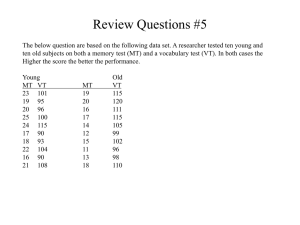
Watching cartoons was one of our favorite past-times back when we were still kids. Are you familiar with the TV cartoon shown on the given picture below? statistics for the rest of Lesson 1 up until Lesson 3. After going through this module, the students will be able to: 1. Distinguish between descriptive statistics and inferential statistics, population and sample, parameter and statistic, and constant and variable. For those who are familiar with the cartoon, we all know that it is centered on the rivalry between the two titular characters Tom and Jerry. As a kid who watched the TV show, how did you find your experience? Due to the rivalry between Tom and Jerry, we would constantly see them fighting over something that sometimes would lead to violence. Because of this, articles were written blaming the TV cartoon or recommending not to watch it due to the violence it depicts. This leads us to the question: Does watching violence on TV affect a child’s behavior? In order to answer this question, a research must be done. We will need to gather information regarding the children’s behavior and the TV programs they watched. Then out of the data we gathered, we analyze it then interpret the result- which are exactly what statistics do. Module 1 introduces us to statistics and its role in research. We have three lessons in this module. Lesson 1 begins with the definition of statistics and a brief discussion of the role of statistics in research. We then introduce the fundamental terms and concepts we use in 2. Distinguish and characterize the three different commonly used research designs in any research endeavors. 3. Classify variables as quantitative or qualitative, independent or dependent, and discrete or continuous and classify measurements as nominal, ordinal, interval or ratio. Lesson 1: Statistics and Research So what is statistics? Is this the same as those we hear from beauty pageants when the host give us the vital statistics of each contestants? The term statistics can mean different in a lot of ways. However, the term statistics that we use here refer to the shortened version of statistical procedures. What are these? Definition 1.1 Statistical procedures consist of formulas, calculations, and procedures used for organizing, summarizing, and interpreting information [1, 2]. So it is statistics that gives sense out of the data we gather from a survey or research. Research on behavioral sciences use statistics to explain the results of the research and to provide evidence whether to support or debunk a certain theory. So how does research and statistics work together? A research always starts with a general question regarding a certain group. These groups can be a group of people, animals, corporations, parts produced in a factory, or anything that a researcher wants to study. Say for example we want to conduct a study that claims “the more you study statistics, the better you’ll learn them.” So who do we subject to this study? This is what we need to figure out first. Definition 1.2 A population refers to the entire group that a researcher wishes to study [1]. The size of the population can vary. It can be extremely large or very small. When the population is extremely large, is it possible to examine all of the individuals belonging in the population? No, it would take forever. So what do we do instead? In this case, researchers typically select a smaller group from the population to subject to their study which we call a sample. Definition 1.3 A sample is a relatively smaller group taken from the population that is intended to represent the population. The individuals measured in a sample are called participants or subjects [2]. Now the population and the sample depends on your perspective. Say for example we want to study the amount of learning the students in your statistics class obtained. If we are only interested in the students in your class, then they already constitute the population. However, if we are interested in all college students studying statistics, then they constitute the population and the sample can be the students in your statistics class. Note that the sample is meant to be a representative of the population. In other words, we assume that the participants from the sample behaves the same way as the individuals we find in the population. So the results we get out of the sample of the students in your statistics class is used to conclude that we will get the same result from the population of all college students. After identifying the population and the sample to observe, the next thing we need to consider is to define the specific situation and behaviors we want to observe and measure from the population or sample. Say for example, we might be interested in the influence of the amount of time one studies to its scores in the major exam. As the amount of study time changes, do the scores in the quiz also change? In this case, we are referring to the variables. Definition 1.4 A variable is a characteristic or a condition that differs from one participant to another. A variable can be the any characteristics of an individual such as age, height, weight, gender, personality, or intelligence. It can also be environmental conditions that change such as temperature or time of day. To show the changes, we need to measure the variables being examined. The measurement we obtain from each