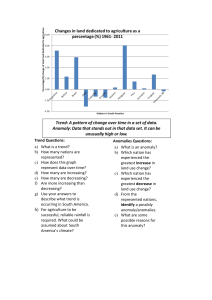
COMP8745-Machine Learning Project Report Learning Anomalous Patterns from Imbalanced Data Group member: Fang Wu U00788000 12/5/2022 1 1 Introduction Anomalies, also known as outliers, novelties, exceptions, etc., are defined as objects that are significantly different from normal and standard instances. Anomalous objects naturally exist in a variety of real-world application scenarios, including (1) deceitful online reviews that can affect the users’ shopping experiences [3], (2) malicious software (i.e., malware) that may cause the privacy leakage issue [2], and (3) fraudulent financial transactions that can make extreme damage to the economic systems [4]. Anomaly detection aims to identify exceptional patterns that remarkably deviate from the majority of normal samples from a given dataset. Extensive research efforts have been devoted to solving this essential task, however, it is nontrivial to train an effective anomaly detection model, due to the following three challenges. First, given an application scenario (e.g., financial transactions), there exist very limited observations of anomalous objects compared to the normal data, which is referred to as the imbalanced data challenge. Second, high-quality labels are difficult to acquire due to the lack of domain-specific knowledge, therefore most of the existing anomaly detection methods are developed in an unsupervised manner. Third, anomalous objects usually possess very different behaviors and hence cannot be simply grouped as one single class. Therefore, we are motivated to investigate the anomaly detection problem where the goal is to learn the fundamental patterns of anomalies from a very imbalanced dataset. Specifically, we consider that it is possible to obtain very few annotated anomalous objects and we then leverage these limited supervised signals to train an anomaly detection model. The key idea is that we formulate the anomaly detection task as a ranking problem where we aim to assign large scores to ground-truth anomalies (i.e., representing high abnormality) and plain scores to normal instances [7]. Ideally, anomalies should have higher ranking scores than normal data. Specifically, in this project, we aim to understand the performance of various machine learning approaches including supervised methods and unsupervised ones in the task of anomaly detection on extremely imbalanced datasets. To summarize, we include the following sections in this report, (1) data preprocessing and visualization, (2) methods description, and (3) experimental results. 2 Data Preprocessing and Visualization Datasets. In this report, we consider the following three publicly available datasets for anomaly detection, detailed as follows, • Credit card is a credit card transaction dataset where anomalies are defined as fraudulent transactions1 . The data set is highly skewed, consisting of 492 frauds in a total of 284,807 examples, which results in only 0.172% fraud cases. This skewed set is justified by the low number of fraudulent transactions. • Backdoor is a dataset for backdoor attack detection which is extracted from UNSW-NB 15 dataset [6] and is a hybrid of the real modern normal and the contemporary synthesized attack activities of the network traffic. The anomalies 1 https://www.kaggle.com/code/naveengowda16/anomaly-detection-credit-card-fraudanalysis/data 2 are defined as the attacks against normal class2 . This dataset contains 2,329 positive examples (i.e., abnormal activities) and the fraudulent ratio is 2.44%. • Donors is from KDD Cup 2014 for predicting excitement of projects proposed by K-12 school teachers, in which exceptionally exciting projects are used as anomalies3 . The total number of anomalies is 36,710, which occupies 5.92% instances. Preprocessing. For both datasets, we perform the column-wise normalization on each column with numerical features to ensure that the values are in the range [0, 1]. For the credict card dataset, we drop the column representing the time when the example was recorded. Visualization. We first utilize principal component analysis (PCA) [1] to transform the original feature representations to a 2D space representing two latent features, then we visualize the transformed representations and the associated labels. The visualization for two datasets is presented in Figure 1 where orange color represents positive samples (i.e., anomalies) and blue color represents negative instances (i.e., normal samples). From Figure 1, we can observe that (1) the number of anomalies is extremely smaller compared to that of normal examples, which verifies the property of imbalanced data, and (2) the anomalous samples generally have larger distances from the normal objects in this 2D space. (a) Credit card dataset (b) Backdoor dataset (c) Donors dataset Figure 1: Data visualization. 