado por
[Figura 10.4 aproximadamente
aquí]
0
1
(z1, z2)0= z ±0,2z1−α / 2 -0,8 , -0,6 -0,4 -0,2
-0,8
-0,6
-0,4
-0,2
0
0,2
3
n
−
En base a la distribución muestral de la transformación z de Fisher,
de
1 elintervalo
1+ r
0
(a) r
(b ) z =
2
log
1− r
log{(1 +normal
ρ)/(1 - estandarizada.
ρ)}/2 viene dado
confianza
100(1
- α)% para
el percentil
1 - αel/2parámetro
de la distribución
Así,por
el
donde
z1-α/2ales
Figura 10.4 Distribución muestral
del coeficiente
de correlación r deaquí]
Pearson (a) y de la transformación
[Figura
10.4 aproximadamente
z deintervalo
Fisher (b)de
entre
el
índice
de
masa
corporal
y
el
colesterol
HDL
en
1000
muestraspoblacional
aleatorias simples
correlación
ρ de
confianza al 100(1 - α)% para el coeficiente
1 deLas
tamaño 50 obtenidas a partir de los controles
del
estudio
EURAMIC.
líneas
verticales
en
trazo
discon,
(z1, z2) = z ± z1−α / 2
tinuo representan los parámetros subyacentes ρ = – 0,276
y log{(1
+
ρ)/(1
–
ρ)}/2
=
–
0,284.
n−3
se obtiene
el inverso
de la transformación
de Fisher
ambos el
límites
del Figura
En basedea aplicar
la distribución
muestral
de la transformación
z dea Fisher,
intervalo
de 10.4
intervalo,
para
log{(1 +normal
ρ)/(1
ρ)}/2 viene
dado
confianza
100(1
- α)%muestral
el percentil
1 - αel/2parámetro
de
Así,por
el confianza
donde
z1-aα/2al
En base
laes
distribución
de la
la distribución
transformación
z de- estandarizada.
Fisher,
el intervalo
de
al 100(1 – α)% para el parámetro log{(1 + ρ)/(1 – ρ)}/2 viene dado por
coeficiente
intervalo de confianza al 100(1
- α)%
exp(
2 z1para
) − 1 elexp(
2 z )1− 1 de correlación poblacional ρ
z ± ,z1−α / 2 2
, .
(z1 , z2 ) =
n
−
3
z
z
exp(
2
)
1
+
exp(
2
)
+
1
1
2
se obtiene de aplicar el inverso de la transformación de Fisher
a ambos límites del
donde z1–α/2 es el percentil 1 – α/2 de la distribución normal estandarizada. Así, el intervalo de
intervalo,
confianza
α)%
de correlación
ρ sepuntual
obtiene
el–percentil
1el- más
αcoeficiente
/2 de
la distribución
normal
Así, elr de aplicar
donde
zal
1-α100(1
/2 es para
ρ espara
tanto
asimétrico
alrededor
depoblacional
laestandarizada.
estimación
Este
intervalo
el inverso de la transformación de Fisher a ambos límites del intervalo,
coeficiente
poblacional
intervalo
de confianza
al 100(1
- α)%
cuanto
mayor
sea r en valor
absoluto
sea2el
muestral. Asimismo,
el ρ
exp(
2 zy1para
)menor
z 2 tamaño
− 1 elexp(
) − 1 de correlación
.
,
1
1 ) + 1 exp( 2 z 2 )
exp(
se obtienededelaaplicar
el inverso
de la2 ztransformación
de+ Fisher
a ambos límites del
contraste
hipótesis
nula H
0: ρ = ρ0 frente a la hipótesis alternativa bilateral H1: ρ ≠
Este intervalo para ρ es tanto más asimétrico alrededor de la estimación puntual r cuanto mayor
intervalo,
seaρ
r0 en
valor absoluto
sea
tamaño muestral.
Asimismo,
el contraste
de la
se intervalo
realiza
mediante
eltanto
estadístico
máselasimétrico
alrededor
de la estimación
puntual
r hipótesis
Este
para ρyesmenor
nula H0: ρ = ρ0 frente a la hipótesis alternativa bilateral H1: ρ ≠ ρ0 se realiza mediante el estadístico
cuanto mayor sea r en valor absoluto
sea el tamaño muestral. Asimismo, el
exp(2 zy1 )menor
1 + ρ20z 2 ) − 1 .
1 − 1 ,exp(
exp(z2−z1 2) +log
1 exp(
2 z 2 ) + 1
1
−
ρ
alternativa bilateral H1: ρ ≠
a la0hipótesis
contraste de la hipótesis nula H0: ρ = ρ0 frente
,
1
ρEste
realiza mediante
estadístico
más asimétrico
de la estimación puntual r
para ρ eseltanto
0 se intervalo
3
n − alrededor
160
que bajo H0 sigue aproximadamente una distribución normal estandarizada. El valor P del
cuanto mayor sea r en valor absoluto y menor sea el tamaño muestral. Asimismo, el
contraste
se Hcalcula,
tanto, como el una
área
bajo
normal
estandarizadaElpara
1 +laρcurva
que bajo
aproximadamente
estandarizada.
valoraquellos
P
1 distribución
0 sigue por
0 normal
log
z
−
valores tanto o más distantes de 0 que el valor
observado
del estadístico.
ρ 0hipótesis
alternativa bilateral H : ρ ≠
contraste de la hipótesis nula H0: ρ = ρ20 frente
1 −a la
, curva normal estandarizada1 para
del contraste se calcula, por tanto, como el área bajo la
1
Ejemplo 10.3 A partir de 533 controles del estudio EURAMIC, la estimación puntual del
ρ0 se realiza
mediante el estadístico
nque
−masa
3 el corporal
aquellos
valores
tanto o másentre
distantes
de 0de
valor observado
del estadístico.
coeficiente
de correlación
el índice
y el colesterol
HDL fue r = – 0,276.
La transformación z de Fisher de esta correlación es z = log{(1 – 0,276)/(1 + 0,276)}/2 = – 0,284.
estimación por una
intervalo
correlación subyacente ρ entre ambas
1 +deρla
quePara
bajoobtener
H0 sigueuna
aproximadamente
1 distribución
0 normal estandarizada. El valor P
− log del estudio
Ejemplo 10.3 A partir de 533zcontroles
EURAMIC, la estimación
2
1 − ρ0
, curva normal estandarizada para
del contraste se calcula, por tanto, como el área bajo la
puntual
del coeficiente de correlación1entre el índice de masa corporal y el
Pastor-Barriuso
R.
− 3 el valor observado del estadístico.
aquellos valores tanto o más distantes de 0nque
8
referencia del estudio EURAMIC, se calcula en primer lugar el IC al 95% para el
1
= -0,284 ± 1,96⋅0,043 = (-0,369; -0,199)
− 0,284 ± z 0,975
ρ entre ambas variables en la población de
intervalo de la correlación533
subyacente
3
−
parámetro log{(1 + ρ)/(1 - ρ)}/2 como
Coeficiente de correlación
referencia del estudio EURAMIC, se calcula en primer lugar el IC al 95% para el
y, a continuación, se aplica el
1 inverso de la transformación de Fisher a ambos
= -0,284 ± 1,96⋅0,043 = (-0,369; -0,199)
− 0,284 ± z 0,975
-533
ρ)}/2
como del estudio EURAMIC, se calcula en primer lugar
parámetro
log{(1
+ ρ)/(1 de
variables en
la población
referencia
3
−
límites
el
IC al del
95%intervalo
para el parámetro log{(1 + ρ)/(1 – ρ)}/2 como
asociación lineal subyacente entre ambas variables. Además, las inferencias basadas en
1 inverso de la transformación de Fisher a ambos
y, a continuación,
aplica el
− 0,284
±2(zse
= − 0,284
± 1,96
= (− 0,369; − 0,199)
0 ,0
975
exp{
,
369
)}
−
− 1 exp{
2(−de
0,199
)} −⋅0,043
1 muestral
la transformación
correlación
asumen que las
533coeficiente
− ,3
de Fisher del
= (-0,353; -0,196).
exp{
2
(
0
,
369
)}
1
−
+
exp{
2
(
−
0
,
199
)}
+
1
límites del intervalo
y, a continuación, se aplica el inverso de la transformación de Fisher a ambos límites del
variables se distribuyen de forma aproximadamente normal y que el tamaño muestral es
intervalo
y,
a continuación, se aplica el inverso de la transformación de Fisher a ambos
Notar que elexp{
intervalo
resultante
es ligeramente
respecto
aevidencia
la
2(−0,En
369
)} − 1 exp{
2(−0,199)} asimétrico
− 1
suficientemente
grande.
aquellas
una
clara
en
= (− 0,353;
− 0,196).
, situaciones dondeexista
límites delintervalo
exp{2(−0,369)} + 1 exp{2(−0,199)} + 1
puntual
estimación
r =o-0,276.
Para contrastar
hipótesis
de ausencia
contra
de la normalidad,
bien cuando
la muestralasea
muy pequeña,
estasde
inferencias
Notar que el intervalo resultante es ligeramente asimétrico respecto a la estimación
exp{
2entre
(−0Para
,369
)}contrastar
− 1variables
exp{2la(−H
0,199
)}0,
−de
1se ausencia
elde
estadístico
asociación
ambas
–intervalo
0,276.
hipótesis
asociación
lineal entre
puntual
r =ellineal
Notar
que
resultante
asimétrico
respecto
a la En este
0: ρ =métodos
calcula
= (-0,353;
-0,196).
, es ligeramente
pueden
resultar
engañosas
y es
preferible
utilizar
no paramétricos.
exp{
2
(
0
,
369
)}
1
−
+
exp{
2
(
−
0
,
199
)}
+
1
ambas variables
H0: ρ = 0, se calcula el estadístico
estimación
puntual
= -0,276. Para
contrastar la
hipótesis
dede
ausencia
de como un
apartado se presenta elrcoeficiente
de correlación
los rangos
Spearman
− 6,53,
−0,284
533 − 3 =de
Notar que el intervalo resultante es ligeramente asimétrico respecto a la
0, se calcula
elrelación
estadístico
asociación
lineal
ambas
Hla
que corresponde
aentre
un valor
P variables
bilateral
bajo
la=distribución
normal
estandarizada
0: ρ
procedimiento
no paramétrico
para
detectar
existencia
de una
monótona 2P(Z ≤
que
corresponde
a
un
valor
P
bilateral
bajo
la
distribución
normal
estandarizada
–
6,53)
=
2F(–
6,53)
<
0,001.
En
conclusión,
existe
una
asociación
lineal
estimación puntual r = -0,276. Para contrastar la hipótesis de ausencia de moderada pero
significativa
entre el índice
corporal y ellineal)
colesterol HDL con un coeficiente de
(creciente
o decreciente,
aunquede
nomasa
necesariamente
-0,284
533 − 3 = -6,53, entre dos variables
correlación
de
–
0,28
(IC
al
95%
–
0,35
a
–
0,20;
P
<
0,001).
≤
-6,53)
=
2
Φ
(-6,53)
<
0,001.
En
conclusión,
unaelasociación
2P(Z
calcula
estadísticolineal
asociación lineal entre ambas variables H0: ρ = 0, seexiste
cualesquiera, que pueden ser variables continuas con distribuciones subyacentes no
moderada
pero de
significativa
el índice
masa
corporal
y el colesterol
HDL
corresponde
a correlación
un valor Pentre
bilateral
bajo de
la de
distribución
normal
estandarizada
10.2.2que
Coeficiente
de los
rangos
Spearman
-0,284 533
− 3 = -6,53,
normales o incluso variables cualitativas
ordinales.
Al igual
que
la
media
y
la
desviación
típica
muestral,
el 95%
coeficiente
correlación
de Pearson es
con
un
coeficiente
de
correlación
de
-0,28
(IC al
-0,35
ade-0,20;
P < 0,001).
existe
una
asociación
lineal
2P(Z ≤ -6,53) = 2Φ(-6,53) < 0,001. En conclusión,
sensible
a
la
presencia
de
valores
extremos
en
alguna
de
las
variables,
que
podrían
distorsionar
la
Si se desea determinar el grado en que dos variables se relacionan de forma
que
corresponde
a
un
valor
P
bilateral
bajo
la
distribución
normal
estandarizada
estimación
resultante,
no siendo entonces
buen reflejo
decorporal
la asociación
lineal subyacente
moderada
pero significativa
entre eluníndice
de masa
y el colesterol
HDL entre
ambas
variables.
Además,
las
inferencias
basadas
en
la
transformación
de
Fisher
del
coeficiente
monótona
sin realizar
ninguna asunción
sobre la
poblacional de ambas
10.2.2
Coeficiente
de
correlación
de los En
rangos
dedistribución
Spearman
≤
-6,53)
=
2
Φ
(-6,53)
<
0,001.
conclusión,
existe
una
asociación
lineal
2P(Z
de correlación
muestral asumen
que lasdevariables
forma
con un coeficiente
de correlación
-0,28 (ICseal distribuyen
95% -0,35 ade
-0,20;
P <aproximadamente
0,001).
normal
y
que
el
tamaño
muestral
es
suficientemente
grande.
En
aquellas
situaciones
donde
exista
variables,
basta
con
utilizar
el
orden
de
las
observaciones
de
cada
variable
en
lugar
Al igual
que la media
y la desviación
típica
muestral,
el coeficiente
de
correlación
de de
moderada
pero
significativa
entre
el
índice
de
masa
corporal
y
el
colesterol
HDL
una clara evidencia en contra de la normalidad, o bien cuando la muestra sea muy pequeña, estas
inferencias
puedenvalores.
resultar Así,
engañosas
ysujeto
es preferible
utilizar
noyparamétricos.
En este
rangos
si en función
sus verdaderos
a cada
se
le de
asignan
losmétodos
Pearson
esunsensible
a lacorrelación
presencia
de
valores
extremos
en alguna
de
lasri variables,
que de
10.2.2
Coeficiente
de
de
los
rangos
Spearman
con
coeficiente
de
correlación
de
-0,28
(IC
al
95%
-0,35
a
-0,20;
P
<
0,001).
apartado se presenta el coeficiente de correlación de los rangos de Spearman como un procedimiento
no la
paramétrico
para
detectar
existencia valores
de una observados
relación monótona
(creciente
decreciente,
yi de
dentro
de la omuestra
posición
que
ocupan
suslarespectivos
xi eun
podrían
distorsionar
layestimación
resultante,
no siendo
entonces
buen
reflejo
dedela
Al
igual
que
la
media
la
desviación
típica
muestral,
el
coeficiente
correlación
aunque no necesariamente lineal) entre dos variables cualesquiera, que pueden ser variables
continuas
conascendentemente
distribuciones
subyacentes
normales
o que
incluso
variables
cualitativas
ordinales.
10.2.2
Coeficiente
de correlación
los
rangos
dede
Spearman
ordenada
por de
Xdeevalores
Y. no
En
elextremos
caso
existan
observaciones
Pearson
es sensible
a la presencia
en alguna
devarias
las variables,
que
9 sin
Si se desea determinar el grado en que dos variables se relacionan de forma monótona
Al
igual
que
la
media
y
la
desviación
típica
muestral,
el
coeficiente
de
correlación
de
con
el
mismo
valor
de
una
variable
(empates),
se
asigna
a
cada
una
de
ellas
la
media
de con
realizar distorsionar
ninguna asunción
sobre la
distribución
poblacional
deun
ambas
basta
podrían
la estimación
resultante,
no siendo
entonces
buen variables,
reflejo de la
utilizar el orden de las observaciones de cada variable en lugar de sus verdaderos valores. Así,
Pearson
es sensible
a la presencia
valores
enlaalguna
las variables,
que
se sus
calcula
los rangos
correspondientes.
Elde
coeficiente
de correlación
rs dedeSpearman
función
de
posición
que
ocupan
respectivos
a cada
sujeto
se
le asignan
los rangos
ri y si enextremos
valores observados xi e yi dentro de la muestra ordenada ascendentemente por X e Y. En 9el caso
podrían
distorsionar
laobservaciones
estimación
resultante,
no siendo
entonces
un buen(empates),
reflejo
la asigna a
como
el
coeficiente
de correlación
de Pearson
los de
valores
de simplemente
que existan
varias
con
el mismo
valor
de unareemplazando
variable
se
cada una de ellas la media de los rangos correspondientes. El coeficiente de correlación rs de
por sus correspondientes
rangos (r
si),
observados
(xi, yi)simplemente
Spearman
se calcula
como el coeficiente
dei, correlación
de Pearson reemplazando
9
los valores observados (xi, yi) por sus correspondientes rangos (ri, si),
n
rs =
(r
i =1
n
(r
i =1
i
i
− r )( s i − s )
− r)2
n
(s
i =1
i
,
− s)2
Pastor-Barriuso R.
10
161
= -1,
verifican
que si =orden
n+
monótona
creciente
perfecta.
De igual forma,
si rs de
decir,
observados
de valores
las variables
Xlose rangos
Y presentan
una relación
yi < yj; es que
correspondientes
la variable
Y preservan
verifican
xi <losxde
j,valores
cálculo
del
correlación
desimplifica
Spearman
se simplifica
notablemente
yadicho
que la
álculo del coeficiente
decoeficiente
correlación
desus
Spearman
se
notablemente
ya que
la
donde
se
deduce
que
losigual
valores
e presentan
Y presentan
relación
1ymonótona
- ri,j;yde
verifican
que
si = n +
creciente
perfecta.
De
forma,
si variables
rs = -1, Xlos
loses
valores
observados
dede
laslas
variables
eXYrangos
unauna
relación
Correlación
regresión
lineal
simple
i<y
de es
losdecir,
rangos
varianza de losvarianza
rangos
es
= 0,
rangos X
están
monótona
decreciente
perfecta.
Cuando
rsde
se deduce
queDe
los
valores
las
e Y incorrelacionados
presentan
una
relación
1 - ri, de donde
rangos
verifican
que
si y=no
n+
monótona
creciente
perfecta.
igual
forma,
silos
rvariables
s = -1, los
n
n
n
n
1
1
2
2
21
21
r
si − s )Elde
− (rs)i =−=sentre
(ri − r monótona
)medios
)= (n
= (son
donde
losrelación
rangos
+ (valores
1)/2.
coeficiente
de correlación de Spearman
i alguna
los
ambas
= 0,
rangos
están
incorrelacionados
y no
monótona
decreciente
perfecta.
Cuando
rsde
donde
se
deduce
que
los
valores
laslos
variables
X
evariables.
Y presentan
una relación
1existe
- r−i,1de
n
n
1
1
−
−
n
n
1
−
i
i
1
1
=
=
i
i
1
1
=
=
siempre toma valores entre – 1 y 1. Si rs = 1, los rangos son necesariamente idénticos si = ri, de
2
2 n
n
tal existe
forma
que
si de
dos
observaciones
variable
verifican
xi < xel
, sus
+de
n(en
nestán
+variables.
1) Xincorrelacionados
nentre
+cualesquiera
nvalores
1perfecta.
1 idénticos
(n0,+n1los
) 1de
la ambas
valores
En el
caso
que
no
haya
(empates)
ninguna
de las que
variables,
relación
monótona
alguna
los
=
rangos
y noj
monótona
decreciente
Cuando
r
s
=
−
=
i
=
−
=
i
correspondientes valores
variable
dicho orden
12 yi < yj; es decir, los valores
n −de
1 i =la
2n −1Yi =preservan
1 12 2
1
observados
de
las
variables
X
e
Y
presentan
una
relación
monótona
creciente
perfecta.
De el
igual
cálculo
del
coeficiente
correlación
de
simplifica
notablemente
ya que
la
En el
caso
demonótona
que nodehaya
valores
(empates)
envariables.
ninguna
de las
variables,
existe
relación
alguna
entreidénticos
losSpearman
valores
deseambas
forma, si rs = – 1, los rangos verifican que si = n + 1 – ri, de donde se deduce que los valores de
y su
y su covarianza
es covarianza
las
variables
ede
Yrangos
presentan
unavalores
relación
decreciente
perfecta.
Cuando
varianza
deXes
los
s = 0,
cálculo
coeficiente
de
correlación
demonótona
Spearman
se simplifica
notablemente
yarque
la los
En eldel
caso
que noes
haya
idénticos
(empates)
en ninguna
de las
variables,
el
rangos están incorrelacionados y no existe relación monótona alguna entre los valores de ambas
n
1 del
1 2 de
1 nvariables.
1 1es
varianza
den coeficiente
los rangos
n
n
cálculo
den correlación
Spearman
se simplifica
notablemente ya que la
2 2
(
r
−
r
)(
s
−
s
)
=
ri s−)(2rs)−2−(+rsi )(−
) − (ri − s i ) 2 }
(
r
−
r
)(
s
−
s
)
=
{(
r
−
r
)
+
( s1{(
2
2s is−
i ( ri − r ) =
i
i i
i −
i ) s}
i
i
− 1 i =de
2(n −
1) i =n1 − 1 (empates) en ninguna de las variables, el cálculo
n − 1 i =1 En elncaso
2(no
n −nhaya
1−) 1i =1valores
idénticos
1 que
i =1
1
de los
rangos es i =nde
delvarianza
coeficiente
de correlación
Spearman
ya que la varianza de los
n(n + 11)
1nn 2 n notablemente
1n(n +2n1) se
1 simplifica
2
2
2
=
−
(
r
−
s
)
.
n
+
n
n
+
r
r
s
s
−
=
−
1
1
(
1
)
(
)
(
)
=
−
(
r
−
s
)
.
rangos es
i )
i
i
= i −(1n
− i i=
i
12n − 1 i =21(n − 112
i =1 n 2
i−
=11) i =1
n
n
n
−
1
2 2
12
1
1 i =n1
2
2
r
r
s
s
(
)
(
)
−
=
−
n(n + 1)
1 i n +1
i
= n −1
n − 1 i =1
=
i =1 i −
Aplicando
ambos
resultados, el
dereduce
Spearman
Aplicando ambos
resultados,
el coeficiente
decoeficiente
correlaciónde
a se reduce a
nde
−correlación
1Spearman
2se
12
i =1
2
y su covarianza es
n(n + 1)
1 n n +1
=
i − 2 = 12
n − 1n i =1
n
6
6
y su covarianza
1 −(ri − 2s i )12 , n(ri − s i ) 2 ,2
rs1= 1n−es 2 rs =
r
−
r
s
−
{( ri − r ) + ( s i − s ) 2 − (ri − s i ) 2 }
(
)(
y su covarianza es ni(n − 1)i i =1 s )n=(n − 1) i =
n − 1 i =1
2(n − 1) 1i =1
y su covarianzanes
n
1
1
n
(ri − r )( s i − s ) =
= n(n + 1)
{( r1i − r ) 2 +(r( s−i −
s) 2).2 − (ri − s i ) 2 }
−
s
i i
fórmula
sólo
emplearse
no
órmula que sólo
puedeque
emplearse
no haycuando
empates.
1 i =cuando
n −puede
2(n12
− 1hay
) i =1empates.
1
n 2( n − 1) i =1
1 n
1
(ri − r )( s i − s ) = n(n + 1) {( r1i − r ) 2n + ( s i − s )2 2 − (ri − s i ) 2 }
n −10.4
1 i =1 En la Tabla 10.1= se
2(npresentan
− 1) −
(ri − si ) .
Ejemplo
12 i =1 2(los
n − niveles
1) i =1 de α-tocoferol y βAplicando ambos resultados, el coeficiente
de
correlación
de Spearman se reduce a
n
n(n + 1)
1
2
(r10
− controles
sα-tocoferol
Aplicando
ambos
resultados,
el coeficiente
de −correlación
de
reduce
iSpearman
i ) . 11sedel
Ejemplo
10.4
En laadiposo
Tabla
10.1
se 12
presentan
los
niveles
de
yestudio
β- a 11
caroteno
en
tejido
en =una
muestra
aleatoria
de
2(n − 1) i =1
Aplicando ambos resultados, el coeficiente
de Spearman se reduce a
n
6 de correlación
2
=
−
(
r
−
s
)
,valores
r
1
s
i
ilos
EURAMIC,
junto con
los rangos
ade
de ambas
caroteno en tejido
adiposo
en unacorrespondientes
10
controles
del estudio
nmuestra
(n 2 − 1)aleatoria
i =1
Aplicando ambos resultados, el coeficiente de correlación
de
Spearman
se reduce a
n
6
2
1 − correspondientes
=cuando
(ri de
− ascorrelación
) ,valores de Spearman
srangos,
fórmula
que sóloApuede
hay
empates.
variables.
partir
de estos
elno
coeficiente
se
EURAMIC,
junto emplearse
con
los rrangos
ambas
ilos
n(n 2 − 1) i =1
fórmula que sólo puede emplearse cuando
n empates.
6 no hay
2
1
=
−
(ri de
−niveles
scorrelación
r
calcula
como
s
variables.
