")
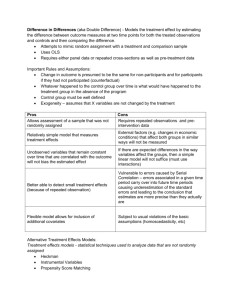
Sketch Answers to Exercises – Week 1 Note: these are only sketches of answers, not full-blown answers. These sketches serve to give you the information that you need to write full answers. Interpretation, Discussion, and Implementation 1. Think of an example for each of the following threats to the identification of causal effects and explain it using your example. Find an example that was not mentioned in the lecture: Note: try to come up with your own example – this is a good exercise to search for potential sources of biases. a. Reverse causality: Europeans in the Middle Ages believed lice to improve health. Why? They observed that sick people do not have lice, whereas healthy people do. However, causality is reversed: lice are sensitive to body temperature and leave sick hosts. b. Simultaneity: Excessive alcohol consumption raises the probability of becoming depressive, but being depressive raises the probability of excessive alcohol consumption. Hence, both cause each other. The correlation between alcohol consumption and depression is thus reflecting both channels (and probably also other channels, such as omitted variable bias and selection bias). c. Omitted variable bias: Students who attend the tutorials have higher grades. So do tutorials help in achieving higher grades? Probably yes, but also students who are more motivated more often attend tutorials, and those who are more motivated also put more effort in preparing for the exam, so they get better grades also because of higher motivation. Students’ motivation thus is an omitted variable that, if not controlled for, leads to omitted variable bias. d. Selection bias: People who went to university have higher wages that those who didn’t. Do they earn higher wages because of attending university? Probably yes, but also there is selection into universities: Only those with sufficient skills make it to university, i.e. these are a selected group. They would probably also earn higher wages if they had not gone to university, because of their higher skills. So their higher wages are only partly due to studying at a university. They are not comparable to those who did not study, and that leads to selection bias. Note: Selection Bias and Omitted Variable Bias are closely related concepts. 2. Discuss the following examples a. You work in the marketing department a company, which has seen its market share decline and responded by introducing a new marketing campaign. Your supervisor wants to know whether the campaign was successful and asks you for the market share before and after the campaign. You do not see a big difference in the market share in the year before and the year after the introduction of the marketing campaign. What do you conclude and why? Key question: what would have happened in the absence of the introduction of the marketing campaign? If the firm was on the decline, then the decline probably would have continued in the absence of the campaign, so the fact that there is no difference in the market share before and after the introduction of the marketing campaign could indicate that it helped to stop the decline. But: we do not know, since we have no good indication of what would have happened without the campaign. b. You work for a hotel company. Your manager wants to reconsider the pricing strategy and asks you to check the effect of prices on the occupancy rate of the hotel. You have data on prices and occupancy for each day of the past 10 years. You see a positive correlation between your hotels’ daily prices and occupancy rate, i.e. days with high prices are also days with high occupancy. What do you conclude? Omitted variable bias: the hotel sets prices high when demand is high, that is probably why there is a positive correlation between prices and occupancy! It’s unlikely that high prices lead to high occupancy, but it is more likely that high demand leads to both, high occupancy and high prices. From the pure correlation, we cannot determine the effect of prices on occupancy. c. You work in an employment agency and want to know whether further training measures for unemployed workers help them in finding jobs. Unemployed workers can apply for the measures and the case workers decide who gets the training. Discuss whether comparing the job finding rates of unemployed workers who participated in a training to those who didn’t identifies the effect of the training. Selection biases: the case workers decide who get’s the training. Depending on their incentives, they might either pic the “good” or the “bad” ones, so that these are not comparable to those who don’t get a training. Also, the unemployed decide themselves whether to participate. Probably those participate who are more motivated, and they are likely to have higher changes to find jobs, anyhow. d. You want to know whether robots destroy jobs. You have data on the number of jobs and the number of robots in the manufacturing industry for the Netherlands for the past 20 years. You see that employment grew strong in industries that adopted robots. Discuss whether this proves that robots do not destroy jobs. Omitted variable bias: Firms are more likely to adopt robots if they grow. If demand for the output of an industry rises, then the firms do both, employ more workers and invest in robots. This tells us little about the effect of robots on the number of jobs, because both are affected by an omitted variable. To know how the adoption of robots affected the number of jobs, we need to control for the rise in demand. 