Uploaded by
Orley Gabutero Fadriquel
Engineering Data Analysis: Descriptive Statistics
advertisement

Engineering Data Analysis
Statistics
The discipline that concerns the collection, organization, displaying, analysis, interpretation and presentation
of data. (Wikipedia, 2019)
Descriptive Statistics
When describing something, it depends partly on the nature of the object and partly on the reason for giving
description. When describing statistical technique, it also depends partly on the nature of the data and partly on the
purpose.
Descriptive statistics is concerned with developing and utilizing techniques for the careful collection and
effective presentation numerical information.
Samples and Populations
The choice of statistical description depend on the nature of themselves. Sometimes a set of data consists of
all the conceivably or hypothetically possible observations of a certain phenomenon and sometimes it contains only
part, that is, a sample of these observations.
Four Basic Kinds of Descriptions and Statistical Data
1) Measures of Location and Dispersion and their Appropriate Uses
2) Measures of Variation
3) Measures of Symmetry and Skewness
4) Measures of Peakedness
Measures of Location and Dispersion and their Appropriate Uses
1) Measures of Location
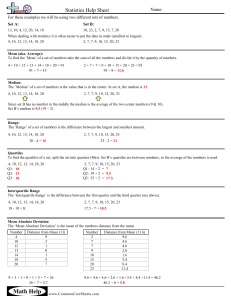
Measures of location describe the central tendency of the data. They include the mean, median and mode.
a) Mean or Average
The (arithmetic) mean, or average, of n observations (pronounced “x bar”) is simply the sum of the
observations divided by the number of observations; thus:
∑ 𝒙𝒊
𝑺𝒖𝒎 𝒐𝒇 𝒂𝒍𝒍 𝑺𝒂𝒎𝒑𝒍𝒆 𝑽𝒂𝒍𝒖𝒆𝒔
̅=
𝒙
=
𝑺𝒂𝒎𝒑𝒍𝒆 𝒔𝒊𝒛𝒆
𝒏
In this equation, xi represents the individual sample values and Σxi their sum. The Greek letter 'Σ'
(sigma) is the Greek capital 'S' and stands for 'sum'. Their calculation is described in example 1, below.
It is easy to calculate: add up all the numbers, then divide by how many numbers there are. In other
words it is the sum divided by the count.
Example 1: What is the Mean of these numbers?
6, 11, 7
Add the numbers: 6 + 11 + 7 = 24
Divide by how many numbers (there are 3 numbers): 24 / 3 = 8
Example 2:
3, 7, 5, 13, 20, 23, 39, 23, 40, 23, 14, 12, 56, 23, 29
The sum of these numbers is 330. There are fifteen numbers. The mean is equal to 330/15 = 22. The mean
of the above numbers is 22
Negative Numbers
How do you handle negative numbers? Adding a negative number is the same as subtracting the number
(without the negative).
For example 3 + (−2) = 3−2 = 1.
Example 3: Find the mean of these numbers:
3, −7, 5, 13, −2
The sum of these numbers is 3 − 7 + 5 + 13 − 2 = 12
There are 5 numbers. The mean is equal to 12 ÷ 5 = 2.4. The mean of the above numbers is 2.4
b) Median
The median is defined as the middle point of the ordered data. It is estimated by first ordering the
data from smallest to largest, and then counting upwards for half the observations. The estimate of the median
is either the observation at the centre of the ordering in the case of an odd number of observations, or the
simple average of the middle two observations if the total number of observations is even. More specifically, if
there are an odd number of observations, it is the [(n+1)/2]th observation, and if there are an even number of
observations, it is the average of the [n/2]th and the [(n/2)+1]th observations.
How to find the Median Value
To find the Median, place the numbers in value order and find the middle.
Example: find the Median of 12, 3 and 5
Put them in order:
3, 5, 12
The middle is 5, so the median is 5.