A
partir
de
estos
rangos,
el
coeficiente
de Spearman
se
Ejemplo 10.4 En la Tabla 10.1 se presentan
los
y b-caroteno
en
i ) , de a-tocoferol
2
n(n − 1) i =1
tejidoque
adiposo
una emplearse
muestra aleatoria
fórmula
sólo en
puede
cuando de
no10
haycontroles
empates.del estudio EURAMIC, junto con
calcula
como
los
rangos
correspondientes
a los valores de ambas variables. A partir de estos rangos, el
1 10
(
r )( s i −no
s ) calcula
coeficiente
de correlación
de
se
como
fórmula
que sólo
puede emplearse
hay empates.
rSpearman
i −cuando
11
5,06
9 i =1
10
rs =
=
0,552,
=
1
3,03 ⋅ 3,03
1 10 (ri −2 r )(
1 s10i − s )
2
11
(
)
(
)
r
r
s
s
−
−
5,06
9
i
i
= 0,552,
rs = 9 i =1 i =1
9 i =1
=
3,03 ⋅ 3,03
1 10
1 10
2
11
(
)
(si − s ) 2
r
r
−
i
9 i =1
9 i =1
o de forma equivalente mediante la fórmula simplificada en ausencia de empates
o de forma equivalente mediante la fórmula simplificada en ausencia de empates
o de forma equivalente
fórmula simplificada en6 ausencia
de empates
6 mediante la
⋅ 74
2
2
rs = 1 −
{(
7
−
3
)
+
...
+
(
6
−
6
)
}
=
1
−
=
0,552,
10(10 2 − 1)
10(10 2 − 1)
6
6 ⋅ 74
− fuerte
= 0,552,
{(7 − 3) 2 + ... + (6 − 6) 2 } = 1 −
rs = 1una
que refleja
2 relación monótonamente creciente entre2 los niveles de a-tocoferol
10(10 − 1)
10(10 − 1)
yque
b-caroteno.
destacar
quemonótonamente
esta estimacióncreciente
no esta influenciada
por elde
valor
refleja unaCabe
fuerte
relación
entre los niveles
α- extremo
1,46 mg/g de b-caroteno ya que el rango de esta observación continuaría siendo 10 para
cualquier
arbitrariamente
mayor que
que esta
los demás.
que reflejayvalor
una
fuerte relación
monótonamente
creciente entre
los influenciada
niveles de α-por
tocoferol
β-caroteno.
Cabe destacar
estimación
no esta
162
Pastor-Barriuso
R. extremo
tocoferol
y β-caroteno.
Cabe
queya
esta
noesta
estaobservación
influenciada
el
valor
1,46 μg/g
dedestacar
β-caroteno
queestimación
el rango de
por
el valor extremo
1,46
de β-caroteno
que el rango de
esta observación
continuaría
siendo
10 μg/g
para cualquier
valorya
arbitrariamente
mayor
que los demás.
Coeficiente de correlación
Tabla 10.1 α-tocoferol y β-caroteno en tejido adiposo en una muestra aleatoria
de 10 controles del estudio EURAMIC.
α-tocoferol
Control
β-caroteno
Rango (ri)
Valor (μg/g)
Valor (μg/g)
rs
Rango (si)
t=
1
163,8
7
0,14
3
110
− rs2
2
331,9
0,45
8
3
125,1
0,07
1
n 4− 2
4
42,9
1
0,44
7
5
211,0
8
1,46
10
sigue aproximadamente
una115,9
distribución t de Student
con n - 2 grados
de libertad,4
6
2
0,18
7
128,6
5
0,37
5
8 tamaño muestral
271,0 sea n > 10. Así,
9 el valor P bilateral
0,66 del contraste puede
9
siempre que el
9
118,8
3
0,11
2
10
128,7
6
0,40
6
aproximarse mediante el área bajo la distribución t para valores tanto o más alejados
n-2
igual
que otros
procedimientos
no t.
paramétricos,
el coeficiente
de correlación
de Al
0 que
el valor
observado
del estadístico
Aparte del mínimo
requerimiento
muestral,de los
rangos de Spearman permite contrastar la hipótesis nula de ausencia de asociación monótona
entre
dos variables.
esta hipótesis
se ha aplicarse
comprobado
que el coeficiente
de correlación
este contraste
tiene Bajo
la ventaja
adicionalnula,
de poder
a cualquier
distribución
rs de Spearman tiende a distribuirse de forma normal o, más concretamente, que el estadístico
rs contraste paramétrico basado en el
subyacente de las variables X e Y, a diferencia del
t=
1 − rs2
coeficiente de correlación de Pearson que requiere de
distribuciones poblacionales
n−2
sigue
aproximadamente
una distribución t de Student con n – 2 grados de libertad, siempre que
aproximadamente
normales.
el tamaño
muestral
sea
n
> 10.
Así,
el valor P bilateral
del contraste
sigue aproximadamente
una
distribución
t de Student
con n - 2 puede
gradosaproximarse
de libertad, mediante
el área bajo la distribución tn–2 para valores tanto o más alejados de 0 que el valor observado del
estadístico
t.que
Aparte
del
mínimo
requerimiento
muestral,
este
la
adicional
Ejemplo
10.5
Como
las distribuciones
subyacentes
delPcontraste
α-tocoferol
el ventaja
βsiempre
el tamaño
muestral
sea n > 10.
Así, el valor
bilateraltiene
delycontraste
puede
de poder aplicarse a cualquier distribución subyacente de las variables X e Y, a diferencia del
contraste
paramétrico
basado
el coeficiente
de tcorrelación
de Pearson
requiere de
caroteno
(Figura
4.3)
marcadamente
asimétricas
en los controles
delque
estudio
aproximarse
mediante
el son
áreaen
bajo
la distribución
n-2 para valores tanto o más alejados
distribuciones poblacionales aproximadamente normales.
contraste bilateral
de la hipótesis
asociación
entre ambas
de EURAMIC,
0 que el valorelobservado
del estadístico
t. Apartede
delnomínimo
requerimiento
muestral,
Ejemplo 10.5 Como las distribuciones subyacentes del a-tocoferol y el b-caroteno
variables
a tiene
partir
deventaja
los 10 controles
de
Tabla
10.1
haade
realizarse
mediante
el
4.3)
son la
marcadamente
asimétricas
enaplicarse
los
controles
del estudio
EURAMIC,
el
este(Figura
contraste
adicional
de la
poder
cualquier
distribución
contraste bilateral de la hipótesis de no asociación entre ambas variables a partir de los 10
estadístico
en10.1
la correlación
de losmediante
rangos
deelSpearman
controles
debasado
la Tabla
estadístico
basado
en la correlación
subyacente
de
las
variables
Xhae de
Y, realizarse
a diferencia
del contraste
paramétrico
basado
en el
de los rangos de Spearman
coeficiente de correlación de Pearson
rs que requiere
0,552 de distribuciones poblacionales
=
= 1,87,
t=
2
2
1
−
r
1
−
0
,
552
s
aproximadamente normales.
8
n−2
que bajo la distribución t de Student con 8 grados de libertad corresponde a un valor
Ejemplo 10.5
subyacentes
del
ydeelcorrelación
β≥distribuciones
1,87)
= 0,098.
Así, aunque
el α-tocoferol
coeficiente
de
aproximado
de PComo
= 2P(tlas
que bajo la distribución
t8de
Student
con 8 grados
de libertad
corresponde
a un
Spearman rs = 0,55 estima una fuerte relación monótonamente creciente entre los valores
caroteno de
(Figura
4.3) sony marcadamente
controles
del estudio
observados
a-tocoferol
b-caroteno,
estaasimétricas
asociaciónennolosllega
a ser estadísticamente
valor aproximado
de P = 2P(t
8 ≥ 1,87) = 0,098. Así, aunque el coeficiente de
significativa, probablemente debido a la escasa potencia del test para detectar cualquier
EURAMIC, el contraste
bilateral
de la hipótesis
de no asociación entre ambas
asociación
conr tan
reducido
muestral.
correlaciónsubyacente
de Spearman
= 0,55
estimatamaño
una fuerte
relación monótonamente
s
variables
a partir
de los 10inferior
controles
de laaTabla
ha de realizarse
mediante el
Cuando
el tamaño
muestral
o de
igual
10, la10.1
distribución
creciente
entre los
valoresesobservados
α-tocoferol
y β-caroteno,t de
estaStudent no es una
buena aproximación a la distribución muestral del estadístico t y, en consecuencia, el contraste
estadístico basado en la correlación de los rangos de Spearman
asociación no llega a ser estadísticamente significativa, probablemente debido a la
Pastor-Barriuso R.
t=
rs
1 − rs2
=
0,552
1 − 0,552 2
= 1,87,
163
dada por 1/n!. Haciendo uso de este resultado, es posible derivar la distribución bajo la
Correlación
regresión
simple
hipótesisynula
dellineal
coeficiente
de correlación de Spearman, cuyos percentiles en
10.3 REGRESIÓN LINEAL SIMPLE
muestras de tamaño n ≤ 10 se presentan en la Tabla 10 del Apéndice. Para un contraste
Lasbasarse
técnicasendelaregresión
evalúan
la relación
entre dosde
variables
siguiendo
una
debe
distribución
exacta
del coeficiente
correlación
de Spearman
bajo la
bilateral con
unSinivel
de significación
α preestablecido,
la hipótesis
de no asociación
seri de la
hipótesis
nula.
no existe
ninguna relación
monótona entre
las variables,
y los rangos
estrategia
análisis
distinta a cualquier
la correlación.
Mientrass ,que
el coeficiente de correlación
variable
X se de
asumen
constantes,
permutación
1 ..., sn de los rangos de la variable Y
rechazará
si elprobable
coeficiente
deprobabilidad
correlación rviene
inferior
al percentil
/2 oresultado,
es
igualmente
y su
dada por es
1/n!.
Haciendo
uso de α
este
s de Spearman
determina
el
grado
de
asociación
lineal
entre
X
e
Y
tratando
ambas
variables
de
forma de
es posible derivar la distribución bajo la hipótesis nula del coeficiente de correlación
Spearman,
cuyos percentiles
muestras
superior al percentil
1 - α/2 deendicha
tabla. de tamaño n ≤ 10 se presentan en la Tabla 10 del
simétrica,
la
regresión
lineal
estudia
variación
el nivel medio
de la variablela hipótesis
10.3
REGRESIÓN
LINEAL
SIMPLE
Apéndice. Para un contraste bilateral conlaun
nivel deen
significación
α preestablecido,
de no asociación se rechazará si el coeficiente de correlación rs de Spearman es inferior al
respuesta
medida
cambia
la– variable
explicativa
X, estableciendo
así una
10.6
El valor
exacto 1de
para
contraste
bilateral
de
la hipótesis
percentil
α/2 Yo asuperior
alque
percentil
de el
dicha
tabla.
LasEjemplo
técnicas
de regresión
evalúan
laPα/2
relación
entre
dos variables
siguiendo
una de no
direccionalidad
en laelrelación
entreydichas
variables.
Aunque
en
ocasiones la elección
asociación
entre
α-tocoferol
el
dadoel
por
estrategia
de10.6
análisis
a la correlación.
que
coeficiente
correlación
Ejemplo
Eldistinta
valor exacto
deβ-caroteno
P paraMientras
el viene
contraste
bilateral
de ladehipótesis
de no
asociación entre el a-tocoferol y el b-caroteno viene dado por
entre la variable respuesta y explicativa es un tanto arbitraria (por ejemplo, en la
determina el grado
de asociación
X e Y tratando
variables
P = P(r
≥ 0,552|H )lineal
+ P(rentre
≤ − 0,552|H
) = 2P(rambas
≥ 0,552|H
), de forma
s
0
s
0
s
0
asociación
el α-tocoferol
y eldel
β-caroteno),
direccionalidad
establecerse
de
ya que laentre
distribución
bajoestudia
H
de
es simétrica
simétrica,
regresión
lineal
lacoeficiente
variaciónlaen
elcorrelación
nivel mediodesuele
deSpearman
la variable
0
ya que la distribución
bajo la
H0Tabla
del coeficiente
de correlación
es el percentil
alrededor
de 0. Utilizando
10 del Apéndice
para n = de
10,Spearman
se tiene que
forma
natural
por
el
propio
diseño
del
estudio
o
la
naturaleza
de
las
variables
(porEste valor
de loque
cualcambia
se deduce
que P =explicativa
2P(rs ≥ 0,552|H
= 0,10.
rs;0,95 = Y0,552,
respuesta
a medida
la variable
X, estableciendo
una
0) ≥ 2⋅0,05 así
simétrica
de 0.
la Tabla mediante
10 del Apéndice
para n =t 10,
tiene en el
exacto
de alrededor
P es similar
al Utilizando
valor aproximado
la distribución
de se
Student
ejemplo,
los
cambios
medios
en
el
colesterol
HDL
conforme
aumenta
el
índice
de
masa
ejemplo anterior.
direccionalidad
en la relación entre dichas variables. Aunque en ocasiones la elección
que el percentil rs;0,95 = 0,552, de lo cual se deduce que P = 2P(rs ≥ 0,552|H0) ≥
corporal).
entre la variable respuesta y explicativa es un tanto arbitraria (por ejemplo, en la
10.3 2⋅0,05
REGRESIÓN
LINEAL
SIMPLE
= 0,10. Este
valor exacto
de P es similar al valor aproximado mediante la
El modelo
de regresión
linealy asume
que la media
de la variable suele
respuesta
Y cambiade
asociación
entre
el α-tocoferol
el β-caroteno),
la direccionalidad
establecerse
Las técnicas
de regresión
evalúan
relaciónanterior.
entre dos variables siguiendo una estrategia de
distribución
t de Student
en ellaejemplo
linealmente
con
lacorrelación.
variable explicativa
X;
esto
es, para un de
valor
fijo x de la
variable el grado
análisis
distinta
a
la
Mientras
que
el
correlación
determina
forma natural por el propio diseño del estudio coeficiente
o la naturaleza
de las variables
(por
de asociación lineal entre X e Y tratando ambas variables de forma simétrica, la regresión lineal
explicativa,
el valor
de la variable
respuesta
es Y a medida que cambia la variable
estudia
la variación
en elesperado
nivel medio
la variable
respuesta
ejemplo,
los cambios
medios
en elde
colesterol
HDL
conforme
aumenta el índice de masa
explicativa X, estableciendo así una direccionalidad en la relación entre dichas variables.
Aunque
en ocasiones la elección entreE(Y|x)
la variable
y explicativa es un tanto arbitraria
corporal).
= β0 +respuesta
β1x,
14
(por ejemplo, en la asociación entre el a-tocoferol y el b-caroteno), la direccionalidad suele
establecerse
de forma
natural lineal
por elasume
propioque
diseño
del estudio
o la naturaleza
variables
El modelo
de regresión
la media
de la variable
respuestadeYlas
cambia
donde
β
y
β
son
la
constante
y
la
pendiente
de
la
recta
de
regresión
,
respectivamente.
0
1 cambios medios en el colesterol HDL conforme aumenta el índice de masa
(por ejemplo,
los
corporal).
linealmente con la variable explicativa X; esto es, para un valor fijo x de la variable
La constante β0 determina la media de Y cuando X = 0, E(Y|0) = β0 + β10 = β0, y la
El modelo de regresión lineal asume que la media de la variable respuesta Y cambia
explicativa,
esperado
de la variable
respuesta
linealmente
conellavalor
variable
explicativa
X; esto es,
para un es
valor fijo x de la variable explicativa,
pendiente
β
corresponde
al
cambio
en
el
valor
medio de Y por cada aumento de una
1
el valor esperado de la variable respuesta es
= β 0 + β 1 x,
unidad en X, E(Y|x + 1) - E(Y|x) = βE(Y|x)
0 + β1(x + 1) - (β0 + β1x) = β1. La especificación del
donde β0 y β1 son la constante y la pendiente de la recta de regresión, respectivamente. La
modelo
completa
los valores
de
la variable
respuesta se
determina
la
media de
Y pendiente
cuando
X de
= individuales
0,la E(Y|0)
= βregresión
constante
donde ββse
β1 son la asumiendo
constante
yque
la
recta de
respectivamente.
00 y
0 + β10 =, β
0, y la pendiente β1
corresponde al cambio en el valor medio de Y por cada aumento de una unidad en X, E(Y|x + 1)
distribuyen
forma
delcuando
valor esperado
definido
la0 recta
ββ
+ 1) normal
– (β0 +laβalrededor
especificación
del
modelo
– E(Y|x)
= β0 + de
La constante
media
Y
X = 0, E(Y|0)
= β0 por
+seβ1completa
= β0, de
y asumiendo
la
1(x
1x) = βde
1. La
0 determina
que los valores individuales de la variable respuesta se distribuyen de forma normal alrededor
Así,
ladefinido
estructura
de regresión
lineal esgeneral del modelo de
delregresión.
valor esperado
porgeneral
la rectadel
demodelo
regresión.
Así, la estructura
pendiente
β
1 corresponde al cambio en el valor medio de Y por cada aumento de una
regresión lineal es
unidad en X, E(Y|x + 1) - E(Y|x) = β0Y+=ββ10(x++β 1)
- (εβ,0 + β1x) = β1. La especificación del
1x +
donde el término de error aleatorio ε, que representa la desviación de cada respuesta individual
modelo se completa asumiendo que los valores individuales de la variable respuesta se
Y respecto de la recta de regresión β0 + β1x, se distribuye de forma normal con media150 y
distribuyen de forma normal alrededor del valor esperado definido por la recta de
164
Pastor-Barriuso R.
regresión. Así, la estructura general del modelo de regresión lineal es
Y = β + β x + ε,
individual Y respecto de la recta de regresión β0 + β1x, se distribuye de forma normal
lineal
con media 0 y varianza σ 2. Por tanto, la regresión lineal establece que para Regresión
un valor
fijosimple
x de la variable explicativa, la variable respuesta Y sigue una distribución normal con
varianza σ 2. Por tanto, la regresión lineal establece que para un valor fijo x de la variable
2
media E(Y|x)
= β0 + respuesta
β1x + E(ε)Y=sigue
β0 + una
β1x distribución
y varianza var(Y|x)
var(
ε) = σE(Y|x)
,
explicativa,
la variable
normal=con
media
= β0 + β1x +
2
E(ε) = β0 + β1x y varianza var(Y|x) = var(ε) = σ ,
Y|x ~ N(β 0 + β 1 x, σ 2 ),
de donde se derivan las siguientes asunciones:
de donde se derivan las siguientes asunciones:
yy Linealidad: El valor esperado de la variable respuesta Y es una función lineal de la variable
explicativa X, de tal forma que cambios de magnitud constante a distintos niveles de X se
• Linealidad: El valor esperado de la variable respuesta Y es una función lineal de
asocian con un mismo cambio en el valor medio de Y.
yy Homogeneidad
de la varianza:
Laforma
varianza
la variable
respuesta
Y es la misma
para
la variable explicativa
X, de tal
que de
cambios
de magnitud
constante
a
cualquier valor de la variable explicativa X; es decir, a diferencia de la media, la varianza
de Ydistintos
no está relacionada
X.
niveles de Xcon
se asocian
con un mismo cambio en el valor medio de Y.
yy Normalidad: Para un valor fijo de la variable explicativa X, la variable respuesta Y sigue
• Homogeneidad
de la varianza: La varianza de la variable respuesta Y es la
una
distribución normal.
Las asunciones
subyacentes
modelo
devariable
regresión
lineal se X;
representan
misma para
cualquieralvalor
de la
explicativa
es decir, agráficamente
diferencia de en
la la
Figura 10.5. Estas asunciones facilitan el proceso de inferencia sobre la recta de regresión y su
idoneidadmedia,
debe ser
evaluadade
utilizando
diagnósticas,
la varianza
Y no estátécnicas
relacionada
con X. algunas de las cuales se presentan
al final de este tema.
Normalidad
Para unsevalor
fijo la
dedistribución
la variable explicativa
la una
variable
respuesta
En •regresión
lineal: simple
estudia
condicionalX,de
variable
respuesta
continua en función de una única variable explicativa. Esta variable explicativa puede ser tanto
siguecategórica
una distribución
continua Ycomo
ya que normal.
el modelo de regresión lineal no establece ninguna asunción
respecto a su distribución. La extensión de estos modelos al análisis de regresión lineal múltiple,
Lasse
asunciones
al modelo
regresión
lineal
se representan
gráficamente
donde
consideransubyacentes
simultáneamente
dos odemás
variables
explicativas,
se tratará
en el Tema 11.
en la Figura 10.5. Estas asunciones facilitan el proceso de inferencia sobre la recta de
regresión y su idoneidad debe ser evaluada utilizando técnicas diagnósticas, algunas de
las cuales se presentan al final de este tema.
Recta de regresión:
E(Y|x) = β0 + β1x
β0 + β1x4
[Figura 10.5
aquí]
β0 +aproximadamente
β1x3
β0 + β1x2
Y
0 + β1x1
Enβregresión
lineal simple se estudia la distribución condicional de una variable
respuesta continua en función de una única variable explicativa. Esta variable
explicativa puede ser tanto continua como categórica ya que el modelo de regresión
16
x1
x2
x3
x4
X
Figura 10.5 Asunciones estadísticas subyacentes al modelo de regresión lineal simple.
Figura 10.5
Pastor-Barriuso R.
165
mutuamente independientes. Intuitivamente, se trataría de identificar la línea recta que
Correlación
y regresión
linealal
simple
más se
aproxime
conjunto
de todos los puntos del diagrama de dispersión entre
ambas variables. Para formalizar esta idea, es preciso calcular la distancia de cada punto
10.3.1 Estimación de la recta de regresión
observado (xi, yi) respecto al punto correspondiente (xi, ŷ i ) = (xi, b0 + b1xi) sobre la
El primer objetivo de la regresión lineal es obtener estimaciones puntuales b0 y b1 de la constante
β0 yrecta
la pendiente
β1 deestimada
la recta de
que mejor
se se
ajuste
a los valores
observados
de regresión
enregresión
xi. Esta distancia,
que
representa
en la Figura
10.6, (xi, yi)
de las variables explicativa y respuesta en una muestra de n sujetos mutuamente independientes.
Intuitivamente,
se trataría
línea
recta que
más se aproxime
viene dada por
el errorde
deidentificar
estimaciónlaen
la variable
respuesta
ei = yi - ŷali =conjunto
yi - b0 - de
b1xtodos
i.
los puntos del diagrama de dispersión entre ambas variables. Para formalizar esta idea, es
correspondiente
preciso
la distancia
cada determinada
punto observado
(xi, yi) respecto
Así, calcular
la recta de
regresiónde
vendrá
por aquellos
valoresalb0punto
y b1 que
hagan
(xi, ŷ i) = (xi, b0 + b1xi) sobre la recta de regresión estimada en xi. Esta distancia, que se representa
en laeste
Figura
viene
dada por
el error
de estimación
en la variable o,
respuesta
ei = yi – ŷ i =que
yi – b0
error10.6,
lo más
pequeño
posible
para
todas las observaciones
equivalentemente,
– b1xi. Así, la recta de regresión vendrá determinada por aquellos valores b0 y b1 que hagan este
error
lo más pequeño
para todas
laserror
observaciones o, equivalentemente, que minimicen
minimicen
la sumaposible
de cuadrados
del
la suma de cuadrados del error
SSE =
n
e
i =1
2
i
n
n
i =1
i =1
= ( y i − yˆ i ) 2 = ( y i − b0 − b1 x i ) 2,
también llamada suma de cuadrados residual. Notar que los errores se elevan al cuadrado
paratambién
evitar llamada
que se compensen
los errores
positivos
negativos.
Este
procedimiento
para
suma de cuadrados
residual.
Notaryque
los errores
se elevan
al
estimar los parámetros de la recta de regresión se conoce como el método de mínimos
cuadrados.
cuadrado para evitar que se compensen los errores positivos y negativos. Este
procedimiento para estimar los parámetros de la recta de regresión se conoce como el
método de mínimos cuadrados.
[Figura 10.6 aproximadamente aquí]
(xi, yi)
ei = yi − yˆ i
17
( xi , yˆ i ) = ( xi , b0 + b1 xi )
y
Recta de regresión estimada:
yˆ = b0 + b1 x
x
Figura 10.6 Error o desviación del valor observado de la variable respuesta respecto a su valor estimado
Figura 10.6
por la recta de regresión.
166
Pastor-Barriuso R.
i =1
1
Para obtener los valores
b0 yi =b11 que minimizan
la suma de cuadrados del error, se
calculan
las derivadas parciales de SSE respecto a b y b1 y se igualan a cero,
resultando
cuya
solución
lineal simple
Para
obtenereslos valores b0 y b1 que minimizan la0suma
de cuadrados delRegresión
error, se
el sistema de ecuaciones lineales
calculan las derivadas parciales denSSE respecto a b0 y b1 y se igualan a cero, resultando
x i − x )( y i −
(minimizan
)
Para obtener los valores b0 y b1 que
la ysuma
de
s y cuadrados del error, se calculan
i n=1
,a cero, resultando el sistema de
brespecto
=r
sistema de
ecuaciones
lineales
1=
las el
derivadas
parciales
de∂SSE
an b0 y bn 1 y se igualan
= −2 ei = −2 ( y2 i − b0 − sbx1 x i ) = 0,
ecuaciones lineales
( x i −i =1x )
∂b0
i =1
i =1
n
n
1.2elMEDIDAS
DE TENDENCIA
CENTRAL
antioxidantes en
riesgo
un primer
infarto agudo de miocardio en
∂SSEde desarrollar
=
−
2
e
=
−
2
(
y
−
b0 − binfarto
n
n
i
i
1 x i ) = 0,
1.2
MEDIDAS
DE
TENDENCIA
CENTRAL
antioxidantes ∂en
de
desarrollar un primer
agudo de miocardio en
SSE
∂elb0riesgo
i =1 b0 = yi =1- b1 x .