3 Methods In this section, we introduce the approaches used in the experiments. In general, we utilize two types of machine learning algorithms on the aforementioned datasets, including (1) supervised: logistic regression, support vector machine with RBF kernel, feed-forward neural networks, and (2) unsupervised: Local Outlier Factor, KMeans and Isolation Forest [5]. For the feed-forward neural networks, we implement a neural architecture with two hidden layers and the corresponding layer dimensions are 32 and 16, respectively. We use ReLU as the hidden layer activation function and the 2 3 https://research.unsw.edu.au/projects/unsw-nb15-dataset https://www.kaggle.com/c/kdd-cup-2014-predicting-excitement-at-donors-choose 3 output layer is 1-dimensional with sigmoid activation, which computes the probability that an example is an anomaly. The learning rate is set as 0.001 and the number of training epochs is 20. Local outlier factor is an unsupervised outlier detection algorithm and it measures the local difference of the density of a given input sample w.r.t. its neighbors. The abnormality is dependent on how isolated the object is w.r.t. the surrounding neighborhood. By comparing the local density of a sample to the local densities of its neighbors, outliers are considered to have a substantially lower density than their neighbors. The Isolation Forest algorithm isolates observations by randomly selecting a feature and splitting the feature according to a selected value. Since recursive partitioning can be represented by a tree structure, the number of splittings required to isolate a sample is equivalent to the path length from the root node to the terminating node, which is a measure of normality and our decision function. If a forest of random trees collectively produces shorter paths for particular samples, they are highly likely to be anomalies. Additionally, we also use Principal Component Analysis (PCA) to obtain dimensionreduced feature representations and then apply the above approaches to the low-dimensional data. We report all the experimental results in Sec. 4. 4 Empirical Evaluations Evaluation metric. Since the datasets are highly imbalanced, it is not appropriate to use prediction accuracy as the metric. For example, if one dataset consists of 95% positive samples, simply predicting all testing instances as positive can achieve approximately 95% accuracy. Hence, in our experiments, we leverage the more comprehensive F1 score as the evaluation metric, which is defined as the harmonic mean 2 of the precision and recall, F1 = recall−1 +precision −1 . In binary classification, precision, is defined as the fraction of correct positive predictions among all positive predictions, P i.e., precision = T PT+F , where TP denotes true positive and FP (false positive) repreP sents negative instances that are predicted as positive (i.e., type I error). Recall, also known as sensitivity, is defined as the ratio of correct positive predictions to all positive P , where FN (false negative) represents the number of posinstances, i.e., recall = T PT+F N itive instances that are predicted as negative (i.e., type II error). From the definition of the F1 score, we can see that it is a comprehensive metric for the classification task, especially since the dataset is extremely imbalanced. The implementation is included in our report submission. Experiment results. For supervised methods, we use 60% data for training and 40% for testing. For unsupervised methods, we use all data as the input. All methods are evaluated on the 40% testing set and we run 5 times for each method and report the average performance. We first present the performance of the aforementioned methods on the original features of three datasets w.r.t. F1 score. The results are summarized in Table 1, we mark the best-performing methods with bold and underline the methods with the second performance. From Table 1, we have the following observation. First, compared to unsupervised approaches (i.e., LOF, KMeans and IsoForest), supervised approaches (logistic regression, SVM and deep neural networks) can achieve better results w.r.t. F1 score. One potential explanation is the supervised knowledge from labeled data can guide the model to learn the patterns of different types of objects 4 and consequently improve the detection performance to a large extent. Second, the deep neural network (DNN) achieves the best performance for all three datasets, which demonstrates the effectiveness of neural-based methods