See discussions, stats, and author profiles for this publication at: https://www.researchgate.net/publication/334038979
A Summary of Introductory Econometrics By Wooldridge
Article in SSRN Electronic Journal · January 2015
DOI: 10.2139/ssrn.3401712
CITATION
READS
1
8,392
1 author:
Marius van Oordt
University of Pretoria
19 PUBLICATIONS 21 CITATIONS
SEE PROFILE
All content following this page was uploaded by Marius van Oordt on 06 August 2019.
The user has requested enhancement of the downloaded file.
A SUMMARY OF INTRODUCTORY
ECONOMETRICS BY WOOLDRIDGE
Marius van Oordt 1
African Tax Institute
University of Pretoria
ABSTRACT
This is a summary of the well-known textbook by Wooldridge titled “Introductory
Econometrics: A Modern Approach” (6th edition). It covers the basics of cross-section, timeseries and panel econometrics. Please inform me where the summary can be improved.
Keywords: Econometrics
JEL Classifications: C01
1
Email: marius.vanoordt@up.ac.za
1
Contents
CROSS-SECTIONAL DATA ................................................................................................... 5
Ordinary Least Squares (OLS) Assumptions ......................................................................... 5
Multiple regression under OLS .............................................................................................. 6
Proxy variables................................................................................................................... 7
Variance in the model and estimates ................................................................................. 7
Statistical inference and hypothesis testing ....................................................................... 9
OLS large sample properties ................................................................................................ 10
Consistency ...................................................................................................................... 10
Asymptotic normality ...................................................................................................... 11
Asymptotic efficiency ...................................................................................................... 11
Transformation of variables ................................................................................................. 11
Models for limited dependent variables ............................................................................... 13
Linear probability model (LPM) for binary dependent variables .................................... 13
Logit and Probit models for binary dependent variables ................................................. 14
Tobit model for continuous dependent variable with many zero observations ............... 16
Poisson regression model for count dependent variables ................................................ 16
Censored regression model for censored dependent variable .......................................... 17
Heteroscedasticity ................................................................................................................ 17
Heteroscedasticity under OLS ......................................................................................... 17
Weighted Least Squares (WLS)....................................................................................... 18
Measurement error ............................................................................................................... 20
Non-random sampling ......................................................................................................... 21
Truncated regression model ............................................................................................. 21
Incidental truncated models ............................................................................................. 22
Outliers ................................................................................................................................. 22
Least absolute deviations (LAD) ..................................................................................... 22
2
Testing whether a variable is endogenous ........................................................................... 23
Independently pooled cross section ..................................................................................... 23
Cluster samples .................................................................................................................... 25
Instrumental variable (IV) estimator .................................................................................... 25
Statistical inference of the IV estimator........................................................................... 27
Two-stage least squares (2SLS) estimator ........................................................................... 28
Assumptions for 2SLS ..................................................................................................... 30
Indicator variables (Multiple indicator solution) ............................................................. 31
Generated independent variables and instruments ............................................................... 31
Control Function Estimator (CF) ......................................................................................... 32
Correlated random coefficient model .................................................................................. 32
Systems of Equations ........................................................................................................... 33
Simultaneity bias and simultaneous equation models (SEM).......................................... 34
TIME SERIES DATA ............................................................................................................. 37
OLS Assumptions for finite samples ................................................................................... 37
Basic time series models using OLS as the estimator.......................................................... 38
Static model ..................................................................................................................... 38
Finite distributed lag model (FDL) .................................................................................. 39
Dynamically complete model .......................................................................................... 39
Possible additions to the above models ........................................................................... 39
OLS asymptotic assumptions............................................................................................... 41
Stationary ......................................................................................................................... 41
Weakly dependent ............................................................................................................ 42
Highly persistent time series ................................................................................................ 44
Spurious regression .......................................................................................................... 45
Serial correlation .................................................................................................................. 46
Tests for serial correlation ............................................................................................... 46
3
Correcting serial correlation ............................................................................................ 47
Heteroscedasticity ................................................................................................................ 49
Serial correlation and heteroscedasticity ............................................................................. 49
2SLS estimator ..................................................................................................................... 50
SEMs ................................................................................................................................ 50
Assumptions for 2SLS ..................................................................................................... 50
Infinite distributed lag (IDL) models ................................................................................... 51
Geometric (Koyck) distributed lag models ...................................................................... 51
Rational distributed lag models ....................................................................................... 52
Forecasting ........................................................................................................................... 52
One-step forecasting ........................................................................................................ 53
Multiple-step forecasting ................................................................................................. 53
PANEL DATA......................................................................................................................... 54
Fixed effects model .............................................................................................................. 54
First-Differencing estimator (FD) .................................................................................... 54
Fixed effects estimator (Within estimator) (FE) .............................................................. 56
Random effects model ......................................................................................................... 58
Random effects estimator (RE) ........................................................................................ 58
FE/FD or RE or pooled OLS? .............................................................................................. 59
The correlated random effects model (CRE) ....................................................................... 60
IV estimator ......................................................................................................................... 60
Dynamic panel data models ................................................................................................. 61
Spatial panels ....................................................................................................................... 61
4
CROSS-SECTIONAL DATA
Ordinary Least Squares (OLS) Assumptions
The assumptions (for finite samples) of OLS are:
1. The parameters are linear (note not the independent variables). OLS cannot be
performed when the equation is e.g. 𝑦𝑦 = 𝛼𝛼 + 𝛽𝛽 2 𝑥𝑥 + 𝑢𝑢
2. The sample is obtained randomly from a population. This is not always the case.
3. There is variance in independent variables. This is always the case and can be ignored
as a requirement.
4. Unbiased parameters, zero mean error assumption, written as
𝐸𝐸(𝑢𝑢|𝑥𝑥1 , 𝑥𝑥2 … 𝑥𝑥𝑘𝑘 ) = 𝐸𝐸(𝑢𝑢) = 0
This means that there are no unobserved factors (included in the error term) that are
correlated with the independent variable. Alternatively stated, all other factors not
included in the model that effect 𝑦𝑦 are uncorrelated with 𝑥𝑥1 , 𝑥𝑥2 … 𝑥𝑥𝑘𝑘 .
If this does not hold, the parameters are biased upwards or downwards and we say that
we have endogenous explanatory variables. Note that this assumption will also not hold
if the incorrect functional form for independent variables is chosen, if there is
measurement error in the independent variables or in the presence of simultaneity bias
(all of these are discussed later). Functional form is less important asymptotically than
the other mentioned.
It is important to understand the omitted variables bias that result if this assumption
does not hold, this can be written 𝐵𝐵𝐵𝐵𝐵𝐵𝐵𝐵 (𝐵𝐵1 ) = 𝐵𝐵2 𝛿𝛿 where 𝐵𝐵2 indicates the correlation
between the omitted variable, 𝑥𝑥𝑗𝑗 and y; and 𝛿𝛿 indicates the correlation between
𝑥𝑥1 𝑎𝑎𝑎𝑎𝑎𝑎 𝑥𝑥𝑗𝑗 , the endogenous variable and the omitted variable. It is not possible to
determine the magnitude of the bias, but we do indicate whether the bias is upwards or
downwards. If 𝐵𝐵2 is positive and 𝛿𝛿 is positive, we have upward bias (this is based on
intuition). Similarly if one is positive and other negative we have downward bias. If
both are negative we have upward bias.
It should be remembered that a bias parameter will influence all parameters that are
correlated with the variable of that parameter. In discussing our results from a multiple
regression, however, we do not discuss whether the exogenous variables, which means
variables not correlated with the error term, are upwards or downwards bias as a result
of including an endogenous variable in the model.
5
5. Homoskedasticity
𝑉𝑉𝑉𝑉𝑉𝑉(𝑢𝑢|𝑥𝑥1 , 𝑥𝑥2 , … 𝑥𝑥𝑘𝑘 ) = 𝜎𝜎 2 = 𝑉𝑉𝑉𝑉𝑉𝑉(𝑦𝑦|𝑥𝑥)
This means that the variance of the dependent variable, given the variance of the
independent variables is constant. This also means the variance of the error terms is
constant around the regression line for each observation and does not change as the
level of the independent variables change.
If this does not hold, the standard errors of the parameters are incorrect and the
parameters are therefore a poorer estimation of the population parameter.
It is also very important to note that increased variability in the independent variable
will decrease the standard error of the parameter.
6. There is no perfect collinearity between the independent variables
An independent variable may not be a constant. There may not be an exact linear
relationship between independent variables, e.g. 𝑥𝑥1 = 𝑘𝑘. 𝑥𝑥2 𝑜𝑜𝑜𝑜 𝑥𝑥1 = 𝑥𝑥2 + 𝑥𝑥3 .
Note that 𝑥𝑥1 𝑎𝑎𝑎𝑎𝑎𝑎 𝑙𝑙𝑙𝑙𝑙𝑙𝑥𝑥1 𝑜𝑜𝑜𝑜 𝑥𝑥12 are not linear relationships and are allowed.
Multiple regression under OLS
The main purpose of including multiple independent variables is to take controls out of the
error terms and put them explicitly in the equation. This is done to adhere to assumption four
above.
For interpretation take the following regression
𝑦𝑦 = 𝛼𝛼 + 𝛽𝛽𝑥𝑥1 + 𝛾𝛾𝑥𝑥2 + 𝑢𝑢
𝛽𝛽 measures the relationship between 𝑦𝑦 and 𝑥𝑥1 after other variables (𝑥𝑥2 ) has been partialled out.
The same is true for all other parameters, unless two parameters use different functional forms
of the same variable, discussed next.
In the case where 𝑥𝑥1 is e.g. income and 𝑥𝑥2 is income squared then the derivative of the equation
would have to be used to interpret 𝛽𝛽, for instance
𝑦𝑦 = 𝑎𝑎 + 𝐵𝐵1 𝑥𝑥 + 𝐵𝐵2 𝑥𝑥 2 + 𝑢𝑢
∆𝑦𝑦
= 𝐵𝐵1 + 2𝐵𝐵2 𝑥𝑥
∆𝑥𝑥
If there are other independent variables included, the partial derivative (treating all other
variables as constant) would need to be taken to interpret 𝐵𝐵1. The same logic is applied to
interaction terms, the interaction term forms part of the interpretation just as would be the case
for a partial derivative.
6
Proxy variables
Before estimating a model, we should always specify the population model. Often a population
model will include unobservable variables (for instance ability) that we cannot include in our
model to be estimated (we cannot observe it). In such instances, it is generally preferable to
include a proxy variable (which can be observed) to reduce or possibly remove the bias of not
including the unobservable variable. The requirements for an ideal proxy are
1. If we were able to include the unobserved variable, the proxy variable would be
irrelevant. This is always met when the population model is correctly specified.
2. The independent variables are not partially correlated with the unobserved variable after
including the proxy variable. If this is not the case then the independent variables will
still be correlated with the error term, although most likely to a lesser extent than if the
proxy was not included (less bias).
It should be noted that even if the second requirement is not met and we have an imperfect
proxy, it is generally still a good idea to include it in the estimation model.
It may also be required that the proxy interact with another independent variable in the
population model. If 𝑞𝑞 is taken as the unobserved variable in the model
𝑦𝑦 = 𝛽𝛽0 + 𝛽𝛽1 𝑥𝑥 + 𝛾𝛾1 𝑞𝑞 + 𝛾𝛾2 𝑥𝑥. 𝑞𝑞 + 𝑢𝑢
Then the interpretation of 𝑥𝑥 will be the partial effect: 𝛽𝛽1 + 𝛾𝛾2 𝑞𝑞. This provides a problem, since
𝑞𝑞 is not observed. We can however obtain the average partial effect if we assume the average
of 𝑞𝑞 in the population is zero, meaning the average partial effect is: 𝛽𝛽1. 2 Once we take a proxy
for 𝑞𝑞, it is therefore required that we demean the proxy in the sample before interaction and
then we obtain the average partial effect for 𝛽𝛽1. Further note that if the interaction term is
significant, the error term will be heteroskedastic. A model with an interaction proxy is called
a random coefficient model.
Variance in the model and estimates
Sum of squares total (SST) = Sum of squares explained (SSE) + Sum of squared residuals
(SSR). 𝑅𝑅 2 is therefore SSE over SST; the explained variance over the total variance. A higher
R squared does not always indicate a better model, additional variables should only be included
if it has a non-zero partial effect on the dependent variable in the population. It is also common
If 𝑥𝑥 is binary, then we call this the average treatment effect. As previously mentioned, all estimated coefficients
are average partial effects.
2
7
1−𝜎𝜎2
to calculate the adjusted 𝑅𝑅 2 𝑎𝑎𝑎𝑎 𝑆𝑆𝑆𝑆𝑆𝑆(𝑛𝑛−1). This is useful as the adjusted 𝑅𝑅 2 is not always
increasing by adding additional variables. If an additional variable has a t-stat of less than one,
the adjusted 𝑅𝑅 2 will decrease. This is also useful for non-nested model selection.
The sampling variance of the OLS slope estimates is calculated as follow:
𝑉𝑉𝑉𝑉𝑉𝑉�𝐵𝐵𝑗𝑗 � = 𝜎𝜎 2 /𝑆𝑆𝑆𝑆𝑇𝑇𝐽𝐽 �1 − 𝑅𝑅𝑗𝑗2 �
Where 𝜎𝜎 2 is the error variance of the regression. This means a larger variance in the error (more
noise) leads to more variance in the estimate. Adding more variables reduces this variance.
Further, 𝑆𝑆𝑆𝑆𝑇𝑇𝐽𝐽 is the total sample variation in 𝑥𝑥𝑗𝑗 . This means that the more variance in the sample
(or alternatively the larger the sample), the smaller will the variance of the estimate become.
Lastly and very importantly, 𝑅𝑅𝑗𝑗2 indicates the extent of multicollinearity between 𝑥𝑥𝑗𝑗 (e.g. the
variable of interest) and the other independent variables. This can for instance be seen by
looking at VIF’s for 𝑥𝑥𝑗𝑗 . In other words, this is the linear relationship between one independent
variable to all other independent variables. The more collinearity between this variable and the
other, the larger will 𝑉𝑉𝑉𝑉𝑉𝑉�𝐵𝐵𝑗𝑗 � become. This is where multicollinearity becomes a “problem”,
but it should be seen that multicollinearity has the same effect as a small sample as this will
reduce 𝑆𝑆𝑆𝑆𝑇𝑇𝐽𝐽 . If a variable is dropped due to multicollinearity, then we may not meet assumption
4 (estimates will be bias) and 𝜎𝜎 2 will increase, so this is not a good idea. Multicollinearity does
not make any OLS assumption invalid and does not need to be addressed (as opposed to perfect
multicollinearity). Further, if other variables are collinear, besides the variable of interest, and
these variables are not correlated with the variable of interest, this will not influence 𝑉𝑉𝑉𝑉𝑉𝑉�𝐵𝐵𝑗𝑗 �.
In conclusion, focus on having 𝜎𝜎 2 as small as possible and 𝑆𝑆𝑆𝑆𝑇𝑇𝐽𝐽 as large as possible and worry
less about multicollinearity.
This, however, does not mean that we should add as many as possible variables in the model.
The ceteris paribus interpretation should always be considered. It does not make sense to add
for instance the amount of beer consumption and the amount of tax collected from beer
consumption in a model where we are interested in the effect of the beer tax on fatalities in
motor vehicle accidents; the ceteris paribus interpretation becomes nonsensical. However, if
we have a variable that affects y and is uncorrelated with all other independent variables, such
a variable should always be included; it does not increase multicollinearity and results in
smaller standard errors.
To calculate 𝜎𝜎 2 in a sample ,we write
8
𝜎𝜎 2 =
𝑆𝑆𝑆𝑆𝑅𝑅
𝑑𝑑𝑑𝑑
Where 𝑑𝑑𝑑𝑑 (degrees of freedom) is 𝑛𝑛 (observations) – 𝑘𝑘 (parameters including intercept) -1.
Take the root to obtain 𝜎𝜎, the standard error of the regression. This standard error is used to
compute the standard deviation of a parameter, 𝑠𝑠𝑠𝑠�𝐵𝐵𝑗𝑗 � = �𝑣𝑣𝑣𝑣𝑣𝑣(𝐵𝐵𝑗𝑗 ). Note that
heteroscedasticity violates this and we cannot be certain that OLS has the smallest variance of
all estimators (that OLS is Best).
Statistical inference and hypothesis testing
Classic linear model assumption
The classic linear model is not an estimator but an assumption important for hypothesis testing
and statistical inference of the sample to the population. The assumption includes 1-6 of OLS
and the normality assumption.
Officially the assumption of CLM is
𝐸𝐸(𝑢𝑢|𝑥𝑥1 , 𝑥𝑥2 … 𝑥𝑥𝑘𝑘 ) = 𝐸𝐸(𝑢𝑢) 𝑎𝑎𝑎𝑎𝑎𝑎 𝑢𝑢~𝑁𝑁𝑁𝑁𝑁𝑁𝑁𝑁𝑁𝑁𝑁𝑁(0, 𝜎𝜎 2 )
The assumption is therefore that the error term follows a normal distribution, which means that
the estimates are normally distributed, linear combination of 𝛽𝛽1 , 𝛽𝛽2 , … 𝛽𝛽𝑘𝑘 is normally
distributed and a subset of 𝛽𝛽𝑗𝑗 has a joint normal distribution.
Single parameter test – T test
For the population hypothesis 𝐻𝐻0 : 𝐵𝐵𝑗𝑗 = 0
�𝚥𝚥 /𝑠𝑠𝑠𝑠(𝐵𝐵
�𝚥𝚥 ) or alternatively stated,
the t-test is 𝐵𝐵
T = (Estimated – Hypothesised value) / Standard error of estimated (this is useful for when
hypothesized value is not zero).
It should be seen that smaller standard errors lead to higher t-stats, this, in turn, means this
decrease the probability of an obtained t-stat, meaning a lower p-value. Standard errors are
calculated based on standard deviations (divided by √𝑛𝑛) and this is in turn is calculated based
on 𝑉𝑉𝑉𝑉𝑉𝑉(𝐵𝐵𝑗𝑗 ). This means for statistical significance under the CLM assumption we want small
𝜎𝜎 2 , large 𝑆𝑆𝑆𝑆𝑇𝑇𝐽𝐽 and small 𝑅𝑅𝑗𝑗2 . Large samples therefore is key to statistical inference. Also,
remember that statistical significance is not necessarily equal to economic significance.
Single linear combination of parameters – T test
For the population hypothesis 𝐻𝐻0 : 𝐵𝐵1 = 𝐵𝐵2 , 𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎 𝐵𝐵1 − 𝐵𝐵2 = 0.
�1 − 𝐵𝐵
�2 − 0/𝑠𝑠𝑠𝑠(𝐵𝐵
�1 − 𝐵𝐵
�2 )
T-test therefore 𝐵𝐵
9
This can be estimated by creating a new variable for 𝐵𝐵1 − 𝐵𝐵2 and replacing this in the original
equation.