=
−
2
x
e
=
−
2
x
(
y
−
b
−
b0,79,
= 0, 1,42, 0,84,
i i
i0,89,
i
0
1 x i ) 1,29,
hombres adultos.
Los
valores
obtenidos
fueron
1,58,
Las medidas
central
informan acerca de cuál
es el valor más representativo
∂b1 de tendencia
i =1
i =1
n fueron 0,89, 1,58, 0,79, 1,29, 1,42, 0,84,
n
hombres
adultos.
Los
valores
obtenidos
∂
SSE
Las medidas de= tendencia
central informan
el valor más representativo
−2
x i (niveles
y i − b0acerca
− b1colesterol
x ide
) =cuál
0, es
i e i = −2
1,06,
0,87, 1,96
1,53
Laxvariable
media
de
los
del
HDL
en estimadores
La
pendiente
estimada
de
regresión
es
igual
al
producto
del
coeficiente
de
1 de la recta
deyuna
o,
dicho
de
forma
equivalente,
estos
indican
∂determinada
bb1mmol/l.
i =1
i =1
cuya solución
es
1,06,de
0,87,
1,96
y
1,53
mmol/l.
La
media
de
los
niveles
del
colesterol
HDL
en
una determinada variable o, dicho de forma equivalente, estos estimadores indican
estos
10 participantes
esde
correlación
r dealrededor
Pearson
porqué
el cociente
las los
desviaciones
típicas muestrales
de Ydeytendencia
cuya
solución
es
valor se entre
agrupan
datos observados.
Las medidas
estos
10
participantes
es
alrededor
de qué valor nse agrupan los datos observados. Las medidas de tendencia
cuya solución
es
y)
( x i − xtanto
)( y −para
X. Así, aunque central
los signos
demuestra
b10,y89rcoinciden,
de la pendiente b no sólo
10 la
+sirven
1 de
1,58 + ... +lai 1,magnitud
53 resumir
s y los resultados 1observados como para
i =1
x
x
=
1,223
=
=
, mmol/l.
r los
central de la
muestra
tanto
para
resultados observados como para
+ 1,58
+ ...resumir
+=1,53
1i b101 = sirven
n 0,n89
10
10
i
=
1
s
2parámetros
x i =acerca
1,223
mmol/l.correspondientes.
=de correlación
depende del coeficiente
r,
sino
también
de
las
desviaciones
típicas sy y sx
x =poblacionales
realizarxinferencias
de
los
A
− yx10
x i (−xxi )(
i) − y )
10 i =1 (
s
y
i =1 i =1de los parámetros poblacionales correspondientes. A
realizar inferencias
b1 =acerca
,
=r
n
de las variables.continuación
Una vez estimada
la pendiente,
la constante
b0 = y -de
b1lax tendencia
corresponde
se describen
los principales
estimadores
central de una
s
2
x
La media aritmética presenta las siguientes
−−xb) 1 x .
b
y
0 (=xpropiedades:
i
continuación se describeni =los
principales estimadores de la tendencia central de una
1
La media aritmética presenta las siguientes
−propiedades:
simplemente
al
valor
que
fuerza
a
la
recta
de regresión
a atravesar
el punto
( xcoeficiente
, y)
variable.
La
pendiente
estimada
b
de
la
recta
de
regresión
es igual
al producto
deldatos
de
• Cambio de origen (traslación).
Si se suma una constante
a cada
uno de los
1
variable.
correlación
r de Pearson
por
el
entre
muestrales
de Ydatos
y X.
=seylas
- desviaciones
b1 xuna
. igual
bSi
• Cambio
de origen
suma
constante
a cada
unocoeficiente
de los
0 regresión
decociente
la recta de
es
altípicas
producto
del
deAsí,
La pendiente
estimada
b1(traslación).
correspondiente
a
la
media
muestral
de
ambas
variables.
Si
la
relación
subyacente
entre
aunque
losmuestra,
signos1.2.1
de
bMedia
coinciden,
la resultante
magnitud es
deigual
la pendiente
b1inicial
no sólo
depende
del
de una
la media
la muestra
a la media
más
la
aritmética
1 y r de
coeficiente
de
correlación
r,
sino
también
de
las
desviaciones
típicas
s
y
s
de
las
variables.
Una
de
una
muestra,
la
media
de
la
muestra
resultante
es
igual
a
la
media
inicial
más
la
1.2.1
Media
aritmética
correlación
r de
Pearson
el recta
cociente
entre las desviaciones
típicas
y
xmuestrales de Y y
La
pendiente
estimada
b por
de la
de regresión
es igual
alestimadores
producto
del
coeficiente
variables
lineal
de linealidad),
insesgados
dede
la que
vezlas
estimada
laespendiente,
la xconstante
b0 = y por
–=bb0x1yx+b,corresponde
simplemente
valor
La
media
denotada
define
como
suma que
dealcada
uno
de los
yi1aritmética,
=
c1se.son
Un
cambio
delaorigen
constante
utilizada;
si(asunción
i + c, entonces
y
=
x
+
c
,
entonces
y
=
x
+
c
.
Un
cambio
de
origen
que
constante
utilizada;
si
La
media
aritmética,
denotada
por
x
,
se
define
como
la
suma
de
cada
uno
de
los
fuerza
a
la
recta
de
regresión
a
atravesar
el
punto
(
,
)
correspondiente
a
la
media
muestral
de
X. Así, aunque
signospor
de el
b1i cociente
y ri coinciden,
la magnitud
de latípicas
pendiente
b1 no sólo
correlación
rydelalos
Pearson
entre
las
desviaciones
muestrales
de Y y
constante
β
pendiente
β
de
la
recta
de
regresión.
0
1
valores
muestrales
dividida
elvariables
número
observaciones
realizadas.
Si denotamos
ambas
variables.
Si
la relación
entre
esconsiste
lineal (asunción
se
essubyacente
el centrado
de por
la las
variable,
quede
en restar
ade linealidad),
querealiza
facilitacon
unafrecuencia
estimación
del
valor esperado
o predicho
de la variable
respuesta
para
valores
muestrales
dividida
por
el
número
de
observaciones
realizadas.
Si
denotamos
b0 yX.
b1Así,
sonse
estimadores
insesgados
der el
la centrado
constante
y variable,
la pendiente
βconsiste
de regresión.
depende
del
coeficiente
dedecorrelación
r, sino la
también
de las
desviaciones
típicas
syay sx
realiza
con
frecuencia
deβmagnitud
restar
0la
1 de la recta
aunque
los
signos
b1 yes
coinciden,
de que
lapor
pendiente
ben
1 no sólo
La valor
recta
de la
regresión
estimada
viene
entonces
determinada
pormuestra
n el tamaño
muestral
y por de
xi el
valor
observado
paraserá,
el sujeto
i-ésimo, i = 1, ..., n,
cada
de
su
media.
La
media
una
variable
centrada
por
cada
valor
de la variable
explicativa.
Paradeterminada
completar lapor
estimación de los
La
recta
de fijo
regresión
estimada
viene
por nUna
el
muestral
ypendiente,
porLa
xi media
el valor
i-ésimo,
i = 1, ..., n,
de las
variables.
la entonces
la constante
b0 =para
y centrada
-elb1sujeto
x típicas
corresponde
cada
detamaño
lavez
muestra
su media.
deobservado
unalas
variable
será,
depende
delvalor
coeficiente
deestimada
correlación
r, sino
también
de
desviaciones
spor
y y sx
la media vendría
dada
por
tanto,
igual del
a 0.
=
b0 +estimarse
b1 x = y también
+ b1 (x − la
x ),varianza σ 2 de la variable
parámetros
modelo lineal,ŷ ha
de
la
media
vendría
dada
por
tanto,
igual
a
0.
simplemente
al
valor
que
fuerza
a
la
recta
de
regresión
a
atravesar
(x, y)
defacilita
las variables.
Una vez del
estimada
pendiente,
la constante
= yel-punto
b1respuesta
x corresponde
que
una estimación
valor la
esperado
o predicho
de lab0variable
para cada
• Cambio de escala (unidades). Si se multiplica cadan uno de los datos de una
+
+
...
+
x
x
x
1
respuesta
alrededor
de
dicha
recta.
A
partir
de
la
suma
de
cuadrados
del
error,
esta
1
2
n
valor fijo
de la variable explicativa. Para completar
la=estimación
de
los. de
parámetros
x =variables.
• Cambio de escala (unidades). Si se multiplica
cada
de...los
datos
una entre del
n x
correspondiente
a la
media
muestral
delaambas
Si
la2 +
relación
subyacente
+uno
+elxrespuesta
xvariable
2 i xa1 atravesar
simplemente
al de
valor
que fuerza
a la recta
de 1regresión
punto
( x ,alrededor
y)
n
n
n
de
la
de
modelo
lineal,
ha
estimarse
también
varianza
σ
=
i
1
= x iresultante
=
muestra por una constante, la media de lax muestra
es igual a .la media
varianza
residual
puede
estimarse
mediante
n
n
dicha recta.
A partir
deuna
la suma
de cuadrados
esta varianza
residual
puede
estimarse
muestra
constante,
mediadel
deerror,
laib=10muestra
resultante
es igual
a la media
18
las variables
espor
lineal
(asunción
delalinealidad),
y b1 son
estimadores
insesgados
de la
correspondiente
a
la
media
muestral
de
ambas
variables.
Si
la
relación
subyacente
entre
mediante
y
=
cx
,
entonces
y
=
c
x
.
inicial por la constante
utilizada;
si
i
La media es la medida
dei tendencia central más utilizada y de más fácil
n
yi regresión.
=
cxi, entonces
y = c x . y de más fácil
inicial
por
la
constante
utilizada;
si
SSE
1
La
media
es
la
medida
de
más
2
constante
β0 yeslalineal
pendiente
β1 dedelalinealidad),
recta
de
= tendencia
(by0i y−central
− b1estimadores
x i ) 2.utilizadainsesgados
s =
las
variables
(asunción
bb10 son
de la
interpretación.
ali =1multiplica
“centro decada
gravedad”
datos
• Cambio simultáneo
de origenCorresponde
uno dede
loslos
datos
dede la muestra. Su
ny −escala.
2 n Si
− 2se
interpretación.
Corresponde
al “centro
de
gravedad”
de uno
los datos
la muestra.
Su
• recta
Cambio
simultáneo
de
origen y escala.
Si se
multiplica
cada
de losdedatos
de
La
de
regresión
estimada
entonces
determinada
por
constante
β0que
y la
pendiente
β1 de laviene
recta
de
regresión.
Cabe
destacar
la
suma
de
cuadrados
del
error
se
divide
por
n
–
2
ya
que,
una
vez
estimadas
principal
limitación
que estáse
muy
influenciada
por los la
valores
una muestra por
una constante
y alesresultado
le suma
otra constante,
mediaextremos y, en este
la constante
la
pendiente
de la
recta
deyregresión,
los
errores
ootra
de
lavez
variable
Cabe destacar
que la
suma
de
cuadrados
error
sesendivide
por
ndesviaciones
- constante,
2 valores
ya que, extremos
una
principal
limitación
es que
está
muy
influenciada
por
los
y, en este
unay muestra
por
una
constante
aldel
resultado
le
suma
la media
La
recta
de
regresión
estimada
viene
entonces
determinada
por
,
b
y
n
–
2
errores,
respuesta
respecto
de
la
recta
contienen
n
–
2
grados
de
libertad
(conocidos
b
ŷ
=
b
+
b
x
=
y
+
b
(x
x
),
0
1
1
0
1
caso, puede
ser aun
reflejo
de la
central
de la distribución.
de la muestra resultante
es no
igual
la fiel
media
inicial
portendencia
la primera
constante,
más la
los 2estimadas
errores
seresultante
derivan
automáticamente).
Asumiendo
sencumplen
constante
ynolaser
pendiente
dea la
la media
recta
deinicial
regresión,
errores
olas hipótesis
puede
un
fiel reflejo
de la
tendencia
central
de
laconstante,
distribución.
de restantes
lalacaso,
muestra
es igual
por2que
lalos
primera
más lade
linealidad
y homogeneidad
varianza,
varianza residual s es un estimador insesgado del
+ bla
= cla
segunda
constante; si2yi de
1x = yy +=bc11(xx - +xc),2.
1xŷ
i +=c2b,0entonces
.
desviaciones
de
la
variable
respuesta
respecto
de la
- 2 grados
de
parámetro
poblacional
σ
Ejemplo
este
en los
sucesivos
estimadores
muestrales, se
= cEn
c2,yentonces
yrecta
= c1contienen
xejemplos
+ c2. n sobre
segunda constante;
si yi1.4
1 xi +
Ejemplo 1.4 En este y en los sucesivos ejemplos sobre estimadores muestrales, se
libertad
(conocidos
butilizarán
, bestudio
2deerrores,
los
errores
restantes
semmol/l
derivan
18 sujetos del
0el
1 y n -los
valores
del
HDL
en
losy10
primeros
Ejemplo
En
la relación
entre
el índice
corporal
else
colesterol
Ejemplo
1.510.7
Para transformar
los
valores
del2colesterol
colesterol
HDLdeobtenidos
demasa
a mg/dl
utilizarán
los valores
del
colesterol
HDL obtenidos
enmmol/l
los 10
primeros
del
HDL,
resulta1.5
natural
el los
índice
de masa
corporal
como
explicativa
ysujetos
el
Ejemplo
Paraconsiderar
transformar
valores
del colesterol
HDLvariable
de
a mg/dl se
automáticamente).
Asumiendo
que
se
cumplen
las
hipótesis
de
linealidad
y
estudio
“European
Study
on
Antioxidants,
Myocardial
andenCancer of
colesterol
HDL
como
variable
respuesta.
El
objetivo
es, por
tanto,
estimar
los cambios
18
multiplica
por
el factor
de
conversión
38,8.
Así,
utilizando
la propiedad
delInfarction
estudio
“European
Study
on
Antioxidants,
Myocardial
Infarction
and
Cancer of
multiplica por el factor de conversión 38,8. Así,
2 utilizando la propiedad del
homogeneidad
de
la
varianza,
la
varianza
residual
s
es
un
estimador
insesgado
del
Breast“
(EURAMIC),
multicéntrico
cambio de escala, lathe
media
del colesterol
HDLun
enestudio
mg/dl se
calcularía de casos y controles realizado
the
Breast“
(EURAMIC),
un
estudio
multicéntrico
de casos y controles realizado
cambio de escala, la
2 media del colesterol HDL en mg/dl se calcularía
Pastor-Barriuso
R. 167de los
parámetro
poblacional
σ
.
y 1992
en ocho
países
Europeos
e Israelmg/dl.
para evaluar
el efecto
⋅38,8 = 47,45
directamente a partirentre
de su1991
media
en mmol/l
como
1,223
entre
1991de
y 1992
en ocho
países como
Europeos
e ⋅Israel
evaluar
38,8 =para
47,45
mg/dl.el efecto de los
directamente
a partir
su media
en mmol/l
1,223
Ejemplo 10.7 En el estudio de la relación entre el índice de masa corporal y6el
5
central de la muestra sirven tanto para resumir los resultados observados como para
1 10
0,89 + 1,58 + ...
1,53 de estos datos, las estimaciones de la pendiente y
variables
A +partir
x
x iacerca
= 1,223 mmol/l.
=
=de r =de-0,276.
realizar inferencias
los parámetros
poblacionales
correspondientes. A
10 yi =regresión
Correlación
lineal simple10
1
delos
la recta
de regresión
por elde
método
de mínimos
cuadrados
continuaciónlaseconstante
describen
principales
estimadores
la tendencia
central
de una son
La media aritmética presenta las siguientes propiedades:
variable. el nivel medio del colesterol HDL
s y conforme 0aumenta
,295 el índice de masa corporal utilizando
= −0,276
= -0,023
1 = r simple.
un modelo de regresiónblineal
En este caso,
tanto la variable respuesta como la
,50 de los datos
sx
Cambio de origen (traslación). Si se suma una constante
a cada3uno
variable explicativa
son continuas.
10.1 se obtuvo
un coeficiente de correlación de Pearson entre ambas
1.2.1 MediaEjemplo
aritmética
En
n =de
533
del un
estudio
la media
y laPearson
desviación
del índice de
de una muestra, la ymedia
lacontroles
muestra
resultante
esEURAMIC,
igual de
a lacorrelación
media
inicial
más
la entretípica
Ejemplo
10.1
se obtuvo
coeficiente
de
ambas
variables
de r =fueron
-0,276.
partir
de
datos,
lasde
2estimaciones de la pendiente y
26,0
y sestos
=
3,50
kg/m
,
y
los
correspondientes
valores del
masa
corporal
La media aritmética,
denotada
por xA,=se
define
como
la
suma
cada
uno
de
los
x
fueron
s1,09
0,295
mmol/l.
Ejemplo y10.1 se
+HDL
cr, entonces
y y=
xb1+xde
cy=. estos
Un
de
origen
que deenlaelpendiente
constante utilizada;colesterol
si yi = xi de
variables
= -0,276.
A
partir
datos,
las
estimaciones
y =cambio
-1,09
+método
0,023
⋅26,0
=Además,
1,69.
b0 =de
la constante
de la
regresión
por
de mínimos
cuadrados
obtuvo
un coeficiente
de correlación
de el
Pearson
entre
ambas
deson
r = – 0,276. A
valores muestrales
dividida
porrecta
el número
de observaciones
realizadas.
Si variables
denotamos
partir
de
las
estimaciones
de consiste
la
y mínimos
la constante
de la recta
se realiza con frecuencia
es estos
el centrado
de de
la variable,
ende
restar
a
la constante
dedatos,
la recta
regresiónque
por
elpendiente
método
cuadrados
sonde regresión
La
= mínimos
1,69
es
una
estimación
del
valor
esperado
de
colesterol
porconstante
el
métodoby0de
cuadrados
son
valor
observado
para
el
sujeto
i-ésimo,
i
=
1,
...,
n,
por n el tamaño
muestral
por
xi elmmol/l
sy
0,295
b1 de
= runa variable
= −0,276centrada=será,
-0,023
cada valor de la muestra su media. La media
por
3
,
50
s xy
0,295 igual a 0 kg/m2, extrapolación
HDL dada
para por
un sujeto con bun=índice
de
masa
corporal
la media vendría
= −0,276
r
= − 0,023
1
sx
3,50
tanto, igual a 0.
y carece de sentido biológico. La pendiente b1 = -0,023 estima que, por cada
que
y
x + x + ... + x n
1 n
. de una
= 1 uno 2de los datos
x = x icada
Cambio de escala (unidades).
Si se multiplica
y
=
b1 x =de1,09
+ 0,023
⋅26,0el=nivel
1,69.medio de colesterol
nmasa
=1 y
incremento de 1 kg/mbn20 ien
el−índice
corporal,
muestra por una constante, la media de la
igual⋅26,0
a la media
=mmol/l
y - b1resultante
x una
= 1,09
+es0,023
= 1,69.
b0 muestra
La constante
b0 =en1,69
es
estimación
del valor
esperado
de colesterol
HDL
disminuye
0,023
mmol/l.
En
general,
la
pendiente
puede
utilizarse
para HDL
La mediapara
es
la
medida
de
tendencia
central
más
utilizada
y
de
más
fácil
2
La constante
b
=
1,69
mmol/l
es
una
estimación
del
valor
esperado
de
colesterol
0
un sujeto con un índice de masa corporal igual a 0 kg/m , extrapolación que carece
inicial por la constante utilizada; si yi = cxi, entonces y = c x .
– 0,023
estima
que,esperado
por cada
incremento
de
sentido
biológico.
Lammol/l
pendiente
b1 =estimación
La Corresponde
constante
b0 =alasociado
1,69
es una
del valor
calcular
el efecto
a incrementos
delos
cualquier
magnitud
c en
la colesterol
variable de 1 kg/
2 de
interpretación.
“centro
de
gravedad”
de
datos
de
la
muestra.
Su
HDL
para
un
sujeto
con
un
índice
de
masa
corporal
igual
a
0
kg/m
,
extrapolación
2
m en el índice de masa corporal, el nivel medio de colesterol HDL disminuye en 0,023
Cambio simultáneommol/l.
de origen
y general,
escala. Silasependiente
multiplicapuede
cada uno
de los datos
de
2el efecto asociado a
Enun
utilizarse
para acalcular
HDL para
sujeto
con influenciada
un índice de
masa
corporal
igual
0 kg/m
, este
extrapolación
explicativa,
principal limitación
es
que
está
muy
por
los
valores
extremos
y,
en
que
carece
de
sentido
biológico.
La
pendiente
b
=
-0,023
estima
que,
por cada
1
incrementos de cualquier magnitud c en la variable explicativa,
una muestra por una constante y al resultado se le suma otra constante, la media
queser
carece
de reflejo
sentidode
biológico.
La pendiente
b = -0,023 estima que, por cada
caso, puede incremento
no
un fiel
la−el
tendencia
(xŷ +=2 c)
ŷ-índice
(x)
= bde
+masa
b1 (x de
+
c)la1−distribución.
(b0 +
cb1 . de colesterol
de 1 ŷkg/m
en
corporal,
el bnivel
0central
1 x) = medio
1,69
0,023x,
de la muestra resultante es igual a la media
inicial
por
la
primera
constante,
más
la
2
incremento
de 1 kg/m
en el índice
de masa
corporal,
el nivel
medio
de colesterol
2
Así,
ejemplo,
de
una
desviación
típica
c=
3,50
kg/m
enpara
el índice de
HDLpor
disminuye
enincrementos
0,023 mmol/l.
general,
la pendiente
puede
utilizarse
ŷ En
= 1,69
- 0,023x,
2
Así,
por
ejemplo,
incrementos
de
una
desviación
típica
c
=
3,50
kg/m
en
el
índice
que
se
muestra
en
la
Figura
10.7.
Esta
recta
regresión
puede
utilizarse
para
Ejemplo
1.4
En
este
y
en
los
sucesivos
ejemplos
sobre
estimadores
muestrales,
se
asocian ycon
disminución
media en el colesterol HDL de cb1 =
c1xi + c2,seentonces
= cuna
c2 .
segunda constante;masa
si yi =corporal
1x +
HDL disminuye
en 0,023
mmol/l.
Enque,
general,
laconsecuencia
pendiente puede
para
3,50(–
0,023)
=
–
0,081
mmol/l.
Notar
como
de lac utilizarse
hipótesis
de
linealidad,
calcular el efecto asociado a incrementos de cualquier magnitud
en la variable
de
masa
corporal
se
asocian
con
una
disminución
media
en
el
colesterol
HDL
de
que
se
muestra
en
la
Figura
10.7.
Esta
recta
de
regresión
puede
utilizarse
para
estimarutilizarán
o predecir
el
valor
esperado
del
colesterol
HDL
en
función
del
índice
de
los
valores
del
colesterol
HDL
obtenidos
en
los
10
primeros
sujetos
del
esta disminución se asume constante a lo largo de todo el rango observado del índice de
calcular el efecto asociado a incrementos de cualquier magnitud c en la variable
masa
corporal;
esto es,del
el colesterol
modelo deHDL
regresión
lineal
estima
explicativa,
Ejemplo 1.5 Para transformar
los valores
de mmol/l
a mg/dl
seuna misma reducción de
2
=
-0,081
mmol/l.
Notar
que,
como
consecuencia
de masa
la
estimar
o
predecir
el
valor
esperado
del
colesterol
HDL
función
del
índice
de
1 = 3,50(-0,023)
,
el
masa corporal.
Por
ejemplo,
para
un
índice
de
masa
corporal
de
25
kg/m
2en and
estudiocb
“European
Study
on
Antioxidants,
Myocardial
Infarction
Cancer
ofhipótesis
0,081 mmol/l en el colesterol HDL entre 25 y 28,5 kg/m del índice
de
corporal
que
explicativa,
2
multiplica por el factor
conversión
Así,
utilizando
propiedad
del
entrede
28,5
y 32 kg/m
2
ŷde
(x38,8.
+. c)
- ŷpara
(x)
b0de
+ bla
(x
+dec)
- (b
b1x) =⋅de
cbtodo
. kg/m
0lo
de
linealidad,
esta
disminución
se=un
asume
acorporal
largo
el rango
, el
masa
corporal.