participant is called a datum, or commonly, a score or a raw score. The complete set of scores is called the data set or simply the data [1]. Now to make a distinction whether the data come from a population or a sample, we use the term parameter to refer to the characteristic describing a population while statistic is used to refer to a characteristic describing a sample. For example, the average score from the population is a parameter while the average score from the sample is a statistic. The research process usually begins with a question regarding the population parameter. When we select a sample from the population to examine, the actual data come from the sample which we then use to compute the sample statistics. It is important to note that for every population parameter, there is always a corresponding sample statistic. Definition 1.6 Inferential statistics consist of techniques that allow us to study samples and then make generalizations about the populations from which they were selected [1]. However, in reality, it is unlikely that the sample statistics are identical to the population parameters. Say for example we have a population of 500 USJ-R college students taking up a Statistics course. We take two sections of any of the Statistics class with 40 students each as our sample. The population parameters and sample statistics obtained are provided below. Descriptive and Inferential Statistics Now, statistics has two divisions namely descriptive and inferential statistics. In descriptive statistics, we take raw scores and organize or summarize them by plotting a table or drawing a graph, or by taking the average of the scores. In this case, even if we have hundreds of scores from our data, the average only provides a single descriptive value for the entire data. Definition 1.5 Descriptive statistics are statistical procedures used to summarize, organize, and simplify data [1]. On the other hand, inferential statistics analyzes the results taken from the sample in order to make a general statement about the population. This is done by using the sample statistics to draw conclusions about population parameters since the sample is assumed to represent the population. Do you see the difference in the statistics between the two samples? Do you see the difference between the sample statistics and the population parameters? In reality, we cannot expect the sample to give the exact same results we have of the whole population because there is always some discrepancy between the sample statistics and the population parameter. This discrepancy is what we call as the sampling error. Definition 1.7 Sampling error is the naturally occurring discrepancy, or error, that exists between a sample statistic and the population parameter [1]. However this discrepancy may not necessarily mean that there is a significant difference between the two groups. The difference might be due to chance. This is what we need to examine through inferential statistics. The role of inferential statistics is to interpret the results. From the table above, we see a difference of 12.4 in the average IQ of the two samples. This leads us to formulate two interpretations. two variables. This can be done using two methods. Measuring two variables for each participant: The correlational Method This method is done by simply measuring the two variables for each participant. Let’s consider the same scenario, say we want to examine if a relationship exists between the number of hours a college student studies to the result of his/her exam. We use a survey to measure the amount of study time and the class record to measure the exam result for each participant. The table below shows an example of the data gathered in the study. Student Study time (in hours) A B C D E F G H I J 3 1 5 4 3 4 4 3 5 2 1. There is no real difference between the average IQ of the students, and the 12.4-point difference between the two samples is just an example of sampling error. 2. There really is a difference between the average IQ of the students, and the 12.4-point difference between the two samples was not due to chance. The problem for inferential statistics is to differentiate the two interpretations. Lesson 2: Research and Statistical Methods Most of the time, the goal of a research is to study the relationship between two or more variables. For example, is there a relationship between the number of hours of study time and the results of the exam of college students? To determine whether a relationship exists or not, we measure the Exam Score (in percentage) 81 68 98 95 78 91 87 69 100 75 We then look if consistent patterns exist in the data in order to provide evidence that a relationship exists between the two variables- as the amount of study time changes from one student to another, is there also a tendency for the exam result to change? Consistent patterns in the data can easily be seen if we plot the scores in a graph such as the one below. Comparing Two (or more) Groups of Scores: Experimental and non-Experimental Methods In comparing two or more groups of scores for a study, the following research design can be used. Definition 2.2 Experimental Method is a research design that can establish a cause Do you see a relationship between the study time and the exam results? A research study that simply measures two different variables for each individual is an example of the correlational method, or the