Multiple linear restrictions – F test
For the population hypothesis 𝐻𝐻0 : 𝐵𝐵3 = 0, 𝐵𝐵4 = 0, 𝐵𝐵5 = 0 one cannot look at individual t-tests
as the other parameters are not restricted and we are interested in the joint significance of three
(or however many) variables. One way to see this is how SSR change with the removal of these
three variables. We therefore have an unrestricted (original) model and a restricted model,
which is the original model after removing the variables that we wish to restrict (indicated in
Ho). The F test is then written
𝐹𝐹 =
(𝑆𝑆𝑆𝑆𝑅𝑅𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟 − 𝑆𝑆𝑆𝑆𝑅𝑅𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢 )/(𝑑𝑑𝑓𝑓𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟 − 𝑑𝑑𝑓𝑓𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢 )
𝑆𝑆𝑆𝑆𝑅𝑅𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢 /𝑑𝑑𝑓𝑓𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢
If the null is rejected then 𝐵𝐵3, 𝐵𝐵4 and 𝐵𝐵5 is jointly statistically significant.
The F-test is also useful for testing the exclusion of a group of variables if highly correlated. It
may often be the case that many similar variables are not significant under the t-test, but they
are jointly significant under the F-test. This is where the F-test becomes very important as we
do not need to drop variables due to multicollinearity. The F-statistics is also shown for each
regression by Stata and this indicates the hypothesis that all parameters are equal to zero.
Multiple linear restrictions – Lagrange multiplier stat (n-R-squared stat)
This test, as an alternative to the F test is performed as follow:
1) Regress 𝑦𝑦 on restricted model, save 𝑢𝑢
2) Regress saved 𝑢𝑢 on unrestricted model, get R squared
3) LM=𝑛𝑛Rsquared, compare this to a critical value to test hypothesis.
OLS large sample properties
As the sample size grows (for large samples) OLS has some additional properties besides being
the estimator with the smallest variance and being unbiased (applicable to finite samples). This
affords us to relax some of the assumptions of OLS previously discussed. These properties are
Consistency
As 𝑛𝑛 grows, 𝐵𝐵�𝑗𝑗 collapses to 𝐵𝐵𝑗𝑗 , meaning the estimate gets closer and closer to the actual
population parameter. This essentially means that there is no bias and the parameter is
consistently correctly estimated. The assumption required for this to hold is
𝐸𝐸(𝑢𝑢) = 0 𝑎𝑎𝑎𝑎𝑎𝑎 𝐶𝐶𝐶𝐶𝐶𝐶(𝑥𝑥𝑖𝑖 |𝑢𝑢) = 0
10
Note that this is a slightly less strict assumption than assumption 4 of OLS for a finite sample
and states that the covariance between all variables individually and the error term should be
zero. If this assumption does not hold, the variable that is correlated with the error term, as well
as all other variables that are correlated with this variable or the error term, will be bias and
inconsistent. This inconsistency increase as the sample size increase, meaning 𝐵𝐵�𝑗𝑗 collapses to
an incorrect population estimate.
Asymptotic normality
The T, F and LM tests rely on a normal distribution of u in the population.
According to the central limit theorem, OLS estimates (and the error term) are approximately
normally distributed in large samples (n>30 about) and we can, therefore, use these tests for
large samples, even if it appears that are errors are non-normally distributed (there are certain
cases where the non-normal distribution may still be an issue). This means that the assumption
of CLM is generally not required for OLS hypothesis testing.
Note that the zero mean and homoscedasticity assumptions are still required.
Other consequences of the asymptotic normality of the estimators are that the error variance is
consistent and that standard errors are expected to shrink at a rate of 1/√𝑛𝑛.
Asymptotic efficiency
If OLS assumptions hold, then it has the smallest asymptotic variance of all estimators. If
heteroscedasticity is present, there may exist better estimators than OLS.
Transformation of variables
Scaling data does not change any measured effect or testing outcome, only the interpretation
changes.
It may be useful in certain scenarios to run a standardized model with only beta coefficients
(also called standardized coefficients) as this gives an indication of the magnitude of the effect
of the different independent variables on the dependent variable. This is done by taking the z
score of all variables and the interpretation is the change in standard deviation to a change in
standard deviation.
Logs are useful for obtaining elasticities or semi-elasticities. Further, taking the natural log of
a variable may increase the normality and reduce heteroscedasticity of the variable by drawing
in large variances (this also increase the likelihood of statistical significance as there is less
variance in the error term). This is particularly useful for significantly skewed variables where
11
the central limited theorem is unlikely to hold (CLM assumption is therefore violated). Also,
the impact of outliers is reduced. It should, however, be noted that the log of a variable is a new
variable with a different interpretation than the original variable. Further, a log should not be
taken for a variable with many values between 0 and 1 or a variable with 0 values. A constant
can be added if there are few 0 values, but this is generally not preferred. Generally, it is not
preferred to transform a variable, outliers should rather be treated separately. Only if a variable
is greatly positively skewed does it make sense (or you are estimating elasticities). Further,
taking the log of the variable of interest make little sense; you cannot argue causality on a logtransformed variable as the variable (particularly its variance) is not the same as the nontransformed variable. Of course, if a variable has a log-linear relationship with the dependent
variable, the log must be taken, otherwise the model will be misspecified and there will be bias
in the parameters.
Quadratic terms are also common, just remember the interpretation of such a term requires the
partial derivative of the equation. The adjusted 𝑅𝑅 2 is particularly useful to determine whether
a quadratic term should be included in addition to the non-quadratic variable. Again, if a
variable has a quadratic relationship with the dependent variable, the quadratic term must be
included, otherwise the model is misspecified and the estimates bias.
Logs and quadratic terms are the most common functional forms for variables. As noted, the
zero mean error assumption will not hold if a model has functional form misspecification,
meaning there is an omitted variable and it is a function of an included dependent variable.
One way to test for additional functional forms is with the F test after including additional
transformed variables. Other tests are
1. RESET (Regression specification error test)
To conduct this test, run the regression and save fitted values 𝑦𝑦�, calculate 𝑦𝑦� 2 , 𝑦𝑦� 3 … Run a
regression that is the same as original, but adding the calculated values as variables.
Conduct an F test on the parameters of the newly added variables (H0 is all is nil). If
rejected then there is misspecification that needs further consideration.
2. Dawidson-MacKinnon test (nonnested model selection)
This test is useful for testing whether some independent variables should be logged. Run
the alternative model that includes the logged variable, save the fitted values 𝑦𝑦�. Run the
original model with the fitted values as an independent variable and see whether this
variable is significant. If it is, it is likely that the logged variable should be preferred.
12
Qualitative independent variables should be transformed into dummy categories. If the
dependent variable has a log function, the interpretation is percentage. Where there are multiple
binary or ordinal variables, the coefficient takes the interpretation of all the 0 categories. Binary
variables can also be used as interaction terms to obtain additional information from an
intercept (binary interact with binary) or a different slope (binary with continuous). Binary
variables can also be used to determine whether e.g. females and males have different models;
this is done by interacting all variables and keeping the original variables and using the F test
where the non-interacted model is the restricted model.
It may also be useful to include a lagged dependent variable in the model. This new independent
variable will control for unobservable historical facts that cause current differences in the
dependent variable.
Models for limited dependent variables
A limited dependent variable is a variable that has a substantially restricted range of values,
such as binary variables and some discrete variables. Models with such dependent variables
can be estimated by OLS, discussed first, although this presents some issues. More advanced
estimators are therefore required in most cases. The predominant reason for this is that the
dependent variable will not follow a normal distribution.
Linear probability model (LPM) for binary dependent variables
This model is run in the exact same manner as a continuous dependent variable model with
OLS as the estimator and hypothesis testing remains the same. The only difference is in
interpreting the parameter estimates. These are interpreted as the change in probability of
success (y=1) when x changes, ceteris paribus. Mathematically
∆𝑃𝑃(𝑦𝑦 = 1|𝑥𝑥) = 𝐵𝐵𝑗𝑗 ∆𝑥𝑥𝑗𝑗
This model is very easy to run and interpret, but has some issues. Some predictions of
probability (for individual cases) will exceed 1 or be less than 0, this is nonsensical. Further, it
is not possible to relate probability linearly to independent variables as this model does; this
means that e.g. the probability of being employed is not a linear function of the number of
children one has. These prediction problems can be resolved by taking 𝑦𝑦� = 1 𝑖𝑖𝑖𝑖 𝑦𝑦� ≥
0.5 𝑎𝑎𝑎𝑎𝑎𝑎 𝑦𝑦� = 0 𝑖𝑖𝑖𝑖 𝑦𝑦� ≤ 0.5 and then see how often the prediction is correct. This goodness of
fit measure is called the percentage correctly predicted approach.
13
The major issue with this model is that heteroscedasticity is always present and the standard
errors under the t or f test can therefore not be trusted. The preferred approach to address this
is to use robust tests since weighted least squares can be complex to calculate.
Logit and Probit models for binary dependent variables
Logit and probit models address the issues mentioned for the LPM models. It allows for nonlinear parameters and the prediction of probability is always between 0 and 1. For both logit
and probit, we are interested in the response probability written
𝑃𝑃(𝑦𝑦 = 1|𝑥𝑥1 , 𝑥𝑥2 , … , 𝑥𝑥𝑘𝑘 ) = 𝑃𝑃(𝑦𝑦 = 1|𝑋𝑋)
If we take 𝑋𝑋 as all independent variables. Written in functional form together with parameters
this is
𝑃𝑃(𝑦𝑦 = 1|𝑋𝑋) = 𝐺𝐺(𝛽𝛽0 + 𝛽𝛽1 𝑥𝑥1 + ⋯ + 𝛽𝛽𝑘𝑘 𝑥𝑥𝑘𝑘 ) = 𝐺𝐺(𝛽𝛽0 + 𝒙𝒙𝒙𝒙)
Note that the shorthand 𝐺𝐺(𝛽𝛽0 + 𝒙𝒙𝜷𝜷) can also be written 𝐺𝐺(𝑥𝑥𝑥𝑥) for simplicity. Since we are
concerned about probability it is required that for all real numbers, 𝑧𝑧
0 < 𝐺𝐺(𝑧𝑧) < 1
We, therefore, need a method to calculate 𝐺𝐺(𝑧𝑧) where it will adhere to this requirement. The
most common methods are the logistic function (used in the logit model) and the normal
cumulative distribution function (used in the probit model). Both of these distributions are nonlinear and look very similar (the logistic distribution has heavier tails). They are useful as they
indicate that probability increase the fastest close to zero and slowest close to one. In the logit
model,
And in the probit model
𝐺𝐺(𝑧𝑧) =
exp(𝑧𝑧)
1 + exp(𝑧𝑧)
1
𝐺𝐺(𝑧𝑧) = (2𝜋𝜋)−2 exp(−
𝑧𝑧 2
)
2
The probit model is more popular than the logit model since it is often assumed that the errors
are normally distributed. Since both the logit and probit models rely on non-linear parameters,
we use Maximum Likelihood Estimation (MLE) to estimate the models.
14
Maximum Likelihood Estimation for logit and probit models
The MLE estimator is based on the distribution of 𝑦𝑦 given 𝑥𝑥 and is therefore very important
for estimating probit or logit models. To see how MLE for LDVs are estimated we first write
the density of 𝑦𝑦 given 𝑥𝑥 as
𝑓𝑓(𝑦𝑦|𝒙𝒙𝒊𝒊 ; 𝜷𝜷) = [𝐺𝐺(𝒙𝒙𝒊𝒊 𝜷𝜷)]𝑦𝑦 [1 − 𝐺𝐺(𝒙𝒙𝒊𝒊 𝜷𝜷)]1−𝑦𝑦
From this, we get the log-likelihood function by taking the log of the density function above
𝑙𝑙𝑖𝑖 (𝜷𝜷) = 𝑦𝑦𝑖𝑖 𝑙𝑙𝑙𝑙𝑙𝑙 [𝐺𝐺(𝒙𝒙𝒊𝒊 𝜷𝜷)] + (1 − 𝑦𝑦𝑖𝑖 )log[1 − 𝐺𝐺(𝒙𝒙𝒊𝒊 𝜷𝜷)]
Summing all 𝑙𝑙𝑖𝑖 (𝜷𝜷) for all n gives the log-likelihood for the sample, 𝐿𝐿(𝜷𝜷). Under MLE, 𝛽𝛽̂ is
obtained by maximizing 𝐿𝐿(𝜷𝜷). If we used 𝐺𝐺(𝑧𝑧) as in the logit model, we call this the logit
estimator and if the used 𝐺𝐺(𝑧𝑧) as in the probit model, we call this the probit estimator. MLE
under general conditions is consistent and asymptotically normal and efficient.
Hypothesis testing (Likelihood ratio test)
Normal t-tests are reported after using the logit or probit estimator. These can be used for single
hypothesis testing. For multiple hypothesis testing, we use the likelihood ratio test. This test
considers the difference in the log-likelihood of the unrestricted and restricted model. The
likelihood ratio statistic is
𝐿𝐿𝐿𝐿 = 2(𝐿𝐿𝑢𝑢𝑢𝑢 − 𝐿𝐿𝑟𝑟 )
Note that the difference in log-likelihood is multiplied by two to allow the statistic to follow a
chi-square distribution. P-values are therefore also obtained from this distribution.
Interpreting logit and probit
Since the econometric package automatically estimates and calculates all of the above, the most
challenging part of logit and probit models is interpreting them. The sign of the obtained
coefficients can be interpreted as usual, but since the parameters are non-linear the magnitude
of the estimated coefficients does not give rise to useful interpretation. If the variable of interest
is binary, the partial effect for that variable can be obtained by
𝐺𝐺(𝛽𝛽0 + 𝛽𝛽1 + 𝛽𝛽2 𝑥𝑥2 + ⋯ ) − 𝐺𝐺(𝛽𝛽0 + 𝛽𝛽2 𝑥𝑥2 + ⋯ )
If the variable of interest is discrete the partial effect for the variable can be obtained by
𝐺𝐺(𝛽𝛽0 + 𝛽𝛽1 (𝑥𝑥1 + 1) + 𝛽𝛽2 𝑥𝑥2 + ⋯ ) − 𝐺𝐺(𝛽𝛽0 + 𝛽𝛽1 𝑥𝑥1 + 𝛽𝛽2 𝑥𝑥2 + ⋯ )
If the variable of interest is continuous then we need to take the partial derivative for the partial
effect which will give
15
𝑔𝑔(𝛽𝛽0 + 𝒙𝒙𝒙𝒙)(𝛽𝛽𝑗𝑗 )
To compare the estimated parameters with OLS, we make use of scale factors based on the
partial effects. This is done by Stata and the most useful is the average partial effects (APE). It
is, therefore, standard to estimate a model by LPM, probit and logit and compare the estimated
coefficients.
Tobit model for continuous dependent variable with many zero observations
Using a linear estimator for models with a continuous dependent variable with many zero
observations (for instance the number of cigarettes smoked per month over the population) will
give negative predictions of 𝑦𝑦�𝚤𝚤 and heteroscedasticity will be present. It is therefore preferred
to use a non-linear estimator that do not allow for negative values of 𝑦𝑦�𝚤𝚤 (meaning the estimated
parameters are more reliable).
Similar to the probit and logit model, for the tobit model we use MLE as the estimator to
maximize the sum of the following log-likelihood function
𝑙𝑙𝑖𝑖 (𝛽𝛽, 𝜎𝜎) = 1(𝑦𝑦𝑖𝑖 = 0) log �1 − Φ �
𝑥𝑥𝑖𝑖 𝛽𝛽
1
𝑦𝑦𝑖𝑖 − 𝑥𝑥𝑖𝑖 𝛽𝛽
�� + 1(𝑦𝑦𝑖𝑖 > 0)log{� � 𝜙𝜙 �
�}
𝜎𝜎
𝜎𝜎
𝜎𝜎
Where Φ indicates the standard normal cdf and 𝜙𝜙 indicates the standard normal pdf. This can
be called the tobit estimator. Hypothesis testing is conducted in the same manner as for the
logit and probit models.
Interpretation of the tobit model
In interpreting the tobit model we again rely on partial derivatives. These are used to calculate
APEs that can be compared to an OLS estimation of the same model and interpreted as a usual
(not probabilities as for binary dependent variables). APEs are routinely calculated by Stata.
Poisson regression model for count dependent variables
A count variable is a variable that takes on non-negative integer values (not continuous as for
the tobit model). Again we are only really interested in this model if the count variable can also
be considered an LDV, meaning the dependent does not take on many integer values (e.g.
number of children in a household). In other words, the dependent variable will not follow a
normal distribution, but rather a nominal distribution that we call the Poisson distribution. This
distribution can be written
𝑃𝑃(𝑦𝑦 = ℎ|𝑥𝑥) = exp[− exp(𝑥𝑥𝑥𝑥)] [exp(𝑥𝑥𝑥𝑥)]ℎ /ℎ!
16
Where ℎ is a count variable and used to indicate that 𝑦𝑦 is a count variable, and ℎ! means
factorial. Further note that exponential function are used as these are strictly positive. The loglikelihood function is therefore
𝑙𝑙𝑖𝑖 (𝛽𝛽) = [𝑦𝑦𝑖𝑖 𝑥𝑥𝑖𝑖 𝛽𝛽 − exp(𝑥𝑥𝑖𝑖 𝛽𝛽)]
And the sum of this over n is again maximized by MLE, t-stats are given and we can use APEs
to compare the coefficients with OLS. It is, however, very important to note that the Poisson
distribution assumes that
𝑉𝑉𝑉𝑉𝑉𝑉(𝑦𝑦|𝑥𝑥) = 𝐸𝐸(𝑦𝑦|𝑥𝑥)
Which is very restrictive an unlikely to hold. If this is not assumed then we should rather use
Quasi MLE (QMLE) as the estimator together with the quasi-likelihood test statistic for
multiple hypotheses.
Censored regression model for censored dependent variable
The dependent variable is censored if a threshold was inserted during data collection, meaning
the dependent variable cannot take on a value greater (or less than for a lower bound threshold)
than a certain value (𝑐𝑐𝑖𝑖 ). An example is for instance a questionnaire where you tick a box if
your income is above a certain amount (with no higher possible selections). Although the
uncensored observations have a normal distribution (and do not pose any difficulty for OLS)
the censored observations (values above the threshold not observed) does not have a normal
distribution. The density for the censored observations is
𝑃𝑃((𝑦𝑦 ≥ 𝑐𝑐𝑖𝑖 |𝑥𝑥) = 1 − Φ �
𝑐𝑐𝑖𝑖 − 𝑥𝑥𝑖𝑖 𝛽𝛽
�
𝜎𝜎
This means that we can again use MLE after taking the log-likelihood where MLE will
maximize the sum. The interpretation of the estimates does not require any scaling and are
directly comparable with OLS. It should, however, be noted that in the presence of
heteroscedasticity or non-normal errors, MLE will be bias and inconsistent.