Por
ejemplo,
índice
de
masa
25
modelothe
estima
un
nivel
medio
colesterol
HDL
ŷ1constante
(25)
=casos
1,69
-+
25
=1realizado
Breast“
(EURAMIC),
un
estudio
multicéntrico
y0,023
controles
La recta de regresión estimada del colesterol HDL sobre el índice de masa corporal es
ŷ (x + HDL
c) - ŷen
(x)mg/dl
= b0 +sebcalcularía
cambio de escala, la media del colesterol
1(x + c) - (b0 + b1x) = cb1.
observado
del
índice
de
masa
corporal;
esto
es,
el modelo
de=efecto
regresión
lineal
2 los
modelo
estima
un
nivel
medio
de
colesterol
HDL
de
ŷ (25)
1,69
0,023
⋅25índice
=
entre
1991
y
1992
en
ocho
países
Europeos
e
Israel
para
evaluar
1,11 mmol/l. Así,
Por supuesto,
los valores
observados
del
colesterol
HDL
de-de
por ejemplo,
incrementos
deŷ una
desviación
típica
c difieren
=el3,50
kg/m
en el
= 1,69
− 0,023x,
directamente a partir de su media en mmol/l como 1,223⋅38,8 = 47,45 mg/dl.
2
Así,
por
ejemplo,
incrementos
una
desviación
típica
c =puede
3,50
kg/m
en25
el
estima
una
misma
reducción
dede
0,081
mmol/l
enregresión
el
colesterol
HDL
entre
yíndice
que
se
muestra
en
Figura
10.7.
Esta
recta
utilizarse
para
estimar o
1,11
mmol/l.
Por
supuesto,
valores
observados
del
colesterol
HDL
difieren
de
los valores medios
predichos
por
recta los
de
La de
varianza
residual
del
de
masa
corporal
selala
asocian
conregresión.
una
disminución
media
en el colesterol
HDL
de
5
que
se
muestra
en
la
Figura
10.7.
Esta
recta
de
regresión
puede
utilizarse
para
predecir el2 valor esperado del colesterol HDL en función del índice
de masa corporal. Por
2
2 y 32
de
masa
corporal
se
asocian
con
una
disminución
media
en
el
colesterol
HDL
de medio
6
28,5
kg/m
del
índice
de
masa
corporal
que
entre
28,5
kg/m
.
,
el
modelo
estima
undel
nivel
ejemplo,
para
un
índice
de
masa
corporal
de
25
kg/m
los1respecto
valores
medios
por laesrecta
regresión.
La varianza residual
colesterol HDL
a la recta
de regresión
cb
= 3,50(-0,023)
=predichos
-0,081
mmol/l.
Notardeque,
como consecuencia
de la hipótesis
estimar
o predecir
colesterol
HDLmmol/l.
en función
índice los
de valores
de colesterol
HDLeldevalor
ŷ(25)esperado
= 1,69 –del
0,023⋅25
= 1,11
Por del
supuesto,
cb
=
3,50(-0,023)
=
-0,081
mmol/l.
Notar
que,
como
consecuencia
de
la
hipótesis
La
recta
de
regresión
estimada
del
colesterol
HDL
sobre
el
índice
de
masa
1
observados
del533
colesterol
difieren
de
los valores
por la recta de
colesterol
HDL
respecto
aHDL
la recta
de regresión
es a lo medios
de
linealidad,
esta
disminución
se
asume
constante
largo depredichos
todo el rango
2
SSE
1
42,63
,
el
masa
corporal.
Por
ejemplo,
para
un
índice
de
masa
corporal
de
25
kg/m
2
es
=
= La varianza
{ y i − (residual
1,69 − 0,del
023colesterol
x i )} = HDL=respecto
0,080. a la recta de regresión
s2 regresión.
de 531
linealidad,
esta
disminución
se
asume
constante
a
lo
largo
de
todo
el
rango
corporal
es531
531
i
=
1
observado del índice
533 corporal; esto es, el modelo de regresión lineal
SSE de medio
1masa
42,63
2ŷ (25)
modelo estima
= 1,69
- 0,023⋅25 =
=
y i colesterol
− (1,69 − 0HDL
= 0,080.
{de
,023xde
s2 = un nivel
i )} =
observado del índice
de
masa
corporal;
esto
es,
el
modelo
de
regresión
lineal
531
531 HDL entre
531 i =1
estimaque
unadebido
misma
mmol/l en de
el colesterol
25 y 20
Notar, por último,
a reducción
la hipótesisdede0,081
homogeneidad
la varianza,
la
1,11 mmol/l. Por supuesto, los valores observados del colesterol HDL difieren de
Notar,
debido de
a la0,081
hipótesis
de homogeneidad
la2 varianza,
estima por
una2último,
misma que
reducción
mmol/l
en el colesteroldeHDL
entre 25lay desviación
28,5
kg/m
del
índice
de
masa
corporal
que
entre
28,5
y
32
kg/m
.
Notar,
por
último,
que
debido
a
la
hipótesis
de
homogeneidad
de
la
típica
residualdel
delcolesterol
colesterolHDL
HDLss== 0,080 ==0,283
constantelaalrededor
desviación típica
residual
0,283mmol/l
mmol/lseseasumevarianza,
los valores2 medios predichos por la recta de regresión. La varianza
2 residual del
de
cualquier
punto
de de
la recta
regresión.
28,5
kg/m del
índice
masade
corporal
que entre 28,5 y 32 kg/m .
La
recta de típica
regresión
estimada
del colesterol
HDL
masa se
desviación
residual
del
colesterol
HDL
= sobre
0,080el=índice
0,283de
mmol/l
asume constante
alrededor
derespecto
cualquiera la
punto
recta
desregresión.
colesterol
HDL
rectadedelaregresión
es
La recta de regresión estimada del colesterol HDL sobre el índice de masa
corporal es
asume constante alrededor de cualquier punto de la recta de regresión.
533
168 Pastor-Barriuso R.
42,63
corporal ess2 = SSE = 1
{ y i − (1,69 − 0,023x i )}2 =
= 0,080.
[Figura 531
10.7 aproximadamente
aquí]
531 i =1
531
20
Regresión lineal simple
2,25
Colesterol HDL (mmol/l)
2
1,5
1
0,5
0,25
20
24
28
antioxidantes en el riesgo de desarrollar un primer infarto
agudo de miocardio en
Indice de masa corporal (kg/m²)
32
36
Figura
10.7del
Figura
10.7
de regresión
del
HDL
sobre1,29,
el índice
de
masa
en el grupo
control
hombres adultos.
Los
valores
obtenidos
1,58,
0,84,corporal
encolesterol
el0,89,
riesgo
de 0,79,
desarrollar
unidoneidad
primer
infarto
agudo
de miocardio
en
sentido
deRecta
queantioxidantes
no
facilitafueron
ninguna
información
sobre
la1,42,
del modelo
lineal
estudio EURAMIC.
1,06, 0,87, 1,96 para
y 1,53
mmol/l.
media
de losLos
niveles
dellas
colesterol
HDL
en0,89, 1,58,
hombres
adultos.
valores
obtenidos
fueron
0,79, 1,29, 1,42, 0,84,
describir
laLa
relación
subyacente
entre
variables
explicativa
y respuesta.
sentido
de que nodel
facilita
ninguna
información
sobre
la idoneidad del modelo lineal
10.3.2
Contraste
modelo
regresión
lineal
simple
estos 10 participantes
es
1,06,del
0,87,
1,96 de
yde
1,53
mmol/l.
media
los niveles
colesterol
La realización
contraste
regresión
seLa
basa
en eldeanálisis
de ladel
varianza
de laHDL en
En para
general,
el contraste
de regresión
lineal
permite
evaluar explicativa
si el modeloyen
su conjunto explica
describir
la relación
subyacente
entre
las variables
respuesta.
estos
10
participantes
es
10significativa
variable
respuesta.
Una
vez
estimada
la
recta
de
regresión,
la
desviación
de cada
valor de la
una
parte
de
la
variabilidad
de
la
variable
respuesta.
En
el
caso
particular
1
0,89 + 1,58 + ... + 1,53
x
x
=
1,223
mmol/l.
=
=
i
regresión
lineal
simple,
hipótesisdenula
del contraste
la pendiente
La realización
dellacontraste
regresión
se basaesensimplemente
el análisis deque
la varianza
de laβ1 de la
10
10
=1
a la media
y
puede
separarse
en
dos
componentes:
el
observado
yi respecto
recta
de iregresión
subyacente
es 0,muestral
ya
tal
caso
la
variable
respuesta
no
se
relacionará
10que en
1
0,89 + 1,58 + ... + 1,53
x
x
=
1,223
mmol/l.
=
=
linealmente
con la única
explicativa
y, en
el modelode
lineal
aportará
lai recta
variable respuesta.
Unavariable
vez estimada
de consecuencia,
regresión, la desviación
cadano
valor
10 i =1de la variable respuesta.
10
explicación
alguna
sobre
la
variabilidad
Es
importante
resaltar
o desviación
del valor
observado yi respecto a su valor estimado por la recta deque este
a media aritméticaerror
presenta
las siguientes
propiedades:
contraste
de regresión
linealidad
y, por
tanto, separarse
no debe interpretarse
como uneltest de
a la media
muestral
y puede
en dos componentes:
observado
yi respectoasume
bondad
del
ajuste,
en
el
sentido
de
que
no
facilita
ninguna
información
sobre
la idoneidad del
regresión
ŷLa
bSi0 +
la distancia
dicho
estimado
1xi, y una
i =media
Cambio de origen
(traslación).
sebsuma
constante
a cada
unovalor
depropiedades:
los
datos ŷ i y la media
aritmética
presentaentre
las
siguientes
modelo
para describir
la relación
subyacente
entre
variables
explicativa
y respuesta.
a sulas
valor
estimado
por la recta
de
errorlineal
o desviación
del valor
observado
yi respecto
Lamedia
realización
deles,contraste
de regresión
el
análisis
de
de la
de una muestra,muestral
la
de
muestra
es igual se
a labasa
inicial
la la varianza
y•; la
esto
Cambio
deresultante
origen
(traslación).
Simedia
se en
suma
una más
constante
a cada uno
devariable
los datos
regresión
= b0estimada
+ b1xi, y la distancia
entre dicholavalor
estimado
y
la
media
respuesta.
Unaŷ i vez
recta de regresión,
desviación
de ŷcada
valor
observado
yi
i
en dos
el error
desviación
respecto
muestral
= xmedia
c, una
entonces
y puede
=la xmedia
+separarse
c. Un
cambio
de componentes:
origen quees igual
constante utilizada;
si yai la
i +de
muestra,
de la
muestra
resultante
a la omedia
inicialdel
más la
yi - y estimado
= ŷ i - y por
+ yi la
- ŷrecta
i.
valor
observado
y
respecto
a
su
valor
de
regresión
ŷ
=
b
+
b
x
,
y
la
muestral y ; esto
i es,
i
0
1 i
entre
valorde
estimado
muestral
=que
xmedia
c, entonces
y ; =esto
+ c. Un cambio de origen que
constante
utilizada;
siŷi yyi la
se realiza condistancia
frecuencia
es eldicho
centrado
la variable,
consiste
en restar
ax es,
i+
Elevando al cuadrado estas desviaciones y sumando sobre todas las observaciones, se
yi − variable
y = ŷ i −centrada
y + y −será,
ŷ i . por
cada valor de la muestra su media.
La media
de una
se realiza
con frecuencia
es el centradoi de
la variable, que consiste en restar a
tiene que
suma deestas
cuadrados
total yessumando sobre todas las observaciones, se tiene que
Elevando
al la
cuadrado
desviaciones
tanto, igual a la
0. suma
cada valor
deesladesviaciones
muestra su media.
La media
unalas
variable
centrada será,
de cuadrados
total
Elevando
al cuadrado
estas
y sumando
sobrede
todas
observaciones,
se por
n
n
n
n
i =1
i =1
i =1
i =1
2
Cambio de escalatiene
(unidades).
Si
multiplica
de
datos
tanto,
igual
ˆ
ˆ
y )a2 0.
= cada
yˆuno
) 2 los
+
( y i −deyˆuna
SSTla=suma
que
es
se( yde
(total
i −cuadrados
i − y
i ) + 2 ( y i − y )( y i − y i )
muestra por una constante,•la Cambio
media dedelaescala
muestra
resultanteSiesnseigual
a la media
n(unidades).
multiplica
cadan uno de los datos de una
n
n
n
2
ˆ
=
(
y
−
y
)
+
(
y
−
yˆ i ) 2 2 = SSR
+ SSE,
2
2
iˆ
i
( y i − y ) +i
( y i − yˆ i ) + 2 ( yˆ i − y )( y i − yˆ i )
SST = ( y i − y ) = i
=1
=1
cxiuna
, entonces
y =lac media
x . i =1 de la muestrai =resultante
inicial por la constante utilizada;
muestra
por
constante,
es igual a la media
i =1si yi =
i =1
1
n
n de
yi =los
cxdatos
porSilaseconstante
utilizada;
si
Cambio simultáneo de origen inicial
y escala.
multiplica
cada uno
de y = c x .
i, entonces
= incorrelacionadas
( yˆ i − y ) 2 + ( y i − yˆ i ) 2 = SSR + SSE,
ya que ambas componentes están
i =1
i =1
Pastor-Barriuso R.
169
una muestra por una constante
y al resultado
se le de
suma
otrayconstante,
• Cambio
simultáneo
origen
escala. Si la
semedia
multiplica cada uno de los datos de
=
Correlación y regresión lineal simple
n
n
i =1
i =1
( yˆ i − y ) 2 + ( y i − yˆ i ) 2 = SSR + SSE,
1.2 en
MEDIDAS
DE TENDENCIA
CENTRAL
ya que ambas
componentes
están
es en el riesgo de desarrollar
un primer
infarto
antioxidantes
agudoincorrelacionadas
de miocardio
en el riesgo
de desarrollar
un primer infarto
agudo de miocardio e
ya que ambas componentes están incorrelacionadas
ultos. Los valores obtenidos fueron
0,89, 1,58,
hombres
0,79, 1,29,
adultos.
Los
0,84,
valores
fueron
0,89, 1,58,
0,79,acerca
1,29, 1,42,
0,84
n
n 1,42,
n obtenidos
n
Las
medidas
de tendencia
central
informan
de cuál
es
ˆ
ˆ
(
y
−
y
)(
y
−
y
)
=
b
(
x
−
x
)
e
=
b
x
e
−
b
x
e
=
0
i
i
i
i
i
1
1 i i
1 i
i =1 los niveles del
i =1 La mediai =de
1 HDL
1 los niveles del colesterol HDL en
1,96 y 1,53 mmol/l. La media de
1,06,
colesterol
0,87,i =1,96
y 1,53
en una
mmol/l.
de
determinada
variable
o, dicho de forma equivalente, e
según las ecuaciones de regresión derivadas del método de mínimos cuadrados. Así, la suma
rticipantes es de cuadrados
estos 10derivadas
participantes
es independientes:
total SST sededescompone
en dos términos
la
de Así,
cuadrados
según las ecuaciones
regresión
del
método
de qué
mínimos
la observados. Las
alrededor
de
valor cuadrados.
sesuma
agrupan
los datos
de la regresión SSR, que representa la variabilidad de la variable respuesta explicada por la
10
delsemodelo
de regresión,
y 0la,89
suma
cuadrados
delresumir
error los resultados
suma
cuadrados
total SST
descompone
en
dos
términos
suma
de
muestra
sirven
+de
+independiente
+independientes:
+
+ 1tanto
1 10 única
0,89variable
1,58
... + 1,53
1central
1,58de
...
,53 lapara
x = x iSSE,
1,223 mmol/l.
x
x i = respuesta que queda=sin
1,223
mmol/l.
= que corresponde a la=variabilidad
=
residual de lavariable
explicar.
10 i =1
10
10 i =1
10
Conviene
recordar
la recta SSR,
de regresión
estimada
por el procedimiento
mínimospoblacionales c
realizar
acerca
de los de
parámetros
que representa
la inferencias
variabilidad
de la variable
de cuadrados
de que
la regresión
cuadrados minimiza la suma de cuadrados del error, maximizando entonces la capacidad
predictiva o explicada
explicativa
modelo
de regresión.
La Figurase
10.8
ilustra
gráficamente
continuación
describen
los
principales
estimadores de la t
pordel
la única
independiente
modelo
de regresión,
y la esta
mética presenta lasrespuesta
siguientes propiedades:
La
mediavariable
aritmética
presenta lasdel
siguientes
propiedades:
descomposición.
variable.a la variabilidad
cuadrados
della
error
SSE,
residual
de la
LaSidescomposición
de
de
la
mediante
origen (traslación).suma
sede
suma
una constante
• variabilidad
Cambio
a cada
uno
deque
origen
de corresponde
losvariable
(traslación).
datos respuesta
Si se suele
suma representarse
una
constante
a cada uno de los datos
la denominada tabla del análisis de la varianza (Tabla 10.2). En primer lugar, esta tabla
explicar.
recordar
que la
recta
de es
regresión
presenta
lasrespuesta
sumas
deque
cuadrados
junto
con inicial
susConviene
grados
de libertad.
La suma
de
stra, la media de
lavariable
muestra
resultante
es queda
igual
deasin
una
la media
muestra,
lacorrespondientes
media
más la
de
la muestra
resultante
igual
a la media
inicial más
1.2.1
Media
aritmética
cuadrados de la regresión contiene únicamente 1 grado de libertad ya que, una vez conocida la
estimados
la recta
dexiregresión
ŷi =
muestral y , =losx valores
xi + c, entonces
+ c. Un
cambio utilizada;
depor
origen
ymedia
+aritmética,
c, entonces
y += bx1(xpor
+i c–. Un
cambio
origen
que
tilizada; si yi = media
constante
sique
La
denotada
x ), quedan
se
definede
como
la sum
i=
22
completamente determinados por su pendiente; mientras que, como se vio en el apartado
la suma
cuadrados
del error
nvalores
de libertad.
continuación,
los
dividida
por
el número
de observaciones
on frecuencia esanterior,
el centrado
de la de
variable,
que
se realiza
consiste
con
entiene
frecuencia
restar
a– 2 grados
esmuestrales
el centrado
de la A
variable,
que consiste
en restar a
términos de la varianza se obtienen de dividir las sumas de cuadrados por sus grados de libertad.
la razón
define
como
el cociente
entre
lamedia
varianza
explicada
por
la
por
n su
el tamaño
muestral
ydepor
xivariable
el valor
observado
parapor
el s
de la muestra suFinalmente,
media. La media
de de
unavarianzas
variable
cada se
centrada
valor
de la
será,
muestra
media.
La
una
centrada
será,
regresión y la varianza residual, que constituye el estadístico del contraste de regresión.
la media vendría dada por
a 0.
tanto, igual a 0.
escala (unidades). Si se multiplica cada uno
• de
Cambio
los datos
de escala
de una(unidades). Si se multiplica cada uno
+ x 2de+una
... + x n
1 nde los xdatos
.
x = xi = 1
n
n
i =1
r una constante, la media de la muestra resultante
muestra
es igual
por una
a laconstante,
media
la media de la muestra resultante es igual a la media
(xi, yi)
= c x . por la constanteLa
yi medida
= cxi, entonces
y = ccentral
x.
a constante utilizada; si yi = cxi, entonces y inicial
utilizada;
media essi la
de tendencia
más utilizada
ei = yi − yˆ i
interpretación.
Corresponde
al “centro de gravedad” de los d
multáneo de origen y escala. Si se multiplica
• cada
Cambio
unosimultáneo
de los datos
dedeorigen
( x , yˆ )y escala. Si se multiplica cada uno de los datos de
i
i
yi − y
principal
limitación
es queseestá
muy otra
influenciada
porlalos
val
a por una constante y al resultado se le suma una
otra( xmuestra
constante,
porlauna
media
constante
y al resultado
le suma
constante,
media
, y)
yˆ − y
y
i
caso,
puede
sermedia
un fiel
reflejo
tendencia
central de
ra resultante es igual a la media inicial por lade
primera
la muestra
constante,
resultante
más es
la
igualno
a la
inicial
pordelalaprimera
constante,
másla
c2 .
nstante; si yi = c1xi + c2, entonces y = c1 x +segunda
constante; si yi = c1xi + c2, entonces y = c1 x + c2.
Recta de regresión estimada:
Ejemplo 1.4 En este y en los sucesivos ejemplos sobre
yˆ = b0 + b1 x = y + b1 ( x − x )
utilizarán
los valores
del colesterol
obtenidos
en
5 Para transformar los valores del colesterol HDL
Ejemplo
de mmol/l
1.5 Paraa transformar
mg/dl se
los valores
del colesterol
HDLHDL
de mmol/l
a mg/dl
“European
Study
on Antioxidants,
Myocardial
por el factor de conversión 38,8. Así, utilizando
multiplica
la propiedad
por eldel
factor deestudio
conversión
38,8. Así,
utilizando
la propiedad
del
thedel
Breast“
(EURAMIC),
un estudio
multicéntrico de c
escala, la media del colesterol HDL en mg/dlcambio
se calcularía
de escala, la media
colesterol
HDL en mg/dl
se calcularía
x
1991
1992 en
ocho1,223
países
Europeos
Israel par
⋅38,8 = 47,45amg/dl.
⋅Figura
38,8
= 47,45emg/dl.
te a partir de su media en mmol/l como 1,223directamente
partir de suentre
media
en ymmol/l
como
10.8
Figura 10.8 Descomposición de la variabilidad de la variable respuesta en la parte explicada y no explicada por la regresión.
6
170
Pastor-Barriuso R.
libertad ya que, una vez conocida la media muestral y , los valores estimados por la
Regresión lineal simple
recta de regresión ŷ i = y + b1(xi - x ) quedan completamente determinados por su
pendiente;
mientras
que,
como
se viodel
enanálisis
el apartado
anterior,
laen
suma
de cuadrados del
Tabla
10.2Tabla
Tabla
genérica
de laen
varianza
regresión
Tabla 10.2
genérica
del análisis
de la varianza
regresión lineal
simple.* lineal
simple.*
varianza
var(b1). Así, bajo la hipótesis nula H0: β1 = 0, el cociente SSR/σ 2 es el
error tiene n - 2 grados de libertad.
Suma de A continuación,
Gradoslos
de términos de la varianza
Razón dese
Suma
de
cuadrados
Grados
de
libertad
Varianza
Razón
de
varianzas
cuadrado de una distribución
normal estandarizada,
definición a
cuadrados
libertadque corresponde por
varianzas
obtienen de dividir las sumas nde cuadrados por sus gradosVarianza
de libertad. Finalmente, la
SSR
Regresión chi-cuadrado
SSR = con
( yˆ i −1ygrado
)
1
SSRparte, basta
F = con
2 que se
una distribución
de libertad.
Por otra
i =1
razón de varianzas se define como
el cociente entre la varianza explicada porsla
2
n
n
cumplan las asunciones subyacentes
al modelo
lineal para que
la varianza residual s2
SSE
2
2
2
( y i constituye
− yˆ i )
n −estadístico
2
s =del contraste de regresión.
Error
SSE =residual,
regresión
y la varianza
el
ei = que
i =1
i =1
sea un estimador insesgado de σ 2 y el cociente
n−2
n
y) 2
SST =[Tabla
( y i −10.2
n −1
aproximadamente
aquí]
2
(n − H
2) s: β = 0, el cociente SSR/σ 2 es el
varianza var(b1). Así, bajo la hipótesis
nula
0
1
2
2
2
*
Coeficiente
de
determinación
R
=
SSR/SST.
* Coeficiente de determinación R = SSR/SST.
σ
Para realizar el contraste de regresión, es preciso conocer la distribución de la razón
cuadrado de una distribución normal estandarizada, que corresponde por definición a
Por unde
lado,
selatiene
que
de
varianzas
bajo
la hipótesis
H
siga
una
distribución
chi-cuadrado
con
-=20.
grados
libertad.
Combinando
ambos
0: βn1es
Para
realizar
el contraste
de nula
regresión,
preciso
conocer
distribución
de
la razón de
una distribución chi-cuadrado con 1 grado de libertad. Por otra parte, basta con que se
varianzas bajo la hipótesis nula H0: β1 = 0. Por un lado, se tiene que
2varianzas
resultados,
sebtiene
quen bajolalahipótesis
hipótesis
nula
: β1 =0,0ella
razón entre
las
2 SSR/
n HH
varianza
σ
es el s2
1). Así,
0: 0β1 =
b12cociente
(que
n − 1la
) s varianza
bal12nula
b12 residual
SSR
1 bajo
cumplan var(
las
asunciones
subyacentes
modelo
lineal
2
2 para
x
ˆ
=
−
=
−
=
=
,
(
y
y
)
(
x
x
)
i
i
2
2
2
2
var(
b
)
σ
σ
σ
σ
i
i
1
1
=
=
1
explicada
y residual
cuadrado
de
una distribución
que corresponde por definición a
sea un estimador
insesgado denormal
σ 2 y elestandarizada,
cociente
donde var(b1) = σ 2/{(n – 1)s2x} es la varianza de la pendiente estimada. Como se comprobará en
2
2 otra parte, basta con que se
una distribución
chi-cuadrado
con
1 grado
Por
donde
var(b
1) s x2 }SSR
eslas
la
varianza
de la
estimada.