correlational research strategy. Definition 2.1 In the correlational method, two different variables are observed to determine whether there is a relationship between them [1]. Although the correlational method can show the existence of a relationship between two variables, it cannot give an explanation, in particular, of a cause-andeffect relationship. From our given example, we see that a systematic relationship exists between the study time and the exam results for a group of college students; those who study more tend to have better exam results. However, there are many possible explanations for this relationship to exist. To demonstrate a cause-and-effect relationship between two variables, we use the experimental method instead. and effect relationship between two variables. The method of observing variables is intended to show that changes in one variable are caused by changes in the other variable. That is, one variable is manipulated while changes are observed in another variable. The variables that are studied in the experimental method consist of the independent and dependent variables. The independent variable is the variable manipulated by the researcher. This variable usually consists of two or more treatment conditions to which subjects are exposed. On the other hand, the dependent variable is a variable that is observed to asses a possible effect of the manipulation of the independent variable. Moreover, there other experiments that will include a condition wherein the subjects do not receive any treatment known as the controlled condition and a condition where the subject do receive the experimental treatment called the experimental condition. For example, consider the data from an experimental study examining the relationship between temperature and eating behavior. The researcher manipulated temperature to create three treatment conditions and then measured eating behavior for a sample of 5 rats in each of the three conditions. scores for a group of males versus a group of females. Definition 2.5: A time variable simply involves comparing individuals at different points in time. For instance, a researcher may measure depression before therapy and then measure it again after therapy. The situation below considers a study that uses a quasi-experimental research design. Definition 2.3 The Quasi – Experimental Method is a research design that deals with research studies that are almost, but not quite, real experiments. This research design uses a non-manipulated variable to define the conditions that are being compared. The non-manipulated variable is usually subject variable (i.e. male versus female) or time variable, such as before treatment and after treatment. The nonmanipulated variable that assumes or defines the conditions is called a quasiindependent variable. Example: An example of data from a quasi – experimental study examining the relationship between IQ and attitude toward school. The researcher used IQ to define three groups of students and then measured attitude toward school for the five students in each group. The resulting attitude toward school for the five students in each different group in terms of IQ levels are shown below. The following are definitions of subject and time variables and its usage in a sample situations of research endeavors. Definition 2.4 A subject variable is a characteristic such as age or gender that varies from one subject to another. For example, a researcher might want to compare communication skills Lesson 3: Variables and measurements The study or assessment in a psychology field generally make use of variables. The variables can be the any characteristics of an individual such as age, height, weight, gender, personality, or intelligence. It can also be environmental conditions that change such as temperature or time of a day. These variables are generally classified as qualitative or quantitative variables. A qualitative variable is a variable that yields categorical responses. For instance, gender variable has male or female categorical responses. An economic status as a variable can assume values such as low, middle, or upper class categorical responses. On the other hand, a quantitative variable is a variable that yields numerical responses representing an amount or quantity. For example, income, IQ scores, expenditures, study time, etc. are variables that assumes or yields numerical responses. Quantitative variables are further characterize as discrete or continuous variables. A discrete quantitative variable consists of separate, indivisible categories. This type of variable contains no intermediate values between two adjacent categories. For example, when we roll a die, the possible outcome that may appear as a result is either a 1, 2, 3, 4, 5, or 6. Observe that in between neighboring values, no other values can ever be observed, that is, the values always pertain to a whole number. The response values for discrete quantitative variables can also be obtained through the process counting. For instance, to get the response value for the variable, number of students in a psychological statistics 1 class, one can employ a counting process, using a natural or counting numbers. Further examples of discrete quantitative variables are income, IQ, expenditures, exam scores, age, etc. On the other hand, continuous quantitative variables are variables that have infinite number of possible values that fall between any two observed values. It is divisible into an infinite number of fractional parts. For instance, suppose a researcher is measuring heights for a group of individuals participating in a certain study. Since height is a continuous quantitative variable, it can be viewed as a continuous line. Observe that there are an infinite number of possible points on the line without any gaps between neighboring values. Furthermore, continuous quantitative variables yield responses that can be obtained through the process of measurements with corresponding units of measurements. The following are some examples of continuous variables whose responses can be obtained through the process of measurements with corresponding units. 