Example:
3, 13, 7, 5, 21, 23, 39, 23, 40, 23, 14, 12, 56, 23, 29
When we put those numbers in order we have:
3, 5, 7, 12, 13, 14, 21, 23, 23, 23, 23, 29, 39, 40, 56
There are fifteen numbers. Our middle is the eighth number:
3, 5, 7, 12, 13, 14, 21, 23, 23, 23, 23, 29, 39, 40, 56
The median value of this set of numbers is 23.
(It doesn't matter that some numbers are the same in the list.)
Two Numbers in the Middle
BUT, with an even amount of numbers things are slightly different.
In that case we find the middle pair of numbers, and then find the value that is half way between them. This is
easily done by adding them together and dividing by two.
Example:
3, 13, 7, 5, 21, 23, 23, 40, 23, 14, 12, 56, 23, 29
When we put those numbers in order we have:
3, 5, 7, 12, 13, 14, 21, 23, 23, 23, 23, 29, 40, 56
There are now fourteen numbers and so we don't have just one middle number, we have a pair of middle
numbers:
3, 5, 7, 12, 13, 14, 21, 23, 23, 23, 23, 29, 40, 56
In this example the middle numbers are 21 and 23.
To find the value halfway between them, add them together and divide by 2:
21 + 23 = 44
then 44 ÷ 2 = 22
So the Median in this example is 22.
(Note that 22 was not in the list of numbers ... but that is OK because half the numbers in the list are less, and
half the numbers are greater.)
Advantages and disadvantages of the mean and median
The major advantage of the mean is that it uses all the data values, and is, in a statistical sense, efficient.
The main disadvantage of the mean is that it is vulnerable to outliers. Outliers are single observations which,
if excluded from the calculations, have noticeable influence on the results. For example, if we had entered '21'
instead of '2.1' in the calculation of the mean in Example 1, we would find the mean changed from 1.50kg to
7.98kg. It does not necessarily follow, however, that outliers should be excluded from the final data summary,
or that they always result from an erroneous measurement.
The median has the advantage that it is not affected by outliers, so for example the median in the example
would be unaffected by replacing '2.1' with '21'. However, it is not statistically efficient, as it does not make use
of all the individual data values.
c) Mode
This is the value that occurs most frequently, or, if the data are grouped, the grouping with the highest
frequency. It is not used much in statistical analysis, since its value depends on the accuracy with which the
data are measured; although it may be useful for categorical data to describe the most frequent category.
Finding the Mode
To find the mode, or modal value, it is best to put the numbers in order. Then count how many of
each number. A number that appears most often is the mode.
Example 1:
3, 7, 5, 13, 20, 23, 39, 23, 40, 23, 14, 12, 56, 23, 29
In order these numbers are:
3, 5, 7, 12, 13, 14, 20, 23, 23, 23, 23, 29, 39, 40, 56
This makes it easy to see which numbers appear most often. In this case the mode is 23.
Example 2: {19, 8, 29, 35, 19, 28, 15}
Arrange them in order: {8, 15, 19, 19, 28, 29, 35}
19 appears twice, all the rest appear only once, so 19 is the mode.
More Than One Mode
We can have more than one mode.
Example: {1, 3, 3, 3, 4, 4, 6, 6, 6, 9}
3 appears three times, as does 6. So there are two modes: at 3 and 6
Having two modes is called "bimodal". Having more than two modes is called "multimodal".
Grouping
In some cases (such as when all values appear the same number of times) the mode is not useful.
But we can group the values to see if one group has more than the others.
Example: {4, 7, 11, 16, 20, 22, 25, 26, 33}
Each value occurs once, so let us try to group them. We can try groups of 10:
0-9: 2 values (4 and 7)
10-19: 2 values (11 and 16)
20-29: 4 values (20, 22, 25 and 26)
30-39: 1 value (33)
In groups of 10, the "20s" appear most often, so we could choose 25 (the middle of the 20s group) as the
mode.
You could use different groupings and get a different answer. Grouping also helps to find what the typical
values are when the real world messes things up!
Example: How long to fill a pallet? Philip recorded how long it takes to fill a pallet in minutes:
{35, 36, 32, 42, 58, 56, 35, 39, 46, 47, 34, 37}
It takes longer when there is break time or lunch so an average is not very useful.