in capturing the key characteristics of normal and abnormal patterns. Dataset LogisticReg SVM DNN LOF KMeans IsoForest Credit card Backdoor Donors 0.841 ± 0.003 0.961 ± 0.003 0.999 ± 0.005 0.881 ± 0.007 0.966 ± 0.002 1.0 ± 0.001 0.902 ± 0.011 0.971 ± 0.009 1.0 ± 0.001 0.486 ± 0.024 0.623 ± 0.005 0.522 ± 0.009 0.825 ± 0.046 0.512 ± 0.039 0.901 ± 0.053 0.525 ± 0.008 0.490 ± 0.013 0.514 ± 0.007 Table 1: Performance of anomaly detection methods on original features (F1 score). We then apply PCA to the original feature representations and obtain dimensionreduced embeddings, which will be used as the new input of the above approaches. Table 2 presents the F1 scores of various methods on transformed representations. From Table 2, we can observe a mixed pattern of performance change after we use the transformed datasets from PCA. For example, the performance of unsupervised methods, i.e., LOF, KMeans and IsoForest generally achieve better F1 scores compared to using original features. On the other hand, for supervised methods, PCA does not achieve additional performance improvement for DNN, but can slightly affect the performance of these comparison methods. Dataset LogisticReg SVM DNN LOF KMeans IsoForest Credit card Backdoor Donors 0.836 ± 0.001 0.933 ± 0.001 0.999 ± 0.005 0.885 ± 0.003 0.958 ± 0.002 1.0 ± 0.001 0.890 ± 0.009 0.960 ± 0.009 1.0 ± 0.001 0.490 ± 0.021 0.517 ± 0.021 0.525 ± 0.010 0.736 ± 0.048 0.498 ± 0.044 0.932 ± 0.058 0.526 ± 0.006 0.509 ± 0.006 0.529 ± 0.011 Table 2: Performance of anomaly detection methods on transformed features from PCA (F1 score). We also compare the total running time, including training and inference, of various approaches. We present a performance vs. efficiency trade-off in Figure 2 for credit card dataset. The top left corner represents good performance in terms of F1 and high efficiency (i.e., low running time). As shown in Figure 2, we can observe that, on original features, DNN, logistic regression and KMeans can good detection performance while using less time compared to other methods. On the other hand, SVM can achieve better efficiency performance if PCA is applied on the original features because PCA can significantly reduce the feature dimension. For other methods, the running time do not change much after PCA is applied. 5 Conclusion In this report, we investigate the important problem of anomaly detection on extremely imbalanced datasets. We comprehensively survey existing studies in this topic and understand various approaches for anomaly detection in am empirical manner. To be specific, we compare 6 approaches on three widely used real-world datasets and evaluate the performance w.r.t. F1 score, which fits the imbalanced setting of anomaly detection. 5 0.9 0.7 0.6 0.5 0 50 100 150 Time (s) F1 score F1 score 0.8 LogisticReg SVM DNN LOF KMeans IsoForest 200 0.90 0.85 0.80 0.75 0.70 0.65 0.60 0.55 0.50 0 (a) F1 vs. running time on original data. 10 20 30 40 Time (s) LogisticReg SVM DNN LOF KMeans IsoForest 50 60 70 (b) F1 vs. running time after PCA. Figure 2: Performance and efficiency trade-off on credit card dataset. Through our study, we observe that the deep learning-based approach can achieve the best performance w.r.t. F1 score on all datasets and requires relatively small amount of time for training and inference. 6 References [1] Hervé Abdi and Lynne J Williams. Principal component analysis. Wiley interdisciplinary reviews: computational statistics, 2(4):433–459, 2010. [2] Ömer Aslan Aslan and Refik Samet. A comprehensive review on malware detection approaches. IEEE Access, 8:6249–6271, 2020. [3] Adrien Benamira, Benjamin Devillers, Etienne Lesot, Ayush K Ray, Manal Saadi, and Fragkiskos D Malliaros. Semi-supervised learning and graph neural networks for fake news detection. In 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), pages 568–569. IEEE, 2019. [4] Can Liu, Qiwei Zhong, Xiang Ao, Li Sun, Wangli Lin, Jinghua Feng, Qing He, and Jiayu Tang. Fraud transactions detection via behavior tree with local intention calibration. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 3035–3043, 2020. [5] Fei Tony Liu, Kai Ming Ting, and Zhi-Hua Zhou. Isolation-based anomaly detection. ACM Transactions on Knowledge Discovery from Data (TKDD), 6(1):1–39, 2012. [6] Nour Moustafa and Jill Slay. Unsw-nb15: a comprehensive data set for network intrusion detection systems (unsw-nb15 network data set). In 2015 military communications and information systems conference (MilCIS), pages 1–6. IEEE, 2015. [7] Guansong Pang, Chunhua Shen, and Anton van den Hengel. Deep anomaly detection with deviation networks. In Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, pages 353–362, 2019. 7