Heteroscedasticity
Heteroscedasticity under OLS
Heteroscedasticity does not cause bias or inconsistency in the OLS estimates and does not
influence R-squared or adjusted R-squared. It does, however, bias the variance of the OLS
estimates, resulting in incorrect standard errors and T, F and LM test results. OLS is then no
longer asymptotic most efficient amongst linear estimators. The first step is to test for
17
heteroscedasticity and then to address it. Note that incorrect functional forms may indicate
heteroscedasticity even when none is present, it is therefore important to first test whether the
functional forms are correct.
Testing for heteroscedasticity
The two most common tests are the Breusch Pagan test and the special case of the White test
for heteroscedasticity.
For the Breuscg Pagan test, OLS is run and 𝑢𝑢 is saved and 𝑢𝑢2 is calculated. This is regressed
on the original model and a F or LM test is conducted to test the null hypothesis that all
parameters are equal to nil. If the null is rejected, heteroscedasticity is present.
For the special case of the White test, OLS is run and 𝑢𝑢� 𝑎𝑎𝑎𝑎𝑎𝑎 𝑦𝑦� is saved, 𝑢𝑢�2 𝑎𝑎𝑎𝑎𝑎𝑎 𝑦𝑦� 2 is computed.
, 𝑢𝑢�2 is regressed on 𝑦𝑦�, 𝑦𝑦� 2 and the null is whether the parameters of these two are equal to nil.
If the null is rejected, heteroscedasticity is present. This test specifically test for the type of
heteroscedasticity that gives bias variances under OLS.
It is important to note that for both these tests, it is required that the errors in the second
regression, 𝑣𝑣𝑖𝑖 be homoscedastic, 𝐸𝐸(𝑣𝑣𝑖𝑖2 �𝑋𝑋) = 𝑘𝑘 (k means constant). This implies that for the
original error 𝐸𝐸(𝑢𝑢𝑖𝑖4 �𝑋𝑋) = 𝑘𝑘 2 (where 𝑘𝑘 2 is also a constant). This is called the homokurtosis
assumption. There are heterokurtosis-robust tests for heteroskedasticity also, but these are
seldom used (see page 141 in Wooldridge (2010) if interested).
Correcting heteroscedasticity under OLS
For large samples, correcting heteroscedasticity is straightforward. All methods use an
alternative way of calculating standard errors that provide standard errors that are correct in the
presence of heteroscedasticity. Robust (Huber White) standard errors can be calculated for the
t-test (robust command in Stata). Note the same factors that influence the size of normal
standard errors influence these standard errors. For exclusions, the robust F statistic (also called
the Wald Statistic) can be calculated (test command in Stata). It is also possible to calculate a
robust LM statistic, although the Wald statistic is more popular and should suffice.
Weighted Least Squares (WLS)
The WLS estimator gives different estimates and standard errors that OLS. This said large
differences in estimates indicate that the other OLS assumptions do not hold or that there is
functional form misspecification. WLS is more efficient than OLS with robust standard errors,
18
assuming all OLS assumptions hold, besides homoscedasticity, and the heteroscedasticity
function (the weight) for WLS is correctly identified (WLS is BLUE).
If we write 𝑉𝑉𝑉𝑉𝑉𝑉(𝑢𝑢𝑖𝑖 |𝑥𝑥𝑖𝑖 ) = 𝜎𝜎 2 ℎ(𝑥𝑥𝑖𝑖 ) = 𝜎𝜎 2 ℎ𝑖𝑖 where ℎ(𝑥𝑥𝑖𝑖 ) is some function of the explanatory
variables that determines the heteroscedasticity, the standard deviation is 𝜎𝜎�ℎ𝑖𝑖 . We can divide
this by 1/�ℎ𝑖𝑖 to get 𝜎𝜎, the standard deviation if heteroscedasticity was not present. To do this,
we weight the original OLS model with 1/�ℎ𝑖𝑖 for each variable, including the dependent and
the intercept. After dividing, the estimators are written 𝛽𝛽𝑗𝑗∗ , this is an example of generalised
least squares (GLS) and is estimated by OLS.
The WLS model does exactly the same as OLS with GLS estimators, the only difference is that
we do not calculate the GLS estimators, but rather divide the entire least squares by ℎ𝑖𝑖 (note
not root square). WLS therefore minimises the weighted sum of squared residuals, where each
squared residual is weighted by 1/ℎ𝑖𝑖 .
Specifying the weighting function ℎ𝑖𝑖 is therefore the key. In a simple model with one
independent variable, the weighting function must be that independent variable. This means
that we do not need a GLS estimator to estimate WLS. For more complex models we need to
estimate the weighting function, meaning we then again need a GLS estimator to estimate by
WLS. This is done by estimating feasible GLS (FGLS).
FGLS has the following steps
•
•
•
•
•
Run y on x1, x2…xk and obtain the residuals, 𝑢𝑢�
�2 )
Square and then log to obtain log(𝑢𝑢
�2 ) on x1, x2,…xk and obtain the fitted values 𝑔𝑔�
Run log(𝑢𝑢
ℎ� = exp(𝑔𝑔�)
Estimate the original equation by WLS using 1/ℎ� as weights.
Note that using FGLS makes WLS biased, but consistent and more efficient than OLS. It is,
therefore, a good idea to run WLS and OLS with robust standard errors. Robust standard errors
should also be calculated for WLS, since the weighting function may be incorrect, meaning
heteroscedasticity remains present. WLS should then still be more efficient than OLS (both
with robust standard errors).
19
Measurement error
Measurement error is not the same as taking a proxy. A proxy is where we have an unobserved
factor and we take an observable variable that is likely correlated with the unobserved factor.
This is always a good idea even if it increases multicollinearity, it will lead to smaller standard
errors and less bias estimates. An example is IQ for ability.
Measurement error is where we have an observable variable, but this variable is measured with
error, for instance, actual income vs declared income for tax purposes. If the measurement error
is in the dependent variable, it is generally not a problem. It is then just assumed that the
measurement error is random and not correlated with the independent variables. OLS,
therefore, remains unbiased and consistent as long as this assumption holds.
Measurement error in the independent variables is a problem. If it can be assumed that the
covariance between the measurement error and the actual variable included in the model is nil,
then there is no bias and OLS is BLUE. This is however unlikely to be the case. The general
assumption that needs to be made is that
𝐶𝐶𝐶𝐶𝐶𝐶�𝑥𝑥1,∗ 𝑒𝑒1 � = 0
Where 𝑥𝑥1∗ is the true variable that should be in the model and 𝑒𝑒1 is the measurement error
calculate as
𝑒𝑒1 = 𝑥𝑥1 − 𝑥𝑥1∗
Where 𝑥𝑥1 is the variable included in the model that contains the measurement error. This
assumption is called the classic-error-in-variance assumption (CEV). This assumption leads to
bias and inconsistency in the estimates of OLS, this bias is called attenuation bias. The bias is
towards zero, e.g. if 𝐵𝐵1 is positive then 𝐵𝐵�1will underestimate 𝐵𝐵1. If any other variable is
correlated with the variable that contains the measurement error, those estimates will also be
biased and inconsistent. This means an alternative estimator to OLS is required to obtain
unbiased and consistent estimates when there is measurement error in the independent
variables.
One way to resolve the measurement error bias is with the use of instrumental variables (IV)
(refer below for a discussion hereon). Taking
𝑥𝑥1 = 𝑥𝑥1∗ + 𝑒𝑒1
the model including the measurement error can be written
20
𝑦𝑦 = 𝛽𝛽0 + 𝛽𝛽1 𝑥𝑥1 + 𝛽𝛽2 𝑥𝑥2 + (𝑢𝑢 − 𝛽𝛽1 𝑒𝑒1 )
In the above model, it is assumed that all independent variables are exogenous. The
requirement for a valid IV is that it is correlated with 𝑥𝑥1 and not correlated with 𝑢𝑢 or 𝑒𝑒1 . If we
have two measures of 𝑥𝑥1 , the second measure can be taken as an IV. Otherwise we ,can always
take other excluded exogenous variables as IV. By doing this we correct the attenuation bias.
Non-random sampling
Non-random sample selection generally violated OLS assumption 2. There are certain
instances where OLS remains BLUE, even though this assumption is violated. This is if 1)
missing data is random and the reason for the missing data is therefore not correlated with any
endogenous or unobservable variables (or the error) in the model, 2) the sample is selected
based on the level of the exogenous independent variable(s) (called exogenous sample
selection), e.g. only adults older than 40 are included in the sample and age is an independent
variable, 3) the sample is selected based on an exogenous variable to the model.
OLS will, however, be biased if 1) missing data is not random and the reason is endogenous to
the model or correlated with the error, 2) the sample is selected based on the level of the
dependent variable, e.g. where firm size is the dependent and only the biggest 20 firms are
sampled, 3) sample is selected based on an endogenous variable in the model.
The key question is therefore whether sample selection is endogenous or exogenous. If
endogenous, specials methods are required to correct this.
Truncated regression model
Where we only sample observations based on the level of the dependent variable, 𝑐𝑐𝑖𝑖 , we have
non-random sampling and OLS will be biased. For example w,e only sample households if
their earnings are above R10 000 per month. Our sample will then no longer follow a normal
distribution and similar to limited dependent variables, we would require an alternative
distribution. For truncated regression models this is written
[𝑓𝑓(𝑦𝑦|𝑥𝑥𝑖𝑖 𝛽𝛽, 𝜎𝜎 2 )]
𝑔𝑔(𝑦𝑦|𝑥𝑥𝑖𝑖 , 𝑐𝑐𝑖𝑖 ) =
𝑦𝑦 ≤ 𝑐𝑐𝑖𝑖
[𝐹𝐹(𝑐𝑐𝑖𝑖 |𝑥𝑥𝑖𝑖 𝛽𝛽, 𝜎𝜎 2 )]
From this, we can take the log-likelihood function and use MLE to maximize the sum for all
observations (Stata does this). The interpretation is the same as for OLS. In the presence of
homoscedasticity or non-normal errors, MLE will, however, be bias and inconsistent.
21
Incidental truncated models
For truncated models, the truncations are generally applied by choice of the data collector. It is
also possible that truncation occurs incidentally. We take a random sample, but due to
truncation, the sample is non-random for estimation purposes. Under incidental truncation,
whether we observe y will depend on external factors. If we, for instance, collect data on labor
variables, some observations will have zero wage, meaning wage is dependent on labor force
participation. We will still have observations on the other variables, but not on wage. If wage
is then used as the dependent variable, OLS will be biased.
To correct for this we follow the Heckman method (Heckman command in Stata):
1) First, we estimate a selection equation with the probit estimator using all observations. This
equation can be written
𝑠𝑠 = 𝑧𝑧𝑧𝑧 + 𝑣𝑣
Where s=1 where we observe 𝑦𝑦𝑖𝑖 and zero otherwise (we make s binary) and 𝑧𝑧 is a set of
independent variables that includes all the population variables, 𝑥𝑥, and at least one
additional variable that is correlated with s (the selection process). 𝛾𝛾 are parameters as
usual.
2) Compute the inverse Mills ratio 𝜆𝜆�𝚤𝚤 = 𝜆𝜆(𝑧𝑧𝑖𝑖 𝛾𝛾�)
3) Run OLS of 𝑦𝑦𝑖𝑖 = 𝑥𝑥𝑖𝑖 𝛽𝛽 + 𝜆𝜆�𝚤𝚤 𝛽𝛽
The significance of 𝜆𝜆�𝚤𝚤 ’s parameter indicate whether selection bias is present. If this
parameter is not zero, then OLS test statistics are not computed correctly and an adjustment
is required (Wooldridge 2010).
Outliers
Studentized residuals, leverage and Cook’s distance is useful to detect outliers in the sample.
This is important since OLS squares residuals, it is very sensitive to outliers. It is generally
recommended to report results with and without outliers unless an outlier is clearly a result of
a data capturing error. It may also be preferred to use an alternative estimator as a supplement
to OLS such as:
Least absolute deviations (LAD)
LAD minimizes the sum of the absolute values of the residuals and is, therefore, less sensitive
to outliers. It should be noted that the estimated parameters are the conditional median and not
the conditional mean as in the case of OLS. This means that unless the residuals are normally
22
symmetric around the zero mean under LAD, the result will greatly differ from OLS and be
biased. Further, the t, F and LM test statistics is only valid in large samples under LAD.
Testing whether a variable is endogenous
The tests used in testing whether the assumptions of an estimator holds are called specification
tests. A key assumption to obtain unbias and consistent estimates are that all variables are
exogenous and not correlated with the error term. To perform this test we need to understand
the instrumental variable (IV) and the two-stage least squares (2SLS) estimator (discussed
below).
To perform the test we need at least one instrument for each perceived endogenous variable.
Then we conduct the test by
1) Estimate each endogenous variable (perceived) in its reduced form (all exogenous
variables)
2) Save the residuals for each estimation
3) Include the residuals as new variables in the structural equation and test for significance
(t test if one endogenous and F test if more than one). It is important to take the robust
test statistics for both types of tests. If the residuals are not significant, the perceived
endogenous variable is exogenous (take robust standard errors). OLS can, therefore, be
preferred if this is the case for all perceived endogenous variables since OLS will be
Best.
This test is the same as the first steps of the Control Function estimator discussed later, so
also refer to this section.
Independently pooled cross section
To increase sample size or for purposes of estimating the impact of a natural or quasiexperiment, we may wish to pool two cross-sections. This can only be done if the two or more
samples of cross-sectional data are drawn randomly from the same population at two or more
different time periods. All cross sections methods discussed can be applied to pooled crosssections.
Since the two samples are not drawn at the same time, the variables will not be identically
distributed between the two periods. To correct this it is required to include a dummy variable
for each year/time period (besides year 1 generally) in the regression that will control for
changes between years. It is often useful to interact this dummy with other variables to
determine how they have changed over time.
23
It is further possible that the functional forms of the variables in the regression should not be
the same for the different periods. This can be tested with an F test in the same manner as was
done for model selection, by conducting the test on each time period individually.
The greatest benefit of pooled cross-section is if a difference-in-difference estimator (DD) is
to be used to estimate the effect of a change in policy or exogenous event. For this estimator,
we would have a treatment and a control group and pre and post event (or policy change) for
each group. The difference-in-difference estimate can be written as
𝛿𝛿1 = (𝑦𝑦�2𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡 − 𝑦𝑦�2𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐 ) − (𝑦𝑦�1𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡 − 𝑦𝑦�1𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐 )
To estimate 𝛿𝛿1 and obtain its standard error we regress
𝑦𝑦 = 𝛽𝛽0 + 𝛿𝛿0 𝑑𝑑2 + 𝛽𝛽1 𝑑𝑑𝑑𝑑 + 𝛿𝛿1 𝑑𝑑2𝑑𝑑𝑑𝑑 + 𝑜𝑜𝑜𝑜ℎ𝑒𝑒𝑒𝑒 𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐 + 𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒
Where 𝑑𝑑2 is a dummy for the post event time period and 𝑑𝑑𝑑𝑑 is a dummy for treatment group
= 1 and control group = 0. The following table indicates the interpretation of the parameters:
Pre
Post
Post-Pre difference
Control
𝛽𝛽0
𝛽𝛽0 + 𝛿𝛿0
𝛿𝛿0
Treatment
𝛽𝛽0 + 𝛽𝛽1
𝛽𝛽0 + 𝛿𝛿0 + 𝛽𝛽1 + 𝛿𝛿1
𝛿𝛿0 + 𝛿𝛿1
Treatment-Control
𝛽𝛽1
𝛽𝛽1 + 𝛿𝛿1
𝛿𝛿1
difference
If for instance, the model indicates the change in student attendance (𝑦𝑦) after giving free
internet access on one campus (treatment), but not on another campus (control) (the population
are students). Then 𝛽𝛽0 indicates the attendance of the control group before free internet; 𝛽𝛽0 +
𝛽𝛽1 indicates the attendance of the treatment group before free internet; 𝛽𝛽0 + 𝛿𝛿0 indicate the
attendance of the control group after free internet; 𝛽𝛽0 + 𝛿𝛿0 + 𝛽𝛽1 + 𝛿𝛿1 indicates the attendance
of the treatment group after free internet. Taking the difference between treatment and control,
pre and post (difference in difference) gives us 𝛿𝛿1 , the estimated effect of giving free internet.
Of course, for this to be causal we will have to control for all other relevant factors, or in other
words, the obtained estimate is most likely bias.
It is also possible to use a difference-in-difference-in-difference (DDD) estimate. If we have
attendance data for another university that did not provide free internet on their campus for the
time periods used, we can use this as an additional ‘difference indicator’. If 𝐶𝐶 is this variable
then the model is
𝑦𝑦 = 𝛽𝛽0 + 𝛿𝛿0 𝑑𝑑2 + 𝛽𝛽1 𝑑𝑑𝑑𝑑 + 𝛿𝛿1 𝑑𝑑2. 𝑑𝑑𝑑𝑑 + 𝛽𝛽2 𝑑𝑑𝑑𝑑 + 𝛽𝛽3 𝑑𝑑𝑑𝑑. 𝑑𝑑𝑑𝑑 + 𝛿𝛿2 𝑑𝑑2. 𝑑𝑑𝑑𝑑 + 𝛿𝛿3 𝑑𝑑2. 𝑑𝑑𝑑𝑑. 𝑑𝑑𝑑𝑑
+ 𝑜𝑜𝑜𝑜ℎ𝑒𝑒𝑒𝑒 𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐 + 𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒
24
The coefficient of interest is therefore 𝛿𝛿3 . It is of course also possible to use more time periods
with either the DD and DDD estimate.
Cluster samples
In cluster sampling, clusters are randomly sampled from a population of clusters and units of
observation are sampled from the clusters. An example is siblings (units) sampled from
families (clusters) where the population is all families (the population of clusters). It is very
important that clustering should not be done ex-post (for instance obtain a random sample of
individuals and cluster them into families) as this will result in incorrect standard errors.
Matched pairs samples are also applicable to this section.
The benefit of cluster sampling is that a fixed cluster effect that influences all of the units in
the cluster can be controlled for in the model. Note that if the key independent variable only
changes at the cluster level and not at unit level then we would not want to include a fixed
cluster effect.
To include a fixed cluster effect, we use panel data methods (first-difference estimator, fixed
effects estimator, random effects estimator, correlation random effects model or pooled OLS)
to control for the cluster effect. These methods are discussed in the section on panel data. Note
that if pooled OLS is used after cluster sampling, the errors will have cluster correlation and
cluster-robust standard errors need to be used.
Instrumental variable (IV) estimator
The main assumption for unbiased estimates is that the independent variables and the
unobservable variables are not correlated (we assume that we have included all relevant
observable variables as independent variables). If this does not hold we have a few options:
1. Ignore the problem and indicate the direction of bias. This is not ideal, but we may still
learn something.