Como se
el siguiente
apartado,
si se- cumplen
asunciones
dependiente
la χregresión
lineal simple,
la pendiente
1) = σ /{(n
σ 2libertad.
SSR /de
1
2
=
F
=
~
(
n
−
2
)
s
2
2
estimada b1 seguirá una distribución
media
y2varianza
var(b1). Así, 2bajo la
s 2 normal
smodelo
χ n2− 2para
/ σcon
/(βn1 −que
) la varianza
cumplan
las
asunciones
subyacentes
al
residual s normal
22 lineal
σ
hipótesis
nula en
H0:elβsiguiente
cociente siSSR/σ
es ellas
cuadrado
de de
unaladistribución
comprobará
se cumplen
asunciones
regresión lineal
1 = 0, el apartado,
estandarizada, que corresponde por 2definición a una distribución chi-cuadrado con 1 grado de
seadistribuye
unPor
estimador
insesgado
de de
σ dos
yseelchi-cuadrado
cociente las asunciones
se
elestimada
cociente
independientes
divididas
libertad.
otracomo
parte,
basta
con
subyacentes
modelo
bque
normal
con
mediaalβpor
y sus lineal
simple,
ladistribución
pendiente
1 seguirá
1ambos
siga una
chi-cuadrado
concumplan
nuna
- 2 distribución
grados de libertad.
Combinando
2
2
para que la varianza residual s sea un estimador insesgado de σ y el cociente
respectivos grados de libertad, que es una distribución
F de Fisher con 1 grado de
23
− 2)Hs 02: β1 = 0 la razón entre las varianzas
resultados, se tiene que bajo la hipótesis(nnula
Total
i =1
2
σ
libertad en el numerador y n - 2 grados de libertad
en el denominador. El valor P del
explicada
y
residual
siga una distribución chi-cuadrado con n – 2 grados de libertad. Combinando ambos resultados,
se tiene
que distribución
bajo
la hipótesis
H0: βcon
= n0 -laH
las varianzas
explicada
y residual
contraste
de regresión
de lanula
hipótesis
: β1 =entre
0defrente
a la Combinando
hipótesis
alternativa
1 nula
0grados
siga una
chi-cuadrado
2razón
libertad.
ambos
χ 12
SSR SSR / σ 2
=
~
F
=
2nula2 la
H1se
: βtiene
derecha
estadístico
bilateral
resultados,
quecalcula
bajo laentonces
hipótesis
: βχ1 2= 0/(la
las del
varianzas
1 ≠ 0 se
s2
scomo
/ σ H0probabilidad
n −razón
2a) la entre
n−2
se distribuye
como
el cociente
F
bajo la distribución
F1,n-2.de dos chi-cuadrado independientes divididas por sus respectivos
explicada
y residual
grados
de libertad,
queelescociente
una distribución
F de Fisher con
1 grado de libertad
enpor
el numerador
se distribuye
como
de dos chi-cuadrado
independientes
divididas
sus
y n – 2La
grados
de
libertad
en
el
denominador.
El
valor
P
del
contraste
de
regresión
de
la
hipótesis
tabla del análisis de la varianza suele ir 2acompañada
del coeficiente de
2
χ
σ
SSR
SSR
/
nularespectivos
H0: β1 = 0 grados
frente adelalibertad,
hipótesis
alternativa
bilateral
0 se calcula
entonces
es
distribución
con 1 grado
de como la
1 ≠Fisher
= una
F = que
~ 2 H1F:1βde
2
2
2
2
.
probabilidad
a
la
derecha
del
estadístico
F
bajo
la
distribución
F
s
s
σ
χ
n
−
/
/(
2
)
determinación R , que se define como la proporción
de la variable
1,n–2
n − 2de la variabilidad
libertad en el numerador y n - 2 grados de libertad en el denominador. El valor P del
La tabla del análisis de la varianza suele ir acompañada del coeficiente de determinación R2,
se explica
por el modelo
de regresión,
querespuesta
sedistribuye
defineque
como
la el
proporción
de dos
la variabilidad
de la variable respuesta
que por
se explica
por
se
como
cociente
chi-cuadrado
divididas
sus
contraste
de regresión
de la hipótesis
nula
H0: β1 = 0independientes
frente a la hipótesis
alternativa
el modelo de regresión,
n
respectivos grados de libertad,n que es una
F de Fisher con 1 grado de
2 distribución
entonces
del estadístico
bilateral H1: β1 ≠ 0 se calcula
b12laprobabilidad
( yˆ i − y )como
( x i − x ) 2 a la derecha
2
SSR i =1
2
2
2 sx
i =1
R =
= b1 2 = rEl. valor P del
libertad en el numerador
y =n -n2 grados de =libertad
en el denominador.
n
sy
F bajo la distribuciónSST
F1,n-2.
2
2
( yi − y)
( yi − y)
i =1
contraste de regresión de la hipótesis
nula H0:i =β1 1 = 0 frente a la hipótesis alternativa
La tabla del análisis de la varianza suele ir
acompañada del coeficiente de
Pastor-Barriuso R.
bilateral H1: β1 ≠ 02 se calcula entonces como la probabilidad a la derecha del estadístico
determinación R , que se define como la proporción de la variabilidad de la variable 24
F
bajo la distribución
F1,n-2
respuesta
que se explica
por. el modelo de regresión,
171
el cuadrado
del coeficiente
de correlación
r de aPearson
entre
las variables
explicativa
observados
del colesterol
HDL respecto
la media
muestral
y = 1,09
mmol/l esy
lineal del10colesterol HDL sobre el índice de masa corporal en 533 controles del
+ 1,53 el análisis de la varianza de la regresión
1 10.8 La0,Tabla
89 + 1,10.3
58 + ...
Ejemplo
presenta
respuesta.
x y=regresión
xlineal
= 1,223 mmol/l.
Correlación
i = simple
533
10 EURAMIC.
10 de cuadrados
estudio
La suma
de)las
desviaciones
de los valores
2
i =1
( y i − de
1,09
46,15, en 533
lineal del colesterol HDL SST
sobre= elíndice
masa=corporal
controles del
i =1
Ejemplo
10.8
Tabla 10.3
presenta
el análisis
de la
varianzay de
la regresión
observados
delLacolesterol
HDL
respecto
a la media
muestral
= 1,09
mmol/l
es
2
En el estudio
casopresenta
deEURAMIC.
la regresión
lineal
simple,
el coeficiente
de determinación
coincide con el
La
suma
de cuadrados
de las desviaciones
de los R
valores
La media aritmética
las siguientes
propiedades:
que del
sedel
descompone
la suma
cuadrados
deentre
lascorporal
desviaciones
colesterol
cuadrado
coeficiente
correlación
de Pearson
las variables
explicativa
y respuesta.
lineal
colesteroldeen
HDL
sobre de
elríndice
de masa
en 533del
controles
del
533
observados
del colesterol
HDL
la
media
muestral
y = 1,09 mmol/l es
• Cambio de origen
(traslación).
Si se suma
una
constante
a cada
de los datos
SST
=respecto
( y i −a1,09
) 2 =uno
46,15,
HDL
respecto
a
la
recta
de
regresión
ŷ
x
=
1,69
0,023
i
EjemploEURAMIC.
10.8 La Tabla
10.3de
presenta
el
la varianza
delos
la regresión
estudio
La suma
cuadrados
de las de
desviaciones
de
valores lineal del
i análisis
i =1
colesterol
el índice
de533
masa
corporal
533 inicial
controles
de una muestra,
la mediaHDL
de lasobre
muestra
resultante
es igual
a la en
media
másdel
laestudio EURAMIC.
2 valores
La suma de del
cuadrados
deSST
las
observados
colesterol
observados
colesterol
HDL
respecto
lademedia
muestral
y = 1,09del
mmol/l
es HDL
=de
( y i −a1,09
)los
= 46,15,
533desviaciones
que
se
descompone
en
la
suma
cuadrados
de
las
desviaciones
del colesterol
2
=
1,09
mmol/l
es
respecto
muestral
i
=
1
= xmedia
+
c
,
entonces
y
=
x
+
c
.
Un
cambio
de
origen
que
constante utilizada;
si yai la
SSE = { y i − (1,69 − 0,023x i )} = 42,63
i
i =1
533
HDL respecto a la recta de regresión
ŷ = 1,692 - 0,023xi
se realiza con que
frecuencia
es
el
centrado
de
la
variable,
en restar a del colesterol
SST
=
( y i i−que
1,09consiste
) las
= 46,15,
se descompone en la suma decuadrados
de
desviaciones
i =1
y la suma de cuadrados de las distancias entre los valores estimados por la recta
533 de una variable centrada será, por
cada valor de que
la muestra
su media.
La de
media
HDL
a la recta
regresión
ŷ i = 1,69 -de0,023
serespecto
descompone
en
la
suma
de cuadrados
las xdesviaciones del colesterol HDL
SSE
=
{ y i − (1,69
− 0,023x i )}2 =i 42,63
de
regresión
y
la
media
muestral
que
se
descompone
en
la
suma
de
cuadrados
de
las
desviaciones del colesterol
respecto a la recta de regresión
i =1 ŷi = 1,69 – 0,023xi
tanto, igual a 0.
533
•
HDL respecto a la recta
de
regresión
x=i 42,63
1,69
- x0,023
533{ y − (1,ŷ
i =
= las
69
−de
0,los
023
)}22 de
i
ivalores
y la suma
de cuadrados
de
distancias
entre
los
estimados por la recta
Cambio de escala
(unidades).
Si seSSE
multiplica
cada
uno
datos
= una
3,53.
SSR = i
=1 (1,69 − 0,023 x i − 1,09)
i =1
•
ydelaconstante,
suma deylacuadrados
de533
las distancias
entre
los2 valores
estimados por la recta de
regresión
lamedia
mediademuestral
muestra por una
la
muestra
resultante
es igual
a la media
SSE
=
{
y
−
(
1
,
69
−
0
,
023
x
)}
=
42,63
regresión
media muestral
y la suma ydelacuadrados
de las
distancias
entre los ivalores estimados por la recta
i
i =1
Así, la proporción de la variabilidad
del colesterol HDL que se explica
inicial por la constante utilizada; si yi = cx533
i, entonces y = c x .
de regresión y la media
muestral
(1,69corporal
− 0,023viene
x i − 1,dada
09) 2 por
= 3,53.
SSR =de
únicamente
con
el
índice
masa
el coeficiente de
y la suma
de cuadrados
i =1 distancias entre los valores estimados por la recta
Cambio simultáneo
de origen
y escala.deSilas
se multiplica cada uno de los datos de
533
Así,
la proporción de la variabilidad
del colesterol HDL
determinación
2 que se explica únicamente con el
de
regresión
y
la
media
muestral
(
1
,
69
−
0
,
023
x
−
1
,
09
)
3,53.
SSR
=
i
una muestra por
una
constante
y
al
resultado
se
le
suma
otra
constante,
la media
índice
masa corporal
viene
dada por
coeficiente
de=que
determinación
Así, la de
proporción
de la variabilidad
delelcolesterol
HDL
se explica
i =1
2
Rinicial
= 3,53/46,15
= 0,076,
de la muestra únicamente
resultante escon
igual
la media
por la primera
constante,
más la
el aíndice
de533
masa
corporal
viene
dada
2 por el coeficiente de
(
1
,
69
−
0
,
023
x
−
1
,
09
)
=
3,53.
SSR
=
Así, coincide
la proporción
decuadrado
la variabilidad
del colesterol
HDL que se
explica
i
que
con elde
del coeficiente
de correlación
i =1
parte significativa
la
variabilidad
total
del
colesterol
HDL,muestral
se realizaentre
el el índice de
y
=
c
x
+
c
,
entonces
y
=
c
x
+
c
.
segunda constante;
si
2
2
i
1
i
2
1
2
determinación
que
coincide
con
el
cuadrado
del
coeficiente
de
correlación
muestral
entre
el
masa corporal y el colesterol HDL r = (– 0,276) = 0,076. Para determinar
si esta
únicamente
con
el
índice
de
masa
corporal
viene
dada
por
el
coeficiente
de
variabilidad
explicada
por
el
índice
de
masa
corporal
es
una
parte
significativa
H0: 2β1 =HDL
0 mediante
razón entre las de la
contraste
de regresión
devariabilidad
la hipótesisdel
nula
2 se la
Así,
la
proporción
de
la
colesterol
que
explica
índice
de
masa
corporal
y
el
colesterol
HDL
r
=
(-0,276)
=
0,076.
Para de la hipótesis
2
variabilidad total del colesterol
se realiza
el contraste de regresión
R HDL,
= 3,53/46,15
= 0,076,
determinación
Ejemplo 1.5 Para
transformar
los
valores
del
colesterol
HDL
de
mmol/l
a
mg/dl
se
2 varianzas explicada SSR = 3,53 y residual
nula
H0: βexplicada
la razón
entre las
1 = 0 mediante
varianzas
SSR =
y corporal
residual
sviene
= 42,63/531
=el0,080,
únicamente
con
el variabilidad
índice
de3,53
masa
dada de
pormasa
coeficiente
deuna
determinar
si
esta
explicada
por
el índice
corporal es
2
s = 42,63/531 = 0,080,
2 coeficiente
coincide
con el cuadrado
correlacióndel
muestral entre el
multiplica porque
el factor
de conversión
38,8.Rdel
Así,
utilizando de
la
propiedad
= 3,53/46,15
= 0,076,
25
determinación
F = 3,53/0,080 = 43,93.
2
2
índice
masa
y elHDL
colesterol
HDL
= (-0,276) = 0,076. Para
cambio de escala,
la de
media
delcorporal
colesterol
en mg/dl
sercalcularía
Bajo
la hipótesis
este estadístico
sigue una distribución F de Fisher con 1 grado de
que coincide
con nula,
el cuadrado
del
2 coeficiente de correlación muestral entre el
R =grados
3,53/46,15
= 0,076,
Bajo la hipótesis
nula, estey estadístico
sigue
una
distribución
F de Fisherluego
con 1
ensusi
elmedia
numerador
531
de
en de
elmg/dl.
denominador,
determinar
esta
variabilidad
explicada
por
el2 índice
masa
corporal es una el valor P
⋅libertad
38,8
= 47,45
directamente alibertad
partir de
en mmol/l
como
1,223
2
En conclusión,
las diferencias en el
bilateral
contraste
índice dedel
masa
corporalesyP(F
el colesterol
HDL< r0,001.
= (-0,276)
= 0,076. Para
1,531 ≥ 43,93)
25 en la
grado
de
libertad
en
el
numerador
y
531
grados
de
libertad
en
el
denominador,
índice
de masa
explican
el 7,6% dedelacorrelación
variabilidad
del colesterol
que
coincide
concorporal
el cuadrado
del coeficiente
muestral
entre el HDL
6 es una
P <corporal
0,001).
población
del estudio
EURAMIC
(R2 = 0,076,
determinarde
si referencia
esta variabilidad
explicada
por el índice
de masa
2
2
luego
el
valor
P
bilateral
del
contraste
es
P
(
F
≥
43,93)
<
0,001.
índice de masa corporal y el colesterol HDL r1,531
= (-0,276) = 0,076. En
Paraconclusión,
25
Tabladeterminar
10.3
Tabla
del
análisis
demasa
la varianza
la regresión
del es
colesterol
HDL
las
diferencias
en el
índice de
corporal
explican
el
de
la variabilidad
si esta
variabilidad
explicada
porde
el índice
de7,6%
masalineal
corporal
una
sobre el índice de masa corporal en el grupo control del estudio EURAMIC.*
2
del colesterol HDLSuma
en ladepoblación de
referencia
del estudio EURAMIC (RRazón
= 25
Grados
de
de
cuadrados
libertad
Varianza
varianzas
3,53
42,63
46,15
1
531
532
3,53
0,080
43,93
0,076, P < 0,001).
Regresión
Error
Total
*
172
Coeficiente de determinación[Tabla
R2 = 3,53/46,15
= 0,076.
10.3 aproximadamente
aquí]
Pastor-Barriuso R.
10.3.3 Inferencia sobre los parámetros de la recta de regresión
0
1
1.2 MEDIDAS DE TENDENCIA CENTRAL
pendiente de la recta de regresión utilizando el método de mínimos cuadrados. A partir
Regresión lineal simple
Las medidas de tendencia central informan acerca de cuál es el valor más representativo
de las distribuciones muestrales de b0 y b1, se derivan a continuación los intervalos de
de una determinada variable o, dicho de forma equivalente,
estos estimadores indican
donde
los coeficientes
clos
xi para
- x )/{(
- de
1) slax2 }recta
dependen
únicamente
valores
confianza
y tests sobre
de hipótesis
losnparámetros
subyacentes
β0 y β1de
dellos
modelo
dede
i = (parámetros
10.3.3
Inferencia
de regresión
alrededor
de qué valor
se agrupan
los datos
de tendencia
En el Apartado
10.3.1
se obtuvieron
los observados.
estimadores Las
b0 y medidas
b1 de la constante
y la pendiente de la
regresión
lineal
simple.que se asumen constantes. Bajo
la
variable
explicativa
las
asunciones
y
recta de regresión utilizando el método de mínimos cuadrados. A partirde
delinealidad
las distribuciones
central
de la muestra
paraa resumir
los resultados
observados
como para
muestrales
de b0 ysirven
b1, setanto
derivan
continuación
los intervalos
de confianza
y tests de hipótesis
El estimador
delamínimos
de la pendiente
homogeneidad
de
varianza,cuadrados
el valor esperado
de b1 esde la recta de regresión puede
para los parámetros subyacentes β0 y β1 del modelo de regresión lineal simple.
realizar inferencias acerca de los parámetros poblacionales correspondientes. A
El
estimadorcomo
de mínimos
cuadrados
de
la pendiente
de la recta
regresión
puede reescribirse
reescribirse
una combinación
lineal
de los
valores
de lade
variable
respuesta
n
n
n
como unasecombinación
lineal
loscivalores
respuesta
E
(principales
b1) =de
Eestimadores
( y i ) =de
β 0lavariable
c i la+ tendencia
β1
c i x i central
= β1 de una
continuación
describen los
de
n
i =1
i =n1
i =1
2
donde los coeficientes ci = ((xxi -− xx)/{(
de los valores de
y ) s x }dependen
)( y in−- 1)
( x i − x ) yúnicamente
variable.
i
i
n
b1 = cii ==1 y(ixnson
=2 }i =n1dependen
= c3.4),
y,
comoloslascoeficientes
observaciones
independientes
(véase Apartado
su varianza
i y i ,de
donde
x
)/{(
n
1)
s
valoreses
i
x
la variable explicativa que se asumen constantes.
Bajo las2únicamente
asunciones
de los
linealidad
yde
2
i =1
−
x
x
x
−
x
(
)
(
)
i
i
1.2.1 Media aritmética
i =1
i =1
n
la
variable explicativa
que se asumen
constantes.
de linealidad y
b1 2eslas asunciones
homogeneidad
de la varianza,
eln valor
esperado 2deBajo
σ2
2
2y ) =σ
var(
=
var(
b
)
=
.
c
c
1
La media
denotada
por
,
se define
la
suma
de valores
los
dondearitmética,
los coeficientes
ci = (x
–i 1)sx }como
dependen
únicamente
de los
de la variable
i de cada uno
i
i – x )/{(n
(n − 1) s x2
i =1
i =1
explicativa
que se de
asumen
constantes.
Bajo
las
asunciones
de
linealidad
y
homogeneidad
de la
b
es
homogeneidad
la varianza,
el
valor
esperado
de
1
n
n
n
valores
muestrales
dividida
por
el número
varianza,
el valor
esperado
b es de observaciones realizadas. Si denotamos
E(bde
1) = 1 c i E ( y i ) = β 0 c i + β 1 c i x i = β1
26
i=
i=
i=
Es decir, b1 es un estimador insesgado
de β1 que
n1
n1 será tanto
n1 más preciso cuanto menor
por n el tamaño muestral y por
observado
para
i = 1, ..., n,
E(bx1i)el
= valor
ci E
( yi ) = β 0
c i el+ sujeto
β 1 ci-ésimo,
i xi = β 1
i =1
i =1
i =1
sea
la varianza
de la variable
respuesta
alrededor (véase
de la recta
de regresión
mayoreses
y, como
las observaciones
yi son
independientes
Apartado
3.4), suyvarianza
la media
vendría
dada
por
y, como las observaciones yi son independientes (véase Apartado 3.4), su varianza es
sean
el tamaño
muestral y la
de la variable
explicativa.
Además,
si el tamaño
y, como
las observaciones
yi dispersión
sonn independientes
(véase
Apartado
3.4),
su varianza
es
n
2
σ
n
2x + x + ... +2 x
2
1
var(
= x=c i 1var( y2 i ) = σ
.
n ci =
2
. una(generalización
x =b1 )
muestral n es suficientemente
grande,
puede aplicarse
del teorema
i1
n
−
1
)
s
1
=
=
i
i
x
2
n
n
n i =1
n
σ
2
2
2
var(b1) = c i var( y i ) = σ c i =
.
2
Es central
decir, bdel
es
un
estimador
insesgado
de
β
que
será
tanto
más
preciso
cuanto
menor
límite
(ver
su
versión
más
simple
en
el
Apartado
4.3.3)
para
demostrar
quesea la
(
n
−
1
)
s
1
1
i
=
=
i
1
1
x
Es
decir,
b
es
un
estimador
insesgado
de
β
que
será
tanto
más
preciso
cuanto
menor
1
1
varianza
de
la
variable
respuesta
alrededor
de
la
recta
de
regresión
y
mayores
sean
el
tamaño
La media es la medida de tendencia central más utilizada y de más fácil
b1 se distribuye
de formadeaproximadamente
normal con
la media
muestral
y la dispersión
la variable explicativa.
Además,
si yelvarianza
tamaño descritas
muestral n es
Es
decir,
b
es
un
estimador
insesgado
de
β
que
será
tanto
más
preciso
cuanto
1
1
sea
la
varianza
de
la
variable
respuesta
alrededor
de
la
recta
de
regresión
y
mayores
suficientemente
grande, al
puede
aplicarse
una generalización
central
límite (ver
interpretación.
Corresponde
“centro
de gravedad”
de los datosdel
de teorema
la muestra.
Su delmenor
su anteriormente,
versión más simple en el Apartado 4.3.3) para demostrar que b1 se distribuye de forma
sea
laelvarianza
variable
respuesta
alrededor
de
laexplicativa.
recta
de regresión
y mayores
sean
tamaño
muestral
y laladispersión
de por
la variable
Además,
si el tamaño
principal
limitación
es de
quelaestá
muy
influenciada
los
valores
extremos
y, en este
aproximadamente
normal
con
media y varianza
descritas
anteriormente,
βde
b1 −puede
1 la~aplicarse
sean
el tamaño
muestral
la la
dispersión
Además,del
si teorema
el tamaño
muestral
n es
grande,
generalización
→variable
N (de
0, la
1)explicativa.
.una
caso, puede
no
ser
unsuficientemente
fiel
reflejoyde
tendencia
central
distribución.
σ
muestral
n es
suficientemente
grande,
una generalización
del teorema
central del
límite
(ver su versión
más
en el Apartado
4.3.3) para demostrar
que
s x simple
npuede
− 1 aplicarse
Ejemplo 1.4 En este y en los sucesivos ejemplos sobre estimadores muestrales, se
central
del
su versión
más simple
en el Apartado
4.3.3)
demostrar
que
Para
usolímite
de este
resultado,
el parámetro
desconocido
de sustituirse
por
la desviación
b1hacer
se distribuye
de(ver
forma
aproximadamente
normal
con σlaha
media
y para
varianza
descritas
Pararesidual
hacer
de este
elHDL
parámetro
desconocido
hadistribución
de sustituirse
por la de b1
típica
s,valores
que
conlleva
un error
adicional
de muestreo.
utilizarán
losuso
delresultado,
colesterol
obtenidos
en los 10σLa
primeros
sujetosresultante
del
b
se
distribuye
de
forma
aproximadamente
normal
con
la
media
y
varianza
descritas
seráanteriormente,
1entonces más dispersa que la normal, siguiendo aproximadamente una distribución t de
desviación
s,Antioxidants,
que conlleva
un error adicional
de muestreo.
