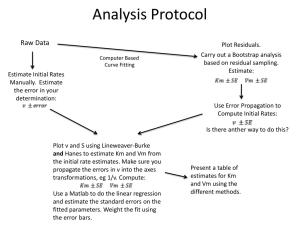
Johaan Tomy Kallany 1940817 PRACTICAL -8 FITTING ARMA MODEL AND RESIDUAL ANALYSIS 08-04-2022 INTRODUCTION: A time series is a sequence of observations 𝑋𝑡 , collected at equal intervals of time. Time series analysis is a specific way of analyzing a sequence of data points collected over an interval of time. In time series analysis, analysts record data points at consistent intervals over a set period of time rather than just recording the data points intermittently or randomly. However, this type of analysis is not merely the act of collecting data over time. What sets time series data apart from other data is that the analysis can show how variables change over time. It provides an additional source of information and a set order of dependencies between the data. For example, Xt may denote the price of a commodity on a day t, or the maximum temperature on a day t, exchange rate of one currency against another, the number of accidents that occurred in a month t, the number of defective items manufactured by a firm in week t, or biomedical measurements on a subject over time such as blood pressure, body temperature, pulse rate, etc. In statistics, econometrics and signal processing, an autoregressive (AR) model is a representation of a type of random process; as such, it is used to describe certain time-varying processes in nature, economics, etc. The autoregressive model specifies that the output variable depends linearly on its own previous values and on a stochastic term (an imperfectly predictable term); thus the model is in the form of a stochastic difference equation (or recurrence relation which should not be confused with differential equation). Together with the moving-average (MA) model, it is a special case and key component of the more general autoregressive–moving-average (ARMA) and autoregressive integrated moving average In time series analysis, the moving-average model, also known as moving-average process, is a common approach for modelling univariate time series. The moving-average model specifies that the output variable depends linearly on the current and various past values of a stochastic term. Together with the autoregressive (AR) model, the moving-average model is a special case and key component of the more general ARMA model of time series, which have a more complicated stochastic structure. Contrary to the AR model, the finite MA model is always stationary. A stationary time series is one whose properties do not depend on the time at which the series is observed. Thus, time series with trends, or with seasonality, are not stationary — the trend and seasonality will affect the value of the time series at different times. In general, a stationary time series will have no predictable patterns in the long-term. Time plots will show the series to be roughly horizontal (although some cyclic behavior is possible), with constant variance. In the statistical analysis of time series, autoregressive–moving-average (ARMA) models provide a parsimonious description of a (weakly) stationary stochastic process in terms of two polynomials, one for the autoregression (AR) and the second for the moving average (MA). The general ARMA model was described in the 1951 thesis of Peter Whittle, Hypothesis testing in time series analysis, and it was popularized in the 1970 book by George E. P. Box and Gwilym Jenkins. Given a time series of data Xt , the ARMA model is a tool for understanding and, perhaps, predicting future values in this series. The AR part involves regressing the variable on its own lagged (i.e., past) values. The MA part involves modelling the error term as a linear combination of error terms occurring contemporaneously and at various times in the past. The model is usually referred to as the ARMA (p, q) model where p is the order of the AR part and q is the order of the MA part (as defined below). AIM: Fit a suitable ARMA model for the given data set and perform residual analysis for the fitted model by testing the assumptions associated with the residuals 1) errors are uncorrelated and 2) errors are normally distributed. Prepare a report by giving proper interpretations for your analysis. Data Description For illustration of fitting an ARMA model and for residual analysis, we will be using the ‘Earthquakes’ data set consisting details about earthquake occurrences in a given year for the time-period the millions) from 1916– 2015 . First, we will load the data set in to R and convert it as