2. Include proxy variables for the unobserved variables. It may be difficult to find applicable
proxies.
3. Control for the time constant unobservable variables by including fixed effects. Refer to
the cluster sampling discussion and panel data methods.
Another popular method is by using the Instrumental variable (IV) estimator. The IV estimator
obtains consistent (although bias) estimates when the OLS estimates will be bias and
inconsistent due to unobservable variable bias. The IV estimator is, therefore, most useful in
25
large samples. To use the IV estimator, we first have to identify and IV or instrument. Taken
the simple regression model
𝑦𝑦 = 𝛽𝛽0 + 𝛽𝛽1 𝑥𝑥 + 𝑢𝑢
Where 𝐶𝐶𝐶𝐶𝐶𝐶(𝑥𝑥, 𝑢𝑢) ≠ 0 the estimated parameter 𝛽𝛽1 will be inconsistent and bias under OLS. If
we take a new variable (𝑧𝑧) that adheres to the following assumptions
𝐶𝐶𝐶𝐶𝐶𝐶(𝑧𝑧, 𝑢𝑢) = 0 and 𝐶𝐶𝐶𝐶𝐶𝐶(𝑧𝑧, 𝑥𝑥) ≠ 0
Then 𝑧𝑧 is a valid instrument for 𝑥𝑥. Note that the first assumption means that the IV may not
have a partial effect on the dependent variable after controlling by the independent variables,
meaning that the IV must be exogenous in the original equation. Because the error cannot be
observed, we cannot test the first assumption and need to rely on logic and theory that argument
this. The second assumption can easily be tested by regressing 𝑧𝑧 on 𝑥𝑥. It is important that the
direction of the found correlation be aligned with logic and theory. Where an endogenous
variable is interacted with another variable, the IV for the interaction variable is the IV for the
endogenous variable interacted with the interacted variable in the model.
Further see that a good proxy is a bad IV since a proxy requires correlation between the proxy
and the error (before including the proxy) and a good IV requires no correlation between the
IV and the error.
If we found a good IV, we can use the IV assumptions to identify3 the parameter 𝛽𝛽1.Write the
simple model above as
𝐶𝐶𝐶𝐶𝐶𝐶(𝑧𝑧, 𝑦𝑦) = 𝛽𝛽1 𝐶𝐶𝐶𝐶𝐶𝐶(𝑧𝑧, 𝑥𝑥) + 𝐶𝐶𝐶𝐶𝐶𝐶(𝑧𝑧, 𝑢𝑢)
Then taken the assumption that 𝐶𝐶𝐶𝐶𝐶𝐶(𝑧𝑧, 𝑢𝑢) = 0
The IV estimator of 𝛽𝛽1 then is
𝛽𝛽1 =
�1 =
𝛽𝛽
𝐶𝐶𝐶𝐶𝐶𝐶(𝑧𝑧, 𝑦𝑦)
𝐶𝐶𝐶𝐶𝐶𝐶(𝑧𝑧, 𝑥𝑥)
∑𝑛𝑛𝑖𝑖=1(𝑧𝑧𝑖𝑖 − 𝑧𝑧̅)(𝑦𝑦𝑖𝑖 − 𝑦𝑦�)
∑𝑛𝑛𝑖𝑖=1(𝑧𝑧𝑖𝑖 − 𝑧𝑧̅)(𝑥𝑥𝑖𝑖 − 𝑥𝑥̅ )
�1 𝑥𝑥̅ . See that if 𝑧𝑧 = 𝑥𝑥 then the IV estimator becomes the OLS estimator. As
�0 = 𝑦𝑦� − 𝛽𝛽
And 𝐵𝐵
�1 is consistent but bias and the IV estimator is therefore only really
previously mentioned 𝛽𝛽
useful in larger samples.
3
This means we can write the parameter in terms of population moments that can be estimated.
26
The above can be extended to a multivariate model. To do this we need to make use of structural
equations and reduced forms. Given the structural equation
𝑦𝑦1 = 𝛽𝛽0 + 𝛽𝛽1 𝑦𝑦2 + 𝛽𝛽2 𝑧𝑧1 + 𝑢𝑢1
The 𝑦𝑦 variables are interpreted as endogenous variables (correlated with the error term) and the
𝑧𝑧 variable is interpreted as exogenous (not correlated with the error term). It is evident that the
independent variable 𝑦𝑦2 is problematic since it is endogenous and if estimated under OLS will
result in bias in all the parameters. To resolve this we can use the IV estimator, but note that 𝑧𝑧1
may not be an IV for 𝑦𝑦2 , since it is already included in the model. We therefore need a new
exogenous variable, 𝑧𝑧2 , to serve as an IV for 𝑦𝑦2 . We therefore need to assume that 𝐶𝐶𝐶𝐶𝐶𝐶(𝑧𝑧2 , 𝑢𝑢1 =
0) and further that the partial correlation between 𝑧𝑧2 and 𝑦𝑦2 is not zero. To test the second
assumption we write 𝑦𝑦2 in its reduced form, meaning we write an endogenous variable in terms
of exogenous variables (including IV’s). This can also be done for dependent variables where
the interpretation of the parameters of the reduced form is intention-to-treat as opposed to treat
in the structural model. 𝑦𝑦2 in its reduced form is therefore
𝑦𝑦2 = 𝜋𝜋0 + 𝜋𝜋1 𝑧𝑧1 + 𝜋𝜋2 𝑧𝑧2 + 𝑣𝑣1
The assumption holds if 𝜋𝜋2 ≠ 0 and the reduced form is estimated by OLS (with the
assumption of no perfect multicollinearity). Note that if the model contained further exogenous
variables then those would also be included in the reduced form.
Statistical inference of the IV estimator
The IV estimator is asymptotically valid under the homoscedasticity assumption of
𝐸𝐸(𝑢𝑢2 |𝑧𝑧) = 𝑉𝑉𝑉𝑉𝑉𝑉(𝑢𝑢) = 𝜎𝜎 2
The asymptotic variance of an estimated parameter is
�1 =
𝛽𝛽
𝜎𝜎 2
2
𝑛𝑛𝜎𝜎𝑥𝑥2 𝜌𝜌𝑥𝑥,𝑧𝑧
2
2
Where 𝜌𝜌𝑥𝑥,𝑧𝑧
is the square of the population correlation between 𝑥𝑥 and 𝑧𝑧 (𝑅𝑅𝑥𝑥,𝑧𝑧
).
The asymptotic standard error of an estimated parameter is
�1 =
𝛽𝛽
�2
𝜎𝜎
2
𝑆𝑆𝑆𝑆𝑇𝑇𝑥𝑥 . 𝑅𝑅𝑥𝑥,𝑧𝑧
2
Note that the only difference between the standard errors of OLS and IV is the term 𝑅𝑅𝑥𝑥,𝑧𝑧
. Since
this is always less than one, the standard errors under IV will always be larger than under OLS
27
(a weakness of IV). Further, if we have a poor IV, meaning there is weak correlation between
the endogenous variable and its instrument, besides large standard errors, IV will also have
large asymptotic bias. Therefore although consistent, IV can be worse than OLS if we have a
poor IV. Generally an, IV is considered to be weak (and should not be used) if the t-stat of the
IV in the reduced form model is less than absolute 3.2 (√10) (reference to Stock and Yogo,
2005).
The obtained R squared from an IV estimation is not useful and should not be reported.
Two-stage least squares (2SLS) estimator
The 2SLS estimator is an IV estimator with multiple exogenous variables not included in the
model as used to estimate an IV. This means that there is either more than one excluded
exogenous variable used with one endogenous independent variable, or the structural model
has more than one endogenous independent variable in which case we require at least as many
excluded exogenous variables as there are endogenous independent variables. Taken the
structural model
𝑦𝑦1 = 𝛽𝛽0 + 𝛽𝛽1 𝑦𝑦2 + 𝛽𝛽2 𝑧𝑧1 + 𝑢𝑢1
And we have two exogenous variables that are correlated with 𝑦𝑦2 called 𝑧𝑧2 and 𝑧𝑧3 , any linear
combination of exogenous variables is a valid IV for 𝑦𝑦2 . The reduced form of 𝑦𝑦2 is therefore
And the best IV for 𝑦𝑦2 is
𝑦𝑦2 = 𝜋𝜋0 + 𝜋𝜋1 𝑧𝑧1 + 𝜋𝜋2 𝑧𝑧2 + 𝜋𝜋3 𝑧𝑧3 + 𝑣𝑣1
𝑦𝑦2∗ = 𝜋𝜋0 + 𝜋𝜋1 𝑧𝑧1 + 𝜋𝜋2 𝑧𝑧2 + 𝜋𝜋3 𝑧𝑧3
In other words, the independent variable 𝑦𝑦2 is divided into two parts, 𝑦𝑦2∗ (the part that is
exogenous in the structural model) and 𝑣𝑣1 (the part that is endogenous in the structural model).
We only wish to use the exogenous part of the variable.
To estimate 𝑦𝑦
�2 we need two OLS estimations, called the first stage and the second stage.
First stage
𝑦𝑦
�2 = 𝜋𝜋
�0 + 𝜋𝜋
�𝑧𝑧
�𝑧𝑧
�𝑧𝑧
1 1 + 𝜋𝜋
2 2 + 𝜋𝜋
3 3 + 𝜀𝜀
Which after we need to test for joint significance (F test) of 𝜋𝜋
�2 and �
𝜋𝜋3 . It is very important to
test and note that if the F stat is less than 10 then we should not proceed with the 2SLS
estimator, since it will result in large asymptotic bias and large variance (reference to Stock
and Yogo, 2005).
28
Second stage
𝑦𝑦1 = 𝛽𝛽0 + 𝛽𝛽1 𝑦𝑦
�2 + 𝛽𝛽2 𝑧𝑧1 + 𝑢𝑢1
It can, therefore, be seen that 2SLS first purges 𝑦𝑦2 of its correlation with 𝑢𝑢1 and it therefore
consistent where OLS would not be. Note that the econometric package automatically estimates
both stages and this should not be done manually. Further, when asking for instrumental
variables, all exogenous variables (included and excluded) are given as all of these are used in
the first stage and therefore estimation of the IV.
The asymptotic variance of an estimated parameter is
�1 =
𝛽𝛽
𝜎𝜎 2
� �2
𝑆𝑆𝑆𝑆𝑇𝑇2 (1 − 𝑅𝑅
2)
�2 is the R squared of the reduced form equation.
Where 𝑆𝑆𝑆𝑆𝑇𝑇2 is the total variation in 𝑦𝑦
�2 and 𝑅𝑅
2
See from this that 2SLS will always have larger variance than OLS since
1. 𝑦𝑦
�2 has less variation than 𝑦𝑦2 (a part of its variation is in the reduced form error term)
2. 𝑦𝑦
�2 is more correlated with the exogenous variables, increasing the multicollinearity
problem.
Taken the structural model
𝑦𝑦1 = 𝛽𝛽0 + 𝛽𝛽1 𝑦𝑦2 + 𝛽𝛽2 𝑦𝑦3 + 𝛽𝛽2 𝑧𝑧1 + 𝑢𝑢1
we would require at least two excluded exogenous variables that are partially correlated with
𝑦𝑦2 and 𝑦𝑦3 . This means that the two or more excluded exogenous variables should be jointly
significant (with an F stat greater than 10) in both the reduce form models of 𝑦𝑦2 and 𝑦𝑦3 . To use
2SLS and to obtain valid estimates we need to adhere to the order condition. The order
condition requires that we have at least as many excluded exogenous variables as included
endogenous variables.
A requirement for a valid instrument is that it is uncorrelated with the error term in the structural
model (endogenous). If we have more instruments than we need to identify an equation (more
instruments than endogenous variables) we can test whether the additional instruments are
uncorrelated with the error term (called testing the overidentification restriction).
1) Estimate the structural equation by 2SLS and save the residuals, 𝑢𝑢
�1
2) Regress 𝑢𝑢
�1 on all exogenous variables (instruments and included) and get the R square
29
3) The null hypothesis that all instruments are uncorrelated with 𝑢𝑢
�1 is tested by testing
whether the R squared multiplied by the sample size follows a chi-square distribution
where the degrees of freedom is the instruments less the endogenous variables. If 𝑛𝑛𝑅𝑅 2
exceeds the critical value in the chi-square distribution we reject the Ho, meaning all
instruments are not exogenous. This means that the additional instruments are useful,
but only to a certain extent. It may still be that one of the additional instruments are
endogenous.
4) To obtain a heteroscedasticity robust test, we regress all endogenous variables on all
exogenous variables (included and additional instrumental variables 4) and save the
�).
fitted values (𝑦𝑦
2 Next ,we regress each of the overidentifying restrictions (instruments
not needed for the model to be just identified) on the exogenous variables included in
the original model and the 𝑦𝑦�
2 ′𝑠𝑠 and we save the residuals 𝑟𝑟�2 . Then we regress the saved
residuals in step 1, 𝑢𝑢
�1 on 𝑟𝑟̂2 and perform the heteroscedasticity robust Wald test on this
regression.
Assumptions for 2SLS
1) Linear parameters, random sampling.
Instrumental variables are denoted as 𝑧𝑧𝑗𝑗
2) Random sampling on 𝑦𝑦, 𝑥𝑥𝑗𝑗 and 𝑧𝑧𝑗𝑗
3) No perfect multicollinearity among instrumental variables and the order condition for
identification holds. This means we need at least one excluded exogenous variable (which
parameter is not zero in the reduced form equation) for each included endogenous variable.
For SEMs the rank condition needs to hold (discussed above).
4) 𝐸𝐸(𝑢𝑢) = 0, 𝐶𝐶𝐶𝐶𝐶𝐶�𝑧𝑧𝑗𝑗 , 𝑢𝑢� = 0
Note that each exogenous independent variable is seen as its own instrumental variable,
therefore all exogenous variables are denoted 𝑧𝑧𝑗𝑗
Under 1-4 2SLS is consistent (although bias)
If 𝑍𝑍 denotes all instrumental variables (all exogenous variables) then
5) 𝐸𝐸(𝑢𝑢2 |𝑍𝑍) = 𝜎𝜎 2
Under 1-5 2SLS is consistent and test statistics are asymptotically valid. The 2SLS estimator
is the best IV estimator under these assumptions.
4
Note that an exogenous variable is its own instrument.
30
If 5 does not hold, then 2SLS is not the most efficient IV estimator. Homoscedasticity can be
tested by saving the residuals from 2SLS and regressing this on all exogenous variables with
the null being the joint significance of all exogenous variables is zero (required for
homoscedasticity). This is analog to the Breusch Pagan test. To correct heteroscedasticity under
2SLS
1) Take robust standard errors as for OLS, or
2) Use weighted 2SLS that is done the same as for OLS, but 2SLS are used after applying the
weights.
Indicator variables (Multiple indicator solution)
A solution to omitted variable bias and/or measurement error exists with the use of indicator
variables. These variables serve a similar purpose than proxy variables under OLS, but we
require 2SLS to use indicator variables. If we have an unobserved variable, 𝑞𝑞 we look to find
at least two indicators 𝑞𝑞1 and 𝑞𝑞2. Both 𝑞𝑞1 and 𝑞𝑞2 are correlated with 𝑞𝑞, but 𝑞𝑞1 and 𝑞𝑞2 are
only correlated with each other as a result of being correlated with 𝑞𝑞. It is further logical that
neither of the instruments are ideal proxies, otherwise we would, just use them as such. This
means that after including one indicator in the structural model, that indicator is endogenous.
We include 𝑞𝑞1 in the model and then use 𝑞𝑞2 as an instrument for 𝑞𝑞1. Doing this provide for
consistency where OLS would have been inconsistent (using 𝑞𝑞1). It is important that 𝑞𝑞2 meets
the normal requirements for a good and valid instrument. This approach is called the multiple
indicator solution.
Similarly, measurement error can be resolved if we have two indicators that measure and
independent variable with error (where we do not have the correctly measured independent
variable). For OLS we would just have been able to include one of the two indicators, but using
2SLS we can use the second indicator as an IV for the first, resulting in consistent estimators
(this is also discussed under measurement error).
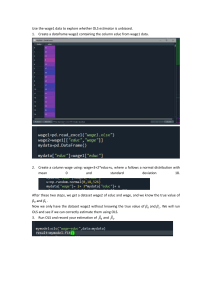
Generated independent variables and instruments
We may wish to include as an independent variable in a model an estimated variable from
another regression, called a generated regressor (Pagan, 1984). This will in most cases be the
residuals from a previously estimated model, but can also, for instance, be the predicted value.
Using such a variable does not result in inconsistent estimates, but the obtained test statistics
are invalid. This is because there is sampling variation in the generated regressor (it was
31
obtained from data). If the parameter for the generated regressor ≠ 0, then all standard errors
and statistics need to be adjusted for valid inference.
A generated instrument does not result in the same problems, 2SLS remains consistent with
valid test statistics (assuming the other assumptions hold). Of course, if a generated regressor
is included in 2SLS then we need to adjust the asymptotic variance.
Control Function Estimator (CF)
Similar to 2SLS, CF is aimed at removing endogeneity. This is done by using extra regressors
(not in the structural model) to break the correlation between the endogenous variable and the
error. Take
𝑦𝑦1 = 𝑧𝑧1 𝛿𝛿1 + 𝛾𝛾𝑦𝑦2 + 𝑢𝑢1
Where 𝑧𝑧1 are all the exogenous variables in the structural model and 𝑦𝑦2 is the endogenous
variable. If we have at least one additional exogenous variable that is not included in the
structural model, the reduced form of 𝑦𝑦2 is
𝑦𝑦2 = 𝑧𝑧𝑧𝑧 + 𝑣𝑣2
Where 𝑧𝑧 includes at least one variable not in 𝑧𝑧1 . This is required to avoid perfect
multicollinearity (see the final model below) . Since 𝑦𝑦2 is correlated with 𝑢𝑢1 , 𝑣𝑣2 must be
correlated with 𝑢𝑢1 as well. Therefore we can write
𝑢𝑢1 = 𝜌𝜌𝑣𝑣2 + 𝑒𝑒1
See that this is a simple test for endogeneity of 𝑦𝑦2 , if 𝜌𝜌 = 0 then 𝑦𝑦2 is actually exogenous.
Further se,e that 𝑣𝑣2 and 𝑒𝑒1 are uncorrelated and consequently 𝑧𝑧 (which includes 𝑧𝑧1 ) are also
uncorrelated with both 𝑣𝑣2 and 𝑒𝑒1. We can therefore substitute 𝑢𝑢1 in the original model to get
𝑦𝑦1 = 𝑧𝑧1 𝛿𝛿1 + 𝛾𝛾𝑦𝑦2 + 𝜌𝜌𝑣𝑣2 + 𝑒𝑒1
Which is a model with no endogeneity and will be consistent by OLS. Since 𝑣𝑣2 is a generated
regressor, we need to correct the standard errors.