But grouping by 5s gives:
30-34: 2
35-39: 5
40-44: 1
45-49: 2
50-54: 0
54-59: 2
"35-39" appear most often, so we can say it normally takes about 37 minutes to fill a pallet.
2) Measures of Dispersion or Variability
Measures of dispersion describe the spread of the data. They include the range, interquartile range, standard deviation
and variance.
Measures of Variation
Measures of variation are used to describe the distribution of the data.
The range is the difference between the greatest and least data values.
Quartiles are values that divide the data set into four equal parts.
a) Range and Interquartile Range
The range is given as the smallest and largest observations. This is the simplest measure of
variability. Note in statistics (unlike physics) a range is given by two numbers, not the difference between the
smallest and largest. For some data it is very useful, because one would want to know these numbers, for
example knowing in a sample the ages of youngest and oldest participant. If outliers are present it may give a
distorted impression of the variability of the data, since only two observations are included in the estimate.
b) Quartiles and Interquartile Range
The quartiles, namely the lower quartile, the median and the upper quartile, divide the data into four
equal parts; that is there will be approximately equal numbers of observations in the four sections (and exactly
equal if the sample size is divisible by four and the measures are all distinct). Note that there are in fact only
three quartiles and these are points not proportions. It is a common misuse of language to refer to being ‘in
the top quartile’. Instead one should refer to being ‘in the top quarter or ‘above the top quartile’. However, the
meaning of the first statement is clear and so the distinction is really only useful to display a superior knowledge
of statistics! The quartiles are calculated in a similar way to the median; first arrange the data in size order and
determine the median, using the method described above. Now split the data in two (the lower half and upper
half, based on the median). The first quartile is the middle observation of the lower half, and the third quartile
is the middle observation of the upper half. This process is demonstrated in example below.
The interquartile range is a useful measure of variability and is given by the lower and upper quartiles.
The interquartile range is not vulnerable to outliers and, whatever the distribution of the data, we know that
50% of observations lie within the interquartile range.
Example:
Jamie asked her classmates how many glasses of water they drink on a typical day.
1. What is the median of the data set?
2. Organize the data into two groups: the top half and the bottom half. How many data values are in each group?
3. What is the median of each group?
One fourth of the data lie below the lower quartile and one fourth of the data lie above the upper quartile. So,
one half of the data lie between the lower quartile and upper quartile. This is called the Interquartile Range.
Upper and Lower Quartiles
The upper and lower quartiles are the medians of the upper half and lower half of a set of data, respectively.
The range of the middle half of the data. It is the difference between the upper quartile and the lower quartile;
in this case, 29 - 18, or 11. The interquartile range is 29 - 18, or 11.
c) Range
The difference between the greatest and least data values; in this case, 31 - 14, or 17.
Practice: Find the measures of variations
a) Speed
b) Sports
Outliers
An outlier is a data value that is either much greater or much less than the median. If a data value is more than 1.5
times the value of the interquartile range beyond the quartiles, it is an outlier.
Exercises: Find the outliers
Problem 1: During elections, the ages of candidates in an election are 23, 48, 49, 55, 57, 63, and 72. Name any outliers
in the data.
a) Find the interquartile range.
63 - 48 = 15
b) Multiply the interquartile range by 1.5.
15 × 1.5 = 22.5
c) Subtract 22.5 from the lower quartile and add 22.5 to the upper quartile.
48 - 22.5 = 25.5 63 + 22.5 = 85.5
Then, the limits for the outliers are between 25.5 and 85.5. The only age beyond this is 23. So, it is the only outlier.
Problem 2. Several bridges are measured and the lengths, in feet, of various bridges are 88, 251, 275, 354, and 1,121.
Name any outliers in the data set.
Problem 3. The table shows a set of scores on a science test in two different classrooms. Compare and contrast their
measures of variation.
Problem 4. The temperatures for the first half of the year are given in Antelope, Montana, and Augusta, Maine. Compare
and contrast the measures of variation of the two cities.