a time series object by properly defining the dates. THEORY: A statistical model is autoregressive if it predicts future values based on past values. For example, an autoregressive model might seek to predict a stock's future prices based on its past performance. Autoregressive models operate under the premise that past values have an effect on current values, which makes the statistical technique popular for analyzing nature, economics, and other processes that vary over time. Multiple regression models forecast a variable using a linear combination of predictors, whereas autoregressive models use a combination of past values of the variable. Auto-regressive model In a multiple regression model, we forecast the variable of interest using a linear combination of predictors. In an autoregression model, we forecast the variable of interest using a linear combination of past values of the variable. The term autoregression indicates that it is a regression of the variable against itself. Thus, an autoregressive model of order: where εt is white noise. This is like a multiple regression but with lagged values of y t as predictors. We refer to this as an AR(p) model, an autoregressive model of order p Autoregressive models are remarkably flexible at handling a wide range of different time series patterns. The two series in show series from an AR (1) model and an AR (2) model. Changing the parameters ϕ1,…,ϕp results in different time series patterns. The variance of the error term εt will only change the scale of the series, not the patterns. can be written as The A process is stationary if the roots of the characteristic polynomial associated with the AR process lies outside the unit circle. This is a non-stationary explosive process. If we combine all the inequalities, we obtain a region bounded by the lines φ2 =1+ φ1; φ2 = 1 − φ1; φ2 = −1. This is the region where the AR (2) process is stationary. Therefore, for AR(p) process to be stationary, the roots of the characteristic polynomial φ(B) associated with the process should be stationary. Auto-regressive moving average model: This is a model that is combined from the AR and MA models. In this model, the impact of previous lags along with the residuals is considered for forecasting the future values of the time series. Here β represents the coefficients of the AR model and α represents the coefficients of the MA model. Therefore, ARMA process is a linear combination of its own past value and also the linear combination of its own past error terms. The ARMA(p,q) is stationary only if the AR(p) process associated with it is stationary. Let’s suppose that “Y” is some random time-series variable. Then, a simple Autoregressive Moving Average model would look something like this: yt = c + ϕ1 yt-1 + θ1 ϵ t-1 + ϵ t yt and yt-1 represent the values in the current period and 1 period ago respectively. As was the case with the AR model, we’re using the past values as a benchmark for future estimates. Similarly, ϵ t and ϵ t-1 are the error terms for the same two periods. The error term from the last period is used to help us correct our predictions. By knowing how far off we were in our last estimate, we can make a more accurate estimation this time. As always, “c” is just a baseline constant factor. In simply means we can plug in any constant factor here. If the equation doesn’t have such a baseline, we just assume c=0. The two remaining parameters are ϕ1 and θ1. The former, ϕ1, expresses on average what part of the value last period (yt-1) is relevant in explaining the current one. Similarly, the latter, θ1, represents the same for the past error term (ϵ t-1). Just like in previous models, these coefficients must range between -1 and 1 to prevent the coefficients from blowing up. Fitting models Choosing p and q: Finding appropriate values of p and q in the ARMA(p,q) model can be facilitated by plotting the partial autocorrelation functions for an estimate of p, and likewise using the autocorrelation functions for an estimate of q. Extended autocorrelation functions (EACF) can be used to simultaneously determine p and q.[5] Further information can be gleaned by considering the same functions for the residuals of a model fitted with an initial selection of p and q. Brockwell & Davis recommend using Akaike information criterion (AIC) for finding p and q.