1. 2. 3. 4. 5. Height Time Temperature Weight Volume Types of Variables according to their level of measurement In a study or assessment in a psychology field, the data collection requires that we make measurements of our observations. Measurement involves assigning individuals or events to categories. The categories can simply be names such as male/female or favorable/unfavorable, or they can be numerical values such as 36 degrees Celsius or 45 degrees Celsius. The categories used to measure a variable make up a scale of measurement, and the relationships between the categories determine different types of scales. Remark: The distinctions among the scales are important since they identify the limitations of certain types of measurements and because certain statistical treatments are appropriate for scores that have been measured on some scales but not on others. For instance, if you were interested in individual’s weight, you could measure a group of individuals by simply classifying them into two categories: light and heavy. However, this typical classification would not tell us much about the actual weights of the individuals, and hence, these measurements would not give us sufficient information to calculate an average weight for the group. Although the above simple classification would be enough for some purposes, we would need more sophisticated measurements before one could answer more detailed questions or research questions of interest. In this lesson, we examine and characterize variables according to their levels of measurement. student would be classified in a category according to his or her preference. Remark: The measurements from a nominal scale can be used to determine whether two individuals are different, however, they do not identify either the direction or the size of the difference. For instance, if one student chooses to prefer on a subject schedule and another, is not preferred for the schedule, then, we can say that they are different, but we cannot say that being preferred is “more than” or “less than” not being preferred and hence, we cannot specify how much difference there is between preferred and not preferred categories. Definition 1: A nominal scale consists of a set of categories that have different names. Measurements on a nominal scale label and categorize observations, but do not make any quantitative distinctions between observations. Remark: Although a nominal scale categories are not quantitative values, they are occasionally represented by numbers. A. Nominal Scale The word nominal means “having to do with names.” The scale of measurement on a nominal scale involves classifying individuals into categories that have different names but are not connected to each other in any way. For example, if you were measuring the preference for a group of psychology college students for a subject time schedule, the categories would be preferred or not preferred. Then each Example: Cell phone numbers can be used to identify the owners or the rooms or offices in a building may be identified by numbers. Observe that cell phone numbers or room or office numbers are simply names and do not reflect any quantitative information. The following are further examples of variables with nominal scale of measurements. 1. Marital Status 2. Gender 3. Ethnicity 4. Racial Origin 5. Civil Status 6. Card Number 7. Occupation and so on B. The ordinal scale An ordinal scale also have different names as its categories as in a nominal scale. However, the categories can be organized in a fixed order corresponding to differences of magnitude. Definition 2: An ordinal scale involves a set of categories that are organized into an ordered sequence. That is, measurement on an ordinal scale involves ranking observations or categories. Examples: 1. Working Performance can be categorized and ranked as follows: 1 - Best Worker 2 - Second Best Worker 3 – Third Best Worker and So on 2. Academic Performance can be categorized and ordered as follows: 4 – Excellent 3 – Very Satisfactory 2 – Satisfactory 1 – Needs Improvement 3. Service Satisfaction Ranked Categories: Very Unsatisfied Fairly Unsatisfied Neutral Fairly Satisfied Very Satisfied 4. Socioeconomic class Upper Class Middle Class Lower Class Remark: Ordinal scales are often used to measure variables for which it is difficult to assign numerical scores. For instance, an individual can rank their song preferences but might have problem explaining “how much” they prefer rock songs than love songs. C. Interval Scale The interval scale consists of an ordered set of categories (like an ordinal scale) with the additional requirement that the categories form a series of intervals that are