CF provides identical results to 2SLS unless there are more than one function of 𝑦𝑦2 included
in the model (for instance 𝑦𝑦2 and 𝑦𝑦22). In such instances on,ly 2SLS will be consistent, but CF
will be more efficient. CF is very useful for non-linear models (discussed later).
Correlated random coefficient model
It may be that in the population model, an endogenous variable should interact with an
unobserved variable (unobserved heterogeneity) and we do not have a valid proxy for the
32
endogenous variable. Taken the model that we can estimate (not having the unobserved
heterogeneity data)
𝑦𝑦1 = 𝛽𝛽1 + 𝛿𝛿1 𝑧𝑧1 + 𝑎𝑎1 𝑦𝑦2 + 𝑢𝑢1
𝑎𝑎1 , the ‘coefficient’ of 𝑦𝑦2 is an unobserved random variable, meaning it will change as 𝑦𝑦2
changes. We can write
𝑎𝑎1 = 𝛼𝛼1 + 𝑣𝑣1
Where 𝛼𝛼1 is the correct (constant) coefficient which we wish to estimate. Substituting this into
the original model gives the population model
𝑦𝑦1 = 𝛽𝛽1 + 𝛿𝛿1 𝑧𝑧1 + 𝛼𝛼1 𝑦𝑦2 + 𝑣𝑣1 𝑦𝑦2 + 𝑢𝑢1
This shows the interaction between the unobserved heterogeneity for which we do not have a
proxy, 𝑣𝑣1 , and the endogenous variable. To address the endogeneity of 𝑦𝑦2 we would want to
use 2SLS. The problem with 2SLS is that the error term (𝑣𝑣1 𝑦𝑦2 + 𝑢𝑢1 )in the model to be
estimated is not necessarily uncorrelated with the instrument (𝑧𝑧) that we would want to use. A
further requirement is therefore necessary being
𝐶𝐶𝐶𝐶𝐶𝐶(𝑣𝑣1 , 𝑦𝑦2 |𝑧𝑧) = 𝐶𝐶𝐶𝐶𝐶𝐶(𝑣𝑣1 , 𝑦𝑦2 )
which means the conditional covariance is not a function of the instrumental variable. Finding
an instrument that satisfies this condition is difficult. One option is to obtain fitted values of a
first stage regression of 𝑦𝑦𝑖𝑖2 on 𝑧𝑧𝑖𝑖 and then use as IV’s 1, 𝑧𝑧𝑖𝑖 and 𝑦𝑦�𝑖𝑖2 (𝑧𝑧𝑖𝑖1 − 𝑧𝑧̅1 ).
Alternatively, a control function approach can be used by first regressing 𝑦𝑦2 on 𝑧𝑧 and save the
reduced form residuals, 𝑣𝑣�2 and then run the OLS regression 𝑦𝑦1 on 1, 𝑧𝑧1 , 𝑦𝑦2 , 𝑣𝑣�2 𝑦𝑦2 and 𝑣𝑣�2 . This
approach requires a stronger assumption which is
Systems of Equations
𝐸𝐸(𝑢𝑢1 |𝑧𝑧, 𝑣𝑣2 ) = 𝜌𝜌1 𝑣𝑣2 , 𝐸𝐸(𝑣𝑣1 |𝑧𝑧, 𝑣𝑣2 ) = 𝜗𝜗1 𝑣𝑣2
It is possible that the population model is a set of equations, for instance in estimating a demand
system, for instance
𝑦𝑦1 = 𝑥𝑥1 𝛽𝛽1 + 𝑢𝑢1
𝑦𝑦2 = 𝑥𝑥2 𝛽𝛽2 + 𝑢𝑢2
𝑦𝑦𝑔𝑔 = 𝑥𝑥𝑔𝑔 𝛽𝛽𝑔𝑔 + 𝑢𝑢𝑔𝑔
33
Since each equation has its own vector of coefficients 𝛽𝛽𝑔𝑔 , this model is known as seemingly
unrelated regression (SUR). In estimating such a system we can use OLS equation by equation,
system OLS (SOLS) or FGLS. From these FGLS will be more efficient if we can assume
system homoscedasticity. SOLS is generally more likely to be consistent as it contains a lesser
assumption; FGLS requires strict exogeneity. If we cannot assume system homoscedasticity,
then either SOLS or FGLS may be more efficient.
Systems of equations often have endogenous variables and IV method is therefore commonly
used (see SEM models). There are more efficient estimators than 2SLS for systems of equations
with endogeneity, for instance, the General Methods of Moments estimator (GMM) and GMM
3SLS.
Simultaneity bias and simultaneous equation models (SEM)
Not previously discussed, the estimated parameters obtained by using OLS as the estimator
will be biased in the presence of simultaneity. Simultaneity arises if one or more of the
independent variables are jointly determined with the dependent variable. As long as we need
to resolve the equation of interested together with another simultaneous equation, the
independent variables will be correlated with the error term. An example of this is the amount
of crime and the amount of policeman; it can be that a change in crime results in a change in
the amount of policeman, but it can also be that a change in the amount of policeman results in
a change in the amount of crime (the correlation goes both ways and crime and police are
jointly determined). Another example is that of supply and demand (or any phenomena that
require a system of equations to resolve, such as general equilibrium models of the economy).
In these situations, we would require at least two (simultaneous) equations to estimate one of
the equations. The most important requirement for each of these equations is that they have a
ceteris paribus interpretation (we cannot willingly leave out any relevant variables).
Taking supply and demand as an example we can write a supply equation as
And a demand equation as
𝐻𝐻𝐻𝐻𝐻𝐻𝐻𝐻𝑠𝑠𝑠𝑠 = 𝑤𝑤𝑤𝑤𝑤𝑤𝑤𝑤 + 𝑧𝑧1 + 𝑢𝑢1
𝐻𝐻𝐻𝐻𝐻𝐻𝐻𝐻𝑠𝑠𝑑𝑑 = 𝑤𝑤𝑤𝑤𝑤𝑤𝑤𝑤 + 𝑧𝑧2 + 𝑢𝑢2
Where 𝑧𝑧 indicated exogenous variables. See that the observed hours are determined by the
intersection of supply and demand and the true hours that workers are willing to supply cannot
34
be observed, but we wish to estimate this. Because we only observe the equilibrium of hours
worked where supply equals demand we can write for each individual
ℎ𝑖𝑖 = 𝛼𝛼𝑤𝑤𝑖𝑖 + 𝛽𝛽1 𝑧𝑧1 + 𝑢𝑢𝑖𝑖1
And
ℎ𝑖𝑖 = 𝛼𝛼𝑤𝑤𝑖𝑖 + 𝛽𝛽1 𝑧𝑧2 + 𝑢𝑢𝑖𝑖2
See that the only difference between these two equations is the subscript for the exogenous
variables. If the exogenous variables are exactly the same, then the two equations will be
exactly the same, meaning we have an identification problem; the true hours that workers wish
to supply cannot be estimated. Taking crime and police as an example the first equation will
be
𝐶𝐶𝐶𝐶𝐶𝐶𝐶𝐶𝑒𝑒𝑖𝑖 = 𝛼𝛼𝛼𝛼𝛼𝛼𝛼𝛼𝛼𝛼𝛼𝛼𝑒𝑒𝑖𝑖 + 𝛽𝛽1 𝑧𝑧1 + 𝑢𝑢𝑖𝑖1
And the second equation will be
𝑃𝑃𝑃𝑃𝑃𝑃𝑃𝑃𝑃𝑃𝑒𝑒𝑖𝑖 = 𝛼𝛼𝛼𝛼𝛼𝛼𝛼𝛼𝛼𝛼𝑒𝑒𝑖𝑖 + 𝛽𝛽1 𝑧𝑧1 + 𝑢𝑢𝑖𝑖1
See that both equations have a ceteris paribus interpretation. Further note that these two
equations describe different behaviors. In the first equation, we are interested in factors that
change in the behavior of criminals and in the second we are interested in factors that change
in the behavior of the country/state etc. in appointing policemen and policewomen. It is,
therefore, most plausible that the exogenous variables will be different and the first (or second)
equation can be estimated. Note, however, that if we use OLS on the first or second equation,
the estimated parameters will be biased because of simultaneity. We, therefore, use 2SLS.
Identification of SEMs with two equations
To use 2SLS to address simultaneity bias, we first need to specify a structural equation for each
endogenous (simultaneous) variable. Secondly, to be able to consistently estimate an equation,
that equation must be identified. Normally, 2SLS only requires the order condition for
identification, but for SEM a stronger condition (together with the order condition) is required,
namely the rank condition. For two equations this requirement states that the non-estimated
equation contains at least one statistically significant exogenous variable that is not present in
the estimated equation.
Identification of SEMs with more than two equations
35
The order condition is again necessary, but not sufficient. The rank condition for SEMs with
more than two equations follows. (Wooldridge 2010, c9).
Estimation of SEMs (any number of equations) by 2SLS
In estimating SEMs we are most often only interested in one equation, with the remaining
equations required to correctly describe the simultaneous effect on the dependent variable of
the equation of interest. It can, therefore, be viewed that the non-estimated equations are used
to identify the instrumental variables applicable to the estimated equation. This can be seen by
taking the reduced form of the first equation (writing it in terms of all the exogenous variables
in the system of equations).
The instrumental variables that are used in estimating the equation of interest are therefore all
exogenous variables in the system of equations. By doing this we remove the simultaneity bias
in the independent variable that is jointly determined with the dependent variable.
In conclusion, the only difference between 2SLS to address endogeneity bias and simultaneity
bias is in how we obtain the instrumental variables to be used and the necessary condition to
estimate an equation.
36
TIME SERIES DATA
OLS Assumptions for finite samples
Assumption 1-3
The OLS assumption for time series data (TSD) to ensure that OLS is BLUE in finite samples
is similar to cross-sectional data. For instance, the model needs to be linear in parameters (1)
and there may not be any perfect collinearity (2). For OLS to be unbiased with TSD, a further
assumption needs to be adhered to. This assumption combines the random sample and zero
conditional mean assumption for cross-sectional data and adds a stricter requirement. If 𝑋𝑋 is
taken to represent all independent variables for all time periods (𝑡𝑡) then
𝐸𝐸(𝑢𝑢𝑡𝑡 |𝑋𝑋) = 0 , 𝑡𝑡 = 1,2,3 … 𝑛𝑛
This means that for each time period the expected value of the error term of that period, given
the independent variables for all time periods is zero (3). In other words, the error in any one
time period may not be correlated with any independent variable in any time period. If this
holds we say the model is strictly exogenous and OLS is unbiased and consistent. This
assumption will not hold if the data does not come from a random sample. Note that this
assumption includes the assumption for cross-sectional data and can be written
𝐸𝐸(𝑢𝑢𝑡𝑡 |𝑥𝑥𝑡𝑡 ) = 0
Which means that the error term and independent variables for one time period are not
correlated. If only the second assumption holds, then the model is said to be contemporaneously
exogenous. OLS will be consistent, but biased. This means this assumption is not sufficient to
have OLS be BLUE.
Assumption 3 may fail due to
1. Omitted variable bias (this is the same as for cross-sectional data)
2. Measurement error
3. When the present level of a variable is influenced by the past level of an independent
variable, e.g the size of the police force may be adjusted due to past crime rates. Note a
strictly exogenous variable such as rainfall does not pose a problem e.g. rainfall in future
years is not influenced by past years of agricultural output.
37
Meeting assumption 1-3 result in OLS being unbiased and consistent. The assumptions
required for OLS to have the smallest variance (to be Best) are
Assumption 4
Homoscedasticity, meaning
𝑉𝑉𝑉𝑉𝑉𝑉(𝑢𝑢𝑡𝑡 |𝑋𝑋) = 𝑉𝑉𝑉𝑉𝑉𝑉(𝑢𝑢𝑡𝑡 ) = 𝜎𝜎 2
Note again that the requirement is on all independent variables at all time periods, this said, in
most cases, the heteroscedasticity in the error for a time period is as a result of the independent
variables of that time period.
Assumption 5
No serial correlation (autocorrelation), meaning the errors (given all independent variables for
all time periods) may not be correlated over time. This can be written
𝐶𝐶𝐶𝐶𝐶𝐶𝐶𝐶(𝑢𝑢𝑡𝑡 , 𝑢𝑢𝑠𝑠 |𝑋𝑋) = 𝑜𝑜 𝑓𝑓𝑓𝑓𝑓𝑓 𝑎𝑎𝑎𝑎𝑎𝑎 𝑡𝑡 ≠ 𝑠𝑠
Note that this does not mean that an independent variable may not be correlated with itself or
other independent variables over time, only the errors (that contain unobserved factors and
measurement error) are of concern.
Under assumptions 1-5 OLS is BLUE for time series data. Further, the OLS sampling variance
is calculated exactly as in cross-sectional data (see above) and the estimated variance of the
error terms are unbiased estimates of the population error term. Therefore OLS has the same
desirable property for time series data.
Assumption 6
To be able to use the t and F test in finite samples, the classic linear model assumption is
required. Without this assumption, the errors will not have an F and T distribution. This
assumption is that 𝑢𝑢𝑡𝑡 are independent of 𝑋𝑋 and independent and identically distributed as
normal.
Basic time series models using OLS as the estimator
Static model
The most basic model for time series data is the static model; this model is essentially the same
as a cross-sectional model, but the assumptions for OLS to be BLUE is different (discussed
above). Such a model can be written
𝑦𝑦𝑡𝑡 = 𝛽𝛽0 + 𝛽𝛽1 𝑧𝑧1𝑡𝑡 + 𝛽𝛽2 𝑧𝑧2𝑡𝑡 + 𝑢𝑢𝑡𝑡 , 𝑡𝑡 = 1,2,3 …
38
This model, therefore, does not make use of data from another time period towards estimating
the effects of the current time period (the same as a cross-sectional analysis). The parameters,
therefore, indicate the immediate effect of the independent variables on the dependent variable
or alternatively stated the trade-off between the independents and dependent variable.
Finite distributed lag model (FDL)
For this model, we allow variables to affect the dependent variable with a lag. The number of
lags included indicates the order of FDL, e.g. one lag is called an FDL of order one. This model
is used to estimate the short-run (immediate) propensity/effect of an independent variable(s)
on the dependent variable, as well as the long-run propensity/effect. A model with one
independent variable included for different time periods can be written as
𝑦𝑦𝑡𝑡 = 𝛽𝛽0 + 𝛽𝛽1 𝑧𝑧𝑡𝑡 + 𝛽𝛽2 𝑧𝑧𝑡𝑡−1 + 𝛽𝛽3 𝑧𝑧𝑡𝑡−2 + 𝛽𝛽4 𝑧𝑧𝑡𝑡−3 + 𝑢𝑢𝑡𝑡
Where 𝛽𝛽1 indicates the immediate propensity, meaning the change in 𝑦𝑦𝑡𝑡 due to a one unit
increase in 𝑧𝑧 at time 𝑡𝑡 ; and 𝛽𝛽1 + 𝛽𝛽2 + 𝛽𝛽3 + 𝛽𝛽4 indicates the long run propensity, meaning the
change in 𝑦𝑦𝑡𝑡 over four time periods (or how many lags are included plus one) due to a one unit
increase in 𝑧𝑧 at time 𝑡𝑡. This means that 𝛽𝛽2 indicates the change in 𝑦𝑦𝑡𝑡 one period after a change
𝑧𝑧 at time 𝑡𝑡 and similar for the remaining parameters individually considered.
Dynamically complete model
A dynamically complete model is a model where enough lags for the dependent and
independent variables have been included as independent variables in the model, so that further
lags do not matter in explaining the dependent variable. A possible model of this kind can be
written
𝑦𝑦𝑡𝑡 = 𝛽𝛽0 + 𝑦𝑦𝑡𝑡−1 + 𝑦𝑦𝑡𝑡−2 + 𝛽𝛽1 𝑧𝑧𝑡𝑡 + 𝛽𝛽2 𝑧𝑧𝑡𝑡−1 + 𝛽𝛽3 𝑧𝑧𝑡𝑡−2 + 𝛽𝛽4 𝑧𝑧𝑡𝑡−3 + 𝑢𝑢𝑡𝑡
For such a model there cannot be any serial correlation, meaning the serial correlation
assumption always holds. This does not mean all models should be dynamically complete. If
the purpose of the regression is to forecast, the model must be dynamically complete. If we are
however interested in the static impact (a static model) or the long run effect (FDL) model,
such a model need not by dynamically complete. It should however then be noted that the
model will have serial correlation and this will have to be corrected (discussed later).
Possible additions to the above models
Similar to cross-sectional data, data can be transformed for time series. A log-log FDL model
has the benefit of interpretation of estimating short-run elasticity and long-run elasticity.
39
Dummy variables and binary variables can also be used. Binary variables are useful for event
studies using time series data.
It should further be noted that for time series data, we always want to use real economic
variables and not nominal economic variables. This means that if data is in nominal form, this
data needs to be adjusted by an index, such as the consumer price index, to obtain the real
economic variable. Alternatively stated, not accounting for inflation gives rise to measurement
error.
A unique aspect of time series data is trends and seasonality.
1. Trends
Often we may think that variables are correlated over time, but this correlation can
partly be described to a similar time trend that variables follow. If a dependent or
independent variable follows a time trend, we need to control for this trend in the model.
Not doing so means that the trend will be included in the error term and this means the
estimates will be biased, called a spurious regression. Including the trend in the model
depends on the type of trend.
For a linear time trend, we can write
𝑦𝑦𝑡𝑡 = 𝛽𝛽0 + 𝐵𝐵1 𝑡𝑡 + 𝑒𝑒𝑡𝑡 , 𝑡𝑡 = 1,2,3 …
Note that the independent variable “t” indicates time where 1 is for instance 2010, 2 is
2011, 3 is 2012, etc. Including this variable detrends the results of the equation. If a
variable has an exponential trend we can include logs and for a quadratic trend, we can
include polynomial functions. Note that when including trends, the R-squared or
adjusted R-squared is biased, but this does not influence the T of F stat.
2. Seasonality
If our time periods are less than a year, data can also be influenced by seasonality, e.g.
crop output is influenced by rainfall and rainfall is seasonal. Most often series are
already seasonally adjusted and we do not have to make any changes to our model. If
the data you receive is not seasonally adjusted and suspect to seasonality, it is required
to do such an adjustment. This is easily done by including dummy variables for the
relevant seasons (for instance for each month (less one) or for each quarter (less one)).
This will control for the seasonality in the data.
40
OLS asymptotic assumptions
In large samples, the assumptions of OLS can be made less strict, as long as the law of large
numbers and the central limit theorem holds. Additional requirements, besides having a large
sample are required for this to be the case. The two additional requirements for OLS and other
estimators are that the time series’ included in a regression are stationary and weakly
dependent. It should be noted that we are interested here in the specific variables individually
and not the regression model. We look at one variable over time (a time series) individually to
see whether it is stationary and weakly dependent. For a time series to be stationary is not
critical, but weakly dependent is.