[ Another possible choice for order determining is the BIC criterion. Residuals The “residuals” in a time series model are what is left over after fitting a model. For many (but not all) time series models, the residuals are equal to the difference between the observations and the corresponding fitted values: Residuals are useful in checking whether a model has adequately captured the information in the data. A good forecasting method will yield residuals with the following properties: 1. The residuals are uncorrelated. If there are correlations between residuals, then there is information left in the residuals which should be used in computing forecasts. 2. The residuals have zero mean. If the residuals have a mean other than zero, then the forecasts are biased. Any forecasting method that does not satisfy these properties can be improved. However, that does not mean that forecasting methods that satisfy these properties cannot be improved. It is possible to have several different forecasting methods for the same data set, all of which satisfy these properties. Checking these properties is important in order to see whether a method is using all of the available information, but it is not a good way to select a forecasting method. If either of these properties is not satisfied, then the forecasting method can be modified to give better forecasts. Adjusting for bias is easy: if the residuals have mean mm, then simply add mm to all forecasts and the bias problem is solved. In addition to these essential properties, it is useful (but not necessary) for the residuals to also have the following two properties. 1. The residuals have constant variance. 2. The residuals are normally distributed. These two properties make the calculation of prediction intervals easier. However, a forecasting method that does not satisfy these properties cannot necessarily be improved. Sometimes applying a Box-Cox transformation may assist with these properties, but otherwise there is usually little that you can do to ensure that your residuals h ave constant variance and a normal distribution. Instead, an alternative approach to obtaining prediction intervals is necessary. Portmanteau tests for autocorrelation In addition to looking at the ACF plot, we can also do a more formal test for autocorrelation by considering a whole set of rk values as a group, rather than treating each one separately. Recall that rk is the autocorrelation for lag k. When we look at the ACF plot to see whether each spike is within the required limits, we are implicitly carrying out multiple hypothesis tests, each one with a small probability of giving a false positive. When enough of these tests are done, it is likely that at least one will give a false positive, and so we may conclude that the residuals have some remaining autocorrelation, when in fact they do not. In order to overcome this problem, we test whether the first h autocorrelations are significantly different from what would be expected from a white noise process. A test for a group of autocorrelations is called a portmanteau test, from a French word describing a suitcase or coat rack carrying several items of clothing. ANALYSIS AND INTERPRETATION Step 1: import the required packages. Step 2: Import the dataset Step 3: convert the given dataset into a time series object by properly defining the dates. Step 4: Check for the stationarity of the time series data. If not, transform the given data into a stationary using appropriate statistical techniques such a method of seasonal differencing, moving average etc. Step 5: Fit a suitable ARMA to the stationary time series Step 6: Obtain the residuals of the model and test for the assumptions associated with the residuals i.e. 1) residuals are uncorrelated to each other and 2)they follows a normal distribution. Importing the required packages: library(UsingR) library(astsa) ## ## Attaching package: 'astsa' ## The following objects are masked from 'package:UsingR': ## ## blood, chicken library(tseries) ## Warning: package 'tseries' was built under R version 4.1.2 ## Registered S3 method overwritten by 'quantmod': ## method from ## as.zoo.data.frame zoo #ASTSA- Applied Statistical Time Series Analysis. This package contains Data sets and scripts to accompany Time Series Analysis and Its Applications #tseries-Time Series Analysis and Computational Finance. #Importing the required dataset library(readxl) earthquakes <- read_excel("C:/Users/DELL G 5/Desktop/earthquakes.xlsx") View(earthquakes) #Let 'data' represents the dataset imported using the above code data=data.frame(earthquakes) head(data,10)#First 10 rows of the data ## ## ## ## ## ## ## ## ## ## ## 1 