Problem 5. The average wind speeds for several cities in Pennsylvania are given in the table. a) Find the range of the
data b) Find the median and the lower and upper quartiles, c) Find the interquartile range, d) Identify the outliers in the
data.
Problem 6. The height of several types of palm trees, in feet, are 40, 25, 15, 22, 50, and 30. The heights of several
types of pine trees, in feet, are 60, 75, 45, 80, 75, and 70. Compare and contrast the measures of variation of both
kinds of trees.
Sampling
Statistical methods are based on the idea of analyzing a sample drawn from a population. For this idea to work, the
sample must be chosen in an appropriate way.
Sample and Population
A population is the entire collection of objects or outcomes about which information is sought.
A sample is a subset of a population, containing the objects or outcomes that are actually observed.
How to determine Sample size from the Population.
Sample refers to the observations drawn from a population. Having the right sample size is crucial in finding a
statistically significant result. The larger the sample size, the more reliable the results; however, larger sample size
means more time and money.
Before you can calculate a sample size, you need to determine a few things about the target population and
the sample you need:
Population size
How many total people fit your demographic? For instance you want to know about mothers living in
Odiongan, your population size would be the number of mothers living in Odiongan. Not all population
sizes needs to be this large. Even of the population is small, just know who fits into the demographics.
Don’t worry if you are unsure about this exact number. It is common for the population to be unknown or
approximated between two educated guesses.
Margin of Error (Confidence Interval)
No sample will be perfect, so you must decide how much error to allow. This confidence interval
determines how much higher or lower than the population mean you are willing to let your sample mean
fall. If you’ve ever seen a political poll on the news, you’ve seen a confidence interval. The margin of error
is the level of precision you require. This is the range in which the true proportion is estimated to be and
should be expressed in percentage points. The margin of error is the level of precision you require. This
is the range in which the true proportion is estimated to be and should be expressed in percentage points
(e.g., ±5%). A lower margin of error requires a larger sample size.
For example, it will look something like this: “68% of voters said YES to proposition Z, with a margin
of error of ± 5%.”
Confidence level
How much confident do you want to be the actual mean falls within your confidence interval. The most
common confident intervals are 90% confident, 95% confident and 99% confident.
Your confidence level corresponds to a Z-score. This is a constant value needed for this equation.
Here are the z-scores for the most common confidence levels: A higher confidence level requires a
larger sample size.
90%
95%
99%
- Z - score
- Z - score
- Z - score
= 1.645
= 1.96
= 2.576
Note: If you choose different confidence level, use the Z – score table.
Standard Deviation – how much variance do you expect in your responses? Since we haven’t actually
administered our survey yet, the safe is to use 0.5 – this is the most forgiving number and ensures that
your sample will be large enough.
Calculating Sample Size
Online sample calculator
By hand
Sample Size Formula: The equation is for unknown population size or a very large population size.
𝑆𝑎𝑚𝑝𝑙𝑒 𝑆𝑖𝑧𝑒 (𝑋) =
(𝑍 − 𝑠𝑐𝑜𝑟𝑒𝑟)2 𝑥[(𝑆𝑡𝐷) − (1 − 𝑆𝑡𝐷)]
(𝑀𝑎𝑟𝑔𝑖𝑛 𝐸𝑟𝑟𝑜𝑟)2
True Sample Size: The population is known
𝑇𝑟𝑢𝑒 𝑆𝑎𝑚𝑝𝑙𝑒 𝑆𝑖𝑧𝑒 (𝑛) =
(𝑁)𝑥 (𝑋)
(𝑋 + 𝑁 − 1)
Example:
Assuming you chose a 95% confidence level, 0.5 standard deviation, and a margin of error (confidence
interval) of ± 5%, later you decided to choose a population of 1000.