Logically, to understand the relationship between variables over time, we need to be able to
assume that this relationship does not change arbitrarily between time periods. This means that
each variable should follow a determinable path over time. For this reason, a time series (one
variable over time) can be seen as a process (and defined in term of a process).
A stochastic process in probability theory means a mathematical object defined in terms of a
sequence of random variables. The opposite of a stochastic process is a deterministic process,
by looking only at the process we can determine the answer correctly (with probability of 1).
An example of a stochastic process is, for instance, tossing a coin, just by looking at the process
we cannot determine the answer (how many heads or tails) correctly, we can only get
probabilities and a joint probability distribution.
For any time series, we are dealing with a stochastic process, meaning that the time series level
is not deterministic in any one period, the data points are determined by probability. The
important aspect of the process is whether it is stationary or non-stationary.
Stationary
A stationary stochastic process is a process where the joint probability distribution of the
sequence of random variables in that process remains unchanged over time. Again, flipping a
coin is a stationary stochastic process, since the joint probability of heads and tails remains
unchanged over time. If a variable, for instance, has a time trend, then the stochastic process
cannot be stationary, meaning it is a non-stationary stochastic process. A stationary stochastic
process is called strictly stationary.
Sometimes a lesser extent of stationary is required. To understand this we need to understand
moments.
41
If we write {𝑥𝑥1𝑠𝑠 , 𝑥𝑥2𝑠𝑠 , 𝑥𝑥3𝑠𝑠 … 𝑥𝑥4𝑠𝑠 }/𝑛𝑛 the first moment is where s = 1 (this is the mean) and the second
moment is where s = 2 (this is the variance). This can continue further to get skewness and
kurtosis.
The lesser form of stationary is called covariance stationary or weak stationary and is more
important than strict stationary (since strict stationary seldom hold) and this holds where all the
random variables have a finite second moment (𝐸𝐸(𝑥𝑥𝑡𝑡2 ) < ∞ for all 𝑡𝑡), the mean and the
variance of the process is constant and the covariance depends only on the time period between
two terms and not the starting time period. Mathematically this can be written
𝐸𝐸(𝑥𝑥𝑡𝑡 ) = 𝜇𝜇
𝑉𝑉𝑉𝑉𝑉𝑉(𝑥𝑥𝑡𝑡 ) = 𝜎𝜎 2
𝐶𝐶𝐶𝐶𝐶𝐶 (𝑥𝑥𝑡𝑡 , 𝑥𝑥𝑡𝑡+ℎ ) = 𝑓𝑓(ℎ) 𝑎𝑎𝑎𝑎𝑎𝑎 ≠ 𝑔𝑔(𝑡𝑡)
This requirement means that there is one data generating process that determine 𝑥𝑥𝑡𝑡 in all time
periods, this data generating process does not change between time periods. The data
generating process is unknown and can be likened to a true model that explains changes in the
time series. If the generating process changes between periods then it would not be possible to
have a linear relationship in the regression model, since the parameter would change greatly
between time periods.
It can be seen that a strictly stationary process with a finite second moment is automatically a
covariance stationary process, but vice versa is not true.
Weakly dependent
The weakly dependent requirement differs between a strictly stationary process and a
covariance stationary process. For a strictly stationary process, it is required that 𝑥𝑥𝑡𝑡 , 𝑥𝑥𝑡𝑡+ℎ are
“almost independent” as h increases without bound. The covariance stationary requirement is
less abstract and generally how we think of weak dependence. This requires that the correlation
between 𝑥𝑥𝑡𝑡 , 𝑥𝑥𝑡𝑡+ℎ goes satisfactorily quickly to zero at h goes to infinity. In other words, we do
not want persistent correlation for a variable with itself over time, only taking into account the
first time period and another time period further away.
One example of a weakly dependent process is a moving average process of order 1 ([MA(1)]).
This can be written as
𝑥𝑥𝑡𝑡 = 𝜖𝜖𝑡𝑡 + 𝜕𝜕𝜖𝜖𝑡𝑡−1 (𝜖𝜖𝑡𝑡 , 𝑖𝑖. 𝑖𝑖. 𝑑𝑑 (0, 𝜎𝜎 2 ))
42
This process states that a once off change in 𝜖𝜖𝑡𝑡 will influence 𝑥𝑥𝑡𝑡 in the period of the change,
the following period, but not thereafter. The covariance therefore goes to zero within two
periods. This process is stationary (since 𝜖𝜖𝑡𝑡 is i.i.d) and weakly dependent.
Another example is an autoregressive process of order 1 [AR(1)]. This can be written
𝑥𝑥𝑡𝑡 = 𝜌𝜌𝑥𝑥𝑡𝑡−1 + 𝜀𝜀𝑡𝑡 , 𝜀𝜀𝑡𝑡 ~𝑖𝑖𝑖𝑖𝑖𝑖(0, 𝜎𝜎 2 )
This process states that as long as 𝜌𝜌 is less than one, a change in 𝑥𝑥𝑡𝑡 will have a persistent effect
on 𝑥𝑥𝑡𝑡 , but the effect will decrease to zero over time. It should be noted that if 𝜌𝜌 gets close to
one, the process will decrease to zero over time, but not satisfactorily quickly (it seems that
below 0.95 is satisfactorily). This process is also weakly dependent and stationary.
It is possible to perform multiple regression if a series is non-stationary and not weakly
independent, but since the law of large numbers and central limit theorem will not hold, this
analysis becomes tricky and the finite sample OLS properties need to be adhered by. If the
series is stationary and weakly independent, the asymptotic properties of OLS can be used (for
large samples).
We now turn back to the regression model as these assumptions need to hold in the model.
Assumption 1
The model must be linear in the parameters and the process must be stationary and weakly
dependent so that LLN and CLT can be applied to sample averages. For this purpose, weakly
dependent is more important.
Assumption 2
No perfect multicollinearity
Assumption 3
The explanatory variables are contemporaneously exogenous, meaning 𝐸𝐸(𝑢𝑢𝑡𝑡 |𝑥𝑥𝑡𝑡 ) = 𝐸𝐸(𝑢𝑢𝑡𝑡 ) =
0. Note that this assumption is less strict than the finite sample assumption as it is not concern
a on how the error for one period are related to the explanatory variables in other time periods.
Under assumptions 1-3 OLS will be consistent, but not necessarily unbiased. Strict exogenous
is required for unbiasedness. In large sample sizes, the bias is likely to be small.
Assumption 4
The errors are contemporaneously homoscedastic, 𝑉𝑉𝑉𝑉𝑉𝑉(𝑢𝑢𝑡𝑡 |𝑥𝑥𝑡𝑡 ) = 𝜎𝜎 2 . Note again this is less
strict than the finite sample assumption. Further note that 𝑥𝑥𝑡𝑡 here can also include lags of either
or both the dependent and independent variables.
Assumption 5
43
The errors for different time periods are uncorrelated, no serial correlation.
Under assumption 1-5, OLS estimators are asymptotically normal and the standard errors, T,
F, and LM test statistics are valid. If a model has trending explanatory variables and the trend
is stationary and included in the model, the assumption 1-5 can be applied.
Highly persistent time series
In this section, we are again concerned with individual variables over time (a time series). We
are not concerned with the regression model.
Many variables do not tend to zero satisfactorily quickly over time, in other words, it is a highly
persistent time series where the level in one period depends greatly on the level in the previous
period(s). A process that describes such a time series is a random walk, which is part of a unit
root process. The term unit root comes from the 𝜌𝜌 in the AR(1) model that equals unity (one).
A random walk can be written
𝑦𝑦𝑡𝑡 = 𝑦𝑦𝑡𝑡−1 + 𝜀𝜀𝑡𝑡 , 𝜀𝜀𝑡𝑡 ~𝑖𝑖𝑖𝑖𝑖𝑖(0, 𝜎𝜎 2 )
In this model, the expected value does not depend on the time period, but the variance does and
increases as a linear function of time and the correlation between 𝑦𝑦𝑡𝑡 𝑎𝑎𝑎𝑎𝑎𝑎 𝑦𝑦𝑡𝑡−1 gets arbitrarily
close to one. This process is not weakly dependent and also non-stationary. It is also possible
for this process to have a time trend, called a random walk with drift.
Luckily, non-weakly dependent processes are easily transformed to weakly dependent
processes (which are often stationary) and this can then be used in the regression. Before
transformation we need to determine whether the process is weakly dependent, called a process
integrated of order zero; I(0), or not, called a process integrated of order one; I(1).
We can, therefore, estimate 𝜌𝜌 by obtaining the correlation between 𝑦𝑦𝑡𝑡 𝑎𝑎𝑎𝑎𝑎𝑎 𝑦𝑦𝑡𝑡−1, but it should
be noted that this estimate is bias and can be largely biased (we therefore rather use the Dickey-
Fuller test discussed below). Note that if the process has a trend, we first need to detrend before
taking the correlation. If |𝜌𝜌| > 0.8 𝑡𝑡𝑡𝑡 0.9 (preference differ on this) then it is better to conclude
that the process is I(1). If the process is I(1), we need to take the first difference of the process
and include this in the regression. For the random walk process, the first difference is therefore
𝑐𝑐𝑐𝑐 = 𝑦𝑦𝑡𝑡 − 𝑦𝑦𝑡𝑡−1
44
Note that 𝑐𝑐𝑦𝑦 = 𝑑𝑑𝑑𝑑 = ∆𝑦𝑦, which all means the first difference in y. Note that we will lose the
first observation, meaning we will start at period 2, as a result of taking the first difference.
Taking the first difference also has the advantage of detrending the time series. This is true
since the first difference of a linear relationship is constant.
A more formal test for a unit root is known as the Dickey-Fuller (DF) test. Taking the AR(1)
model above and subtracting 𝑦𝑦𝑡𝑡−1 gives
∆𝑦𝑦𝑡𝑡 = 𝛼𝛼 + 𝜃𝜃𝑦𝑦𝑡𝑡−1 + 𝑒𝑒𝑡𝑡
Where 𝜃𝜃 = (1 − 𝜌𝜌). This module can be estimated by OLS, but 𝜃𝜃 does not follow a normal
distribution, but what is known as the Dickey-Fuller distribution. We therefore need alternative
critical values which can then be used in the t-test. Higher order AR processes to address serial
correlation are also allowed and can be written
∆𝑦𝑦𝑡𝑡 = 𝛼𝛼 + 𝜃𝜃𝑦𝑦𝑡𝑡−1 + 𝛾𝛾∆𝑦𝑦𝑡𝑡−1 +. . . +𝑒𝑒𝑡𝑡
If a series has a time trend, we need to include the trend in the Dickey-Fuller test. Note,
however, that alternative critical values need to be used after including the time trend.
Spurious regression
It is possible for two variables to be correlated only because both are correlated with a third
variable not included in the model. Including this variable removes the correlation between the
first two variables. If this is the case we have a spurious regression. This is of course also
possible for time series, but time series has an additional issue. If we have an I(1) dependent
variable and at least one I(1) independent variable, this will in most instances result in spurious
regression. This means the t-statistics cannot be trusted.
One way to address this is by differencing the variables, but this limits our application. Another
possibility is to determine whether the two I(1) variables are co-integrated.
Co-integration
If two I(1) variables have a long run relationship it is possible that the difference between the
two variables is an I(1) process. This can be written
𝑦𝑦𝑡𝑡 − 𝛽𝛽𝑥𝑥𝑡𝑡 is 𝐼𝐼(0) for certain 𝛽𝛽 ≠ 0
To test whether two I(1) variables are co-integrated we perform the Engle-Granger test
1) Estimate 𝑦𝑦𝑡𝑡 = 𝛼𝛼 + 𝛽𝛽𝑥𝑥𝑡𝑡 by OLS
2) Apply the DF test to the residuals by estimating ∆𝑢𝑢𝑡𝑡 = 𝛼𝛼 + 𝜃𝜃𝑢𝑢𝑡𝑡−1 + 𝑒𝑒𝑡𝑡
45
3) Use the Engle-Granger critical values to determine whether 𝜃𝜃 is significant.
4) If t-stat is below critical value then 𝑦𝑦𝑡𝑡 − 𝛽𝛽𝑥𝑥𝑡𝑡 is 𝐼𝐼(0), meaning we can calculate a new
variable that often has economic interpretation.
If we include this new variable, we call the model an error correction model and this can be
written (note that variables are differenced because y and x are I(1))
Serial correlation
∆𝑦𝑦𝑡𝑡 = 𝛼𝛼0 + 𝛾𝛾∆𝑥𝑥𝑥𝑥 + 𝛿𝛿(𝑦𝑦𝑡𝑡−1 − 𝛽𝛽𝑥𝑥𝑡𝑡−1 ) + 𝑢𝑢𝑡𝑡
Remember, in a dynamically complete model there is no serial correlation. Serial correlation
can, however, exist in other types of models, or where there is misspecification in a dynamically
complete model. When there is serial correlation, OLS remains consistent and unbiased (even
if the model includes lagged dependent variables). OLS will, however, be less efficient (no
longer BLUE) and the test statistics will be invalid. The goodness of fit tests (Rsquared)
remains valid.
Tests for serial correlation
Tests when independent variables are strictly exogenous (e.g. no lagged dependent variables)
For time series data, the error terms can also be viewed as processes. This means the error terms
can be related to past error terms in various manners. Commonly, errors terms are written as
AR(1) processes:
𝑢𝑢𝑡𝑡 = 𝜌𝜌𝑢𝑢𝑡𝑡−1 + 𝜀𝜀𝑡𝑡 , 𝜀𝜀𝑡𝑡 ~𝑖𝑖𝑖𝑖𝑖𝑖(0, 𝜎𝜎 2 )
If there is no serial correlation in adjacent errors, then 𝜌𝜌 = 0. This is therefore the null
hypothesis of the test. Since we only have strictly exogenous variables, the estimate of 𝑢𝑢𝑡𝑡 is
unbiased and can be used for testing the null. Therefore
I. Run OLS of 𝑦𝑦𝑡𝑡 on xt1 , 𝑥𝑥𝑡𝑡2 , … . . 𝑥𝑥𝑡𝑡𝑡𝑡 and take 𝑢𝑢�𝑡𝑡 for all 𝑡𝑡′𝑠𝑠
II. Run 𝑢𝑢�𝑡𝑡 𝑜𝑜𝑜𝑜 𝑢𝑢�𝑡𝑡−1 for all 𝑡𝑡. The parameter 𝜌𝜌’s p-value indicates serial correlation.
Generally the nul,l can be rejected at the 5 percent level. The test can be made robust
to heteroscedasticity by computing robust standard errors.
It should be remembered that this test only tests for AR(1) serial correlation, meaning only
correlation in adjacent error terms. It may be that there is serial correlation in non-adjacent
error terms.
46
Another possible test is the Durbin-Watson test, but this requires that the classical assumptions
all hold and provides the same answer as above. It is therefore suggested that this test is rather
not used.
Tests when independent variables are not strictly exogenous
Since strict exogeneity is unlikely to hold, but OLS will still be asymptotically consistent
(although bias and the bias can be small if the time series are non-persistent), serial correlation
tests where the variables are not strictly exogenous are often required. The previously discussed
tests are not valid.
The Durbin’s alternative statistic test holds whether the variables are strict exogenous variables
or not, so it can always be used. This test must be used if there is a lagged dependent variable
(such a model can never be strictly exogenous). For AR(1) errors
I. Run OLS on 𝑦𝑦𝑡𝑡 on xt1 , 𝑥𝑥𝑡𝑡2 , … . . 𝑥𝑥𝑡𝑡𝑡𝑡 and take 𝑢𝑢�𝑡𝑡 for all 𝑡𝑡′𝑠𝑠
II. Run 𝑢𝑢�𝑡𝑡 𝑜𝑜𝑜𝑜 xt1 , 𝑥𝑥𝑡𝑡2 , … . . 𝑥𝑥𝑡𝑡𝑡𝑡 , 𝑢𝑢�𝑡𝑡−1 for all 𝑡𝑡
III. The null is the same as the previous test (the parameter of 𝑢𝑢�𝑡𝑡−1 = 0) and the test can
again be made robust to heteroscedasticity.
For higher order (e.g. AR(2) errors, meaning there are two lags) serial correlation the same test
can be done, but with including the higher order error terms in step 2. The F test is then used
to test for joint significance (all parameters of the residuals should be zero) and the test can be
made robust to heteroscedasticity as discussed for cross-sectional data.
Correcting serial correlation
Strictly exogenous variables
In the test for serial correlation, we obtain the parameter 𝜌𝜌 for AR(1) serial correlation. We can
use this parameter to transform the data in the model and thereby correct serial correlation.
This is done with a FGLS estimator and the estimation is also called the Cochrane Orcult (OC)
or Prais-Winsten (PW) estimation. The OC estimation only make use of t>1 and the PW
estimation make use of all time periods in the data. The PW can therefore be preferred in small
samples, although asymptotically these two estimations does not differ. Most regression
packages include an iterated version of the estimates, meaning an iterated FGLS is used as the
estimator.
To understand the estimator, you need to understand how the data is transformed. AR(1) errors
(residuals as we are using 𝑝𝑝,
� but for ease just writing 𝜌𝜌) are written
𝑢𝑢𝑡𝑡 = 𝜌𝜌𝑢𝑢𝑡𝑡−1 + 𝜀𝜀𝑡𝑡
47
Where 𝑣𝑣𝑣𝑣𝑣𝑣(𝑢𝑢𝑡𝑡 ) = 𝜎𝜎𝑒𝑒2 /(1 − 𝜌𝜌2 ). Note that 𝜌𝜌 indicates the extent of the serial correlation and if
0 then 𝑣𝑣𝑣𝑣𝑣𝑣(𝑢𝑢𝑡𝑡 ) = 𝜎𝜎𝑒𝑒2 , meeting the serial correlation and homoscedasticity assumption. To
obtain this we take the quasi-difference for each variable in the regression besides in time
period 1. This is done by multiplying the t>1 time period, multiplying each variable by 𝜌𝜌 and
the deducting this from the previous time period (e.g for time period 2, this time period is
multiplied by 𝜌𝜌 and the we deduct this from time period 1). Note that if 𝜌𝜌 were equal to one
(which we assume not to be the case) then this will be the exact same process as taking the
difference to transform a variable to be weakly dependent.
To include time period 1 in our estimation, each variable in this time period is multiplied by
1
(1 − 𝜌𝜌2 )2 . Note that these transformations are performed automatically by the regression
software.
For higher order serial correlation (AR(q)) a similar approach is followed by quasitransforming all variables. This again is done automatically by the regression software.