2 3 4 5 6 7 8 9 10 Year Quakes 1916 2 1917 5 1918 12 1919 8 1920 7 1921 9 1922 7 1923 12 1924 9 1925 12 attach(data) We need to convert the given dataset into a time series object using the ts() function in R. The function ts() is used to create time-series objects. These are vectors or matrices with class of "ts" (and additional attributes) which represent data which has been sampled at equispaced points in time. Syntax: ts(data = NA, start = 1, end = numeric(), frequency = 1,deltat = 1, ts.eps = getOption("ts.eps"), class = , names = ) earthquakes=ts(Quakes,start=1916,end=2015) earthquakes ## ## ## ## ## 21 ## 17 ## 11 ## 19 Time Series: Start = 1916 End = 2015 Frequency = 1 [1] 2 5 12 8 7 9 7 12 9 12 14 7 [26] 13 11 18 13 5 10 13 11 9 13 12 18 [51] 9 11 22 14 17 20 16 9 11 13 9 18 [76] 17 13 12 13 20 15 16 12 18 15 12 19 13 11 16 15 11 7 9 14 10 12 9 19 6 10 8 9 8 21 6 10 8 12 14 11 8 9 8 13 12 10 7 14 14 15 11 13 16 13 15 16 11 11 18 12 17 24 20 16 class(earthquakes) ## [1] "ts" #Plotting the time series data ts.plot(earthquakes,col="blue",lwd=3,main="Annual earthquake occurences",g pars=list(xlab="Time (in years)", ylab="Frequency")) grid(nx = NULL, ny = NULL, lty = 3, # Grid line type col = "gray", # Grid line color lwd = 2) # Grid line width From the above time series plot, we can observe a slightly increasing trend of annual earthquake occurrences with time. As a result, the trend component 𝑚𝑡 might exists. However, there is no evident repetitive pattern or periodic fluctuations. Therefore, the seasonal component 𝑆𝑡 does not exists. Therefore, the time series plot indicates that the data is non-stationary ARMA model for a non-stationary data set by removing the non-stationarity component from the data set. For that, we can either use Moving average smoothing or the method of differencing. Here, stationary version is extracted by using the differencing operator to the data set. Transforming non-stationary series into stationary We can transform the above non-stationary series into a stationary series by using the method of differencing to eliminate any trend component. diffdata=diff(earthquakes)#diff command can be used to perform the first o rder differencing operation. ts.plot(diffdata,col="red",lwd=3,main="Time series plot after elimination of trend",gpars=list(xlab="Time (in years)", ylab="Frequency")) grid(nx = NULL, ny = NULL, lty = 3, # Grid line type col = "gray", # Grid line color lwd = 2) # Grid line width From the above time series plot, we can see that there is no deterministic/predictable pattern in the plot and time series data is free of trend and seasonality components. Hence, the plot indicates that the given time series data is stationary. Checking stationarity for the given time series data ADF Test Augmented Dickey Fuller test (ADF Test) is a common statistical test used to test whether a given Time series is stationary or not. The null and the alternative hypotheses under this test are: H0 , Null Hypothesis: The given time-series is non-stationary H1 , Alternative Hypothesis: The given time-series is stationary adf.test(diffdata) ## Warning in adf.test(diffdata): p-value smaller than printed p-value ## ## Augmented Dickey-Fuller Test ## ## data: diffdata ## Dickey-Fuller = -6.7817, Lag order = 4, p-value = 0.01 ## alternative hypothesis: stationary Here, the p-value is lesser than the significance level 0.05 (5%). Hence, there is not enough statistical evidence in favour of the null hypothesis and we may reject the null hypothesis. Hence, we conclude that the given time series data is stationary. acf(diffdata,main="ACF plot of stationary series",col="red",lwd=2) From the above ACF plot, it is clear that the ACF at almost all non-zero lags lies below the threshold level of the plot. This implies that the ACF or the degree of auto-correlation is insignificant for most non-zero lags, indicating that there exist no dependencies among the residuals. So, the ACF plot indicates that the differenced data is stationary.. Fitting an ARMA model for the given data #Fitting an ARMA model library(forecast) fit=auto.arima(diffdata,seasonal="FALSE") fit ## ## ## ## ## ## ## ## ## ## Series: diffdata ARIMA(0,0,1) with zero mean Coefficients: ma1 -0.8092 s.e. 0.0710 sigma^2 = 15.53: log likelihood = -276.26 AIC=556.53 AICc=556.65 BIC=561.72 auto.arima command in R gives us the best fitted ARMA model among the class of ARMA models. From the result we can see that, the ARMA model fitted for the data is of the form ARIMA(0,0,1) or MA(1). Therefore, the model can be written as: 𝒁𝒕 = 𝒂𝒕 + 𝟎. 