all exactly the same size. The distances between any two numbers are known which are numeric in nature and does not have a stable starting point or absolute zero. That is, a value of zero does not indicate a total absence of the variable being measured. For example, a temperature of 0° Celsius does not mean that there is no temperature, and it does not prohibit the temperature from going even lower. The following are further examples of variables with interval scale of measurements. Examples: Fahrenheit, IQ Scores, Personality Test, Scholastic Achievement Test, Calendar Time (Gregorian, Hebrew, or Islamic), Etc.. D. Ratio Scale Ratio Scale are also an interval scale with the additional feature of an absolute zero point. That is, a zero point is not arbitrary and has a meaningful value representing none or a complete absence of the variable being measured. The existence of an absolute, non arbitrary zero point implies that we can measure the absolute amount of the variable; that is, we can measure the distance from 0. Thus, it is possible to compare measurements in terms of ratios. For example, an individual who needs 60 minutes to solve a puzzle has taken twice as much time as an individual who finishes in only 30 minutes. Remark: Using a ratio scale, we can measure the direction and the size of the difference between two measurements and describe the difference in terms of a ratio. The following are further examples of variables with ratio scale of measurements. 1. 2. 3. 4. Height Weight Reaction Time Number of Errors on a Test Module 2: Organization and Presentation of Data Introduction In conducting a behavioral research or assessment, one must gather data for the variable/s under investigation. In order to describe situations, create conclusions or making inferences about the occurrence of events, one must organize the data gathered in a more meaningful manner. Once the data is organized, the next move that one can do is to present the data so that those who will be benefited directly or indirectly from reading the study or assessment can understand it. The most commonly used procedure of presenting data is through using graphs and charts. Each of these graphs and charts has its specific functions depending on the nature of the variables being investigated. Module 2 discusses on how to organize data by constructing frequency distribution and the manner the data will be presented by constructing graphs and charts. After going through this module, the students will be able to: 1. Discuss and explain the methods in organizing and presenting data. 2. Organize the data into a frequency distribution using excel data analysis. 3. Represents frequency distribution graphically using histogram, frequency polygons, and cumulative frequency polygon (ogives). 4. Plot the data using bar graph (multiple bar graph), pie chart, time series graph and scatter plot. 5. Analyse and interpret the Cla ss graphs/charts in the context of the variable/s under investigation. 6. Show volunteerism and innovativeness in organizing and presenting data concerning real life behavioural application problems. Lesson 1: constructing the Frequency Distribution Table A grouped frequency distribution is useful whenever the range of the data set is quiet large. Hence, the data must be grouped into classes whether it is categorical or interval or ratio data. The following shows the procedure for constructing the frequency distribution. A. Categorical Frequency Distribution The categorical frequency distribution is utilized to organize nominal or ordinal type of data. For instance, we can employ categorical frequency distribution for variables such as gender, marital status, socio-economic status, political affiliation and so on. Example: Twenty psychological statistics students were given an academic performance evaluation by their instructor. The data set is shown as follows: Average High Low Average Low High Low High High Average High Average Low High Average High Low Average Average Average The following shows the categorical frequency distribution for the data. T a ll y || || | || || ||| | || || ||| Lo w Av era ge Hig h Freq uenc y Pe rce nt 5 25 8 40 7 35 Remark: The percentage is computed using the formula: %=f/n x 100, where f=frequency of the class and n is the total number of categorical values. Learning Check Construct the frequency distribution for the data on Job Satisfaction by rank and file employees of a certain company. Slightly Satisfied Satisfied Quite Satisfied Satisfied Very Satisfied Satisfied Quite Satisfied Satisfied Slightly Satisfied Satisfied Very Satisfied Quite Satisfied Satisfied Slightly satisfied Satisfied Quite Satisfied Slightly Quite Slightly Very Quite Satisfied Very Satisfied Very Quite Satisfied Quite Satisfied Slightly Quite B. The Frequency Distribution for numerical data (Interval or Ratio data) Data in its original form and structure are called raw data. Example: The following is a raw data depicting the number of students taking the IQ test during a year in 60 randomly selected classes in a certain university. 