From the above, there are two possible estimators when the errors are serially correlated with
strictly exogenous variables, OLS and FGLS. FGLS is generally preferred since the
transformation ensures all variables are I(0) and that there is no serial correlation. FGLS will
however only be consistent if
𝐶𝐶𝐶𝐶𝐶𝐶(𝑥𝑥𝑡𝑡 , 𝑢𝑢𝑡𝑡 ) = 0
𝐶𝐶𝐶𝐶𝐶𝐶((𝑥𝑥𝑡𝑡−1 + 𝑥𝑥𝑡𝑡+1 ), 𝑢𝑢𝑡𝑡 = 0
Note that this is a stronger requirement than OLS, which only needs the first written covariance
to hold. If the second written covariance does not hold, then OLS can be preferred to FGLS
since OLS will be consistent (although the test statistics will be invalid). Taking the difference
for variables with OLS, especially when 𝜌𝜌 is large, eliminates most of the serial correlation.
Both OLS and FGLS should be used and reported to show (hopefully) that there are no large
differences between the estimated parameters.
Independent variables not strictly endogenous
When the independent variables are not strictly endogenous, the OC and PW estimations are
not consistent or efficient. This means that we will have to use OLS as the estimator. After
OLS, serial correlation –robust standard errors can be computed (refer Woolridge 1989 for how
this is computed). These standard errors are also robust to heteroscedasticity. This is therefore
also called heteroscedasticity and autocorrelation consistent (HAC) standard errors.
48
It may further be a good idea to compute these standard errors even when the independent
variables are strictly endogenous after using OLS or FGLS. FGLS is included since the
parameter 𝜌𝜌 may not account for all serial correlation (the errors did not follow the selected
AR model) and there may be heteroscedasticity in the errors.
Heteroscedasticity
If the errors are heteroskedastic, but there is no serial correlation, the same procedures as
discussed for cross-sectional data can be applied to time series. A specific type of
heteroscedasticity in time series is autoregressive conditional heteroscedasticity (ARCH). The
type of heteroscedasticity does not result in OLS not being BLUE and all the OLS assumptions
remain to hold, but in the presence of ARCH, there may be estimators that are asymptotically
more efficient than OLS, for instance, weighted least squares. An ARCH(1) model for the
errors can be written
2
𝑢𝑢𝑡𝑡2 = 𝛼𝛼0 + 𝛼𝛼1 𝑢𝑢𝑡𝑡−1
+ 𝜀𝜀𝑡𝑡
Where 𝛼𝛼1 contains the serial correlation in the square of the errors even though there is no
serial correlation in the errors (non-squared). This type of heteroscedasticity is often found if
the model contains lagged dependent variables (therefore the name), although it may be present
even when the model does not contain lagged dependent variables.
Serial correlation and heteroscedasticity
It is possible that the errors are both heteroskedastic and serially correlated. If this is the case
it is possible to use HAC standard errors after OLS. It is further possible to combine the WLS
procedure to address heteroscedasticity (discussed for cross-sectional data) with the AR(1)
procedure (OC or PW estimations) discussed above. To do this
𝑢𝑢𝑡𝑡 for all 𝑡𝑡′s
1. Regress 𝑦𝑦𝑡𝑡 on 𝑥𝑥𝑡𝑡1 , … , 𝑥𝑥𝑡𝑡𝑡𝑡 and save �
2. Regress log(𝑢𝑢𝑡𝑡2 ) on 𝑥𝑥𝑡𝑡1 , … , 𝑥𝑥𝑡𝑡𝑡𝑡 and obtain the fitted values, �
𝑔𝑔𝑡𝑡
3. Obtain ℎ�𝑡𝑡 = exp(𝑔𝑔
�)
𝑡𝑡
1
−
4. Multiply all variables by ℎ�𝑡𝑡 2 to remove the heteroscedasticity
5. Estimate with the new variables by way of OC or PW.
Note that this approach can only be used for strict exogenous variables.
49
2SLS estimator
The mechanics of the 2SLS estimator is identical for time series and cross-sectional data. Just
as variables are differenced for time series, so instrumental variables can be differenced. The
tests and correction for serial correlation change slightly when using the 2SLS estimator.
To test for AR(1) serial correlation:
1) Estimate the 2SLS and save the residuals, 𝑢𝑢�𝑡𝑡
2) Estimate 𝑦𝑦𝑡𝑡 = 𝛽𝛽0 + 𝛽𝛽1 𝑥𝑥𝑡𝑡1 + ⋯ + 𝜌𝜌𝑢𝑢𝑡𝑡−1 + 𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒
3) The null hypothesis is that the parameter for 𝑢𝑢𝑡𝑡−1 is zero (no serial correlation).
To correct serial correlation
Serially robust standard errors can be taken or we can use quasi-difference data by
1) Estimate the 2SLS and save the residuals, 𝑢𝑢�𝑡𝑡
2) Run 𝑢𝑢�𝑡𝑡 on 𝑢𝑢𝑡𝑡−1 and get 𝜌𝜌
3) Construct quasi-differenced variables for all variables including the instrumental variables
4) Estimate quasi differenced variables by 2SLS
5) The first period can also be calculated with the usual quasi-differenced approach to the first
period.
SEMs
For time series, using 2SLS for simultaneous equation models and to address simultaneity bias
is no different than for cross-sectional data. In SEMs lagged variables are often called
predetermined variables. It should further be noted that SEMs generally are highly persistent
and the correct treatment for these series are required (for instance first differencing).
Assumptions for 2SLS
1) Linear parameters, all series (including instrumental variables) are stationary and weakly
dependent.
Instrumental variables are denoted as 𝑧𝑧𝑗𝑗
2) No perfect multicollinearity among instrumental variables and the order condition for
identification holds. This means we need at least one excluded exogenous variable (which
parameter is not zero in the reduced form equation) for each included endogenous variable.
For SEMs the rank condition is required.
3) 𝐸𝐸(𝑢𝑢) = 0, 𝐶𝐶𝐶𝐶𝐶𝐶�𝑧𝑧𝑗𝑗 , 𝑢𝑢� = 0
50
Note that each exogenous independent variable is seen as its own instrumental variable,
therefore all exogenous variables are denoted 𝑧𝑧𝑗𝑗
Under 1-4 2SLS is consistent (although bias)
4) 𝐸𝐸(𝑢𝑢𝑡𝑡2 |𝑧𝑧𝑡𝑡1 , … , 𝑧𝑧𝑡𝑡𝑡𝑡 ) = 𝜎𝜎 2
If 𝑍𝑍 denotes all instrumental variables (all exogenous variables) then
5) 𝐸𝐸(𝑢𝑢𝑡𝑡 𝑢𝑢𝑠𝑠 |𝑍𝑍𝑡𝑡 𝑍𝑍𝑠𝑠 ) = 0
Under 1-5 2SLS is consistent and test statistics are asymptotically valid. The 2SLS estimator
is the best IV estimator under these assumptions.
Infinite distributed lag (IDL) models
IDL models are similar to FDL models discussed previously, with the only difference being
that the lag is included in the model indefinitely. Such a model can be written
𝑦𝑦𝑡𝑡 = 𝛼𝛼 + 𝛿𝛿0 𝑧𝑧𝑡𝑡 + 𝛿𝛿1 𝑧𝑧𝑡𝑡−1 + 𝛿𝛿2 𝑧𝑧𝑡𝑡−2 … . +𝑢𝑢𝑡𝑡
Where it is required that 𝛿𝛿𝑗𝑗 → 0, 𝑗𝑗 → ∞, which makes logical sense since the distant past has
less of an impact than the recent past for nearly all series’. The interpretation of this model is
also the same as FDL; 𝛿𝛿𝑗𝑗 is the change in the expected value of the dependent variable for a
one-unit temporary change in the independent variable at time zero (after j periods). 𝛿𝛿0 is again
the impact propensity and the sum of all the coefficients that are sufficiently large can be used
to approximate the long run propensity (this is required since the model is indefinite).
Similar to FDL we need to assume strict exogeneity
𝐸𝐸(𝑢𝑢𝑡𝑡 | … , 𝑧𝑧𝑡𝑡−1 , 𝑧𝑧𝑡𝑡 , 𝑧𝑧𝑡𝑡+1 , … ) = 0
Although in certain situations this assumption can be weakened to only include present and
past periods (not 𝑧𝑧𝑡𝑡+1 , …).
There are multiple models that can be used to estimate IDL’s:
Geometric (Koyck) distributed lag models
In estimating IDL we need to be able to have a finite model (we do not have infinite data). If
we take
𝛿𝛿𝑗𝑗 = 𝛾𝛾𝜌𝜌𝑗𝑗
Where 𝜌𝜌 is in absolute form between zero and one (to ensure 𝛿𝛿𝑗𝑗 → 0, 𝑗𝑗 → ∞) and 𝑗𝑗 = 0,1,2, …
then the original IDL model at time t is written
51
𝑦𝑦𝑡𝑡 = 𝛼𝛼 + 𝛾𝛾𝑧𝑧𝑡𝑡 + 𝛾𝛾𝛾𝛾𝑧𝑧𝑡𝑡−1 + 𝛾𝛾𝜌𝜌2 𝑧𝑧𝑡𝑡−2 … . +𝑢𝑢𝑡𝑡
If we also write this for time t-1, multiply the t-1 equation by 𝜌𝜌 and subtract it from the from
the time t equation we get the geometric lag model
𝑦𝑦𝑡𝑡 = 𝛼𝛼0 + 𝛾𝛾𝑧𝑧𝑡𝑡 + 𝜌𝜌𝑦𝑦𝑡𝑡−1 + 𝑣𝑣𝑡𝑡
Where 𝑣𝑣𝑡𝑡 = 𝑢𝑢𝑡𝑡 − 𝜌𝜌𝑢𝑢𝑡𝑡−1 , an MA(1). The impact propensity is 𝛾𝛾 and the long run propensity
𝛾𝛾
can be shown to be 1− 𝜌𝜌.
This equation can be estimated by OLS, but there is a few problems. Firstly, 𝑦𝑦𝑡𝑡−1 is endogenous
and 𝑣𝑣𝑡𝑡 is serially correlated where 𝜌𝜌𝑢𝑢𝑡𝑡−1 ≠ 0 and the model is not dynamically complete. The
endogeneity can be resolved by using 2SLS and a good instrumental variable for 𝑦𝑦𝑡𝑡−1 is
generally 𝑧𝑧𝑡𝑡−1 (𝑧𝑧𝑡𝑡 and 𝑧𝑧𝑡𝑡−1 are IVs). Note that using 𝑧𝑧𝑡𝑡−1 requries the strict exogeneity
assumption to hold (otherwise it is correlated with 𝑦𝑦𝑡𝑡 ) Afterwards, we can adjust the standard
errors as discussed previously.
Rational distributed lag models
This model is similar to the geometric lag model but is written
𝑦𝑦𝑡𝑡 = 𝛼𝛼0 + 𝛾𝛾0 𝑧𝑧𝑡𝑡 + 𝜌𝜌𝑦𝑦𝑡𝑡−1 + 𝛾𝛾1 𝑧𝑧𝑡𝑡−1 + 𝑣𝑣𝑡𝑡
The impact propensity is 𝛾𝛾0 and the long run propensity is
Forecasting
𝛾𝛾0 +𝛾𝛾1
1− 𝜌𝜌
.
Some terminology:
𝑓𝑓𝑡𝑡 denotes the forecast of 𝑦𝑦𝑡𝑡+1 at time t (one-step ahead forecasting)
𝑓𝑓𝑡𝑡,ℎ denotes the forecast of 𝑦𝑦𝑡𝑡+ℎ at time t (multiple-step ahead forecasting)
The forecast error 𝑒𝑒𝑡𝑡+1 = 𝑦𝑦𝑡𝑡+1 − 𝑓𝑓𝑡𝑡
2
The most common lost function is 𝑒𝑒𝑡𝑡+1
, which we want to minimize (the same as for OLS).
Note however that we do not observe this, so we want to minimize the expected loss function.
𝐼𝐼𝑡𝑡 denotes a set of information known at time t.
Conditional forecasting is where we know the future values of the independent variables. It is
then easy to forecast the future dependent variable. We can write
𝐸𝐸(𝑦𝑦𝑡𝑡+1 |𝐼𝐼𝑡𝑡 ) = 𝛼𝛼 + 𝛽𝛽1 𝑧𝑧𝑡𝑡+1
52
Where we need to assume that 𝐸𝐸(𝑢𝑢𝑡𝑡+1 |𝐼𝐼𝑡𝑡 )=0.
The problem with conditional forecasting is that we rarely know 𝑧𝑧𝑡𝑡+1 . If we for instance want
to forecast a trend, then we can use conditional forecasting as we know 𝑧𝑧𝑡𝑡+1 .
Unconditional forecasting is where we do not know the level of the independent variables it is
not included in 𝐼𝐼𝑡𝑡 . This would mean that we would have to first forecast 𝑧𝑧𝑡𝑡+1 before we can
forecast 𝑦𝑦𝑡𝑡+1 .
One-step forecasting
The conditional forecasting problem of not knowing 𝑧𝑧𝑡𝑡+1 can be resolved by forecasting the
dependent variable based on the lags of the dependent and independent variables. This will
allow us to know 𝑧𝑧𝑡𝑡+1 as it is the variable observed in the current time period. A model that
makes use of this approach is called a vector autoregressive model (VAR) and can be written
𝑦𝑦𝑡𝑡 = 𝛿𝛿0 + 𝛼𝛼1 𝑦𝑦𝑡𝑡−1 + 𝛽𝛽1 𝑧𝑧𝑡𝑡−1 + 𝛼𝛼2 𝑦𝑦𝑡𝑡−2 + 𝛽𝛽2 𝑧𝑧𝑡𝑡−2 + ⋯ + 𝑢𝑢𝑡𝑡
Where we include as many variables as to make the model dynamically complete. See that to
forecast we would have
𝑦𝑦𝑡𝑡+1 = 𝛿𝛿0 + 𝛼𝛼1 𝑦𝑦𝑡𝑡 + 𝛽𝛽1 𝑧𝑧𝑡𝑡 + 𝛼𝛼2 𝑦𝑦𝑡𝑡−1 + 𝛽𝛽2 𝑧𝑧𝑡𝑡−1 + ⋯ + 𝑢𝑢𝑡𝑡
And all the independent variables are included in 𝐼𝐼𝑡𝑡 . As we obtain additional data we can then
repeat the estimation. If after controlling for past y, z helps to forecast y, we say that z Granger
causes y. If we include additional variables, w, we say that z Granger causes y conditional on
w. If we consider different models that can forecast the dependent variable, the model with the
lowest root mean square error or mean absolute error can be generally preferred.
Multiple-step forecasting
Multiple-step forecasting is less reliable than one-step forecasting since the error variance
increase as the forecast horizon increases. We can use the VAR model above to also forecast
the independent variables. We can then use the forecasted dependent and independent variables
as lags to forecast 𝑦𝑦𝑡𝑡+2 . This process can be repeated indefinitely, but obviously becomes less
reliable as the forecast horizon increases.
53
PANEL DATA
Panel data is similar to pooled cross-sectional data, with the difference being that the same
individual, country, firm, etc. are sampled for different time periods. A panel dataset is
therefore organized as
City
Pretoria
Pretoria
Johannesburg
Johannesburg
Year
2015 (t=1)
2016 (t=2)
2015 (t=1)
2016 (t=2)
Variables
421
464
658
863
One estimator that can be used on this data is pooled OLS, but this is seldom used since it does
not make use of the benefits of panel data. The fact that the same individual, firm, country, etc.
is sampled over time, gives an advantage of panel data sets to control for fixed factors of the
individuals, firms countries, etc. that are correlated with the dependent variable over time. To
see this we can write the error term for a panel as
𝑣𝑣𝑖𝑖𝑖𝑖 = 𝑎𝑎𝑖𝑖 + 𝑢𝑢𝑖𝑖𝑖𝑖
Where 𝑣𝑣𝑖𝑖𝑖𝑖 is known as the composite error and includes both constant (𝑎𝑎𝑖𝑖 ) and variable (𝑢𝑢𝑖𝑖𝑖𝑖 )
unobserved factors explaining the dependent variable. 𝑎𝑎𝑖𝑖 is called the fixed effect, unobserved
heterogeneity or individual/firm/country etc. heterogeneity and 𝑢𝑢𝑖𝑖𝑖𝑖 is called the idiosyncratic
error. A fixed effects model is used to include the fixed effect. It is useful to control for these
fixed effects as this removes a lot of the persistence in the variables.
Fixed effects model
The fixed effects model for a two-period panel dataset (as above) can be written
𝑦𝑦𝑖𝑖𝑖𝑖 = 𝛽𝛽0 + 𝛿𝛿0 𝑑𝑑2𝑡𝑡 + 𝛽𝛽1 𝑥𝑥𝑖𝑖𝑖𝑖 + 𝑎𝑎𝑖𝑖 + 𝑢𝑢𝑖𝑖𝑖𝑖
Where 𝑑𝑑2𝑡𝑡 is a dummy for time period two that control for changes due to using different time
periods (it is generally a good idea to include this) and 𝑎𝑎𝑖𝑖 is the fixed effect. See that if 𝑎𝑎𝑖𝑖 is
not included in the model and is correlated with the independent variables, the estimates of the
model will be bias due to omitted variables. This bias is called heterogeneity bias. Of course if
𝑢𝑢𝑖𝑖𝑖𝑖 is correlated with any independent variable then the estimates are also bias.
Since 𝑎𝑎𝑖𝑖 is not known, we need a method to control for 𝑎𝑎𝑖𝑖 . One method to do this is by first-
differencing.
First-Differencing estimator (FD)
The First-Differencing estimator is an OLS estimator applied to first-differenced data.
54
For a two-period panel, we simply take the first-difference between the model for t=2 and t=1
(note that 𝛿𝛿0 𝑑𝑑2𝑡𝑡 = 0 for period 1) which gives one cross section
∆𝑦𝑦𝑖𝑖 = 𝛿𝛿0 + 𝛽𝛽1 ∆𝑥𝑥𝑖𝑖 + ∆𝑢𝑢𝑖𝑖
Using this model is the same as saying we are only modeling what has changed over time (nonconstant), which is the same as saying that 𝑎𝑎𝑖𝑖 is controlled for. This model is also similar to the
difference-in-difference estimator for pooled cross sections, with the only difference being that
it is the same individual, firm, country etc. that has been sampled.