Student
lostípica
n – 2residual
grados
de
libertad
correspondientes
aInfarction
la estimación
de laLa
varianza
residual,
estudiocon
“European
Study on
Myocardial
and Cancer
of
anteriormente,
b1b−1 −β 1βmás
1 ~ ~dispersa que la normal, siguiendo
distribución
resultante deun
b1 estudio
será entonces
.casos
→→Nt(n0de
) . y controles realizado
the
Breast“ (EURAMIC),
multicéntrico
−,2 1
s
σ
b − β1 ~
aproximadamente
una
distribución
- 2 grados
de libertad
n 1−e1→
Ncon
(0para
, los
1) . nevaluar
stxs1de
−
x n Student
entre
1991 y 1992 en
ocho
países Europeos
Israel
el efecto
de los
σ
Cabe
destacar que este
resultado
se hade
independencia de la asunción de normalidad
correspondientes
a la
estimación
varianza
sderivado
− 1 con residual,
x la n
y, en
consecuencia,
válido
para cualquier
distribución
subyacente
la variable
Cabe
destacar
este
resultado
se
derivado
con independencia
de
asunción
de
Para
hacer
usoque
deeseste
resultado,
el ha
parámetro
desconocido
σ ha dede
sustituirse
por
la
5 respuesta,
siempre que el tamaño muestral sea suficientemente grande.
normalidad
y, en
para
cualquier
distribución
subyacente
Para
hacer uso
deconsecuencia,
este resultado,
elválido
parámetro
desconocido
σdehamuestreo.
de sustituirse
desviación
típica
residual
s, quees
conlleva
un error
adicional
La pordelala
variable
respuesta,
siempre
tamaño un
muestral
sea suficientemente
grande.
desviación
típica
residual
que
error
adicional
muestreo.
La
distribución
resultante
de bs,1que
seráelconlleva
entonces
más
dispersa
que de
la normal,
siguiendo
A partir deresultante
la distribución
muestral
b1más
, el intervalo
de
100(1 - α)%
distribución
de b1 será
entonces
dispersa
la
normal,
aproximadamente
una distribución
t dedeStudent
con los nque
- 2confianza
grados
dealsiguiendo
libertad
27
Pastor-Barriuso R.
aproximadamente
distribución
t la
de
Student
con los nviene
- 2 grados
de libertad
para
la pendiente subyacente
β1 dedela
recta
de regresión
dado por
correspondientes
auna
la estimación
varianza
residual,
173
A partir de la distribución muestral
b , el intervalo. de confianza al 100(1 - α)%
b1 ± t nde
− 2 ,1−α1 / 2
s x n sea
− 1 suficientemente grande.
variable respuesta, siempre que el tamaño muestral
para la pendiente subyacente β1 de la recta de regresión viene dado por
Correlación y regresión lineal simple
partir
de la el
distribución
muestraldedelabhipótesis
de confianza
al 100(1 lineal
- α)%
1, el intervalo
DeAigual
forma,
contraste bilateral
de ausencia
de asociación
s
.realiza
b1 ±
para
lalaspendiente
subyacente
βy1 respuesta
de
la trecta
regresión
viene dado
por el estadístico
n − 2 ,1−H
αde
/ 2: β
=
mediante
entre
variables
explicativa
0
1
A partir de la distribución muestral de b1, el intervalo
confianza
al 100(1 – α)% para la
s x n0−se
1de
pendiente subyacente β1 de la recta de regresión viene dado por
s
b
.
b1 ± ttde
De igual forma, el contraste bilateral
de asociación lineal
− 2la
,1−αhipótesis
/2 1
n=
, de ausencia
ss x n − 1
sH
=de
0 se
realiza de
mediante
el estadístico
variables
explicativa
y respuesta
11
Deentre
iguallas
forma,
el contraste
bilateral
de la hipótesis
ausencia
asociación
lineal entre las
x 0:nβ−
De
igual
forma,
el
contraste
bilateral
de
la
hipótesis
de
ausencia
de
asociación
variables explicativa
y respuesta
H0: βun
0 se realiza
mediante
el miocardio
estadísticoen lineal
1 =primer
1.2
DE TENDENCIA
CENTRAL
antioxidantes
en elMEDIDAS
riesgo
de desarrollar
infarto
agudo de
s en el riesgo de desarrollar
un primer
agudosedepresentan
miocardio
en
b el
quePara
se distribuye
aproximadamente
como
una
t de
Studentde
con
n - 2 grados
de libertad
completar
la infarto
exposición,
intervalo
confianza
y el test
de
t = H0: 1β
entre
las
variables
explicativa
y
respuesta
1 = ,0 se realiza mediante el estadístico
hombres adultos.
Los
valores
obtenidos
fueron
0,89,
1,58,
0,79,
1,29,
1,42,
0,84,
s
Las medidas de tendencia central informan acerca de cuál es el valor más representativo
ultos. Los valores obtenidos
fueron
0,89,
1,58,de0,79,
1,29,es
0,84, aunque
si laPara
hipótesis
nula
esexposición,
cierta.
Este
test
equivalente
de
regresión
lineal
hipótesis
para
la constante
la recta
de1,42,
regresión,
inferencias
suelen
completar
la
se
presentan
deestas
confianza
y el test
de tener
s x nel− intervalo
1 al contraste
1,06, 0,87, 1,96
y
1,53
mmol/l.
La
media
de
los
niveles
del
colesterol
HDL
en
b
de una determinada variable o,
1de forma equivalente, estos estimadores indican
, el estadístico
t =dicho
,96 y 1,53 mmol/l.
La
media
de los
niveles
del
colesterol
HDL
en
simple
presentado
en
el
apartado
anterior.
De
hecho,
del
contraste
de
queescasa
se
distribuye
aproximadamente
como
una
t
de
Student
con
n –en
2Fla
grados
de
libertad
si la
importancia
porque
la
relación
en
x
=
0
carece
de sentido
mayoría
de las
s
hipótesis para la constante de la recta de regresión,
aunque
estas
inferencias
suelen
tener
estos
10
es
queparticipantes
senula
distribuye
aproximadamente
como
una
t
de
Student
con
n
2
grados
de
libertad
hipótesis
es
cierta.
Este
test
es
equivalente
al
contraste
de
regresión
lineal
simple
presentado
valor se se
agrupan
observados.
Las medidas
dede
tendencia
Para alrededor
completarde
la qué
exposición,
presentan
el− intervalo
de confianza
y el test
s xlosntdatos
1este
ticipantes es en el
regresión
es
igual
al
cuadrado
del
estadístico
de
contraste,
apartado
anterior.
De
hecho,
el
estadístico
F
del
contraste
de
regresión
es
igual
al
cuadrado
aplicaciones.
El
estimador
mínimo-cuadrático
de
la
constante
b
=
y
b
x
es
una
1
escasa importancia porque la relación en x = 0 carece de sentido0 en la mayoría
de las
la hipótesis
nula
es
cierta.
Este
test
es
equivalente
al
contraste
de
regresión
lineal
delsi
estadístico
t
de
este
contraste,
10 la muestra sirven tanto para resumir los resultados observados como para
0,89de+la
1,58
...de+ 1regresión,
,53 el intervalo
hipótesis
para1lade
constante
recta
aunquedeestas
inferencias
suelen
Para central
completar
la exposición,
se+presentan
confianza
y el test
de tener
x
xde
1,223
=
10
2 =
2 mmol/l.
que
se
distribuye
como
una
t
de
Student
con
n
2
grados
de
libertad
i =dos estimadores
1
0combinación
,89 + 1,58 + ...10
,aproximadamente
53
aplicaciones.
El+ 1estimador
mínimo-cuadrático
de
la
constante
b
=
y
b
x
es
una
lineal
independientes
y
y
b
que
tienden
a
distribuirse
0
1
1
(
−
1
)
b
n
s
SSR
2
1
x
i =1 en el
x = x i = simple presentado
= 1,223
mmol/l.
apartado
anterior.
De
hecho,
el=estadístico
F del contraste de A
F
=10
=parámetros
tsentido
,
realizar
acerca
de2los
poblacionales
2
escasa importancia
porque de
la
relación
en
x
=
0
carece
de
en correspondientes.
la mayoría
de las
hipótesis
para lainferencias
constante
la recta
de
regresión,
aunque
estas inferencias
suelen
tener
10 i =1
10
s
s
si
laforma
hipótesis
nulaconforme
es
Este testelestamaño
equivalente
al contraste
detienden
regresión
lineal
combinación
lineal
decierta.
dos estimadores
independientes
ydey lo
b1 cual
que
a distribuirse
de
normal
aumenta
muestral,
se
deduce
que
la
es igual
al cuadrado
del estadístico
t de este
contraste,
de regresión
tal
forma
que
ambos
procedimientos
lossentido
mismos
(lacentral
distribución
continuación
se describen
losfacilitan
principales
estimadores
aplicaciones.
El
estimador
mínimo-cuadrático
de
la constante
bde0 en
=lavalores
ytendencia
b1 xP es
una
importancia
porque
la relación
en x = 0siempre
carece
de
la -mayoría
de
las de una
La mediaescasa
aritmética
presenta
las siguientes
propiedades:
simple
presentado
en
el
apartado
anterior.
De
hecho,
el
estadístico
F
del
contraste
de
F
de
Fisher
con
1
grado
de
libertad
en
el
numerador
y
n
–
2
grados
de
libertad
en
el
denominador
de
tal
forma
que
ambos
procedimientos
facilitan
siempre
los
mismos
valores
P
(la
distribución
muestral
de b0 aumenta
también será
aproximadamente
media que la
ética presenta las siguientes
propiedades:
de forma normal
conforme
el tamaño
muestral, de normal
lo cual con
se deduce
2
es, aplicaciones.
por definición,
elestimador
cuadrado
de la distribución
de
n0 –= 2tienden
grados
libertad).
variable.
El
mínimo-cuadrático
- b1 xade
es
una
− 1la
)Student
b12 (ntde
saxconstante
SSR
combinación
lineal
de dosSiestimadores
y 2uno
ycon
b1 bde
que
distribuirse
• Cambio
de origen (traslación).
se suma
unaindependientes
constante
cada
losy datos
Fdel
= estadístico
,
=
=
t
regresión
es
igual
al
cuadrado
t
de
este
contraste,
distribución
F
de
Fisher
con
1
grado
de
libertad
en
el
numerador
y
n
2
grados
de
2
2
origen (traslación).Para
Si secompletar
suma una
constante
cada
uno
de los el
datos
la
exposición,
intervalo
de normal
confianza
el test de hipótesis
distribución
muestral
de b)0a=también
conymedia
E(sey presentan
) -sserá
E(b1aproximadamente
) x = sβ
E(b
0
0 + β1 x - β1 x = β0
laforma
constante
de
laconforme
recta
regresión,
aunque
estas
inferencias
tener
escasa
importancia
de para
unacombinación
la media
lademuestra
resultante
es
igual
a laymedia
inicial
más
1.2.1
Media
lineal
dearitmética
dos
estimadores
independientes
y blosuelen
que
tienden
aladistribuirse
demuestra,
normal
aumenta
el tamaño
muestral,
de
se
deduce
que
la
1 cual
libertad
en
el
denominador
es,
por
definición,
el
cuadrado
de
la
distribución
t
de
Student
2
2
tra, la media deporque
la muestra
resultante
a la media
inicial
la relación
en xes=igual
0 carece
deSSR
sentido
la
de
las
aplicaciones.
El
estimador
(nmás
− 1mayoría
)la
b1en
sx
) = E(
+ β1 =
x t-2los
xmismos
= β0 valores P (la
E(bprocedimientos
de tal forma que ambos
1) x = β0siempre
F =yb ) =- E(b
,β1 de
=facilitan
2y por
2.una
–=
bx1 x +,esse
combinación
lineal
decada
dosque
estimadores
mínimo-cuadrático
constante
=laxide
+ 0bc,0 entonces
c
Un
cambio
origen
que
ydistribución
varianza
constante
utilizada;
si yde
Lanormal
media
denotada
define
como
suma
de
uno
iaritmética,
muestral
también
aproximadamente
condeduce
media
de
forma
conforme
aumenta
el
tamaño
muestral,
de normal
lo la
cual
se
lade los
0 sserá
s
con
n
2
grados
de
libertad).
+
c
,
entonces
y
=
x
+
c
.
Un
cambio
de
origen
que
ilizada; si yi = xindependientes
y b1 que tienden a distribuirse de forma normal conforme aumenta el tamaño
i
distribución
F deseFisher
conque
1 grado
de libertad
en el numerador
y n -será
2 grados
de
también
aproximadamente
muestral,
de
lo
cual
deduce
la distribución
muestral
de b0normal
valores
muestrales
elaproximadamente
número
deconsiste
observaciones
realizadas.
Si denotamos
y varianza
se realiza
con frecuencia
es de
el centrado
depor
la variable,
que
en2restar
amedia
distribución
muestral
b)0 dividida
también
será
con
=
E(
y
)
E(b
)
x
=
β
+
β
x
β
x
=
β
E(b
x
0
1
1 mismos
0 valores P (la
de
tal
forma
que
ambos
procedimientos
facilitan
2 0siempre
21 1 los
normal
con
media
n frecuencia es el centrado de la variable,
consiste
restar
a=σ +
.
) = es,
var(
y )definición,
+ en
var(b
var(b0que
1) xel
28
2
libertad en el denominador
por
cuadrado
la− 1distribución
t de Student
n de
(
n
)
s
por
n
el
tamaño
muestral
y
por
x
el
valor
observado
para
el
sujeto
x por i-ésimo, i = 1, ..., n,
centrada 2será,
i una variable
cada valor de la muestra su media. La media de
E(grado
y ) − E(b
β 0 + el
β21numerador
x1− β 1 x x= βy 0n - 2 grados de
distribución
F de
con
de será,
libertad
0) = 1
1) x =
2 en
e la muestra su media.
La media
de Fisher
unaE(b
variable
centrada
por
y varianza
0) = var( y ) + var(b1) x = σ
con
n - 2 grados devar(b
libertad).
+ (n − 1) s 2 .
la media vendría dada 2por
tanto,
igual a 0.
2 n
y varianza
x
Reemplazando
el parámetroes,
σ por
pordefinición,
su estimación
s , el intervalo
de confianza
al Student
100(1 libertad
en el denominador
el cuadrado
de la distribución
t de
a 0.
y varianza
2
1 datos de
x una
2
• Cambio de escala (unidades).
Si se multiplica
cada
.
2 y ) + var(b
σx21,2los
var(b
+
+ xintervalo
1 1)n xuno= de
0) = var(
2 + ... + xde
con
n
2
grados
de
libertad).
α
)%
para
la
constante
poblacional
β
es
Reemplazando
el
parámetro
σ
por
su
estimación
s
el
al 100(128
0
escala (unidades). Si se multiplica cada uno de los datosxde
= una
xi =
n (n − 1)ns x2. confianza
n i =1resultante
n xa2 la media
2
21
muestra por una constante,
la media
de la muestra
es+igual
.
)
=
var(b
2var( y ) + var(b1) x =
2 σ
0
2
Reemplazando
el
parámetro
σ
por
su
estimación
s
,
el
intervalo
de
confianza
al 100(1 – α)%
α
)%
para
la
constante
poblacional
β
es
0 a la media
una constante, la media de la muestra resultante es
igual
2n
(
n
−
1
)
s
x
2
2
1
x
paraReemplazando
la constante
poblacional
βsi
es
el utilizada;
parámetro
por
estimación
s ,cel
de confianza al 100(128by0i =
± cx
t n −su
+y =
0σ
xmás
.intervalo
inicial
por
la constante
i,2tendencia
,entonces
1−α / 2 s
La media
es la medida
de
central
2 utilizada y de más fácil
n (n − 1) s x
a constante utilizada; si yi = cxi, entonces y = c x .
2
1 s2, xel2 intervalo de confianza al 100(1 Reemplazando
parámetro
σb por
su
estimación
α)% para
la constante
poblacional
β
0ales
±
t
s
+ cada
interpretación.
Corresponde
“centro
de
gravedad”
delos
losdatos
datosdede la muestra. Su
• Cambio simultáneo
deelorigen
y escala.
Si
se
multiplica
uno
n − 2 ,1−α / 2
0
2 de
n
−
(
n
1
)
s
x
ultáneo de origen yy escala.
Si se multiplica
cadadeuno
de los datos
el estadístico
del contraste
la hipótesis
nuladeH0: β0 = 0 es
α)% para
launa
constante
poblacional
βestá
0 esse
principal
limitación
es
que
muy
influenciada
por los valores
unay muestra
por
constante
y
al
resultado
le
otra constante,
la mediaextremos y, en este
el estadístico del contraste de la hipótesis nulasuma
H
1 0: β0 =x02 es
por una constanteyyelalestadístico
resultado se
suma otrade
bconstante,
± hipótesis
t n − 2,1−α /la2 smedia
+H : β = 20 es
0 la
dellecontraste
nula
0 − 01) s
bpor
x constante,
0ntendencia
puedeesno
ser aunlafiel
reflejo
de
la
de la distribución.
de la muestra caso,
resultante
igual
media
inicial
la(nprimera
más la
,2 central
t=
1
x
2
a resultante es igual a la media inicial por la primera
más
b0 ± tconstante,
+
x la
n − 2 ,1−α1/ 2 s
+
s
n
(nc22−. 1) s x2
b
y
=
c
x
+
c
,
entonces
y
=
c
x
+
segunda
constante;
si
0
i
1 i
2
1
n nula
(n − H
1)0s:xβ0, = 0 es
y el estadístico del contraste de lat hipótesis
=
ejemplos sobre estimadores muestrales, se
y = c1 x1.4
+ cEn
stante; si yi = c1xi + c2, entoncesEjemplo
2. este y en los sucesivos
1
x2
+
queybajo
H0 seguirádel
aproximadamente
unas distribución
de =
Student
n – 2 grados de libertad.
el estadístico
contraste
de la hipótesis
H)0s:tx2β
0 es con
n nula
utilizarán
los
valores
del
colesterol
en
los 10
primeros
del
b(n0 − 1HDL
Ejemplo
Para
los valores deluna
colesterol
HDL0 obtenidos
a con
mg/dl
seguirá aproximadamente
distribución
tdedemmol/l
Student
n -se
2 grados sujetos
de
que1.5
bajo
H0 transformar
,
t
=
Para transformar los valores del colesterol HDL de mmol/l a mg/dl2 se
1
x
estudio
“European38,8.
Study
on +Antioxidants,
Myocardial
Infarction
and Cancer
of
sAsí,
b0
multiplica
por el
factor
de aproximadamente
conversión
utilizando
libertad.
seguirá
una
distribución
de Studentdel
con
n - 2 grados
de
que
bajo
H
2 la tpropiedad
0
,
t
=
174 Pastor-Barriuso R.
n
(
n
1
)
s
−
x
or el factor de conversión 38,8. Así, utilizando la propiedad del
1 estudio
x 2 multicéntrico de casos y controles realizado
the
Breast“
(EURAMIC),
un
s en
+ mg/dl se2 calcularía
cambio
de escala, la media del colesterol HDL
libertad.
n (n −obtenidas
1) s x
scala, la media delque
colesterol
HDL
en
mg/dl
se
calcularía
Ejemplo
10.9
Las
estimaciones
puntuales
el Ejemplo
para losde
t deenStudent
con n10.7
- 2 grados
bajo H seguirá aproximadamente una distribución
0
constante es
0,283
2 s
2
1
x
1 estándar
26,0de
SE(b
)
=
= 0,0035.
=
1
1,69,
b
=
-0,023
y
s
=
0,283.
El
error
la estimación
de lalineal simple
fueron b0 =SE(b
1
s
= 0,092Regresión
+
=
0
,
283
+
)
=
0
s n − 1 3,50 532
n (n − x1) s x2
533 532 ⋅ 3,50 2
1
x2
1
26,0 2
constante es
= 0,092
+ y s = 0,283.
= 0,283
+
=1 s= -0,023
0) b
1,69,
El error estándar
de la
fueron b0 =SE(b
2 estimación de la
533
(n − 1) syx2la pendiente
⋅ 3,de
50regresión
Los ICs al 95% para
lanconstante
de la532
recta
Ejemplo
10.9 Las estimaciones puntuales obtenidas en el Ejemplo 10.7 para los
y de la pendiente
2
2
constante
parámetrosesde la regresión
HDL 1sobre el26,0
índice
de masa corporal fueron
1 delx colesterol
poblacional
son0)entonces
s
= 0,092
+
=
0
,
283
+
=
SE(b
by0de
= 1,69,
b1 = – 0,023 y s = 0,283. 2El error estándar de la estimación
de la constante es
la pendiente
n (n − 1) ssx
533 532 ⋅ 3,50 2
0,283
SE(b1) = 2
= 0,0035.
=
2
1 SE(b
xs x0) =
1532 =26,0
n −1,69
1 ±3,50
±
t
1,96⋅0,092
(1,51;
1,87)
b
0
531;0,975
+
+
= 0,092
SE(b0 ) = s
2
s2 = 0,2830,283
n
533
(
n
−
1
)
s
532
⋅
3
,
50
= 0,0035.
x
=
y de la pendiente SE(b1) =
s x n − 1 3,50 532
yy
de ICs
la pendiente
Los
al 95% para la constante
y la pendiente de la recta de regresión
s
0,283
y de la pendiente
SE(b
0,0035.
=
1) =
poblacional
son
entonces
Los ICs al b95%
constante
yn la
de la==recta
de regresión
− 1pendiente
3,50 532
± t para laSE(b
) =s -0,023
± 1,96⋅0,0035
(-0,030;
-0,016).
1
531;0,975
1
x
s
0,283
poblacional
son
entonces
Los
ICs al 95%
la constante
y la pendiente
de la= recta
de regresión poblacional son
0,0035.
=
1) =
± tSE(b
b0para
531;0,975SE(b0) = 1,69 ± 1,96⋅0,092 = (1,51; 1,87)
s xpuede
− 1pendiente
3,50 532
Del
para
la pendiente
concluirse
con
del 95% que
Los intervalo
ICs al 95%
para
la constante
yn la
de
la una
rectaconfianza
de regresión
entonces
t531;0,975 SE(b
b0 ±colesterol
0 ) = 1,69 ± 1,96⋅0,092 = (1,51; 1,87)
ypoblacional
el
nivel medio
HDL
en la población de referencia del estudio
sonde
entonces
Los ICs al 95% para la constante y la pendiente de la recta de regresión
y significativa ya que el contraste de la hipótesis nula H0: β1 = 0 mediante el
EURAMIC
disminuye
entre)0,016
y 0,030
mmol/l por cada
incremento
de 1
y
± bt531;0,975
SE(b
± 1,96⋅0,0035
0,030;
− 0,016).
1 = −0)0,023
poblacionalb1son
± t531;0,975
SE(b
= 1,69
± 1,96⋅0,092==(−(1,51;
1,87)
0entonces
estadístico
2
kg/mintervalo
en el índice
dependiente
masa corporal.
general, con
el intervalo
de confianza
para
Del
para la
puedeEn
concluirse
una confianza
del 95%
queelel nivel
t531;0,975
SE(b1) = puede
-0,023concluirse
± 1,96⋅0,0035
= (-0,030;
-0,016).
b1 ±para
Del
intervalo
la
pendiente
con
una
confianza
del
95%
que
±
t
SE(b
)
=
1,69
±
1,96⋅0,092
=
(1,51;
1,87)
b
y
medio
de colesterol
HDL en la población
de referencia del estudio EURAMIC disminuye
0
531;0,975
0
2 la variable explicativa
bincremento
−incremento
0,023
efecto0,016
subyacente
a cualquier
c en
entre
y 0,030cβ
mmol/l
port =cada
de 1=kg/m
en el índice de masa corporal.
1
1 asociado
=
-6,63
el
nivel
medio
de
colesterol
HDL
en
la
población
de
referencia
Del
intervalo
para
la
pendiente
puede
concluirse
con
una
confianza
del 95% que
de confianza
efecto subyacente del
cβ1 estudio
asociado
a cualquier
SE (bpara
) el0,0035
yEn general,b1el±intervalo
t531;0,975SE(b
1) = -0,0231± 1,96⋅0,0035 = (-0,030; -0,016).
incremento
c en la variable
obtienepara
multiplicando
losincremento,
límites del intervalo
se obtiene multiplicando
losexplicativa
límites del se
intervalo
β1 por dicho
EURAMIC
disminuye
entre HDL
0,016en
y 0,030
mmol/lde
porreferencia
cada incremento
de 1
el nivel
medio
de incremento,
colesterol
la población
del estudio
para
β1 por
dicho
≤
-6,63)
≈
2Φ(-6,63)
<
0,001.
Notar
que este
resulta
en
un
valor
P
bilateral
2P(t
t531;0,975
SE(b1) = puede
-0,023531
± 1,96⋅0,0035
(-0,030;
-0,016).
b1 ±para
Del intervalo
la pendiente
concluirse
con =
una
confianza
del 95% que
2
±
t
SE(cb
)
=
c{b
±
t
SE(b
)}.
cb
n − 2,1corporal.
α /2
1
1
nel
1de confianza
−0,016
− 2,1
− α /2cada incremento
kg/m
en el índice
de1 masa
En
general,
intervalo
EURAMIC
disminuye
entre
y 0,030
mmol/l
por
depara
1 el
test arroja
mismo
valorHDL
P queenellacontraste
dede
regresión
deldel
ejemplo
anterior ya
el1.2
nivel
medioelde
colesterol
población
referencia
estudio
Así,
por
con
un primer
nivel de
confianza
delde95%,
los confianza
incrementos
unaque
desviación
TENDENCIA
CENTRAL
intervalo
paraDE
la pendiente
puede
concluirse
con
una
delde
95%
antioxidantes en elDel
riesgo
deejemplo,
desarrollar
un
infarto
agudo
miocardio
envariable
2MEDIDAS
efecto
subyacente
c
β
asociado
a
cualquier
incremento
c
en
la
explicativa
kg/m
en
el
índice
de
masa
corporal.
