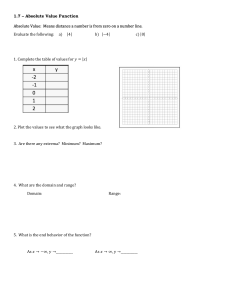
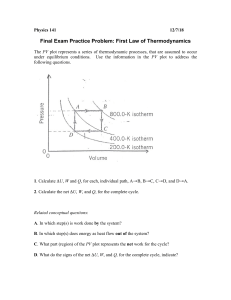
Worksheet for Data Visualization 1) Draw a histogram for the data diamonds taking the aesthetic variable as a caret. 2) Using the data diamonds create grouped bar plot taking x as cut and fill as clarity. Customize the plot with appropriate labels, and titles. Also, position the legend at the top. 3) Using the economics data set, create a line plot with multiple lines where the aesthetic x variable can be date and the multiple lines can be based on unemployment and population. Also, add different colors to the line using scale_color_manual(). 4) Using the mtcars data based on wt and mpg variables draw a scatter plot with regression line. Customize the plot with appropriate labels, and titles. 5) What is recorded in the ChickWeight data? How many rows are in this data set? How many columns? Create a plot showing how a chick’s weight changes over time. Create a plot showing whether the change in a chick’s weight over time is different according to the type of diet of a chick. 6) Using the "mtcars" dataset from R, create a bar plot to visualize the count of cars for each number of gears (gear). 7) Load the BOD data set. Add the time and demand to the x and y aesthetics. Add a border around the entire plot using themes in ggplot2. 8) Given the “diamonds” dataset in R which is part of the “ggplot2” library. It contains prices of approximately 50,000 round-cut diamonds. How would you use an approach to plot a bar graph that will display a type of diamond based on the quality of cut (Ideal, Premium, Good, etc.) 9) Demonstrate the 3 methods that are used in geom_smooth taking any in-built data set. 10) Using the diamonds data set, visualize the three different position adjustments using a bar plot. 11) Create the data df <- data.frame(x = 1:3, y = 1:3) Use the built-in themes theme_dark(), theme_linedraw(), theme_bw() Demonstrate the built-in element functions: text, lines, rectangles for the same data. 12) Recreate the R code necessary to generate the following graph using geom_jitter and geom_abline. Do some changes for the above like: a. Improving the axes and legend labels. Adding a title for the plot, Tweaking the colour scale. b. The background should be white, not pale grey. c. The legend should be placed inside the plot if there’s room. d. Major gridlines should be a pale grey and minor gridlines should be removed. e. The plot title should be 12pt bold text. 13) Using the "iris" dataset from R, create a grouped bar plot to compare the average petal width (Petal.Width) for different species of iris flowers (Species) based on their sepal length (Sepal.Length) categories. 14) Using the "diamonds" dataset from R, create a scatter plot to visualize the relationship between diamond carat weight (carat) and price (price). However, flip the coordinate system to have carat on the y-axis and price on the x-axis. Color the points based on the cut quality (cut) of the diamonds and add appropriate labels and titles to make the plot informative. 15) Using the "maps" package in R, create a map to visualize the locations of major cities around the world like USA, Canada, Japan. Customize the map with appropriate labels, titles, and aesthetics to make it informative and visually appealing. 16) Using the "mtcars" dataset from R, create a scatter plot to visualize the relationship between horsepower (hp) and miles per gallon (mpg) for cars. Color the points based on the number of cylinders (cylinders) and add a trend line to show the general trend between horsepower and miles per gallon. Customize the plot with appropriate labels, titles, and aesthetics. 17) What does the se argument to geom_smooth() do? Show it with example. 18) Using the "mpg" dataset from the ggplot2 package, create a box plot to compare the highway miles per gallon (hwy) for different types of vehicles (class). Add custom labels for the x-axis and y-axis, and display the median values on the plot. 19) Using the "world" dataset from the "maps" package, create a basic map to visualize the outlines of countries. 20) Load the "iris" dataset. Choose a specific species (i.e., "versicolor"). Subset the data for the selected species. Create a histogram to visualize the distribution of petal lengths (Petal.Length) for a specific species of iris flowers. 21) Turn a stacked bar chart into a pie chart using coord_polar() taking the inbuilt data set mpg. 22) Map a continuous variable to color, size, and shape. How do these aesthetics behave differently for categorical vs. continuous variables? 23) What does show. legend = FALSE do? What happens if you remove it? Demonstrate with any inbuilt data set. 24) Using the "iris" dataset in R, create a combination of plots to compare the distribution of sepal length (Sepal.Length) and sepal width (Sepal.Width) for different species of flowers (Species). Specifically, create a scatter plot with marginal histograms on the sides to show the univariate distribution of each variable, and color the points based on the petal length (Petal.Length) of the flowers. Add custom labels for the x-axis, yaxis, and title. 25) Consider “mpg” dataset in R which has the fuel economy data from 1999 to 2008 for 38 popular models of car. Given this data scenario, how will you generate facet row-wise and facet column-wise considering engine displacement (displ) in x-axis and highway miles per gallon (hwy) in the y-axis and consider drv (front-wheel drive etc.) as 3rd parameter? 26) Create a box plot with different colors for each group for the below data. data <- data.frame(group = rep(c("A", "B", "C"), each = 20), values = rnorm(60)) 27) Create a line plot with 3 lines. Give different colors for each line. X=1:10, y1=1:10, y2=1:10, y3=3:12 28) Create a data frame as below: data <- data.frame(category = c("A", "B", "A", "C", "B", "A", "C", "B", "A")) Write the code to get the below plot. 29) Below is the data. Create a data frame for it. Customize the appearance of a scatter plot, adding labels, titles, and text on each point and adjusting axis scales. X Y Label 1 2 A 2 4 B 3 1 C 4 6 D 5 3 E 30) Recreate the R code necessary to generate the following graphs.