This model can be extended for more time periods and the process of taking the first difference
(t2-t1;t3-t2 etc.) remains the same. To ensure that the R-squared for the model is correctly
calculated, it is advised to drop the dummy parameter for t2-1 and include an intercept. The
model is therefore written as
∆𝑦𝑦𝑖𝑖𝑖𝑖 = 𝛼𝛼0 + 𝛼𝛼3 𝑑𝑑3𝑡𝑡 + 𝛼𝛼4 𝑑𝑑4𝑡𝑡 + ⋯ + 𝛽𝛽1 ∆𝑥𝑥𝑖𝑖𝑖𝑖1 + 𝛽𝛽2 ∆𝑥𝑥𝑖𝑖𝑖𝑖2 + ⋯ + ∆𝑢𝑢𝑖𝑖𝑖𝑖
Assumptions for OLS using the First-Differencing estimator
1. Random sample
2. Independent variables have variance over time for at least some 𝑖𝑖
3. No perfect multicollinearity
If 𝑋𝑋𝑖𝑖 indicates all independent variables over all time periods (such as for time series)
4. 𝐸𝐸(∆𝑢𝑢𝑖𝑖𝑖𝑖 |𝑋𝑋𝑖𝑖 ) = 𝐸𝐸(∆𝑢𝑢𝑖𝑖𝑖𝑖 ) = 0 to obtain unbiased, consistent estimates (strict exogeneity
assumption). Note ∆𝑢𝑢𝑖𝑖𝑖𝑖 is the differenced idiosyncratic error
𝐸𝐸�∆𝑢𝑢𝑖𝑖𝑖𝑖 �∆𝑥𝑥𝑖𝑖𝑖𝑖𝑖𝑖 � = 𝐸𝐸(∆𝑢𝑢𝑖𝑖𝑖𝑖 ) = 0 for consistent but bias estimates
Under 1-4, FD is unbiased and consistent.
5. 𝑉𝑉𝑉𝑉𝑉𝑉(∆𝑢𝑢𝑖𝑖𝑖𝑖 |𝑋𝑋𝑖𝑖 ) = 𝜎𝜎 2 (Homoscedasticity)
6. 𝐶𝐶𝐶𝐶𝐶𝐶(∆𝑢𝑢𝑖𝑖𝑖𝑖 , ∆𝑢𝑢𝑖𝑖𝑖𝑖 |𝑋𝑋𝑖𝑖 ) = 0 (Serial correlation)
Note that this will only hold if the non-differenced errors (𝑢𝑢𝑖𝑖𝑖𝑖 ) follows a random walk. If they
are AR(q) then this will not hold.
Under 5-6, OLS test statistics are asymptotically valid.
7. Conditional on 𝑋𝑋𝑖𝑖 the ∆𝑢𝑢𝑖𝑖𝑖𝑖 are independent and identically distributed normal random
variables.
Under 5-7, OLS test statistics are valid, under 5-6 asymptotically valid.
Treatment if 5 or 6 does not hold
55
Testing for homoscedasticity and serial correlation can be done in exactly the same manner as
for cross section and time series, respectively. If we only have heteroscedasticity (no serial
correlation) the corrections for cross sections can be used. If we only have serial correlation
this can be corrected by way of the PW transformation. Note, however, that this needs to be
done by hand as the regression software assumes that the serial correlation is over 𝑖𝑖 and 𝑡𝑡, but
in panel data we have independent 𝑖𝑖. The HAC standard errors can also be used.
If we have both heteroscedasticity and serial correlation then one option is to run OLS and take
HAC standard errors. The general approach, however, is clustering. In this approach, each
cross-sectional unit is defined as a cluster over time and arbitrary correlation is allowed within
each cluster. Clustered standard errors are valid in large panel datasets with any kind of serial
correlation and heteroskedasticity.
Fixed effects estimator (Within estimator) (FE)
The fixed effects estimator is an OLS estimator on data that has been time-demeaned. Within
transformation is another method of controlling for 𝑎𝑎𝑖𝑖 in a fixed effects model. Take the model
𝑦𝑦𝑖𝑖𝑖𝑖 = 𝛽𝛽1 𝑥𝑥𝑖𝑖𝑖𝑖 + 𝑎𝑎𝑖𝑖 + 𝑢𝑢𝑖𝑖𝑖𝑖
Taking the mean over time for each variable gives
𝑦𝑦�𝚤𝚤 = 𝛽𝛽1 𝑥𝑥�𝚤𝚤 + 𝑎𝑎𝑖𝑖 + 𝑢𝑢�𝚤𝚤
Taking the difference between these two equations gives
𝑦𝑦𝚤𝚤𝚤𝚤̈ = 𝛽𝛽1 𝑥𝑥𝚤𝚤𝚤𝚤̈ + 𝑢𝑢𝚤𝚤𝚤𝚤̈
Where for instance 𝑥𝑥𝚤𝚤𝚤𝚤̈ = (𝑥𝑥𝑖𝑖𝑖𝑖 − 𝑥𝑥�𝚤𝚤 ) and ̈ indicates time demeaned data.
Note that the intercept has been eliminated and the degrees of freedom is calculated as 𝑑𝑑𝑑𝑑 =
𝑁𝑁𝑁𝑁 − 𝑁𝑁 − 𝐾𝐾 (automatically done by regression software).
It is important to see that for the fixed effects estimator we cannot include time-consistent
variables (such as gender, race or for instance the distance that a house is from a river). Further,
if we include dummy variables for time, then we cannot include variables with constant change
over time, such as age or years of experience. To calculate the fixed effect 𝑎𝑎�𝑖𝑖 (if of importance
we write
�1 ����
�𝑘𝑘 ����
𝑎𝑎�𝚤𝚤 = 𝑦𝑦�𝚤𝚤 − 𝛽𝛽
𝑥𝑥11 − ⋯ − 𝛽𝛽
𝑥𝑥𝚤𝚤𝚤𝚤
56
FD or FE
Although FD and FE both provide the same estimates of the parameters (assuming all
assumptions related to this hold), the extent of serial correlation changes which estimator is
most efficient. If 𝑢𝑢𝑖𝑖𝑖𝑖 is not serially correlated, FE is more efficient. If 𝑢𝑢𝑖𝑖𝑖𝑖 follows a random
walk then FD is more efficient. If there is a substantial negative correlation in ∆𝑢𝑢𝑖𝑖𝑖𝑖 then FE is
more efficient. If T is large and N is not large the use FD as inference on FE can be very
sensitive to violations. If the model includes a lagged dependent variable then the bias is much
less under FE than FD, therefore use FE.
Unbalanced panels for fixed effects models
If data is missing for some units in one or more year, the computation does not change. The
only major issue with unbalanced panels is whether the random sampling assumption is
adhered to. If the reason for a unit not being sampled for a year is related to the idiosyncratic
error (it can be related to the fixed effect), then the estimates will be biased. This is called
attrition bias.
Assumptions of the fixed effects estimator
1. Random sample
2. Independent variables have variance over time for at least some 𝑖𝑖
3. No perfect multicollinearity
If 𝑋𝑋𝑖𝑖 indicates all independent variables over all time periods (such as for time series)
4. 𝐸𝐸(𝑢𝑢𝑖𝑖𝑖𝑖 |𝑋𝑋𝑖𝑖 , 𝑎𝑎𝑖𝑖 ) = 𝐸𝐸(𝑢𝑢𝑖𝑖𝑖𝑖 ) = 0 (strict exogeneity assumption).
Under 1-4, FE is unbiased and consistent.
5. 𝑉𝑉𝑉𝑉𝑉𝑉(𝑢𝑢𝑖𝑖𝑖𝑖 |𝑋𝑋𝑖𝑖 , 𝑎𝑎𝑖𝑖 ) = 𝜎𝜎𝑢𝑢2 (Homoscedasticity)
6. 𝐶𝐶𝐶𝐶𝐶𝐶(𝑢𝑢𝑖𝑖𝑖𝑖 , 𝑢𝑢𝑖𝑖𝑖𝑖 |𝑋𝑋𝑖𝑖 , 𝑎𝑎𝑖𝑖 ) = 0 (Serial correlation)
Under 1-6 FE is BLUE (smaller variances than FD since idiosyncratic errors are uncorrelated,
which is not the case for FD)
If 5 and 6 do not hold, use clustered standard errors(discussed under FD assumptions).
7. Conditional on 𝑋𝑋𝑖𝑖 and 𝑎𝑎𝑖𝑖 , the 𝑢𝑢𝑖𝑖𝑖𝑖 are independent and identically distributed normal random
variables.
Under 5-7 the test statistics are valid, under 5-6 asymptotically valid (large N, small T)
57
Random effects model
It is generally preferred to use fixed effects in panel data (this is one of the strengths of panel
data), but if 𝑐𝑐𝑐𝑐𝑐𝑐�𝑥𝑥𝑖𝑖𝑖𝑖𝑖𝑖 , 𝑎𝑎𝑖𝑖 � = 0 then the FE/FD estimator is not the most efficient. If we were to
then use pooled OLS with a model that can be written as
𝑦𝑦𝑖𝑖𝑖𝑖 = 𝛽𝛽0 + 𝛽𝛽1 𝑥𝑥𝑖𝑖𝑖𝑖1 + ⋯ + 𝛽𝛽𝑘𝑘 𝑥𝑥𝑖𝑖𝑖𝑖𝑖𝑖 + 𝑢𝑢𝑖𝑖𝑖𝑖
Where the error term includes both the fixed effects and the idiosyncratic error. Because all
fixed effects are left in the error, 𝑢𝑢𝑖𝑖𝑖𝑖 will necessarily be serially correlated across time and
therefore pooled OLS will have invalid standard errors (unless serial and heteroscedasticity
robust standard errors are calculated). Further, we lose all the benefit of being able to control
for fixed effects. To alleviate these issues we use GLS and the random effects estimator.
Random effects estimator (RE)
The random effects estimator is an FGLS estimator using quasi-demeaned data. To understand
the quasi-demeaning process define
1
2
𝜎𝜎𝑢𝑢2
𝜃𝜃 = 1 − � 2
�
𝜎𝜎𝑢𝑢 + 𝑇𝑇𝜎𝜎𝑎𝑎2
Where 𝜎𝜎𝑢𝑢2 is the variance of the idiosyncratic error, 𝑇𝑇 is the total number of time periods that
data is observed (note in an unbalanced panel this will change over i’s) and 𝜎𝜎𝑎𝑎2 is the variance
of the fixed effects. After quasi-demeaning the data (where demeaning is the same as for the
fixed effects estimator) the equation becomes 5
𝑦𝑦𝑖𝑖𝑖𝑖 − 𝜃𝜃𝑦𝑦�𝚤𝚤 = 𝛽𝛽0 (1 − 𝜃𝜃) + 𝛽𝛽1 (𝑥𝑥𝑖𝑖𝑖𝑖1 − 𝜃𝜃𝑥𝑥
����)
����
�𝚤𝚤 )
𝚤𝚤1 + ⋯ + 𝛽𝛽𝑘𝑘 (𝑥𝑥𝑖𝑖𝑖𝑖𝑖𝑖 − 𝜃𝜃𝑥𝑥
𝚤𝚤𝚤𝚤 + (𝑣𝑣𝑖𝑖𝑖𝑖 − 𝜃𝜃𝑣𝑣
It can, therefore, be seen that the random effects estimator subtracts a fraction (𝜃𝜃) of the time
average from the data. Further, the errors are serially uncorrelated. Also, see that is 𝜃𝜃 = 0 the
random effects estimator becomes the pooled OLS estimator. Also if 𝜃𝜃 = 1 then the random
effects estimator becomes the fixed effects estimator. There is further a tendency for 𝜃𝜃 to
approach one as the amount of time periods increase, meaning that RE and FE will give very
similar results. Note that 𝜃𝜃 is never known, but can be estimated and therefore we use FGLS.
Assumptions of the random effects estimator
1. Random sample
5
Note that the original equation here is the same as the fixed effects model, but with a composite error term.
58
2. No perfect multicollinearity. Due to time constant independent variables being allowed,
additional assumptions are required on how the unobserved fixed effect is related to the
independent variables.
3. 𝐸𝐸(𝑢𝑢𝑖𝑖𝑖𝑖 |𝑋𝑋𝑖𝑖 , 𝑎𝑎𝑖𝑖 ) = 𝐸𝐸(𝑢𝑢𝑖𝑖𝑖𝑖 ) = 0 (strict exogeneity assumption) and 𝐸𝐸(𝑎𝑎𝑖𝑖 |𝑋𝑋𝑖𝑖 ) = 𝛽𝛽0 which
means that there is no correlation between the unobserved effect and the explanatory
variables.
Under 1-4, RE is consistent, but bias due to using FGLS.
4. 𝑉𝑉𝑉𝑉𝑉𝑉(𝑢𝑢𝑖𝑖𝑖𝑖 |𝑋𝑋𝑖𝑖 , 𝑎𝑎𝑖𝑖 ) = 𝜎𝜎𝑢𝑢2 and 𝑣𝑣𝑣𝑣𝑣𝑣(𝑎𝑎𝑖𝑖 |𝑋𝑋𝑖𝑖 ) = 𝜎𝜎𝑎𝑎2 (Homoscedasticity)
5. 𝐶𝐶𝐶𝐶𝐶𝐶(𝑢𝑢𝑖𝑖𝑖𝑖 , 𝑢𝑢𝑖𝑖𝑖𝑖 |𝑋𝑋𝑖𝑖 , 𝑎𝑎𝑖𝑖 ) = 0 (Serial correlation)
Under 1-5, RE is consistent and test statistics are asymptotically valid (Large N, small T).
Asymptotically RE is also more efficient than pooled OLS and more efficient than FE for timevarying variables’ estimates. FE is more robust (no bias) and therefore BLUE, but RE is more
efficient (but not BLUE since it is biased).
If 4 and 5 do not hold, use clustered standard errors (discussed under FD assumptions).
FE/FD or RE or pooled OLS?
In practice, it is a good idea to estimate all three estimators (the choice between FE and FD is
discussed above) to gain an understanding the of the bias that results from leaving the fixed
effect in the error term. Note that pooled OLS leaves the entire fixed effect in the error, random
effects partially leaves the fixed effect in the error and FE/FD completely removed the fixed
effects from the error.
A benefit of random effects over fixed effects is that it is serially uncorrelated (although this is
easily corrected for under FE/FD and pooled OLS) and time-constant independent variables
can be included in the model. Therefore, if the variable of interest is time-constant (e.g. gender)
then FE/FD cannot be used and another estimator should be used.
Generally, it cannot be easily assumed that 𝑐𝑐𝑐𝑐𝑐𝑐�𝑥𝑥𝑖𝑖𝑖𝑖𝑖𝑖 , 𝑎𝑎𝑖𝑖 � = 0, which means that FE/FD should
be used (otherwise we have bias estimates). The Hausman test can be used to test this
assumption, but note that failure to reject does not mean that we should use RE, it means that
we can use either test. If the Hausman test rejects the nul, it means that we should be careful to
assume that 𝑐𝑐𝑐𝑐𝑐𝑐�𝑥𝑥𝑖𝑖𝑖𝑖𝑖𝑖 , 𝑎𝑎𝑖𝑖 � = 0 and that FE/FD may be preferred. Note, however, that the
Hausman test is not a model selection test and should not be used as such.
59
Further, if we have reason to believe that we do not have a random sample from the population,
FE/FD should be used as this is the same as allowing for a unique intercept for each unit. FE/FD
is also more robust in unbalanced panels where the reason for selection may be correlated with
the error term.
The correlated random effects model (CRE)
CRE use a pooled OLS estimator after including the correlation between 𝑎𝑎𝑖𝑖 and 𝑥𝑥𝑖𝑖𝑖𝑖 in the model
and provide the same estimates as FE/FD. The term random effects is included in the name
since 𝑎𝑎𝑖𝑖 is not completely eliminated by estimation. This approach does not require that
𝑐𝑐𝑐𝑐𝑐𝑐�𝑥𝑥𝑖𝑖𝑖𝑖𝑖𝑖 , 𝑎𝑎𝑖𝑖 � = 0. The benefit of this model over the FE estimator is that time-constant
independent variables can be included.
If we assume a linear relationship
𝑎𝑎𝑖𝑖 = 𝛼𝛼 + 𝛾𝛾𝑥𝑥�𝚤𝚤 + 𝑟𝑟𝑖𝑖
Then 𝛾𝛾 indicates the correlation between 𝑎𝑎𝑖𝑖 and 𝑥𝑥𝑖𝑖𝑖𝑖 . Substituting 𝑎𝑎𝑖𝑖 as assumed above into the
fixed effects model gives
𝑦𝑦𝑖𝑖𝑖𝑖 = 𝛼𝛼 + 𝛽𝛽𝑥𝑥𝑖𝑖𝑖𝑖 + 𝛾𝛾𝑥𝑥�𝚤𝚤 + 𝑟𝑟𝑖𝑖 + 𝑢𝑢𝑖𝑖𝑖𝑖
Where 𝑟𝑟𝑖𝑖 + 𝑢𝑢𝑖𝑖𝑖𝑖 is a composite error and 𝑟𝑟𝑖𝑖 is a time constant unobservable. Note the only
difference is the inclusion of the time average variable 𝑥𝑥�𝚤𝚤 . Including this variable (which can
easily be calculated for each independent variable) is the same as demeaning the data and
therefore the estimate of 𝛽𝛽 is exactly the same under CRE and FE. However, because we are
not demeaning, we can include time-constant variables in the model. Further, 𝛾𝛾 can be seen as
a further test between FE and RE, if 𝛾𝛾 = 0 then there is no correlation between 𝑎𝑎𝑖𝑖 and 𝑥𝑥𝑖𝑖𝑖𝑖 ,
meaning the FE or RE estimator can be used. If 𝛾𝛾 is statistically significant then the assumption
for RE does not hold (economic significance should also be considered) and we may prefer FE.
When using the CRE model, it is important not to include time averages of variables that
change only over time and not over units (for instance dummies for years), but if the panel is
unbalanced, these should be included. Further, in unbalanced panels, the time averages should
be calculated based on the number of periods that data is available per unit which will be
different for different units in the panel. The assumptions for CRE follows the FE estimator.
IV estimator
For panel data, the mechanics of the 2SLS estimator remains the same as for cross-sectional
data. The unobserved constant effect is first removed by FE/FD and then the 2SLS estimator
60
is used. Because the constant effect is removed, it is most likely that the instrumental variables
will have to be time-variant, otherwise, they are unlikely to be correlated with the FE/FD
endogenous variable. SEMs also do not pose any particular challenge.
To ensure that all assumptions are met, refer to the assumptions for 2SLS for cross-sectional
data, read together with the homoscedasticity and serial correlation 2SLS assumption for time
series data and then the relevant effect estimator assumptions.
There are multiple estimators that can be used. Refer to the Stata manual for xtivreg.
Dynamic panel data models
For dynamic economic relationships, it is useful to include a lagged dependent variable as an
independent variable. This removes the persistence and serial correlation in the error term. One
problem with doing this is that the lagged dependent variable will be endogenous. To address
this problem a number of estimators are used including the Arellano and Bond estimator, the
Arellano and Bover estimator and the Blundell and Bond estimator. Stata can perform all these
estimations.
Spatial panels
When observing firms, countries and other similar samples, cross-sectional correlation (also
called spatial correlation) can cause problems. The correlation mainly arise as a result of spatial
dependency and spatial structure. This results in inefficient standard errors. For a correction,
see the stata paper on xtscc.
61
View publication stats