En
general,
el
intervalo
de
confianza
para
el media
1
2 un nivel de confianza del 95%, los incrementos de una
Así,
por
ejemplo,
con
típica
c = 3,50yakg/m
el índice
dela
masa
con
una disminución
mediante
el
significativa
que elencontraste
de
hipótesis
nulaseHasocian
0 : β1 = 0
2 corporal
2
EURAMIC
disminuye
entre
yentre
0,030
mmol/l
cada yincremento
de
1
que 2P(t
≤el-6,63)
= P( HDL
t0,016
6,63
)=
P(F
43,93).
531
1,531 por
531 ≥
poblacional
en
colesterol
de
3,50⋅0,016
=de
0,057
3,50∙0,030
= 0,105
mmol/l.
el
nivel
medio
de
colesterol
en
la población
de≥1,42,
referencia
delvalor
estudio
hombres adultos. Los
valores
obtenidos
fueronHDL
0,89,
0,79,
1,29,
0,84,
2 1,58,
Las
medidas
de
tendencia
central
informan
acerca
cuál
es
el
más
representativo
se
obtiene
multiplicando
los
límites
del
intervalo
para
β
por
dicho
incremento,
efecto
subyacente
c
β
asociado
a
cualquier
incremento
c
explicativa
1 en la variable
desviación
típica
c
=
3,50
kg/m
en
el
índice
de
masa
corporal
se
asocian
con
una
1
Por
supuesto, esta disminución es estadísticamente significativa ya que el contraste de la
estadístico
kg/m2 en el índice de masa corporal. En general, el intervalo de confianza para el
EURAMIC
disminuye
y 0,030
mmol/l
por
cada
de 1
hipótesis
nula
H0media
: β1 =variable
0entre
el
estadístico
1,06, 0,87, 1,96 y 1,53
mmol/l.
La
demediante
los0,016
niveles
deldecolesterol
HDL
en incremento
una determinada
o,en
dicho
forma
equivalente,
estos
estimadores
sedeobtiene
multiplicando
los
límites
del
intervalo
para
β
por
dicho
incremento,
disminución
media
poblacional
el
colesterol
HDL
de
3,50⋅0,016
= 0,057indican
1entre
)
=
c{b
±
t
SE(b
)}.
cb1 ± tn-2,110.3.4
Bandas
de
confianza
y
predicción
para
la
recta
de
regresión
α/2SE(cb
1
1
n-2,1α
/2
1
− 0,incremento
023
efecto
c en la variable
explicativa
2 subyacente cβ1 asociado abcualquier
1
kg/m
índice
masa
En
general,
confianza
el
= datos
=
=el−intervalo
6,63 Lasdemedidas
estos 10 participantes
es en el de
alrededor
qué de
valor
setcorporal.
agrupan
los
observados.
de para
tendencia
SE (supuesto,
b1 ) 0,0035
y
3,50⋅0,030
=
0,105
mmol/l.
Por
esta
disminución
es
estadísticamente
Además
de ejemplo,
realizar inferencias
sobre
los1parámetros
β0 yαlos
β1,incrementos
es a)}.
menudodeinteresante
± tn-2,1SE(cb
) = c{bdel
tn-2,1cb1 un
α/2de
1 ±95%,
Así,
por
con
nivel
confianza
una
se obtiene
multiplicando
los límites
del intervalo
para
β/2c1SE(b
porla1dicho
incremento,
efecto
subyacente
c
β
asociado
a
cualquier
incremento
en
variable
explicativa
1
10
resulta
en
un
valor
P
bilateral
2P(t
≤
–
6,63)
≈
2F(–
6,63)
<
0,001.
Notar
que este
central
de
la
muestra
sirven
tanto
para
resumir
los
resultados
observados
como
paratest
531
1
0,89 + 1,58 + ... + 1,53
xcalcular
xelen
1,223
mmol/l.
= arroja
=un valor
30
2 =la
intervalos
de
confianza
para
propia
recta
de
regresión
β
+
β
x.
Más
i
mismo
valor
P
que
el
contraste
de
regresión
del
ejemplo
anterior
ya
que
≤
-6,63)
≈
2Φ(-6,63)
<
0,001.
Notar
que
este
resulta
P
bilateral
2P(t
0
1
531
desviación
típica ccon
=10
3,50
kg/mdeenconfianza
el índicedel
de masa
corporal
se asocian
con una 2P(t531
Así,
por ejemplo,
un2 los
nivel
95%,
los
incrementos
de una
10obtiene
i =1
2
se
multiplicando
límites
del
intervalo
para
β
por
dicho
incremento,
±
t
SE(cb
)
=
c{b
±
t
SE(b
)}.
cb
1
1acerca
α/2los
1
1 poblacionales
n-2,1-α/2
1correspondientes. A
de
parámetros
≤ realizar
– 6,63) =inferencias
P(t 531 ≥ 6,63
)n-2,1= P(F
1,531 ≥ 43,93).
2
concretamente,
dado
un
determinado
valor
x
de
la
variable
explicativa,
se
pretende
test
arroja eltípica
mismo
valor
queen
el
contraste
del ejemplo
anterior
ya
0 de
disminución
media
HDL
entre
3,50⋅0,016
=con
0,057
desviación
c =poblacional
3,50 P
kg/m
enel
elcolesterol
índice
de regresión
masa de
corporal
se asocian
una
continuación
se
describen
los
principales
estimadores
de
la
tendencia
central
SE(cb
= c{bdel
tn-2,1-αde
cb1 ±
Así,
porlas
ejemplo,
con
untn-2,1confianza
95%,
los
incrementos
de una de una
α/2de
1) para
1 ±recta
/2SE(b
1)}.
La media aritmética
siguientes
propiedades:
10.3.4presenta
Bandas
de
confianza
ynivel
predicción
la
regresión
2el valor esperado β + β x de la variable
2
obtener
un
intervalo
de
confianza
para
1 es
03,50⋅0,016
2P(t531 ≤media
=mmol/l.
P( t 531 ≥Por
6,63
= P(F1,531
≥disminución
43,93).
yque
3,50⋅0,030
=-6,63)
0,105poblacional
estaHDL
estadísticamente
disminución
ensupuesto,
el) colesterol
de0 entre
= 0,057
2
variable.
Además
de realizar
inferencias
sobre
los
βmasa
y
β
,
es
a
menudo
interesante
desviación
típica
csuma
= 3,50
kg/m
en parámetros
el aíndice
de
corporal
se
asocian
con unacalcular
Cambio de origen
(traslación).
Si
se
una
constante
cada
uno
de
los
datos
0
1
Así, porEl
ejemplo,
conpuntual
un niveldedeeste
confianza
del 95%,
losŷ incrementos
de yuna
respuesta.
estimador
valor
esperado
es
+
b
x
=
+ b1(xdado
=
b
0
1
0
0intervalos
de
confianza
para
la
propia
recta
de
regresión
β
+
β
x.
Más
concretamente,
un
01
y 3,50⋅0,030 = 0,105 mmol/l. Por supuesto, esta disminución
es estadísticamente
0
30
determinado
valor
x0aritmética
dec la
variable
pretende
obtener
unasocian
intervalo
deuna
confianza
disminución
media
en
elelpara
colesterol
HDL
de
entre
3,50⋅0,016
= 0,057
2es
1.2.1 de
Media
de una muestra,
la desviación
media
latípica
muestra
resultante
a lase
inicial
más la
=poblacional
3,50
kg/mexplicativa,
enigual
índice
de
masa
se
con
10.3.4
Bandas
de
confianza
y predicción
lamedia
recta
decorporal
regresión
parax el
valor
esperadounβ0razonamiento
+ β1x0 de la análogo
variable al
respuesta.
El estimador
puntual una
de este
) que,
siguiendo
del apartado
anterior, presenta
30 valor
esperado
es
ŷ
=
b
+
b
x
=
+
b
(x
–
)
que,
siguiendo
un
razonamiento
análogo
La
media
aritmética,
denotada
por
x
,
se
define
como
la
suma
de
cada
uno
de
los
y
=
x
+
c
,
entonces
y
=
x
+
c
.
Un
cambio
de
origen
que
constante utilizada;
si
y
3,50⋅0,030
=
0,105
mmol/l.
Por
supuesto,
esta
disminución
es
estadísticamente
0i
0 inferencias
1 poblacional
0
Además
dei realizar
sobre1 los
parámetros
, esentre
a menudo
interesante
disminución
media
en0 el
colesterolβHDL
3,50⋅0,016
= 0,057 al del
0 y β1de
distribución
aproximadamente
en muestras
suficientemente grandes,
apartado
anterior,
presenta unanormal
distribución
aproximadamente
normal con
en media
muestras
valores
muestrales
dividida
por
el
número
de
observaciones
realizadas.
Si
denotamos
suficientemente
grandes,
con
media
se realiza concalcular
frecuencia
es el centrado
de
la para
variable,
que consiste
en
restar a β es+ estadísticamente
30
intervalos
confianza
la supuesto,
propia
recta
dedisminución
regresión
β1x. Más
y 3,50⋅0,030
=de0,105
mmol/l.
Por
esta
0
E( ŷ 0 ) = E( y ) + E(b1 )(x0 − x ) = β 0 + β 1 x + β 1 (x0 − x ) = β 0 + β 1 x0
por nsuelmedia.
tamañoLa
muestral
y por
xvariable
observado
para
i-ésimo, i = 1, ..., n,
i el valorcentrada
cada valor deconcretamente,
la muestra
media de
una
será,
porel sujeto
dado un determinado
valor
x0 de la variable
explicativa,
se pretende 30
la media vendría dada por
tanto, igual a 0. y varianza
obtener un intervalo de confianza para el valor esperado β0 + β1x0 de la variable
Pastor-Barriuso R.
Cambio de escala (unidades). Si se multiplica cada uno
n los datos de una
2
x + x + ... + x
1 de
respuesta. El estimador puntual de este
valor
1x0x )= y + b1(x0 =
x
x i = 1 2 es2 ŷ2 0 1= b0n(+x.0b−
esperado
ˆ
175
explicativa. Esta banda de1.2
confianza
está DE
delimitada
por las ramas
de una hipérbola y su
MEDIDAS
TENDENCIA
CENTRAL
176
medidas
2(x
E( ŷ 0 )en
β10 + β(1xque
x −+Las
- x )de
=de
βsu0tendencia
+media
β1x0 central informan acerca de
= E(
1)(x0 - x )a=medida
0aleja
aumentando
xxβ0)1se
amplitud es mínima
x0 =y )x+, E(b
0
Las
tendencia+central informan
acerca de cuál es el valor más representa
Correlación y regresión lineal simple
b0 +medidas
b1 x 0 ± t nde
.
− 2 ,1−α / 2 s
2
n (n − de
1) suna
determinada variable o, dicho de forma equiv
x
la intuición
de que
el valor
de la variable
muestral x , lo que confirma
de una
determinada
variable
o, esperado
dicho de forma
equivalente, estos estimadores indica
y varianza
alrededor de qué valor se agrupan los datos observad
y varianza
La
bandapuede
de confianza
para
recta de
regresión no
es más que la representación
respuesta
estimarse
conlamayor
en valores
alrededor
de precisión
qué valoren
se valores
agrupancentrados
los datos que
observados.
Las medidas de tendencia
( x 0la−muestra
x ) 2 sirven tanto para resumir los re
2
2 1
central
de
.
− x ) observado
var( ŷ 0explicativa.
y ) +devar(b
= σ +de la variable
) =a var(
gráfica dede
estos
intervalos
lo largo
todo1 )(x
el 0rango
2
extremos
la variable
(n − 1) slos
central de la muestra sirven tanto para
x resultados observados como para
n resumir
realizar2 inferencias acerca de
los parámetros poblaci
explicativa.
Esta banda
confianzatestá
delimitada
por
las ramas
de la
unaestimación
hipérbola sy2,su
Por tanto, utilizando
la de
distribución
resultante
de
sustituir
σ
por
se
tiene
n–2
realizar inferencias acerca de los parámetros
poblacionales correspondientes.
A
2
2
Ejemplo
10.10
Para
cada
valor
fijo
x
del
índice
de
masa
corporal,
el
modelo
de
0resultante
quePor
el intervalo
de confianza
al 100(1 –tn-2
α)%
para el valor
esperado
βdescriben
tanto, utilizando
la distribución
de sustituir
σ βpor
estimación
, se
0 +
1x
0 es
continuación
sela
loss principales
estimadore
amplitud es mínima en x0 = x , aumentando a medida que x0 se aleja de su media
continuación se describen los principales
estimadores de la tendencia central de una
(esperado
x 0el− valor
x ) 2 del
regresión
lineal estima
un IC al 95%
para- el
valor
colesterol
1 para
tiene
que el intervalo
de confianza
al1.2
α
)%
esperado
β0 +HDL
β1x0 de
es
variable.
b0 + b1 x 0 ±
t100(1
s
.
+
DE
TENDENCIA
CENTRAL
,1−α / 2
n − 2MEDIDAS
2
esperado
de
la
variable
muestral x , lo que confirma la intuición de que el valor
n (n − 1) s x
variable.
2
(centrados
26central
,0)que
x 0 que
−Media
1 estendencia
aritmética
La bandapuede
de confianza
recta
de
regresión
no
más
la
representación
gráfica
respuesta
estimarse
con
mayor
en valores
valoresacerca
de
informan
dede
cuál es el valor m
1,69para
023
1Las
,96
0,283
− 0,la
x 0 ±precisión
⋅medidas
+1.2.1
. en
2
La intervalos
banda de aconfianza
la el
recta
de observado
regresión533
no
representación
estos
lo largo1.2.1
depara
todo
rango
dees
la más
variable
explicativa.
Esta banda de
Media
aritmética
532
3,50la
⋅que
media
aritmética,
x ,, se define
com
confianzade
está
por las ramasdedeuna
unadeterminada
hipérbolaLayvariable
su amplitud
es mínima
enequivalente,
xpor
extremos
la delimitada
variable explicativa.
o, dicho
dedenotada
forma
estos estim
0 =
aumentando
medida
que
dedesutodo
media
muestral
intuición
de uno de los
gráfica de aestos
intervalos
aseloaleja
largo
el rango
observado
de confirma
la variable
x ,, lo
se que
define
como lalasuma
de31cada
Lax0media
aritmética,
denotada
por
áreaesperado
en gris oscuro
de la Figura
10.9 representa
lavalores
banda
demayor
confianza
al 95%
que elEl
valor
de la variable
respuesta
puede
estimarse
con
precisión
en
valores
muestrales
dividida
por
el número
observd
alrededor
de qué
valor se
agrupan
los
datos observados.
Las de
medidas
centrados
que en
valores
extremos
defijo
la está
variable
explicativa.
explicativa.
Esta
banda
de confianza
delimitada
las ramas
una
hipérbola
y su
Ejemplo
10.10
Paravalores
cada
valor
x0 del
índice
depor
masa
corporal,
el modelo
derealizadas.
muestrales
dividida
por
el
número
dede
observaciones
Si denotamo
para toda la recta de regresión del colesterol HDL sobre
demuestral
masa y por xi el valor observado
por sirven
nelelíndice
tamaño
central de la muestra
tanto para
resumir los resultados observad
=
x
,
aumentando
a
medida
que
x
se
aleja
de
su
media
amplitud
es
mínima
en
x
regresión
lineal
estima
un
IC
al
95%
para
el
valor
esperado
del
colesterol
HDL
de
por
n
el
tamaño
muestral
y
por
x
el
valor
observado
para
el sujeto
i-ésimo, i = 1, ...,
0corporal, el modelo
i
Ejemplo 10.10 Para0cada valor fijo x0 del índice de masa
de
regresión
corporal, que se obtiene de calcular estos
intervaloslaenmedia
sucesivos
valores
dentro
vendría
dada
lineal estima un IC al 95%
elrealizar
valor± esperado
del=acerca
colesterol
HDL
de por poblacionales correspond
inferencias
los
parámetros
1,69 para
- 0,023⋅32
1,96⋅0,024
(0,90; de
1,00).
la vendría
intuicióndada
de que
la
variable
muestral x , lo que confirma
la media
porel valor esperado de
2
del rango observado del índice de masa corporal.
esta banda de
− 26los
,de
0)principales
1 Los( xlímites
estimadores
.
1,69 − 0,023 x 0 ± 1continuación
,96 ⋅ 0,283 se describen
+ 0
x + x2 +
1 nde la tendencia
2
=
x
xi = 1
respuesta puede estimarse con mayor precisión en533
valores
centrados
que
en
valores
532
⋅
3
,
50
n
x1 + x 2 + ... + x n
1
confianza tienen forma1,69
de hipérbola
y su
amplitud
n i =1
n
- 0,023⋅32
± 1,96⋅0,024
=
(0,90;
1,00).
.
x =aumenta
x i =gradualmente
variable.
[Figura
10.9
aproximadamente
aquí]
El
área
en
gris
oscuro
de
la
Figura
10.9
representa
la
banda
de
confianza
al
95%
para
toda
n
n
i =1
extremos de la variable explicativa.
la recta
dexgris
regresión
del
HDL
sobre
de masa
corporal,
se obtiene
El
área en
delacolesterol
lamedia
Figurax 10.9
representa
la índice
banda
de masa
confianza
alque
95%
aleja de
= 26,0
kg/mel2 índice
del
corporal.
Así,
conforme
0 se oscuro
La
media
es
la
medida
de
tendencia
1.2.1 Media
de calcular estos intervalos en sucesivos
valoresaritmética
dentro del rango observado del índice
de central más u
La recta de regresión puede
utilizarse
no sólode
para
estimarcentral
la media
poblacional
dedelamás fácil
La
media
es
la
medida
tendencia
más
utilizada
y
masa
corporal.
Los
de
esta
banda
deHDL
confianza
tienen
forma
hipérbola
y su
para
toda
la 10.10
recta
de
regresión
del
colesterol
sobre
el
índice
de
masa
por
ejemplo,
el IC
allímites
95%
para
el
valor
del colesterol
HDL
entre
sujetos
[Figura
10.9
aproximadamente
aquí]
Ejemplo
Para
cada
valor
fijo
xmedio
de masa
corporal,
eldelos
modelo
de“centro
0 del índice interpretación.
Corresponde
al
de gravedad”
2
media aritmética,
por x ,=se26,0
define
como
de cada
de la media
kg/m
della suma
amplitud aumenta gradualmente La
conforme
x0 se alejadenotada
de la variable
variable respuesta entre
los sujetos con
un determinado
valorde
x0 gravedad”
2
interpretación.
Corresponde
al
“centro
de
los
datos
de
la
muestra.
Su
corporal,
que
se
obtiene
de
calcular
estos
intervalos
en
sucesivos
valores
dentro
con
unde
índice
decorporal.
masa
corporal
25
kg/m
índice
masa
Así,
porde
el, IC
al 95%
para el valor
medio del
colesterol
regresión
lineal
estima
un IC
alejemplo,
95%
para
el valor
esperado
del
colesterol
HDL
de
principal
limitación
es que
po
2el número
valores
muestrales
dividida
por
deestá
observaciones
realizadas
La recta
de
regresión
utilizarse
sólocorporal
para
estimar
media
de muy
la influenciada
, poblacional
HDL
entre
los
sujetospuede
con
índice
de
masa
de 25laykg/m
sujeto
explicativa,
sino
también
paraun
predecir
lano
respuesta
individual
0 de un nuevo
principal
limitación
es
que
está
muy
influenciada
por
los
valores
extremos
y,
en
este
del rango observado del índice de masa corporal. Los límites de esta banda de
1,69 − 0,023⋅25 ± 1,96⋅0,013 = (1,09;
1,14), no ser
2
un fiel
reflejo depara
la tendencia
cen
porun
n eldeterminado
tamaño muestral
y−0 por
el valor
observado
el sujeto i-és
( xpuede
26,la
0x)i variable
de
variable
respuesta
entre la
losestructura
sujetos con
valor
1caso,
0x
del
modelo
de
regresión
lineal,
el
valor
subyacente
dado su valor
x0. Según
1
,
69
0
,
023
1
,
96
0
,
283
−
x
±
⋅
+
.
caso,
puede
no
ser
un
fiel
reflejo
de
la
tendencia
central
de
la
distribución.
2
0
confianza
tienen más
forma
de hipérbola
yaquellos
su amplitud
aumenta
gradualmente
es sensiblemente
preciso
que entre
con533
un
índice
532de
,50 2 corporal de 32 kg/m ,
⋅ 3masa
media
vendría
dada
por y0 de
es sensiblemente
más preciso
quelaentre
aquellos
con
un índice
de un
masa
corporal
nuevo
sujeto
explicativa,
sino también
para
predecir
respuesta
individual
− 0,023⋅32
1,69
±la1,96⋅0,024
(0,90;
1,00).
1.4 En
viene dado
poreste
y =y βen +los sucesivos ejempl
de la variable respuesta
para
un determinado
sujeto =
con
x = xEjemplo
conforme x0 se aleja de la media x = 26,0 kg/m2 del índice0 de masa corporal.0 Así,0
1.4 En este
y en loslasucesivos
sobre
estimadores muestrales
2 gris oscuro Ejemplo
El valor
área
de la Figura
representa
banda
deejemplos
confianza
al 95%
de su
32
kg/men
del 10.9
modelo
de regresión
lineal,
el valor
subyacente
dado
x,0. Según la estructura
n
+
+ ...la+ x n HDL obten
x
1los poblacional
valores1 delx 2colesterol
La
regresión
puede
utilizarsedenonuevo
sólo para
de
β1xpor
+ ejemplo,
ε0, de
cuyo
estimador
insesgado
yaxmedia
que
ŷ 0 =colesterol
bestimar
0recta
0 + butilizarán
1x0la
.
= entre
xlos
el IC al 95%
para el es
valor medio del
HDL
i = sujetos
utilizarán
los
valores
del
colesterol
HDL
obtenidos
en
los
10
primeros
sujetos
variable respuesta
entre
los
sujetos
con
un
determinado
valor
x
de
la
variable
explicativa,
sino
n
n
32
0
=
i
1
para todarespuesta
la recta de
regresión
del
colesterol
el índice
depor
masa
dado
y0Study
= β0 +on Antioxidants, Myo
de la variable
para
un determinado
sujetoHDL
con aquí]
xsobre
= xestudio
0 viene “European
[Figura
10.9
aproximadamente
también para predecir la respuesta individual y0 de
2 un nuevo sujeto dado su valor x0. Según la
con un índice de
masa
25 kg/m
E(y
- ŷcorporal
+deβ
E(ε0,)Study
- β0 - on
β1xAntioxidants,
E(laε0variable
) = 0.Myocardial
= β0lineal,
0 regresión
1x0el+valor
0 =de
“European
Infarction
0 )estudio
estructuracorporal,
del modelo
de
subyacente
respuesta
para un and Cancer o
que
se obtiene
de calcular
estos
intervalos
enb1sucesivos
valores
dentro
β
x
+
ε
,
cuyo
estimador
insesgado
es
de
nuevo
+
x
ya
que
ŷ
=
b
La
media
es
la
medida
de
tendencia
central
más
de más
1
0
0
0
0
0
Breast“
(EURAMIC),
unutilizada
estudio ymulticént
, cuyo
estimador
insesgado
es
determinado sujeto con x = x0 viene dado por y0 = β0 + β1x0 + εthe
La recta de regresión puede utilizarse no sólo para estimar la0 media poblacional de la
-the
0,023⋅25
1,96⋅0,013
= (1,09;
1,14),multicéntrico
Breast“
(EURAMIC),
un
estudio
dede
casos y controles realiza
b0 + observado
b x ya1,69
quedel
de nuevodel
ŷ0 =rango
índice
de±por
masa
corporal.
Los
límites
de
esta
banda
Asimismo,
como 1el0 valor estimado
es
independiente
ŷinterpretación.
la recta
de
regresión
en
x
0
Corresponde
al
“centro
de
gravedad”
de losEuropeos
datos deelaI
0
entre 1991 y 1992 en ocho países
E(ylos
+ βun
+ E(ε 0 ) − β 0 −valor
β 1 x0 x=0 E(
= 0.