Solution:
𝑆𝑎𝑚𝑝𝑙𝑒 𝑆𝑖𝑧𝑒 (𝑛) =
(1.96)2 𝑥[(0.5) − (1 − 0.5)]
= 384.16 = 385 𝑟𝑒𝑠𝑝𝑜𝑛𝑑𝑒𝑛𝑡𝑠 𝑎𝑟𝑒 𝑛𝑒𝑒𝑑𝑒𝑑
(0.05)2
𝑇𝑟𝑢𝑒 𝑆𝑎𝑚𝑝𝑙𝑒 𝑆𝑖𝑧𝑒 (𝑛) =
(1000)𝑥 (385)
= 278 𝑟𝑒𝑠𝑝𝑜𝑛𝑑𝑒𝑛𝑡𝑠
(385 + 10000 − 1)
If you find your sample size is too large to handle, try slightly decreasing your confidence level or increasing
your margin of error – this will increase the chance for error sampling, but it can greatly decrease the number of
responses your need.
Standard Deviation and Variance
The standard deviation is a measure of how spread or close the data or out numbers are. Here are two lists
of numbers: 28, 29, 30, 31, 32 and 10, 20, 30, 40, 50. Both lists have the same mean of 30. But clearly the lists differ
in an important way that is not captured by the mean: the second list is much more spread out than the first. The
standard deviation is a quantity that measures the degree of spread in a sample. Let X1, . . . , Xn be a sample. The basic
idea behind the standard deviation is that when the spread is large, the sample values will tend to be far from their
mean, but when the spread is small, the values will tend to be close to their mean. So the first step in calculating the
standard deviation is to compute the differences (also called deviations) between each sample value and the sample
mean.
The standard deviation of a sample (s) is calculated as follows:
Population Standard Deviation
𝜎= √
2
∑𝑁
𝑖=1(𝑥𝑖 − 𝜇)
𝑁
Sample Standard Deviation
∑𝑛 (𝑥𝑖 − 𝑥̅ )2
𝑠 = √ 𝑖=1
𝑛−1
𝑛 Σ𝑥 2 − (Σx)2
𝑠= √
𝑛(𝑛 − 1)
Example 1:
A simple random sample of five men is chosen from a large population of men, and their heights are measured.
The five heights (in inches) are 65.51, 72.30, 68.31, 67.05, and 70.68. Find the sample mean, the variance and the
standard deviation.
Solution:
The mean:
65.51 + 72.30 + 68.31 + 67.05 + 70.68
= 68.77
5
The variance and the standard variations in tabular form
𝑥̅ =
Height
65.51
72.30
68.31
67.05
70.68
Mean (𝑥̅ )
68.77
68.77
68.77
68.77
68.77
Variance
-3.26
3.53
-0.46
-1.65
1.91
∑ x = 0.07
(x – 𝑥̅ )2
10.6276
12.4609
0.2116
2.7225
3.6481
∑(x – 𝑥̅ )2 = 29.6707
∑𝑛 (𝑥𝑖 − 𝑥̅ )2
𝑠 = √ 𝑖=1
𝑛−1
29.6707
𝑠=√
= 2.73
5−1
Or you may use direct substitution:
s2 = [(65.51 − 68.77)2 + (72.30 − 68.77)2 + (68.31 − 68.77)2 + (67.05 − 68.77)2 + (70.68 − 68.77)2] = 7.47665
s = 2.73
Example 2:
A group of 15 graduating ME students were given and intensive review for the comprehensive exam. Data
obtained are illustrated. Determine the standard deviation of the and whether the review has an effect on the
performance of the students.
Student
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Pre-test
22
22
23
30
33
35
28
27
23
25
20
15
21
19
18
Post Test
26
27
25
24
32
36
29
27
27
23
23
19
24
20
22
Solution:
𝑛 Σ𝑥 2 − (Σx)2
𝑠= √
𝑛(𝑛 − 1)
(15) (155) − (−23)2
𝑠= √
= 2.92
15(15 − 1)
d
-4
-5
-2
6
1
-1
-1
0
-4
2
-3
-4
-3
-1
-4
∑d = -23
d2
16
25
4
36
1
1
1
0
16
4
9
16
9
1
16
∑d2 = 155