𝟖𝟎𝟗𝟐 𝒂𝒕−𝟏 𝑍𝑡 represents the annual earthquakes for the tth year. Here, 𝑍𝑡 depends only on the error/white noise term at its previous lag i.e., 𝑎𝑡−1 . Here, -0.8092 is the value of the moving-average parameter and SE of the coefficient is 0.0710. The AIC score of the model is 556.53 and we can see that the MA(1) process has the least AIC score among all the ARMA models. Hence, the best fitted model is the MA(1) model above RESIDUAL ANALYSIS Step 1: Extract the residuals from the fitted model Residuals can be extracted by using the command res res=resid(fit) ## Time Series: ## Start = 1917 ## End = 2015 ## Frequency = 1 ## [1] 2.33211693 06620 ## [7] 4.61231041 84340 ## [13] 3.75417346 01441 ## [19] 2.54279055 74960 ## [25] 0.92581097 81266 ## [31] 1.72567970 71352 ## [37] -1.49384416 24137 ## [43] -2.81212552 99950 7.54571402 1.35324173 0.02693396 1.97488805 -0.432 0.69348767 3.54399128 3.84687375 1.10315547 5.884 7.60123596 -3.85026100 -4.11444125 0.671 -2.96293958 -0.94248272 -2.76255305 -1.25084406 2.72446023 0.90116951 -6.270 5.98782301 -0.15473105 -8.12519993 -1.574 -0.60360009 -2.48842580 -4.20880149 9.76447505 1.98639444 -0.39263249 -4.317 0.59428608 -1.51911050 11.77075312 -3.475 1.20460202 -1.02524984 6.17037957 -0.006 ## [49] 5.99433608 -4.14945187 -1.35768895 9.90137365 0.01207819 3.009 77354 ## [55] 5.43547429 0.39832356 -6.67768114 -3.40350312 -0.75407576 0.389 81053 ## [61] -3.68456978 -0.98151168 -4.79422802 -5.87943442 -0.75757102 -3.613 01779 ## [67] 4.07638737 3.29856599 3.66916183 -1.03095626 1.16576200 -1.056 67874 ## [73] -2.85505233 6.68972434 4.41324834 -0.42884997 -1.34702048 -0.089 99355 ## [79] 6.92717825 0.60539333 1.48987735 -2.79440831 3.73879679 0.025 39156 ## [85] 1.02054656 -2.17418541 0.24067406 1.19475069 -4.03322142 -3.263 63659 ## [91] 4.35910263 -2.47266406 2.99914855 9.42687667 3.62812067 -1.064 16629 ## [97] 2.13888882 -5.26923565 2.73619484 Checking assumption 1: Errors are uncorrelated We can examine this assumption either by plotting the time series plot/ACF of residuals or by using a statistical test called" Portmanteu". ts.plot(res,col="red",lwd=3,main="Time series plot of residuals",gpars=lis t(xlab="Time (in years)")) grid(nx = NULL, ny = NULL, lty = 3, # Grid line type col = "gray", # Grid line color lwd = 2) # Grid line width From the above time series plot of the residuals, we can see that there is no deterministic/predictable pattern in the plot and residuals data is free of trend and seasonality components. Hence, the plot indicates that the residuals are uncorrelated to each other. acf(res,col="red",lwd=2,main="ACF plot of residuals") From the above ACF plot of the residuals, it is clear that the ACF at almost all non-zero lags lies below the threshold level of the plot. This implies that the ACF or the degree of autocorrelation is insignificant for most non-zero lags, indicating that there exist no dependencies among the residuals. So, the ACF plot indicates that the residuals are uncorrelated to each other. For a good model, ACF values for all lags should lie inside the threshold line. But for sample of observations, sometime you can see one or two lags are significant. Generally, you can ignore such cases and can conclude that the most of the dependencies in the data set is explained by the fitted model. Portmanteau test The null and alternative hypotheses of portmanteau test are given below: H0 , Null Hypothesis: There is no significant correlation among the residual series H1 , Alternative Hypothesis: There is significant correlation among the residual Based on the p value you can comment on the presence of autocorrelation. Box.test(res)## portmanteau test ## ## Box-Pierce test ## ## data: res ## X-squared = 0.034748, df = 1, p-value = 0.8521 Here, the p-value is greater than the significance level 0.05 (5%). Hence, there is sufficient statistical evidence in favour of the null hypothesis and we may accept the null hypothesis. Hence, we conclude that there is no significant correlation among the residual series i.e. residuals are uncorrelated to each other. Checking assumption 2: Residuals are normally distributed For checking this assumption, we can either use QQ plots or some statistical test such as Shapiro Wilk test. Quantile-Quantile plot The quantile-quantile (q-q) plot is a graphical technique for determining if two data sets come from populations with a common distribution. A q-q plot is a plot of the quantiles of the first data set against