3. In WW2, the Navy wanted to know where to improve armor on their planes to make sure that they make it back home. They ran an analysis of where the planes got shot – illustrated by the picture, below. What do you think, where should the Navy increase armor? Explain! Selection bias: the data is only available for planes that returned. Since these planes survived, the damage at the indicated places probably was not fatal. However, without additional information, or additional assumptions, we cannot determine where planes are most vulnerable. If we assume that planes are randomly hit at all places, then the fact that those planes which returned do not show any hits at specific places (engines, cockpit) suggests that these are the most vulnerable places. However, this conclusion is based on an assumption. Repetition 4. What is a “counterfactual situation”? How does a counterfactual situation help in identifying causal effects? And how does this relate to potential outcomes? The counterfactual situation describes what would have happened to the treated unit had it not been treated. By comparing the actual situation to the counterfactual situation, we identify the causal effect. There are two potential outcomes for a unit, Y_0i describes the outcome that unit i would get if it was not treated, Y_1i describes the outcome that unit i would get if it was treated. If unit i receives the treatment, then Y_1i realizes. Y_1i then is the actual situation and Y_0i is the counterfactual situation (and vice versa if unit i does not receive the treatment). 5. “The problem of identifying causal effects is basically a problem of missing data.” – Explain this statement. What data is missing? Explain whether it is possible to solve the problem by collecting the missing data. (see also answer to last exercise) We only observe one of the potential outcomes, but never both. We observe the actual situation, but never the counterfactual situation. The counterfactual situation is the missing data. It is impossible to observe the counterfactual situation, because a unit is either treated or not, but never both. We therefore can identify causal effects only by developing a credible counterfactual situation to which we can compare the actual situation. 6. Why is it impossible to identify the causal effect of a treatment for an individual unit of observation (e.g. for a specific person)? What can you do instead? A unit (e.g. a person) is either treated, or not, but never both. We therefore cannot estimate the treatment effect for an individual unit. What we can do is to is to try to find a suitable group of untreated units that serves as a good comparison group for treated units. The average differences between these treated and comparable untreated units then is a good estimate of the average causal effect for those units (individuals). This is the average causal effect. However, it is based on the assumption that the control group is in fact comparable. 7. Explain the following equation: 𝐴𝑣𝑔𝑛 [𝑌1𝑖 |𝐷𝑖 = 1] − 𝐴𝑣𝑔𝑛 [𝑌0𝑖 |𝐷𝑖 = 0] = 𝛥 + 𝐴𝑣𝑔𝑛 [𝑌0𝑖 |𝐷𝑖 = 1] − 𝐴𝑣𝑔𝑛 [𝑌0𝑖 |𝐷𝑖 = 0] a. In particular, explain the meaning of each element of the equation separately (hint: you have to distinguish between potential outcomes and observed outcomes) 𝑌1𝑖 – potential outcome of unit i if it would be treated 𝑌0𝑖 – potential outcome of unit i if would not be treated 𝐷𝑖 = 1 – unit i is treated 𝐷𝑖 = 0 – unit i is not treated 𝐴𝑣𝑔𝑛 [𝑌1𝑖 |𝐷𝑖 = 1] – Average of the potential outcome if treated for those individuals which are also treated in reality (i.e. average observed outcome of treated units) 𝐴𝑣𝑔𝑛 [𝑌0𝑖 |𝐷𝑖 = 0] – Average of the potential outcome if untreated for those individuals which are also not treated in reality (i.e. average observed outcome of untreated units) 𝛥 – average causal effect 𝐴𝑣𝑔𝑛 [𝑌0𝑖 |𝐷𝑖 = 1] – Average of the potential outcome if untreated for those individuals which in reality did receive the treatment (counterfactual situation) b. And explain the overall meaning of the equation in general. The equation states that the average differences in observed outcomes between treated and untreated units reflects the sum of the average causal effect as well as the selection bias (i.e. the differences in outcomes between treated and untreated units that would exist even without any treatment, i.e. genuine differences between treated and untreated units that are not caused by the treatment). 8. What is the Stable Unit Treatment Value Assumption (SUTVA)? What does the SUTVA imply for the interpretation of causal effects? The Stable Unit Treatment Value Assumption (SUTVA) is the assumption that the treatment effect does not depend on who else receives the treatment. The important implication is that causal effects that were estimated under this assumption (which applies to most estimates of causal effects) only have a marginal or local interpretation. The background is that in reality scaling up of a treatment often does cause feedback effects. Think for example of a marketing campaign: if only a few firms implement it, then these firm likely profit a lot. But if everybody does it, then the effects for each individual firm likely become weaker because firms marketing campaigns might cannibalize each other. The treatment effect of the campaign thus are only valid “locally” or “marginally” for few firms, but not if many firms adopt it. 9. Explain the difference between applied data analysis I & visualization vs. applied microeconometric methods using the regression model: Population Model: 𝑌 = 𝛽0 + 𝛽1 𝑋 + 𝜀 Estimated Model in Sample: ̂0 + 𝛽 ̂1 𝑋 + 𝑒 , Y=𝛽 ̂0 + 𝛽 ̂1 𝑋, 𝑌 = 𝑌̂ + 𝑒 𝑌̂ = 𝛽 Make use of the difference (which?) between the population model and the estimated model in the sample inf your explanation. What is the key challenge in applied microeconometrics? Applied data analysis I & visualization focuses on prediction, i.e. on the 𝑌̂. That is, the aim is to get a good prediction of the outcome variable. In applied microeconometrics, we instead ̂1 . In Applied data analysis I & visualization, we try to estimate the effect of X on Y, which is 𝛽 can see how well we do by comparing the estimated outcome 𝑌̂ to the true outcome Y. In ̂1 to the true effect 𝛽1 , applied microeconometrics, we cannot compare the estimated effect 𝛽 ̂1 under the assumption that 𝜀 is uncorrelated with because 𝛽1 is unobservable. We estimate 𝛽 𝑋, but that assumption cannot be tested, because we do not observe the error term 𝜀. We only observe the realized residuals 𝑒. The realized residuals 𝑒 are always uncorrelated with 𝑋, but that is what we have assumed in the first place. But we never know whether that also holds true for the error term 𝜀. Hence, the main problem in applied microeconometrics is that we never can test whether we truly estimate the causal effect. All we can do is to choose our models such that it is as plausible as possible that 𝜀 is uncorrelated with 𝑋.