ŷ 0 ) = β 0con
deεla
variable respuesta entre
0 − sujetos
1 x0determinado
0 ) variable
entre
1991 y 1992
en
ocho países
Europeos
e Israel para evaluar el efecto de lo
confianza tienen
forma
de hipérbola
sulimitación
amplitud
aumenta
gradualmente
es
sensiblemente
más
preciso
queprincipal
entre yaquellos
con un
índice
de
masainfluenciada
corporal
es
que
está
muy
,
se
sigue
que
de
la
nueva
observación
y
0
Asimismo, como el valor estimado
ŷ0 por la recta de regresión en x0 es independiente por
de lalos valores extre
explicativa, sino también para predecir la respuesta individual
y
0 de un nuevo sujeto
nueva
observación
, sealeja
sigue
2 y0el
Asimismo,
como
estimado
es independiente
ŷ 0 xpor= la
recta
de 2regresión
endex0masa
deque
la media
26,0
kg/m
índice
, x0 sevalor
de conforme
32 kg/m
caso, puede
no ser del
un fiel
reflejo
de
lacorporal.
tendenciaAsí,
central de la distribuc
2
( x 0 el
− xvalor
) subyacente
1lineal,
dado su valor x0. Según la estructura del modelo de regresión
2
1 +colesterol
;
ε 0) +
= var(
) = σ del
var(yel0 −ICŷal
+
32
0y ),95%
2 entre los sujetos
por ejemplo,
para
elvar(
valorŷ 0medio
HDL
que
de la nueva
observación
0 se sigue
n
(
n
−
1
)
s
x
Ejemplo
y en
lospor
sucesivos
sobre estimado
viene
dado
y0 = β0 ejemplos
+
de la variable respuesta para un determinado sujeto
con1.4
x =Enx0este
con un índice de masa corporal de 25 kg/m2,
x 0 − xde) 2regresión
1 la (recta
2
decir,
la
predicción
de
una
nueva
observación
a
partir
de
;
utilizarán
los
valores
del
HDL obtenidos en los 10 pri
var(y
ε
)
+
var(
ŷ
)
=
var(
ŷ
)
=
1
+
+
σ
β1xes
+
ε
,
cuyo
estimador
insesgado
es
de
nuevo
+
b
x
ya
quecolesterol
ŷ
=
b
0
0
0
0
0
1 0
0
0 0
2
n (n − 1) s x
Pastor-Barriuso R.
1,69 - 0,023⋅25 ± 1,96⋅0,013 = (1,09; 1,14),
estimada está sujeta a dos fuentes de error:estudio
la varianza
inherente
de on
cada
respuesta Myocardial Infarction
“European
Study
Antioxidants,
E(y0 - ŷ 0 ) = β0 + β1x0 + E(ε0) - β0 - β1x0 = E(ε0) = 0.
es
decir,
larespecto
predicción
una
nueva
observación
a partir
la índice
recta
regresión
es sensiblemente
más
preciso
que
entre
aquellos
con
un
de
masa
corporal
individual
a lade
recta
de
regresión
subyacente
eldeerror
en lade
estimación
de
the
Breast“ y(EURAMIC),
un
estudio
multicéntrico
de casos y co
explicativa, sino también para predecir la respuesta individual y0 de un nuevo sujeto
Regresión lineal simple
dado su valor x0. Según la estructura del modelo de regresión lineal, el valor subyacente
de la variable respuesta para un determinado sujeto con x = x0 viene dado por y0 = β0 +
2,25
Colesterol HDL (mmol/l)
β1x0 + ε0, cuyo
estimador insesgado es de nuevo ŷ 0 = b0 + b1x0 ya que
2
E(y0 - ŷ 0 ) = β0 + β1x0 + E(ε0) - β0 - β1x0 = E(ε0) = 0.
1,5
Asimismo, como el valor estimado ŷ 0 por la recta de regresión en x0 es independiente
de la nueva1observación y0, se sigue que
1 ( x0 − x ) 2
var(y0 - ŷ 0 ) = var(ε0) + var( ŷ 0 ) = σ 1 + +
n (n − 1) s x2
2
0,5
;
0,25
es decir, la predicción de una nueva observación a partir de la recta de regresión
20
24
28
32
36
estimada está sujeta a dos fuentes de error: la varianza inherente de cada respuesta
Indice de masa corporal (kg/m²)
individual respecto a la recta de regresión subyacente y el error en la estimación deFigura 10.9
Figura 10.9 Bandas de confianza (área en gris oscuro) y predicción (área en gris claro) al 95% para la recta
de regresión
del colesterol
el índice
de masa
corporal
en el grupo
control
del estudio
EURAMIC.
ε0 se
distribuye
de forma
normal
(asunción
dicha recta.
Además,HDL
si elsobre
término
de error
ŷ 0 también seguirá
normal,estimada
de tal está
de normalidad),
la diferencia
y0 - observación
es decir,
la predicción
de una nueva
a partir una
de ladistribución
recta de regresión
sujeta a dos fuentes de error: la varianza inherente de cada respuesta individual respecto a la
recta
de regresión
subyacente
y el error al
en100(1
la estimación
de una
dicha
recta.observación
Además, si el término
nueva
forma
que el intervalo
de predicción
- α)% para
de error ε0 se distribuye de forma normal (asunción de normalidad), la diferencia y0 – ŷ0 también
seguirá
una distribución
normal, de tal forma que el intervalo de predicción al 100(1 – α)% para
individual
y0 es
una nueva observación individual y0 es
2
1 ( x0 − x )
b0 + b1 x 0 ± t n − 2,1−α / 2 s 1 + +
.
n (n − 1) s x2
La banda de predicción viene entonces determinada por estos intervalos de predicción en los
33
distintos valores observados x0 de la variable explicativa. En general, la banda de predicción
será substancialmente más amplia que la banda de confianza, particularmente cuando el tamaño
muestral es grande, lo que refleja el hecho de que existe mucha más incertidumbre en la
predicción de la respuesta individual de un único sujeto que en la estimación del valor medio de
la variable respuesta para todos los sujetos con un mismo valor de la variable explicativa.
Cabe destacar, por último, que los intervalos de confianza para el valor esperado de la
variable respuesta se basan únicamente en las asunciones de linealidad y homogeneidad de la
varianza, mientras que los intervalos de predicción para una nueva observación requieren
además de la hipótesis de normalidad, siendo estos últimos incorrectos si la distribución
subyacente de la variable respuesta no es normal.
Ejemplo 10.11 A partir del modelo de regresión lineal del colesterol HDL sobre el
índice de masa corporal se tiene que el intervalo de predicción al 95% para el nivel de
colesterol HDL de un sujeto con un índice de masa corporal x0 es
Pastor-Barriuso R.
177
Ejemplo 10.11 A partir del modelo de regresión lineal del colesterol HDL sobre el
índice de masa corporal se tiene que el intervalo de predicción al 95% para el
Correlación y regresión lineal simple
nivel de colesterol HDL de un sujeto con un índice de masa corporal x0 es
1,69 − 0,023 x 0 ± 1,96 ⋅ 0,283 1 +
( x − 26,0) 2
1
.
+ 0
533 532 ⋅ 3,50 2
El cálculo de estos intervalos en distintos valores x0 del índice de masa corporal da lugar
a lacálculo
banda de predicción
en grisenclaro
de la valores
Figura 10.9.
igual de
quemasa
la banda
de confianza,
El
estos intervalos
distintos
x0 delAlíndice
corporal
la banda de predicción está centrada alrededor de la recta de regresión estimada, pero su
amplitud
mayor alenincorporar
de cada
respuesta
da
lugar aeslanotablemente
banda de predicción
gris claro la
devariabilidad
la Figura 10.9.
Al igual
que laindividual
respecto a su valor esperado. Por ejemplo, el intervalo de predicción al 95% para el nivel
2
de centrada
índice dealrededor
masa corporal
vienede
dado por
de colesterol
HDL delaun
sujeto
25 kg/mestá
banda
de confianza,
banda
decon
predicción
de la recta
1,69 − 0,023⋅25 ± 1,96⋅0,284 = (0,56; 1,67),
regresión estimada, pero su amplitud es notablemente mayor al incorporar la
que es mucho más impreciso que el intervalo de confianza calculado en el ejemplo anterior
que
más
que
el
intervalo
de los
confianza
el del índice de
paraes
el mucho
valorde
medio
del
colesterol
HDL
enrespecto
todos
sujetos
con
dichoen
valor
variabilidad
cadaimpreciso
respuesta
individual
a su
valorcalculado
esperado.
Por
masa corporal (IC al 95% 1,09-1,14 mmol/l).
ejemplo anterior
parade
el predicción
valor medioaldel
colesterol
HDLde
encolesterol
todos los HDL
sujetos
ejemplo,
el intervalo
95%
para el nivel
decon
un
10.3.5 Evaluación de las
2 asunciones del modelo de regresión lineal simple
dicho valor
índice
masade
corporal
(IC al 95%
1,09−1,14
dede
índice
masa corporal
viene
dado pormmol/l).
sujeto
con 25del
kg/m
Los procedimientos de estimación e inferencia derivados en los apartados anteriores se basan
en las asunciones de linealidad, homogeneidad de la varianza y normalidad. La violación de
34
estas asunciones
puede
darasunciones
lugar a conclusiones
erróneas
del modelo
lineal,
siendo así necesario
10.3.5
Evaluación
de las
del modelo
de regresión
lineal
simple
evaluar su idoneidad en cada aplicación práctica. Aunque existen diversos tests para contrastar
curvilíneas y con similar dispersión a lo largo de toda la recta. Tal parece ser el caso del
estadísticamente
cada
de las hipótesis
delderivados
modelo lineal
referencias
Los
procedimientos
de una
estimación
e inferencia
en los (véase
apartados
anterioresalsefinal del
tema), en este apartado se presentan algunas técnicas diagnósticas basadas en el análisis gráfico
diagrama de dispersión entre el índice de masa corporal y el colesterol HDL de la
de los en
residuos,
proponiéndose
asimismo
extensiones básicas
del modelo
y transformaciones
de
basan
las asunciones
de linealidad,
homogeneidad
de la varianza
y normalidad.
La
los datos para acomodar posibles desviaciones de estas asunciones. En particular, se presta
Figura 10.7, donde no se aprecian desviaciones obvias de estas asunciones. En la Figura
especial atención
a las hipótesis
dedar
linealidad
y homogeneidad
de la
violación
de estas asunciones
puede
lugar a conclusiones
erróneas
delvarianza,
modelo ya que las
principales inferencias relativas a la pendiente de la recta de regresión y al valor esperado de la
10.2(d), sin embargo, se muestra un claro ejemplo de violación de la asunción de
variable
respuesta
son aproximadamente
válidas en
encada
muestras
moderadamente
grandes aunque
lineal,
siendo
así necesario
evaluar su idoneidad
aplicación
práctica. Aunque
la distribución
subyacente
de
la
variable
respuesta
no
sea
normal.
linealidad, ya que la relación subyacente es visiblemente cuadrática. No obstante, el
existen
diversos
para
contrastar
cada unade
delas
lasasunciones
hipótesis del
El gráfico
mástests
simple
para
evaluar estadísticamente
el grado de cumplimiento
de la regresión
gráfico
más
parade
chequear
las entre
asunciones
de la regresión
lineal
es el diagrama
lineal
simple
esutilizado
el diagrama
dispersión
las variables
explicativa
y respuesta,
junto con
modelo
lineal
(véase estimada.
referenciasSialsefinal
del tema),
en este apartado
se presentan
algunas de la
la recta de
regresión
cumplen
las hipótesis
de linealidad
y homogeneidad
= ydispersión
a los
valores predichos
ŷ i = b0 +alrededor
b1xi por de
de dispersión
de los
varianza,
los puntos
delresiduos
diagramaei de
han
de distribuirse
aleatoriamente
i - ŷ i frente
técnicas
diagnósticas
basadas
en elde
análisis
gráfico
de los residuos,
proponiéndose
la recta de
regresión sin
evidencia
relaciones
curvilíneas
y con similar
dispersión a lo largo
de la
toda
la de
recta.
Tal parece
el caso
del diagrama
de dispersión
entre elentre
índice
yi masa
recta
regresión.
Este ser
gráfico
es equivalente
al diagrama
de dispersión
xi ede
asimismo
dellamodelo
transformaciones
los datos
para
corporal yextensiones
el colesterolbásicas
HDL de
Figuray10.7,
donde no se de
aprecian
desviaciones
obvias de
estas
En lasimple,
Figurapero
10.2(d),
embargo,
un claro
ejemplo deaviolación
enasunciones.
regresión lineal
tienesin
la ventaja
de se
sermuestra
directamente
generalizable
la
acomodar
posibles
estas
En particular,
se presta especial
de la asunción
de desviaciones
linealidad, yadeque
la asunciones.
relación subyacente
es visiblemente
cuadrática. No
obstante,
el gráfico
másuna
utilizado
chequear
asunciones
la regresión lineal es el
presencia
de más de
variablepara
explicativa
en las
regresión
lineal de
múltiple.
atención
lasdispersión
hipótesis de
de los
linealidad
de
la varianza,
ya que lasŷ = b + b x por
=
y
–
ŷ
frente
a
los
valores
predichos
diagramaade
residuosy ehomogeneidad
i
i
i
i
0
1 i
la recta
de regresión.
Este
gráfico gráfico
es equivalente
al diagrama
de dispersión
entre
xi e yi en
Antes
de proceder
al análisis
de los residuos,
es importante
describir
algunas
principales
inferencias
a la
recta de regresión
y al valor
regresión lineal
simple,relativas
pero tiene
la pendiente
ventaja de de
serladirectamente
generalizable
a la presencia de
másdedesus
unapropiedades.
variable explicativa
en regresión
lineal múltiple.
Bajo las hipótesis
de linealidad
y homogeneidad de la varianza, los
esperado de la variable respuesta son aproximadamente válidas en muestras
Antes de proceder al análisis gráfico de los residuos, es importante describir algunas de
- ŷ i las
tienen
un valor
residuos
ei = yiBajo
sus
propiedades.
hipótesis
de esperado
linealidadsubyacente
y homogeneidad
de la varianza,
moderadamente
grandes
aunque
la distribución
de la variable
respuestalos
noresiduos
ei = yi – ŷi tienen un valor esperado
sea normal.
178
E(ei) = E( yi) − E( ŷ i ) = 0
El gráfico más simple para evaluar el grado de cumplimiento de las asunciones de la
y una varianza
Pastor-Barriuso R.
regresión lineal simple es el diagrama de dispersión entre las variables explicativa y
1 ( xi − x ) 2
2
.
var(yide
) +regresión
var( ŷ i ) - estimada.
2cov(yi, ŷSi
= σcumplen
var(e
− hipótesis
respuesta, junto
coni)la= recta
i ) se
2 de
1 − las
residuos
realizar
del
modelo
los
residuos
estandarizados
realizarelresiduos
eldiagnóstico
diagnóstico
delcomparables
modelomediante
mediante
losniveles
sean
comparables
a distintos
deestandarizados
la
variable
explicativa,
es preferible
residuos
sean
a distintos
niveles
de
la variable
explicativa,
es preferible
valor se agrupan los datos observados. Las medidas
de
tendencia
E(ei) = E(yi) - E( ŷ i ) = 0
Regresión lineal simple
residuos
estandarizados
realizar
el diagnóstico
deldel
modelo
mediante
los los
residuos
estandarizados
realizar
elsean
diagnóstico
modelo
mediante
e
e
residuos
comparables
a
distintos
niveles
de
la
variable
explicativa,
es
preferible
e
e
i i
i i
stra sirven tanto para resumir losrirresultados
observados
como
== para
=
,,
i=
22
y una varianza
11 ( x( ix i−−x x) ) s s 11−−hhi i
realizar el poblacionales
diagnóstico
mediante
los residuos
s s 11−del
−−
− modelo
e e
e eestandarizados
as acerca de losy parámetros
una varianza
n=rni =(n(n−−1)1s) xs2 ix2 i A = = i i , ,
ri correspondientes.
2
s 1s −1h−i hi
1 1( x i (−x ix−) 2x )CENTRAL
1.2 MEDIDASsDE
TENDENCIA
1 ( xi − x ) 2
2
1
−
−
s
1
−
−
describen los principales estimadores
de
la
tendencia
central
de
una
.
ei−(n1)−s12i,) sŷ2i ) = σ ei 1 − −
var(ei) = var(yi) + var( nŷ i )n−(n2cov(y
2
r
=
,
x
x =
i
n
(
n
−
1
)
s
xEl
que
dedesusu
típica.
El
− h
queseseobtienen
obtienendededividir
dividirlos
losresiduos
residuoseiepor
unaestimación
estimación
típica.
i poruna
1desviación
s desviación
comparables
a distintos
niveles
de la variable expli
(residuos
x i − informan
x ) 2 sean
1 central
i
Las medidas de tendencia
acerca
de
cuál
es
el
valor
más representativo
s 1 − −de homogeneidad
Así, aun cuando se cumpla la asunción
de
la
varianza,
los
residuos
ei
2
n por
(por
− una
1)estimación
nuna
conoce
como
eldividir
leverage
dederesiduos
una
observación
ys yxes
una
medida
término
conoce
como
el
leverage
una
observación
es
una
medida
términohtendrán
hi se
que
se
obtienen
de
los
residuos
e
de
su
desviación
típica.
El
i se
que
se
obtienen
de
dividir
los
e
estimación
de
su
desviación
típica.
El
i
i
diferente
varianza
alrededor
de
los
distintos
puntos
de
la
recta
de
regresión
estimada.
Así, aun cuando se cumpla la asunción derealizar
homogeneidad
varianza,
losmediante
residuos elos
del modelo
i residuos estanda
de una determinada variable o, dicho el
dediagnóstico
forma equivalente,
estos
estimadores
indican
Más concretamente, los residuos tenderán a ser mayores en valores centrados que en valores
mética
la
variable
yysu
x x x muy distante
estandarizada
dedela
entre
cada
xixde
dees
ladebido
variable
explicativa
su
media
estandarizada
ladistancia
entre
cada
valor
se
conoce
como
el los
leverage
observación
y puntos
esyde
una
medida
término
ide
sevariable
conoce
como
elvalor
leverage
de
una
observación
es
una
medida
término
hdistancia
ila
con
extremos
explicativa.
Esto
a explicativa
que
los
(xmedia
tendrán
diferente
alrededor
de
los
distintos
puntos
lasu
recta
regresión
que
sehide
obtienen
devarianza
dividir
residuos
euna
una
de
desviación
i, yi)de
i típica. El
i por
alrededor
de qué
valor
se agrupan
losestimación
datos observados.
Las medidas
ede tendencia ei
mucha
influencia
encada
la estimación
de x ,tienen
ica, denotada por
se define
como
la suma de
uno de losde la pendiente, de tal
ri =forma que lai recta de =
,
que
en
el
apartado
siguiente.
No
obstante,
si
el
tamaño
muestral
es
grande
y
2
quesesetratará
tratará
en
el
apartado
siguiente.
No
obstante,
si
el
tamaño
muestral
es
grande
y
de
la
variable
explicativa
y
su
media
x
estandarizada
de
la
distancia
entre
cada
valor
x
residuos
sean
comparables
a
distintos
niveles
de
la
variable
explicativa,
es
preferible
de
la
variable
explicativa
y
su
media
x
estandarizada
de
la
distancia
entre
cada
valor
x
i
regresión
resultante
tenderá
a
aproximarse
a
estos
puntos
que
presentarán
entonces
pequeños
i
1
−
s
h
(
−
)
x
x
estimada.hi Más
concretamente,
los residuos
tenderán
a ser mayores
valores 1centrados
secentral
conoce
el leverage
de
una
observación
y esresultados
unaen
medida
término
i
decomo
laobjeto
muestra
sirven
tanto
para
resumir
los
para
s observados
1 − niveles
− i como
Por
ello, y con
de que
residuos
sean
comparables
a distintos
de
la
2
es dividida por residuos
el númeroei.de
observaciones
realizadas.
Silosdenotamos
n (n − 1) s x
no
extremos
de
la
variable
explicativa
(observaciones
con
alto
nohay
hayvalores
valores
muy
extremos
de
la
variable
explicativa
(observaciones
con
alto
querealizar
semuy
tratará
en el
apartado
siguiente.
Noexplicativa.
obstante,
sila
elsivariable
tamaño
muestral
eslos
grande
residuos
estandarizados
el
diagnóstico
del
modelo
mediante
los
que
se
tratará
en
el
apartado
No
eldel
tamaño
muestral
essu
grande
variable
explicativa,
es
preferible
realizar
el obstante,
diagnóstico
modelo
mediante
losyresiduos
que
en
valores
extremos
de
lasiguiente.
variable
Esto
es
debido
a que
puntos
(xyix,
de
explicativa
y
media
estandarizada
de
la
distancia
entre
cada
valor
x
i
realizar
inferencias
acerca
de
los
parámetros
poblacionales
correspondientes.
A
muestral y por xestandarizados
i el valor observado para el sujeto i-ésimo, i = 1, ..., n,
se
comportan
análoga.
leverage),
residuos
emuy
yrirextremos
comportan
deforma
forma
análoga.
leverage),
ambos
residuos
iey
iextremos
i se
noambos
hay
valores
muy
la
explicativa
con
alto
hay
devariable
lade
variable
explicativa
con
alto
se
obtienen
deestimación
dividir
los
ei por
de su
xvalores
distante
de
xdesiguiente.
tienen
mucha
influencia
enel(observaciones
la
deresiduos
laespendiente,
yno
que
se
tratará
el
apartado
No
obstante,
si(observaciones
muestral
grande
y unadeestimación
i) con
i muyen
ei que
etamaño
i
continuación
se
describen
los
principales
estimadores
de la tendencia
central
una
=
=
,
r
i
dada por
2
a alos
En
casos
el
gráfico
de
estandarizados
r1análoga.
sanáloga.
−frente
hi como
frente
los
valores
Endeterminados
determinados
casos
el
gráfico
de
estandarizados
(término
− xforma
)tenderá
x i de
1 resultante
y
riregresión
comportan
leverage),
ambos
residuos
e
yse
rresiduos
se
comportan
de
leverage),
ambos
residuos
elos
i
ilos
i residuos
elvalores
de una observación y es u
hforma
de tal
que
la
recta
de
airiaproximarse
aleverage
estos
i se conoce
no
hayforma
valores
muy
extremos
de
la
variable
explicativa
(observaciones
con
altopuntos
s 1− −
variable.
2
n (n − 1) s x
n
+ ...
+casos
x1 + xapreciar
xclaramente
1ŷEn
no
permite
las
posibles
dede
las
predichos
2apreciar
nclaramente
ŷ
no
permite
las
posibles
desviaciones
las
asunciones
predichos
a los
valores
determinados
casos
el
gráfico
de
los
residuos
estandarizados
rasunciones
alos
los
valores
En
determinados
el
gráfico
de
los
residuos
estandarizados
ri frente
i
i frente
i
estandarizada
de
distancia
entre
cada
valor
xi de la variable exp
. pequeños
= ambosentonces
x=
Por
ello,
y la
con
objeto
de
que
quex ipresentarán
residuos
edesviaciones
forma
análoga.
leverage),
residuos
ei y ri se comportan
i.de
n
n
=
i
1
que se obtienen 1.2.1
de dividir
losaritmética
residuos ei por una estimación de su desviación típica. El término hi
Media
que
se
obtienen
de
dividir
residuos
por
una
estimación
de su desviación
típica.
Elentre si el tamaño
ŷ
no
permite
apreciar
claramente
las
posibles
desviaciones
de
las
asunciones
predichos
iobtener
ŷ
no
permite
apreciar
claramente
las
posibles
de
asunciones
predichos
se
conoce
como
el
leverage
de
una
observación
yresiduos
es
medida
delas
laa distancia
dedelinealidad
yyEn
homogeneidad
de
la
varianza.
Para
una
representación
más
clara
linealidad
homogeneidad
de
la
varianza.
Para
una
representación
clara
i
que
se
tratará
en desviaciones
elestandarizada
apartado
siguiente.
No
obstante,
i
los
valores
determinados
casos los
el
gráfico
deeobtener
los
estandarizados
rmás
i frente
36
de
la
variable
explicativa
y
su
media
que
se
tratará
en
el
apartado
siguiente.
cada
valor
x
La
media
aritmética,
denotada
por
x
,
se
define
como
la
suma
de
cada
uno
deNo
los
i
a medida de tendencia central más utilizada y de más fácil
se
conoce
como
el
leverage
de
una
observación
y
es
una
medida
término
h
i
en
K
grupos
de
tamaño
n
enentales
es
aconsejable
dividir
los
n
residuos
r
en
K
grupos
de
tamaño
n
talescircunstancias,
circunstancias,
es
aconsejable
dividir
los
n
residuos
r
i
k
obstante,
si elyŷ ihomogeneidad
tamaño
muestral
es varianza.
grande
yPara
no
hay
valores
muy
extremos
de
la clara
variable
no
hay
valores
muy
extremos
de las
lamás
explicativa (observac
iobtener
kvariable
de predichos
linealidad
de la
obtener
una
representación
clara
de linealidad
ynohomogeneidad
de
la
varianza.
Para
una
representación
más
permite
apreciar
claramente
las
posibles
desviaciones
de
asunciones
valores
muestrales
dividida
por
el
número
de
observaciones
realizadas.
Si
denotamos
y
r
se
comportan
de
forma
explicativa
(observaciones
con
alto
leverage),
ambos
residuos
e
i
i
orresponde al “centro de gravedad” de los datos de la muestra. Su
de
la
variable
explicativa
y
su
media
x
estandarizada
de
la
distancia
entre
cada
valor
x
i
ŷ
(por
ejemplo,
deciles)
y
calcular
la
media
ordenados
por
valores
crecientes
de
ŷ
(por
ejemplo,
deciles)
y
calcular
la
media
ordenados
por
valores
crecientes
de
le