the quantiles of the second data set. A 45-degree reference line is also plotted. If the two sets come from a population with the same distribution, the points should fall approximately along this reference line. The greater the departure from this reference line, the greater the evidence for the conclusion that the two data sets have come from populations with different distributions. In the above Q-Q plot, we can see that most of the observation lie on and near the 45o straight line. This implies that the sample quantiles almost coincides with the theoretical (normal) quantiles, indicating that the residuals are normally distributed. We can affirm the normality of the residuals with the help of Shapiro-wilk test as given below. Normality test- Shapiro Wilks test The null and alternative hypotheses of portmanteau test are given below: H0 , Null Hypothesis: Residuals are normally distributed H1 , Alternative Hypothesis: Residuals are not normally distributed shapiro.test(res) ## ## Shapiro-Wilk normality test ## ## data: res ## W = 0.98327, p-value = 0.2428 Here, the p-value is 0.248 which is greater than the significance level 0.05 (5%). Hence, there is sufficient statistical evidence in favour of the null hypothesis and we may accept the null hypothesis. Hence, we conclude that the residuals are normally distributed. Conclusion From the time series plot of the given data, we can observe an increasing trend of annual earthquake occurrences with time. As a result, the trend component 𝑚𝑡 exists. However, there is no evident repetitive pattern or periodic fluctuations. Therefore, the seasonal component 𝑆𝑡 does not exists. Since the trend component exists, the given time series data is non-stationary. The non-stationary data has been transformed into a stationary series by the method of first order differencing and the stationarity nature is verified with the help of ADF test. An ARMA model has been fitted to the differenced data and the best fitted model was found to be a MA(1) process given by: 𝑍𝑡 = 𝑎𝑡 + 0.8092 𝑎𝑡−1 Where 𝑍𝑡 represents the annual earthquakes for the tth year. Here, 𝑍𝑡 depends only on the error/white noise term at its previous lag i.e., 𝑎𝑡−1 . Here, -0.8092 is the value of the movingaverage parameter and SE of the coefficient is 0.0710. The AIC score of the model is 556.53 and we can see that the MA(1) process has the least AIC score among all the ARMA models. Hence, the best fitted model is the MA(1) model above The residuals from the fitted model have been extracted and assumptions associated with the residuals i.e. 1) residuals are uncorrelated and 2) residual are normally distributed had been tested with the help of both graphical tools and statistical tests. Residuals are useful in checking whether a model has adequately captured the information in the data. From the time series plot of the residuals, it was observed that there was no deterministic/predictable pattern in the plot and residuals is free of trend and seasonality components. Hence, the plot indicates that the residuals are uncorrelated to each other. From the ACF plot of the residuals, the ACF at almost all non-zero lags lies below the threshold level of the plot. This implies that the ACF or the degree of auto-correlation is insignificant at most non-zero lags, indicating that there exist no dependencies among the residuals. So, the ACF plot indicates that the residuals are uncorrelated to each other. The p-value obtained from the Portmanteau test is greater than 0.05 and hence we conclude that there is no significant correlation among the residual series i.e. residuals are uncorrelated to each other. From the Q-Q plot, we can see that most of the observation lie on and near the 45o straight line. This implies that the sample quantiles almost coincides with the theoretical (normal) quantiles, indicating that the residuals are normally distributed. In addition, the results from the Shapirowilk test shows that the residuals are normally distributed. Violation of any one of the above assumptions could question the reliability of the fitted model. Any forecasting method that does not satisfy these properties can be improved. For example, if the residuals are autocorrelated, it indicates the mis-specification of the model. Also, if the errors are not normally distributed, the non-normal data should first be transformed into a normal distribution by log-transformation or Box-cox transformation and then the above procedure has to be repeated for the transformed data. .