60 – 69 Components of Distribution Table 1 15 a Frequency The following are the components of a Frequency Distribution Table I. Class Interval These are the numbers defining the class. It consist of the end numbers called the class limits namely the lower limit and upper limit. II. Class Frequency (f) This component shows the number of observations falling in the class. When these scores are arranged in either ascending or descending magnitude, then such an arrangement is called an array. It is usually helpful to put the raw data in an array because it is easy to identify the extreme values or the values where the scores most cluster. When the data are placed into a system wherein they are organized, then these partake the nature of grouped data. Definition: The procedure of organizing data into groups is called a Frequency Distribution Table (FDT) Example: The following presents a frequency distribution table of the exam scores of fifteen Behavioral Students. Scores Frequenc y 20 – 29 30 – 39 40 – 49 50 – 59 5 4 3 2 III. Class Boundaries These are the so called “true class limits”. They are classified as: Lower Class Boundary (LCB), which is defined as the middle value of the lower class limits of the class and the upper class limit of the preceding class and Upper Class Boundary that is, the middle value between the upper class limit of the class and the lower limit of the next class. IV. Class Size The difference between consecutive upper limits or consecutive lower limits. two two V. Class Mark (CM) This component is the midpoint or the middle value of a class interval. VI. Cumulative frequency (CF) This component shows the accumulated frequencies of successive classes. There are two types of Cumulative Frequencies. A. Greater than CF (> CF) – shows the number of observations greater than the lower class boundary (LCB). B. Less than CF (< CF) - shows the number of observations less than the upper class boundary (UCB). In constructing a Frequency Distribution Table, attention must be given in selecting the number of class intervals or groupings in the table. There are no exact rules for determining this number of class intervals. However, one suggestion in literature for determining the number of class intervals is to use Sturges’ rule such as the one specified in Step 1. 1. Determine the number of classes. For first approximation, it is suggested to use the Sturge’s Approximation Formula. K= 1 + 3.332 log n where K = approximate number of classes n = number of cases 2. Determine the range R, where R = maximum value – minimum value 3. Determine the approximate class size C using the formula C = R / K. It is usually convenient to round off C to a nearest whole number 4. Determine the lowest class interval (or the first class). This class should include the minimum value in the data set. For uniformity, let us agree that for our purposes, the lower limit of the class interval should start at the minimum value. 5. Determine all class limits by adding the class size C to the limits of the previous class. 6. Tally the scores / observations falling in each class. Example: Construct a Frequency Distribution Table for the number of students taking the IQ test during a year in 60 randomly selected classes in a certain university Solution: 1. Using the Sturge’s Approximation Formula, K= 1 + 3.332 log n, where K, approximate number of classes and n, number of cases, then the approximated number of class intervals for the data set is given by K= 1 + 3.332 log(60) = 1 + 3.332(1.77815125) K= 6.92 or 7 2. The range R is given by 27 – 32 33 – 38 39 – 44 45 – 50 51 – 56 57 – 62 Total R=Maximum ValueMinimum Value =59 – 21 = 38 3. The approximate class size C is: C=R/K =38/7 =5.43 or 6 4. The lowest class interval (or the first class) is 21 – 26. 11 28.33 18.33 4 35.00 6.67 6 45.00 10.00 9 60.00 15.00 17 88.33 28.33 7 100.00 11.67 n=60 100. 00 Thus, the Complete Frequency Distribution Table is as follows: 5. Adding the class size C=6 to the class limit beginning with the lowest class interval, we then obtain the other class intervals shown as follows: Class Intervals 21 – 26 27 – 32 33 – 38 39 – 44 45 – 50 51 – 56 57 - 62 6. Tally of Scores and the Frequency Distribution Table Class Inter val 21 – 26 Freque ncy 6 Cumula tive Percent 10.00 Perc ent 10.00 Clas s Inte rval 21 – 26 27 – 32 33 – 38 39 – 44 45 – 50 51 – 56 57 – 62 Tota l Frequ ency 6 11 4 6 9 17 7 n=60 Class Bound aries 20.5 – 26.5 26.5 – 32.5 32.5 – 37.5 38.5 – 44.5 44.5 – 50.5 50.5 – 56.5 56.5 – 62.5 Cla ss Ma rk 23. 5 29. 5 35. 5 41. 5 47. 5 53. 5 59. 5 Cumulat ive Frequen cy Gre Le ater ss than th CF an (> CF CF) (< CF ) 60 6 54 17 43 21 39 27 33 36 24 53 7 60 Note: Data analysis found in excel can be used to generate the frequency distribution once the class intervals are already set. Just use histogram function under data analysis window as shown below. For the bin range, the upper class limits of each class intervals is being used. For the input range, enter the range of occupied cells of data defined by the variable number of students taking the IQ test. Then, enter the range of upper class limits into the bin range. Consequently, check levels, cumulative percentage, chart output and click ok. Excel Output Bin Range 26 32 38 44 50 56 62 More Frequency 6 11 4 6 9 17 7 0 Cumulative % 10.00% 28.33% 35.00% 45.00% 60.00% 88.33% 100.00% 100.00% Learning Check 2 A research study has been conducted examining the number of children in the families living in a certain community. The following data has been collected based on a random sample of n = 40 families from the community. 2, 2, 5, 3, 0, 1, 3, 2, 3, 4, 1, 3, 4, 5, 7, 3, 2, 4, 1, 0, 5, 8, 6, 5, 4 , 2, 4, 4, 7, 6, 3, 5, 5, 2, 2, 1, 1, 3, 4, 6. Organize this data in a Frequency Distribution Table.